
Upload 23 files
Browse files- zhongjing_7_26/.DS_Store +0 -0
- zhongjing_7_26/README.md +12 -0
- zhongjing_7_26/adapter_config.json +21 -0
- zhongjing_7_26/adapter_model.bin +3 -0
- zhongjing_7_26/all_results.json +11 -0
- zhongjing_7_26/checkpoint-100/README.md +9 -0
- zhongjing_7_26/checkpoint-100/adapter_config.json +21 -0
- zhongjing_7_26/checkpoint-100/adapter_model.bin +3 -0
- zhongjing_7_26/checkpoint-100/finetuning_args.json +13 -0
- zhongjing_7_26/checkpoint-100/optimizer.pt +3 -0
- zhongjing_7_26/checkpoint-100/rng_state.pth +3 -0
- zhongjing_7_26/checkpoint-100/scheduler.pt +3 -0
- zhongjing_7_26/checkpoint-100/trainer_state.json +156 -0
- zhongjing_7_26/checkpoint-100/training_args.bin +3 -0
- zhongjing_7_26/description.txt +1 -0
- zhongjing_7_26/eval_results.json +7 -0
- zhongjing_7_26/finetuning_args.json +13 -0
- zhongjing_7_26/train_results.json +7 -0
- zhongjing_7_26/trainer_log.jsonl +10 -0
- zhongjing_7_26/trainer_state.json +165 -0
- zhongjing_7_26/training_args.bin +3 -0
- zhongjing_7_26/training_eval_loss.png +0 -0
- zhongjing_7_26/training_loss.png +0 -0
zhongjing_7_26/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
zhongjing_7_26/README.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: peft
|
| 3 |
+
---
|
| 4 |
+
## Training procedure
|
| 5 |
+
|
| 6 |
+
### Framework versions
|
| 7 |
+
|
| 8 |
+
- PEFT 0.4.0
|
| 9 |
+
- PEFT 0.4.0
|
| 10 |
+
- PEFT 0.4.0
|
| 11 |
+
|
| 12 |
+
- PEFT 0.4.0
|
zhongjing_7_26/adapter_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_mapping": null,
|
| 3 |
+
"base_model_name_or_path": "/hy-tmp/Ziya-LLaMA-13B-v1",
|
| 4 |
+
"bias": "none",
|
| 5 |
+
"fan_in_fan_out": false,
|
| 6 |
+
"inference_mode": true,
|
| 7 |
+
"init_lora_weights": true,
|
| 8 |
+
"layers_pattern": null,
|
| 9 |
+
"layers_to_transform": null,
|
| 10 |
+
"lora_alpha": 32.0,
|
| 11 |
+
"lora_dropout": 0.1,
|
| 12 |
+
"modules_to_save": null,
|
| 13 |
+
"peft_type": "LORA",
|
| 14 |
+
"r": 8,
|
| 15 |
+
"revision": null,
|
| 16 |
+
"target_modules": [
|
| 17 |
+
"q_proj",
|
| 18 |
+
"v_proj"
|
| 19 |
+
],
|
| 20 |
+
"task_type": "CAUSAL_LM"
|
| 21 |
+
}
|
zhongjing_7_26/adapter_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e5c74024cb89ffb00caf85b182d5521e4ac581d40c73d20aa928c90bb1f4d7e
|
| 3 |
+
size 26272269
|
zhongjing_7_26/all_results.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 100.0,
|
| 3 |
+
"eval_loss": 1.051451325416565,
|
| 4 |
+
"eval_runtime": 0.2614,
|
| 5 |
+
"eval_samples_per_second": 26.783,
|
| 6 |
+
"eval_steps_per_second": 3.826,
|
| 7 |
+
"train_loss": 0.2177230092138052,
|
| 8 |
+
"train_runtime": 600.5927,
|
| 9 |
+
"train_samples_per_second": 8.991,
|
| 10 |
+
"train_steps_per_second": 0.167
|
| 11 |
+
}
|
zhongjing_7_26/checkpoint-100/README.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: peft
|
| 3 |
+
---
|
| 4 |
+
## Training procedure
|
| 5 |
+
|
| 6 |
+
### Framework versions
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
- PEFT 0.4.0
|
zhongjing_7_26/checkpoint-100/adapter_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_mapping": null,
