

support for true batches with multipack (#1230)
Browse files* support for true batches with multipack
* patch the map dataset fetcher to handle batches with packed indexes
* patch 4d mask creation for sdp attention
* better handling for BetterTransformer
* patch general case for 4d mask
* setup forward patch. WIP
* fix patch file
* support for multipack w/o flash attention for llama
* cleanup
* add warning about bf16 vs fp16 for multipack with sdpa
* bugfixes
* add 4d multipack tests, refactor patches
* update tests and add warnings
* fix e2e file check
* skip sdpa test if not at least torch 2.1.1, update docs
- README.md +3 -0
- docs/images/4d-mask.png +0 -0
- docs/multipack.md +23 -1
- src/axolotl/common/cli.py +1 -0
- src/axolotl/core/trainer_builder.py +32 -4
- src/axolotl/monkeypatch/data/__init__.py +0 -0
- src/axolotl/monkeypatch/data/batch_dataset_fetcher.py +46 -0
- src/axolotl/monkeypatch/llama_attn_hijack_sdp.py +0 -142
- src/axolotl/monkeypatch/llama_expand_mask.py +3 -30
- src/axolotl/monkeypatch/llama_patch_multipack.py +26 -0
- src/axolotl/monkeypatch/utils.py +78 -2
- src/axolotl/train.py +11 -4
- src/axolotl/utils/collators.py +40 -36
- src/axolotl/utils/config.py +26 -5
- src/axolotl/utils/data.py +10 -9
- src/axolotl/utils/models.py +13 -6
- src/axolotl/utils/samplers/multipack.py +9 -3
- src/axolotl/utils/trainer.py +9 -3
- tests/e2e/patched/test_4d_multipack_llama.py +114 -0
- tests/e2e/patched/test_fused_llama.py +1 -0
- tests/e2e/utils.py +14 -0
- tests/monkeypatch/test_llama_attn_hijack_flash.py +14 -0
- tests/test_packed_batch_sampler.py +99 -0
- tests/test_packed_pretraining.py +1 -1
README.md
CHANGED
|
@@ -37,6 +37,9 @@ Features:
|
|
| 37 |
- [Inference](#inference)
|
| 38 |
- [Merge LORA to Base](#merge-lora-to-base)
|
| 39 |
- [Special Tokens](#special-tokens)
|
|
|
|
|
|
|
|
|
|
| 40 |
- [Common Errors](#common-errors-)
|
| 41 |
- [Tokenization Mismatch b/w Training & Inference](#tokenization-mismatch-bw-inference--training)
|
| 42 |
- [Debugging Axolotl](#debugging-axolotl)
|
|
|
|
| 37 |
- [Inference](#inference)
|
| 38 |
- [Merge LORA to Base](#merge-lora-to-base)
|
| 39 |
- [Special Tokens](#special-tokens)
|
| 40 |
+
- Advanced Topics
|
| 41 |
+
- [Multipack](./docs/multipack.md)<svg width="24" height="24" viewBox="0 0 24 24" xmlns="http://www.w3.org/2000/svg"><path d="M17 13.5v6H5v-12h6m3-3h6v6m0-6-9 9" class="icon_svg-stroke" stroke="#666" stroke-width="1.5" fill="none" fill-rule="evenodd" stroke-linecap="round" stroke-linejoin="round"></path></svg>
|
| 42 |
+
- [RLHF & DPO](./docs/rlhf.md)<svg width="24" height="24" viewBox="0 0 24 24" xmlns="http://www.w3.org/2000/svg"><path d="M17 13.5v6H5v-12h6m3-3h6v6m0-6-9 9" class="icon_svg-stroke" stroke="#666" stroke-width="1.5" fill="none" fill-rule="evenodd" stroke-linecap="round" stroke-linejoin="round"></path></svg>
|
| 43 |
- [Common Errors](#common-errors-)
|
| 44 |
- [Tokenization Mismatch b/w Training & Inference](#tokenization-mismatch-bw-inference--training)
|
| 45 |
- [Debugging Axolotl](#debugging-axolotl)
|
docs/images/4d-mask.png
ADDED
|
docs/multipack.md
CHANGED
|
@@ -1,4 +1,11 @@
|
|
| 1 |
-
# Multipack
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
4k context, bsz =4,
|
| 4 |
each character represents 256 tokens
|
|
@@ -49,3 +56,18 @@ w packing ( note it's the same effective number of tokens per step, but a true b
|
|
| 49 |
E E E E F F F F F G G G H H H H
|
| 50 |
I I I J J J J K K K K K L L L X ]]
|
| 51 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Multipack (Sample Packing)
|
| 2 |
+
|
| 3 |
+
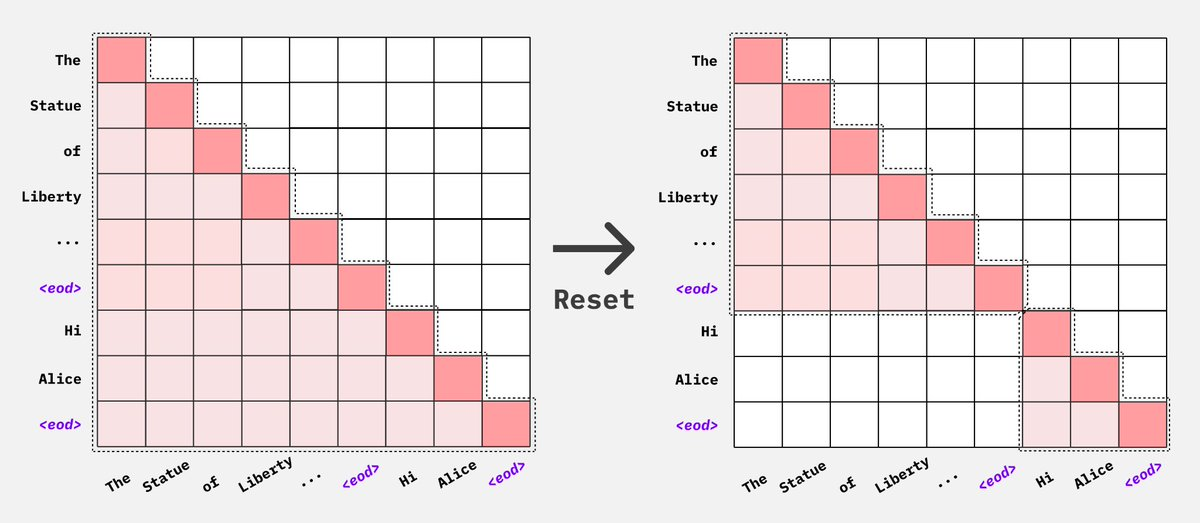
## Visualization of Multipack with Flash Attention
|
| 4 |
+
|
| 5 |
+
Because Flash Attention simply drops the attention mask, we do not need to
|
| 6 |
+
construct a 4d attention mask. We only need to concatenate the sequences into
|
| 7 |
+
a single batch and let flash attention know where each new sequence begins.
|
| 8 |
+
|
| 9 |
|
| 10 |
4k context, bsz =4,
|
| 11 |
each character represents 256 tokens
|
|
|
|
| 56 |
E E E E F F F F F G G G H H H H
|
| 57 |
I I I J J J J K K K K K L L L X ]]
|
| 58 |
```
|
| 59 |
+
|
| 60 |
+
cu_seqlens:
|
| 61 |
+
[[ 0, 11, 17, 24, 28, 36, 41 44, 48, 51, 55, 60, 64]]
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
## Multipack without Flash Attention
|
| 65 |
+
|
| 66 |
+
Multipack can still be achieved without Flash attention, but with lower packing
|
| 67 |
+
efficiency as we are not able to join multiple batches into a single batch due to
|
| 68 |
+
context length limits without flash attention. We can use either Pytorch's Scaled
|
| 69 |
+
Dot Product Attention implementation or native Pytorch attention implementation
|
| 70 |
+
along with [4d attention masks](https://github.com/huggingface/transformers/pull/27539)
|
| 71 |
+
to pack sequences together and avoid cross attention.
