Spaces:
Sleeping

Sleeping
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +57 -0
- flash-attention/.eggs/README.txt +6 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/AUTHORS.rst +5 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/LICENSE_Apache_20 +191 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/PKG-INFO +110 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/RECORD +13 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/WHEEL +6 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/entry_points.txt +2 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/requires.txt +10 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/top_level.txt +1 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/__init__.py +55 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/__main__.py +5 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/_version.py +16 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/data/bin/ninja.exe +0 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/ninja_syntax.py +199 -0
- flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/py.typed +0 -0
- flash-attention/.github/workflows/publish.yml +235 -0
- flash-attention/.gitignore +27 -0
- flash-attention/.gitmodules +3 -0
- flash-attention/AUTHORS +1 -0
- flash-attention/LICENSE +29 -0
- flash-attention/MANIFEST.in +11 -0
- flash-attention/Makefile +9 -0
- flash-attention/README.md +412 -0
- flash-attention/assets/flash2_a100_fwd_bwd_benchmark.png +0 -0
- flash-attention/assets/flash2_h100_fwd_bwd_benchmark.png +0 -0
- flash-attention/assets/flashattention_logo.png +3 -0
- flash-attention/assets/flashattn_banner.jpg +0 -0
- flash-attention/assets/flashattn_banner.pdf +0 -0
- flash-attention/assets/flashattn_memory.jpg +0 -0
- flash-attention/assets/flashattn_speedup.jpg +0 -0
- flash-attention/assets/flashattn_speedup_3090.jpg +0 -0
- flash-attention/assets/flashattn_speedup_a100_d128.jpg +0 -0
- flash-attention/assets/flashattn_speedup_t4.jpg +0 -0
- flash-attention/assets/flashattn_speedup_t4_fwd.jpg +0 -0
- flash-attention/assets/gpt2_training_curve.jpg +0 -0
- flash-attention/assets/gpt2_training_efficiency.jpg +0 -0
- flash-attention/assets/gpt3_training_curve.jpg +0 -0
- flash-attention/assets/gpt3_training_efficiency.jpg +0 -0
- flash-attention/benchmarks/benchmark_alibi.py +275 -0
- flash-attention/benchmarks/benchmark_causal.py +225 -0
- flash-attention/benchmarks/benchmark_flash_attention.py +180 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/__init__.py +11 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/bert_padding.py +213 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_attn_interface.py +1217 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_attn_triton.py +1160 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_attn_triton_og.py +365 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_blocksparse_attention.py +197 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_blocksparse_attn_interface.py +200 -0
- flash-attention/build/lib.win-amd64-3.10/flash_attn/fused_softmax.py +201 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,60 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
flash-attention/assets/flashattention_logo.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
flash-attention/build/lib.win-amd64-3.10/flash_attn_2_cuda.cp310-win_amd64.pyd filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/flash_api.obj filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim128_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim128_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim160_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim160_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim192_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim192_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim224_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim224_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim256_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim256_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim32_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim32_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim64_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim64_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim96_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_bwd_hdim96_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim128_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim128_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim160_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim160_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim192_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim192_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim224_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim224_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim256_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 64 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim256_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 65 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim32_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 66 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim32_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 67 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim64_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 68 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim64_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 69 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim96_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 70 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_hdim96_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 71 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim128_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 72 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim128_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 73 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim160_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 74 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim160_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 75 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim192_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 76 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim192_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 77 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim224_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 78 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim224_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 79 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim256_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 80 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim256_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 81 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim32_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 82 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim32_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 83 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim64_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 84 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim64_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 85 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim96_bf16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 86 |
+
flash-attention/build/temp.win-amd64-3.10/Release/csrc/flash_attn/src/flash_fwd_split_hdim96_fp16_sm80.obj filter=lfs diff=lfs merge=lfs -text
|
| 87 |
+
flash-attention/csrc/cutlass/media/images/cute/gmma_wg_n_slice.png filter=lfs diff=lfs merge=lfs -text
|
| 88 |
+
flash-attention/csrc/cutlass/media/images/cute/TiledCopyA.png filter=lfs diff=lfs merge=lfs -text
|
| 89 |
+
flash-attention/csrc/cutlass/media/images/cute/tv_layout.png filter=lfs diff=lfs merge=lfs -text
|
| 90 |
+
flash-attention/csrc/cutlass/media/images/cutlass-2.9-implicit-gemm-performance.png filter=lfs diff=lfs merge=lfs -text
|
| 91 |
+
flash-attention/csrc/cutlass/media/images/ldmatrix-tensorop-32x32x32.png filter=lfs diff=lfs merge=lfs -text
|
| 92 |
+
flash-attention/dist/flash_attn-2.5.9.post1-py3.10-win-amd64.egg filter=lfs diff=lfs merge=lfs -text
|
flash-attention/.eggs/README.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This directory contains eggs that were downloaded by setuptools to build, test, and run plug-ins.
|
| 2 |
+
|
| 3 |
+
This directory caches those eggs to prevent repeated downloads.
|
| 4 |
+
|
| 5 |
+
However, it is safe to delete this directory.
|
| 6 |
+
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/AUTHORS.rst
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
=======
|
| 2 |
+
Credits
|
| 3 |
+
=======
|
| 4 |
+
|
| 5 |
+
Please see the GitHub project page at https://github.com/scikit-build/ninja-python-distributions/graphs/contributors
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/LICENSE_Apache_20
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction, and
|
| 10 |
+
distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by the copyright
|
| 13 |
+
owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all other entities
|
| 16 |
+
that control, are controlled by, or are under common control with that entity.
|
| 17 |
+
For the purposes of this definition, "control" means (i) the power, direct or
|
| 18 |
+
indirect, to cause the direction or management of such entity, whether by
|
| 19 |
+
contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 20 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 21 |
+
|
| 22 |
+
"You" (or "Your") shall mean an individual or Legal Entity exercising
|
| 23 |
+
permissions granted by this License.
|
| 24 |
+
|
| 25 |
+
"Source" form shall mean the preferred form for making modifications, including
|
| 26 |
+
but not limited to software source code, documentation source, and configuration
|
| 27 |
+
files.
|
| 28 |
+
|
| 29 |
+
"Object" form shall mean any form resulting from mechanical transformation or
|
| 30 |
+
translation of a Source form, including but not limited to compiled object code,
|
| 31 |
+
generated documentation, and conversions to other media types.
|
| 32 |
+
|
| 33 |
+
"Work" shall mean the work of authorship, whether in Source or Object form, made
|
| 34 |
+
available under the License, as indicated by a copyright notice that is included
|
| 35 |
+
in or attached to the work (an example is provided in the Appendix below).
|
| 36 |
+
|
| 37 |
+
"Derivative Works" shall mean any work, whether in Source or Object form, that
|
| 38 |
+
is based on (or derived from) the Work and for which the editorial revisions,
|
| 39 |
+
annotations, elaborations, or other modifications represent, as a whole, an
|
| 40 |
+
original work of authorship. For the purposes of this License, Derivative Works
|
| 41 |
+
shall not include works that remain separable from, or merely link (or bind by
|
| 42 |
+
name) to the interfaces of, the Work and Derivative Works thereof.
|
| 43 |
+
|
| 44 |
+
"Contribution" shall mean any work of authorship, including the original version
|
| 45 |
+
of the Work and any modifications or additions to that Work or Derivative Works
|
| 46 |
+
thereof, that is intentionally submitted to Licensor for inclusion in the Work
|
| 47 |
+
by the copyright owner or by an individual or Legal Entity authorized to submit
|
| 48 |
+
on behalf of the copyright owner. For the purposes of this definition,
|
| 49 |
+
"submitted" means any form of electronic, verbal, or written communication sent
|
| 50 |
+
to the Licensor or its representatives, including but not limited to
|
| 51 |
+
communication on electronic mailing lists, source code control systems, and
|
| 52 |
+
issue tracking systems that are managed by, or on behalf of, the Licensor for
|
| 53 |
+
the purpose of discussing and improving the Work, but excluding communication
|
| 54 |
+
that is conspicuously marked or otherwise designated in writing by the copyright
|
| 55 |
+
owner as "Not a Contribution."
|
| 56 |
+
|
| 57 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf
|
| 58 |
+
of whom a Contribution has been received by Licensor and subsequently
|
| 59 |
+
incorporated within the Work.
|
| 60 |
+
|
| 61 |
+
2. Grant of Copyright License.
|
| 62 |
+
|
| 63 |
+
Subject to the terms and conditions of this License, each Contributor hereby
|
| 64 |
+
grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free,
|
| 65 |
+
irrevocable copyright license to reproduce, prepare Derivative Works of,
|
| 66 |
+
publicly display, publicly perform, sublicense, and distribute the Work and such
|
| 67 |
+
Derivative Works in Source or Object form.
|
| 68 |
+
|
| 69 |
+
3. Grant of Patent License.
|
| 70 |
+
|
| 71 |
+
Subject to the terms and conditions of this License, each Contributor hereby
|
| 72 |
+
grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free,
|
| 73 |
+
irrevocable (except as stated in this section) patent license to make, have
|
| 74 |
+
made, use, offer to sell, sell, import, and otherwise transfer the Work, where
|
| 75 |
+
such license applies only to those patent claims licensable by such Contributor
|
| 76 |
+
that are necessarily infringed by their Contribution(s) alone or by combination
|
| 77 |
+
of their Contribution(s) with the Work to which such Contribution(s) was
|
| 78 |
+
submitted. If You institute patent litigation against any entity (including a
|
| 79 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work or a
|
| 80 |
+
Contribution incorporated within the Work constitutes direct or contributory
|
| 81 |
+
patent infringement, then any patent licenses granted to You under this License
|
| 82 |
+
for that Work shall terminate as of the date such litigation is filed.
|
| 83 |
+
|
| 84 |
+
4. Redistribution.
|
| 85 |
+
|
| 86 |
+
You may reproduce and distribute copies of the Work or Derivative Works thereof
|
| 87 |
+
in any medium, with or without modifications, and in Source or Object form,
|
| 88 |
+
provided that You meet the following conditions:
|
| 89 |
+
|
| 90 |
+
You must give any other recipients of the Work or Derivative Works a copy of
|
| 91 |
+
this License; and
|
| 92 |
+
You must cause any modified files to carry prominent notices stating that You
|
| 93 |
+
changed the files; and
|
| 94 |
+
You must retain, in the Source form of any Derivative Works that You distribute,
|
| 95 |
+
all copyright, patent, trademark, and attribution notices from the Source form
|
| 96 |
+
of the Work, excluding those notices that do not pertain to any part of the
|
| 97 |
+
Derivative Works; and
|
| 98 |
+
If the Work includes a "NOTICE" text file as part of its distribution, then any
|
| 99 |
+
Derivative Works that You distribute must include a readable copy of the
|
| 100 |
+
attribution notices contained within such NOTICE file, excluding those notices
|
| 101 |
+
that do not pertain to any part of the Derivative Works, in at least one of the
|
| 102 |
+
following places: within a NOTICE text file distributed as part of the
|
| 103 |
+
Derivative Works; within the Source form or documentation, if provided along
|
| 104 |
+
with the Derivative Works; or, within a display generated by the Derivative
|
| 105 |
+
Works, if and wherever such third-party notices normally appear. The contents of
|
| 106 |
+
the NOTICE file are for informational purposes only and do not modify the
|
| 107 |
+
License. You may add Your own attribution notices within Derivative Works that
|
| 108 |
+
You distribute, alongside or as an addendum to the NOTICE text from the Work,
|
| 109 |
+
provided that such additional attribution notices cannot be construed as
|
| 110 |
+
modifying the License.
|
| 111 |
+
You may add Your own copyright statement to Your modifications and may provide
|
| 112 |
+
additional or different license terms and conditions for use, reproduction, or
|
| 113 |
+
distribution of Your modifications, or for any such Derivative Works as a whole,
|
| 114 |
+
provided Your use, reproduction, and distribution of the Work otherwise complies
|
| 115 |
+
with the conditions stated in this License.
|
| 116 |
+
|
| 117 |
+
5. Submission of Contributions.
|
| 118 |
+
|
| 119 |
+
Unless You explicitly state otherwise, any Contribution intentionally submitted
|
| 120 |
+
for inclusion in the Work by You to the Licensor shall be under the terms and
|
| 121 |
+
conditions of this License, without any additional terms or conditions.
|
| 122 |
+
Notwithstanding the above, nothing herein shall supersede or modify the terms of
|
| 123 |
+
any separate license agreement you may have executed with Licensor regarding
|
| 124 |
+
such Contributions.
|
| 125 |
+
|
| 126 |
+
6. Trademarks.
|
| 127 |
+
|
| 128 |
+
This License does not grant permission to use the trade names, trademarks,
|
| 129 |
+
service marks, or product names of the Licensor, except as required for
|
| 130 |
+
reasonable and customary use in describing the origin of the Work and
|
| 131 |
+
reproducing the content of the NOTICE file.
|
| 132 |
+
|
| 133 |
+
7. Disclaimer of Warranty.
|
| 134 |
+
|
| 135 |
+
Unless required by applicable law or agreed to in writing, Licensor provides the
|
| 136 |
+
Work (and each Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 137 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied,
|
| 138 |
+
including, without limitation, any warranties or conditions of TITLE,
|
| 139 |
+
NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are
|
| 140 |
+
solely responsible for determining the appropriateness of using or
|
| 141 |
+
redistributing the Work and assume any risks associated with Your exercise of
|
| 142 |
+
permissions under this License.
|
| 143 |
+
|
| 144 |
+
8. Limitation of Liability.
|
| 145 |
+
|
| 146 |
+
In no event and under no legal theory, whether in tort (including negligence),
|
| 147 |
+
contract, or otherwise, unless required by applicable law (such as deliberate
|
| 148 |
+
and grossly negligent acts) or agreed to in writing, shall any Contributor be
|
| 149 |
+
liable to You for damages, including any direct, indirect, special, incidental,
|
| 150 |
+
or consequential damages of any character arising as a result of this License or
|
| 151 |
+
out of the use or inability to use the Work (including but not limited to
|
| 152 |
+
damages for loss of goodwill, work stoppage, computer failure or malfunction, or
|
| 153 |
+
any and all other commercial damages or losses), even if such Contributor has
|
| 154 |
+
been advised of the possibility of such damages.
|
| 155 |
+
|
| 156 |
+
9. Accepting Warranty or Additional Liability.
|
| 157 |
+
|
| 158 |
+
While redistributing the Work or Derivative Works thereof, You may choose to
|
| 159 |
+
offer, and charge a fee for, acceptance of support, warranty, indemnity, or
|
| 160 |
+
other liability obligations and/or rights consistent with this License. However,
|
| 161 |
+
in accepting such obligations, You may act only on Your own behalf and on Your
|
| 162 |
+
sole responsibility, not on behalf of any other Contributor, and only if You
|
| 163 |
+
agree to indemnify, defend, and hold each Contributor harmless for any liability
|
| 164 |
+
incurred by, or claims asserted against, such Contributor by reason of your
|
| 165 |
+
accepting any such warranty or additional liability.
|
| 166 |
+
|
| 167 |
+
END OF TERMS AND CONDITIONS
|
| 168 |
+
|
| 169 |
+
APPENDIX: How to apply the Apache License to your work
|
| 170 |
+
|
| 171 |
+
To apply the Apache License to your work, attach the following boilerplate
|
| 172 |
+
notice, with the fields enclosed by brackets "[]" replaced with your own
|
| 173 |
+
identifying information. (Don't include the brackets!) The text should be
|
| 174 |
+
enclosed in the appropriate comment syntax for the file format. We also
|
| 175 |
+
recommend that a file or class name and description of purpose be included on
|
| 176 |
+
the same "printed page" as the copyright notice for easier identification within
|
| 177 |
+
third-party archives.
|
| 178 |
+
|
| 179 |
+
Copyright [yyyy] [name of copyright owner]
|
| 180 |
+
|
| 181 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 182 |
+
you may not use this file except in compliance with the License.
|
| 183 |
+
You may obtain a copy of the License at
|
| 184 |
+
|
| 185 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 186 |
+
|
| 187 |
+
Unless required by applicable law or agreed to in writing, software
|
| 188 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 189 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 190 |
+
See the License for the specific language governing permissions and
|
| 191 |
+
limitations under the License.
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/PKG-INFO
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.1
|
| 2 |
+
Name: ninja
|
| 3 |
+
Version: 1.11.1.1
|
| 4 |
+
Summary: Ninja is a small build system with a focus on speed
|
| 5 |
+
Home-page: http://ninja-build.org/
|
| 6 |
+
Download-URL: https://github.com/ninja-build/ninja/releases
|
| 7 |
+
Author: Jean-Christophe Fillion-Robin
|
| 8 |
+
Author-email: scikit-build@googlegroups.com
|
| 9 |
+
License: Apache 2.0
|
| 10 |
+
Project-URL: Documentation, https://github.com/scikit-build/ninja-python-distributions#readme
|
| 11 |
+
Project-URL: Source Code, https://github.com/scikit-build/ninja-python-distributions
|
| 12 |
+
Project-URL: Mailing list, https://groups.google.com/forum/#!forum/scikit-build
|
| 13 |
+
Project-URL: Bug Tracker, https://github.com/scikit-build/ninja-python-distributions/issues
|
| 14 |
+
Keywords: ninja build c++ fortran cross-platform cross-compilation
|
| 15 |
+
Classifier: License :: OSI Approved :: Apache Software License
|
| 16 |
+
Classifier: License :: OSI Approved :: BSD License
|
| 17 |
+
Classifier: Programming Language :: C
|
| 18 |
+
Classifier: Programming Language :: C++
|
| 19 |
+
Classifier: Programming Language :: Fortran
|
| 20 |
+
Classifier: Programming Language :: Python
|
| 21 |
+
Classifier: Operating System :: OS Independent
|
| 22 |
+
Classifier: Development Status :: 5 - Production/Stable
|
| 23 |
+
Classifier: Intended Audience :: Developers
|
| 24 |
+
Classifier: Topic :: Software Development :: Build Tools
|
| 25 |
+
Classifier: Typing :: Typed
|
| 26 |
+
Description-Content-Type: text/x-rst
|
| 27 |
+
License-File: LICENSE_Apache_20
|
| 28 |
+
License-File: AUTHORS.rst
|
| 29 |
+
Provides-Extra: test
|
| 30 |
+
Requires-Dist: codecov >=2.0.5 ; extra == 'test'
|
| 31 |
+
Requires-Dist: coverage >=4.2 ; extra == 'test'
|
| 32 |
+
Requires-Dist: flake8 >=3.0.4 ; extra == 'test'
|
| 33 |
+
Requires-Dist: pytest >=4.5.0 ; extra == 'test'
|
| 34 |
+
Requires-Dist: pytest-cov >=2.7.1 ; extra == 'test'
|
| 35 |
+
Requires-Dist: pytest-runner >=5.1 ; extra == 'test'
|
| 36 |
+
Requires-Dist: pytest-virtualenv >=1.7.0 ; extra == 'test'
|
| 37 |
+
Requires-Dist: virtualenv >=15.0.3 ; extra == 'test'
|
| 38 |
+
|
| 39 |
+
==========================
|
| 40 |
+
Ninja Python Distributions
|
| 41 |
+
==========================
|
| 42 |
+
|
| 43 |
+
`Ninja <http://www.ninja-build.org>`_ is a small build system with a focus on speed.
|
| 44 |
+
|
| 45 |
+
The latest Ninja python wheels provide `ninja 1.11.1.g95dee.kitware.jobserver-1 <https://ninja-build.org/manual.html>`_ executable
|
| 46 |
+
and `ninja_syntax.py` for generating `.ninja` files.
|
| 47 |
+
|
| 48 |
+
.. image:: https://raw.githubusercontent.com/scikit-build/ninja-python-distributions/master/ninja-python-distributions-logo.png
|
| 49 |
+
|
| 50 |
+
Latest Release
|
| 51 |
+
--------------
|
| 52 |
+
|
| 53 |
+
.. table::
|
| 54 |
+
|
| 55 |
+
+----------------------------------------------------------------------+---------------------------------------------------------------------------+
|
| 56 |
+
| Versions | Downloads |
|
| 57 |
+
+======================================================================+===========================================================================+
|
| 58 |
+
| .. image:: https://img.shields.io/pypi/v/ninja.svg | .. image:: https://img.shields.io/badge/downloads-2535k%20total-green.svg |
|
| 59 |
+
| :target: https://pypi.python.org/pypi/ninja | :target: https://pypi.python.org/pypi/ninja |
|
| 60 |
+
+----------------------------------------------------------------------+---------------------------------------------------------------------------+
|
| 61 |
+
|
| 62 |
+
Build Status
|
| 63 |
+
------------
|
| 64 |
+
|
| 65 |
+
.. table::
|
| 66 |
+
|
| 67 |
+
+---------------+-------------------------------------------------------------------------------------------------------------+
|
| 68 |
+
| | GitHub Actions (Windows, macOS, Linux) |
|
| 69 |
+
+===============+=============================================================================================================+
|
| 70 |
+
| PyPI | .. image:: https://github.com/scikit-build/ninja-python-distributions/actions/workflows/build.yml/badge.svg |
|
| 71 |
+
| | :target: https://github.com/scikit-build/ninja-python-distributions/actions/workflows/build.yml |
|
| 72 |
+
+---------------+-------------------------------------------------------------------------------------------------------------+
|
| 73 |
+
|
| 74 |
+
Maintainers
|
| 75 |
+
-----------
|
| 76 |
+
|
| 77 |
+
* `How to update ninja version ? <https://github.com/scikit-build/ninja-python-distributions/blob/master/docs/update_ninja_version.rst>`_
|
| 78 |
+
|
| 79 |
+
* `How to make a release ? <https://github.com/scikit-build/ninja-python-distributions/blob/master/docs/make_a_release.rst>`_
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
Miscellaneous
|
| 83 |
+
-------------
|
| 84 |
+
|
| 85 |
+
* Documentation: https://github.com/scikit-build/ninja-python-distributions#readme
|
| 86 |
+
* Source code: https://github.com/scikit-build/ninja-python-distributions
|
| 87 |
+
* Mailing list: https://groups.google.com/forum/#!forum/scikit-build
|
| 88 |
+
|
| 89 |
+
License
|
| 90 |
+
-------
|
| 91 |
+
|
| 92 |
+
This project is maintained by Jean-Christophe Fillion-Robin from Kitware Inc.
|
| 93 |
+
It is covered by the `Apache License, Version 2.0 <http://www.apache.org/licenses/LICENSE-2.0>`_.
|
| 94 |
+
|
| 95 |
+
Ninja is also distributed under the `Apache License, Version 2.0 <http://www.apache.org/licenses/LICENSE-2.0>`_.
|
| 96 |
+
For more information about Ninja, visit https://ninja-build.org
|
| 97 |
+
|
| 98 |
+
Logo was originally created by Libby Rose from Kitware Inc.
|
| 99 |
+
It is covered by `CC BY 4.0 <https://creativecommons.org/licenses/by/4.0/>`_.
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
History
|
| 105 |
+
-------
|
| 106 |
+
|
| 107 |
+
ninja-python-distributions was initially developed in November 2016 by
|
| 108 |
+
Jean-Christophe Fillion-Robin to facilitate the distribution of project using
|
| 109 |
+
`scikit-build <http://scikit-build.readthedocs.io/>`_ and depending on CMake
|
| 110 |
+
and Ninja.
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/RECORD
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ninja/__init__.py,sha256=0BcySAlWKb-IQ81BSRJnMV8DgO4kEqC6bRBVZoQrU6Q,1868
|
| 2 |
+
ninja/__main__.py,sha256=yxj4P3gNFZjBHHnxKkzJTVbGcYmUldoCmyfuLsVlvPs,93
|
| 3 |
+
ninja/_version.py,sha256=9ZUjDVbuPUSWZJSRKc98SaggjOPN8jdUUtjmmLsuzNk,434
|
| 4 |
+
ninja/ninja_syntax.py,sha256=AZt1YK1waQ_waJOZs42QhRBTP8pSwWhBc3nyIQEUGQk,6948
|
| 5 |
+
ninja/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
|
| 6 |
+
ninja/data/bin/ninja.exe,sha256=2xx0o9p6p5rO0H271P6QEKx3f0UBJzyfMvVLcYQCjgg,596992
|
| 7 |
+
ninja-1.11.1.1.dist-info/AUTHORS.rst,sha256=xY9m6KrIojc9WCdA08VLPR8YnaS4O_B1lTbj72xKW3I,147
|
| 8 |
+
ninja-1.11.1.1.dist-info/LICENSE_Apache_20,sha256=3B9dLUPFUx3-Csr06VDqXb4-YeGFDPDpg72n78ENZpM,10464
|
| 9 |
+
ninja-1.11.1.1.dist-info/METADATA,sha256=0fYUVdVMUzIvogaz5ovLj3wp98rsRZr1IkzCJP1WA-c,5444
|
| 10 |
+
ninja-1.11.1.1.dist-info/WHEEL,sha256=by-_ZrExntraUIwU5cYQ3fpnvee1ucoL1_66A72Rxic,123
|
| 11 |
+
ninja-1.11.1.1.dist-info/entry_points.txt,sha256=zZQG_ZObDvtm-DUhgcGr4lCsN6T96aAvS7DcFarSSiM,38
|
| 12 |
+
ninja-1.11.1.1.dist-info/top_level.txt,sha256=AaPljJrazyz43svwe5IEyrCImzMf0IMbUnwKTE9prk0,6
|
| 13 |
+
ninja-1.11.1.1.dist-info/RECORD,,
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/WHEEL
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Wheel-Version: 1.0
|
| 2 |
+
Generator: skbuild 0.17.6
|
| 3 |
+
Root-Is-Purelib: false
|
| 4 |
+
|
| 5 |
+
Tag: py2-none-win_amd64
|
| 6 |
+
Tag: py3-none-win_amd64
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/entry_points.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[console_scripts]
|
| 2 |
+
ninja = ninja:ninja
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/requires.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
[test]
|
| 3 |
+
codecov>=2.0.5
|
| 4 |
+
coverage>=4.2
|
| 5 |
+
flake8>=3.0.4
|
| 6 |
+
pytest-cov>=2.7.1
|
| 7 |
+
pytest-runner>=5.1
|
| 8 |
+
pytest-virtualenv>=1.7.0
|
| 9 |
+
pytest>=4.5.0
|
| 10 |
+
virtualenv>=15.0.3
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/EGG-INFO/top_level.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
ninja
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/__init__.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
import os
|
| 3 |
+
import platform
|
| 4 |
+
import subprocess
|
| 5 |
+
import sys
|
| 6 |
+
|
| 7 |
+
from ._version import version as __version__
|
| 8 |
+
|
| 9 |
+
__all__ = ["__version__", "DATA", "BIN_DIR", "ninja"]
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def __dir__():
|
| 13 |
+
return __all__
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
from .ninja_syntax import Writer, escape, expand
|
| 18 |
+
except ImportError:
|
| 19 |
+
# Support importing `ninja_syntax` from the source tree
|
| 20 |
+
if not os.path.exists(
|
| 21 |
+
os.path.join(os.path.dirname(__file__), 'ninja_syntax.py')):
|
| 22 |
+
sys.path.insert(0, os.path.abspath(os.path.join(
|
| 23 |
+
os.path.dirname(__file__), '../../Ninja-src/misc')))
|
| 24 |
+
from ninja_syntax import Writer, escape, expand # noqa: F401
|
| 25 |
+
|
| 26 |
+
DATA = os.path.join(os.path.dirname(__file__), 'data')
|
| 27 |
+
|
| 28 |
+
# Support running tests from the source tree
|
| 29 |
+
if not os.path.exists(DATA):
|
| 30 |
+
from skbuild.constants import CMAKE_INSTALL_DIR as SKBUILD_CMAKE_INSTALL_DIR
|
| 31 |
+
from skbuild.constants import set_skbuild_plat_name
|
| 32 |
+
|
| 33 |
+
if platform.system().lower() == "darwin":
|
| 34 |
+
# Since building the project specifying --plat-name or CMAKE_OSX_* variables
|
| 35 |
+
# leads to different SKBUILD_DIR, the code below attempt to guess the most
|
| 36 |
+
# likely plat-name.
|
| 37 |
+
_skbuild_dirs = os.listdir(os.path.join(os.path.dirname(__file__), '..', '..', '_skbuild'))
|
| 38 |
+
if _skbuild_dirs:
|
| 39 |
+
_likely_plat_name = '-'.join(_skbuild_dirs[0].split('-')[:3])
|
| 40 |
+
set_skbuild_plat_name(_likely_plat_name)
|
| 41 |
+
|
| 42 |
+
_data = os.path.abspath(os.path.join(
|
| 43 |
+
os.path.dirname(__file__), '..', '..', SKBUILD_CMAKE_INSTALL_DIR(), 'src/ninja/data'))
|
| 44 |
+
if os.path.exists(_data):
|
| 45 |
+
DATA = _data
|
| 46 |
+
|
| 47 |
+
BIN_DIR = os.path.join(DATA, 'bin')
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def _program(name, args):
|
| 51 |
+
return subprocess.call([os.path.join(BIN_DIR, name)] + args, close_fds=False)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def ninja():
|
| 55 |
+
raise SystemExit(_program('ninja', sys.argv[1:]))
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/__main__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
from ninja import ninja
|
| 3 |
+
|
| 4 |
+
if __name__ == '__main__':
|
| 5 |
+
ninja()
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/_version.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# file generated by setuptools_scm
|
| 2 |
+
# don't change, don't track in version control
|
| 3 |
+
TYPE_CHECKING = False
|
| 4 |
+
if TYPE_CHECKING:
|
| 5 |
+
from typing import Tuple, Union
|
| 6 |
+
VERSION_TUPLE = Tuple[Union[int, str], ...]
|
| 7 |
+
else:
|
| 8 |
+
VERSION_TUPLE = object
|
| 9 |
+
|
| 10 |
+
version: str
|
| 11 |
+
__version__: str
|
| 12 |
+
__version_tuple__: VERSION_TUPLE
|
| 13 |
+
version_tuple: VERSION_TUPLE
|
| 14 |
+
|
| 15 |
+
__version__ = version = '1.11.1.1'
|
| 16 |
+
__version_tuple__ = version_tuple = (1, 11, 1, 1)
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/data/bin/ninja.exe
ADDED
|
Binary file (597 kB). View file
|
|
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/ninja_syntax.py
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/python
|
| 2 |
+
|
| 3 |
+
# Copyright 2011 Google Inc. All Rights Reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
"""Python module for generating .ninja files.
|
| 18 |
+
|
| 19 |
+
Note that this is emphatically not a required piece of Ninja; it's
|
| 20 |
+
just a helpful utility for build-file-generation systems that already
|
| 21 |
+
use Python.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
import re
|
| 25 |
+
import textwrap
|
| 26 |
+
|
| 27 |
+
def escape_path(word):
|
| 28 |
+
return word.replace('$ ', '$$ ').replace(' ', '$ ').replace(':', '$:')
|
| 29 |
+
|
| 30 |
+
class Writer(object):
|
| 31 |
+
def __init__(self, output, width=78):
|
| 32 |
+
self.output = output
|
| 33 |
+
self.width = width
|
| 34 |
+
|
| 35 |
+
def newline(self):
|
| 36 |
+
self.output.write('\n')
|
| 37 |
+
|
| 38 |
+
def comment(self, text):
|
| 39 |
+
for line in textwrap.wrap(text, self.width - 2, break_long_words=False,
|
| 40 |
+
break_on_hyphens=False):
|
| 41 |
+
self.output.write('# ' + line + '\n')
|
| 42 |
+
|
| 43 |
+
def variable(self, key, value, indent=0):
|
| 44 |
+
if value is None:
|
| 45 |
+
return
|
| 46 |
+
if isinstance(value, list):
|
| 47 |
+
value = ' '.join(filter(None, value)) # Filter out empty strings.
|
| 48 |
+
self._line('%s = %s' % (key, value), indent)
|
| 49 |
+
|
| 50 |
+
def pool(self, name, depth):
|
| 51 |
+
self._line('pool %s' % name)
|
| 52 |
+
self.variable('depth', depth, indent=1)
|
| 53 |
+
|
| 54 |
+
def rule(self, name, command, description=None, depfile=None,
|
| 55 |
+
generator=False, pool=None, restat=False, rspfile=None,
|
| 56 |
+
rspfile_content=None, deps=None):
|
| 57 |
+
self._line('rule %s' % name)
|
| 58 |
+
self.variable('command', command, indent=1)
|
| 59 |
+
if description:
|
| 60 |
+
self.variable('description', description, indent=1)
|
| 61 |
+
if depfile:
|
| 62 |
+
self.variable('depfile', depfile, indent=1)
|
| 63 |
+
if generator:
|
| 64 |
+
self.variable('generator', '1', indent=1)
|
| 65 |
+
if pool:
|
| 66 |
+
self.variable('pool', pool, indent=1)
|
| 67 |
+
if restat:
|
| 68 |
+
self.variable('restat', '1', indent=1)
|
| 69 |
+
if rspfile:
|
| 70 |
+
self.variable('rspfile', rspfile, indent=1)
|
| 71 |
+
if rspfile_content:
|
| 72 |
+
self.variable('rspfile_content', rspfile_content, indent=1)
|
| 73 |
+
if deps:
|
| 74 |
+
self.variable('deps', deps, indent=1)
|
| 75 |
+
|
| 76 |
+
def build(self, outputs, rule, inputs=None, implicit=None, order_only=None,
|
| 77 |
+
variables=None, implicit_outputs=None, pool=None, dyndep=None):
|
| 78 |
+
outputs = as_list(outputs)
|
| 79 |
+
out_outputs = [escape_path(x) for x in outputs]
|
| 80 |
+
all_inputs = [escape_path(x) for x in as_list(inputs)]
|
| 81 |
+
|
| 82 |
+
if implicit:
|
| 83 |
+
implicit = [escape_path(x) for x in as_list(implicit)]
|
| 84 |
+
all_inputs.append('|')
|
| 85 |
+
all_inputs.extend(implicit)
|
| 86 |
+
if order_only:
|
| 87 |
+
order_only = [escape_path(x) for x in as_list(order_only)]
|
| 88 |
+
all_inputs.append('||')
|
| 89 |
+
all_inputs.extend(order_only)
|
| 90 |
+
if implicit_outputs:
|
| 91 |
+
implicit_outputs = [escape_path(x)
|
| 92 |
+
for x in as_list(implicit_outputs)]
|
| 93 |
+
out_outputs.append('|')
|
| 94 |
+
out_outputs.extend(implicit_outputs)
|
| 95 |
+
|
| 96 |
+
self._line('build %s: %s' % (' '.join(out_outputs),
|
| 97 |
+
' '.join([rule] + all_inputs)))
|
| 98 |
+
if pool is not None:
|
| 99 |
+
self._line(' pool = %s' % pool)
|
| 100 |
+
if dyndep is not None:
|
| 101 |
+
self._line(' dyndep = %s' % dyndep)
|
| 102 |
+
|
| 103 |
+
if variables:
|
| 104 |
+
if isinstance(variables, dict):
|
| 105 |
+
iterator = iter(variables.items())
|
| 106 |
+
else:
|
| 107 |
+
iterator = iter(variables)
|
| 108 |
+
|
| 109 |
+
for key, val in iterator:
|
| 110 |
+
self.variable(key, val, indent=1)
|
| 111 |
+
|
| 112 |
+
return outputs
|
| 113 |
+
|
| 114 |
+
def include(self, path):
|
| 115 |
+
self._line('include %s' % path)
|
| 116 |
+
|
| 117 |
+
def subninja(self, path):
|
| 118 |
+
self._line('subninja %s' % path)
|
| 119 |
+
|
| 120 |
+
def default(self, paths):
|
| 121 |
+
self._line('default %s' % ' '.join(as_list(paths)))
|
| 122 |
+
|
| 123 |
+
def _count_dollars_before_index(self, s, i):
|
| 124 |
+
"""Returns the number of '$' characters right in front of s[i]."""
|
| 125 |
+
dollar_count = 0
|
| 126 |
+
dollar_index = i - 1
|
| 127 |
+
while dollar_index > 0 and s[dollar_index] == '$':
|
| 128 |
+
dollar_count += 1
|
| 129 |
+
dollar_index -= 1
|
| 130 |
+
return dollar_count
|
| 131 |
+
|
| 132 |
+
def _line(self, text, indent=0):
|
| 133 |
+
"""Write 'text' word-wrapped at self.width characters."""
|
| 134 |
+
leading_space = ' ' * indent
|
| 135 |
+
while len(leading_space) + len(text) > self.width:
|
| 136 |
+
# The text is too wide; wrap if possible.
|
| 137 |
+
|
| 138 |
+
# Find the rightmost space that would obey our width constraint and
|
| 139 |
+
# that's not an escaped space.
|
| 140 |
+
available_space = self.width - len(leading_space) - len(' $')
|
| 141 |
+
space = available_space
|
| 142 |
+
while True:
|
| 143 |
+
space = text.rfind(' ', 0, space)
|
| 144 |
+
if (space < 0 or
|
| 145 |
+
self._count_dollars_before_index(text, space) % 2 == 0):
|
| 146 |
+
break
|
| 147 |
+
|
| 148 |
+
if space < 0:
|
| 149 |
+
# No such space; just use the first unescaped space we can find.
|
| 150 |
+
space = available_space - 1
|
| 151 |
+
while True:
|
| 152 |
+
space = text.find(' ', space + 1)
|
| 153 |
+
if (space < 0 or
|
| 154 |
+
self._count_dollars_before_index(text, space) % 2 == 0):
|
| 155 |
+
break
|
| 156 |
+
if space < 0:
|
| 157 |
+
# Give up on breaking.
|
| 158 |
+
break
|
| 159 |
+
|
| 160 |
+
self.output.write(leading_space + text[0:space] + ' $\n')
|
| 161 |
+
text = text[space+1:]
|
| 162 |
+
|
| 163 |
+
# Subsequent lines are continuations, so indent them.
|
| 164 |
+
leading_space = ' ' * (indent+2)
|
| 165 |
+
|
| 166 |
+
self.output.write(leading_space + text + '\n')
|
| 167 |
+
|
| 168 |
+
def close(self):
|
| 169 |
+
self.output.close()
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def as_list(input):
|
| 173 |
+
if input is None:
|
| 174 |
+
return []
|
| 175 |
+
if isinstance(input, list):
|
| 176 |
+
return input
|
| 177 |
+
return [input]
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def escape(string):
|
| 181 |
+
"""Escape a string such that it can be embedded into a Ninja file without
|
| 182 |
+
further interpretation."""
|
| 183 |
+
assert '\n' not in string, 'Ninja syntax does not allow newlines'
|
| 184 |
+
# We only have one special metacharacter: '$'.
|
| 185 |
+
return string.replace('$', '$$')
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def expand(string, vars, local_vars={}):
|
| 189 |
+
"""Expand a string containing $vars as Ninja would.
|
| 190 |
+
|
| 191 |
+
Note: doesn't handle the full Ninja variable syntax, but it's enough
|
| 192 |
+
to make configure.py's use of it work.
