
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installation
Install 🤗 Transformers for whichever deep learning library you're working with, setup your cache, and optionally configure 🤗 Transformers to run offline.
🤗 Transformers is tested on Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, and Flax. Follow the installation instructions below for the deep learning library you are using:
* [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) installation instructions.
* [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
## Install with pip
You should install 🤗 Transformers in a [virtual environment](https://docs.python.org/3/library/venv.html). If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
Start by creating a virtual environment in your project directory:
```bash
python -m venv .env
```
Activate the virtual environment. On Linux and MacOs:
```bash
source .env/bin/activate
```
Activate Virtual environment on Windows
```bash
.env/Scripts/activate
```
Now you're ready to install 🤗 Transformers with the following command:
```bash
pip install transformers
```
For CPU-support only, you can conveniently install 🤗 Transformers and a deep learning library in one line. For example, install 🤗 Transformers and PyTorch with:
```bash
pip install 'transformers[torch]'
```
🤗 Transformers and TensorFlow 2.0:
```bash
pip install 'transformers[tf-cpu]'
```
<Tip warning={true}>
M1 / ARM Users
You will need to install the following before installing TensorFLow 2.0
```
brew install cmake
brew install pkg-config
```
</Tip>
🤗 Transformers and Flax:
```bash
pip install 'transformers[flax]'
```
Finally, check if 🤗 Transformers has been properly installed by running the following command. It will download a pretrained model:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Then print out the label and score:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Install from source
Install 🤗 Transformers from source with the following command:
```bash
pip install git+https://github.com/huggingface/transformers
```
This command installs the bleeding edge `main` version rather than the latest `stable` version. The `main` version is useful for staying up-to-date with the latest developments. For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet. However, this means the `main` version may not always be stable. We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day. If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues) so we can fix it even sooner!
Check if 🤗 Transformers has been properly installed by running the following command:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Editable install
You will need an editable install if you'd like to:
* Use the `main` version of the source code.
* Contribute to 🤗 Transformers and need to test changes in the code.
Clone the repository and install 🤗 Transformers with the following commands:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
These commands will link the folder you cloned the repository to and your Python library paths. Python will now look inside the folder you cloned to in addition to the normal library paths. For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/transformers/`.
<Tip warning={true}>
You must keep the `transformers` folder if you want to keep using the library.
</Tip>
Now you can easily update your clone to the latest version of 🤗 Transformers with the following command:
```bash
cd ~/transformers/
git pull
```
Your Python environment will find the `main` version of 🤗 Transformers on the next run.
## Install with conda
Install from the conda channel `huggingface`:
```bash
conda install -c huggingface transformers
```
## Cache setup
Pretrained models are downloaded and locally cached at: `~/.cache/huggingface/hub`. This is the default directory given by the shell environment variable `TRANSFORMERS_CACHE`. On Windows, the default directory is given by `C:\Users\username\.cache\huggingface\hub`. You can change the shell environment variables shown below - in order of priority - to specify a different cache directory:
1. Shell environment variable (default): `HUGGINGFACE_HUB_CACHE` or `TRANSFORMERS_CACHE`.
2. Shell environment variable: `HF_HOME`.
3. Shell environment variable: `XDG_CACHE_HOME` + `/huggingface`.
<Tip>
🤗 Transformers will use the shell environment variables `PYTORCH_TRANSFORMERS_CACHE` or `PYTORCH_PRETRAINED_BERT_CACHE` if you are coming from an earlier iteration of this library and have set those environment variables, unless you specify the shell environment variable `TRANSFORMERS_CACHE`.
</Tip>
## Offline mode
Run 🤗 Transformers in a firewalled or offline environment with locally cached files by setting the environment variable `TRANSFORMERS_OFFLINE=1`.
<Tip>
Add [🤗 Datasets](https://huggingface.co/docs/datasets/) to your offline training workflow with the environment variable `HF_DATASETS_OFFLINE=1`.
</Tip>
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
This script should run without hanging or waiting to timeout because it won't attempt to download the model from the Hub.
You can also bypass loading a model from the Hub from each [`~PreTrainedModel.from_pretrained`] call with the [`local_files_only`] parameter. When set to `True`, only local files are loaded:
```py
from transformers import T5Model
model = T5Model.from_pretrained("./path/to/local/directory", local_files_only=True)
```
### Fetch models and tokenizers to use offline
Another option for using 🤗 Transformers offline is to download the files ahead of time, and then point to their local path when you need to use them offline. There are three ways to do this:
* Download a file through the user interface on the [Model Hub](https://huggingface.co/models) by clicking on the ↓ icon.

* Use the [`PreTrainedModel.from_pretrained`] and [`PreTrainedModel.save_pretrained`] workflow:
1. Download your files ahead of time with [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Save your files to a specified directory with [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Now when you're offline, reload your files with [`PreTrainedModel.from_pretrained`] from the specified directory:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Programmatically download files with the [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) library:
1. Install the `huggingface_hub` library in your virtual environment:
```bash
python -m pip install huggingface_hub
```
2. Use the [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) function to download a file to a specific path. For example, the following command downloads the `config.json` file from the [T0](https://huggingface.co/bigscience/T0_3B) model to your desired path:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Once your file is downloaded and locally cached, specify it's local path to load and use it:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
See the [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) section for more details on downloading files stored on the Hub.
</Tip>
| huggingface/transformers/blob/main/docs/source/en/installation.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPT Neo
## Overview
The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the
[Pile](https://pile.eleuther.ai/) dataset.
The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of
256 tokens.
This model was contributed by [valhalla](https://huggingface.co/valhalla).
## Usage example
The `generate()` method can be used to generate text using GPT Neo model.
```python
>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## Combining GPT-Neo and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature, and make sure your hardware is compatible with Flash-Attention 2. More details are available [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2) concerning the installation.
Make sure as well to load your model in half-precision (e.g. `torch.float16`).
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"def hello_world():\n >>> run_script("hello.py")\n >>> exit(0)\n<|endoftext|>"
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `EleutherAI/gpt-neo-2.7B` checkpoint and the Flash Attention 2 version of the model.
Note that for GPT-Neo it is not possible to train / run on very long context as the max [position embeddings](https://huggingface.co/EleutherAI/gpt-neo-2.7B/blob/main/config.json#L58 ) is limited to 2048 - but this is applicable to all gpt-neo models and not specific to FA-2
<div style="text-align: center">
<img src="https://user-images.githubusercontent.com/49240599/272241893-b1c66b75-3a48-4265-bc47-688448568b3d.png">
</div>
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## GPTNeoConfig
[[autodoc]] GPTNeoConfig
<frameworkcontent>
<pt>
## GPTNeoModel
[[autodoc]] GPTNeoModel
- forward
## GPTNeoForCausalLM
[[autodoc]] GPTNeoForCausalLM
- forward
## GPTNeoForQuestionAnswering
[[autodoc]] GPTNeoForQuestionAnswering
- forward
## GPTNeoForSequenceClassification
[[autodoc]] GPTNeoForSequenceClassification
- forward
## GPTNeoForTokenClassification
[[autodoc]] GPTNeoForTokenClassification
- forward
</pt>
<jax>
## FlaxGPTNeoModel
[[autodoc]] FlaxGPTNeoModel
- __call__
## FlaxGPTNeoForCausalLM
[[autodoc]] FlaxGPTNeoForCausalLM
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/gpt_neo.md |
Gradio Demo: rows_and_columns
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('images')
!wget -q -O images/cheetah.jpg https://github.com/gradio-app/gradio/raw/main/demo/rows_and_columns/images/cheetah.jpg
```
```
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
text1 = gr.Textbox(label="t1")
slider2 = gr.Textbox(label="s2")
drop3 = gr.Dropdown(["a", "b", "c"], label="d3")
with gr.Row():
with gr.Column(scale=1, min_width=600):
text1 = gr.Textbox(label="prompt 1")
text2 = gr.Textbox(label="prompt 2")
inbtw = gr.Button("Between")
text4 = gr.Textbox(label="prompt 1")
text5 = gr.Textbox(label="prompt 2")
with gr.Column(scale=2, min_width=600):
img1 = gr.Image("images/cheetah.jpg")
btn = gr.Button("Go")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/rows_and_columns/run.ipynb |
Gradio Demo: lineplot_component
```
!pip install -q gradio vega_datasets
```
```
import gradio as gr
from vega_datasets import data
with gr.Blocks() as demo:
gr.LinePlot(
data.stocks(),
x="date",
y="price",
color="symbol",
color_legend_position="bottom",
title="Stock Prices",
tooltip=["date", "price", "symbol"],
height=300,
width=300,
container=False,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/lineplot_component/run.ipynb |
@gradio/box
## 0.1.6
### Patch Changes
- Updated dependencies [[`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/atoms@0.4.1
## 0.1.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/atoms@0.4.0
## 0.1.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
## 0.1.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
## 0.1.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.7
### Patch Changes
- Updated dependencies [[`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a), [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13)]:
- @gradio/atoms@0.2.0-beta.6
## 0.1.0-beta.6
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.5
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#5949](https://github.com/gradio-app/gradio/pull/5949) [`1c390f101`](https://github.com/gradio-app/gradio/commit/1c390f10199142a41722ba493a0c86b58245da15) - Merge main again. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.7
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
## 0.0.6
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.4
## 0.0.5
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.3
## 0.0.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.2
## 0.0.3
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.1
## 0.0.2
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
| gradio-app/gradio/blob/main/js/box/CHANGELOG.md |
FrameworkSwitchCourse {fw} />
<!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={4}
classNames="absolute z-10 right-0 top-0"
/>
Let's test what you learned in this chapter!
### 1. What are models on the Hub limited to?
<Question
choices={[
{
text: "Models from the 🤗 Transformers library.",
explain: "While models from the 🤗 Transformers library are supported on the Hugging Face Hub, they're not the only ones!"
},
{
text: "All models with a similar interface to 🤗 Transformers.",
explain: "No interface requirement is set when uploading models to the Hugging Face Hub. "
},
{
text: "There are no limits.",
explain: "Right! There are no limits when uploading models to the Hub.",
correct: true
},
{
text: "Models that are in some way related to NLP.",
explain: "No requirement is set regarding the field of application!"
}
]}
/>
### 2. How can you manage models on the Hub?
<Question
choices={[
{
text: "Through a GCP account.",
explain: "Incorrect!"
},
{
text: "Through peer-to-peer distribution.",
explain: "Incorrect!"
},
{
text: "Through git and git-lfs.",
explain: "Correct! Models on the Hub are simple Git repositories, leveraging <code>git-lfs</code> for large files.",
correct: true
}
]}
/>
### 3. What can you do using the Hugging Face Hub web interface?
<Question
choices={[
{
text: "Fork an existing repository.",
explain: "Forking a repository is not possible on the Hugging Face Hub."
},
{
text: "Create a new model repository.",
explain: "Correct! That's not all you can do, though.",
correct: true
},
{
text: "Manage and edit files.",
explain: "Correct! That's not the only right answer, though.",
correct: true
},
{
text: "Upload files.",
explain: "Right! But that's not all.",
correct: true
},
{
text: "See diffs across versions.",
explain: "Correct! That's not all you can do, though.",
correct: true
}
]}
/>
### 4. What is a model card?
<Question
choices={[
{
text: "A rough description of the model, therefore less important than the model and tokenizer files.",
explain: "It is indeed a description of the model, but it's an important piece: if it's incomplete or absent the model's utility is drastically reduced."
},
{
text: "A way to ensure reproducibility, reusability, and fairness.",
explain: "Correct! Sharing the right information in the model card will help users leverage your model and be aware of its limits and biases. ",
correct: true
},
{
text: "A Python file that can be run to retrieve information about the model.",
explain: "Model cards are simple Markdown files."
}
]}
/>
### 5. Which of these objects of the 🤗 Transformers library can be directly shared on the Hub with `push_to_hub()`?
{#if fw === 'pt'}
<Question
choices={[
{
text: "A tokenizer",
explain: "Correct! All tokenizers have the <code>push_to_hub</code> method, and using it will push all the tokenizer files (vocabulary, architecture of the tokenizer, etc.) to a given repo. That's not the only right answer, though!",
correct: true
},
{
text: "A model configuration",
explain: "Right! All model configurations have the <code>push_to_hub</code> method, and using it will push them to a given repo. What else can you share?",
correct: true
},
{
text: "A model",
explain: "Correct! All models have the <code>push_to_hub</code> method, and using it will push them and their configuration files to a given repo. That's not all you can share, though.",
correct: true
},
{
text: "A Trainer",
explain: "That's right — the <code>Trainer</code> also implements the <code>push_to_hub</code> method, and using it will upload the model, its configuration, the tokenizer, and a model card draft to a given repo. Try another answer!",
correct: true
}
]}
/>
{:else}
<Question
choices={[
{
text: "A tokenizer",
explain: "Correct! All tokenizers have the <code>push_to_hub</code> method, and using it will push all the tokenizer files (vocabulary, architecture of the tokenizer, etc.) to a given repo. That's not the only right answer, though!",
correct: true
},
{
text: "A model configuration",
explain: "Right! All model configurations have the <code>push_to_hub</code> method, and using it will push them to a given repo. What else can you share?",
correct: true
},
{
text: "A model",
explain: "Correct! All models have the <code>push_to_hub</code> method, and using it will push them and their configuration files to a given repo. That's not all you can share, though.",
correct: true
},
{
text: "All of the above with a dedicated callback",
explain: "That's right — the <code>PushToHubCallback</code> will regularly send all of those objects to a repo during training.",
correct: true
}
]}
/>
{/if}
### 6. What is the first step when using the `push_to_hub()` method or the CLI tools?
<Question
choices={[
{
text: "Log in on the website.",
explain: "This won't help you on your local machine."
},
{
text: "Run 'huggingface-cli login' in a terminal.",
explain: "Correct — this will download and cache your personal token.",
correct: true
},
{
text: "Run 'notebook_login()' in a notebook.",
explain: "Correct — this will display a widget to let you authenticate.",
correct: true
},
]}
/>
### 7. You're using a model and a tokenizer — how can you upload them to the Hub?
<Question
choices={[
{
text: "By calling the push_to_hub method directly on the model and the tokenizer.",
explain: "Correct!",
correct: true
},
{
text: "Within the Python runtime, by wrapping them in a <code>huggingface_hub</code> utility.",
explain: "Models and tokenizers already benefit from <code>huggingface_hub</code> utilities: no need for additional wrapping!"
},
{
text: "By saving them to disk and calling <code>transformers-cli upload-model</code>",
explain: "The command <code>upload-model</code> does not exist."
}
]}
/>
### 8. Which git operations can you do with the `Repository` class?
<Question
choices={[
{
text: "A commit.",
explain: "Correct, the <code>git_commit()</code> method is there for that.",
correct: true
},
{
text: "A pull",
explain: "That is the purpose of the <code>git_pull()</code> method.",
correct: true
},
{
text: "A push",
explain: "The method <code>git_push()</code> does this.",
correct: true
},
{
text: "A merge",
explain: "No, that operation will never be possible with this API."
}
]}
/>
| huggingface/course/blob/main/chapters/en/chapter4/6.mdx |
Panel on Spaces
[Panel](https://panel.holoviz.org/) is an open-source Python library that lets you easily build powerful tools, dashboards and complex applications entirely in Python. It has a batteries-included philosophy, putting the PyData ecosystem, powerful data tables and much more at your fingertips. High-level reactive APIs and lower-level callback based APIs ensure you can quickly build exploratory applications, but you aren’t limited if you build complex, multi-page apps with rich interactivity. Panel is a member of the [HoloViz](https://holoviz.org/) ecosystem, your gateway into a connected ecosystem of data exploration tools.
Visit [Panel documentation](https://panel.holoviz.org/) to learn more about making powerful applications.
## 🚀 Deploy Panel on Spaces
You can deploy Panel on Spaces with just a few clicks:
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg"/> </a>
There are a few key parameters you need to define: the Owner (either your personal account or an organization), a Space name, and Visibility. In case you intend to execute computationally intensive deep learning models, consider upgrading to a GPU to boost performance.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel.png" style="width:70%">
Once you have created the Space, it will start out in “Building” status, which will change to “Running” once your Space is ready to go.
## ⚡️ What will you see?
When your Space is built and ready, you will see this image classification Panel app which will let you fetch a random image and run the OpenAI CLIP classifier model on it. Check out our [blog post](https://blog.holoviz.org/building_an_interactive_ml_dashboard_in_panel.html) for a walkthrough of this app.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel-demo.gif" style="width:70%">
## 🛠️ How to customize and make your own app?
The Space template will populate a few files to get your app started:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel-files.png" style="width:70%">
Three files are important:
### 1. app.py
This file defines your Panel application code. You can start by modifying the existing application or replace it entirely to build your own application. To learn more about writing your own Panel app, refer to the [Panel documentation](https://panel.holoviz.org/).
### 2. Dockerfile
The Dockerfile contains a sequence of commands that Docker will execute to construct and launch an image as a container that your Panel app will run in. Typically, to serve a Panel app, we use the command `panel serve app.py`. In this specific file, we divide the command into a list of strings. Furthermore, we must define the address and port because Hugging Face will expect to serve your application on port 7860. Additionally, we need to specify the `allow-websocket-origin` flag to enable the connection to the server's websocket.
### 3. requirements.txt
This file defines the required packages for our Panel app. When using Space, dependencies listed in the requirements.txt file will be automatically installed. You have the freedom to modify this file by removing unnecessary packages or adding additional ones that are required for your application. Feel free to make the necessary changes to ensure your app has the appropriate packages installed.
## 🌐 Join Our Community
The Panel community is vibrant and supportive, with experienced developers and data scientists eager to help and share their knowledge. Join us and connect with us:
- [Discord](https://discord.gg/aRFhC3Dz9w)
- [Discourse](https://discourse.holoviz.org/)
- [Twitter](https://twitter.com/Panel_Org)
- [LinkedIn](https://www.linkedin.com/company/panel-org)
- [Github](https://github.com/holoviz/panel)
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-panel.md |
--
title: "Interactively explore your Huggingface dataset with one line of code"
thumbnail: /blog/assets/scalable-data-inspection/thumbnail.png
authors:
- user: sps44
guest: true
- user: druzsan
guest: true
- user: neindochoh
guest: true
- user: MarkusStoll
guest: true
---
# Interactively explore your Huggingface dataset with one line of code
The Hugging Face [*datasets* library](https://huggingface.co/docs/datasets/index) not only provides access to more than 70k publicly available datasets, but also offers very convenient data preparation pipelines for custom datasets.
[Renumics Spotlight](https://github.com/Renumics/spotlight) allows you to create **interactive visualizations** to **identify critical clusters** in your data. Because Spotlight understands the data semantics within Hugging Face datasets, you can **[get started with just one line of code](https://renumics.com/docs)**:
```python
import datasets
from renumics import spotlight
ds = datasets.load_dataset('speech_commands', 'v0.01', split='validation')
spotlight.show(ds)
```
<p align="center"><a href="https://github.com/Renumics/spotlight"><img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/speech_commands_vis_s.gif" width="100%"/></a></p>
Spotlight allows to **leverage model results** such as predictions and embeddings to gain a deeper understanding in data segments and model failure modes:
```python
ds_results = datasets.load_dataset('renumics/speech_commands-ast-finetuned-results', 'v0.01', split='validation')
ds = datasets.concatenate_datasets([ds, ds_results], axis=1)
spotlight.show(ds, dtype={'embedding': spotlight.Embedding}, layout=spotlight.layouts.debug_classification(embedding='embedding', inspect={'audio': spotlight.dtypes.audio_dtype}))
```
Data inspection is a very important task in almost all ML development stages, but it can also be very time consuming.
> “Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.” — Greg Brockman
>
[Spotlight](https://renumics.com/docs) helps you to **make data inspection more scalable** along two dimensions: Setting up and maintaining custom data inspection workflows and finding relevant data samples and clusters to inspect. In the following sections we show some examples based on Hugging Face datasets.
## Spotlight 🤝 Hugging Face datasets
The *datasets* library has several features that makes it an ideal tool for working with ML datasets: It stores tabular data (e.g. metadata, labels) along with unstructured data (e.g. images, audio) in a common Arrows table. *Datasets* also describes important data semantics through features (e.g. images, audio) and additional task-specific metadata.
Spotlight directly works on top of the *datasets* library. This means that there is no need to copy or pre-process the dataset for data visualization and inspection. Spotlight loads the tabular data into memory to allow for efficient, client-side data analytics. Memory-intensive unstructured data samples (e.g. audio, images, video) are loaded lazily on demand. In most cases, data types and label mappings are inferred directly from the dataset. Here, we visualize the CIFAR-100 dataset with one line of code:
```python
ds = datasets.load_dataset('cifar100', split='test')
spotlight.show(ds)
```
In cases where the data types are ambiguous or not specified, the Spotlight API allows to manually assign them:
```python
label_mapping = dict(zip(ds.features['fine_label'].names, range(len(ds.features['fine_label'].names))))
spotlight.show(ds, dtype={'img': spotlight.Image, 'fine_label': spotlight.dtypes.CategoryDType(categories=label_mapping)})
```
## **Leveraging model results for data inspection**
Exploring raw unstructured datasets often yield little insights. Leveraging model results such as predictions or embeddings can help to uncover critical data samples and clusters. Spotlight has several visualization options (e.g. similarity map, confusion matrix) that specifically make use of model results.
We recommend storing your prediction results directly in a Hugging Face dataset. This not only allows you to take advantage of the batch processing capabilities of the datasets library, but also keeps label mappings.
We can use the [*transformers* library](https://huggingface.co/docs/transformers) to compute embeddings and predictions on the CIFAR-100 image classification problem. We install the libraries via pip:
```bash
pip install renumics-spotlight datasets transformers[torch]
```
Now we can compute the enrichment:
```python
import torch
import transformers
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_name = "Ahmed9275/Vit-Cifar100"
processor = transformers.ViTImageProcessor.from_pretrained(model_name)
cls_model = transformers.ViTForImageClassification.from_pretrained(model_name).to(device)
fe_model = transformers.ViTModel.from_pretrained(model_name).to(device)
def infer(batch):
images = [image.convert("RGB") for image in batch]
inputs = processor(images=images, return_tensors="pt").to(device)
with torch.no_grad():
outputs = cls_model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1).cpu().numpy()
embeddings = fe_model(**inputs).last_hidden_state[:, 0].cpu().numpy()
preds = probs.argmax(axis=-1)
return {"prediction": preds, "embedding": embeddings}
features = datasets.Features({**ds.features, "prediction": ds.features["fine_label"], "embedding": datasets.Sequence(feature=datasets.Value("float32"), length=768)})
ds_enriched = ds.map(infer, input_columns="img", batched=True, batch_size=2, features=features)
```
If you don’t want to perform the full inference run, you can alternatively download pre-computed model results for CIFAR-100 to follow this tutorial:
```python
ds_results = datasets.load_dataset('renumics/spotlight-cifar100-enrichment', split='test')
ds_enriched = datasets.concatenate_datasets([ds, ds_results], axis=1)
```
We can now use the results to interactively explore relevant data samples and clusters in Spotlight:
```python
layout = spotlight.layouts.debug_classification(label='fine_label', embedding='embedding', inspect={'img': spotlight.dtypes.image_dtype})
spotlight.show(ds_enriched, dtype={'embedding': spotlight.Embedding}, layout=layout)
```
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/cifar-100-model-debugging.png" alt="CIFAR-100 model debugging layout example.">
</figure>
## Customizing data inspection workflows
Visualization layouts can be interactively changed, saved and loaded in the GUI: You can select different widget types and configurations. The *Inspector* widget allows to represent multimodal data samples including text, image, audio, video and time series data.
You can also define layouts through the [Python API](https://renumics.com/api/spotlight/). This option is especially useful for building custom data inspection and curation workflows including EDA, model debugging and model monitoring tasks.
In combination with the data issues widget, the Python API offers a great way to integrate the results of existing scripts (e.g. data quality checks or model monitoring) into a scalable data inspection workflow.
## Using Spotlight on the Hugging Face hub
You can use Spotlight directly on your local NLP, audio, CV or multimodal dataset. If you would like to showcase your dataset or model results on the Hugging Face hub, you can use Hugging Face spaces to launch a Spotlight visualization for it.
We have already prepared [example spaces](https://huggingface.co/renumics) for many popular NLP, audio and CV datasets on the hub. You can simply duplicate one of these spaces and specify your dataset in the `HF_DATASET` variable.
You can optionally choose a dataset that contains model results and other configuration options such as splits, subsets or dataset revisions.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/space_duplication.png" alt="Creating a new dataset visualization with Spotlight by duplicating a Hugging Face space.">
</figure>
## What’s next?
With Spotlight you can create **interactive visualizations** and leverage data enrichments to **identify critical clusters** in your Hugging Face datasets. In this blog, we have seen both an audio ML and a computer vision example.
You can use Spotlight directly to explore and curate your NLP, audio, CV or multimodal dataset:
- Install Spotlight: *pip install renumics-spotlight*
- Check out the [documentation](https://renumics.com/docs) or open an issue on [Github](https://github.com/Renumics/spotlight)
- Join the [Spotlight community](https://discord.gg/VAQdFCU5YD) on Discord
- Follow us on [Twitter](https://twitter.com/renumics) and [LinkedIn](https://www.linkedin.com/company/renumics) | huggingface/blog/blob/main/scalable-data-inspection.md |
DeeBERT: Early Exiting for *BERT
This is the code base for the paper [DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference](https://www.aclweb.org/anthology/2020.acl-main.204/), modified from its [original code base](https://github.com/castorini/deebert).
The original code base also has information for downloading sample models that we have trained in advance.
## Usage
There are three scripts in the folder which can be run directly.
In each script, there are several things to modify before running:
* `PATH_TO_DATA`: path to the GLUE dataset.
* `--output_dir`: path for saving fine-tuned models. Default: `./saved_models`.
* `--plot_data_dir`: path for saving evaluation results. Default: `./results`. Results are printed to stdout and also saved to `npy` files in this directory to facilitate plotting figures and further analyses.
* `MODEL_TYPE`: bert or roberta
* `MODEL_SIZE`: base or large
* `DATASET`: SST-2, MRPC, RTE, QNLI, QQP, or MNLI
#### train_deebert.sh
This is for fine-tuning DeeBERT models.
#### eval_deebert.sh
This is for evaluating each exit layer for fine-tuned DeeBERT models.
#### entropy_eval.sh
This is for evaluating fine-tuned DeeBERT models, given a number of different early exit entropy thresholds.
## Citation
Please cite our paper if you find the resource useful:
```
@inproceedings{xin-etal-2020-deebert,
title = "{D}ee{BERT}: Dynamic Early Exiting for Accelerating {BERT} Inference",
author = "Xin, Ji and
Tang, Raphael and
Lee, Jaejun and
Yu, Yaoliang and
Lin, Jimmy",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.204",
pages = "2246--2251",
}
```
| huggingface/transformers/blob/main/examples/research_projects/deebert/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Multitask Prompt Tuning
[Multitask Prompt Tuning](https://huggingface.co/papers/2303.02861) decomposes the soft prompts of each task into a single learned transferable prompt instead of a separate prompt for each task. The single learned prompt can be adapted for each task by multiplicative low rank updates.
The abstract from the paper is:
*Prompt tuning, in which a base pretrained model is adapted to each task via conditioning on learned prompt vectors, has emerged as a promising approach for efficiently adapting large language models to multiple downstream tasks. However, existing methods typically learn soft prompt vectors from scratch, and it has not been clear how to exploit the rich cross-task knowledge with prompt vectors in a multitask learning setting. We propose multitask prompt tuning (MPT), which first learns a single transferable prompt by distilling knowledge from multiple task-specific source prompts. We then learn multiplicative low rank updates to this shared prompt to efficiently adapt it to each downstream target task. Extensive experiments on 23 NLP datasets demonstrate that our proposed approach outperforms the state-of-the-art methods, including the full finetuning baseline in some cases, despite only tuning 0.035% as many task-specific parameters*.
## MultitaskPromptTuningConfig
[[autodoc]] tuners.multitask_prompt_tuning.config.MultitaskPromptTuningConfig
## MultitaskPromptEmbedding
[[autodoc]] tuners.multitask_prompt_tuning.model.MultitaskPromptEmbedding | huggingface/peft/blob/main/docs/source/package_reference/multitask_prompt_tuning.md |
(Tensorflow) EfficientNet Lite
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use \\( 2^N \\) times more computational resources, then we can simply increase the network depth by \\( \alpha ^ N \\), width by \\( \beta ^ N \\), and image size by \\( \gamma ^ N \\), where \\( \alpha, \beta, \gamma \\) are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient \\( \phi \\) to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2).
EfficientNet-Lite makes EfficientNet more suitable for mobile devices by introducing [ReLU6](https://paperswithcode.com/method/relu6) activation functions and removing [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation).
The weights from this model were ported from [Tensorflow/TPU](https://github.com/tensorflow/tpu).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('tf_efficientnet_lite0', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `tf_efficientnet_lite0`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('tf_efficientnet_lite0', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: TF EfficientNet Lite
Paper:
Title: 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/efficientnet-rethinking-model-scaling-for
Models:
- Name: tf_efficientnet_lite0
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 488052032
Parameters: 4650000
File Size: 18820223
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite0
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1596
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite0-0aa007d2.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.83%
Top 5 Accuracy: 92.17%
- Name: tf_efficientnet_lite1
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 773639520
Parameters: 5420000
File Size: 21939331
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite1
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1607
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite1-bde8b488.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.67%
Top 5 Accuracy: 93.24%
- Name: tf_efficientnet_lite2
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 1068494432
Parameters: 6090000
File Size: 24658687
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite2
Crop Pct: '0.89'
Image Size: '260'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1618
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite2-dcccb7df.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.48%
Top 5 Accuracy: 93.75%
- Name: tf_efficientnet_lite3
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 2011534304
Parameters: 8199999
File Size: 33161413
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite3
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1629
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite3-b733e338.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.83%
Top 5 Accuracy: 94.91%
- Name: tf_efficientnet_lite4
In Collection: TF EfficientNet Lite
Metadata:
FLOPs: 5164802912
Parameters: 13010000
File Size: 52558819
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- RELU6
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: tf_efficientnet_lite4
Crop Pct: '0.92'
Image Size: '380'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1640
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_lite4-741542c3.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.54%
Top 5 Accuracy: 95.66%
-->
| huggingface/pytorch-image-models/blob/main/hfdocs/source/models/tf-efficientnet-lite.mdx |
User Studies
## Model Card Audiences and Use Cases
During our investigation into the landscape of model documentation tools (data cards etc), we noted how different stakeholders make use of existing infrastructure to create a kind of model card with information focused on their needed domain.
One such example are ‘business analysts’ or those whose focus is on B2B as well as an internal only audience.The static and more manual approach for this audience is using Confluence pages. (*if PMs write the page, we are detaching the model creators from its theoretical consumption; if ML engineers write the page, they may tend to stress only a certain type of information.* [^1]) or a proposed combination of HTML (Jinja) templates, Metaflow classes and external APi keys, in order to create model cards that include a perspective of the model information that is needed for their domain/use case.
We conducted a user study, with the aim of validating a literature informed model card structure and to understand sections/ areas of ranked importance for the different stakeholders perspectives. The study aimed to validate the following components:
* **Model Card Layout**
During our examination of the state of the art of model cards, which noted recurring sections from the top ~100 downloaded models on the hub that had model cards. From this analysis we catalogued the top recurring model card sections and recurring information, this coupled with the structure of the Bloom model card, lead us to the initial version of a standard model card structure.
As we began to structure our user studies, two variations of model cards - that made use of the [initial model card structure](./model-card-annotated) - were used as interactive demonstrations. The aim of these demo’s was to understand not only the different user perspectives on the visual elements of the model card’s but also the content presented to users. The {desired} outcome would enable us to further understand what makes a model card both easier to read, still providing some level of interactivity within the model cards, all while presenting the information in an easily understandable [approachable] manner.
* **Stakeholder Perspectives**
As different people, of varying technical backgrounds, could be collaborating on a model and subsequently the model card, we sought to validate the need for different stakeholders perspectives. Based on the ease of use of writing the different model card sections and the sections that one would read first
Participants ranked the different sections of model cards in the perspective of one reading a model card and then as an author of a model card. An ordering scheme - 1 being the highest weight and 10 being the lowest - was applied to the different sections that the user would usually read first in a model card and the sections of a model card that a model card author would find easiest to write.
## Summary of Responses to the User Studies Survey
Our user studies provided further clarity on the sections that different user profiles/stakeholders would find more challenging or easier to write.
The results illustrated below show that while the Bias, Risks and Limitations section ranks second for both model card writers and model card readers for *In what order do you write the model card and What section do you look at first*, respectively, it is also noted as the most challenging/longest section to write. This favoured/endorsed the need to further evaluate the Bias, Risks and Limitations sections in order to assist with writing this decisive/imperative section.
These templates were then used to generate model cards for the top 200 most downloaded Hugging Face (HF) models.
* We first began by pulling all Hugging Face model's on the hub and, in particular, subsections on Limitations and Bias ("Risks" subsections were largely not present).
* Based on inputs that were the most continuously used with a higher number of model downloads, grouped by model typed, the tool provides prompted text within the Bias, Risks and Limitations sections. We also prompt a default text if the model type is not specified.
Using this information, we returned back to our analysis of all model cards on the hub, coupled with suggestions from other researchers and peers at HF and additional research on the type of prompted information we could provide to users while they are creating model cards. These defaulted prompted text allowed us to satisfy the aims:
1) For those who have not created model cards before or who do not usually make a model card or any other type of model documentation for their model’s, the prompted text enables these users to easily create a model card. This in turn increased the number of model cards created.
2) Users who already write model cards, the prompted text invites them to add more to their model card, further developing the content/standard of model cards.
## User Study Details
We selected people from a variety of different backgrounds relevant to machine learning and model documentation. Below, we detail their demographics, the questions they were asked, and the corresponding insights from their responses. Full details on responses are available in [Appendix A](./model-card-appendix#appendix-a-user-study).
### Respondent Demographics
* Tech & Regulatory Affairs Counsel
* ML Engineer (x2)
* Developer Advocate
* Executive Assistant
* Monetization Lead
* Policy Manager/AI Researcher
* Research Intern
**What are the key pieces of information you want or need to know about a model when interacting with a machine learning model?**
**Insight:**
* Respondents prioritised information about the model task/domain (x3), training data/training procedure (x2), how to use the model (with code) (x2), bias and limitations, and the model licence
### Feedback on Specific Model Card Formats
#### Format 1:
**Current [distilgpt2 model card](https://huggingface.co/distilgpt2) on the Hub**
**Insights:**
* Respondents found this model card format to be concise, complete, and readable.
* There was no consensus about the collapsible sections (some liked them and wanted more, some disliked them).
* Some respondents said “Risks and Limitations” should go with “Out of Scope Uses”
#### Format 2:
**Nazneen Rajani's [Interactive Model Card space](https://huggingface.co/spaces/nazneen/interactive-model-cards)**
**Insights:**
* While a few respondents really liked this format, most found it overwhelming or as an overload of information. Several suggested this could be a nice tool to layer onto a base model card for more advanced audiences.
#### Format 3:
**Ezi Ozoani's [Semi-Interactive Model Card Space](https://huggingface.co/spaces/Ezi/ModelCardsAnalysis)**
**Insights:**
* Several respondents found this format overwhelming, but they generally found it less overwhelming than format 2.
* Several respondents disagreed with the current layout and gave specific feedback about which sections should be prioritised within each column.
### Section Rankings
*Ordered based on average ranking. Arrows are shown relative to the order of the associated section in the question on the survey.*
**Insights:**
* When writing model cards, respondents generally said they would write a model card in the same order in which the sections were listed in the survey question.
* When ranking the sections of the model card by ease/quickness of writing, consensus was that the sections on uses and limitations and risks were the most difficult.
* When reading model cards, respondents said they looked at the cards’ sections in an order that was close to – but not perfectly aligned with – the order in which the sections were listed in the survey question.
.png)
.png)
<Tip>
[Checkout the Appendix](./model-card-appendix)
</Tip>
Acknowledgements
================
We want to acknowledge and thank [Bibi Ofuya](https://www.figma.com/proto/qrPCjWfFz5HEpWqQ0PJSWW/Bibi's-Portfolio?page-id=0%3A1&node-id=1%3A28&viewport=243%2C48%2C0.2&scaling=min-zoom&starting-point-node-id=1%3A28) for her question creation and her guidance on user-focused ordering and presentation during the user studies.
[^1]: See https://towardsdatascience.com/dag-card-is-the-new-model-card-70754847a111
| huggingface/hub-docs/blob/main/docs/hub/model-cards-user-studies.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Evaluating Diffusion Models
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/evaluation.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Evaluation of generative models like [Stable Diffusion](https://huggingface.co/docs/diffusers/stable_diffusion) is subjective in nature. But as practitioners and researchers, we often have to make careful choices amongst many different possibilities. So, when working with different generative models (like GANs, Diffusion, etc.), how do we choose one over the other?
Qualitative evaluation of such models can be error-prone and might incorrectly influence a decision.
However, quantitative metrics don't necessarily correspond to image quality. So, usually, a combination
of both qualitative and quantitative evaluations provides a stronger signal when choosing one model
over the other.
In this document, we provide a non-exhaustive overview of qualitative and quantitative methods to evaluate Diffusion models. For quantitative methods, we specifically focus on how to implement them alongside `diffusers`.
The methods shown in this document can also be used to evaluate different [noise schedulers](https://huggingface.co/docs/diffusers/main/en/api/schedulers/overview) keeping the underlying generation model fixed.
## Scenarios
We cover Diffusion models with the following pipelines:
- Text-guided image generation (such as the [`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/text2img)).
- Text-guided image generation, additionally conditioned on an input image (such as the [`StableDiffusionImg2ImgPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/img2img) and [`StableDiffusionInstructPix2PixPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pix2pix)).
- Class-conditioned image generation models (such as the [`DiTPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/dit)).
## Qualitative Evaluation
Qualitative evaluation typically involves human assessment of generated images. Quality is measured across aspects such as compositionality, image-text alignment, and spatial relations. Common prompts provide a degree of uniformity for subjective metrics.
DrawBench and PartiPrompts are prompt datasets used for qualitative benchmarking. DrawBench and PartiPrompts were introduced by [Imagen](https://imagen.research.google/) and [Parti](https://parti.research.google/) respectively.
From the [official Parti website](https://parti.research.google/):
> PartiPrompts (P2) is a rich set of over 1600 prompts in English that we release as part of this work. P2 can be used to measure model capabilities across various categories and challenge aspects.
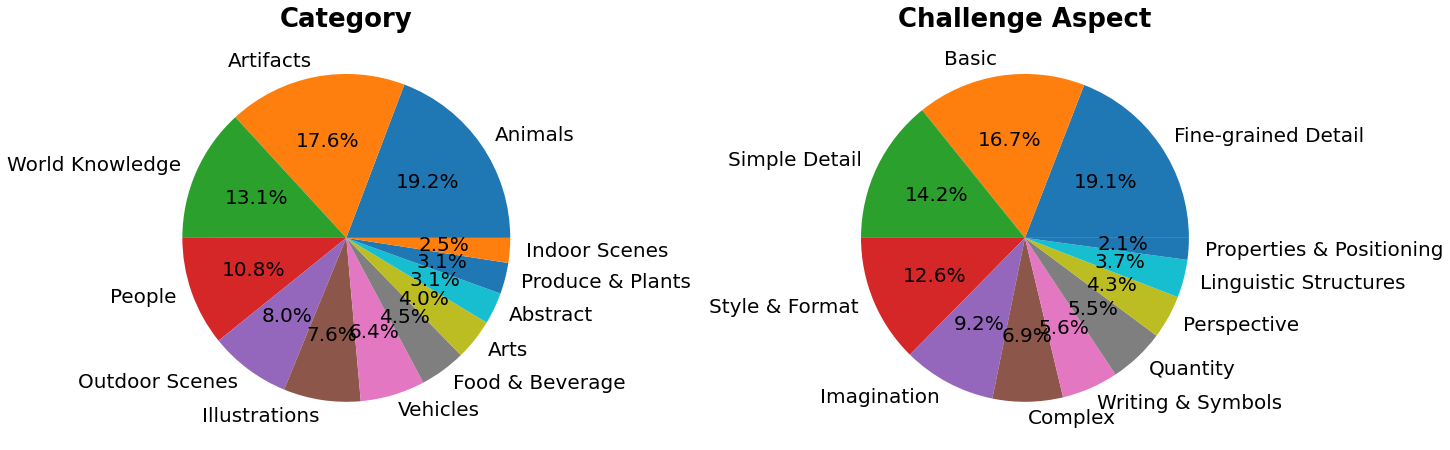
PartiPrompts has the following columns:
- Prompt
- Category of the prompt (such as “Abstract”, “World Knowledge”, etc.)
- Challenge reflecting the difficulty (such as “Basic”, “Complex”, “Writing & Symbols”, etc.)
These benchmarks allow for side-by-side human evaluation of different image generation models.
For this, the 🧨 Diffusers team has built **Open Parti Prompts**, which is a community-driven qualitative benchmark based on Parti Prompts to compare state-of-the-art open-source diffusion models:
- [Open Parti Prompts Game](https://huggingface.co/spaces/OpenGenAI/open-parti-prompts): For 10 parti prompts, 4 generated images are shown and the user selects the image that suits the prompt best.
- [Open Parti Prompts Leaderboard](https://huggingface.co/spaces/OpenGenAI/parti-prompts-leaderboard): The leaderboard comparing the currently best open-sourced diffusion models to each other.
To manually compare images, let’s see how we can use `diffusers` on a couple of PartiPrompts.
Below we show some prompts sampled across different challenges: Basic, Complex, Linguistic Structures, Imagination, and Writing & Symbols. Here we are using PartiPrompts as a [dataset](https://huggingface.co/datasets/nateraw/parti-prompts).
```python
from datasets import load_dataset
# prompts = load_dataset("nateraw/parti-prompts", split="train")
# prompts = prompts.shuffle()
# sample_prompts = [prompts[i]["Prompt"] for i in range(5)]
# Fixing these sample prompts in the interest of reproducibility.
sample_prompts = [
"a corgi",
"a hot air balloon with a yin-yang symbol, with the moon visible in the daytime sky",
"a car with no windows",
"a cube made of porcupine",
'The saying "BE EXCELLENT TO EACH OTHER" written on a red brick wall with a graffiti image of a green alien wearing a tuxedo. A yellow fire hydrant is on a sidewalk in the foreground.',
]
```
Now we can use these prompts to generate some images using Stable Diffusion ([v1-4 checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4)):
```python
import torch
seed = 0
generator = torch.manual_seed(seed)
images = sd_pipeline(sample_prompts, num_images_per_prompt=1, generator=generator).images
```

We can also set `num_images_per_prompt` accordingly to compare different images for the same prompt. Running the same pipeline but with a different checkpoint ([v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)), yields:

Once several images are generated from all the prompts using multiple models (under evaluation), these results are presented to human evaluators for scoring. For
more details on the DrawBench and PartiPrompts benchmarks, refer to their respective papers.
<Tip>
It is useful to look at some inference samples while a model is training to measure the
training progress. In our [training scripts](https://github.com/huggingface/diffusers/tree/main/examples/), we support this utility with additional support for
logging to TensorBoard and Weights & Biases.
</Tip>
## Quantitative Evaluation
In this section, we will walk you through how to evaluate three different diffusion pipelines using:
- CLIP score
- CLIP directional similarity
- FID
### Text-guided image generation
[CLIP score](https://arxiv.org/abs/2104.08718) measures the compatibility of image-caption pairs. Higher CLIP scores imply higher compatibility 🔼. The CLIP score is a quantitative measurement of the qualitative concept "compatibility". Image-caption pair compatibility can also be thought of as the semantic similarity between the image and the caption. CLIP score was found to have high correlation with human judgement.
Let's first load a [`StableDiffusionPipeline`]:
```python
from diffusers import StableDiffusionPipeline
import torch
model_ckpt = "CompVis/stable-diffusion-v1-4"
sd_pipeline = StableDiffusionPipeline.from_pretrained(model_ckpt, torch_dtype=torch.float16).to("cuda")
```
Generate some images with multiple prompts:
```python
prompts = [
"a photo of an astronaut riding a horse on mars",
"A high tech solarpunk utopia in the Amazon rainforest",
"A pikachu fine dining with a view to the Eiffel Tower",
"A mecha robot in a favela in expressionist style",
"an insect robot preparing a delicious meal",
"A small cabin on top of a snowy mountain in the style of Disney, artstation",
]
images = sd_pipeline(prompts, num_images_per_prompt=1, output_type="np").images
print(images.shape)
# (6, 512, 512, 3)
```
And then, we calculate the CLIP score.
```python
from torchmetrics.functional.multimodal import clip_score
from functools import partial
clip_score_fn = partial(clip_score, model_name_or_path="openai/clip-vit-base-patch16")
def calculate_clip_score(images, prompts):
images_int = (images * 255).astype("uint8")
clip_score = clip_score_fn(torch.from_numpy(images_int).permute(0, 3, 1, 2), prompts).detach()
return round(float(clip_score), 4)
sd_clip_score = calculate_clip_score(images, prompts)
print(f"CLIP score: {sd_clip_score}")
# CLIP score: 35.7038
```
In the above example, we generated one image per prompt. If we generated multiple images per prompt, we would have to take the average score from the generated images per prompt.
Now, if we wanted to compare two checkpoints compatible with the [`StableDiffusionPipeline`] we should pass a generator while calling the pipeline. First, we generate images with a
fixed seed with the [v1-4 Stable Diffusion checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4):
```python
seed = 0
generator = torch.manual_seed(seed)
images = sd_pipeline(prompts, num_images_per_prompt=1, generator=generator, output_type="np").images
```
Then we load the [v1-5 checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5) to generate images:
```python
model_ckpt_1_5 = "runwayml/stable-diffusion-v1-5"
sd_pipeline_1_5 = StableDiffusionPipeline.from_pretrained(model_ckpt_1_5, torch_dtype=weight_dtype).to(device)
images_1_5 = sd_pipeline_1_5(prompts, num_images_per_prompt=1, generator=generator, output_type="np").images
```
And finally, we compare their CLIP scores:
```python
sd_clip_score_1_4 = calculate_clip_score(images, prompts)
print(f"CLIP Score with v-1-4: {sd_clip_score_1_4}")
# CLIP Score with v-1-4: 34.9102
sd_clip_score_1_5 = calculate_clip_score(images_1_5, prompts)
print(f"CLIP Score with v-1-5: {sd_clip_score_1_5}")
# CLIP Score with v-1-5: 36.2137
```
It seems like the [v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint performs better than its predecessor. Note, however, that the number of prompts we used to compute the CLIP scores is quite low. For a more practical evaluation, this number should be way higher, and the prompts should be diverse.
<Tip warning={true}>
By construction, there are some limitations in this score. The captions in the training dataset
were crawled from the web and extracted from `alt` and similar tags associated an image on the internet.
They are not necessarily representative of what a human being would use to describe an image. Hence we
had to "engineer" some prompts here.
</Tip>
### Image-conditioned text-to-image generation
In this case, we condition the generation pipeline with an input image as well as a text prompt. Let's take the [`StableDiffusionInstructPix2PixPipeline`], as an example. It takes an edit instruction as an input prompt and an input image to be edited.
Here is one example:

One strategy to evaluate such a model is to measure the consistency of the change between the two images (in [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) space) with the change between the two image captions (as shown in [CLIP-Guided Domain Adaptation of Image Generators](https://arxiv.org/abs/2108.00946)). This is referred to as the "**CLIP directional similarity**".
- Caption 1 corresponds to the input image (image 1) that is to be edited.
- Caption 2 corresponds to the edited image (image 2). It should reflect the edit instruction.
Following is a pictorial overview:

We have prepared a mini dataset to implement this metric. Let's first load the dataset.
```python
from datasets import load_dataset
dataset = load_dataset("sayakpaul/instructpix2pix-demo", split="train")
dataset.features
```
```bash
{'input': Value(dtype='string', id=None),
'edit': Value(dtype='string', id=None),
'output': Value(dtype='string', id=None),
'image': Image(decode=True, id=None)}
```
Here we have:
- `input` is a caption corresponding to the `image`.
- `edit` denotes the edit instruction.
- `output` denotes the modified caption reflecting the `edit` instruction.
Let's take a look at a sample.
```python
idx = 0
print(f"Original caption: {dataset[idx]['input']}")
print(f"Edit instruction: {dataset[idx]['edit']}")
print(f"Modified caption: {dataset[idx]['output']}")
```
```bash
Original caption: 2. FAROE ISLANDS: An archipelago of 18 mountainous isles in the North Atlantic Ocean between Norway and Iceland, the Faroe Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
Edit instruction: make the isles all white marble
Modified caption: 2. WHITE MARBLE ISLANDS: An archipelago of 18 mountainous white marble isles in the North Atlantic Ocean between Norway and Iceland, the White Marble Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
```
And here is the image:
```python
dataset[idx]["image"]
```

We will first edit the images of our dataset with the edit instruction and compute the directional similarity.
Let's first load the [`StableDiffusionInstructPix2PixPipeline`]:
```python
from diffusers import StableDiffusionInstructPix2PixPipeline
instruct_pix2pix_pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
"timbrooks/instruct-pix2pix", torch_dtype=torch.float16
).to(device)
```
Now, we perform the edits:
```python
import numpy as np
def edit_image(input_image, instruction):
image = instruct_pix2pix_pipeline(
instruction,
image=input_image,
output_type="np",
generator=generator,
).images[0]
return image
input_images = []
original_captions = []
modified_captions = []
edited_images = []
for idx in range(len(dataset)):
input_image = dataset[idx]["image"]
edit_instruction = dataset[idx]["edit"]
edited_image = edit_image(input_image, edit_instruction)
input_images.append(np.array(input_image))
original_captions.append(dataset[idx]["input"])
modified_captions.append(dataset[idx]["output"])
edited_images.append(edited_image)
```
To measure the directional similarity, we first load CLIP's image and text encoders:
```python
from transformers import (
CLIPTokenizer,
CLIPTextModelWithProjection,
CLIPVisionModelWithProjection,
CLIPImageProcessor,
)
clip_id = "openai/clip-vit-large-patch14"
tokenizer = CLIPTokenizer.from_pretrained(clip_id)
text_encoder = CLIPTextModelWithProjection.from_pretrained(clip_id).to(device)
image_processor = CLIPImageProcessor.from_pretrained(clip_id)
image_encoder = CLIPVisionModelWithProjection.from_pretrained(clip_id).to(device)
```
Notice that we are using a particular CLIP checkpoint, i.e., `openai/clip-vit-large-patch14`. This is because the Stable Diffusion pre-training was performed with this CLIP variant. For more details, refer to the [documentation](https://huggingface.co/docs/transformers/model_doc/clip).
Next, we prepare a PyTorch `nn.Module` to compute directional similarity:
```python
import torch.nn as nn
import torch.nn.functional as F
class DirectionalSimilarity(nn.Module):
def __init__(self, tokenizer, text_encoder, image_processor, image_encoder):
super().__init__()
self.tokenizer = tokenizer
self.text_encoder = text_encoder
self.image_processor = image_processor
self.image_encoder = image_encoder
def preprocess_image(self, image):
image = self.image_processor(image, return_tensors="pt")["pixel_values"]
return {"pixel_values": image.to(device)}
def tokenize_text(self, text):
inputs = self.tokenizer(
text,
max_length=self.tokenizer.model_max_length,
padding="max_length",
truncation=True,
return_tensors="pt",
)
return {"input_ids": inputs.input_ids.to(device)}
def encode_image(self, image):
preprocessed_image = self.preprocess_image(image)
image_features = self.image_encoder(**preprocessed_image).image_embeds
image_features = image_features / image_features.norm(dim=1, keepdim=True)
return image_features
def encode_text(self, text):
tokenized_text = self.tokenize_text(text)
text_features = self.text_encoder(**tokenized_text).text_embeds
text_features = text_features / text_features.norm(dim=1, keepdim=True)
return text_features
def compute_directional_similarity(self, img_feat_one, img_feat_two, text_feat_one, text_feat_two):
sim_direction = F.cosine_similarity(img_feat_two - img_feat_one, text_feat_two - text_feat_one)
return sim_direction
def forward(self, image_one, image_two, caption_one, caption_two):
img_feat_one = self.encode_image(image_one)
img_feat_two = self.encode_image(image_two)
text_feat_one = self.encode_text(caption_one)
text_feat_two = self.encode_text(caption_two)
directional_similarity = self.compute_directional_similarity(
img_feat_one, img_feat_two, text_feat_one, text_feat_two
)
return directional_similarity
```
Let's put `DirectionalSimilarity` to use now.
```python
dir_similarity = DirectionalSimilarity(tokenizer, text_encoder, image_processor, image_encoder)
scores = []
for i in range(len(input_images)):
original_image = input_images[i]
original_caption = original_captions[i]
edited_image = edited_images[i]
modified_caption = modified_captions[i]
similarity_score = dir_similarity(original_image, edited_image, original_caption, modified_caption)
scores.append(float(similarity_score.detach().cpu()))
print(f"CLIP directional similarity: {np.mean(scores)}")
# CLIP directional similarity: 0.0797976553440094
```
Like the CLIP Score, the higher the CLIP directional similarity, the better it is.
It should be noted that the `StableDiffusionInstructPix2PixPipeline` exposes two arguments, namely, `image_guidance_scale` and `guidance_scale` that let you control the quality of the final edited image. We encourage you to experiment with these two arguments and see the impact of that on the directional similarity.
We can extend the idea of this metric to measure how similar the original image and edited version are. To do that, we can just do `F.cosine_similarity(img_feat_two, img_feat_one)`. For these kinds of edits, we would still want the primary semantics of the images to be preserved as much as possible, i.e., a high similarity score.
We can use these metrics for similar pipelines such as the [`StableDiffusionPix2PixZeroPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pix2pix_zero#diffusers.StableDiffusionPix2PixZeroPipeline).
<Tip>
Both CLIP score and CLIP direction similarity rely on the CLIP model, which can make the evaluations biased.
</Tip>
***Extending metrics like IS, FID (discussed later), or KID can be difficult*** when the model under evaluation was pre-trained on a large image-captioning dataset (such as the [LAION-5B dataset](https://laion.ai/blog/laion-5b/)). This is because underlying these metrics is an InceptionNet (pre-trained on the ImageNet-1k dataset) used for extracting intermediate image features. The pre-training dataset of Stable Diffusion may have limited overlap with the pre-training dataset of InceptionNet, so it is not a good candidate here for feature extraction.
***Using the above metrics helps evaluate models that are class-conditioned. For example, [DiT](https://huggingface.co/docs/diffusers/main/en/api/pipelines/dit). It was pre-trained being conditioned on the ImageNet-1k classes.***
### Class-conditioned image generation
Class-conditioned generative models are usually pre-trained on a class-labeled dataset such as [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k). Popular metrics for evaluating these models include Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and Inception Score (IS). In this document, we focus on FID ([Heusel et al.](https://arxiv.org/abs/1706.08500)). We show how to compute it with the [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit), which uses the [DiT model](https://arxiv.org/abs/2212.09748) under the hood.
FID aims to measure how similar are two datasets of images. As per [this resource](https://mmgeneration.readthedocs.io/en/latest/quick_run.html#fid):
> Fréchet Inception Distance is a measure of similarity between two datasets of images. It was shown to correlate well with the human judgment of visual quality and is most often used to evaluate the quality of samples of Generative Adversarial Networks. FID is calculated by computing the Fréchet distance between two Gaussians fitted to feature representations of the Inception network.
These two datasets are essentially the dataset of real images and the dataset of fake images (generated images in our case). FID is usually calculated with two large datasets. However, for this document, we will work with two mini datasets.
Let's first download a few images from the ImageNet-1k training set:
```python
from zipfile import ZipFile
import requests
def download(url, local_filepath):
r = requests.get(url)
with open(local_filepath, "wb") as f:
f.write(r.content)
return local_filepath
dummy_dataset_url = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/sample-imagenet-images.zip"
local_filepath = download(dummy_dataset_url, dummy_dataset_url.split("/")[-1])
with ZipFile(local_filepath, "r") as zipper:
zipper.extractall(".")
```
```python
from PIL import Image
import os
dataset_path = "sample-imagenet-images"
image_paths = sorted([os.path.join(dataset_path, x) for x in os.listdir(dataset_path)])
real_images = [np.array(Image.open(path).convert("RGB")) for path in image_paths]
```
These are 10 images from the following ImageNet-1k classes: "cassette_player", "chain_saw" (x2), "church", "gas_pump" (x3), "parachute" (x2), and "tench".
<p align="center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/real-images.png" alt="real-images"><br>
<em>Real images.</em>
</p>
Now that the images are loaded, let's apply some lightweight pre-processing on them to use them for FID calculation.
```python
from torchvision.transforms import functional as F
def preprocess_image(image):
image = torch.tensor(image).unsqueeze(0)
image = image.permute(0, 3, 1, 2) / 255.0
return F.center_crop(image, (256, 256))
real_images = torch.cat([preprocess_image(image) for image in real_images])
print(real_images.shape)
# torch.Size([10, 3, 256, 256])
```
We now load the [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit) to generate images conditioned on the above-mentioned classes.
```python
from diffusers import DiTPipeline, DPMSolverMultistepScheduler
dit_pipeline = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256", torch_dtype=torch.float16)
dit_pipeline.scheduler = DPMSolverMultistepScheduler.from_config(dit_pipeline.scheduler.config)
dit_pipeline = dit_pipeline.to("cuda")
words = [
"cassette player",
"chainsaw",
"chainsaw",
"church",
"gas pump",
"gas pump",
"gas pump",
"parachute",
"parachute",
"tench",
]
class_ids = dit_pipeline.get_label_ids(words)
output = dit_pipeline(class_labels=class_ids, generator=generator, output_type="np")
fake_images = output.images
fake_images = torch.tensor(fake_images)
fake_images = fake_images.permute(0, 3, 1, 2)
print(fake_images.shape)
# torch.Size([10, 3, 256, 256])
```
Now, we can compute the FID using [`torchmetrics`](https://torchmetrics.readthedocs.io/).
```python
from torchmetrics.image.fid import FrechetInceptionDistance
fid = FrechetInceptionDistance(normalize=True)
fid.update(real_images, real=True)
fid.update(fake_images, real=False)
print(f"FID: {float(fid.compute())}")
# FID: 177.7147216796875
```
The lower the FID, the better it is. Several things can influence FID here:
- Number of images (both real and fake)
- Randomness induced in the diffusion process
- Number of inference steps in the diffusion process
- The scheduler being used in the diffusion process
For the last two points, it is, therefore, a good practice to run the evaluation across different seeds and inference steps, and then report an average result.
<Tip warning={true}>
FID results tend to be fragile as they depend on a lot of factors:
* The specific Inception model used during computation.
* The implementation accuracy of the computation.
* The image format (not the same if we start from PNGs vs JPGs).
Keeping that in mind, FID is often most useful when comparing similar runs, but it is
hard to reproduce paper results unless the authors carefully disclose the FID
measurement code.
These points apply to other related metrics too, such as KID and IS.
</Tip>
As a final step, let's visually inspect the `fake_images`.
<p align="center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/fake-images.png" alt="fake-images"><br>
<em>Fake images.</em>
</p>
| huggingface/diffusers/blob/main/docs/source/en/conceptual/evaluation.md |
Docker Spaces Examples
We gathered some example demos in the [Spaces Examples](https://huggingface.co/SpacesExamples) organization. Please check them out!
* Dummy FastAPI app: https://huggingface.co/spaces/DockerTemplates/fastapi_dummy
* FastAPI app serving a static site and using `transformers`: https://huggingface.co/spaces/DockerTemplates/fastapi_t5
* Phoenix app for https://huggingface.co/spaces/DockerTemplates/single_file_phx_bumblebee_ml
* HTTP endpoint in Go with query parameters https://huggingface.co/spaces/XciD/test-docker-go?q=Adrien
* Shiny app written in Python https://huggingface.co/spaces/elonmuskceo/shiny-orbit-simulation
* Genie.jl app in Julia https://huggingface.co/spaces/nooji/GenieOnHuggingFaceSpaces
* Argilla app for data labelling and curation: https://huggingface.co/spaces/argilla/live-demo and [write-up about hosting Argilla on Spaces](./spaces-sdks-docker-argilla) by [@dvilasuero](https://huggingface.co/dvilasuero) 🎉
* JupyterLab and VSCode: https://huggingface.co/spaces/DockerTemplates/docker-examples
* Zeno app for interactive model evaluation: https://huggingface.co/spaces/zeno-ml/diffusiondb and [instructions for setup](https://zenoml.com/docs/deployment#hugging-face-spaces)
* Gradio App: https://huggingface.co/spaces/sayakpaul/demo-docker-gradio
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-examples.md |
Datasets
The Hugging Face Hub is home to a growing collection of datasets that span a variety of domains and tasks. These docs will guide you through interacting with the datasets on the Hub, uploading new datasets, exploring the datasets contents, and using datasets in your projects.
This documentation focuses on the datasets functionality in the Hugging Face Hub and how to use the datasets with supported libraries. For detailed information about the 🤗 Datasets python package, visit the [🤗 Datasets documentation](https://huggingface.co/docs/datasets/index).
## Contents
- [Datasets Overview](./datasets-overview)
- [Dataset Cards](./datasets-cards)
- [Gated Datasets](./datasets-gated)
- [Uploading Datasets](./datasets-adding)
- [Downloading Datasets](./datasets-downloading)
- [Libraries](./datasets-libraries)
- [Dataset Viewer](./datasets-viewer)
- [Data files Configuration](./datasets-data-files-configuration)
| huggingface/hub-docs/blob/main/docs/hub/datasets.md |
Advantage Actor-Critic (A2C) [[advantage-actor-critic]]
## Reducing variance with Actor-Critic methods
The solution to reducing the variance of the Reinforce algorithm and training our agent faster and better is to use a combination of Policy-Based and Value-Based methods: *the Actor-Critic method*.
To understand the Actor-Critic, imagine you're playing a video game. You can play with a friend that will provide you with some feedback. You're the Actor and your friend is the Critic.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/ac.jpg" alt="Actor Critic"/>
You don't know how to play at the beginning, **so you try some actions randomly**. The Critic observes your action and **provides feedback**.
Learning from this feedback, **you'll update your policy and be better at playing that game.**
On the other hand, your friend (Critic) will also update their way to provide feedback so it can be better next time.
This is the idea behind Actor-Critic. We learn two function approximations:
- *A policy* that **controls how our agent acts**: \\( \pi_{\theta}(s) \\)
- *A value function* to assist the policy update by measuring how good the action taken is: \\( \hat{q}_{w}(s,a) \\)
## The Actor-Critic Process
Now that we have seen the Actor Critic's big picture, let's dive deeper to understand how the Actor and Critic improve together during the training.
As we saw, with Actor-Critic methods, there are two function approximations (two neural networks):
- *Actor*, a **policy function** parameterized by theta: \\( \pi_{\theta}(s) \\)
- *Critic*, a **value function** parameterized by w: \\( \hat{q}_{w}(s,a) \\)
Let's see the training process to understand how the Actor and Critic are optimized:
- At each timestep, t, we get the current state \\( S_t\\) from the environment and **pass it as input through our Actor and Critic**.
- Our Policy takes the state and **outputs an action** \\( A_t \\).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step1.jpg" alt="Step 1 Actor Critic"/>
- The Critic takes that action also as input and, using \\( S_t\\) and \\( A_t \\), **computes the value of taking that action at that state: the Q-value**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step2.jpg" alt="Step 2 Actor Critic"/>
- The action \\( A_t\\) performed in the environment outputs a new state \\( S_{t+1}\\) and a reward \\( R_{t+1} \\) .
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step3.jpg" alt="Step 3 Actor Critic"/>
- The Actor updates its policy parameters using the Q value.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step4.jpg" alt="Step 4 Actor Critic"/>
- Thanks to its updated parameters, the Actor produces the next action to take at \\( A_{t+1} \\) given the new state \\( S_{t+1} \\).