|
| 72 |
+
|
| 73 |
+
<img src="./images/4d-mask.png" alt="axolotl" width="800">
|
src/axolotl/common/cli.py
CHANGED
|
@@ -6,6 +6,7 @@ import logging
|
|
| 6 |
from dataclasses import dataclass, field
|
| 7 |
from typing import Optional
|
| 8 |
|
|
|
|
| 9 |
from axolotl.logging_config import configure_logging
|
| 10 |
from axolotl.utils.dict import DictDefault
|
| 11 |
from axolotl.utils.models import load_model, load_tokenizer
|
|
|
|
| 6 |
from dataclasses import dataclass, field
|
| 7 |
from typing import Optional
|
| 8 |
|
| 9 |
+
import axolotl.monkeypatch.data.batch_dataset_fetcher # pylint: disable=unused-import # noqa: F401
|
| 10 |
from axolotl.logging_config import configure_logging
|
| 11 |
from axolotl.utils.dict import DictDefault
|
| 12 |
from axolotl.utils.models import load_model, load_tokenizer
|
src/axolotl/core/trainer_builder.py
CHANGED
|
@@ -98,6 +98,10 @@ class AxolotlTrainingArguments(TrainingArguments):
|
|
| 98 |
default=False,
|
| 99 |
metadata={"help": "Use sample packing for efficient training."},
|
| 100 |
)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 101 |
eval_sample_packing: Optional[bool] = field(
|
| 102 |
default=None,
|
| 103 |
metadata={"help": "Use sample packing for efficient evals."},
|
|
@@ -229,11 +233,19 @@ class AxolotlTrainer(Trainer):
|
|
| 229 |
|
| 230 |
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
|
| 231 |
if self.args.sample_packing and not self.args.pretraining:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 232 |
return MultipackBatchSampler(
|
| 233 |
RandomSampler(self.train_dataset),
|
| 234 |
-
|
| 235 |
drop_last=True,
|
| 236 |
-
batch_max_len=
|
| 237 |
lengths=get_dataset_lengths(self.train_dataset),
|
| 238 |
packing_efficiency_estimate=self.args.sample_packing_efficiency,
|
| 239 |
)
|
|
@@ -243,11 +255,19 @@ class AxolotlTrainer(Trainer):
|
|
| 243 |
self, eval_dataset: Dataset
|
| 244 |
) -> Optional[torch.utils.data.Sampler]:
|
| 245 |
if self.args.sample_packing and self.args.eval_sample_packing is not False:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 246 |
return MultipackBatchSampler(
|
| 247 |
SequentialSampler(eval_dataset),
|
| 248 |
-
|
| 249 |
drop_last=True,
|
| 250 |
-
batch_max_len=
|
| 251 |
lengths=get_dataset_lengths(eval_dataset),
|
| 252 |
packing_efficiency_estimate=self.args.sample_packing_efficiency,
|
| 253 |
)
|
|
@@ -860,6 +880,9 @@ class HFCausalTrainerBuilder(TrainerBuilderBase):
|
|
| 860 |
training_arguments_kwargs["sample_packing"] = (
|
| 861 |
self.cfg.sample_packing if self.cfg.sample_packing else False
|
| 862 |
)
|
|
|
|
|
|
|
|
|
|
| 863 |
training_arguments_kwargs["eval_sample_packing"] = (
|
| 864 |
self.cfg.sample_packing
|
| 865 |
if self.cfg.eval_sample_packing is not False
|
|
@@ -964,6 +987,11 @@ class HFCausalTrainerBuilder(TrainerBuilderBase):
|
|
| 964 |
if use_batch_sampler_collator:
|
| 965 |
if self.cfg.model_config_type in ["mixtral", "qwen2", "falcon", "phi"]:
|
| 966 |
collator = V2BatchSamplerDataCollatorForSeq2Seq
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 967 |
else:
|
| 968 |
collator = BatchSamplerDataCollatorForSeq2Seq
|
| 969 |
else:
|
|
|
|
| 98 |
default=False,
|
| 99 |
metadata={"help": "Use sample packing for efficient training."},
|
| 100 |
)
|
| 101 |
+
multipack_real_batches: bool = field(
|
| 102 |
+
default=False,
|
| 103 |
+
metadata={"help": "Use real batches for efficient training."},
|
| 104 |
+
)
|
| 105 |
eval_sample_packing: Optional[bool] = field(
|
| 106 |
default=None,
|
| 107 |
metadata={"help": "Use sample packing for efficient evals."},
|
|
|
|
| 233 |
|
| 234 |
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
|
| 235 |
if self.args.sample_packing and not self.args.pretraining:
|
| 236 |
+
if self.args.multipack_real_batches:
|
| 237 |
+
batch_size = self.args.per_device_train_batch_size
|
| 238 |
+
batch_max_len = self.args.max_seq_length
|
| 239 |
+
else:
|
| 240 |
+
batch_size = 1
|
| 241 |
+
batch_max_len = (
|
| 242 |
+
self.args.per_device_train_batch_size * self.args.max_seq_length
|
| 243 |
+
)
|
| 244 |
return MultipackBatchSampler(
|
| 245 |
RandomSampler(self.train_dataset),
|
| 246 |
+
batch_size=batch_size,
|
| 247 |
drop_last=True,
|
| 248 |
+
batch_max_len=batch_max_len,
|
| 249 |
lengths=get_dataset_lengths(self.train_dataset),
|
| 250 |
packing_efficiency_estimate=self.args.sample_packing_efficiency,
|
| 251 |
)
|
|
|
|
| 255 |
self, eval_dataset: Dataset
|
| 256 |
) -> Optional[torch.utils.data.Sampler]:
|
| 257 |
if self.args.sample_packing and self.args.eval_sample_packing is not False:
|
| 258 |
+
if self.args.multipack_real_batches:
|
| 259 |
+
batch_size = self.args.per_device_eval_batch_size
|
| 260 |
+
batch_max_len = self.args.max_seq_length
|
| 261 |
+
else:
|
| 262 |
+
batch_size = 1
|
| 263 |
+
batch_max_len = (
|
| 264 |
+
self.args.per_device_eval_batch_size * self.args.max_seq_length
|
| 265 |
+
)
|
| 266 |
return MultipackBatchSampler(
|
| 267 |
SequentialSampler(eval_dataset),
|
| 268 |
+
batch_size=batch_size,
|
| 269 |
drop_last=True,
|
| 270 |
+
batch_max_len=batch_max_len,
|
| 271 |
lengths=get_dataset_lengths(eval_dataset),
|
| 272 |
packing_efficiency_estimate=self.args.sample_packing_efficiency,
|
| 273 |
)
|
|
|
|
| 880 |
training_arguments_kwargs["sample_packing"] = (
|
| 881 |
self.cfg.sample_packing if self.cfg.sample_packing else False
|
| 882 |
)
|
| 883 |
+
training_arguments_kwargs["multipack_real_batches"] = (
|
| 884 |
+
self.cfg.flash_attention is not True
|
| 885 |
+
)
|
| 886 |
training_arguments_kwargs["eval_sample_packing"] = (
|
| 887 |
self.cfg.sample_packing
|
| 888 |
if self.cfg.eval_sample_packing is not False
|
|
|
|
| 987 |
if use_batch_sampler_collator:
|
| 988 |
if self.cfg.model_config_type in ["mixtral", "qwen2", "falcon", "phi"]:
|
| 989 |
collator = V2BatchSamplerDataCollatorForSeq2Seq
|
| 990 |
+
elif (
|
| 991 |
+
self.cfg.model_config_type in ["llama"]
|
| 992 |
+
and self.cfg.flash_attention is not True
|
| 993 |
+
):
|
| 994 |
+
collator = V2BatchSamplerDataCollatorForSeq2Seq
|
| 995 |
else:
|
| 996 |
collator = BatchSamplerDataCollatorForSeq2Seq
|
| 997 |
else:
|
src/axolotl/monkeypatch/data/__init__.py
ADDED
|
File without changes
|
src/axolotl/monkeypatch/data/batch_dataset_fetcher.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""monkey patches for the dataset fetcher to handle batches of packed indexes"""
|
| 2 |
+
# pylint: disable=protected-access
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch.utils.data._utils.fetch import _BaseDatasetFetcher
|
| 6 |
+
from torch.utils.data._utils.worker import _worker_loop
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class _MapDatasetFetcher(_BaseDatasetFetcher):
|
| 10 |
+
def fetch(self, possibly_batched_index):
|
| 11 |
+
if isinstance(possibly_batched_index[0], list):
|
| 12 |
+
data = [None for i in possibly_batched_index]
|
| 13 |
+
for i, possibly_batched_index_ in enumerate(possibly_batched_index):
|
| 14 |
+
if self.auto_collation:
|
| 15 |
+
if (
|
| 16 |
+
hasattr(self.dataset, "__getitems__")
|
| 17 |
+
and self.dataset.__getitems__
|
| 18 |
+
):
|
| 19 |
+
data[i] = self.dataset.__getitems__(possibly_batched_index_)
|
| 20 |
+
else:
|
| 21 |
+
data[i] = [self.dataset[idx] for idx in possibly_batched_index_]
|
| 22 |
+
else:
|
| 23 |
+
data[i] = self.dataset[possibly_batched_index_]
|
| 24 |
+
else:
|
| 25 |
+
if self.auto_collation:
|
| 26 |
+
if hasattr(self.dataset, "__getitems__") and self.dataset.__getitems__:
|
| 27 |
+
