
metadata
language:
- ko
metrics:
- accuracy
- f1
pipeline_tag: text-classification
XLM-Roberta-base --> 8emotions!
Label Dictionry
- label_dictionary
- emo2int = { "기쁨": 0, "당황": 1, "분노": 2, "불안": 3, "상처": 4, "슬픔": 5, "중립": 6 }
- kore2en = { "기쁨": "joy", "당황": "surprise", "분노": "anger", "불안": "fear", "상처": "hurt", "슬픔": "sadness", "중립": "neutral" }
Dataset
감성대화말뭉치(AI Hub)
- input format(recommendation) - this model is trained by ChatBOT dataset.
- ref: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=86
한국어 감정 정보가 포함된 연속적 대화 데이터셋(AIHub)
And.. this dataset doesn't have neutral class..
So additional dataset is used.
ref: https://aihub.or.kr/aihubdata/data/view.do?dataSetSn=271
finally I Concatenate 2 Datasets.
Input Format(Please Use Special Tokens [USR], [BOT] to use model API!)
(example) [USR] 안녕. [BOT] 안녕하세요! 무엇을 도와드릴까요? [USR] 별일 없어.
이 두개의 특수 토큰은 반드시 사용해주시길 부탁드립니다.
And these are a part of real data.


Metrics(F1, Accuracy, and Confusion Matrix!)
and confusion matrix like this..
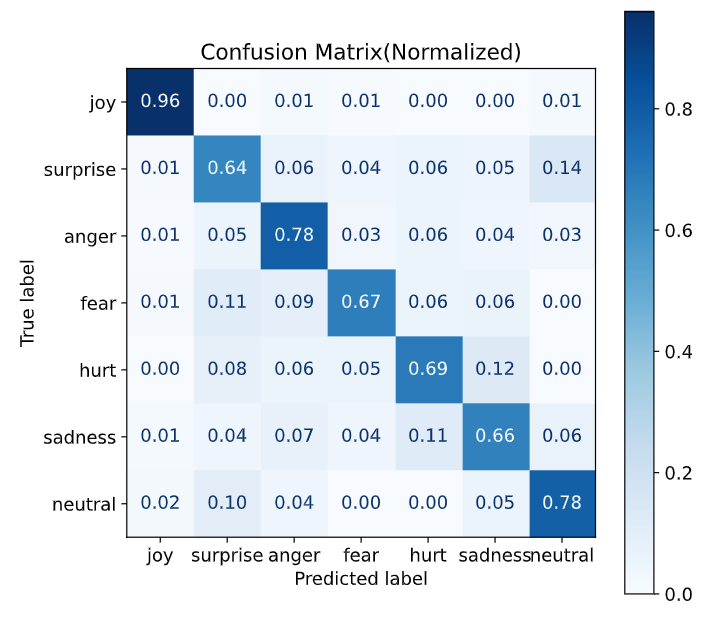
and so on.. F1, Accuracy