- The Critic then updates its value parameters.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/step5.jpg" alt="Step 5 Actor Critic"/>
## Adding Advantage in Actor-Critic (A2C)
We can stabilize learning further by **using the Advantage function as Critic instead of the Action value function**.
The idea is that the Advantage function calculates the relative advantage of an action compared to the others possible at a state: **how taking that action at a state is better compared to the average value of the state**. It's subtracting the mean value of the state from the state action pair:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/advantage1.jpg" alt="Advantage Function"/>
In other words, this function calculates **the extra reward we get if we take this action at that state compared to the mean reward we get at that state**.
The extra reward is what's beyond the expected value of that state.
- If A(s,a) > 0: our gradient is **pushed in that direction**.
- If A(s,a) < 0 (our action does worse than the average value of that state), **our gradient is pushed in the opposite direction**.
The problem with implementing this advantage function is that it requires two value functions — \\( Q(s,a)\\) and \\( V(s)\\). Fortunately, **we can use the TD error as a good estimator of the advantage function.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/advantage2.jpg" alt="Advantage Function"/>
| huggingface/deep-rl-class/blob/main/units/en/unit6/advantage-actor-critic.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# UniDiffuser
The UniDiffuser model was proposed in [One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale](https://huggingface.co/papers/2303.06555) by Fan Bao, Shen Nie, Kaiwen Xue, Chongxuan Li, Shi Pu, Yaole Wang, Gang Yue, Yue Cao, Hang Su, Jun Zhu.
The abstract from the paper is:
*This paper proposes a unified diffusion framework (dubbed UniDiffuser) to fit all distributions relevant to a set of multi-modal data in one model. Our key insight is -- learning diffusion models for marginal, conditional, and joint distributions can be unified as predicting the noise in the perturbed data, where the perturbation levels (i.e. timesteps) can be different for different modalities. Inspired by the unified view, UniDiffuser learns all distributions simultaneously with a minimal modification to the original diffusion model -- perturbs data in all modalities instead of a single modality, inputs individual timesteps in different modalities, and predicts the noise of all modalities instead of a single modality. UniDiffuser is parameterized by a transformer for diffusion models to handle input types of different modalities. Implemented on large-scale paired image-text data, UniDiffuser is able to perform image, text, text-to-image, image-to-text, and image-text pair generation by setting proper timesteps without additional overhead. In particular, UniDiffuser is able to produce perceptually realistic samples in all tasks and its quantitative results (e.g., the FID and CLIP score) are not only superior to existing general-purpose models but also comparable to the bespoken models (e.g., Stable Diffusion and DALL-E 2) in representative tasks (e.g., text-to-image generation).*
You can find the original codebase at [thu-ml/unidiffuser](https://github.com/thu-ml/unidiffuser) and additional checkpoints at [thu-ml](https://huggingface.co/thu-ml).
<Tip warning={true}>
There is currently an issue on PyTorch 1.X where the output images are all black or the pixel values become `NaNs`. This issue can be mitigated by switching to PyTorch 2.X.
</Tip>
This pipeline was contributed by [dg845](https://github.com/dg845). ❤️
## Usage Examples
Because the UniDiffuser model is trained to model the joint distribution of (image, text) pairs, it is capable of performing a diverse range of generation tasks:
### Unconditional Image and Text Generation
Unconditional generation (where we start from only latents sampled from a standard Gaussian prior) from a [`UniDiffuserPipeline`] will produce a (image, text) pair:
```python
import torch
from diffusers import UniDiffuserPipeline
device = "cuda"
model_id_or_path = "thu-ml/unidiffuser-v1"
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Unconditional image and text generation. The generation task is automatically inferred.
sample = pipe(num_inference_steps=20, guidance_scale=8.0)
image = sample.images[0]
text = sample.text[0]
image.save("unidiffuser_joint_sample_image.png")
print(text)
```
This is also called "joint" generation in the UniDiffuser paper, since we are sampling from the joint image-text distribution.
Note that the generation task is inferred from the inputs used when calling the pipeline.
It is also possible to manually specify the unconditional generation task ("mode") manually with [`UniDiffuserPipeline.set_joint_mode`]:
```python
# Equivalent to the above.
pipe.set_joint_mode()
sample = pipe(num_inference_steps=20, guidance_scale=8.0)
```
When the mode is set manually, subsequent calls to the pipeline will use the set mode without attempting to infer the mode.
You can reset the mode with [`UniDiffuserPipeline.reset_mode`], after which the pipeline will once again infer the mode.
You can also generate only an image or only text (which the UniDiffuser paper calls "marginal" generation since we sample from the marginal distribution of images and text, respectively):
```python
# Unlike other generation tasks, image-only and text-only generation don't use classifier-free guidance
# Image-only generation
pipe.set_image_mode()
sample_image = pipe(num_inference_steps=20).images[0]
# Text-only generation
pipe.set_text_mode()
sample_text = pipe(num_inference_steps=20).text[0]
```
### Text-to-Image Generation
UniDiffuser is also capable of sampling from conditional distributions; that is, the distribution of images conditioned on a text prompt or the distribution of texts conditioned on an image.
Here is an example of sampling from the conditional image distribution (text-to-image generation or text-conditioned image generation):
```python
import torch
from diffusers import UniDiffuserPipeline
device = "cuda"
model_id_or_path = "thu-ml/unidiffuser-v1"
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Text-to-image generation
prompt = "an elephant under the sea"
sample = pipe(prompt=prompt, num_inference_steps=20, guidance_scale=8.0)
t2i_image = sample.images[0]
t2i_image
```
The `text2img` mode requires that either an input `prompt` or `prompt_embeds` be supplied. You can set the `text2img` mode manually with [`UniDiffuserPipeline.set_text_to_image_mode`].
### Image-to-Text Generation
Similarly, UniDiffuser can also produce text samples given an image (image-to-text or image-conditioned text generation):
```python
import torch
from diffusers import UniDiffuserPipeline
from diffusers.utils import load_image
device = "cuda"
model_id_or_path = "thu-ml/unidiffuser-v1"
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Image-to-text generation
image_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/unidiffuser/unidiffuser_example_image.jpg"
init_image = load_image(image_url).resize((512, 512))
sample = pipe(image=init_image, num_inference_steps=20, guidance_scale=8.0)
i2t_text = sample.text[0]
print(i2t_text)
```
The `img2text` mode requires that an input `image` be supplied. You can set the `img2text` mode manually with [`UniDiffuserPipeline.set_image_to_text_mode`].
### Image Variation
The UniDiffuser authors suggest performing image variation through a "round-trip" generation method, where given an input image, we first perform an image-to-text generation, and then perform a text-to-image generation on the outputs of the first generation.
This produces a new image which is semantically similar to the input image:
```python
import torch
from diffusers import UniDiffuserPipeline
from diffusers.utils import load_image
device = "cuda"
model_id_or_path = "thu-ml/unidiffuser-v1"
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Image variation can be performed with an image-to-text generation followed by a text-to-image generation:
# 1. Image-to-text generation
image_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/unidiffuser/unidiffuser_example_image.jpg"
init_image = load_image(image_url).resize((512, 512))
sample = pipe(image=init_image, num_inference_steps=20, guidance_scale=8.0)
i2t_text = sample.text[0]
print(i2t_text)
# 2. Text-to-image generation
sample = pipe(prompt=i2t_text, num_inference_steps=20, guidance_scale=8.0)
final_image = sample.images[0]
final_image.save("unidiffuser_image_variation_sample.png")
```
### Text Variation
Similarly, text variation can be performed on an input prompt with a text-to-image generation followed by a image-to-text generation:
```python
import torch
from diffusers import UniDiffuserPipeline
device = "cuda"
model_id_or_path = "thu-ml/unidiffuser-v1"
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Text variation can be performed with a text-to-image generation followed by a image-to-text generation:
# 1. Text-to-image generation
prompt = "an elephant under the sea"
sample = pipe(prompt=prompt, num_inference_steps=20, guidance_scale=8.0)
t2i_image = sample.images[0]
t2i_image.save("unidiffuser_text2img_sample_image.png")
# 2. Image-to-text generation
sample = pipe(image=t2i_image, num_inference_steps=20, guidance_scale=8.0)
final_prompt = sample.text[0]
print(final_prompt)
```
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## UniDiffuserPipeline
[[autodoc]] UniDiffuserPipeline
- all
- __call__
## ImageTextPipelineOutput
[[autodoc]] pipelines.ImageTextPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/unidiffuser.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Object detection
[[open-in-colab]]
Object detection is the computer vision task of detecting instances (such as humans, buildings, or cars) in an image. Object detection models receive an image as input and output
coordinates of the bounding boxes and associated labels of the detected objects. An image can contain multiple objects,
each with its own bounding box and a label (e.g. it can have a car and a building), and each object can
be present in different parts of an image (e.g. the image can have several cars).
This task is commonly used in autonomous driving for detecting things like pedestrians, road signs, and traffic lights.
Other applications include counting objects in images, image search, and more.
In this guide, you will learn how to:
1. Finetune [DETR](https://huggingface.co/docs/transformers/model_doc/detr), a model that combines a convolutional
backbone with an encoder-decoder Transformer, on the [CPPE-5](https://huggingface.co/datasets/cppe-5)
dataset.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Conditional DETR](../model_doc/conditional_detr), [Deformable DETR](../model_doc/deformable_detr), [DETA](../model_doc/deta), [DETR](../model_doc/detr), [Table Transformer](../model_doc/table-transformer), [YOLOS](../model_doc/yolos)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q datasets transformers evaluate timm albumentations
```
You'll use 🤗 Datasets to load a dataset from the Hugging Face Hub, 🤗 Transformers to train your model,
and `albumentations` to augment the data. `timm` is currently required to load a convolutional backbone for the DETR model.
We encourage you to share your model with the community. Log in to your Hugging Face account to upload it to the Hub.
When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load the CPPE-5 dataset
The [CPPE-5 dataset](https://huggingface.co/datasets/cppe-5) contains images with
annotations identifying medical personal protective equipment (PPE) in the context of the COVID-19 pandemic.
Start by loading the dataset:
```py
>>> from datasets import load_dataset
>>> cppe5 = load_dataset("cppe-5")
>>> cppe5
DatasetDict({
train: Dataset({
features: ['image_id', 'image', 'width', 'height', 'objects'],
num_rows: 1000
})
test: Dataset({
features: ['image_id', 'image', 'width', 'height', 'objects'],
num_rows: 29
})
})
```
You'll see that this dataset already comes with a training set containing 1000 images and a test set with 29 images.
To get familiar with the data, explore what the examples look like.
```py
>>> cppe5["train"][0]
{'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=943x663 at 0x7F9EC9E77C10>,
'width': 943,
'height': 663,
'objects': {'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]],
'category': [4, 4, 0, 0]}}
```
The examples in the dataset have the following fields:
- `image_id`: the example image id
- `image`: a `PIL.Image.Image` object containing the image
- `width`: width of the image
- `height`: height of the image
- `objects`: a dictionary containing bounding box metadata for the objects in the image:
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [COCO format](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) )
- `category`: the object's category, with possible values including `Coverall (0)`, `Face_Shield (1)`, `Gloves (2)`, `Goggles (3)` and `Mask (4)`
You may notice that the `bbox` field follows the COCO format, which is the format that the DETR model expects.
However, the grouping of the fields inside `objects` differs from the annotation format DETR requires. You will
need to apply some preprocessing transformations before using this data for training.
To get an even better understanding of the data, visualize an example in the dataset.
```py
>>> import numpy as np
>>> import os
>>> from PIL import Image, ImageDraw
>>> image = cppe5["train"][0]["image"]
>>> annotations = cppe5["train"][0]["objects"]
>>> draw = ImageDraw.Draw(image)
>>> categories = cppe5["train"].features["objects"].feature["category"].names
>>> id2label = {index: x for index, x in enumerate(categories, start=0)}
>>> label2id = {v: k for k, v in id2label.items()}
>>> for i in range(len(annotations["id"])):
... box = annotations["bbox"][i]
... class_idx = annotations["category"][i]
... x, y, w, h = tuple(box)
... draw.rectangle((x, y, x + w, y + h), outline="red", width=1)
... draw.text((x, y), id2label[class_idx], fill="white")
>>> image
```
<div class="flex justify-center">
<img src="https://i.imgur.com/TdaqPJO.png" alt="CPPE-5 Image Example"/>
</div>
To visualize the bounding boxes with associated labels, you can get the labels from the dataset's metadata, specifically
the `category` field.
You'll also want to create dictionaries that map a label id to a label class (`id2label`) and the other way around (`label2id`).
You can use them later when setting up the model. Including these maps will make your model reusable by others if you share
it on the Hugging Face Hub.
As a final step of getting familiar with the data, explore it for potential issues. One common problem with datasets for
object detection is bounding boxes that "stretch" beyond the edge of the image. Such "runaway" bounding boxes can raise
errors during training and should be addressed at this stage. There are a few examples with this issue in this dataset.
To keep things simple in this guide, we remove these images from the data.
```py
>>> remove_idx = [590, 821, 822, 875, 876, 878, 879]
>>> keep = [i for i in range(len(cppe5["train"])) if i not in remove_idx]
>>> cppe5["train"] = cppe5["train"].select(keep)
```
## Preprocess the data
To finetune a model, you must preprocess the data you plan to use to match precisely the approach used for the pre-trained model.
[`AutoImageProcessor`] takes care of processing image data to create `pixel_values`, `pixel_mask`, and
`labels` that a DETR model can train with. The image processor has some attributes that you won't have to worry about:
- `image_mean = [0.485, 0.456, 0.406 ]`
- `image_std = [0.229, 0.224, 0.225]`
These are the mean and standard deviation used to normalize images during the model pre-training. These values are crucial
to replicate when doing inference or finetuning a pre-trained image model.
Instantiate the image processor from the same checkpoint as the model you want to finetune.
```py
>>> from transformers import AutoImageProcessor
>>> checkpoint = "facebook/detr-resnet-50"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
```
Before passing the images to the `image_processor`, apply two preprocessing transformations to the dataset:
- Augmenting images
- Reformatting annotations to meet DETR expectations
First, to make sure the model does not overfit on the training data, you can apply image augmentation with any data augmentation library. Here we use [Albumentations](https://albumentations.ai/docs/) ...
This library ensures that transformations affect the image and update the bounding boxes accordingly.
The 🤗 Datasets library documentation has a detailed [guide on how to augment images for object detection](https://huggingface.co/docs/datasets/object_detection),
and it uses the exact same dataset as an example. Apply the same approach here, resize each image to (480, 480),
flip it horizontally, and brighten it:
```py
>>> import albumentations
>>> import numpy as np
>>> import torch
>>> transform = albumentations.Compose(
... [
... albumentations.Resize(480, 480),
... albumentations.HorizontalFlip(p=1.0),
... albumentations.RandomBrightnessContrast(p=1.0),
... ],
... bbox_params=albumentations.BboxParams(format="coco", label_fields=["category"]),
... )
```
The `image_processor` expects the annotations to be in the following format: `{'image_id': int, 'annotations': List[Dict]}`,
where each dictionary is a COCO object annotation. Let's add a function to reformat annotations for a single example:
```py
>>> def formatted_anns(image_id, category, area, bbox):
... annotations = []
... for i in range(0, len(category)):
... new_ann = {
... "image_id": image_id,
... "category_id": category[i],
... "isCrowd": 0,
... "area": area[i],
... "bbox": list(bbox[i]),
... }
... annotations.append(new_ann)
... return annotations
```
Now you can combine the image and annotation transformations to use on a batch of examples:
```py
>>> # transforming a batch
>>> def transform_aug_ann(examples):
... image_ids = examples["image_id"]
... images, bboxes, area, categories = [], [], [], []
... for image, objects in zip(examples["image"], examples["objects"]):
... image = np.array(image.convert("RGB"))[:, :, ::-1]
... out = transform(image=image, bboxes=objects["bbox"], category=objects["category"])
... area.append(objects["area"])
... images.append(out["image"])
... bboxes.append(out["bboxes"])
... categories.append(out["category"])
... targets = [
... {"image_id": id_, "annotations": formatted_anns(id_, cat_, ar_, box_)}
... for id_, cat_, ar_, box_ in zip(image_ids, categories, area, bboxes)
... ]
... return image_processor(images=images, annotations=targets, return_tensors="pt")
```
Apply this preprocessing function to the entire dataset using 🤗 Datasets [`~datasets.Dataset.with_transform`] method. This method applies
transformations on the fly when you load an element of the dataset.
At this point, you can check what an example from the dataset looks like after the transformations. You should see a tensor
with `pixel_values`, a tensor with `pixel_mask`, and `labels`.
```py
>>> cppe5["train"] = cppe5["train"].with_transform(transform_aug_ann)
>>> cppe5["train"][15]
{'pixel_values': tensor([[[ 0.9132, 0.9132, 0.9132, ..., -1.9809, -1.9809, -1.9809],
[ 0.9132, 0.9132, 0.9132, ..., -1.9809, -1.9809, -1.9809],
[ 0.9132, 0.9132, 0.9132, ..., -1.9638, -1.9638, -1.9638],
...,
[-1.5699, -1.5699, -1.5699, ..., -1.9980, -1.9980, -1.9980],
[-1.5528, -1.5528, -1.5528, ..., -1.9980, -1.9809, -1.9809],
[-1.5528, -1.5528, -1.5528, ..., -1.9980, -1.9809, -1.9809]],
[[ 1.3081, 1.3081, 1.3081, ..., -1.8431, -1.8431, -1.8431],
[ 1.3081, 1.3081, 1.3081, ..., -1.8431, -1.8431, -1.8431],
[ 1.3081, 1.3081, 1.3081, ..., -1.8256, -1.8256, -1.8256],
...,
[-1.3179, -1.3179, -1.3179, ..., -1.8606, -1.8606, -1.8606],
[-1.3004, -1.3004, -1.3004, ..., -1.8606, -1.8431, -1.8431],
[-1.3004, -1.3004, -1.3004, ..., -1.8606, -1.8431, -1.8431]],
[[ 1.4200, 1.4200, 1.4200, ..., -1.6476, -1.6476, -1.6476],
[ 1.4200, 1.4200, 1.4200, ..., -1.6476, -1.6476, -1.6476],
[ 1.4200, 1.4200, 1.4200, ..., -1.6302, -1.6302, -1.6302],
...,
[-1.0201, -1.0201, -1.0201, ..., -1.5604, -1.5604, -1.5604],
[-1.0027, -1.0027, -1.0027, ..., -1.5604, -1.5430, -1.5430],
[-1.0027, -1.0027, -1.0027, ..., -1.5604, -1.5430, -1.5430]]]),
'pixel_mask': tensor([[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
...,
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1],
[1, 1, 1, ..., 1, 1, 1]]),
'labels': {'size': tensor([800, 800]), 'image_id': tensor([756]), 'class_labels': tensor([4]), 'boxes': tensor([[0.7340, 0.6986, 0.3414, 0.5944]]), 'area': tensor([519544.4375]), 'iscrowd': tensor([0]), 'orig_size': tensor([480, 480])}}
```
You have successfully augmented the individual images and prepared their annotations. However, preprocessing isn't
complete yet. In the final step, create a custom `collate_fn` to batch images together.
Pad images (which are now `pixel_values`) to the largest image in a batch, and create a corresponding `pixel_mask`
to indicate which pixels are real (1) and which are padding (0).
```py
>>> def collate_fn(batch):
... pixel_values = [item["pixel_values"] for item in batch]
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
... labels = [item["labels"] for item in batch]
... batch = {}
... batch["pixel_values"] = encoding["pixel_values"]
... batch["pixel_mask"] = encoding["pixel_mask"]
... batch["labels"] = labels
... return batch
```
## Training the DETR model
You have done most of the heavy lifting in the previous sections, so now you are ready to train your model!
The images in this dataset are still quite large, even after resizing. This means that finetuning this model will
require at least one GPU.
Training involves the following steps:
1. Load the model with [`AutoModelForObjectDetection`] using the same checkpoint as in the preprocessing.
2. Define your training hyperparameters in [`TrainingArguments`].
3. Pass the training arguments to [`Trainer`] along with the model, dataset, image processor, and data collator.
4. Call [`~Trainer.train`] to finetune your model.
When loading the model from the same checkpoint that you used for the preprocessing, remember to pass the `label2id`
and `id2label` maps that you created earlier from the dataset's metadata. Additionally, we specify `ignore_mismatched_sizes=True` to replace the existing classification head with a new one.
```py
>>> from transformers import AutoModelForObjectDetection
>>> model = AutoModelForObjectDetection.from_pretrained(
... checkpoint,
... id2label=id2label,
... label2id=label2id,
... ignore_mismatched_sizes=True,
... )
```
In the [`TrainingArguments`] use `output_dir` to specify where to save your model, then configure hyperparameters as you see fit.
It is important you do not remove unused columns because this will drop the image column. Without the image column, you
can't create `pixel_values`. For this reason, set `remove_unused_columns` to `False`.
If you wish to share your model by pushing to the Hub, set `push_to_hub` to `True` (you must be signed in to Hugging
Face to upload your model).
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="detr-resnet-50_finetuned_cppe5",
... per_device_train_batch_size=8,
... num_train_epochs=10,
... fp16=True,
... save_steps=200,
... logging_steps=50,
... learning_rate=1e-5,
... weight_decay=1e-4,
... save_total_limit=2,
... remove_unused_columns=False,
... push_to_hub=True,
... )
```
Finally, bring everything together, and call [`~transformers.Trainer.train`]:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... data_collator=collate_fn,
... train_dataset=cppe5["train"],
... tokenizer=image_processor,
... )
>>> trainer.train()
```
If you have set `push_to_hub` to `True` in the `training_args`, the training checkpoints are pushed to the
Hugging Face Hub. Upon training completion, push the final model to the Hub as well by calling the [`~transformers.Trainer.push_to_hub`] method.
```py
>>> trainer.push_to_hub()
```
## Evaluate
Object detection models are commonly evaluated with a set of <a href="https://cocodataset.org/#detection-eval">COCO-style metrics</a>.
You can use one of the existing metrics implementations, but here you'll use the one from `torchvision` to evaluate the final
model that you pushed to the Hub.
To use the `torchvision` evaluator, you'll need to prepare a ground truth COCO dataset. The API to build a COCO dataset
requires the data to be stored in a certain format, so you'll need to save images and annotations to disk first. Just like
when you prepared your data for training, the annotations from the `cppe5["test"]` need to be formatted. However, images
should stay as they are.
The evaluation step requires a bit of work, but it can be split in three major steps.
First, prepare the `cppe5["test"]` set: format the annotations and save the data to disk.
```py
>>> import json
>>> # format annotations the same as for training, no need for data augmentation
>>> def val_formatted_anns(image_id, objects):
... annotations = []
... for i in range(0, len(objects["id"])):
... new_ann = {
... "id": objects["id"][i],
... "category_id": objects["category"][i],
... "iscrowd": 0,
... "image_id": image_id,
... "area": objects["area"][i],
... "bbox": objects["bbox"][i],
... }
... annotations.append(new_ann)
... return annotations
>>> # Save images and annotations into the files torchvision.datasets.CocoDetection expects
>>> def save_cppe5_annotation_file_images(cppe5):
... output_json = {}
... path_output_cppe5 = f"{os.getcwd()}/cppe5/"
... if not os.path.exists(path_output_cppe5):
... os.makedirs(path_output_cppe5)
... path_anno = os.path.join(path_output_cppe5, "cppe5_ann.json")
... categories_json = [{"supercategory": "none", "id": id, "name": id2label[id]} for id in id2label]
... output_json["images"] = []
... output_json["annotations"] = []
... for example in cppe5:
... ann = val_formatted_anns(example["image_id"], example["objects"])
... output_json["images"].append(
... {
... "id": example["image_id"],
... "width": example["image"].width,
... "height": example["image"].height,
... "file_name": f"{example['image_id']}.png",
... }
... )
... output_json["annotations"].extend(ann)
... output_json["categories"] = categories_json
... with open(path_anno, "w") as file:
... json.dump(output_json, file, ensure_ascii=False, indent=4)
... for im, img_id in zip(cppe5["image"], cppe5["image_id"]):
... path_img = os.path.join(path_output_cppe5, f"{img_id}.png")
... im.save(path_img)
... return path_output_cppe5, path_anno
```
Next, prepare an instance of a `CocoDetection` class that can be used with `cocoevaluator`.
```py
>>> import torchvision
>>> class CocoDetection(torchvision.datasets.CocoDetection):
... def __init__(self, img_folder, image_processor, ann_file):
... super().__init__(img_folder, ann_file)
... self.image_processor = image_processor
... def __getitem__(self, idx):
... # read in PIL image and target in COCO format
... img, target = super(CocoDetection, self).__getitem__(idx)
... # preprocess image and target: converting target to DETR format,
... # resizing + normalization of both image and target)
... image_id = self.ids[idx]
... target = {"image_id": image_id, "annotations": target}
... encoding = self.image_processor(images=img, annotations=target, return_tensors="pt")
... pixel_values = encoding["pixel_values"].squeeze() # remove batch dimension
... target = encoding["labels"][0] # remove batch dimension
... return {"pixel_values": pixel_values, "labels": target}
>>> im_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> path_output_cppe5, path_anno = save_cppe5_annotation_file_images(cppe5["test"])
>>> test_ds_coco_format = CocoDetection(path_output_cppe5, im_processor, path_anno)
```
Finally, load the metrics and run the evaluation.
```py
>>> import evaluate
>>> from tqdm import tqdm
>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> module = evaluate.load("ybelkada/cocoevaluate", coco=test_ds_coco_format.coco)
>>> val_dataloader = torch.utils.data.DataLoader(
... test_ds_coco_format, batch_size=8, shuffle=False, num_workers=4, collate_fn=collate_fn
... )
>>> with torch.no_grad():
... for idx, batch in enumerate(tqdm(val_dataloader)):
... pixel_values = batch["pixel_values"]
... pixel_mask = batch["pixel_mask"]
... labels = [
... {k: v for k, v in t.items()} for t in batch["labels"]
... ] # these are in DETR format, resized + normalized
... # forward pass
... outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
... orig_target_sizes = torch.stack([target["orig_size"] for target in labels], dim=0)
... results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to Pascal VOC format (xmin, ymin, xmax, ymax)
... module.add(prediction=results, reference=labels)
... del batch
>>> results = module.compute()
>>> print(results)
Accumulating evaluation results...
DONE (t=0.08s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.352
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.681
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.292
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.168
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.208
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.429
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.274
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.484
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.501
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.323
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.590
```
These results can be further improved by adjusting the hyperparameters in [`~transformers.TrainingArguments`]. Give it a go!
## Inference
Now that you have finetuned a DETR model, evaluated it, and uploaded it to the Hugging Face Hub, you can use it for inference.
The simplest way to try out your finetuned model for inference is to use it in a [`Pipeline`]. Instantiate a pipeline
for object detection with your model, and pass an image to it:
```py
>>> from transformers import pipeline
>>> import requests
>>> url = "https://i.imgur.com/2lnWoly.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> obj_detector = pipeline("object-detection", model="devonho/detr-resnet-50_finetuned_cppe5")
>>> obj_detector(image)
```
You can also manually replicate the results of the pipeline if you'd like:
```py
>>> image_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
>>> with torch.no_grad():
... inputs = image_processor(images=image, return_tensors="pt")
... outputs = model(**inputs)
... target_sizes = torch.tensor([image.size[::-1]])
... results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[0]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
... f"Detected {model.config.id2label[label.item()]} with confidence "
... f"{round(score.item(), 3)} at location {box}"
... )
Detected Coverall with confidence 0.566 at location [1215.32, 147.38, 4401.81, 3227.08]
Detected Mask with confidence 0.584 at location [2449.06, 823.19, 3256.43, 1413.9]
```
Let's plot the result:
```py
>>> draw = ImageDraw.Draw(image)
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... x, y, x2, y2 = tuple(box)
... draw.rectangle((x, y, x2, y2), outline="red", width=1)
... draw.text((x, y), model.config.id2label[label.item()], fill="white")
>>> image
```
<div class="flex justify-center">
<img src="https://i.imgur.com/4QZnf9A.png" alt="Object detection result on a new image"/>
</div>
| huggingface/transformers/blob/main/docs/source/en/tasks/object_detection.md |
Gradio Demo: webcam
```
!pip install -q gradio
```
```
import gradio as gr
def snap(image, video):
return [image, video]
demo = gr.Interface(
snap,
[gr.Image(sources=["webcam"]), gr.Video(sources=["webcam"])],
["image", "video"],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/webcam/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# InstructPix2Pix
[InstructPix2Pix](https://hf.co/papers/2211.09800) is a Stable Diffusion model trained to edit images from human-provided instructions. For example, your prompt can be "turn the clouds rainy" and the model will edit the input image accordingly. This model is conditioned on the text prompt (or editing instruction) and the input image.
This guide will explore the [train_instruct_pix2pix.py](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py) training script to help you become familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/instruct_pix2pix
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment:
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py) and let us know if you have any questions or concerns.
</Tip>
## Script parameters
The training script has many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L65) function. Default values are provided for most parameters that work pretty well, but you can also set your own values in the training command if you'd like.
For example, to increase the resolution of the input image:
```bash
accelerate launch train_instruct_pix2pix.py \
--resolution=512 \
```
Many of the basic and important parameters are described in the [Text-to-image](text2image#script-parameters) training guide, so this guide just focuses on the relevant parameters for InstructPix2Pix:
- `--original_image_column`: the original image before the edits are made
- `--edited_image_column`: the image after the edits are made
- `--edit_prompt_column`: the instructions to edit the image
- `--conditioning_dropout_prob`: the dropout probability for the edited image and edit prompts during training which enables classifier-free guidance (CFG) for one or both conditioning inputs
## Training script
The dataset preprocessing code and training loop are found in the [`main()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L374) function. This is where you'll make your changes to the training script to adapt it for your own use-case.
As with the script parameters, a walkthrough of the training script is provided in the [Text-to-image](text2image#training-script) training guide. Instead, this guide takes a look at the InstructPix2Pix relevant parts of the script.
The script begins by modifing the [number of input channels](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L445) in the first convolutional layer of the UNet to account for InstructPix2Pix's additional conditioning image:
```py
in_channels = 8
out_channels = unet.conv_in.out_channels
unet.register_to_config(in_channels=in_channels)
with torch.no_grad():
new_conv_in = nn.Conv2d(
in_channels, out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding
)
new_conv_in.weight.zero_()
new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
unet.conv_in = new_conv_in
```
These UNet parameters are [updated](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L545C1-L551C6) by the optimizer:
```py
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Next, the edited images and and edit instructions are [preprocessed](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L624) and [tokenized](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L610C24-L610C24). It is important the same image transformations are applied to the original and edited images.
```py
def preprocess_train(examples):
preprocessed_images = preprocess_images(examples)
original_images, edited_images = preprocessed_images.chunk(2)
original_images = original_images.reshape(-1, 3, args.resolution, args.resolution)
edited_images = edited_images.reshape(-1, 3, args.resolution, args.resolution)
examples["original_pixel_values"] = original_images
examples["edited_pixel_values"] = edited_images
captions = list(examples[edit_prompt_column])
examples["input_ids"] = tokenize_captions(captions)
return examples
```
Finally, in the [training loop](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L730), it starts by encoding the edited images into latent space:
```py
latents = vae.encode(batch["edited_pixel_values"].to(weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
```
Then, the script applies dropout to the original image and edit instruction embeddings to support CFG. This is what enables the model to modulate the influence of the edit instruction and original image on the edited image.
```py
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
original_image_embeds = vae.encode(batch["original_pixel_values"].to(weight_dtype)).latent_dist.mode()
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(bsz, device=latents.device, generator=generator)
prompt_mask = random_p < 2 * args.conditioning_dropout_prob
prompt_mask = prompt_mask.reshape(bsz, 1, 1)
null_conditioning = text_encoder(tokenize_captions([""]).to(accelerator.device))[0]
encoder_hidden_states = torch.where(prompt_mask, null_conditioning, encoder_hidden_states)
image_mask_dtype = original_image_embeds.dtype
image_mask = 1 - (
(random_p >= args.conditioning_dropout_prob).to(image_mask_dtype)
* (random_p < 3 * args.conditioning_dropout_prob).to(image_mask_dtype)
)
image_mask = image_mask.reshape(bsz, 1, 1, 1)
original_image_embeds = image_mask * original_image_embeds
```
That's pretty much it! Aside from the differences described here, the rest of the script is very similar to the [Text-to-image](text2image#training-script) training script, so feel free to check it out for more details. If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers](../using-diffusers/write_own_pipeline) tutorial which breaks down the basic pattern of the denoising process.
## Launch the script
Once you're happy with the changes to your script or if you're okay with the default configuration, you're ready to launch the training script! 🚀
This guide uses the [fusing/instructpix2pix-1000-samples](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) dataset, which is a smaller version of the [original dataset](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered). You can also create and use your own dataset if you'd like (see the [Create a dataset for training](create_dataset) guide).
Set the `MODEL_NAME` environment variable to the name of the model (can be a model id on the Hub or a path to a local model), and the `DATASET_ID` to the name of the dataset on the Hub. The script creates and saves all the components (feature extractor, scheduler, text encoder, UNet, etc.) to a subfolder in your repository.
<Tip>
For better results, try longer training runs with a larger dataset. We've only tested this training script on a smaller-scale dataset.
<br>
To monitor training progress with Weights and Biases, add the `--report_to=wandb` parameter to the training command and specify a validation image with `--val_image_url` and a validation prompt with `--validation_prompt`. This can be really useful for debugging the model.
</Tip>
If you’re training on more than one GPU, add the `--multi_gpu` parameter to the `accelerate launch` command.
```bash
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--enable_xformers_memory_efficient_attention \
--resolution=256 \
--random_flip \
--train_batch_size=4 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 \
--checkpoints_total_limit=1 \
--learning_rate=5e-05 \
--max_grad_norm=1 \
--lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--mixed_precision=fp16 \
--seed=42 \
--push_to_hub
```
After training is finished, you can use your new InstructPix2Pix for inference:
```py
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
from diffusers.utils import load_image
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained("your_cool_model", torch_dtype=torch.float16).to("cuda")
generator = torch.Generator("cuda").manual_seed(0)
image = load_image("https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/test_pix2pix_4.png")
prompt = "add some ducks to the lake"
num_inference_steps = 20
image_guidance_scale = 1.5
guidance_scale = 10
edited_image = pipeline(
prompt,
image=image,
num_inference_steps=num_inference_steps,
image_guidance_scale=image_guidance_scale,
guidance_scale=guidance_scale,
generator=generator,
).images[0]
edited_image.save("edited_image.png")
```
You should experiment with different `num_inference_steps`, `image_guidance_scale`, and `guidance_scale` values to see how they affect inference speed and quality. The guidance scale parameters are especially impactful because they control how much the original image and edit instructions affect the edited image.
## Stable Diffusion XL
Stable Diffusion XL (SDXL) is a powerful text-to-image model that generates high-resolution images, and it adds a second text-encoder to its architecture. Use the [`train_instruct_pix2pix_sdxl.py`](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py) script to train a SDXL model to follow image editing instructions.
The SDXL training script is discussed in more detail in the [SDXL training](sdxl) guide.
## Next steps
Congratulations on training your own InstructPix2Pix model! 🥳 To learn more about the model, it may be helpful to:
- Read the [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd) blog post to learn more about some experiments we've done with InstructPix2Pix, dataset preparation, and results for different instructions. | huggingface/diffusers/blob/main/docs/source/en/training/instructpix2pix.md |
Fine-Tuning week of XLSR-Wav2Vec2 on 60 languages 🌍
Welcome to the fine-tuning week! The goal of this week is to have state-of-the-art automatic speech recognition (ASR) models in as many languages as possible. The fine-tuning week ends on Friday, the 26th March at midnight PST time.
Participants are encouraged to fine-tune the pretrained [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) checkpoint on one or more of the 60 languages of [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets).
Furthermore, it is very much appreciated if participants fine-tune XLSR-Wav2Vec2 on a language that is not included in the Common Voice dataset.
All fine-tuned models uploaded until Friday, the 26th March midnight PST, will be taken into account for competition, and the best model per language will be awarded a prize if the best model performs reasonably well.
The testing data to evaluate the models will be the official [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets) *`test data`* of version 6.1. Again, participants are very much encouraged to fine-tune XLSR-Wav2Vec2 on languages that are not found in the Common Voice dataset since those languages are even more likely to be underrepresented in the speech community.
Each model fine-tuned on a language not found in Common Voice, will be evaluated by the Hugging Face team after Friday, the 26th March at midnight PST, and if the model performs reasonably well, the model receives a prize as well.
For more information on which data can be used for training, how the models are evaluated exactly, and what type of data preprocessing can be used, please see ["Training and Evaluation Rules"](#training-and-evaluation-rules).
**Please keep in mind:**
The spirit of the fine-tuning week is to provide state-of-the-art speech recognition in as many languages as possible to the community!
So while we encourage healthy competition between people/groups of the same language so that better results are obtained, it is extremely important that we help each other and share our insights with the whole team/community.
What matters in the end is what has been achieved by the team as a whole during the fine-tuning week.
That being said, we strongly encourage people to share tips & tricks on the forum or Slack, help each other when team members encounter bugs, and work in groups.
To make it easier to share and help, forum threads have been created under the name {language} ASR: Fine-Tuning Wav2Vec2, e.g. here.
It is very much possible that prizes will be given to groups of people instead of individuals. Also, don't hesitate to ask questions, propose improvements to the organization, to the material given to participants, etc...🤗
## Table of Contents
- [Organization of the fine tuning week](#organization-of-the-fine-tuning-week)
- [How to fine tune XLSR Wav2Vec2](#how-to-fine-tune-xlsr-wav2vec2)
- [Google colab setup](#google-colab-setup)
- [Local machine](#local-machine)
- [How to upload my trained checkpoint](#how-to-upload-my-trained-checkpoint)
- [How to create the README](#how-to-create-the-readme)
- [How to evaluate my trained checkpoint](#how-to-evaluate-my-trained-checkpoint)
- [Rules of training and evaluation](#rules-of-training-and-evaluation)
- [Tips and tricks](#tips-and-tricks)
- [How to combine multiple datasests into one](#how-to-combine-multiple-datasets-into-one)
- [How to effectively preprocess the data](#how-to-effectively-preprocess-the-data)
- [How to efficiently preproces the data](#how-to-do-efficiently-load-datasets-with-limited-ram-and-hard-drive-space)
- [How to do hyperparameter tuning](#how-to-do-hyperparameter-tuning)
- [How to preprocess and evaluate character based languages](#how-to-preprocess-and-evaluate-character-based-languages)
- [Further reading material](#further-reading-material)
- [FAQ](#faq)
## Organization of the fine tuning week
The week officially starts on 22.03.2021 and ends on 29.03.2021, but you are more than welcome to start fine-tuning models before the start date.
General questions you might have, general problems you encounter, and general tips can be shared directly on the Slack channel (see [this post](https://discuss.huggingface.co/t/open-to-the-community-xlsr-wav2vec2-fine-tuning-week-for-low-resource-languages/4467) on how to be added to Slack).
More language-specific questions or specific bugs should be posted on the [forum](https://discuss.huggingface.co/) (feel free to use already existing language-specific threads, *e.g.* [this one](https://discuss.huggingface.co/t/arabic-asr-fine-tuning-wav2vec2/4608) or open a new one if there is no thread for your language yet) or directly on [github](https://github.com/huggingface/transformers) if you think some code or document needs correction/improvement.
Starting on Monday, the 22.03.2021, the Hugging Face team will try to provide an overview of currently trained models along with their evaluation results.
All the necessary information on:
- How to fine-tune the XLSR model
- How to upload the model
- How to share your evaluation results & training/eval script
- What are the training/evaluation rules
can be found in the sections below. If something is still unclear, feel free to drop a message in the Slack channel.
## How to fine tune XLSR Wav2Vec2
This chapter gives an in-detail explanation of how to fine-tune [Facebook's multi-lingual Wav2vec2](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on any language of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets).
Two possible setups can be used to fine-tune Wav2Vec2. The easiest setup is to simply use [google colab](https://colab.research.google.com/). It is possible to train the full model in a *free* google colab, but it is recommended to use google colab pro since it is more stable.
The other option is to run a script locally. While this can be more difficult to set up, it also means that you have more control over the training run and probably access to better GPUs than you would have in a google colab.
For small datasets, it is usually totally sufficient to train your model
in a google colab. For larger and thus more memory-intensive datasets, it is probably
better to fine-tune the model locally.
For each option, we explain in detail how to fine-tune XLSR-Wav2Vec2 in the following.
### Google colab setup
**Note**: Instead of reading the following section, you can simply watch [this](https://www.youtube.com/watch?v=UynYn2C3tI0&ab_channel=PatrickvonPlaten) video, where Patrick explains how to adapt the google colab for your specific language.
**1.**: If you plan on training XLSR-Wav2Vec2 in a google colab, you should first make sure to have a valid gmail account. You can sign up for a gmail account [here](https://accounts.google.com/signup/v2/webcreateaccount?hl=en&flowName=GlifWebSignIn&flowEntry=SignUp).
Having successfully signed up for gmail, you can now sign in to your account to make sure you are logged in when opening new tabs in your browser.
**2.**: Next, head over to the official [Fine-Tune XLSR-Wav2Vec2 with 🤗 Transformes](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_%F0%9F%A4%97_Transformers.ipynb) google colab. The first thing you should do is to make a copy of it - click `->File->Save a copy in Drive`. This should save a copy of the google colab in your google drive.
**3.**: Now it is highly recommended to carefully read the google colab without running the cells yet.
You should get an understanding of the model is trained and what you will have to change when training the model in a different language.
Having done so, you can again head over to [Common Voice](https://commonvoice.mozilla.org/en/datasets) and pick a language you want to fine-tune [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on. Make sure you remember the language code (For each language, you can find it under the field "*Version*". It corresponds to **all characters before the first underscore**. *E.g.* for Greek it is *el*, while for Irish it is *ga-IE*.
**4.**: Now you should replace the language code used for the demo of this colab, being *tr* for Turkish with the language code corresponding to the language you just chose in the **second** cell of the google colab. This will load the correct data for your language.
**5.**: It is time to start running the google colab! Make sure that you have selected "GPU" as your runtime environment and you can start running the cells one-by-one. Make sure you attentively read the text between the cells to understand what is happening and to eventually correct the cells to improve the fine-tuning script for your language. Things you might want to improve/change:
- Data loading. It is very much recommended to use more than just the official training data of the Common Voice dataset. If you find more data on the internet, feel free to use it! Check out the section ["How to combined multiple datasets into one"](#how-to-combine-multiple-datasets-into-one)
- Data Processing. You should adapt the data processing to your specific language. In data processing, you should make the data more uniform so that it will be easier for the model to learn how to classify speech in your data. Here it can be really helpful to be proficient in the language to know what can be done to simplify the language without changing the meaning.
Data processing methods include, but are not limited to:
- Normalizing your data. Make sure all characters are lower-cased.
- Remove typographical symbols and punctuation marks. See a list [here](https://en.wikipedia.org/wiki/List_of_typographical_symbols_and_punctuation_marks). Be careful to not remove punctuation marks that can change the meaning of the sentence. *E.g.* you should not remove the single quotation mark `'` in English, as it would change the words `"it's"` to `"its"` which is a different word and has thus a different meaning. For more tips on data processing see ["How to effectively preprocess the data"](#how-to-effectively-preprocess-the-data")
- Hyperparameter Tuning. Depending on the size of the data you should probably change the hyperparameters of the google colab. You can change any parameter you like. For more tips and tricks see ["How to do hyperparameter tuning for my language"](#how-to-do-hyperparameter-tuning-for-my-language)
When running the google colab make sure that you uncomment the cell corresponding to mounting your google drive to the colab. This cell looks as follows:
```python
# from google.colab import drive
# drive.mount('/content/gdrive/')
```
Uncomment it, run it, and follow the instructions to mount your google drive. This way you can be sure that the model parameters and created tokenizer & feature extractor files are saved in **your** google drive.
Also, make sure that you uncomment the cells corresponding to save the preprocessing files and trained model weights to your drive. Otherwise, you might lose a trained model if you google crashes. You should change the name of your model from `wav2vec2-large-xlsr-turkish-demo` to `wav2vec2-large-xlsr-{your_favorite_name}`.
Those cells correspond to:
```python
# processor.save_pretrained("/content/gdrive/MyDrive/wav2vec2-large-xlsr-turkish-demo")
```
and the line:
```python
output_dir="/content/gdrive/MyDrive/wav2vec2-large-xlsr-turkish-demo",
```
further below (which should already be uncommented).
Having finished the training you should find the following files/folders under the folder `wav2vec2-large-xlsr-{your_favorite_name}` in your google drive:
- `preprocessor_config.json` - the parameters of the feature extractor
- `special_tokens_map.json` - the special token map of the tokenizer
- `tokenizer_config.json` - the parameters of the tokenizer
- `vocab.json` - the vocabulary of the tokenizer
- `checkpoint-{...}/` - the saved checkpoints saved during training. Each checkpoint should contain the files: `config.json`, `optimizer.pt`, `pytorch_model.bin`, `scheduler.pt`, `training_args.bin`. The files `config.json` and `pytorch_model.bin` define your model.
If you are happy with your training results it is time to upload your model!
Download the following files to your local computer: **`preprocessor_config.json`, `special_tokens_map.json`, `tokenizer_config.json`, `vocab.json`, `config.json`, `pytorch_model.bin`**. Those files fully define a XLSR-Wav2Vec2 model checkpoint.
Awesome you have successfully trained a XLSR-Wav2Vec2 model 😎. Now you can jump to the section ["How to upload my trained checkpoint"](#how-to-upload-my-trained-checkpoint)
### Local machine
We have provided `run_common_voice.py` script to run fine-tuning on local machine. The script is similar to the colab but allows you to launch training using command line, save and continue training from previous checkpoints and launch training on multiple GPUs.
For bigger datasets, we recommend to train Wav2Vec2 locally instead of in a google colab.
1. To begin with, we should clone transformers localy and install all the required packages.
First, you need to clone the `transformers` repo with:
```
$ git clone https://github.com/huggingface/transformers.git
```
Second, head over to the `examples/research_projects/wav2vec2` directory, where the `run_common_voice.py` script is located.
```
$ cd transformers/examples/research_projects/wav2vec2
```
Third, install the required packages. The
packages are listed in the `requirements.txt` file and can be installed with
```
$ pip install -r requirements.txt
```
**Note**: Installing the latest version of `torchaudio` will also upgrade `torch` to it's latest stable version. If you are using specific version of `torch` then make sure
to use the correct `torchaudio` version compatible with your version of `torch`. By default the `requirements.txt` will install the latest version of `torchaudio`.
2. Next, take a look at the `run_common_voice.py` script to get an understanding of how it works. In short the script does the following:
- Load the given common voice dataset
- Create vocab for the language
- Load the model with given hyperparameters
- Pre-process the dataset to input into the model
- Run training
- Run evaluation
3. The following examples show how you can launch fine-tuning for the common voice dataset.
Here we will run the script on the *Turkish* Common Voice dataset for demonstration purposes.
**To lanuch fine-tuninig on a single GPU:**
```bash
python run_common_voice.py \
--model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
--dataset_config_name="tr" \ # use this argument to specify the language code
--output_dir=./wav2vec2-large-xlsr-turkish-demo \
--overwrite_output_dir \
--num_train_epochs="5" \
--per_device_train_batch_size="16" \
--learning_rate="3e-4" \
--warmup_steps="500" \
--evaluation_strategy="steps" \
--save_steps="400" \
--eval_steps="400" \
--logging_steps="400" \
--save_total_limit="3" \
--freeze_feature_extractor \
--feat_proj_dropout="0.0" \
--layerdrop="0.1" \
--gradient_checkpointing \
--fp16 \
--group_by_length \
--do_train --do_eval
```
**To lanuch fine-tuninig on multiple GPUs:**
```bash
python -m torch.distributed.launch \
--nproc_per_node 4 run_common_voice.py \
--model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
--dataset_config_name="tr" \ # use this argument to specify the language code
--output_dir=./wav2vec2-large-xlsr-turkish-demo \
--overwrite_output_dir \
--num_train_epochs="5" \
--per_device_train_batch_size="16" \
--learning_rate="3e-4" \
--warmup_steps="500" \
--evaluation_strategy="steps" \
--save_steps="400" \
--eval_steps="400" \
--logging_steps="400" \
--save_total_limit="3" \
--freeze_feature_extractor \
--feat_proj_dropout="0.0" \
--layerdrop="0.1" \
--gradient_checkpointing \
--fp16 \
--group_by_length \
--do_train --do_eval
```
The above command will launch the training on 4 GPUs. Use the `--nproc_per_node` option to specify the number of GPUs.
Once the training is finished, the model and checkpoints will be saved under the directory specified by the `--output_dir` argument.
4. The script also allows you to resume training from the last saved checkpoint. To resume training from last saved checkpoint remove the `--overwrite_output_dir` option and run the same command again. And to continue training from a specific checkpoint, keep the `--overwrite_output_dir`
option and pass the path of the checkpoint as `--model_name_or_path`.
As the script is based on the `Trainer` API, refer to the [Trainer docs](https://huggingface.co/transformers/main_classes/trainer.html) for more information about ``Trainer`` and ``TrainingArguments``.
[OVH cloud](https://www.ovh.com/world/) has generously offered free compute for this sprint. Please refer to [this video](https://www.youtube.com/watch?v=2hlkWAESMk8&ab_channel=Databuzzword) to get started with OVH.
## How to upload my trained checkpoint
To upload your trained checkpoint, you have to create a new model repository on the 🤗 model hub, from this page: https://huggingface.co/new
> You can also follow the more in-depth instructions [here](https://huggingface.co/transformers/model_sharing.html) if needed.
Having created your model repository on the hub, you should clone it locally:
```bash
git lfs install
git clone https://huggingface.co/username/your-model-name
```
Then and add the following files that fully define a XLSR-Wav2Vec2 checkpoint into the repository. You should have added the following files.
- `preprocessor_config.json`
- `special_tokens_map.json`
- `tokenizer_config.json`
- `vocab.json`
- `config.json`
- `pytorch_model.bin`
Having added the above files, you should run the following to push files to your model repository.
```
git add . && git commit -m "Add model files" && git push
```
The next **very important** step is to create the model card. For people to use your fine-tuned
model it is important to understand:
- What kind of model is it?
- What is your model useful for?
- What data was your model trained on?
- How well does your model perform?
All these questions should be answered in a model card which is the first thing people see when
visiting your model on the hub under `https://huggingface.co/{your_username}/{your_modelname}`.
**Note**:
It is extremely important that you add this model card or else we cannot find your model and thus cannot take the model into
account for the final evaluation.
### How to create the readme
The model card is written in markdown (`.md`) and should be added by simply clicking on the "Add model card" button which is found on the top right corner.
You are encouraged to copy-paste the following template into your model card.
**Make sure that** instead of copying the output of the markdown file you copy the **raw** version of the following part.
To get the raw version of this file, simply click on the "`raw`" button on the top right corner of this file next to "`blame`" and copy everything below the marker.
Make sure that you read and consequently remove all #TODO: statements from the model card.
<======================Copy **raw** version from here=========================
---
language: {lang_id} #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
datasets:
- common_voice #TODO: remove if you did not use the common voice dataset
- TODO: add more datasets if you have used additional datasets. Make sure to use the exact same
dataset name as the one found [here](https://huggingface.co/datasets). If the dataset can not be found in the official datasets, just give it a new name
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: {human_readable_name} #TODO: replace {human_readable_name} with a name of your model as it should appear on the leaderboard. It could be something like `Elgeish XLSR Wav2Vec2 Large 53`
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice {lang_id} #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
type: common_voice
args: {lang_id} #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
metrics:
- name: Test WER
type: wer
value: {wer_result_on_test} #TODO (IMPORTANT): replace {wer_result_on_test} with the WER error rate you achieved on the common_voice test set. It should be in the format XX.XX (don't add the % sign here). **Please** remember to fill out this value after you evaluated your model, so that your model appears on the leaderboard. If you fill out this model card before evaluating your model, please remember to edit the model card afterward to fill in your value
---
# Wav2Vec2-Large-XLSR-53-{language} #TODO: replace language with your {language}, *e.g.* French
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on {language} using the [Common Voice](https://huggingface.co/datasets/common_voice), ... and ... dataset{s}. #TODO: replace {language} with your language, *e.g.* French and eventually add more datasets that were used and eventually remove common voice if model was not trained on common voice
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "{lang_id}", split="test[:2%]") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
processor = Wav2Vec2Processor.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model = Wav2Vec2ForCTC.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset[:2]["sentence"])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "{lang_id}", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model = Wav2Vec2ForCTC.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]' # TODO: adapt this list to include all special characters you removed from the data
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: XX.XX % # TODO: write output of print here. IMPORTANT: Please remember to also replace {wer_result_on_test} at the top of with this value here. tags.
## Training
The Common Voice `train`, `validation`, and ... datasets were used for training as well as ... and ... # TODO: adapt to state all the datasets that were used for training.
The script used for training can be found [here](...) # TODO: fill in a link to your training script here. If you trained your model in a colab, simply fill in the link here. If you trained the model locally, it would be great if you could upload the training script on github and paste the link here.
=======================To here===============================>
Your model in then available under *huggingface.co/{your_username}/{your_chosen_xlsr-large_model_name}* for everybody to use 🎉.
## How to evaluate my trained checkpoint
Having uploaded your model, you should now evaluate your model in a final step. This should be as simple as
copying the evaluation code of your model card into a python script and running it. Make sure to note
the final result on the model card **both** under the YAML tags at the very top **and** below your evaluation code under "Test Results".
## Rules of training and evaluation
In this section, we will quickly go over what data is allowed to be used as training
data, what kind of data preprocessing is allowed be used, and how the model should be evaluated.
To make it very simple regarding the first point: **All data except the official common voice `test` data set can be used as training data**. For models trained in a language that is not included in Common Voice, the author of the model is responsible to
leave a reasonable amount of data for evaluation.
Second, the rules regarding the preprocessing are not that as straight-forward. It is allowed (and recommended) to
normalize the data to only have lower-case characters. It is also allowed (and recommended) to remove typographical
symbols and punctuation marks. A list of such symbols can *e.g.* be fonud [here](https://en.wikipedia.org/wiki/List_of_typographical_symbols_and_punctuation_marks) - however here we already must be careful. We should **not** remove a symbol that
would change the meaning of the words, *e.g.* in English, we should not remove the single quotation mark `'` since it
would change the meaning of the word `"it's"` to `"its"` which would then be incorrect. So the golden rule here is to
not remove any characters that could change the meaning of a word into another word. This is not always obvious and should
be given some consideration. As another example, it is fine to remove the "Hypen-minus" sign "`-`" since it doesn't change the
meaninng of a word to another one. *E.g.* "`fine-tuning`" would be changed to "`finetuning`" which has still the same meaning.
Since those choices are not always obvious when in doubt feel free to ask on Slack or even better post on the forum, as was
done, *e.g.* [here](https://discuss.huggingface.co/t/spanish-asr-fine-tuning-wav2vec2/4586).
## Tips and tricks
This section summarizes a couple of tips and tricks across various topics. It will continously be updated during the week.
### How to combine multiple datasets into one
Check out [this](https://discuss.huggingface.co/t/how-to-combine-local-data-files-with-an-official-dataset/4685) post.
### How to effectively preprocess the data
### How to do efficiently load datasets with limited ram and hard drive space
Check out [this](https://discuss.huggingface.co/t/german-asr-fine-tuning-wav2vec2/4558/8?u=patrickvonplaten) post.
### How to do hyperparameter tuning
### How to preprocess and evaluate character based languages
## Further reading material
It is recommended that take some time to read up on how Wav2vec2 works in theory.
Getting a better understanding of the theory and the inner mechanisms of the model often helps when fine-tuning the model.
**However**, if you don't like reading blog posts/papers, don't worry - it is by no means necessary to go through the theory to fine-tune Wav2Vec2 on your language of choice.
If you are interested in learning more about the model though, here are a couple of resources that are important to better understand Wav2Vec2:
- [Facebook's Wav2Vec2 blog post](https://ai.facebook.com/blog/wav2vec-state-of-the-art-speech-recognition-through-self-supervision/)
- [Official Wav2Vec2 paper](https://arxiv.org/abs/2006.11477)
- [Official XLSR Wav2vec2 paper](https://arxiv.org/pdf/2006.13979.pdf)
- [Hugging Face Blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)
- [How does CTC (Connectionist Temporal Classification) work](https://distill.pub/2017/ctc/)
It helps to have a good understanding of the following points:
- How was XLSR-Wav2Vec2 pretrained? -> Feature vectors were masked and had to be predicted by the model; very similar in spirit to masked language model of BERT.
- What parts of XLSR-Wav2Vec2 are responsible for what? What is the feature extractor part used for? -> extract feature vectors from the 1D raw audio waveform; What is the transformer part doing? -> mapping feature vectors to contextualized feature vectors; ...
- What part of the model needs to be fine-tuned? -> The pretrained model **does not** include a language head to classify the contextualized features to letters. This is randomly initialized when loading the pretrained checkpoint and has to be fine-tuned. Also, note that the authors recommend to **not** further fine-tune the feature extractor.
- What data was used to XLSR-Wav2Vec2? The checkpoint we will use for further fine-tuning was pretrained on **53** languages.
- What languages are considered to be similar by XLSR-Wav2Vec2? In the official [XLSR Wav2Vec2 paper](https://arxiv.org/pdf/2006.13979.pdf), the authors show nicely which languages share a common contextualized latent space. It might be useful for you to extend your training data with data of other languages that are considered to be very similar by the model (or you).
## FAQ
- Can a participant fine-tune models for more than one language?
Yes! A participant can fine-tune models in as many languages she/he likes
- Can a participant use extra data (apart from the common voice data)?
Yes! All data except the official common voice `test data` can be used for training.
If a participant wants to train a model on a language that is not part of Common Voice (which
is very much encouraged!), the participant should make sure that some test data is held out to
make sure the model is not overfitting.
- Can we fine-tune for high-resource languages?
Yes! While we do not really recommend people to fine-tune models in English since there are
already so many fine-tuned speech recognition models in English. However, it is very much
appreciated if participants want to fine-tune models in other "high-resource" languages, such
as French, Spanish, or German. For such cases, one probably needs to train locally and apply
might have to apply tricks such as lazy data loading (check the ["Lazy data loading"](#how-to-do-lazy-data-loading) section for more details).
| huggingface/transformers/blob/main/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md |
--
title: Hugging Face Collaborates with Microsoft to launch Hugging Face Model Catalog on Azure
thumbnail: /blog/assets/75_hugging_face_endpoints_on_azure/01.jpg
authors:
- user: jeffboudier
- user: philschmid
- user: juliensimon
---
# Hugging Face Collaborates with Microsoft to launch Hugging Face Model Catalog on Azure

Today, we are thrilled to announce that Hugging Face expands its collaboration with Microsoft to bring open-source models from the Hugging Face Hub to Azure Machine Learning. Together we built a new Hugging Face Hub Model Catalog available directly within Azure Machine Learning Studio, filled with thousands of the most popular Transformers models from the [Hugging Face Hub](https://huggingface.co/models). With this new integration, you can now deploy Hugging Face models in just a few clicks on managed endpoints, running onto secure and scalable Azure infrastructure.

This new experience expands upon the strategic partnership we announced last year when we launched Azure Machine Learning Endpoints as a new managed app in Azure Marketplace, to simplify the experience of deploying large language models on Azure. Although our previous marketplace solution was a promising initial step, it had some limitations we could only overcome through a native integration within Azure Machine Learning. To address these challenges and enhance customers experience, we collaborated with Microsoft to offer a fully integrated experience for Hugging Face users within Azure Machine Learning Studio.
[Hosting over 200,000 open-source models](https://huggingface.co/models), and serving over 1 million model downloads a day, Hugging Face is the go-to destination for all of Machine Learning. But deploying Transformers to production remains a challenge today.
One of the main problems developers and organizations face is how difficult it is to deploy and scale production-grade inference APIs. Of course, an easy option is to rely on cloud-based AI services. Although they’re extremely simple to use, these services are usually powered by a limited set of models that may not support the [task type](https://huggingface.co/tasks) you need, and that cannot be deeply customized, if at all. Alternatively, cloud-based ML services or in-house platforms give you full control, but at the expense of more time, complexity and cost. In addition, many companies have strict security, compliance, and privacy requirements mandating that they only deploy models on infrastructure over which they have administrative control.
_“With the new Hugging Face Hub model catalog, natively integrated within Azure Machine Learning, we are opening a new page in our partnership with Microsoft, offering a super easy way for enterprise customers to deploy Hugging Face models for real-time inference, all within their secure Azure environment.”_ said Julien Simon, Chief Evangelist at Hugging Face.
_"The integration of Hugging Face's open-source models into Azure Machine Learning represents our commitment to empowering developers with industry-leading AI tools,"_ said John Montgomery, Corporate Vice President, Azure AI Platform at Microsoft. _"This collaboration not only simplifies the deployment process of large language models but also provides a secure and scalable environment for real-time inferencing. It's an exciting milestone in our mission to accelerate AI initiatives and bring innovative solutions to the market swiftly and securely, backed by the power of Azure infrastructure."_
Deploying Hugging Face models on Azure Machine Learning has never been easier:
* Open the Hugging Face registry in Azure Machine Learning Studio.
* Click on the Hugging Face Model Catalog.
* Filter by task or license and search the models.
* Click the model tile to open the model page and choose the real-time deployment option to deploy the model.
* Select an Azure instance type and click deploy.

Within minutes, you can test your endpoint and add its inference API to your application. It’s never been easier!

If you'd like to see the service in action, you can click on the image below to launch a video walkthrough.
[](https://youtu.be/cjXYjN2mNVM "Video walkthrough of Hugging Face Endpoints")
Hugging Face Model Catalog on Azure Machine Learning is available today in public preview in all Azure Regions where Azure Machine Learning is available. Give the service a try and [let us know your feedback and questions in the forum](https://discuss.huggingface.co/c/azureml/68)! | huggingface/blog/blob/main/hugging-face-endpoints-on-azure.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MPT
## Overview
The MPT model was proposed by the [MosaicML](https://www.mosaicml.com/) team and released with multiple sizes and finetuned variants. The MPT models is a series of open source and commercially usable LLMs pre-trained on 1T tokens.
MPT models are GPT-style decoder-only transformers with several improvements: performance-optimized layer implementations, architecture changes that provide greater training stability, and the elimination of context length limits by replacing positional embeddings with ALiBi.
- MPT base: MPT base pre-trained models on next token prediction
- MPT instruct: MPT base models fine-tuned on instruction based tasks
- MPT storywriter: MPT base models fine-tuned for 2500 steps on 65k-token excerpts of fiction books contained in the books3 corpus, this enables the model to handle very long sequences
The original code is available at the [`llm-foundry`](https://github.com/mosaicml/llm-foundry/tree/main) repository.
Read more about it [in the release blogpost](https://www.mosaicml.com/blog/mpt-7b)
## Usage tips
- Learn more about some techniques behind training of the model [in this section of llm-foundry repository](https://github.com/mosaicml/llm-foundry/blob/main/TUTORIAL.md#faqs)
- If you want to use the advanced version of the model (triton kernels, direct flash attention integration), you can still use the original model implementation by adding `trust_remote_code=True` when calling `from_pretrained`.
## Resources
- [Fine-tuning Notebook](https://colab.research.google.com/drive/1HCpQkLL7UXW8xJUJJ29X7QAeNJKO0frZ?usp=sharing) on how to fine-tune MPT-7B on a free Google Colab instance to turn the model into a Chatbot.