|
| 3 |
+
"base_model_name_or_path": "/hy-tmp/Ziya-LLaMA-13B-v1",
|
| 4 |
+
"bias": "none",
|
| 5 |
+
"fan_in_fan_out": false,
|
| 6 |
+
"inference_mode": true,
|
| 7 |
+
"init_lora_weights": true,
|
| 8 |
+
"layers_pattern": null,
|
| 9 |
+
"layers_to_transform": null,
|
| 10 |
+
"lora_alpha": 32.0,
|
| 11 |
+
"lora_dropout": 0.1,
|
| 12 |
+
"modules_to_save": null,
|
| 13 |
+
"peft_type": "LORA",
|
| 14 |
+
"r": 8,
|
| 15 |
+
"revision": null,
|
| 16 |
+
"target_modules": [
|
| 17 |
+
"q_proj",
|
| 18 |
+
"v_proj"
|
| 19 |
+
],
|
| 20 |
+
"task_type": "CAUSAL_LM"
|
| 21 |
+
}
|
zhongjing_7_26/checkpoint-100/adapter_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e5c74024cb89ffb00caf85b182d5521e4ac581d40c73d20aa928c90bb1f4d7e
|
| 3 |
+
size 26272269
|
zhongjing_7_26/checkpoint-100/finetuning_args.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"finetuning_type": "lora",
|
| 3 |
+
"lora_alpha": 32.0,
|
| 4 |
+
"lora_dropout": 0.1,
|
| 5 |
+
"lora_rank": 8,
|
| 6 |
+
"lora_target": [
|
| 7 |
+
"q_proj",
|
| 8 |
+
"v_proj"
|
| 9 |
+
],
|
| 10 |
+
"name_module_trainable": "mlp",
|
| 11 |
+
"num_hidden_layers": 32,
|
| 12 |
+
"num_layer_trainable": 3
|
| 13 |
+
}
|
zhongjing_7_26/checkpoint-100/optimizer.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0b92148a73ead707fa106ccc6df242e611eea77a880a977ebae5c90bec2cf0c
|
| 3 |
+
size 52571013
|
zhongjing_7_26/checkpoint-100/rng_state.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb7dff83b0b70ec2b3f5ce6616e303966e6ba95f6f26fe460148516e079ebac9
|
| 3 |
+
size 14639
|
zhongjing_7_26/checkpoint-100/scheduler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a0dd8ae8cf7db4c90d2e0e9df3695287fc4664c776f1e98ce5de482cdaba04d
|
| 3 |
+
size 627
|
zhongjing_7_26/checkpoint-100/trainer_state.json
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
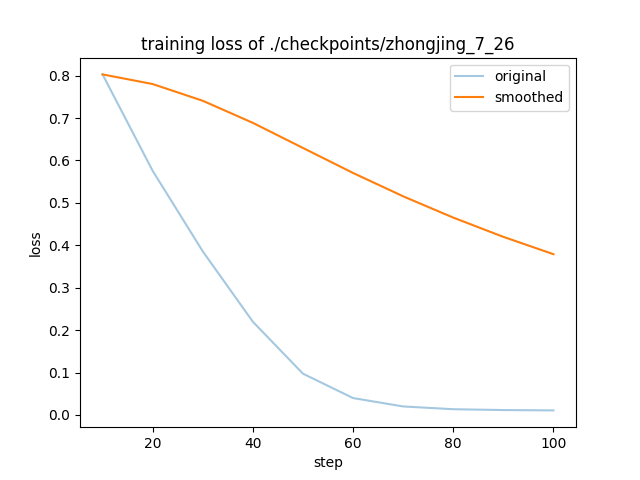
| 1 |
+
{
|
| 2 |
+
"best_metric": 1.051451325416565,
|
| 3 |
+
"best_model_checkpoint": "./checkpoints/zhongjing_7_26/checkpoint-100",
|
| 4 |
+
"epoch": 100.0,
|
| 5 |
+
"global_step": 100,
|
| 6 |
+
"is_hyper_param_search": false,
|
| 7 |
+
"is_local_process_zero": true,
|
| 8 |
+
"is_world_process_zero": true,
|
| 9 |
+
"log_history": [
|
| 10 |
+
{
|
| 11 |
+
"epoch": 10.0,
|
| 12 |
+
"learning_rate": 9.755282581475769e-05,
|
| 13 |
+
"loss": 0.803,
|
| 14 |
+
"step": 10
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"epoch": 10.0,
|
| 18 |
+
"eval_loss": 0.6868318915367126,
|
| 19 |
+
"eval_runtime": 0.263,
|
| 20 |
+
"eval_samples_per_second": 26.615,
|
| 21 |
+
"eval_steps_per_second": 3.802,
|
| 22 |
+
"step": 10
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"epoch": 20.0,
|
| 26 |
+
"learning_rate": 9.045084971874738e-05,
|
| 27 |
+
"loss": 0.5757,
|
| 28 |
+
"step": 20
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"epoch": 20.0,
|
| 32 |
+
"eval_loss": 0.5540383458137512,
|
| 33 |
+
"eval_runtime": 0.2628,
|
| 34 |
+
"eval_samples_per_second": 26.639,
|
| 35 |
+
"eval_steps_per_second": 3.806,
|
| 36 |
+
"step": 20