|
| 193 |
+
"""
|
| 194 |
+
def exp(m):
|
| 195 |
+
var = m.group(1)
|
| 196 |
+
if var == '$':
|
| 197 |
+
return '$'
|
| 198 |
+
return local_vars.get(var, vars.get(var, ''))
|
| 199 |
+
return re.sub(r'\$(\$|\w*)', exp, string)
|
flash-attention/.eggs/ninja-1.11.1.1-py3.9-win-amd64.egg/ninja/py.typed
ADDED
|
File without changes
|
flash-attention/.github/workflows/publish.yml
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This workflow will:
|
| 2 |
+
# - Create a new Github release
|
| 3 |
+
# - Build wheels for supported architectures
|
| 4 |
+
# - Deploy the wheels to the Github release
|
| 5 |
+
# - Release the static code to PyPi
|
| 6 |
+
# For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
|
| 7 |
+
|
| 8 |
+
name: Build wheels and deploy
|
| 9 |
+
|
| 10 |
+
on:
|
| 11 |
+
create:
|
| 12 |
+
tags:
|
| 13 |
+
- v*
|
| 14 |
+
|
| 15 |
+
jobs:
|
| 16 |
+
|
| 17 |
+
setup_release:
|
| 18 |
+
name: Create Release
|
| 19 |
+
runs-on: ubuntu-latest
|
| 20 |
+
steps:
|
| 21 |
+
- name: Get the tag version
|
| 22 |
+
id: extract_branch
|
| 23 |
+
run: echo ::set-output name=branch::${GITHUB_REF#refs/tags/}
|
| 24 |
+
shell: bash
|
| 25 |
+
|
| 26 |
+
- name: Create Release
|
| 27 |
+
id: create_release
|
| 28 |
+
uses: actions/create-release@v1
|
| 29 |
+
env:
|
| 30 |
+
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
| 31 |
+
with:
|
| 32 |
+
tag_name: ${{ steps.extract_branch.outputs.branch }}
|
| 33 |
+
release_name: ${{ steps.extract_branch.outputs.branch }}
|
| 34 |
+
|
| 35 |
+
build_wheels:
|
| 36 |
+
name: Build Wheel
|
| 37 |
+
needs: setup_release
|
| 38 |
+
runs-on: ${{ matrix.os }}
|
| 39 |
+
|
| 40 |
+
strategy:
|
| 41 |
+
fail-fast: false
|
| 42 |
+
matrix:
|
| 43 |
+
# Using ubuntu-20.04 instead of 22.04 for more compatibility (glibc). Ideally we'd use the
|
| 44 |
+
# manylinux docker image, but I haven't figured out how to install CUDA on manylinux.
|
| 45 |
+
os: [ubuntu-20.04]
|
| 46 |
+
python-version: ['3.7', '3.8', '3.9', '3.10', '3.11', '3.12']
|
| 47 |
+
torch-version: ['1.12.1', '1.13.1', '2.0.1', '2.1.2', '2.2.2', '2.3.0', '2.4.0.dev20240407']
|
| 48 |
+
cuda-version: ['11.8.0', '12.2.2']
|
| 49 |
+
# We need separate wheels that either uses C++11 ABI (-D_GLIBCXX_USE_CXX11_ABI) or not.
|
| 50 |
+
# Pytorch wheels currently don't use it, but nvcr images have Pytorch compiled with C++11 ABI.
|
| 51 |
+
# Without this we get import error (undefined symbol: _ZN3c105ErrorC2ENS_14SourceLocationESs)
|
| 52 |
+
# when building without C++11 ABI and using it on nvcr images.
|
| 53 |
+
cxx11_abi: ['FALSE', 'TRUE']
|
| 54 |
+
exclude:
|
| 55 |
+
# see https://github.com/pytorch/pytorch/blob/main/RELEASE.md#release-compatibility-matrix
|
| 56 |
+
# Pytorch < 2.2 does not support Python 3.12
|
| 57 |
+
- torch-version: '1.12.1'
|
| 58 |
+
python-version: '3.12'
|
| 59 |
+
- torch-version: '1.13.1'
|
| 60 |
+
python-version: '3.12'
|
| 61 |
+
- torch-version: '2.0.1'
|
| 62 |
+
python-version: '3.12'
|
| 63 |
+
- torch-version: '2.1.2'
|
| 64 |
+
python-version: '3.12'
|
| 65 |
+
# Pytorch <= 1.12 does not support Python 3.11
|
| 66 |
+
- torch-version: '1.12.1'
|
| 67 |
+
python-version: '3.11'
|
| 68 |
+
# Pytorch >= 2.0 only supports Python >= 3.8
|
| 69 |
+
- torch-version: '2.0.1'
|
| 70 |
+
python-version: '3.7'
|
| 71 |
+
- torch-version: '2.1.2'
|
| 72 |
+
python-version: '3.7'
|
| 73 |
+
- torch-version: '2.2.2'
|
| 74 |
+
python-version: '3.7'
|
| 75 |
+
- torch-version: '2.3.0'
|
| 76 |
+
python-version: '3.7'
|
| 77 |
+
- torch-version: '2.4.0.dev20240407'
|
| 78 |
+
python-version: '3.7'
|
| 79 |
+
# Pytorch <= 2.0 only supports CUDA <= 11.8
|
| 80 |
+
- torch-version: '1.12.1'
|
| 81 |
+
cuda-version: '12.2.2'
|
| 82 |
+
- torch-version: '1.13.1'
|
| 83 |
+
cuda-version: '12.2.2'
|
| 84 |
+
- torch-version: '2.0.1'
|
| 85 |
+
cuda-version: '12.2.2'
|
| 86 |
+
|
| 87 |
+
steps:
|
| 88 |
+
- name: Checkout
|
| 89 |
+
uses: actions/checkout@v3
|
| 90 |
+
|
| 91 |
+
- name: Set up Python
|
| 92 |
+
uses: actions/setup-python@v4
|
| 93 |
+
with:
|
| 94 |
+
python-version: ${{ matrix.python-version }}
|
| 95 |
+
|
| 96 |
+
- name: Set CUDA and PyTorch versions
|
| 97 |
+
run: |
|
| 98 |
+
echo "MATRIX_CUDA_VERSION=$(echo ${{ matrix.cuda-version }} | awk -F \. {'print $1 $2'})" >> $GITHUB_ENV
|
| 99 |
+
echo "MATRIX_TORCH_VERSION=$(echo ${{ matrix.torch-version }} | awk -F \. {'print $1 "." $2'})" >> $GITHUB_ENV
|
| 100 |
+
echo "MATRIX_PYTHON_VERSION=$(echo ${{ matrix.python-version }} | awk -F \. {'print $1 $2'})" >> $GITHUB_ENV
|
| 101 |
+
|
| 102 |
+
- name: Free up disk space
|
| 103 |
+
if: ${{ runner.os == 'Linux' }}
|
| 104 |
+
# https://github.com/easimon/maximize-build-space/blob/master/action.yml
|
| 105 |
+
# https://github.com/easimon/maximize-build-space/tree/test-report
|
| 106 |
+
run: |
|
| 107 |
+
sudo rm -rf /usr/share/dotnet
|
| 108 |
+
sudo rm -rf /opt/ghc
|
| 109 |
+
sudo rm -rf /opt/hostedtoolcache/CodeQL
|
| 110 |
+
|
| 111 |
+
- name: Set up swap space
|
| 112 |
+
if: runner.os == 'Linux'
|
| 113 |
+
uses: pierotofy/set-swap-space@v1.0
|
| 114 |
+
with:
|
| 115 |
+
swap-size-gb: 10
|
| 116 |
+
|
| 117 |
+
- name: Install CUDA ${{ matrix.cuda-version }}
|
| 118 |
+
if: ${{ matrix.cuda-version != 'cpu' }}
|
| 119 |
+
uses: Jimver/cuda-toolkit@v0.2.14
|
| 120 |
+
id: cuda-toolkit
|
| 121 |
+
with:
|
| 122 |
+
cuda: ${{ matrix.cuda-version }}
|
| 123 |
+
linux-local-args: '["--toolkit"]'
|
| 124 |
+
# default method is "local", and we're hitting some error with caching for CUDA 11.8 and 12.1
|
| 125 |
+
# method: ${{ (matrix.cuda-version == '11.8.0' || matrix.cuda-version == '12.1.0') && 'network' || 'local' }}
|
| 126 |
+
method: 'network'
|
| 127 |
+
# We need the cuda libraries (e.g. cuSparse, cuSolver) for compiling PyTorch extensions,
|
| 128 |
+
# not just nvcc
|
| 129 |
+
# sub-packages: '["nvcc"]'
|
| 130 |
+
|
| 131 |
+
- name: Install PyTorch ${{ matrix.torch-version }}+cu${{ matrix.cuda-version }}
|
| 132 |
+
run: |
|
| 133 |
+
pip install --upgrade pip
|
| 134 |
+
# If we don't install before installing Pytorch, we get error for torch 2.0.1
|
| 135 |
+
# ERROR: Could not find a version that satisfies the requirement setuptools>=40.8.0 (from versions: none)
|
| 136 |
+
pip install lit
|
| 137 |
+
# For some reason torch 2.2.0 on python 3.12 errors saying no setuptools
|
| 138 |
+
pip install setuptools
|
| 139 |
+
# We want to figure out the CUDA version to download pytorch
|
| 140 |
+
# e.g. we can have system CUDA version being 11.7 but if torch==1.12 then we need to download the wheel from cu116
|
| 141 |
+
# see https://github.com/pytorch/pytorch/blob/main/RELEASE.md#release-compatibility-matrix
|
| 142 |
+
# This code is ugly, maybe there's a better way to do this.
|
| 143 |
+
export TORCH_CUDA_VERSION=$(python -c "from os import environ as env; \
|
| 144 |
+
minv = {'1.12': 113, '1.13': 116, '2.0': 117, '2.1': 118, '2.2': 118, '2.3': 118, '2.4': 118}[env['MATRIX_TORCH_VERSION']]; \
|
| 145 |
+
maxv = {'1.12': 116, '1.13': 117, '2.0': 118, '2.1': 121, '2.2': 121, '2.3': 121, '2.4': 121}[env['MATRIX_TORCH_VERSION']]; \
|
| 146 |
+
print(max(min(int(env['MATRIX_CUDA_VERSION']), maxv), minv))" \
|
| 147 |
+
)
|
| 148 |
+
if [[ ${{ matrix.torch-version }} == *"dev"* ]]; then
|
| 149 |
+
pip install --no-cache-dir --pre torch==${{ matrix.torch-version }} --index-url https://download.pytorch.org/whl/nightly/cu${TORCH_CUDA_VERSION}
|
| 150 |
+
else
|
| 151 |
+
pip install --no-cache-dir torch==${{ matrix.torch-version }} --index-url https://download.pytorch.org/whl/cu${TORCH_CUDA_VERSION}
|
| 152 |
+
fi
|
| 153 |
+
nvcc --version
|
| 154 |
+
python --version
|
| 155 |
+
python -c "import torch; print('PyTorch:', torch.__version__)"
|
| 156 |
+
python -c "import torch; print('CUDA:', torch.version.cuda)"
|
| 157 |
+
python -c "from torch.utils import cpp_extension; print (cpp_extension.CUDA_HOME)"
|
| 158 |
+
shell:
|
| 159 |
+
bash
|
| 160 |
+
|
| 161 |
+
- name: Build wheel
|
| 162 |
+
run: |
|
| 163 |
+
# We want setuptools >= 49.6.0 otherwise we can't compile the extension if system CUDA version is 11.7 and pytorch cuda version is 11.6
|
| 164 |
+
# https://github.com/pytorch/pytorch/blob/664058fa83f1d8eede5d66418abff6e20bd76ca8/torch/utils/cpp_extension.py#L810
|
| 165 |
+
# However this still fails so I'm using a newer version of setuptools
|
| 166 |
+
pip install setuptools==68.0.0
|
| 167 |
+
pip install ninja packaging wheel
|
| 168 |
+
export PATH=/usr/local/nvidia/bin:/usr/local/nvidia/lib64:$PATH
|
| 169 |
+
export LD_LIBRARY_PATH=/usr/local/nvidia/lib64:/usr/local/cuda/lib64:$LD_LIBRARY_PATH
|
| 170 |
+
# Limit MAX_JOBS otherwise the github runner goes OOM
|
| 171 |
+
# CUDA 11.8 can compile with 2 jobs, but CUDA 12.2 goes OOM
|
| 172 |
+
MAX_JOBS=$([ "$MATRIX_CUDA_VERSION" == "122" ] && echo 1 || echo 2) FLASH_ATTENTION_FORCE_BUILD="TRUE" FLASH_ATTENTION_FORCE_CXX11_ABI=${{ matrix.cxx11_abi}} python setup.py bdist_wheel --dist-dir=dist
|
| 173 |
+
tmpname=cu${MATRIX_CUDA_VERSION}torch${MATRIX_TORCH_VERSION}cxx11abi${{ matrix.cxx11_abi }}
|
| 174 |
+
wheel_name=$(ls dist/*whl | xargs -n 1 basename | sed "s/-/+$tmpname-/2")
|
| 175 |
+
ls dist/*whl |xargs -I {} mv {} dist/${wheel_name}
|
| 176 |
+
echo "wheel_name=${wheel_name}" >> $GITHUB_ENV
|
| 177 |
+
|
| 178 |
+
- name: Log Built Wheels
|
| 179 |
+
run: |
|
| 180 |
+
ls dist
|
| 181 |
+
|
| 182 |
+
- name: Get the tag version
|
| 183 |
+
id: extract_branch
|
| 184 |
+
run: echo ::set-output name=branch::${GITHUB_REF#refs/tags/}
|
| 185 |
+
|
| 186 |
+
- name: Get Release with tag
|
| 187 |
+
id: get_current_release
|
| 188 |
+
uses: joutvhu/get-release@v1
|
| 189 |
+
with:
|
| 190 |
+
tag_name: ${{ steps.extract_branch.outputs.branch }}
|
| 191 |
+
env:
|
| 192 |
+
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
| 193 |
+
|
| 194 |
+
- name: Upload Release Asset
|
| 195 |
+
id: upload_release_asset
|
| 196 |
+
uses: actions/upload-release-asset@v1
|
| 197 |
+
env:
|
| 198 |
+
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
| 199 |
+
with:
|
| 200 |
+
upload_url: ${{ steps.get_current_release.outputs.upload_url }}
|
| 201 |
+
asset_path: ./dist/${{env.wheel_name}}
|
| 202 |
+
asset_name: ${{env.wheel_name}}
|
| 203 |
+
asset_content_type: application/*
|
| 204 |
+
|
| 205 |
+
publish_package:
|
| 206 |
+
name: Publish package
|
| 207 |
+
needs: [build_wheels]
|
| 208 |
+
|
| 209 |
+
runs-on: ubuntu-latest
|
| 210 |
+
|
| 211 |
+
steps:
|
| 212 |
+
- uses: actions/checkout@v3
|
| 213 |
+
|
| 214 |
+
- uses: actions/setup-python@v4
|
| 215 |
+
with:
|
| 216 |
+
python-version: '3.10'
|
| 217 |
+
|
| 218 |
+
- name: Install dependencies
|
| 219 |
+
run: |
|
| 220 |
+
pip install ninja packaging setuptools wheel twine
|
| 221 |
+
# We don't want to download anything CUDA-related here
|
| 222 |
+
pip install torch --index-url https://download.pytorch.org/whl/cpu
|
| 223 |
+
|
| 224 |
+
- name: Build core package
|
| 225 |
+
env:
|
| 226 |
+
FLASH_ATTENTION_SKIP_CUDA_BUILD: "TRUE"
|
| 227 |
+
run: |
|
| 228 |
+
python setup.py sdist --dist-dir=dist
|
| 229 |
+
|
| 230 |
+
- name: Deploy
|
| 231 |
+
env:
|
| 232 |
+
TWINE_USERNAME: "__token__"
|
| 233 |
+
TWINE_PASSWORD: ${{ secrets.PYPI_API_TOKEN }}
|
| 234 |
+
run: |
|
| 235 |
+
python -m twine upload dist/*
|
flash-attention/.gitignore
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
|
| 5 |
+
# C extensions
|
| 6 |
+
*.so
|
| 7 |
+
|
| 8 |
+
# Distribution / packaging
|
| 9 |
+
bin/
|
| 10 |
+
build/
|
| 11 |
+
develop-eggs/
|
| 12 |
+
dist/
|
| 13 |
+
eggs/
|
| 14 |
+
lib/
|
| 15 |
+
lib64/
|
| 16 |
+
parts/
|
| 17 |
+
sdist/
|
| 18 |
+
var/
|
| 19 |
+
*.egg-info/
|
| 20 |
+
.installed.cfg
|
| 21 |
+
*.egg
|
| 22 |
+
|
| 23 |
+
# IDE-related
|
| 24 |
+
.idea/
|
| 25 |
+
|
| 26 |
+
# Dev
|
| 27 |
+
venv
|
flash-attention/.gitmodules
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[submodule "csrc/cutlass"]
|
| 2 |
+
path = csrc/cutlass
|
| 3 |
+
url = https://github.com/NVIDIA/cutlass.git
|
flash-attention/AUTHORS
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Tri Dao, trid@cs.stanford.edu
|
flash-attention/LICENSE
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022, the respective contributors, as shown by the AUTHORS file.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without
|
| 7 |
+
modification, are permitted provided that the following conditions are met:
|
| 8 |
+
|
| 9 |
+
* Redistributions of source code must retain the above copyright notice, this
|
| 10 |
+
list of conditions and the following disclaimer.
|
| 11 |
+
|
| 12 |
+
* Redistributions in binary form must reproduce the above copyright notice,
|
| 13 |
+
this list of conditions and the following disclaimer in the documentation
|
| 14 |
+
and/or other materials provided with the distribution.
|
| 15 |
+
|
| 16 |
+
* Neither the name of the copyright holder nor the names of its
|
| 17 |
+
contributors may be used to endorse or promote products derived from
|
| 18 |
+
this software without specific prior written permission.
|
| 19 |
+
|
| 20 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 21 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 22 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 23 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 24 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 25 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 26 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 27 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 28 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 29 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
flash-attention/MANIFEST.in
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
recursive-include csrc *.cu
|
| 2 |
+
recursive-include csrc *.h
|
| 3 |
+
recursive-include csrc *.cuh
|
| 4 |
+
recursive-include csrc *.cpp
|
| 5 |
+
recursive-include csrc *.hpp
|
| 6 |
+
|
| 7 |
+
recursive-include flash_attn *.cu
|
| 8 |
+
recursive-include flash_attn *.h
|
| 9 |
+
recursive-include flash_attn *.cuh
|
| 10 |
+
recursive-include flash_attn *.cpp
|
| 11 |
+
recursive-include flash_attn *.hpp
|
flash-attention/Makefile
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
clean_dist:
|
| 3 |
+
rm -rf dist/*
|
| 4 |
+
|
| 5 |
+
create_dist: clean_dist
|
| 6 |
+
python setup.py sdist
|
| 7 |
+
|
| 8 |
+
upload_package: create_dist
|
| 9 |
+
twine upload dist/*
|
flash-attention/README.md
ADDED
|
@@ -0,0 +1,412 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FlashAttention
|
| 2 |
+
This repository provides the official implementation of FlashAttention and
|
| 3 |
+
FlashAttention-2 from the
|
| 4 |
+
following papers.
|
| 5 |
+
|
| 6 |
+
**FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness**
|
| 7 |
+
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
|
| 8 |
+
Paper: https://arxiv.org/abs/2205.14135
|
| 9 |
+
IEEE Spectrum [article](https://spectrum.ieee.org/mlperf-rankings-2022) about our submission to the MLPerf 2.0 benchmark using FlashAttention.
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
**FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning**
|
| 13 |
+
Tri Dao
|
| 14 |
+
|
| 15 |
+
Paper: https://tridao.me/publications/flash2/flash2.pdf
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
## Usage
|
| 21 |
+
|
| 22 |
+
We've been very happy to see FlashAttention being widely adopted in such a short
|
| 23 |
+
time after its release. This [page](https://github.com/Dao-AILab/flash-attention/blob/main/usage.md)
|
| 24 |
+
contains a partial list of places where FlashAttention is being used.
|
| 25 |
+
|
| 26 |
+
FlashAttention and FlashAttention-2 are free to use and modify (see LICENSE).
|
| 27 |
+
Please cite and credit FlashAttention if you use it.
|
| 28 |
+
|
| 29 |
+
## Installation and features
|
| 30 |
+
|
| 31 |
+
Requirements:
|
| 32 |
+
- CUDA 11.6 and above.
|
| 33 |
+
- PyTorch 1.12 and above.
|
| 34 |
+
- Linux. Might work for Windows starting v2.3.2 (we've seen a few positive [reports](https://github.com/Dao-AILab/flash-attention/issues/595)) but Windows compilation still requires more testing. If you have ideas on how to set up prebuilt CUDA wheels for Windows, please reach out via Github issue.
|
| 35 |
+
|
| 36 |
+
We recommend the
|
| 37 |
+
[Pytorch](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch)
|
| 38 |
+
container from Nvidia, which has all the required tools to install FlashAttention.
|
| 39 |
+
|
| 40 |
+
To install:
|
| 41 |
+
1. Make sure that PyTorch is installed.
|
| 42 |
+
2. Make sure that `packaging` is installed (`pip install packaging`)
|
| 43 |
+
3. Make sure that `ninja` is installed and that it works correctly (e.g. `ninja
|
| 44 |
+
--version` then `echo $?` should return exit code 0). If not (sometimes `ninja
|
| 45 |
+
--version` then `echo $?` returns a nonzero exit code), uninstall then reinstall
|
| 46 |
+
`ninja` (`pip uninstall -y ninja && pip install ninja`). Without `ninja`,
|
| 47 |
+
compiling can take a very long time (2h) since it does not use multiple CPU
|
| 48 |
+
cores. With `ninja` compiling takes 3-5 minutes on a 64-core machine.
|
| 49 |
+
4. Then:
|
| 50 |
+
```sh
|
| 51 |
+
pip install flash-attn --no-build-isolation
|
| 52 |
+
```
|
| 53 |
+
Alternatively you can compile from source:
|
| 54 |
+
```sh
|
| 55 |
+
python setup.py install
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
If your machine has less than 96GB of RAM and lots of CPU cores, `ninja` might
|
| 59 |
+
run too many parallel compilation jobs that could exhaust the amount of RAM. To
|
| 60 |
+
limit the number of parallel compilation jobs, you can set the environment
|
| 61 |
+
variable `MAX_JOBS`:
|
| 62 |
+
```sh
|
| 63 |
+
MAX_JOBS=4 pip install flash-attn --no-build-isolation
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
Interface: `src/flash_attention_interface.py`
|
| 67 |
+
|
| 68 |
+
FlashAttention-2 currently supports:
|
| 69 |
+
1. Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing
|
| 70 |
+
GPUs (T4, RTX 2080) is coming soon, please use FlashAttention 1.x for Turing
|
| 71 |
+
GPUs for now.
|
| 72 |
+
2. Datatype fp16 and bf16 (bf16 requires Ampere, Ada, or Hopper GPUs).
|
| 73 |
+
3. All head dimensions up to 256. ~~Head dim > 192 backward requires A100/A800 or H100/H800~~. Head dim 256 backward now works on consumer GPUs (if there's no dropout) as of flash-attn 2.5.5.
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
## How to use FlashAttention
|
| 77 |
+
|
| 78 |
+
The main functions implement scaled dot product attention (softmax(Q @ K^T *
|
| 79 |
+
softmax_scale) @ V):
|
| 80 |
+
```python
|
| 81 |
+
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
flash_attn_qkvpacked_func(qkv, dropout_p=0.0, softmax_scale=None, causal=False,
|
| 86 |
+
window_size=(-1, -1), alibi_slopes=None, deterministic=False):
|
| 87 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 88 |
+
If Q, K, V are already stacked into 1 tensor, this function will be faster than
|
| 89 |
+
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
|
| 90 |
+
of the gradients of Q, K, V.
|
| 91 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 92 |
+
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
|
| 93 |
+
Arguments:
|
| 94 |
+
qkv: (batch_size, seqlen, 3, nheads, headdim)
|
| 95 |
+
dropout_p: float. Dropout probability.
|
| 96 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 97 |
+
Default to 1 / sqrt(headdim).
|
| 98 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 99 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 100 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
|
| 101 |
+
the attention score of query i and key j.
|
| 102 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 103 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 104 |
+
Return:
|
| 105 |
+
out: (batch_size, seqlen, nheads, headdim).
|
| 106 |
+
"""
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
```python
|
| 110 |
+
flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=None, causal=False,
|
| 111 |
+
window_size=(-1, -1), alibi_slopes=None, deterministic=False):
|
| 112 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 113 |
+
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
|
| 114 |
+
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
|
| 115 |
+
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
|
| 116 |
+
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
|
| 117 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 118 |
+
will only attend to keys between
|
| 119 |
+
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
|
| 120 |
+
|
| 121 |
+
Arguments:
|
| 122 |
+
q: (batch_size, seqlen, nheads, headdim)
|
| 123 |
+
k: (batch_size, seqlen, nheads_k, headdim)
|
| 124 |
+
v: (batch_size, seqlen, nheads_k, headdim)
|
| 125 |
+
dropout_p: float. Dropout probability.
|
| 126 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 127 |
+
Default to 1 / sqrt(headdim).
|
| 128 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 129 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 130 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
|
| 131 |
+
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
|
| 132 |
+
is added to the attention score of query i and key j.
|
| 133 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 134 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 135 |
+
Return:
|
| 136 |
+
out: (batch_size, seqlen, nheads, headdim).
|
| 137 |
+
"""
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
```python
|
| 141 |
+
def flash_attn_with_kvcache(
|
| 142 |
+
q,
|
| 143 |
+
k_cache,
|
| 144 |
+
v_cache,
|
| 145 |
+
k=None,
|
| 146 |
+
v=None,
|
| 147 |
+
rotary_cos=None,
|
| 148 |
+
rotary_sin=None,
|
| 149 |
+
cache_seqlens: Optional[Union[(int, torch.Tensor)]] = None,
|
| 150 |
+
cache_batch_idx: Optional[torch.Tensor] = None,
|
| 151 |
+
block_table: Optional[torch.Tensor] = None,
|
| 152 |
+
softmax_scale=None,
|
| 153 |
+
causal=False,
|
| 154 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 155 |
+
rotary_interleaved=True,
|
| 156 |
+
alibi_slopes=None,
|
| 157 |
+
):
|
| 158 |
+
"""
|
| 159 |
+
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
|
| 160 |
+
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
|
| 161 |
+
the previous step, and update them with the new keys/values from the current step, and do
|
| 162 |
+
attention with the updated cache, all in 1 kernel.
|
| 163 |
+
|
| 164 |
+
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
|
| 165 |
+
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
|
| 166 |
+
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
|
| 167 |
+
|
| 168 |
+
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
|
| 169 |
+
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
|
| 170 |
+
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
|
| 171 |
+
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
|
| 172 |
+
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
|
| 173 |
+
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
|
| 174 |
+
|
| 175 |
+
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
|
| 176 |
+
|
| 177 |
+
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
|
| 178 |
+
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
|
| 179 |
+
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
|
| 180 |
+
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
|
| 181 |
+
|
| 182 |
+
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
|
| 183 |
+
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
|
| 184 |
+
1 1 1 1 0
|
| 185 |
+
1 1 1 1 1
|
| 186 |
+
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
|
| 187 |
+
0 0
|
| 188 |
+
0 0
|
| 189 |
+
0 0
|
| 190 |
+
1 0
|
| 191 |
+
1 1
|
| 192 |
+
If the row of the mask is all zero, the output will be zero.
|
| 193 |
+
|
| 194 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 195 |
+
will only attend to keys between
|
| 196 |
+
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
|
| 197 |
+
|
| 198 |
+
Note: Does not support backward pass.
|
| 199 |
+
|
| 200 |
+
Arguments:
|
| 201 |
+
q: (batch_size, seqlen, nheads, headdim)
|
| 202 |
+
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
|
| 203 |
+
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
|
| 204 |
+
page_block_size must be a multiple of 256.
|
| 205 |
+
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
|
| 206 |
+
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
|
| 207 |
+
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
|
| 208 |
+
k with k_cache, starting at the indices specified by cache_seqlens.
|
| 209 |
+
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
|
| 210 |
+
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
|
| 211 |
+
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
|
| 212 |
+
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
|
| 213 |
+
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
|
| 214 |
+
KV cache.
|
| 215 |
+
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
|
| 216 |
+
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
|
| 217 |
+
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
|
| 218 |
+
If the indices are not distinct, and k and v are provided, the values updated in the cache
|
| 219 |
+
might come from any of the duplicate indices.
|
| 220 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 221 |
+
Default to 1 / sqrt(headdim).
|
| 222 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 223 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 224 |
+
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
|
| 225 |
+
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
|
| 226 |
+
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
|
| 227 |
+
(i.e. GPT-NeoX style).
|
| 228 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
|
| 229 |
+
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
|
| 230 |
+
is added to the attention score of query i and key j.
|
| 231 |
+
|
| 232 |
+
Return:
|
| 233 |
+
out: (batch_size, seqlen, nheads, headdim).
|
| 234 |
+
"""
|
| 235 |
+
```
|
| 236 |
+
|
| 237 |
+
To see how these functions are used in a multi-head attention layer (which
|
| 238 |
+
includes QKV projection, output projection), see the MHA [implementation](https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/modules/mha.py).
|
| 239 |
+
|
| 240 |
+
## Changelog
|
| 241 |
+
|
| 242 |
+
### 2.0: Complete rewrite, 2x faster
|
| 243 |
+
Upgrading from FlashAttention (1.x) to FlashAttention-2
|
| 244 |
+
|
| 245 |
+
These functions have been renamed:
|
| 246 |
+
- `flash_attn_unpadded_func` -> `flash_attn_varlen_func`
|
| 247 |
+
- `flash_attn_unpadded_qkvpacked_func` -> `flash_attn_varlen_qkvpacked_func`
|
| 248 |
+
- `flash_attn_unpadded_kvpacked_func` -> `flash_attn_varlen_kvpacked_func`
|
| 249 |
+
|
| 250 |
+
If the inputs have the same sequence lengths in the same batch, it is simpler
|
| 251 |
+
and faster to use these functions:
|
| 252 |
+
```python
|
| 253 |
+
flash_attn_qkvpacked_func(qkv, dropout_p=0.0, softmax_scale=None, causal=False)
|
| 254 |
+
```
|
| 255 |
+
```python
|
| 256 |
+
flash_attn_func(q, k, v, dropout_p=0.0, softmax_scale=None, causal=False)
|
| 257 |
+
```
|
| 258 |
+
### 2.1: Change behavior of causal flag
|
| 259 |
+
|
| 260 |
+
If seqlen_q != seqlen_k and causal=True, the causal mask is aligned to the
|
| 261 |
+
bottom right corner of the attention matrix, instead of the top-left corner.
|
| 262 |
+
|
| 263 |
+
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 =
|
| 264 |
+
masked out) is:
|
| 265 |
+
v2.0:
|
| 266 |
+
1 0 0 0 0
|
| 267 |
+
1 1 0 0 0
|
| 268 |
+
v2.1:
|
| 269 |
+
1 1 1 1 0
|
| 270 |
+
1 1 1 1 1
|
| 271 |
+
|
| 272 |
+
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
|
| 273 |
+
v2.0:
|
| 274 |
+
1 0
|
| 275 |
+
1 1
|
| 276 |
+
1 1
|
| 277 |
+
1 1
|
| 278 |
+
1 1
|
| 279 |
+
v2.1:
|
| 280 |
+
0 0
|
| 281 |
+
0 0
|
| 282 |
+
0 0
|
| 283 |
+
1 0
|
| 284 |
+
1 1
|
| 285 |
+
If the row of the mask is all zero, the output will be zero.
|
| 286 |
+
|
| 287 |
+
### 2.2: Optimize for inference
|
| 288 |
+
|
| 289 |
+
Optimize for inference (iterative decoding) when query has very small sequence
|
| 290 |
+
length (e.g., query sequence length = 1). The bottleneck here is to load KV
|
| 291 |
+
cache as fast as possible, and we split the loading across different thread
|
| 292 |
+
blocks, with a separate kernel to combine results.
|
| 293 |
+
|
| 294 |
+
See the function `flash_attn_with_kvcache` with more features for inference
|
| 295 |
+
(perform rotary embedding, updating KV cache inplace).
|
| 296 |
+
|
| 297 |
+
Thanks to the xformers team, and in particular Daniel Haziza, for this
|
| 298 |
+
collaboration.
|
| 299 |
+
|
| 300 |
+
### 2.3: Local (i.e., sliding window) attention
|
| 301 |
+
|
| 302 |
+
Implement sliding window attention (i.e., local attention). Thanks to [Mistral
|
| 303 |
+
AI](https://mistral.ai/) and in particular Timothée Lacroix for this
|
| 304 |
+
contribution. Sliding window was used in the [Mistral 7B](https://mistral.ai/news/announcing-mistral-7b/) model.
|
| 305 |
+
|
| 306 |
+
### 2.4: ALiBi (attention with linear bias), deterministic backward pass.
|
| 307 |
+
|
| 308 |
+
Implement ALiBi (Press et al., 2021). Thanks to Sanghun Cho from Kakao Brain for this contribution.
|
| 309 |
+
|
| 310 |
+
Implement deterministic backward pass. Thanks to engineers from [Meituan](www.meituan.com) for this contribution.
|
| 311 |
+
|
| 312 |
+
### 2.5: Paged KV cache.
|
| 313 |
+
|
| 314 |
+
Support paged KV cache (i.e., [PagedAttention](https://arxiv.org/abs/2309.06180)).
|
| 315 |
+
Thanks to @beginlner for this contribution.
|
| 316 |
+
|
| 317 |
+
## Performance
|
| 318 |
+
|
| 319 |
+
We present expected speedup (combined forward + backward pass) and memory savings from using FlashAttention against PyTorch standard attention, depending on sequence length, on different GPUs (speedup depends on memory bandwidth - we see more speedup on slower GPU memory).
|
| 320 |
+
|
| 321 |
+
We currently have benchmarks for these GPUs:
|
| 322 |
+
* [A100](#a100)
|
| 323 |
+
* [H100](#h100)
|
| 324 |
+
<!-- * [RTX 3090](#rtx-3090) -->
|
| 325 |
+
<!-- * [T4](#t4) -->
|
| 326 |
+
|
| 327 |
+
### A100
|
| 328 |
+
|
| 329 |
+
We display FlashAttention speedup using these parameters:
|
| 330 |
+
* Head dimension 64 or 128, hidden dimension 2048 (i.e. either 32 or 16 heads).
|
| 331 |
+
* Sequence length 512, 1k, 2k, 4k, 8k, 16k.
|
| 332 |
+
* Batch size set to 16k / seqlen.
|
| 333 |
+
|
| 334 |
+
#### Speedup
|
| 335 |
+
|
| 336 |
+

|
| 337 |
+
|
| 338 |
+
#### Memory
|
| 339 |
+
|
| 340 |
+

|
| 341 |
+
|
| 342 |
+
We show memory savings in this graph (note that memory footprint is the same no matter if you use dropout or masking).
|
| 343 |
+
Memory savings are proportional to sequence length -- since standard attention has memory quadratic in sequence length, whereas FlashAttention has memory linear in sequence length.
|
| 344 |
+
We see 10X memory savings at sequence length 2K, and 20X at 4K.
|
| 345 |
+
As a result, FlashAttention can scale to much longer sequence lengths.
|
| 346 |
+
|
| 347 |
+
### H100
|
| 348 |
+
|
| 349 |
+

|
| 350 |
+
|
| 351 |
+
## Full model code and training script
|
| 352 |
+
|
| 353 |
+
We have released the full GPT model
|
| 354 |
+
[implementation](https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/models/gpt.py).
|
| 355 |
+
We also provide optimized implementations of other layers (e.g., MLP, LayerNorm,
|
| 356 |
+
cross-entropy loss, rotary embedding). Overall this speeds up training by 3-5x
|
| 357 |
+
compared to the baseline implementation from Huggingface, reaching up to 225
|
| 358 |
+
TFLOPs/sec per A100, equivalent to 72% model FLOPs utilization (we don't need
|
| 359 |
+
any activation checkpointing).
|
| 360 |
+
|
| 361 |
+
We also include a training
|
| 362 |
+
[script](https://github.com/Dao-AILab/flash-attention/tree/main/training) to
|
| 363 |
+
train GPT2 on Openwebtext and GPT3 on The Pile.
|
| 364 |
+
|
| 365 |
+
## Triton implementation of FlashAttention
|
| 366 |
+
|
| 367 |
+
Phil Tillet (OpenAI) has an experimental implementation of FlashAttention in Triton:
|
| 368 |
+
https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
|
| 369 |
+
|
| 370 |
+
As Triton is a higher-level language than CUDA, it might be easier to understand
|
| 371 |
+
and experiment with. The notations in the Triton implementation are also closer
|
| 372 |
+
to what's used in our paper.
|
| 373 |
+
|
| 374 |
+
We also have an experimental implementation in Triton that support attention
|
| 375 |
+
bias (e.g. ALiBi):
|
| 376 |
+
https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
## Tests
|
| 380 |
+
We test that FlashAttention produces the same output and gradient as a reference
|
| 381 |
+
implementation, up to some numerical tolerance. In particular, we check that the
|
| 382 |
+
maximum numerical error of FlashAttention is at most twice the numerical error
|
| 383 |
+
of a baseline implementation in Pytorch (for different head dimensions, input
|
| 384 |
+
dtype, sequence length, causal / non-causal).
|
| 385 |
+
|
| 386 |
+
To run the tests:
|
| 387 |
+
```sh
|
| 388 |
+
pytest -q -s tests/test_flash_attn.py
|
| 389 |
+
```
|
| 390 |
+
## When you encounter issues
|
| 391 |
+
|
| 392 |
+
This new release of FlashAttention-2 has been tested on several GPT-style
|
| 393 |
+
models, mostly on A100 GPUs.
|
| 394 |
+
|
| 395 |
+
If you encounter bugs, please open a GitHub Issue!