## MptConfig
[[autodoc]] MptConfig
- all
## MptModel
[[autodoc]] MptModel
- forward
## MptForCausalLM
[[autodoc]] MptForCausalLM
- forward
## MptForSequenceClassification
[[autodoc]] MptForSequenceClassification
- forward
## MptForTokenClassification
[[autodoc]] MptForTokenClassification
- forward
## MptForQuestionAnswering
[[autodoc]] MptForQuestionAnswering
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/mpt.md |
ext embeddings and semantic search. In this video we’ll explore how Transformer models represent text as embedding vectors and how these vectors can be used to find similar documents in a corpus. Text embeddings are just a fancy way of saying that we can represent text as an array of numbers called a vector. To create these embeddings we usually use an encoder-based model like BERT. In this example, you can see how we feed three sentences to the encoder and get three vectors as the output. Reading the text, we can see that walking the dog seems to be most similar to walking the cat, but let's see if we can quantify this! The trick to do the comparison is to compute a similarity metric between each pair of embedding vectors. These vectors usually live in a high-dimensional space, so a similarity metric can be anything that measures some sort of distance between vectors. One popular metric is cosine similarity, which uses the angle between two vectors to measure how close they are. In this example, our embedding vectors live in 3D and we can see that the orange and grey vectors are close to each other and have a smaller angle. Now one problem we have to deal with is that Transformer models like BERT will actually return one embedding vector per token. For example in the sentence "I took my dog for a walk", we can expect several embedding vectors, one for each word. For example, here we can see the output of our model has produced 9 embedding vectors per sentence, and each vector has 384 dimensions. But what we really want is a single embedding vector for the whole sentence. To deal with this, we can use a technique called pooling. The simplest pooling method is to just take the token embedding of the CLS token. Alternatively, we can average the token embeddings which is called mean pooling. With mean pooling only thing we need to make sure is that we don't include the padding tokens in the average, which is why you can see the attention mask being used here. This now gives us one 384 dimensional vector per sentence which is exactly what we want! And once we have our sentence embeddings, we can compute the cosine similarity for each pair of vectors. In this example we use the function from scikit-learn and you can see that the sentence "I took my dog for a walk" has an overlap of 0.83 with "I took my cat for a walk". Hooray! We can take this idea one step further by comparing the similarity between a question and a corpus of documents. For example, suppose we embed every post in the Hugging Face forums. We can then ask a question, embed it, and check which forum posts are most similar. This process is often called semantic search, because it allows us to compare queries with context. To create a semantic search engine is quite simple in Datasets. First we need to embed all the documents. In this example, we take a small sample from the SQUAD dataset and apply the same embedding logic as before. This gives us a new column called "embeddings" that stores the embedding of every passage. Once we have our embeddings, we need a way to find nearest neighbours to a query. Datasets provides a special object called a FAISS index that allows you to quickly compare embedding vectors. So we add the FAISS index, embed a question and voila! we've now found the 3 most similar articles which might store the answer. | huggingface/course/blob/main/subtitles/en/raw/chapter5/06_text-embeddings.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OWLv2
## Overview
OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
The abstract from the paper is the following:
*Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can be expanded by using Web image-text pairs as weak supervision, this has not been done at scales comparable to image-level pretraining. Here, we scale up detection data with self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. Major challenges in scaling self-training are the choice of label space, pseudo-annotation filtering, and training efficiency. We present the OWLv2 model and OWL-ST self-training recipe, which address these challenges. OWLv2 surpasses the performance of previous state-of-the-art open-vocabulary detectors already at comparable training scales (~10M examples). However, with OWL-ST, we can scale to over 1B examples, yielding further large improvement: With an L/14 architecture, OWL-ST improves AP on LVIS rare classes, for which the model has seen no human box annotations, from 31.2% to 44.6% (43% relative improvement). OWL-ST unlocks Web-scale training for open-world localization, similar to what has been seen for image classification and language modelling.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/owlv2_overview.png"
alt="drawing" width="600"/>
<small> OWLv2 high-level overview. Taken from the <a href="https://arxiv.org/abs/2306.09683">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
## Usage example
OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
```python
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC Format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.614 at location [341.67, 17.54, 642.32, 278.51]
Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62, 354.85]
```
## Resources
- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
<Tip>
The architecture of OWLv2 is identical to [OWL-ViT](owlvit), however the object detection head now also includes an objectness classifier, which predicts the (query-agnostic) likelihood that a predicted box contains an object (as opposed to background). The objectness score can be used to rank or filter predictions independently of text queries.
Usage of OWLv2 is identical to [OWL-ViT](owlvit) with a new, updated image processor ([`Owlv2ImageProcessor`]).
</Tip>
## Owlv2Config
[[autodoc]] Owlv2Config
- from_text_vision_configs
## Owlv2TextConfig
[[autodoc]] Owlv2TextConfig
## Owlv2VisionConfig
[[autodoc]] Owlv2VisionConfig
## Owlv2ImageProcessor
[[autodoc]] Owlv2ImageProcessor
- preprocess
- post_process_object_detection
- post_process_image_guided_detection
## Owlv2Processor
[[autodoc]] Owlv2Processor
## Owlv2Model
[[autodoc]] Owlv2Model
- forward
- get_text_features
- get_image_features
## Owlv2TextModel
[[autodoc]] Owlv2TextModel
- forward
## Owlv2VisionModel
[[autodoc]] Owlv2VisionModel
- forward
## Owlv2ForObjectDetection
[[autodoc]] Owlv2ForObjectDetection
- forward
- image_guided_detection
| huggingface/transformers/blob/main/docs/source/en/model_doc/owlv2.md |
CSP-DarkNet
**CSPDarknet53** is a convolutional neural network and backbone for object detection that uses [DarkNet-53](https://paperswithcode.com/method/darknet-53). It employs a CSPNet strategy to partition the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network.
This CNN is used as the backbone for [YOLOv4](https://paperswithcode.com/method/yolov4).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('cspdarknet53', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `cspdarknet53`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('cspdarknet53', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{bochkovskiy2020yolov4,
title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
year={2020},
eprint={2004.10934},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: CSP DarkNet
Paper:
Title: 'YOLOv4: Optimal Speed and Accuracy of Object Detection'
URL: https://paperswithcode.com/paper/yolov4-optimal-speed-and-accuracy-of-object
Models:
- Name: cspdarknet53
In Collection: CSP DarkNet
Metadata:
FLOPs: 8545018880
Parameters: 27640000
File Size: 110775135
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Mish
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- CutMix
- Label Smoothing
- Mosaic
- Polynomial Learning Rate Decay
- SGD with Momentum
- Self-Adversarial Training
- Weight Decay
Training Data:
- ImageNet
Training Resources: 1x NVIDIA RTX 2070 GPU
ID: cspdarknet53
LR: 0.1
Layers: 53
Crop Pct: '0.887'
Momentum: 0.9
Batch Size: 128
Image Size: '256'
Warmup Steps: 1000
Weight Decay: 0.0005
Interpolation: bilinear
Training Steps: 8000000
FPS (GPU RTX 2070): 66
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/cspnet.py#L441
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/cspdarknet53_ra_256-d05c7c21.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.05%
Top 5 Accuracy: 95.09%
--> | huggingface/pytorch-image-models/blob/main/docs/models/csp-darknet.md |
EfficientNet
**EfficientNet** is a convolutional neural network architecture and scaling method that uniformly scales all dimensions of depth/width/resolution using a *compound coefficient*. Unlike conventional practice that arbitrary scales these factors, the EfficientNet scaling method uniformly scales network width, depth, and resolution with a set of fixed scaling coefficients. For example, if we want to use \\( 2^N \\) times more computational resources, then we can simply increase the network depth by \\( \alpha ^ N \\), width by \\( \beta ^ N \\), and image size by \\( \gamma ^ N \\), where \\( \alpha, \beta, \gamma \\) are constant coefficients determined by a small grid search on the original small model. EfficientNet uses a compound coefficient \\( \phi \\) to uniformly scales network width, depth, and resolution in a principled way.
The compound scaling method is justified by the intuition that if the input image is bigger, then the network needs more layers to increase the receptive field and more channels to capture more fine-grained patterns on the bigger image.
The base EfficientNet-B0 network is based on the inverted bottleneck residual blocks of [MobileNetV2](https://paperswithcode.com/method/mobilenetv2), in addition to [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('efficientnet_b0', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `efficientnet_b0`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('efficientnet_b0', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2020efficientnet,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
year={2020},
eprint={1905.11946},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: EfficientNet
Paper:
Title: 'EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks'
URL: https://paperswithcode.com/paper/efficientnet-rethinking-model-scaling-for
Models:
- Name: efficientnet_b0
In Collection: EfficientNet
Metadata:
FLOPs: 511241564
Parameters: 5290000
File Size: 21376743
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b0
Layers: 18
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1002
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b0_ra-3dd342df.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.71%
Top 5 Accuracy: 93.52%
- Name: efficientnet_b1
In Collection: EfficientNet
Metadata:
FLOPs: 909691920
Parameters: 7790000
File Size: 31502706
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b1
Crop Pct: '0.875'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1011
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b1-533bc792.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.71%
Top 5 Accuracy: 94.15%
- Name: efficientnet_b2
In Collection: EfficientNet
Metadata:
FLOPs: 1265324514
Parameters: 9110000
File Size: 36788104
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b2
Crop Pct: '0.875'
Image Size: '260'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1020
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b2_ra-bcdf34b7.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.38%
Top 5 Accuracy: 95.08%
- Name: efficientnet_b2a
In Collection: EfficientNet
Metadata:
FLOPs: 1452041554
Parameters: 9110000
File Size: 49369973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b2a
Crop Pct: '1.0'
Image Size: '288'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1029
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b3_ra2-cf984f9c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.61%
Top 5 Accuracy: 95.32%
- Name: efficientnet_b3
In Collection: EfficientNet
Metadata:
FLOPs: 2327905920
Parameters: 12230000
File Size: 49369973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b3
Crop Pct: '0.904'
Image Size: '300'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1038
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b3_ra2-cf984f9c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.08%
Top 5 Accuracy: 96.03%
- Name: efficientnet_b3a
In Collection: EfficientNet
Metadata:
FLOPs: 2600628304
Parameters: 12230000
File Size: 49369973
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_b3a
Crop Pct: '1.0'
Image Size: '320'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1047
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_b3_ra2-cf984f9c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 82.25%
Top 5 Accuracy: 96.11%
- Name: efficientnet_em
In Collection: EfficientNet
Metadata:
FLOPs: 3935516480
Parameters: 6900000
File Size: 27927309
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_em
Crop Pct: '0.882'
Image Size: '240'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1118
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_em_ra2-66250f76.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.26%
Top 5 Accuracy: 94.79%
- Name: efficientnet_es
In Collection: EfficientNet
Metadata:
FLOPs: 2317181824
Parameters: 5440000
File Size: 22003339
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_es
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1110
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_es_ra-f111e99c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.09%
Top 5 Accuracy: 93.93%
- Name: efficientnet_lite0
In Collection: EfficientNet
Metadata:
FLOPs: 510605024
Parameters: 4650000
File Size: 18820005
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inverted Residual Block
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: efficientnet_lite0
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/efficientnet.py#L1163
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/efficientnet_lite0_ra-37913777.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.5%
Top 5 Accuracy: 92.51%
-->
| huggingface/pytorch-image-models/blob/main/hfdocs/source/models/efficientnet.mdx |
Flax/JAX community week 🤗
Welcome to the Flax/JAX community week! The goal of this week is to make compute-intensive NLP and CV projects (like pre-training BERT, GPT2, CLIP, ViT)
practicable for a wider audience of engineers and researchers.
To do so, we will try to teach **you** how to effectively use JAX/Flax on TPU and help you to complete a fun NLP and/or CV project in JAX/Flax during the community week.
Free access to a TPUv3-8 will kindly be provided by the Google Cloud team!
In this document, we list all the important information that you will need during the Flax/JAX community week.
Don't forget to sign up [here](https://forms.gle/tVGPhjKXyEsSgUcs8)!
## Table of Contents
- [Organization](#organization)
- [Important dates](#important-dates)
- [Communication](#communication)
- [Projects](#projects)
- [How to propose](#how-to-propose-a-project)
- [How to form a team](#how-to-form-a-team-around-a-project)
- [Tips & Tricks for project](#tips-on-how-to-organize-the-project)
- [How to install flax, jax, optax, transformers, datasets](#how-to-install-relevant-libraries)
- [Quickstart Flax/JAX](#quickstart-flax-and-jax)
- [Quickstart Flax/JAX in 🤗 Transformers](#quickstart-flax-and-jax-in-transformers)
- [Flax design philosophy in 🤗 Transformers](#flax-design-philosophy-in-transformers)
- [How to use flax models & scripts](#how-to-use-flax-models-and-example-scripts)
- [Talks](#talks)
- [How to use the 🤗 Hub for training](#how-to-use-the-hub-for-collaboration)
- [How to setup TPU VM](#how-to-setup-tpu-vm)
- [How to build a demo](#how-to-build-a-demo)
- [Using the Hugging Face Widgets](#using-the-hugging-face-widgets)
- [Using a Streamlit demo](#using-a-streamlit-demo)
- [Using a Gradio demo](#using-a-gradio-demo)
- [Project evaluation](#project-evaluation)
- [General Tips & Tricks](#general-tips-and-tricks)
- [FAQ](#faq)
## Organization
Participants can propose ideas for an interesting NLP and/or CV project. Teams of 3 to 5 will then be formed around the most promising and interesting projects. Make sure to read through the [Projects](#projects) section on how to propose projects, comment on other participants' project ideas, and create a team.
To help each team successfully finish their project, we have organized talks by leading scientists and engineers from Google, Hugging Face, and the open-source NLP & CV community. The talks will take place before the community week from June 30th to July 2nd. Make sure to attend the talks to get the most out of your participation! Check out the [Talks](#talks) section to get an overview of the talks, including the speaker and the time of the talk.
Each team is then given **free access to a TPUv3-8 VM** from July 7th to July 14th. In addition, we will provide training examples in JAX/Flax for a variety of NLP and Vision models to kick-start your project. During the week, we'll make sure to answer any questions you might have about JAX/Flax and Transformers and help each team as much as possible to complete their project!
At the end of the community week, each team should submit a demo of their project. All demonstrations will be evaluated by a jury and the top-3 demos will be awarded a prize. Check out the [How to submit a demo](#how-to-submit-a-demo) section for more information and suggestions on how to submit your project.
## Important dates
- **23.06.** Official announcement of the community week. Make sure to sign-up in [this google form](https://forms.gle/tVGPhjKXyEsSgUcs8).
- **23.06. - 30.06.** Participants will be added to an internal Slack channel. Project ideas can be proposed here and groups of 3-5 are formed. Read this document for more information.
- **30.06.** Release of all relevant training scripts in JAX/Flax as well as other documents on how to set up a TPU, how to use the training scripts, how to submit a demo, tips & tricks for JAX/Flax, tips & tricks for efficient use of the hub.
- **30.06. - 2.07.** Talks about JAX/Flax, TPU, Transformers, Computer Vision & NLP will be held.
- **7.07.** Start of the community week! Access to TPUv3-8 will be given to each team.
- **7.07. - 14.07.** The Hugging Face & JAX/Flax & Cloud team will be available for any questions, problems the teams might run into.
- **15.07.** Access to TPU is deactivated and community week officially ends.
- **16.07.** Deadline for each team to submit a demo.
## Communication
All important communication will take place in an internal Slack channel, called `#flax-jax-community-week`.
Important announcements of the Hugging Face, Flax/JAX, and Google Cloud team will be posted there.
Such announcements include general information about the community week (Dates, Rules, ...), release of relevant training scripts (Flax/JAX example scripts for NLP and Vision), release of other important documents (How to access the TPU), etc.
The Slack channel will also be the central place for participants to post about their results, share their learning experiences, ask questions, etc.
For issues with Flax/JAX, Transformers, Datasets or for questions that are specific to your project we would be **very happy** if you could use the following public repositories and forums:
- Flax: [Issues](https://github.com/google/flax/issues), [Questions](https://github.com/google/flax/discussions)
- JAX: [Issues](https://github.com/google/jax/issues), [Questions](https://github.com/google/jax/discussions)
- 🤗 Transformers: [Issues](https://github.com/huggingface/transformers/issues), [Questions](https://discuss.huggingface.co/c/transformers/9)
- 🤗 Datasets: [Issues](https://github.com/huggingface/datasets/issues), [Questions](https://discuss.huggingface.co/c/datasets/10)
- Project specific questions: [Forum](https://discuss.huggingface.co/c/flax-jax-projects/22)
- TPU related questions: [TODO]()
Please do **not** post the complete issue/project-specific question in the Slack channel, but instead a link to your issue/question that we will try to answer as soon as possible.
This way, we make sure that the everybody in the community can benefit from your questions - even after the community week - and that the same question is not answered twice.
To be invited to the Slack channel, please make sure you have signed up [on the Google form](https://forms.gle/tVGPhjKXyEsSgUcs8).
**Note**: If you have signed up on the google form, but you are not in the Slack channel, please leave a message on [(TODO) the official forum announcement]( ) and ping `@Suzana` and `@patrickvonplaten`.
## Projects
During the first week after the community week announcement, **23.06. - 30.06.**, teams will be formed around the most promising and interesting project ideas. Each team can consist of 2 to 10 participants. Projects can be accessed [here](https://discuss.huggingface.co/c/flax-jax-projects/22).
All officially defined projects can be seen [here](https://docs.google.com/spreadsheets/d/1GpHebL7qrwJOc9olTpIPgjf8vOS0jNb6zR_B8x_Jtik/edit?usp=sharing).
### How to propose a project
Some default project ideas are given by the organizers. **However, we strongly encourage participants to submit their own project ideas!**
Check out the [HOW_TO_PROPOSE_PROJECT.md](https://github.com/huggingface/transformers/tree/main/examples/research_projects/jax-projects/HOW_TO_PROPOSE_PROJECT.md) for more information on how to propose a new project.
### How to form a team around a project
You can check out all existing projects ideas on the forum under [Flax/JAX projects category](https://discuss.huggingface.co/c/flax-jax-projects/22).
Make sure to quickly check out each project idea and leave a ❤️ if you like an idea.
Feel free to leave comments, suggestions for improvement, or questions about more details directly on the discussion thread.
If you have found the project that you ❤️ the most, leave a message "I would like to join this project" on the discussion thread.
We strongly advise you to also shortly state who you are, which time zone you are in and why you would like to work on this project, how you can contribute to the project and what your vision is for the project.
For projects that see a lot of interest and for which enough participants have expressed interest in joining, an official team will be created by the organizers.
One of the organizers (`@Suzana`, `@valhalla`, `@osanseviero`, `@patrickvonplaten`) will leave a message "For this project the team: `<team_name>`, `<team_members>` , is officially created" on the thread and note down the teams on [this google sheet](https://docs.google.com/spreadsheets/d/1GpHebL7qrwJOc9olTpIPgjf8vOS0jNb6zR_B8x_Jtik/edit?usp=sharing).
Once created, the team can start refining their project:
- What is the goal of the project? *E.g.*, Present a language model that writes poetry in Russian.
- What model will we use? *E.g.*, FlaxGPT2
- What data will we use? *E.g.* Russian dataset of OSCAR & publicly available book on poetry
- Should we use a pre-trained model or train a model from scratch? E.g. Train a model from scratch
- What training scripts do we need? *E.g.* `transformers/examples/flax/run_clm_flax.py` can be used
- What kind of demo would we like to present? E.g. Text-generation API of the 🤗 Hub in combination with a Streamlit demo that lets the user generate a poem of a given length
- How will the work be divided? *E.g.* Team member 1 works on data preprocessing, Team member 2 works on adapting the Flax script, ...
We highly recommend that each team discusses all relevant ideas for their project directly on the forum thread.
This way valuable learning experiences are shared and accessible by the whole community in the future.
Additionally, the organizers, other participants, or anybody in the community really can read through your discussions and leave comments/tips for improvement. Obviously, you can also create private chats, ... to discuss more sensitive topics, etc.
**Important**:
- For project ideas that see a lot of interest, we are more than happy to create more than one team.
- Participants are welcome to join multiple teams, even though we encourage them to only work on a single project.
- Under special circumstances, participants can change/create new teams. Please note that we would like to keep this the exception. If however, you would like to change/leave existing teams, please leave a post on the project's thread where you ping the corresponding organizer that created the group.
- It is often easy to propose/join a project that is done in your native language. Feel free to reach out to existing [language-specific groups](https://discuss.huggingface.co/c/languages-at-hugging-face/15) to look for community members that might be interested in joining your project.
## Tips on how to organize the project
This section gives you some tips on how to most efficiently & effectively
work as a team to achieve your goal. It is by no means a strict recipe to follow,
but rather a collection of tips from the 🤗 team.
Once your team is defined, you can start working on the project as soon as possible.
### Communication
At first, it is always useful to get to know each other and to set up a means of communication.
While we recommend that all technical aspects of work can be discussed directly on the [forum](https://discuss.huggingface.co/c/flax-jax-projects/22) under your project thread,
it can be very helpful to have a more direct way of communicating, *e.g.* in a channel.
For this we have created a discord that you can access [here](https://discord.com/channels/858019234139602994/858019234139602997).
This discord will not be managed by anybody and is just there so that you can communicate more effectively with your team members.
Feel free to create a new channel for you and your team where you can discuss everything. If you and your team have already set up other ways of communicating, it is absolutely not required to make use of the discord. However, we do recommend each team to set up some kind
of channel or group for quick discussions.
### Project definition
In the very beginning, you should make sure your project is well-defined and that
everybody in the team understands the goal of the project and the work that needs to be
done in order to achieve the goal. A well-defined project:
- has defined the task on which the model will be trained
- has defined the model that will be trained
- has defined the datasets that will be used for training
- has defined the type of training scripts that need to be written
- has defined the desired outcome of the project
- has defined the workflows
By "has defined" we don't meant that the corresponding code already has to be written and ready
to be used, but that everybody in team is on the same page on what type of model, data and training script should be used.
To give an example, a well-defined project would be the following:
- task: summarization
- model: [t5-small](https://huggingface.co/t5-small)
- dataset: [CNN/Daily mail](https://huggingface.co/datasets/cnn_dailymail)
- training script: [run_summarization_flax.py](https://github.com/huggingface/transformers/blob/main/examples/flax/summarization/run_summarization_flax.py)
- outcome: t5 model that can summarize news
- work flow: adapt `run_summarization_flax.py` to work with `t5-small`.
This example is a very easy and not the most interesting project since a `t5-small`
summarization model exists already for CNN/Daily mail and pretty much no code has to be
written.
A well-defined project does not need to have the dataset be part of
the `datasets` library and the training script already be pre-written, however it should
be clear how the desired dataset can be accessed and how the training script can be
written.
It is also important to have a clear plan regarding the workflow. Usually, the
data processing is done in a first step. Once the data is in a format that the model can
work with, the training script can be written, etc. These steps should be more detailed
once the team has a clearly defined project. It can be helpful to set deadlines for each step.
### Workload division
To effectively work as a team, it is crucial to divide the workload among everybody.
Some team members will be more motivated and experienced than others and
some team members simply want to participate to learn more and cannot contribute that
much to the team. This is totally fine! One cannot expect everybody in the team to have the same level of experience and time/motivation during the community week.
As a conclusion, being honest about one's expected involvement is crucial so that
the workload can be divided accordingly. If someone doesn't think her/his tasks are feasible - let
the team know early on so that someone else can take care of it!
It is recommended that the motivated and experienced team members take the lead in dividing the work and are ready to take over the tasks of another team member if necessary.
The workload can often be divided according to:
- data preprocessing (load the data and preprocess data in the correct format)
- data tokenization / data collator (process data samples into tokens or images)
- model configuration (writing the code that defines the model)
- model forward pass (make sure input / output work correctly)
- loss function (define the loss function)
- putting the pieces together in a training script
Many of the steps above require other steps to be finished, so it often makes sense
to use dummy data in the expected format to start, *e.g.*, with the model forward pass
before the data preprocessing is done.
### Expectations
It is also very important to stay realistic with the scope of your project. Each team
has access to a TPUv3-8 for only *ca.* 10 days, so it's important to keep the scope of
the project reasonable. While we do want each team to work on interesting projects, each
team should make sure that the project goals can be achieved within the provided compute
time on TPU. For instance, pretraining a 11 billion parameters T5 model is not really a realistic
task with just 10 days of TPUv3-8 compute.
Also, it might be difficult to finish a project where the whole modeling, dataset and training code has to be written from scratch.
Having defined your project, feel free to reach out on Slack or the forum for feedback from the organizers. We can surely give you our opinion on whether the project is feasible and what can be done to improve it.
the project is feasible.
### Other tips
Here is a collection of some more tips:
- We strongly recommend to work as publicly and collaboratively as possible during the week so that other teams
and the organizers can best help you. This includes publishing important discussions on
the forum and making use of the [🤗 hub](http://huggingface.co/) to have a version
control for your models and training logs.
- When debugging, it is important that the debugging cycle is kept as short as possible to
be able to effectively debug. *E.g.* if there is a problem with your training script,
you should run it with just a couple of hundreds of examples and not the whole dataset script. This can be done by either making use of [datasets streaming](https://huggingface.co/docs/datasets/master/dataset_streaming?highlight=streaming) or by selecting just the first
X number of data samples after loading:
```python
datasets["train"] = datasets["train"].select(range(1000))
```
- Ask for help. If you are stuck, use the public Slack channel or the [forum](https://discuss.huggingface.co/c/flax-jax-projects/22) to ask for help.
## How to install relevant libraries
In the following we will explain how to install all relevant libraries on your local computer and on TPU VM.
It is recommended to install all relevant libraries both on your local machine
and on the TPU virtual machine. This way, quick prototyping and testing can be done on
your local machine and the actual training can be done on the TPU VM.
### Local computer
The following libraries are required to train a JAX/Flax model with 🤗 Transformers and 🤗 Datasets:
- [JAX](https://github.com/google/jax/)
- [Flax](https://github.com/google/flax)
- [Optax](https://github.com/deepmind/optax)
- [Transformers](https://github.com/huggingface/transformers)
- [Datasets](https://github.com/huggingface/datasets)
You should install the above libraries in a [virtual environment](https://docs.python.org/3/library/venv.html).
If you're unfamiliar with Python virtual environments, check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Create a virtual environment with the version of Python you're going
to use and activate it.
You should be able to run the command:
```bash
python3 -m venv <your-venv-name>
```
You can activate your venv by running
```bash
source ~/<your-venv-name>/bin/activate
```
We strongly recommend to make use of the provided JAX/Flax examples scripts in [transformers/examples/flax](https://github.com/huggingface/transformers/tree/main/examples/flax) even if you want to train a JAX/Flax model of another github repository that is not integrated into 🤗 Transformers.
In all likelihood, you will need to adapt one of the example scripts, so we recommend forking and cloning the 🤗 Transformers repository as follows.
Doing so will allow you to share your fork of the Transformers library with your team members so that the team effectively works on the same code base. It will also automatically install the newest versions of `flax`, `jax` and `optax`.
1. Fork the [repository](https://github.com/huggingface/transformers) by
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
$ git clone https://github.com/<your Github handle>/transformers.git
$ cd transformers
$ git remote add upstream https://github.com/huggingface/transformers.git
```
3. Create a new branch to hold your development changes. This is especially useful to share code changes with your team:
```bash
$ git checkout -b a-descriptive-name-for-my-project
```
4. Set up a flax environment by running the following command in a virtual environment:
```bash
$ pip install -e ".[flax]"
```
(If transformers was already installed in the virtual environment, remove
it with `pip uninstall transformers` before reinstalling it in editable
mode with the `-e` flag.)
If you have already cloned that repo, you might need to `git pull` to get the most recent changes in the `datasets`
library.
Running this command will automatically install `flax`, `jax` and `optax`.
Next, you should also install the 🤗 Datasets library. We strongly recommend installing the
library from source to profit from the most current additions during the community week.
Simply run the following steps:
```
$ cd ~/
$ git clone https://github.com/huggingface/datasets.git
$ cd datasets
$ pip install -e ".[streaming]"
```
If you plan on contributing a specific dataset during
the community week, please fork the datasets repository and follow the instructions
[here](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-create-a-pull-request).
To verify that all libraries are correctly installed, you can run the following command.
It assumes that both `transformers` and `datasets` were installed from main - otherwise
datasets streaming will not work correctly.
```python
from transformers import FlaxRobertaModel, RobertaTokenizerFast
from datasets import load_dataset
import jax
dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True)
dummy_input = next(iter(dataset))["text"]
tokenizer = RobertaTokenizerFast.from_pretrained("roberta-base")
input_ids = tokenizer(dummy_input, return_tensors="np").input_ids[:, :10]
model = FlaxRobertaModel.from_pretrained("julien-c/dummy-unknown")
# run a forward pass, should return an object `FlaxBaseModelOutputWithPooling`
model(input_ids)
```
### TPU VM
**VERY IMPORTANT** - Only one process can access the TPU cores at a time. This means that if multiple team members
are trying to connect to the TPU cores errors, such as:
```
libtpu.so already in used by another process. Not attempting to load libtpu.so in this process.
```
are thrown. As a conclusion, we recommend every team member to create her/his own virtual environment, but only one
person should run the heavy training processes. Also, please take turns when setting up the TPUv3-8 so that everybody
can verify that JAX is correctly installed.
The following libraries are required to train a JAX/Flax model with 🤗 Transformers and 🤗 Datasets on TPU VM:
- [JAX](https://github.com/google/jax/)
- [Flax](https://github.com/google/flax)
- [Optax](https://github.com/deepmind/optax)
- [Transformers](https://github.com/huggingface/transformers)
- [Datasets](https://github.com/huggingface/datasets)
You should install the above libraries in a [virtual environment](https://docs.python.org/3/library/venv.html).
If you're unfamiliar with Python virtual environments, check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Create a virtual environment with the version of Python you're going
to use and activate it.
You should be able to run the command:
```bash
python3 -m venv <your-venv-name>
```
If this doesn't work, you first might to have install `python3-venv`. You can do this as follows:
```bash
sudo apt-get install python3-venv
```
You can activate your venv by running
```bash
source ~/<your-venv-name>/bin/activate
```
Next you should install JAX's TPU version on TPU by running the following command:
```
$ pip install requests
```
and then:
```
$ pip install "jax[tpu]>=0.2.16" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
```
**Note**: Running this command might actually throw an error, such as:
```
Building wheel for jax (setup.py) ... error
ERROR: Command errored out with exit status 1:
command: /home/patrick/patrick/bin/python3 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-lwseckn1/jax/setup.py'"'"'; __file__='"'"'/tmp/pip-install-lwseckn1/jax/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' bdist_wheel -d /tmp/pip-wheel-pydotzlo
cwd: /tmp/pip-install-lwseckn1/jax/
Complete output (6 lines):
usage: setup.py [global_opts] cmd1 [cmd1_opts] [cmd2 [cmd2_opts] ...]
or: setup.py --help [cmd1 cmd2 ...]
or: setup.py --help-commands
or: setup.py cmd --help
error: invalid command 'bdist_wheel'
----------------------------------------
ERROR: Failed building wheel for jax
```
Jax should have been installed correctly nevertheless.
To verify that JAX was correctly installed, you can run the following command:
```python
import jax
jax.device_count()
```
This should display the number of TPU cores, which should be 8 on a TPUv3-8 VM.
We strongly recommend to make use of the provided JAX/Flax examples scripts in [transformers/examples/flax](https://github.com/huggingface/transformers/tree/main/examples/flax) even if you want to train a JAX/Flax model of another github repository that is not integrated into 🤗 Transformers.
In all likelihood, you will need to adapt one of the example scripts, so we recommend forking and cloning the 🤗 Transformers repository as follows.
Doing so will allow you to share your fork of the Transformers library with your team members so that the team effectively works on the same code base. It will also automatically install the newest versions of `flax`, `jax` and `optax`.
1. Fork the [repository](https://github.com/huggingface/transformers) by
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
$ git clone https://github.com/<your Github handle>/transformers.git
$ cd transformers
$ git remote add upstream https://github.com/huggingface/transformers.git
```
3. Create a new branch to hold your development changes. This is especially useful to share code changes with your team:
```bash
$ git checkout -b a-descriptive-name-for-my-project
```
4. Set up a flax environment by running the following command in a virtual environment:
```bash
$ pip install -e ".[flax]"
```
(If transformers was already installed in the virtual environment, remove
it with `pip uninstall transformers` before reinstalling it in editable
mode with the `-e` flag.)
If you have already cloned that repo, you might need to `git pull` to get the most recent changes in the `datasets`
library.
Running this command will automatically install `flax`, `jax` and `optax`.
Next, you should also install the 🤗 Datasets library. We strongly recommend installing the
library from source to profit from the most current additions during the community week.
Simply run the following steps:
```
$ cd ~/
$ git clone https://github.com/huggingface/datasets.git
$ cd datasets
$ pip install -e ".[streaming]"
```
If you plan on contributing a specific dataset during
the community week, please fork the datasets repository and follow the instructions
[here](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-create-a-pull-request).
To verify that all libraries are correctly installed, you can run the following command.
It assumes that both `transformers` and `datasets` were installed from main - otherwise
datasets streaming will not work correctly.
```python
from transformers import FlaxRobertaModel, RobertaTokenizerFast
from datasets import load_dataset
import jax
dataset = load_dataset('oscar', "unshuffled_deduplicated_en", split='train', streaming=True)
dummy_input = next(iter(dataset))["text"]
tokenizer = RobertaTokenizerFast.from_pretrained("roberta-base")
input_ids = tokenizer(dummy_input, return_tensors="np").input_ids[:, :10]
model = FlaxRobertaModel.from_pretrained("julien-c/dummy-unknown")
# run a forward pass, should return an object `FlaxBaseModelOutputWithPooling`
model(input_ids)
```
## Quickstart flax and jax
[JAX](https://jax.readthedocs.io/en/latest/index.html) is Autograd and XLA, brought together for high-performance numerical computing and machine learning research. It provides composable transformations of Python+NumPy programs: differentiate, vectorize, parallelize, Just-In-Time compile to GPU/TPU, and more. A great place for getting started with JAX is the [JAX 101 Tutorial](https://jax.readthedocs.io/en/latest/jax-101/index.html).
[Flax](https://flax.readthedocs.io/en/latest/index.html) is a high-performance neural network library designed for flexibility built on top of JAX. It aims to provide users with full control of their training code and is carefully designed to work well with JAX transformations such as `grad` and `pmap` (see the [Flax philosophy](https://flax.readthedocs.io/en/latest/philosophy.html)). For an introduction to Flax see the [Flax Basics Colab](https://flax.readthedocs.io/en/latest/notebooks/flax_basics.html) or the list of curated [Flax examples](https://flax.readthedocs.io/en/latest/examples.html).
## Quickstart flax and jax in transformers
Currently, we support the following models in Flax.
Note that some models are about to be merged to `main` and will
be available in a couple of days.
- [BART](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/modeling_flax_bart.py)
- [BERT](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_flax_bert.py)
- [BigBird](https://github.com/huggingface/transformers/blob/main/src/transformers/models/big_bird/modeling_flax_big_bird.py)
- [CLIP](https://github.com/huggingface/transformers/blob/main/src/transformers/models/clip/modeling_flax_clip.py)
- [ELECTRA](https://github.com/huggingface/transformers/blob/main/src/transformers/models/electra/modeling_flax_electra.py)
- [GPT2](https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/modeling_flax_gpt2.py)
- [(TODO) MBART](https://github.com/huggingface/transformers/blob/main/src/transformers/models/mbart/modeling_flax_mbart.py)
- [RoBERTa](https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_flax_roberta.py)
- [T5](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_flax_t5.py)
- [ViT](https://github.com/huggingface/transformers/blob/main/src/transformers/models/vit/modeling_flax_vit.py)
- [Wav2Vec2](https://github.com/huggingface/transformers/blob/main/src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py)
You can find all available training scripts for JAX/Flax under the
official [flax example folder](https://github.com/huggingface/transformers/tree/main/examples/flax). Note that a couple of training scripts will be released in the following week.
- [Causal language modeling (GPT2)](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_clm_flax.py)
- [Masked language modeling (BERT, RoBERTa, ELECTRA, BigBird)](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_mlm_flax.py)
- [Text classification (BERT, RoBERTa, ELECTRA, BigBird)](https://github.com/huggingface/transformers/blob/main/examples/flax/text-classification/run_flax_glue.py)
- [Summarization / Seq2Seq (BART, MBART, T5)](https://github.com/huggingface/transformers/blob/main/examples/flax/summarization/run_summarization_flax.py)
- [Masked Seq2Seq pret-training (T5)](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_t5_mlm_flax.py)
- [Contrastive Loss pretraining for Wav2Vec2](https://github.com/huggingface/transformers/blob/main/examples/research_projects/jax-projects/wav2vec2)
- [Fine-tuning long-range QA for BigBird](https://github.com/huggingface/transformers/blob/main/examples/research_projects/jax-projects/big_bird)
- [(TODO) Image classification (ViT)]( )
- [(TODO) CLIP pretraining, fine-tuning (CLIP)]( )
### **Flax design philosophy in Transformers**
This section will explain how Flax models are implemented in Transformers and how the design differs from PyTorch.
Let's first go over the difference between Flax and PyTorch.
In JAX, most transformations (notably `jax.jit`) require functions that are transformed to be stateless so that they have no side effects. This is because any such side-effects will only be executed once when the transformed function is run during compilation and all subsequent calls of the compiled function would re-use the same side-effects of the compiled run instead of the "actual" side-effects (see [Stateful Computations in JAX](https://jax.readthedocs.io/en/latest/jax-101/07-state.html)). As a consequence, Flax models, which are designed to work well with JAX transformations, are stateless. This means that when running a model in inference, both the inputs and the model weights are passed to the forward pass. In contrast, PyTorch model are very much stateful with the weights being stored within the model instance and the user just passing the inputs to the forward pass.
Let's illustrate the difference between stateful models in PyTorch and stateless models in Flax.
For simplicity, let's assume the language model consists simply of a single attention layer [`key_proj`, `value_proj`, `query_proj`] and a linear layer `logits_proj` to project the transformed word embeddings to the output logit vectors.
#### **Stateful models in PyTorch**
In PyTorch, the weights matrices would be stored as `torch.nn.Linear` objects alongside the model's config inside the model class `ModelPyTorch`:
```python
class ModelPyTorch:
def __init__(self, config):
self.config = config
self.key_proj = torch.nn.Linear(config)
self.value_proj = torch.nn.Linear(config)
self.query_proj = torch.nn.Linear(config)
self.logits_proj = torch.nn.Linear(config)
```
Instantiating an object `model_pytorch` of the class `ModelPyTorch` would actually allocate memory for the model weights and attach them to the attributes `self.key_proj`, `self.value_proj`, `self.query_proj`, and `self.logits.proj`. We could access the weights via:
```
key_projection_matrix = model_pytorch.key_proj.weight.data
```
Visually, we would represent an object of `model_pytorch` therefore as follows:
Executing a forward pass then simply corresponds to passing the `input_ids` to the object `model_pytorch`:
```python
sequences = model_pytorch(input_ids)
```
In a more abstract way, this can be represented as passing the word embeddings to the model function to get the output logits:

This design is called **stateful** because the output logits, the `sequences`, can change even if the word embeddings, the `input_ids`, stay the same. Hence, the function's output does not only depend on its inputs, but also on its **state**, `[self.key_proj, self.value_proj, self.query_proj, self.logits_proj]`, which makes `model_pytorch` stateful.
#### **Stateless models in Flax/JAX**
Now, let's see how the mathematically equivalent model would be written in JAX/Flax. The model class `ModelFlax` would define the self-attention and logits projection weights as [**`flax.linen.Dense`**](https://flax.readthedocs.io/en/latest/_autosummary/flax.linen.Dense.html#flax.linen.Dense) objects:
```python
class ModelFlax:
def __init__(self, config):
self.config = config
self.key_proj = flax.linen.Dense(config)
self.value_proj = flax.linen.Dense(config)
self.query_proj = flax.linen.Dense(config)
self.logits_proj = flax.linen.Dense(config)
```
At first glance the linear layer class `flax.linen.Dense` looks very similar to PyTorch's `torch.nn.Linear` class. However, instantiating an object `model_flax` only defines the linear transformation functions and does **not** allocate memory to store the linear transformation weights. In a way, the attribute `self.key_proj` tell the instantiated object `model_flax` to perform a linear transformation on some input and force it to expect a weight, called `key_proj`, as an input.
This time we would illustrate the object `model_flax` without the weight matrices:

Accordingly, the forward pass requires both `input_ids` as well as a dictionary consisting of the model's weights (called `state` here) to compute the `sequences`:
To get the initial `state` we need to explicitly do a forward pass by passing a dummy input:
```python
state = model_flax.init(rng, dummy_input_ids)
```
and then we can do the forward pass.
```python
sequences = model_flax.apply(state, input_ids)
```
Visually, the forward pass would now be represented as passing all tensors required for the computation to the model's object:
This design is called **stateless** because the output logits, the `sequences`, **cannot** change if the word embeddings, the `input_ids`, stay the same. Hence, the function's output only depends on its inputs, being the `input_ids` and the `state` dictionary consisting of the weights **state**, `[key_proj, value_proj, query_proj, logits_proj]`.
Another term which is often used to describe the design difference between Flax/JAX and PyTorch is **immutable** vs **mutable**. A instantiated Flax model, `model_flax`, is **immutable** as a logical consequence of `model_flax`'s output being fully defined by its input: If calling `model_flax` could mutate `model_flax`, then calling `model_flax` twice with the same inputs could lead to different results which would violate the "*statelessness*" of Flax models.
#### **Flax models in Transformers**
Now let us see how this is handled in `Transformers.` If you have used a Flax model in Transformers already, you might wonder how come you don't always have to pass the parameters to the function of the forward pass. This is because the `FlaxPreTrainedModel` class abstracts it away.
It is designed this way so that the Flax models in Transformers will have a similar API to PyTorch and Tensorflow models.
The `FlaxPreTrainedModel` is an abstract class that holds a Flax module, handles weights initialization, and provides a simple interface for downloading and loading pre-trained weights i.e. the `save_pretrained` and `from_pretrained` methods. Each Flax model then defines its own subclass of `FlaxPreTrainedModel`; *e.g.* the BERT model has `FlaxBertPreTrainedModel`. Each such class provides two important methods, `init_weights` and `__call__`. Let's see what each of those methods do:
- The `init_weights` method takes the expected input shape and a [`PRNGKey`](https://jax.readthedocs.io/en/latest/_autosummary/jax.random.PRNGKey.html) (and any other arguments that are required to get initial weights) and calls `module.init` by passing it a random example to get the initial weights with the given `dtype` (for ex. `fp32` or `bf16` etc). This method is called when we create an instance of the model class, so the weights are already initialized when you create a model i.e., when you do
model = FlaxBertModel(config)
- The `__call__` method defines forward pass. It takes all necessary model inputs and parameters (and any other arguments required for the forward pass). The parameters are optional; when no parameters are passed, it uses the previously initialized or loaded parameters which can be accessed using `model.params`. It then calls the `module.apply` method, passing it the parameters and inputs to do the actual forward pass. So we can do a forward pass using
output = model(inputs, params=params)
Let's look at an example to see how this works. We will write a simple two-layer MLP model.
First, write a Flax module that will declare the layers and computation.
```python
import flax.linen as nn
import jax.numpy as jnp
class MLPModule(nn.Module):
config: MLPConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
self.dense1 = nn.Dense(self.config.hidden_dim, dtype=self.dtype)
self.dense2 = nn.Desne(self.config.hidden_dim, dtype=self.dtype)
def __call__(self, inputs):
hidden_states = self.dense1(inputs)
hidden_states = nn.relu(hidden_states)
hidden_states = self.dense2(hidden_states)
return hidden_states
```
Now let's define the `FlaxPreTrainedModel` model class.
```python
from transformers.modeling_flax_utils import FlaxPreTrainedModel
class FlaxMLPPreTrainedModel(FlaxPreTrainedModel):
config_class = MLPConfig
base_model_prefix = "model"
module_class: nn.Module = None
def __init__(self, config: BertConfig, input_shape: Tuple = (1, 8), seed: int = 0, dtype: jnp.dtype = jnp.float32, **kwargs):
# initialize the flax module
module = self.module_class(config=config, dtype=dtype, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype)
def init_weights(self, rng, input_shape):
# init input tensors
inputs = jnp.zeros(input_shape, dtype="i4")
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
params = self.module.init(rngs, inputs)["params"]
return params
def __call__(self, inputs, params: dict = None):
params = {"params": params or self.params}
outputs = self.module.apply(params, jnp.array(inputs))
return outputs
```
Now we can define our model class as follows.
```python
class FlaxMLPModel(FlaxMLPPreTrainedModel):
module_class = FlaxMLPModule
```
Now the `FlaxMLPModel` will have a similar interface as PyTorch or Tensorflow models and allows us to attach loaded or randomly initialized weights to the model instance.
So the important point to remember is that the `model` is not an instance of `nn.Module`; it's an abstract class, like a container that holds a Flax module, its parameters and provides convenient methods for initialization and forward pass. The key take-away here is that an instance of `FlaxMLPModel` is very much stateful now since it holds all the model parameters, whereas the underlying Flax module `FlaxMLPModule` is still stateless. Now to make `FlaxMLPModel` fully compliant with JAX transformations, it is always possible to pass the parameters to `FlaxMLPModel` as well to make it stateless and easier to work with during training. Feel free to take a look at the code to see how exactly this is implemented for ex. [`modeling_flax_bert.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_flax_bert.py#L536)
Another significant difference between Flax and PyTorch models is that, we can pass the `labels` directly to PyTorch's forward pass to compute the loss, whereas Flax models never accept `labels` as an input argument. In PyTorch, gradient backpropagation is performed by simply calling `.backward()` on the computed loss which makes it very handy for the user to be able to pass the `labels`. In Flax however, gradient backpropagation cannot be done by simply calling `.backward()` on the loss output, but the loss function itself has to be transformed by `jax.grad` or `jax.value_and_grad` to return the gradients of all parameters. This transformation cannot happen under-the-hood when one passes the `labels` to Flax's forward function, so that in Flax, we simply don't allow `labels` to be passed by design and force the user to implement the loss function oneself. As a conclusion, you will see that all training-related code is decoupled from the modeling code and always defined in the training scripts themselves.
### **How to use flax models and example scripts**
#### **How to do a forward pass**
Let's first see how to load, save and do inference with Flax models. As explained in the above section, all Flax models in Transformers have similar API to PyTorch models, so we can use the familiar `from_pretrained` and `save_pretrained` methods to load and save Flax models.
Let's use the base `FlaxRobertaModel` without any heads as an example.
```python
from transformers import FlaxRobertaModel, RobertaTokenizerFast
import jax
tokenizer = RobertaTokenizerFast.from_pretrained("roberta-base")
inputs = tokenizer("JAX/Flax is amazing ", padding="max_length", max_length=128, return_tensors="np")
model = FlaxRobertaModel.from_pretrained("julien-c/dummy-unknown")
@jax.jit
def run_model(input_ids, attention_mask):
# run a forward pass, should return an object `FlaxBaseModelOutputWithPooling`
return model(input_ids, attention_mask)
outputs = run_model(**inputs)
```
We use `jax.jit` to compile the function to get maximum performance. Note that in the above example, we set `padding=max_length` to pad all examples to the same length. We do this because JAX's compiler has to recompile a function everytime its input shape changes - in a sense a compiled function is not only defined by its code but also by its input and output shape. It is usually much more effective to pad the input to be of a fixed static shape than having to recompile every the function multiple times.
#### **How to write a training loop**
Now let's see how we can write a simple training loop to train Flax models, we will use `FlaxGPT2ForCausalLM` as an example.
A training loop for Flax models typically consists of
- A loss function that takes the parameters and inputs, runs the forward pass and returns the loss.
- We then transform the loss function using `jax.grad` or `jax.value_and_grad` so that we get the gradients of all parameters.
- An optimizer to update the paramteres using the gradients returned by the transformed loss function.
- A train step function which combines the loss function and optimizer update, does the forward and backward pass and returns the updated parameters.
Lets see how that looks like in code:
First initialize our model
```python
import jax
import jax.numpy as jnp
from transformers import FlaxGPT2ForCausalLM
model = FlaxGPT2ForCausalLM(config)
```
As explained above we don't compute the loss inside the model, but rather in the task-specific training script.
For demonstration purposes, we write a pseudo training script for causal language modeling in the following.
```python
from flax.training.common_utils import onehot
def cross_entropy(logits, labels):
return -jnp.sum(labels * jax.nn.log_softmax(logits, axis=-1), axis=-1)
# define a function which will run the forward pass return loss
def compute_loss(params, input_ids, labels):
logits = model(input_ids, params=params, train=True)
num_classes = logits.shape[-1]
loss = cross_entropy(logits, onehot(labels, num_classes)).mean()
return loss
```
Now we transform the loss function with `jax.value_and_grad`.
```python
# transform the loss function to get the gradients
grad_fn = jax.value_and_grad(compute_loss)
```
We use the [optax](https://github.com/deepmind/optax) library to Initialize the optimizer.
```python
import optax
params = model.params
tx = optax.sgd(learning_rate=3e-3)
opt_state = tx.init(params)
```
Now we define a single training step which will do a forward and a backward pass.
```python
def _train_step(params, opt_state, input_ids, labels)
# do the forward pass and get the loss and gradients
loss, grads = grad_fn(params, input_ids, labels)
# use the gradients to update parameters
updates, opt_state = tx.update(grads, opt_state)
updated_params = optax.apply_updates(params, updates)
return updates_params, opt_state, loss
train_step = jax.jit(_train_step)
```
Finally, let's run our training loop.
```python
# train loop
for i in range(10):
params, opt_state, loss = train_step(params, opt_state, input_ids, labels)
```
Note how we always pass the `params` and `opt_state` to the `train_step` which then returns the updated `params` and `opt_state`. This is because of the staless nature of JAX/Flax models, all the state
like parameters, optimizer state is kept external.
We can now save the model with the trained parameters using
```python
model.save_pretrained("awesome-flax-model", params=params)
```
Note that, as JAX is backed by the [XLA](https://www.tensorflow.org/xla) compiler any JAX/Flax code can run on all `XLA` compliant device without code change!
That menas you could use the same training script on CPUs, GPUs, TPUs.
To know more about how to train the Flax models on different devices (GPU, multi-GPUs, TPUs) and use the example scripts, please look at the [examples README](https://github.com/huggingface/transformers/tree/main/examples/flax).
## Talks
3 days of talks around JAX / Flax, Transformers, large-scale language modeling and other great topics during our community event!
### Wednesday, June 30th
- [Watch the talks on YouTube](https://www.youtube.com/watch?v=fuAyUQcVzTY)
- [Chat history](https://docs.google.com/spreadsheets/d/1PZ5xYV2hVwlAVQSqDag65ympv5YNCSDmXyG-eWTaZ_o/edit?usp=sharing)
Speaker | Topic | Time | Video |
|-------------|---------------------------------|------------------------|------------------------|
| Skye Wanderman-Milne, Google Brain | Intro to JAX on Cloud TPUs | 6.00pm-6.45pm CEST / 9.00am-9.45am PST | [](https://www.youtube.com/watch?v=fuAyUQcVzTY) |
| Marc van Zee, Google Brain | Introduction to Flax | 6.45pm-7.30pm CEST / 9.45am-10.30am PST | [](https://youtu.be/fuAyUQcVzTY?t=2569) |
| Pablo Castro, Google Brain | Using Jax & Flax for RL with the Dopamine library | 7.30pm-8.00pm CEST / 10.30am-11.00am PST | [](https://youtu.be/fuAyUQcVzTY?t=5306) |
### Thursday, July 1st
- [Watch the talks on YouTube](https://www.youtube.com/watch?v=__eG63ZP_5g)
- [Chat history](https://docs.google.com/spreadsheets/d/1PZ5xYV2hVwlAVQSqDag65ympv5YNCSDmXyG-eWTaZ_o/edit#gid=1515796400)
Speaker | Topic | Time | Video |
|-------------|---------------------------------|------------------------|------------------------|
| Suraj Patil & Patrick von Platen, Hugging Face | How to use JAX/Flax with Transformers | 5.30pm-6.00pm CEST / 8.30am-9.00am PST | [](https://www.youtube.com/watch?v=__eG63ZP_5g) |
| Sabrina J. Mielke, Johns Hopkins University & HuggingFace | From stateful code to purified JAX: how to build your neural net framework | 6.00pm-6.30pm CEST / 9.00am-9.30am PST | [](https://youtu.be/__eG63ZP_5g?t=1576) |
| Mostafa Dehghani, Google Brain | Long Range Arena: Benchmarking Efficient Transformers | 6.30pm-7.00pm CEST / 9.30am-10.00am PST | [](https://youtu.be/__eG63ZP_5g?t=3695) |
| Rohan Anil, Google Brain | Scalable Second Order Optimization for Deep Learning | 7.00pm-7.30pm CEST / 10.00am-10.30am PST | [](https://youtu.be/__eG63ZP_5g?t=5285) |
### Friday, July 2nd
- [Watch the talks on YouTube](https://www.youtube.com/watch?v=ZCMOPkcTu3s)
- [Chat history](https://docs.google.com/spreadsheets/d/1PZ5xYV2hVwlAVQSqDag65ympv5YNCSDmXyG-eWTaZ_o/edit#gid=1166061401)
Speaker | Topic | Time | Video |
|-------------|---------------------------------|------------------------|------------------------|
| Lucas Beyer, Google Brain | Vision Transformer | 5.00pm-5.30 CEST / 8.00am-8.30 PST | [](https://www.youtube.com/watch?v=ZCMOPkcTu3s) |
| Ben Wang, EleutherAI | Multihost Training in Mesh Transformer JAX | 5.30pm-6.00 CEST / 8.30am-9.00 PST | [](https://youtu.be/ZCMOPkcTu3s?t=1803) |
| Iurii Kemaev, Soňa Mokrá, Junhyuk Oh, DeepMind | DeepMind JAX Ecosystem | 6.00pm-6.30 CEST / 9.00am-9.30am PST | [](https://youtu.be/ZCMOPkcTu3s?t=3388) |
| Siddhartha Kamalakara, Joanna Yoo & João G M Araújo, Cohere | Training large scale language models | 6:30pm-7.00pm CEST / 9:30am-10.00am PST | [](https://youtu.be/ZCMOPkcTu3s?t=5095) |
### Talks & Speakers
#### Skye Wanderman-Milne, JAX developer, Google Brain
- Talk: Intro to JAX on Cloud TPUs
- Abstract: JAX is a system for high-performance machine-learning research that combines the familiarity of Python + NumPy together with the power of hardware acceleration on CPUs, GPUs, and TPUs. It offers composable function transformations for automatic differentiation, automatic batching, end-to-end compilation, and both data and model parallelism. This talk will show you how to get up and running with JAX on a Cloud TPU VM.
- Speaker info: Skye Wanderman-Milne is a software engineer working on JAX. She has previously worked on TensorFlow and Apache Impala, a high-performance distributed database.
#### Marc van Zee, Research SWE, Google Brain (Flax team)
- Talk: Introduction to Flax
- Abstract: In this talk I will provide a high-level introduction to the neural network library Flax. I will discuss the Flax philosophy, talk about the ecosystem around Flax and provide a high-level introduction to the code. I explain the Module abstraction and how to use it to train your models.
- Speaker info: Marc is at Google Research for over 4 years. First he worked on conceptual AI, developing a next generation language understanding and reasoning prototype and he authored the CFQ dataset for compositional generalization. Currently, Marc works as a research software engineer in the Flax team.
#### Pablo Castro, Staff Research Software Developer; Google Research, Brain Team
- Talk: Using Jax & Flax for RL with the Dopamine library
- Abstract: The Dopamine library was launched with TensorFlow in 2018 and we added a Jax/Flax variant of it last year. Internally, Jax's flexibility has facilitated our RL research tremendously, and we are excited to demonstrate its potential.
- Speaker info: Pablo Samuel has been at Google for over 9 years, and is currently a researcher with the Brain team, focusing on fundamental reinforcement learning, as well as machine learning and creativity. Aside from his research, Pablo Samuel is an active musician (with a channel exploring the intersection of music and computer science), and is helping increase the representation of the LatinX community in the research world.
- Dopamine repo: https://github.com/google/dopamine
- Homepage: https://psc-g.github.io/
- Twitter: https://twitter.com/pcastr
#### Suraj Patil & Patrick von Platen, Machine Learning Engineers at Hugging Face
- Talk: How to use JAX/Flax with Transformers
- Abstract: Transformers is one of the most popular open-source ML libraries and supports PyTorch, Tensorflow, and JAX/Flax. In this talk, we will explain how JAX/Flax models should be used in Transformers and compare their design in Transformers with the design of PyTorch models in Transformers. In the second part, we will give you a hands-on presentation of how a model can be trained end-to-end with the official JAX/Flax example scripts using Transformers & Datasets. Along the way, we want to give you some tips and tricks on how to best realize your project.
- Speaker info: Suraj and Patrick are part of Hugging Face’s open source team and lead the integration of JAX/Flax into Transformers.
- GitHub: https://github.com/patil-suraj & https://github.com/patrickvonplaten
#### Sabrina J. Mielke, PhD student at The Johns Hopkins University & Part-time research intern at HuggingFace
- Talk: From stateful code to purified JAX: how to build your neural net framework
- Abstract: Moving from object-oriented (and stateful) PyTorch- or TF2-code with tape-based backprop to JAX isn't easy---and while running grad() on numpy-oneliners is cool and all, you do wonder... how do I build actual big neural nets? Libraries like flax, trax, or haiku make it easy---but how could you build machinery like that yourself?
- Speaker info: Sabrina is a PhD student at the Johns Hopkins University and a part-time research intern at HuggingFace, researching open-vocabulary language models for segmentation and tokenization. She has published and co-organized workshops and shared tasks on these topics as well as on morphology and typological analysis in ACL, NAACL, EMNLP, LREC, and AAAI. You can find her reminisce for a time when formal language theory played a bigger role in NLP on Twitter at @sjmielke.
- Links: The 2020 blogpost this talk will be based on: https://sjmielke.com/jax-purify.htm, leading to our experiment Parallax and eventually Haiku
#### Mostafa Dehghani, Research Scientist, Google Brain
- Talk: Long Range Arena: Benchmarking Efficient Transformers
- Abstract: Transformers do not scale very well to long sequence lengths largely because of quadratic self-attention complexity. In the recent months, a wide spectrum of efficient, fast Transformers have been proposed to tackle this problem, more often than not claiming superior or comparable model quality to vanilla Transformer models. So, we now need a well-established consensus on how to evaluate this class of models. Moreover, inconsistent benchmarking on a wide spectrum of tasks and datasets makes it difficult to assess relative model quality amongst many models. I'll talk about a systematic and unified benchmark, LRA, specifically focused on evaluating model quality under long-context scenarios. LRA is a suite of tasks consisting of sequences ranging from 1K to 16K tokens, encompassing a wide range of data types and modalities such as text, natural, synthetic images, and mathematical expressions requiring similarity, structural, and visual-spatial reasoning. We systematically evaluate ten well-established long-range Transformer models (Reformers, Linformers, Linear Transformers, Sinkhorn Transformers, Performers, Synthesizers, Sparse Transformers, and Longformers) on LRA. LRA paves the way towards better understanding this class of efficient Transformer models, facilitates more research in this direction, and presents new challenging tasks to tackle.
- Speaker info: https://mostafadehghani.com/
#### Rohan Anil, Senior Staff Software Engineer, Google Research, Brain Team
- Talk: Scalable Second Order Optimization for Deep Learning
- Abstract: Optimization in machine learning, both theoretical and applied, is presently dominated by first-order gradient methods such as stochastic gradient descent. Second-order optimization methods, that involve second derivatives and/or second order statistics of the data, are far less prevalent despite strong theoretical properties, due to their prohibitive computation, memory and communication costs. In an attempt to bridge this gap between theoretical and practical optimization, we present a scalable implementation of a second-order preconditioned method (concretely, a variant of full-matrix Adagrad), that along with several critical algorithmic and numerical improvements, provides significant convergence and wall-clock time improvements compared to conventional first-order methods on state-of-the-art deep models. Our novel design effectively utilizes the prevalent heterogeneous hardware architecture for training deep models, consisting of a multicore CPU coupled with multiple accelerator units. We demonstrate superior performance compared to state-of-the-art on very large learning tasks such as machine translation with Transformers, language modeling with BERT, click-through rate prediction on Criteo, and image classification on ImageNet with ResNet-50.
- Speaker info: Rohan Anil is a software engineer at Google Research, Mountain View. Lately, he has been working on scalable and practical optimization techniques for efficient training of neural networks in various regimes.
- Resources:
- https://arxiv.org/abs/2002.09018
- https://arxiv.org/abs/1901.11150
- https://arxiv.org/abs/2106.06199
#### Lucas Beyer, Senior Research Engineer, Google Brain
- Talk: Vision Transformer
- Abstract: This talk will discuss the learning of general visual representations via large-scale pre-training and few-shot transfer, with a special focus on the Vision Transformer (ViT) architecture, which popularized transformers for the visual domain.
- Speaker info: Lucas Beyer is a self-taught hacker and studied engineer. He went on to do his PhD in robotic perception at RWTH Aachen and is currently on a quest to find the ultimate visual representation at Google Brain in Zürich
#### Ben Wang, Independent AI Researcher, EleutherAI
- Talk: Multihost Training in Mesh Transformer JAX
- Abstract: As models become larger, training must be scaled across multiple nodes. This talk discusses some design decisions and tradeoffs made for scaling to multiple nodes in Mesh Transformer JAX, a library for running model parallel transformers on TPU pods.
- Speaker info: Ben is an independent AI researcher who contributes to EleutherAI, an open source research collective centered around democratizing access to powerful AI models. Recently he has released GPT-J-6B, a 6 billion parameter transformer which is the most powerful autoregressive language model in terms of zero-shot performance with public weights.
- Website: https://www.eleuther.ai/
#### Iurii Kemaev, Research Engineer, Soňa Mokrá, Research Engineer, and Junhyuk Oh, Research Scientist, DeepMind
- Talk: DeepMind JAX Ecosystem
- Abstract: The DeepMind JAX Ecosystem is an effort to build a shared substrate of components to enable all aspects of AGI Research. In this talk, our researchers and engineers will give a high-level overview of our Ecosystem goals and design philosophies, using our Haiku (neural network), Optax (optimization) and RLax (reinforcement learning) libraries as examples. We will then deep dive on two examples of recent DeepMind research that have been enabled by JAX and these libraries: generative models and meta-gradient reinforcement learning.
- Speaker info:
- Iurii Kemaev is a Research Engineer at DeepMind. He has been using JAX for 2 years advancing RL research. Iurii is one of the DM JAX ecosystem leads.
- Soňa Mokrá is a Research Engineer at DeepMind. She has a background in machine translation and has been using JAX as the main ML framework for the past 6 months.
- Junhyuk Oh is a Research Scientist at DeepMind, working on reinforcement learning and meta-learning. More information is available at https://junhyuk.com/
#### Siddhartha Kamalakara, Joanna Yoo, João G M Araújo, MLE at Cohere
- Talk: Training large scale language models
- Abstract: A journey through Cohere’s experiences with training large scale language models. Join us in our exploration of pipeline and model parallelism as strategies for efficient training of large language models. We will present and motivate our recent transition to JAX+Flax as our choice of internal tech stack.
- Speaker info:
- João G M Araújo is a Brazilian college student with a passion for mathematics and a fascination for Deep Learning. João conducted research on representation learning and spent 3 months in Japan working on NeuroEvolution. João likes reading fantasy books and spending quality time with family and friends, and also runs a YouTube series on theoretical understanding of Deep Learning where researchers talk about their findings
- Joanna Yoo is one of the founding engineers at Cohere, working on scaling language models for the last year and half. Joanna loves live concerts and rock climbing!
- Siddhartha Rao Kamalakara is an MLE at Cohere and a researcher at FOR.ai with research interests at the intersection of efficient training and empirical understanding of DL.
- Website: https://cohere.ai/
## How to use the hub for collaboration
In this section, we will explain how a team can use the 🤗 hub to collaborate on a project.