data = self.dataset.__getitems__(possibly_batched_index)
|
| 28 |
+
else:
|
| 29 |
+
data = [self.dataset[idx] for idx in possibly_batched_index]
|
| 30 |
+
else:
|
| 31 |
+
data = self.dataset[possibly_batched_index]
|
| 32 |
+
return self.collate_fn(data)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def patch_fetchers():
|
| 36 |
+
torch.utils.data._utils.fetch._MapDatasetFetcher = _MapDatasetFetcher
|
| 37 |
+
torch.utils.data.dataloader._utils.fetch._MapDatasetFetcher = _MapDatasetFetcher
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def patched_worker_loop(*args, **kwargs):
|
| 41 |
+
patch_fetchers()
|
| 42 |
+
return _worker_loop(*args, **kwargs)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
torch.utils.data._utils.worker._worker_loop = patched_worker_loop
|
| 46 |
+
patch_fetchers()
|
src/axolotl/monkeypatch/llama_attn_hijack_sdp.py
DELETED
|
@@ -1,142 +0,0 @@
|
|
| 1 |
-
"""
|
| 2 |
-
Patched LlamaAttention to use torch.nn.functional.scaled_dot_product_attention
|
| 3 |
-
"""
|
| 4 |
-
|
| 5 |
-
import warnings
|
| 6 |
-
from typing import Optional, Tuple
|
| 7 |
-
|
| 8 |
-
import torch
|
| 9 |
-
import torch.nn.functional as F
|
| 10 |
-
import transformers.models.llama.modeling_llama
|
| 11 |
-
from transformers.models.llama.modeling_llama import apply_rotary_pos_emb, repeat_kv
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
def hijack_llama_sdp_attention():
|
| 15 |
-
transformers.models.llama.modeling_llama.LlamaAttention.forward = (
|
| 16 |
-
sdp_attention_forward
|
| 17 |
-
)
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
def sdp_attention_forward(
|
| 21 |
-
self,
|
| 22 |
-
hidden_states: torch.Tensor,
|
| 23 |
-
attention_mask: Optional[torch.Tensor] = None,
|
| 24 |
-
position_ids: Optional[torch.LongTensor] = None,
|
| 25 |
-
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 26 |
-
output_attentions: bool = False,
|
| 27 |
-
use_cache: bool = False,
|
| 28 |
-
padding_mask: Optional[torch.LongTensor] = None, # pylint: disable=unused-argument
|
| 29 |
-
**kwargs, # pylint: disable=unused-argument
|
| 30 |
-
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 31 |
-
# pylint: disable=duplicate-code
|
| 32 |
-
bsz, q_len, _ = hidden_states.size()
|
| 33 |
-
|
| 34 |
-
if not hasattr(self, "pretraining_tp"):
|
| 35 |
-
self.pretraining_tp = 1
|
| 36 |
-
|
| 37 |
-
if self.pretraining_tp > 1:
|
| 38 |
-
key_value_slicing = (
|
| 39 |
-
self.num_key_value_heads * self.head_dim
|
| 40 |
-
) // self.pretraining_tp
|
| 41 |
-
query_slices = self.q_proj.weight.split(
|
| 42 |
-
(self.num_heads * self.head_dim) // self.pretraining_tp, dim=0
|
| 43 |
-
)
|
| 44 |
-
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
|
| 45 |
-
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
|
| 46 |
-
|
| 47 |
-
query_states = [
|
| 48 |
-
F.linear(hidden_states, query_slices[i]) for i in range(self.pretraining_tp)
|
| 49 |
-
]
|
| 50 |
-
query_states = torch.cat(query_states, dim=-1)
|
| 51 |
-
|
| 52 |
-
key_states = [
|
| 53 |
-
F.linear(hidden_states, key_slices[i]) for i in range(self.pretraining_tp)
|
| 54 |
-
]
|
| 55 |
-
key_states = torch.cat(key_states, dim=-1)
|
| 56 |
-
|
| 57 |
-
value_states = [
|
| 58 |
-
F.linear(hidden_states, value_slices[i]) for i in range(self.pretraining_tp)
|
| 59 |
-
]
|
| 60 |
-
value_states = torch.cat(value_states, dim=-1)
|
| 61 |
-
|
| 62 |
-
else:
|
| 63 |
-
query_states = self.q_proj(hidden_states)
|
| 64 |
-
key_states = self.k_proj(hidden_states)
|
| 65 |
-
value_states = self.v_proj(hidden_states)
|
| 66 |
-
|
| 67 |
-
query_states = query_states.view(
|
| 68 |
-
bsz, q_len, self.num_heads, self.head_dim
|
| 69 |
-
).transpose(1, 2)
|
| 70 |
-
key_states = key_states.view(
|
| 71 |
-
bsz, q_len, self.num_key_value_heads, self.head_dim
|
| 72 |
-
).transpose(1, 2)
|
| 73 |
-
value_states = value_states.view(
|
| 74 |
-
bsz, q_len, self.num_key_value_heads, self.head_dim
|
| 75 |
-
).transpose(1, 2)
|
| 76 |
-
# [bsz, q_len, nh, hd]
|
| 77 |
-
# [bsz, nh, q_len, hd]
|
| 78 |
-
|
| 79 |
-
kv_seq_len = key_states.shape[-2]
|
| 80 |
-
if past_key_value is not None:
|
| 81 |
-
kv_seq_len += past_key_value[0].shape[-2]
|
| 82 |
-
|
| 83 |
-
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 84 |
-
query_states, key_states = apply_rotary_pos_emb(
|
| 85 |
-
query_states, key_states, cos, sin, position_ids
|
| 86 |
-
)
|
| 87 |
-
# [bsz, nh, t, hd]
|
| 88 |
-
|
| 89 |
-
if past_key_value is not None:
|
| 90 |
-
# reuse k, v, self_attention
|
| 91 |
-
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 92 |
-
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 93 |
-
|
| 94 |
-
past_key_value = (key_states, value_states) if use_cache else None
|
| 95 |
-
|
| 96 |
-
# repeat k/v heads if n_kv_heads < n_heads
|
| 97 |
-
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 98 |
-
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 99 |
-
|
| 100 |
-
if output_attentions:
|
| 101 |
-
warnings.warn(
|
| 102 |
-
"Output attentions is not supported for patched `LlamaAttention`, returning `None` instead."
|
| 103 |
-
)
|
| 104 |
-
|
| 105 |
-
#
|
| 106 |
-
# sdp-attn start
|
| 107 |
-
#
|
| 108 |
-
|
| 109 |
-
with torch.backends.cuda.sdp_kernel():
|
| 110 |
-
attn_output = torch.nn.functional.scaled_dot_product_attention(
|
| 111 |
-
query_states,
|
| 112 |
-
key_states,
|
| 113 |
-
value_states,
|
| 114 |
-
attn_mask=attention_mask,
|
| 115 |
-
is_causal=False,
|
| 116 |
-
)
|
| 117 |
-
|
| 118 |
-
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 119 |
-
raise ValueError(
|
| 120 |
-
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
| 121 |
-
f" {attn_output.size()}"
|
| 122 |
-
)
|
| 123 |
-
attn_output = attn_output.transpose(1, 2)
|
| 124 |
-
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 125 |
-
|
| 126 |
-
#
|
| 127 |
-
# sdp-attn end
|
| 128 |
-
#
|
| 129 |
-
|
| 130 |
-
if self.pretraining_tp > 1:
|
| 131 |
-
attn_output = attn_output.split(self.hidden_size // self.pretraining_tp, dim=2)
|
| 132 |
-
o_proj_slices = self.o_proj.weight.split(
|
| 133 |
-
self.hidden_size // self.pretraining_tp, dim=1
|
| 134 |
-
)
|
| 135 |
-
attn_output = sum(
|
| 136 |
-
F.linear(attn_output[i], o_proj_slices[i])
|
| 137 |
-
for i in range(self.pretraining_tp)
|
| 138 |
-
)
|
| 139 |
-
else:
|
| 140 |
-
attn_output = self.o_proj(attn_output)
|
| 141 |
-
|
| 142 |
-
return attn_output, None, past_key_value
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
src/axolotl/monkeypatch/llama_expand_mask.py
CHANGED
|
@@ -5,38 +5,11 @@ from typing import Optional
|
|
| 5 |
|
| 6 |
import torch
|
| 7 |
|
|
|
|
| 8 |
|
| 9 |
-
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 10 |
-
"""
|
| 11 |
-
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 12 |
-
This expansion handles packed sequences so that sequences share the same attention mask integer value
|
| 13 |
-
when they attend to each other within that sequence.
|
| 14 |
-
This expansion transforms the mask to lower triangular form to prevent future peeking.
|
| 15 |
-
"""
|
| 16 |
-
bsz, src_len = mask.size()
|
| 17 |
-
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 18 |
-
|
| 19 |
-
mask = mask.unsqueeze(1).unsqueeze(2)
|
| 20 |
-
mask = mask.expand(bsz, 1, tgt_len, src_len)
|
| 21 |
-
|
| 22 |
-
# Create a binary mask from the original mask where zeros remain zeros and all other values are set to one
|
| 23 |
-
binary_mask = torch.where(
|
| 24 |
-
mask != 0,
|
| 25 |
-
torch.tensor(1).to(dtype),
|
| 26 |
-
torch.tensor(0).to(dtype),
|
| 27 |
-
)