|
| 396 |
+
|
| 397 |
+
## Citation
|
| 398 |
+
If you use this codebase, or otherwise found our work valuable, please cite:
|
| 399 |
+
```
|
| 400 |
+
@inproceedings{dao2022flashattention,
|
| 401 |
+
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
|
| 402 |
+
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
|
| 403 |
+
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
|
| 404 |
+
year={2022}
|
| 405 |
+
}
|
| 406 |
+
@inproceedings{dao2023flashattention2,
|
| 407 |
+
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
|
| 408 |
+
author={Dao, Tri},
|
| 409 |
+
booktitle={International Conference on Learning Representations (ICLR)},
|
| 410 |
+
year={2024}
|
| 411 |
+
}
|
| 412 |
+
```
|
flash-attention/assets/flash2_a100_fwd_bwd_benchmark.png
ADDED

|
flash-attention/assets/flash2_h100_fwd_bwd_benchmark.png
ADDED

|
flash-attention/assets/flashattention_logo.png
ADDED
|
|
Git LFS Details
|
flash-attention/assets/flashattn_banner.jpg
ADDED

|
flash-attention/assets/flashattn_banner.pdf
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
flash-attention/assets/flashattn_memory.jpg
ADDED
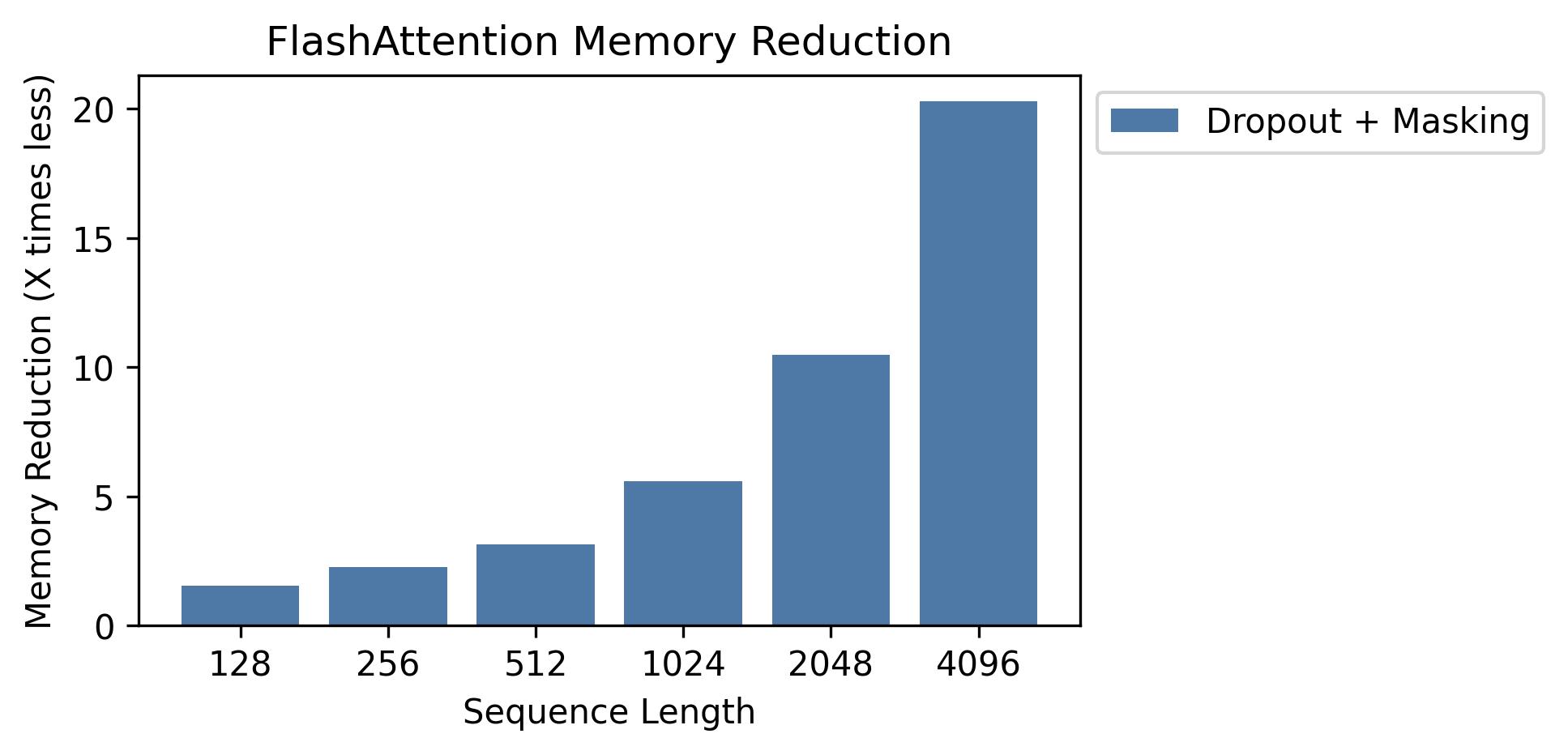
|
flash-attention/assets/flashattn_speedup.jpg
ADDED
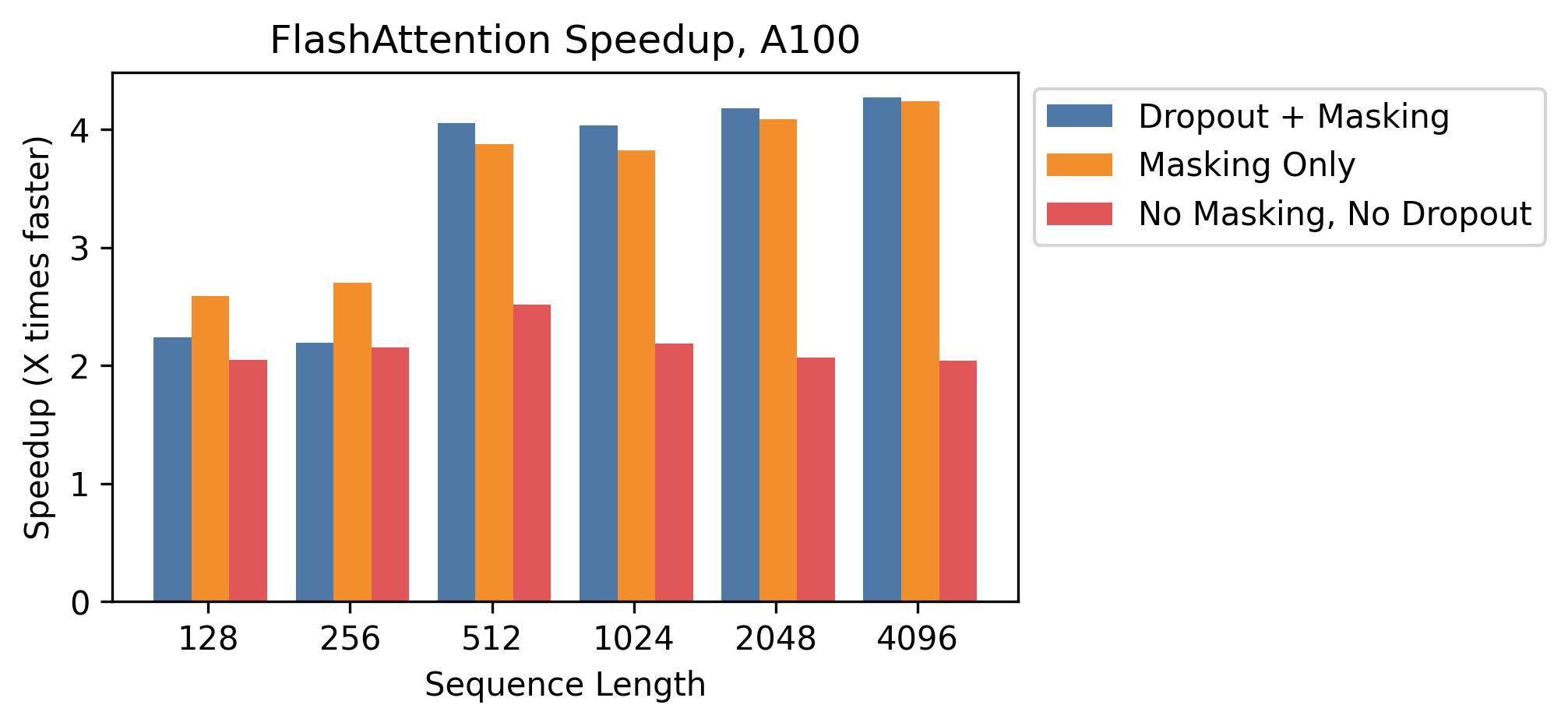
|
flash-attention/assets/flashattn_speedup_3090.jpg
ADDED

|
flash-attention/assets/flashattn_speedup_a100_d128.jpg
ADDED

|
flash-attention/assets/flashattn_speedup_t4.jpg
ADDED

|
flash-attention/assets/flashattn_speedup_t4_fwd.jpg
ADDED
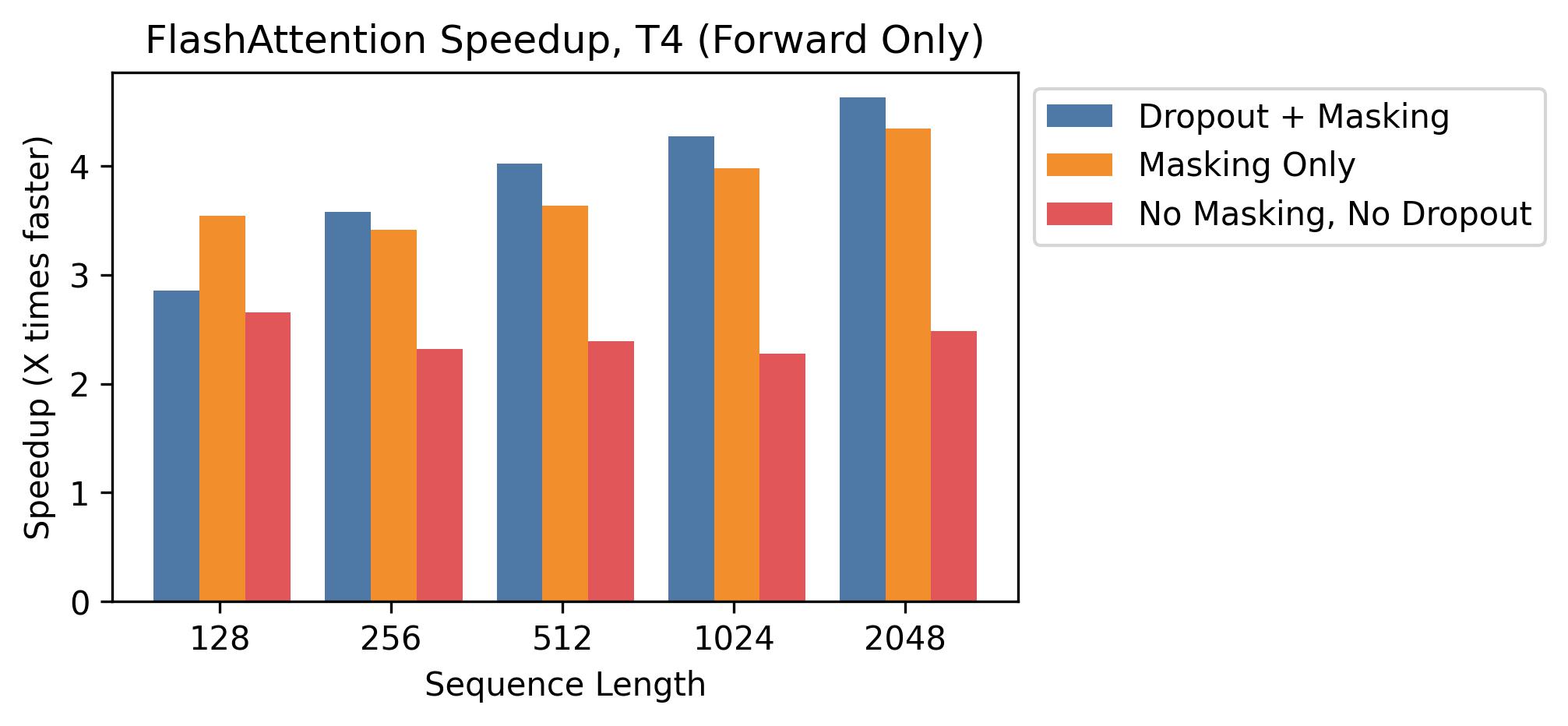
|
flash-attention/assets/gpt2_training_curve.jpg
ADDED

|
flash-attention/assets/gpt2_training_efficiency.jpg
ADDED

|
flash-attention/assets/gpt3_training_curve.jpg
ADDED

|
flash-attention/assets/gpt3_training_efficiency.jpg
ADDED

|
flash-attention/benchmarks/benchmark_alibi.py
ADDED
|
@@ -0,0 +1,275 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024, Sanghun Cho, Tri Dao.
|
| 2 |
+
|
| 3 |
+
import pickle
|
| 4 |
+
import math
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
|
| 9 |
+
from einops import rearrange, repeat
|
| 10 |
+
from flash_attn.layers.rotary import apply_rotary_emb
|
| 11 |
+
|
| 12 |
+
from flash_attn.utils.benchmark import benchmark_all, benchmark_forward, benchmark_backward
|
| 13 |
+
from flash_attn.utils.benchmark import benchmark_fwd_bwd, benchmark_combined
|
| 14 |
+
|
| 15 |
+
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
|
| 16 |
+
|
| 17 |
+
try:
|
| 18 |
+
import xformers.ops as xops
|
| 19 |
+
except ImportError:
|
| 20 |
+
xops = None
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def generate_cos_sin(seqlen, rotary_dim, device, dtype):
|
| 24 |
+
assert rotary_dim % 2 == 0
|
| 25 |
+
angle = torch.rand(seqlen * 2, rotary_dim // 2, device=device) * 2 * math.pi
|
| 26 |
+
cos = torch.cos(angle).to(dtype=dtype)
|
| 27 |
+
sin = torch.sin(angle).to(dtype=dtype)
|
| 28 |
+
return cos, sin
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def flash_rotary(q, k, v, cos, sin, causal=False):
|
| 32 |
+
# corrected by @tridao comments
|
| 33 |
+
q = apply_rotary_emb(
|
| 34 |
+
q, cos, sin, seqlen_offsets=0, interleaved=False, inplace=True
|
| 35 |
+
)
|
| 36 |
+
k = apply_rotary_emb(
|
| 37 |
+
k, cos, sin, seqlen_offsets=0, interleaved=False, inplace=True
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
return flash_attn_func(q, k, v, causal=causal)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def attn_bias_from_alibi_slopes(
|
| 44 |
+
slopes, seqlen_q, seqlen_k, query_padding_mask=None, key_padding_mask=None, causal=False
|
| 45 |
+
):
|
| 46 |
+
batch, nheads = slopes.shape
|
| 47 |
+
device = slopes.device
|
| 48 |
+
slopes = rearrange(slopes, "b h -> b h 1 1")
|
| 49 |
+
if causal:
|
| 50 |
+
return torch.arange(-seqlen_k + 1, 1, device=device, dtype=torch.float32) * slopes
|
| 51 |
+
else:
|
| 52 |
+
row_idx = rearrange(torch.arange(seqlen_q, device=device, dtype=torch.long), "s -> s 1")
|
| 53 |
+
col_idx = torch.arange(seqlen_k, device=device, dtype=torch.long)
|
| 54 |
+
sk = (
|
| 55 |
+
seqlen_k
|
| 56 |
+
if key_padding_mask is None
|
| 57 |
+
else rearrange(key_padding_mask.sum(-1), "b -> b 1 1 1")
|
| 58 |
+
)
|
| 59 |
+
sq = (
|
| 60 |
+
seqlen_q
|
| 61 |
+
if query_padding_mask is None
|
| 62 |
+
else rearrange(query_padding_mask.sum(-1), "b -> b 1 1 1")
|
| 63 |
+
)
|
| 64 |
+
relative_pos = torch.abs(row_idx + sk - sq - col_idx)
|
| 65 |
+
return -slopes * relative_pos.to(dtype=slopes.dtype)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def flops(batch, seqlen, headdim, nheads, causal, mode="fwd"):
|
| 69 |
+
assert mode in ["fwd", "bwd", "fwd_bwd"]
|
| 70 |
+
f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
|
| 71 |
+
return f if mode == "fwd" else (2.5 * f if mode == "bwd" else 3.5 * f)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def efficiency(flop, time):
|
| 75 |
+
return (flop / time / 10**12) if not math.isnan(time) else 0.0
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def attention_pytorch(q, k, v, dropout_p=0.0, causal=True, attn_bias=None):
|
| 79 |
+
"""
|
| 80 |
+
Arguments:
|
| 81 |
+
q, k, v: (batch_size, seqlen, nheads, head_dim)
|
| 82 |
+
dropout_p: float
|
| 83 |
+
attn_bias: (batch_size, nheads, seqlen, seqlen) or (1, nheads, seqlen, seqlen)
|
| 84 |
+
Output:
|
| 85 |
+
output: (batch_size, seqlen, nheads, head_dim)
|
| 86 |
+
"""
|
| 87 |
+
batch_size, seqlen, nheads, d = q.shape
|
| 88 |
+
q = rearrange(q, 'b t h d -> (b h) t d')
|
| 89 |
+
k = rearrange(k, 'b s h d -> (b h) d s')
|
| 90 |
+
softmax_scale = 1.0 / math.sqrt(d)
|
| 91 |
+
# Preallocate attn_weights for `baddbmm`
|
| 92 |
+
if attn_bias is not None:
|
| 93 |
+
scores = rearrange(attn_bias, 'b h t s -> (b h) t s')
|
| 94 |
+
else:
|
| 95 |
+
scores = torch.empty(batch_size * nheads, seqlen, seqlen, dtype=q.dtype, device=q.device)
|
| 96 |
+
scores = rearrange(torch.baddbmm(scores, q, k, beta=1.0, alpha=softmax_scale),
|
| 97 |
+
'(b h) t s -> b h t s', h=nheads)
|
| 98 |
+
if causal:
|
| 99 |
+
# "triu_tril_cuda_template" not implemented for 'BFloat16'
|
| 100 |
+
# So we have to construct the mask in float
|
| 101 |
+
causal_mask = torch.triu(torch.full((seqlen, seqlen), -10000.0, device=scores.device), 1)
|
| 102 |
+
# TD [2022-09-30]: Adding is faster than masked_fill_ (idk why, just better kernel I guess)
|
| 103 |
+
scores = scores + causal_mask.to(dtype=scores.dtype)
|
| 104 |
+
attention = torch.softmax(scores, dim=-1)
|
| 105 |
+
attention_drop = F.dropout(attention, dropout_p)
|
| 106 |
+
output = torch.einsum('bhts,bshd->bthd', attention_drop , v)
|
| 107 |
+
return output.to(dtype=q.dtype)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def time_fwd_bwd(func, *args, **kwargs):
|
| 111 |
+
time_f, time_b = benchmark_fwd_bwd(func, *args, **kwargs)
|
| 112 |
+
return time_f[1].mean, time_b[1].mean
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
repeats = 30
|
| 116 |
+
device = 'cuda'
|
| 117 |
+
dtype = torch.float16
|
| 118 |
+
|
| 119 |
+
bs_seqlen_vals = [(32, 512), (16, 1024), (8, 2048), (4, 4096), (2, 8192), (1, 16384)]
|
| 120 |
+
causal_vals = [False, True]
|
| 121 |
+
headdim_vals = [64, 128]
|
| 122 |
+
dim = 2048
|
| 123 |
+
dropout_p = 0.0
|
| 124 |
+
|
| 125 |
+
methods = (["fa2_alibi", "torch"]
|
| 126 |
+
+ (["xformers"] if xops is not None else [])
|
| 127 |
+
+ ["sdpa"]
|
| 128 |
+
+ ["fa2_baseline"]
|
| 129 |
+
+ ["fa2_rotary"])
|
| 130 |
+
|
| 131 |
+
time_f = {}
|
| 132 |
+
time_b = {}
|
| 133 |
+
time_f_b = {}
|
| 134 |
+
speed_f = {}
|
| 135 |
+
speed_b = {}
|
| 136 |
+
speed_f_b = {}
|
| 137 |
+
for causal in causal_vals:
|
| 138 |
+
for headdim in headdim_vals:
|
| 139 |
+
for batch_size, seqlen in bs_seqlen_vals:
|
| 140 |
+
config = (causal, headdim, batch_size, seqlen)
|
| 141 |
+
nheads = dim // headdim
|
| 142 |
+
q, k, v = [torch.randn(batch_size, seqlen, nheads, headdim, device=device, dtype=dtype,
|
| 143 |
+
requires_grad=True) for _ in range(3)]
|
| 144 |
+
# alibi_slopes = torch.rand(batch_size, nheads, device=device, dtype=torch.float32) * 0.3
|
| 145 |
+
alibi_slopes = torch.rand(1, nheads, device=device, dtype=torch.float32) * 0.3
|
| 146 |
+
attn_bias = attn_bias_from_alibi_slopes(alibi_slopes, seqlen, seqlen, causal=causal).to(dtype)
|
| 147 |
+
attn_bias = repeat(attn_bias, "1 ... -> b ...", b=batch_size)
|
| 148 |
+
f, b = time_fwd_bwd(
|
| 149 |
+
flash_attn_func,
|
| 150 |
+
q, k, v,
|
| 151 |
+
dropout_p,
|
| 152 |
+
causal=causal,
|
| 153 |
+
# alibi_slopes=alibi_slopes,
|
| 154 |
+
alibi_slopes=None,
|
| 155 |
+
repeats=repeats,
|
| 156 |
+
verbose=False
|
| 157 |
+
)
|
| 158 |
+
time_f[config, "fa2_baseline"] = f
|
| 159 |
+
time_b[config, "fa2_baseline"] = b
|
| 160 |
+
|
| 161 |
+
q = q.detach().requires_grad_(True)
|
| 162 |
+
k = k.detach().requires_grad_(True)
|
| 163 |
+
v = v.detach().requires_grad_(True)
|
| 164 |
+
f, b = time_fwd_bwd(
|
| 165 |
+
flash_attn_func,
|
| 166 |
+
q, k, v,
|
| 167 |
+
dropout_p,
|
| 168 |
+
causal=causal,
|
| 169 |
+
alibi_slopes=rearrange(alibi_slopes, "1 h -> h"),
|
| 170 |
+
# alibi_slopes=None,
|
| 171 |
+
repeats=repeats,
|
| 172 |
+
verbose=False
|
| 173 |
+
)
|
| 174 |
+
time_f[config, "fa2_alibi"] = f
|
| 175 |
+
time_b[config, "fa2_alibi"] = b
|
| 176 |
+
|
| 177 |
+
try:
|
| 178 |
+
q = q.detach().requires_grad_(True)
|
| 179 |
+
k = k.detach().requires_grad_(True)
|
| 180 |
+
v = v.detach().requires_grad_(True)
|
| 181 |
+
f, b = time_fwd_bwd(
|
| 182 |
+
attention_pytorch,
|
| 183 |
+
q, k, v,
|
| 184 |
+
dropout_p,
|
| 185 |
+
causal=causal,
|
| 186 |
+
attn_bias=attn_bias,
|
| 187 |
+
repeats=repeats,
|
| 188 |
+
verbose=False
|
| 189 |
+
)
|
| 190 |
+
except: # Skip if OOM
|
| 191 |
+
f, b = float('nan'), float('nan')
|
| 192 |
+
time_f[config, "torch"] = f
|
| 193 |
+
time_b[config, "torch"] = b
|
| 194 |
+
|
| 195 |
+
# F.sdpa doesn't currently (torch 2.1) dispatch to flash-attn but just to be safe
|
| 196 |
+
with torch.backends.cuda.sdp_kernel(enable_flash=False):
|
| 197 |
+
q_pt = q.detach().requires_grad_(True).transpose(1, 2)
|
| 198 |
+
k_pt = k.detach().requires_grad_(True).transpose(1, 2)
|
| 199 |
+
v_pt = v.detach().requires_grad_(True).transpose(1, 2)
|
| 200 |
+
f, b = time_fwd_bwd(
|
| 201 |
+
F.scaled_dot_product_attention,
|
| 202 |
+
q_pt, k_pt, v_pt,
|
| 203 |
+
attn_mask=attn_bias,
|
| 204 |
+
dropout_p=dropout_p,
|
| 205 |
+
is_causal=causal,
|
| 206 |
+
repeats=repeats,
|
| 207 |
+
verbose=False
|
| 208 |
+
)
|
| 209 |
+
time_f[config, "sdpa"] = f
|
| 210 |
+
time_b[config, "sdpa"] = b
|
| 211 |
+
|
| 212 |
+
if xops is not None:
|
| 213 |
+
q = q.detach().requires_grad_(True)
|
| 214 |
+
k = k.detach().requires_grad_(True)
|
| 215 |
+
v = v.detach().requires_grad_(True)
|
| 216 |
+
if causal:
|
| 217 |
+
attn_bias_xops = xops.LowerTriangularMask().add_bias(attn_bias.expand(-1, -1, seqlen, -1).to(dtype=q.dtype))
|
| 218 |
+
# NotImplementedError: No operator found for `memory_efficient_attention_backward` with inputs:
|
| 219 |
+
# `flshattB@v2.3.6` is not supported because:
|
| 220 |
+
# attn_bias type is <class 'xformers.ops.fmha.attn_bias.LowerTriangularMaskWithTensorBias'>
|
| 221 |
+
# `cutlassB` is not supported because:
|
| 222 |
+
# attn_bias type is <class 'xformers.ops.fmha.attn_bias.LowerTriangularMaskWithTensorBias'>
|
| 223 |
+
attn_bias_xops = attn_bias_xops.materialize((batch_size, nheads, seqlen, seqlen), dtype=q.dtype, device=device)
|
| 224 |
+
else:
|
| 225 |
+
attn_bias_xops = attn_bias.to(dtype=q.dtype)
|
| 226 |
+
f, b = time_fwd_bwd(
|
| 227 |
+
xops.memory_efficient_attention,
|
| 228 |
+
q, k, v,
|
| 229 |
+
attn_bias_xops,
|
| 230 |
+
dropout_p,
|
| 231 |
+
repeats=repeats,
|
| 232 |
+
verbose=False
|
| 233 |
+
)
|
| 234 |
+
time_f[config, "xformers"] = f
|
| 235 |
+
time_b[config, "xformers"] = b
|
| 236 |
+
|
| 237 |
+
q = q.detach().requires_grad_(True)
|
| 238 |
+
k = k.detach().requires_grad_(True)
|
| 239 |
+
v = v.detach().requires_grad_(True)
|
| 240 |
+
cos, sin = generate_cos_sin(seqlen, headdim, device, dtype)
|
| 241 |
+
f, b = time_fwd_bwd(
|
| 242 |
+
flash_rotary,
|
| 243 |
+
q, k, v,
|
| 244 |
+
cos, sin,
|
| 245 |
+
causal,
|
| 246 |
+
repeats=repeats,
|
| 247 |
+
verbose=False
|
| 248 |
+
)
|
| 249 |
+
time_f[config, "fa2_rotary"] = f
|
| 250 |
+
time_b[config, "fa2_rotary"] = b
|
| 251 |
+
|
| 252 |
+
print(f"### causal={causal}, headdim={headdim}, batch_size={batch_size}, seqlen={seqlen} ###")
|
| 253 |
+
csv_output = ""
|
| 254 |
+
csv_output += f"{causal},{headdim},{batch_size},{seqlen},"
|
| 255 |
+
for method in methods:
|
| 256 |
+
time_f_b[config, method] = time_f[config, method] + time_b[config, method]
|
| 257 |
+
speed_f[config, method] = efficiency(
|
| 258 |
+
flops(batch_size, seqlen, headdim, nheads, causal, mode="fwd"),
|
| 259 |
+
time_f[config, method]
|
| 260 |
+
)
|
| 261 |
+
speed_b[config, method] = efficiency(
|
| 262 |
+
flops(batch_size, seqlen, headdim, nheads, causal, mode="bwd"),
|
| 263 |
+
time_b[config, method]
|
| 264 |
+
)
|
| 265 |
+
speed_f_b[config, method] = efficiency(
|
| 266 |
+
flops(batch_size, seqlen, headdim, nheads, causal, mode="fwd_bwd"),
|
| 267 |
+
time_f_b[config, method]
|
| 268 |
+
)
|
| 269 |
+
print(
|
| 270 |
+
f"{method} fwd: {speed_f[config, method]:.2f} TFLOPs/s, "
|
| 271 |
+
f"bwd: {speed_b[config, method]:.2f} TFLOPs/s, "
|
| 272 |
+
f"fwd + bwd: {speed_f_b[config, method]:.2f} TFLOPs/s"
|
| 273 |
+
)
|
| 274 |
+
csv_output += f"{speed_f[config, method]:.2f},{speed_b[config, method]:.2f},{speed_f_b[config, method]:.2f},"
|
| 275 |
+
print(csv_output)
|
flash-attention/benchmarks/benchmark_causal.py
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
from einops import rearrange, repeat
|
| 8 |
+
|
| 9 |
+
# from flash_attn.utils.benchmark import benchmark_forward, benchmark_backward, benchmark_combined, benchmark_all, benchmark_fwd_bwd, pytorch_profiler
|
| 10 |
+
from flash_attn.utils.benchmark import benchmark_forward, benchmark_backward, benchmark_combined, benchmark_all, benchmark_fwd_bwd, pytorch_profiler
|
| 11 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_qkvpacked_func
|
| 12 |
+
# # from flash_attn.triton.fused_attention import attention as attention
|
| 13 |
+
# from flash_attn.flash_attn_triton import flash_attn_qkvpacked_func
|
| 14 |
+
# from flash_attn.flash_attn_triton_og import attention as attention_og
|
| 15 |
+
|
| 16 |
+
# from triton.ops.flash_attention import attention as attention_triton
|
| 17 |
+
|
| 18 |
+
from flash_attn import flash_attn_qkvpacked_func, flash_attn_kvpacked_func
|
| 19 |
+
|
| 20 |
+
try:
|
| 21 |
+
from flash_attn.fused_softmax import scaled_upper_triang_masked_softmax
|
| 22 |
+
except ImportError:
|
| 23 |
+
scaled_upper_triang_masked_softmax = None
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def attention_pytorch(qkv, dropout_p=0.0, causal=True):
|
| 27 |
+
"""
|
| 28 |
+
Arguments:
|
| 29 |
+
qkv: (batch_size, seqlen, 3, nheads, head_dim)
|
| 30 |
+
dropout_p: float
|
| 31 |
+
Output:
|
| 32 |
+
output: (batch_size, seqlen, nheads, head_dim)
|
| 33 |
+
"""
|
| 34 |
+
batch_size, seqlen, _, nheads, d = qkv.shape
|
| 35 |
+
q, k, v = qkv.unbind(dim=2)
|
| 36 |
+
q = rearrange(q, 'b t h d -> (b h) t d')
|
| 37 |
+
k = rearrange(k, 'b s h d -> (b h) d s')
|
| 38 |
+
softmax_scale = 1.0 / math.sqrt(d)
|
| 39 |
+
# Preallocate attn_weights for `baddbmm`
|
| 40 |
+
scores = torch.empty(batch_size * nheads, seqlen, seqlen, dtype=qkv.dtype, device=qkv.device)
|
| 41 |
+
scores = rearrange(torch.baddbmm(scores, q, k, beta=0, alpha=softmax_scale),
|
| 42 |
+
'(b h) t s -> b h t s', h=nheads)
|
| 43 |
+
if causal:
|
| 44 |
+
# "triu_tril_cuda_template" not implemented for 'BFloat16'
|
| 45 |
+
# So we have to construct the mask in float
|
| 46 |
+
causal_mask = torch.triu(torch.full((seqlen, seqlen), -10000.0, device=scores.device), 1)
|
| 47 |
+
# TD [2022-09-30]: Adding is faster than masked_fill_ (idk why, just better kernel I guess)
|
| 48 |
+
scores = scores + causal_mask.to(dtype=scores.dtype)
|
| 49 |
+
attention = torch.softmax(scores, dim=-1)
|
| 50 |
+
attention_drop = F.dropout(attention, dropout_p)
|
| 51 |
+
output = torch.einsum('bhts,bshd->bthd', attention_drop , v)
|
| 52 |
+
return output.to(dtype=qkv.dtype)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def attention_megatron(qkv):
|
| 56 |
+
"""
|
| 57 |
+
Arguments:
|
| 58 |
+
qkv: (batch_size, seqlen, 3, nheads, head_dim)
|
| 59 |
+
Output:
|
| 60 |
+
output: (batch_size, seqlen, nheads, head_dim)
|
| 61 |
+
"""
|
| 62 |
+
batch_size, seqlen, _, nheads, d = qkv.shape
|
| 63 |
+
q, k, v = qkv.unbind(dim=2)
|
| 64 |
+
q = rearrange(q, 'b t h d -> (b h) t d')
|
| 65 |
+
k = rearrange(k, 'b s h d -> (b h) d s')
|
| 66 |
+
softmax_scale = 1.0 / math.sqrt(d)
|
| 67 |
+
# Preallocate attn_weights for `baddbmm`
|
| 68 |
+
scores = torch.empty(batch_size * nheads, seqlen, seqlen, dtype=qkv.dtype, device=qkv.device)
|
| 69 |
+
scores = rearrange(torch.baddbmm(scores, q, k, beta=0, alpha=softmax_scale),
|
| 70 |
+
'(b h) t s -> b h t s', h=nheads)
|
| 71 |
+
attention = scaled_upper_triang_masked_softmax(scores, None, scale=1.0)
|
| 72 |
+
output = torch.einsum('bhts,bshd->bthd', attention, v)
|
| 73 |
+
return output.to(dtype=qkv.dtype)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
torch.manual_seed(0)
|
| 77 |
+
repeats = 30
|
| 78 |
+
batch_size = 8
|
| 79 |
+
seqlen = 2048
|
| 80 |
+
nheads = 12
|
| 81 |
+
headdim = 128
|
| 82 |
+
# nheads = 24
|
| 83 |
+
# headdim = 64
|
| 84 |
+
# batch_size = 64
|
| 85 |
+
# seqlen = 512
|
| 86 |
+
# nheads = 8
|
| 87 |
+
# headdim = 128
|
| 88 |
+
dropout_p = 0.0
|
| 89 |
+
causal = True
|
| 90 |
+
dtype = torch.float16
|
| 91 |
+
device = 'cuda'
|
| 92 |
+
|
| 93 |
+
qkv = torch.randn(batch_size, seqlen, 3, nheads, headdim, device=device, dtype=dtype,
|
| 94 |
+
requires_grad=True)
|
| 95 |
+
cu_seqlens = torch.arange(0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32,
|
| 96 |
+
device=qkv.device)
|
| 97 |
+
|
| 98 |
+
qkv_unpad = rearrange(qkv, 'b s ... -> (b s) ...').detach().requires_grad_(True)
|
| 99 |
+
# benchmark_all(flash_attn_varlen_qkvpacked_func, qkv_unpad,
|
| 100 |
+
# cu_seqlens, seqlen, dropout_p, causal=causal, repeats=repeats, desc='FlashAttention')
|
| 101 |
+
# pytorch_profiler(flash_attn_varlen_qkvpacked_func, qkv_unpad,
|
| 102 |
+
# cu_seqlens, seqlen, dropout_p, causal=causal, backward=True)
|
| 103 |
+
benchmark_forward(flash_attn_qkvpacked_func, qkv, dropout_p, causal=causal, repeats=repeats, desc='Fav2')
|
| 104 |
+
pytorch_profiler(flash_attn_qkvpacked_func, qkv, dropout_p, causal=causal, backward=False)
|
| 105 |
+
|
| 106 |
+
# for dropout_p in [0.1, 0.0]:
|
| 107 |
+
# for causal in [False, True]:
|
| 108 |
+
# print(f"### {dropout_p = }, {causal = } ###")
|
| 109 |
+
# pytorch_profiler(fav2_qkvpacked_func, qkv, dropout_p, causal=causal, backward=True)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
# nheads_k = 2
|
| 113 |
+
# q = torch.randn(batch_size, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
|
| 114 |
+
# kv = torch.randn(batch_size, seqlen, 2, nheads_k, headdim, device=device, dtype=dtype,
|
| 115 |
+
# requires_grad=True)
|
| 116 |
+
# if fav2_kvpacked_func is not None:
|
| 117 |
+
# benchmark_all(fav2_kvpacked_func, q, kv, dropout_p, causal=causal, repeats=repeats, desc='Fav2')
|
| 118 |
+
# pytorch_profiler(fav2_kvpacked_func, q, kv, dropout_p, causal=causal, backward=True)
|
| 119 |
+
|
| 120 |
+
# dropout_p = 0.0
|
| 121 |
+
# causal = False
|
| 122 |
+
# benchmark_all(attention_pytorch, qkv, dropout_p, causal=causal,
|
| 123 |
+
# repeats=repeats, desc='PyTorch Attention')
|
| 124 |
+
|
| 125 |
+
# benchmark_all(flash_attn_qkvpacked_func, qkv, None, causal, repeats=repeats, desc='FlashAttention Triton')
|
| 126 |
+
# pytorch_profiler(flash_attn_qkvpacked_func, qkv, None, causal, backward=True)
|
| 127 |
+
|
| 128 |
+
# q, k, v = [torch.randn(batch_size, nheads, seqlen, headdim, device=device, dtype=dtype,
|
| 129 |
+
# requires_grad=True) for _ in range(3)]
|
| 130 |
+
# benchmark_all(attention_og, q, k, v, 1.0, repeats=repeats, desc='FlashAttention Triton OG')
|
| 131 |
+
# # pytorch_profiler(attention, q, k, v, 1.0, backward=True)
|
| 132 |
+
|
| 133 |
+
# if scaled_upper_triang_masked_softmax is not None:
|
| 134 |
+
# benchmark_all(attention_megatron, qkv, repeats=repeats, desc='Megatron Attention')
|
| 135 |
+
|
| 136 |
+
# from src.ops.fftconv import fftconv_func
|
| 137 |
+
|
| 138 |
+
# dim = nheads * headdim
|
| 139 |
+
# u = torch.randn(batch_size, dim, seqlen, device=device, dtype=dtype, requires_grad=True)
|
| 140 |
+
# k = torch.randn(dim, seqlen, device=device, requires_grad=True)
|
| 141 |
+
# D = torch.randn(dim, device=device, requires_grad=True)
|
| 142 |
+
# benchmark_all(fftconv_func, u, k, D, repeats=repeats, desc='FFTConv')
|
| 143 |
+
# pytorch_profiler(fftconv_func, u, k, D, backward=True)
|
| 144 |
+
# pytorch_profiler(torch.fft.rfft, u.float())
|
| 145 |
+
|
| 146 |
+
flops = 4 * batch_size * seqlen ** 2 * nheads * headdim
|
| 147 |
+
ideal_a100_time = flops / 312 / 1e9
|
| 148 |
+
print(f"Ideal A100 fwd time: {ideal_a100_time:.3f}ms, bwd time: {ideal_a100_time * 2.5:.3f}ms")
|
| 149 |
+
exit(0)
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def time_fwd_bwd(func, *args, **kwargs):
|
| 153 |
+
time_f, time_b = benchmark_fwd_bwd(func, *args, **kwargs)
|
| 154 |
+
return time_f[1].mean, time_b[1].mean
|
| 155 |
+
|
| 156 |
+
bs_seqlen_vals = [(32, 512), (16, 1024), (8, 2048), (4, 4096), (2, 8192), (1, 16384)]
|
| 157 |
+
causal_vals = [False, True]
|
| 158 |
+
headdim_vals = [64, 128]
|
| 159 |
+
dim = 2048
|
| 160 |
+
dropout_p = 0.0
|
| 161 |
+
|
| 162 |
+
time_f = {}
|
| 163 |
+
time_b = {}
|
| 164 |
+
for causal in causal_vals:
|
| 165 |
+
for headdim in headdim_vals:
|
| 166 |
+
for batch_size, seqlen in bs_seqlen_vals:
|
| 167 |
+
nheads = dim // headdim
|
| 168 |
+
qkv = torch.randn(batch_size, seqlen, 3, nheads, headdim, device=device, dtype=dtype,
|
| 169 |
+
requires_grad=True)
|
| 170 |
+
cu_seqlens = torch.arange(0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32,
|
| 171 |
+
device=qkv.device)
|
| 172 |
+
qkv_unpad = rearrange(qkv, 'b s ... -> (b s) ...').detach().requires_grad_(True)
|
| 173 |
+
f, b = time_fwd_bwd(
|
| 174 |
+
flash_attn_varlen_qkvpacked_func, qkv_unpad, cu_seqlens, seqlen, dropout_p,
|
| 175 |
+
causal=causal, repeats=repeats, verbose=False
|
| 176 |
+
)
|
| 177 |
+
time_f[(causal, headdim, batch_size, seqlen), "Flash"] = f
|
| 178 |
+
time_b[(causal, headdim, batch_size, seqlen), "Flash"] = b
|
| 179 |
+
|
| 180 |
+
qkv = qkv.detach().requires_grad_(True)
|
| 181 |
+
f, b = time_fwd_bwd(
|
| 182 |
+
fav2_qkvpacked_func, qkv, dropout_p, causal=causal, repeats=repeats, verbose=False
|
| 183 |
+
)
|
| 184 |
+
time_f[(causal, headdim, batch_size, seqlen), "Flash2"] = f
|
| 185 |
+
time_b[(causal, headdim, batch_size, seqlen), "Flash2"] = b
|
| 186 |
+
|
| 187 |
+
# q, k, v = [torch.randn(batch_size, nheads, seqlen, headdim, device=device, dtype=dtype,
|
| 188 |
+
# requires_grad=True) for _ in range(3)]
|
| 189 |
+
# # Try both values of sequence_parallel and pick the faster one
|
| 190 |
+
# f, b = time_fwd_bwd(
|
| 191 |
+
# attention_triton, q, k, v, causal, headdim**(-0.5),
|
| 192 |
+
# False, repeats=repeats, verbose=False
|
| 193 |
+
# )
|
| 194 |
+
# _, b0 = time_fwd_bwd(
|
| 195 |
+
# attention_triton, q, k, v, causal, headdim**(-0.5),
|
| 196 |
+
# True, repeats=repeats, verbose=False
|
| 197 |
+
# )
|
| 198 |
+
# time_f[(causal, headdim, batch_size, seqlen), "Triton"] = f
|
| 199 |
+
# time_b[(causal, headdim, batch_size, seqlen), "Triton"] = min(b, b0)
|
| 200 |
+
|
| 201 |
+
if seqlen <= 8 * 1024:
|
| 202 |
+
qkv = qkv.detach().requires_grad_(True)
|
| 203 |
+
f, b = time_fwd_bwd(
|
| 204 |
+
attention_pytorch, qkv, dropout_p, causal=causal, repeats=repeats, verbose=False
|
| 205 |
+
)
|
| 206 |
+
else:
|
| 207 |
+
f, b = float('nan'), float('nan')
|
| 208 |
+
time_f[(causal, headdim, batch_size, seqlen), "Pytorch"] = f
|
| 209 |
+
time_b[(causal, headdim, batch_size, seqlen), "Pytorch"] = b
|
| 210 |
+
|
| 211 |
+
# q, k, v = [torch.randn(batch_size, seqlen, nheads, headdim, device=device, dtype=dtype,
|
| 212 |
+
# requires_grad=True) for _ in range(3)]
|
| 213 |
+
# import xformers.ops as xops
|
| 214 |
+
# f, b = time_fwd_bwd(
|
| 215 |
+
# xops.memory_efficient_attention, q, k, v,
|
| 216 |
+
# attn_bias=xops.LowerTriangularMask() if causal else None,
|
| 217 |
+
# op=(xops.fmha.cutlass.FwOp, xops.fmha.cutlass.BwOp)
|
| 218 |
+
# )
|
| 219 |
+
# time_f[(causal, headdim, batch_size, seqlen), "xformers"] = f
|
| 220 |
+
# time_b[(causal, headdim, batch_size, seqlen), "xformers"] = b
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
import pickle
|
| 224 |
+
with open('flash2_attn_time_h100.plk', 'wb') as fp:
|
| 225 |
+
pickle.dump((time_f, time_b), fp, protocol=pickle.HIGHEST_PROTOCOL)
|
flash-attention/benchmarks/benchmark_flash_attention.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Install the newest triton version with
|
| 2 |
+
# pip install "git+https://github.com/openai/triton.git#egg=triton&subdirectory=python"
|
| 3 |
+
import pickle
|
| 4 |
+
import math
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
|
| 9 |
+
from einops import rearrange, repeat
|
| 10 |
+
|
| 11 |
+
from flash_attn.utils.benchmark import benchmark_all, benchmark_forward, benchmark_backward
|
| 12 |
+
from flash_attn.utils.benchmark import benchmark_fwd_bwd, benchmark_combined
|
| 13 |
+
|
| 14 |
+
from flash_attn import flash_attn_qkvpacked_func
|
| 15 |
+
|
| 16 |
+
try:
|
| 17 |
+
from triton.ops.flash_attention import attention as attention_triton
|
| 18 |
+
except ImportError:
|
| 19 |
+
attention_triton = None
|
| 20 |
+
|
| 21 |
+
try:
|
| 22 |
+
import xformers.ops as xops
|
| 23 |
+
except ImportError:
|
| 24 |
+
xops = None
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def flops(batch, seqlen, headdim, nheads, causal, mode="fwd"):
|
| 28 |
+
assert mode in ["fwd", "bwd", "fwd_bwd"]
|
| 29 |
+
f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
|
| 30 |
+
return f if mode == "fwd" else (2.5 * f if mode == "bwd" else 3.5 * f)
|
| 31 |
+
|
| 32 |
+
def efficiency(flop, time):
|
| 33 |
+
return (flop / time / 10**12) if not math.isnan(time) else 0.0
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def attention_pytorch(qkv, dropout_p=0.0, causal=True):
|
| 37 |
+
"""
|
| 38 |
+
Arguments:
|
| 39 |
+
qkv: (batch_size, seqlen, 3, nheads, head_dim)
|
| 40 |
+
dropout_p: float
|
| 41 |
+
Output:
|
| 42 |
+
output: (batch_size, seqlen, nheads, head_dim)
|
| 43 |
+
"""
|
| 44 |
+
batch_size, seqlen, _, nheads, d = qkv.shape
|
| 45 |
+
q, k, v = qkv.unbind(dim=2)
|
| 46 |
+
q = rearrange(q, 'b t h d -> (b h) t d')
|
| 47 |
+
k = rearrange(k, 'b s h d -> (b h) d s')
|
| 48 |
+
softmax_scale = 1.0 / math.sqrt(d)
|
| 49 |
+
# Preallocate attn_weights for `baddbmm`
|
| 50 |
+
scores = torch.empty(batch_size * nheads, seqlen, seqlen, dtype=qkv.dtype, device=qkv.device)
|
| 51 |
+
scores = rearrange(torch.baddbmm(scores, q, k, beta=0, alpha=softmax_scale),
|
| 52 |
+
'(b h) t s -> b h t s', h=nheads)
|
| 53 |
+
if causal:
|
| 54 |
+
# "triu_tril_cuda_template" not implemented for 'BFloat16'
|
| 55 |
+
# So we have to construct the mask in float
|
| 56 |
+
causal_mask = torch.triu(torch.full((seqlen, seqlen), -10000.0, device=scores.device), 1)
|
| 57 |
+
# TD [2022-09-30]: Adding is faster than masked_fill_ (idk why, just better kernel I guess)
|
| 58 |
+
scores = scores + causal_mask.to(dtype=scores.dtype)
|
| 59 |
+
attention = torch.softmax(scores, dim=-1)
|
| 60 |
+
attention_drop = F.dropout(attention, dropout_p)
|
| 61 |
+
output = torch.einsum('bhts,bshd->bthd', attention_drop , v)
|
| 62 |
+
return output.to(dtype=qkv.dtype)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def time_fwd_bwd(func, *args, **kwargs):
|
| 66 |
+
time_f, time_b = benchmark_fwd_bwd(func, *args, **kwargs)
|
| 67 |
+
return time_f[1].mean, time_b[1].mean
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
repeats = 30
|
| 71 |
+
device = 'cuda'
|
| 72 |
+
dtype = torch.float16
|
| 73 |
+
|
| 74 |
+
bs_seqlen_vals = [(32, 512), (16, 1024), (8, 2048), (4, 4096), (2, 8192), (1, 16384)]
|
| 75 |
+
causal_vals = [False, True]
|
| 76 |
+
headdim_vals = [64, 128]
|
| 77 |
+
dim = 2048
|
| 78 |
+
dropout_p = 0.0
|
| 79 |
+
|
| 80 |
+
methods = (["Flash2", "Pytorch"]
|
| 81 |
+
+ (["Triton"] if attention_triton is not None else [])
|
| 82 |
+
+ (["xformers.c"] if xops is not None else [])
|
| 83 |
+
+ (["xformers.f"] if xops is not None else []))
|
| 84 |
+
|
| 85 |
+
time_f = {}
|
| 86 |
+
time_b = {}
|
| 87 |
+
time_f_b = {}
|
| 88 |
+
speed_f = {}
|
| 89 |
+
speed_b = {}
|
| 90 |
+
speed_f_b = {}
|
| 91 |
+
for causal in causal_vals:
|
| 92 |
+
for headdim in headdim_vals:
|
| 93 |
+
for batch_size, seqlen in bs_seqlen_vals:
|
| 94 |
+
config = (causal, headdim, batch_size, seqlen)
|
| 95 |
+
nheads = dim // headdim
|
| 96 |
+
qkv = torch.randn(batch_size, seqlen, 3, nheads, headdim, device=device, dtype=dtype,
|
| 97 |
+
requires_grad=True)
|
| 98 |
+
f, b = time_fwd_bwd(
|
| 99 |
+
flash_attn_qkvpacked_func, qkv, dropout_p, causal=causal, repeats=repeats, verbose=False
|
| 100 |
+
)
|
| 101 |
+
time_f[config, "Flash2"] = f
|
| 102 |
+
time_b[config, "Flash2"] = b
|
| 103 |
+
|
| 104 |
+
try:
|
| 105 |
+
qkv = qkv.detach().requires_grad_(True)
|
| 106 |
+
f, b = time_fwd_bwd(
|
| 107 |
+
attention_pytorch, qkv, dropout_p, causal=causal, repeats=repeats, verbose=False
|
| 108 |
+
)
|
| 109 |
+
except: # Skip if OOM
|
| 110 |
+
f, b = float('nan'), float('nan')
|
| 111 |
+
time_f[config, "Pytorch"] = f
|
| 112 |
+
time_b[config, "Pytorch"] = b
|
| 113 |
+
|
| 114 |
+
if attention_triton is not None:
|
| 115 |
+
q, k, v = [torch.randn(batch_size, nheads, seqlen, headdim, device=device, dtype=dtype,
|
| 116 |
+
requires_grad=True) for _ in range(3)]
|
| 117 |
+
# Try both values of sequence_parallel and pick the faster one
|
| 118 |
+
try:
|
| 119 |
+
f, b = time_fwd_bwd(
|
| 120 |
+
attention_triton, q, k, v, causal, headdim**(-0.5),
|
| 121 |
+
False, repeats=repeats, verbose=False
|
| 122 |
+
)
|
| 123 |
+
except:
|
| 124 |
+
f, b = float('nan'), float('inf')
|
| 125 |
+
try:
|
| 126 |
+
_, b0 = time_fwd_bwd(
|
| 127 |
+
attention_triton, q, k, v, causal, headdim**(-0.5),
|
| 128 |
+
True, repeats=repeats, verbose=False
|
| 129 |
+
)
|
| 130 |
+
except:
|
| 131 |
+
b0 = float('inf')
|
| 132 |
+
time_f[config, "Triton"] = f
|
| 133 |
+
time_b[config, "Triton"] = min(b, b0) if min(b, b0) < float('inf') else float('nan')
|
| 134 |
+
|
| 135 |
+
if xops is not None:
|
| 136 |
+
q, k, v = [torch.randn(batch_size, seqlen, nheads, headdim, device=device, dtype=dtype,
|
| 137 |
+
requires_grad=True) for _ in range(3)]
|
| 138 |
+
f, b = time_fwd_bwd(
|
| 139 |
+
xops.memory_efficient_attention, q, k, v,
|
| 140 |
+
attn_bias=xops.LowerTriangularMask() if causal else None,
|
| 141 |
+
op=(xops.fmha.cutlass.FwOp, xops.fmha.cutlass.BwOp)
|
| 142 |
+
)
|
| 143 |
+
time_f[config, "xformers.c"] = f
|
| 144 |
+
time_b[config, "xformers.c"] = b
|
| 145 |
+
|
| 146 |
+
if xops is not None:
|
| 147 |
+
q, k, v = [torch.randn(batch_size, seqlen, nheads, headdim, device=device, dtype=dtype,
|
| 148 |
+
requires_grad=True) for _ in range(3)]
|
| 149 |
+
f, b = time_fwd_bwd(
|
| 150 |
+
xops.memory_efficient_attention, q, k, v,
|
| 151 |
+
attn_bias=xops.LowerTriangularMask() if causal else None,
|
| 152 |
+
op=(xops.fmha.flash.FwOp, xops.fmha.flash.BwOp)
|
| 153 |
+
)
|
| 154 |
+
time_f[config, "xformers.f"] = f
|
| 155 |
+
time_b[config, "xformers.f"] = b
|
| 156 |
+
|
| 157 |
+
print(f"### causal={causal}, headdim={headdim}, batch_size={batch_size}, seqlen={seqlen} ###")
|
| 158 |
+
for method in methods:
|
| 159 |
+
time_f_b[config, method] = time_f[config, method] + time_b[config, method]
|
| 160 |
+
speed_f[config, method] = efficiency(
|
| 161 |
+
flops(batch_size, seqlen, headdim, nheads, causal, mode="fwd"),
|
| 162 |
+
time_f[config, method]
|
| 163 |
+
)
|
| 164 |
+
speed_b[config, method] = efficiency(
|
| 165 |
+
flops(batch_size, seqlen, headdim, nheads, causal, mode="bwd"),
|
| 166 |
+
time_b[config, method]
|
| 167 |
+
)
|
| 168 |
+
speed_f_b[config, method] = efficiency(
|
| 169 |
+
flops(batch_size, seqlen, headdim, nheads, causal, mode="fwd_bwd"),
|
| 170 |
+
time_f_b[config, method]
|
| 171 |
+
)
|
| 172 |
+
print(
|
| 173 |
+
f"{method} fwd: {speed_f[config, method]:.2f} TFLOPs/s, "
|
| 174 |
+
f"bwd: {speed_b[config, method]:.2f} TFLOPs/s, "
|
| 175 |
+
f"fwd + bwd: {speed_f_b[config, method]:.2f} TFLOPs/s"
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# with open('flash2_attn_time.plk', 'wb') as fp:
|
| 180 |
+
# pickle.dump((speed_f, speed_b, speed_f_b), fp, protocol=pickle.HIGHEST_PROTOCOL)
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__version__ = "2.5.9.post1"
|
| 2 |
+
|
| 3 |
+
from flash_attn.flash_attn_interface import (
|
| 4 |
+
flash_attn_func,
|
| 5 |
+
flash_attn_kvpacked_func,
|
| 6 |
+
flash_attn_qkvpacked_func,
|
| 7 |
+
flash_attn_varlen_func,
|
| 8 |
+
flash_attn_varlen_kvpacked_func,
|
| 9 |
+
flash_attn_varlen_qkvpacked_func,
|
| 10 |
+
flash_attn_with_kvcache,
|
| 11 |
+
)
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/bert_padding.py
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapted from https://github.com/mlcommons/training_results_v1.1/blob/main/NVIDIA/benchmarks/bert/implementations/pytorch/padding.py
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from einops import rearrange, repeat
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class IndexFirstAxis(torch.autograd.Function):
|
| 9 |
+
@staticmethod
|
| 10 |
+
def forward(ctx, input, indices):
|
| 11 |
+
ctx.save_for_backward(indices)
|
| 12 |
+
assert input.ndim >= 2
|
| 13 |
+
ctx.first_axis_dim, other_shape = input.shape[0], input.shape[1:]
|
| 14 |
+
second_dim = other_shape.numel()