The 🤗 hub allows each team to create a repository with integrated git version control that
should be used for their project.
The advantages of using a repository on the 🤗 hub are:
- easy collaboration - each team member has write access to the model repository
- integrated git version control - code scripts as well as large model files are tracked using git version control
- easy sharing - the hub allows each team to easily share their work during and after the event
- integrated tensorboard functionality - uploaded tensorboard traces are automatically displayed on an integrated tensorboard tab
We highly recommend each team to make use of the 🤗 hub during the event.
To better understand how the repository and the hub in general functions, please take a look at the documentation and the videos [here](https://huggingface.co/docs/hub).
Now let's explain in more detail how a project can be created on the hub. Having an officially defined project on [this](https://docs.google.com/spreadsheets/d/1GpHebL7qrwJOc9olTpIPgjf8vOS0jNb6zR_B8x_Jtik/edit?usp=sharing) Google Sheet you should be part of [the Flax Community organization on the hub](https://huggingface.co/flax-community). All repositories should be created under this organization so that write access can be shared and everybody can easily access other participants'
work 🤗. Note that we are giving each team member access to all repositories created under [flax-community](https://huggingface.co/flax-community), but we encourage participants to only clone and edit repositories corresponding to one's teams. If you want to help other teams, please ask them before changing files in their repository! The integrated git version control keeps track of
all changes, so in case a file was deleted by mistake, it is trivial to re-create it.
Awesome! Now, let's first go over a simple example where most of the required we'll pre-train a RoBERTa model on a low-resource language. To begin with, we create a repository
under [the Flax Community organization on the hub](https://huggingface.co/flax-community) by logging in to the hub and going to [*"Add model"*](https://huggingface.co/new). By default
the username should be displayed under "*Owner*", which we want to change to *flax-community*. Next, we give our repository a fitting name for the project - here we'll just call it
*roberta-base-als* because we'll be pretraining a RoBERTa model on the super low-resource language *Alemannic* (`als`). We make sure that the model is a public repository and create it!
It should then be displayed on [the Flax Community organization on the hub](https://huggingface.co/flax-community).
Great, now we have a project directory with integrated git version control and a public model page, which we can access under [flax-community/roberta-base-als](https://huggingface.co/flax-community/roberta-base-als). Let's create a short README so that other participants know what this model is about. You can create the README.md directly on the model page as a markdown file.
Let's now make use of the repository for training.
We assume that the 🤗 Transformers library and [git-lfs](https://git-lfs.github.com/) are correctly installed on our machine or the TPU attributed to us.
If this is not the case, please refer to the [Installation guide](#how-to-install-relevant-libraries) and the official [git-lfs](https://git-lfs.github.com/) website.
At first we should log in:
```bash
$ huggingface-cli login
```
Next we can clone the repo:
```bash
$ git clone https://huggingface.co/flax-community/roberta-base-als
```
We have now cloned the model's repository and it should be under `roberta-base-als`. As you can see,
we have all the usual git functionalities in this repo - when adding a file, we can do `git add .`, `git commit -m "add file"` and `git push`
as usual. Let's try it out by adding the model's config.
We go into the folder:
```bash
$ cd ./roberta-base-als
```
and run the following commands in a Python shell to save a config.
```python
from transformers import RobertaConfig
config = RobertaConfig.from_pretrained("roberta-base")
config.save_pretrained("./")
```
Now we've added a `config.json` file and can upload it by running
```bash
$ git add . && git commit -m "add config" && git push
```
Cool! The file is now displayed on the model page under the [files tab](https://huggingface.co/flax-community/roberta-base-als/tree/main).
We encourage you to upload all files except maybe the actual data files to the repository. This includes training scripts, model weights,
model configurations, training logs, etc...
Next, let's create a tokenizer and save it to the model dir by following the instructions of the [official Flax MLM README](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#train-tokenizer). We can again use a simple Python shell.
```python
from datasets import load_dataset
from tokenizers import ByteLevelBPETokenizer
# load dataset
dataset = load_dataset("oscar", "unshuffled_deduplicated_als", split="train")
# Instantiate tokenizer
tokenizer = ByteLevelBPETokenizer()
def batch_iterator(batch_size=1000):
for i in range(0, len(dataset), batch_size):
yield dataset[i: i + batch_size]["text"]
# Customized training
tokenizer.train_from_iterator(batch_iterator(), vocab_size=50265, min_frequency=2, special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>",
])
# Save files to disk
tokenizer.save("./tokenizer.json")
```
This creates and saves our tokenizer directly in the cloned repository.
Finally, we can start training. For now, we'll simply use the official [`run_mlm_flax`](https://github.com/huggingface/transformers/blob/main/examples/flax/language-modeling/run_mlm_flax.py)
script, but we might make some changes later. So let's copy the script into our model repository.
```bash
$ cp ~/transformers/examples/flax/language-modeling/run_mlm_flax.py ./
```
This way we are certain to have all the code used to train the model tracked in our repository.
Let's start training by running:
```bash
./run_mlm_flax.py \
--output_dir="./" \
--model_type="roberta" \
--config_name="./" \
--tokenizer_name="./" \
--dataset_name="oscar" \
--dataset_config_name="unshuffled_deduplicated_als" \
--max_seq_length="128" \
--per_device_train_batch_size="4" \
--per_device_eval_batch_size="4" \
--learning_rate="3e-4" \
--warmup_steps="1000" \
--overwrite_output_dir \
--num_train_epochs="8" \
--push_to_hub
```
Since the dataset is tiny this command should actually run in less than 5 minutes. Note that we attach
the flag ``--push_to_hub`` so that both model weights and tensorboard traces are automatically uploaded to the hub.
You can see the tensorboard directly on the model page, under the [Training metrics tab](https://huggingface.co/flax-community/roberta-base-als/tensorboard).
As you can see, it is pretty simple to upload model weights and training logs to the model hub. Since the repository
has git version control, you & your team probably already have the necessary skills to collaborate. Thanks
to `git-lfs` being integrated into the hub, model weights and other larger file can just as easily be uploaded
and changed. Finally, at Hugging Face, we believe that the model hub is a great platform to share your project
while you are still working on it:
- Bugs in training scripts can be found and corrected by anybody participating in the event
- Loss curves can be analyzed directly on the model page
- Model weights can be accessed and analyzed by everybody from the model repository
If you are not using a transformers model, don't worry - you should still be able to make use of the hub's functionalities!
The [huggingface_hub](https://github.com/huggingface/huggingface_hub) allows you to upload essentially any JAX/Flax model to the hub with
just a couple of lines of code. *E.g.* assuming you want to call your model simply `flax-model-dummy`, you can upload it to the hub with
just three lines of code:
```python
from flax import serialization
from jax import random
from flax import linen as nn
from huggingface_hub import Repository
model = nn.Dense(features=5)
key1, key2 = random.split(random.PRNGKey(0))
x = random.normal(key1, (10,))
params = model.init(key2, x)
bytes_output = serialization.to_bytes(params)
repo = Repository("flax-model", clone_from="flax-community/flax-model-dummy", token=True)
with repo.commit("My cool Flax model :)"):
with open("flax_model.msgpack", "wb") as f:
f.write(bytes_output)
# Repo is created and available here: https://huggingface.co/flax-community/flax-model-dummy
```
**Note**: Make sure to have `huggingface_hub >= 0.0.13` to make this command work.
For more information, check out [this PR](https://github.com/huggingface/huggingface_hub/pull/143) on how to upload any framework to the hub.
## How to setup TPU VM
In this section we will explain how you can ssh into a TPU VM that has been given to your team.
If your username is in one of the officially defined projects [here](https://docs.google.com/spreadsheets/d/1GpHebL7qrwJOc9olTpIPgjf8vOS0jNb6zR_B8x_Jtik/edit?usp=sharing), you should have received two emails:
- one that states that you have been granted the role "Community Week Participants" for the project hf-flax, and
- one (or more if you are in multiple projects) that gives you the TPU name and the TPU zone for the TPU of your team
You should click on "Open Cloud Console" on the first mail and agree to the pop up windows that follows. It will allow you to use a TPU VM. Don't worry if you cannot access the actual project `hf-flax` visually on the google cloud console and receive an error:
```
You don't have sufficient permission to view this page
```
- this is expected!
Great, now you and your team can access your TPU VM!
In the following, we will describe how to do so using a standard console, but you should also be able to connect to the TPU VM via IDEs, like Visual Studio Code, etc.
1. You need to install the Google Cloud SDK. Please follow the instructions on [cloud.google.com/sdk](https://cloud.google.com/sdk/docs/install#linux).
2. Once you've installed the google cloud sdk, you should set your account by running the following command. Make sure that `<your-email-address>` corresponds to the gmail address you used to sign up for this event.
```bash
$ gcloud config set account <your-email-adress>
```
3. Let's also make sure the correct project is set in case your email is used for multiple gcloud projects:
```bash
$ gcloud config set project hf-flax
```
4. Next, you will need to authenticate yourself. You can do so by running:
```bash
$ gcloud auth login
```
This should give you a link to a website, where you can authenticate your gmail account.
5. Finally, you can ssh into the TPU VM! Please run the following command by setting <zone> to either `europe-west4-a` or `us-central1-a` (depending on what is stated in the second email you received) and <tpu-name> to the TPU name also sent to you in the second email.
```bash
$ gcloud alpha compute tpus tpu-vm ssh <tpu-name> --zone <zone> --project hf-flax
```
This should ssh you into the TPU VM!
Now you can follow the steps of the section [How to install relevant libraries](#how-to-install-relevant-libraries) to install all necessary
libraries. Make sure to carefully follow the explanations of the "**IMPORTANT**" statement to correctly install JAX on TPU.
Also feel free to install other `python` or `apt` packages on your machine if it helps you to work more efficiently!
## How to build a demo
### Using the Hugging Face Widgets
Hugging Face has over [15 widgets](https://huggingface-widgets.netlify.app/) for different use cases using 🤗 Transformers library. Some of them also support [3rd party libraries](https://huggingface.co/docs/hub/libraries) such as [Sentence Similarity](https://huggingface.co/sentence-transformers/paraphrase-xlm-r-multilingual-v1) with Sentence Transformers and [Text to Speech](https://huggingface.co/julien-c/ljspeech_tts_train_tacotron2_raw_phn_tacotron_g2p_en_no_space_train) with [ESPnet](https://github.com/espnet/espnet).
All the widgets are open sourced in the `huggingface_hub` [repo](https://github.com/huggingface/huggingface_hub/tree/main/widgets). Here is a summary of existing widgets:
**NLP**
* **Conversational:** To have the best conversations!. [Example](https://huggingface.co/microsoft/DialoGPT-large?).
* **Feature Extraction:** Retrieve the input embeddings. [Example](https://huggingface.co/sentence-transformers/distilbert-base-nli-mean-tokens?text=test).
* **Fill Mask:** Predict potential words for a mask token. [Example](https://huggingface.co/bert-base-uncased?).
* **Question Answering:** Given a context and a question, predict the answer. [Example](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad).
* **Sentence Simmilarity:** Predict how similar a set of sentences are. Useful for Sentence Transformers.
* **Summarization:** Given a text, output a summary of it. [Example](https://huggingface.co/sshleifer/distilbart-cnn-12-6).
* **Table Question Answering:** Given a table and a question, predict the answer. [Example](https://huggingface.co/google/tapas-base-finetuned-wtq).
* **Text Generation:** Generate text based on a prompt. [Example](https://huggingface.co/gpt2)
* **Token Classification:** Useful for tasks such as Named Entity Recognition and Part of Speech. [Example](https://huggingface.co/dslim/bert-base-NER).
* **Zero-Shot Classification:** Too cool to explain with words. Here is an [example](https://huggingface.co/typeform/distilbert-base-uncased-mnli)
* ([WIP](https://github.com/huggingface/huggingface_hub/issues/99)) **Table to Text Generation**.
**Speech**
* **Audio to Audio:** For tasks such as audio source separation or speech enhancement.
* **Automatic Speech Recognition:** Convert audio to text. [Example](https://huggingface.co/facebook/wav2vec2-base-960h)
* **Text to Speech**: Convert text to audio.
**Image**
* **Image Classification:** Given an image, predict its class. [Example](https://huggingface.co/osanseviero/llamastic).
* ([WIP](https://github.com/huggingface/huggingface_hub/issues/100)) **Zero Shot Image Classification**
* ([WIP](https://github.com/huggingface/huggingface_hub/issues/112)) **Image Captioning**
* ([WIP](https://github.com/huggingface/huggingface_hub/issues/113)) **Text to Image Generation**
* ([Proposed](https://github.com/huggingface/huggingface_hub/issues/127)) **Visual Question Answering**
You can propose and implement new widgets by [opening an issue](https://github.com/huggingface/huggingface_hub/issues). Contributions are welcomed!
### Using a Streamlit demo
Sometimes you might be using different libraries or a very specific application that is not well supported by the current widgets. In this case, [Streamlit](https://streamlit.io/) can be an excellent option to build a cool visual demo. Setting up a Streamlit application is straightforward and in Python!
A common use case is how to load files you have in your model repository in the Hub from the Streamlit demo. The `huggingface_hub` library is here to help you!
```
pip install huggingface_hub
```
Here is an example downloading (and caching!) a specific file directly from the Hub
```
from huggingface_hub import hf_hub_download
filepath = hf_hub_download("flax-community/roberta-base-als", "flax_model.msgpack");
```
In many cases you will want to download the full repository. Here is an example downloading all the files from a repo. You can even specify specific revisions!
```
from huggingface_hub import snapshot_download
local_path = snapshot_download("flax-community/roberta-base-als");
```
Note that if you're using 🤗 Transformers library, you can quickly load the model and tokenizer as follows
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("REPO_ID")
model = AutoModelForMaskedLM.from_pretrained("REPO_ID")
```
We'll provide more examples on Streamlit demos next week. Stay tuned!
### Using a Gradio demo
You can also use [Gradio](https://gradio.app/) to share your demos! [Here](https://huggingface.co/blog/gradio) is an example using the Gradio library to create a GUI for a Hugging Face model.
More to come!
## Project evaluation
For your project to be evaluated, please fill out [this google form](https://forms.gle/jQaMkj3JJdD4Xcwn9).
Please make sure that your submitted project includes a demo as well as information about the model, data, training methods, etc.
### Criteria
* **Demo.** All projects are required to have a demo. It’s open ended, but we provide some ideas on how to build demos in the [How to build a demo](#how-to-build-a-demo) section.
* **Technical difficulty.** Difficulty has different aspects, such as working with complex architectures, obtaining better evaluation metrics than existing models, or implementing models for low-resource languages.
* **Social impact.** The project is expected to have a positive social impact, e.g. by tackling under-explored area of practical interest for minorities or under-represented group (low-ressources languages, specific focus on bias, fairness or ethical issues in ML) or by tackling general societal challenges, e.g. health or climate related challenges.
* **Innovativeness.** Projects that propose novel applications or bring new ideas will be rewarded more.
### Jury
* [Niki Parmar](https://research.google/people/NikiParmar/): Staff Research Scientist at Google.
* [Ross Wightman](https://www.linkedin.com/in/wightmanr/): Angel Investor.
* [Thomas Wolf](https://www.linkedin.com/in/thomas-wolf-a056857/): Co-founder and CSO at Hugging Face.
* [Ashish Vaswani](https://research.google/people/AshishVaswani/): Staff Research Scientist at Google Brain.
### Process
* **July 17, 12h00 CEST**: TPU VM access closes.
* **July 19, 12h00 CEST**: Project completition ends (including demo).
* **July 19-21** A group of event organizers (Suraj, Patrick, Suzana, and Omar) will do an initial filter to find the top 15 projects.
* **July 22-26** The jury will go over the 15 projects and pick the top three projects out of them.
* **July 27.** Winner projects are announced
## General tips and tricks
TODO (will be filled continuously)...
## FAQ
TODO (will be filled continuously)...
| huggingface/transformers/blob/main/examples/research_projects/jax-projects/README.md |
Gradio Demo: theme_new_step_2
```
!pip install -q gradio
```
```
from __future__ import annotations
from typing import Iterable
import gradio as gr
from gradio.themes.base import Base
from gradio.themes.utils import colors, fonts, sizes
import time
class Seafoam(Base):
def __init__(
self,
*,
primary_hue: colors.Color | str = colors.emerald,
secondary_hue: colors.Color | str = colors.blue,
neutral_hue: colors.Color | str = colors.gray,
spacing_size: sizes.Size | str = sizes.spacing_md,
radius_size: sizes.Size | str = sizes.radius_md,
text_size: sizes.Size | str = sizes.text_lg,
font: fonts.Font
| str
| Iterable[fonts.Font | str] = (
fonts.GoogleFont("Quicksand"),
"ui-sans-serif",
"sans-serif",
),
font_mono: fonts.Font
| str
| Iterable[fonts.Font | str] = (
fonts.GoogleFont("IBM Plex Mono"),
"ui-monospace",
"monospace",
),
):
super().__init__(
primary_hue=primary_hue,
secondary_hue=secondary_hue,
neutral_hue=neutral_hue,
spacing_size=spacing_size,
radius_size=radius_size,
text_size=text_size,
font=font,
font_mono=font_mono,
)
seafoam = Seafoam()
with gr.Blocks(theme=seafoam) as demo:
textbox = gr.Textbox(label="Name")
slider = gr.Slider(label="Count", minimum=0, maximum=100, step=1)
with gr.Row():
button = gr.Button("Submit", variant="primary")
clear = gr.Button("Clear")
output = gr.Textbox(label="Output")
def repeat(name, count):
time.sleep(3)
return name * count
button.click(repeat, [textbox, slider], output)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/theme_new_step_2/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BLIP-2
## Overview
The BLIP-2 model was proposed in [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. BLIP-2 leverages frozen pre-trained image encoders and large language models (LLMs) by training a lightweight, 12-layer Transformer
encoder in between them, achieving state-of-the-art performance on various vision-language tasks. Most notably, BLIP-2 improves upon [Flamingo](https://arxiv.org/abs/2204.14198), an 80 billion parameter model, by 8.7%
on zero-shot VQAv2 with 54x fewer trainable parameters.
The abstract from the paper is the following:
*The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/blip2_architecture.jpg"
alt="drawing" width="600"/>
<small> BLIP-2 architecture. Taken from the <a href="https://arxiv.org/abs/2301.12597">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
## Usage tips
- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLIP-2.
- Demo notebooks for BLIP-2 for image captioning, visual question answering (VQA) and chat-like conversations can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Blip2Config
[[autodoc]] Blip2Config
- from_vision_qformer_text_configs
## Blip2VisionConfig
[[autodoc]] Blip2VisionConfig
## Blip2QFormerConfig
[[autodoc]] Blip2QFormerConfig
## Blip2Processor
[[autodoc]] Blip2Processor
## Blip2VisionModel
[[autodoc]] Blip2VisionModel
- forward
## Blip2QFormerModel
[[autodoc]] Blip2QFormerModel
- forward
## Blip2Model
[[autodoc]] Blip2Model
- forward
- get_text_features
- get_image_features
- get_qformer_features
## Blip2ForConditionalGeneration
[[autodoc]] Blip2ForConditionalGeneration
- forward
- generate | huggingface/transformers/blob/main/docs/source/en/model_doc/blip-2.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Adding BetterTransformer support for new architectures
You want to add a new model for `Better Transformer`, the fast path of PyTorch Transformer API? Check this guideline!
## Models that should be supported
In theory, any model that has a transformer encoder layer, similar to the classic encoder described in the ["Attention Is All You Need"](https://arxiv.org/abs/1706.03762) paper should be supported.
More specifically, a model that has an encoder block with a MultiHead-Attention module (with pre or post-attention layer norm) should be convertible to its `BetterTransformer` equivalent. The conditions can be summarized as follows:
- Use classic Multi Head attention module (for example, [DeBERTa](https://arxiv.org/abs/2006.03654) cannot be supported)
- Use either `gelu` or `relu` activation function
- Have an even number of attention heads
- Do not use any attention bias (for eg `T5` uses attention bias, therefore cannot be supported)
- `eps` must be equal between the first and second layer norms for each layer
## How to convert a model into its `BetterTransformer` format?
### Step 1: Identifying the source layer to change
First, go to `optimum/bettertransformer/__init__.py` and you'll see the dictionary `BetterTransformerManager.MODEL_MAPPING`. This should contain the mapping between a model type, and the `Tuple[str, BetterTransformerBaseLayer]` composed of the name of the `nn.Module` that can be converted to its `BetterTransformer` equivalent, and effectively the equivalent `BetterTransformer` layer class.
Let us try to do it step by step for `Bert`, first we need to identify the layers that needs to be replaced:
```python
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("bert-base-uncased")
>>> print(model) # doctest: +IGNORE_RESULT
...
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
```
You can clearly see that the layers that need to be replaced are the `BertLayer` modules since they contain the whole encoder layer module.
### Step 2: Building the `xxxLayerBetterTransformer` module
Check that the identified module is not already copied from another module (by inspecting the source code in [`transformers`](https://github.com/huggingface/transformers) and checking that the class definition does not start with `# Copied from ...`) - and if not, create a class in `bettertransformer/models/encoder_model.py`.
Start with those lines:
```python
import torch
import torch.nn as nn
from ..base import BetterTransformerBaseLayer
class BertLayerBetterTransformer(BetterTransformerBaseLayer):
def __init__(self, bert_layer, config):
...
```
Now, make sure to fill all the necessary attributes, the list of attributes are:
- `in_proj_weight`
- `in_proj_bias`
- `out_proj_weight`
- `out_proj_bias`
- `linear1_weight`
- `linear1_bias`
- `linear2_weight`
- `linear2_bias`
- `norm1_eps`
- `norm1_weight`
- `norm1_bias`
- `norm2_weight`
- `norm2_bias`
- `num_heads`
- `embed_dim`
Note that these attributes correspond to all the components that are necessary to run a Transformer Encoder module, check the figure 1 on the ["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf) paper.
Once you filled all these attributes (sometimes the `query`, `key` and `value` layers needs to be "contigufied", check the [`modeling_encoder.py`](https://github.com/huggingface/optimum/blob/main/optimum/bettertransformer/models/encoder_models.py) file to understand more.)
Make sure also to add the lines:
```python
self.is_last_layer = False
self.validate_bettertransformer()
```
### Step 3: Building the forward pass
First of all, start with the line `super().forward_checker()`, this is needed so that the parent class can run all the safety checkers before.
After the first forward pass, the hidden states needs to be *nested* using the attention mask. Once they are nested, the attention mask is not needed anymore, therefore can be set to `None`. This is how the forward pass is built for `Bert`, these lines should remain pretty much similar accross models, but sometimes the shapes of the attention masks are different across models.
```python
super().forward_checker()
if hidden_states.is_nested:
attention_mask = None
if attention_mask is not None:
# attention mask comes in with values 0 and -inf. we convert to torch.nn.TransformerEncoder style bool mask
# 0->false->keep this token -inf->true->mask this token
attention_mask = attention_mask.bool()
attention_mask = torch.reshape(attention_mask, (attention_mask.shape[0], attention_mask.shape[-1]))
seqlen = attention_mask.shape[1]
lengths = torch.sum(~attention_mask, 1)
if not all([l == seqlen for l in lengths]):
hidden_states = torch._nested_tensor_from_mask(hidden_states, ~attention_mask)
attention_mask = None
```
Once the `hidden_states` are nested, call `torch._transformer_encoder_layer_fwd` using the right arguments as follows:
```python
hidden_states = torch._transformer_encoder_layer_fwd(
hidden_states,
self.embed_dim,
self.num_heads,
self.in_proj_weight,
self.in_proj_bias,
self.out_proj_weight,
self.out_proj_bias,
self.use_gelu,
self.norm_first,
self.norm1_eps,
self.norm1_weight,
self.norm1_bias,
self.norm2_weight,
self.norm2_bias,
self.linear1_weight,
self.linear1_bias,
self.linear2_weight,
self.linear2_bias,
attention_mask,
)
```
At the last layer, it is important to "un-nest" the hidden_states so that it can be processed by the next modules, this is done in these lines:
```python
if hidden_states.is_nested and self.is_last_layer:
hidden_states = hidden_states.to_padded_tensor(0.0)
return (hidden_states,)
```
Also make sure to return a `tuple` to follow the convention of `transformers`.
The best way to reproduce this experiment on your own model is to try it by get some inspiration from the provided modeling scripts. Of course, we will be happy to help you converting your model if you open an issue or a Pull Request on `optimum`!
### Step 4: Sanity check!
As a last step, make sure to update the `BetterTransformerManager.MODEL_MAPPING` dictionary in `optimum/bettertransformer/__init__.py` with the correct names, and you should be ready to convert your model. For example, for Bert that would be:
```
MODEL_MAPPING = {
...
"bert": ("BertLayer", BertLayerBetterTransformer),
...
}
```
Try it out with the conversion method that is presented in the [tutorials sections](../tutorials/convert)!
| huggingface/optimum/blob/main/docs/source/bettertransformer/tutorials/contribute.mdx |
Using GPU Spaces
You can upgrade your Space to use a GPU accelerator using the _Settings_ button in the top navigation bar of the Space. You can even request a free upgrade if you are building a cool demo for a side project!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-gpu-settings.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-gpu-settings-dark.png"/>
</div>
<Tip>
Longer-term, we would also like to expose non-GPU hardware, like HPU, IPU or TPU. If you have a specific AI hardware you'd like to run on, please let us know (website at huggingface.co).
</Tip>
As soon as your Space is running on GPU you can see which hardware it’s running on directly from this badge:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-running-badge.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-running-badge-dark.png"/>
</div>
## Hardware Specs
In the following table, you can see the Specs for the different upgrade options.
| **Hardware** | **GPU Memory** | **CPU** | **Memory** | **Disk** | **Hourly Price** |
|--------------------- |----------------- |---------- |-------------- |---------- | ---------------- |
| CPU Basic | - | 2 vCPU | 16 GB | 50 GB | Free! |
| CPU Upgrade | - | 8 vCPU | 32 GB | 50 GB | $0.03 |
| Nvidia T4 - small | 16GB | 4 vCPU | 15 GB | 50 GB | $0.60 |
| Nvidia T4 - medium | 16GB | 8 vCPU | 30 GB | 100 GB | $0.90 |
| Nvidia A10G - small | 24GB | 4 vCPU | 15 GB | 110 GB | $1.05 |
| Nvidia A10G - large | 24GB | 12 vCPU | 46 GB | 200 GB | $3.15 |
| Nvidia A100 - large | 40GB | 12 vCPU | 142 GB | 1000 GB | $4.13 |
## Configure hardware programmatically
You can programmatically configure your Space hardware using `huggingface_hub`. This allows for a wide range of use cases where you need to dynamically assign GPUs.
Check out [this guide](https://huggingface.co/docs/huggingface_hub/main/en/guides/manage_spaces) for more details.
## Framework specific requirements[[frameworks]]
Most Spaces should run out of the box after a GPU upgrade, but sometimes you'll need to install CUDA versions of the machine learning frameworks you use. Please, follow this guide to ensure your Space takes advantage of the improved hardware.
### PyTorch
You'll need to install a version of PyTorch compatible with the built-in CUDA drivers. Adding the following two lines to your `requirements.txt` file should work:
```
--extra-index-url https://download.pytorch.org/whl/cu113
torch
```
You can verify whether the installation was successful by running the following code in your `app.py` and checking the output in your Space logs:
```Python
import torch
print(f"Is CUDA available: {torch.cuda.is_available()}")
# True
print(f"CUDA device: {torch.cuda.get_device_name(torch.cuda.current_device())}")
# Tesla T4
```
Many frameworks automatically use the GPU if one is available. This is the case for the Pipelines in 🤗 `transformers`, `fastai` and many others. In other cases, or if you use PyTorch directly, you may need to move your models and data to the GPU to ensure computation is done on the accelerator and not on the CPU. You can use PyTorch's `.to()` syntax, for example:
```Python
model = load_pytorch_model()
model = model.to("cuda")
```
### JAX
If you use JAX, you need to specify the URL that contains CUDA compatible packages. Please, add the following lines to your `requirements.txt` file:
```
-f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
jax[cuda11_pip]
jaxlib
```
After that, you can verify the installation by printing the output from the following code and checking it in your Space logs.
```Python
import jax
print(f"JAX devices: {jax.devices()}")
# JAX devices: [StreamExecutorGpuDevice(id=0, process_index=0)]
print(f"JAX device type: {jax.devices()[0].device_kind}")
# JAX device type: Tesla T4
```
### Tensorflow
The default `tensorflow` installation should recognize the CUDA device. Just add `tensorflow` to your `requirements.txt` file and use the following code in your `app.py` to verify in your Space logs.
```Python
import tensorflow as tf
print(tf.config.list_physical_devices('GPU'))
# [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
```
## Billing
Billing on Spaces is based on hardware usage and is computed by the minute: you get charged for every minute the Space runs on the requested hardware,
regardless of whether the Space is used.
During a Space's lifecycle, it is only billed when the Space is actually `Running`. This means that there is no cost during build or startup.
If a running Space starts to fail, it will be automatically suspended and the billing will stop.
Spaces running on free hardware are suspended automatically if they are not used for an extended period of time (e.g. two days). Upgraded Spaces run indefinitely by default, even if there is no usage. You can change this behavior by [setting a custom "sleep time"](#sleep-time) in the Space's settings. To interrupt the billing on your Space, you can change the Hardware to CPU basic, or [pause](#pause) it.
Additional information about billing can be found in the [dedicated Hub-wide section](./billing).
### Community GPU Grants
Do you have an awesome Space but need help covering the GPU hardware upgrade costs? We love helping out those with an innovative Space so please feel free to apply for a community GPU grant and see if yours makes the cut! This application can be found in your Space hardware repo settings in the lower left corner under "sleep time settings":
## Set a custom sleep time[[sleep-time]]
If your Space runs on the default `cpu-basic` hardware, it will go to sleep if inactive for more than a set time (currently, 48 hours). Anyone visiting your Space will restart it automatically.
If you want your Space never to deactivate or if you want to set a custom sleep time, you need to upgrade to a paid Hardware.
By default, an upgraded Space will never go to sleep. However, you can use this setting for your upgraded Space to become idle (`stopped` stage) when it's unused 😴. You are not going to be charged for the upgraded hardware while it is asleep. The Space will 'wake up' or get restarted once it receives a new visitor.
The following interface will then be available in your Spaces hardware settings:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-sleep-time.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-sleep-time-dark.png"/>
</div>
The following options are available:
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-sleep-time-options.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-sleep-time-options-dark.png"/>
</div>
## Pausing a Space[[pause]]
You can `pause` a Space from the repo settings. A "paused" Space means that the Space is on hold and will not use resources until manually restarted, and only the owner of a paused Space can restart it. Paused time is not billed.
| huggingface/hub-docs/blob/main/docs/hub/spaces-gpus.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Contributing to PEFT
We are happy to accept contributions to PEFT. If you plan to contribute, please read this document to make the process as smooth as possible.
## Installation
The installation instructions can be found [here](https://huggingface.co/docs/peft/install). If you want to provide code contributions to PEFT, you should choose the "source" installation method.
If you are new to creating a pull request, follow [these instructions from GitHub](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request).
## Running tests and code quality checks
Regardless of the type of contribution (unless it’s only about the docs), you should run tests and code quality checks before creating a PR to ensure that your contribution doesn’t break anything and follows the standards of the project.
We provide a Makefile to facilitate those steps. Run the code below for the unit test:
```sh
make test
```
Run one of the following to either check or check and fix code quality and style:
```sh
make quality # just check
make style # check and fix
```
Running all the tests can take a couple of minutes. Therefore, during development, it can be useful to run only those tests specific to your change:
```sh
pytest tests/ -k <name-of-test>
```
This should finish much quicker and allow faster iteration. Before creating the PR, however, please still run the whole test suite, as some changes can inadvertently break tests that at first glance are unrelated.
If your change is specific to a hardware setting (e.g. it requires CUDA), take a look at `tests/test_gpu_examples.py` and `tests/test_common_gpu.py` – maybe it makes sense to add a test there. If your change could have an effect on saving and loading models, please run the tests with the `--regression` flag to trigger regression tests.
It can happen that while you’re working on your PR, the underlying code base changes due to other changes being merged. If that happens – especially when there is a merge conflict – please update your branch to be on the latest changes. This can be a merge or a rebase, whatever you prefer. We will squash and merge the PR once it’s ready.
## PR description
When opening the PR, please provide a nice description of the change you provide. If it relates to other issues or PRs, please reference them. Providing a good description will not only help the reviewers review your code better and faster, it can also later be used (as a basis) for the commit message, which helps with long term maintenance of the project.
If your code makes some non-trivial changes, it can also be a good idea to add comments to the code to explain those changes. For example, if you had to iterate on your implementation multiple times because the most obvious way didn’t work, it’s a good indication that a code comment is needed.
## Providing a bugfix
Please give a description of the circumstances that lead to the bug. If there is an existing issue, please link to it (e.g. “Resolves #12345”).
Ideally, when a bugfix is provided, it should be accompanied by a test for this bug. The test should fail with the current code and pass with the bugfix. Add a comment to the test that references the issue or PR. Without such a test, it is difficult to prevent regressions in the future.
## Adding a new fine-tuning method
New parameter-efficient fine-tuning methods are developed all the time. If you would like to add a new, promising method to PEFT, please follow these steps.
**Requirements**
1. Please add a link to the source (usually a paper) of the method.
2. Some evidence should be provided that there is general interest in using the method. We will not add new methods that are freshly published but without evidence that there is demand for it.
3. Ideally, we want to not only add the implementation of the new method, but also examples (notebooks, scripts), documentation, and an extensive test suite that proves that the method works with a variety of tasks. However, this can be very daunting. Therefore, it is also acceptable to only provide the implementation and at least one working example. Documentation and tests can be added in follow up PRs.
**Steps**
Before you start to implement the new method, please open an issue on GitHub with your proposal. That way, the maintainers can give you some early feedback.
When implementing the method, it makes sense to look for existing implementations that already exist as a guide. Moreover, when you structure your code, please take inspiration from the other PEFT methods. For example, if your method is similar to LoRA, it makes sense to structure your code similarly or even re-use some functions or classes where it makes sense (but don’t overdo it, some code duplication is okay).
Once you have something that seems to be working, don’t hesitate to create a draft PR, even if it’s not in a mergeable state yet. The maintainers will be happy to give you feedback and guidance along the way.
## Adding other features
It is best if you first open an issue on GitHub with a proposal to add the new feature. That way, you can discuss with the maintainers if it makes sense to add the feature before spending too much time on implementing it.
New features should generally be accompanied by tests and documentation or examples. Without the latter, users will have a hard time discovering your cool new feature.
Changes to the code should be implemented in a backward-compatible way. For example, existing code should continue to work the same way after the feature is merged.
| huggingface/peft/blob/main/docs/source/developer_guides/contributing.md |
!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={8}
classNames="absolute z-10 right-0 top-0"
/>
Let's test what you learned in this chapter!
### 1. In which order should you read a Python traceback?
<Question
choices={[
{
text: "From top to bottom",
explain: "Try again -- although most other programming languages print the exception at the top, Python is special in this regard."
},
{
text: "From bottom to top",
explain: "Correct! One advantage of Python's tracebacks showing the exception at the bottom is that it's easier to debug when you're working in the terminal and this is the last line you see.",
correct: true
}
]}
/>
### 2. What is a minimal reproducible example?
<Question
choices={[
{
text: "A simple implementation of a Transformer architecture from a research article",
explain: "Although it is very educational to implement your own Transformer models from scratch, this is not what we're talking about here."
},
{
text: "A compact and self-contained block of code that can be run without any external dependencies on private files or data",
explain: "Correct! Minimal reproducible examples help the library's maintainers reproduce the problem you are having, so they can find solutions faster.",
correct: true
},
{
text: "A screenshot of the Python traceback",
explain: "Try again -- although it is tempting to include a screenshot of the error you are facing when filing an issue, this makes it very difficult for others to reproduce the error."
},
{
text: "A notebook that contains your whole analysis, including parts unrelated to the error",
explain: "Not quite -- although it can be helpful to share a Google Colab notebook that shows the error, make sure it is short and only contains the relevant code."
}
]}
/>
### 3. Suppose you try to run the following code, which throws an error:
```py
from transformers import GPT3ForSequenceClassification
# ImportError: cannot import name 'GPT3ForSequenceClassification' from 'transformers' (/Users/lewtun/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/__init__.py)
# ---------------------------------------------------------------------------
# ImportError Traceback (most recent call last)
# /var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_30848/333858878.py in <module>
# ----> 1 from transformers import GPT3ForSequenceClassification
# ImportError: cannot import name 'GPT3ForSequenceClassification' from 'transformers' (/Users/lewtun/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/__init__.py)
```
Which of the following might be a good choice for the title of a forum topic to ask for help?
<Question
choices={[
{
text: "<code>ImportError: cannot import name 'GPT3ForSequenceClassification' from 'transformers' (/Users/lewtun/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/__init__.py)</code>",
explain: "Including the last line of the traceback can be descriptive, but this is better reserved for the main body of the topic. Try again!"
},
{
text: "Problem with <code>from transformers import GPT3ForSequenceClassification</code>",
explain: "Try again -- although this provides useful information, it's probably best reserved for the main body of the text.",
},
{
text: "Why can't I import <code>GPT3ForSequenceClassification</code>?",
explain: "Good choice! This title is concise and gives the reader a clue about what might be wrong (i.e., that GPT-3 is not supported in 🤗 Transformers).",
correct: true
},
{
text: "Is GPT-3 supported in 🤗 Transformers?",
explain: "Good one! Using questions as topic titles is a great way to communicate the problem to the community.",
correct: true
}
]}
/>
### 4. Suppose you've tried to run `trainer.train()` and are faced with a cryptic error that doesn't tell you exactly where the error is coming from. Which of the following is the first place you should look for errors in your training pipeline?
<Question
choices={[
{
text: "The optimization step where we compute gradients and perform backpropagation",
explain: "Although there may be bugs in your optimizer, this is usually several steps into the training pipeline, so there are other things to check first. Try again!"
},
{
text: "The evaluation step where we compute metrics",
explain: "Evaluation is usually what you do after training for a full epoch, so you should first check somewhere earlier in the training pipeline.",
},
{
text: "The datasets",
explain: "Correct! Looking at your data is almost always the first thing you should do, to make sure the text is encoded appropriately, has the expected features, and so on.",
correct: true
},
{
text: "The dataloaders",
explain: "Try again -- this is very close to the first thing you should check. Do you remember what object we pass to the dataloaders?"
}
]}
/>
### 5. What is the best way to debug a CUDA error?
<Question
choices={[
{
text: "Post the error message on the forums or GitHub.",
explain: "That won't help anyone as CUDA error messages are usually very uninformative."
},
{
text: "Execute the same code on the CPU.",
explain: "Exactly, that should give you a better error message!",
correct: true
},
{
text: "Read the traceback to find out what caused the error.",
explain: "That's what you would do for any other error, but CUDA errors are usually not raised where they happened because most CUDA operations are asynchronous."
},
{
text: "Reduce the batch size.",
explain: "Reducing the batch size is usually a good strategy for handling CUDA out-of-memory errors, but not for this particular problem. Try again!"
},
{
text: "Restart the Jupyter kernel.",
explain: "Try again -- restarting the kernel won't make the error magically go away!",
}
]}
/>
### 6. What is the best way to get an issue on GitHub fixed?
<Question
choices={[
{
text: "Post a full reproducible example of the bug.",
explain: "Yes, that's the best way to help the maintainers find your bug. What else should you do?",
correct: true
},
{
text: "Ask every day for an update.",
explain: "That's unlikely to get you any help; people will probably ignore you more.",
},
{
text: "Inspect the source code around the bug and try to find the reason why it happens. Post the results in the issue.",
explain: "That will definitely help the maintainers! And if you do find the source of the bug and a fix, you can even open a pull request. What else should you do?",
correct: true
}
]}
/>
### 7. Why is overfitting to one batch usually a good debugging technique?
<Question
choices={[
{
text: "It isn't; overfitting is always bad and should be avoided.",
explain: "When training over the whole dataset, overfitting can indeed be a sign that your model won't generalize well to new examples. For debugging, though, we don't usually train over the whole dataset. Try again!"
},
{
text: "It allows us to verify that the model is able to reduce the loss to zero.",
explain: "Correct! With a small batch with as little as two examples, we can quickly verify whether the model is capable of learning.",
correct: true
},
{
text: "It allows us to verify that the tensor shapes of our inputs and labels are correct.",
explain: "Try again -- if your tensor shapes are misaligned, then you certainly won't be able to train, even on a single batch.",
}
]}
/>
### 8. Why is it a good idea to include details on your compute environment with `transformers-cli env` when creating a new issue in the 🤗 Transformers repo?
<Question
choices={[
{
text: "It allows the maintainers to understand which version of the library you're using.",
explain: "Correct! Since each major version of the library may have changes in the API, knowing which specific version you are using can help narrow down the problem. What are the other benefits?",
correct: true
},
{
text: "It allows the maintainers to know whether you're running code on Windows, macOS, or Linux.",
explain: "Correct! Errors can sometimes be caused by the specific operating system you are using, and knowing this helps the maintainers reproduce them locally. That's not the only reason, though.",
correct: true
},
{
text: "It allows the maintainers to know whether you're running code on a GPU or CPU.",
explain: "Correct! As we've seen in this chapter, code ran on GPUs or CPUs may produce diffferent results or errors, and knowing which hardware you're using can help focus the maintainers' attention. But this isn't the only benefit...",
correct: true
}
]}
/>
| huggingface/course/blob/main/chapters/en/chapter8/7.mdx |
Advanced Setup (Instance Types, Auto Scaling, Versioning)
We have seen how fast and easy it is to deploy an Endpoint in [Create your first Endpoint](/docs/inference-endpoints/guides/create_endpoint), but that's not all you can manage. During the creation process and after selecting your Cloud Provider and Region, click on the [Advanced configuration] button to reveal further configuration options for your Endpoint.
**Instance type**
🤗 Inference Endpoints offers a selection of curated CPU and GPU instances.
_Note: Your Hugging Face account comes with a capacity quota for CPU and GPU instances. To increase your quota or request new instance types, please check with us._
_Default: CPU-medium_
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/instance_types.png" alt="copy curl" />
**Replica autoscaling**
Set the range (minimum (>=1) and maximum ) of replicas you want your Endpoint to automatically scale within based on utilization.
_Default: min 1; max 2_
**Task**
Select a [supported Machine Learning Task](/docs/inference-endpoints/supported_tasks), or set to [Custom](/docs/inference-endpoints/guides/custom_handler). [Custom](/docs/inference-endpoints/guides/custom_handler) can/should be used when you are not using a Transformers-based model or when you want to customize the inference pipeline, see [Create your own Inference handler](/docs/inference-endpoints/guides/custom_handler).
_Default: derived from the model repository._
**Framework**
For Transformers models, if both PyTorch and TensorFlow weights are both available, you can select which model weights to use. This will help reduce the image artifact size and accelerate startups/scaling of your endpoints.
_Default: PyTorch if available._
**Revision**
Create your Endpoint targeting a specific revision commit for its source Hugging Face Model Repository. This allows you to version your endpoint and make sure you are always using the same weights even if you are updating the Model Repository.
_Default: The most recent commit._
**Image**
Allows you to provide a custom container image you want to deploy into an Endpoint. Those can be public images, e.g _tensorflow/serving:2.7.3,_ or private Images hosted on [Docker hub](https://hub.docker.com/), [AWS ECR](https://aws.amazon.com/ecr/?nc1=h_ls), [Azure ACR](https://azure.microsoft.com/de-de/services/container-registry/), or [Google GCR](https://cloud.google.com/container-registry?hl=de).
More on how to ["Use your own custom container"](/docs/inference-endpoints/guides/custom_handler) below.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/advanced.mdx |
How to Add a Space to ArXiv
Demos on Hugging Face Spaces allow a wide audience to try out state-of-the-art machine
learning research without writing any code. [Hugging Face and ArXiv have collaborated](https://huggingface.co/blog/arxiv)
to embed these demos directly along side papers on ArXiv!
Thanks to this integration, users can now find the most popular demos for a paper on its arXiv abstract page. For example, if you want to try out demos of the LayoutLM document classification model, you can go to [the LayoutLM paper's arXiv page](https://arxiv.org/abs/1912.13318), and navigate to the demo tab. You will see open-source demos built by the machine learning community for this model, which you can try out immediately in your browser:
We'll cover two different ways to add your Space to ArXiv and have it show up in the Demos tab.
**Prerequisites**
* There's an existing paper on ArXiv that you'd like to create a demo for
* You have built or (can build) a demo for the model on Spaces
**Method 1 (Recommended): Linking from the Space README**
The simplest way to add a Space to an ArXiv paper is to include the link to the paper in the Space README file (`README.md`). It's good practice to include a full citation as well. You can see an example of a link and a citation on this [Echocardiogram Segmentation Space README](https://huggingface.co/spaces/abidlabs/echocardiogram-arxiv/blob/main/README.md).
And that's it! Your Space should appear in the Demo tab next to the paper on ArXiv in a few minutes 🤗
**Method 2: Linking a Related Model**
An alternative approach can be used to link Spaces to papers by linking an intermediate model to the Space. This requires that the paper is **associated with a model** that is on the Hugging Face Hub (or can be uploaded there)
1. First, upload the model associated with the ArXiv paper onto the Hugging Face Hub if it is not already there. ([Detailed instructions are here](./models-uploading))
2. When writing the model card (README.md) for the model, include a link to the ArXiv paper. It's good practice to include a full citation as well. You can see an example of a link and a citation on the [LayoutLM model card](https://huggingface.co/microsoft/layoutlm-base-uncased)
*Note*: you can verify this step has been carried out successfully by seeing if an ArXiv button appears above the model card. In the case of LayoutLM, the button says: "arxiv:1912.13318" and links to the LayoutLM paper on ArXiv.

3. Then, create a demo on Spaces that loads this model. Somewhere within the code, the model name must be included in order for Hugging Face to detect that a Space is associated with it.
For example, the [docformer_for_document_classification](https://huggingface.co/spaces/iakarshu/docformer_for_document_classification) Space loads the LayoutLM [like this](https://huggingface.co/spaces/iakarshu/docformer_for_document_classification/blob/main/modeling.py#L484) and include the string `"microsoft/layoutlm-base-uncased"`:
```py
from transformers import LayoutLMForTokenClassification
layoutlm_dummy = LayoutLMForTokenClassification.from_pretrained("microsoft/layoutlm-base-uncased", num_labels=1)
```
*Note*: Here's an [overview on building demos on Hugging Face Spaces](./spaces-overview) and here are more specific instructions for [Gradio](./spaces-sdks-gradio) and [Streamlit](./spaces-sdks-streamlit).
4. As soon as your Space is built, Hugging Face will detect that it is associated with the model. A "Linked Models" button should appear in the top right corner of the Space, as shown here:

*Note*: You can also add linked models manually by explicitly updating them in the [README metadata for the Space, as described here](https://huggingface.co/docs/hub/spaces-config-reference).
Your Space should appear in the Demo tab next to the paper on ArXiv in a few minutes 🤗
| huggingface/hub-docs/blob/main/docs/hub/spaces-add-to-arxiv.md |
Datasets Overview
## Datasets on the Hub
The Hugging Face Hub hosts a [large number of community-curated datasets](https://huggingface.co/datasets) for a diverse range of tasks such as translation, automatic speech recognition, and image classification. Alongside the information contained in the [dataset card](./datasets-cards), many datasets, such as [GLUE](https://huggingface.co/datasets/glue), include a [Dataset Viewer](./datasets-viewer) to showcase the data.
Each dataset is a [Git repository](./repositories) that contains the data required to generate splits for training, evaluation, and testing. For information on how a dataset repository is structured, refer to the [Data files Configuration page](./datasets-data-files-configuration). Following the supported repo structure will ensure that the dataset page on the Hub will have a Viewer.
## Search for datasets
Like models and spaces, you can search the Hub for datasets using the search bar in the top navigation or on the [main datasets page](https://huggingface.co/datasets). There's a large number of languages, tasks, and licenses that you can use to filter your results to find a dataset that's right for you.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-main.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/datasets-main-dark.png"/>
</div>
## Privacy
Since datasets are repositories, you can [toggle their visibility between private and public](./repositories-settings#private-repositories) through the Settings tab. If a dataset is owned by an [organization](./organizations), the privacy settings apply to all the members of the organization.
| huggingface/hub-docs/blob/main/docs/hub/datasets-overview.md |
Text Summarization with Pretrained Encoders
This folder contains part of the code necessary to reproduce the results on abstractive summarization from the article [Text Summarization with Pretrained Encoders](https://arxiv.org/pdf/1908.08345.pdf) by [Yang Liu](https://nlp-yang.github.io/) and [Mirella Lapata](https://homepages.inf.ed.ac.uk/mlap/). It can also be used to summarize any document.
The original code can be found on the Yang Liu's [github repository](https://github.com/nlpyang/PreSumm).
The model is loaded with the pre-trained weights for the abstractive summarization model trained on the CNN/Daily Mail dataset with an extractive and then abstractive tasks.
## Setup
```
git clone https://github.com/huggingface/transformers && cd transformers
pip install .
pip install nltk py-rouge
cd examples/seq2seq/bertabs
```
## Reproduce the authors' ROUGE score
To be able to reproduce the authors' results on the CNN/Daily Mail dataset you first need to download both CNN and Daily Mail datasets [from Kyunghyun Cho's website](https://cs.nyu.edu/~kcho/DMQA/) (the links next to "Stories") in the same folder. Then uncompress the archives by running:
```bash
tar -xvf cnn_stories.tgz && tar -xvf dailymail_stories.tgz
```
And move all the stories to the same folder. We will refer as `$DATA_PATH` the path to where you uncompressed both archive. Then run the following in the same folder as `run_summarization.py`:
```bash
python run_summarization.py \
--documents_dir $DATA_PATH \
--summaries_output_dir $SUMMARIES_PATH \ # optional
--no_cuda false \
--batch_size 4 \
--min_length 50 \
--max_length 200 \
--beam_size 5 \
--alpha 0.95 \
--block_trigram true \
--compute_rouge true
```
The scripts executes on GPU if one is available and if `no_cuda` is not set to `true`. Inference on multiple GPUs is not supported yet. The ROUGE scores will be displayed in the console at the end of evaluation and written in a `rouge_scores.txt` file. The script takes 30 hours to compute with a single Tesla V100 GPU and a batch size of 10 (300,000 texts to summarize).
## Summarize any text
Put the documents that you would like to summarize in a folder (the path to which is referred to as `$DATA_PATH` below) and run the following in the same folder as `run_summarization.py`:
```bash
python run_summarization.py \
--documents_dir $DATA_PATH \
--summaries_output_dir $SUMMARIES_PATH \ # optional
--no_cuda false \
--batch_size 4 \
--min_length 50 \
--max_length 200 \
--beam_size 5 \
--alpha 0.95 \
--block_trigram true \
```
You may want to play around with `min_length`, `max_length` and `alpha` to suit your use case. If you want to compute ROUGE on another dataset you will need to tweak the stories/summaries import in `utils_summarization.py` and tell it where to fetch the reference summaries.
| huggingface/transformers/blob/main/examples/research_projects/bertabs/README.md |
timm
<img class="float-left !m-0 !border-0 !dark:border-0 !shadow-none !max-w-lg w-[150px]" src="https://huggingface.co/front/thumbnails/docs/timm.png"/>
`timm` is a library containing SOTA computer vision models, layers, utilities, optimizers, schedulers, data-loaders, augmentations, and training/evaluation scripts.
It comes packaged with >700 pretrained models, and is designed to be flexible and easy to use.
Read the [quick start guide](quickstart) to get up and running with the `timm` library. You will learn how to load, discover, and use pretrained models included in the library.
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./feature_extraction"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Tutorials</div>
<p class="text-gray-700">Learn the basics and become familiar with timm. Start here if you are using timm for the first time!</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./reference/models"
><div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Reference</div>
<p class="text-gray-700">Technical descriptions of how timm classes and methods work.</p>
</a>
</div>
</div>
| huggingface/pytorch-image-models/blob/main/hfdocs/source/index.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Swin Transformer
## Overview
The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
The abstract from the paper is the following:
*This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone
for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains,
such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
To address these differences, we propose a hierarchical Transformer whose representation is computed with \bold{S}hifted
\bold{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping
local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at
various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it
compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense
prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation
(53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and
+2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/swin_transformer_architecture.png"
alt="drawing" width="600"/>
<small> Swin Transformer architecture. Taken from the <a href="https://arxiv.org/abs/2102.03334">original paper</a>.</small>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
## Usage tips
- Swin pads the inputs supporting any input height and width (if divisible by `32`).
- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer.
<PipelineTag pipeline="image-classification"/>
- [`SwinForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
Besides that:
- [`SwinForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SwinConfig
[[autodoc]] SwinConfig
<frameworkcontent>
<pt>
## SwinModel
[[autodoc]] SwinModel
- forward
## SwinForMaskedImageModeling
[[autodoc]] SwinForMaskedImageModeling
- forward
## SwinForImageClassification
[[autodoc]] transformers.SwinForImageClassification
- forward
</pt>
<tf>
## TFSwinModel
[[autodoc]] TFSwinModel
- call
## TFSwinForMaskedImageModeling
[[autodoc]] TFSwinForMaskedImageModeling
- call
## TFSwinForImageClassification
[[autodoc]] transformers.TFSwinForImageClassification
- call
</tf>
</frameworkcontent> | huggingface/transformers/blob/main/docs/source/en/model_doc/swin.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Unconditional image generation
[[open-in-colab]]
Unconditional image generation generates images that look like a random sample from the training data the model was trained on because the denoising process is not guided by any additional context like text or image.
To get started, use the [`DiffusionPipeline`] to load the [anton-l/ddpm-butterflies-128](https://huggingface.co/anton-l/ddpm-butterflies-128) checkpoint to generate images of butterflies. The [`DiffusionPipeline`] downloads and caches all the model components required to generate an image.
```py
from diffusers import DiffusionPipeline
generator = DiffusionPipeline.from_pretrained("anton-l/ddpm-butterflies-128").to("cuda")
image = generator().images[0]
image
```
<Tip>
Want to generate images of something else? Take a look at the training [guide](../training/unconditional_training) to learn how to train a model to generate your own images.
</Tip>
The output image is a [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class) object that can be saved:
```py
image.save("generated_image.png")
```
You can also try experimenting with the `num_inference_steps` parameter, which controls the number of denoising steps. More denoising steps typically produce higher quality images, but it'll take longer to generate. Feel free to play around with this parameter to see how it affects the image quality.
```py
image = generator(num_inference_steps=100).images[0]
image
```
Try out the Space below to generate an image of a butterfly!
<iframe
src="https://stevhliu-unconditional-image-generation.hf.space"
frameborder="0"
width="850"
height="500"
></iframe>
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/unconditional_image_generation.md |
Gradio 和 ONNX 在 Hugging Face 上
Related spaces: https://huggingface.co/spaces/onnx/EfficientNet-Lite4
Tags: ONNX,SPACES
由 Gradio 和 <a href="https://onnx.ai/">ONNX</a> 团队贡献
## 介绍
在这个指南中,我们将为您介绍以下内容:
- ONNX、ONNX 模型仓库、Gradio 和 Hugging Face Spaces 的介绍
- 如何为 EfficientNet-Lite4 设置 Gradio 演示
- 如何为 Hugging Face 上的 ONNX 组织贡献自己的 Gradio 演示
下面是一个 ONNX 模型的示例:在下面尝试 EfficientNet-Lite4 演示。
<iframe src="https://onnx-efficientnet-lite4.hf.space" frameBorder="0" height="810" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
## ONNX 模型仓库是什么?
Open Neural Network Exchange([ONNX](https://onnx.ai/))是一种表示机器学习模型的开放标准格式。ONNX 由一个实现了该格式的合作伙伴社区支持,该社区将其实施到许多框架和工具中。例如,如果您在 TensorFlow 或 PyTorch 中训练了一个模型,您可以轻松地将其转换为 ONNX,然后使用类似 ONNX Runtime 的引擎 / 编译器在各种设备上运行它。
[ONNX 模型仓库](https://github.com/onnx/models)是由社区成员贡献的一组预训练的先进模型,格式为 ONNX。每个模型都附带了用于模型训练和运行推理的 Jupyter 笔记本。这些笔记本以 Python 编写,并包含到训练数据集的链接,以及描述模型架构的原始论文的参考文献。
## Hugging Face Spaces 和 Gradio 是什么?
### Gradio
Gradio 可让用户使用 Python 代码将其机器学习模型演示为 Web 应用程序。Gradio 将 Python 函数封装到用户界面中,演示可以在 jupyter 笔记本、colab 笔记本中启动,并可以嵌入到您自己的网站上,并在 Hugging Face Spaces 上免费托管。
在此处开始[https://gradio.app/getting_started](https://gradio.app/getting_started)
### Hugging Face Spaces
Hugging Face Spaces 是 Gradio 演示的免费托管选项。Spaces 提供了 3 种 SDK 选项:Gradio、Streamlit 和静态 HTML 演示。Spaces 可以是公共的或私有的,工作流程与 github repos 类似。目前 Hugging Face 上有 2000 多个 Spaces。在此处了解更多关于 Spaces 的信息[https://huggingface.co/spaces/launch](https://huggingface.co/spaces/launch)。
### Hugging Face 模型
Hugging Face 模型中心还支持 ONNX 模型,并且可以通过[ONNX 标签](https://huggingface.co/models?library=onnx&sort=downloads)对 ONNX 模型进行筛选
## Hugging Face 是如何帮助 ONNX 模型仓库的?
ONNX 模型仓库中有许多 Jupyter 笔记本供用户测试模型。以前,用户需要自己下载模型并在本地运行这些笔记本测试。有了 Hugging Face,测试过程可以更简单和用户友好。用户可以在 Hugging Face Spaces 上轻松尝试 ONNX 模型仓库中的某个模型,并使用 ONNX Runtime 运行由 Gradio 提供支持的快速演示,全部在云端进行,无需在本地下载任何内容。请注意,ONNX 有各种运行时,例如[ONNX Runtime](https://github.com/microsoft/onnxruntime)、[MXNet](https://github.com/apache/incubator-mxnet)等
## ONNX Runtime 的作用是什么?
ONNX Runtime 是一个跨平台的推理和训练机器学习加速器。它使得在 Hugging Face 上使用 ONNX 模型仓库中的模型进行实时 Gradio 演示成为可能。
ONNX Runtime 可以实现更快的客户体验和更低的成本,支持来自 PyTorch 和 TensorFlow/Keras 等深度学习框架以及 scikit-learn、LightGBM、XGBoost 等传统机器学习库的模型。ONNX Runtime 与不同的硬件、驱动程序和操作系统兼容,并通过利用适用的硬件加速器以及图形优化和转换提供最佳性能。有关更多信息,请参阅[官方网站](https://onnxruntime.ai/)。
## 为 EfficientNet-Lite4 设置 Gradio 演示
EfficientNet-Lite 4 是 EfficientNet-Lite 系列中最大和最准确的模型。它是一个仅使用整数量化的模型,能够在所有 EfficientNet 模型中提供最高的准确率。在 Pixel 4 CPU 上以实时方式运行(例如 30ms/ 图像)时,可以实现 80.4%的 ImageNet top-1 准确率。要了解更多信息,请阅读[模型卡片](https://github.com/onnx/models/tree/main/vision/classification/efficientnet-lite4)
在这里,我们将演示如何使用 Gradio 为 EfficientNet-Lite4 设置示例演示
首先,我们导入所需的依赖项并下载和载入来自 ONNX 模型仓库的 efficientnet-lite4 模型。然后从 labels_map.txt 文件加载标签。接下来,我们设置预处理函数、加载用于推理的模型并设置推理函数。最后,将推理函数封装到 Gradio 接口中,供用户进行交互。下面是完整的代码。
```python
import numpy as np
import math
import matplotlib.pyplot as plt
import cv2
import json
import gradio as gr
from huggingface_hub import hf_hub_download
from onnx import hub
import onnxruntime as ort
# 从ONNX模型仓库加载ONNX模型
model = hub.load("efficientnet-lite4")
# 加载标签文本文件
labels = json.load(open("labels_map.txt", "r"))
# 通过将图像从中心调整大小并裁剪到224x224来设置图像文件的尺寸
def pre_process_edgetpu(img, dims):
output_height, output_width, _ = dims
img = resize_with_aspectratio(img, output_height, output_width, inter_pol=cv2.INTER_LINEAR)
img = center_crop(img, output_height, output_width)
img = np.asarray(img, dtype='float32')
# 将jpg像素值从[0 - 255]转换为浮点数组[-1.0 - 1.0]
img -= [127.0, 127.0, 127.0]
img /= [128.0, 128.0, 128.0]
return img
# 使用等比例缩放调整图像尺寸
def resize_with_aspectratio(img, out_height, out_width, scale=87.5, inter_pol=cv2.INTER_LINEAR):
height, width, _ = img.shape
new_height = int(100. * out_height / scale)
new_width = int(100. * out_width / scale)
if height > width:
w = new_width
h = int(new_height * height / width)
else:
h = new_height
w = int(new_width * width / height)
img = cv2.resize(img, (w, h), interpolation=inter_pol)
return img
# crops the image around the center based on given height and width
def center_crop(img, out_height, out_width):
height, width, _ = img.shape
left = int((width - out_width) / 2)
right = int((width + out_width) / 2)
top = int((height - out_height) / 2)
bottom = int((height + out_height) / 2)
img = img[top:bottom, left:right]
return img
sess = ort.InferenceSession(model)
def inference(img):
img = cv2.imread(img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = pre_process_edgetpu(img, (224, 224, 3))
img_batch = np.expand_dims(img, axis=0)
results = sess.run(["Softmax:0"], {"images:0": img_batch})[0]
result = reversed(results[0].argsort()[-5:])
resultdic = {}
for r in result:
resultdic[labels[str(r)]] = float(results[0][r])
return resultdic
title = "EfficientNet-Lite4"
description = "EfficientNet-Lite 4是最大的变体,也是EfficientNet-Lite模型集合中最准确的。它是一个仅包含整数的量化模型,具有所有EfficientNet模型中最高的准确度。在Pixel 4 CPU上,它实现了80.4%的ImageNet top-1准确度,同时仍然可以实时运行(例如30ms/图像)。"
examples = [['catonnx.jpg']]
gr.Interface(inference, gr.Image(type="filepath"), "label", title=title, description=description, examples=examples).launch()
```
## 如何使用 ONNX 模型在 HF Spaces 上贡献 Gradio 演示
- 将模型添加到[onnx model zoo](https://github.com/onnx/models/blob/main/.github/PULL_REQUEST_TEMPLATE.md)
- 在 Hugging Face 上创建一个账号[here](https://huggingface.co/join).
- 要查看还有哪些模型需要添加到 ONNX 组织中,请参阅[Models list](https://github.com/onnx/models#models)中的列表
- 在您的用户名下添加 Gradio Demo,请参阅此[博文](https://huggingface.co/blog/gradio-spaces)以在 Hugging Face 上设置 Gradio Demo。
- 请求加入 ONNX 组织[here](https://huggingface.co/onnx).
- 一旦获准,将模型从您的用户名下转移到 ONNX 组织
- 在模型表中为模型添加徽章,在[Models list](https://github.com/onnx/models#models)中查看示例
| gradio-app/gradio/blob/main/guides/cn/04_integrating-other-frameworks/Gradio-and-ONNX-on-Hugging-Face.md |
The Hugging Face Blog Repository 🤗
This is the official repository of the [Hugging Face Blog](https://hf.co/blog).
**If you are an external contributor**: If your blog post is not a collaboration post with Hugging Face, please consider creating a [community blog](https://huggingface.co/blog-explorers) instead. Community blog posts appear on our blogs main page just like the blogs in this repository.
## How to write an article? 📝
1️⃣ Create a branch `YourName/Title`
2️⃣ Create a md (markdown) file, **use a short file name**.
For instance, if your title is "Introduction to Deep Reinforcement Learning", the md file name could be `intro-rl.md`. This is important because the **file name will be the blogpost's URL**.
