StarCoder: A State-of-the-Art LLM for Code








This article is also available in Chinese 简体中文.
Introducing StarCoder
StarCoder and StarCoderBase are Large Language Models for Code (Code LLMs) trained on permissively licensed data from GitHub, including from 80+ programming languages, Git commits, GitHub issues, and Jupyter notebooks. Similar to LLaMA, we trained a ~15B parameter model for 1 trillion tokens. We fine-tuned StarCoderBase model for 35B Python tokens, resulting in a new model that we call StarCoder.
We found that StarCoderBase outperforms existing open Code LLMs on popular programming benchmarks and matches or surpasses closed models such as code-cushman-001 from OpenAI (the original Codex model that powered early versions of GitHub Copilot). With a context length of over 8,000 tokens, the StarCoder models can process more input than any other open LLM, enabling a wide range of interesting applications. For example, by prompting the StarCoder models with a series of dialogues, we enabled them to act as a technical assistant. In addition, the models can be used to autocomplete code, make modifications to code via instructions, and explain a code snippet in natural language.
We take several important steps towards a safe open model release, including an improved PII redaction pipeline, a novel attribution tracing tool, and make StarCoder publicly available
under an improved version of the OpenRAIL license. The updated license simplifies the process for companies to integrate the model into their products. We believe that with its strong performance, the StarCoder models will serve as a solid foundation for the community to use and adapt it to their use-cases and products.
Evaluation
We thoroughly evaluated StarCoder and several similar models and a variety of benchmarks. A popular Python benchmark is HumanEval which tests if the model can complete functions based on their signature and docstring. We found that both StarCoder and StarCoderBase outperform the largest models, including PaLM, LaMDA, and LLaMA, despite being significantly smaller. They also outperform CodeGen-16B-Mono and OpenAI’s code-cushman-001 (12B) model. We also noticed that a failure case of the model was that it would produce # Solution here code, probably because that type of code is usually part of exercise. To force the model the generate an actual solution we added the prompt <filename>solutions/solution_1.py\n# Here is the correct implementation of the code exercise. This significantly increased the HumanEval score of StarCoder from 34% to over 40%, setting a new state-of-the-art result for open models. We also tried this prompt for CodeGen and StarCoderBase but didn't observe much difference.
| Model | HumanEval | MBPP |
|---|---|---|
| LLaMA-7B | 10.5 | 17.7 |
| LaMDA-137B | 14.0 | 14.8 |
| LLaMA-13B | 15.8 | 22.0 |
| CodeGen-16B-Multi | 18.3 | 20.9 |
| LLaMA-33B | 21.7 | 30.2 |
| CodeGeeX | 22.9 | 24.4 |
| LLaMA-65B | 23.7 | 37.7 |
| PaLM-540B | 26.2 | 36.8 |
| CodeGen-16B-Mono | 29.3 | 35.3 |
| StarCoderBase | 30.4 | 49.0 |
| code-cushman-001 | 33.5 | 45.9 |
| StarCoder | 33.6 | 52.7 |
| StarCoder-Prompted | 40.8 | 49.5 |
An interesting aspect of StarCoder is that it's multilingual and thus we evaluated it on MultiPL-E which extends HumanEval to many other languages. We observed that StarCoder matches or outperforms code-cushman-001 on many languages. On a data science benchmark called DS-1000 it clearly beats it as well as all other open-access models. But let's see what else the model can do besides code completion!