|
| 15 |
+
# TD [2022-03-04] For some reason torch.gather is a bit faster than indexing.
|
| 16 |
+
# return input[indices]
|
| 17 |
+
return torch.gather(
|
| 18 |
+
rearrange(input, "b ... -> b (...)"), 0, repeat(indices, "z -> z d", d=second_dim)
|
| 19 |
+
).reshape(-1, *other_shape)
|
| 20 |
+
|
| 21 |
+
@staticmethod
|
| 22 |
+
def backward(ctx, grad_output):
|
| 23 |
+
(indices,) = ctx.saved_tensors
|
| 24 |
+
assert grad_output.ndim >= 2
|
| 25 |
+
other_shape = grad_output.shape[1:]
|
| 26 |
+
grad_output = rearrange(grad_output, "b ... -> b (...)")
|
| 27 |
+
grad_input = torch.zeros(
|
| 28 |
+
[ctx.first_axis_dim, grad_output.shape[1]],
|
| 29 |
+
device=grad_output.device,
|
| 30 |
+
dtype=grad_output.dtype,
|
| 31 |
+
)
|
| 32 |
+
# TD [2022-03-04] For some reason torch.scatter is a bit faster than indexing.
|
| 33 |
+
# grad_input[indices] = grad_output
|
| 34 |
+
grad_input.scatter_(0, repeat(indices, "z -> z d", d=grad_output.shape[1]), grad_output)
|
| 35 |
+
return grad_input.reshape(ctx.first_axis_dim, *other_shape), None
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
index_first_axis = IndexFirstAxis.apply
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class IndexPutFirstAxis(torch.autograd.Function):
|
| 42 |
+
@staticmethod
|
| 43 |
+
def forward(ctx, values, indices, first_axis_dim):
|
| 44 |
+
ctx.save_for_backward(indices)
|
| 45 |
+
assert indices.ndim == 1
|
| 46 |
+
assert values.ndim >= 2
|
| 47 |
+
output = torch.zeros(
|
| 48 |
+
first_axis_dim, *values.shape[1:], device=values.device, dtype=values.dtype
|
| 49 |
+
)
|
| 50 |
+
# TD [2022-03-04] For some reason torch.scatter is a bit faster than indexing.
|
| 51 |
+
output[indices] = values
|
| 52 |
+
# output.scatter_(0, repeat(indices, 'z -> z d', d=values.shape[1]), values)
|
| 53 |
+
return output
|
| 54 |
+
|
| 55 |
+
@staticmethod
|
| 56 |
+
def backward(ctx, grad_output):
|
| 57 |
+
(indices,) = ctx.saved_tensors
|
| 58 |
+
# TD [2022-03-04] For some reason torch.gather is a bit faster than indexing.
|
| 59 |
+
grad_values = grad_output[indices]
|
| 60 |
+
# grad_values = torch.gather(grad_output, 0, repeat(indices, 'z -> z d', d=grad_output.shape[1]))
|
| 61 |
+
return grad_values, None, None
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
index_put_first_axis = IndexPutFirstAxis.apply
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class IndexFirstAxisResidual(torch.autograd.Function):
|
| 68 |
+
@staticmethod
|
| 69 |
+
def forward(ctx, input, indices):
|
| 70 |
+
ctx.save_for_backward(indices)
|
| 71 |
+
assert input.ndim >= 2
|
| 72 |
+
ctx.first_axis_dim, other_shape = input.shape[0], input.shape[1:]
|
| 73 |
+
second_dim = other_shape.numel()
|
| 74 |
+
# TD [2022-03-04] For some reason torch.gather is a bit faster than indexing.
|
| 75 |
+
output = input[indices]
|
| 76 |
+
# We don't want to reshape input (b ... -> b (...)) since it could change the channel_last
|
| 77 |
+
# memory format to channel_first. In other words, input might not be contiguous.
|
| 78 |
+
# If we don't detach, Pytorch complains about output being a view and is being modified inplace
|
| 79 |
+
return output, input.detach()
|
| 80 |
+
|
| 81 |
+
@staticmethod
|
| 82 |
+
def backward(ctx, grad_output, grad_residual):
|
| 83 |
+
(indices,) = ctx.saved_tensors
|
| 84 |
+
assert grad_output.ndim >= 2
|
| 85 |
+
other_shape = grad_output.shape[1:]
|
| 86 |
+
assert grad_residual.shape[1:] == other_shape
|
| 87 |
+
grad_input = grad_residual
|
| 88 |
+
# grad_input[indices] += grad_output
|
| 89 |
+
indices = indices.reshape(indices.shape[0], *((1,) * (grad_output.ndim - 1)))
|
| 90 |
+
indices = indices.expand_as(grad_output)
|
| 91 |
+
grad_input.scatter_add_(0, indices, grad_output)
|
| 92 |
+
return grad_input.reshape(ctx.first_axis_dim, *other_shape), None
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
index_first_axis_residual = IndexFirstAxisResidual.apply
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def unpad_input(hidden_states, attention_mask):
|
| 99 |
+
"""
|
| 100 |
+
Arguments:
|
| 101 |
+
hidden_states: (batch, seqlen, ...)
|
| 102 |
+
attention_mask: (batch, seqlen), bool / int, 1 means valid and 0 means not valid.
|
| 103 |
+
Return:
|
| 104 |
+
hidden_states: (total_nnz, ...), where total_nnz = number of tokens in selected in attention_mask.
|
| 105 |
+
indices: (total_nnz), the indices of non-masked tokens from the flattened input sequence.
|
| 106 |
+
cu_seqlens: (batch + 1), the cumulative sequence lengths, used to index into hidden_states.
|
| 107 |
+
max_seqlen_in_batch: int
|
| 108 |
+
"""
|
| 109 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 110 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 111 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 112 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 113 |
+
# TD [2022-03-04] We don't want to index with a bool mask, because Pytorch will expand the
|
| 114 |
+
# bool mask, then call nonzero to get the indices, then index with those. The indices is @dim
|
| 115 |
+
# times larger than it needs to be, wasting memory. It's faster and more memory-efficient to
|
| 116 |
+
# index with integer indices. Moreover, torch's index is a bit slower than it needs to be,
|
| 117 |
+
# so we write custom forward and backward to make it a bit faster.
|
| 118 |
+
return (
|
| 119 |
+
index_first_axis(rearrange(hidden_states, "b s ... -> (b s) ..."), indices),
|
| 120 |
+
indices,
|
| 121 |
+
cu_seqlens,
|
| 122 |
+
max_seqlen_in_batch,
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def unpad_input_for_concatenated_sequences(hidden_states, attention_mask_in_length):
|
| 127 |
+
"""
|
| 128 |
+
Supports concatenating short samples in one sequence. The attention_mask_in_length is utilized to mask other short samples. It helps efficient training of variant lengths-based samples (e.g., the supervised fine-tuning task in large language model).
|
| 129 |
+
The motivation for this function is explained [here](https://github.com/Dao-AILab/flash-attention/issues/432#issuecomment-1668822286).
|
| 130 |
+
|
| 131 |
+
For example, if batch = 3 and seqlen = 6, the attention_mask_in_length is:
|
| 132 |
+
```
|
| 133 |
+
[
|
| 134 |
+
[2, 3, 0, 0, 0, 0],
|
| 135 |
+
[3, 2, 0, 0, 0, 0],
|
| 136 |
+
[6, 0, 0, 0, 0, 0]
|
| 137 |
+
]
|
| 138 |
+
```
|
| 139 |
+
, which refers to the 3D-attention mask:
|
| 140 |
+
```
|
| 141 |
+
[
|
| 142 |
+
[
|
| 143 |
+
[1, 0, 0, 0, 0, 0],
|
| 144 |
+
[1, 1, 0, 0, 0, 0],
|
| 145 |
+
[0, 0, 1, 0, 0, 0],
|
| 146 |
+
[0, 0, 1, 1, 0, 0],
|
| 147 |
+
[0, 0, 1, 1, 1, 0],
|
| 148 |
+
[0, 0, 0, 0, 0, 1]
|
| 149 |
+
],
|
| 150 |
+
[
|
| 151 |
+
[1, 0, 0, 0, 0, 0],
|
| 152 |
+
[1, 1, 0, 0, 0, 0],
|
| 153 |
+
[1, 1, 1, 0, 0, 0],
|
| 154 |
+
[0, 0, 0, 1, 0, 0],
|
| 155 |
+
[0, 0, 0, 1, 1, 0],
|
| 156 |
+
[0, 0, 0, 0, 0, 1]
|
| 157 |
+
],
|
| 158 |
+
[
|
| 159 |
+
[1, 0, 0, 0, 0, 0],
|
| 160 |
+
[1, 1, 0, 0, 0, 0],
|
| 161 |
+
[1, 1, 1, 0, 0, 0],
|
| 162 |
+
[1, 1, 1, 1, 0, 0],
|
| 163 |
+
[1, 1, 1, 1, 1, 0],
|
| 164 |
+
[1, 1, 1, 1, 1, 1]
|
| 165 |
+
]
|
| 166 |
+
]
|
| 167 |
+
```.
|
| 168 |
+
|
| 169 |
+
Arguments:
|
| 170 |
+
hidden_states: (batch, seqlen, ...)
|
| 171 |
+
attention_mask_in_length: (batch, seqlen), int, a nonzero number (e.g., 1, 2, 3, etc.) means length of concatenated sequence in b-th batch, and 0 means none.
|
| 172 |
+
Return:
|
| 173 |
+
hidden_states: (total_nnz, ...), where total_nnz = number of tokens in selected in attention_mask.
|
| 174 |
+
indices: (total_nnz), the indices of non-masked tokens from the flattened input sequence.
|
| 175 |
+
cu_seqlens: (batch + 1), the cumulative sequence lengths, used to index into hidden_states.
|
| 176 |
+
max_seqlen_in_batch: int
|
| 177 |
+
"""
|
| 178 |
+
length = attention_mask_in_length.sum(dim=-1)
|
| 179 |
+
seqlen = attention_mask_in_length.size(-1)
|
| 180 |
+
attention_mask_2d = torch.arange(seqlen, device=length.device, dtype=length.dtype).expand(len(length), seqlen) < length.unsqueeze(1)
|
| 181 |
+
real_indices_idx = torch.nonzero(attention_mask_in_length.flatten(), as_tuple=False).flatten()
|
| 182 |
+
seqlens_in_batch = attention_mask_in_length.flatten()[real_indices_idx]
|
| 183 |
+
indices = torch.nonzero(attention_mask_2d.flatten(), as_tuple=False).flatten()
|
| 184 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 185 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 186 |
+
# TD [2022-03-04] We don't want to index with a bool mask, because Pytorch will expand the
|
| 187 |
+
# bool mask, then call nonzero to get the indices, then index with those. The indices is @dim
|
| 188 |
+
# times larger than it needs to be, wasting memory. It's faster and more memory-efficient to
|
| 189 |
+
# index with integer indices. Moreover, torch's index is a bit slower than it needs to be,
|
| 190 |
+
# so we write custom forward and backward to make it a bit faster.
|
| 191 |
+
return (
|
| 192 |
+
index_first_axis(rearrange(hidden_states, "b s ... -> (b s) ..."), indices),
|
| 193 |
+
indices,
|
| 194 |
+
cu_seqlens,
|
| 195 |
+
max_seqlen_in_batch,
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def pad_input(hidden_states, indices, batch, seqlen):
|
| 200 |
+
"""
|
| 201 |
+
Arguments:
|
| 202 |
+
hidden_states: (total_nnz, ...), where total_nnz = number of tokens in selected in attention_mask.
|
| 203 |
+
indices: (total_nnz), the indices that represent the non-masked tokens of the original padded input sequence.
|
| 204 |
+
batch: int, batch size for the padded sequence.
|
| 205 |
+
seqlen: int, maximum sequence length for the padded sequence.
|
| 206 |
+
Return:
|
| 207 |
+
hidden_states: (batch, seqlen, ...)
|
| 208 |
+
"""
|
| 209 |
+
dim = hidden_states.shape[-1]
|
| 210 |
+
# output = torch.zeros((batch * seqlen), dim, device=hidden_states.device, dtype=hidden_states.dtype)
|
| 211 |
+
# output[indices] = hidden_states
|
| 212 |
+
output = index_put_first_axis(hidden_states, indices, batch * seqlen)
|
| 213 |
+
return rearrange(output, "(b s) ... -> b s ...", b=batch)
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_attn_interface.py
ADDED
|
@@ -0,0 +1,1217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023, Tri Dao.
|
| 2 |
+
|
| 3 |
+
from typing import Optional, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
# isort: off
|
| 9 |
+
# We need to import the CUDA kernels after importing torch
|
| 10 |
+
import flash_attn_2_cuda as flash_attn_cuda
|
| 11 |
+
|
| 12 |
+
# isort: on
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def _get_block_size_n(device, head_dim, is_dropout, is_causal):
|
| 16 |
+
# This should match the block sizes in the CUDA kernel
|
| 17 |
+
assert head_dim <= 256
|
| 18 |
+
major, minor = torch.cuda.get_device_capability(device)
|
| 19 |
+
is_sm8x = major == 8 and minor > 0 # Only include sm86 and sm89, exclude sm80 (A100)
|
| 20 |
+
is_sm80 = major == 8 and minor == 0
|
| 21 |
+
is_sm90 = major == 9 and minor == 0
|
| 22 |
+
if head_dim <= 32:
|
| 23 |
+
return 128
|
| 24 |
+
if head_dim <= 64:
|
| 25 |
+
return 128 if not is_dropout else 64
|
| 26 |
+
elif head_dim <= 96:
|
| 27 |
+
return 64
|
| 28 |
+
elif head_dim <= 128:
|
| 29 |
+
if is_sm8x:
|
| 30 |
+
return 64 if (not is_dropout and is_causal) else 32
|
| 31 |
+
else:
|
| 32 |
+
return 64 if not is_dropout else 32
|
| 33 |
+
elif head_dim <= 160:
|
| 34 |
+
if is_sm8x:
|
| 35 |
+
return 64
|
| 36 |
+
else:
|
| 37 |
+
return 32
|
| 38 |
+
elif head_dim <= 192:
|
| 39 |
+
return 64
|
| 40 |
+
elif head_dim <= 224:
|
| 41 |
+
return 64
|
| 42 |
+
elif head_dim <= 256:
|
| 43 |
+
return 64
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def _flash_attn_forward(
|
| 47 |
+
q, k, v, dropout_p, softmax_scale, causal, window_size, alibi_slopes, return_softmax
|
| 48 |
+
):
|
| 49 |
+
maybe_contiguous = lambda x: x.contiguous() if x.stride(-1) != 1 else x
|
| 50 |
+
q, k, v = [maybe_contiguous(x) for x in (q, k, v)]
|
| 51 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = flash_attn_cuda.fwd(
|
| 52 |
+
q,
|
| 53 |
+
k,
|
| 54 |
+
v,
|
| 55 |
+
None,
|
| 56 |
+
alibi_slopes,
|
| 57 |
+
dropout_p,
|
| 58 |
+
softmax_scale,
|
| 59 |
+
causal,
|
| 60 |
+
window_size[0],
|
| 61 |
+
window_size[1],
|
| 62 |
+
return_softmax,
|
| 63 |
+
None,
|
| 64 |
+
)
|
| 65 |
+
return out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def _flash_attn_varlen_forward(
|
| 69 |
+
q,
|
| 70 |
+
k,
|
| 71 |
+
v,
|
| 72 |
+
cu_seqlens_q,
|
| 73 |
+
cu_seqlens_k,
|
| 74 |
+
max_seqlen_q,
|
| 75 |
+
max_seqlen_k,
|
| 76 |
+
dropout_p,
|
| 77 |
+
softmax_scale,
|
| 78 |
+
causal,
|
| 79 |
+
window_size,
|
| 80 |
+
alibi_slopes,
|
| 81 |
+
return_softmax,
|
| 82 |
+
block_table,
|
| 83 |
+
):
|
| 84 |
+
maybe_contiguous = lambda x: x.contiguous() if x.stride(-1) != 1 else x
|
| 85 |
+
q, k, v = [maybe_contiguous(x) for x in (q, k, v)]
|
| 86 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = flash_attn_cuda.varlen_fwd(
|
| 87 |
+
q,
|
| 88 |
+
k,
|
| 89 |
+
v,
|
| 90 |
+
None,
|
| 91 |
+
cu_seqlens_q,
|
| 92 |
+
cu_seqlens_k,
|
| 93 |
+
None,
|
| 94 |
+
block_table,
|
| 95 |
+
alibi_slopes,
|
| 96 |
+
max_seqlen_q,
|
| 97 |
+
max_seqlen_k,
|
| 98 |
+
dropout_p,
|
| 99 |
+
softmax_scale,
|
| 100 |
+
False,
|
| 101 |
+
causal,
|
| 102 |
+
window_size[0],
|
| 103 |
+
window_size[1],
|
| 104 |
+
return_softmax,
|
| 105 |
+
None,
|
| 106 |
+
)
|
| 107 |
+
# if out.isnan().any() or softmax_lse.isnan().any():
|
| 108 |
+
# breakpoint()
|
| 109 |
+
return out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def _flash_attn_backward(
|
| 113 |
+
dout,
|
| 114 |
+
q,
|
| 115 |
+
k,
|
| 116 |
+
v,
|
| 117 |
+
out,
|
| 118 |
+
softmax_lse,
|
| 119 |
+
dq,
|
| 120 |
+
dk,
|
| 121 |
+
dv,
|
| 122 |
+
dropout_p,
|
| 123 |
+
softmax_scale,
|
| 124 |
+
causal,
|
| 125 |
+
window_size,
|
| 126 |
+
alibi_slopes,
|
| 127 |
+
deterministic,
|
| 128 |
+
rng_state=None,
|
| 129 |
+
):
|
| 130 |
+
maybe_contiguous = lambda x: x.contiguous() if x.stride(-1) != 1 else x
|
| 131 |
+
# dq, dk, dv are allocated by us so they should already be contiguous
|
| 132 |
+
dout, q, k, v, out = [maybe_contiguous(x) for x in (dout, q, k, v, out)]
|
| 133 |
+
dq, dk, dv, softmax_d, = flash_attn_cuda.bwd(
|
| 134 |
+
dout,
|
| 135 |
+
q,
|
| 136 |
+
k,
|
| 137 |
+
v,
|
| 138 |
+
out,
|
| 139 |
+
softmax_lse,
|
| 140 |
+
dq,
|
| 141 |
+
dk,
|
| 142 |
+
dv,
|
| 143 |
+
alibi_slopes,
|
| 144 |
+
dropout_p,
|
| 145 |
+
softmax_scale,
|
| 146 |
+
causal,
|
| 147 |
+
window_size[0],
|
| 148 |
+
window_size[1],
|
| 149 |
+
deterministic,
|
| 150 |
+
None,
|
| 151 |
+
rng_state,
|
| 152 |
+
)
|
| 153 |
+
return dq, dk, dv, softmax_d
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def _flash_attn_varlen_backward(
|
| 157 |
+
dout,
|
| 158 |
+
q,
|
| 159 |
+
k,
|
| 160 |
+
v,
|
| 161 |
+
out,
|
| 162 |
+
softmax_lse,
|
| 163 |
+
dq,
|
| 164 |
+
dk,
|
| 165 |
+
dv,
|
| 166 |
+
cu_seqlens_q,
|
| 167 |
+
cu_seqlens_k,
|
| 168 |
+
max_seqlen_q,
|
| 169 |
+
max_seqlen_k,
|
| 170 |
+
dropout_p,
|
| 171 |
+
softmax_scale,
|
| 172 |
+
causal,
|
| 173 |
+
window_size,
|
| 174 |
+
alibi_slopes,
|
| 175 |
+
deterministic,
|
| 176 |
+
rng_state=None,
|
| 177 |
+
):
|
| 178 |
+
maybe_contiguous = lambda x: x.contiguous() if x.stride(-1) != 1 else x
|
| 179 |
+
# dq, dk, dv are allocated by us so they should already be contiguous
|
| 180 |
+
dout, q, k, v, out = [maybe_contiguous(x) for x in (dout, q, k, v, out)]
|
| 181 |
+
dq, dk, dv, softmax_d, = flash_attn_cuda.varlen_bwd(
|
| 182 |
+
dout,
|
| 183 |
+
q,
|
| 184 |
+
k,
|
| 185 |
+
v,
|
| 186 |
+
out,
|
| 187 |
+
softmax_lse,
|
| 188 |
+
dq,
|
| 189 |
+
dk,
|
| 190 |
+
dv,
|
| 191 |
+
cu_seqlens_q,
|
| 192 |
+
cu_seqlens_k,
|
| 193 |
+
alibi_slopes,
|
| 194 |
+
max_seqlen_q,
|
| 195 |
+
max_seqlen_k,
|
| 196 |
+
dropout_p,
|
| 197 |
+
softmax_scale,
|
| 198 |
+
False,
|
| 199 |
+
causal,
|
| 200 |
+
window_size[0],
|
| 201 |
+
window_size[1],
|
| 202 |
+
deterministic,
|
| 203 |
+
None,
|
| 204 |
+
rng_state,
|
| 205 |
+
)
|
| 206 |
+
# if dk.isnan().any() or dk.isnan().any() or dv.isnan().any() or softmax_d.isnan().any():
|
| 207 |
+
# breakpoint()
|
| 208 |
+
return dq, dk, dv, softmax_d
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class FlashAttnQKVPackedFunc(torch.autograd.Function):
|
| 212 |
+
@staticmethod
|
| 213 |
+
def forward(
|
| 214 |
+
ctx,
|
| 215 |
+
qkv,
|
| 216 |
+
dropout_p,
|
| 217 |
+
softmax_scale,
|
| 218 |
+
causal,
|
| 219 |
+
window_size,
|
| 220 |
+
alibi_slopes,
|
| 221 |
+
deterministic,
|
| 222 |
+
return_softmax,
|
| 223 |
+
):
|
| 224 |
+
if softmax_scale is None:
|
| 225 |
+
softmax_scale = qkv.shape[-1] ** (-0.5)
|
| 226 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_forward(
|
| 227 |
+
qkv[:, :, 0],
|
| 228 |
+
qkv[:, :, 1],
|
| 229 |
+
qkv[:, :, 2],
|
| 230 |
+
dropout_p,
|
| 231 |
+
softmax_scale,
|
| 232 |
+
causal=causal,
|
| 233 |
+
window_size=window_size,
|
| 234 |
+
alibi_slopes=alibi_slopes,
|
| 235 |
+
return_softmax=return_softmax and dropout_p > 0,
|
| 236 |
+
)
|
| 237 |
+
ctx.save_for_backward(q, k, v, out_padded, softmax_lse, rng_state)
|
| 238 |
+
ctx.dropout_p = dropout_p
|
| 239 |
+
ctx.softmax_scale = softmax_scale
|
| 240 |
+
ctx.causal = causal
|
| 241 |
+
ctx.window_size = window_size
|
| 242 |
+
ctx.alibi_slopes = alibi_slopes
|
| 243 |
+
ctx.deterministic = deterministic
|
| 244 |
+
return out if not return_softmax else (out, softmax_lse, S_dmask)
|
| 245 |
+
|
| 246 |
+
@staticmethod
|
| 247 |
+
def backward(ctx, dout, *args):
|
| 248 |
+
q, k, v, out, softmax_lse, rng_state = ctx.saved_tensors
|
| 249 |
+
qkv_shape = q.shape[:-2] + (3, *q.shape[-2:])
|
| 250 |
+
dqkv = torch.empty(qkv_shape, dtype=q.dtype, device=q.device)
|
| 251 |
+
_flash_attn_backward(
|
| 252 |
+
dout,
|
| 253 |
+
q,
|
| 254 |
+
k,
|
| 255 |
+
v,
|
| 256 |
+
out,
|
| 257 |
+
softmax_lse,
|
| 258 |
+
dqkv[:, :, 0],
|
| 259 |
+
dqkv[:, :, 1],
|
| 260 |
+
dqkv[:, :, 2],
|
| 261 |
+
ctx.dropout_p,
|
| 262 |
+
ctx.softmax_scale,
|
| 263 |
+
ctx.causal,
|
| 264 |
+
ctx.window_size,
|
| 265 |
+
ctx.alibi_slopes,
|
| 266 |
+
ctx.deterministic,
|
| 267 |
+
rng_state=rng_state,
|
| 268 |
+
)
|
| 269 |
+
dqkv = dqkv[..., : dout.shape[-1]] # We could have padded the head dimension
|
| 270 |
+
return dqkv, None, None, None, None, None, None, None
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
class FlashAttnVarlenQKVPackedFunc(torch.autograd.Function):
|
| 274 |
+
@staticmethod
|
| 275 |
+
def forward(
|
| 276 |
+
ctx,
|
| 277 |
+
qkv,
|
| 278 |
+
cu_seqlens,
|
| 279 |
+
max_seqlen,
|
| 280 |
+
dropout_p,
|
| 281 |
+
softmax_scale,
|
| 282 |
+
causal,
|
| 283 |
+
window_size,
|
| 284 |
+
alibi_slopes,
|
| 285 |
+
deterministic,
|
| 286 |
+
return_softmax,
|
| 287 |
+
):
|
| 288 |
+
if softmax_scale is None:
|
| 289 |
+
softmax_scale = qkv.shape[-1] ** (-0.5)
|
| 290 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_varlen_forward(
|
| 291 |
+
qkv[:, 0],
|
| 292 |
+
qkv[:, 1],
|
| 293 |
+
qkv[:, 2],
|
| 294 |
+
cu_seqlens,
|
| 295 |
+
cu_seqlens,
|
| 296 |
+
max_seqlen,
|
| 297 |
+
max_seqlen,
|
| 298 |
+
dropout_p,
|
| 299 |
+
softmax_scale,
|
| 300 |
+
causal=causal,
|
| 301 |
+
window_size=window_size,
|
| 302 |
+
alibi_slopes=alibi_slopes,
|
| 303 |
+
return_softmax=return_softmax and dropout_p > 0,
|
| 304 |
+
block_table=None,
|
| 305 |
+
)
|
| 306 |
+
ctx.save_for_backward(q, k, v, out_padded, softmax_lse, cu_seqlens, rng_state)
|
| 307 |
+
ctx.dropout_p = dropout_p
|
| 308 |
+
ctx.max_seqlen = max_seqlen
|
| 309 |
+
ctx.softmax_scale = softmax_scale
|
| 310 |
+
ctx.causal = causal
|
| 311 |
+
ctx.window_size = window_size
|
| 312 |
+
ctx.alibi_slopes = alibi_slopes
|
| 313 |
+
ctx.deterministic = deterministic
|
| 314 |
+
return out if not return_softmax else (out, softmax_lse, S_dmask)
|
| 315 |
+
|
| 316 |
+
@staticmethod
|
| 317 |
+
def backward(ctx, dout, *args):
|
| 318 |
+
q, k, v, out, softmax_lse, cu_seqlens, rng_state = ctx.saved_tensors
|
| 319 |
+
qkv_shape = q.shape[:-2] + (3, *q.shape[-2:])
|
| 320 |
+
dqkv = torch.empty(qkv_shape, dtype=q.dtype, device=q.device)
|
| 321 |
+
_flash_attn_varlen_backward(
|
| 322 |
+
dout,
|
| 323 |
+
q,
|
| 324 |
+
k,
|
| 325 |
+
v,
|
| 326 |
+
out,
|
| 327 |
+
softmax_lse,
|
| 328 |
+
dqkv[:, 0],
|
| 329 |
+
dqkv[:, 1],
|
| 330 |
+
dqkv[:, 2],
|
| 331 |
+
cu_seqlens,
|
| 332 |
+
cu_seqlens,
|
| 333 |
+
ctx.max_seqlen,
|
| 334 |
+
ctx.max_seqlen,
|
| 335 |
+
ctx.dropout_p,
|
| 336 |
+
ctx.softmax_scale,
|
| 337 |
+
ctx.causal,
|
| 338 |
+
ctx.window_size,
|
| 339 |
+
ctx.alibi_slopes,
|
| 340 |
+
ctx.deterministic,
|
| 341 |
+
rng_state=rng_state,
|
| 342 |
+
)
|
| 343 |
+
dqkv = dqkv[..., : dout.shape[-1]] # We could have padded the head dimension
|
| 344 |
+
return dqkv, None, None, None, None, None, None, None, None, None
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
class FlashAttnKVPackedFunc(torch.autograd.Function):
|
| 348 |
+
@staticmethod
|
| 349 |
+
def forward(
|
| 350 |
+
ctx,
|
| 351 |
+
q,
|
| 352 |
+
kv,
|
| 353 |
+
dropout_p,
|
| 354 |
+
softmax_scale,
|
| 355 |
+
causal,
|
| 356 |
+
window_size,
|
| 357 |
+
alibi_slopes,
|
| 358 |
+
deterministic,
|
| 359 |
+
return_softmax,
|
| 360 |
+
):
|
| 361 |
+
if softmax_scale is None:
|
| 362 |
+
softmax_scale = q.shape[-1] ** (-0.5)
|
| 363 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_forward(
|
| 364 |
+
q,
|
| 365 |
+
kv[:, :, 0],
|
| 366 |
+
kv[:, :, 1],
|
| 367 |
+
dropout_p,
|
| 368 |
+
softmax_scale,
|
| 369 |
+
causal=causal,
|
| 370 |
+
window_size=window_size,
|
| 371 |
+
alibi_slopes=alibi_slopes,
|
| 372 |
+
return_softmax=return_softmax and dropout_p > 0,
|
| 373 |
+
)
|
| 374 |
+
ctx.save_for_backward(q, k, v, out_padded, softmax_lse, rng_state)
|
| 375 |
+
ctx.dropout_p = dropout_p
|
| 376 |
+
ctx.softmax_scale = softmax_scale
|
| 377 |
+
ctx.causal = causal
|
| 378 |
+
ctx.window_size = window_size
|
| 379 |
+
ctx.alibi_slopes = alibi_slopes
|
| 380 |
+
ctx.deterministic = deterministic
|
| 381 |
+
return out if not return_softmax else (out, softmax_lse, S_dmask)
|
| 382 |
+
|
| 383 |
+
@staticmethod
|
| 384 |
+
def backward(ctx, dout, *args):
|
| 385 |
+
q, k, v, out, softmax_lse, rng_state = ctx.saved_tensors
|
| 386 |
+
dq = torch.empty_like(q)
|
| 387 |
+
kv_shape = k.shape[:-2] + (2, *k.shape[-2:])
|
| 388 |
+
dkv = torch.empty(kv_shape, dtype=k.dtype, device=k.device)
|
| 389 |
+
_flash_attn_backward(
|
| 390 |
+
dout,
|
| 391 |
+
q,
|
| 392 |
+
k,
|
| 393 |
+
v,
|
| 394 |
+
out,
|
| 395 |
+
softmax_lse,
|
| 396 |
+
dq,
|
| 397 |
+
dkv[:, :, 0],
|
| 398 |
+
dkv[:, :, 1],
|
| 399 |
+
ctx.dropout_p,
|
| 400 |
+
ctx.softmax_scale,
|
| 401 |
+
ctx.causal,
|
| 402 |
+
ctx.window_size,
|
| 403 |
+
ctx.alibi_slopes,
|
| 404 |
+
ctx.deterministic,
|
| 405 |
+
rng_state=rng_state,
|
| 406 |
+
)
|
| 407 |
+
dq = dq[..., : dout.shape[-1]] # We could have padded the head dimension
|
| 408 |
+
dkv = dkv[..., : dout.shape[-1]]
|
| 409 |
+
return dq, dkv, None, None, None, None, None, None, None
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
class FlashAttnVarlenKVPackedFunc(torch.autograd.Function):
|
| 413 |
+
@staticmethod
|
| 414 |
+
def forward(
|
| 415 |
+
ctx,
|
| 416 |
+
q,
|
| 417 |
+
kv,
|
| 418 |
+
cu_seqlens_q,
|
| 419 |
+
cu_seqlens_k,
|
| 420 |
+
max_seqlen_q,
|
| 421 |
+
max_seqlen_k,
|
| 422 |
+
dropout_p,
|
| 423 |
+
softmax_scale,
|
| 424 |
+
causal,
|
| 425 |
+
window_size,
|
| 426 |
+
alibi_slopes,
|
| 427 |
+
deterministic,
|
| 428 |
+
return_softmax,
|
| 429 |
+
):
|
| 430 |
+
if softmax_scale is None:
|
| 431 |
+
softmax_scale = q.shape[-1] ** (-0.5)
|
| 432 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_varlen_forward(
|
| 433 |
+
q,
|
| 434 |
+
kv[:, 0],
|
| 435 |
+
kv[:, 1],
|
| 436 |
+
cu_seqlens_q,
|
| 437 |
+
cu_seqlens_k,
|
| 438 |
+
max_seqlen_q,
|
| 439 |
+
max_seqlen_k,
|
| 440 |
+
dropout_p,
|
| 441 |
+
softmax_scale,
|
| 442 |
+
causal=causal,
|
| 443 |
+
window_size=window_size,
|
| 444 |
+
alibi_slopes=alibi_slopes,
|
| 445 |
+
return_softmax=return_softmax and dropout_p > 0,
|
| 446 |
+
block_table=None,
|
| 447 |
+
)
|
| 448 |
+
ctx.save_for_backward(
|
| 449 |
+
q, k, v, out_padded, softmax_lse, cu_seqlens_q, cu_seqlens_k, rng_state
|
| 450 |
+
)
|
| 451 |
+
ctx.dropout_p = dropout_p
|
| 452 |
+
ctx.max_seqlen_q = max_seqlen_q
|
| 453 |
+
ctx.max_seqlen_k = max_seqlen_k
|
| 454 |
+
ctx.softmax_scale = softmax_scale
|
| 455 |
+
ctx.causal = causal
|
| 456 |
+
ctx.window_size = window_size
|
| 457 |
+
ctx.alibi_slopes = alibi_slopes
|
| 458 |
+
ctx.deterministic = deterministic
|
| 459 |
+
return out if not return_softmax else (out, softmax_lse, S_dmask)
|
| 460 |
+
|
| 461 |
+
@staticmethod
|
| 462 |
+
def backward(ctx, dout, *args):
|
| 463 |
+
q, k, v, out, softmax_lse, cu_seqlens_q, cu_seqlens_k, rng_state = ctx.saved_tensors
|
| 464 |
+
dq = torch.empty_like(q)
|
| 465 |
+
kv_shape = k.shape[:-2] + (2, *k.shape[-2:])
|
| 466 |
+
dkv = torch.empty(kv_shape, dtype=k.dtype, device=k.device)
|
| 467 |
+
_flash_attn_varlen_backward(
|
| 468 |
+
dout,
|
| 469 |
+
q,
|
| 470 |
+
k,
|
| 471 |
+
v,
|
| 472 |
+
out,
|
| 473 |
+
softmax_lse,
|
| 474 |
+
dq,
|
| 475 |
+
dkv[:, 0],
|
| 476 |
+
dkv[:, 1],
|
| 477 |
+
cu_seqlens_q,
|
| 478 |
+
cu_seqlens_k,
|
| 479 |
+
ctx.max_seqlen_q,
|
| 480 |
+
ctx.max_seqlen_k,
|
| 481 |
+
ctx.dropout_p,
|
| 482 |
+
ctx.softmax_scale,
|
| 483 |
+
ctx.causal,
|
| 484 |
+
ctx.window_size,
|
| 485 |
+
ctx.alibi_slopes,
|
| 486 |
+
ctx.deterministic,
|
| 487 |
+
rng_state=rng_state,
|
| 488 |
+
)
|
| 489 |
+
dq = dq[..., : dout.shape[-1]] # We could have padded the head dimension
|
| 490 |
+
dkv = dkv[..., : dout.shape[-1]]
|
| 491 |
+
return dq, dkv, None, None, None, None, None, None, None, None, None, None, None
|
| 492 |
+
|
| 493 |
+
|
| 494 |
+
class FlashAttnFunc(torch.autograd.Function):
|
| 495 |
+
@staticmethod
|
| 496 |
+
def forward(
|
| 497 |
+
ctx,
|
| 498 |
+
q,
|
| 499 |
+
k,
|
| 500 |
+
v,
|
| 501 |
+
dropout_p,
|
| 502 |
+
softmax_scale,
|
| 503 |
+
causal,
|
| 504 |
+
window_size,
|
| 505 |
+
alibi_slopes,
|
| 506 |
+
deterministic,
|
| 507 |
+
return_softmax,
|
| 508 |
+
):
|
| 509 |
+
if softmax_scale is None:
|
| 510 |
+
softmax_scale = q.shape[-1] ** (-0.5)
|
| 511 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_forward(
|
| 512 |
+
q,
|
| 513 |
+
k,
|
| 514 |
+
v,
|
| 515 |
+
dropout_p,
|
| 516 |
+
softmax_scale,
|
| 517 |
+
causal=causal,
|
| 518 |
+
window_size=window_size,
|
| 519 |
+
alibi_slopes=alibi_slopes,
|
| 520 |
+
return_softmax=return_softmax and dropout_p > 0,
|
| 521 |
+
)
|
| 522 |
+
ctx.save_for_backward(q, k, v, out_padded, softmax_lse, rng_state)
|
| 523 |
+
ctx.dropout_p = dropout_p
|
| 524 |
+
ctx.softmax_scale = softmax_scale
|
| 525 |
+
ctx.causal = causal
|
| 526 |
+
ctx.window_size = window_size
|
| 527 |
+
ctx.alibi_slopes = alibi_slopes
|
| 528 |
+
ctx.deterministic = deterministic
|
| 529 |
+
return out if not return_softmax else (out, softmax_lse, S_dmask)
|
| 530 |
+
|
| 531 |
+
@staticmethod
|
| 532 |
+
def backward(ctx, dout, *args):
|
| 533 |
+
q, k, v, out, softmax_lse, rng_state = ctx.saved_tensors
|
| 534 |
+
dq, dk, dv = torch.empty_like(q), torch.empty_like(k), torch.empty_like(v)
|
| 535 |
+
_flash_attn_backward(
|
| 536 |
+
dout,
|
| 537 |
+
q,
|
| 538 |
+
k,
|
| 539 |
+
v,
|
| 540 |
+
out,
|
| 541 |
+
softmax_lse,
|
| 542 |
+
dq,
|
| 543 |
+
dk,
|
| 544 |
+
dv,
|
| 545 |
+
ctx.dropout_p,
|
| 546 |
+
ctx.softmax_scale,
|
| 547 |
+
ctx.causal,
|
| 548 |
+
ctx.window_size,
|
| 549 |
+
ctx.alibi_slopes,
|
| 550 |
+
ctx.deterministic,
|
| 551 |
+
rng_state=rng_state,
|
| 552 |
+
)
|
| 553 |
+
dq = dq[..., : dout.shape[-1]] # We could have padded the head dimension
|
| 554 |
+
dk = dk[..., : dout.shape[-1]]
|
| 555 |
+
dv = dv[..., : dout.shape[-1]]
|
| 556 |
+
return dq, dk, dv, None, None, None, None, None, None, None
|
| 557 |
+
|
| 558 |
+
|
| 559 |
+
class FlashAttnVarlenFunc(torch.autograd.Function):
|
| 560 |
+
@staticmethod
|
| 561 |
+
def forward(
|
| 562 |
+
ctx,
|
| 563 |
+
q,
|
| 564 |
+
k,
|
| 565 |
+
v,
|
| 566 |
+
cu_seqlens_q,
|
| 567 |
+
cu_seqlens_k,
|
| 568 |
+
max_seqlen_q,
|
| 569 |
+
max_seqlen_k,
|
| 570 |
+
dropout_p,
|
| 571 |
+
softmax_scale,
|
| 572 |
+
causal,
|
| 573 |
+
window_size,
|
| 574 |
+
alibi_slopes,
|
| 575 |
+
deterministic,
|
| 576 |
+
return_softmax,
|
| 577 |
+
block_table,
|
| 578 |
+
):
|
| 579 |
+
if softmax_scale is None:
|
| 580 |
+
softmax_scale = q.shape[-1] ** (-0.5)
|
| 581 |
+
out, q, k, v, out_padded, softmax_lse, S_dmask, rng_state = _flash_attn_varlen_forward(
|
| 582 |
+
q,
|
| 583 |
+
k,
|
| 584 |
+
v,
|
| 585 |
+
cu_seqlens_q,
|
| 586 |
+
cu_seqlens_k,
|
| 587 |
+
max_seqlen_q,
|
| 588 |
+
max_seqlen_k,
|
| 589 |
+
dropout_p,
|
| 590 |
+
softmax_scale,
|
| 591 |
+
causal=causal,
|
| 592 |
+
window_size=window_size,
|
| 593 |
+
alibi_slopes=alibi_slopes,
|
| 594 |
+
return_softmax=return_softmax and dropout_p > 0,
|
| 595 |
+
block_table=block_table,
|
| 596 |
+
)
|
| 597 |
+
ctx.save_for_backward(
|
| 598 |
+
q, k, v, out_padded, softmax_lse, cu_seqlens_q, cu_seqlens_k, rng_state
|
| 599 |
+
)
|
| 600 |
+
ctx.dropout_p = dropout_p
|
| 601 |
+
ctx.max_seqlen_q = max_seqlen_q
|
| 602 |
+
ctx.max_seqlen_k = max_seqlen_k
|
| 603 |
+
ctx.softmax_scale = softmax_scale
|
| 604 |
+
ctx.causal = causal
|
| 605 |
+
ctx.window_size = window_size
|
| 606 |
+
ctx.alibi_slopes = alibi_slopes
|
| 607 |
+
ctx.deterministic = deterministic
|
| 608 |
+
return out if not return_softmax else (out, softmax_lse, S_dmask)
|
| 609 |
+
|
| 610 |
+
@staticmethod
|
| 611 |
+
def backward(ctx, dout, *args):
|
| 612 |
+
q, k, v, out, softmax_lse, cu_seqlens_q, cu_seqlens_k, rng_state = ctx.saved_tensors
|
| 613 |
+
dq, dk, dv = torch.empty_like(q), torch.empty_like(k), torch.empty_like(v)
|
| 614 |
+
_flash_attn_varlen_backward(
|
| 615 |
+
dout,
|
| 616 |
+
q,
|
| 617 |
+
k,
|
| 618 |
+
v,
|
| 619 |
+
out,
|
| 620 |
+
softmax_lse,
|
| 621 |
+
dq,
|
| 622 |
+
dk,
|
| 623 |
+
dv,
|
| 624 |
+
cu_seqlens_q,
|
| 625 |
+
cu_seqlens_k,
|
| 626 |
