
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
反应式界面 (Reactive Interfaces)
本指南介绍了如何使 Gradio 界面自动刷新或连续流式传输数据。
## 实时界面 (Live Interfaces)
您可以通过在界面中设置 `live=True` 来使界面自动刷新。现在,只要用户输入发生变化,界面就会重新计算。
$code_calculator_live
$demo_calculator_live
注意,因为界面在更改时会自动重新提交,所以没有提交按钮。
## 流式组件 (Streaming Components)
某些组件具有“流式”模式,比如麦克风模式下的 `Audio` 组件或网络摄像头模式下的 `Image` 组件。流式传输意味着数据会持续发送到后端,并且 `Interface` 函数会持续重新运行。
当在 `gr.Interface(live=True)` 中同时使用 `gr.Audio(sources=['microphone'])` 和 `gr.Audio(sources=['microphone'], streaming=True)` 时,两者的区别在于第一个 `Component` 会在用户停止录制时自动提交数据并运行 `Interface` 函数,而第二个 `Component` 会在录制过程中持续发送数据并运行 `Interface` 函数。
以下是从网络摄像头实时流式传输图像的示例代码。
$code_stream_frames
| gradio-app/gradio/blob/main/guides/cn/02_building-interfaces/02_reactive-interfaces.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Phi
## Overview
The Phi-1 model was proposed in [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
### Summary
In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size.
They selected high quality "textbook" data alongside with synthetically generated data for training their small sized Transformer
based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP.
They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable
to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability
to “think step by step” or perform some rudimentary in-context learning.
With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
The abstract from the Phi-1 paper is the following:
*We introduce phi-1, a new large language model for code, with significantly smaller size than
competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on
8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically
generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains
pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent
properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding
exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as
phi-1 that still achieves 45% on HumanEval.*
The abstract from the Phi-1.5 paper is the following:
*We continue the investigation into the power of smaller Transformer-based language models as
initiated by TinyStories – a 10 million parameter model that can produce coherent English – and
the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close
to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to
generate “textbook quality” data as a way to enhance the learning process compared to traditional
web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common
sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5,
with performance on natural language tasks comparable to models 5x larger, and surpassing most
non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic
coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good –such
as the ability to “think step by step” or perform some rudimentary in-context learning– and bad,
including hallucinations and the potential for toxic and biased generations –encouragingly though, we
are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to
promote further research on these urgent topics.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code for Phi-1 and Phi-1.5 can be found [here](https://huggingface.co/microsoft/phi-1/blob/main/modeling_mixformer_sequential.py) and [here](https://huggingface.co/microsoft/phi-1_5/blob/main/modeling_mixformer_sequential.py) respectively.
## Usage tips
- This model is quite similar to `Llama` with the main difference in [`PhiDecoderLayer`], where they used [`PhiAttention`] and [`PhiMLP`] layers in parallel configuration.
- The tokenizer used for this model is identical to the [`CodeGenTokenizer`].
### Example :
```python
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
## Combining Phi and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
>>> model = PhiForCausalLM.from_pretrained("susnato/phi-1_5_dev", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
>>> tokenizer = AutoTokenizer.from_pretrained("susnato/phi-1_5_dev")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt").to("cuda")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `susnato/phi-1_dev` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/phi_1_speedup_plot.jpg">
</div>
## PhiConfig
[[autodoc]] PhiConfig
<frameworkcontent>
<pt>
## PhiModel
[[autodoc]] PhiModel
- forward
## PhiForCausalLM
[[autodoc]] PhiForCausalLM
- forward
- generate
## PhiForSequenceClassification
[[autodoc]] PhiForSequenceClassification
- forward
## PhiForTokenClassification
[[autodoc]] PhiForTokenClassification
- forward
</pt>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/phi.md |
Gradio Demo: gpt2_xl
```
!pip install -q gradio
```
```
import gradio as gr
title = "gpt2-xl"
examples = [
["The tower is 324 metres (1,063 ft) tall,"],
["The Moon's orbit around Earth has"],
["The smooth Borealis basin in the Northern Hemisphere covers 40%"],
]
demo = gr.load(
"huggingface/gpt2-xl",
inputs=gr.Textbox(lines=5, max_lines=6, label="Input Text"),
title=title,
examples=examples,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/gpt2_xl/run.ipynb |
--
title: "Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU"
thumbnail: assets/133_trl_peft/thumbnail.png
authors:
- user: edbeeching
- user: ybelkada
- user: lvwerra
- user: smangrul
- user: lewtun
- user: kashif
---
# Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
We are excited to officially release the integration of `trl` with `peft` to make Large Language Model (LLM) fine-tuning with Reinforcement Learning more accessible to anyone! In this post, we explain why this is a competitive alternative to existing fine-tuning approaches.
Note `peft` is a general tool that can be applied to many ML use-cases but it’s particularly interesting for RLHF as this method is especially memory-hungry!
If you want to directly deep dive into the code, check out the example scripts directly on the [documentation page of TRL](https://huggingface.co/docs/trl/main/en/sentiment_tuning_peft).
## Introduction
### LLMs & RLHF
LLMs combined with RLHF (Reinforcement Learning with Human Feedback) seems to be the next go-to approach for building very powerful AI systems such as ChatGPT.
Training a language model with RLHF typically involves the following three steps:
1- Fine-tune a pretrained LLM on a specific domain or corpus of instructions and human demonstrations
2- Collect a human annotated dataset and train a reward model
3- Further fine-tune the LLM from step 1 with the reward model and this dataset using RL (e.g. PPO)
| 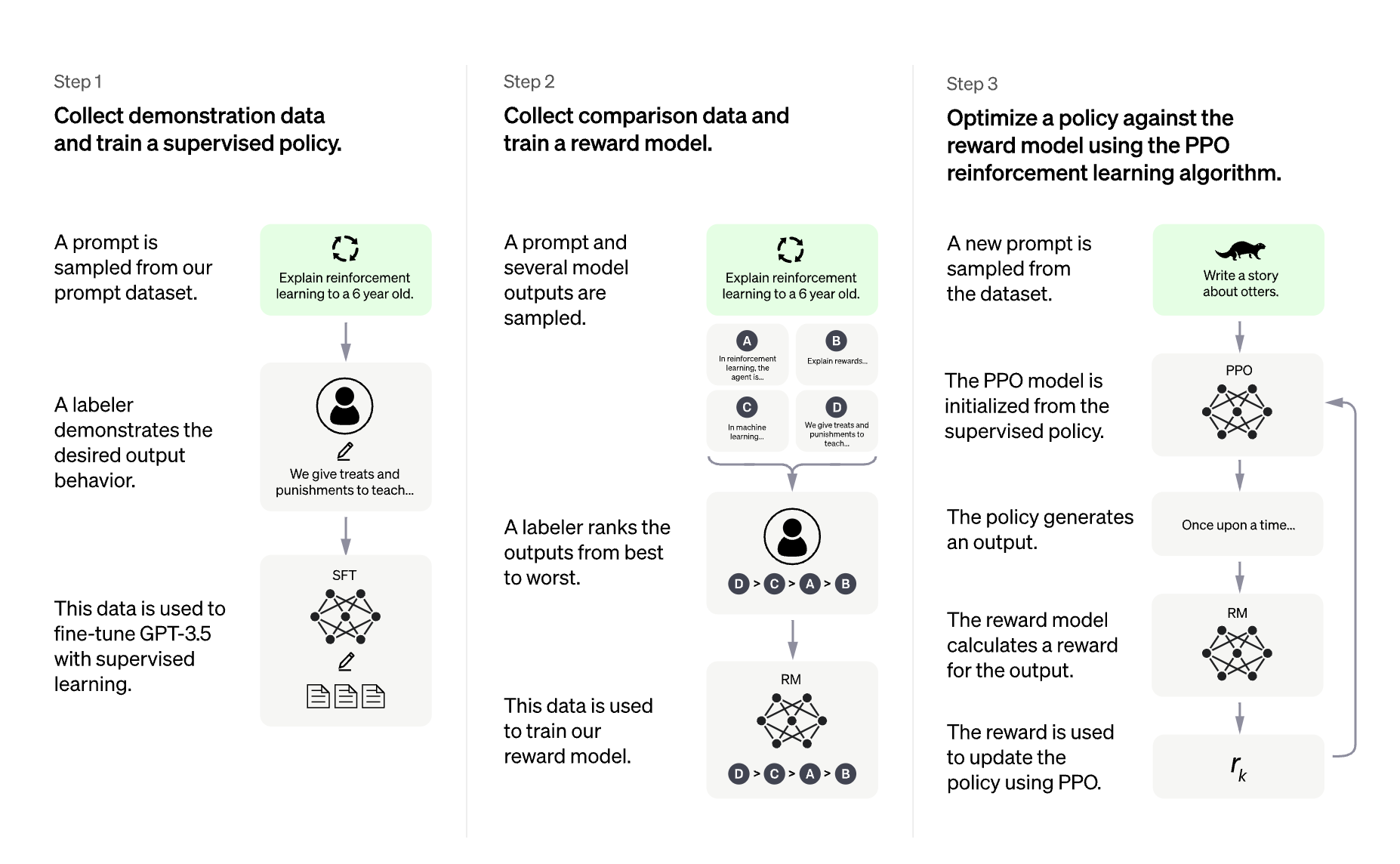 |
|:--:|
| <b>Overview of ChatGPT's training protocol, from the data collection to the RL part. Source: <a href="https://openai.com/blog/chatgpt" rel="noopener" target="_blank" >OpenAI's ChatGPT blogpost</a> </b>|
The choice of the base LLM is quite crucial here. At this time of writing, the “best” open-source LLM that can be used “out-of-the-box” for many tasks are instruction finetuned LLMs. Notable models being: [BLOOMZ](https://huggingface.co/bigscience/bloomz), [Flan-T5](https://huggingface.co/google/flan-t5-xxl), [Flan-UL2](https://huggingface.co/google/flan-ul2), and [OPT-IML](https://huggingface.co/facebook/opt-iml-max-30b). The downside of these models is their size. To get a decent model, you need at least to play with 10B+ scale models which would require up to 40GB GPU memory in full precision, just to fit the model on a single GPU device without doing any training at all!
### What is TRL?
The `trl` library aims at making the RL step much easier and more flexible so that anyone can fine-tune their LM using RL on their custom dataset and training setup. Among many other applications, you can use this algorithm to fine-tune a model to generate [positive movie reviews](https://huggingface.co/docs/trl/sentiment_tuning), do [controlled generation](https://github.com/lvwerra/trl/blob/main/examples/sentiment/notebooks/gpt2-sentiment-control.ipynb) or [make the model less toxic](https://huggingface.co/docs/trl/detoxifying_a_lm).