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"epoch": 30.0,
|
| 40 |
+
"learning_rate": 7.938926261462366e-05,
|
| 41 |
+
"loss": 0.3858,
|
| 42 |
+
"step": 30
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"epoch": 30.0,
|
| 46 |
+
"eval_loss": 0.5853456854820251,
|
| 47 |
+
"eval_runtime": 0.2612,
|
| 48 |
+
"eval_samples_per_second": 26.799,
|
| 49 |
+
"eval_steps_per_second": 3.828,
|
| 50 |
+
"step": 30
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"epoch": 40.0,
|
| 54 |
+
"learning_rate": 6.545084971874738e-05,
|
| 55 |
+
"loss": 0.2198,
|
| 56 |
+
"step": 40
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"epoch": 40.0,
|
| 60 |
+
"eval_loss": 0.6874333620071411,
|
| 61 |
+
"eval_runtime": 0.2605,
|
| 62 |
+
"eval_samples_per_second": 26.873,
|
| 63 |
+
"eval_steps_per_second": 3.839,
|
| 64 |
+
"step": 40
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"epoch": 50.0,
|
| 68 |
+
"learning_rate": 5e-05,
|
| 69 |
+
"loss": 0.0973,
|
| 70 |
+
"step": 50
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"epoch": 50.0,
|
| 74 |
+
"eval_loss": 0.8139681816101074,
|
| 75 |
+
"eval_runtime": 0.2601,
|
| 76 |
+
"eval_samples_per_second": 26.91,
|
| 77 |
+
"eval_steps_per_second": 3.844,
|
| 78 |
+
"step": 50
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"epoch": 60.0,
|
| 82 |
+
"learning_rate": 3.4549150281252636e-05,
|
| 83 |
+
"loss": 0.0398,
|
| 84 |
+
"step": 60
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
"epoch": 60.0,
|
| 88 |
+
"eval_loss": 0.9051175713539124,
|
| 89 |
+
"eval_runtime": 0.2596,
|
| 90 |
+
"eval_samples_per_second": 26.963,
|
| 91 |
+
"eval_steps_per_second": 3.852,
|
| 92 |
+
"step": 60
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 70.0,
|
| 96 |
+
"learning_rate": 2.061073738537635e-05,
|
| 97 |
+
"loss": 0.02,
|
| 98 |
+
"step": 70
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"epoch": 70.0,
|
| 102 |
+
"eval_loss": 1.000623345375061,
|
| 103 |
+
"eval_runtime": 0.2584,
|
| 104 |
+
"eval_samples_per_second": 27.089,
|
| 105 |
+
"eval_steps_per_second": 3.87,
|
| 106 |
+
"step": 70
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"epoch": 80.0,
|
| 110 |
+
"learning_rate": 9.549150281252633e-06,
|
| 111 |
+
"loss": 0.0135,
|
| 112 |
+
"step": 80
|
| 113 |
+
},
|
| 114 |
+
{
|
| 115 |
+
"epoch": 80.0,
|
| 116 |
+
"eval_loss": 1.0337673425674438,
|
| 117 |
+
"eval_runtime": 0.2607,
|
| 118 |
+
"eval_samples_per_second": 26.848,
|
| 119 |
+
"eval_steps_per_second": 3.835,
|
| 120 |
+
"step": 80
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"epoch": 90.0,
|
| 124 |
+
"learning_rate": 2.4471741852423237e-06,
|
| 125 |
+
"loss": 0.0115,
|
| 126 |
+
"step": 90
|
| 127 |
+
},
|
| 128 |
+
{
|
| 129 |
+
"epoch": 90.0,
|
| 130 |
+
"eval_loss": 1.0473424196243286,
|
| 131 |
+
"eval_runtime": 0.2628,
|
| 132 |
+
"eval_samples_per_second": 26.64,
|
| 133 |
+
"eval_steps_per_second": 3.806,
|
| 134 |
+
"step": 90
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"epoch": 100.0,
|
| 138 |
+
"learning_rate": 0.0,
|
| 139 |
+
"loss": 0.0107,
|
| 140 |
+
"step": 100