3️⃣ Create a new folder in `assets`. Use the same name as the name of the md file. Optionally you may add a numerical prefix to that folder, using the number that hasn't been used yet. But this is no longer required. i.e. the asset folder in this example could be `123_intro-rl` or `intro-rl`. This folder will contain **your thumbnail only**. The folder number is mostly for (rough) ordering purposes, so it's no big deal if two concurrent articles use the same number.
For the rest of your files, create a mirrored folder in the HuggingFace Documentation Images [repo](https://huggingface.co/datasets/huggingface/documentation-images/tree/main/blog). This is to reduce bloat in the GitHub base repo when cloning and pulling.
🖼️: In terms of images, **try to have small files** to avoid having a slow loading user experience:
- Use compressed images, you can use this website: https://tinypng.com or https://www.iloveimg.com/compress-image
4️⃣ Copy and paste this to your md file and change the elements
- title
- thumbnail
- authors
```
---
title: "PUT YOUR TITLE HERE"
thumbnail: /blog/assets/101_decision-transformers-train/thumbnail.gif
authors:
- user: your_hf_user
- user: your_coauthor
---
# Train your first Decision Transformer
Your content here [...]
```
When published, the Hub will insert the following UI elements right after the blogpost's main header (i.e. the line that starts with a single `#`, aka. the `<h1>`):
- "Published on [date]"
- "Update on GitHub" button
- avatars of the authors that were listed in authors.
5️⃣ Then, you can add your content. It's markdown system so if you wrote your text on notion just control shift v to copy/paste as markdown.
6️⃣ Modify `_blog.yml` to add your blogpost.
7️⃣ When your article is ready, **open a pull request**.
8️⃣ To check how your blog will look like before merging it, check out the [CodeSpace instructions](https://github.com/huggingface/moon-landing/tree/main#codespace) (internal for HF team)
9️⃣ The article will be **published automatically when you merge your pull request**.
## How to get a nice responsive thumbnail?
1️⃣ Create a `1300x650` image
2️⃣ Use [this template](https://github.com/huggingface/blog/blob/main/assets/thumbnail-template.svg) and fill the content part.
➡️ Or select a background you like and follow the instructions in [this Figma template](https://www.figma.com/file/sXrf9VtkkbWI7kCIesMkDY/HF-Blog-Template?node-id=351%3A39).
## Using LaTeX
Just add:
```
\\(your_latex_here\\)
```
For instance:
``` \\( Q(S_t, A_t) \\) ``` ➡️ $Q(S_t, A_t)$
| huggingface/blog/blob/main/README.md |
Gradio Demo: slider_release
```
!pip install -q gradio
```
```
import gradio as gr
def identity(x, state):
state += 1
return x, state, state
with gr.Blocks() as demo:
slider = gr.Slider(0, 100, step=0.1)
state = gr.State(value=0)
with gr.Row():
number = gr.Number(label="On release")
number2 = gr.Number(label="Number of events fired")
slider.release(identity, inputs=[slider, state], outputs=[number, state, number2], api_name="predict")
if __name__ == "__main__":
print("here")
demo.launch()
print(demo.server_port)
```
| gradio-app/gradio/blob/main/demo/slider_release/run.ipynb |
--
title: MAUVE
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
MAUVE is a measure of the statistical gap between two text distributions, e.g., how far the text written by a model is the distribution of human text, using samples from both distributions.
MAUVE is obtained by computing Kullback–Leibler (KL) divergences between the two distributions in a quantized embedding space of a large language model. It can quantify differences in the quality of generated text based on the size of the model, the decoding algorithm, and the length of the generated text. MAUVE was found to correlate the strongest with human evaluations over baseline metrics for open-ended text generation.
---
# Metric Card for MAUVE
## Metric description
MAUVE is a measure of the gap between neural text and human text. It is computed using the [Kullback–Leibler (KL) divergences](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) between the two distributions of text in a quantized embedding space of a large language model. MAUVE can identify differences in quality arising from model sizes and decoding algorithms.
This metric is a wrapper around the [official implementation](https://github.com/krishnap25/mauve) of MAUVE.
For more details, consult the [MAUVE paper](https://arxiv.org/abs/2102.01454).
## How to use
The metric takes two lists of strings of tokens separated by spaces: one representing `predictions` (i.e. the text generated by the model) and the second representing `references` (a reference text for each prediction):
```python
from evaluate import load
mauve = load('mauve')
predictions = ["hello world", "goodnight moon"]
references = ["hello world", "goodnight moon"]
mauve_results = mauve.compute(predictions=predictions, references=references)
```
It also has several optional arguments:
`num_buckets`: the size of the histogram to quantize P and Q. Options: `auto` (default) or an integer.
`pca_max_data`: the number of data points to use for PCA dimensionality reduction prior to clustering. If -1, use all the data. The default is `-1`.
`kmeans_explained_var`: the amount of variance of the data to keep in dimensionality reduction by PCA. The default is `0.9`.
`kmeans_num_redo`: number of times to redo k-means clustering (the best objective is kept). The default is `5`.
`kmeans_max_iter`: maximum number of k-means iterations. The default is `500`.
`featurize_model_name`: name of the model from which features are obtained, from one of the following: `gpt2`, `gpt2-medium`, `gpt2-large`, `gpt2-xl`. The default is `gpt2-large`.
`device_id`: Device for featurization. Supply a GPU id (e.g. `0` or `3`) to use GPU. If no GPU with this id is found, the metric will use CPU.
`max_text_length`: maximum number of tokens to consider. The default is `1024`.
`divergence_curve_discretization_size` Number of points to consider on the divergence curve. The default is `25`.
`mauve_scaling_factor`: Hyperparameter for scaling. The default is `5`.
`verbose`: If `True` (default), running the metric will print running time updates.
`seed`: random seed to initialize k-means cluster assignments, randomly assigned by default.
## Output values
This metric outputs a dictionary with 5 key-value pairs:
`mauve`: MAUVE score, which ranges between 0 and 1. **Larger** values indicate that P and Q are closer.
`frontier_integral`: Frontier Integral, which ranges between 0 and 1. **Smaller** values indicate that P and Q are closer.
`divergence_curve`: a numpy.ndarray of shape (m, 2); plot it with `matplotlib` to view the divergence curve.
`p_hist`: a discrete distribution, which is a quantized version of the text distribution `p_text`.
`q_hist`: same as above, but with `q_text`.
### Values from popular papers
The [original MAUVE paper](https://arxiv.org/abs/2102.01454) reported values ranging from 0.88 to 0.94 for open-ended text generation using a text completion task in the web text domain. The authors found that bigger models resulted in higher MAUVE scores and that MAUVE is correlated with human judgments.
## Examples
Perfect match between prediction and reference:
```python
from evaluate import load
mauve = load('mauve')
predictions = ["hello world", "goodnight moon"]
references = ["hello world", "goodnight moon"]
mauve_results = mauve.compute(predictions=predictions, references=references)
print(mauve_results.mauve)
1.0
```
Partial match between prediction and reference:
```python
from evaluate import load
mauve = load('mauve')
predictions = ["hello world", "goodnight moon"]
references = ["hello there", "general kenobi"]
mauve_results = mauve.compute(predictions=predictions, references=references)
print(mauve_results.mauve)
0.27811372536724027
```
## Limitations and bias
The [original MAUVE paper](https://arxiv.org/abs/2102.01454) did not analyze the inductive biases present in different embedding models, but related work has shown different kinds of biases exist in many popular generative language models including GPT-2 (see [Kirk et al., 2021](https://arxiv.org/pdf/2102.04130.pdf), [Abid et al., 2021](https://arxiv.org/abs/2101.05783)). The extent to which these biases can impact the MAUVE score has not been quantified.
Also, calculating the MAUVE metric involves downloading the model from which features are obtained -- the default model, `gpt2-large`, takes over 3GB of storage space and downloading it can take a significant amount of time depending on the speed of your internet connection. If this is an issue, choose a smaller model; for instance, `gpt` is 523MB.
It is a good idea to use at least 1000 samples for each distribution to compute MAUVE (the original paper uses 5000).
MAUVE is unable to identify very small differences between different settings of generation (e.g., between top-p sampling with p=0.95 versus 0.96). It is important, therefore, to account for the randomness inside the generation (e.g., due to sampling) and within the MAUVE estimation procedure (see the `seed` parameter above). Concretely, it is a good idea to obtain generations using multiple random seeds and/or to use rerun MAUVE with multiple values of the parameter `seed`.
For MAUVE to be large, the model distribution must be close to the human text distribution as seen by the embeddings. It is possible to have high-quality model text that still has a small MAUVE score (i.e., large gap) if it contains text about different topics/subjects, or uses a different writing style or vocabulary, or contains texts of a different length distribution. MAUVE summarizes the statistical gap (as measured by the large language model embeddings) --- this includes all these factors in addition to the quality-related aspects such as grammaticality.
See the [official implementation](https://github.com/krishnap25/mauve#best-practices-for-mauve) for more details about best practices.
## Citation
```bibtex
@inproceedings{pillutla-etal:mauve:neurips2021,
title={MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers},
author={Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid},
booktitle = {NeurIPS},
year = {2021}
}
```
## Further References
- [Official MAUVE implementation](https://github.com/krishnap25/mauve)
- [Hugging Face Tasks - Text Generation](https://huggingface.co/tasks/text-generation)
| huggingface/evaluate/blob/main/metrics/mauve/README.md |
--
title: Training CodeParrot 🦜 from Scratch
thumbnail: /blog/assets/40_codeparrot/thumbnail.png
authors:
- user: leandro
---
# Training CodeParrot 🦜 from Scratch
In this blog post we'll take a look at what it takes to build the technology behind [GitHub CoPilot](https://copilot.github.com/), an application that provides suggestions to programmers as they code. In this step by step guide, we'll learn how to train a large GPT-2 model called CodeParrot 🦜, entirely from scratch. CodeParrot can auto-complete your Python code - give it a spin [here](https://huggingface.co/spaces/lvwerra/codeparrot-generation). Let's get to building it from scratch!

## Creating a Large Dataset of Source Code
The first thing we need is a large training dataset. With the goal to train a Python code generation model, we accessed the GitHub dump available on Google's BigQuery and filtered for all Python files. The result is a 180 GB dataset with 20 million files (available [here](http://hf.co/datasets/transformersbook/codeparrot)). After initial training experiments, we found that the duplicates in the dataset severely impacted the model performance. Further investigating the dataset we found that:
- 0.1% of the unique files make up 15% of all files
- 1% of the unique files make up 35% of all files
- 10% of the unique files make up 66% of all files
You can learn more about our findings in [this Twitter thread](https://twitter.com/lvwerra/status/1458470994146996225). We removed the duplicates and applied the same cleaning heuristics found in the [Codex paper](https://arxiv.org/abs/2107.03374). Codex is the model behind CoPilot and is a GPT-3 model fine-tuned on GitHub code.
The cleaned dataset is still 50GB big and available on the Hugging Face Hub: [codeparrot-clean](http://hf.co/datasets/lvwerra/codeparrot-clean). With that we can setup a new tokenizer and train a model.
## Initializing the Tokenizer and Model
First we need a tokenizer. Let's train one specifically on code so it splits code tokens well. We can take an existing tokenizer (e.g. GPT-2) and directly train it on our own dataset with the `train_new_from_iterator()` method. We then push it to the Hub. Note that we omit imports, arguments parsing and logging from the code examples to keep the code blocks compact. But you'll find the full code including preprocessing and downstream task evaluation [here](https://github.com/huggingface/transformers/tree/master/examples/research_projects/codeparrot).
```Python
# Iterator for Training
def batch_iterator(batch_size=10):
for _ in tqdm(range(0, args.n_examples, batch_size)):
yield [next(iter_dataset)["content"] for _ in range(batch_size)]
# Base tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
base_vocab = list(bytes_to_unicode().values())
# Load dataset
dataset = load_dataset("lvwerra/codeparrot-clean", split="train", streaming=True)
iter_dataset = iter(dataset)
# Training and saving
new_tokenizer = tokenizer.train_new_from_iterator(batch_iterator(),
vocab_size=args.vocab_size,
initial_alphabet=base_vocab)
new_tokenizer.save_pretrained(args.tokenizer_name, push_to_hub=args.push_to_hub)
```
Learn more about tokenizers and how to build them in the [Hugging Face course](https://huggingface.co/course/chapter6/1?fw=pt).
See that inconspicuous `streaming=True` argument? This small change has a big impact: instead of downloading the full (50GB) dataset this will stream individual samples as needed saving a lot of disk space! Checkout the [Hugging Face course](https://huggingface.co/course/chapter5/4?fw=pt
) for more information on streaming.
Now, we initialize a new model. We’ll use the same hyperparameters as GPT-2 large (1.5B parameters) and adjust the embedding layer to fit our new tokenizer also adding some stability tweaks. The `scale_attn_by_layer_idx` flag makes sure we scale the attention by the layer id and `reorder_and_upcast_attn` mainly makes sure that we compute the attention in full precision to avoid numerical issues. We push the freshly initialized model to the same repo as the tokenizer.
```Python
# Load codeparrot tokenizer trained for Python code tokenization
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name)
# Configuration
config_kwargs = {"vocab_size": len(tokenizer),
"scale_attn_by_layer_idx": True,
"reorder_and_upcast_attn": True}
# Load model with config and push to hub
config = AutoConfig.from_pretrained('gpt2-large', **config_kwargs)
model = AutoModelForCausalLM.from_config(config)
model.save_pretrained(args.model_name, push_to_hub=args.push_to_hub)
```
Now that we have an efficient tokenizer and a freshly initialized model we can start with the actual training loop.
## Implementing the Training Loop
We train with the [🤗 Accelerate](https://github.com/huggingface/accelerate) library which allows us to scale the training from our laptop to a multi-GPU machine without changing a single line of code. We just create an accelerator and do some argument housekeeping:
```Python
accelerator = Accelerator()
acc_state = {str(k): str(v) for k, v in accelerator.state.__dict__.items()}
parser = HfArgumentParser(TrainingArguments)
args = parser.parse_args()
args = Namespace(**vars(args), **acc_state)
samples_per_step = accelerator.state.num_processes * args.train_batch_size
set_seed(args.seed)
```
We are now ready to train! Let's use the `huggingface_hub` client library to clone the repository with the new tokenizer and model. We will checkout to a new branch for this experiment. With that setup, we can run many experiments in parallel and in the end we just merge the best one into the main branch.
```Python
# Clone model repository
if accelerator.is_main_process:
hf_repo = Repository(args.save_dir, clone_from=args.model_ckpt)
# Checkout new branch on repo
if accelerator.is_main_process:
hf_repo.git_checkout(run_name, create_branch_ok=True)
```
We can directly load the tokenizer and model from the local repository. Since we are dealing with big models we might want to turn on [gradient checkpointing](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9) to decrease the GPU memory footprint during training.
```Python
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(args.save_dir)
if args.gradient_checkpointing:
model.gradient_checkpointing_enable()
tokenizer = AutoTokenizer.from_pretrained(args.save_dir)
```
Next up is the dataset. We make training simpler with a dataset that yields examples with a fixed context size. To not waste too much data (some samples are too short or too long) we can concatenate many examples with an EOS token and then chunk them.

The more sequences we prepare together, the smaller the fraction of tokens we discard (the grey ones in the previous figure). Since we want to stream the dataset instead of preparing everything in advance we use an `IterableDataset`. The full dataset class looks as follows:
```Python
class ConstantLengthDataset(IterableDataset):
def __init__(
self, tokenizer, dataset, infinite=False, seq_length=1024, num_of_sequences=1024, chars_per_token=3.6
):
self.tokenizer = tokenizer
self.concat_token_id = tokenizer.bos_token_id
self.dataset = dataset
self.seq_length = seq_length
self.input_characters = seq_length * chars_per_token * num_of_sequences
self.epoch = 0
self.infinite = infinite
def __iter__(self):
iterator = iter(self.dataset)
more_examples = True
while more_examples:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.input_characters:
break
try:
buffer.append(next(iterator)["content"])
buffer_len += len(buffer[-1])
except StopIteration:
if self.infinite:
iterator = iter(self.dataset)
self.epoch += 1
logger.info(f"Dataset epoch: {self.epoch}")
else:
more_examples = False
break
tokenized_inputs = self.tokenizer(buffer, truncation=False)["input_ids"]
all_token_ids = []
for tokenized_input in tokenized_inputs:
all_token_ids.extend(tokenized_input + [self.concat_token_id])
for i in range(0, len(all_token_ids), self.seq_length):
input_ids = all_token_ids[i : i + self.seq_length]
if len(input_ids) == self.seq_length:
yield torch.tensor(input_ids)
```
Texts in the buffer are tokenized in parallel and then concatenated. Chunked samples are then yielded until the buffer is empty and the process starts again. If we set `infinite=True` the dataset iterator restarts at its end.
```Python
def create_dataloaders(args):
ds_kwargs = {"streaming": True}
train_data = load_dataset(args.dataset_name_train, split="train", streaming=True)
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
valid_data = load_dataset(args.dataset_name_valid, split="train", streaming=True)
train_dataset = ConstantLengthDataset(tokenizer, train_data, infinite=True, seq_length=args.seq_length)
valid_dataset = ConstantLengthDataset(tokenizer, valid_data, infinite=False, seq_length=args.seq_length)
train_dataloader = DataLoader(train_dataset, batch_size=args.train_batch_size)
eval_dataloader = DataLoader(valid_dataset, batch_size=args.valid_batch_size)
return train_dataloader, eval_dataloader
train_dataloader, eval_dataloader = create_dataloaders(args)
```
Before we start training we need to set up the optimizer and learning rate schedule. We don’t want to apply weight decay to biases and LayerNorm weights so we use a helper function to exclude those.
```Python
def get_grouped_params(model, args, no_decay=["bias", "LayerNorm.weight"]):
params_with_wd, params_without_wd = [], []
for n, p in model.named_parameters():
if any(nd in n for nd in no_decay): params_without_wd.append(p)
else: params_with_wd.append(p)
return [{"params": params_with_wd, "weight_decay": args.weight_decay},
{"params": params_without_wd, "weight_decay": 0.0},]
optimizer = AdamW(get_grouped_params(model, args), lr=args.learning_rate)
lr_scheduler = get_scheduler(name=args.lr_scheduler_type, optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,)
```
A big question that remains is how all the data and models will be distributed across several GPUs. This sounds like a complex task but actually only requires a single line of code with 🤗 Accelerate.
```Python
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader)
```
Under the hood it'll use DistributedDataParallel, which means a batch is sent to each GPU worker which has its own copy of the model. There the gradients are computed and then aggregated to update the model on each worker.

We also want to evaluate the model from time to time on the validation set so let’s write a function to do just that. This is done automatically in a distributed fashion and we just need to gather all the losses from the workers. We also want to report the [perplexity](https://huggingface.co/course/chapter7/3#perplexity-for-language-models).
```Python
def evaluate(args):
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(batch, labels=batch)
loss = outputs.loss.repeat(args.valid_batch_size)
losses.append(accelerator.gather(loss))
if args.max_eval_steps > 0 and step >= args.max_eval_steps:
break
loss = torch.mean(torch.cat(losses))
try:
perplexity = torch.exp(loss)
except OverflowError:
perplexity = float("inf")
return loss.item(), perplexity.item()
```
We are now ready to write the main training loop. It will look pretty much like a normal PyTorch training loop. Here and there you can see that we use the accelerator functions rather than native PyTorch. Also, we push the model to the branch after each evaluation.
```Python
# Train model
model.train()
completed_steps = 0
for step, batch in enumerate(train_dataloader, start=1):
loss = model(batch, labels=batch, use_cache=False).loss
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
completed_steps += 1
if step % args.save_checkpoint_steps == 0:
eval_loss, perplexity = evaluate(args)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message=f"step {step}")
model.train()
if completed_steps >= args.max_train_steps:
break
```
When we call `wait_for_everyone()` and `unwrap_model()` we make sure that all workers are ready and any model layers that have been added by `prepare()` earlier are removed. We also use gradient accumulation and gradient clipping that are easily implemented. Lastly, after training is complete we run a last evaluation and save the final model and push it to the hub.
```Python
# Evaluate and save the last checkpoint
logger.info("Evaluating and saving model after training")
eval_loss, perplexity = evaluate(args)
log_metrics(step, {"loss/eval": eval_loss, "perplexity": perplexity})
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message="final model")
```
Done! That's all the code to train a full GPT-2 model from scratch with as little as 150 lines. We did not show the imports and logs of the scripts to make the code a little bit more compact. Now let's actually train it!
With this code we trained models for our upcoming [book on Transformers and NLP](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/): a [110M](https://hf.co/lvwerra/codeparrot-small) and [1.5B](https://hf.co/lvwerra/codeparrot) parameter GPT-2 model. We used a 16 x A100 GPU machine to train these models for 1 day and 1 week, respectively. Enough time to get a coffee and read a book or two!
## Evaluation
This is still relatively short training time for pretraining but we can already observe good downstream performance as compared to similar models. We evaluated the models on OpenAI's HumanEval benchmark that was introduced in the Codex paper. It measures the performance of code generation models on almost 200 coding challenges.

Note that we trained CodeParrot on roughly 25-30B tokens whereas GPT-neo was trained on 300B tokens and Codex on 300B (GPT-3 checkpoint) + 100B (code) tokens. So you definitely get a good bang for your buck here.
But what is this _pass@k_ metric exactly? Simply put it measures the probability of at least one program passing the unittest of a programming problem given _k_ candidate generations from the model. Naturally, the metric increases with k as more candidates can potentially solve the coding challenge. You can use the metric with `datasets`:
```Python
from datasets import load_metric
code_eval = datasets.load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
print(pass_at_k)
# -> {'pass@1': 0.5, 'pass@2': 1.0}
```
You can also load OpenAI's HumanEval dataset with `datasets`:
```Python
from datasets import load_dataset
dataset = load_dataset("openai_humaneval")
```
Now let's have a look at what we get after anxiously waiting for so long!
## Results
Let's start slow and check if we can prompt the model to write a function to return the size of a file given its path:
**Prompt:**
```Python
def get_files_size(filename):
```
**Completion:**
```Python
"""
Returns the file size of a file.
:param filepath: The path to the file.
:type filepath: str
:return: The file size.
:rtype: int
"""
return os.path.getsize(filepath)
```
So far so good, but let's take this a step further and try something a bit more interesting. One of the less exciting aspects of building production ready code is writing unittest. Let's see if we can use CodeParrot to do this for us!
**Prompt:**
```Python
def is_even(value):
"""Returns True if value is an even number."""
return value % 2 == 0
# setup unit tests for is_even
import unittest
```
**Completion:**
```Python
class TestIsEven(unittest.TestCase):
"""Tests for is_even function."""
def test_is_even(self):
"""Test is_even function."""
self.assertTrue(is_even(0))
self.assertTrue(is_even(1))
self.assertTrue
```
Although the test condition itself does not look quite right the model has built all the boilerplate code for us. This alone could already be quite useful and save us a couple of minutes time!
But what we really want to do is build better transformer models. Let's use CodeParrot to help us do that:
**Prompt:**
```Python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# build a BERT classifier
```
**Completion:**
```Python
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
```
Looking at a few examples is nice but by now you probably want to try it yourself. We prepared a few online demos just for that!
## Demos
You can play with the models in two demos we added to [Hugging Face Spaces](https://huggingface.co/spaces/launch). With the first you can quickly generate code with the model and with the second you can highlight your code with the model to spot bugs!
- [Code Generation](https://hf.co/spaces/lvwerra/codeparrot-generation)
- [Code Highlighting](https://hf.co/spaces/lvwerra/codeparrot-highlighting)
You can also directly use the models from the `transformers` library:
```Python
from transformers import pipeline
pipe = pipeline('text-generation', model='lvwerra/codeparrot')
pipe('def hello_world():')
```
## Summary
In this short blog post we walked through all the steps involved for training a large GPT-2 model called CodeParrot 🦜 for code generation. Using 🤗 Accelerate we built a training script with less than 200 lines of code that we can effortlessly scale across many GPUs. With that you can now train your own GPT-2 model!
This post gives a brief overview of CodeParrot 🦜, but if you are interested in diving deeper into how to pretrain this models, we recommend reading its dedicated chapter in the upcoming [book on Transformers and NLP](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/). This chapter provides many more details around building custom datasets, design considerations when training a new tokenizer, and architecture choice.
| huggingface/blog/blob/main/codeparrot.md |
et's study the transformer architecture. This video is the introductory video to the encoders, decoders, and encoder-decoder series of videos. In this series, we'll try to understand what makes a Transformer network, and we'll try to explain it in simple, high-level terms. No understanding of neural networks is necessary, only an understanding of basic vectors and tensors may help. To get started, we'll take up this diagram from the original transformer paper, entitled "Attention is all you need". As we'll see here we can leverage only some parts of it, according to what we're trying to do. We won't dive into the specific layers building up that architecture, but we'll try to understand the different ways this architecture can be used. Let's first start by splitting that architecture into two parts. On the left we have the encoder, and on the right, the decoder. These two can be used together, but they can also be used independently! Let's understand how these work: The encoder accepts inputs that represent text. It converts this text, these words, into numerical representations. These numerical representations can also be called embeddings, or features. We'll see that it uses the self-attention mechanism as its main component. We recommend you check out the video on encoders especially to understand what is this numerical representation, as well as how it works. We'll study the self-attention mechanism as well as its bi-directional properties. The decoder is similar to the encoder: it can also accept the same inputs as the encoder: inputs that represent text. It uses a similar mechanism as the encoder, which is the masked self-attention as well. It differs from the encoder due to its uni-directional property, and is traditionally used in an auto-regressive manner. Here too, we recommend you check out the video on decoders especially to understand how all of this works. Combining the two parts results in what is known as an encoder-decoder, or a sequence-to-sequence transformer. The encoder accepts inputs and computes a high-level representation of those inputs. These outputs are then passed to the decoder. The decoder uses the encoder's output alongside other inputs, in order to generate a prediction. It then predicts an output, which it will re-use in future iterations, hence the term "auto-regressive". Finally, to get an understanding of the encoder-decoders as a whole, we recommend you check out the video on encoder-decoders. | huggingface/course/blob/main/subtitles/en/raw/chapter1/04c_the-transformer-architecture.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Exporting 🤗 Transformers models to ONNX
🤗 Transformers provides a `transformers.onnx` package that enables you to
convert model checkpoints to an ONNX graph by leveraging configuration objects.
See the [guide](../serialization) on exporting 🤗 Transformers models for more
details.
## ONNX Configurations
We provide three abstract classes that you should inherit from, depending on the
type of model architecture you wish to export:
* Encoder-based models inherit from [`~onnx.config.OnnxConfig`]
* Decoder-based models inherit from [`~onnx.config.OnnxConfigWithPast`]
* Encoder-decoder models inherit from [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
### OnnxConfig
[[autodoc]] onnx.config.OnnxConfig
### OnnxConfigWithPast
[[autodoc]] onnx.config.OnnxConfigWithPast
### OnnxSeq2SeqConfigWithPast
[[autodoc]] onnx.config.OnnxSeq2SeqConfigWithPast
## ONNX Features
Each ONNX configuration is associated with a set of _features_ that enable you
to export models for different types of topologies or tasks.
### FeaturesManager
[[autodoc]] onnx.features.FeaturesManager
| huggingface/transformers/blob/main/docs/source/en/main_classes/onnx.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Diffusion XL Turbo
[[open-in-colab]]
SDXL Turbo is an adversarial time-distilled [Stable Diffusion XL](https://huggingface.co/papers/2307.01952) (SDXL) model capable
of running inference in as little as 1 step.
This guide will show you how to use SDXL-Turbo for text-to-image and image-to-image.
Before you begin, make sure you have the following libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q diffusers transformers accelerate omegaconf
```
## Load model checkpoints
Model weights may be stored in separate subfolders on the Hub or locally, in which case, you should use the [`~StableDiffusionXLPipeline.from_pretrained`] method:
```py
from diffusers import AutoPipelineForText2Image, AutoPipelineForImage2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipeline = pipeline.to("cuda")
```
You can also use the [`~StableDiffusionXLPipeline.from_single_file`] method to load a model checkpoint stored in a single file format (`.ckpt` or `.safetensors`) from the Hub or locally:
```py
from diffusers import StableDiffusionXLPipeline
import torch
pipeline = StableDiffusionXLPipeline.from_single_file(
"https://huggingface.co/stabilityai/sdxl-turbo/blob/main/sd_xl_turbo_1.0_fp16.safetensors", torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")
```
## Text-to-image
For text-to-image, pass a text prompt. By default, SDXL Turbo generates a 512x512 image, and that resolution gives the best results. You can try setting the `height` and `width` parameters to 768x768 or 1024x1024, but you should expect quality degradations when doing so.
Make sure to set `guidance_scale` to 0.0 to disable, as the model was trained without it. A single inference step is enough to generate high quality images.
Increasing the number of steps to 2, 3 or 4 should improve image quality.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline_text2image = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipeline_text2image = pipeline_text2image.to("cuda")
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image = pipeline_text2image(prompt=prompt, guidance_scale=0.0, num_inference_steps=1).images[0]
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/sdxl-turbo-text2img.png" alt="generated image of a racoon in a robe"/>
</div>
## Image-to-image
For image-to-image generation, make sure that `num_inference_steps * strength` is larger or equal to 1.
The image-to-image pipeline will run for `int(num_inference_steps * strength)` steps, e.g. `0.5 * 2.0 = 1` step in
our example below.
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image, make_image_grid
# use from_pipe to avoid consuming additional memory when loading a checkpoint
pipeline = AutoPipelineForImage2Image.from_pipe(pipeline_text2image).to("cuda")
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png")
init_image = init_image.resize((512, 512))
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
image = pipeline(prompt, image=init_image, strength=0.5, guidance_scale=0.0, num_inference_steps=2).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/sdxl-turbo-img2img.png" alt="Image-to-image generation sample using SDXL Turbo"/>
</div>
## Speed-up SDXL Turbo even more
- Compile the UNet if you are using PyTorch version 2 or better. The first inference run will be very slow, but subsequent ones will be much faster.
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
- When using the default VAE, keep it in `float32` to avoid costly `dtype` conversions before and after each generation. You only need to do this one before your first generation:
```py
pipe.upcast_vae()
```
As an alternative, you can also use a [16-bit VAE](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix) created by community member [`@madebyollin`](https://huggingface.co/madebyollin) that does not need to be upcasted to `float32`.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/sdxl_turbo.md |
Introduction to Gradio Blocks[[introduction-to-gradio-blocks]]
<CourseFloatingBanner chapter={9}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter9/section7.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter9/section7.ipynb"},
]} />
In the previous sections we have explored and created demos using the `Interface` class. In this section we will introduce our **newly developed** low-level API called `gradio.Blocks`.
Now, what's the difference between `Interface` and `Blocks`?
- ⚡ `Interface`: a high-level API that allows you to create a full machine learning demo simply by providing a list of inputs and outputs.
- 🧱 `Blocks`: a low-level API that allows you to have full control over the data flows and layout of your application. You can build very complex, multi-step applications using `Blocks` (as in "building blocks").
### Why Blocks 🧱?[[why-blocks-]]
As we saw in the previous sections, the `Interface` class allows you to easily create full-fledged machine learning demos with just a few lines of code. The `Interface` API is extremely easy to use but lacks the flexibility that the `Blocks` API provides. For example, you might want to:
- Group together related demos as multiple tabs in one web application
- Change the layout of your demo, e.g. to specify where the inputs and outputs are located
- Have multi-step interfaces, in which the output of one model becomes the input to the next model, or have more flexible data flows in general
- Change a component's properties (for example, the choices in a dropdown) or its visibility based on user input
We will explore all of these concepts below.
### Creating a simple demo using Blocks[[creating-a-simple-demo-using-blocks]]
After you have installed Gradio, run the code below as a Python script, a Jupyter notebook, or a Colab notebook.
```py
import gradio as gr
def flip_text(x):
return x[::-1]
demo = gr.Blocks()
with demo:
gr.Markdown(
"""
# Flip Text!
Start typing below to see the output.
"""
)
input = gr.Textbox(placeholder="Flip this text")
output = gr.Textbox()
input.change(fn=flip_text, inputs=input, outputs=output)
demo.launch()
```
<iframe src="https://course-demos-flip-text.hf.space" frameBorder="0" height="400" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
This simple example above introduces 4 concepts that underlie Blocks:
1. Blocks allow you to build web applications that combine markdown, HTML, buttons, and interactive components simply by instantiating objects in Python inside of a `with gradio.Blocks` context.
<Tip>
🙋If you're not familiar with the `with` statement in Python, we recommend checking out the excellent [tutorial](https://realpython.com/python-with-statement/) from Real Python. Come back here after reading that 🤗
</Tip>
The order in which you instantiate components matters as each element gets rendered into the web app in the order it was created. (More complex layouts are discussed below)
2. You can define regular Python functions anywhere in your code and run them with user input using `Blocks`. In our example, we have a simple function that "flips" the input text, but you can write any Python function, from a simple calculation to processing the predictions from a machine learning model.
3. You can assign events to any `Blocks` component. This will run your function when the component is clicked, changed, etc. When you assign an event, you pass in three parameters: `fn`: the function that should be called, `inputs`: the (list) of input component(s), and `outputs`: the (list) of output components that should be called.
In the example above, we run the `flip_text()` function when the value in the `Textbox` named input `input` changes. The event reads the value in `input`, passes it as the name parameter to `flip_text()`, which then returns a value that gets assigned to our second `Textbox` named `output`.
To see a list of events that each component supports, see the Gradio [documentation](https://www.gradio.app/docs/).
4. Blocks automatically figures out whether a component should be interactive (accept user input) or not, based on the event triggers you define. In our example, the first textbox is interactive, since its value is used by the `flip_text()` function. The second textbox is not interactive, since its value is never used as an input. In some cases, you might want to override this, which you can do by passing a boolean to the `interactive` parameter of the component (e.g. `gr.Textbox(placeholder="Flip this text", interactive=True)`).
### Customizing the layout of your demo[[customizing-the-layout-of-your-demo]]
How can we use `Blocks` to customize the layout of our demo? By default, `Blocks` renders the components that you create vertically in one column. You can change that by creating additional columns `with gradio.Column():` or rows `with gradio.Row():` and creating components within those contexts.
Here's what you should keep in mind: any components created under a `Column` (this is also the default) will be laid out vertically. Any component created under a `Row` will be laid out horizontally, similar to the [flexbox model in web development](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Flexible_Box_Layout/Basic_Concepts_of_Flexbox).
Finally, you can also create tabs for your demo by using the `with gradio.Tabs()` context manager. Within this context, you can create multiple tabs by specifying `with gradio.TabItem(name_of_tab):` children. Any component created inside of a `with gradio.TabItem(name_of_tab):` context appears in that tab.
Now let's add a `flip_image()` function to our demo and add a new tab that flips images. Below is an example with 2 tabs and also uses a Row:
```py
import numpy as np
import gradio as gr
demo = gr.Blocks()
def flip_text(x):
return x[::-1]
def flip_image(x):
return np.fliplr(x)
with demo:
gr.Markdown("Flip text or image files using this demo.")
with gr.Tabs():
with gr.TabItem("Flip Text"):
with gr.Row():
text_input = gr.Textbox()
text_output = gr.Textbox()
text_button = gr.Button("Flip")
with gr.TabItem("Flip Image"):
with gr.Row():
image_input = gr.Image()
image_output = gr.Image()
image_button = gr.Button("Flip")
text_button.click(flip_text, inputs=text_input, outputs=text_output)
image_button.click(flip_image, inputs=image_input, outputs=image_output)
demo.launch()
```
<iframe src="https://course-demos-flip-text-image.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
You'll notice that in this example, we've also created a `Button` component in each tab, and we've assigned a click event to each button, which is what actually runs the function.
### Exploring events and state[[exploring-events-and-state]]
Just as you can control the layout, `Blocks` gives you fine-grained control over what events trigger function calls. Each component and many layouts have specific events that they support.
For example, the `Textbox` component has 2 events: `change()` (when the value inside of the textbox changes), and `submit()` (when a user presses the enter key while focused on the textbox). More complex components can have even more events: for example, the `Audio` component also has separate events for when the audio file is played, cleared, paused, etc. See the documentation for the events each component supports.
You can attach event trigger to none, one, or more of these events. You create an event trigger by calling the name of the event on the component instance as a function -- e.g. `textbox.change(...)` or `btn.click(...)`. The function takes in three parameters, as discussed above:
- `fn`: the function to run
- `inputs`: a (list of) component(s) whose values should supplied as the input parameters to the function. Each component's value gets mapped to the corresponding function parameter, in order. This parameter can be None if the function does not take any parameters.
- `outputs`: a (list of) component(s) whose values should be updated based on the values returned by the function. Each return value sets the corresponding component's value, in order. This parameter can be None if the function does not return anything.
You can even make the input and output component be the same component, as we do in this example that uses a GPT model to do text completion:
```py
import gradio as gr
api = gr.Interface.load("huggingface/EleutherAI/gpt-j-6B")
def complete_with_gpt(text):
# Use the last 50 characters of the text as context
return text[:-50] + api(text[-50:])
with gr.Blocks() as demo:
textbox = gr.Textbox(placeholder="Type here and press enter...", lines=4)
btn = gr.Button("Generate")
btn.click(complete_with_gpt, textbox, textbox)
demo.launch()
```
<iframe src="https://course-demos-blocks-gpt.hf.space" frameBorder="0" height="300" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
### Creating multi-step demos[[creating-multi-step-demos]]
In some cases, you might want a _multi-step demo_, in which you reuse the output of one function as the input to the next. This is really easy to do with `Blocks`, as you can use a component for the input of one event trigger but the output of another. Take a look at the text component in the example below, its value is the result of a speech-to-text model, but also gets passed into a sentiment analysis model:
```py
from transformers import pipeline
import gradio as gr
asr = pipeline("automatic-speech-recognition", "facebook/wav2vec2-base-960h")
classifier = pipeline("text-classification")
def speech_to_text(speech):
text = asr(speech)["text"]
return text
def text_to_sentiment(text):
return classifier(text)[0]["label"]
demo = gr.Blocks()
with demo:
audio_file = gr.Audio(type="filepath")
text = gr.Textbox()
label = gr.Label()
b1 = gr.Button("Recognize Speech")
b2 = gr.Button("Classify Sentiment")
b1.click(speech_to_text, inputs=audio_file, outputs=text)
b2.click(text_to_sentiment, inputs=text, outputs=label)
demo.launch()
```
<iframe src="https://course-demos-blocks-multi-step.hf.space" frameBorder="0" height="600" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
### Updating Component Properties[[updating-component-properties]]
So far, we have seen how to create events to update the value of another component. But what happens if you want to change other properties of a component, like the visibility of a textbox or the choices in a radio button group? You can do this by returning a component class's `update()` method instead of a regular return value from your function.
This is most easily illustrated with an example:
```py
import gradio as gr
def change_textbox(choice):
if choice == "short":
return gr.Textbox.update(lines=2, visible=True)
elif choice == "long":
return gr.Textbox.update(lines=8, visible=True)
else:
return gr.Textbox.update(visible=False)
with gr.Blocks() as block:
radio = gr.Radio(
["short", "long", "none"], label="What kind of essay would you like to write?"
)
text = gr.Textbox(lines=2, interactive=True)
radio.change(fn=change_textbox, inputs=radio, outputs=text)
block.launch()
```
<iframe src="https://course-demos-blocks-update-component-properties.hf.space" frameBorder="0" height="300" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
We just explored all the core concepts of `Blocks`! Just like with `Interfaces`, you can create cool demos that can be shared by using `share=True` in the `launch()` method or deployed on [Hugging Face Spaces](https://huggingface.co/spaces). | huggingface/course/blob/main/chapters/en/chapter9/7.mdx |
!--Copyright 2023 The Intel Team Authors and HuggingFace Inc. team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# TVP
## Overview
The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
The abstract from the paper is the following:
*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/tvp_architecture.png"
alt="drawing" width="600"/>
<small> TVP architecture. Taken from the <a href="https://arxiv.org/abs/2303.04995">original paper.</a> </small>
This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
## Usage tips and examples
Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
```python
import av
import cv2
import numpy as np
import torch
from huggingface_hub import hf_hub_download
from transformers import AutoProcessor, TvpForVideoGrounding
def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video. Return None if the no
video stream was found.
fps (float): the number of frames per second of the video.
'''
video = container.streams.video[0]
fps = float(video.average_rate)
clip_size = sampling_rate * num_frames / target_fps * fps
delta = max(num_frames - clip_size, 0)
start_idx = delta * clip_idx / num_clips
end_idx = start_idx + clip_size - 1
timebase = video.duration / num_frames
video_start_pts = int(start_idx * timebase)
video_end_pts = int(end_idx * timebase)
seek_offset = max(video_start_pts - 1024, 0)
container.seek(seek_offset, any_frame=False, backward=True, stream=video)
frames = {}
for frame in container.decode(video=0):
if frame.pts < video_start_pts:
continue
frames[frame.pts] = frame
if frame.pts > video_end_pts:
break
frames = [frames[pts] for pts in sorted(frames)]
return frames, fps
def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Decode the video and perform temporal sampling.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video.
'''
assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
clip_size = sampling_rate * num_frames / target_fps * fps
index = np.linspace(0, clip_size - 1, num_frames)
index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
frames = frames.transpose(0, 3, 1, 2)
return frames
file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
decoder_kwargs = dict(
container=av.open(file, metadata_errors="ignore"),
sampling_rate=1,
num_frames=model.config.num_frames,
clip_idx=0,
num_clips=1,
target_fps=3,
)
raw_sampled_frms = decode(**decoder_kwargs)
text = "a person is sitting on a bed."
processor = AutoProcessor.from_pretrained("Intel/tvp-base")
model_inputs = processor(
text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
)
model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
output = model(**model_inputs)
def get_video_duration(filename):
cap = cv2.VideoCapture(filename)
if cap.isOpened():
rate = cap.get(5)
frame_num = cap.get(7)
duration = frame_num/rate
return duration
return -1
duration = get_video_duration(file)
start, end = processor.post_process_video_grounding(output.logits, duration)
print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
```
Tips:
- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
## TvpConfig
[[autodoc]] TvpConfig
## TvpImageProcessor
[[autodoc]] TvpImageProcessor
- preprocess
## TvpProcessor
[[autodoc]] TvpProcessor
- __call__
## TvpModel
[[autodoc]] TvpModel
- forward
## TvpForVideoGrounding
[[autodoc]] TvpForVideoGrounding
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/tvp.md |
Symbolic tracer
In Torch FX, the symbolic tracer feeds dummy values through the code to record the underlying operations. | huggingface/optimum/blob/main/docs/source/torch_fx/concept_guides/symbolic_tracer.mdx |
# Adversarial evaluation of model performances
Here is an example on evaluating a model using adversarial evaluation of natural language inference with the Heuristic Analysis for NLI Systems (HANS) dataset [McCoy et al., 2019](https://arxiv.org/abs/1902.01007). The example was gracefully provided by [Nafise Sadat Moosavi](https://github.com/ns-moosavi).
The HANS dataset can be downloaded from [this location](https://github.com/tommccoy1/hans).
This is an example of using test_hans.py:
```bash
export HANS_DIR=path-to-hans
export MODEL_TYPE=type-of-the-model-e.g.-bert-roberta-xlnet-etc
export MODEL_PATH=path-to-the-model-directory-that-is-trained-on-NLI-e.g.-by-using-run_glue.py
python run_hans.py \
--task_name hans \
--model_type $MODEL_TYPE \
--do_eval \
--data_dir $HANS_DIR \
--model_name_or_path $MODEL_PATH \
--max_seq_length 128 \
--output_dir $MODEL_PATH \
```
This will create the hans_predictions.txt file in MODEL_PATH, which can then be evaluated using hans/evaluate_heur_output.py from the HANS dataset.
The results of the BERT-base model that is trained on MNLI using batch size 8 and the random seed 42 on the HANS dataset is as follows:
```bash
Heuristic entailed results:
lexical_overlap: 0.9702
subsequence: 0.9942
constituent: 0.9962
Heuristic non-entailed results:
lexical_overlap: 0.199
subsequence: 0.0396
constituent: 0.118
```
| huggingface/transformers/blob/main/examples/research_projects/adversarial/README.md |
How to add support for more languages
We would love to support more languages for Gradio 🌎
To add your language, do the following steps:
1. Create a new json file in this directory
2. Name the file after the language code (Here's a list: http://4umi.com/web/html/languagecodes.php)
3. Please provide clear and complete translations. Take a look at the [`en.json`](https://github.com/gradio-app/gradio/blob/master/js/app/public/lang/en.json) file for the corresponding English text.
That's it!
| gradio-app/gradio/blob/main/js/app/src/lang/README.md |
--
title: BLEURT
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
BLEURT a learnt evaluation metric for Natural Language Generation. It is built using multiple phases of transfer learning starting from a pretrained BERT model (Devlin et al. 2018)
and then employing another pre-training phrase using synthetic data. Finally it is trained on WMT human annotations. You may run BLEURT out-of-the-box or fine-tune
it for your specific application (the latter is expected to perform better).
See the project's README at https://github.com/google-research/bleurt#readme for more information.
---
# Metric Card for BLEURT
## Metric Description
BLEURT is a learned evaluation metric for Natural Language Generation. It is built using multiple phases of transfer learning starting from a pretrained BERT model [Devlin et al. 2018](https://arxiv.org/abs/1810.04805), employing another pre-training phrase using synthetic data, and finally trained on WMT human annotations.
It is possible to run BLEURT out-of-the-box or fine-tune it for your specific application (the latter is expected to perform better).
See the project's [README](https://github.com/google-research/bleurt#readme) for more information.
## Intended Uses
BLEURT is intended to be used for evaluating text produced by language models.
## How to Use
This metric takes as input lists of predicted sentences and reference sentences:
```python
>>> predictions = ["hello there", "general kenobi"]
>>> references = ["hello there", "general kenobi"]
>>> bleurt = load("bleurt", module_type="metric")
>>> results = bleurt.compute(predictions=predictions, references=references)
```
### Inputs
- **predictions** (`list` of `str`s): List of generated sentences to score.
- **references** (`list` of `str`s): List of references to compare to.
- **checkpoint** (`str`): BLEURT checkpoint. Will default to `BLEURT-tiny` if not specified. Other models that can be chosen are: `"bleurt-tiny-128"`, `"bleurt-tiny-512"`, `"bleurt-base-128"`, `"bleurt-base-512"`, `"bleurt-large-128"`, `"bleurt-large-512"`, `"BLEURT-20-D3"`, `"BLEURT-20-D6"`, `"BLEURT-20-D12"` and `"BLEURT-20"`.
### Output Values
- **scores** : a `list` of scores, one per prediction.
Output Example:
```python
{'scores': [1.0295498371124268, 1.0445425510406494]}
```
BLEURT's output is always a number between 0 and (approximately 1). This value indicates how similar the generated text is to the reference texts, with values closer to 1 representing more similar texts.
#### Values from Popular Papers
The [original BLEURT paper](https://arxiv.org/pdf/2004.04696.pdf) reported that the metric is better correlated with human judgment compared to similar metrics such as BERT and BERTscore.
BLEURT is used to compare models across different asks (e.g. (Table to text generation)[https://paperswithcode.com/sota/table-to-text-generation-on-dart?metric=BLEURT]).
### Examples
Example with the default model:
```python
>>> predictions = ["hello there", "general kenobi"]
>>> references = ["hello there", "general kenobi"]
>>> bleurt = load("bleurt", module_type="metric")
>>> results = bleurt.compute(predictions=predictions, references=references)
>>> print(results)
{'scores': [1.0295498371124268, 1.0445425510406494]}
```
Example with the `"bleurt-base-128"` model checkpoint:
```python
>>> predictions = ["hello there", "general kenobi"]
>>> references = ["hello there", "general kenobi"]
>>> bleurt = load("bleurt", module_type="metric", checkpoint="bleurt-base-128")
>>> results = bleurt.compute(predictions=predictions, references=references)
>>> print(results)
{'scores': [1.0295498371124268, 1.0445425510406494]}
```
## Limitations and Bias
The [original BLEURT paper](https://arxiv.org/pdf/2004.04696.pdf) showed that BLEURT correlates well with human judgment, but this depends on the model and language pair selected.
Furthermore, currently BLEURT only supports English-language scoring, given that it leverages models trained on English corpora. It may also reflect, to a certain extent, biases and correlations that were present in the model training data.
Finally, calculating the BLEURT metric involves downloading the BLEURT model that is used to compute the score, which can take a significant amount of time depending on the model chosen. Starting with the default model, `bleurt-tiny`, and testing out larger models if necessary can be a useful approach if memory or internet speed is an issue.
## Citation
```bibtex
@inproceedings{bleurt,
title={BLEURT: Learning Robust Metrics for Text Generation},
author={Thibault Sellam and Dipanjan Das and Ankur P. Parikh},
booktitle={ACL},
year={2020},
url={https://arxiv.org/abs/2004.04696}
}
```
## Further References
- The original [BLEURT GitHub repo](https://github.com/google-research/bleurt/)
| huggingface/evaluate/blob/main/metrics/bleurt/README.md |
Scripts
A train, validation, inference, and checkpoint cleaning script included in the github root folder. Scripts are not currently packaged in the pip release.
The training and validation scripts evolved from early versions of the [PyTorch Imagenet Examples](https://github.com/pytorch/examples). I have added significant functionality over time, including CUDA specific performance enhancements based on
[NVIDIA's APEX Examples](https://github.com/NVIDIA/apex/tree/master/examples).
## Training Script
The variety of training args is large and not all combinations of options (or even options) have been fully tested. For the training dataset folder, specify the folder to the base that contains a `train` and `validation` folder.
To train an SE-ResNet34 on ImageNet, locally distributed, 4 GPUs, one process per GPU w/ cosine schedule, random-erasing prob of 50% and per-pixel random value:
`./distributed_train.sh 4 /data/imagenet --model seresnet34 --sched cosine --epochs 150 --warmup-epochs 5 --lr 0.4 --reprob 0.5 --remode pixel --batch-size 256 --amp -j 4`
NOTE: It is recommended to use PyTorch 1.9+ w/ PyTorch native AMP and DDP instead of APEX AMP. `--amp` defaults to native AMP as of timm ver 0.4.3. `--apex-amp` will force use of APEX components if they are installed.
## Validation / Inference Scripts
Validation and inference scripts are similar in usage. One outputs metrics on a validation set and the other outputs topk class ids in a csv. Specify the folder containing validation images, not the base as in training script.
To validate with the model's pretrained weights (if they exist):
`python validate.py /imagenet/validation/ --model seresnext26_32x4d --pretrained`
To run inference from a checkpoint:
`python inference.py /imagenet/validation/ --model mobilenetv3_large_100 --checkpoint ./output/train/model_best.pth.tar` | huggingface/pytorch-image-models/blob/main/docs/scripts.md |
Setting Up a Demo for Maximum Performance
Tags: CONCURRENCY, LATENCY, PERFORMANCE
Let's say that your Gradio demo goes _viral_ on social media -- you have lots of users trying it out simultaneously, and you want to provide your users with the best possible experience or, in other words, minimize the amount of time that each user has to wait in the queue to see their prediction.
How can you configure your Gradio demo to handle the most traffic? In this Guide, we dive into some of the parameters of Gradio's `.queue()` method as well as some other related parameters, and discuss how to set these parameters in a way that allows you to serve lots of users simultaneously with minimal latency.
This is an advanced guide, so make sure you know the basics of Gradio already, such as [how to create and launch a Gradio Interface](https://gradio.app/guides/quickstart/). Most of the information in this Guide is relevant whether you are hosting your demo on [Hugging Face Spaces](https://hf.space) or on your own server.
## Overview of Gradio's Queueing System
By default, every Gradio demo includes a built-in queuing system that scales to thousands of requests. When a user of your app submits a request (i.e. submits an input to your function), Gradio adds the request to the queue, and requests are processed in order, generally speaking (this is not exactly true, as discussed below). When the user's request has finished processing, the Gradio server returns the result back to the user using server-side events (SSE). The SSE protocol has several advantages over simply using HTTP POST requests:
(1) They do not time out -- most browsers raise a timeout error if they do not get a response to a POST request after a short period of time (e.g. 1 min). This can be a problem if your inference function takes longer than 1 minute to run or if many people are trying out your demo at the same time, resulting in increased latency.
(2) They allow the server to send multiple updates to the frontend. This means, for example, that the server can send a real-time ETA of how long your prediction will take to complete.
To configure the queue, simply call the `.queue()` method before launching an `Interface`, `TabbedInterface`, `ChatInterface` or any `Blocks`. Here's an example:
```py
import gradio as gr
app = gr.Interface(lambda x:x, "image", "image")
app.queue() # <-- Sets up a queue with default parameters
app.launch()
```
**How Requests are Processed from the Queue**
When a Gradio server is launched, a pool of threads is used to execute requests from the queue. By default, the maximum size of this thread pool is `40` (which is the default inherited from FastAPI, on which the Gradio server is based). However, this does *not* mean that 40 requests are always processed in parallel from the queue.
Instead, Gradio uses a **single-function-single-worker** model by default. This means that each worker thread is only assigned a single function from among all of the functions that could be part of your Gradio app. This ensures that you do not see, for example, out-of-memory errors, due to multiple workers calling a machine learning model at the same time. Suppose you have 3 functions in your Gradio app: A, B, and C. And you see the following sequence of 7 requests come in from users using your app:
```
1 2 3 4 5 6 7
-------------
A B A A C B A
```
Initially, 3 workers will get dispatched to handle requests 1, 2, and 5 (corresponding to functions: A, B, C). As soon as any of these workers finish, they will start processing the next function in the queue of the same function type, e.g. the worker that finished processing request 1 will start processing request 3, and so on.
If you want to change this behavior, there are several parameters that can be used to configure the queue and help reduce latency. Let's go through them one-by-one.
### The `default_concurrency_limit` parameter in `queue()`
The first parameter we will explore is the `default_concurrency_limit` parameter in `queue()`. This controls how many workers can execute the same event. By default, this is set to `1`, but you can set it to a higher integer: `2`, `10`, or even `None` (in the last case, there is no limit besides the total number of available workers).
This is useful, for example, if your Gradio app does not call any resource-intensive functions. If your app only queries external APIs, then you can set the `default_concurrency_limit` much higher. Increasing this parameter can **linearly multiply the capacity of your server to handle requests**.
So why not set this parameter much higher all the time? Keep in mind that since requests are processed in parallel, each request will consume memory to store the data and weights for processing. This means that you might get out-of-memory errors if you increase the `default_concurrency_limit` too high. You may also start to get diminishing returns if the `default_concurrency_limit` is too high because of costs of switching between different worker threads.
**Recommendation**: Increase the `default_concurrency_limit` parameter as high as you can while you continue to see performance gains or until you hit memory limits on your machine. You can [read about Hugging Face Spaces machine specs here](https://huggingface.co/docs/hub/spaces-overview).
### The `concurrency_limit` parameter in events
You can also set the number of requests that can be processed in parallel for each event individually. These take priority over the `default_concurrency_limit` parameter described previously.
To do this, set the `concurrency_limit` parameter of any event listener, e.g. `btn.click(..., concurrency_limit=20)` or in the `Interface` or `ChatInterface` classes: e.g. `gr.Interface(..., concurrency_limit=20)`. By default, this parameter is set to the global `default_concurrency_limit`.
### The `max_workers` parameter in `launch()`
If you have maxed out the `concurrency_count` and you'd like to further increase the number of requests that should be processed in parallel, you can increase the number of threads that can process requests from the queue.
You do this by setting the `max_workers` parameter in the `launch()` method. (The default value is 40.)
### The `max_size` parameter in `queue()`
A more blunt way to reduce the wait times is simply to prevent too many people from joining the queue in the first place. You can set the maximum number of requests that the queue processes using the `max_size` parameter of `queue()`. If a request arrives when the queue is already of the maximum size, it will not be allowed to join the queue and instead, the user will receive an error saying that the queue is full and to try again. By default, `max_size=None`, meaning that there is no limit to the number of users that can join the queue.
Paradoxically, setting a `max_size` can often improve user experience because it prevents users from being dissuaded by very long queue wait times. Users who are more interested and invested in your demo will keep trying to join the queue, and will be able to get their results faster.
**Recommendation**: For a better user experience, set a `max_size` that is reasonable given your expectations of how long users might be willing to wait for a prediction.
### The `max_batch_size` parameter in events
Another way to increase the parallelism of your Gradio demo is to write your function so that it can accept **batches** of inputs. Most deep learning models can process batches of samples more efficiently than processing individual samples.
If you write your function to process a batch of samples, Gradio will automatically batch incoming requests together and pass them into your function as a batch of samples. You need to set `batch` to `True` (by default it is `False`) and set a `max_batch_size` (by default it is `4`) based on the maximum number of samples your function is able to handle. These two parameters can be passed into `gr.Interface()` or to an event in Blocks such as `.click()`.
While setting a batch is conceptually similar to having workers process requests in parallel, it is often _faster_ than setting the `concurrency_count` for deep learning models. The downside is that you might need to adapt your function a little bit to accept batches of samples instead of individual samples.
Here's an example of a function that does _not_ accept a batch of inputs -- it processes a single input at a time:
```py
import time
def trim_words(word, length):
return word[:int(length)]
```
Here's the same function rewritten to take in a batch of samples:
```py
import time
def trim_words(words, lengths):
trimmed_words = []
for w, l in zip(words, lengths):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
```
The second function can be used with `batch=True` and an appropriate `max_batch_size` parameter.
**Recommendation**: If possible, write your function to accept batches of samples, and then set `batch` to `True` and the `max_batch_size` as high as possible based on your machine's memory limits.
## Upgrading your Hardware (GPUs, TPUs, etc.)
If you have done everything above, and your demo is still not fast enough, you can upgrade the hardware that your model is running on. Changing the model from running on CPUs to running on GPUs will usually provide a 10x-50x increase in inference time for deep learning models.
It is particularly straightforward to upgrade your Hardware on Hugging Face Spaces. Simply click on the "Settings" tab in your Space and choose the Space Hardware you'd like.
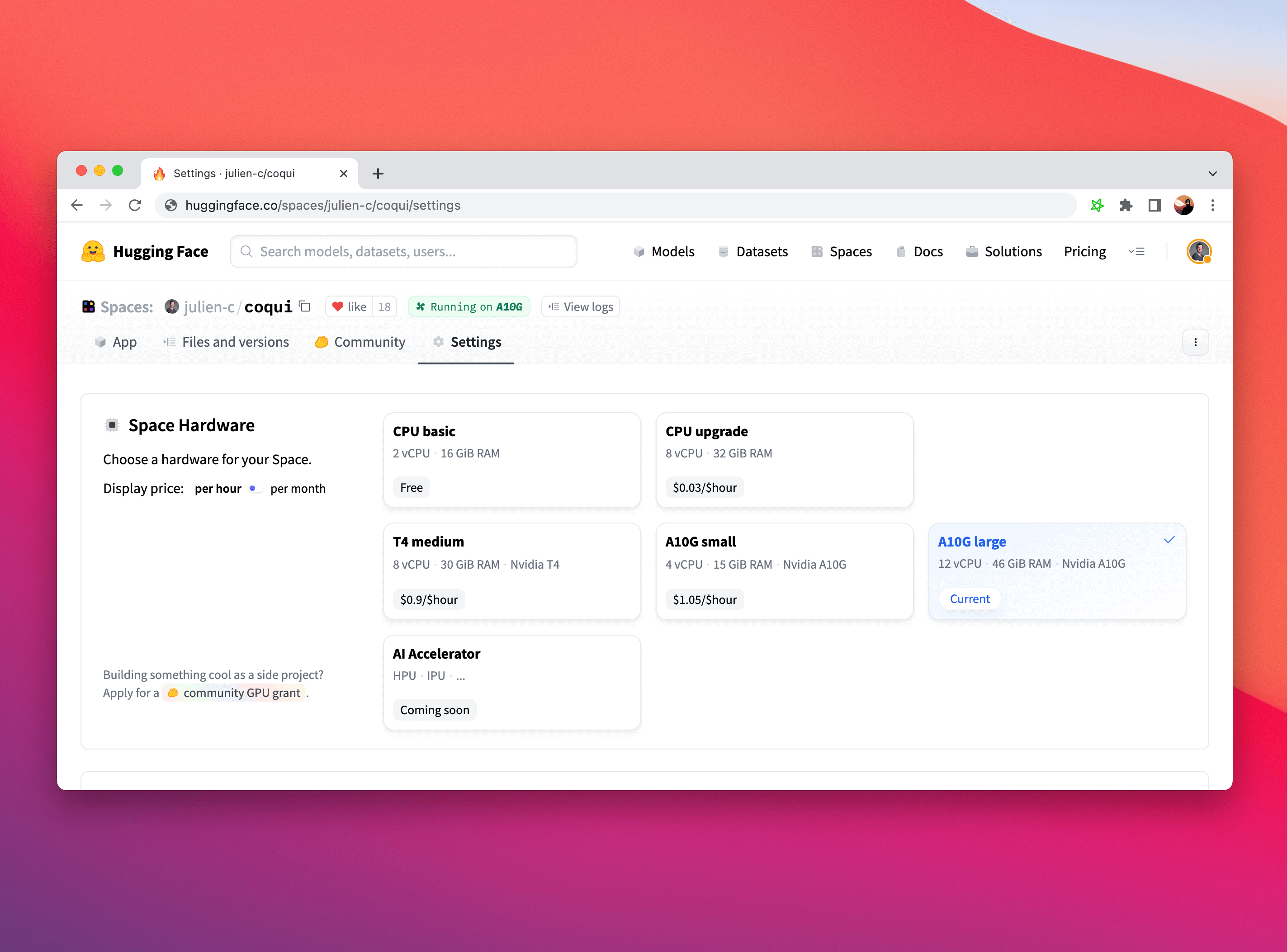
While you might need to adapt portions of your machine learning inference code to run on a GPU (here's a [handy guide](https://cnvrg.io/pytorch-cuda/) if you are using PyTorch), Gradio is completely agnostic to the choice of hardware and will work completely fine if you use it with CPUs, GPUs, TPUs, or any other hardware!
Note: your GPU memory is different than your CPU memory, so if you upgrade your hardware,
you might need to adjust the value of the `default_concurrency_limit` parameter described above.
## Conclusion
Congratulations! You know how to set up a Gradio demo for maximum performance. Good luck on your next viral demo!
| gradio-app/gradio/blob/main/guides/09_other-tutorials/setting-up-a-demo-for-maximum-performance.md |
--
title: "Optimizing Bark using 🤗 Transformers"
thumbnail: /blog/assets/bark_optimization/thumbnail.png
authors:
- user: ylacombe
---
# Optimizing a Text-To-Speech model using 🤗 Transformers
<a target="_blank" href="https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg"/>
</a>
🤗 Transformers provides many of the latest state-of-the-art (SoTA) models across domains and tasks. To get the best performance from these models, they need to be optimized for inference speed and memory usage.
The 🤗 Hugging Face ecosystem offers precisely such ready & easy to use optimization tools that can be applied across the board to all the models in the library. This makes it easy to **reduce memory footprint** and **improve inference** with just a few extra lines of code.
In this hands-on tutorial, I'll demonstrate how you can optimize [Bark](https://huggingface.co/docs/transformers/main/en/model_doc/bark#overview), a Text-To-Speech (TTS) model supported by 🤗 Transformers, based on three simple optimizations. These optimizations rely solely on the [Transformers](https://github.com/huggingface/transformers), [Optimum](https://github.com/huggingface/optimum) and [Accelerate](https://github.com/huggingface/accelerate) libraries from the 🤗 ecosystem.
This tutorial is also a demonstration of how one can benchmark a non-optimized model and its varying optimizations.
For a more streamlined version of the tutorial
with fewer explanations but all the code, see the accompanying [Google Colab](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb).