Using `trl` you can run one of the most popular Deep RL algorithms, [PPO](https://huggingface.co/deep-rl-course/unit8/introduction?fw=pt), in a distributed manner or on a single device! We leverage `accelerate` from the Hugging Face ecosystem to make this possible, so that any user can scale up the experiments up to an interesting scale.
Fine-tuning a language model with RL follows roughly the protocol detailed below. This requires having 2 copies of the original model; to avoid the active model deviating too much from its original behavior / distribution you need to compute the logits of the reference model at each optimization step. This adds a hard constraint on the optimization process as you need always at least two copies of the model per GPU device. If the model grows in size, it becomes more and more tricky to fit the setup on a single GPU.
|  |
|:--:|
| <b>Overview of the PPO training setup in TRL.</b>|
In `trl` you can also use shared layers between reference and active models to avoid entire copies. A concrete example of this feature is showcased in the detoxification example.
### Training at scale
Training at scale can be challenging. The first challenge is fitting the model and its optimizer states on the available GPU devices. The amount of GPU memory a single parameter takes depends on its “precision” (or more specifically `dtype`). The most common `dtype` being `float32` (32-bit), `float16`, and `bfloat16` (16-bit). More recently “exotic” precisions are supported out-of-the-box for training and inference (with certain conditions and constraints) such as `int8` (8-bit). In a nutshell, to load a model on a GPU device each billion parameters costs 4GB in float32 precision, 2GB in float16, and 1GB in int8. If you would like to learn more about this topic, have a look at this blogpost which dives deeper: [https://huggingface.co/blog/hf-bitsandbytes-integration](https://huggingface.co/blog/hf-bitsandbytes-integration).
If you use an AdamW optimizer each parameter needs 8 bytes (e.g. if your model has 1B parameters, the full AdamW optimizer of the model would require 8GB GPU memory - [source](https://huggingface.co/docs/transformers/v4.20.1/en/perf_train_gpu_one)).
Many techniques have been adopted to tackle these challenges at scale. The most familiar paradigms are Pipeline Parallelism, Tensor Parallelism, and Data Parallelism.
| 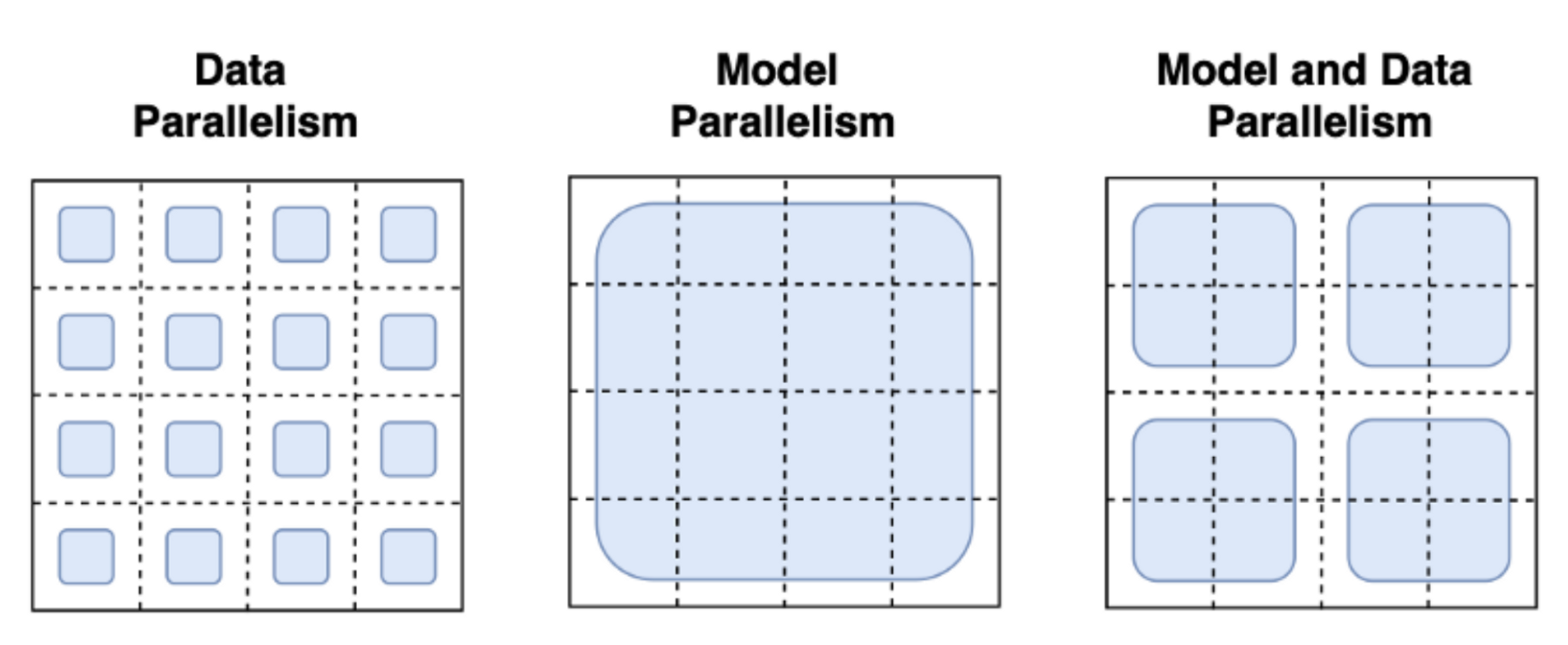 |
|:--:|
| <b>Image Credits to <a href="https://towardsdatascience.com/distributed-parallel-training-data-parallelism-and-model-parallelism-ec2d234e3214" rel="noopener" target="_blank" >this blogpost</a> </b>|
With data parallelism the same model is hosted in parallel on several machines and each instance is fed a different data batch. This is the most straight forward parallelism strategy essentially replicating the single-GPU case and is already supported by `trl`. With Pipeline and Tensor Parallelism the model itself is distributed across machines: in Pipeline Parallelism the model is split layer-wise, whereas Tensor Parallelism splits tensor operations across GPUs (e.g. matrix multiplications). With these Model Parallelism strategies, you need to shard the model weights across many devices which requires you to define a communication protocol of the activations and gradients across processes. This is not trivial to implement and might need the adoption of some frameworks such as [`Megatron-DeepSpeed`](https://github.com/microsoft/Megatron-DeepSpeed) or [`Nemo`](https://github.com/NVIDIA/NeMo). It is also important to highlight other tools that are essential for scaling LLM training such as Adaptive activation checkpointing and fused kernels. Further reading about parallelism paradigms can be found [here](https://huggingface.co/docs/transformers/v4.17.0/en/parallelism).
Therefore, we asked ourselves the following question: how far can we go with just data parallelism? Can we use existing tools to fit super-large training processes (including active model, reference model and optimizer states) in a single device? The answer appears to be yes. The main ingredients are: adapters and 8bit matrix multiplication! Let us cover these topics in the following sections:
### 8-bit matrix multiplication
Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper LLM.int8() and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8.
| 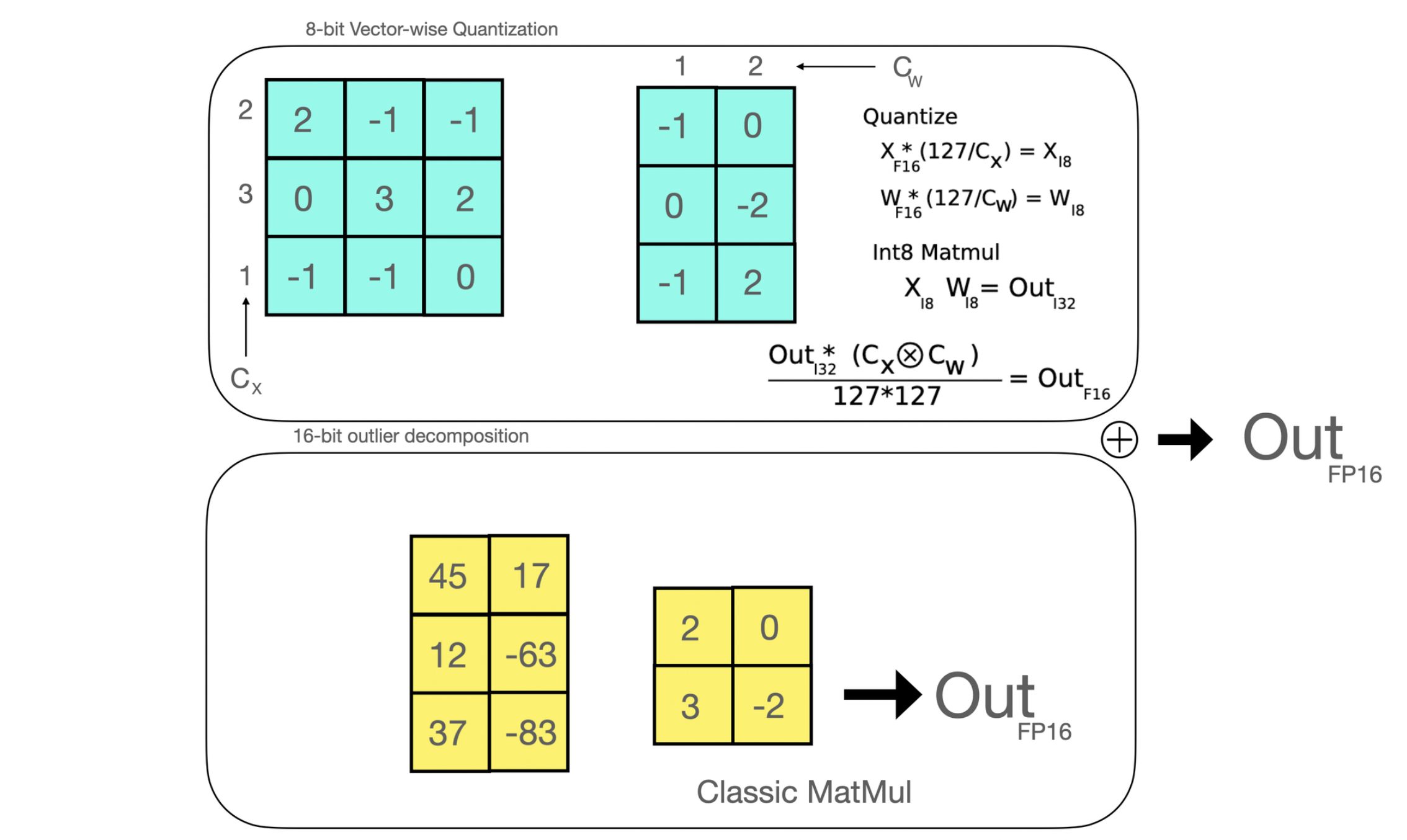 |
|:--:|
| <b>Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper [LLM.int8()](https://arxiv.org/abs/2208.07339) and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8. </b>|
In a nutshell, you can reduce the size of a full-precision model by 4 (thus, by 2 for half-precision models) if you use 8-bit matrix multiplication.