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"epoch": 100.0,
|
| 144 |
+
"eval_loss": 1.051451325416565,
|
| 145 |
+
"eval_runtime": 0.2626,
|
| 146 |
+
"eval_samples_per_second": 26.659,
|
| 147 |
+
"eval_steps_per_second": 3.808,
|
| 148 |
+
"step": 100
|
| 149 |
+
}
|
| 150 |
+
],
|
| 151 |
+
"max_steps": 100,
|
| 152 |
+
"num_train_epochs": 100,
|
| 153 |
+
"total_flos": 8.61449315165184e+16,
|
| 154 |
+
"trial_name": null,
|
| 155 |
+
"trial_params": null
|
| 156 |
+
}
|
zhongjing_7_26/checkpoint-100/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:18dd2a9b9c5b2fbe298de025168c26d81ad8e13b46d3efa3b67d69d5707f54f6
|
| 3 |
+
size 3389
|
zhongjing_7_26/description.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
用于完成关于 zhongjing 自我认知的修改
|
zhongjing_7_26/eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 100.0,
|
| 3 |
+
"eval_loss": 1.051451325416565,
|
| 4 |
+
"eval_runtime": 0.2614,
|
| 5 |
+
"eval_samples_per_second": 26.783,
|
| 6 |
+
"eval_steps_per_second": 3.826
|
| 7 |
+
}
|
zhongjing_7_26/finetuning_args.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"finetuning_type": "lora",
|
| 3 |
+
"lora_alpha": 32.0,
|
| 4 |
+
"lora_dropout": 0.1,
|
| 5 |
+
"lora_rank": 8,
|
| 6 |
+
"lora_target": [
|
| 7 |
+
"q_proj",
|
| 8 |
+
"v_proj"
|
| 9 |
+
],
|
| 10 |
+
"name_module_trainable": "mlp",
|
| 11 |
+
"num_hidden_layers": 32,
|
| 12 |
+
"num_layer_trainable": 3
|
| 13 |
+
}
|
zhongjing_7_26/train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 100.0,
|
| 3 |
+
"train_loss": 0.2177230092138052,
|
| 4 |
+
"train_runtime": 600.5927,
|
| 5 |
+
"train_samples_per_second": 8.991,
|
| 6 |
+
"train_steps_per_second": 0.167
|
| 7 |
+
}
|
zhongjing_7_26/trainer_log.jsonl
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 10, "total_steps": 100, "loss": 0.803, "reward": null, "learning_rate": 9.755282581475769e-05, "epoch": 10.0, "percentage": 10.0, "elapsed_time": "0:01:09", "remaining_time": "0:10:21"}
|
| 2 |
+
{"current_steps": 20, "total_steps": 100, "loss": 0.5757, "reward": null, "learning_rate": 9.045084971874738e-05, "epoch": 20.0, "percentage": 20.0, "elapsed_time": "0:02:08", "remaining_time": "0:08:35"}
|
| 3 |
+
{"current_steps": 30, "total_steps": 100, "loss": 0.3858, "reward": null, "learning_rate": 7.938926261462366e-05, "epoch": 30.0, "percentage": 30.0, "elapsed_time": "0:03:09", "remaining_time": "0:07:21"}
|
| 4 |
+
{"current_steps": 40, "total_steps": 100, "loss": 0.2198, "reward": null, "learning_rate": 6.545084971874738e-05, "epoch": 40.0, "percentage": 40.0, "elapsed_time": "0:04:09", "remaining_time": "0:06:13"}
|
| 5 |
+
{"current_steps": 50, "total_steps": 100, "loss": 0.0973, "reward": null, "learning_rate": 5e-05, "epoch": 50.0, "percentage": 50.0, "elapsed_time": "0:05:08", "remaining_time": "0:05:08"}
|
| 6 |
+
{"current_steps": 60, "total_steps": 100, "loss": 0.0398, "reward": null, "learning_rate": 3.4549150281252636e-05, "epoch": 60.0, "percentage": 60.0, "elapsed_time": "0:06:08", "remaining_time": "0:04:05"}
|
| 7 |
+