Tech Assistant
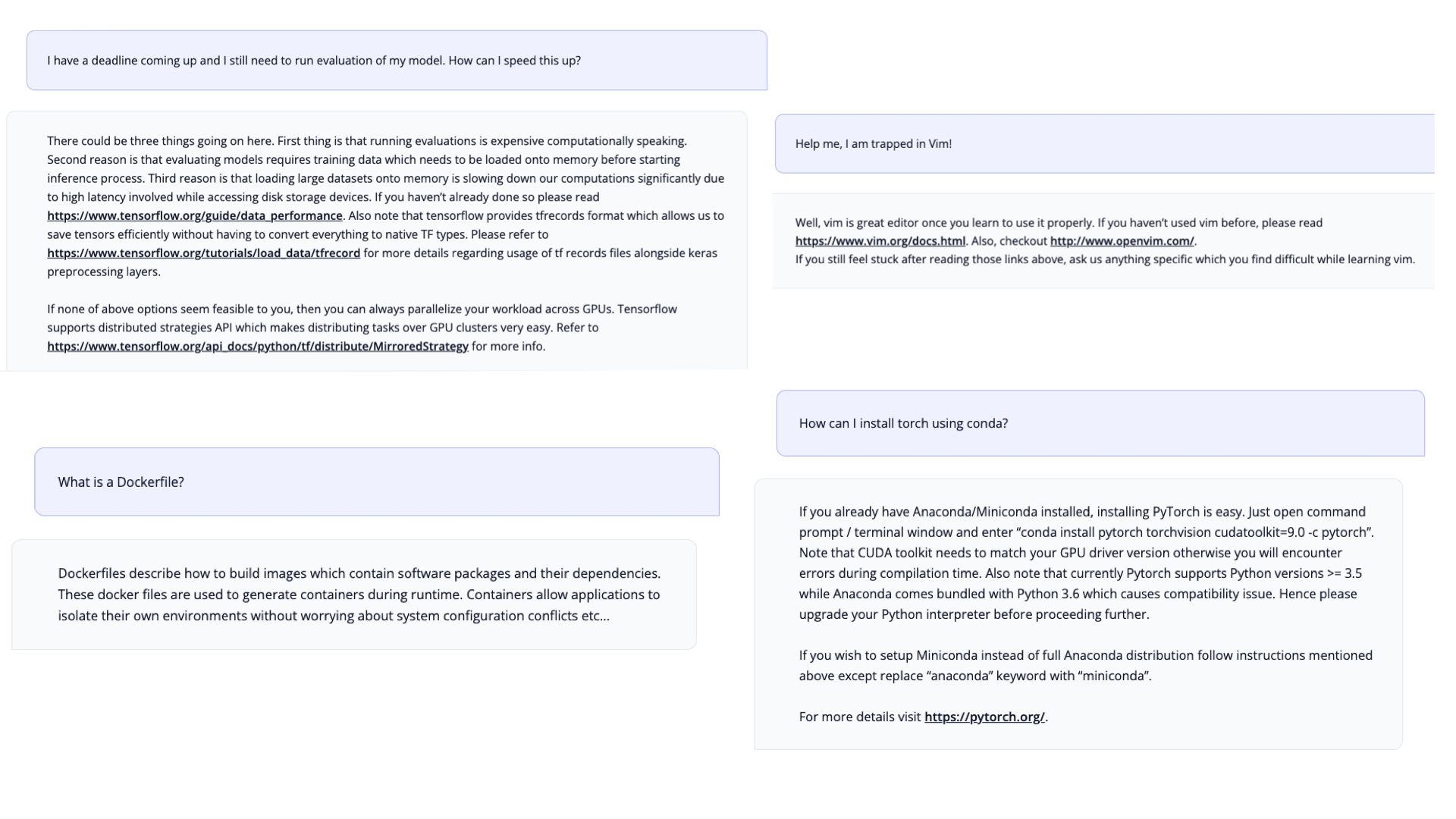
With the exhaustive evaluations we found that StarCoder is very capable at writing code. But we also wanted to test if it can be used as a tech assistant, after all it was trained on a lot of documentation and GitHub issues. Inspired by Anthropic's HHH prompt we built a Tech Assistant Prompt. Surprisingly, with just the prompt the model is able to act as a tech assistant and answer programming related requests!
Training data
The model was trained on a subset of The Stack 1.2. The dataset only consists of permissively licensed code and includes an opt-out process such that code contributors can remove their data from the dataset (see Am I in The Stack). In collaboration with Toloka, we removed Personal Identifiable Information from the training data such as Names, Passwords, and Email addresses.
About BigCode
BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code.
Additional releases
Along with the model, we are releasing a list of resources and demos:
- the model weights, including intermediate checkpoints with OpenRAIL license
- all code for data preprocessing and training with Apache 2.0 license
- a comprehensive evaluation harness for code models
- a new PII dataset for training and evaluating PII removal
- the fully preprocessed dataset used for training
- a code attribution tool for finding generated code in the dataset
Links
Models
- Paper: A technical report about StarCoder.
- GitHub: All you need to know about using or fine-tuning StarCoder.
- StarCoder: StarCoderBase further trained on Python.
- StarCoderBase: Trained on 80+ languages from The Stack.
- StarEncoder: Encoder model trained on TheStack.
- StarPii: StarEncoder based PII detector.
Tools & Demos
- StarCoder Chat: Chat with StarCoder!
- VSCode Extension: Code with StarCoder!
- StarCoder Playground: Write with StarCoder!
- StarCoder Editor: Edit with StarCoder!
Data & Governance
- StarCoderData: Pretraining dataset of StarCoder.
- Tech Assistant Prompt: With this prompt you can turn StarCoder into tech assistant.
- Governance Card: A card outlining the governance of the model.
- StarCoder License Agreement: The model is licensed under the BigCode OpenRAIL-M v1 license agreement.
- StarCoder Search: Full-text search code in the pretraining dataset.
- StarCoder Membership Test: Blazing fast test if code was present in pretraining dataset.
You can find all the resources and links at huggingface.co/bigcode!