### Low rank adaptation and PEFT
In 2021, a paper called LoRA: Low-Rank Adaption of Large Language Models demonstrated that fine tuning of large language models can be performed by freezing the pretrained weights and creating low rank versions of the query and value layers attention matrices. These low rank matrices have far fewer parameters than the original model, enabling fine-tuning with far less GPU memory. The authors demonstrate that fine-tuning of low-rank adapters achieved comparable results to fine-tuning the full pretrained model.
|  |
|:--:|
| <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right). </b>|
This technique allows the fine tuning of LLMs using a fraction of the memory requirements. There are, however, some downsides. The forward and backward pass is approximately twice as slow, due to the additional matrix multiplications in the adapter layers.
### What is PEFT?
[Parameter-Efficient Fine-Tuning (PEFT)](https://github.com/huggingface/peft), is a Hugging Face library, created to support the creation and fine tuning of adapter layers on LLMs.`peft` is seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
The library supports many state of the art models and has an extensive set of examples, including:
- Causal language modeling
- Conditional generation
- Image classification
- 8-bit int8 training
- Low Rank adaption of Dreambooth models
- Semantic segmentation
- Sequence classification
- Token classification
The library is still under extensive and active development, with many upcoming features to be announced in the coming months.
## Fine-tuning 20B parameter models with Low Rank Adapters
Now that the prerequisites are out of the way, let us go through the entire pipeline step by step, and explain with figures how you can fine-tune a 20B parameter LLM with RL using the tools mentioned above on a single 24GB GPU!
### Step 1: Load your active model in 8-bit precision
| 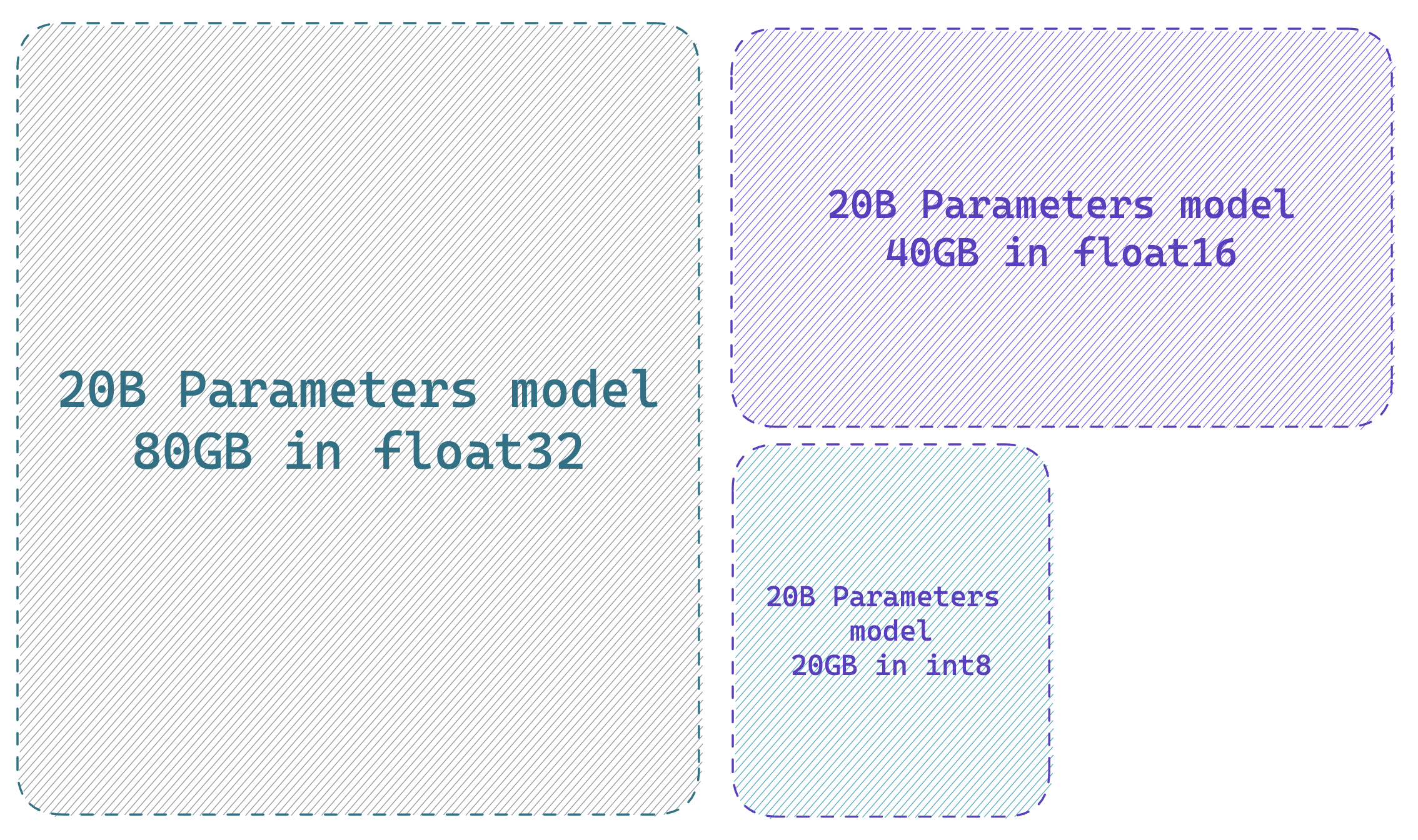 |
|:--:|
| <b> Loading a model in 8-bit precision can save up to 4x memory compared to full precision model</b>|
A “free-lunch” memory reduction of a LLM using `transformers` is to load your model in 8-bit precision using the method described in LLM.int8. This can be performed by simply adding the flag `load_in_8bit=True` when calling the `from_pretrained` method (you can read more about that [here](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)).
As stated in the previous section, a “hack” to compute the amount of GPU memory you should need to load your model is to think in terms of “billions of parameters”. As one byte needs 8 bits, you need 4GB per billion parameters for a full-precision model (32bit = 4bytes), 2GB per billion parameters for a half-precision model, and 1GB per billion parameters for an int8 model.
So in the first place, let’s just load the active model in 8-bit. Let’s see what we need to do for the second step!
### Step 2: Add extra trainable adapters using `peft`
| 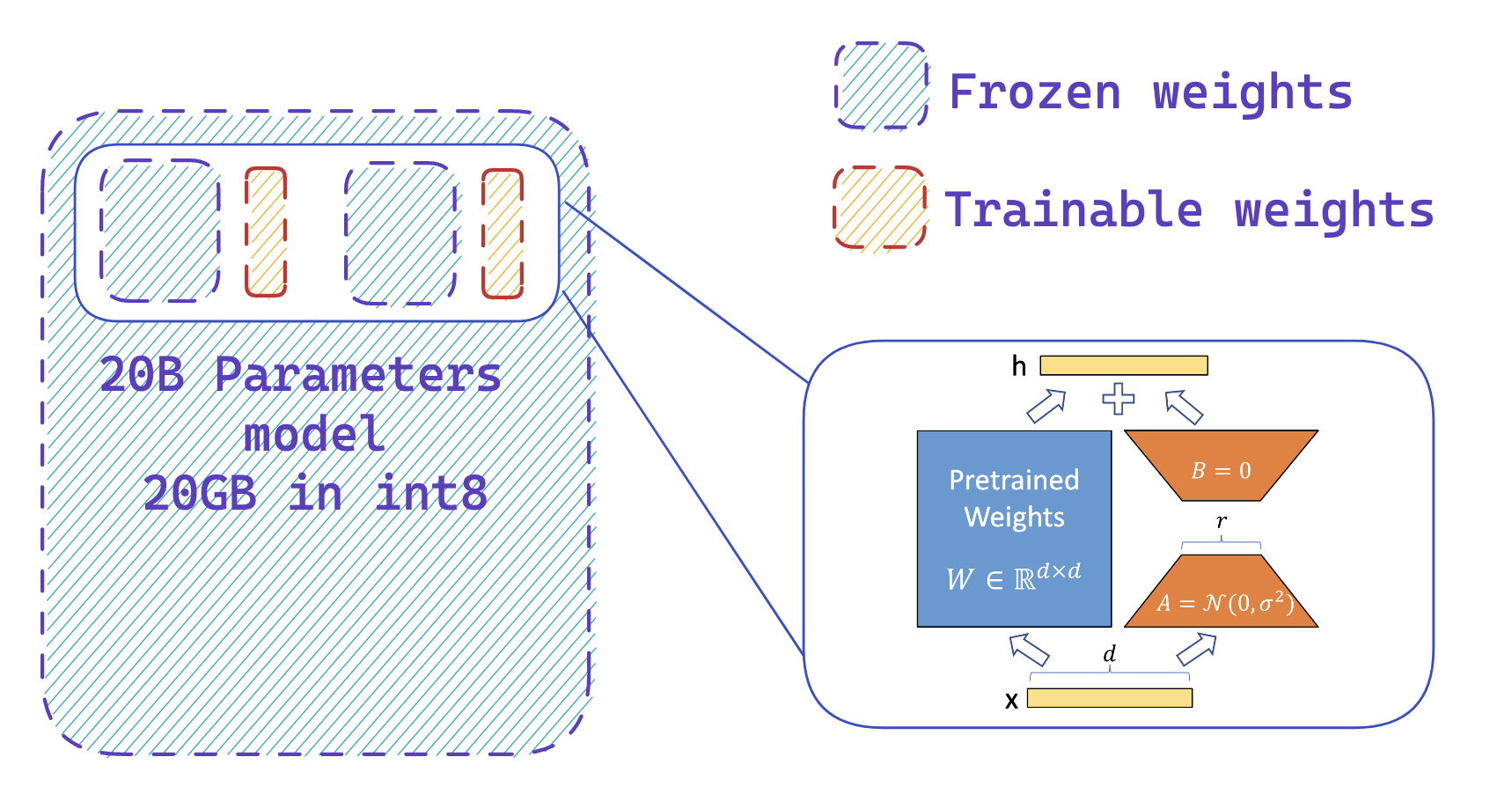 |
|:--:|
| <b> You easily add adapters on a frozen 8-bit model thus reducing the memory requirements of the optimizer states, by training a small fraction of parameters</b>|
The second step is to load adapters inside the model and make these adapters trainable. This enables a drastic reduction of the number of trainable weights that are needed for the active model. This step leverages `peft` library and can be performed with a few lines of code. Note that once the adapters are trained, you can easily push them to the Hub to use them later.