{"current_steps": 70, "total_steps": 100, "loss": 0.02, "reward": null, "learning_rate": 2.061073738537635e-05, "epoch": 70.0, "percentage": 70.0, "elapsed_time": "0:07:08", "remaining_time": "0:03:03"}
|
| 8 |
+
{"current_steps": 80, "total_steps": 100, "loss": 0.0135, "reward": null, "learning_rate": 9.549150281252633e-06, "epoch": 80.0, "percentage": 80.0, "elapsed_time": "0:08:08", "remaining_time": "0:02:02"}
|
| 9 |
+
{"current_steps": 90, "total_steps": 100, "loss": 0.0115, "reward": null, "learning_rate": 2.4471741852423237e-06, "epoch": 90.0, "percentage": 90.0, "elapsed_time": "0:09:08", "remaining_time": "0:01:00"}
|
| 10 |
+
{"current_steps": 100, "total_steps": 100, "loss": 0.0107, "reward": null, "learning_rate": 0.0, "epoch": 100.0, "percentage": 100.0, "elapsed_time": "0:10:08", "remaining_time": "0:00:00"}
|
zhongjing_7_26/trainer_state.json
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 1.051451325416565,
|
| 3 |
+
"best_model_checkpoint": "./checkpoints/zhongjing_7_26/checkpoint-100",
|
| 4 |
+
"epoch": 100.0,
|
| 5 |
+
"global_step": 100,
|
| 6 |
+
"is_hyper_param_search": false,
|
| 7 |
+
"is_local_process_zero": true,
|
| 8 |
+
"is_world_process_zero": true,
|
| 9 |
+
"log_history": [
|
| 10 |
+
{
|
| 11 |
+
"epoch": 10.0,
|
| 12 |
+
"learning_rate": 9.755282581475769e-05,
|
| 13 |
+
"loss": 0.803,
|
| 14 |
+
"step": 10
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"epoch": 10.0,
|
| 18 |
+
"eval_loss": 0.6868318915367126,
|
| 19 |
+
"eval_runtime": 0.263,
|
| 20 |
+
"eval_samples_per_second": 26.615,
|
| 21 |
+
"eval_steps_per_second": 3.802,
|
| 22 |
+
"step": 10
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"epoch": 20.0,
|
| 26 |
+
"learning_rate": 9.045084971874738e-05,
|
| 27 |
+
"loss": 0.5757,
|
| 28 |
+
"step": 20
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"epoch": 20.0,
|
| 32 |
+
"eval_loss": 0.5540383458137512,
|
| 33 |
+
"eval_runtime": 0.2628,
|
| 34 |
+
"eval_samples_per_second": 26.639,
|
| 35 |
+
"eval_steps_per_second": 3.806,
|
| 36 |
+
"step": 20
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"epoch": 30.0,
|
| 40 |
+
"learning_rate": 7.938926261462366e-05,
|
| 41 |
+
"loss": 0.3858,
|
| 42 |
+
"step": 30
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"epoch": 30.0,
|
| 46 |
+
"eval_loss": 0.5853456854820251,
|
| 47 |
+
"eval_runtime": 0.2612,
|
| 48 |
+
"eval_samples_per_second": 26.799,
|
| 49 |
+
"eval_steps_per_second": 3.828,
|
| 50 |
+
"step": 30
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"epoch": 40.0,
|
| 54 |
+
"learning_rate": 6.545084971874738e-05,
|
| 55 |
+
"loss": 0.2198,
|
| 56 |
+
"step": 40
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"epoch": 40.0,
|
| 60 |
+
"eval_loss": 0.6874333620071411,
|
| 61 |
+
"eval_runtime": 0.2605,
|
| 62 |
+
"eval_samples_per_second": 26.873,
|
| 63 |
+
"eval_steps_per_second": 3.839,
|
| 64 |
+
"step": 40
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"epoch": 50.0,
|
| 68 |
+
"learning_rate": 5e-05,
|
| 69 |
+
"loss": 0.0973,
|
| 70 |
+
"step": 50
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"epoch": 50.0,