+
ctx.max_seqlen_q,
|
| 627 |
+
ctx.max_seqlen_k,
|
| 628 |
+
ctx.dropout_p,
|
| 629 |
+
ctx.softmax_scale,
|
| 630 |
+
ctx.causal,
|
| 631 |
+
ctx.window_size,
|
| 632 |
+
ctx.alibi_slopes,
|
| 633 |
+
ctx.deterministic,
|
| 634 |
+
rng_state=rng_state,
|
| 635 |
+
)
|
| 636 |
+
dq = dq[..., : dout.shape[-1]] # We could have padded the head dimension
|
| 637 |
+
dk = dk[..., : dout.shape[-1]]
|
| 638 |
+
dv = dv[..., : dout.shape[-1]]
|
| 639 |
+
return dq, dk, dv, None, None, None, None, None, None, None, None, None, None, None, None
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
def flash_attn_qkvpacked_func(
|
| 643 |
+
qkv,
|
| 644 |
+
dropout_p=0.0,
|
| 645 |
+
softmax_scale=None,
|
| 646 |
+
causal=False,
|
| 647 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 648 |
+
alibi_slopes=None,
|
| 649 |
+
deterministic=False,
|
| 650 |
+
return_attn_probs=False,
|
| 651 |
+
):
|
| 652 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 653 |
+
If Q, K, V are already stacked into 1 tensor, this function will be faster than
|
| 654 |
+
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
|
| 655 |
+
of the gradients of Q, K, V.
|
| 656 |
+
For multi-query and grouped-query attention (MQA/GQA), please see
|
| 657 |
+
flash_attn_kvpacked_func and flash_attn_func.
|
| 658 |
+
|
| 659 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 660 |
+
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
|
| 661 |
+
|
| 662 |
+
Arguments:
|
| 663 |
+
qkv: (batch_size, seqlen, 3, nheads, headdim)
|
| 664 |
+
dropout_p: float. Dropout probability.
|
| 665 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 666 |
+
Default to 1 / sqrt(headdim).
|
| 667 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 668 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 669 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
|
| 670 |
+
the attention score of query i and key j.
|
| 671 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 672 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 673 |
+
return_attn_probs: bool. Whether to return the attention probabilities. This option is for
|
| 674 |
+
testing only. The returned probabilities are not guaranteed to be correct
|
| 675 |
+
(they might not have the right scaling).
|
| 676 |
+
Return:
|
| 677 |
+
out: (batch_size, seqlen, nheads, headdim).
|
| 678 |
+
softmax_lse [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen). The
|
| 679 |
+
logsumexp of each row of the matrix QK^T * scaling (e.g., log of the softmax
|
| 680 |
+
normalization factor).
|
| 681 |
+
S_dmask [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen, seqlen).
|
| 682 |
+
The output of softmax (possibly with different scaling). It also encodes the dropout
|
| 683 |
+
pattern (negative means that location was dropped, nonnegative means it was kept).
|
| 684 |
+
"""
|
| 685 |
+
return FlashAttnQKVPackedFunc.apply(
|
| 686 |
+
qkv,
|
| 687 |
+
dropout_p,
|
| 688 |
+
softmax_scale,
|
| 689 |
+
causal,
|
| 690 |
+
window_size,
|
| 691 |
+
alibi_slopes,
|
| 692 |
+
deterministic,
|
| 693 |
+
return_attn_probs,
|
| 694 |
+
)
|
| 695 |
+
|
| 696 |
+
|
| 697 |
+
def flash_attn_kvpacked_func(
|
| 698 |
+
q,
|
| 699 |
+
kv,
|
| 700 |
+
dropout_p=0.0,
|
| 701 |
+
softmax_scale=None,
|
| 702 |
+
causal=False,
|
| 703 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 704 |
+
alibi_slopes=None,
|
| 705 |
+
deterministic=False,
|
| 706 |
+
return_attn_probs=False,
|
| 707 |
+
):
|
| 708 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 709 |
+
If K, V are already stacked into 1 tensor, this function will be faster than
|
| 710 |
+
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
|
| 711 |
+
of the gradients of K, V.
|
| 712 |
+
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
|
| 713 |
+
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
|
| 714 |
+
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
|
| 715 |
+
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
|
| 716 |
+
|
| 717 |
+
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
|
| 718 |
+
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
|
| 719 |
+
1 1 1 1 0
|
| 720 |
+
1 1 1 1 1
|
| 721 |
+
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
|
| 722 |
+
0 0
|
| 723 |
+
0 0
|
| 724 |
+
0 0
|
| 725 |
+
1 0
|
| 726 |
+
1 1
|
| 727 |
+
If the row of the mask is all zero, the output will be zero.
|
| 728 |
+
|
| 729 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 730 |
+
will only attend to keys between
|
| 731 |
+
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
|
| 732 |
+
|
| 733 |
+
Arguments:
|
| 734 |
+
q: (batch_size, seqlen, nheads, headdim)
|
| 735 |
+
kv: (batch_size, seqlen, 2, nheads_k, headdim)
|
| 736 |
+
dropout_p: float. Dropout probability.
|
| 737 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 738 |
+
Default to 1 / sqrt(headdim).
|
| 739 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 740 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 741 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
|
| 742 |
+
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
|
| 743 |
+
is added to the attention score of query i and key j.
|
| 744 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 745 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 746 |
+
return_attn_probs: bool. Whether to return the attention probabilities. This option is for
|
| 747 |
+
testing only. The returned probabilities are not guaranteed to be correct
|
| 748 |
+
(they might not have the right scaling).
|
| 749 |
+
Return:
|
| 750 |
+
out: (batch_size, seqlen, nheads, headdim).
|
| 751 |
+
softmax_lse [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen). The
|
| 752 |
+
logsumexp of each row of the matrix QK^T * scaling (e.g., log of the softmax
|
| 753 |
+
normalization factor).
|
| 754 |
+
S_dmask [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen, seqlen).
|
| 755 |
+
The output of softmax (possibly with different scaling). It also encodes the dropout
|
| 756 |
+
pattern (negative means that location was dropped, nonnegative means it was kept).
|
| 757 |
+
"""
|
| 758 |
+
return FlashAttnKVPackedFunc.apply(
|
| 759 |
+
q,
|
| 760 |
+
kv,
|
| 761 |
+
dropout_p,
|
| 762 |
+
softmax_scale,
|
| 763 |
+
causal,
|
| 764 |
+
window_size,
|
| 765 |
+
alibi_slopes,
|
| 766 |
+
deterministic,
|
| 767 |
+
return_attn_probs,
|
| 768 |
+
)
|
| 769 |
+
|
| 770 |
+
|
| 771 |
+
def flash_attn_func(
|
| 772 |
+
q,
|
| 773 |
+
k,
|
| 774 |
+
v,
|
| 775 |
+
dropout_p=0.0,
|
| 776 |
+
softmax_scale=None,
|
| 777 |
+
causal=False,
|
| 778 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 779 |
+
alibi_slopes=None,
|
| 780 |
+
deterministic=False,
|
| 781 |
+
return_attn_probs=False,
|
| 782 |
+
):
|
| 783 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 784 |
+
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
|
| 785 |
+
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
|
| 786 |
+
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
|
| 787 |
+
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
|
| 788 |
+
|
| 789 |
+
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
|
| 790 |
+
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
|
| 791 |
+
1 1 1 1 0
|
| 792 |
+
1 1 1 1 1
|
| 793 |
+
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
|
| 794 |
+
0 0
|
| 795 |
+
0 0
|
| 796 |
+
0 0
|
| 797 |
+
1 0
|
| 798 |
+
1 1
|
| 799 |
+
If the row of the mask is all zero, the output will be zero.
|
| 800 |
+
|
| 801 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 802 |
+
will only attend to keys between
|
| 803 |
+
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
|
| 804 |
+
|
| 805 |
+
Arguments:
|
| 806 |
+
q: (batch_size, seqlen, nheads, headdim)
|
| 807 |
+
k: (batch_size, seqlen, nheads_k, headdim)
|
| 808 |
+
v: (batch_size, seqlen, nheads_k, headdim)
|
| 809 |
+
dropout_p: float. Dropout probability.
|
| 810 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 811 |
+
Default to 1 / sqrt(headdim).
|
| 812 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 813 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 814 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
|
| 815 |
+
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
|
| 816 |
+
is added to the attention score of query i and key j.
|
| 817 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 818 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 819 |
+
return_attn_probs: bool. Whether to return the attention probabilities. This option is for
|
| 820 |
+
testing only. The returned probabilities are not guaranteed to be correct
|
| 821 |
+
(they might not have the right scaling).
|
| 822 |
+
Return:
|
| 823 |
+
out: (batch_size, seqlen, nheads, headdim).
|
| 824 |
+
softmax_lse [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen). The
|
| 825 |
+
logsumexp of each row of the matrix QK^T * scaling (e.g., log of the softmax
|
| 826 |
+
normalization factor).
|
| 827 |
+
S_dmask [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen, seqlen).
|
| 828 |
+
The output of softmax (possibly with different scaling). It also encodes the dropout
|
| 829 |
+
pattern (negative means that location was dropped, nonnegative means it was kept).
|
| 830 |
+
"""
|
| 831 |
+
return FlashAttnFunc.apply(
|
| 832 |
+
q,
|
| 833 |
+
k,
|
| 834 |
+
v,
|
| 835 |
+
dropout_p,
|
| 836 |
+
softmax_scale,
|
| 837 |
+
causal,
|
| 838 |
+
window_size,
|
| 839 |
+
alibi_slopes,
|
| 840 |
+
deterministic,
|
| 841 |
+
return_attn_probs,
|
| 842 |
+
)
|
| 843 |
+
|
| 844 |
+
|
| 845 |
+
def flash_attn_varlen_qkvpacked_func(
|
| 846 |
+
qkv,
|
| 847 |
+
cu_seqlens,
|
| 848 |
+
max_seqlen,
|
| 849 |
+
dropout_p=0.0,
|
| 850 |
+
softmax_scale=None,
|
| 851 |
+
causal=False,
|
| 852 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 853 |
+
alibi_slopes=None,
|
| 854 |
+
deterministic=False,
|
| 855 |
+
return_attn_probs=False,
|
| 856 |
+
):
|
| 857 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 858 |
+
If Q, K, V are already stacked into 1 tensor, this function will be faster than
|
| 859 |
+
calling flash_attn_varlen_func on Q, K, V since the backward pass avoids explicit concatenation
|
| 860 |
+
of the gradients of Q, K, V.
|
| 861 |
+
For multi-query and grouped-query attention (MQA/GQA), please see
|
| 862 |
+
flash_attn_varlen_kvpacked_func and flash_attn_varlen_func.
|
| 863 |
+
|
| 864 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 865 |
+
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
|
| 866 |
+
|
| 867 |
+
Arguments:
|
| 868 |
+
qkv: (total, 3, nheads, headdim), where total = total number of tokens in the batch.
|
| 869 |
+
cu_seqlens: (batch_size + 1,), dtype torch.int32. The cumulative sequence lengths
|
| 870 |
+
of the sequences in the batch, used to index into qkv.
|
| 871 |
+
max_seqlen: int. Maximum sequence length in the batch.
|
| 872 |
+
dropout_p: float. Dropout probability.
|
| 873 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 874 |
+
Default to 1 / sqrt(headdim).
|
| 875 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 876 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 877 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|)
|
| 878 |
+
is added to the attention score of query i and key j.
|
| 879 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 880 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 881 |
+
return_attn_probs: bool. Whether to return the attention probabilities. This option is for
|
| 882 |
+
testing only. The returned probabilities are not guaranteed to be correct
|
| 883 |
+
(they might not have the right scaling).
|
| 884 |
+
Return:
|
| 885 |
+
out: (total, nheads, headdim).
|
| 886 |
+
softmax_lse [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen). The
|
| 887 |
+
logsumexp of each row of the matrix QK^T * scaling (e.g., log of the softmax
|
| 888 |
+
normalization factor).
|
| 889 |
+
S_dmask [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen, seqlen).
|
| 890 |
+
The output of softmax (possibly with different scaling). It also encodes the dropout
|
| 891 |
+
pattern (negative means that location was dropped, nonnegative means it was kept).
|
| 892 |
+
"""
|
| 893 |
+
return FlashAttnVarlenQKVPackedFunc.apply(
|
| 894 |
+
qkv,
|
| 895 |
+
cu_seqlens,
|
| 896 |
+
max_seqlen,
|
| 897 |
+
dropout_p,
|
| 898 |
+
softmax_scale,
|
| 899 |
+
causal,
|
| 900 |
+
window_size,
|
| 901 |
+
alibi_slopes,
|
| 902 |
+
deterministic,
|
| 903 |
+
return_attn_probs,
|
| 904 |
+
)
|
| 905 |
+
|
| 906 |
+
|
| 907 |
+
def flash_attn_varlen_kvpacked_func(
|
| 908 |
+
q,
|
| 909 |
+
kv,
|
| 910 |
+
cu_seqlens_q,
|
| 911 |
+
cu_seqlens_k,
|
| 912 |
+
max_seqlen_q,
|
| 913 |
+
max_seqlen_k,
|
| 914 |
+
dropout_p=0.0,
|
| 915 |
+
softmax_scale=None,
|
| 916 |
+
causal=False,
|
| 917 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 918 |
+
alibi_slopes=None,
|
| 919 |
+
deterministic=False,
|
| 920 |
+
return_attn_probs=False,
|
| 921 |
+
):
|
| 922 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 923 |
+
If K, V are already stacked into 1 tensor, this function will be faster than
|
| 924 |
+
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
|
| 925 |
+
of the gradients of K, V.
|
| 926 |
+
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
|
| 927 |
+
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
|
| 928 |
+
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
|
| 929 |
+
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
|
| 930 |
+
|
| 931 |
+
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
|
| 932 |
+
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
|
| 933 |
+
1 1 1 1 0
|
| 934 |
+
1 1 1 1 1
|
| 935 |
+
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
|
| 936 |
+
0 0
|
| 937 |
+
0 0
|
| 938 |
+
0 0
|
| 939 |
+
1 0
|
| 940 |
+
1 1
|
| 941 |
+
If the row of the mask is all zero, the output will be zero.
|
| 942 |
+
|
| 943 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 944 |
+
will only attend to keys between
|
| 945 |
+
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
|
| 946 |
+
|
| 947 |
+
Arguments:
|
| 948 |
+
q: (total_q, nheads, headdim), where total_q = total number of query tokens in the batch.
|
| 949 |
+
kv: (total_k, 2, nheads_k, headdim), where total_k = total number of key tokens in the batch.
|
| 950 |
+
cu_seqlens_q: (batch_size + 1,), dtype torch.int32. The cumulative sequence lengths
|
| 951 |
+
of the sequences in the batch, used to index into q.
|
| 952 |
+
cu_seqlens_k: (batch_size + 1,), dtype torch.int32. The cumulative sequence lengths
|
| 953 |
+
of the sequences in the batch, used to index into kv.
|
| 954 |
+
max_seqlen_q: int. Maximum query sequence length in the batch.
|
| 955 |
+
max_seqlen_k: int. Maximum key sequence length in the batch.
|
| 956 |
+
dropout_p: float. Dropout probability.
|
| 957 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 958 |
+
Default to 1 / sqrt(headdim).
|
| 959 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 960 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 961 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
|
| 962 |
+
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
|
| 963 |
+
is added to the attention score of query i and key j.
|
| 964 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 965 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 966 |
+
return_attn_probs: bool. Whether to return the attention probabilities. This option is for
|
| 967 |
+
testing only. The returned probabilities are not guaranteed to be correct
|
| 968 |
+
(they might not have the right scaling).
|
| 969 |
+
Return:
|
| 970 |
+
out: (total, nheads, headdim).
|
| 971 |
+
softmax_lse [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen). The
|
| 972 |
+
logsumexp of each row of the matrix QK^T * scaling (e.g., log of the softmax
|
| 973 |
+
normalization factor).
|
| 974 |
+
S_dmask [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen, seqlen).
|
| 975 |
+
The output of softmax (possibly with different scaling). It also encodes the dropout
|
| 976 |
+
pattern (negative means that location was dropped, nonnegative means it was kept).
|
| 977 |
+
"""
|
| 978 |
+
return FlashAttnVarlenKVPackedFunc.apply(
|
| 979 |
+
q,
|
| 980 |
+
kv,
|
| 981 |
+
cu_seqlens_q,
|
| 982 |
+
cu_seqlens_k,
|
| 983 |
+
max_seqlen_q,
|
| 984 |
+
max_seqlen_k,
|
| 985 |
+
dropout_p,
|
| 986 |
+
softmax_scale,
|
| 987 |
+
causal,
|
| 988 |
+
window_size,
|
| 989 |
+
alibi_slopes,
|
| 990 |
+
deterministic,
|
| 991 |
+
return_attn_probs,
|
| 992 |
+
)
|
| 993 |
+
|
| 994 |
+
|
| 995 |
+
def flash_attn_varlen_func(
|
| 996 |
+
q,
|
| 997 |
+
k,
|
| 998 |
+
v,
|
| 999 |
+
cu_seqlens_q,
|
| 1000 |
+
cu_seqlens_k,
|
| 1001 |
+
max_seqlen_q,
|
| 1002 |
+
max_seqlen_k,
|
| 1003 |
+
dropout_p=0.0,
|
| 1004 |
+
softmax_scale=None,
|
| 1005 |
+
causal=False,
|
| 1006 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 1007 |
+
alibi_slopes=None,
|
| 1008 |
+
deterministic=False,
|
| 1009 |
+
return_attn_probs=False,
|
| 1010 |
+
block_table=None,
|
| 1011 |
+
):
|
| 1012 |
+
"""dropout_p should be set to 0.0 during evaluation
|
| 1013 |
+
Supports multi-query and grouped-query attention (MQA/GQA) by passing in K, V with fewer heads
|
| 1014 |
+
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
|
| 1015 |
+
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
|
| 1016 |
+
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
|
| 1017 |
+
|
| 1018 |
+
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
|
| 1019 |
+
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
|
| 1020 |
+
1 1 1 1 0
|
| 1021 |
+
1 1 1 1 1
|
| 1022 |
+
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
|
| 1023 |
+
0 0
|
| 1024 |
+
0 0
|
| 1025 |
+
0 0
|
| 1026 |
+
1 0
|
| 1027 |
+
1 1
|
| 1028 |
+
If the row of the mask is all zero, the output will be zero.
|
| 1029 |
+
|
| 1030 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 1031 |
+
will only attend to keys between
|
| 1032 |
+
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
|
| 1033 |
+
|
| 1034 |
+
Arguments:
|
| 1035 |
+
q: (total_q, nheads, headdim), where total_q = total number of query tokens in the batch.
|
| 1036 |
+
k: (total_k, nheads_k, headdim), where total_k = total number of key tokens in the batch.
|
| 1037 |
+
v: (total_k, nheads_k, headdim), where total_k = total number of key tokens in the batch.
|
| 1038 |
+
cu_seqlens_q: (batch_size + 1,), dtype torch.int32. The cumulative sequence lengths
|
| 1039 |
+
of the sequences in the batch, used to index into q.
|
| 1040 |
+
cu_seqlens_k: (batch_size + 1,), dtype torch.int32. The cumulative sequence lengths
|
| 1041 |
+
of the sequences in the batch, used to index into kv.
|
| 1042 |
+
max_seqlen_q: int. Maximum query sequence length in the batch.
|
| 1043 |
+
max_seqlen_k: int. Maximum key sequence length in the batch.
|
| 1044 |
+
dropout_p: float. Dropout probability.
|
| 1045 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 1046 |
+
Default to 1 / sqrt(headdim).
|
| 1047 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 1048 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 1049 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
|
| 1050 |
+
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
|
| 1051 |
+
is added to the attention score of query i and key j.
|
| 1052 |
+
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
|
| 1053 |
+
which is slightly slower and uses more memory. The forward pass is always deterministic.
|
| 1054 |
+
return_attn_probs: bool. Whether to return the attention probabilities. This option is for
|
| 1055 |
+
testing only. The returned probabilities are not guaranteed to be correct
|
| 1056 |
+
(they might not have the right scaling).
|
| 1057 |
+
Return:
|
| 1058 |
+
out: (total, nheads, headdim).
|
| 1059 |
+
softmax_lse [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen). The
|
| 1060 |
+
logsumexp of each row of the matrix QK^T * scaling (e.g., log of the softmax
|
| 1061 |
+
normalization factor).
|
| 1062 |
+
S_dmask [optional, if return_attn_probs=True]: (batch_size, nheads, seqlen, seqlen).
|
| 1063 |
+
The output of softmax (possibly with different scaling). It also encodes the dropout
|
| 1064 |
+
pattern (negative means that location was dropped, nonnegative means it was kept).
|
| 1065 |
+
"""
|
| 1066 |
+
return FlashAttnVarlenFunc.apply(
|
| 1067 |
+
q,
|
| 1068 |
+
k,
|
| 1069 |
+
v,
|
| 1070 |
+
cu_seqlens_q,
|
| 1071 |
+
cu_seqlens_k,
|
| 1072 |
+
max_seqlen_q,
|
| 1073 |
+
max_seqlen_k,
|
| 1074 |
+
dropout_p,
|
| 1075 |
+
softmax_scale,
|
| 1076 |
+
causal,
|
| 1077 |
+
window_size,
|
| 1078 |
+
alibi_slopes,
|
| 1079 |
+
deterministic,
|
| 1080 |
+
return_attn_probs,
|
| 1081 |
+
block_table,
|
| 1082 |
+
)
|
| 1083 |
+
|
| 1084 |
+
|
| 1085 |
+
def flash_attn_with_kvcache(
|
| 1086 |
+
q,
|
| 1087 |
+
k_cache,
|
| 1088 |
+
v_cache,
|
| 1089 |
+
k=None,
|
| 1090 |
+
v=None,
|
| 1091 |
+
rotary_cos=None,
|
| 1092 |
+
rotary_sin=None,
|
| 1093 |
+
cache_seqlens: Optional[Union[(int, torch.Tensor)]] = None,
|
| 1094 |
+
cache_batch_idx: Optional[torch.Tensor] = None,
|
| 1095 |
+
block_table: Optional[torch.Tensor] = None,
|
| 1096 |
+
softmax_scale=None,
|
| 1097 |
+
causal=False,
|
| 1098 |
+
window_size=(-1, -1), # -1 means infinite context window
|
| 1099 |
+
rotary_interleaved=True,
|
| 1100 |
+
alibi_slopes=None,
|
| 1101 |
+
num_splits=0,
|
| 1102 |
+
):
|
| 1103 |
+
"""
|
| 1104 |
+
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
|
| 1105 |
+
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
|
| 1106 |
+
the previous step, and update them with the new keys/values from the current step, and do
|
| 1107 |
+
attention with the updated cache, all in 1 kernel.
|
| 1108 |
+
|
| 1109 |
+
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
|
| 1110 |
+
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
|
| 1111 |
+
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
|
| 1112 |
+
|
| 1113 |
+
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
|
| 1114 |
+
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
|
| 1115 |
+
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
|
| 1116 |
+
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
|
| 1117 |
+
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
|
| 1118 |
+
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
|
| 1119 |
+
|
| 1120 |
+
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
|
| 1121 |
+
|
| 1122 |
+
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
|
| 1123 |
+
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
|
| 1124 |
+
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
|
| 1125 |
+
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
|
| 1126 |
+
|
| 1127 |
+
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
|
| 1128 |
+
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
|
| 1129 |
+
1 1 1 1 0
|
| 1130 |
+
1 1 1 1 1
|
| 1131 |
+
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
|
| 1132 |
+
0 0
|
| 1133 |
+
0 0
|
| 1134 |
+
0 0
|
| 1135 |
+
1 0
|
| 1136 |
+
1 1
|
| 1137 |
+
If the row of the mask is all zero, the output will be zero.
|
| 1138 |
+
|
| 1139 |
+
If window_size != (-1, -1), implements sliding window local attention. Query at position i
|
| 1140 |
+
will only attend to keys between
|
| 1141 |
+
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
|
| 1142 |
+
|
| 1143 |
+
Note: Does not support backward pass.
|
| 1144 |
+
|
| 1145 |
+
Arguments:
|
| 1146 |
+
q: (batch_size, seqlen, nheads, headdim)
|
| 1147 |
+
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
|
| 1148 |
+
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
|
| 1149 |
+
page_block_size must be a multiple of 256.
|
| 1150 |
+
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
|
| 1151 |
+
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
|
| 1152 |
+
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
|
| 1153 |
+
k with k_cache, starting at the indices specified by cache_seqlens.
|
| 1154 |
+
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
|
| 1155 |
+
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
|
| 1156 |
+
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
|
| 1157 |
+
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
|
| 1158 |
+
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
|
| 1159 |
+
KV cache.
|
| 1160 |
+
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
|
| 1161 |
+
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
|
| 1162 |
+
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
|
| 1163 |
+
If the indices are not distinct, and k and v are provided, the values updated in the cache
|
| 1164 |
+
might come from any of the duplicate indices.
|
| 1165 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 1166 |
+
Default to 1 / sqrt(headdim).
|
| 1167 |
+
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
|
| 1168 |
+
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
|
| 1169 |
+
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
|
| 1170 |
+
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
|
| 1171 |
+
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
|
| 1172 |
+
(i.e. GPT-NeoX style).
|
| 1173 |
+
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
|
| 1174 |
+
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
|
| 1175 |
+
is added to the attention score of query i and key j.
|
| 1176 |
+
num_splits: int. If > 1, split the key/value into this many chunks along the sequence.
|
| 1177 |
+
If num_splits == 1, we don't split the key/value. If num_splits == 0, we use a heuristic
|
| 1178 |
+
to automatically determine the number of splits.
|
| 1179 |
+
Don't change this unless you know what you are doing.
|
| 1180 |
+
|
| 1181 |
+
Return:
|
| 1182 |
+
out: (batch_size, seqlen, nheads, headdim).
|
| 1183 |
+
"""
|
| 1184 |
+
assert k_cache.stride(-1) == 1, "k_cache must have contiguous last dimension"
|
| 1185 |
+
assert v_cache.stride(-1) == 1, "v_cache must have contiguous last dimension"
|
| 1186 |
+
maybe_contiguous = lambda x: x.contiguous() if x is not None and x.stride(-1) != 1 else x
|
| 1187 |
+
q, k, v = [maybe_contiguous(x) for x in (q, k, v)]
|
| 1188 |
+
if softmax_scale is None:
|
| 1189 |
+
softmax_scale = q.shape[-1] ** (-0.5)
|
| 1190 |
+
if cache_seqlens is not None and isinstance(cache_seqlens, int):
|
| 1191 |
+
cache_seqlens = torch.full(
|
| 1192 |
+
(k_cache.shape[0],), cache_seqlens, dtype=torch.int32, device=k_cache.device
|
| 1193 |
+
)
|
| 1194 |
+
cache_seqlens = maybe_contiguous(cache_seqlens)
|
| 1195 |
+
cache_batch_idx = maybe_contiguous(cache_batch_idx)
|
| 1196 |
+
block_table = maybe_contiguous(block_table)
|
| 1197 |
+
out, softmax_lse = flash_attn_cuda.fwd_kvcache(
|
| 1198 |
+
q,
|
| 1199 |
+
k_cache,
|
| 1200 |
+
v_cache,
|
| 1201 |
+
k,
|
| 1202 |
+
v,
|
| 1203 |
+
cache_seqlens,
|
| 1204 |
+
rotary_cos,
|
| 1205 |
+
rotary_sin,
|
| 1206 |
+
cache_batch_idx,
|
| 1207 |
+
block_table,
|
| 1208 |
+
alibi_slopes,
|
| 1209 |
+
None,
|
| 1210 |
+
softmax_scale,
|
| 1211 |
+
causal,
|
| 1212 |
+
window_size[0],
|
| 1213 |
+
window_size[1],
|
| 1214 |
+
rotary_interleaved,
|
| 1215 |
+
num_splits,
|
| 1216 |
+
)
|
| 1217 |
+
return out
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_attn_triton.py
ADDED
|
@@ -0,0 +1,1160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
*Experimental* implementation of FlashAttention in Triton.
|
| 3 |
+
Tested with triton==2.0.0.dev20221202.
|
| 4 |
+
Triton 2.0 has a new backend (MLIR) but seems like it doesn't yet work for head dimensions
|
| 5 |
+
other than 64:
|
| 6 |
+
https://github.com/openai/triton/blob/d376020f90002757eea3ea9475d4f7cfc2ec5ead/python/triton/ops/flash_attention.py#L207
|
| 7 |
+
We'll update this implementation with the new Triton backend once this is fixed.
|
| 8 |
+
|
| 9 |
+
We use the FlashAttention implementation from Phil Tillet a starting point.
|
| 10 |
+
https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
|
| 11 |
+
|
| 12 |
+
Changes:
|
| 13 |
+
- Implement both causal and non-causal attention.
|
| 14 |
+
- Implement both self-attention and cross-attention.
|
| 15 |
+
- Support arbitrary seqlens (not just multiples of 128), for both forward and backward.
|
| 16 |
+
- Support all head dimensions up to 128 (not just 16, 32, 64, 128), for both forward and backward.
|
| 17 |
+
- Support attention bias.
|
| 18 |
+
- Speed up the forward pass a bit, and only store the LSE instead of m and l.
|
| 19 |
+
- Make the backward for d=128 much faster by reducing register spilling.
|
| 20 |
+
- Optionally parallelize the backward pass across seqlen_k, to deal with the case of
|
| 21 |
+
small batch size * nheads.
|
| 22 |
+
|
| 23 |
+
Caution:
|
| 24 |
+
- This is an *experimental* implementation. The forward pass should be quite robust but
|
| 25 |
+
I'm not 100% sure that the backward pass doesn't have race conditions (due to the Triton compiler).
|
| 26 |
+
- This implementation has only been tested on A100.
|
| 27 |
+
- If you plan to use headdim other than 64 and 128, you should test for race conditions
|
| 28 |
+
(due to the Triton compiler), as done in tests/test_flash_attn.py
|
| 29 |
+
"test_flash_attn_triton_race_condition". I've tested and fixed many race conditions
|
| 30 |
+
for different head dimensions (40, 48, 64, 128, 80, 88, 96), but I'm still not 100% confident
|
| 31 |
+
that there are none left for other head dimensions.
|
| 32 |
+
|
| 33 |
+
Differences between this Triton version and the CUDA version:
|
| 34 |
+
- Triton version doesn't support dropout.
|
| 35 |
+
- Triton forward is generally faster than CUDA forward, while Triton backward is
|
| 36 |
+
generally slower than CUDA backward. Overall Triton forward + backward is slightly slower
|
| 37 |
+
than CUDA forward + backward.
|
| 38 |
+
- Triton version doesn't support different sequence lengths in a batch (i.e., RaggedTensor/NestedTensor).
|
| 39 |
+
- Triton version supports attention bias, while CUDA version doesn't.