### Step 3: Use the same model to get the reference and active logits
| 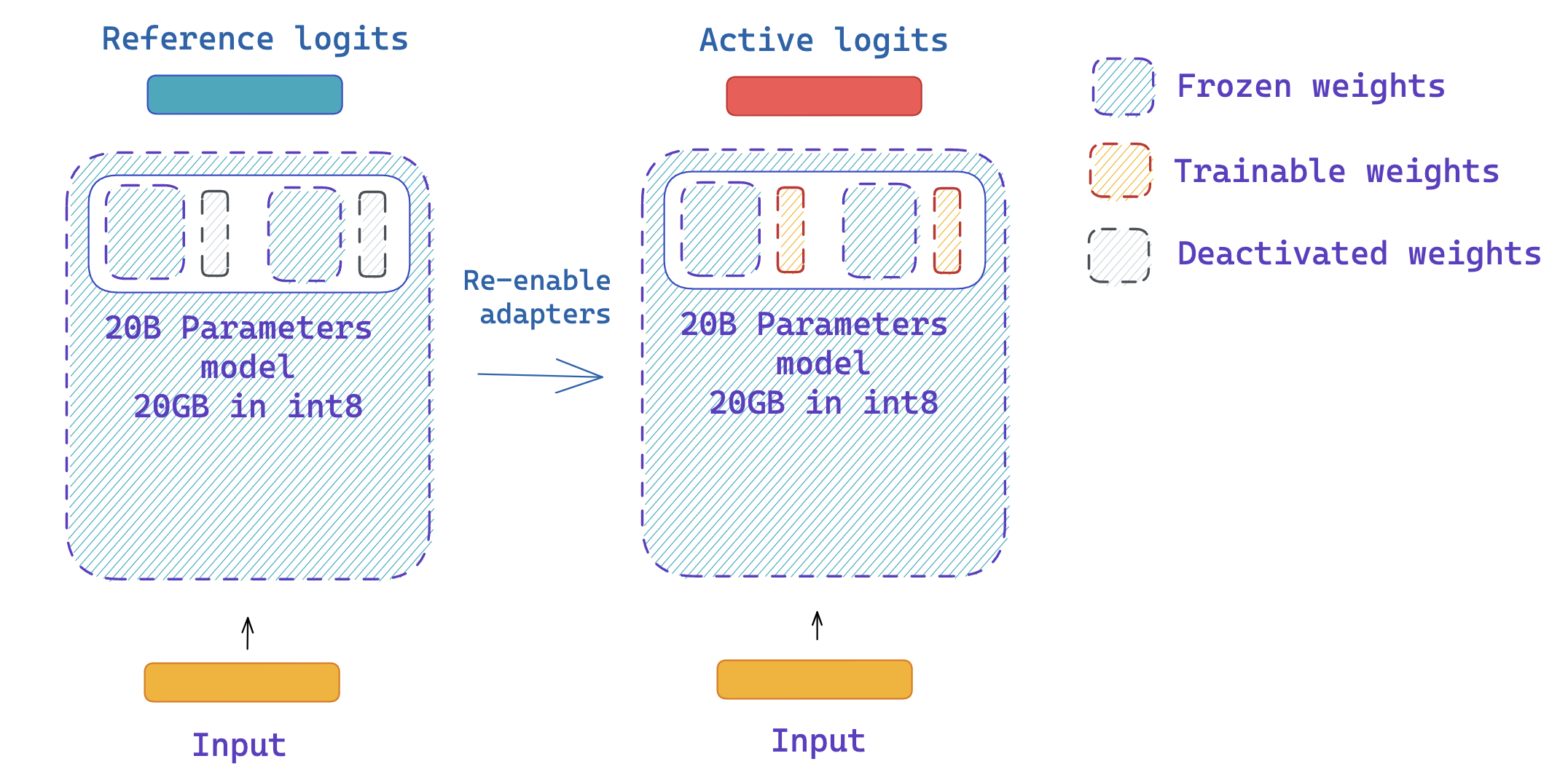 |
|:--:|
| <b> You can easily disable and enable adapters using the `peft` API.</b>|
Since adapters can be deactivated, we can use the same model to get the reference and active logits for PPO, without having to create two copies of the same model! This leverages a feature in `peft` library, which is the `disable_adapters` context manager.
### Overview of the training scripts:
We will now describe how we trained a 20B parameter [gpt-neox model](https://huggingface.co/EleutherAI/gpt-neox-20b) using `transformers`, `peft` and `trl`. The end goal of this example was to fine-tune a LLM to generate positive movie reviews in a memory constrained settting. Similar steps could be applied for other tasks, such as dialogue models.
Overall there were three key steps and training scripts:
1. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/clm_finetune_peft_imdb.py)** - Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset.
2. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/merge_peft_adapter.py)** - Merging of the adapter layers into the base model’s weights and storing these on the hub.
3. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/gpt-neo-20b_sentiment_peft.py)** - Sentiment fine-tuning of a Low Rank Adapter to create positive reviews.
We tested these steps on a 24GB NVIDIA 4090 GPU. While it is possible to perform the entire training run on a 24 GB GPU, the full training runs were untaken on a single A100 on the 🤗 reseach cluster.
The first step in the training process was fine-tuning on the pretrained model. Typically this would require several high-end 80GB A100 GPUs, so we chose to train a low rank adapter. We treated this as a Causal Language modeling setting and trained for one epoch of examples from the [imdb](https://huggingface.co/datasets/imdb) dataset, which features movie reviews and labels indicating whether they are of positive or negative sentiment.
| 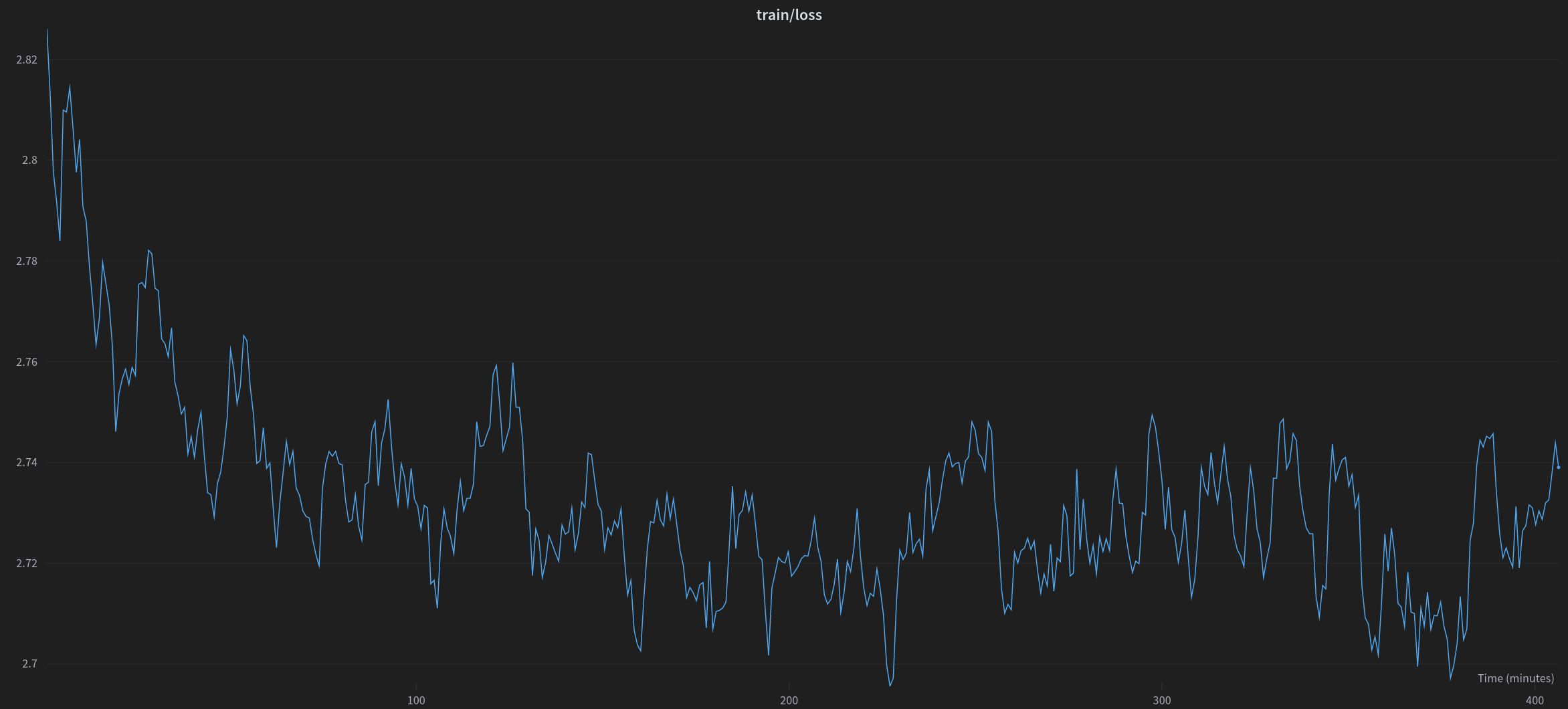 |
|:--:|
| <b> Training loss during one epoch of training of a gpt-neox-20b model for one epoch on the imdb dataset</b>|
In order to take the adapted model and perform further finetuning with RL, we first needed to combine the adapted weights, this was achieved by loading the pretrained model and adapter in 16-bit floating point and summary with weight matrices (with the appropriate scaling applied).