This blog post is organized as follows:
## Table of Contents
1. A [reminder](#bark-architecture) of Bark architecture
2. An [overview](#optimization-techniques) of different optimization techniques and their advantages
3. A [presentation](#benchmark-results) of benchmark results
# Bark Architecture
**Bark** is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark). It is capable of generating a wide range of audio outputs, including speech, music, background noise, and simple sound effects. Additionally, it can produce nonverbal communication sounds such as laughter, sighs, and sobs.
Bark has been available in 🤗 Transformers since v4.31.0 onwards!
You can play around with Bark and discover it's abilities [here](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Bark_HuggingFace_Demo.ipynb).
Bark is made of 4 main models:
- `BarkSemanticModel` (also referred to as the 'text' model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- `BarkCoarseModel` (also referred to as the 'coarse acoustics' model): a causal autoregressive transformer, that takes as input the results of the `BarkSemanticModel` model. It aims at predicting the first two audio codebooks necessary for EnCodec.
- `BarkFineModel` (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the [`EncodecModel`](https://huggingface.co/docs/transformers/v4.31.0/model_doc/encodec), Bark uses it to decode the output audio array.
At the time of writing, two Bark checkpoints are available, a [smaller](https://huggingface.co/suno/bark-small) and a [larger](https://huggingface.co/suno/bark) version.
## Load the Model and its Processor
The pre-trained Bark small and large checkpoints can be loaded from the [pre-trained weights](https://huggingface.co/suno/bark) on the Hugging Face Hub. You can change the repo-id with the checkpoint size that you wish to use.
We'll default to the small checkpoint, to keep it fast. But you can try the large checkpoint by using `"suno/bark"` instead of `"suno/bark-small"`.
```python
from transformers import BarkModel
model = BarkModel.from_pretrained("suno/bark-small")
```
Place the model to an accelerator device to get the most of the optimization techniques:
```python
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model = model.to(device)
```
Load the processor, which will take care of tokenization and optional speaker embeddings.
```python
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("suno/bark-small")
```
# Optimization techniques
In this section, we'll explore how to use off-the-shelf features from the 🤗 Optimum and 🤗 Accelerate libraries to optimize the Bark model, with minimal changes to the code.
## Some set-ups
Let's prepare the inputs and define a function to measure the latency and GPU memory footprint of the Bark generation method.
```python
text_prompt = "Let's try generating speech, with Bark, a text-to-speech model"
inputs = processor(text_prompt).to(device)
```
Measuring the latency and GPU memory footprint requires the use of specific CUDA methods. We define a utility function that measures both the latency and GPU memory footprint of the model at inference time. To ensure we get an accurate picture of these metrics, we average over a specified number of runs `nb_loops`:
```python
import torch
from transformers import set_seed
def measure_latency_and_memory_use(model, inputs, nb_loops = 5):
# define Events that measure start and end of the generate pass
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
# reset cuda memory stats and empty cache
torch.cuda.reset_peak_memory_stats(device)
torch.cuda.empty_cache()
torch.cuda.synchronize()
# get the start time
start_event.record()
# actually generate
for _ in range(nb_loops):
# set seed for reproducibility
set_seed(0)
output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8)
# get the end time
end_event.record()
torch.cuda.synchronize()
# measure memory footprint and elapsed time
max_memory = torch.cuda.max_memory_allocated(device)
elapsed_time = start_event.elapsed_time(end_event) * 1.0e-3
print('Execution time:', elapsed_time/nb_loops, 'seconds')
print('Max memory footprint', max_memory*1e-9, ' GB')
return output
```
## Base case
Before incorporating any optimizations, let's measure the performance of the baseline model and listen to a generated example. We'll benchmark the model over five iterations and report an average of the metrics:
```python
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 9.3841625 seconds
Max memory footprint 1.914612224 GB
```
Now, listen to the output:
```python
from IPython.display import Audio
# now, listen to the output
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0].cpu().numpy(), rate=sampling_rate)
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_base.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
### Important note:
Here, the number of iterations is actually quite low. To accurately measure and compare results, one should increase it to at least 100.
One of the main reasons for the importance of increasing `nb_loops` is that the speech lengths generated vary greatly between different iterations, even with a fixed input.
One consequence of this is that the latency measured by `measure_latency_and_memory_use` may not actually reflect the actual performance of optimization techniques! The benchmark at the end of the blog post reports the results averaged over 100 iterations, which gives a true indication of the performance of the model.
## 1. 🤗 Better Transformer
Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. This means that certain model operations will be better optimized on the GPU and that the model will ultimately be faster.
To be more specific, most models supported by 🤗 Transformers rely on attention, which allows them to selectively focus on certain parts of the input when generating output. This enables the models to effectively handle long-range dependencies and capture complex contextual relationships in the data.
The naive attention technique can be greatly optimized via a technique called [Flash Attention](https://arxiv.org/abs/2205.14135), proposed by the authors Dao et. al. in 2022.
Flash Attention is a faster and more efficient algorithm for attention computations that combines traditional methods (such as tiling and recomputation) to minimize memory usage and increase speed. Unlike previous algorithms, Flash Attention reduces memory usage from quadratic to linear in sequence length, making it particularly useful for applications where memory efficiency is important.
Turns out that Flash Attention is supported by 🤗 Better Transformer out of the box! It requires one line of code to export the model to 🤗 Better Transformer and enable Flash Attention:
```python
model = model.to_bettertransformer()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 5.43284375 seconds
Max memory footprint 1.9151841280000002 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_bettertransformer.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
There's no performance degradation, which means you can get exactly the same result as without this function, while gaining 20% to 30% in speed! Want to know more? See this [blog post](https://pytorch.org/blog/out-of-the-box-acceleration/).
## 2. Half-precision
Most AI models typically use a storage format called single-precision floating point, i.e. `fp32`. What does it mean in practice? Each number is stored using 32 bits.
You can thus choose to encode the numbers using 16 bits, with what is called half-precision floating point, i.e. `fp16`, and use half as much storage as before! More than that, you also get inference speed-up!
Of course, it also comes with small performance degradation since operations inside the model won't be as precise as using `fp32`.
You can load a 🤗 Transformers model with half-precision by simpling adding `torch_dtype=torch.float16` to the `BarkModel.from_pretrained(...)` line!
In other words:
```python
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 7.00045390625 seconds
Max memory footprint 2.7436124160000004 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_fp16.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
With a slight degradation in performance, you benefit from a memory footprint reduced by 50% and a speed gain of 5%.
## 3. CPU offload
As mentioned in the first section of this booklet, Bark comprises 4 sub-models, which are called up sequentially during audio generation. **In other words, while one sub-model is in use, the other sub-models are idle.**
Why is this a problem? GPU memory is precious in AI, because it's where operations are fastest, and it's often a bottleneck.
A simple solution is to unload sub-models from the GPU when inactive. This operation is called CPU offload.
**Good news:** CPU offload for Bark was integrated into 🤗 Transformers and you can use it with only one line of code.
You only need to make sure 🤗 Accelerate is installed!
```python
model = BarkModel.from_pretrained("suno/bark-small")
# Enable CPU offload
model.enable_cpu_offload()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 8.97633828125 seconds
Max memory footprint 1.3231160320000002 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
With a slight degradation in speed (10%), you benefit from a huge memory footprint reduction (60% 🤯).
With this feature enabled, `bark-large` footprint is now only 2GB instead of 5GB.
That's the same memory footprint as `bark-small`!
Want more? With `fp16` enabled, it's even down to 1GB. We'll see this in practice in the next section!
## 4. Combine
Let's bring it all together. The good news is that you can combine optimization techniques, which means you can use CPU offload, as well as half-precision and 🤗 Better Transformer!
```python
# load in fp16
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
# convert to bettertransformer
model = BetterTransformer.transform(model, keep_original_model=False)
# enable CPU offload
model.enable_cpu_offload()
with torch.inference_mode():
speech_output = measure_latency_and_memory_use(model, inputs, nb_loops = 5)
```
**Output:**
```
Execution time: 7.4496484375000005 seconds
Max memory footprint 0.46871091200000004 GB
```
The output sounds like this ([download audio](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_cpu_offload.wav)):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_optimized.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
**What does it bring to the table?**
Ultimately, you get a 23% speed-up and a huge 80% memory saving!
## Using batching
Want more?
Altogether, the 3 optimization techniques bring even better results when batching.
Batching means combining operations for multiple samples to bring the overall time spent generating the samples lower than generating sample per sample.
Here is a quick example of how you can use it:
```python
text_prompt = [
"Let's try generating speech, with Bark, a text-to-speech model",
"Wow, batching is so great!",
"I love Hugging Face, it's so cool."]
inputs = processor(text_prompt).to(device)
with torch.inference_mode():
# samples are generated all at once
speech_output = model.generate(**inputs, do_sample = True, fine_temperature = 0.4, coarse_temperature = 0.8)
```
The output sounds like this (download [first](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav), [second](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav), and [last](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav) audio):
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_0.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_1.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/bark_optimization/audio_sample_batch_2.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
# Benchmark results
As mentioned above, the little experiment we've carried out is an exercise in thinking and needs to be extended for a better measure of performance. One also needs to warm up the GPU with a few blank iterations before properly measuring performance.
Here are the results of a 100-sample benchmark extending the measurements, **using the large version of Bark**.
The benchmark was run on an NVIDIA TITAN RTX 24GB with a maximum of 256 new tokens.
## How to read the results?
### Latency
It measures the duration of a single call to the generation method, regardless of batch size.
In other words, it's equal to \\(\frac{elapsedTime}{nbLoops}\\).
**A lower latency is preferred.**
### Maximum memory footprint
It measures the maximum memory used during a single call to the generation method.
**A lower footprint is preferred.**
### Throughput
It measures the number of samples generated per second. This time, the batch size is taken into account.
In other words, it's equal to \\(\frac{nbLoops*batchSize}{elapsedTime}\\).
**A higher throughput is preferred.**
## No batching
Here are the results with `batch_size=1`.
| Absolute values | Latency | Memory |
|-----------------------------|---------|---------|
| no optimization | 10.48 | 5025.0M |
| bettertransformer only | 7.70 | 4974.3M |
| offload + bettertransformer | 8.90 | 2040.7M |
| offload + bettertransformer + fp16 | 8.10 | 1010.4M |
| Relative value | Latency | Memory |
|-----------------------------|---------|--------|
| no optimization | 0% | 0% |
| bettertransformer only | -27% | -1% |
| offload + bettertransformer | -15% | -59% |
| offload + bettertransformer + fp16 | -23% | -80% |
### Comment
As expected, CPU offload greatly reduces memory footprint while slightly increasing latency.
However, combined with bettertransformer and `fp16`, we get the best of both worlds, huge latency and memory decrease!
## Batch size set to 8
And here are the benchmark results but with `batch_size=8` and throughput measurement.
Note that since `bettertransformer` is a free optimization because it does exactly the same operation and has the same memory footprint as the non-optimized model while being faster, the benchmark was run with **this optimization enabled by default**.
| absolute values | Latency | Memory | Throghput |
|-------------------------------|---------|---------|-----------|
| base case (bettertransformer) | 19.26 | 8329.2M | 0.42 |
| + fp16 | 10.32 | 4198.8M | 0.78 |
| + offload | 20.46 | 5172.1M | 0.39 |
| + offload + fp16 | 10.91 | 2619.5M | 0.73 |
| Relative value | Latency | Memory | Throughput |
|-------------------------------|---------|--------|------------|
| + base case (bettertransformer) | 0% | 0% | 0% |
| + fp16 | -46% | -50% | 87% |
| + offload | 6% | -38% | -6% |
| + offload + fp16 | -43% | -69% | 77% |
### Comment
This is where we can see the potential of combining all three optimization features!
The impact of `fp16` on latency is less marked with `batch_size = 1`, but here it is of enormous interest as it can reduce latency by almost half, and almost double throughput!
# Concluding remarks
This blog post showcased a few simple optimization tricks bundled in the 🤗 ecosystem. Using anyone of these techniques, or a combination of all three, can greatly improve Bark inference speed and memory footprint.
* You can use the large version of Bark without any performance degradation and a footprint of just 2GB instead of 5GB, 15% faster, **using 🤗 Better Transformer and CPU offload**.
* Do you prefer high throughput? **Batch by 8 with 🤗 Better Transformer and half-precision**.
* You can get the best of both worlds by using **fp16, 🤗 Better Transformer and CPU offload**!
| huggingface/blog/blob/main/optimizing-bark.md |
# Installation
```
pip install safetensors
```
## Usage
### Numpy
```python
from safetensors.numpy import save_file, load_file
import numpy as np
tensors = {
"a": np.zeros((2, 2)),
"b": np.zeros((2, 3), dtype=np.uint8)
}
save_file(tensors, "./model.safetensors")
# Now loading
loaded = load_file("./model.safetensors")
```
### Torch
```python
from safetensors.torch import save_file, load_file
import torch
tensors = {
"a": torch.zeros((2, 2)),
"b": torch.zeros((2, 3), dtype=torch.uint8)
}
save_file(tensors, "./model.safetensors")
# Now loading
loaded = load_file("./model.safetensors")
```
### Developing
```
# inside ./safetensors/bindings/python
pip install .[dev]
```
Should be enough to install this library locally.
### Testing
```
# inside ./safetensors/bindings/python
pip install .[dev]
pytest -sv tests/
```
| huggingface/safetensors/blob/main/bindings/python/README.md |
Gradio Demo: blocks_outputs
```
!pip install -q gradio
```
```
import gradio as gr
def make_markdown():
return [
[
"# hello again",
"Hello my name is frank, I am liking the small turtle you have there. It would be a shame if it went missing.",
'<img src="https://images.unsplash.com/photo-1574613362884-f79513a5128c?fit=crop&w=500&q=80"/>',
],
[
"## hello again again",
"Hello my name is frank, I am liking the small turtle you have there. It would be a shame if it went missing.",
'<img src="https://images.unsplash.com/photo-1574613362884-f79513a5128c?fit=crop&w=500&q=80"/>',
],
[
"### hello thrice",
"Hello my name is frank, I am liking the small turtle you have there. It would be a shame if it went missing.",
'<img src="https://images.unsplash.com/photo-1574613362884-f79513a5128c?fit=crop&w=500&q=80"/>',
],
]
with gr.Blocks() as demo:
with gr.Column():
txt = gr.Textbox(label="Small Textbox", lines=1, show_label=False)
txt = gr.Textbox(label="Large Textbox", lines=5, show_label=False)
num = gr.Number(label="Number", show_label=False)
check = gr.Checkbox(label="Checkbox", show_label=False)
check_g = gr.CheckboxGroup(
label="Checkbox Group", choices=["One", "Two", "Three"], show_label=False
)
radio = gr.Radio(
label="Radio", choices=["One", "Two", "Three"], show_label=False
)
drop = gr.Dropdown(
label="Dropdown", choices=["One", "Two", "Three"], show_label=False
)
slider = gr.Slider(label="Slider", show_label=False)
audio = gr.Audio(show_label=False)
file = gr.File(show_label=False)
video = gr.Video(show_label=False)
image = gr.Image(show_label=False)
df = gr.Dataframe(show_label=False)
html = gr.HTML(show_label=False)
json = gr.JSON(show_label=False)
md = gr.Markdown(show_label=False)
label = gr.Label(show_label=False)
highlight = gr.HighlightedText(show_label=False)
gr.Dataframe(interactive=True, col_count=(3, "fixed"), label="Dataframe")
gr.Dataframe(interactive=True, col_count=4, label="Dataframe")
gr.Dataframe(
interactive=True, headers=["One", "Two", "Three", "Four"], label="Dataframe"
)
gr.Dataframe(
interactive=True,
headers=["One", "Two", "Three", "Four"],
col_count=(4, "fixed"),
row_count=(7, "fixed"),
value=[[0, 0, 0, 0]],
label="Dataframe",
)
gr.Dataframe(
interactive=True, headers=["One", "Two", "Three", "Four"], col_count=4
)
df = gr.DataFrame(
[
[
"# hello",
"Hello my name is frank, I am liking the small turtle you have there. It would be a shame if it went missing.",
'<img src="https://images.unsplash.com/photo-1574613362884-f79513a5128c?fit=crop&w=500&q=80"/>',
],
[
"## hello",
"Hello my name is frank, I am liking the small turtle you have there. It would be a shame if it went missing.",
'<img src="https://images.unsplash.com/photo-1574613362884-f79513a5128c?fit=crop&w=500&q=80"/>',
],
[
"### hello",
"Hello my name is frank, I am liking the small turtle you have there. It would be a shame if it went missing.",
'<img src="https://images.unsplash.com/photo-1574613362884-f79513a5128c?fit=crop&w=500&q=80"/>',
],
],
headers=["One", "Two", "Three"],
wrap=True,
datatype=["markdown", "markdown", "html"],
interactive=True,
)
btn = gr.Button("Run")
btn.click(fn=make_markdown, inputs=None, outputs=df)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_outputs/run.ipynb |
Gradio Demo: slider_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.Slider()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/slider_component/run.ipynb |
Process audio data
This guide shows specific methods for processing audio datasets. Learn how to:
- Resample the sampling rate.
- Use [`~Dataset.map`] with audio datasets.
For a guide on how to process any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./process">general process guide</a>.
## Cast
The [`~Dataset.cast_column`] function is used to cast a column to another feature to be decoded. When you use this function with the [`Audio`] feature, you can resample the sampling rate:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
```
Audio files are decoded and resampled on-the-fly, so the next time you access an example, the audio file is resampled to 16kHz:
```py
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/resample.gif"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/resample-dark.gif"/>
</div>
## Map
The [`~Dataset.map`] function helps preprocess your entire dataset at once. Depending on the type of model you're working with, you'll need to either load a [feature extractor](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoFeatureExtractor) or a [processor](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoProcessor).
- For pretrained speech recognition models, load a feature extractor and tokenizer and combine them in a `processor`:
```py
>>> from transformers import AutoTokenizer, AutoFeatureExtractor, AutoProcessor
>>> model_checkpoint = "facebook/wav2vec2-large-xlsr-53"
# after defining a vocab.json file you can instantiate a tokenizer object:
>>> tokenizer = AutoTokenizer("./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(model_checkpoint)
>>> processor = AutoProcessor.from_pretrained(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
- For fine-tuned speech recognition models, you only need to load a `processor`:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
When you use [`~Dataset.map`] with your preprocessing function, include the `audio` column to ensure you're actually resampling the audio data:
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
... batch["input_length"] = len(batch["input_values"])
... with processor.as_target_processor():
... batch["labels"] = processor(batch["sentence"]).input_ids
... return batch
>>> dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
```
| huggingface/datasets/blob/main/docs/source/audio_process.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# LoRA
LoRA is a fast and lightweight training method that inserts and trains a significantly smaller number of parameters instead of all the model parameters. This produces a smaller file (~100 MBs) and makes it easier to quickly train a model to learn a new concept. LoRA weights are typically loaded into the UNet, text encoder or both. There are two classes for loading LoRA weights:
- [`LoraLoaderMixin`] provides functions for loading and unloading, fusing and unfusing, enabling and disabling, and more functions for managing LoRA weights. This class can be used with any model.
- [`StableDiffusionXLLoraLoaderMixin`] is a [Stable Diffusion (SDXL)](../../api/pipelines/stable_diffusion/stable_diffusion_xl) version of the [`LoraLoaderMixin`] class for loading and saving LoRA weights. It can only be used with the SDXL model.
<Tip>
To learn more about how to load LoRA weights, see the [LoRA](../../using-diffusers/loading_adapters#lora) loading guide.
</Tip>
## LoraLoaderMixin
[[autodoc]] loaders.lora.LoraLoaderMixin
## StableDiffusionXLLoraLoaderMixin
[[autodoc]] loaders.lora.StableDiffusionXLLoraLoaderMixin | huggingface/diffusers/blob/main/docs/source/en/api/loaders/lora.md |
(Legacy) SE-ResNeXt
**SE ResNeXt** is a variant of a [ResNeXt](https://www.paperswithcode.com/method/resnext) that employs [squeeze-and-excitation blocks](https://paperswithcode.com/method/squeeze-and-excitation-block) to enable the network to perform dynamic channel-wise feature recalibration.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('legacy_seresnext101_32x4d', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `legacy_seresnext101_32x4d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('legacy_seresnext101_32x4d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{hu2019squeezeandexcitation,
title={Squeeze-and-Excitation Networks},
author={Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Enhua Wu},
year={2019},
eprint={1709.01507},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: Legacy SE ResNeXt
Paper:
Title: Squeeze-and-Excitation Networks
URL: https://paperswithcode.com/paper/squeeze-and-excitation-networks
Models:
- Name: legacy_seresnext101_32x4d
In Collection: Legacy SE ResNeXt
Metadata:
FLOPs: 10287698672
Parameters: 48960000
File Size: 196466866
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnext101_32x4d
LR: 0.6
Epochs: 100
Layers: 101
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L462
Weights: http://data.lip6.fr/cadene/pretrainedmodels/se_resnext101_32x4d-3b2fe3d8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.23%
Top 5 Accuracy: 95.02%
- Name: legacy_seresnext26_32x4d
In Collection: Legacy SE ResNeXt
Metadata:
FLOPs: 3187342304
Parameters: 16790000
File Size: 67346327
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnext26_32x4d
LR: 0.6
Epochs: 100
Layers: 26
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L448
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/seresnext26_32x4d-65ebdb501.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.11%
Top 5 Accuracy: 93.31%
- Name: legacy_seresnext50_32x4d
In Collection: Legacy SE ResNeXt
Metadata:
FLOPs: 5459954352
Parameters: 27560000
File Size: 110559176
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
- Squeeze-and-Excitation Block
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
Training Resources: 8x NVIDIA Titan X GPUs
ID: legacy_seresnext50_32x4d
LR: 0.6
Epochs: 100
Layers: 50
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 1024
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/senet.py#L455
Weights: http://data.lip6.fr/cadene/pretrainedmodels/se_resnext50_32x4d-a260b3a4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.08%
Top 5 Accuracy: 94.43%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/legacy-se-resnext.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DiffEdit
[DiffEdit: Diffusion-based semantic image editing with mask guidance](https://huggingface.co/papers/2210.11427) is by Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord.
The abstract from the paper is:
*Image generation has recently seen tremendous advances, with diffusion models allowing to synthesize convincing images for a large variety of text prompts. In this article, we propose DiffEdit, a method to take advantage of text-conditioned diffusion models for the task of semantic image editing, where the goal is to edit an image based on a text query. Semantic image editing is an extension of image generation, with the additional constraint that the generated image should be as similar as possible to a given input image. Current editing methods based on diffusion models usually require to provide a mask, making the task much easier by treating it as a conditional inpainting task. In contrast, our main contribution is able to automatically generate a mask highlighting regions of the input image that need to be edited, by contrasting predictions of a diffusion model conditioned on different text prompts. Moreover, we rely on latent inference to preserve content in those regions of interest and show excellent synergies with mask-based diffusion. DiffEdit achieves state-of-the-art editing performance on ImageNet. In addition, we evaluate semantic image editing in more challenging settings, using images from the COCO dataset as well as text-based generated images.*
The original codebase can be found at [Xiang-cd/DiffEdit-stable-diffusion](https://github.com/Xiang-cd/DiffEdit-stable-diffusion), and you can try it out in this [demo](https://blog.problemsolversguild.com/technical/research/2022/11/02/DiffEdit-Implementation.html).
This pipeline was contributed by [clarencechen](https://github.com/clarencechen). ❤️
## Tips
* The pipeline can generate masks that can be fed into other inpainting pipelines.
* In order to generate an image using this pipeline, both an image mask (source and target prompts can be manually specified or generated, and passed to [`~StableDiffusionDiffEditPipeline.generate_mask`])
and a set of partially inverted latents (generated using [`~StableDiffusionDiffEditPipeline.invert`]) _must_ be provided as arguments when calling the pipeline to generate the final edited image.
* The function [`~StableDiffusionDiffEditPipeline.generate_mask`] exposes two prompt arguments, `source_prompt` and `target_prompt`
that let you control the locations of the semantic edits in the final image to be generated. Let's say,
you wanted to translate from "cat" to "dog". In this case, the edit direction will be "cat -> dog". To reflect
this in the generated mask, you simply have to set the embeddings related to the phrases including "cat" to
`source_prompt` and "dog" to `target_prompt`.
* When generating partially inverted latents using `invert`, assign a caption or text embedding describing the
overall image to the `prompt` argument to help guide the inverse latent sampling process. In most cases, the
source concept is sufficiently descriptive to yield good results, but feel free to explore alternatives.
* When calling the pipeline to generate the final edited image, assign the source concept to `negative_prompt`
and the target concept to `prompt`. Taking the above example, you simply have to set the embeddings related to
the phrases including "cat" to `negative_prompt` and "dog" to `prompt`.
* If you wanted to reverse the direction in the example above, i.e., "dog -> cat", then it's recommended to:
* Swap the `source_prompt` and `target_prompt` in the arguments to `generate_mask`.
* Change the input prompt in [`~StableDiffusionDiffEditPipeline.invert`] to include "dog".
* Swap the `prompt` and `negative_prompt` in the arguments to call the pipeline to generate the final edited image.
* The source and target prompts, or their corresponding embeddings, can also be automatically generated. Please refer to the [DiffEdit](../../using-diffusers/diffedit) guide for more details.
## StableDiffusionDiffEditPipeline
[[autodoc]] StableDiffusionDiffEditPipeline
- all
- generate_mask
- invert
- __call__
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/diffedit.md |
Polars
[Polars](https://pola-rs.github.io/polars-book/user-guide/) is a fast DataFrame library written in Rust with Arrow as its foundation.
<Tip>
💡 Learn more about how to get the dataset URLs in the [List Parquet files](parquet) guide.
</Tip>
Let's start by grabbing the URLs to the `train` split of the [`blog_authorship_corpus`](https://huggingface.co/datasets/blog_authorship_corpus) dataset from Datasets Server:
```py
r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=blog_authorship_corpus")
j = r.json()
urls = [f['url'] for f in j['parquet_files'] if f['split'] == 'train']
urls
['https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/train/0000.parquet',
'https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/train/0001.parquet']
```
To read from a single Parquet file, use the [`read_parquet`](https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.read_parquet.html) function to read it into a DataFrame and then execute your query:
```py
import polars as pl
df = (
pl.read_parquet("https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/train/0000.parquet")
.groupby("horoscope")
.agg(
[
pl.count(),
pl.col("text").str.n_chars().mean().alias("avg_blog_length")
]
)
.sort("avg_blog_length", descending=True)
.limit(5)
)
print(df)
shape: (5, 3)
┌───────────┬───────┬─────────────────┐
│ horoscope ┆ count ┆ avg_blog_length │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ f64 │
╞═══════════╪═══════╪═════════════════╡
│ Aquarius ┆ 34062 ┆ 1129.218836 │
│ Cancer ┆ 41509 ┆ 1098.366812 │
│ Capricorn ┆ 33961 ┆ 1073.2002 │
│ Libra ┆ 40302 ┆ 1072.071833 │
│ Leo ┆ 40587 ┆ 1064.053687 │
└───────────┴───────┴─────────────────┘
```
To read multiple Parquet files - for example, if the dataset is sharded - you'll need to use the [`concat`](https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.concat.html) function to concatenate the files into a single DataFrame:
```py
import polars as pl
df = (
pl.concat([pl.read_parquet(url) for url in urls])
.groupby("horoscope")
.agg(
[
pl.count(),
pl.col("text").str.n_chars().mean().alias("avg_blog_length")
]
)
.sort("avg_blog_length", descending=True)
.limit(5)
)
print(df)
shape: (5, 3)
┌─────────────┬───────┬─────────────────┐
│ horoscope ┆ count ┆ avg_blog_length │
│ --- ┆ --- ┆ --- │
│ str ┆ u32 ┆ f64 │
╞═════════════╪═══════╪═════════════════╡
│ Aquarius ┆ 49568 ┆ 1125.830677 │
│ Cancer ┆ 63512 ┆ 1097.956087 │
│ Libra ┆ 60304 ┆ 1060.611054 │
│ Capricorn ┆ 49402 ┆ 1059.555261 │
│ Sagittarius ┆ 50431 ┆ 1057.458984 │
└─────────────┴───────┴─────────────────┘
```
## Lazy API
Polars offers a [lazy API](https://pola-rs.github.io/polars-book/user-guide/lazy/using/) that is more performant and memory-efficient for large Parquet files. The LazyFrame API keeps track of what you want to do, and it'll only execute the entire query when you're ready. This way, the lazy API doesn't load everything into RAM beforehand, and it allows you to work with datasets larger than your available RAM.
To lazily read a Parquet file, use the [`scan_parquet`](https://pola-rs.github.io/polars/py-polars/html/reference/api/polars.scan_parquet.html) function instead. Then, execute the entire query with the [`collect`](https://pola-rs.github.io/polars/py-polars/html/reference/lazyframe/api/polars.LazyFrame.collect.html) function:
```py
import polars as pl
q = (
pl.scan_parquet("https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/train/0000.parquet")
.groupby("horoscope")
.agg(
[
pl.count(),
pl.col("text").str.n_chars().mean().alias("avg_blog_length")
]
)
.sort("avg_blog_length", descending=True)
.limit(5)
)
df = q.collect()
``` | huggingface/datasets-server/blob/main/docs/source/polars.mdx |
`tokenizers-darwin-arm64`
This is the **aarch64-apple-darwin** binary for `tokenizers`
| huggingface/tokenizers/blob/main/bindings/node/npm/darwin-arm64/README.md |
`@gradio/radio`
```html
<script>
import { BaseRadio, BaseExample } from "@gradio/radio";
</script>
```
BaseRadio
```javascript
export let display_value: string;
export let internal_value: string | number;
export let disabled = false;
export let elem_id = "";
export let selected: string | number | null = null;
```
BaseExample
```javascript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
``` | gradio-app/gradio/blob/main/js/radio/README.md |
Gradio Demo: clearbutton_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
textbox = gr.Textbox(value="This is some text")
gr.ClearButton(textbox)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/clearbutton_component/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FLAN-UL2
## Overview
Flan-UL2 is an encoder decoder model based on the T5 architecture. It uses the same configuration as the [UL2](ul2) model released earlier last year.
It was fine tuned using the "Flan" prompt tuning and dataset collection. Similar to `Flan-T5`, one can directly use FLAN-UL2 weights without finetuning the model:
According to the original blog here are the notable improvements:
- The original UL2 model was only trained with receptive field of 512, which made it non-ideal for N-shot prompting where N is large.
- The Flan-UL2 checkpoint uses a receptive field of 2048 which makes it more usable for few-shot in-context learning.
- The original UL2 model also had mode switch tokens that was rather mandatory to get good performance. However, they were a little cumbersome as this requires often some changes during inference or finetuning. In this update/change, we continue training UL2 20B for an additional 100k steps (with small batch) to forget “mode tokens” before applying Flan instruction tuning. This Flan-UL2 checkpoint does not require mode tokens anymore.
Google has released the following variants:
The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints).
## Running on low resource devices
The model is pretty heavy (~40GB in half precision) so if you just want to run the model, make sure you load your model in 8bit, and use `device_map="auto"` to make sure you don't have any OOM issue!
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-ul2", load_in_8bit=True, device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['In a large skillet, brown the ground beef and onion over medium heat. Add the garlic']
```
<Tip>
Refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
</Tip>
| huggingface/transformers/blob/main/docs/source/en/model_doc/flan-ul2.md |
--
title: "Director of Machine Learning Insights [Part 4]"
thumbnail: /blog/assets/78_ml_director_insights/part4.png
---
# Director of Machine Learning Insights [Part 4]
_If you're interested in building ML solutions faster visit: [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) today!_
👋 Welcome back to our Director of ML Insights Series! If you missed earlier Editions you can find them here:
- [Director of Machine Learning Insights [Part 1]](https://huggingface.co/blog/ml-director-insights)
- [Director of Machine Learning Insights [Part 2 : SaaS Edition]](https://huggingface.co/blog/ml-director-insights-2)
- [Director of Machine Learning Insights [Part 3 : Finance Edition]](https://huggingface.co/blog/ml-director-insights-3)
🚀 In this fourth installment, you’ll hear what the following top Machine Learning Directors say about Machine Learning’s impact on their respective industries: Javier Mansilla, Shaun Gittens, Samuel Franklin, and Evan Castle. —All are currently Directors of Machine Learning with rich field insights.
_Disclaimer: All views are from individuals and not from any past or current employers._
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Javier.png"></a>
### [Javier Mansilla](https://www.linkedin.com/in/javimansilla/?originalSubdomain=ar) - Director of Machine Learning, Marketing Science at [Mercado Libre](https://mercadolibre.com/)
**Background:** Seasoned entrepreneur and leader, Javier was co-founder and CTO of Machinalis, a high-end company building Machine Learning since 2010 (yes, before the breakthrough of neural nets). When Machinalis was acquired by Mercado Libre, that small team evolved to enable Machine Learning as a capability for a tech giant with more than 10k devs, impacting the lives of almost 100 million direct users. Daily, Javier leads not only the tech and product roadmap of their Machine Learning Platform (NASDAQ MELI), but also their users' tracking system, the AB Testing framework, and the open-source office. Javier is an active member & contributor of [Python-Argentina non-profit PyAr](https://www.python.org.ar/), he loves hanging out with family and friends, python, biking, football, carpentry, and slow-paced holidays in nature!
**Fun Fact:** I love reading science fiction, and my idea of retirement includes resuming the teenage dream of writing short stories.📚
**Mercado Libre:** The biggest company in Latam and the eCommerce & fintech omnipresent solution for the continent
#### **1. How has ML made a positive impact on e-commerce?**
I would say that ML made the impossible possible in specific cases like fraud prevention and optimized processes and flows in ways we couldn't have imagined in a vast majority of other areas.
In the middle, there are applications where ML enabled a next-level of UX that otherwise would be very expensive (but maybe possible). For example, the discovery and serendipity added to users' journey navigating between listings and offers.
We ran search, recommendations, ads, credit-scoring, moderations, forecasting of several key aspects, logistics, and a lot more core units with Machine Learning optimizing at least one of its fundamental metrics.
We even use ML to optimize the way we reserve and use infrastructure.
#### **2. What are the biggest ML challenges within e-commerce?**
Besides all the technical challenges ahead (for instance, more and more real timeless and personalization), the biggest challenge is the always present focus on the end-user.
E-commerce is scaling its share of the market year after year, and Machine Learning is always a probabilistic approach that doesn't provide 100% perfection. We need to be careful to keep optimizing our products while still paying attention to the long tail and the experience of each individual person.
Finally, a growing challenge is coordinating and fostering data (inputs and outputs) co-existence in a multi-channel and multi-business world—marketplace, logistics, credits, insurance, payments on brick-and-mortar stores, etc.
#### **3. A common mistake you see people make trying to integrate ML into e-commerce?**
The most common mistakes are related to using the wrong tool for the wrong problem.
For instance, starting complex instead of with the simplest baseline possible. For instance not measuring the with/without machine learning impact. For instance, investing in tech without having a clear clue of the boundaries of the expected gain.
Last but not least: thinking only in the short term, forgetting about the hidden impacts, technical debts, maintenance, and so on.
#### **4. What excites you most about the future of ML?**
Talking from the perspective of being on the trench crafting technology with our bare hands like we used to do ten years ago, definitely what I like the most is to see that we as an industry are solving most of the slow, repetitive and boring pieces of the challenge.
It’s of course an ever-moving target, and new difficulties arise.
But we are getting better at incorporating mature tools and practices that will lead to shorter cycles of model-building which, at the end of the day, reduces time to market.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Shaun.png"></a>
### [Shaun Gittens](https://www.linkedin.com/in/shaungittens/) - Director of Machine Learning at [MasterPeace Solutions](https://www.masterpeaceltd.com/)
**Background:** Dr. Shaun Gittens is the Director of the Machine Learning Capability of MasterPeace Solutions, Ltd., a company specializing in providing advanced technology and mission-critical cyber services to its clients. In this role, he is:
1. Growing the core of machine learning experts and practitioners at the company.
2. Increasing the knowledge of bleeding-edge machine learning practices among its existing employees.
3. Ensuring the delivery of effective machine learning solutions and consulting support not only to the company’s clientele but also to the start-up companies currently being nurtured from within MasterPeace.
Before joining MasterPeace, Dr. Gittens served as Principal Data Scientist for the Applied Technology Group, LLC. He built his career on training and deploying machine learning solutions on distributed big data and streaming platforms such as Apache Hadoop, Apache Spark, and Apache Storm. As a postdoctoral fellow at Auburn University, he investigated effective methods for visualizing the knowledge gained from trained non-linear machine-learned models.
**Fun Fact:** Addicted to playing tennis & Huge anime fan. 🎾
**MasterPeace Solutions:** MasterPeace Solutions has emerged as one of the fastest-growing advanced technology companies in the Mid-Atlantic region. The company designs and develops software, systems, solutions and products to solve some of the most pressing challenges facing the Intelligence Community.
#### **1. How has ML made a positive impact on Engineering?**
Engineering is vast in its applications and can encompass a great many areas. That said, more recently, we are seeing ML affect a range of engineering facets addressing obvious fields such as robotics and automobile engineering to not-so-obvious fields such as chemical and civil engineering. ML is so broad in its application that merely the very existence of training data consisting of prior recorded labor processes is all required to attempt to have ML affect your bottom line. In essence, we are in an age where ML has significantly impacted the automation of all sorts of previously human-only-operated engineering processes.
#### **2. What are the biggest ML challenges within Engineering?**
1. The biggest challenges come with the operationalization and deployment of ML-trained solutions in a manner in which human operations can be replaced with minimal consequences. We’re seeing it now with fully self-driving automobiles. It’s challenging to automate processes with little to no fear of jeopardizing humans or processes that humans rely on. One of the most significant examples of this phenomenon that concerns me is ML and Bias. It is a reality that ML models trained on data containing, even if unaware, prejudiced decision-making can reproduce said bias in operation. Bias needs to be put front and center in the attempt to incorporate ML into engineering such that systemic racism isn’t propagated into future technological advances to then cause harm to disadvantaged populations. ML systems trained on data emanating from biased processes are doomed to repeat them, mainly if those training the ML solutions aren’t acutely aware of all forms of data present in the process to be automated.
2. Another critical challenge regarding ML in engineering is that the field is mainly categorized by the need for problem-solving, which often requires creativity. As of now, few great cases exist today of ML agents being truly “creative” and capable of “thinking out-of-the-box” since current ML solutions tend to result merely from a search through all possible solutions. In my humble opinion, though a great many solutions can be found via these methods, ML will have somewhat of a ceiling in engineering until the former can consistently demonstrate creativity in a variety of problem spaces. That said, that ceiling is still pretty high, and there is much left to be accomplished in ML applications in engineering.
#### **3. What’s a common mistake you see people make when trying to integrate ML into Engineering?**
Using an overpowered ML technique on a small problem dataset is one common mistake I see people making in integrating ML into Engineering. Deep Learning, for example, is moving AI and ML to heights unimagined in such a short period, but it may not be one’s best method for solving a problem, depending on your problem space. Often more straightforward methods work just as well or better when working with small training datasets on limited hardware.
Also, not setting up an effective CI/CD (continuous integration/ continuous deployment) structure for your ML solution is another mistake I see. Very often, a once-trained model won’t suffice not only because data changes over time but resources and personnel do as well. Today’s ML practitioner needs to:
1. secure consistent flow of data as it changes and continuously retrain new models to keep it accurate and useful,
2. ensure the structure is in place to allow for seamless replacement of older models by newly trained models while,
3. allowing for minimal disruption to the consumer of the ML model outputs.
#### **4. What excites you most about the future of ML?**
The future of ML continues to be exciting and seemingly every month there are advances reported in the field that even wow the experts to this day. As 1) ML techniques improve and become more accessible to established practitioners and novices alike, 2) everyday hardware becomes faster, 3) power consumption becomes less problematic for miniaturized edge devices, and 4) memory limitations diminish over time, the ceiling for ML in Engineering will be bright for years to come.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Samuel.png
"></a>
### [Samuel Franklin](https://www.linkedin.com/in/samuelcfranklin/) - Senior Director of Data Science & ML Engineering at [Pluralsight](https://www.pluralsight.com/)
**Background:** Samuel is a senior Data Science and ML Engineering leader at Pluralsight with a Ph.D. in cognitive science. He leads talented teams of Data Scientists and ML Engineers building intelligent services that power Pluralsight’s Skills platform.
Outside the virtual office, Dr. Franklin teaches Data Science and Machine Learning seminars for Emory University. He also serves as Chairman of the Board of Directors for the Atlanta Humane Society.
**Fun Fact:** I live in a log cabin on top of a mountain in the Appalachian range.
**Pluralsight:** We are a technology workforce development company and our Skills platform is used by 70% of the Fortune 500 to help their employees build business-critical tech skills.
#### **1. How has ML made a positive impact on Education?**
Online, on-demand educational content has made lifelong learning more accessible than ever for billions of people globally. Decades of cognitive research show that the relevance, format, and sequence of educational content significantly impact students’ success. Advances in deep learning content search and recommendation algorithms have greatly improved our ability to create customized, efficient learning paths at-scale that can adapt to individual student’s needs over time.
#### **2. What are the biggest ML challenges within Education?**
I see MLOps technology as a key opportunity area for improving ML across industries. The state of MLOps technology today reminds me of the Container Orchestration Wars circa 2015-16. There are competing visions for the ML Train-Deploy-Monitor stack, each evangelized by enthusiastic communities and supported by large organizations. If a predominant vision eventually emerges, then consensus on MLOps engineering patterns could follow, reducing the decision-making complexity that currently creates friction for ML teams.
#### **3. What’s a common mistake you see people make trying to integrate ML into existing products?**
There are two critical mistakes that I’ve seen organizations of all sizes make when getting started with ML. The first mistake is underestimating the importance of investing in senior leaders with substantial hands-on ML experience. ML strategy and operations leadership benefits from a depth of technical expertise beyond what is typically found in the BI / Analytics domain or provided by educational programs that offer a limited introduction to the field. The second mistake is waiting too long to design, test, and implement production deployment pipelines. Effective prototype models can languish in repos for months – even years – while waiting on ML pipeline development. This can impose significant opportunity costs on an organization and frustrate ML teams to the point of increasing attrition risk.
#### **4. What excites you most about the future of ML?**
I’m excited about the opportunity to mentor the next generation of ML leaders. My career began when cloud computing platforms were just getting started and ML tooling was much less mature than it is now. It was exciting to explore different engineering patterns for ML experimentation and deployment, since established best practices were rare. But, that exploration included learning too many technical and people leadership lessons the hard way. Sharing those lessons with the next generation of ML leaders will help empower them to advance the field farther and faster than what we’ve seen over the past 10+ years.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/evan.png"></a>
### [Evan Castle](https://www.linkedin.com/in/evan-castle-ai/) - Director of ML, Product Marketing, Elastic Stack at [Elastic](www.elastic.co)
**Background:** Over a decade of leadership experience in the intersection of data science, product, and strategy. Evan worked in various industries, from building risk models at Fortune 100s like Capital One to launching ML products at Sisense and Elastic.
**Fun Fact:** Met Paul McCarthy. 🎤
**MasterPeace Solutions:** MasterPeace Solutions has emerged as one of the fastest-growing advanced technology companies in the Mid-Atlantic region. The company designs and develops software, systems, solutions and products to solve some of the most pressing challenges facing the Intelligence Community.
#### **1. How has ML made a positive impact on SaaS?**
Machine learning has become truly operational in SaaS, powering multiple uses from personalization, semantic and image search, recommendations to anomaly detection, and a ton of other business scenarios. The real impact is that ML comes baked right into more and more applications. It's becoming an expectation and more often than not it's invisible to end users.
For example, at Elastic we invested in ML for anomaly detection, optimized for endpoint security and SIEM. It delivers some heavy firepower out of the box with an amalgamation of different techniques like time series decomposition, clustering, correlation analysis, and Bayesian distribution modeling. The big benefit for security analysts is threat detection is automated in many different ways. So anomalies are quickly bubbled up related to temporal deviations, unusual geographic locations, statistical rarity, and many other factors. That's the huge positive impact of integrating ML.
#### **2. What are the biggest ML challenges within SaaS?**
To maximize the benefits of ML there is a double challenge of delivering value to users that are new to machine learning and also to seasoned data scientists. There's obviously a huge difference in demands for these two folks. If an ML capability is a total black box it's likely to be too rigid or simple to have a real impact. On the other hand, if you solely deliver a developer toolkit it's only useful if you have a data science team in-house. Striking the right balance is about making sure ML is open enough for the data science team to have transparency and control over models and also packing in battle-tested models that are easy to configure and deploy without being a pro.
#### **3. What’s a common mistake you see people make trying to integrate ML into SaaS?**
To get it right, any integrated model has to work at scale, which means support for massive data sets while ensuring results are still performant and accurate. Let's illustrate this with a real example. There has been a surge in interest in vector search. All sorts of things can be represented in vectors from text, and images to events. Vectors can be used to capture similarities between content and are great for things like search relevance and recommendations. The challenge is developing algorithms that can compare vectors taking into account trade-offs in speed, complexity, and cost.
At Elastic, we spent a lot of time evaluating and benchmarking the performance of models for vector search. We decided on an approach for the approximate nearest neighbor (ANN) algorithm called Hierarchical Navigable Small World graphs (HNSW), which basically maps vectors into a
graph based on their similarity to each other. HNSW delivers an order of magnitude increase in speed and accuracy across a variety of ANN-benchmarks. This is just one example of non-trivial decisions more and more product and engineering teams need to take to successfully integrate ML into their products.
#### **4. What excites you most about the future of ML?**
Machine learning will become as simple as ordering online. The big advances in NLP especially have made ML more human by understanding context, intent, and meaning. I think we are in an era of foundational models that will blossom into many interesting directions. At Elastic we are thrilled with our own integration to Hugging Face and excited to already see how our customers are leveraging NLP for observability, security, and search.
---
🤗 Thank you for joining us in this fourth installment of ML Director Insights.
Big thanks to Javier Mansilla, Shaun Gittens, Samuel Franklin, and Evan Castle for their brilliant insights and participation in this piece. We look forward to watching your continued success and will be cheering you on each step of the way. 🎉
If you're' interested in accelerating your ML roadmap with Hugging Face Experts please visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) to learn more.
| huggingface/blog/blob/main/ml-director-insights-4.md |
`@gradio/html`
```javascript
import { BaseHTML } from "@gradio/html";
```
BaseHTML
```javascript
export let elem_id = "";
export let elem_classes: string[] = [];
export let value: string;
export let visible = true;
export let min_height = false;
``` | gradio-app/gradio/blob/main/js/html/README.md |
Task templates
<Tip warning={true}>
The Task API is deprecated in favor of [`train-eval-index`](https://github.com/huggingface/hub-docs/blob/9ab2555e1c146122056aba6f89af404a8bc9a6f1/datasetcard.md?plain=1#L90-L106) and will be removed in the next major release.
</Tip>
The tasks supported by [`Dataset.prepare_for_task`] and [`DatasetDict.prepare_for_task`].
[[autodoc]] datasets.tasks.AutomaticSpeechRecognition
[[autodoc]] datasets.tasks.AudioClassification
[[autodoc]] datasets.tasks.ImageClassification
- align_with_features
[[autodoc]] datasets.tasks.LanguageModeling
[[autodoc]] datasets.tasks.QuestionAnsweringExtractive
[[autodoc]] datasets.tasks.Summarization
[[autodoc]] datasets.tasks.TextClassification
- align_with_features
| huggingface/datasets/blob/main/docs/source/package_reference/task_templates.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# aMUSEd
Amused is a lightweight text to image model based off of the [muse](https://arxiv.org/pdf/2301.00704.pdf) architecture. Amused is particularly useful in applications that require a lightweight and fast model such as generating many images quickly at once.
Amused is a vqvae token based transformer that can generate an image in fewer forward passes than many diffusion models. In contrast with muse, it uses the smaller text encoder CLIP-L/14 instead of t5-xxl. Due to its small parameter count and few forward pass generation process, amused can generate many images quickly. This benefit is seen particularly at larger batch sizes.
| Model | Params |
|-------|--------|
| [amused-256](https://huggingface.co/huggingface/amused-256) | 603M |
| [amused-512](https://huggingface.co/huggingface/amused-512) | 608M |
## AmusedPipeline
[[autodoc]] AmusedPipeline
- __call__
- all
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention | huggingface/diffusers/blob/main/docs/source/en/api/pipelines/amused.md |
Explore statistics over split data
Datasets Server provides a `/statistics` endpoint for fetching some basic statistics precomputed for a requested dataset. This will get you a quick insight on how the data is distributed.
<Tip warning={true}>
Currently, statistics are computed only for <a href="./parquet">datasets with Parquet exports</a>.
</Tip>
The `/statistics` endpoint requires three query parameters:
- `dataset`: the dataset name, for example `glue`
- `config`: the configuration name, for example `cola`
- `split`: the split name, for example `train`
Let's get some stats for `glue` dataset, `cola` config, `train` split:
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/statistics?dataset=glue&config=cola&split=train"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/statistics?dataset=glue&config=cola&split=train",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/statistics?dataset=glue&config=cola&split=train \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
The response JSON contains two keys:
* `num_examples` - number of samples in a split
* `statistics` - list of dictionaries of statistics per each column, each dictionary has three keys: `column_name`, `column_type`, and `column_statistics`. Content of `column_statistics` depends on a column type, see [Response structure by data types](./statistics#response-structure-by-data-type) for more details
```json
{
"num_examples": 8551,
"statistics": [
{
"column_name": "idx",
"column_type": "int",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0,
"min": 0,
"max": 8550,
"mean": 4275,
"median": 4275,
"std": 2468.60541,
"histogram": {
"hist": [
856,
856,
856,
856,
856,
856,
856,
856,
856,
847
],
"bin_edges": [
0,
856,
1712,
2568,
3424,
4280,
5136,
5992,
6848,
7704,
8550
]
}
}
},
{
"column_name": "label",
"column_type": "class_label",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0,
"no_label_count": 0,
"no_label_proportion": 0,
"n_unique": 2,
"frequencies": {
"unacceptable": 2528,
"acceptable": 6023
}
}
},
{
"column_name": "sentence",
"column_type": "string_text",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0,
"min": 6,
"max": 231,
"mean": 40.70074,
"median": 37,
"std": 19.14431,
"histogram": {
"hist": [
2260,
4512,
1262,
380,
102,
26,
6,
1,
1,
1
],
"bin_edges": [
6,
29,
52,
75,
98,
121,
144,
167,
190,
213,
231
]
}
}
}
]
}
```
## Response structure by data type
Currently, statistics are supported for strings, float and integer numbers, and the special [`datasets.ClassLabel`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.ClassLabel) feature type of the [`datasets`](https://huggingface.co/docs/datasets/) library.
`column_type` in response can be one of the following values:
* `class_label` - for [`datasets.ClassLabel`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.ClassLabel) feature
* `float` - for float dtypes
* `int` - for integer dtypes
* `bool` - for boolean dtype
* `string_label` - for string dtypes, if there are less than or equal to 30 unique values in a string column in a given split
* `string_text` - for string dtypes, if there are more than 30 unique values in a string column in a given split
### `class_label`
This type represents categorical data encoded as [`ClassLabel`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.ClassLabel) feature. The following measures are computed:
* number and proportion of `null` values
* number and proportion of values with no label
* number of unique values (excluding `null` and `no label`)
* value counts for each label (excluding `null` and `no label`)
<details><summary>Example </summary>
<p>
```json
{
"column_name": "label",
"column_type": "class_label",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0,
"no_label_count": 0,
"no_label_proportion": 0,
"n_unique": 2,
"frequencies": {
"unacceptable": 2528,
"acceptable": 6023
}
}
}
```
</p>
</details>
### float
The following measures are returned for float data types:
* minimum, maximum, mean, and standard deviation values
* number and proportion of `null` values
* histogram with 10 bins
<details><summary>Example </summary>
<p>
```json
{
"column_name": "clarity",
"column_type": "float",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0,
"min": 0,
"max": 2,
"mean": 1.67206,
"median": 1.8,
"std": 0.38714,
"histogram": {
"hist": [
17,
12,
48,
52,
135,
188,
814,
15,
1628,
2048
],
"bin_edges": [
0,
0.2,
0.4,
0.6,
0.8,
1,
1.2,
1.4,
1.6,
1.8,
2
]
}
}
}
```
</p>
</details>
### int
The following measures are returned for integer data types:
* minimum, maximum, mean, and standard deviation values
* number and proportion of `null` values
* histogram with less than or equal to 10 bins
<details><summary>Example </summary>
<p>
```json
{
"column_name": "direction",
"column_type": "int",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0.0,
"min": 0,
"max": 1,
"mean": 0.49925,
"median": 0.0,
"std": 0.5,
"histogram": {
"hist": [
50075,
49925
],
"bin_edges": [
0,
1,
1
]
}
}
}
```
</p>
</details>
### bool
The following measures are returned for bool data type:
* number and proportion of `null` values
* value counts for `'True'` and `'False'` values
<details><summary>Example </summary>
<p>
```json
{
"column_name": "penalty",
"column_type": "bool",
"column_statistics":
{
"nan_count": 3,
"nan_proportion": 0.15,
"frequencies": {
"False": 7,
"True": 10
}
}
}
```
</p>
</details>
### string_label
If string column has less than or equal to 30 unique values within the requested split, it is considered to be a category. The following measures are returned:
* number and proportion of `null` values
* number of unique values (excluding `null`)
* value counts for each label (excluding `null`)
<details><summary>Example </summary>
<p>
```json
{
"column_name": "answerKey",
"column_type": "string_label",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0,
"n_unique": 4,
"frequencies": {
"D": 1221,
"C": 1146,
"A": 1378,
"B": 1212
}
}
}
```
</p>
</details>
### string_text
If string column has more than 30 unique values within the requested split, it is considered to be a column containing texts and response contains statistics over text lengths. The following measures are computed:
* minimum, maximum, mean, and standard deviation of text lengths
* number and proportion of `null` values
* histogram of text lengths with 10 bins
<details><summary>Example </summary>
<p>
```json
{
"column_name": "sentence",
"column_type": "string_text",
"column_statistics": {
"nan_count": 0,
"nan_proportion": 0,
"min": 6,
"max": 231,
"mean": 40.70074,
"median": 37,
"std": 19.14431,
"histogram": {
"hist": [
2260,
4512,
1262,
380,
102,
26,
6,
1,
1,
1
],
"bin_edges": [
6,
29,
52,
75,
98,
121,
144,
167,
190,
213,
231
]
}
}
}
```
</p>
</details> | huggingface/datasets-server/blob/main/docs/source/statistics.mdx |
Object detection
Object detection models identify something in an image, and object detection datasets are used for applications such as autonomous driving and detecting natural hazards like wildfire. This guide will show you how to apply transformations to an object detection dataset following the [tutorial](https://albumentations.ai/docs/examples/example_bboxes/) from [Albumentations](https://albumentations.ai/docs/).
To run these examples, make sure you have up-to-date versions of `albumentations` and `cv2` installed:
```
pip install -U albumentations opencv-python
```
In this example, you'll use the [`cppe-5`](https://huggingface.co/datasets/cppe-5) dataset for identifying medical personal protective equipment (PPE) in the context of the COVID-19 pandemic.
Load the dataset and take a look at an example:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset("cppe-5")
>>> example = ds['train'][0]
>>> example
{'height': 663,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=943x663 at 0x7FC3DC756250>,
'image_id': 15,
'objects': {'area': [3796, 1596, 152768, 81002],
'bbox': [[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]],
'category': [4, 4, 0, 0],
'id': [114, 115, 116, 117]},
'width': 943}
```
The dataset has the following fields:
- `image`: PIL.Image.Image object containing the image.
- `image_id`: The image ID.
- `height`: The image height.
- `width`: The image width.
- `objects`: A dictionary containing bounding box metadata for the objects in the image:
- `id`: The annotation id.
- `area`: The area of the bounding box.
- `bbox`: The object's bounding box (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format).
- `category`: The object's category, with possible values including `Coverall (0)`, `Face_Shield (1)`, `Gloves (2)`, `Goggles (3)` and `Mask (4)`.
You can visualize the `bboxes` on the image using some internal torch utilities. To do that, you will need to reference the [`~datasets.ClassLabel`] feature associated with the category IDs so you can look up the string labels:
```py
>>> import torch
>>> from torchvision.ops import box_convert
>>> from torchvision.utils import draw_bounding_boxes
>>> from torchvision.transforms.functional import pil_to_tensor, to_pil_image
>>> categories = ds['train'].features['objects'].feature['category']
>>> boxes_xywh = torch.tensor(example['objects']['bbox'])
>>> boxes_xyxy = box_convert(boxes_xywh, 'xywh', 'xyxy')
>>> labels = [categories.int2str(x) for x in example['objects']['category']]
>>> to_pil_image(
... draw_bounding_boxes(
... pil_to_tensor(example['image']),
... boxes_xyxy,
... colors="red",
... labels=labels,
... )
... )
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/visualize_detection_example.png">
</div>
With `albumentations`, you can apply transforms that will affect the image while also updating the `bboxes` accordingly. In this case, the image is resized to (480, 480), flipped horizontally, and brightened.
```py
>>> import albumentations
>>> import numpy as np
>>> transform = albumentations.Compose([
... albumentations.Resize(480, 480),
... albumentations.HorizontalFlip(p=1.0),
... albumentations.RandomBrightnessContrast(p=1.0),
... ], bbox_params=albumentations.BboxParams(format='coco', label_fields=['category']))
>>> image = np.array(example['image'])
>>> out = transform(
... image=image,
... bboxes=example['objects']['bbox'],
... category=example['objects']['category'],
... )
```
Now when you visualize the result, the image should be flipped, but the `bboxes` should still be in the right places.
```py
>>> image = torch.tensor(out['image']).permute(2, 0, 1)
>>> boxes_xywh = torch.stack([torch.tensor(x) for x in out['bboxes']])
>>> boxes_xyxy = box_convert(boxes_xywh, 'xywh', 'xyxy')
>>> labels = [categories.int2str(x) for x in out['category']]
>>> to_pil_image(
... draw_bounding_boxes(
... image,
... boxes_xyxy,
... colors='red',
... labels=labels
... )
... )
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/visualize_detection_example_transformed.png">
</div>
Create a function to apply the transform to a batch of examples:
```py
>>> def transforms(examples):
... images, bboxes, categories = [], [], []
... for image, objects in zip(examples['image'], examples['objects']):
... image = np.array(image.convert("RGB"))
... out = transform(
... image=image,
... bboxes=objects['bbox'],
... category=objects['category']
... )
... images.append(torch.tensor(out['image']).permute(2, 0, 1))
... bboxes.append(torch.tensor(out['bboxes']))
... categories.append(out['category'])
... return {'image': images, 'bbox': bboxes, 'category': categories}
```
Use the [`~Dataset.set_transform`] function to apply the transform on-the-fly which consumes less disk space. The randomness of data augmentation may return a different image if you access the same example twice. It is especially useful when training a model for several epochs.
```py
>>> ds['train'].set_transform(transforms)
```
You can verify the transform works by visualizing the 10th example:
```py
>>> example = ds['train'][10]
>>> to_pil_image(
... draw_bounding_boxes(
... example['image'],
... box_convert(example['bbox'], 'xywh', 'xyxy'),
... colors='red',
... labels=[categories.int2str(x) for x in example['category']]
... )
... )
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/visualize_detection_example_transformed_2.png">
</div>
<Tip>
Now that you know how to process a dataset for object detection, learn
[how to train an object detection model](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/YOLOS/Fine_tuning_YOLOS_for_object_detection_on_custom_dataset_(balloon).ipynb)
and use it for inference.
</Tip>
| huggingface/datasets/blob/main/docs/source/object_detection.mdx |
RexNet
**Rank Expansion Networks** (ReXNets) follow a set of new design principles for designing bottlenecks in image classification models. Authors refine each layer by 1) expanding the input channel size of the convolution layer and 2) replacing the [ReLU6s](https://www.paperswithcode.com/method/relu6).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('rexnet_100', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `rexnet_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('rexnet_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{han2020rexnet,
title={ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network},
author={Dongyoon Han and Sangdoo Yun and Byeongho Heo and YoungJoon Yoo},
year={2020},
eprint={2007.00992},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: RexNet
Paper:
Title: 'ReXNet: Diminishing Representational Bottleneck on Convolutional Neural
Network'
URL: https://paperswithcode.com/paper/rexnet-diminishing-representational
Models:
- Name: rexnet_100
In Collection: RexNet
Metadata:
FLOPs: 509989377
Parameters: 4800000
File Size: 19417552
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_100
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L212
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_100-1b4dddf4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.86%
Top 5 Accuracy: 93.88%
- Name: rexnet_130
In Collection: RexNet
Metadata:
FLOPs: 848364461
Parameters: 7560000
File Size: 30508197
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_130
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L218
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_130-590d768e.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 79.49%
Top 5 Accuracy: 94.67%
- Name: rexnet_150
In Collection: RexNet
Metadata:
FLOPs: 1122374469
Parameters: 9730000
File Size: 39227315
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_150
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L224
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_150-bd1a6aa8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.31%
Top 5 Accuracy: 95.16%
- Name: rexnet_200
In Collection: RexNet
Metadata:
FLOPs: 1960224938
Parameters: 16370000
File Size: 65862221
Architecture:
- Batch Normalization
- Convolution
- Dropout
- ReLU6
- Residual Connection
Tasks:
- Image Classification
Training Techniques:
- Label Smoothing
- Linear Warmup With Cosine Annealing
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
Training Resources: 4x NVIDIA V100 GPUs
ID: rexnet_200
LR: 0.5
Epochs: 400
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 512
Image Size: '224'
Weight Decay: 1.0e-05
Interpolation: bicubic
Label Smoothing: 0.1
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/rexnet.py#L230
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-rexnet/rexnetv1_200-8c0b7f2d.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.63%
Top 5 Accuracy: 95.67%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/rexnet.mdx |
!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={9}
classNames="absolute z-10 right-0 top-0"
/>
Let's test what you learned in this chapter!
### 1. What can you use Gradio to do?
<Question
choices={[
{
text: "Create a demo for your machine learning model",
explain: "With a few lines of python code you can generate a demo for your ML model using our library of pre-built components.",
correct: true
},
{
text: "Share your machine learning model with others",
explain: "Using the <code>share=True</code> parameter in the launch method, you can generate a share link to send to anyone.",
correct: true
},
{
text: "Debug your model",
explain: "One advantage of a gradio demo is being able to test your model with real data which you can change and observe the model's predictions change in real time, helping you debug your model.",
correct: true
},
{
text: "Train your model",
explain: "Gradio is designed to be used for model inference, AFTER your model is trained.",
}
]}
/>
### 2. Gradio ONLY works with PyTorch models
<Question
choices={[
{
text: "True",
explain: "Gradio works with PyTorch models, but also works for any type of machine learning model!"
},
{
text: "False",
explain: "Gradio is model agnostic, meaning you can create a demo for any type of machine learning model.",
correct: true
}
]}
/>
### 3. Where can you launch a Gradio demo from?
<Question
choices={[
{
text: "Standard python IDEs",
explain: "Gradio works great with your favorite IDE.",
correct: true
},
{
text: "Google Colab notebooks",
explain: "You can create and launch a demo within your Google colab notebook.",
correct: true
},
{
text: "Jupyter notebooks",
explain: "Good choice - You can create and launch a demo within your Jupyter notebook.",
correct: true
}
]}
/>
### 4. Gradio is designed primarily for NLP models
<Question
choices={[
{
text: "True",
explain: "Gradio works with pretty much any data type, not just NLP."
},
{
text: "False",
explain: "Gradio supplies developers with a library of pre-built components for pretty much all data types.",
correct: true
}
]}
/>
### 5. Which of the following features are supported by Gradio?
<Question
choices={[
{
text: "Multiple inputs and outputs",
explain: "Multiple inputs and outputs is possible with gradio. All you need to do is pass in a list of inputs and outputs to their corresponding parameters",
correct: true
},
{
text: "State for data persistance",
explain: "Gradio is capable of adding state to your interface.",
correct: true
},
{
text: "Username and passwords authentication",
explain: "Pass in a list of username/password tuples to the launch method to add authentication.",
correct: true
},
{
text: "Automatic analytics for who uses your gradio demo",
explain: "Try again - Gradio does not supply developers analytics on who uses their demos."