|
| 28 |
-
|
| 29 |
-
# Create a block-diagonal mask.
|
| 30 |
-
# we multiply by the binary mask so that 0's in the original mask are correctly excluded
|
| 31 |
-
zero_one_mask = torch.eq(mask, mask.transpose(-1, -2)).int() * binary_mask
|
| 32 |
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
mask.device
|
| 36 |
-
)
|
| 37 |
-
|
| 38 |
-
# Use the lower triangular mask to zero out the upper triangular part of the zero_one_mask
|
| 39 |
-
masked_zero_one_mask = zero_one_mask * lower_triangular_ones
|
| 40 |
inverted_mask = 1.0 - masked_zero_one_mask
|
| 41 |
|
| 42 |
return inverted_mask.masked_fill(
|
|
|
|
| 5 |
|
| 6 |
import torch
|
| 7 |
|
| 8 |
+
from axolotl.monkeypatch.utils import mask_2d_to_4d
|
| 9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
|
| 11 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 12 |
+
masked_zero_one_mask = mask_2d_to_4d(mask, dtype, tgt_len)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
inverted_mask = 1.0 - masked_zero_one_mask
|
| 14 |
|
| 15 |
return inverted_mask.masked_fill(
|
src/axolotl/monkeypatch/llama_patch_multipack.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Patched LlamaAttention to use torch.nn.functional.scaled_dot_product_attention
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
from axolotl.monkeypatch.utils import (
|
| 6 |
+
patched_prepare_4d_causal_attention_mask,
|
| 7 |
+
patched_prepare_4d_causal_attention_mask_for_sdpa,
|
| 8 |
+
)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def hijack_llama_prepare_4d_mask():
|
| 12 |
+
import transformers.modeling_attn_mask_utils
|
| 13 |
+
import transformers.models.llama.modeling_llama
|
| 14 |
+
|
| 15 |
+
transformers.models.llama.modeling_llama._prepare_4d_causal_attention_mask_for_sdpa = ( # pylint: disable=protected-access
|
| 16 |
+
patched_prepare_4d_causal_attention_mask_for_sdpa
|
| 17 |
+
)
|
| 18 |
+
transformers.modeling_attn_mask_utils._prepare_4d_causal_attention_mask_for_sdpa = ( # pylint: disable=protected-access
|
| 19 |
+
patched_prepare_4d_causal_attention_mask_for_sdpa
|
| 20 |
+
)
|
| 21 |
+
transformers.models.llama.modeling_llama._prepare_4d_causal_attention_mask = ( # pylint: disable=protected-access
|
| 22 |
+
patched_prepare_4d_causal_attention_mask
|
| 23 |
+
)
|
| 24 |
+
transformers.modeling_attn_mask_utils._prepare_4d_causal_attention_mask = ( # pylint: disable=protected-access
|
| 25 |
+
patched_prepare_4d_causal_attention_mask
|
| 26 |
+
)
|
src/axolotl/monkeypatch/utils.py
CHANGED
|
@@ -1,8 +1,15 @@
|
|
| 1 |
"""
|
| 2 |
Shared utils for the monkeypatches
|
| 3 |
"""
|
|
|
|
|
|
|
| 4 |
import torch
|
| 5 |
import torch.nn.functional as F
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
|
| 7 |
|
| 8 |
@torch.jit.script
|
|
@@ -89,7 +96,6 @@ def get_cu_seqlens(attn_mask):
|
|
| 89 |
return torch.stack(results).to(dtype=torch.int32), torch.stack(max_seq_lens)
|
| 90 |
|
| 91 |
|
| 92 |
-
@torch.jit.script
|
| 93 |
def get_cu_seqlens_from_pos_ids(position_ids):
|
| 94 |
"""generate a cumulative sequence length mask for flash attention using pos ids"""
|
| 95 |
if len(position_ids.shape) == 1:
|
|
@@ -135,7 +141,18 @@ def get_cu_seqlens_from_pos_ids(position_ids):
|
|
| 135 |
results.append(cu_seqlens)
|
| 136 |
max_seq_lens.append(max_seq_len)
|
| 137 |
|
| 138 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 139 |
|
| 140 |
|
| 141 |
def set_module_name(model, name, value):
|
|
@@ -149,3 +166,62 @@ def set_module_name(model, name, value):
|
|
| 149 |
child_name = name
|
| 150 |
|
| 151 |
setattr(parent, child_name, value)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
"""
|
| 2 |
Shared utils for the monkeypatches
|
| 3 |
"""
|
| 4 |
+
from typing import Optional
|
| 5 |
+
|
| 6 |
import torch
|
| 7 |
import torch.nn.functional as F
|
| 8 |
+
from transformers.modeling_attn_mask_utils import (
|
| 9 |
+
_prepare_4d_causal_attention_mask,
|
| 10 |
+
_prepare_4d_causal_attention_mask_for_sdpa,
|
| 11 |
+
)
|
| 12 |
+
from transformers.utils import is_torch_bf16_gpu_available
|
| 13 |
|
| 14 |
|
| 15 |
@torch.jit.script
|
|
|
|
| 96 |
return torch.stack(results).to(dtype=torch.int32), torch.stack(max_seq_lens)
|
| 97 |
|
| 98 |
|
|
|
|
| 99 |
def get_cu_seqlens_from_pos_ids(position_ids):
|
| 100 |
"""generate a cumulative sequence length mask for flash attention using pos ids"""
|
| 101 |
if len(position_ids.shape) == 1:
|
|
|
|
| 141 |
results.append(cu_seqlens)
|
| 142 |
max_seq_lens.append(max_seq_len)
|
| 143 |
|
| 144 |
+
# Find the maximum value across all tensors
|
| 145 |
+
max_value = max(t.max() for t in results)
|
| 146 |
+
|
| 147 |
+
# Find the length of the longest tensor
|
| 148 |
+
max_length = max(t.size(0) for t in results)
|
| 149 |
+
|
| 150 |
+
# Pad each tensor to the same length and collect them in a list
|
| 151 |
+
padded_results = [
|
| 152 |
+
F.pad(t, (0, max_length - t.size(0)), "constant", max_value) for t in results
|
| 153 |
+
]
|
| 154 |
+
|
| 155 |
+
return torch.stack(padded_results).to(dtype=torch.int32), torch.stack(max_seq_lens)
|
| 156 |
|
| 157 |
|
| 158 |
def set_module_name(model, name, value):
|
|
|
|
| 166 |
child_name = name
|
| 167 |
|
| 168 |
setattr(parent, child_name, value)
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def mask_2d_to_4d(
|
| 172 |
+
mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None
|
| 173 |
+
):
|
| 174 |
+
"""
|
| 175 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 176 |
+
This expansion handles packed sequences so that sequences share the same attention mask integer value
|
| 177 |
+
when they attend to each other within that sequence.
|
| 178 |
+
This expansion transforms the mask to lower triangular form to prevent future peeking.
|
| 179 |
+
"""
|
| 180 |
+
bsz, src_len = mask.size()
|
| 181 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 182 |
+
|
| 183 |
+
mask = mask.unsqueeze(1).unsqueeze(2)
|
| 184 |
+
mask = mask.expand(bsz, 1, tgt_len, src_len)
|
| 185 |
+
|
| 186 |
+
# Create a binary mask from the original mask where zeros remain zeros and all other values are set to one
|
| 187 |
+
binary_mask = torch.where(
|
| 188 |
+
mask != 0,
|
| 189 |
+
torch.tensor(1).to(dtype),
|
| 190 |
+
torch.tensor(0).to(dtype),
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
# Create a block-diagonal mask.
|
| 194 |
+
# we multiply by the binary mask so that 0's in the original mask are correctly excluded
|
| 195 |
+
zero_one_mask = torch.eq(mask, mask.transpose(-1, -2)).int() * binary_mask
|
| 196 |
+
|
| 197 |
+
# Now let's create a lower triangular mask of ones that will zero out the upper triangular part
|
| 198 |
+
lower_triangular_ones = torch.tril(torch.ones((tgt_len, src_len), dtype=dtype)).to(
|
| 199 |
+
mask.device
|
| 200 |
+
)
|
| 201 |
+
|
| 202 |
+
# Use the lower triangular mask to zero out the upper triangular part of the zero_one_mask
|
| 203 |
+
masked_zero_one_mask = zero_one_mask * lower_triangular_ones
|
| 204 |
+
|
| 205 |
+
return masked_zero_one_mask
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def patched_prepare_4d_causal_attention_mask(
|
| 209 |
+
attention_mask: Optional[torch.Tensor],
|
| 210 |
+
*args,
|
| 211 |
+
):
|
| 212 |
+
dtype = torch.bfloat16 if is_torch_bf16_gpu_available() else torch.float32
|
| 213 |
+
return _prepare_4d_causal_attention_mask(
|
| 214 |
+
mask_2d_to_4d(attention_mask, dtype=dtype),
|
| 215 |
+
*args,
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def patched_prepare_4d_causal_attention_mask_for_sdpa(
|
| 220 |
+
attention_mask: Optional[torch.Tensor],
|
| 221 |
+
*args,
|
| 222 |
+
):
|
| 223 |
+
dtype = torch.bfloat16 if is_torch_bf16_gpu_available() else torch.float32
|
| 224 |
+
return _prepare_4d_causal_attention_mask_for_sdpa(
|
| 225 |
+
mask_2d_to_4d(attention_mask, dtype=dtype),
|
| 226 |
+
*args,
|
| 227 |
+
)
|
src/axolotl/train.py
CHANGED
|
@@ -11,7 +11,6 @@ import torch
|
|
| 11 |
import transformers.modelcard
|
| 12 |
from accelerate.logging import get_logger
|
| 13 |
from datasets import Dataset
|
| 14 |
-
from optimum.bettertransformer import BetterTransformer
|
| 15 |
from peft import PeftModel
|
| 16 |
from pkg_resources import get_distribution # type: ignore
|
| 17 |
from transformers import PreTrainedModel, PreTrainedTokenizer
|
|
@@ -24,6 +23,11 @@ from axolotl.utils.freeze import freeze_parameters_except
|
|
| 24 |
from axolotl.utils.models import load_model, load_tokenizer
|
| 25 |
from axolotl.utils.trainer import setup_trainer
|
| 26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
|
| 28 |
src_dir = os.path.join(project_root, "src")
|
| 29 |
sys.path.insert(0, src_dir)
|
|
@@ -124,7 +128,7 @@ def train(
|
|
| 124 |
if cfg.local_rank == 0:
|
| 125 |
|
| 126 |
def terminate_handler(_, __, model):
|
| 127 |
-
if cfg.flash_optimum:
|
| 128 |
model = BetterTransformer.reverse(model)
|
| 129 |
model.save_pretrained(cfg.output_dir, safe_serialization=safe_serialization)
|
| 130 |
sys.exit(0)
|
|
@@ -149,7 +153,10 @@ def train(
|
|
| 149 |
pretrain_hooks(cfg, trainer)
|
| 150 |
if cfg.flash_optimum:
|
| 151 |
with torch.backends.cuda.sdp_kernel(
|
| 152 |
-
|
|
|
|
|
|
|
|
|
|
| 153 |
):
|
| 154 |
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
|
| 155 |
else:
|
|
@@ -195,7 +202,7 @@ def train(
|
|
| 195 |
state_dict=trainer.accelerator.get_state_dict(trainer.model_wrapped),
|
| 196 |
)
|
| 197 |
elif cfg.local_rank == 0:
|
| 198 |
-
if cfg.flash_optimum:
|
| 199 |
model = BetterTransformer.reverse(model)
|
| 200 |
|
| 201 |
model.save_pretrained(cfg.output_dir, safe_serialization=safe_serialization)
|
|
|
|
| 11 |
import transformers.modelcard
|
| 12 |
from accelerate.logging import get_logger
|
| 13 |
from datasets import Dataset
|
|
|
|
| 14 |
from peft import PeftModel
|
| 15 |
from pkg_resources import get_distribution # type: ignore
|
| 16 |
from transformers import PreTrainedModel, PreTrainedTokenizer
|
|
|
|
| 23 |
from axolotl.utils.models import load_model, load_tokenizer
|
| 24 |
from axolotl.utils.trainer import setup_trainer
|
| 25 |
|
| 26 |
+
try:
|
| 27 |
+
from optimum.bettertransformer import BetterTransformer
|
| 28 |
+
except ImportError:
|
| 29 |
+
BetterTransformer = None
|
| 30 |
+
|
| 31 |
project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
|
| 32 |
src_dir = os.path.join(project_root, "src")
|
| 33 |
sys.path.insert(0, src_dir)
|
|
|
|
| 128 |
if cfg.local_rank == 0:
|
| 129 |
|
| 130 |
def terminate_handler(_, __, model):
|
| 131 |
+
if cfg.flash_optimum and BetterTransformer:
|
| 132 |
model = BetterTransformer.reverse(model)
|
| 133 |
model.save_pretrained(cfg.output_dir, safe_serialization=safe_serialization)
|
| 134 |
sys.exit(0)
|
|
|
|
| 153 |
pretrain_hooks(cfg, trainer)
|
| 154 |
if cfg.flash_optimum:
|
| 155 |
with torch.backends.cuda.sdp_kernel(
|
| 156 |
+
# TODO configure these from the YAML w/ sdp_kernel_kwargs: ...
|
| 157 |
+
enable_flash=True,
|
| 158 |
+
enable_math=True,
|
| 159 |
+
enable_mem_efficient=True,
|
| 160 |
):
|
| 161 |
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
|
| 162 |
else:
|
|
|
|
| 202 |
state_dict=trainer.accelerator.get_state_dict(trainer.model_wrapped),
|
| 203 |
)
|
| 204 |
elif cfg.local_rank == 0:
|
| 205 |
+
if cfg.flash_optimum and BetterTransformer:
|
| 206 |
model = BetterTransformer.reverse(model)
|
| 207 |
|
| 208 |
model.save_pretrained(cfg.output_dir, safe_serialization=safe_serialization)
|
src/axolotl/utils/collators.py
CHANGED
|
@@ -132,24 +132,26 @@ class BatchSamplerDataCollatorForSeq2Seq(DataCollatorForSeq2Seq):
|
|
| 132 |
"""
|
| 133 |
|
| 134 |
def __call__(self, features, return_tensors=None):
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
|
|
|
|
|
|
| 153 |
|
| 154 |
|
| 155 |
@dataclass
|
|
@@ -159,24 +161,26 @@ class V2BatchSamplerDataCollatorForSeq2Seq(DataCollatorForSeq2Seq):
|
|
| 159 |
"""
|
| 160 |
|
| 161 |
def __call__(self, features, return_tensors=None):
|
| 162 |
-
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
|
| 169 |
-
|
| 170 |
-
|
| 171 |
-
|
| 172 |
-
|
| 173 |
-
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
|
|
|
|
|
|
|
| 180 |
|
| 181 |
|
| 182 |
@dataclass
|
|
|
|
| 132 |
"""
|
| 133 |
|
| 134 |
def __call__(self, features, return_tensors=None):
|
| 135 |
+
if not isinstance(features[0], list):
|
| 136 |
+
features = [features]
|
| 137 |
+
out_features = [{} for _ in features]
|
| 138 |
+
for i, features_ in enumerate(features):
|
| 139 |
+
for feature in features_[0].keys():
|
| 140 |
+
if feature == "length":
|
| 141 |
+
continue
|
| 142 |
+
if feature == "attention_mask":
|
| 143 |
+
arrays = [
|
| 144 |
+
(1) * np.array(item[feature])
|
| 145 |
+
for i, item in enumerate(features_)
|
| 146 |
+
if feature in item
|
| 147 |
+
]
|
| 148 |
+
out_features[i][feature] = np.concatenate(arrays)
|
| 149 |
+
else:
|
| 150 |
+
arrays = [
|
| 151 |
+
np.array(item[feature]) for item in features_ if feature in item
|
| 152 |
+
]
|
| 153 |
+
out_features[i][feature] = np.concatenate(arrays)
|
| 154 |
+
return super().__call__(out_features, return_tensors=return_tensors)
|
| 155 |
|
| 156 |
|
| 157 |
@dataclass
|
|
|
|
| 161 |
"""
|
| 162 |
|
| 163 |
def __call__(self, features, return_tensors=None):
|
| 164 |
+
if not isinstance(features[0], list):
|
| 165 |
+
features = [features]
|
| 166 |
+
out_features = [{} for _ in features]
|
| 167 |
+
for i, features_ in enumerate(features):
|
| 168 |
+
for feature in features_[0].keys():
|
| 169 |
+
if feature == "length":
|
| 170 |
+
continue
|
| 171 |
+
if feature == "attention_mask":
|
| 172 |
+
arrays = [
|
| 173 |
+
(i + 1) * np.array(item[feature])
|
| 174 |
+
for i, item in enumerate(features_)
|
| 175 |
+
if feature in item
|
| 176 |
+
]
|
| 177 |
+
out_features[i][feature] = np.concatenate(arrays)
|
| 178 |
+
else:
|
| 179 |
+
arrays = [
|
| 180 |
+
np.array(item[feature]) for item in features_ if feature in item
|
| 181 |
+
]
|
| 182 |
+
out_features[i][feature] = np.concatenate(arrays)
|
| 183 |
+
return super().__call__(out_features, return_tensors=return_tensors)
|
| 184 |
|
| 185 |
|
| 186 |
@dataclass
|
src/axolotl/utils/config.py
CHANGED
|
@@ -202,6 +202,20 @@ def validate_config(cfg):
|
|
| 202 |
raise ValueError(
|
| 203 |
"bf16 requested, but AMP is not supported on this GPU. Requires Ampere series or above."
|
| 204 |
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 205 |
if cfg.max_packed_sequence_len:
|
| 206 |
raise DeprecationWarning("`max_packed_sequence_len` is no longer supported")
|
| 207 |
|
|
@@ -350,17 +364,24 @@ def validate_config(cfg):
|
|
| 350 |
+ "point to its path, and remove model_revision from the config."
|
| 351 |
)
|
| 352 |
|
| 353 |
-
if cfg.sample_packing and cfg.sdp_attention:
|
| 354 |
-
|
| 355 |
-
|
| 356 |
-
|
| 357 |
-
|
| 358 |
|
| 359 |
if cfg.sample_packing and cfg.xformers_attention:
|
| 360 |
raise ValueError(
|
| 361 |
"sample_packing not compatible with xformers_attention. Use flash_attention"
|
| 362 |
)
|
| 363 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 364 |
if cfg.early_stopping_patience:
|
| 365 |
if not cfg.save_steps or not cfg.eval_steps:
|
| 366 |
raise ValueError(
|
|
|
|
| 202 |
raise ValueError(
|
| 203 |
"bf16 requested, but AMP is not supported on this GPU. Requires Ampere series or above."
|
| 204 |
)
|
| 205 |
+
if (
|
| 206 |
+
# pylint: disable=too-many-boolean-expressions
|
| 207 |
+
not (cfg.bf16 or cfg.bfloat16)
|
| 208 |
+
and (cfg.fp16 or cfg.float16)
|
| 209 |
+
and not cfg.adapter
|
| 210 |
+
and not cfg.flash_attention
|
| 211 |
+
and cfg.sample_packing
|
| 212 |
+
):
|
| 213 |
+
LOG.warning(
|
| 214 |
+
"Full fine tune w/o FA2 w/ sample packing and fp16/float16 is likely to raise errors. Try LoRA."
|
| 215 |
+
)
|
| 216 |
+
# ValueError: Attempting to unscale FP16 gradients.
|
| 217 |
+
# OR
|
| 218 |
+
# RuntimeError: expected mat1 and mat2 to have the same dtype, but got: float != c10::Half
|
| 219 |
if cfg.max_packed_sequence_len:
|
| 220 |
raise DeprecationWarning("`max_packed_sequence_len` is no longer supported")
|
| 221 |
|
|
|
|
| 364 |
+ "point to its path, and remove model_revision from the config."
|
| 365 |
)
|
| 366 |
|
| 367 |
+
# if cfg.sample_packing and cfg.sdp_attention:
|
| 368 |
+
# # incompatible due to bug w/ accelerate causing 0.0 loss when using llama2
|
| 369 |
+
# raise ValueError(
|
| 370 |
+
# "sample_packing not compatible with sdp_attention. Use flash_attention"
|
| 371 |
+
# )
|
| 372 |
|
| 373 |
if cfg.sample_packing and cfg.xformers_attention:
|
| 374 |
raise ValueError(
|
| 375 |
"sample_packing not compatible with xformers_attention. Use flash_attention"
|
| 376 |
)
|
| 377 |
|
| 378 |
+
if cfg.sample_packing and cfg.sdp_attention and (cfg.bfloat16 or cfg.bf16):
|
| 379 |
+
# https://github.com/pytorch/pytorch/blob/1b03423526536b5f3d35bdfa95ccc6197556cf9b/test/test_transformers.py#L2440-L2450
|
| 380 |
+
LOG.warning(
|
| 381 |
+
"sample_packing & torch sdpa with bf16 is unsupported may results in 0.0 loss. "
|
| 382 |
+
"This may work on H100s."