Finally, we could then fine-tune another low-rank adapter, on top of the frozen imdb-finetuned model. We use an [imdb sentiment classifier](https://huggingface.co/lvwerra/distilbert-imdb) to provide the rewards for the RL algorithm.
| 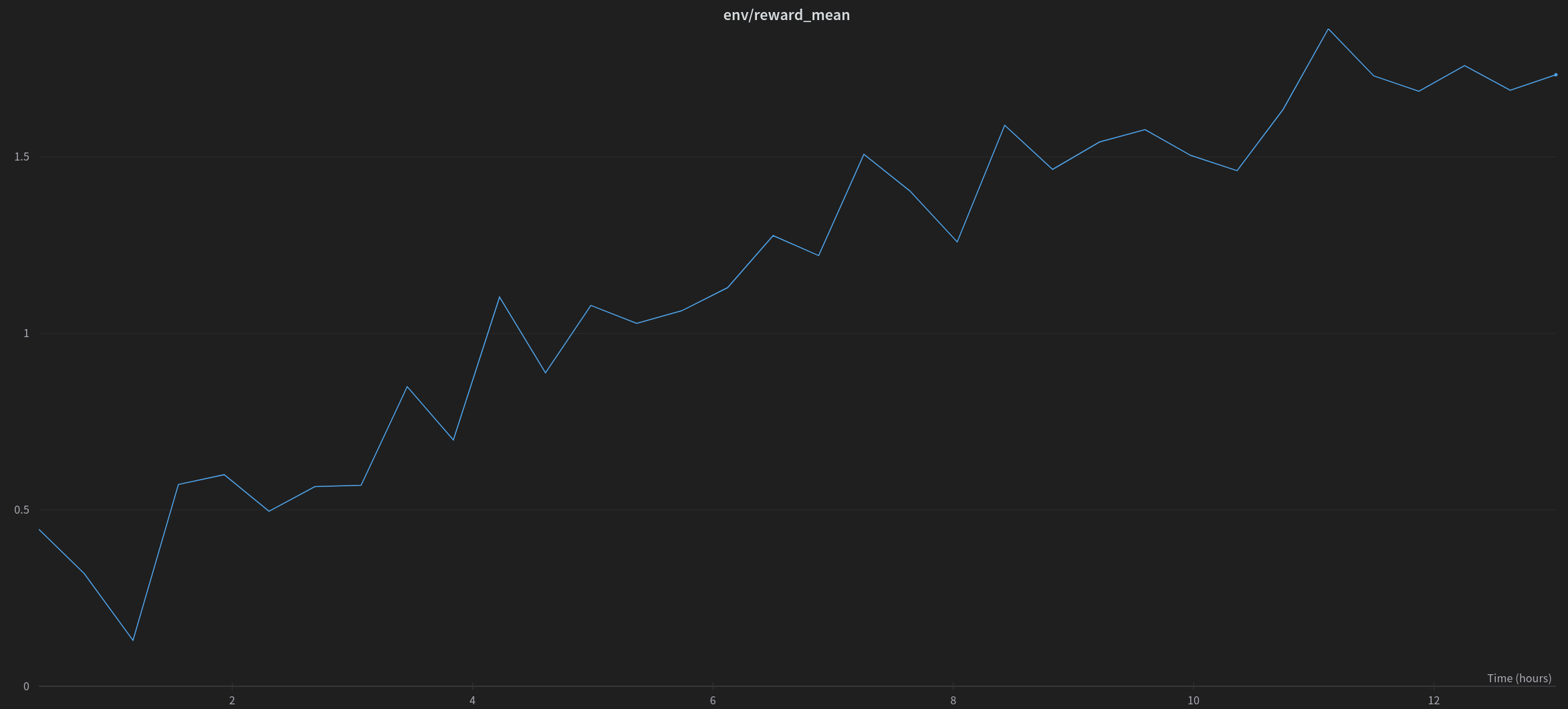 |
|:--:|
| <b> Mean of rewards when RL fine-tuning of a peft adapted 20B parameter model to generate positive movie reviews.</b>|
The full Weights and Biases report is available for this experiment [here](https://wandb.ai/edbeeching/trl/runs/l8e7uwm6?workspace=user-edbeeching), if you want to check out more plots and text generations.
## Conclusion
We have implemented a new functionality in `trl` that allows users to fine-tune large language models using RLHF at a reasonable cost by leveraging the `peft` and `bitsandbytes` libraries. We demonstrated that fine-tuning `gpt-neo-x` (40GB in `bfloat16`!) on a 24GB consumer GPU is possible, and we expect that this integration will be widely used by the community to fine-tune larger models utilizing RLHF and share great artifacts.
We have identified some interesting directions for the next steps to push the limits of this integration
- *How this will scale in the multi-GPU setting?* We’ll mainly explore how this integration will scale with respect to the number of GPUs, whether it is possible to apply Data Parallelism out-of-the-box or if it’ll require some new feature adoption on any of the involved libraries.
- *What tools can we leverage to increase training speed?* We have observed that the main downside of this integration is the overall training speed. In the future we would be keen to explore the possible directions to make the training much faster.
## References
- parallelism paradigms: [https://huggingface.co/docs/transformers/v4.17.0/en/parallelism](https://huggingface.co/docs/transformers/v4.17.0/en/parallelism)
- 8-bit integration in `transformers`: [https://huggingface.co/blog/hf-bitsandbytes-integration](https://huggingface.co/blog/hf-bitsandbytes-integration)
- LLM.int8 paper: [https://arxiv.org/abs/2208.07339](https://arxiv.org/abs/2208.07339)
- Gradient checkpoiting explained: [https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html)
| huggingface/blog/blob/main/trl-peft.md |
!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Text classification examples
This folder contains some scripts showing examples of *text classification* with the 🤗 Transformers library.
For straightforward use-cases you may be able to use these scripts without modification, although we have also
included comments in the code to indicate areas that you may need to adapt to your own projects.
## run_text_classification.py
This script handles perhaps the single most common use-case for this entire library: Training an NLP classifier
on your own training data. This can be whatever you want - you could classify text as abusive/hateful or
allowable, or forum posts as spam or not-spam, or classify the genre of a headline as politics, sports or any
number of other categories. Any task that involves classifying natural language into two or more different categories
can work with this! You can even do regression, such as predicting the score on a 1-10 scale that a user gave,
given the text of their review.
The preferred input format is either a CSV or newline-delimited JSON file that contains a `sentence1` and
`label` field. If your task involves comparing two texts (for example, if your classifier
is deciding whether two sentences are paraphrases of each other, or were written by the same author) then you should also include a `sentence2` field in each example. If you do not have a `sentence1` field then the script will assume the non-label fields are the input text, which
may not always be what you want, especially if you have more than two fields!
Here is a snippet of a valid input JSON file, though note that your texts can be much longer than these, and are not constrained
(despite the field name) to being single grammatical sentences:
```
{"sentence1": "COVID-19 vaccine updates: How is the rollout proceeding?", "label": "news"}
{"sentence1": "Manchester United celebrates Europa League success", "label": "sports"}
```
### Usage notes
If your inputs are long (more than ~60-70 words), you may wish to increase the `--max_seq_length` argument
beyond the default value of 128. The maximum supported value for most models is 512 (about 200-300 words),
and some can handle even longer. This will come at a cost in runtime and memory use, however.
We assume that your labels represent *categories*, even if they are integers, since text classification
is a much more common task than text regression. If your labels are floats, however, the script will assume
you want to do regression. This is something you can edit yourself if your use-case requires it!
After training, the model will be saved to `--output_dir`. Once your model is trained, you can get predictions
by calling the script without a `--train_file` or `--validation_file`; simply pass it the output_dir containing
the trained model and a `--test_file` and it will write its predictions to a text file for you.
### Multi-GPU and TPU usage
By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Memory usage and data loading
One thing to note is that all data is loaded into memory in this script. Most text classification datasets are small
enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
README, but for more information you can see the 'Input Datasets' section of
[this document](https://www.tensorflow.org/guide/tpu).
### Example command
```
python run_text_classification.py \
--model_name_or_path distilbert-base-cased \
--train_file training_data.json \
--validation_file validation_data.json \
--output_dir output/ \
--test_file data_to_predict.json
```
## run_glue.py
This script handles training on the GLUE dataset for various text classification and regression tasks. The GLUE datasets will be loaded automatically, so you only need to specify the task you want (with the `--task_name` argument). You can also supply your own files for prediction with the `--predict_file` argument, for example if you want to train a model on GLUE for e.g. paraphrase detection and then predict whether your own data contains paraphrases or not. Please ensure the names of your input fields match the names of the features in the relevant GLUE dataset - you can see a list of the column names in the `task_to_keys` dict in the `run_glue.py` file.
### Usage notes
The `--do_train`, `--do_eval` and `--do_predict` arguments control whether training, evaluations or predictions are performed. After training, the model will be saved to `--output_dir`. Once your model is trained, you can call the script without the `--do_train` or `--do_eval` arguments to quickly get predictions from your saved model.
### Multi-GPU and TPU usage
By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
can also be used by passing the name of the TPU resource with the `--tpu` argument.
### Memory usage and data loading
One thing to note is that all data is loaded into memory in this script. Most text classification datasets are small
enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
README, but for more information you can see the 'Input Datasets' section of
[this document](https://www.tensorflow.org/guide/tpu).
### Example command
```
python run_glue.py \
--model_name_or_path distilbert-base-cased \
--task_name mnli \
--do_train \
--do_eval \
--do_predict \
--predict_file data_to_predict.json
```
| huggingface/transformers/blob/main/examples/tensorflow/text-classification/README.md |
The cache
The cache is one of the reasons why 🤗 Datasets is so efficient. It stores previously downloaded and processed datasets so when you need to use them again, they are reloaded directly from the cache. This avoids having to download a dataset all over again, or reapplying processing functions. Even after you close and start another Python session, 🤗 Datasets will reload your dataset directly from the cache!
## Fingerprint
How does the cache keeps track of what transforms are applied to a dataset? Well, 🤗 Datasets assigns a fingerprint to the cache file. A fingerprint keeps track of the current state of a dataset. The initial fingerprint is computed using a hash from the Arrow table, or a hash of the Arrow files if the dataset is on disk. Subsequent fingerprints are computed by combining the fingerprint of the previous state, and a hash of the latest transform applied.
<Tip>
Transforms are any of the processing methods from the [How-to Process](./process) guides such as [`Dataset.map`] or [`Dataset.shuffle`].
</Tip>
Here are what the actual fingerprints look like:
```py
>>> from datasets import Dataset
>>> dataset1 = Dataset.from_dict({"a": [0, 1, 2]})
>>> dataset2 = dataset1.map(lambda x: {"a": x["a"] + 1})
>>> print(dataset1._fingerprint, dataset2._fingerprint)
d19493523d95e2dc 5b86abacd4b42434
```
In order for a transform to be hashable, it needs to be picklable by [dill](https://dill.readthedocs.io/en/latest/) or [pickle](https://docs.python.org/3/library/pickle).