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
import math
|
| 43 |
+
|
| 44 |
+
import torch
|
| 45 |
+
import triton
|
| 46 |
+
import triton.language as tl
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# Disabling autotune for now, set num_warps=4 if headdim=64 and num_warps=8 if headdim=128
|
| 50 |
+
# @triton.autotune(
|
| 51 |
+
# configs=[
|
| 52 |
+
# triton.Config({"BLOCK_M": 128, "BLOCK_N": 128}, num_warps=4, num_stages=1),
|
| 53 |
+
# # This config has a race condition when EVEN_M == False, disabling it for now.
|
| 54 |
+
# # triton.Config({"BLOCK_M": 64, "BLOCK_N": 64}, num_warps=4, num_stages=1),
|
| 55 |
+
# ],
|
| 56 |
+
# key=['CACHE_KEY_SEQLEN_Q', 'CACHE_KEY_SEQLEN_K', 'BIAS_TYPE', 'IS_CAUSAL', 'BLOCK_HEADDIM']
|
| 57 |
+
# )
|
| 58 |
+
@triton.heuristics(
|
| 59 |
+
{
|
| 60 |
+
"EVEN_M": lambda args: args["seqlen_q"] % args["BLOCK_M"] == 0,
|
| 61 |
+
"EVEN_N": lambda args: args["seqlen_k"] % args["BLOCK_N"] == 0,
|
| 62 |
+
"EVEN_HEADDIM": lambda args: args["headdim"] == args["BLOCK_HEADDIM"],
|
| 63 |
+
}
|
| 64 |
+
)
|
| 65 |
+
@triton.jit
|
| 66 |
+
def _fwd_kernel(
|
| 67 |
+
Q,
|
| 68 |
+
K,
|
| 69 |
+
V,
|
| 70 |
+
Bias,
|
| 71 |
+
Out,
|
| 72 |
+
Lse,
|
| 73 |
+
TMP, # NOTE: TMP is a scratchpad buffer to workaround a compiler bug
|
| 74 |
+
softmax_scale,
|
| 75 |
+
stride_qb,
|
| 76 |
+
stride_qh,
|
| 77 |
+
stride_qm,
|
| 78 |
+
stride_kb,
|
| 79 |
+
stride_kh,
|
| 80 |
+
stride_kn,
|
| 81 |
+
stride_vb,
|
| 82 |
+
stride_vh,
|
| 83 |
+
stride_vn,
|
| 84 |
+
stride_bb,
|
| 85 |
+
stride_bh,
|
| 86 |
+
stride_bm,
|
| 87 |
+
stride_ob,
|
| 88 |
+
stride_oh,
|
| 89 |
+
stride_om,
|
| 90 |
+
nheads,
|
| 91 |
+
seqlen_q,
|
| 92 |
+
seqlen_k,
|
| 93 |
+
seqlen_q_rounded,
|
| 94 |
+
headdim,
|
| 95 |
+
CACHE_KEY_SEQLEN_Q,
|
| 96 |
+
CACHE_KEY_SEQLEN_K,
|
| 97 |
+
BIAS_TYPE: tl.constexpr,
|
| 98 |
+
IS_CAUSAL: tl.constexpr,
|
| 99 |
+
BLOCK_HEADDIM: tl.constexpr,
|
| 100 |
+
EVEN_M: tl.constexpr,
|
| 101 |
+
EVEN_N: tl.constexpr,
|
| 102 |
+
EVEN_HEADDIM: tl.constexpr,
|
| 103 |
+
BLOCK_M: tl.constexpr,
|
| 104 |
+
BLOCK_N: tl.constexpr,
|
| 105 |
+
):
|
| 106 |
+
start_m = tl.program_id(0)
|
| 107 |
+
off_hb = tl.program_id(1)
|
| 108 |
+
off_b = off_hb // nheads
|
| 109 |
+
off_h = off_hb % nheads
|
| 110 |
+
# off_b = tl.program_id(1)
|
| 111 |
+
# off_h = tl.program_id(2)
|
| 112 |
+
# off_hb = off_b * nheads + off_h
|
| 113 |
+
# initialize offsets
|
| 114 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 115 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 116 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 117 |
+
# Initialize pointers to Q, K, V
|
| 118 |
+
# Adding parenthesis around indexing might use int32 math instead of int64 math?
|
| 119 |
+
# https://github.com/openai/triton/issues/741
|
| 120 |
+
# I'm seeing a tiny bit of difference (5-7us)
|
| 121 |
+
q_ptrs = (
|
| 122 |
+
Q + off_b * stride_qb + off_h * stride_qh + (offs_m[:, None] * stride_qm + offs_d[None, :])
|
| 123 |
+
)
|
| 124 |
+
k_ptrs = (
|
| 125 |
+
K + off_b * stride_kb + off_h * stride_kh + (offs_n[:, None] * stride_kn + offs_d[None, :])
|
| 126 |
+
)
|
| 127 |
+
v_ptrs = (
|
| 128 |
+
V + off_b * stride_vb + off_h * stride_vh + (offs_n[:, None] * stride_vn + offs_d[None, :])
|
| 129 |
+
)
|
| 130 |
+
if BIAS_TYPE == "vector":
|
| 131 |
+
b_ptrs = Bias + off_b * stride_bb + off_h * stride_bh + offs_n
|
| 132 |
+
elif BIAS_TYPE == "matrix":
|
| 133 |
+
b_ptrs = (
|
| 134 |
+
Bias
|
| 135 |
+
+ off_b * stride_bb
|
| 136 |
+
+ off_h * stride_bh
|
| 137 |
+
+ (offs_m[:, None] * stride_bm + offs_n[None, :])
|
| 138 |
+
)
|
| 139 |
+
# initialize pointer to m and l
|
| 140 |
+
t_ptrs = TMP + off_hb * seqlen_q_rounded + offs_m
|
| 141 |
+
lse_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 142 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 143 |
+
acc_o = tl.zeros([BLOCK_M, BLOCK_HEADDIM], dtype=tl.float32)
|
| 144 |
+
# load q: it will stay in SRAM throughout
|
| 145 |
+
# [2022-10-30] TD: Triton bug - in the case of EVEN_M=True and EVEN_N=False, if we just call
|
| 146 |
+
# tl.load(q_ptrs), we get the wrong output!
|
| 147 |
+
if EVEN_M & EVEN_N:
|
| 148 |
+
if EVEN_HEADDIM:
|
| 149 |
+
q = tl.load(q_ptrs)
|
| 150 |
+
else:
|
| 151 |
+
q = tl.load(q_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
|
| 152 |
+
else:
|
| 153 |
+
if EVEN_HEADDIM:
|
| 154 |
+
q = tl.load(q_ptrs, mask=offs_m[:, None] < seqlen_q, other=0.0)
|
| 155 |
+
else:
|
| 156 |
+
q = tl.load(
|
| 157 |
+
q_ptrs, mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0
|
| 158 |
+
)
|
| 159 |
+
# loop over k, v and update accumulator
|
| 160 |
+
end_n = seqlen_k if not IS_CAUSAL else tl.minimum((start_m + 1) * BLOCK_M, seqlen_k)
|
| 161 |
+
for start_n in range(0, end_n, BLOCK_N):
|
| 162 |
+
start_n = tl.multiple_of(start_n, BLOCK_N)
|
| 163 |
+
# -- compute qk ----
|
| 164 |
+
if EVEN_N & EVEN_M: # If we just do "if EVEN_N", there seems to be some race condition
|
| 165 |
+
if EVEN_HEADDIM:
|
| 166 |
+
k = tl.load(k_ptrs + start_n * stride_kn)
|
| 167 |
+
else:
|
| 168 |
+
k = tl.load(k_ptrs + start_n * stride_kn, mask=offs_d[None, :] < headdim, other=0.0)
|
| 169 |
+
else:
|
| 170 |
+
if EVEN_HEADDIM:
|
| 171 |
+
k = tl.load(
|
| 172 |
+
k_ptrs + start_n * stride_kn,
|
| 173 |
+
mask=(start_n + offs_n)[:, None] < seqlen_k,
|
| 174 |
+
other=0.0,
|
| 175 |
+
)
|
| 176 |
+
else:
|
| 177 |
+
k = tl.load(
|
| 178 |
+
k_ptrs + start_n * stride_kn,
|
| 179 |
+
mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
|
| 180 |
+
other=0.0,
|
| 181 |
+
)
|
| 182 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 183 |
+
qk += tl.dot(q, k, trans_b=True)
|
| 184 |
+
# Trying to combine the two masks seem to make the result wrong
|
| 185 |
+
if not EVEN_N: # Need to mask out otherwise the softmax is wrong
|
| 186 |
+
qk += tl.where((start_n + offs_n)[None, :] < seqlen_k, 0, float("-inf"))
|
| 187 |
+
if IS_CAUSAL:
|
| 188 |
+
qk += tl.where(offs_m[:, None] >= (start_n + offs_n)[None, :], 0, float("-inf"))
|
| 189 |
+
if BIAS_TYPE != "none":
|
| 190 |
+
if BIAS_TYPE == "vector":
|
| 191 |
+
if EVEN_N:
|
| 192 |
+
bias = tl.load(b_ptrs + start_n).to(tl.float32)
|
| 193 |
+
else:
|
| 194 |
+
bias = tl.load(
|
| 195 |
+
b_ptrs + start_n, mask=(start_n + offs_n) < seqlen_k, other=0.0
|
| 196 |
+
).to(tl.float32)
|
| 197 |
+
bias = bias[None, :]
|
| 198 |
+
elif BIAS_TYPE == "matrix":
|
| 199 |
+
if EVEN_M & EVEN_N:
|
| 200 |
+
bias = tl.load(b_ptrs + start_n).to(tl.float32)
|
| 201 |
+
else:
|
| 202 |
+
bias = tl.load(
|
| 203 |
+
b_ptrs + start_n,
|
| 204 |
+
mask=(offs_m[:, None] < seqlen_q)
|
| 205 |
+
& ((start_n + offs_n)[None, :] < seqlen_k),
|
| 206 |
+
other=0.0,
|
| 207 |
+
).to(tl.float32)
|
| 208 |
+
# Slightly faster to multiply the softmax_scale in the tl.exp below since the compiler
|
| 209 |
+
# can then fuse the mult and add into an fma instruction. But if we have bias we need to
|
| 210 |
+
# to multiply with softmax_scale here.
|
| 211 |
+
qk = qk * softmax_scale + bias
|
| 212 |
+
m_ij = tl.maximum(tl.max(qk, 1), lse_i)
|
| 213 |
+
p = tl.exp(qk - m_ij[:, None])
|
| 214 |
+
else:
|
| 215 |
+
m_ij = tl.maximum(tl.max(qk, 1) * softmax_scale, lse_i)
|
| 216 |
+
p = tl.exp(qk * softmax_scale - m_ij[:, None])
|
| 217 |
+
l_ij = tl.sum(p, 1)
|
| 218 |
+
|
| 219 |
+
# scale acc_o
|
| 220 |
+
acc_o_scale = tl.exp(m_i - m_ij)
|
| 221 |
+
|
| 222 |
+
# # -- update output accumulator --
|
| 223 |
+
# BUG: have to store and immediately load
|
| 224 |
+
tl.store(t_ptrs, acc_o_scale)
|
| 225 |
+
acc_o_scale = tl.load(t_ptrs)
|
| 226 |
+
acc_o = acc_o * acc_o_scale[:, None]
|
| 227 |
+
# update acc_o
|
| 228 |
+
if EVEN_N & EVEN_M: # If we just do "if EVEN_N", there seems to be some race condition
|
| 229 |
+
if EVEN_HEADDIM:
|
| 230 |
+
v = tl.load(v_ptrs + start_n * stride_vn)
|
| 231 |
+
else:
|
| 232 |
+
v = tl.load(v_ptrs + start_n * stride_vn, mask=offs_d[None, :] < headdim, other=0.0)
|
| 233 |
+
else:
|
| 234 |
+
if EVEN_HEADDIM:
|
| 235 |
+
v = tl.load(
|
| 236 |
+
v_ptrs + start_n * stride_vn,
|
| 237 |
+
mask=(start_n + offs_n)[:, None] < seqlen_k,
|
| 238 |
+
other=0.0,
|
| 239 |
+
)
|
| 240 |
+
else:
|
| 241 |
+
v = tl.load(
|
| 242 |
+
v_ptrs + start_n * stride_vn,
|
| 243 |
+
mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim),
|
| 244 |
+
other=0.0,
|
| 245 |
+
)
|
| 246 |
+
p = p.to(v.dtype)
|
| 247 |
+
acc_o += tl.dot(p, v)
|
| 248 |
+
|
| 249 |
+
# -- update statistics
|
| 250 |
+
m_i = m_ij
|
| 251 |
+
l_i_new = tl.exp(lse_i - m_ij) + l_ij
|
| 252 |
+
lse_i = m_ij + tl.log(l_i_new)
|
| 253 |
+
|
| 254 |
+
o_scale = tl.exp(m_i - lse_i)
|
| 255 |
+
# BUG: have to store and immediately load
|
| 256 |
+
tl.store(t_ptrs, o_scale)
|
| 257 |
+
o_scale = tl.load(t_ptrs)
|
| 258 |
+
acc_o = acc_o * o_scale[:, None]
|
| 259 |
+
# rematerialize offsets to save registers
|
| 260 |
+
start_m = tl.program_id(0)
|
| 261 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 262 |
+
# write back l and m
|
| 263 |
+
lse_ptrs = Lse + off_hb * seqlen_q_rounded + offs_m
|
| 264 |
+
tl.store(lse_ptrs, lse_i)
|
| 265 |
+
# initialize pointers to output
|
| 266 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 267 |
+
out_ptrs = (
|
| 268 |
+
Out
|
| 269 |
+
+ off_b * stride_ob
|
| 270 |
+
+ off_h * stride_oh
|
| 271 |
+
+ (offs_m[:, None] * stride_om + offs_d[None, :])
|
| 272 |
+
)
|
| 273 |
+
if EVEN_M:
|
| 274 |
+
if EVEN_HEADDIM:
|
| 275 |
+
tl.store(out_ptrs, acc_o)
|
| 276 |
+
else:
|
| 277 |
+
tl.store(out_ptrs, acc_o, mask=offs_d[None, :] < headdim)
|
| 278 |
+
else:
|
| 279 |
+
if EVEN_HEADDIM:
|
| 280 |
+
tl.store(out_ptrs, acc_o, mask=offs_m[:, None] < seqlen_q)
|
| 281 |
+
else:
|
| 282 |
+
tl.store(
|
| 283 |
+
out_ptrs, acc_o, mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim)
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
@triton.jit
|
| 288 |
+
def _bwd_preprocess_do_o_dot(
|
| 289 |
+
Out,
|
| 290 |
+
DO,
|
| 291 |
+
Delta,
|
| 292 |
+
stride_ob,
|
| 293 |
+
stride_oh,
|
| 294 |
+
stride_om,
|
| 295 |
+
stride_dob,
|
| 296 |
+
stride_doh,
|
| 297 |
+
stride_dom,
|
| 298 |
+
nheads,
|
| 299 |
+
seqlen_q,
|
| 300 |
+
seqlen_q_rounded,
|
| 301 |
+
headdim,
|
| 302 |
+
BLOCK_M: tl.constexpr,
|
| 303 |
+
BLOCK_HEADDIM: tl.constexpr,
|
| 304 |
+
):
|
| 305 |
+
start_m = tl.program_id(0)
|
| 306 |
+
off_hb = tl.program_id(1)
|
| 307 |
+
off_b = off_hb // nheads
|
| 308 |
+
off_h = off_hb % nheads
|
| 309 |
+
# initialize offsets
|
| 310 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 311 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 312 |
+
# load
|
| 313 |
+
o = tl.load(
|
| 314 |
+
Out + off_b * stride_ob + off_h * stride_oh + offs_m[:, None] * stride_om + offs_d[None, :],
|
| 315 |
+
mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
|
| 316 |
+
other=0.0,
|
| 317 |
+
).to(tl.float32)
|
| 318 |
+
do = tl.load(
|
| 319 |
+
DO
|
| 320 |
+
+ off_b * stride_dob
|
| 321 |
+
+ off_h * stride_doh
|
| 322 |
+
+ offs_m[:, None] * stride_dom
|
| 323 |
+
+ offs_d[None, :],
|
| 324 |
+
mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
|
| 325 |
+
other=0.0,
|
| 326 |
+
).to(tl.float32)
|
| 327 |
+
delta = tl.sum(o * do, axis=1)
|
| 328 |
+
# write-back
|
| 329 |
+
tl.store(Delta + off_hb * seqlen_q_rounded + offs_m, delta)
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
@triton.jit
|
| 333 |
+
def _bwd_store_dk_dv(
|
| 334 |
+
dk_ptrs,
|
| 335 |
+
dv_ptrs,
|
| 336 |
+
dk,
|
| 337 |
+
dv,
|
| 338 |
+
offs_n,
|
| 339 |
+
offs_d,
|
| 340 |
+
seqlen_k,
|
| 341 |
+
headdim,
|
| 342 |
+
EVEN_M: tl.constexpr,
|
| 343 |
+
EVEN_N: tl.constexpr,
|
| 344 |
+
EVEN_HEADDIM: tl.constexpr,
|
| 345 |
+
):
|
| 346 |
+
# [2022-11-01] TD: Same bug. In the case of EVEN_N=True and EVEN_M=False,
|
| 347 |
+
# if we just call tl.store(dv_ptrs), there's a race condition
|
| 348 |
+
if EVEN_N & EVEN_M:
|
| 349 |
+
if EVEN_HEADDIM:
|
| 350 |
+
tl.store(dv_ptrs, dv)
|
| 351 |
+
tl.store(dk_ptrs, dk)
|
| 352 |
+
else:
|
| 353 |
+
tl.store(dv_ptrs, dv, mask=offs_d[None, :] < headdim)
|
| 354 |
+
tl.store(dk_ptrs, dk, mask=offs_d[None, :] < headdim)
|
| 355 |
+
else:
|
| 356 |
+
if EVEN_HEADDIM:
|
| 357 |
+
tl.store(dv_ptrs, dv, mask=offs_n[:, None] < seqlen_k)
|
| 358 |
+
tl.store(dk_ptrs, dk, mask=offs_n[:, None] < seqlen_k)
|
| 359 |
+
else:
|
| 360 |
+
tl.store(dv_ptrs, dv, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim))
|
| 361 |
+
tl.store(dk_ptrs, dk, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim))
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
@triton.jit
|
| 365 |
+
def _bwd_kernel_one_col_block(
|
| 366 |
+
start_n,
|
| 367 |
+
Q,
|
| 368 |
+
K,
|
| 369 |
+
V,
|
| 370 |
+
Bias,
|
| 371 |
+
DO,
|
| 372 |
+
DQ,
|
| 373 |
+
DK,
|
| 374 |
+
DV,
|
| 375 |
+
LSE,
|
| 376 |
+
D,
|
| 377 |
+
softmax_scale,
|
| 378 |
+
stride_qm,
|
| 379 |
+
stride_kn,
|
| 380 |
+
stride_vn,
|
| 381 |
+
stride_bm,
|
| 382 |
+
stride_dom,
|
| 383 |
+
stride_dqm,
|
| 384 |
+
stride_dkn,
|
| 385 |
+
stride_dvn,
|
| 386 |
+
seqlen_q,
|
| 387 |
+
seqlen_k,
|
| 388 |
+
headdim,
|
| 389 |
+
ATOMIC_ADD: tl.constexpr,
|
| 390 |
+
BIAS_TYPE: tl.constexpr,
|
| 391 |
+
IS_CAUSAL: tl.constexpr,
|
| 392 |
+
BLOCK_HEADDIM: tl.constexpr,
|
| 393 |
+
EVEN_M: tl.constexpr,
|
| 394 |
+
EVEN_N: tl.constexpr,
|
| 395 |
+
EVEN_HEADDIM: tl.constexpr,
|
| 396 |
+
BLOCK_M: tl.constexpr,
|
| 397 |
+
BLOCK_N: tl.constexpr,
|
| 398 |
+
):
|
| 399 |
+
# We need to make sure begin_m is a multiple of BLOCK_M (not BLOCK_N)
|
| 400 |
+
begin_m = 0 if not IS_CAUSAL else ((start_n * BLOCK_N) // BLOCK_M) * BLOCK_M
|
| 401 |
+
# initialize row/col offsets
|
| 402 |
+
offs_qm = begin_m + tl.arange(0, BLOCK_M)
|
| 403 |
+
offs_n = start_n * BLOCK_N + tl.arange(0, BLOCK_N)
|
| 404 |
+
offs_m = tl.arange(0, BLOCK_M)
|
| 405 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 406 |
+
# initialize pointers to value-like data
|
| 407 |
+
q_ptrs = Q + (offs_qm[:, None] * stride_qm + offs_d[None, :])
|
| 408 |
+
k_ptrs = K + (offs_n[:, None] * stride_kn + offs_d[None, :])
|
| 409 |
+
v_ptrs = V + (offs_n[:, None] * stride_vn + offs_d[None, :])
|
| 410 |
+
do_ptrs = DO + (offs_qm[:, None] * stride_dom + offs_d[None, :])
|
| 411 |
+
dq_ptrs = DQ + (offs_qm[:, None] * stride_dqm + offs_d[None, :])
|
| 412 |
+
if BIAS_TYPE == "vector":
|
| 413 |
+
b_ptrs = Bias + offs_n
|
| 414 |
+
elif BIAS_TYPE == "matrix":
|
| 415 |
+
b_ptrs = Bias + (offs_qm[:, None] * stride_bm + offs_n[None, :])
|
| 416 |
+
# initialize dv and dk
|
| 417 |
+
dv = tl.zeros([BLOCK_N, BLOCK_HEADDIM], dtype=tl.float32)
|
| 418 |
+
dk = tl.zeros([BLOCK_N, BLOCK_HEADDIM], dtype=tl.float32)
|
| 419 |
+
# There seems to be some problem with Triton pipelining that makes results wrong for
|
| 420 |
+
# headdim=64, seqlen=(113, 255), bias_type='matrix'. In this case the for loop
|
| 421 |
+
# may have zero step, and pipelining with the bias matrix could screw it up.
|
| 422 |
+
# So we just exit early.
|
| 423 |
+
if begin_m >= seqlen_q:
|
| 424 |
+
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
|
| 425 |
+
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
|
| 426 |
+
_bwd_store_dk_dv(
|
| 427 |
+
dk_ptrs,
|
| 428 |
+
dv_ptrs,
|
| 429 |
+
dk,
|
| 430 |
+
dv,
|
| 431 |
+
offs_n,
|
| 432 |
+
offs_d,
|
| 433 |
+
seqlen_k,
|
| 434 |
+
headdim,
|
| 435 |
+
EVEN_M=EVEN_M,
|
| 436 |
+
EVEN_N=EVEN_N,
|
| 437 |
+
EVEN_HEADDIM=EVEN_HEADDIM,
|
| 438 |
+
)
|
| 439 |
+
return
|
| 440 |
+
# k and v stay in SRAM throughout
|
| 441 |
+
# [2022-10-30] TD: Same bug as the fwd. In the case of EVEN_N=True and EVEN_M=False,
|
| 442 |
+
# if we just call tl.load(k_ptrs), we get the wrong output!
|
| 443 |
+
if EVEN_N & EVEN_M:
|
| 444 |
+
if EVEN_HEADDIM:
|
| 445 |
+
k = tl.load(k_ptrs)
|
| 446 |
+
v = tl.load(v_ptrs)
|
| 447 |
+
else:
|
| 448 |
+
k = tl.load(k_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
|
| 449 |
+
v = tl.load(v_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
|
| 450 |
+
else:
|
| 451 |
+
if EVEN_HEADDIM:
|
| 452 |
+
k = tl.load(k_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
|
| 453 |
+
v = tl.load(v_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
|
| 454 |
+
else:
|
| 455 |
+
k = tl.load(
|
| 456 |
+
k_ptrs, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0
|
| 457 |
+
)
|
| 458 |
+
v = tl.load(
|
| 459 |
+
v_ptrs, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0
|
| 460 |
+
)
|
| 461 |
+
# loop over rows
|
| 462 |
+
num_block_m = tl.cdiv(seqlen_q, BLOCK_M)
|
| 463 |
+
for start_m in range(begin_m, num_block_m * BLOCK_M, BLOCK_M):
|
| 464 |
+
start_m = tl.multiple_of(start_m, BLOCK_M)
|
| 465 |
+
offs_m_curr = start_m + offs_m
|
| 466 |
+
# load q, k, v, do on-chip
|
| 467 |
+
# Same bug as below. Otherwise gives wrong result for headdim=40, seqlen=(128, 117)
|
| 468 |
+
if EVEN_M & EVEN_HEADDIM:
|
| 469 |
+
q = tl.load(q_ptrs)
|
| 470 |
+
else:
|
| 471 |
+
if EVEN_HEADDIM:
|
| 472 |
+
q = tl.load(q_ptrs, mask=offs_m_curr[:, None] < seqlen_q, other=0.0)
|
| 473 |
+
else:
|
| 474 |
+
q = tl.load(
|
| 475 |
+
q_ptrs,
|
| 476 |
+
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
|
| 477 |
+
other=0.0,
|
| 478 |
+
)
|
| 479 |
+
# recompute p = softmax(qk, dim=-1).T
|
| 480 |
+
qk = tl.dot(q, k, trans_b=True)
|
| 481 |
+
# Trying to combine the two masks seem to make the result wrong
|
| 482 |
+
if not EVEN_N: # Need to mask out otherwise the softmax is wrong
|
| 483 |
+
qk = tl.where(offs_n[None, :] < seqlen_k, qk, float("-inf"))
|
| 484 |
+
if IS_CAUSAL:
|
| 485 |
+
qk = tl.where(offs_m_curr[:, None] >= (offs_n[None, :]), qk, float("-inf"))
|
| 486 |
+
if BIAS_TYPE != "none":
|
| 487 |
+
tl.debug_barrier() # Race condition otherwise
|
| 488 |
+
if BIAS_TYPE == "vector":
|
| 489 |
+
if EVEN_N:
|
| 490 |
+
bias = tl.load(b_ptrs).to(tl.float32)
|
| 491 |
+
else:
|
| 492 |
+
bias = tl.load(b_ptrs, mask=offs_n < seqlen_k, other=0.0).to(tl.float32)
|
| 493 |
+
bias = bias[None, :]
|
| 494 |
+
elif BIAS_TYPE == "matrix":
|
| 495 |
+
if EVEN_M & EVEN_N:
|
| 496 |
+
bias = tl.load(b_ptrs).to(tl.float32)
|
| 497 |
+
else:
|
| 498 |
+
bias = tl.load(
|
| 499 |
+
b_ptrs,
|
| 500 |
+
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_n[None, :] < seqlen_k),
|
| 501 |
+
other=0.0,
|
| 502 |
+
).to(tl.float32)
|
| 503 |
+
qk = qk * softmax_scale + bias
|
| 504 |
+
# There seems to be a race condition when headdim=48/96, and dq, dk, dv are wrong.
|
| 505 |
+
# Also wrong for headdim=64.
|
| 506 |
+
if not (EVEN_M & EVEN_HEADDIM):
|
| 507 |
+
tl.debug_barrier()
|
| 508 |
+
lse_i = tl.load(LSE + offs_m_curr)
|
| 509 |
+
if BIAS_TYPE == "none":
|
| 510 |
+
p = tl.exp(qk * softmax_scale - lse_i[:, None])
|
| 511 |
+
else:
|
| 512 |
+
p = tl.exp(qk - lse_i[:, None])
|
| 513 |
+
# compute dv
|
| 514 |
+
# [2022-10-30] TD: A Triton bug: if EVEN_M=True and EVEN_HEADDIM=False, if we call
|
| 515 |
+
# do = tl.load(do_ptrs, mask=offs_d[None, :] < headdim, other=0.0), we get wrong outputs
|
| 516 |
+
# in the case of headdim=48/96, seqlen_q & seqlen_k >= 512. If headdim=40 or seqlen < 512,
|
| 517 |
+
# the output is correct.
|
| 518 |
+
if EVEN_M & EVEN_HEADDIM:
|
| 519 |
+
do = tl.load(do_ptrs)
|
| 520 |
+
else:
|
| 521 |
+
# [2022-11-01] TD: Triton bug, there's a race condition if we just use m_mask and not d_mask.
|
| 522 |
+
do = tl.load(
|
| 523 |
+
do_ptrs,
|
| 524 |
+
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
|
| 525 |
+
other=0.0,
|
| 526 |
+
)
|
| 527 |
+
# if EVEN_M:
|
| 528 |
+
# if EVEN_HEADDIM:
|
| 529 |
+
# do = tl.load(do_ptrs)
|
| 530 |
+
# else:
|
| 531 |
+
# do = tl.load(do_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
|
| 532 |
+
# else:
|
| 533 |
+
# if EVEN_HEADDIM:
|
| 534 |
+
# do = tl.load(do_ptrs, mask=offs_m_curr[:, None] < seqlen_q, other=0.0)
|
| 535 |
+
# else:
|
| 536 |
+
# do = tl.load(do_ptrs, mask=(offs_m_curr[:, None] < seqlen_q)
|
| 537 |
+
# & (offs_d[None, :] < headdim), other=0.0)
|
| 538 |
+
dv += tl.dot(p.to(do.dtype), do, trans_a=True)