|
| 74 |
+
"eval_loss": 0.8139681816101074,
|
| 75 |
+
"eval_runtime": 0.2601,
|
| 76 |
+
"eval_samples_per_second": 26.91,
|
| 77 |
+
"eval_steps_per_second": 3.844,
|
| 78 |
+
"step": 50
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"epoch": 60.0,
|
| 82 |
+
"learning_rate": 3.4549150281252636e-05,
|
| 83 |
+
"loss": 0.0398,
|
| 84 |
+
"step": 60
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
"epoch": 60.0,
|
| 88 |
+
"eval_loss": 0.9051175713539124,
|
| 89 |
+
"eval_runtime": 0.2596,
|
| 90 |
+
"eval_samples_per_second": 26.963,
|
| 91 |
+
"eval_steps_per_second": 3.852,
|
| 92 |
+
"step": 60
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 70.0,
|
| 96 |
+
"learning_rate": 2.061073738537635e-05,
|
| 97 |
+
"loss": 0.02,
|
| 98 |
+
"step": 70
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"epoch": 70.0,
|
| 102 |
+
"eval_loss": 1.000623345375061,
|
| 103 |
+
"eval_runtime": 0.2584,
|
| 104 |
+
"eval_samples_per_second": 27.089,
|
| 105 |
+
"eval_steps_per_second": 3.87,
|
| 106 |
+
"step": 70
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"epoch": 80.0,
|
| 110 |
+
"learning_rate": 9.549150281252633e-06,
|
| 111 |
+
"loss": 0.0135,
|
| 112 |
+
"step": 80
|
| 113 |
+
},
|
| 114 |
+
{
|
| 115 |
+
"epoch": 80.0,
|
| 116 |
+
"eval_loss": 1.0337673425674438,
|
| 117 |
+
"eval_runtime": 0.2607,
|
| 118 |
+
"eval_samples_per_second": 26.848,
|
| 119 |
+
"eval_steps_per_second": 3.835,
|
| 120 |
+
"step": 80
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"epoch": 90.0,
|
| 124 |
+
"learning_rate": 2.4471741852423237e-06,
|
| 125 |
+
"loss": 0.0115,
|
| 126 |
+
"step": 90
|
| 127 |
+
},
|
| 128 |
+
{
|
| 129 |
+
"epoch": 90.0,
|
| 130 |
+
"eval_loss": 1.0473424196243286,
|
| 131 |
+
"eval_runtime": 0.2628,
|
| 132 |
+
"eval_samples_per_second": 26.64,
|
| 133 |
+
"eval_steps_per_second": 3.806,
|
| 134 |
+
"step": 90
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"epoch": 100.0,
|
| 138 |
+
"learning_rate": 0.0,
|
| 139 |
+
"loss": 0.0107,
|
| 140 |
+
"step": 100
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"epoch": 100.0,
|
| 144 |
+
"eval_loss": 1.051451325416565,
|
| 145 |
+
"eval_runtime": 0.2626,
|
| 146 |
+
"eval_samples_per_second": 26.659,
|
| 147 |
+
"eval_steps_per_second": 3.808,
|
| 148 |
+
"step": 100
|
| 149 |
+
},
|
| 150 |
+
{
|
| 151 |
+
"epoch": 100.0,
|
| 152 |
+
"step": 100,
|
| 153 |
+
"total_flos": 8.61449315165184e+16,
|
| 154 |
+
"train_loss": 0.2177230092138052,
|
| 155 |
+
"train_runtime": 600.5927,
|
| 156 |
+
"train_samples_per_second": 8.991,
|
| 157 |
+
"train_steps_per_second": 0.167
|
| 158 |
+
}
|
| 159 |
+
],
|
| 160 |
+
"max_steps": 100,
|
| 161 |
+
"num_train_epochs": 100,
|
| 162 |
+
"total_flos": 8.61449315165184e+16,
|
| 163 |
+
"trial_name": null,
|
| 164 |
+
"trial_params": null
|
| 165 |
+
}
|
zhongjing_7_26/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:18dd2a9b9c5b2fbe298de025168c26d81ad8e13b46d3efa3b67d69d5707f54f6
|
| 3 |
+
size 3389
|
zhongjing_7_26/training_eval_loss.png
ADDED

|
zhongjing_7_26/training_loss.png
ADDED
|