When you use a non-hashable transform, 🤗 Datasets uses a random fingerprint instead and raises a warning. The non-hashable transform is considered different from the previous transforms. As a result, 🤗 Datasets will recompute all the transforms. Make sure your transforms are serializable with pickle or dill to avoid this!
An example of when 🤗 Datasets recomputes everything is when caching is disabled. When this happens, the cache files are generated every time and they get written to a temporary directory. Once your Python session ends, the cache files in the temporary directory are deleted. A random hash is assigned to these cache files, instead of a fingerprint.
<Tip>
When caching is disabled, use [`Dataset.save_to_disk`] to save your transformed dataset or it will be deleted once the session ends.
</Tip>
## Hashing
The fingerprint of a dataset is updated by hashing the function passed to `map` as well as the `map` parameters (`batch_size`, `remove_columns`, etc.).
You can check the hash of any Python object using the [`fingerprint.Hasher`]:
```py
>>> from datasets.fingerprint import Hasher
>>> my_func = lambda example: {"length": len(example["text"])}
>>> print(Hasher.hash(my_func))
'3d35e2b3e94c81d6'
```
The hash is computed by dumping the object using a `dill` pickler and hashing the dumped bytes.
The pickler recursively dumps all the variables used in your function, so any change you do to an object that is used in your function, will cause the hash to change.
If one of your functions doesn't seem to have the same hash across sessions, it means at least one of its variables contains a Python object that is not deterministic.
When this happens, feel free to hash any object you find suspicious to try to find the object that caused the hash to change.
For example, if you use a list for which the order of its elements is not deterministic across sessions, then the hash won't be the same across sessions either.
| huggingface/datasets/blob/main/docs/source/about_cache.mdx |
Metric Card for chrF(++)
## Metric Description
ChrF and ChrF++ are two MT evaluation metrics that use the F-score statistic for character n-gram matches. ChrF++ additionally includes word n-grams, which correlate more strongly with direct assessment. We use the implementation that is already present in sacrebleu.
While this metric is included in sacreBLEU, the implementation here is slightly different from sacreBLEU in terms of the required input format. Here, the length of the references and hypotheses lists need to be the same, so you may need to transpose your references compared to sacrebleu's required input format. See https://github.com/huggingface/datasets/issues/3154#issuecomment-950746534
See the [sacreBLEU README.md](https://github.com/mjpost/sacreBLEU#chrf--chrf) for more information.
## How to Use
At minimum, this metric requires a `list` of predictions and a `list` of `list`s of references:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction, references=reference)
>>> print(results)
{'score': 84.64214891738334, 'char_order': 6, 'word_order': 0, 'beta': 2}
```
### Inputs
- **`predictions`** (`list` of `str`): The predicted sentences.
- **`references`** (`list` of `list` of `str`): The references. There should be one reference sub-list for each prediction sentence.
- **`char_order`** (`int`): Character n-gram order. Defaults to `6`.
- **`word_order`** (`int`): Word n-gram order. If equals to 2, the metric is referred to as chrF++. Defaults to `0`.
- **`beta`** (`int`): Determine the importance of recall w.r.t precision. Defaults to `2`.
- **`lowercase`** (`bool`): If `True`, enables case-insensitivity. Defaults to `False`.
- **`whitespace`** (`bool`): If `True`, include whitespaces when extracting character n-grams. Defaults to `False`.
- **`eps_smoothing`** (`bool`): If `True`, applies epsilon smoothing similar to reference chrF++.py, NLTK, and Moses implementations. If `False`, takes into account effective match order similar to sacreBLEU < 2.0.0. Defaults to `False`.
### Output Values
The output is a dictionary containing the following fields:
- **`'score'`** (`float`): The chrF (chrF++) score.
- **`'char_order'`** (`int`): The character n-gram order.
- **`'word_order'`** (`int`): The word n-gram order. If equals to `2`, the metric is referred to as chrF++.
- **`'beta'`** (`int`): Determine the importance of recall w.r.t precision.
The output is formatted as below:
```python
{'score': 61.576379378113785, 'char_order': 6, 'word_order': 0, 'beta': 2}
```
The chrF(++) score can be any value between `0.0` and `100.0`, inclusive.
#### Values from Popular Papers
### Examples
A simple example of calculating chrF:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction, references=reference)
>>> print(results)
{'score': 84.64214891738334, 'char_order': 6, 'word_order': 0, 'beta': 2}
```
The same example, but with the argument `word_order=2`, to calculate chrF++ instead of chrF:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction,
... references=reference,
... word_order=2)
>>> print(results)
{'score': 82.87263732906315, 'char_order': 6, 'word_order': 2, 'beta': 2}
```
The same chrF++ example as above, but with `lowercase=True` to normalize all case:
```python
>>> prediction = ["The relationship between cats and dogs is not exactly friendly.", "a good bookshop is just a genteel black hole that knows how to read."]
>>> reference = [["The relationship between dogs and cats is not exactly friendly.", ], ["A good bookshop is just a genteel Black Hole that knows how to read."]]
>>> chrf = datasets.load_metric("chrf")
>>> results = chrf.compute(predictions=prediction,
... references=reference,
... word_order=2,
... lowercase=True)
>>> print(results)
{'score': 92.12853119829202, 'char_order': 6, 'word_order': 2, 'beta': 2}
```
## Limitations and Bias
- According to [Popović 2017](https://www.statmt.org/wmt17/pdf/WMT70.pdf), chrF+ (where `word_order=1`) and chrF++ (where `word_order=2`) produce scores that correlate better with human judgements than chrF (where `word_order=0`) does.
## Citation
```bibtex
@inproceedings{popovic-2015-chrf,
title = "chr{F}: character n-gram {F}-score for automatic {MT} evaluation",
author = "Popovi{\'c}, Maja",
booktitle = "Proceedings of the Tenth Workshop on Statistical Machine Translation",
month = sep,
year = "2015",
address = "Lisbon, Portugal",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W15-3049",
doi = "10.18653/v1/W15-3049",
pages = "392--395",
}
@inproceedings{popovic-2017-chrf,
title = "chr{F}++: words helping character n-grams",
author = "Popovi{\'c}, Maja",
booktitle = "Proceedings of the Second Conference on Machine Translation",
month = sep,
year = "2017",
address = "Copenhagen, Denmark",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W17-4770",
doi = "10.18653/v1/W17-4770",
pages = "612--618",
}
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
```
## Further References
- See the [sacreBLEU README.md](https://github.com/mjpost/sacreBLEU#chrf--chrf) for more information on this implementation. | huggingface/datasets/blob/main/metrics/chrf/README.md |
Gradio Demo: uploadbutton_component
```
!pip install -q gradio
```
```
import gradio as gr
def upload_file(files):
file_paths = [file.name for file in files]
return file_paths
with gr.Blocks() as demo:
file_output = gr.File()
upload_button = gr.UploadButton("Click to Upload an Image or Video File", file_types=["image", "video"], file_count="multiple")
upload_button.upload(upload_file, upload_button, file_output)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/uploadbutton_component/run.ipynb |
SelecSLS
**SelecSLS** uses novel selective long and short range skip connections to improve the information flow allowing for a drastically faster network without compromising accuracy.
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('selecsls42b', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `selecsls42b`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('selecsls42b', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{Mehta_2020,
title={XNect},
volume={39},
ISSN={1557-7368},
url={http://dx.doi.org/10.1145/3386569.3392410},
DOI={10.1145/3386569.3392410},
number={4},
journal={ACM Transactions on Graphics},
publisher={Association for Computing Machinery (ACM)},
author={Mehta, Dushyant and Sotnychenko, Oleksandr and Mueller, Franziska and Xu, Weipeng and Elgharib, Mohamed and Fua, Pascal and Seidel, Hans-Peter and Rhodin, Helge and Pons-Moll, Gerard and Theobalt, Christian},
year={2020},
month={Jul}
}
```
<!--
Type: model-index
Collections:
- Name: SelecSLS
Paper:
Title: 'XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera'
URL: https://paperswithcode.com/paper/xnect-real-time-multi-person-3d-human-pose
Models:
- Name: selecsls42b
In Collection: SelecSLS
Metadata:
FLOPs: 3824022528
Parameters: 32460000
File Size: 129948954
Architecture:
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Global Average Pooling
- ReLU
- SelecSLS Block
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Random Erasing
Training Data:
- ImageNet
ID: selecsls42b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/selecsls.py#L335
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-selecsls/selecsls42b-8af30141.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.18%
Top 5 Accuracy: 93.39%
- Name: selecsls60
In Collection: SelecSLS
Metadata:
FLOPs: 4610472600
Parameters: 30670000
File Size: 122839714
Architecture:
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Global Average Pooling
- ReLU
- SelecSLS Block
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Random Erasing
Training Data:
- ImageNet
ID: selecsls60
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/selecsls.py#L342
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-selecsls/selecsls60-bbf87526.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.99%
Top 5 Accuracy: 93.83%
- Name: selecsls60b
In Collection: SelecSLS
Metadata:
FLOPs: 4657653144
Parameters: 32770000
File Size: 131252898
Architecture:
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Global Average Pooling
- ReLU
- SelecSLS Block
Tasks:
- Image Classification
Training Techniques:
- Cosine Annealing
- Random Erasing
Training Data:
- ImageNet
ID: selecsls60b
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/b9843f954b0457af2db4f9dea41a8538f51f5d78/timm/models/selecsls.py#L349
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-selecsls/selecsls60b-94e619b5.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.41%
Top 5 Accuracy: 94.18%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/selecsls.mdx |
Vision Transformers 图像分类
相关空间:https://huggingface.co/spaces/abidlabs/vision-transformer
标签:VISION, TRANSFORMERS, HUB
## 简介
图像分类是计算机视觉中的重要任务。构建更好的分类器以确定图像中存在的对象是当前研究的热点领域,因为它在从人脸识别到制造质量控制等方面都有应用。
最先进的图像分类器基于 _transformers_ 架构,该架构最初在自然语言处理任务中很受欢迎。这种架构通常被称为 vision transformers (ViT)。这些模型非常适合与 Gradio 的*图像*输入组件一起使用,因此在本教程中,我们将构建一个使用 Gradio 进行图像分类的 Web 演示。我们只需用**一行 Python 代码**即可构建整个 Web 应用程序,其效果如下(试用一下示例之一!):
<iframe src="https://abidlabs-vision-transformer.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
让我们开始吧!