|
| 539 |
+
# compute dp = dot(v, do)
|
| 540 |
+
# There seems to be a race condition when headdim=48/96, and dq, dk are wrong.
|
| 541 |
+
# Also wrong for headdim=128, seqlen=(108, 256), and ATOMIC_ADD=True
|
| 542 |
+
# Also wrong for headdim=64, seqlen=(1023, 1024), and ATOMIC_ADD=False
|
| 543 |
+
if not (EVEN_M & EVEN_HEADDIM):
|
| 544 |
+
tl.debug_barrier()
|
| 545 |
+
dp = tl.dot(do, v, trans_b=True)
|
| 546 |
+
# There's a race condition for headdim=48
|
| 547 |
+
if not EVEN_HEADDIM:
|
| 548 |
+
tl.debug_barrier()
|
| 549 |
+
# compute ds = p * (dp - delta[:, None])
|
| 550 |
+
# Putting the subtraction after the dp matmul (instead of before) is slightly faster
|
| 551 |
+
Di = tl.load(D + offs_m_curr)
|
| 552 |
+
# Converting ds to q.dtype here reduces register pressure and makes it much faster
|
| 553 |
+
# for BLOCK_HEADDIM=128
|
| 554 |
+
ds = (p * (dp - Di[:, None]) * softmax_scale).to(q.dtype)
|
| 555 |
+
# compute dk = dot(ds.T, q)
|
| 556 |
+
dk += tl.dot(ds, q, trans_a=True)
|
| 557 |
+
# compute dq
|
| 558 |
+
if not (
|
| 559 |
+
EVEN_M & EVEN_HEADDIM
|
| 560 |
+
): # Otherewise there's a race condition when BIAS_TYPE='matrix'
|
| 561 |
+
tl.debug_barrier()
|
| 562 |
+
if not ATOMIC_ADD:
|
| 563 |
+
if EVEN_M & EVEN_HEADDIM: # Race condition if we just do EVEN_M
|
| 564 |
+
dq = tl.load(dq_ptrs, eviction_policy="evict_last")
|
| 565 |
+
dq += tl.dot(ds, k)
|
| 566 |
+
tl.store(dq_ptrs, dq, eviction_policy="evict_last")
|
| 567 |
+
else:
|
| 568 |
+
if EVEN_HEADDIM:
|
| 569 |
+
dq = tl.load(
|
| 570 |
+
dq_ptrs,
|
| 571 |
+
mask=offs_m_curr[:, None] < seqlen_q,
|
| 572 |
+
other=0.0,
|
| 573 |
+
eviction_policy="evict_last",
|
| 574 |
+
)
|
| 575 |
+
dq += tl.dot(ds, k)
|
| 576 |
+
tl.store(
|
| 577 |
+
dq_ptrs,
|
| 578 |
+
dq,
|
| 579 |
+
mask=offs_m_curr[:, None] < seqlen_q,
|
| 580 |
+
eviction_policy="evict_last",
|
| 581 |
+
)
|
| 582 |
+
else:
|
| 583 |
+
dq = tl.load(
|
| 584 |
+
dq_ptrs,
|
| 585 |
+
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
|
| 586 |
+
other=0.0,
|
| 587 |
+
eviction_policy="evict_last",
|
| 588 |
+
)
|
| 589 |
+
dq += tl.dot(ds, k)
|
| 590 |
+
tl.store(
|
| 591 |
+
dq_ptrs,
|
| 592 |
+
dq,
|
| 593 |
+
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
|
| 594 |
+
eviction_policy="evict_last",
|
| 595 |
+
)
|
| 596 |
+
else: # If we're parallelizing across the seqlen_k dimension
|
| 597 |
+
dq = tl.dot(ds, k)
|
| 598 |
+
if EVEN_M & EVEN_HEADDIM: # Race condition if we just do EVEN_M
|
| 599 |
+
tl.atomic_add(dq_ptrs, dq)
|
| 600 |
+
else:
|
| 601 |
+
if EVEN_HEADDIM:
|
| 602 |
+
tl.atomic_add(dq_ptrs, dq, mask=offs_m_curr[:, None] < seqlen_q)
|
| 603 |
+
else:
|
| 604 |
+
tl.atomic_add(
|
| 605 |
+
dq_ptrs,
|
| 606 |
+
dq,
|
| 607 |
+
mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim),
|
| 608 |
+
)
|
| 609 |
+
# increment pointers
|
| 610 |
+
dq_ptrs += BLOCK_M * stride_dqm
|
| 611 |
+
q_ptrs += BLOCK_M * stride_qm
|
| 612 |
+
do_ptrs += BLOCK_M * stride_dom
|
| 613 |
+
if BIAS_TYPE == "matrix":
|
| 614 |
+
b_ptrs += BLOCK_M * stride_bm
|
| 615 |
+
# write-back
|
| 616 |
+
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
|
| 617 |
+
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
|
| 618 |
+
_bwd_store_dk_dv(
|
| 619 |
+
dk_ptrs,
|
| 620 |
+
dv_ptrs,
|
| 621 |
+
dk,
|
| 622 |
+
dv,
|
| 623 |
+
offs_n,
|
| 624 |
+
offs_d,
|
| 625 |
+
seqlen_k,
|
| 626 |
+
headdim,
|
| 627 |
+
EVEN_M=EVEN_M,
|
| 628 |
+
EVEN_N=EVEN_N,
|
| 629 |
+
EVEN_HEADDIM=EVEN_HEADDIM,
|
| 630 |
+
)
|
| 631 |
+
|
| 632 |
+
|
| 633 |
+
def init_to_zero(name):
|
| 634 |
+
return lambda nargs: nargs[name].zero_()
|
| 635 |
+
|
| 636 |
+
|
| 637 |
+
@triton.autotune(
|
| 638 |
+
configs=[
|
| 639 |
+
triton.Config(
|
| 640 |
+
{"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": False},
|
| 641 |
+
num_warps=8,
|
| 642 |
+
num_stages=1,
|
| 643 |
+
pre_hook=init_to_zero("DQ"),
|
| 644 |
+
),
|
| 645 |
+
triton.Config(
|
| 646 |
+
{"BLOCK_M": 128, "BLOCK_N": 128, "SEQUENCE_PARALLEL": True},
|
| 647 |
+
num_warps=8,
|
| 648 |
+
num_stages=1,
|
| 649 |
+
pre_hook=init_to_zero("DQ"),
|
| 650 |
+
),
|
| 651 |
+
# Other configs seem to give wrong results when seqlen_q % 128 != 0, disabling them for now
|
| 652 |
+
# # Kernel is buggy (give wrong result) if we set BLOCK_m=128, BLOCK_n=64, num_warps=*4*
|
| 653 |
+
# triton.Config({"BLOCK_M": 128, "BLOCK_N": 64, "SEQUENCE_PARALLEL": False}, num_warps=8, num_stages=1, pre_hook=init_to_zero('DQ')),
|
| 654 |
+
# triton.Config({"BLOCK_M": 128, "BLOCK_N": 64, "SEQUENCE_PARALLEL": True}, num_warps=8, num_stages=1, pre_hook=init_to_zero('DQ')),
|
| 655 |
+
# triton.Config({"BLOCK_M": 64, "BLOCK_N": 64, "SEQUENCE_PARALLEL": False}, num_warps=4, num_stages=1, pre_hook=init_to_zero('DQ')),
|
| 656 |
+
# triton.Config({"BLOCK_M": 64, "BLOCK_N": 64, "SEQUENCE_PARALLEL": True}, num_warps=4, num_stages=1, pre_hook=init_to_zero('DQ')),
|
| 657 |
+
],
|
| 658 |
+
key=["CACHE_KEY_SEQLEN_Q", "CACHE_KEY_SEQLEN_K", "BIAS_TYPE", "IS_CAUSAL", "BLOCK_HEADDIM"],
|
| 659 |
+
)
|
| 660 |
+
@triton.heuristics(
|
| 661 |
+
{
|
| 662 |
+
"EVEN_M": lambda args: args["seqlen_q"] % args["BLOCK_M"] == 0,
|
| 663 |
+
"EVEN_N": lambda args: args["seqlen_k"] % args["BLOCK_N"] == 0,
|
| 664 |
+
"EVEN_HEADDIM": lambda args: args["headdim"] == args["BLOCK_HEADDIM"],
|
| 665 |
+
}
|
| 666 |
+
)
|
| 667 |
+
@triton.jit
|
| 668 |
+
def _bwd_kernel(
|
| 669 |
+
Q,
|
| 670 |
+
K,
|
| 671 |
+
V,
|
| 672 |
+
Bias,
|
| 673 |
+
DO,
|
| 674 |
+
DQ,
|
| 675 |
+
DK,
|
| 676 |
+
DV,
|
| 677 |
+
LSE,
|
| 678 |
+
D,
|
| 679 |
+
softmax_scale,
|
| 680 |
+
stride_qb,
|
| 681 |
+
stride_qh,
|
| 682 |
+
stride_qm,
|
| 683 |
+
stride_kb,
|
| 684 |
+
stride_kh,
|
| 685 |
+
stride_kn,
|
| 686 |
+
stride_vb,
|
| 687 |
+
stride_vh,
|
| 688 |
+
stride_vn,
|
| 689 |
+
stride_bb,
|
| 690 |
+
stride_bh,
|
| 691 |
+
stride_bm,
|
| 692 |
+
stride_dob,
|
| 693 |
+
stride_doh,
|
| 694 |
+
stride_dom,
|
| 695 |
+
stride_dqb,
|
| 696 |
+
stride_dqh,
|
| 697 |
+
stride_dqm,
|
| 698 |
+
stride_dkb,
|
| 699 |
+
stride_dkh,
|
| 700 |
+
stride_dkn,
|
| 701 |
+
stride_dvb,
|
| 702 |
+
stride_dvh,
|
| 703 |
+
stride_dvn,
|
| 704 |
+
nheads,
|
| 705 |
+
seqlen_q,
|
| 706 |
+
seqlen_k,
|
| 707 |
+
seqlen_q_rounded,
|
| 708 |
+
headdim,
|
| 709 |
+
CACHE_KEY_SEQLEN_Q,
|
| 710 |
+
CACHE_KEY_SEQLEN_K,
|
| 711 |
+
BIAS_TYPE: tl.constexpr,
|
| 712 |
+
IS_CAUSAL: tl.constexpr,
|
| 713 |
+
BLOCK_HEADDIM: tl.constexpr,
|
| 714 |
+
SEQUENCE_PARALLEL: tl.constexpr,
|
| 715 |
+
EVEN_M: tl.constexpr,
|
| 716 |
+
EVEN_N: tl.constexpr,
|
| 717 |
+
EVEN_HEADDIM: tl.constexpr,
|
| 718 |
+
BLOCK_M: tl.constexpr,
|
| 719 |
+
BLOCK_N: tl.constexpr,
|
| 720 |
+
):
|
| 721 |
+
off_hb = tl.program_id(1)
|
| 722 |
+
off_b = off_hb // nheads
|
| 723 |
+
off_h = off_hb % nheads
|
| 724 |
+
# offset pointers for batch/head
|
| 725 |
+
Q += off_b * stride_qb + off_h * stride_qh
|
| 726 |
+
K += off_b * stride_kb + off_h * stride_kh
|
| 727 |
+
V += off_b * stride_vb + off_h * stride_vh
|
| 728 |
+
DO += off_b * stride_dob + off_h * stride_doh
|
| 729 |
+
DQ += off_b * stride_dqb + off_h * stride_dqh
|
| 730 |
+
DK += off_b * stride_dkb + off_h * stride_dkh
|
| 731 |
+
DV += off_b * stride_dvb + off_h * stride_dvh
|
| 732 |
+
if BIAS_TYPE != "none":
|
| 733 |
+
Bias += off_b * stride_bb + off_h * stride_bh
|
| 734 |
+
# pointer to row-wise quantities in value-like data
|
| 735 |
+
D += off_hb * seqlen_q_rounded
|
| 736 |
+
LSE += off_hb * seqlen_q_rounded
|
| 737 |
+
if not SEQUENCE_PARALLEL:
|
| 738 |
+
num_block_n = tl.cdiv(seqlen_k, BLOCK_N)
|
| 739 |
+
for start_n in range(0, num_block_n):
|
| 740 |
+
_bwd_kernel_one_col_block(
|
| 741 |
+
start_n,
|
| 742 |
+
Q,
|
| 743 |
+
K,
|
| 744 |
+
V,
|
| 745 |
+
Bias,
|
| 746 |
+
DO,
|
| 747 |
+
DQ,
|
| 748 |
+
DK,
|
| 749 |
+
DV,
|
| 750 |
+
LSE,
|
| 751 |
+
D,
|
| 752 |
+
softmax_scale,
|
| 753 |
+
stride_qm,
|
| 754 |
+
stride_kn,
|
| 755 |
+
stride_vn,
|
| 756 |
+
stride_bm,
|
| 757 |
+
stride_dom,
|
| 758 |
+
stride_dqm,
|
| 759 |
+
stride_dkn,
|
| 760 |
+
stride_dvn,
|
| 761 |
+
seqlen_q,
|
| 762 |
+
seqlen_k,
|
| 763 |
+
headdim,
|
| 764 |
+
ATOMIC_ADD=False,
|
| 765 |
+
BIAS_TYPE=BIAS_TYPE,
|
| 766 |
+
IS_CAUSAL=IS_CAUSAL,
|
| 767 |
+
BLOCK_HEADDIM=BLOCK_HEADDIM,
|
| 768 |
+
EVEN_M=EVEN_M,
|
| 769 |
+
EVEN_N=EVEN_N,
|
| 770 |
+
EVEN_HEADDIM=EVEN_HEADDIM,
|
| 771 |
+
BLOCK_M=BLOCK_M,
|
| 772 |
+
BLOCK_N=BLOCK_N,
|
| 773 |
+
)
|
| 774 |
+
else:
|
| 775 |
+
start_n = tl.program_id(0)
|
| 776 |
+
_bwd_kernel_one_col_block(
|
| 777 |
+
start_n,
|
| 778 |
+
Q,
|
| 779 |
+
K,
|
| 780 |
+
V,
|
| 781 |
+
Bias,
|
| 782 |
+
DO,
|
| 783 |
+
DQ,
|
| 784 |
+
DK,
|
| 785 |
+
DV,
|
| 786 |
+
LSE,
|
| 787 |
+
D,
|
| 788 |
+
softmax_scale,
|
| 789 |
+
stride_qm,
|
| 790 |
+
stride_kn,
|
| 791 |
+
stride_vn,
|
| 792 |
+
stride_bm,
|
| 793 |
+
stride_dom,
|
| 794 |
+
stride_dqm,
|
| 795 |
+
stride_dkn,
|
| 796 |
+
stride_dvn,
|
| 797 |
+
seqlen_q,
|
| 798 |
+
seqlen_k,
|
| 799 |
+
headdim,
|
| 800 |
+
ATOMIC_ADD=True,
|
| 801 |
+
BIAS_TYPE=BIAS_TYPE,
|
| 802 |
+
IS_CAUSAL=IS_CAUSAL,
|
| 803 |
+
BLOCK_HEADDIM=BLOCK_HEADDIM,
|
| 804 |
+
EVEN_M=EVEN_M,
|
| 805 |
+
EVEN_N=EVEN_N,
|
| 806 |
+
EVEN_HEADDIM=EVEN_HEADDIM,
|
| 807 |
+
BLOCK_M=BLOCK_M,
|
| 808 |
+
BLOCK_N=BLOCK_N,
|
| 809 |
+
)
|
| 810 |
+
|
| 811 |
+
|
| 812 |
+
def _flash_attn_forward(q, k, v, bias=None, causal=False, softmax_scale=None):
|
| 813 |
+
# shape constraints
|
| 814 |
+
batch, seqlen_q, nheads, d = q.shape
|
| 815 |
+
_, seqlen_k, _, _ = k.shape
|
| 816 |
+
assert k.shape == (batch, seqlen_k, nheads, d)
|
| 817 |
+
assert v.shape == (batch, seqlen_k, nheads, d)
|
| 818 |
+
assert d <= 128, "FlashAttention only support head dimensions up to 128"
|
| 819 |
+
assert q.dtype == k.dtype == v.dtype, "All tensors must have the same type"
|
| 820 |
+
assert q.dtype in [torch.float16, torch.bfloat16], "Only support fp16 and bf16"
|
| 821 |
+
assert q.is_cuda and k.is_cuda and v.is_cuda
|
| 822 |
+
softmax_scale = softmax_scale or 1.0 / math.sqrt(d)
|
| 823 |
+
|
| 824 |
+
has_bias = bias is not None
|
| 825 |
+
bias_type = "none"
|
| 826 |
+
if has_bias:
|
| 827 |
+
assert bias.dtype in [q.dtype, torch.float]
|
| 828 |
+
assert bias.is_cuda
|
| 829 |
+
assert bias.dim() == 4
|
| 830 |
+
if bias.stride(-1) != 1:
|
| 831 |
+
bias = bias.contiguous()
|
| 832 |
+
if bias.shape[2:] == (1, seqlen_k):
|
| 833 |
+
bias_type = "vector"
|
| 834 |
+
elif bias.shape[2:] == (seqlen_q, seqlen_k):
|
| 835 |
+
bias_type = "matrix"
|
| 836 |
+
else:
|
| 837 |
+
raise RuntimeError(
|
| 838 |
+
"Last 2 dimensions of bias must be (1, seqlen_k)" " or (seqlen_q, seqlen_k)"
|
| 839 |
+
)
|
| 840 |
+
bias = bias.expand(batch, nheads, seqlen_q, seqlen_k)
|
| 841 |
+
bias_strides = (bias.stride(0), bias.stride(1), bias.stride(2)) if has_bias else (0, 0, 0)
|
| 842 |
+
|
| 843 |
+
seqlen_q_rounded = math.ceil(seqlen_q / 128) * 128
|
| 844 |
+
lse = torch.empty((batch, nheads, seqlen_q_rounded), device=q.device, dtype=torch.float32)
|
| 845 |
+
tmp = torch.empty((batch, nheads, seqlen_q_rounded), device=q.device, dtype=torch.float32)
|
| 846 |
+
o = torch.empty_like(q)
|
| 847 |
+
|
| 848 |
+
BLOCK_HEADDIM = max(triton.next_power_of_2(d), 16)
|
| 849 |
+
BLOCK = 128
|
| 850 |
+
num_warps = 4 if d <= 64 else 8
|
| 851 |
+
grid = lambda META: (triton.cdiv(seqlen_q, META["BLOCK_M"]), batch * nheads)
|
| 852 |
+
_fwd_kernel[grid](
|
| 853 |
+
q,
|
| 854 |
+
k,
|
| 855 |
+
v,
|
| 856 |
+
bias,
|
| 857 |
+
o,
|
| 858 |
+
lse,
|
| 859 |
+
tmp,
|
| 860 |
+
softmax_scale,
|
| 861 |
+
q.stride(0),
|
| 862 |
+
q.stride(2),
|
| 863 |
+
q.stride(1),
|
| 864 |
+
k.stride(0),
|
| 865 |
+
k.stride(2),
|
| 866 |
+
k.stride(1),
|
| 867 |
+
v.stride(0),
|
| 868 |
+
v.stride(2),
|
| 869 |
+
v.stride(1),
|
| 870 |
+
*bias_strides,
|
| 871 |
+
o.stride(0),
|
| 872 |
+
o.stride(2),
|
| 873 |
+
o.stride(1),
|
| 874 |
+
nheads,
|
| 875 |
+
seqlen_q,
|
| 876 |
+
seqlen_k,
|
| 877 |
+
seqlen_q_rounded,
|
| 878 |
+
d,
|
| 879 |
+
seqlen_q // 32,
|
| 880 |
+
seqlen_k // 32, # key for triton cache (limit number of compilations)
|
| 881 |
+
# Can't use kwargs here because triton autotune expects key to be args, not kwargs
|
| 882 |
+
# IS_CAUSAL=causal, BLOCK_HEADDIM=d,
|
| 883 |
+
bias_type,
|
| 884 |
+
causal,
|
| 885 |
+
BLOCK_HEADDIM,
|
| 886 |
+
BLOCK_M=BLOCK,
|
| 887 |
+
BLOCK_N=BLOCK,
|
| 888 |
+
num_warps=num_warps,
|
| 889 |
+
num_stages=1,
|
| 890 |
+
)
|
| 891 |
+
return o, lse, softmax_scale # softmax_scale could have been updated
|
| 892 |
+
|
| 893 |
+
|
| 894 |
+
def _flash_attn_backward(
|
| 895 |
+
do, q, k, v, o, lse, dq, dk, dv, bias=None, causal=False, softmax_scale=None
|
| 896 |
+
):
|
| 897 |
+
# Make sure that the last dimension is contiguous
|
| 898 |
+
if do.stride(-1) != 1:
|
| 899 |
+
do = do.contiguous()
|
| 900 |
+
batch, seqlen_q, nheads, d = q.shape
|
| 901 |
+
_, seqlen_k, _, _ = k.shape
|
| 902 |
+
# assert d in {16, 32, 64, 128}
|
| 903 |
+
assert d <= 128
|
| 904 |
+
seqlen_q_rounded = math.ceil(seqlen_q / 128) * 128
|
| 905 |
+
assert lse.shape == (batch, nheads, seqlen_q_rounded)
|
| 906 |
+
assert q.stride(-1) == k.stride(-1) == v.stride(-1) == o.stride(-1) == 1
|
| 907 |
+
assert dq.stride(-1) == dk.stride(-1) == dv.stride(-1) == 1
|
| 908 |
+
softmax_scale = softmax_scale or 1.0 / math.sqrt(d)
|
| 909 |
+
# dq_accum = torch.zeros_like(q, dtype=torch.float32)
|
| 910 |
+
dq_accum = torch.empty_like(q, dtype=torch.float32)
|
| 911 |
+
delta = torch.empty_like(lse)
|
| 912 |
+
# delta = torch.zeros_like(lse)
|
| 913 |
+
|
| 914 |
+
BLOCK_HEADDIM = max(triton.next_power_of_2(d), 16)
|
| 915 |
+
grid = lambda META: (triton.cdiv(seqlen_q, META["BLOCK_M"]), batch * nheads)
|
| 916 |
+
_bwd_preprocess_do_o_dot[grid](
|
| 917 |
+
o,
|
| 918 |
+
do,
|
| 919 |
+
delta,
|
| 920 |
+
o.stride(0),
|
| 921 |
+
o.stride(2),
|
| 922 |
+
o.stride(1),
|
| 923 |
+
do.stride(0),
|
| 924 |
+
do.stride(2),
|
| 925 |
+
do.stride(1),
|
| 926 |
+
nheads,
|
| 927 |
+
seqlen_q,
|
| 928 |
+
seqlen_q_rounded,
|
| 929 |
+
d,
|
| 930 |
+
BLOCK_M=128,
|
| 931 |
+
BLOCK_HEADDIM=BLOCK_HEADDIM,
|
| 932 |
+
)
|
| 933 |
+
|
| 934 |
+
has_bias = bias is not None
|
| 935 |
+
bias_type = "none"
|
| 936 |
+
if has_bias:
|
| 937 |
+
assert bias.dtype in [q.dtype, torch.float]
|
| 938 |
+
assert bias.is_cuda
|
| 939 |
+
assert bias.dim() == 4
|
| 940 |
+
assert bias.stride(-1) == 1
|
| 941 |
+
if bias.shape[2:] == (1, seqlen_k):
|
| 942 |
+
bias_type = "vector"
|
| 943 |
+
elif bias.shape[2:] == (seqlen_q, seqlen_k):
|
| 944 |
+
bias_type = "matrix"
|
| 945 |
+
else:
|
| 946 |
+
raise RuntimeError(
|
| 947 |
+
"Last 2 dimensions of bias must be (1, seqlen_k)" " or (seqlen_q, seqlen_k)"
|
| 948 |
+
)
|
| 949 |
+
bias = bias.expand(batch, nheads, seqlen_q, seqlen_k)
|
| 950 |
+
bias_strides = (bias.stride(0), bias.stride(1), bias.stride(2)) if has_bias else (0, 0, 0)
|
| 951 |
+
|
| 952 |
+
# BLOCK_M = 128
|
| 953 |
+
# BLOCK_N = 64
|
| 954 |
+
# num_warps = 4
|
| 955 |
+
grid = lambda META: (
|
| 956 |
+
triton.cdiv(seqlen_k, META["BLOCK_N"]) if META["SEQUENCE_PARALLEL"] else 1,
|
| 957 |
+
batch * nheads,
|
| 958 |
+
)
|
| 959 |
+
_bwd_kernel[grid](
|
| 960 |
+
q,
|
| 961 |
+
k,
|
| 962 |
+
v,
|
| 963 |
+
bias,
|
| 964 |
+
do,
|
| 965 |
+
dq_accum,
|
| 966 |
+
dk,
|
| 967 |
+
dv,
|
| 968 |
+
lse,
|
| 969 |
+
delta,
|
| 970 |
+
softmax_scale,
|
| 971 |
+
q.stride(0),
|
| 972 |
+
q.stride(2),
|
| 973 |
+
q.stride(1),
|
| 974 |
+
k.stride(0),
|
| 975 |
+
k.stride(2),
|
| 976 |
+
k.stride(1),
|
| 977 |
+
v.stride(0),
|
| 978 |
+
v.stride(2),
|
| 979 |
+
v.stride(1),
|
| 980 |
+
*bias_strides,
|
| 981 |
+
do.stride(0),
|
| 982 |
+
do.stride(2),
|
| 983 |
+
do.stride(1),
|
| 984 |
+
dq_accum.stride(0),
|
| 985 |
+
dq_accum.stride(2),
|
| 986 |
+
dq_accum.stride(1),
|
| 987 |
+
dk.stride(0),
|
| 988 |
+
dk.stride(2),
|
| 989 |
+
dk.stride(1),
|
| 990 |
+
dv.stride(0),
|
| 991 |
+
dv.stride(2),
|
| 992 |
+
dv.stride(1),
|
| 993 |
+
nheads,
|
| 994 |
+
seqlen_q,
|
| 995 |
+
seqlen_k,
|
| 996 |
+
seqlen_q_rounded,
|
| 997 |
+
d,
|
| 998 |
+
seqlen_q // 32,
|
| 999 |
+
seqlen_k // 32, # key for triton cache (limit number of compilations)
|
| 1000 |
+
# Can't use kwargs here because triton autotune expects key to be args, not kwargs
|
| 1001 |
+
# IS_CAUSAL=causal, BLOCK_HEADDIM=d,
|
| 1002 |
+
bias_type,
|
| 1003 |
+
causal,
|
| 1004 |
+
BLOCK_HEADDIM,
|
| 1005 |
+
# SEQUENCE_PARALLEL=False,
|
| 1006 |
+
# BLOCK_M=BLOCK_M, BLOCK_N=BLOCK_N,
|
| 1007 |
+
# num_warps=num_warps,
|
| 1008 |
+
# num_stages=1,
|
| 1009 |
+
)
|
| 1010 |
+
dq.copy_(dq_accum)
|
| 1011 |
+
|
| 1012 |
+
|
| 1013 |
+
class FlashAttnQKVPackedFunc(torch.autograd.Function):
|
| 1014 |
+
@staticmethod
|
| 1015 |
+
def forward(ctx, qkv, bias=None, causal=False, softmax_scale=None):
|
| 1016 |
+
"""
|
| 1017 |
+
qkv: (batch, seqlen, 3, nheads, headdim)
|
| 1018 |
+
bias: optional, shape broadcastible to (batch, nheads, seqlen, seqlen).
|
| 1019 |
+
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen).
|
| 1020 |
+
ALiBi mask for non-causal would have shape (1, nheads, seqlen, seqlen)
|
| 1021 |
+
"""
|
| 1022 |
+
# Make sure that the last dimension is contiguous
|
| 1023 |
+
if qkv.stride(-1) != 1:
|
| 1024 |
+
qkv = qkv.contiguous()
|
| 1025 |
+
o, lse, ctx.softmax_scale = _flash_attn_forward(
|
| 1026 |
+
qkv[:, :, 0],
|
| 1027 |
+
qkv[:, :, 1],
|
| 1028 |
+
qkv[:, :, 2],
|
| 1029 |
+
bias=bias,
|
| 1030 |
+
causal=causal,
|
| 1031 |
+
softmax_scale=softmax_scale,
|
| 1032 |
+
)
|
| 1033 |
+
ctx.save_for_backward(qkv, o, lse, bias)
|
| 1034 |
+
ctx.causal = causal
|
| 1035 |
+
return o
|
| 1036 |
+
|
| 1037 |
+
@staticmethod
|
| 1038 |
+
def backward(ctx, do):
|
| 1039 |
+
qkv, o, lse, bias = ctx.saved_tensors
|
| 1040 |
+
assert not ctx.needs_input_grad[1], "FlashAttention does not support bias gradient yet"
|
| 1041 |
+
# Triton's autotune causes the Tensor._version to change, and so Pytorch autograd
|
| 1042 |
+
# does a memcpy. To avoid this we run in inference_mode, which doesn't track the version.
|
| 1043 |
+
with torch.inference_mode():
|
| 1044 |
+
dqkv = torch.empty_like(qkv)
|
| 1045 |
+
_flash_attn_backward(
|
| 1046 |
+
do,
|
| 1047 |
+
qkv[:, :, 0],
|
| 1048 |
+
qkv[:, :, 1],
|
| 1049 |
+
qkv[:, :, 2],
|
| 1050 |
+
o,
|
| 1051 |
+
lse,
|
| 1052 |
+
dqkv[:, :, 0],
|
| 1053 |
+
dqkv[:, :, 1],
|
| 1054 |
+
dqkv[:, :, 2],
|
| 1055 |
+
bias=bias,
|
| 1056 |
+
causal=ctx.causal,
|
| 1057 |
+
softmax_scale=ctx.softmax_scale,
|
| 1058 |
+
)
|
| 1059 |
+
return dqkv, None, None, None
|
| 1060 |
+
|
| 1061 |
+
|
| 1062 |
+
flash_attn_qkvpacked_func = FlashAttnQKVPackedFunc.apply
|
| 1063 |
+
|
| 1064 |
+
|
| 1065 |
+
class FlashAttnKVPackedFunc(torch.autograd.Function):
|
| 1066 |
+
@staticmethod
|
| 1067 |
+
def forward(ctx, q, kv, bias=None, causal=False, softmax_scale=None):
|
| 1068 |
+
"""
|
| 1069 |
+
q: (batch, seqlen_q, nheads, headdim)
|
| 1070 |
+
kv: (batch, seqlen_k, 2, nheads, headdim)
|
| 1071 |
+
bias: optional, shape broadcastible to (batch, nheads, seqlen_q, seqlen_k).
|
| 1072 |
+
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen_k).
|
| 1073 |
+
ALiBi mask for non-causal would have shape (1, nheads, seqlen_q, seqlen_k)
|
| 1074 |
+
"""
|
| 1075 |
+
# Make sure that the last dimension is contiguous
|
| 1076 |
+
q, kv = [x if x.stride(-1) == 1 else x.contiguous() for x in [q, kv]]
|
| 1077 |
+
o, lse, ctx.softmax_scale = _flash_attn_forward(
|
| 1078 |
+
q, kv[:, :, 0], kv[:, :, 1], bias=bias, causal=causal, softmax_scale=softmax_scale
|
| 1079 |
+
)
|
| 1080 |
+
ctx.save_for_backward(q, kv, o, lse, bias)
|
| 1081 |
+
ctx.causal = causal
|
| 1082 |
+
return o
|
| 1083 |
+
|
| 1084 |
+
@staticmethod
|
| 1085 |
+
def backward(ctx, do):
|
| 1086 |
+
q, kv, o, lse, bias = ctx.saved_tensors
|
| 1087 |
+
if len(ctx.needs_input_grad) >= 3:
|
| 1088 |
+
assert not ctx.needs_input_grad[2], "FlashAttention does not support bias gradient yet"
|
| 1089 |
+
# Triton's autotune causes the Tensor._version to change, and so Pytorch autograd
|
| 1090 |
+
# does a memcpy. To avoid this we run in inference_mode, which doesn't track the version.
|
| 1091 |
+
with torch.inference_mode():
|
| 1092 |
+
dq = torch.empty_like(q)
|
| 1093 |
+
dkv = torch.empty_like(kv)
|
| 1094 |
+
_flash_attn_backward(
|
| 1095 |
+
do,
|
| 1096 |
+
q,
|
| 1097 |
+
kv[:, :, 0],
|
| 1098 |
+
kv[:, :, 1],
|
| 1099 |
+
o,
|
| 1100 |
+
lse,
|
| 1101 |
+
dq,
|
| 1102 |
+
dkv[:, :, 0],
|
| 1103 |
+
dkv[:, :, 1],
|
| 1104 |
+
bias=bias,
|
| 1105 |
+
causal=ctx.causal,
|
| 1106 |
+
softmax_scale=ctx.softmax_scale,
|
| 1107 |
+
)
|
| 1108 |
+
return dq, dkv, None, None, None
|
| 1109 |
+
|
| 1110 |
+
|
| 1111 |
+
flash_attn_kvpacked_func = FlashAttnKVPackedFunc.apply
|
| 1112 |
+
|
| 1113 |
+
|
| 1114 |
+
class FlashAttnFunc(torch.autograd.Function):
|
| 1115 |
+
@staticmethod
|
| 1116 |
+
def forward(ctx, q, k, v, bias=None, causal=False, softmax_scale=None):
|
| 1117 |
+
"""
|
| 1118 |
+
q: (batch_size, seqlen_q, nheads, headdim)
|
| 1119 |
+
k, v: (batch_size, seqlen_k, nheads, headdim)
|
| 1120 |
+
bias: optional, shape broadcastible to (batch, nheads, seqlen_q, seqlen_k).
|
| 1121 |
+
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen_k).
|
| 1122 |
+
ALiBi mask for non-causal would have shape (1, nheads, seqlen_q, seqlen_k)
|
| 1123 |
+
"""
|
| 1124 |
+
# Make sure that the last dimension is contiguous
|
| 1125 |
+
q, k, v = [x if x.stride(-1) == 1 else x.contiguous() for x in [q, k, v]]
|
| 1126 |
+
o, lse, ctx.softmax_scale = _flash_attn_forward(
|
| 1127 |
+
q, k, v, bias=bias, causal=causal, softmax_scale=softmax_scale
|
| 1128 |
+
)
|
| 1129 |
+
ctx.save_for_backward(q, k, v, o, lse, bias)
|
| 1130 |
+
ctx.causal = causal
|
| 1131 |
+
return o
|
| 1132 |
+
|
| 1133 |
+
@staticmethod
|
| 1134 |
+
def backward(ctx, do):
|
| 1135 |
+
q, k, v, o, lse, bias = ctx.saved_tensors
|
| 1136 |
+
assert not ctx.needs_input_grad[3], "FlashAttention does not support bias gradient yet"
|
| 1137 |
+
# Triton's autotune causes the Tensor._version to change, and so Pytorch autograd
|
| 1138 |
+
# does a memcpy. To avoid this we run in inference_mode, which doesn't track the version.
|
| 1139 |
+
with torch.inference_mode():
|
| 1140 |
+
dq = torch.empty_like(q)
|
| 1141 |
+
dk = torch.empty_like(k)
|
| 1142 |
+
dv = torch.empty_like(v)
|
| 1143 |
+
_flash_attn_backward(
|
| 1144 |
+
do,
|
| 1145 |
+
q,
|
| 1146 |
+
k,
|
| 1147 |
+
v,
|
| 1148 |
+
o,
|
| 1149 |
+
lse,
|
| 1150 |
+
dq,
|
| 1151 |
+
dk,
|
| 1152 |
+
dv,
|
| 1153 |
+
bias=bias,
|
| 1154 |
+
causal=ctx.causal,
|
| 1155 |
+
softmax_scale=ctx.softmax_scale,
|
| 1156 |
+
)
|
| 1157 |
+
return dq, dk, dv, None, None, None
|
| 1158 |
+
|
| 1159 |
+
|
| 1160 |
+
flash_attn_func = FlashAttnFunc.apply
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_attn_triton_og.py
ADDED
|
@@ -0,0 +1,365 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# [2022-10-23] Downloaded from https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
|
| 2 |
+
# for benchmarking.
|
| 3 |
+
# We fixed a few dtype cast to make it work for bf16
|
| 4 |
+
|
| 5 |
+
"""
|
| 6 |
+
Fused Attention
|
| 7 |
+
===============
|
| 8 |
+
This is a Triton implementation of the Flash Attention algorithm
|
| 9 |
+
(see: Dao et al., https://arxiv.org/pdf/2205.14135v2.pdf; Rabe and Staats https://arxiv.org/pdf/2112.05682v2.pdf)
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
import pytest
|
| 13 |
+
import torch
|
| 14 |
+
import triton
|
| 15 |
+
import triton.language as tl
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
@triton.jit
|
| 19 |
+
def _fwd_kernel(
|
| 20 |
+
Q,
|
| 21 |
+
K,
|
| 22 |
+
V,
|
| 23 |
+
sm_scale,
|
| 24 |
+
TMP,
|
| 25 |
+
L,
|
| 26 |
+
M, # NOTE: TMP is a scratchpad buffer to workaround a compiler bug
|
| 27 |
+
Out,
|
| 28 |
+
stride_qz,
|
| 29 |
+
stride_qh,
|
| 30 |
+
stride_qm,
|
| 31 |
+
stride_qk,
|
| 32 |
+
stride_kz,
|
| 33 |
+
stride_kh,
|
| 34 |
+
stride_kn,
|
| 35 |
+
stride_kk,
|
| 36 |
+
stride_vz,
|
| 37 |
+
stride_vh,
|
| 38 |
+
stride_vk,
|
| 39 |
+
stride_vn,
|
| 40 |
+
stride_oz,
|
| 41 |
+
stride_oh,
|
| 42 |
+
stride_om,
|
| 43 |
+
stride_on,
|
| 44 |
+
Z,
|
| 45 |
+
H,
|
| 46 |
+
N_CTX,
|
| 47 |
+
BLOCK_M: tl.constexpr,
|
| 48 |
+
BLOCK_DMODEL: tl.constexpr,
|
| 49 |
+
BLOCK_N: tl.constexpr,
|
| 50 |
+
):
|
| 51 |
+
start_m = tl.program_id(0)
|
| 52 |
+
off_hz = tl.program_id(1)
|
| 53 |
+
# initialize offsets
|
| 54 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 55 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 56 |
+
offs_d = tl.arange(0, BLOCK_DMODEL)
|
| 57 |
+
off_q = off_hz * stride_qh + offs_m[:, None] * stride_qm + offs_d[None, :] * stride_qk
|
| 58 |
+
off_k = off_hz * stride_qh + offs_n[:, None] * stride_kn + offs_d[None, :] * stride_kk
|
| 59 |
+
off_v = off_hz * stride_qh + offs_n[:, None] * stride_qm + offs_d[None, :] * stride_qk
|
| 60 |
+
# Initialize pointers to Q, K, V
|
| 61 |
+
q_ptrs = Q + off_q
|
| 62 |
+
k_ptrs = K + off_k
|
| 63 |
+
v_ptrs = V + off_v
|
| 64 |
+
# initialize pointer to m and l
|
| 65 |
+
t_ptrs = TMP + off_hz * N_CTX + offs_m
|
| 66 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 67 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 68 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 69 |
+
# load q: it will stay in SRAM throughout
|
| 70 |
+
q = tl.load(q_ptrs)
|
| 71 |
+
# loop over k, v and update accumulator
|
| 72 |
+
for start_n in range(0, (start_m + 1) * BLOCK_M, BLOCK_N):
|
| 73 |
+
start_n = tl.multiple_of(start_n, BLOCK_N)
|
| 74 |
+
# -- compute qk ----
|
| 75 |
+
k = tl.load(k_ptrs + start_n * stride_kn)
|
| 76 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 77 |
+
qk += tl.dot(q, k, trans_b=True)
|
| 78 |
+
qk *= sm_scale
|
| 79 |
+
qk += tl.where(offs_m[:, None] >= (start_n + offs_n[None, :]), 0, float("-inf"))
|
| 80 |
+
# -- compute m_ij, p, l_ij
|
| 81 |
+
m_ij = tl.max(qk, 1)
|
| 82 |
+
p = tl.exp(qk - m_ij[:, None])
|
| 83 |
+
l_ij = tl.sum(p, 1)
|
| 84 |
+
# -- update m_i and l_i
|
| 85 |
+
m_i_new = tl.maximum(m_i, m_ij)
|
| 86 |
+
alpha = tl.exp(m_i - m_i_new)
|
| 87 |
+
beta = tl.exp(m_ij - m_i_new)
|
| 88 |
+
l_i_new = alpha * l_i + beta * l_ij
|
| 89 |
+
# -- update output accumulator --
|
| 90 |
+
# scale p
|
| 91 |
+
p_scale = beta / l_i_new
|
| 92 |
+
p = p * p_scale[:, None]
|
| 93 |
+
# scale acc
|
| 94 |
+
acc_scale = l_i / l_i_new * alpha
|
| 95 |
+
tl.store(t_ptrs, acc_scale)
|
| 96 |
+
acc_scale = tl.load(t_ptrs) # BUG: have to store and immediately load
|
| 97 |
+
acc = acc * acc_scale[:, None]
|
| 98 |
+
# update acc
|
| 99 |
+
v = tl.load(v_ptrs + start_n * stride_vk)
|
| 100 |
+
p = p.to(v.dtype)
|
| 101 |
+
acc += tl.dot(p, v)
|
| 102 |
+
# update m_i and l_i
|
| 103 |
+
l_i = l_i_new
|
| 104 |
+
m_i = m_i_new
|
| 105 |
+
# rematerialize offsets to save registers
|
| 106 |
+
start_m = tl.program_id(0)
|
| 107 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 108 |
+
# write back l and m
|
| 109 |
+
l_ptrs = L + off_hz * N_CTX + offs_m
|
| 110 |
+
m_ptrs = M + off_hz * N_CTX + offs_m
|
| 111 |
+
tl.store(l_ptrs, l_i)
|
| 112 |
+
tl.store(m_ptrs, m_i)
|
| 113 |
+
# initialize pointers to output
|
| 114 |
+
offs_n = tl.arange(0, BLOCK_DMODEL)
|
| 115 |
+
off_o = off_hz * stride_oh + offs_m[:, None] * stride_om + offs_n[None, :] * stride_on
|
| 116 |
+
out_ptrs = Out + off_o
|
| 117 |
+
tl.store(out_ptrs, acc)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
@triton.jit
|
| 121 |
+
def _bwd_preprocess(
|
| 122 |
+
Out,
|
| 123 |
+
DO,
|
| 124 |
+
L,
|
| 125 |
+
NewDO,
|
| 126 |
+
Delta,
|
| 127 |
+
BLOCK_M: tl.constexpr,
|
| 128 |
+
D_HEAD: tl.constexpr,
|
| 129 |
+
):
|
| 130 |
+
off_m = tl.program_id(0) * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 131 |
+
off_n = tl.arange(0, D_HEAD)
|
| 132 |
+
# load
|
| 133 |
+
o = tl.load(Out + off_m[:, None] * D_HEAD + off_n[None, :]).to(tl.float32)
|
| 134 |
+
do = tl.load(DO + off_m[:, None] * D_HEAD + off_n[None, :]).to(tl.float32)
|
| 135 |
+
denom = tl.load(L + off_m).to(tl.float32)
|
| 136 |
+
# compute
|
| 137 |
+
do = do / denom[:, None]
|
| 138 |
+
delta = tl.sum(o * do, axis=1)
|
| 139 |
+
# write-back
|
| 140 |
+
tl.store(NewDO + off_m[:, None] * D_HEAD + off_n[None, :], do)
|
| 141 |
+
tl.store(Delta + off_m, delta)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
@triton.jit
|
| 145 |
+
def _bwd_kernel(
|
| 146 |
+
Q,
|
| 147 |
+
K,
|
| 148 |
+
V,
|
| 149 |
+
sm_scale,
|
| 150 |
+
Out,
|
| 151 |
+
DO,
|
| 152 |
+
DQ,
|
| 153 |
+
DK,
|
| 154 |
+
DV,
|
| 155 |
+
L,
|
| 156 |
+
M,
|
| 157 |
+
D,
|
| 158 |
+
stride_qz,
|
| 159 |
+
stride_qh,
|
| 160 |
+
stride_qm,
|
| 161 |
+
stride_qk,
|
| 162 |
+
stride_kz,
|
| 163 |
+
stride_kh,
|
| 164 |
+
stride_kn,
|
| 165 |
+
stride_kk,
|
| 166 |
+
stride_vz,
|
| 167 |
+
stride_vh,
|
| 168 |
+
stride_vk,
|
| 169 |
+
stride_vn,
|
| 170 |
+
Z,
|
| 171 |
+
H,
|
| 172 |
+
N_CTX,
|
| 173 |
+
num_block,
|
| 174 |
+
BLOCK_M: tl.constexpr,
|
| 175 |
+
BLOCK_DMODEL: tl.constexpr,
|
| 176 |
+
BLOCK_N: tl.constexpr,
|
| 177 |
+
):
|
| 178 |
+
off_hz = tl.program_id(0)
|
| 179 |
+
off_z = off_hz // H
|
| 180 |
+
off_h = off_hz % H
|
| 181 |
+
# offset pointers for batch/head
|
| 182 |
+
Q += off_z * stride_qz + off_h * stride_qh
|
| 183 |
+
K += off_z * stride_qz + off_h * stride_qh
|
| 184 |
+
V += off_z * stride_qz + off_h * stride_qh
|
| 185 |
+
DO += off_z * stride_qz + off_h * stride_qh
|
| 186 |
+
DQ += off_z * stride_qz + off_h * stride_qh
|
| 187 |
+
DK += off_z * stride_qz + off_h * stride_qh
|
| 188 |
+
DV += off_z * stride_qz + off_h * stride_qh
|
| 189 |
+
for start_n in range(0, num_block):
|
| 190 |
+
lo = start_n * BLOCK_M
|
| 191 |
+
# initialize row/col offsets
|
| 192 |
+
offs_qm = lo + tl.arange(0, BLOCK_M)
|
| 193 |
+
offs_n = start_n * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 194 |
+
offs_m = tl.arange(0, BLOCK_N)
|
| 195 |
+
offs_k = tl.arange(0, BLOCK_DMODEL)
|
| 196 |
+
# initialize pointers to value-like data
|
| 197 |
+
q_ptrs = Q + (offs_qm[:, None] * stride_qm + offs_k[None, :] * stride_qk)
|
| 198 |
+
k_ptrs = K + (offs_n[:, None] * stride_kn + offs_k[None, :] * stride_kk)
|
| 199 |
+
v_ptrs = V + (offs_n[:, None] * stride_qm + offs_k[None, :] * stride_qk)
|
| 200 |
+
do_ptrs = DO + (offs_qm[:, None] * stride_qm + offs_k[None, :] * stride_qk)
|
| 201 |
+
dq_ptrs = DQ + (offs_qm[:, None] * stride_qm + offs_k[None, :] * stride_qk)
|
| 202 |
+
# pointer to row-wise quantities in value-like data
|
| 203 |
+
D_ptrs = D + off_hz * N_CTX
|
| 204 |
+
m_ptrs = M + off_hz * N_CTX
|
| 205 |
+
# initialize dv amd dk
|
| 206 |
+
dv = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 207 |
+
dk = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 208 |
+
# k and v stay in SRAM throughout
|
| 209 |
+
k = tl.load(k_ptrs)
|
| 210 |
+
v = tl.load(v_ptrs)
|
| 211 |
+
# loop over rows
|
| 212 |
+
for start_m in range(lo, num_block * BLOCK_M, BLOCK_M):
|
| 213 |
+
offs_m_curr = start_m + offs_m
|
| 214 |
+
# load q, k, v, do on-chip
|
| 215 |
+
q = tl.load(q_ptrs)
|
| 216 |
+
# recompute p = softmax(qk, dim=-1).T
|
| 217 |
+
# NOTE: `do` is pre-divided by `l`; no normalization here
|
| 218 |
+
qk = tl.dot(q, k, trans_b=True)
|
| 219 |
+
qk = tl.where(offs_m_curr[:, None] >= (offs_n[None, :]), qk, float("-inf"))
|
| 220 |
+
m = tl.load(m_ptrs + offs_m_curr)
|
| 221 |
+
p = tl.exp(qk * sm_scale - m[:, None])
|
| 222 |
+
# compute dv
|
| 223 |
+
do = tl.load(do_ptrs)
|
| 224 |
+
dv += tl.dot(p.to(do.dtype), do, trans_a=True)
|
| 225 |
+
# compute dp = dot(v, do)
|
| 226 |
+
Di = tl.load(D_ptrs + offs_m_curr)
|
| 227 |
+
dp = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32) - Di[:, None]
|
| 228 |
+
dp += tl.dot(do, v, trans_b=True)
|
| 229 |
+
# compute ds = p * (dp - delta[:, None])
|
| 230 |
+
ds = p * dp * sm_scale
|
| 231 |
+
# compute dk = dot(ds.T, q)
|
| 232 |
+
dk += tl.dot(ds.to(q.dtype), q, trans_a=True)
|
| 233 |
+
# # compute dq
|
| 234 |
+
dq = tl.load(dq_ptrs, eviction_policy="evict_last")
|
| 235 |
+
dq += tl.dot(ds.to(k.dtype), k)
|
| 236 |
+
tl.store(dq_ptrs, dq, eviction_policy="evict_last")
|
| 237 |
+
# # increment pointers
|
| 238 |
+
dq_ptrs += BLOCK_M * stride_qm
|
| 239 |
+
q_ptrs += BLOCK_M * stride_qm
|
| 240 |
+
do_ptrs += BLOCK_M * stride_qm
|
| 241 |
+
# write-back
|
| 242 |
+
dv_ptrs = DV + (offs_n[:, None] * stride_qm + offs_k[None, :] * stride_qk)
|
| 243 |
+
dk_ptrs = DK + (offs_n[:, None] * stride_kn + offs_k[None, :] * stride_kk)
|
| 244 |
+
tl.store(dv_ptrs, dv)
|
| 245 |
+
tl.store(dk_ptrs, dk)
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
class _attention(torch.autograd.Function):
|
| 249 |
+
@staticmethod
|
| 250 |
+
def forward(ctx, q, k, v, sm_scale):
|
| 251 |
+
BLOCK = 128
|
| 252 |
+
# shape constraints
|
| 253 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 254 |
+
assert Lq == Lk and Lk == Lv
|
| 255 |
+
assert Lk in {16, 32, 64, 128}
|
| 256 |
+
o = torch.empty_like(q)
|
| 257 |
+
grid = (triton.cdiv(q.shape[2], BLOCK), q.shape[0] * q.shape[1])
|
| 258 |
+
tmp = torch.empty(
|
| 259 |
+
(q.shape[0] * q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32
|
| 260 |
+
)
|
| 261 |
+
L = torch.empty((q.shape[0] * q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
|
| 262 |
+
m = torch.empty((q.shape[0] * q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
|
| 263 |
+
num_warps = 4 if Lk <= 64 else 8
|
| 264 |
+
|
| 265 |
+
_fwd_kernel[grid](
|
| 266 |
+
q,
|
| 267 |
+
k,
|
| 268 |
+
v,
|
| 269 |
+
sm_scale,
|
| 270 |
+
tmp,
|
| 271 |
+
L,
|
| 272 |
+
m,
|
| 273 |
+
o,
|
| 274 |
+
q.stride(0),
|
| 275 |
+
q.stride(1),
|
| 276 |
+
q.stride(2),
|
| 277 |
+
q.stride(3),
|
| 278 |
+
k.stride(0),
|
| 279 |
+
k.stride(1),
|
| 280 |
+
k.stride(2),
|
| 281 |
+
k.stride(3),
|
| 282 |
+
v.stride(0),
|
| 283 |
+
v.stride(1),
|
| 284 |
+
v.stride(2),
|
| 285 |
+
v.stride(3),
|
| 286 |
+
o.stride(0),
|
| 287 |
+
o.stride(1),
|
| 288 |
+
o.stride(2),
|
| 289 |
+
o.stride(3),
|
| 290 |
+
q.shape[0],
|
| 291 |
+
q.shape[1],
|
| 292 |
+
q.shape[2],
|
| 293 |
+
BLOCK_M=BLOCK,
|
| 294 |
+
BLOCK_N=BLOCK,
|
| 295 |
+
BLOCK_DMODEL=Lk,
|
| 296 |
+
num_warps=num_warps,
|
| 297 |
+
num_stages=1,
|
| 298 |
+
)
|
| 299 |
+
ctx.save_for_backward(q, k, v, o, L, m)
|
| 300 |
+
ctx.BLOCK = BLOCK
|
| 301 |
+
ctx.grid = grid
|
| 302 |
+
ctx.sm_scale = sm_scale
|
| 303 |
+
ctx.BLOCK_DMODEL = Lk
|
| 304 |
+
return o
|
| 305 |
+
|
| 306 |
+
@staticmethod
|
| 307 |
+
def backward(ctx, do):
|
| 308 |
+
q, k, v, o, l, m = ctx.saved_tensors
|
| 309 |
+
do = do.contiguous()
|
| 310 |
+
dq = torch.zeros_like(q, dtype=torch.float32)
|
| 311 |
+
dk = torch.empty_like(k)
|
| 312 |
+
dv = torch.empty_like(v)
|
| 313 |
+
do_scaled = torch.empty_like(do)
|
| 314 |
+
delta = torch.empty_like(l)
|
| 315 |
+
_bwd_preprocess[(ctx.grid[0] * ctx.grid[1],)](
|
| 316 |
+
o,
|
| 317 |
+
do,
|
| 318 |
+
l,
|
| 319 |
+
do_scaled,
|
| 320 |
+
delta,
|
| 321 |
+
BLOCK_M=ctx.BLOCK,
|
| 322 |
+
D_HEAD=ctx.BLOCK_DMODEL,
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
# NOTE: kernel currently buggy for other values of `num_warps`
|
| 326 |
+
num_warps = 8
|
| 327 |
+
_bwd_kernel[(ctx.grid[1],)](
|
| 328 |
+
q,
|
| 329 |
+
k,
|
| 330 |
+
v,
|
| 331 |
+
ctx.sm_scale,
|
| 332 |
+
o,
|
| 333 |
+
do_scaled,
|
| 334 |
+
dq,
|
| 335 |
+
dk,
|
| 336 |
+
dv,
|
| 337 |
+
l,
|
| 338 |
+
m,
|
| 339 |
+
delta,
|
| 340 |
+
q.stride(0),
|
| 341 |
+
q.stride(1),
|
| 342 |
+
q.stride(2),
|
| 343 |
+
q.stride(3),
|
| 344 |
+
k.stride(0),
|
| 345 |
+
k.stride(1),
|
| 346 |
+
k.stride(2),
|
| 347 |
+
k.stride(3),
|
| 348 |
+
v.stride(0),
|
| 349 |
+
v.stride(1),
|
| 350 |
+
v.stride(2),
|
| 351 |
+
v.stride(3),
|
| 352 |
+
q.shape[0],
|
| 353 |
+
q.shape[1],
|
| 354 |
+
q.shape[2],
|
| 355 |
+
ctx.grid[0],
|
| 356 |
+
BLOCK_M=ctx.BLOCK,
|
| 357 |
+
BLOCK_N=ctx.BLOCK,
|
| 358 |
+
BLOCK_DMODEL=ctx.BLOCK_DMODEL,
|
| 359 |
+
num_warps=num_warps,
|
| 360 |
+
num_stages=1,
|
| 361 |
+
)
|
| 362 |
+
return dq.to(q.dtype), dk, dv, None
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
attention = _attention.apply
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_blocksparse_attention.py
ADDED
|
@@ -0,0 +1,197 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
import hydra
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
|
| 8 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input
|
| 9 |
+
from flash_attn.flash_blocksparse_attn_interface import (
|
| 10 |
+
convert_blockmask,
|
| 11 |
+
flash_blocksparse_attn_func,
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class FlashBlocksparseAttention(nn.Module):
|
| 16 |
+
"""Implement the scaled dot product attention with softmax.