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
if cfg.early_stopping_patience:
|
| 386 |
if not cfg.save_steps or not cfg.eval_steps:
|
| 387 |
raise ValueError(
|
src/axolotl/utils/data.py
CHANGED
|
@@ -834,7 +834,7 @@ def encode_packed_pretraining(
|
|
| 834 |
|
| 835 |
sampler = MultipackBatchSampler(
|
| 836 |
RandomSampler(train_dataset),
|
| 837 |
-
batch_size=
|
| 838 |
drop_last=True,
|
| 839 |
batch_max_len=batch_size * max_seq_length,
|
| 840 |
lengths=get_dataset_lengths(train_dataset),
|
|
@@ -842,15 +842,16 @@ def encode_packed_pretraining(
|
|
| 842 |
|
| 843 |
chunked_data = defaultdict(list)
|
| 844 |
|
| 845 |
-
for
|
| 846 |
-
|
| 847 |
-
|
| 848 |
-
|
|
|
|
| 849 |
|
| 850 |
-
|
| 851 |
-
|
| 852 |
-
|
| 853 |
-
|
| 854 |
|
| 855 |
return chunked_data
|
| 856 |
|
|
|
|
| 834 |
|
| 835 |
sampler = MultipackBatchSampler(
|
| 836 |
RandomSampler(train_dataset),
|
| 837 |
+
batch_size=1,
|
| 838 |
drop_last=True,
|
| 839 |
batch_max_len=batch_size * max_seq_length,
|
| 840 |
lengths=get_dataset_lengths(train_dataset),
|
|
|
|
| 842 |
|
| 843 |
chunked_data = defaultdict(list)
|
| 844 |
|
| 845 |
+
for batch in sampler:
|
| 846 |
+
for data in batch:
|
| 847 |
+
features = train_dataset[data]
|
| 848 |
+
features["labels"] = features["input_ids"].copy()
|
| 849 |
+
collated_features = collate_fn(features)
|
| 850 |
|
| 851 |
+
for feature in features.keys():
|
| 852 |
+
if feature == "length":
|
| 853 |
+
continue
|
| 854 |
+
chunked_data[feature].append(collated_features[feature].squeeze(0))
|
| 855 |
|
| 856 |
return chunked_data
|
| 857 |
|
src/axolotl/utils/models.py
CHANGED
|
@@ -8,7 +8,6 @@ import addict
|
|
| 8 |
import bitsandbytes as bnb
|
| 9 |
import torch
|
| 10 |
import transformers
|
| 11 |
-
from optimum.bettertransformer import BetterTransformer
|
| 12 |
from peft import LoftQConfig, PeftConfig, prepare_model_for_kbit_training
|
| 13 |
from peft.tuners.lora import QuantLinear
|
| 14 |
from transformers import ( # noqa: F401
|
|
@@ -324,13 +323,13 @@ def load_model(
|
|
| 324 |
|
| 325 |
LOG.info("patching with xformers attention")
|
| 326 |
hijack_llama_attention()
|
| 327 |
-
elif cfg.
|
| 328 |
-
from axolotl.monkeypatch.
|
| 329 |
-
|
| 330 |
)
|
| 331 |
|
| 332 |
-
LOG.info("patching
|
| 333 |
-
|
| 334 |
elif cfg.s2_attention:
|
| 335 |
raise NotImplementedError(
|
| 336 |
"Shifted-sparse attention not currently implemented without flash attention."
|
|
@@ -506,6 +505,12 @@ def load_model(
|
|
| 506 |
model_config._attn_implementation = ( # pylint: disable=protected-access
|
| 507 |
"eager"
|
| 508 |
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 509 |
|
| 510 |
try:
|
| 511 |
if (
|
|
@@ -749,6 +754,8 @@ def load_model(
|
|
| 749 |
model.config.use_cache = False
|
| 750 |
|
| 751 |
if cfg.flash_optimum:
|
|
|
|
|
|
|
| 752 |
model = BetterTransformer.transform(model)
|
| 753 |
|
| 754 |
if cfg.adapter is not None:
|
|
|
|
| 8 |
import bitsandbytes as bnb
|
| 9 |
import torch
|
| 10 |
import transformers
|
|
|
|
| 11 |
from peft import LoftQConfig, PeftConfig, prepare_model_for_kbit_training
|
| 12 |
from peft.tuners.lora import QuantLinear
|
| 13 |
from transformers import ( # noqa: F401
|
|
|
|
| 323 |
|
| 324 |
LOG.info("patching with xformers attention")
|
| 325 |
hijack_llama_attention()
|
| 326 |
+
elif cfg.sample_packing:
|
| 327 |
+
from axolotl.monkeypatch.llama_patch_multipack import (
|
| 328 |
+
hijack_llama_prepare_4d_mask,
|
| 329 |
)
|
| 330 |
|
| 331 |
+
LOG.info("patching llama _prepare_4d_causal_attention_mask*")
|
| 332 |
+
hijack_llama_prepare_4d_mask()
|
| 333 |
elif cfg.s2_attention:
|
| 334 |
raise NotImplementedError(
|
| 335 |
"Shifted-sparse attention not currently implemented without flash attention."
|
|
|
|
| 505 |
model_config._attn_implementation = ( # pylint: disable=protected-access
|
| 506 |
"eager"
|
| 507 |
)
|
| 508 |
+
elif cfg.sdp_attention:
|
| 509 |
+
model_kwargs["attn_implementation"] = "sdpa"
|
| 510 |
+
model_config._attn_implementation = "sdpa" # pylint: disable=protected-access
|
| 511 |
+
elif cfg.eager_attention:
|
| 512 |
+
model_kwargs["attn_implementation"] = "eager"
|
| 513 |
+
model_config._attn_implementation = "eager" # pylint: disable=protected-access
|
| 514 |
|
| 515 |
try:
|
| 516 |
if (
|
|
|
|
| 754 |
model.config.use_cache = False
|
| 755 |
|
| 756 |
if cfg.flash_optimum:
|
| 757 |
+
from optimum.bettertransformer import BetterTransformer
|
| 758 |
+
|
| 759 |
model = BetterTransformer.transform(model)
|
| 760 |
|
| 761 |
if cfg.adapter is not None:
|
src/axolotl/utils/samplers/multipack.py
CHANGED
|
@@ -117,7 +117,7 @@ class MultipackBatchSampler(BatchSampler):
|
|
| 117 |
packing_efficiency_estimate: float = 1.0,
|
| 118 |
):
|
| 119 |
super().__init__(sampler, batch_size, drop_last)
|
| 120 |
-
self.batch_size =
|
| 121 |
self.batch_max_len = batch_max_len
|
| 122 |
self.lengths: np.ndarray = lengths
|
| 123 |
self.packing_efficiency_estimate = packing_efficiency_estimate or 1.0
|
|
@@ -147,7 +147,13 @@ class MultipackBatchSampler(BatchSampler):
|
|
| 147 |
n=1,
|
| 148 |
)
|
| 149 |
|
| 150 |
-
batches = [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 151 |
|
| 152 |
# statistics
|
| 153 |
if set_stats:
|
|
@@ -189,7 +195,7 @@ class MultipackBatchSampler(BatchSampler):
|
|
| 189 |
0.99
|
| 190 |
* lengths_sum_per_device
|
| 191 |
/ self.packing_efficiency_estimate
|
| 192 |
-
// self.batch_max_len
|
| 193 |
)
|
| 194 |
- 1
|
| 195 |
),
|
|
|
|
| 117 |
packing_efficiency_estimate: float = 1.0,
|
| 118 |
):
|
| 119 |
super().__init__(sampler, batch_size, drop_last)
|
| 120 |
+
self.batch_size = batch_size
|
| 121 |
self.batch_max_len = batch_max_len
|
| 122 |
self.lengths: np.ndarray = lengths
|
| 123 |
self.packing_efficiency_estimate = packing_efficiency_estimate or 1.0
|
|
|
|
| 147 |
n=1,
|
| 148 |
)
|
| 149 |
|
| 150 |
+
batches = [
|
| 151 |
+
[
|
| 152 |
+
[indices[b_idx] for b_idx in batch]
|
| 153 |
+
for batch in batches[i : i + self.batch_size]
|
| 154 |
+
]
|
| 155 |
+
for i in range(0, len(batches), self.batch_size)
|
| 156 |
+
]
|
| 157 |
|
| 158 |
# statistics
|
| 159 |
if set_stats:
|
|
|
|
| 195 |
0.99
|
| 196 |
* lengths_sum_per_device
|
| 197 |
/ self.packing_efficiency_estimate
|
| 198 |
+
// (self.batch_max_len * self.batch_size)
|
| 199 |
)
|
| 200 |
- 1
|
| 201 |
),
|
src/axolotl/utils/trainer.py
CHANGED
|
@@ -237,11 +237,17 @@ def calculate_total_num_steps(cfg, train_dataset, update=True):
|
|
| 237 |
main_process_only=True,
|
| 238 |
)
|
| 239 |
else:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 240 |