### 先决条件
确保您已经[安装](/getting_started)了 `gradio` Python 包。
## 步骤 1 - 选择 Vision 图像分类模型
首先,我们需要一个图像分类模型。在本教程中,我们将使用[Hugging Face Model Hub](https://huggingface.co/models?pipeline_tag=image-classification)上的一个模型。该 Hub 包含数千个模型,涵盖了多种不同的机器学习任务。
在左侧边栏中展开 Tasks 类别,并选择我们感兴趣的“Image Classification”作为我们的任务。然后,您将看到 Hub 上为图像分类设计的所有模型。
在撰写时,最受欢迎的模型是 `google/vit-base-patch16-224`,该模型在分辨率为 224x224 像素的 ImageNet 图像上进行了训练。我们将在演示中使用此模型。
## 步骤 2 - 使用 Gradio 加载 Vision Transformer 模型
当使用 Hugging Face Hub 上的模型时,我们无需为演示定义输入或输出组件。同样,我们不需要关心预处理或后处理的细节。所有这些都可以从模型标签中自动推断出来。
除了导入语句外,我们只需要一行代码即可加载并启动演示。
我们使用 `gr.Interface.load()` 方法,并传入包含 `huggingface/` 的模型路径,以指定它来自 Hugging Face Hub。
```python
import gradio as gr
gr.Interface.load(
"huggingface/google/vit-base-patch16-224",
examples=["alligator.jpg", "laptop.jpg"]).launch()
```
请注意,我们添加了一个 `examples` 参数,允许我们使用一些预定义的示例预填充我们的界面。
这将生成以下接口,您可以直接在浏览器中尝试。当您输入图像时,它会自动进行预处理并发送到 Hugging Face Hub API,通过模型处理,并以人类可解释的预测结果返回。尝试上传您自己的图像!
<iframe src="https://abidlabs-vision-transformer.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
---
完成!只需一行代码,您就建立了一个图像分类器的 Web 演示。如果您想与他人分享,请在 `launch()` 接口时设置 `share=True`。
| gradio-app/gradio/blob/main/guides/cn/04_integrating-other-frameworks/image-classification-with-vision-transformers.md |
ConsistencyDecoderScheduler
This scheduler is a part of the [`ConsistencyDecoderPipeline`] and was introduced in [DALL-E 3](https://openai.com/dall-e-3).
The original codebase can be found at [openai/consistency_models](https://github.com/openai/consistency_models).
## ConsistencyDecoderScheduler
[[autodoc]] schedulers.scheduling_consistency_decoder.ConsistencyDecoderScheduler | huggingface/diffusers/blob/main/docs/source/en/api/schedulers/consistency_decoder.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How-to guides
In this section, you will find practical guides to help you achieve a specific goal.
Take a look at these guides to learn how to use huggingface_hub to solve real-world problems:
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-3 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./repository">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Repository
</div><p class="text-gray-700">
How to create a repository on the Hub? How to configure it? How to interact with it?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./download">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Download files
</div><p class="text-gray-700">
How do I download a file from the Hub? How do I download a repository?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./upload">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Upload files
</div><p class="text-gray-700">
How to upload a file or a folder? How to make changes to an existing repository on the Hub?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./search">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Search
</div><p class="text-gray-700">
How to efficiently search through the 200k+ public models, datasets and spaces?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./hf_file_system">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
HfFileSystem
</div><p class="text-gray-700">
How to interact with the Hub through a convenient interface that mimics Python's file interface?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./inference">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Inference
</div><p class="text-gray-700">
How to make predictions using the accelerated Inference API?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./community">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Community Tab
</div><p class="text-gray-700">
How to interact with the Community tab (Discussions and Pull Requests)?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./collections">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Collections
</div><p class="text-gray-700">
How to programmatically build collections?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./manage-cache">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Cache
</div><p class="text-gray-700">
How does the cache-system work? How to benefit from it?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./model-cards">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Model Cards
</div><p class="text-gray-700">
How to create and share Model Cards?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./manage-spaces">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Manage your Space
</div><p class="text-gray-700">
How to manage your Space hardware and configuration?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./integrations">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Integrate a library
</div><p class="text-gray-700">
What does it mean to integrate a library with the Hub? And how to do it?
</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg"
href="./webhooks_server">
<div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">
Webhooks server
</div><p class="text-gray-700">
How to create a server to receive Webhooks and deploy it as a Space?
</p>
</a>
</div>
</div>
| huggingface/huggingface_hub/blob/main/docs/source/en/guides/overview.md |
--
title: "Sentiment Analysis on Encrypted Data with Homomorphic Encryption"
thumbnail: /blog/assets/sentiment-analysis-fhe/thumbnail.png
authors:
- user: jfrery-zama
guest: true
---
# Sentiment Analysis on Encrypted Data with Homomorphic Encryption
It is well-known that a sentiment analysis model determines whether a text is positive, negative, or neutral. However, this process typically requires access to unencrypted text, which can pose privacy concerns.
Homomorphic encryption is a type of encryption that allows for computation on encrypted data without needing to decrypt it first. This makes it well-suited for applications where user's personal and potentially sensitive data is at risk (e.g. sentiment analysis of private messages).
This blog post uses the [Concrete-ML library](https://github.com/zama-ai/concrete-ml), allowing data scientists to use machine learning models in fully homomorphic encryption (FHE) settings without any prior knowledge of cryptography. We provide a practical tutorial on how to use the library to build a sentiment analysis model on encrypted data.
The post covers:
- transformers
- how to use transformers with XGBoost to perform sentiment analysis
- how to do the training
- how to use Concrete-ML to turn predictions into predictions over encrypted data
- how to [deploy to the cloud](https://docs.zama.ai/concrete-ml/getting-started/cloud) using a client/server protocol
Last but not least, we’ll finish with a complete demo over [Hugging Face Spaces](https://huggingface.co/spaces) to show this functionality in action.
## Setup the environment
First make sure your pip and setuptools are up to date by running:
```
pip install -U pip setuptools
```
Now we can install all the required libraries for the this blog with the following command.
```
pip install concrete-ml transformers datasets
```
## Using a public dataset
The dataset we use in this notebook can be found [here](https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment).
To represent the text for sentiment analysis, we chose to use a transformer hidden representation as it yields high accuracy for the final model in a very efficient way. For a comparison of this representation set against a more common procedure like the TF-IDF approach, please see this [full notebook](https://github.com/zama-ai/concrete-ml/blob/release/0.4.x/use_case_examples/encrypted_sentiment_analysis/SentimentClassification.ipynb).
We can start by opening the dataset and visualize some statistics.
```python
from datasets import load_datasets
train = load_dataset("osanseviero/twitter-airline-sentiment")["train"].to_pandas()
text_X = train['text']
y = train['airline_sentiment']
y = y.replace(['negative', 'neutral', 'positive'], [0, 1, 2])
pos_ratio = y.value_counts()[2] / y.value_counts().sum()
neg_ratio = y.value_counts()[0] / y.value_counts().sum()
neutral_ratio = y.value_counts()[1] / y.value_counts().sum()
print(f'Proportion of positive examples: {round(pos_ratio * 100, 2)}%')
print(f'Proportion of negative examples: {round(neg_ratio * 100, 2)}%')
print(f'Proportion of neutral examples: {round(neutral_ratio * 100, 2)}%')
```
The output, then, looks like this:
```
Proportion of positive examples: 16.14%
Proportion of negative examples: 62.69%
Proportion of neutral examples: 21.17%
```
The ratio of positive and neutral examples is rather similar, though we have significantly more negative examples. Let’s keep this in mind to select the final evaluation metric.
Now we can split our dataset into training and test sets. We will use a seed for this code to ensure it is perfectly reproducible.
```python
from sklearn.model_selection import train_test_split
text_X_train, text_X_test, y_train, y_test = train_test_split(text_X, y,
test_size=0.1, random_state=42)
```
## Text representation using a transformer
[Transformers](https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)) are neural networks often trained to predict the next words to appear in a text (this task is commonly called self-supervised learning). They can also be fine-tuned on some specific subtasks such that they specialize and get better results on a given problem.
They are powerful tools for all kinds of Natural Language Processing tasks. In fact, we can leverage their representation for any text and feed it to a more FHE-friendly machine-learning model for classification. In this notebook, we will use XGBoost.
We start by importing the requirements for transformers. Here, we use the popular library from [Hugging Face](https://huggingface.co) to get a transformer quickly.
The model we have chosen is a BERT transformer, fine-tuned on the Stanford Sentiment Treebank dataset.
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Load the tokenizer (converts text to tokens)
tokenizer = AutoTokenizer.from_pretrained("cardiffnlp/twitter-roberta-base-sentiment-latest")
# Load the pre-trained model
transformer_model = AutoModelForSequenceClassification.from_pretrained(
"cardiffnlp/twitter-roberta-base-sentiment-latest"
)
```
This should download the model, which is now ready to be used.
Using the hidden representation for some text can be tricky at first, mainly because we could tackle this with many different approaches. Below is the approach we chose.
First, we tokenize the text. Tokenizing means splitting the text into tokens (a sequence of specific characters that can also be words) and replacing each with a number. Then, we send the tokenized text to the transformer model, which outputs a hidden representation (output of the self attention layers which are often used as input to the classification layers) for each word. Finally, we average the representations for each word to get a text-level representation.
The result is a matrix of shape (number of examples, hidden size). The hidden size is the number of dimensions in the hidden representation. For BERT, the hidden size is 768. The hidden representation is a vector of numbers that represents the text that can be used for many different tasks. In this case, we will use it for classification with [XGBoost](https://github.com/dmlc/xgboost) afterwards.