|
| 17 |
+
Arguments
|
| 18 |
+
---------
|
| 19 |
+
softmax_temp: The temperature to use for the softmax attention.
|
| 20 |
+
(default: 1/sqrt(d_keys) where d_keys is computed at
|
| 21 |
+
runtime)
|
| 22 |
+
attention_dropout: The dropout rate to apply to the attention
|
| 23 |
+
(default: 0.1)
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
def __init__(
|
| 27 |
+
self,
|
| 28 |
+
sparsity_config,
|
| 29 |
+
softmax_temp=None,
|
| 30 |
+
attention_dropout=0.0,
|
| 31 |
+
max_seq_length=2048,
|
| 32 |
+
device=None,
|
| 33 |
+
dtype=None,
|
| 34 |
+
):
|
| 35 |
+
super().__init__()
|
| 36 |
+
self.sparsity_config = hydra.utils.instantiate(sparsity_config)
|
| 37 |
+
self.softmax_temp = softmax_temp
|
| 38 |
+
self.dropout_p = attention_dropout
|
| 39 |
+
|
| 40 |
+
# initialize sparse layout and register as buffer
|
| 41 |
+
max_seq_length = ((max_seq_length + 256 - 1) // 256) * 256
|
| 42 |
+
layout = self.sparsity_config.make_layout(max_seq_length)
|
| 43 |
+
self.register_buffer("layout", layout)
|
| 44 |
+
blockmask_converted = convert_blockmask(self.layout, causal=False)
|
| 45 |
+
self.register_buffer("blockmask_converted", blockmask_converted)
|
| 46 |
+
# logger.info(f'Attention class {self.__class__}: saving={self.layout.float().mean()}')
|
| 47 |
+
|
| 48 |
+
def forward(
|
| 49 |
+
self,
|
| 50 |
+
qkv,
|
| 51 |
+
attn_mask=None,
|
| 52 |
+
key_padding_mask=None,
|
| 53 |
+
causal=False,
|
| 54 |
+
cu_seqlens=None,
|
| 55 |
+
max_s=None,
|
| 56 |
+
need_weights=False,
|
| 57 |
+
convert_mask=True,
|
| 58 |
+
):
|
| 59 |
+
"""Implements the multihead softmax attention.
|
| 60 |
+
Arguments
|
| 61 |
+
---------
|
| 62 |
+
qkv: The tensor containing the query, key, and value. (B, S, 3, H, D) if key_padding_mask is None
|
| 63 |
+
attn_mask: An implementation of BaseMask that encodes where each
|
| 64 |
+
query can attend to
|
| 65 |
+
key_padding_mask: An implementation of BaseMask that encodes how
|
| 66 |
+
many query each sequence in the batch consists of
|
| 67 |
+
"""
|
| 68 |
+
assert not need_weights
|
| 69 |
+
assert attn_mask is None
|
| 70 |
+
assert qkv.dtype == torch.float16
|
| 71 |
+
assert qkv.is_cuda
|
| 72 |
+
|
| 73 |
+
if cu_seqlens is None:
|
| 74 |
+
batch_size = qkv.shape[0]
|
| 75 |
+
seqlen = qkv.shape[1]
|
| 76 |
+
# Convert mask to take a subset
|
| 77 |
+
seqlen_rounded = ((seqlen + 256 - 1) // 256) * 256
|
| 78 |
+
assert seqlen_rounded // 16 <= self.layout.shape[0], (
|
| 79 |
+
seqlen_rounded // 256 <= self.layout.shape[1]
|
| 80 |
+
)
|
| 81 |
+
blockmask = self.layout[: seqlen_rounded // 16, : seqlen_rounded // 256]
|
| 82 |
+
if key_padding_mask is None:
|
| 83 |
+
qkv = rearrange(qkv, "b s ... -> (b s) ...")
|
| 84 |
+
max_s = seqlen
|
| 85 |
+
cu_seqlens = torch.arange(
|
| 86 |
+
0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32, device=qkv.device
|
| 87 |
+
)
|
| 88 |
+
output = flash_blocksparse_attn_func(
|
| 89 |
+
qkv,
|
| 90 |
+
cu_seqlens,
|
| 91 |
+
blockmask,
|
| 92 |
+
self.dropout_p if self.training else 0.0,
|
| 93 |
+
max_s,
|
| 94 |
+
softmax_scale=self.softmax_temp,
|
| 95 |
+
causal=causal,
|
| 96 |
+
)
|
| 97 |
+
output = rearrange(output, "(b s) ... -> b s ...", b=batch_size)
|
| 98 |
+
else:
|
| 99 |
+
key_padding_mask_bool = key_padding_mask.bool_matrix
|
| 100 |
+
nheads = qkv.shape[-2]
|
| 101 |
+
x = rearrange(qkv, "b s three h d -> b s (three h d)")
|
| 102 |
+
x_unpad, indices, cu_seqlens, max_s = unpad_input(x, key_padding_mask_bool)
|
| 103 |
+
x_unpad = rearrange(x_unpad, "nnz (three h d) -> nnz three h d", three=3, h=nheads)
|
| 104 |
+
output_unpad = flash_blocksparse_attn_func(
|
| 105 |
+
x_unpad,
|
| 106 |
+
cu_seqlens,
|
| 107 |
+
blockmask,
|
| 108 |
+
self.dropout_p if self.training else 0.0,
|
| 109 |
+
max_s,
|
| 110 |
+
softmax_scale=self.softmax_temp,
|
| 111 |
+
causal=causal,
|
| 112 |
+
)
|
| 113 |
+
output = rearrange(
|
| 114 |
+
pad_input(
|
| 115 |
+
rearrange(output_unpad, "nnz h d -> nnz (h d)"), indices, batch_size, seqlen
|
| 116 |
+
),
|
| 117 |
+
"b s (h d) -> b s h d",
|
| 118 |
+
h=nheads,
|
| 119 |
+
)
|
| 120 |
+
else:
|
| 121 |
+
assert max_s is not None
|
| 122 |
+
seqlen = max_s
|
| 123 |
+
# Convert mask to take a subset
|
| 124 |
+
seqlen_rounded = ((seqlen + 256 - 1) // 256) * 256
|
| 125 |
+
assert seqlen_rounded // 16 <= self.layout.shape[0], (
|
| 126 |
+
seqlen_rounded // 256 <= self.layout.shape[1]
|
| 127 |
+
)
|
| 128 |
+
blockmask = self.layout[: seqlen_rounded // 16, : seqlen_rounded // 256]
|
| 129 |
+
if convert_mask:
|
| 130 |
+
output = flash_blocksparse_attn_func(
|
| 131 |
+
qkv,
|
| 132 |
+
cu_seqlens,
|
| 133 |
+
blockmask,
|
| 134 |
+
self.dropout_p if self.training else 0.0,
|
| 135 |
+
max_s,
|
| 136 |
+
softmax_scale=self.softmax_temp,
|
| 137 |
+
causal=causal,
|
| 138 |
+
)
|
| 139 |
+
else:
|
| 140 |
+
output = flash_blocksparse_attn_func(
|
| 141 |
+
qkv,
|
| 142 |
+
cu_seqlens,
|
| 143 |
+
self.blockmask_converted,
|
| 144 |
+
self.dropout_p if self.training else 0.0,
|
| 145 |
+
max_s,
|
| 146 |
+
softmax_scale=self.softmax_temp,
|
| 147 |
+
causal=causal,
|
| 148 |
+
convert_mask=False,
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
return output, None
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class FlashBlocksparseMHA(nn.Module):
|
| 155 |
+
def __init__(
|
| 156 |
+
self,
|
| 157 |
+
embed_dim,
|
| 158 |
+
num_heads,
|
| 159 |
+
sparsity_config,
|
| 160 |
+
bias=True,
|
| 161 |
+
batch_first=True,
|
| 162 |
+
attention_dropout=0.0,
|
| 163 |
+
causal=False,
|
| 164 |
+
max_seq_length=2048,
|
| 165 |
+
device=None,
|
| 166 |
+
dtype=None,
|
| 167 |
+
**kwargs,
|
| 168 |
+
) -> None:
|
| 169 |
+
assert batch_first
|
| 170 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 171 |
+
super().__init__()
|
| 172 |
+
self.embed_dim = embed_dim
|
| 173 |
+
self.causal = causal
|
| 174 |
+
|
| 175 |
+
self.num_heads = num_heads
|
| 176 |
+
assert self.embed_dim % num_heads == 0, "self.kdim must be divisible by num_heads"
|
| 177 |
+
self.head_dim = self.embed_dim // num_heads
|
| 178 |
+
assert self.head_dim in [16, 32, 64], "Only support head_dim == 16, 32, or 64"
|
| 179 |
+
|
| 180 |
+
self.Wqkv = nn.Linear(embed_dim, 3 * embed_dim, bias=bias, **factory_kwargs)
|
| 181 |
+
self.inner_attn = FlashBlocksparseAttention(
|
| 182 |
+
sparsity_config,
|
| 183 |
+
attention_dropout=attention_dropout,
|
| 184 |
+
max_seq_length=max_seq_length,
|
| 185 |
+
**factory_kwargs,
|
| 186 |
+
)
|
| 187 |
+
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias, **factory_kwargs)
|
| 188 |
+
|
| 189 |
+
def forward(
|
| 190 |
+
self, x, x_ignored_, x_ignored_1_, attn_mask=None, key_padding_mask=None, need_weights=False
|
| 191 |
+
):
|
| 192 |
+
qkv = self.Wqkv(x)
|
| 193 |
+
qkv = rearrange(qkv, "b s (three h d) -> b s three h d", three=3, h=self.num_heads)
|
| 194 |
+
context, attn_weights = self.inner_attn(
|
| 195 |
+
qkv, key_padding_mask=key_padding_mask, need_weights=need_weights, causal=self.causal
|
| 196 |
+
)
|
| 197 |
+
return self.out_proj(rearrange(context, "b s h d -> b s (h d)")), attn_weights
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/flash_blocksparse_attn_interface.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapted from https://github.com/mlcommons/training_results_v1.1/blob/main/NVIDIA/benchmarks/bert/implementations/pytorch/fmha.py
|
| 2 |
+
import flash_attn_cuda
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def convert_blockmask(blockmask, causal):
|
| 8 |
+
"""Convert from the 0-1 format to the format used by the CUDA code.
|
| 9 |
+
0 means the block is skipped.
|
| 10 |
+
nonzero means the block is not skipped.
|
| 11 |
+
Argument:
|
| 12 |
+
blockmask: (row, col): a 0-1 tensor
|
| 13 |
+
Return:
|
| 14 |
+
blockmask_converted: (col, row), dtype torch.int32: for each column, it contains the row
|
| 15 |
+
indices of the nonzero blocks, padded with -1 to reach length @row.
|
| 16 |
+
The indices are multiplied by 4, with the smallest bit used to encode whether
|
| 17 |
+
it is the first nonzero in its row, and the 2nd smallest bit to encode whether it is
|
| 18 |
+
the last nonzero in its row..
|
| 19 |
+
"""
|
| 20 |
+
assert not causal
|
| 21 |
+
# TD [2022-05-13]: The indexing and sorting is very tricky
|
| 22 |
+
nrow, ncol = blockmask.shape
|
| 23 |
+
# Sort does not support bool on CUDA
|
| 24 |
+
blockmask = blockmask.to(dtype=torch.uint8)
|
| 25 |
+
nonzero_val, nonzero_sorted_rowidx = blockmask.sort(dim=0, stable=True, descending=True)
|
| 26 |
+
nonzero_unsorted_rowidx = nonzero_sorted_rowidx.argsort(dim=0)
|
| 27 |
+
last_nonzero_col_per_row = blockmask.sort(dim=-1, stable=True).indices[:, -1]
|
| 28 |
+
last_nonzero_col_per_row_after_sort = nonzero_unsorted_rowidx[
|
| 29 |
+
torch.arange(nrow, device=blockmask.device), last_nonzero_col_per_row
|
| 30 |
+
]
|
| 31 |
+
first_nonzero_col_per_row = blockmask.sort(dim=-1, stable=True, descending=True).indices[:, 0]
|
| 32 |
+
first_nonzero_col_per_row_after_sort = nonzero_unsorted_rowidx[
|
| 33 |
+
torch.arange(nrow, device=blockmask.device), first_nonzero_col_per_row
|
| 34 |
+
]
|
| 35 |
+
nonzero_idx = nonzero_sorted_rowidx * 4
|
| 36 |
+
nonzero_idx[last_nonzero_col_per_row_after_sort, last_nonzero_col_per_row] += 2
|
| 37 |
+
nonzero_idx[first_nonzero_col_per_row_after_sort, first_nonzero_col_per_row] += 1
|
| 38 |
+
nonzero_idx[nonzero_val == 0] = -1
|
| 39 |
+
return nonzero_idx.T.contiguous().to(dtype=torch.int32)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def _flash_blocksparse_attn_forward(
|
| 43 |
+
qkv, cu_seqlens, blockmask, dropout_p, max_s, softmax_scale, causal, return_softmax
|
| 44 |
+
):
|
| 45 |
+
context, softmax_lse, *rest = flash_attn_cuda.fwd_block(
|
| 46 |
+
qkv, cu_seqlens, blockmask, dropout_p, max_s, softmax_scale, causal, return_softmax, None
|
| 47 |
+
)
|
| 48 |
+
# if context.isnan().any() or softmax_lse.isnan().any():
|
| 49 |
+
# breakpoint()
|
| 50 |
+
S_dmask = rest[0] if return_softmax else None
|
| 51 |
+
return context, softmax_lse, S_dmask
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def _flash_blocksparse_attn_backward(
|
| 55 |
+
dout,
|
| 56 |
+
qkv,
|
| 57 |
+
out,
|
| 58 |
+
S_dmask,
|
| 59 |
+
softmax_lse,
|
| 60 |
+
cu_seqlens,
|
| 61 |
+
blockmask,
|
| 62 |
+
dropout_p,
|
| 63 |
+
max_s,
|
| 64 |
+
softmax_scale,
|
| 65 |
+
causal,
|
| 66 |
+
):
|
| 67 |
+
dqkv, dp, softmax_d = flash_attn_cuda.bwd_block(
|
| 68 |
+
dout,
|
| 69 |
+
qkv,
|
| 70 |
+
out,
|
| 71 |
+
S_dmask,
|
| 72 |
+
softmax_lse,
|
| 73 |
+
cu_seqlens,
|
| 74 |
+
blockmask,
|
| 75 |
+
dropout_p,
|
| 76 |
+
softmax_scale,
|
| 77 |
+
max_s,
|
| 78 |
+
causal,
|
| 79 |
+
None,
|
| 80 |
+
)
|
| 81 |
+
# if dqkv.isnan().any() or softmax_d.isnan().any():
|
| 82 |
+
# breakpoint()
|
| 83 |
+
return dqkv
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class FlashBlocksparseAttnFun(torch.autograd.Function):
|
| 87 |
+
@staticmethod
|
| 88 |
+
def forward(ctx, qkv, cu_seqlens, blockmask, dropout_p, max_s, softmax_scale, causal):
|
| 89 |
+
# Save rng_state because the backward pass will regenerate the dropout mask
|
| 90 |
+
rng_state = torch.cuda.get_rng_state() if dropout_p > 0 else None
|
| 91 |
+
if softmax_scale is None:
|
| 92 |
+
softmax_scale = qkv.shape[-1] ** (-0.5)
|
| 93 |
+
context, softmax_lse, S_dmask = _flash_blocksparse_attn_forward(
|
| 94 |
+
qkv,
|
| 95 |
+
cu_seqlens,
|
| 96 |
+
blockmask,
|
| 97 |
+
dropout_p,
|
| 98 |
+
max_s,
|
| 99 |
+
softmax_scale,
|
| 100 |
+
causal=causal,
|
| 101 |
+
return_softmax=False,
|
| 102 |
+
)
|
| 103 |
+
ctx.save_for_backward(qkv, context, S_dmask, softmax_lse, cu_seqlens, blockmask, rng_state)
|
| 104 |
+
ctx.dropout_p = dropout_p
|
| 105 |
+
ctx.max_s = max_s
|
| 106 |
+
ctx.softmax_scale = softmax_scale
|
| 107 |
+
ctx.causal = causal
|
| 108 |
+
return context
|
| 109 |
+
|
| 110 |
+
@staticmethod
|
| 111 |
+
def backward(ctx, dout):
|
| 112 |
+
qkv, context, S_dmask, softmax_lse, cu_seqlens, blockmask, rng_state = ctx.saved_tensors
|
| 113 |
+
if rng_state is not None:
|
| 114 |
+
cur_rng_state = torch.cuda.get_rng_state()
|
| 115 |
+
torch.cuda.set_rng_state(rng_state)
|
| 116 |
+
# S_dmask is None, temporarily use another tensor just to get it running
|
| 117 |
+
dqkv = _flash_blocksparse_attn_backward(
|
| 118 |
+
dout,
|
| 119 |
+
qkv,
|
| 120 |
+
context,
|
| 121 |
+
context,
|
| 122 |
+
softmax_lse,
|
| 123 |
+
cu_seqlens,
|
| 124 |
+
blockmask,
|
| 125 |
+
ctx.dropout_p,
|
| 126 |
+
ctx.max_s,
|
| 127 |
+
ctx.softmax_scale,
|
| 128 |
+
ctx.causal,
|
| 129 |
+
)
|
| 130 |
+
if rng_state is not None:
|
| 131 |
+
torch.cuda.set_rng_state(cur_rng_state)
|
| 132 |
+
return dqkv, None, None, None, None, None, None, None
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
# We duplicate code to return both the output and the softmax for testing
|
| 136 |
+
# Returning both makes backward a bit slower, so we want to keep using the other version for speed.
|
| 137 |
+
class FlashBlocksparseAttnFunWithS(torch.autograd.Function):
|
| 138 |
+
@staticmethod
|
| 139 |
+
def forward(ctx, qkv, cu_seqlens, blockmask, dropout_p, max_s, softmax_scale, causal):
|
| 140 |
+
# Save rng_state because the backward pass is gonna regenerate the dropout mask
|
| 141 |
+
rng_state = torch.cuda.get_rng_state() if dropout_p > 0 else None
|
| 142 |
+
if softmax_scale is None:
|
| 143 |
+
softmax_scale = qkv.shape[-1] ** (-0.5)
|
| 144 |
+
context, softmax_lse, S_dmask = _flash_blocksparse_attn_forward(
|
| 145 |
+
qkv,
|
| 146 |
+
cu_seqlens,
|
| 147 |
+
blockmask,
|
| 148 |
+
dropout_p,
|
| 149 |
+
max_s,
|
| 150 |
+
softmax_scale,
|
| 151 |
+
causal=causal,
|
| 152 |
+
return_softmax=True,
|
| 153 |
+
)
|
| 154 |
+
ctx.save_for_backward(qkv, context, S_dmask, softmax_lse, cu_seqlens, blockmask, rng_state)
|
| 155 |
+
ctx.dropout_p = dropout_p
|
| 156 |
+
ctx.max_s = max_s
|
| 157 |
+
ctx.softmax_scale = softmax_scale
|
| 158 |
+
ctx.causal = causal
|
| 159 |
+
return context, S_dmask, softmax_lse
|
| 160 |
+
|
| 161 |
+
@staticmethod
|
| 162 |
+
def backward(ctx, dout, _dS_dmask_ignored, _dsoftmax_sum_ignored):
|
| 163 |
+
qkv, context, S_dmask, softmax_lse, cu_seqlens, blockmask, rng_state = ctx.saved_tensors
|
| 164 |
+
if rng_state is not None:
|
| 165 |
+
cur_rng_state = torch.cuda.get_rng_state()
|
| 166 |
+
torch.cuda.set_rng_state(rng_state)
|
| 167 |
+
dqkv = _flash_blocksparse_attn_backward(
|
| 168 |
+
dout,
|
| 169 |
+
qkv,
|
| 170 |
+
context,
|
| 171 |
+
S_dmask,
|
| 172 |
+
softmax_lse,
|
| 173 |
+
cu_seqlens,
|
| 174 |
+
blockmask,
|
| 175 |
+
ctx.dropout_p,
|
| 176 |
+
ctx.max_s,
|
| 177 |
+
ctx.softmax_scale,
|
| 178 |
+
ctx.causal,
|
| 179 |
+
)
|
| 180 |
+
if rng_state is not None:
|
| 181 |
+
torch.cuda.set_rng_state(cur_rng_state)
|
| 182 |
+
return dqkv, None, None, None, None, None, None
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def flash_blocksparse_attn_func(
|
| 186 |
+
qkv,
|
| 187 |
+
cu_seqlens,
|
| 188 |
+
blockmask,
|
| 189 |
+
dropout_p,
|
| 190 |
+
max_s,
|
| 191 |
+
softmax_scale=None,
|
| 192 |
+
causal=False,
|
| 193 |
+
return_attn_probs=False,
|
| 194 |
+
convert_mask=True,
|
| 195 |
+
):
|
| 196 |
+
"""dropout_p should be set to 0.0 during evaluation"""
|
| 197 |
+
func = FlashBlocksparseAttnFun if not return_attn_probs else FlashBlocksparseAttnFunWithS
|
| 198 |
+
if convert_mask:
|
| 199 |
+
blockmask = convert_blockmask(blockmask, causal=causal)
|
| 200 |
+
return func.apply(qkv, cu_seqlens, blockmask, dropout_p, max_s, softmax_scale, causal)
|
flash-attention/build/lib.win-amd64-3.10/flash_attn/fused_softmax.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# [2022-10-23] Copied from https://github.com/NVIDIA/apex/blob/master/apex/transformer/functional/fused_softmax.py
|
| 2 |
+
# for benchmarking.
|
| 3 |
+
# We added support for seqlen=2k and seqlen=4k
|
| 4 |
+
|
| 5 |
+
# coding=utf-8
|
| 6 |
+
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
|
| 7 |
+
#
|
| 8 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 9 |
+
# you may not use this file except in compliance with the License.
|
| 10 |
+
# You may obtain a copy of the License at
|
| 11 |
+
#
|
| 12 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 13 |
+
#
|
| 14 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 15 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 16 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 17 |
+
# See the License for the specific language governing permissions and
|
| 18 |
+
# limitations under the License.
|
| 19 |
+
import torch
|
| 20 |
+
from apex._autocast_utils import _cast_if_autocast_enabled
|
| 21 |
+
from apex.transformer.enums import AttnMaskType
|
| 22 |
+
from fused_softmax_lib import (
|
| 23 |
+
scaled_masked_softmax_backward,
|
| 24 |
+
scaled_masked_softmax_forward,
|
| 25 |
+
scaled_masked_softmax_get_batch_per_block,
|
| 26 |
+
scaled_upper_triang_masked_softmax_backward,
|
| 27 |
+
scaled_upper_triang_masked_softmax_forward,
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class ScaledUpperTriangMaskedSoftmax(torch.autograd.Function):
|
| 32 |
+
"""
|
| 33 |
+
Fused operation which performs following three operations in sequence
|
| 34 |
+
1. Scale the tensor.
|
| 35 |
+
2. Apply upper triangular mask (typically used in gpt models).
|
| 36 |
+
3. Perform softmax.
|
| 37 |
+
"""
|
| 38 |
+
|
| 39 |
+
@staticmethod
|
| 40 |
+
def forward(ctx, inputs, scale):
|
| 41 |
+
scale_t = torch.tensor([scale])
|
| 42 |
+
softmax_results = scaled_upper_triang_masked_softmax_forward(inputs, scale_t[0])
|
| 43 |
+
ctx.save_for_backward(softmax_results, scale_t)
|
| 44 |
+
return softmax_results
|
| 45 |
+
|
| 46 |
+
@staticmethod
|
| 47 |
+
def backward(ctx, output_grads):
|
| 48 |
+
softmax_results, scale_t = ctx.saved_tensors
|
| 49 |
+
input_grads = scaled_upper_triang_masked_softmax_backward(
|
| 50 |
+
output_grads, softmax_results, scale_t[0]
|
| 51 |
+
)
|
| 52 |
+
return input_grads, None
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def scaled_upper_triang_masked_softmax(inputs, _, scale):
|
| 56 |
+
b, np, sq, sk = inputs.size()
|
| 57 |
+
assert sq == sk, "causal mask is only for self attention"
|
| 58 |
+
# Reshaping input to 3D tensor (attn_batches, sq, sk)
|
| 59 |
+
inputs = inputs.view(-1, sq, sk)
|
| 60 |
+
args = _cast_if_autocast_enabled(inputs, scale)
|
| 61 |
+
with torch.cuda.amp.autocast(enabled=False):
|
| 62 |
+
probs = ScaledUpperTriangMaskedSoftmax.apply(*args)
|
| 63 |
+
return probs.view(b, np, sq, sk)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
# NOTE (mkozuki): `ScaledMaskedSoftmax` somehow doesn't work well with `torch.cuda.amp.custom_fwd`.
|
| 67 |
+
# Without `cast_inputs` kwarg, somehow inputs are not cast to dtype used in the autocast context.
|
| 68 |
+
# So I needed to manually write two `torch.autograd.Function` inheritances.
|
| 69 |
+
# Fused operation which performs following three operations in sequence
|
| 70 |
+
# 1. Scale the tensor.
|
| 71 |
+
# 2. Apply the mask.
|
| 72 |
+
# 3. Perform softmax.
|
| 73 |
+
class ScaledMaskedSoftmax(torch.autograd.Function):
|
| 74 |
+
@staticmethod
|
| 75 |
+
def forward(ctx, inputs, mask, scale):
|
| 76 |
+
scale_t = torch.tensor([scale])
|
| 77 |
+
softmax_results = scaled_masked_softmax_forward(inputs, mask, scale_t[0])
|
| 78 |
+
ctx.save_for_backward(softmax_results, scale_t)
|
| 79 |
+
return softmax_results
|
| 80 |
+
|
| 81 |
+
@staticmethod
|
| 82 |
+
def backward(ctx, output_grads):
|
| 83 |
+
softmax_results, scale_t = ctx.saved_tensors
|
| 84 |
+
input_grads = scaled_masked_softmax_backward(output_grads, softmax_results, scale_t[0])
|
| 85 |
+
return input_grads, None, None
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def scaled_masked_softmax(inputs, mask, scale):
|
| 89 |
+
# input is 4D tensor (b, np, sq, sk)
|
| 90 |
+
args = _cast_if_autocast_enabled(inputs, mask, scale)
|
| 91 |
+
with torch.cuda.amp.autocast(enabled=False):
|
| 92 |
+
return ScaledMaskedSoftmax.apply(*args)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class FusedScaleMaskSoftmax(torch.nn.Module):
|
| 96 |
+
"""
|
| 97 |
+
fused operation: scaling + mask + softmax
|
| 98 |
+
|
| 99 |
+
Arguments:
|
| 100 |
+
input_in_fp16: flag to indicate if input in fp16 data format.
|
| 101 |
+
input_in_bf16: flag to indicate if input in bf16 data format.
|
| 102 |
+
attn_mask_type: attention mask type (pad or causal)
|
| 103 |
+
scaled_masked_softmax_fusion: flag to indicate user want to use softmax fusion
|
| 104 |
+
mask_func: mask function to be applied.
|
| 105 |
+
softmax_in_fp32: if true, softmax in performed at fp32 precision.
|
| 106 |
+
scale: scaling factor used in input tensor scaling.
|
| 107 |
+
"""
|
| 108 |
+
|
| 109 |
+
def __init__(
|
| 110 |
+
self,
|
| 111 |
+
input_in_fp16,
|
| 112 |
+
input_in_bf16,
|
| 113 |
+
attn_mask_type,
|
| 114 |
+
scaled_masked_softmax_fusion,
|
| 115 |
+
mask_func,
|
| 116 |
+
softmax_in_fp32,
|
| 117 |
+
scale,
|
| 118 |
+
):
|
| 119 |
+
super().__init__()
|
| 120 |
+
self.input_in_fp16 = input_in_fp16
|
| 121 |
+
self.input_in_bf16 = input_in_bf16
|
| 122 |
+
if self.input_in_fp16 and self.input_in_bf16:
|
| 123 |
+
raise RuntimeError("both fp16 and bf16 flags cannot be active at the same time.")
|
| 124 |
+
self.input_in_float16 = self.input_in_fp16 or self.input_in_bf16
|
| 125 |
+
self.attn_mask_type = attn_mask_type
|
| 126 |
+
self.scaled_masked_softmax_fusion = scaled_masked_softmax_fusion
|
| 127 |
+
self.mask_func = mask_func
|
| 128 |
+
self.softmax_in_fp32 = softmax_in_fp32
|
| 129 |
+
self.scale = scale
|
| 130 |
+
|
| 131 |
+
if not (self.scale is None or softmax_in_fp32):
|
| 132 |
+
raise RuntimeError("softmax should be in fp32 when scaled")
|
| 133 |
+
|
| 134 |
+
if self.scaled_masked_softmax_fusion:
|
| 135 |
+
if self.attn_mask_type == AttnMaskType.causal:
|
| 136 |
+
self.fused_softmax_func = scaled_upper_triang_masked_softmax
|
| 137 |
+
elif self.attn_mask_type == AttnMaskType.padding:
|
| 138 |
+
self.fused_softmax_func = scaled_masked_softmax
|
| 139 |
+
else:
|
| 140 |
+
raise ValueError("Invalid attn_mask_type.")
|
| 141 |
+
|
| 142 |
+
def forward(self, input, mask):
|
| 143 |
+
# [b, np, sq, sk]
|
| 144 |
+
assert input.dim() == 4
|
| 145 |
+
|
| 146 |
+
if self.is_kernel_available(mask, *input.size()):
|
| 147 |
+
return self.forward_fused_softmax(input, mask)
|
| 148 |
+
else:
|
| 149 |
+
return self.forward_torch_softmax(input, mask)
|
| 150 |
+
|
| 151 |
+
def is_kernel_available(self, mask, b, np, sq, sk):
|
| 152 |
+
attn_batches = b * np
|
| 153 |
+
|
| 154 |
+
if (
|
| 155 |
+
self.scaled_masked_softmax_fusion # user want to fuse
|
| 156 |
+
and self.input_in_float16 # input must be fp16
|
| 157 |
+
and (
|
| 158 |
+
self.attn_mask_type == AttnMaskType.causal
|
| 159 |
+
or (self.attn_mask_type == AttnMaskType.padding and mask is not None)
|
| 160 |
+
)
|
| 161 |
+
and 16 < sk <= 8192 # sk must be 16 ~ 8192
|
| 162 |
+
and sq % 4 == 0 # sq must be divisor of 4
|
| 163 |
+
and sk % 4 == 0 # sk must be divisor of 4
|
| 164 |
+
and attn_batches % 4 == 0 # np * b must be divisor of 4
|
| 165 |
+
):
|
| 166 |
+
if 0 <= sk <= 8192:
|
| 167 |
+
batch_per_block = self.get_batch_per_block(sq, sk, b, np)
|
| 168 |
+
|
| 169 |
+
if self.attn_mask_type == AttnMaskType.causal:
|
| 170 |
+
if attn_batches % batch_per_block == 0:
|
| 171 |
+
return True
|
| 172 |
+
else:
|
| 173 |
+
if sq % batch_per_block == 0:
|
| 174 |
+
return True
|
| 175 |
+
return False
|
| 176 |
+
|
| 177 |
+
def forward_fused_softmax(self, input, mask):
|
| 178 |
+
# input.shape = [b, np, sq, sk]
|
| 179 |
+
scale = self.scale if self.scale is not None else 1.0
|
| 180 |
+
return self.fused_softmax_func(input, mask, scale)
|
| 181 |
+
|
| 182 |
+
def forward_torch_softmax(self, input, mask):
|
| 183 |
+
if self.input_in_float16 and self.softmax_in_fp32:
|
| 184 |
+
input = input.float()
|
| 185 |
+
|
| 186 |
+
if self.scale is not None:
|
| 187 |
+
input = input * self.scale
|
| 188 |
+
mask_output = self.mask_func(input, mask) if mask is not None else input
|
| 189 |
+
probs = torch.nn.Softmax(dim=-1)(mask_output)
|
| 190 |
+
|
| 191 |
+
if self.input_in_float16 and self.softmax_in_fp32:
|
| 192 |
+
if self.input_in_fp16:
|
| 193 |
+
probs = probs.half()
|
| 194 |
+
else:
|
| 195 |
+
probs = probs.bfloat16()
|
| 196 |
+
|
| 197 |
+
return probs
|
| 198 |
+
|
| 199 |
+
@staticmethod
|
| 200 |
+
def get_batch_per_block(sq, sk, b, np):
|
| 201 |
+
return scaled_masked_softmax_get_batch_per_block(sq, sk, b, np)
|