sampler = MultipackBatchSampler(
|
| 241 |
sampler=RandomSampler(train_dataset),
|
| 242 |
-
batch_size=
|
| 243 |
drop_last=True,
|
| 244 |
-
batch_max_len=
|
| 245 |
lengths=get_dataset_lengths(train_dataset),
|
| 246 |
)
|
| 247 |
|
|
@@ -249,7 +255,7 @@ def calculate_total_num_steps(cfg, train_dataset, update=True):
|
|
| 249 |
train_dataset.remove_columns(["length"]),
|
| 250 |
batch_sampler=sampler,
|
| 251 |
)
|
| 252 |
-
data_loader_len = len(data_loader)
|
| 253 |
actual_eff = sampler.efficiency()
|
| 254 |
LOG.debug(f"data_loader_len: {data_loader_len}", main_process_only=True)
|
| 255 |
# FIXME: is there a bug here somewhere? the total num steps depends
|
|
|
|
| 237 |
main_process_only=True,
|
| 238 |
)
|
| 239 |
else:
|
| 240 |
+
if cfg.flash_attention:
|
| 241 |
+
batch_size = 1
|
| 242 |
+
batch_max_len = cfg.micro_batch_size * cfg.sequence_len
|
| 243 |
+
else:
|
| 244 |
+
batch_size = cfg.micro_batch_size
|
| 245 |
+
batch_max_len = cfg.sequence_len
|
| 246 |
sampler = MultipackBatchSampler(
|
| 247 |
sampler=RandomSampler(train_dataset),
|
| 248 |
+
batch_size=batch_size,
|
| 249 |
drop_last=True,
|
| 250 |
+
batch_max_len=batch_max_len,
|
| 251 |
lengths=get_dataset_lengths(train_dataset),
|
| 252 |
)
|
| 253 |
|
|
|
|
| 255 |
train_dataset.remove_columns(["length"]),
|
| 256 |
batch_sampler=sampler,
|
| 257 |
)
|
| 258 |
+
data_loader_len = len(data_loader) // batch_size
|
| 259 |
actual_eff = sampler.efficiency()
|
| 260 |
LOG.debug(f"data_loader_len: {data_loader_len}", main_process_only=True)
|
| 261 |
# FIXME: is there a bug here somewhere? the total num steps depends
|
tests/e2e/patched/test_4d_multipack_llama.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
E2E tests for multipack fft llama using 4d attention masks
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import logging
|
| 6 |
+
import os
|
| 7 |
+
import unittest
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
|
| 10 |
+
from axolotl.cli import load_datasets
|
| 11 |
+
from axolotl.common.cli import TrainerCliArgs
|
| 12 |
+
from axolotl.train import train
|
| 13 |
+
from axolotl.utils.config import normalize_config
|
| 14 |
+
from axolotl.utils.dict import DictDefault
|
| 15 |
+
|
| 16 |
+
from ..utils import require_torch_2_1_1, with_temp_dir
|
| 17 |
+
|
| 18 |
+
LOG = logging.getLogger("axolotl.tests.e2e")
|
| 19 |
+
os.environ["WANDB_DISABLED"] = "true"
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class Test4dMultipackLlama(unittest.TestCase):
|
| 23 |
+
"""
|
| 24 |
+
Test case for Llama models using 4d attention with multipack
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
@require_torch_2_1_1
|
| 28 |
+
@with_temp_dir
|
| 29 |
+
def test_sdp_lora_packing(self, temp_dir):
|
| 30 |
+
# pylint: disable=duplicate-code
|
| 31 |
+
cfg = DictDefault(
|
| 32 |
+
{
|
| 33 |
+
"base_model": "JackFram/llama-68m",
|
| 34 |
+
"flash_attention": False,
|
| 35 |
+
"sdp_attention": True,
|
| 36 |
+
"sample_packing": True,
|
| 37 |
+
"pad_to_sequence_len": True,
|
| 38 |
+
"load_in_8bit": True,
|
| 39 |
+
"adapter": "lora",
|
| 40 |
+
"lora_r": 32,
|
| 41 |
+
"lora_alpha": 16,
|
| 42 |
+
"lora_dropout": 0.05,
|
| 43 |
+
"lora_target_linear": True,
|
| 44 |
+
"sequence_len": 1024,
|
| 45 |
+
"val_set_size": 0.1,
|
| 46 |
+
"datasets": [
|
| 47 |
+
{
|
| 48 |
+
"path": "mhenrichsen/alpaca_2k_test",
|
| 49 |
+
"type": "alpaca",
|
| 50 |
+
},
|
| 51 |
+
],
|
| 52 |
+
"num_epochs": 2,
|
| 53 |
+
"micro_batch_size": 2,
|
| 54 |
+
"gradient_accumulation_steps": 1,
|
| 55 |
+
"output_dir": temp_dir,
|
| 56 |
+
"learning_rate": 0.00001,
|
| 57 |
+
"optimizer": "adamw_torch",
|
| 58 |
+
"lr_scheduler": "cosine",
|
| 59 |
+
"max_steps": 20,
|
| 60 |
+
"save_steps": 10,
|
| 61 |
+
"eval_steps": 10,
|
| 62 |
+
"fp16": True,
|
| 63 |
+
}
|
| 64 |
+
)
|
| 65 |
+
normalize_config(cfg)
|
| 66 |
+
cli_args = TrainerCliArgs()
|
| 67 |
+
dataset_meta = load_datasets(cfg=cfg, cli_args=cli_args)
|
| 68 |
+
|
| 69 |
+
train(cfg=cfg, cli_args=cli_args, dataset_meta=dataset_meta)
|
| 70 |
+
assert (Path(temp_dir) / "adapter_model.bin").exists()
|
| 71 |
+
|
| 72 |
+
@with_temp_dir
|
| 73 |
+
def test_torch_lora_packing(self, temp_dir):
|
| 74 |
+
# pylint: disable=duplicate-code
|
| 75 |
+
cfg = DictDefault(
|
| 76 |
+
{
|
| 77 |
+
"base_model": "JackFram/llama-68m",
|
| 78 |
+
"flash_attention": False,
|
| 79 |
+
"sdp_attention": False,
|
| 80 |
+
"sample_packing": True,
|
| 81 |
+
"pad_to_sequence_len": True,
|
| 82 |
+
"sequence_len": 1024,
|
| 83 |
+
"load_in_8bit": True,
|
| 84 |
+
"adapter": "lora",
|
| 85 |
+
"lora_r": 32,
|
| 86 |
+
"lora_alpha": 16,
|
| 87 |
+
"lora_dropout": 0.05,
|
| 88 |
+
"lora_target_linear": True,
|
| 89 |
+
"val_set_size": 0.1,
|
| 90 |
+
"datasets": [
|
| 91 |
+
{
|
| 92 |
+
"path": "mhenrichsen/alpaca_2k_test",
|
| 93 |
+
"type": "alpaca",
|
| 94 |
+
},
|
| 95 |
+
],
|
| 96 |
+
"num_epochs": 2,
|
| 97 |
+
"micro_batch_size": 2,
|
| 98 |
+
"gradient_accumulation_steps": 1,
|
| 99 |
+
"output_dir": temp_dir,
|
| 100 |
+
"learning_rate": 0.00001,
|
| 101 |
+
"optimizer": "adamw_torch",
|
| 102 |
+
"lr_scheduler": "cosine",
|
| 103 |
+
"max_steps": 20,
|
| 104 |
+
"save_steps": 10,
|
| 105 |
+
"eval_steps": 10,
|
| 106 |
+
"fp16": True,
|
| 107 |
+
}
|
| 108 |
+
)
|
| 109 |
+
normalize_config(cfg)
|
| 110 |
+
cli_args = TrainerCliArgs()
|
| 111 |
+
dataset_meta = load_datasets(cfg=cfg, cli_args=cli_args)
|
| 112 |
+
|
| 113 |
+
train(cfg=cfg, cli_args=cli_args, dataset_meta=dataset_meta)
|
| 114 |
+
assert (Path(temp_dir) / "adapter_model.bin").exists()
|
tests/e2e/patched/test_fused_llama.py
CHANGED
|
@@ -33,6 +33,7 @@ class TestFusedLlama(unittest.TestCase):
|
|
| 33 |
{
|
| 34 |
"base_model": "JackFram/llama-68m",
|
| 35 |
"flash_attention": True,
|
|
|
|
| 36 |
"flash_attn_fuse_qkv": True,
|
| 37 |
"flash_attn_fuse_mlp": True,
|
| 38 |
"sample_packing": True,
|
|
|
|
| 33 |
{
|
| 34 |
"base_model": "JackFram/llama-68m",
|
| 35 |
"flash_attention": True,
|
| 36 |
+
"pad_to_sequence_len": True,
|
| 37 |
"flash_attn_fuse_qkv": True,
|
| 38 |
"flash_attn_fuse_mlp": True,
|
| 39 |
"sample_packing": True,
|
tests/e2e/utils.py
CHANGED
|
@@ -4,7 +4,9 @@ helper utils for tests
|
|
| 4 |
import os
|
| 5 |
import shutil
|
| 6 |
import tempfile
|
|
|
|
| 7 |
from functools import wraps
|
|
|
|
| 8 |
from pathlib import Path
|
| 9 |
|
| 10 |
|
|
@@ -31,3 +33,15 @@ def most_recent_subdir(path):
|
|
| 31 |
subdir = max(subdirectories, key=os.path.getctime)
|
| 32 |
|
| 33 |
return subdir
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