},
{
text: "Loading a model from Hugging Face's model hub or Hugging Face Spaces",
explain: "Absolutely - load any Hugging Face model using the <code>gr.Interface.load()</code> method",
correct: true
}
]}
/>
### 6. Which of the following are valid ways of loading a Hugging Face model from Hub or Spaces?
<Question
choices={[
{
text: "gr.Interface.load('huggingface/{user}/{model_name}')",
explain: "This is a valid method of loading a Hugging Face model from the Hub",
correct: true
},
{
text: "gr.Interface.load('model/{user}/{model_name}')",
explain: "This is a valid method of loading a Hugging Face model from the Hub",
correct: true
},
{
text: "gr.Interface.load('demos/{user}/{model_name}')",
explain: "Try again -- you cannot load a model by using the 'demos' prefix."
},
{
text: "gr.Interface.load('spaces/{user}/{model_name}')",
explain: "This is a valid method of loading a Hugging Face model from Spaces",
correct: true
}
]}
/>
### 7. Select all the steps necessary for adding state to your Gradio interface
<Question
choices={[
{
text: "Pass in an extra parameter into your prediction function, which represents the state of the interface.",
explain: "An extra parameter storing history or state of your interface is necessary.",
correct: true
},
{
text: "At the end of the prediction function, return the updated value of the state as an extra return value.",
explain: "This history or state value needs to be returned by your function.",
correct: true
},
{
text: "Add the state input and state output components when creating your Interface",
explain: "Gradio provides a state input and output component to persist data.",
correct: true
}
]}
/>
### 8. Which of the following are components included in the Gradio library?
<Question
choices={[
{
text: "Textbox.",
explain: "Yes, you can create textboxes with the Textbox component.",
correct: true
},
{
text: "Graph.",
explain: "There is currently no Graph component.",
},
{
text: "Image.",
explain: "Yes, you can create an image upload widget with the Image component.",
correct: true
},
{
text: "Audio.",
explain: "Yes, you can create an audio upload widget with the Audio component.",
correct: true
},
]}
/>
### 9. What does Gradio `Blocks` allow you to do?
<Question
choices={[
{
text: "Combine multiple demos into one web app",
explain: "You can use the `with gradio.Tabs():` to add tabs for multiple demos",
correct: true
},
{
text: "Assign event triggers such as clicked/changed/etc to `Blocks` components",
explain: "When you assign an event, you pass in three parameters: fn: the function that should be called, inputs: the (list) of input component(s), and outputs: the (list) of output components that should be called.",
correct: true
},
{
text: "Automatically determine which `Blocks` component should be interactive vs. static",
explain: "Based on the event triggers you define, `Blocks` automatically figures out whether a component should accept user input or not.",
correct: true
},
{
text: "Create multi-step demos; meaning allowing you to reuse the output of one component as the input to the next",
explain: "You can use a component for the input of one event trigger but the output of another.",
correct: true
},
]}
/>
### 10. You can share a public link to a `Blocks` demo and host a `Blocks` demo on Hugging Face spaces.
<Question
choices={[
{
text: "True",
explain: "Just like `Interface`, all of the sharing and hosting capabilities are the same for `Blocks` demos!",
correct: true
},
{
text: "False",
explain: "Just like `Interface`, all of the sharing and hosting capabilities are the same for `Blocks` demos!",
correct: false
}
]}
/> | huggingface/course/blob/main/chapters/en/chapter9/9.mdx |
--
title: "Panel on Hugging Face"
thumbnail: /blog/assets/panel-on-hugging-face/thumbnail.png
authors:
- user: philippjfr
guest: true
- user: sophiamyang
guest: true
---
# Panel on Hugging Face
We are thrilled to announce the collaboration between Panel and Hugging Face! 🎉 We have integrated a Panel template in Hugging Face Spaces to help you get started building Panel apps and deploy them on Hugging Face effortlessly.
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/raw/main/deploy-to-spaces-lg.svg"/> </a>
## What does Panel offer?
[Panel](https://panel.holoviz.org/) is an open-source Python library that lets you easily build powerful tools, dashboards and complex applications entirely in Python. It has a batteries-included philosophy, putting the PyData ecosystem, powerful data tables and much more at your fingertips. High-level reactive APIs and lower-level callback based APIs ensure you can quickly build exploratory applications, but you aren’t limited if you build complex, multi-page apps with rich interactivity. Panel is a member of the [HoloViz](https://holoviz.org/) ecosystem, your gateway into a connected ecosystem of data exploration tools. Panel, like the other HoloViz tools, is a NumFocus-sponsored project, with support from Anaconda and Blackstone.
Here are some notable features of Panel that our users find valuable.
- Panel provides extensive support for various plotting libraries, such as Matplotlib, Seaborn, Altair, Plotly, Bokeh, PyDeck,Vizzu, and more.
- All interactivity works the same in Jupyter and in a standalone deployment. Panel allows seamless integration of components from a Jupyter notebook into a dashboard, enabling smooth transitions between data exploration and sharing results.
- Panel empowers users to build complex multi-page applications, advanced interactive features, visualize large datasets, and stream real-time data.
- Integration with Pyodide and WebAssembly enables seamless execution of Panel applications in web browsers.
Ready to build Panel apps on Hugging Face? Check out our [Hugging Face deployment docs](https://panel.holoviz.org/how_to/deployment/huggingface.html#hugging-face), click this button, and begin your journey:
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template"> <img src="https://huggingface.co/datasets/huggingface/badges/raw/main/deploy-to-spaces-lg.svg"/> </a>
<a href="https://huggingface.co/new-space?template=Panel-Org/panel-template">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-panel.png" style="width:70%"> </a>
## 🌐 Join Our Community
The Panel community is vibrant and supportive, with experienced developers and data scientists eager to help and share their knowledge. Join us and connect with us:
- [Discord](https://discord.gg/aRFhC3Dz9w)
- [Discourse](https://discourse.holoviz.org/)
- [Twitter](https://twitter.com/Panel_Org)
- [LinkedIn](https://www.linkedin.com/company/panel-org)
- [Github](https://github.com/holoviz/panel)
| huggingface/blog/blob/main/panel-on-hugging-face.md |
Gradio Demo: hello_world
### The simplest possible Gradio demo. It wraps a 'Hello {name}!' function in an Interface that accepts and returns text.
```
!pip install -q gradio
```
```
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="textbox", outputs="textbox")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/hello_world/run.ipynb |
--
title: "Diffusion Models Live Event"
thumbnail: /blog/assets/diffusion-models-event/thumbnail.png
authors:
- user: lewtun
- user: johnowhitaker
---
# Diffusion Models Live Event
We are excited to share that the [Diffusion Models Class](https://github.com/huggingface/diffusion-models-class) with Hugging Face and Jonathan Whitaker will be **released on November 28th** 🥳! In this free course, you will learn all about the theory and application of diffusion models -- one of the most exciting developments in deep learning this year. If you've never heard of diffusion models, here's a demo to give you a taste of what they can do:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.6/gradio.js "></script>
<gradio-app theme_mode="light" space="runwayml/stable-diffusion-v1-5"></gradio-app>
To go with this release, we are organising a **live community event on November 30th** to which you are invited! The program includes exciting talks from the creators of Stable Diffusion, researchers at Stability AI and Meta, and more!
To register, please fill out [this form](http://eepurl.com/icSzXv). More details on the speakers and talks are provided below.
## Live Talks
The talks will focus on a high-level presentation of diffusion models and the tools we can use to build applications with them.
<div
class="container md:grid md:grid-cols-2 gap-2 max-w-7xl"
>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/david-ha.png" width=50% style="border-radius: 50%;">
<p><strong>David Ha: <em>Collective Intelligence and Creative AI</em></strong></p>
<p>David Ha is the Head of Strategy at Stability AI. He previously worked as a Research Scientist at Google, working in the Brain team in Japan. His research interests include complex systems, self-organization, and creative applications of machine learning. Prior to joining Google, He worked at Goldman Sachs as a Managing Director, where he co-ran the fixed-income trading business in Japan. He obtained undergraduate and masters degrees from the University of Toronto, and a PhD from the University of Tokyo.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/devi-parikh.png" width=50% style="border-radius: 50%;">
<p><strong>Devi Parikh: <em>Make-A-Video: Diffusion Models for Text-to-Video Generation without Text-Video Data</em></strong></p>
<p>Devi Parikh is a Research Director at the Fundamental AI Research (FAIR) lab at Meta, and an Associate Professor in the School of Interactive Computing at Georgia Tech. She has held visiting positions at Cornell University, University of Texas at Austin, Microsoft Research, MIT, Carnegie Mellon University, and Facebook AI Research. She received her M.S. and Ph.D. degrees from the Electrical and Computer Engineering department at Carnegie Mellon University in 2007 and 2009 respectively. Her research interests are in computer vision, natural language processing, embodied AI, human-AI collaboration, and AI for creativity.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/patrick-esser.png" width=50% style="border-radius: 50%;">
<p><strong>Patrick Esser: <em>Food for Diffusion</em></strong></p>
<p>Patrick Esser is a Principal Research Scientist at Runway, leading applied research efforts including the core model behind Stable Diffusion, otherwise known as High-Resolution Image Synthesis with Latent Diffusion Models.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/justin-pinkey.png" width=50% style="border-radius: 50%;">
<p><strong>Justin Pinkney: <em>Beyond text - giving Stable Diffusion new abilities</em></strong></p>
<p>Justin is a Senior Machine Learning Researcher at Lambda Labs working on image generation and editing, particularly for artistic and creative applications. He loves to play and tweak pre-trained models to add new capabilities to them, and is probably best known for models like: Toonify, Stable Diffusion Image Variations, and Text-to-Pokemon.</p>
</div>
<div class="text-center flex flex-col items-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/diffusion-models-event/poli.png" width=50% style="border-radius: 50%;">
<p><strong>Apolinário Passos: <em>DALL-E 2 is cool but... what will come after the generative media hype?</em></strong></p>
<p>Apolinário Passos is a Machine Learning Art Engineer at Hugging Face and an artist who focuses on generative art and generative media. He founded the platform multimodal.art and the corresponding Twitter account, and works on the organization, aggregation, and platformization of open-source generative media machine learning models.</p>
</div>
</div>
| huggingface/blog/blob/main/diffusion-models-event.md |
Gradio Demo: ner_pipeline
```
!pip install -q gradio torch transformers
```
```
from transformers import pipeline
import gradio as gr
ner_pipeline = pipeline("ner")
examples = [
"Does Chicago have any stores and does Joe live here?",
]
def ner(text):
output = ner_pipeline(text)
return {"text": text, "entities": output}
demo = gr.Interface(ner,
gr.Textbox(placeholder="Enter sentence here..."),
gr.HighlightedText(),
examples=examples)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/ner_pipeline/run.ipynb |
接口状态 (Interface State)
本指南介绍了 Gradio 中如何处理状态。了解全局状态和会话状态的区别,以及如何同时使用它们。
## 全局状态 (Global State)
您的函数可能使用超出单个函数调用的持久性数据。如果数据是所有函数调用和所有用户都可访问的内容,您可以在函数调用外部创建一个变量,并在函数内部访问它。例如,您可能会在函数外部加载一个大模型,并在函数内部使用它,以便每个函数调用都不需要重新加载模型。
$code_score_tracker
在上面的代码中,'scores' 数组在所有用户之间共享。如果多个用户访问此演示,他们的得分将全部添加到同一列表中,并且返回的前 3 个得分将从此共享引用中收集。
## 全局状态 (Global State)
Gradio 支持的另一种数据持久性是会话状态,其中数据在页面会话中的多个提交之间持久存在。但是,不同用户之间的数据*不*共享。要将数据存储在会话状态中,需要执行以下三个步骤:
1. 将额外的参数传递给您的函数,表示接口的状态。
2. 在函数的末尾,作为额外的返回值返回状态的更新值。
3. 在创建界面时添加 `'state'` 输入和 `'state'` 输出组件。
聊天机器人就是需要会话状态的一个例子 - 您希望访问用户之前的提交,但不能将聊天记录存储在全局变量中,因为这样聊天记录会在不同用户之间混乱。
$code_chatbot_dialogpt
$demo_chatbot_dialogpt
请注意,在每个页面中,状态在提交之间保持不变,但是如果在另一个标签中加载此演示(或刷新页面),演示将不共享聊天记录。
`state` 的默认值为 None。如果您将默认值传递给函数的状态参数,则该默认值将用作状态的默认值。`Interface` 类仅支持单个输入和输出状态变量,但可以是具有多个元素的列表。对于更复杂的用例,您可以使用 Blocks,[它支持多个 `State` 变量](/state_in_blocks/)。
| gradio-app/gradio/blob/main/guides/cn/02_building-interfaces/01_interface-state.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPU inference
GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia and AMD GPUs.
<Tip>
The majority of the optimizations described here also apply to multi-GPU setups!
</Tip>
## FlashAttention-2
<Tip>
FlashAttention-2 is experimental and may change considerably in future versions.
</Tip>
[FlashAttention-2](https://huggingface.co/papers/2205.14135) is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by:
1. additionally parallelizing the attention computation over sequence length
2. partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
FlashAttention-2 is currently supported for the following architectures:
* [Bark](https://huggingface.co/docs/transformers/model_doc/bark#transformers.BarkModel)
* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
* [DistilBert](https://huggingface.co/docs/transformers/model_doc/distilbert#transformers.DistilBertModel)
* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
* [GPTNeo](https://huggingface.co/docs/transformers/model_doc/gpt_neo#transformers.GPTNeoModel)
* [GPTNeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox#transformers.GPTNeoXModel)
* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
* [Llava](https://huggingface.co/docs/transformers/model_doc/llava)
* [VipLlava](https://huggingface.co/docs/transformers/model_doc/vipllava)
* [MBart](https://huggingface.co/docs/transformers/model_doc/mbart#transformers.MBartModel)
* [Mistral](https://huggingface.co/docs/transformers/model_doc/mistral#transformers.MistralModel)
* [Mixtral](https://huggingface.co/docs/transformers/model_doc/mixtral#transformers.MixtralModel)
* [OPT](https://huggingface.co/docs/transformers/model_doc/opt#transformers.OPTModel)
* [Phi](https://huggingface.co/docs/transformers/model_doc/phi#transformers.PhiModel)
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
Before you begin, make sure you have FlashAttention-2 installed.
<hfoptions id="install">
<hfoption id="NVIDIA">
```bash
pip install flash-attn --no-build-isolation
```
We strongly suggest referring to the detailed [installation instructions](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features) to learn more about supported hardware and data types!
</hfoption>
<hfoption id="AMD">
FlashAttention-2 is also supported on AMD GPUs and current support is limited to **Instinct MI210** and **Instinct MI250**. We strongly suggest using this [Dockerfile](https://github.com/huggingface/optimum-amd/tree/main/docker/transformers-pytorch-amd-gpu-flash/Dockerfile) to use FlashAttention-2 on AMD GPUs.
</hfoption>
</hfoptions>
To enable FlashAttention-2, pass the argument `attn_implementation="flash_attention_2"` to [`~AutoModelForCausalLM.from_pretrained`]:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
```
<Tip>
FlashAttention-2 can only be used when the model's dtype is `fp16` or `bf16`. Make sure to cast your model to the appropriate dtype and load them on a supported device before using FlashAttention-2.
<br>
You can also set `use_flash_attention_2=True` to enable FlashAttention-2 but it is deprecated in favor of `attn_implementation="flash_attention_2"`.
</Tip>
FlashAttention-2 can be combined with other optimization techniques like quantization to further speedup inference. For example, you can combine FlashAttention-2 with 8-bit or 4-bit quantization:
```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
```
### Expected speedups
You can benefit from considerable speedups for inference, especially for inputs with long sequences. However, since FlashAttention-2 does not support computing attention scores with padding tokens, you must manually pad/unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
To overcome this, you should use FlashAttention-2 without padding tokens in the sequence during training (by packing a dataset or [concatenating sequences](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py#L516) until reaching the maximum sequence length).
For a single forward pass on [tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b) with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/falcon-7b-inference-large-seqlen.png">
</div>
For a single forward pass on [meta-llama/Llama-7b-hf](https://hf.co/meta-llama/Llama-7b-hf) with a sequence length of 4096 and various batch sizes without padding tokens, the expected speedup is:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/llama-7b-inference-large-seqlen.png">
</div>
For sequences with padding tokens (generating with padding tokens), you need to unpad/pad the input sequences to correctly compute the attention scores. With a relatively small sequence length, a single forward pass creates overhead leading to a small speedup (in the example below, 30% of the input is filled with padding tokens):
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/llama-2-small-seqlen-padding.png">
</div>
But for larger sequence lengths, you can expect even more speedup benefits:
<Tip>
FlashAttention is more memory efficient, meaning you can train on much larger sequence lengths without running into out-of-memory issues. You can potentially reduce memory usage up to 20x for larger sequence lengths. Take a look at the [flash-attention](https://github.com/Dao-AILab/flash-attention) repository for more details.
</Tip>
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/llama-2-large-seqlen-padding.png">
</div>
## PyTorch scaled dot product attention
PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for `torch>=2.1.1` when an implementation is available.
For now, Transformers supports SDPA inference and training for the following architectures:
* [Bart](https://huggingface.co/docs/transformers/model_doc/bart#transformers.BartModel)
* [GPTBigCode](https://huggingface.co/docs/transformers/model_doc/gpt_bigcode#transformers.GPTBigCodeModel)
* [Falcon](https://huggingface.co/docs/transformers/model_doc/falcon#transformers.FalconModel)
* [Llama](https://huggingface.co/docs/transformers/model_doc/llama#transformers.LlamaModel)
* [Idefics](https://huggingface.co/docs/transformers/model_doc/idefics#transformers.IdeficsModel)
* [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperModel)
<Tip>
FlashAttention can only be used for models with the `fp16` or `bf16` torch type, so make sure to cast your model to the appropriate type first.
</Tip>
By default, SDPA selects the most performant kernel available but you can check whether a backend is available in a given setting (hardware, problem size) with [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
```diff
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
# convert the model to BetterTransformer
model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
If you see a bug with the traceback below, try using the nightly version of PyTorch which may have broader coverage for FlashAttention:
```bash
RuntimeError: No available kernel. Aborting execution.
# install PyTorch nightly
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
```
## BetterTransformer
<Tip warning={true}>
Some BetterTransformer features are being upstreamed to Transformers with default support for native `torch.nn.scaled_dot_product_attention`. BetterTransformer still has a wider coverage than the Transformers SDPA integration, but you can expect more and more architectures to natively support SDPA in Transformers.
</Tip>
<Tip>
Check out our benchmarks with BetterTransformer and scaled dot product attention in the [Out of the box acceleration and memory savings of 🤗 decoder models with PyTorch 2.0](https://pytorch.org/blog/out-of-the-box-acceleration/) and learn more about the fastpath execution in the [BetterTransformer](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2) blog post.
</Tip>
BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention (SDPA)](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention), and it calls optimized kernels like [FlashAttention](https://huggingface.co/papers/2205.14135) under the hood.
Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
Then you can enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
```python
model = model.to_bettertransformer()
```
You can return the original Transformers model with the [`~PreTrainedModel.reverse_bettertransformer`] method. You should use this before saving your model to use the canonical Transformers modeling:
```py
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")
```
## bitsandbytes
bitsandbytes is a quantization library that includes support for 4-bit and 8-bit quantization. Quantization reduces your model size compared to its native full precision version, making it easier to fit large models onto GPUs with limited memory.
Make sure you have bitsandbytes and 🤗 Accelerate installed:
```bash
# these versions support 8-bit and 4-bit
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
# install Transformers
pip install transformers
```
### 4-bit
To load a model in 4-bit for inference, use the `load_in_4bit` parameter. The `device_map` parameter is optional, but we recommend setting it to `"auto"` to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment.
```py
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
```
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 600MB of memory to the first GPU and 1GB of memory to the second GPU:
```py
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)
```
### 8-bit
<Tip>
If you're curious and interested in learning more about the concepts underlying 8-bit quantization, read the [Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes](https://huggingface.co/blog/hf-bitsandbytes-integration) blog post.
</Tip>
To load a model in 8-bit for inference, use the `load_in_8bit` parameter. The `device_map` parameter is optional, but we recommend setting it to `"auto"` to allow 🤗 Accelerate to automatically and efficiently allocate the model given the available resources in the environment:
```py
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
```
If you're loading a model in 8-bit for text generation, you should use the [`~transformers.GenerationMixin.generate`] method instead of the [`Pipeline`] function which is not optimized for 8-bit models and will be slower. Some sampling strategies, like nucleus sampling, are also not supported by the [`Pipeline`] for 8-bit models. You should also place all inputs on the same device as the model:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
```
To load a model in 4-bit for inference with multiple GPUs, you can control how much GPU RAM you want to allocate to each GPU. For example, to distribute 1GB of memory to the first GPU and 2GB of memory to the second GPU:
```py
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
```
<Tip>
Feel free to try running a 11 billion parameter [T5 model](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing) or the 3 billion parameter [BLOOM model](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing) for inference on Google Colab's free tier GPUs!
</Tip>
## 🤗 Optimum
<Tip>
Learn more details about using ORT with 🤗 Optimum in the [Accelerated inference on NVIDIA GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#accelerated-inference-on-nvidia-gpus) and [Accelerated inference on AMD GPUs](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/amdgpu#accelerated-inference-on-amd-gpus) guides. This section only provides a brief and simple example.
</Tip>
ONNX Runtime (ORT) is a model accelerator that supports accelerated inference on Nvidia GPUs, and AMD GPUs that use [ROCm](https://www.amd.com/en/products/software/rocm.html) stack. ORT uses optimization techniques like fusing common operations into a single node and constant folding to reduce the number of computations performed and speedup inference. ORT also places the most computationally intensive operations on the GPU and the rest on the CPU to intelligently distribute the workload between the two devices.
ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers. You'll need to use an [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and specify the `provider` parameter which can be set to either [`CUDAExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#cudaexecutionprovider), [`ROCMExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/amdgpu) or [`TensorrtExecutionProvider`](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/gpu#tensorrtexecutionprovider). If you want to load a model that was not yet exported to ONNX, you can set `export=True` to convert your model on-the-fly to the ONNX format:
```py
from optimum.onnxruntime import ORTModelForSequenceClassification
ort_model = ORTModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased-finetuned-sst-2-english",
export=True,
provider="CUDAExecutionProvider",
)
```
Now you're free to use the model for inference:
```py
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")
```
## Combine optimizations
It is often possible to combine several of the optimization techniques described above to get the best inference performance possible for your model. For example, you can load a model in 4-bit, and then enable BetterTransformer with FlashAttention:
```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# load model in 4-bit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
# enable BetterTransformer
model = model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# enable FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
| huggingface/transformers/blob/main/docs/source/en/perf_infer_gpu_one.md |
Using AllenNLP at Hugging Face
`allennlp` is a NLP library for developing state-of-the-art models on different linguistic tasks. It provides high-level abstractions and APIs for common components and models in modern NLP. It also provides an extensible framework that makes it easy to run and manage NLP experiments.
## Exploring allennlp in the Hub
You can find `allennlp` models on the Hub by filtering at the left of the [models page](https://huggingface.co/models?library=allennlp).
All models on the Hub come up with useful features
1. A training metrics tab with automatically hosted TensorBoard traces.
2. Metadata tags that help for discoverability.
3. An interactive widget you can use to play out with the model directly in the browser.
4. An Inference API that allows to make inference requests.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-allennlp_widget.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-allennlp_widget-dark.png"/>
</div>
## Using existing models
You can use the `Predictor` class to load existing models on the Hub. To achieve this, use the `from_path` method and use the `"hf://"` prefix with the repository id. Here is an end-to-end example.
```py
import allennlp_models
from allennlp.predictors.predictor import Predictor
predictor = Predictor.from_path("hf://allenai/bidaf-elmo")
predictor_input = {
"passage": "My name is Wolfgang and I live in Berlin",
"question": "Where do I live?"
}
predictions = predictor.predict_json(predictor_input)
```
To get a snippet such as this, you can click `Use in AllenNLP` at the top right,
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-allennlp_snippet.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/libraries-allennlp_snippet-dark.png"/>
</div>
## Sharing your models
The first step is to save the model locally. For example, you can use the [`archive_model`](https://docs.allennlp.org/main/api/models/archival/#archive_model) method to save the model as a `model.tar.gz` file. You can then push the zipped model to the Hub. When you train a model with `allennlp`, the model is automatically serialized so you can use that as a preferred option.
### Using the AllenNLP CLI
To push with the CLI, you can use the `allennlp push_to_hf` command as seen below.
```bash
allennlp push_to_hf --repo_name test_allennlp --archive_path model
```
| Argument | Type | Description |
|----------------------------- |-------------- |------------------------------------------------------------------------------------------------------------------------------- |
| `--repo_name`, `-n` | str / `Path` | Name of the repository on the Hub. |
| `--organization`, `-o` | str | Optional name of organization to which the pipeline should be uploaded. |
| `--serialization-dir`, `-s` | str / `Path` | Path to directory with the serialized model. |
| `--archive-path`, `-a` | str / `Path` | If instead of a serialization path you're using a zipped model (e.g. model/model.tar.gz), you can use this flag. |
| `--local-repo-path`, `-l` | str / `Path` | Local path to the model repository (will be created if it doesn't exist). Defaults to `hub` in the current working directory. |
| `--commit-message`, `-c` | str | Commit message to use for update. Defaults to `"update repository"`. |
### From a Python script
The `push_to_hf` function has the same parameters as the bash script.
```py
from allennlp.common.push_to_hf import push_to_hf
serialization_dir = "path/to/serialization/directory"
push_to_hf(
repo_name="my_repo_name",
serialization_dir=serialization_dir,
local_repo_path=self.local_repo_path
)
```
In just a minute, you can get your model in the Hub, try it out directly in the browser, and share it with the rest of the community. All the required metadata will be uploaded for you!
## Additional resources
* AllenNLP [website](https://allenai.org/allennlp).
* AllenNLP [repository](https://github.com/allenai/allennlp). | huggingface/hub-docs/blob/main/docs/hub/allennlp.md |
Webhook guide: Setup an automatic system to re-train a model when a dataset changes
<Tip>
Webhooks are now publicly available!
</Tip>
This guide will help walk you through the setup of an automatic training pipeline on the Hugging Face platform
using HF Datasets, Webhooks, Spaces, and AutoTrain.
We will build a Webhook that listens to changes on an image classification dataset and triggers a fine-tuning
of [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50) using [AutoTrain](https://huggingface.co/autotrain).
## Prerequisite: Upload your dataset to the Hub
We will use a [simple image classification dataset](https://huggingface.co/datasets/huggingface-projects/auto-retrain-input-dataset) for the sake
of the example. Learn more about uploading your data to the Hub [here](https://huggingface.co/docs/datasets/upload_dataset).
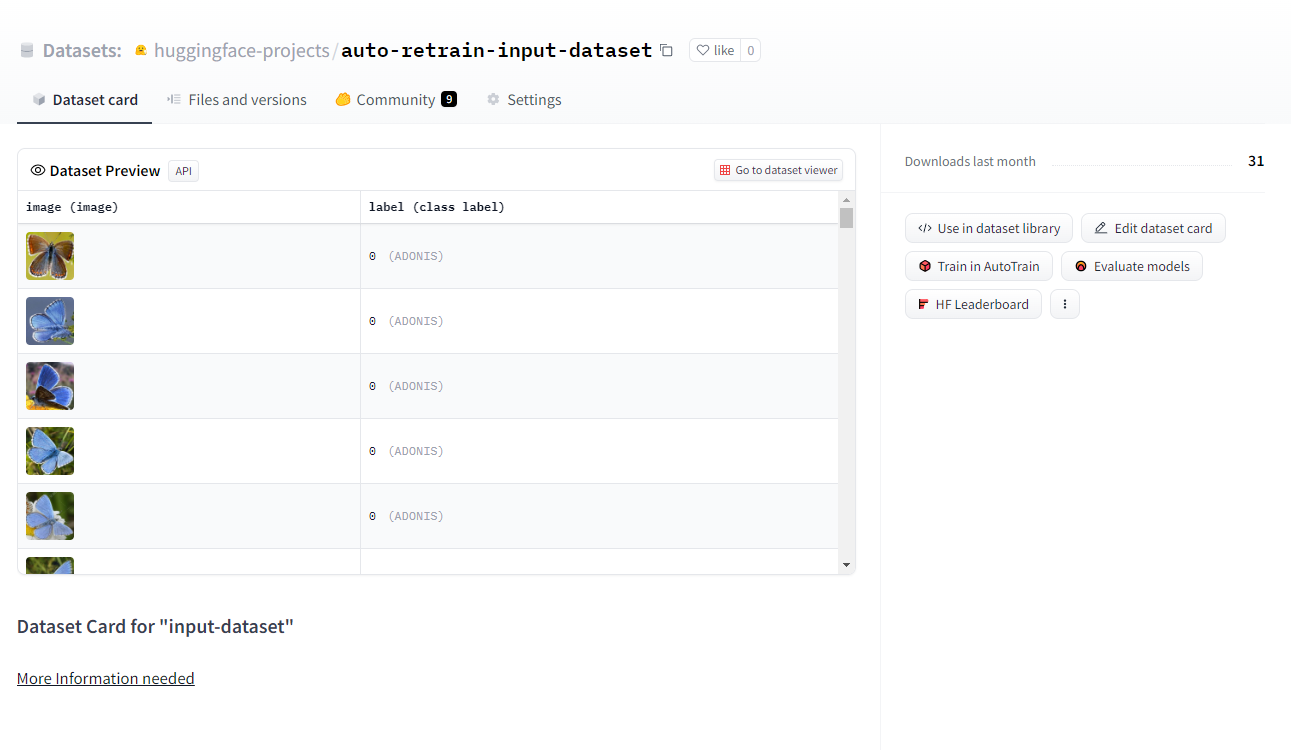
## Create a Webhook to react to the dataset's changes
First, let's create a Webhook from your [settings]( https://huggingface.co/settings/webhooks).
- Select your dataset as the target repository. We will target [huggingface-projects/input-dataset](https://huggingface.co/datasets/huggingface-projects/input-dataset) in this example.
- You can put a dummy Webhook URL for now. Defining your Webhook will let you look at the events that will be sent to it. You can also replay them, which will be useful for debugging!
- Input a secret to make it more secure.
- Subscribe to "Repo update" events as we want to react to data changes
Your Webhook will look like this:
## Create a Space to react to your Webhook
We now need a way to react to your Webhook events. An easy way to do this is to use a [Space](https://huggingface.co/docs/hub/spaces-overview)!
You can find an example Space [here](https://huggingface.co/spaces/huggingface-projects/auto-retrain/tree/main).
This Space uses Docker, Python, [FastAPI](https://fastapi.tiangolo.com/), and [uvicorn](https://www.uvicorn.org) to run a simple HTTP server. Read more about Docker Spaces [here](https://huggingface.co/docs/hub/spaces-sdks-docker).
The entry point is [src/main.py](https://huggingface.co/spaces/huggingface-projects/auto-retrain/blob/main/src/main.py). Let's walk through this file and detail what it does:
1. It spawns a FastAPI app that will listen to HTTP `POST` requests on `/webhook`:
```python
from fastapi import FastAPI
# [...]
@app.post("/webhook")
async def post_webhook(
# ...
):
# ...
```
2. 2. This route checks that the `X-Webhook-Secret` header is present and that its value is the same as the one you set in your Webhook's settings. The `WEBHOOK_SECRET` secret must be set in the Space's settings and be the same as the secret set in your Webhook.
```python
# [...]
WEBHOOK_SECRET = os.getenv("WEBHOOK_SECRET")
# [...]
@app.post("/webhook")
async def post_webhook(
# [...]
x_webhook_secret: Optional[str] = Header(default=None),
# ^ checks for the X-Webhook-Secret HTTP header
):
if x_webhook_secret is None:
raise HTTPException(401)
if x_webhook_secret != WEBHOOK_SECRET:
raise HTTPException(403)
# [...]
```
3. The event's payload is encoded as JSON. Here, we'll be using pydantic models to parse the event payload. We also specify that we will run our Webhook only when:
- the event concerns the input dataset
- the event is an update on the repo's content, i.e., there has been a new commit
```python
# defined in src/models.py
class WebhookPayloadEvent(BaseModel):
action: Literal["create", "update", "delete"]
scope: str
class WebhookPayloadRepo(BaseModel):
type: Literal["dataset", "model", "space"]
name: str
id: str
private: bool
headSha: str
class WebhookPayload(BaseModel):
event: WebhookPayloadEvent
repo: WebhookPayloadRepo
# [...]
@app.post("/webhook")
async def post_webhook(
# [...]
payload: WebhookPayload,
# ^ Pydantic model defining the payload format
):
# [...]
if not (
payload.event.action == "update"
and payload.event.scope.startswith("repo.content")
and payload.repo.name == config.input_dataset
and payload.repo.type == "dataset"
):
# no-op if the payload does not match our expectations
return {"processed": False}
#[...]
```
4. If the payload is valid, the next step is to create a project on AutoTrain, schedule a fine-tuning of the input model (`microsoft/resnet-50` in our example) on the input dataset, and create a discussion on the dataset when it's done!
```python
def schedule_retrain(payload: WebhookPayload):
# Create the autotrain project
try:
project = AutoTrain.create_project(payload)
AutoTrain.add_data(project_id=project["id"])
AutoTrain.start_processing(project_id=project["id"])
except requests.HTTPError as err:
print("ERROR while requesting AutoTrain API:")
print(f" code: {err.response.status_code}")
print(f" {err.response.json()}")
raise
# Notify in the community tab
notify_success(project["id"])
```
Visit the link inside the comment to review the training cost estimate, and start fine-tuning the model!
In this example, we used Hugging Face AutoTrain to fine-tune our model quickly, but you can of course plug in your training infrastructure!
Feel free to duplicate the Space to your personal namespace and play with it. You will need to provide two secrets:
- `WEBHOOK_SECRET` : the secret from your Webhook.
- `HF_ACCESS_TOKEN` : a User Access Token with `write` rights. You can create one [from your settings](https://huggingface.co/settings/tokens).
You will also need to tweak the [`config.json` file](https://huggingface.co/spaces/huggingface-projects/auto-retrain/blob/main/config.json) to use the dataset and model of you choice:
```json
{
"target_namespace": "the namespace where the trained model should end up",
"input_dataset": "the dataset on which the model will be trained",
"input_model": "the base model to re-train",
"autotrain_project_prefix": "A prefix for the AutoTrain project"
}
```
## Configure your Webhook to send events to your Space
Last but not least, you'll need to configure your webhook to send POST requests to your Space.
Let's first grab our Space's "direct URL" from the contextual menu. Click on "Embed this Space" and copy the "Direct URL".
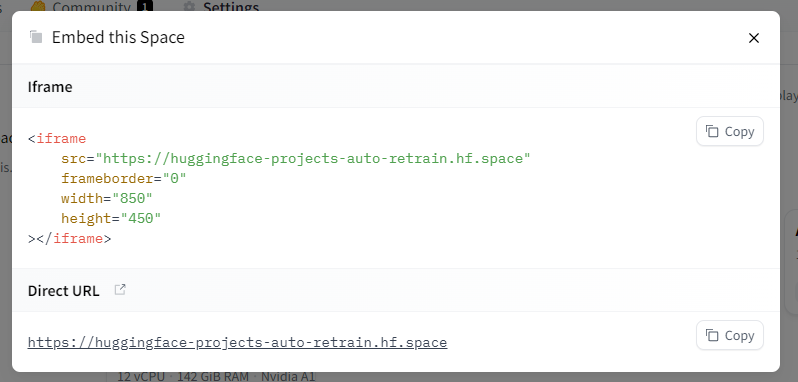
Update your Webhook to send requests to that URL:
And that's it! Now every commit to the input dataset will trigger a fine-tuning of ResNet-50 with AutoTrain 🎉
| huggingface/hub-docs/blob/main/docs/hub/webhooks-guide-auto-retrain.md |
--
title: "Habana Labs and Hugging Face Partner to Accelerate Transformer Model Training"
thumbnail: /blog/assets/60_habana/habana.png
authors:
- user: susanlansing
guest: true
---
# Habana Labs and Hugging Face Partner to Accelerate Transformer Model Training
*Santa Clara and San Francisco, CA, April 12th, 2022*
Powered by deep learning, transformer models deliver state-of-the-art performance on a wide range of machine learning tasks, such as natural language processing, computer vision, speech, and more. However, training them at scale often requires a large amount of computing power, making the whole process unnecessarily long, complex, and costly.
Today, [Habana® Labs](https://habana.ai/), a pioneer in high-efficiency, purpose-built deep learning processors, and Hugging Face, the home of [Transformer](https://github.com/huggingface/transformers) models, are happy to announce that they’re joining forces to make it easier and quicker to train high-quality transformer models. Thanks to the integration of Habana’s [SynapseAI software suite](https://habana.ai/training-software/) with the Hugging Face [Optimum open-source library](https://github.com/huggingface/optimum), data scientists and machine learning engineers can now accelerate their Transformer training jobs on Habana processors with just a few lines of code and enjoy greater productivity as well as lower training cost.
[Habana Gaudi](https://habana.ai/training/) training solutions, which power Amazon’s EC2 DL1 instances and Supermicro’s X12 Gaudi AI Training Server, deliver price/performance up to 40% lower than comparable training solutions and enable customers to train more while spending less. The integration of ten 100 Gigabit Ethernet ports onto every Gaudi processor enables system scaling from 1 to thousands of Gaudis with ease and cost-efficiency. Habana’s SynapseAI® is optimized—at inception—to enable Gaudi performance and usability, supports TensorFlow and PyTorch frameworks, with a focus on computer vision and natural language processing applications.
With 60,000+ stars on Github, 30,000+ models, and millions of monthly visits, Hugging Face is one of the fastest-growing projects in open source software history, and the go-to place for the machine learning community.
With its [Hardware Partner Program](https://huggingface.co/hardware), Hugging Face provides Gaudi’s advanced deep learning hardware with the ultimate Transformer toolset. This partnership will enable rapid expansion of the Habana Gaudi training transformer model library, bringing Gaudi efficiency and ease of use to a wide array of customer use cases like natural language processing, computer vision, speech, and more.
“*We’re excited to partner with Hugging Face and its many open-source developers to address the growing demand for transformer models that benefit from the efficiency, usability, and scalability of the Gaudi training platform*”, said Sree Ganesan, head of software product management, Habana Labs.
“Habana Gaudi brings a new level of efficiency to deep learning model training, and we’re super excited to make this performance easily accessible to Transformer users with minimal code changes through Optimum”, said Jeff Boudier, product director at Hugging Face.
To learn how to get started training with Habana Gaudi, please visit [https://developer.habana.ai](https://developer.habana.ai).
For more info on the Hugging Face and Habana Gaudi collaboration, please visit [https://huggingface.co/Habana](https://huggingface.co/Habana).
| huggingface/blog/blob/main/habana.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Summary of the tokenizers
[[open-in-colab]]
On this page, we will have a closer look at tokenization.
<Youtube id="VFp38yj8h3A"/>
As we saw in [the preprocessing tutorial](preprocessing), tokenizing a text is splitting it into words or
subwords, which then are converted to ids through a look-up table. Converting words or subwords to ids is
straightforward, so in this summary, we will focus on splitting a text into words or subwords (i.e. tokenizing a text).
More specifically, we will look at the three main types of tokenizers used in 🤗 Transformers: [Byte-Pair Encoding
(BPE)](#byte-pair-encoding), [WordPiece](#wordpiece), and [SentencePiece](#sentencepiece), and show examples
of which tokenizer type is used by which model.
Note that on each model page, you can look at the documentation of the associated tokenizer to know which tokenizer
type was used by the pretrained model. For instance, if we look at [`BertTokenizer`], we can see
that the model uses [WordPiece](#wordpiece).
## Introduction
Splitting a text into smaller chunks is a task that is harder than it looks, and there are multiple ways of doing so.
For instance, let's look at the sentence `"Don't you love 🤗 Transformers? We sure do."`
<Youtube id="nhJxYji1aho"/>
A simple way of tokenizing this text is to split it by spaces, which would give:
```
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
```
This is a sensible first step, but if we look at the tokens `"Transformers?"` and `"do."`, we notice that the
punctuation is attached to the words `"Transformer"` and `"do"`, which is suboptimal. We should take the
punctuation into account so that a model does not have to learn a different representation of a word and every possible
punctuation symbol that could follow it, which would explode the number of representations the model has to learn.
Taking punctuation into account, tokenizing our exemplary text would give:
```
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
Better. However, it is disadvantageous, how the tokenization dealt with the word `"Don't"`. `"Don't"` stands for
`"do not"`, so it would be better tokenized as `["Do", "n't"]`. This is where things start getting complicated, and
part of the reason each model has its own tokenizer type. Depending on the rules we apply for tokenizing a text, a
different tokenized output is generated for the same text. A pretrained model only performs properly if you feed it an
input that was tokenized with the same rules that were used to tokenize its training data.
[spaCy](https://spacy.io/) and [Moses](http://www.statmt.org/moses/?n=Development.GetStarted) are two popular
rule-based tokenizers. Applying them on our example, *spaCy* and *Moses* would output something like:
```
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
As can be seen space and punctuation tokenization, as well as rule-based tokenization, is used here. Space and
punctuation tokenization and rule-based tokenization are both examples of word tokenization, which is loosely defined
as splitting sentences into words. While it's the most intuitive way to split texts into smaller chunks, this
tokenization method can lead to problems for massive text corpora. In this case, space and punctuation tokenization
usually generates a very big vocabulary (the set of all unique words and tokens used). *E.g.*, [Transformer XL](model_doc/transformerxl) uses space and punctuation tokenization, resulting in a vocabulary size of 267,735!
Such a big vocabulary size forces the model to have an enormous embedding matrix as the input and output layer, which
causes both an increased memory and time complexity. In general, transformers models rarely have a vocabulary size
greater than 50,000, especially if they are pretrained only on a single language.
So if simple space and punctuation tokenization is unsatisfactory, why not simply tokenize on characters?
<Youtube id="ssLq_EK2jLE"/>
While character tokenization is very simple and would greatly reduce memory and time complexity it makes it much harder
for the model to learn meaningful input representations. *E.g.* learning a meaningful context-independent
representation for the letter `"t"` is much harder than learning a context-independent representation for the word
`"today"`. Therefore, character tokenization is often accompanied by a loss of performance. So to get the best of
both worlds, transformers models use a hybrid between word-level and character-level tokenization called **subword**
tokenization.
## Subword tokenization
<Youtube id="zHvTiHr506c"/>
Subword tokenization algorithms rely on the principle that frequently used words should not be split into smaller
subwords, but rare words should be decomposed into meaningful subwords. For instance `"annoyingly"` might be
considered a rare word and could be decomposed into `"annoying"` and `"ly"`. Both `"annoying"` and `"ly"` as
stand-alone subwords would appear more frequently while at the same time the meaning of `"annoyingly"` is kept by the
composite meaning of `"annoying"` and `"ly"`. This is especially useful in agglutinative languages such as Turkish,
where you can form (almost) arbitrarily long complex words by stringing together subwords.
Subword tokenization allows the model to have a reasonable vocabulary size while being able to learn meaningful
context-independent representations. In addition, subword tokenization enables the model to process words it has never
seen before, by decomposing them into known subwords. For instance, the [`~transformers.BertTokenizer`] tokenizes
`"I have a new GPU!"` as follows:
```py
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> tokenizer.tokenize("I have a new GPU!")
["i", "have", "a", "new", "gp", "##u", "!"]
```
Because we are considering the uncased model, the sentence was lowercased first. We can see that the words `["i", "have", "a", "new"]` are present in the tokenizer's vocabulary, but the word `"gpu"` is not. Consequently, the
tokenizer splits `"gpu"` into known subwords: `["gp" and "##u"]`. `"##"` means that the rest of the token should
be attached to the previous one, without space (for decoding or reversal of the tokenization).
As another example, [`~transformers.XLNetTokenizer`] tokenizes our previously exemplary text as follows:
```py
>>> from transformers import XLNetTokenizer
>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
```
We'll get back to the meaning of those `"▁"` when we look at [SentencePiece](#sentencepiece). As one can see,
the rare word `"Transformers"` has been split into the more frequent subwords `"Transform"` and `"ers"`.
Let's now look at how the different subword tokenization algorithms work. Note that all of those tokenization
algorithms rely on some form of training which is usually done on the corpus the corresponding model will be trained
on.
<a id='byte-pair-encoding'></a>
### Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE) was introduced in [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
al., 2015)](https://arxiv.org/abs/1508.07909). BPE relies on a pre-tokenizer that splits the training data into
words. Pretokenization can be as simple as space tokenization, e.g. [GPT-2](model_doc/gpt2), [RoBERTa](model_doc/roberta). More advanced pre-tokenization include rule-based tokenization, e.g. [XLM](model_doc/xlm),
[FlauBERT](model_doc/flaubert) which uses Moses for most languages, or [GPT](model_doc/gpt) which uses
Spacy and ftfy, to count the frequency of each word in the training corpus.
After pre-tokenization, a set of unique words has been created and the frequency with which each word occurred in the
training data has been determined. Next, BPE creates a base vocabulary consisting of all symbols that occur in the set
of unique words and learns merge rules to form a new symbol from two symbols of the base vocabulary. It does so until
the vocabulary has attained the desired vocabulary size. Note that the desired vocabulary size is a hyperparameter to
define before training the tokenizer.
As an example, let's assume that after pre-tokenization, the following set of words including their frequency has been
determined:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
Consequently, the base vocabulary is `["b", "g", "h", "n", "p", "s", "u"]`. Splitting all words into symbols of the
base vocabulary, we obtain:
```
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
```
BPE then counts the frequency of each possible symbol pair and picks the symbol pair that occurs most frequently. In
the example above `"h"` followed by `"u"` is present _10 + 5 = 15_ times (10 times in the 10 occurrences of
`"hug"`, 5 times in the 5 occurrences of `"hugs"`). However, the most frequent symbol pair is `"u"` followed by
`"g"`, occurring _10 + 5 + 5 = 20_ times in total. Thus, the first merge rule the tokenizer learns is to group all
`"u"` symbols followed by a `"g"` symbol together. Next, `"ug"` is added to the vocabulary. The set of words then
becomes
```
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
```
BPE then identifies the next most common symbol pair. It's `"u"` followed by `"n"`, which occurs 16 times. `"u"`,
`"n"` is merged to `"un"` and added to the vocabulary. The next most frequent symbol pair is `"h"` followed by
`"ug"`, occurring 15 times. Again the pair is merged and `"hug"` can be added to the vocabulary.
At this stage, the vocabulary is `["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]` and our set of unique words
is represented as
```
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
```
Assuming, that the Byte-Pair Encoding training would stop at this point, the learned merge rules would then be applied
to new words (as long as those new words do not include symbols that were not in the base vocabulary). For instance,
the word `"bug"` would be tokenized to `["b", "ug"]` but `"mug"` would be tokenized as `["<unk>", "ug"]` since
the symbol `"m"` is not in the base vocabulary. In general, single letters such as `"m"` are not replaced by the
`"<unk>"` symbol because the training data usually includes at least one occurrence of each letter, but it is likely
to happen for very special characters like emojis.
As mentioned earlier, the vocabulary size, *i.e.* the base vocabulary size + the number of merges, is a hyperparameter
to choose. For instance [GPT](model_doc/gpt) has a vocabulary size of 40,478 since they have 478 base characters
and chose to stop training after 40,000 merges.
#### Byte-level BPE
A base vocabulary that includes all possible base characters can be quite large if *e.g.* all unicode characters are
considered as base characters. To have a better base vocabulary, [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) uses bytes
as the base vocabulary, which is a clever trick to force the base vocabulary to be of size 256 while ensuring that
every base character is included in the vocabulary. With some additional rules to deal with punctuation, the GPT2's
tokenizer can tokenize every text without the need for the <unk> symbol. [GPT-2](model_doc/gpt) has a vocabulary
size of 50,257, which corresponds to the 256 bytes base tokens, a special end-of-text token and the symbols learned
with 50,000 merges.
<a id='wordpiece'></a>
### WordPiece
WordPiece is the subword tokenization algorithm used for [BERT](model_doc/bert), [DistilBERT](model_doc/distilbert), and [Electra](model_doc/electra). The algorithm was outlined in [Japanese and Korean
Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf) and is very similar to
BPE. WordPiece first initializes the vocabulary to include every character present in the training data and
progressively learns a given number of merge rules. In contrast to BPE, WordPiece does not choose the most frequent
symbol pair, but the one that maximizes the likelihood of the training data once added to the vocabulary.
So what does this mean exactly? Referring to the previous example, maximizing the likelihood of the training data is
equivalent to finding the symbol pair, whose probability divided by the probabilities of its first symbol followed by
its second symbol is the greatest among all symbol pairs. *E.g.* `"u"`, followed by `"g"` would have only been
merged if the probability of `"ug"` divided by `"u"`, `"g"` would have been greater than for any other symbol
pair. Intuitively, WordPiece is slightly different to BPE in that it evaluates what it _loses_ by merging two symbols
to ensure it's _worth it_.
<a id='unigram'></a>
### Unigram
Unigram is a subword tokenization algorithm introduced in [Subword Regularization: Improving Neural Network Translation
Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf). In contrast to BPE or
WordPiece, Unigram initializes its base vocabulary to a large number of symbols and progressively trims down each
symbol to obtain a smaller vocabulary. The base vocabulary could for instance correspond to all pre-tokenized words and
the most common substrings. Unigram is not used directly for any of the models in the transformers, but it's used in
conjunction with [SentencePiece](#sentencepiece).
At each training step, the Unigram algorithm defines a loss (often defined as the log-likelihood) over the training
data given the current vocabulary and a unigram language model. Then, for each symbol in the vocabulary, the algorithm
computes how much the overall loss would increase if the symbol was to be removed from the vocabulary. Unigram then
removes p (with p usually being 10% or 20%) percent of the symbols whose loss increase is the lowest, *i.e.* those
symbols that least affect the overall loss over the training data. This process is repeated until the vocabulary has
reached the desired size. The Unigram algorithm always keeps the base characters so that any word can be tokenized.
Because Unigram is not based on merge rules (in contrast to BPE and WordPiece), the algorithm has several ways of
tokenizing new text after training. As an example, if a trained Unigram tokenizer exhibits the vocabulary:
```
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
```
`"hugs"` could be tokenized both as `["hug", "s"]`, `["h", "ug", "s"]` or `["h", "u", "g", "s"]`. So which one
to choose? Unigram saves the probability of each token in the training corpus on top of saving the vocabulary so that
the probability of each possible tokenization can be computed after training. The algorithm simply picks the most
likely tokenization in practice, but also offers the possibility to sample a possible tokenization according to their
probabilities.
Those probabilities are defined by the loss the tokenizer is trained on. Assuming that the training data consists of
the words \\(x_{1}, \dots, x_{N}\\) and that the set of all possible tokenizations for a word \\(x_{i}\\) is
defined as \\(S(x_{i})\\), then the overall loss is defined as
$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
<a id='sentencepiece'></a>
### SentencePiece
All tokenization algorithms described so far have the same problem: It is assumed that the input text uses spaces to
separate words. However, not all languages use spaces to separate words. One possible solution is to use language
specific pre-tokenizers, *e.g.* [XLM](model_doc/xlm) uses a specific Chinese, Japanese, and Thai pre-tokenizer).
To solve this problem more generally, [SentencePiece: A simple and language independent subword tokenizer and
detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf) treats the input
as a raw input stream, thus including the space in the set of characters to use. It then uses the BPE or unigram
algorithm to construct the appropriate vocabulary.
The [`XLNetTokenizer`] uses SentencePiece for example, which is also why in the example earlier the
`"▁"` character was included in the vocabulary. Decoding with SentencePiece is very easy since all tokens can just be
concatenated and `"▁"` is replaced by a space.
All transformers models in the library that use SentencePiece use it in combination with unigram. Examples of models
using SentencePiece are [ALBERT](model_doc/albert), [XLNet](model_doc/xlnet), [Marian](model_doc/marian), and [T5](model_doc/t5).
| huggingface/transformers/blob/main/docs/source/en/tokenizer_summary.md |
--
title: "Fine-tune Llama 2 with DPO"
thumbnail: /blog/assets/157_dpo_trl/dpo_thumbnail.png
authors:
- user: kashif
- user: ybelkada
- user: lvwerra
---
# Fine-tune Llama 2 with DPO
## Introduction
Reinforcement Learning from Human Feedback (RLHF) has become the de facto last training step of LLMs such as GPT-4 or Claude to ensure that the language model's outputs are aligned with human expectations such as chattiness or safety features. However, it brings some of the complexity of RL into NLP: we need to build a good reward function, train the model to estimate the value of a state, and at the same time be careful not to strive too far from the original model and produce gibberish instead of sensible text. Such a process is quite involved requiring a number of complex moving parts where it is not always easy to get things right.
The recent paper [Direct Preference Optimization](https://arxiv.org/abs/2305.18290) by Rafailov, Sharma, Mitchell et al. proposes to cast the RL-based objective used by existing methods to an objective which can be directly optimized via a simple binary cross-entropy loss which simplifies this process of refining LLMs greatly.
This blog-post introduces the Direct Preference Optimization (DPO) method which is now available in the [TRL library](https://github.com/lvwerra/trl) and shows how one can fine tune the recent Llama v2 7B-parameter model on the [stack-exchange preference](https://huggingface.co/datasets/lvwerra/stack-exchange-paired) dataset which contains ranked answers to questions on the various stack-exchange portals.
## DPO vs PPO
In the traditional model of optimising human derived preferences via RL, the goto method has been to use an auxiliary reward model and fine-tune the model of interest so that it maximizes this given reward via the machinery of RL. Intuitively we use the reward model to provide feedback to the model we are optimising so that it generates high-reward samples more often and low-reward samples less often. At the same time we use a frozen reference model to make sure that whatever is generated does not deviate too much and continues to maintain generation diversity. This is typically done by adding a KL penalty to the full reward maximisation objective via a reference model, which serves to prevent the model from learning to cheat or exploit the reward model.
The DPO formulation bypasses the reward modeling step and directly optimises the language model on preference data via a key insight: namely an analytical mapping from the reward function to the optimal RL policy that enables the authors to transform the RL loss over the reward and reference models to a loss over the reference model directly! This mapping intuitively measures how well a given reward function aligns with the given preference data. DPO thus starts with the optimal solution to the RLHF loss and via a change of variables derives a loss over *only* the reference model!
Thus this direct likelihood objective can be optimized without the need for a reward model or the need to perform the potentially fiddly RL based optimisation.
## How to train with TRL
As mentioned, typically the RLHF pipeline consists of these distinct parts:
1. a supervised fine-tuning (SFT) step
2. the process of annotating data with preference labels
3. training a reward model on the preference data
4. and the RL optmization step
The TRL library comes with helpers for all these parts, however the DPO training does away with the task of reward modeling and RL (steps 3 and 4) and directly optimizes the DPO object on preference annotated data.
In this respect we would still need to do the step 1, but instead of steps 3 and 4 we need to provide the `DPOTrainer` in TRL with preference data from step 2 which has a very specific format, namely a dictionary with the following three keys:
- `prompt` this consists of the context prompt which is given to a model at inference time for text generation
- `chosen` contains the preferred generated response to the corresponding prompt
- `rejected` contains the response which is not preferred or should not be the sampled response with respect to the given prompt
As an example, for the stack-exchange preference pairs dataset, we can map the dataset entries to return the desired dictionary via the following helper and drop all the original columns:
```python
def return_prompt_and_responses(samples) -> Dict[str, str, str]:
return {
"prompt": [
"Question: " + question + "\n\nAnswer: "
for question in samples["question"]
],
"chosen": samples["response_j"], # rated better than k
"rejected": samples["response_k"], # rated worse than j
}
dataset = load_dataset(
"lvwerra/stack-exchange-paired",
split="train",
data_dir="data/rl"
)
original_columns = dataset.column_names
dataset.map(
return_prompt_and_responses,
batched=True,
remove_columns=original_columns
)
```
Once we have the dataset sorted the DPO loss is essentially a supervised loss which obtains an implicit reward via a reference model and thus at a high-level the `DPOTrainer` requires the base model we wish to optimize as well as a reference model:
```python
dpo_trainer = DPOTrainer(
model, # base model from SFT pipeline
model_ref, # typically a copy of the SFT trained base model
beta=0.1, # temperature hyperparameter of DPO
train_dataset=dataset, # dataset prepared above
tokenizer=tokenizer, # tokenizer
args=training_args, # training arguments e.g. batch size, lr, etc.
)
```
where the `beta` hyper-parameter is the temperature parameter for the DPO loss, typically in the range `0.1` to `0.5`. This controls how much we pay attention to the reference model in the sense that as `beta` gets smaller the more we ignore the reference model. Once we have our trainer initialised we can then train it on the dataset with the given `training_args` by simply calling:
```python
dpo_trainer.train()
```
## Experiment with Llama v2
The benefit of implementing the DPO trainer in TRL is that one can take advantage of all the extra bells and whistles of training large LLMs which come with TRL and its dependent libraries like Peft and Accelerate. With these libraries we are even able to train a Llama v2 model using the [QLoRA technique](https://huggingface.co/blog/4bit-transformers-bitsandbytes) provided by the [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) library.
### Supervised Fine Tuning
The process as introduced above involves the supervised fine-tuning step using [QLoRA](https://arxiv.org/abs/2305.14314) on the 7B Llama v2 model on the SFT split of the data via TRL’s `SFTTrainer`:
```python
# load the base model in 4-bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
base_model = AutoModelForCausalLM.from_pretrained(
script_args.model_name, # "meta-llama/Llama-2-7b-hf"
quantization_config=bnb_config,
device_map={"": 0},
trust_remote_code=True,
use_auth_token=True,
)
base_model.config.use_cache = False
# add LoRA layers on top of the quantized base model
peft_config = LoraConfig(
r=script_args.lora_r,
lora_alpha=script_args.lora_alpha,
lora_dropout=script_args.lora_dropout,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
...
trainer = SFTTrainer(
model=base_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
packing=True,
max_seq_length=None,
tokenizer=tokenizer,
args=training_args, # HF Trainer arguments
)
trainer.train()
```
### DPO Training
Once the SFT has finished, we can save the resulting model and move onto the DPO training. As is typically done we will utilize the saved model from the previous SFT step for both the base model as well as reference model of DPO. Then we can use these to train the model with the DPO objective on the stack-exchange preference data shown above. Since the models were trained via LoRa adapters, we load the models via Peft’s `AutoPeftModelForCausalLM` helpers:
```python
model = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # location of saved SFT model
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
is_trainable=True,
)
model_ref = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # same model as the main one
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
)
...
dpo_trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=script_args.beta,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
)
dpo_trainer.train()
dpo_trainer.save_model()
```
So as can be seen we load the model in the 4-bit configuration and then train it via the QLora method via the `peft_config` arguments. The trainer will also evaluate the progress during training with respect to the evaluation dataset and report back a number of key metrics like the implicit reward which can be recorded and displayed via WandB for example. We can then push the final trained model to the HuggingFace Hub.
## Conclusion
The full source code of the training scripts for the SFT and DPO are available in the following [examples/stack_llama_2](https://github.com/lvwerra/trl/tree/main/examples/research_projects/stack_llama_2) directory and the trained model with the merged adapters can be found on the HF Hub [here](https://huggingface.co/kashif/stack-llama-2).
The WandB logs for the DPO training run can be found [here](https://wandb.ai/krasul/huggingface/runs/c54lmder) where during training and evaluation the `DPOTrainer` records the following reward metrics:
* `rewards/chosen`: the mean difference between the log probabilities of the policy model and the reference model for the chosen responses scaled by `beta`
* `rewards/rejected`: the mean difference between the log probabilities of the policy model and the reference model for the rejected responses scaled by `beta`
* `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards
* `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards.
Intuitively, during training we want the margins to increase and the accuracies to go to 1.0, or in other words the chosen reward to be higher than the rejected reward (or the margin bigger than zero). These metrics can then be calculated over some evaluation dataset.
We hope with the code release it lowers the barrier to entry for you the readers to try out this method of aligning large language models on your own datasets and we cannot wait to see what you build! And if you want to try out the model yourself you can do so here: [trl-lib/stack-llama](https://huggingface.co/spaces/trl-lib/stack-llama).
| huggingface/blog/blob/main/dpo-trl.md |
使用 Hugging Face 集成
相关空间:https://huggingface.co/spaces/gradio/helsinki_translation_en_es
标签:HUB,SPACES,EMBED
由 <a href="https://huggingface.co/osanseviero">Omar Sanseviero</a> 贡献🦙
## 介绍
Hugging Face Hub 是一个集成平台,拥有超过 190,000 个[模型](https://huggingface.co/models),32,000 个[数据集](https://huggingface.co/datasets)和 40,000 个[演示](https://huggingface.co/spaces),也被称为 Spaces。虽然 Hugging Face 以其🤗 transformers 和 diffusers 库而闻名,但 Hub 还支持许多机器学习库,如 PyTorch,TensorFlow,spaCy 等,涵盖了从计算机视觉到强化学习等各个领域。
Gradio 拥有多个功能,使其非常容易利用 Hub 上的现有模型和 Spaces。本指南将介绍这些功能。
## 使用 `pipeline` 进行常规推理
首先,让我们构建一个简单的界面,将英文翻译成西班牙文。在赫尔辛基大学共享的一千多个模型中,有一个[现有模型](https://huggingface.co/Helsinki-NLP/opus-mt-en-es),名为 `opus-mt-en-es`,可以正好做到这一点!
🤗 transformers 库有一个非常易于使用的抽象层,[`pipeline()`](https://huggingface.co/docs/transformers/v4.16.2/en/main_classes/pipelines#transformers.pipeline)处理大部分复杂代码,为常见任务提供简单的 API。通过指定任务和(可选)模型,您可以使用几行代码使用现有模型:
```python
import gradio as gr
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
def predict(text):
return pipe(text)[0]["translation_text"]
demo = gr.Interface(
fn=predict,
inputs='text',
outputs='text',
)
demo.launch()
```
但是,`gradio` 实际上使将 `pipeline` 转换为演示更加容易,只需使用 `gradio.Interface.from_pipeline` 方法,无需指定输入和输出组件:
```python
from transformers import pipeline
import gradio as gr
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
demo = gr.Interface.from_pipeline(pipe)
demo.launch()
```
上述代码生成了以下界面,您可以在浏览器中直接尝试:
<gradio-app space="Helsinki-NLP/opus-mt-en-es"></gradio-app>
## Using Hugging Face Inference API
Hugging Face 提供了一个名为[Inference API](https://huggingface.co/inference-api)的免费服务,允许您向 Hub 中的模型发送 HTTP 请求。对于基于 transformers 或 diffusers 的模型,API 的速度可以比自己运行推理快 2 到 10 倍。该 API 是免费的(受速率限制),您可以在想要在生产中使用时切换到专用的[推理端点](https://huggingface.co/pricing)。
让我们尝试使用推理 API 而不是自己加载模型的方式进行相同的演示。鉴于 Inference API 支持的 Hugging Face 模型,Gradio 可以自动推断出预期的输入和输出,并进行底层服务器调用,因此您不必担心定义预测函数。以下是代码示例!