import os
|
| 5 |
import shutil
|
| 6 |
import tempfile
|
| 7 |
+
import unittest
|
| 8 |
from functools import wraps
|
| 9 |
+
from importlib.metadata import version
|
| 10 |
from pathlib import Path
|
| 11 |
|
| 12 |
|
|
|
|
| 33 |
subdir = max(subdirectories, key=os.path.getctime)
|
| 34 |
|
| 35 |
return subdir
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def require_torch_2_1_1(test_case):
|
| 39 |
+
"""
|
| 40 |
+
Decorator marking a test that requires torch >= 2.1.1
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
def is_min_2_1_1():
|
| 44 |
+
torch_version = version("torch")
|
| 45 |
+
return torch_version >= "2.1.1"
|
| 46 |
+
|
| 47 |
+
return unittest.skipUnless(is_min_2_1_1(), "test torch 2.1.1")(test_case)
|
tests/monkeypatch/test_llama_attn_hijack_flash.py
CHANGED
|
@@ -30,6 +30,20 @@ class TestMonkeyPatchUtils(unittest.TestCase):
|
|
| 30 |
torch.allclose(get_cu_seqlens_from_pos_ids(position_ids)[0], target_res)
|
| 31 |
)
|
| 32 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
def test_get_max_seqlen_in_batch(self):
|
| 34 |
attn_mask = torch.tensor([[1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 0, 0]])
|
| 35 |
target_res = torch.tensor([4, 3, 5, 2], dtype=torch.int32)
|
|
|
|
| 30 |
torch.allclose(get_cu_seqlens_from_pos_ids(position_ids)[0], target_res)
|
| 31 |
)
|
| 32 |
|
| 33 |
+
def test_get_cu_seqlens_from_pos_ids_2d(self):
|
| 34 |
+
position_ids = torch.tensor(
|
| 35 |
+
[
|
| 36 |
+
[0, 1, 2, 3, 0, 1, 2, 0, 1, 2, 3, 4, 0, 1, 0, 0],
|
| 37 |
+
[0, 1, 2, 3, 4, 0, 1, 2, 0, 1, 2, 3, 4, 5, 6, 0],
|
| 38 |
+
]
|
| 39 |
+
)
|
| 40 |
+
target_res = torch.tensor(
|
| 41 |
+
[[0, 4, 7, 12, 14, 16], [0, 5, 8, 15, 16, 16]], dtype=torch.int32
|
| 42 |
+
)
|
| 43 |
+
self.assertTrue(
|
| 44 |
+
torch.allclose(get_cu_seqlens_from_pos_ids(position_ids)[0], target_res)
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
def test_get_max_seqlen_in_batch(self):
|
| 48 |
attn_mask = torch.tensor([[1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 0, 0]])
|
| 49 |
target_res = torch.tensor([4, 3, 5, 2], dtype=torch.int32)
|
tests/test_packed_batch_sampler.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Module for testing streaming dataset sequence packing"""
|
| 2 |
+
import pytest
|
| 3 |
+
from datasets import concatenate_datasets, load_dataset
|
| 4 |
+
from torch.utils.data import DataLoader, RandomSampler
|
| 5 |
+
from transformers import AutoTokenizer
|
| 6 |
+
|
| 7 |
+
from axolotl.datasets import TokenizedPromptDataset
|
| 8 |
+
from axolotl.prompt_strategies.completion import load
|
| 9 |
+
from axolotl.utils.collators import V2BatchSamplerDataCollatorForSeq2Seq
|
| 10 |
+
from axolotl.utils.dict import DictDefault
|
| 11 |
+
from axolotl.utils.samplers import MultipackBatchSampler, get_dataset_lengths
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@pytest.fixture(name="tokenizer")
|
| 15 |
+
def fixture_tokenizer():
|
| 16 |
+
tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
|
| 17 |
+
tokenizer.pad_token = "</s>"
|
| 18 |
+
return tokenizer
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@pytest.fixture(name="max_seq_length")
|
| 22 |
+
def fixture_max_seq_length():
|
| 23 |
+
return 4096
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class TestBatchedSamplerPacking:
|
| 27 |
+
"""
|
| 28 |
+
Test class for packing streaming dataset sequences
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
@pytest.mark.parametrize(
|
| 32 |
+
"batch_size, num_workers",
|
| 33 |
+
[
|
| 34 |
+
(1, 0),
|
| 35 |
+
(2, 0),
|
| 36 |
+
(1, 2),
|
| 37 |
+
(2, 2),
|
| 38 |
+
],
|
| 39 |
+
)
|
| 40 |
+
def test_packing(self, batch_size, num_workers, tokenizer, max_seq_length):
|
| 41 |
+
import axolotl.monkeypatch.data.batch_dataset_fetcher # pylint: disable=unused-import # noqa: F401
|
| 42 |
+
|
| 43 |
+
dataset = load_dataset(
|
| 44 |
+
"Trelis/tiny-shakespeare",
|
| 45 |
+
split="train",
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
cfg = DictDefault(
|
| 49 |
+
{
|
| 50 |
+
"train_on_inputs": True,
|
| 51 |
+
"sequence_len": max_seq_length,
|
| 52 |
+
}
|
| 53 |
+
)
|
| 54 |
+
ds_cfg = DictDefault(
|
| 55 |
+
{
|
| 56 |
+
"field": "Text",
|
| 57 |
+
}
|
| 58 |
+
)
|
| 59 |
+
completion_strategy = load(tokenizer, cfg, ds_cfg)
|
| 60 |
+
dataset_wrapper = TokenizedPromptDataset(
|
| 61 |
+
completion_strategy,
|
| 62 |
+
dataset,
|
| 63 |
+
)
|
| 64 |
+
train_dataset = concatenate_datasets([dataset_wrapper])
|
| 65 |
+
batch_sampler = MultipackBatchSampler(
|
| 66 |
+
sampler=RandomSampler(train_dataset),
|
| 67 |
+
batch_size=batch_size,
|
| 68 |
+
drop_last=True,
|
| 69 |
+
batch_max_len=max_seq_length,
|
| 70 |
+
lengths=get_dataset_lengths(train_dataset),
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
loader = DataLoader(
|
| 74 |
+
train_dataset,
|
| 75 |
+
batch_sampler=batch_sampler,
|
| 76 |
+
collate_fn=V2BatchSamplerDataCollatorForSeq2Seq( # pylint: disable=unexpected-keyword-arg
|
| 77 |
+
tokenizer=tokenizer,
|
| 78 |
+
padding=True,
|
| 79 |
+
pad_to_multiple_of=max_seq_length,
|
| 80 |
+
return_tensors="pt",
|
| 81 |
+
),
|
| 82 |
+
num_workers=num_workers,
|
| 83 |
+
)
|
| 84 |
+
inputs = next(iter(loader))
|
| 85 |
+
|
| 86 |
+
assert inputs["input_ids"].shape == (batch_size, max_seq_length)
|
| 87 |
+
assert inputs["labels"].shape == (batch_size, max_seq_length)
|
| 88 |
+
assert inputs["attention_mask"].shape == (batch_size, max_seq_length)
|
| 89 |
+
|
| 90 |
+
assert inputs["input_ids"].tolist()[0][0] == 2
|
| 91 |
+
assert inputs["labels"].tolist()[0][0] == -100
|
| 92 |
+
assert inputs["attention_mask"].tolist()[0][0] == 0
|
| 93 |
+
assert inputs["attention_mask"].tolist()[0][-1] > 1
|
| 94 |
+
|
| 95 |
+
if batch_size >= 2:
|
| 96 |
+
assert inputs["input_ids"].tolist()[1][0] == 2
|
| 97 |
+
assert inputs["labels"].tolist()[1][0] == -100
|
| 98 |
+
assert inputs["attention_mask"].tolist()[1][0] == 0
|
| 99 |
+
assert inputs["attention_mask"].tolist()[1][-1] > 1
|
tests/test_packed_pretraining.py
CHANGED
|
@@ -11,7 +11,7 @@ from axolotl.utils.collators import PretrainingBatchSamplerDataCollatorForSeq2Se
|
|
| 11 |
from axolotl.utils.data import encode_packed_pretraining
|
| 12 |
|
| 13 |
|
| 14 |
-
class
|
| 15 |
"""
|
| 16 |
Test class for packing streaming dataset sequences
|
| 17 |
"""
|
|
|
|
| 11 |
from axolotl.utils.data import encode_packed_pretraining
|
| 12 |
|
| 13 |
|
| 14 |
+
class TestPretrainingPacking(unittest.TestCase):
|
| 15 |
"""
|
| 16 |
Test class for packing streaming dataset sequences
|
| 17 |
"""
|