```python
import gradio as gr
demo = gr.load("Helsinki-NLP/opus-mt-en-es", src="models")
demo.launch()
```
请注意,我们只需指定模型名称并说明 `src` 应为 `models`(Hugging Face 的 Model Hub)。由于您不会在计算机上加载模型,因此无需安装任何依赖项(除了 `gradio`)。
您可能会注意到,第一次推理大约需要 20 秒。这是因为推理 API 正在服务器中加载模型。之后您会获得一些好处:
- 推理速度更快。
- 服务器缓存您的请求。
- 您获得内置的自动缩放功能。
## 托管您的 Gradio 演示
[Hugging Face Spaces](https://hf.co/spaces)允许任何人免费托管其 Gradio 演示,上传 Gradio 演示只需几分钟。您可以前往[hf.co/new-space](https://huggingface.co/new-space),选择 Gradio SDK,创建一个 `app.py` 文件,完成!您将拥有一个可以与任何人共享的演示。要了解更多信息,请阅读[此指南以使用网站在 Hugging Face Spaces 上托管](https://huggingface.co/blog/gradio-spaces)。
或者,您可以通过使用[huggingface_hub client library](https://huggingface.co/docs/huggingface_hub/index)库来以编程方式创建一个 Space。这是一个示例:
```python
from huggingface_hub import (
create_repo,
get_full_repo_name,
upload_file,
)
create_repo(name=target_space_name, token=hf_token, repo_type="space", space_sdk="gradio")
repo_name = get_full_repo_name(model_id=target_space_name, token=hf_token)
file_url = upload_file(
path_or_fileobj="file.txt",
path_in_repo="app.py",
repo_id=repo_name,
repo_type="space",
token=hf_token,
)
```
在这里,`create_repo` 使用特定帐户的 Write Token 在特定帐户下创建一个带有目标名称的 gradio repo。`repo_name` 获取相关存储库的完整存储库名称。最后,`upload_file` 将文件上传到存储库中,并将其命名为 `app.py`。
## 在其他网站上嵌入您的 Space 演示
在本指南中,您已经看到了许多嵌入的 Gradio 演示。您也可以在自己的网站上这样做!第一步是创建一个包含您想展示的演示的 Hugging Face Space。然后,[按照此处的步骤将 Space 嵌入到您的网站上](/sharing-your-app/#embedding-hosted-spaces)。
## 从 Spaces 加载演示
您还可以在 Hugging Face Spaces 上使用和混合现有的 Gradio 演示。例如,您可以将两个现有的 Gradio 演示放在单独的选项卡中并创建一个新的演示。您可以在本地运行此新演示,或将其上传到 Spaces,为混合和创建新的演示提供无限可能性!
以下是一个完全实现此目标的示例:
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Tab("Translate to Spanish"):
gr.load("gradio/helsinki_translation_en_es", src="spaces")
with gr.Tab("Translate to French"):
gr.load("abidlabs/en2fr", src="spaces")
demo.launch()
```
请注意,我们使用了 `gr.load()`,这与使用推理 API 加载模型所使用的方法相同。但是,在这里,我们指定 `src` 为 `spaces`(Hugging Face Spaces)。
## 小结
就是这样!让我们回顾一下 Gradio 和 Hugging Face 共同工作的各种方式:
1. 您可以使用 `from_pipeline()` 将 `transformers` pipeline 转换为 Gradio 演示
2. 您可以使用 `gr.load()` 轻松地围绕推理 API 构建演示,而无需加载模型
3. 您可以在 Hugging Face Spaces 上托管您的 Gradio 演示,可以使用 GUI 或完全使用 Python。
4. 您可以将托管在 Hugging Face Spaces 上的 Gradio 演示嵌入到自己的网站上。
5. 您可以使用 `gr.load()` 从 Hugging Face Spaces 加载演示,以重新混合和创建新的 Gradio 演示。
🤗
| gradio-app/gradio/blob/main/guides/cn/04_integrating-other-frameworks/01_using-hugging-face-integrations.md |
Gradio Demo: chatbot_dialogpt
```
!pip install -q gradio torch transformers
```
```
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")
def user(message, history):
return "", history + [[message, None]]
def bot(history):
user_message = history[-1][0]
new_user_input_ids = tokenizer.encode(
user_message + tokenizer.eos_token, return_tensors="pt"
)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([torch.LongTensor([]), new_user_input_ids], dim=-1)
# generate a response
response = model.generate(
bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id
).tolist()
# convert the tokens to text, and then split the responses into lines
response = tokenizer.decode(response[0]).split("<|endoftext|>")
response = [
(response[i], response[i + 1]) for i in range(0, len(response) - 1, 2)
] # convert to tuples of list
history[-1] = response[0]
return history
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.Button("Clear")
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
bot, chatbot, chatbot
)
clear.click(lambda: None, None, chatbot, queue=False)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/chatbot_dialogpt/run.ipynb |
MixNet
**MixNet** is a type of convolutional neural network discovered via AutoML that utilises [MixConvs](https://paperswithcode.com/method/mixconv) instead of regular [depthwise convolutions](https://paperswithcode.com/method/depthwise-convolution).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('mixnet_l', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `mixnet_l`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('mixnet_l', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2019mixconv,
title={MixConv: Mixed Depthwise Convolutional Kernels},
author={Mingxing Tan and Quoc V. Le},
year={2019},
eprint={1907.09595},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: MixNet
Paper:
Title: 'MixConv: Mixed Depthwise Convolutional Kernels'
URL: https://paperswithcode.com/paper/mixnet-mixed-depthwise-convolutional-kernels
Models:
- Name: mixnet_l
In Collection: MixNet
Metadata:
FLOPs: 738671316
Parameters: 7330000
File Size: 29608232
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_l
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1669
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_l-5a9a2ed8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.98%
Top 5 Accuracy: 94.18%
- Name: mixnet_m
In Collection: MixNet
Metadata:
FLOPs: 454543374
Parameters: 5010000
File Size: 20298347
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_m
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1660
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_m-4647fc68.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.27%
Top 5 Accuracy: 93.42%
- Name: mixnet_s
In Collection: MixNet
Metadata:
FLOPs: 321264910
Parameters: 4130000
File Size: 16727982
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1651
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_s-a907afbc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.99%
Top 5 Accuracy: 92.79%
- Name: mixnet_xl
In Collection: MixNet
Metadata:
FLOPs: 1195880424
Parameters: 11900000
File Size: 48001170
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_xl
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1678
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_xl_ra-aac3c00c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.47%
Top 5 Accuracy: 94.93%
--> | huggingface/pytorch-image-models/blob/main/docs/models/mixnet.md |
i, this is going to be a video about the push_to_hub API for Tensorflow and Keras. So, to get started, we'll open up our notebook, and the first thing you'll need to do is log in to your HuggingFace account, for example with the notebook login function. So to do that, you simply call the function, the popup will emerge, you enter your username and password, which I'm going to pull out of my password manager here, and you're logged in. The next two cells are just getting everything ready for training. So we're just going to load a dataset, we're going to tokenize that dataset, and then we're going to load our model and compile it with the standard Adam optimizer. So I'm just going to run all of those, we'll wait a few seconds, and everything should be ready for training. Okay, so now we're ready to train I'm going to show you the two ways you can push your model to the Hub. So the first is with the PushToHubCallback. So a callback in Keras is a function that's called regularly during training. You can set it to be called after a certain number of steps, or every epoch, or even just once at the end of training. So a lot of callbacks in Keras, for example, control learning rate decaying on plateau and things like that. And so this callback, by default, will save your model to the Hub once every epoch. And that's really helpful especially if your training is very long, because that means you can resume from that save, so you get this automatic cloud-saving of your model, and you can even run inference with the checkpoints of your model that have been uploaded by this callback, and that means you can, y'know, actually run some test inputs and actually see how your model works at various stages during training, which is a really nice feature. So we're going to add the PushToHubCallback, and it takes just a few arguments. So the first argument is the temporary directory that files are going to be saved to before they're uploaded to the Hub. The second argument is the tokenizer, and the third argument here is the keyword argument hub_model_id. So that's the name it's going to be saved under on the HuggingFace Hub. You can also upload to an organization account just by adding the organization name before the repository name with a slash like this. So you probably don't have permissions to upload to the Hugging Face organization, if you do please file a bug and let us know extremely urgently. But if you do have access to your own organization then you can use that same approach to upload models to their account instead of to your own personal set of models. So, once you've made your callback you simply add it to the callbacks list when you're called model.fit() and everything is uploaded for you from there, and there's nothing else to worry about. The second way to upload a model, though, is to call model.push_to_hub(). So this is more of a once-off method - it's not called regularly during training. You can just call this manually whenever you want to upload a model to the hub. So we recommend running this after the end of training, just to make sure that you have a commit message just to guarantee that this was the final version of the model at the end of training. And it just makes sure that you're working with the definitive end-of-training model and not accidentally using a model that's from a checkpoint somewhere along the way. So I'm going to run both of these cells and then I'm going to cut the video here, just because training is going to take a couple of minutes, and so I'll skip forward to the end of that, when the models have all been uploaded, and I'm gonna show you how you can access the models in the Hub and the other things you can do with them from there. Okay, we're back and our model was uploaded, both by the PushToHubCallback and also by our call to model.push_to_hub() after training. So everything's looking good! So now if we drop over to my profile on HuggingFace, and you can get there just by clicking the profile button in the dropdown, we can see that the bert-fine-tuned-cola model is here, and was updated 3 minutes ago. So it'll always be at the top of your list, because they're sorted by how recently they were updated. And we can start querying our model immediately! So the dataset we were training on is the Glue CoLA dataset, and CoLA is an acronym for Corpus of Linguistic Acceptability. So what that means is that the model is being trained to decide if a sentence is grammatically or linguistically okay, or if there's a problem with it. For example, we could say "This is a legitimate sentence" and hopefully it realizes that this is in fact a legitimate sentence. So it might take a couple of seconds for the model to load when you call it for the first time, so I might cut a couple of seconds out of this video here. Okay, we're back! The model loaded and we got an output, but there's an obvious problem here. So these labels aren't really telling us what categories the model has actually assigned to this input sentence. So if we want to fix that, we want to make sure the model config has the correct names for each of the label classes, and then we want to upload that config. So we can do that down here. To get the label_names, we can get that from the dataset we loaded, from the 'features' attribute it has. And then we can create dictionaries "id2label" and "label2id" and just assign them to the model config, and then we can just push our updated config and that'll override the existing config in the Hub repo. So that's just been done, so now if we go back here, I'm going to use a slightly different sentence because the outputs for sentences are sometimes cached, and so if we want to generate new results I'm going to use something slightly different. So let's try an incorrect sentence, so this is not valid English grammar and hopefully the model will see that. It's going to reload here, so I'm going to cut a couple of seconds here, and then we'll see what the model is going to say. Okay! So the model's confidence isn't very good, because of course we didn't really optimize our hyperparameters at all, but it has decided that this sentence is more likely to be unacceptable than acceptable. Presumably if we tried a bit harder with training we could get a much lower validation loss and therefore the model's predictions would be more precise. But let's try our original sentence again - of course, because of the caching issue we're seeing that the original answers are unchanged. So let's try a different, valid sentence. So let's try "This is a valid English sentence". And we see that now the model correctly decides that it has a very high probability of being acceptable and a very low probability of being unacceptable. So you can use this inference API even with the checkpoints that are uploaded during training, so it can be very interesting to see how the model's predictions for sample inputs change with each epoch of training. Also, the model we've uploaded is going to be accessible to you and, if it's shared publicly, to anyone else. So if you want to load that model all you, or anyone else, needs to do is just to load it in either a pipeline or you can just load it with, for example, TFAutoModelForSequenceClassification and then for the name you would just simply pass the path to the repo you want to upload - or to download, excuse me. So if I want to use this model again, if I want to load it from the hub, I just run this one line of code, the model will be downloaded and with any luck it'll be ready to fine-tune on a different dataset, make predictions with, or do anything else you wanna do. So that was a quick overview of how, after your training or during your training, you can upload models to the Hub, you can checkpoint there, you can resume training from there, and you can get inference results from the models you've uploaded. So thank you, and I hope to see you in a future video! | huggingface/course/blob/main/subtitles/en/raw/chapter4/03b_push-to-hub-tf.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ConvBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=convbert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-convbert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/conv-bert-base">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The ConvBERT model was proposed in [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng
Yan.
The abstract from the paper is the following:
*Pre-trained language models like BERT and its variants have recently achieved impressive performance in various
natural language understanding tasks. However, BERT heavily relies on the global self-attention block and thus suffers
large memory footprint and computation cost. Although all its attention heads query on the whole input sequence for
generating the attention map from a global perspective, we observe some heads only need to learn local dependencies,
which means the existence of computation redundancy. We therefore propose a novel span-based dynamic convolution to
replace these self-attention heads to directly model local dependencies. The novel convolution heads, together with the
rest self-attention heads, form a new mixed attention block that is more efficient at both global and local context
learning. We equip BERT with this mixed attention design and build a ConvBERT model. Experiments have shown that
ConvBERT significantly outperforms BERT and its variants in various downstream tasks, with lower training cost and
fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while
using less than 1/4 training cost. Code and pre-trained models will be released.*
This model was contributed by [abhishek](https://huggingface.co/abhishek). The original implementation can be found
here: https://github.com/yitu-opensource/ConvBert
## Usage tips
ConvBERT training tips are similar to those of BERT. For usage tips refer to [BERT documentation](bert).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## ConvBertConfig
[[autodoc]] ConvBertConfig
## ConvBertTokenizer
[[autodoc]] ConvBertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## ConvBertTokenizerFast
[[autodoc]] ConvBertTokenizerFast
<frameworkcontent>
<pt>
## ConvBertModel
[[autodoc]] ConvBertModel
- forward
## ConvBertForMaskedLM
[[autodoc]] ConvBertForMaskedLM
- forward
## ConvBertForSequenceClassification
[[autodoc]] ConvBertForSequenceClassification
- forward
## ConvBertForMultipleChoice
[[autodoc]] ConvBertForMultipleChoice
- forward
## ConvBertForTokenClassification
[[autodoc]] ConvBertForTokenClassification
- forward
## ConvBertForQuestionAnswering
[[autodoc]] ConvBertForQuestionAnswering
- forward
</pt>
<tf>
## TFConvBertModel
[[autodoc]] TFConvBertModel
- call
## TFConvBertForMaskedLM
[[autodoc]] TFConvBertForMaskedLM
- call
## TFConvBertForSequenceClassification
[[autodoc]] TFConvBertForSequenceClassification
- call
## TFConvBertForMultipleChoice
[[autodoc]] TFConvBertForMultipleChoice
- call
## TFConvBertForTokenClassification
[[autodoc]] TFConvBertForTokenClassification
- call
## TFConvBertForQuestionAnswering
[[autodoc]] TFConvBertForQuestionAnswering
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/convbert.md |
Gradio Demo: blocks_joined
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/cheetah1.jpg https://github.com/gradio-app/gradio/raw/main/demo/blocks_joined/files/cheetah1.jpg
```
```
from time import sleep
import gradio as gr
import os
cheetah = os.path.join(os.path.abspath(''), "files/cheetah1.jpg")
def img(text):
sleep(3)
return [
cheetah,
cheetah,
cheetah,
cheetah,
cheetah,
cheetah,
cheetah,
cheetah,
cheetah,
]
with gr.Blocks(css=".container { max-width: 800px; margin: auto; }") as demo:
gr.Markdown("<h1><center>DALL·E mini</center></h1>")
gr.Markdown(
"DALL·E mini is an AI model that generates images from any prompt you give!"
)
with gr.Group():
with gr.Row(equal_height=True):
text = gr.Textbox(
label="Enter your prompt",
max_lines=1,
container=False,
)
btn = gr.Button("Run", scale=0)
gallery = gr.Gallery(
label="Generated images",
show_label=False,
columns=(1, 3),
height="auto",
)
btn.click(img, inputs=text, outputs=gallery)
if __name__ == "__main__":
demo.launch()
# margin = (TOP, RIGHT, BOTTOM, LEFT)
# rounded = (TOPLEFT, TOPRIGHT, BOTTOMRIGHT, BOTTOMLEFT)
```
| gradio-app/gradio/blob/main/demo/blocks_joined/run.ipynb |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Vision Encoder Decoder Models
## Overview
The [`VisionEncoderDecoderModel`] can be used to initialize an image-to-text model with any
pretrained Transformer-based vision model as the encoder (*e.g.* [ViT](vit), [BEiT](beit), [DeiT](deit), [Swin](swin))
and any pretrained language model as the decoder (*e.g.* [RoBERTa](roberta), [GPT2](gpt2), [BERT](bert), [DistilBERT](distilbert)).
The effectiveness of initializing image-to-text-sequence models with pretrained checkpoints has been shown in (for
example) [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
Zhoujun Li, Furu Wei.
After such a [`VisionEncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like any other models (see the examples below
for more information).
An example application is image captioning, in which the encoder is used to encode the image, after which an autoregressive language model generates
the caption. Another example is optical character recognition. Refer to [TrOCR](trocr), which is an instance of [`VisionEncoderDecoderModel`].
## Randomly initializing `VisionEncoderDecoderModel` from model configurations.
[`VisionEncoderDecoderModel`] can be randomly initialized from an encoder and a decoder config. In the following example, we show how to do this using the default [`ViTModel`] configuration for the encoder
and the default [`BertForCausalLM`] configuration for the decoder.
```python
>>> from transformers import BertConfig, ViTConfig, VisionEncoderDecoderConfig, VisionEncoderDecoderModel
>>> config_encoder = ViTConfig()
>>> config_decoder = BertConfig()
>>> config = VisionEncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
>>> model = VisionEncoderDecoderModel(config=config)
```
## Initialising `VisionEncoderDecoderModel` from a pretrained encoder and a pretrained decoder.
[`VisionEncoderDecoderModel`] can be initialized from a pretrained encoder checkpoint and a pretrained decoder checkpoint. Note that any pretrained Transformer-based vision model, *e.g.* [Swin](swin), can serve as the encoder and both pretrained auto-encoding models, *e.g.* BERT, pretrained causal language models, *e.g.* GPT2, as well as the pretrained decoder part of sequence-to-sequence models, *e.g.* decoder of BART, can be used as the decoder.
Depending on which architecture you choose as the decoder, the cross-attention layers might be randomly initialized.
Initializing [`VisionEncoderDecoderModel`] from a pretrained encoder and decoder checkpoint requires the model to be fine-tuned on a downstream task, as has been shown in [the *Warm-starting-encoder-decoder blog post*](https://huggingface.co/blog/warm-starting-encoder-decoder).
To do so, the `VisionEncoderDecoderModel` class provides a [`VisionEncoderDecoderModel.from_encoder_decoder_pretrained`] method.
```python
>>> from transformers import VisionEncoderDecoderModel
>>> model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "microsoft/swin-base-patch4-window7-224-in22k", "bert-base-uncased"
... )
```
## Loading an existing `VisionEncoderDecoderModel` checkpoint and perform inference.
To load fine-tuned checkpoints of the `VisionEncoderDecoderModel` class, [`VisionEncoderDecoderModel`] provides the `from_pretrained(...)` method just like any other model architecture in Transformers.
To perform inference, one uses the [`generate`] method, which allows to autoregressively generate text. This method supports various forms of decoding, such as greedy, beam search and multinomial sampling.
```python
>>> import requests
>>> from PIL import Image
>>> from transformers import GPT2TokenizerFast, ViTImageProcessor, VisionEncoderDecoderModel
>>> # load a fine-tuned image captioning model and corresponding tokenizer and image processor
>>> model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> tokenizer = GPT2TokenizerFast.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> image_processor = ViTImageProcessor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> # let's perform inference on an image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
>>> # autoregressively generate caption (uses greedy decoding by default)
>>> generated_ids = model.generate(pixel_values)
>>> generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
>>> print(generated_text)
a cat laying on a blanket next to a cat laying on a bed
```
## Loading a PyTorch checkpoint into `TFVisionEncoderDecoderModel`.
[`TFVisionEncoderDecoderModel.from_pretrained`] currently doesn't support initializing the model from a
PyTorch checkpoint. Passing `from_pt=True` to this method will throw an exception. If there are only PyTorch
checkpoints for a particular vision encoder-decoder model, a workaround is:
```python
>>> from transformers import VisionEncoderDecoderModel, TFVisionEncoderDecoderModel
>>> _model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
>>> _model.encoder.save_pretrained("./encoder")
>>> _model.decoder.save_pretrained("./decoder")
>>> model = TFVisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "./encoder", "./decoder", encoder_from_pt=True, decoder_from_pt=True
... )
>>> # This is only for copying some specific attributes of this particular model.
>>> model.config = _model.config
```
## Training
Once the model is created, it can be fine-tuned similar to BART, T5 or any other encoder-decoder model on a dataset of (image, text) pairs.
As you can see, only 2 inputs are required for the model in order to compute a loss: `pixel_values` (which are the
images) and `labels` (which are the `input_ids` of the encoded target sequence).
```python
>>> from transformers import ViTImageProcessor, BertTokenizer, VisionEncoderDecoderModel
>>> from datasets import load_dataset
>>> image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(
... "google/vit-base-patch16-224-in21k", "bert-base-uncased"
... )
>>> model.config.decoder_start_token_id = tokenizer.cls_token_id
>>> model.config.pad_token_id = tokenizer.pad_token_id
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
>>> labels = tokenizer(
... "an image of two cats chilling on a couch",
... return_tensors="pt",
... ).input_ids
>>> # the forward function automatically creates the correct decoder_input_ids
>>> loss = model(pixel_values=pixel_values, labels=labels).loss
```
This model was contributed by [nielsr](https://github.com/nielsrogge). This model's TensorFlow and Flax versions
were contributed by [ydshieh](https://github.com/ydshieh).
## VisionEncoderDecoderConfig
[[autodoc]] VisionEncoderDecoderConfig
<frameworkcontent>
<pt>
## VisionEncoderDecoderModel
[[autodoc]] VisionEncoderDecoderModel
- forward
- from_encoder_decoder_pretrained
</pt>
<tf>
## TFVisionEncoderDecoderModel
[[autodoc]] TFVisionEncoderDecoderModel
- call
- from_encoder_decoder_pretrained
</tf>
<jax>
## FlaxVisionEncoderDecoderModel
[[autodoc]] FlaxVisionEncoderDecoderModel
- __call__
- from_encoder_decoder_pretrained
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/vision-encoder-decoder.md |
Distil*
Author: @VictorSanh
This folder contains the original code used to train Distil* as well as examples showcasing how to use DistilBERT, DistilRoBERTa and DistilGPT2.
**January 20, 2020 - Bug fixing** We have recently discovered and fixed [a bug](https://github.com/huggingface/transformers/commit/48cbf267c988b56c71a2380f748a3e6092ccaed3) in the evaluation of our `run_*.py` scripts that caused the reported metrics to be over-estimated on average. We have updated all the metrics with the latest runs.
**December 6, 2019 - Update** We release **DistilmBERT**: 92% of `bert-base-multilingual-cased` on XNLI. The model supports 104 different languages listed [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages).
**November 19, 2019 - Update** We release German **DistilBERT**: 98.8% of `bert-base-german-dbmdz-cased` on NER tasks.
**October 23, 2019 - Update** We release **DistilRoBERTa**: 95% of `RoBERTa-base`'s performance on GLUE, twice as fast as RoBERTa while being 35% smaller.
**October 3, 2019 - Update** We release our [NeurIPS workshop paper](https://arxiv.org/abs/1910.01108) explaining our approach on **DistilBERT**. It includes updated results and further experiments. We applied the same method to GPT2 and release the weights of **DistilGPT2**. DistilGPT2 is two times faster and 33% smaller than GPT2. **The paper supersedes our [previous blogpost](https://medium.com/huggingface/distilbert-8cf3380435b5) with a different distillation loss and better performances. Please use the paper as a reference when comparing/reporting results on DistilBERT.**
**September 19, 2019 - Update:** We fixed bugs in the code and released an updated version of the weights trained with a modification of the distillation loss. DistilBERT now reaches 99% of `BERT-base`'s performance on GLUE, and 86.9 F1 score on SQuAD v1.1 dev set (compared to 88.5 for `BERT-base`). We will publish a formal write-up of our approach in the near future!
## What is Distil*
Distil* is a class of compressed models that started with DistilBERT. DistilBERT stands for Distilled-BERT. DistilBERT is a small, fast, cheap and light Transformer model based on Bert architecture. It has 40% less parameters than `bert-base-uncased`, runs 60% faster while preserving 97% of BERT's performances as measured on the GLUE language understanding benchmark. DistilBERT is trained using knowledge distillation, a technique to compress a large model called the teacher into a smaller model called the student. By distillating Bert, we obtain a smaller Transformer model that bears a lot of similarities with the original BERT model while being lighter, smaller and faster to run. DistilBERT is thus an interesting option to put large-scaled trained Transformer model into production.
We have applied the same method to other Transformer architectures and released the weights:
- GPT2: on the [WikiText-103](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/) benchmark, GPT2 reaches a perplexity on the test set of 16.3 compared to 21.1 for **DistilGPT2** (after fine-tuning on the train set).
- RoBERTa: **DistilRoBERTa** reaches 95% of `RoBERTa-base`'s performance on GLUE while being twice faster and 35% smaller.
- German BERT: **German DistilBERT** reaches 99% of `bert-base-german-dbmdz-cased`'s performance on German NER (CoNLL-2003).
- Multilingual BERT: **DistilmBERT** reaches 92% of Multilingual BERT's performance on XNLI while being twice faster and 25% smaller. The model supports 104 languages listed [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages).
For more information on DistilBERT, please refer to our [NeurIPS workshop paper](https://arxiv.org/abs/1910.01108).
Here are the results on the dev sets of GLUE:
| Model | Macro-score | CoLA | MNLI | MRPC | QNLI | QQP | RTE | SST-2| STS-B| WNLI |
| :---: | :---: | :---:| :---:| :---:| :---:| :---:| :---:| :---:| :---:| :---: |
| BERT-base-uncased | **79.5** | 56.3 | 84.7 | 88.6 | 91.8 | 89.6 | 69.3 | 92.7 | 89.0 | 53.5 |
| DistilBERT-base-uncased | **77.0** | 51.3 | 82.1 | 87.5 | 89.2 | 88.5 | 59.9 | 91.3 | 86.9 | 56.3 |
| BERT-base-cased | **78.2** | 58.2 | 83.9 | 87.8 | 91.0 | 89.2 | 66.1 | 91.7 | 89.2 | 46.5 |
| DistilBERT-base-cased | **75.9** | 47.2 | 81.5 | 85.6 | 88.2 | 87.8 | 60.6 | 90.4 | 85.5 | 56.3 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| RoBERTa-base (reported) | **83.2**/**86.4**<sup>2</sup> | 63.6 | 87.6 | 90.2 | 92.8 | 91.9 | 78.7 | 94.8 | 91.2 | 57.7<sup>3</sup> |
| DistilRoBERTa<sup>1</sup> | **79.0**/**82.3**<sup>2</sup> | 59.3 | 84.0 | 86.6 | 90.8 | 89.4 | 67.9 | 92.5 | 88.3 | 52.1 |
<sup>1</sup> We did not use the MNLI checkpoint for fine-tuning but directly perform transfer learning on the pre-trained DistilRoBERTa.
<sup>2</sup> Macro-score computed without WNLI.
<sup>3</sup> We compute this score ourselves for completeness.
Here are the results on the *test* sets for 6 of the languages available in XNLI. The results are computed in the zero shot setting (trained on the English portion and evaluated on the target language portion):
| Model | English | Spanish | Chinese | German | Arabic | Urdu |
| :---: | :---: | :---: | :---: | :---: | :---: | :---:|
| mBERT base cased (computed) | 82.1 | 74.6 | 69.1 | 72.3 | 66.4 | 58.5 |
| mBERT base uncased (reported)| 81.4 | 74.3 | 63.8 | 70.5 | 62.1 | 58.3 |
| DistilmBERT | 78.2 | 69.1 | 64.0 | 66.3 | 59.1 | 54.7 |
## Setup
This part of the library has only be tested with Python3.6+. There are few specific dependencies to install before launching a distillation, you can install them with the command `pip install -r requirements.txt`.
**Important note:** The training scripts have been updated to support PyTorch v1.2.0 (there are breaking changes compared to v1.1.0).
## How to use DistilBERT
Transformers includes five pre-trained Distil* models, currently only provided for English and German (we are investigating the possibility to train and release a multilingual version of DistilBERT):
- `distilbert-base-uncased`: DistilBERT English language model pretrained on the same data used to pretrain Bert (concatenation of the Toronto Book Corpus and full English Wikipedia) using distillation with the supervision of the `bert-base-uncased` version of Bert. The model has 6 layers, 768 dimension and 12 heads, totalizing 66M parameters.
- `distilbert-base-uncased-distilled-squad`: A finetuned version of `distilbert-base-uncased` finetuned using (a second step of) knowledge distillation on SQuAD 1.0. This model reaches a F1 score of 86.9 on the dev set (for comparison, Bert `bert-base-uncased` version reaches a 88.5 F1 score).
- `distilbert-base-cased`: DistilBERT English language model pretrained on the same data used to pretrain Bert (concatenation of the Toronto Book Corpus and full English Wikipedia) using distillation with the supervision of the `bert-base-cased` version of Bert. The model has 6 layers, 768 dimension and 12 heads, totalizing 65M parameters.
- `distilbert-base-cased-distilled-squad`: A finetuned version of `distilbert-base-cased` finetuned using (a second step of) knowledge distillation on SQuAD 1.0. This model reaches a F1 score of 87.1 on the dev set (for comparison, Bert `bert-base-cased` version reaches a 88.7 F1 score).
- `distilbert-base-german-cased`: DistilBERT German language model pretrained on 1/2 of the data used to pretrain Bert using distillation with the supervision of the `bert-base-german-dbmdz-cased` version of German DBMDZ Bert. For NER tasks the model reaches a F1 score of 83.49 on the CoNLL-2003 test set (for comparison, `bert-base-german-dbmdz-cased` reaches a 84.52 F1 score), and a F1 score of 85.23 on the GermEval 2014 test set (`bert-base-german-dbmdz-cased` reaches a 86.89 F1 score).
- `distilgpt2`: DistilGPT2 English language model pretrained with the supervision of `gpt2` (the smallest version of GPT2) on [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/), a reproduction of OpenAI's WebText dataset. The model has 6 layers, 768 dimension and 12 heads, totalizing 82M parameters (compared to 124M parameters for GPT2). On average, DistilGPT2 is two times faster than GPT2.
- `distilroberta-base`: DistilRoBERTa English language model pretrained with the supervision of `roberta-base` solely on [OpenWebTextCorpus](https://skylion007.github.io/OpenWebTextCorpus/), a reproduction of OpenAI's WebText dataset (it is ~4 times less training data than the teacher RoBERTa). The model has 6 layers, 768 dimension and 12 heads, totalizing 82M parameters (compared to 125M parameters for RoBERTa-base). On average DistilRoBERTa is twice as fast as Roberta-base.
- `distilbert-base-multilingual-cased`: DistilmBERT multilingual model pretrained with the supervision of `bert-base-multilingual-cased` on the concatenation of Wikipedia in 104 different languages. The model supports the 104 languages listed [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages). The model has 6 layers, 768 dimension and 12 heads, totalizing 134M parameters (compared to 177M parameters for mBERT-base). On average DistilmBERT is twice as fast as mBERT-base.
Using DistilBERT is very similar to using BERT. DistilBERT share the same tokenizer as BERT's `bert-base-uncased` even though we provide a link to this tokenizer under the `DistilBertTokenizer` name to have a consistent naming between the library models.
```python
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-cased')
model = DistilBertModel.from_pretrained('distilbert-base-cased')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
```
Similarly, using the other Distil* models simply consists in calling the base classes with a different pretrained checkpoint:
- DistilBERT uncased: `model = DistilBertModel.from_pretrained('distilbert-base-uncased')`
- DistilGPT2: `model = GPT2Model.from_pretrained('distilgpt2')`
- DistilRoBERTa: `model = RobertaModel.from_pretrained('distilroberta-base')`
- DistilmBERT: `model = DistilBertModel.from_pretrained('distilbert-base-multilingual-cased')`
## How to train Distil*
In the following, we will explain how you can train DistilBERT.
### A. Preparing the data
The weights we release are trained using a concatenation of Toronto Book Corpus and English Wikipedia (same training data as the English version of BERT).
To avoid processing the data several time, we do it once and for all before the training. From now on, will suppose that you have a text file `dump.txt` which contains one sequence per line (a sequence being composed of one of several coherent sentences).
First, we will binarize the data, i.e. tokenize the data and convert each token in an index in our model's vocabulary.
```bash
python scripts/binarized_data.py \
--file_path data/dump.txt \
--tokenizer_type bert \
--tokenizer_name bert-base-uncased \
--dump_file data/binarized_text
```
Our implementation of masked language modeling loss follows [XLM](https://github.com/facebookresearch/XLM)'s one and smooths the probability of masking with a factor that put more emphasis on rare words. Thus we count the occurrences of each tokens in the data:
```bash
python scripts/token_counts.py \
--data_file data/binarized_text.bert-base-uncased.pickle \
--token_counts_dump data/token_counts.bert-base-uncased.pickle \
--vocab_size 30522
```
### B. Training
Training with distillation is really simple once you have pre-processed the data:
```bash
python train.py \
--student_type distilbert \
--student_config training_configs/distilbert-base-uncased.json \
--teacher_type bert \
--teacher_name bert-base-uncased \
--alpha_ce 5.0 --alpha_mlm 2.0 --alpha_cos 1.0 --alpha_clm 0.0 --mlm \
--freeze_pos_embs \
--dump_path serialization_dir/my_first_training \
--data_file data/binarized_text.bert-base-uncased.pickle \
--token_counts data/token_counts.bert-base-uncased.pickle \
--force # overwrites the `dump_path` if it already exists.
```
By default, this will launch a training on a single GPU (even if more are available on the cluster). Other parameters are available in the command line, please look in `train.py` or run `python train.py --help` to list them.
We highly encourage you to use distributed training for training DistilBERT as the training corpus is quite large. Here's an example that runs a distributed training on a single node having 4 GPUs:
```bash
export NODE_RANK=0
export N_NODES=1
export N_GPU_NODE=4
export WORLD_SIZE=4
export MASTER_PORT=<AN_OPEN_PORT>
export MASTER_ADDR=<I.P.>
pkill -f 'python -u train.py'
python -m torch.distributed.launch \
--nproc_per_node=$N_GPU_NODE \
--nnodes=$N_NODES \
--node_rank $NODE_RANK \
--master_addr $MASTER_ADDR \
--master_port $MASTER_PORT \
train.py \
--force \
--n_gpu $WORLD_SIZE \
--student_type distilbert \
--student_config training_configs/distilbert-base-uncased.json \
--teacher_type bert \
--teacher_name bert-base-uncased \
--alpha_ce 0.33 --alpha_mlm 0.33 --alpha_cos 0.33 --alpha_clm 0.0 --mlm \
--freeze_pos_embs \
--dump_path serialization_dir/my_first_training \
--data_file data/binarized_text.bert-base-uncased.pickle \
--token_counts data/token_counts.bert-base-uncased.pickle
```
**Tips:** Starting distilled training with good initialization of the model weights is crucial to reach decent performance. In our experiments, we initialized our model from a few layers of the teacher (Bert) itself! Please refer to `scripts/extract.py` and `scripts/extract_distilbert.py` to create a valid initialization checkpoint and use `--student_pretrained_weights` argument to use this initialization for the distilled training!
Happy distillation!
## Citation
If you find the resource useful, you should cite the following paper:
```
@inproceedings{sanh2019distilbert,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Sanh, Victor and Debut, Lysandre and Chaumond, Julien and Wolf, Thomas},
booktitle={NeurIPS EMC^2 Workshop},
year={2019}
}
```
| huggingface/transformers/blob/main/examples/research_projects/distillation/README.md |
How to propose a Flax/JAX + Transformers project
Great that you've opened this document!
While we at 🤗 are proposing a couple of projects, we strongly
believe that the community can come up with much more **creative**, **fun**, and
**impactful** projects on their own. This being said, we are really looking forward
to seeing your project proposal!
## What a project should be about
The proposed project should fall into the machine learning fields of **Natural Language Processing (NLP)** and/or **Computer Vision (CV)** (possibly also **Speech Recognition (ASR)** depending on whether Speech Recognition models are available in Flax in due time) and aim at solving a specific task.
Possible tasks can belong to:
* text classification
* text generation
* image recognition
* image processing
* image captioning
* audio classification
* and other tasks you can think of!
The clearer a task is defined, the better your project proposal is.
*E.g.* "Using a T5 model to learn grammar correction in French" or "Adapting a pre-trained CLIP model for zero-shot image classification in Spanish" are **well-defined and clear** project proposals, while something like "Train a language model" or "Image classification" are **too vague**.
There is no limit to your creativity as long as the project is feasible and ethical.
The more creative & specific your project proposal, the more interesting it will be,
and the more likely will you find motivated team members to work on your project!
To get an idea of how to formulate your project proposals, you can browse through
existing project proposals on the [forum](https://discuss.huggingface.co/c/flax-jax-projects/22).
## How to submit a project proposal
First, you should make sure that you are [logged in](https://huggingface.co/login?sso=bm9uY2U9OTRlNjZjZmZhYjMwMmJmMWMyYjc5MmFiMTMyMzY5ODYmcmV0dXJuX3Nzb191cmw9aHR0cHMlM0ElMkYlMkZkaXNjdXNzLmh1Z2dpbmdmYWNlLmNvJTJGc2Vzc2lvbiUyRnNzb19sb2dpbg%3D%3D&sig=429ad8924bcb33c40f9823027ea749abb55d393f4f58924f36a2dba3ab0a48da) with your Hugging Face account on the forum.
Second, make sure that your project idea doesn't already exist by checking [existing projects](https://discuss.huggingface.co/c/flax-jax-projects/22).
If your project already exists - great! This means that you can comment and improve
the existing idea and join the project to form a team! If your project idea already
exists for a different language, feel free to submit the same project idea, just in
a different language.
Third, having ensured that your project doesn't exist, click on the *"New Topic"*
button on the [Flax/JAX Projects Forum category](https://discuss.huggingface.co/c/flax-jax-projects/22) to create a new project proposal.
Fourth, make sure that your project proposal includes the following information:
1. *A clear description of the project*
2. *In which language should the project be conducted?* English, German, Chinese, ...? It can also be a multi-lingual project
3. *Which model should be used?* If you want to adapt an existing model, you can add the link to one of the 4000 available checkpoints in JAX [here](https://huggingface.co/models?filter=jax) If you want to train a model from scratch, you can simply state the model architecture to be used, *e.g.* BERT, CLIP, etc. You can also base your project on a model that is not part of transformers. For an overview of libraries based on JAX, you can take a look at [awesome-jax](https://github.com/n2cholas/awesome-jax#awesome-jax-). **Note** that for a project that is not based on Transformers it will be more difficult for the 🤗 team to help you. Also have a look at the section [Quickstart Flax & Jax in Transformers](https://github.com/huggingface/transformers/tree/main/examples/research_projects/jax-projects#quickstart-flax-and-jax-in-transformers) to see what model architectures are currently supported in 🤗 Transformers.
4. *What data should be used?* It is important to state at least what kind of data you would like to use. Ideally, you can already point to publicly available data or a dataset in the 🤗 Datasets library.
5. *Are similar training scripts available in Flax/JAX?* It would be important to find similar training scripts that already exist in Flax/JAX. *E.g.* if you are working on a Seq-to-Seq task, you can make use of the [`run_summarization_flax.py`](https://github.com/huggingface/transformers/blob/main/examples/flax/summarization/run_summarization_flax.py) script which is very similar to any seq2seq training. Also have a look at the section [Quickstart Flax & Jax in Transformers](https://github.com/huggingface/transformers/tree/main/examples/research_projects/jax-projects#quickstart-flax-and-jax-in-transformers) to see what training scripts are currently supported in 🤗 Transformers.
6. *(Optionally) What are possible challenges?* List possible difficulties with your project. *E.g.* If you know that training convergence usually takes a lot of time, it is worth stating this here!
7. *(Optionally) What is the desired project outcome?* - How would you like to demo your project? One could *e.g.* create a Streamlit application.
8. *(Optionally) Links to read upon* - Can you provide any links that would help the reader to better understand your project idea?
Feel free to copy-paste the following format for your project proposal and fill out the respective sections:
```
# <FILL ME: Name of project>
<FILL ME: A clear description of the project>
## 2. Language
The model will be trained in <FILL ME: which language?>.
## 3. Model
<FILL ME: 3. Which model should be used?>
## 4. Datasets
<FILL ME: 4. Which data should be used?>
Possible links to publicly available datasets include:
- <FILL ME: Link 1 to dataset>
- <FILL ME: Link 2 to dataset>
- <FILL ME: Link 3 to dataset>
## 5. Training scripts
<FILL ME: 5. Are there publicly available training scripts that can be used/tweaked for the project?>
We can make use of <FILL ME: link to training script> to train the model.>
## 6. (Optional) Challenges
<(Optionally) FILL ME: 6. What are possible challenges?>
## 7. (Optional) Desired project outcome
<(Optionally) FILL ME: 7. What is the desired project outcome? A demo?>
## 8. (Optional) Reads
The following links can be useful to better understand the project and
what has previously been done.
- <FILL ME: Link 1 to read>
- <FILL ME: Link 2 to read>
- <FILL ME: Link 3 to read>
```
To see how a proposed project looks like, please have a look at submitted project
proposals [here](https://discuss.huggingface.co/c/flax-jax-projects/22).
## Will my project proposal be selected?
Having submitted a project proposal, you can now promote your idea in the Slack channel `#flax-jax-community-week` to try to convince other participants to join your project!
Once other people have joined your project, one of the organizers (`@Suzana, @valhalla, @osanseviero, @patrickvonplaten`) will officially create a team for your project and add your project to [this google sheet](https://docs.google.com/spreadsheets/d/1GpHebL7qrwJOc9olTpIPgjf8vOS0jNb6zR_B8x_Jtik/edit?usp=sharing).
| huggingface/transformers/blob/main/examples/research_projects/jax-projects/HOW_TO_PROPOSE_PROJECT.md |
Load
Your data can be stored in various places; they can be on your local machine's disk, in a Github repository, and in in-memory data structures like Python dictionaries and Pandas DataFrames. Wherever a dataset is stored, 🤗 Datasets can help you load it.
This guide will show you how to load a dataset from:
- The Hub without a dataset loading script
- Local loading script
- Local files
- In-memory data
- Offline
- A specific slice of a split
For more details specific to loading other dataset modalities, take a look at the <a class="underline decoration-pink-400 decoration-2 font-semibold" href="./audio_load">load audio dataset guide</a>, the <a class="underline decoration-yellow-400 decoration-2 font-semibold" href="./image_load">load image dataset guide</a>, or the <a class="underline decoration-green-400 decoration-2 font-semibold" href="./nlp_load">load text dataset guide</a>.
<a id='load-from-the-hub'></a>
## Hugging Face Hub
Datasets are loaded from a dataset loading script that downloads and generates the dataset. However, you can also load a dataset from any dataset repository on the Hub without a loading script! Begin by [creating a dataset repository](share#create-the-repository) and upload your data files. Now you can use the [`load_dataset`] function to load the dataset.
For example, try loading the files from this [demo repository](https://huggingface.co/datasets/lhoestq/demo1) by providing the repository namespace and dataset name. This dataset repository contains CSV files, and the code below loads the dataset from the CSV files:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("lhoestq/demo1")
```
Some datasets may have more than one version based on Git tags, branches, or commits. Use the `revision` parameter to specify the dataset version you want to load:
```py
>>> dataset = load_dataset(
... "lhoestq/custom_squad",
... revision="main" # tag name, or branch name, or commit hash
... )
```
<Tip>
Refer to the [Upload a dataset to the Hub](./upload_dataset) tutorial for more details on how to create a dataset repository on the Hub, and how to upload your data files.
</Tip>
A dataset without a loading script by default loads all the data into the `train` split. Use the `data_files` parameter to map data files to splits like `train`, `validation` and `test`:
```py
>>> data_files = {"train": "train.csv", "test": "test.csv"}
>>> dataset = load_dataset("namespace/your_dataset_name", data_files=data_files)
```
<Tip warning={true}>
If you don't specify which data files to use, [`load_dataset`] will return all the data files. This can take a long time if you load a large dataset like C4, which is approximately 13TB of data.
</Tip>
You can also load a specific subset of the files with the `data_files` or `data_dir` parameter. These parameters can accept a relative path which resolves to the base path corresponding to where the dataset is loaded from.
```py
>>> from datasets import load_dataset
# load files that match the grep pattern
>>> c4_subset = load_dataset("allenai/c4", data_files="en/c4-train.0000*-of-01024.json.gz")
# load dataset from the en directory on the Hub
>>> c4_subset = load_dataset("allenai/c4", data_dir="en")
```
The `split` parameter can also map a data file to a specific split:
```py
>>> data_files = {"validation": "en/c4-validation.*.json.gz"}
>>> c4_validation = load_dataset("allenai/c4", data_files=data_files, split="validation")
```
## Local loading script
You may have a 🤗 Datasets loading script locally on your computer. In this case, load the dataset by passing one of the following paths to [`load_dataset`]:
- The local path to the loading script file.
- The local path to the directory containing the loading script file (only if the script file has the same name as the directory).
Pass `trust_remote_code=True` to allow 🤗 Datasets to execute the loading script:
```py
>>> dataset = load_dataset("path/to/local/loading_script/loading_script.py", split="train", trust_remote_code=True)
>>> dataset = load_dataset("path/to/local/loading_script", split="train", trust_remote_code=True) # equivalent because the file has the same name as the directory
```
### Edit loading script
You can also edit a loading script from the Hub to add your own modifications. Download the dataset repository locally so any data files referenced by a relative path in the loading script can be loaded:
```bash
git clone https://huggingface.co/datasets/eli5
```
Make your edits to the loading script and then load it by passing its local path to [`~datasets.load_dataset`]:
```py
>>> from datasets import load_dataset
>>> eli5 = load_dataset("path/to/local/eli5")
```
## Local and remote files
Datasets can be loaded from local files stored on your computer and from remote files. The datasets are most likely stored as a `csv`, `json`, `txt` or `parquet` file. The [`load_dataset`] function can load each of these file types.
### CSV
🤗 Datasets can read a dataset made up of one or several CSV files (in this case, pass your CSV files as a list):
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("csv", data_files="my_file.csv")
```
<Tip>
For more details, check out the [how to load tabular datasets from CSV files](tabular_load#csv-files) guide.
</Tip>
### JSON
JSON files are loaded directly with [`load_dataset`] as shown below:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("json", data_files="my_file.json")
```
JSON files have diverse formats, but we think the most efficient format is to have multiple JSON objects; each line represents an individual row of data. For example:
```json
{"a": 1, "b": 2.0, "c": "foo", "d": false}
{"a": 4, "b": -5.5, "c": null, "d": true}
```
Another JSON format you may encounter is a nested field, in which case you'll need to specify the `field` argument as shown in the following:
```py
{"version": "0.1.0",
"data": [{"a": 1, "b": 2.0, "c": "foo", "d": false},
{"a": 4, "b": -5.5, "c": null, "d": true}]
}
>>> from datasets import load_dataset
>>> dataset = load_dataset("json", data_files="my_file.json", field="data")
```
To load remote JSON files via HTTP, pass the URLs instead:
```py
>>> base_url = "https://rajpurkar.github.io/SQuAD-explorer/dataset/"
>>> dataset = load_dataset("json", data_files={"train": base_url + "train-v1.1.json", "validation": base_url + "dev-v1.1.json"}, field="data")
```
While these are the most common JSON formats, you'll see other datasets that are formatted differently. 🤗 Datasets recognizes these other formats and will fallback accordingly on the Python JSON loading methods to handle them.
### Parquet
Parquet files are stored in a columnar format, unlike row-based files like a CSV. Large datasets may be stored in a Parquet file because it is more efficient and faster at returning your query.
To load a Parquet file:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("parquet", data_files={'train': 'train.parquet', 'test': 'test.parquet'})
```
To load remote Parquet files via HTTP, pass the URLs instead:
```py
>>> base_url = "https://storage.googleapis.com/huggingface-nlp/cache/datasets/wikipedia/20200501.en/1.0.0/"
>>> data_files = {"train": base_url + "wikipedia-train.parquet"}
>>> wiki = load_dataset("parquet", data_files=data_files, split="train")
```
### Arrow
Arrow files are stored in an in-memory columnar format, unlike row-based formats like CSV and uncompressed formats like Parquet.
To load an Arrow file:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("arrow", data_files={'train': 'train.arrow', 'test': 'test.arrow'})
```
To load remote Arrow files via HTTP, pass the URLs instead:
```py
>>> base_url = "https://storage.googleapis.com/huggingface-nlp/cache/datasets/wikipedia/20200501.en/1.0.0/"
>>> data_files = {"train": base_url + "wikipedia-train.arrow"}
>>> wiki = load_dataset("arrow", data_files=data_files, split="train")
```
Arrow is the file format used by 🤗 Datasets under the hood, therefore you can load a local Arrow file using [`Dataset.from_file`] directly:
```py
>>> from datasets import Dataset
>>> dataset = Dataset.from_file("data.arrow")
```
Unlike [`load_dataset`], [`Dataset.from_file`] memory maps the Arrow file without preparing the dataset in the cache, saving you disk space.
The cache directory to store intermediate processing results will be the Arrow file directory in that case.
For now only the Arrow streaming format is supported. The Arrow IPC file format (also known as Feather V2) is not supported.
### SQL
Read database contents with [`~datasets.Dataset.from_sql`] by specifying the URI to connect to your database. You can read both table names and queries:
```py
>>> from datasets import Dataset
# load entire table
>>> dataset = Dataset.from_sql("data_table_name", con="sqlite:///sqlite_file.db")
# load from query
>>> dataset = Dataset.from_sql("SELECT text FROM table WHERE length(text) > 100 LIMIT 10", con="sqlite:///sqlite_file.db")
```
<Tip>
For more details, check out the [how to load tabular datasets from SQL databases](tabular_load#databases) guide.
</Tip>
### WebDataset
The [WebDataset](https://github.com/webdataset/webdataset) format is based on TAR archives and is suitable for big image datasets.
Because of their size, WebDatasets are generally loaded in streaming mode (using `streaming=True`).
You can load a WebDataset like this:
```python
>>> from datasets import load_dataset
>>>
>>> path = "path/to/train/*.tar"
>>> dataset = load_dataset("webdataset", data_files={"train": path}, split="train", streaming=True)
```
To load remote WebDatasets via HTTP, pass the URLs instead:
```python
>>> from datasets import load_dataset
>>>
>>> base_url = "https://huggingface.co/datasets/lhoestq/small-publaynet-wds/resolve/main/publaynet-train-{i:06d}.tar"
>>> urls = [base_url.format(i=i) for i in range(4)]
>>> dataset = load_dataset("webdataset", data_files={"train": urls}, split="train", streaming=True)
```
## Multiprocessing
When a dataset is made of several files (that we call "shards"), it is possible to significantly speed up the dataset downloading and preparation step.
You can choose how many processes you'd like to use to prepare a dataset in parallel using `num_proc`.
In this case, each process is given a subset of shards to prepare:
```python
from datasets import load_dataset
imagenet = load_dataset("imagenet-1k", num_proc=8)
ml_librispeech_spanish = load_dataset("facebook/multilingual_librispeech", "spanish", num_proc=8)
```
## In-memory data
🤗 Datasets will also allow you to create a [`Dataset`] directly from in-memory data structures like Python dictionaries and Pandas DataFrames.
### Python dictionary
Load Python dictionaries with [`~Dataset.from_dict`]:
```py
>>> from datasets import Dataset
>>> my_dict = {"a": [1, 2, 3]}
>>> dataset = Dataset.from_dict(my_dict)
```
### Python list of dictionaries
Load a list of Python dictionaries with [`~Dataset.from_list`]:
```py
>>> from datasets import Dataset
>>> my_list = [{"a": 1}, {"a": 2}, {"a": 3}]
>>> dataset = Dataset.from_list(my_list)
```
### Python generator
Create a dataset from a Python generator with [`~Dataset.from_generator`]:
```py
>>> from datasets import Dataset
>>> def my_gen():
... for i in range(1, 4):
... yield {"a": i}
...
>>> dataset = Dataset.from_generator(my_gen)
```
This approach supports loading data larger than available memory.
You can also define a sharded dataset by passing lists to `gen_kwargs`:
```py
>>> def gen(shards):
... for shard in shards:
... with open(shard) as f:
... for line in f:
... yield {"line": line}
...
>>> shards = [f"data{i}.txt" for i in range(32)]
>>> ds = IterableDataset.from_generator(gen, gen_kwargs={"shards": shards})
>>> ds = ds.shuffle(seed=42, buffer_size=10_000) # shuffles the shards order + uses a shuffle buffer
>>> from torch.utils.data import DataLoader
>>> dataloader = DataLoader(ds.with_format("torch"), num_workers=4) # give each worker a subset of 32/4=8 shards
```
### Pandas DataFrame
Load Pandas DataFrames with [`~Dataset.from_pandas`]:
```py
>>> from datasets import Dataset
>>> import pandas as pd
>>> df = pd.DataFrame({"a": [1, 2, 3]})
>>> dataset = Dataset.from_pandas(df)
```
<Tip>
For more details, check out the [how to load tabular datasets from Pandas DataFrames](tabular_load#pandas-dataframes) guide.
</Tip>
## Offline
Even if you don't have an internet connection, it is still possible to load a dataset. As long as you've downloaded a dataset from the Hub repository before, it should be cached. This means you can reload the dataset from the cache and use it offline.
If you know you won't have internet access, you can run 🤗 Datasets in full offline mode. This saves time because instead of waiting for the Dataset builder download to time out, 🤗 Datasets will look directly in the cache. Set the environment variable `HF_DATASETS_OFFLINE` to `1` to enable full offline mode.
## Slice splits
You can also choose only to load specific slices of a split. There are two options for slicing a split: using strings or the [`ReadInstruction`] API. Strings are more compact and readable for simple cases, while [`ReadInstruction`] is easier to use with variable slicing parameters.
Concatenate a `train` and `test` split by:
```py
>>> train_test_ds = datasets.load_dataset("bookcorpus", split="train+test")
===STRINGAPI-READINSTRUCTION-SPLIT===
>>> ri = datasets.ReadInstruction("train") + datasets.ReadInstruction("test")
>>> train_test_ds = datasets.load_dataset("bookcorpus", split=ri)
```
Select specific rows of the `train` split:
```py
>>> train_10_20_ds = datasets.load_dataset("bookcorpus", split="train[10:20]")
===STRINGAPI-READINSTRUCTION-SPLIT===
>>> train_10_20_ds = datasets.load_dataset("bookcorpu", split=datasets.ReadInstruction("train", from_=10, to=20, unit="abs"))
```
Or select a percentage of a split with:
```py
>>> train_10pct_ds = datasets.load_dataset("bookcorpus", split="train[:10%]")
===STRINGAPI-READINSTRUCTION-SPLIT===
>>> train_10_20_ds = datasets.load_dataset("bookcorpus", split=datasets.ReadInstruction("train", to=10, unit="%"))
```
Select a combination of percentages from each split:
```py
>>> train_10_80pct_ds = datasets.load_dataset("bookcorpus", split="train[:10%]+train[-80%:]")
===STRINGAPI-READINSTRUCTION-SPLIT===
>>> ri = (datasets.ReadInstruction("train", to=10, unit="%") + datasets.ReadInstruction("train", from_=-80, unit="%"))
>>> train_10_80pct_ds = datasets.load_dataset("bookcorpus", split=ri)
```
Finally, you can even create cross-validated splits. The example below creates 10-fold cross-validated splits. Each validation dataset is a 10% chunk, and the training dataset makes up the remaining complementary 90% chunk:
```py
>>> val_ds = datasets.load_dataset("bookcorpus", split=[f"train[{k}%:{k+10}%]" for k in range(0, 100, 10)])
>>> train_ds = datasets.load_dataset("bookcorpus", split=[f"train[:{k}%]+train[{k+10}%:]" for k in range(0, 100, 10)])
===STRINGAPI-READINSTRUCTION-SPLIT===
>>> val_ds = datasets.load_dataset("bookcorpus", [datasets.ReadInstruction("train", from_=k, to=k+10, unit="%") for k in range(0, 100, 10)])
>>> train_ds = datasets.load_dataset("bookcorpus", [(datasets.ReadInstruction("train", to=k, unit="%") + datasets.ReadInstruction("train", from_=k+10, unit="%")) for k in range(0, 100, 10)])
```
### Percent slicing and rounding
The default behavior is to round the boundaries to the nearest integer for datasets where the requested slice boundaries do not divide evenly by 100. As shown below, some slices may contain more examples than others. For instance, if the following train split includes 999 records, then:
```py
# 19 records, from 500 (included) to 519 (excluded).
>>> train_50_52_ds = datasets.load_dataset("bookcorpus", split="train[50%:52%]")
# 20 records, from 519 (included) to 539 (excluded).
>>> train_52_54_ds = datasets.load_dataset("bookcorpus", split="train[52%:54%]")
```
If you want equal sized splits, use `pct1_dropremainder` rounding instead. This treats the specified percentage boundaries as multiples of 1%.
```py
# 18 records, from 450 (included) to 468 (excluded).
>>> train_50_52pct1_ds = datasets.load_dataset("bookcorpus", split=datasets.ReadInstruction("train", from_=50, to=52, unit="%", rounding="pct1_dropremainder"))
# 18 records, from 468 (included) to 486 (excluded).
>>> train_52_54pct1_ds = datasets.load_dataset("bookcorpus", split=datasets.ReadInstruction("train",from_=52, to=54, unit="%", rounding="pct1_dropremainder"))
# Or equivalently:
>>> train_50_52pct1_ds = datasets.load_dataset("bookcorpus", split="train[50%:52%](pct1_dropremainder)")
>>> train_52_54pct1_ds = datasets.load_dataset("bookcorpus", split="train[52%:54%](pct1_dropremainder)")
```
<Tip warning={true}>
`pct1_dropremainder` rounding may truncate the last examples in a dataset if the number of examples in your dataset don't divide evenly by 100.
</Tip>
<a id='troubleshoot'></a>
## Troubleshooting
Sometimes, you may get unexpected results when you load a dataset. Two of the most common issues you may encounter are manually downloading a dataset and specifying features of a dataset.
### Manual download
Certain datasets require you to manually download the dataset files due to licensing incompatibility or if the files are hidden behind a login page. This causes [`load_dataset`] to throw an `AssertionError`. But 🤗 Datasets provides detailed instructions for downloading the missing files. After you've downloaded the files, use the `data_dir` argument to specify the path to the files you just downloaded.
For example, if you try to download a configuration from the [MATINF](https://huggingface.co/datasets/matinf) dataset:
```py
>>> dataset = load_dataset("matinf", "summarization")
Downloading and preparing dataset matinf/summarization (download: Unknown size, generated: 246.89 MiB, post-processed: Unknown size, total: 246.89 MiB) to /root/.cache/huggingface/datasets/matinf/summarization/1.0.0/82eee5e71c3ceaf20d909bca36ff237452b4e4ab195d3be7ee1c78b53e6f540e...
AssertionError: The dataset matinf with config summarization requires manual data.
Please follow the manual download instructions: To use MATINF you have to download it manually. Please fill this google form (https://forms.gle/nkH4LVE4iNQeDzsc9). You will receive a download link and a password once you complete the form. Please extract all files in one folder and load the dataset with: *datasets.load_dataset('matinf', data_dir='path/to/folder/folder_name')*.
Manual data can be loaded with `datasets.load_dataset(matinf, data_dir='<path/to/manual/data>')
```
If you've already downloaded a dataset from the *Hub with a loading script* to your computer, then you need to pass an absolute path to the `data_dir` or `data_files` parameter to load that dataset. Otherwise, if you pass a relative path, [`load_dataset`] will load the directory from the repository on the Hub instead of the local directory.
### Specify features
When you create a dataset from local files, the [`Features`] are automatically inferred by [Apache Arrow](https://arrow.apache.org/docs/). However, the dataset's features may not always align with your expectations, or you may want to define the features yourself. The following example shows how you can add custom labels with the [`ClassLabel`] feature.
Start by defining your own labels with the [`Features`] class:
```py
>>> class_names = ["sadness", "joy", "love", "anger", "fear", "surprise"]
>>> emotion_features = Features({'text': Value('string'), 'label': ClassLabel(names=class_names)})
```
Next, specify the `features` parameter in [`load_dataset`] with the features you just created:
```py
>>> dataset = load_dataset('csv', data_files=file_dict, delimiter=';', column_names=['text', 'label'], features=emotion_features)
```
Now when you look at your dataset features, you can see it uses the custom labels you defined:
```py
>>> dataset['train'].features
{'text': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], names_file=None, id=None)}
```
## Metrics
<Tip warning={true}>
Metrics is deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at the library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, you can find more tools for evaluating models and datasets.
</Tip>
When the metric you want to use is not supported by 🤗 Datasets, you can write and use your own metric script. Load your metric by providing the path to your local metric loading script:
```py
>>> from datasets import load_metric
>>> metric = load_metric('PATH/TO/MY/METRIC/SCRIPT')
>>> # Example of typical usage
>>> for batch in dataset:
... inputs, references = batch
... predictions = model(inputs)
... metric.add_batch(predictions=predictions, references=references)
>>> score = metric.compute()
```
<Tip>
See the [Metrics](./how_to_metrics#custom-metric-loading-script) guide for more details on how to write your own metric loading script.
</Tip>
### Load configurations
It is possible for a metric to have different configurations. The configurations are stored in the `config_name` parameter in [`MetricInfo`] attribute. When you load a metric, provide the configuration name as shown in the following:
```
>>> from datasets import load_metric
>>> metric = load_metric('bleurt', name='bleurt-base-128')
>>> metric = load_metric('bleurt', name='bleurt-base-512')
```
### Distributed setup
When working in a distributed or parallel processing environment, loading and computing a metric can be tricky because these processes are executed in parallel on separate subsets of the data. 🤗 Datasets supports distributed usage with a few additional arguments when you load a metric.
For example, imagine you are training and evaluating on eight parallel processes. Here's how you would load a metric in this distributed setting:
1. Define the total number of processes with the `num_process` argument.
2. Set the process `rank` as an integer between zero and `num_process - 1`.
3. Load your metric with [`load_metric`] with these arguments:
```py
>>> from datasets import load_metric
>>> metric = load_metric('glue', 'mrpc', num_process=num_process, process_id=rank)
```
<Tip>
Once you've loaded a metric for distributed usage, you can compute the metric as usual. Behind the scenes, [`Metric.compute`] gathers all the predictions and references from the nodes, and computes the final metric.
</Tip>
In some instances, you may be simultaneously running multiple independent distributed evaluations on the same server and files. To avoid any conflicts, it is important to provide an `experiment_id` to distinguish the separate evaluations:
```py
>>> from datasets import load_metric
>>> metric = load_metric('glue', 'mrpc', num_process=num_process, process_id=process_id, experiment_id="My_experiment_10")
```
| huggingface/datasets/blob/main/docs/source/loading.mdx |
Downloading models
## Integrated libraries
If a model on the Hub is tied to a [supported library](./models-libraries), loading the model can be done in just a few lines. For information on accessing the model, you can click on the "Use in _Library_" button on the model page to see how to do so. For example, `distilgpt2` shows how to do so with 🤗 Transformers below.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-usage.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-usage-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-usage-modal.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/models-usage-modal-dark.png"/>
</div>
## Using the Hugging Face Client Library
You can use the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library to create, delete, update and retrieve information from repos. You can also download files from repos or integrate them into your library! For example, you can quickly load a Scikit-learn model with a few lines.
```py
from huggingface_hub import hf_hub_download
import joblib
REPO_ID = "YOUR_REPO_ID"
FILENAME = "sklearn_model.joblib"
model = joblib.load(
hf_hub_download(repo_id=REPO_ID, filename=FILENAME)
)
```
## Using Git
Since all models on the Model Hub are Git repositories, you can clone the models locally by running:
```bash
git lfs install
git clone git@hf.co:<MODEL ID> # example: git clone git@hf.co:bigscience/bloom
```
If you have write-access to the particular model repo, you'll also have the ability to commit and push revisions to the model.
Add your SSH public key to [your user settings](https://huggingface.co/settings/keys) to push changes and/or access private repos.
| huggingface/hub-docs/blob/main/docs/hub/models-downloading.md |