```python
import numpy as np
import tqdm
# Function that transforms a list of texts to their representation
# learned by the transformer.
def text_to_tensor(
list_text_X_train: list,
transformer_model: AutoModelForSequenceClassification,
tokenizer: AutoTokenizer,
device: str,
) -> np.ndarray:
# Tokenize each text in the list one by one
tokenized_text_X_train_split = []
tokenized_text_X_train_split = [
tokenizer.encode(text_x_train, return_tensors="pt")
for text_x_train in list_text_X_train
]
# Send the model to the device
transformer_model = transformer_model.to(device)
output_hidden_states_list = [None] * len(tokenized_text_X_train_split)
for i, tokenized_x in enumerate(tqdm.tqdm(tokenized_text_X_train_split)):
# Pass the tokens through the transformer model and get the hidden states
# Only keep the last hidden layer state for now
output_hidden_states = transformer_model(tokenized_x.to(device), output_hidden_states=True)[
1
][-1]
# Average over the tokens axis to get a representation at the text level.
output_hidden_states = output_hidden_states.mean(dim=1)
output_hidden_states = output_hidden_states.detach().cpu().numpy()
output_hidden_states_list[i] = output_hidden_states
return np.concatenate(output_hidden_states_list, axis=0)
```
```python
# Let's vectorize the text using the transformer
list_text_X_train = text_X_train.tolist()
list_text_X_test = text_X_test.tolist()
X_train_transformer = text_to_tensor(list_text_X_train, transformer_model, tokenizer, device)
X_test_transformer = text_to_tensor(list_text_X_test, transformer_model, tokenizer, device)
```
This transformation of the text (text to transformer representation) would need to be executed on the client machine as the encryption is done over the transformer representation.
## Classifying with XGBoost
Now that we have our training and test sets properly built to train a classifier, next comes the training of our FHE model. Here it will be very straightforward, using a hyper-parameter tuning tool such as GridSearch from scikit-learn.
```python
from concrete.ml.sklearn import XGBClassifier
from sklearn.model_selection import GridSearchCV
# Let's build our model
model = XGBClassifier()
# A gridsearch to find the best parameters
parameters = {
"n_bits": [2, 3],
"max_depth": [1],
"n_estimators": [10, 30, 50],
"n_jobs": [-1],
}
# Now we have a representation for each tweet, we can train a model on these.
grid_search = GridSearchCV(model, parameters, cv=5, n_jobs=1, scoring="accuracy")
grid_search.fit(X_train_transformer, y_train)
# Check the accuracy of the best model
print(f"Best score: {grid_search.best_score_}")
# Check best hyperparameters
print(f"Best parameters: {grid_search.best_params_}")
# Extract best model
best_model = grid_search.best_estimator_
```
The output is as follows:
```
Best score: 0.8378111718275654
Best parameters: {'max_depth': 1, 'n_bits': 3, 'n_estimators': 50, 'n_jobs': -1}
```
Now, let’s see how the model performs on the test set.
```python
from sklearn.metrics import ConfusionMatrixDisplay
# Compute the metrics on the test set
y_pred = best_model.predict(X_test_transformer)
y_proba = best_model.predict_proba(X_test_transformer)
# Compute and plot the confusion matrix
matrix = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(matrix).plot()
# Compute the accuracy
accuracy_transformer_xgboost = np.mean(y_pred == y_test)
print(f"Accuracy: {accuracy_transformer_xgboost:.4f}")
```
With the following output:
```
Accuracy: 0.8504
```
## Predicting over encrypted data
Now let’s predict over encrypted text. The idea here is that we will encrypt the representation given by the transformer rather than the raw text itself. In Concrete-ML, you can do this very quickly by setting the parameter `execute_in_fhe=True` in the predict function. This is just a developer feature (mainly used to check the running time of the FHE model). We will see how we can make this work in a deployment setting a bit further down.
```python
import time
# Compile the model to get the FHE inference engine
# (this may take a few minutes depending on the selected model)
start = time.perf_counter()
best_model.compile(X_train_transformer)
end = time.perf_counter()
print(f"Compilation time: {end - start:.4f} seconds")
# Let's write a custom example and predict in FHE
tested_tweet = ["AirFrance is awesome, almost as much as Zama!"]
X_tested_tweet = text_to_tensor(tested_tweet, transformer_model, tokenizer, device)
clear_proba = best_model.predict_proba(X_tested_tweet)
# Now let's predict with FHE over a single tweet and print the time it takes
start = time.perf_counter()
decrypted_proba = best_model.predict_proba(X_tested_tweet, execute_in_fhe=True)
end = time.perf_counter()
fhe_exec_time = end - start
print(f"FHE inference time: {fhe_exec_time:.4f} seconds")
```
The output becomes:
```
Compilation time: 9.3354 seconds
FHE inference time: 4.4085 seconds
```
A check that the FHE predictions are the same as the clear predictions is also necessary.
```python
print(f"Probabilities from the FHE inference: {decrypted_proba}")
print(f"Probabilities from the clear model: {clear_proba}")
```
This output reads:
```
Probabilities from the FHE inference: [[0.08434131 0.05571389 0.8599448 ]]
Probabilities from the clear model: [[0.08434131 0.05571389 0.8599448 ]]
```
## Deployment
At this point, our model is fully trained and compiled, ready to be deployed. In Concrete-ML, you can use a [deployment API](https://docs.zama.ai/concrete-ml/advanced-topics/client_server) to do this easily:
```python
# Let's save the model to be pushed to a server later
from concrete.ml.deployment import FHEModelDev
fhe_api = FHEModelDev("sentiment_fhe_model", best_model)
fhe_api.save()
```
These few lines are enough to export all the files needed for both the client and the server. You can check out the notebook explaining this deployment API in detail [here](https://github.com/zama-ai/concrete-ml/blob/release/0.4.x/docs/advanced_examples/ClientServer.ipynb).
## Full example in a Hugging Face Space
You can also have a look at the [final application on Hugging Face Space](https://huggingface.co/spaces/zama-fhe/encrypted_sentiment_analysis). The client app was developed with [Gradio](https://gradio.app/) while the server runs with [Uvicorn](https://www.uvicorn.org/) and was developed with [FastAPI](https://fastapi.tiangolo.com/).
The process is as follows:
- User generates a new private/public key

- User types a message that will be encoded, quantized, and encrypted

- Server receives the encrypted data and starts the prediction over encrypted data, using the public evaluation key
- Server sends back the encrypted predictions and the client can decrypt them using his private key

## Conclusion
We have presented a way to leverage the power of transformers where the representation is then used to:
1. train a machine learning model to classify tweets, and
2. predict over encrypted data using this model with FHE.
The final model (Transformer representation + XGboost) has a final accuracy of 85%, which is above the transformer itself with 80% accuracy (please see this [notebook](https://github.com/zama-ai/concrete-ml/blob/release/0.4.x/use_case_examples/encrypted_sentiment_analysis/SentimentClassification.ipynb) for the comparisons).
The FHE execution time per example is 4.4 seconds on a 16 cores cpu.
The files for deployment are used for a sentiment analysis app that allows a client to request sentiment analysis predictions from a server while keeping its data encrypted all along the chain of communication.
[Concrete-ML](https://github.com/zama-ai/concrete-ml) (Don't forget to star us on Github ⭐️💛) allows straightforward ML model building and conversion to the FHE equivalent to be able to predict over encrypted data.
Hope you enjoyed this post and let us know your thoughts/feedback!
And special thanks to [Abubakar Abid](https://huggingface.co/abidlabs) for his previous advice on how to build our first Hugging Face Space!
| huggingface/blog/blob/main/sentiment-analysis-fhe.md |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Language Modeling
## Language Modeling Training
By running the scripts [`run_clm.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/language-modeling/run_clm.py)
and [`run_mlm.py`](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/language-modeling/run_mlm.py),
we will be able to leverage the [`ONNX Runtime`](https://github.com/microsoft/onnxruntime) accelerator to train the language models from the
[HuggingFace hub](https://huggingface.co/models).
__The following example applies the acceleration features powered by ONNX Runtime.__
### ONNX Runtime Training
The following example trains GPT2 on wikitext-2 with mixed precision (fp16).
```bash
torchrun --nproc_per_node=NUM_GPUS_YOU_HAVE run_clm.py \
--model_name_or_path gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--do_train \
--output_dir /tmp/test-clm \
--fp16
```
__Note__
> *To enable ONNX Runtime training, your devices need to be equipped with GPU. Install the dependencies either with our prepared*
*[Dockerfiles](https://github.com/huggingface/optimum/blob/main/examples/onnxruntime/training/docker/) or follow the instructions*
*in [`torch_ort`](https://github.com/pytorch/ort/blob/main/torch_ort/docker/README.md).*
> *The inference will use PyTorch by default, if you want to use ONNX Runtime backend instead, add the flag `--inference_with_ort`.*
---
| huggingface/optimum/blob/main/examples/onnxruntime/training/language-modeling/README.md |
Gradio Demo: blocks_speech_text_sentiment
```
!pip install -q gradio torch transformers
```
```
from transformers import pipeline
import gradio as gr
asr = pipeline("automatic-speech-recognition", "facebook/wav2vec2-base-960h")
classifier = pipeline("text-classification")
def speech_to_text(speech):
text = asr(speech)["text"]
return text
def text_to_sentiment(text):
return classifier(text)[0]["label"]
demo = gr.Blocks()
with demo:
audio_file = gr.Audio(type="filepath")
text = gr.Textbox()
label = gr.Label()
b1 = gr.Button("Recognize Speech")
b2 = gr.Button("Classify Sentiment")
b1.click(speech_to_text, inputs=audio_file, outputs=text)
b2.click(text_to_sentiment, inputs=text, outputs=label)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_speech_text_sentiment/run.ipynb |
--
title: "How to host a Unity game in a Space"
thumbnail: /blog/assets/124_ml-for-games/unity-in-spaces-thumbnail.png
authors:
- user: dylanebert
---
# How to host a Unity game in a Space
<!-- {authors} -->
Did you know you can host a Unity game in a Hugging Face Space? No? Well, you can!
Hugging Face Spaces are an easy way to build, host, and share demos. While they are typically used for Machine Learning demos,
they can also host playable Unity games. Here are some examples:
- [Huggy](https://huggingface.co/spaces/ThomasSimonini/Huggy)
- [Farming Game](https://huggingface.co/spaces/dylanebert/FarmingGame)
- [Unity API Demo](https://huggingface.co/spaces/dylanebert/UnityDemo)
Here's how you can host your own Unity game in a Space.
## Step 1: Create a Space using the Static HTML template
First, navigate to [Hugging Face Spaces](https://huggingface.co/new-space) to create a space.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/1.png">
</figure>
Select the "Static HTML" template, give your Space a name, and create it.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/2.png">
</figure>
## Step 2: Use Git to Clone the Space
Clone your newly created Space to your local machine using Git. You can do this by running the following command in your terminal or command prompt:
```
git clone https://huggingface.co/spaces/{your-username}/{your-space-name}
```
## Step 3: Open your Unity Project
Open the Unity project you want to host in your Space.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/3.png">
</figure>
## Step 4: Switch the Build Target to WebGL
Navigate to `File > Build Settings` and switch the Build Target to WebGL.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/4.png">
</figure>
## Step 5: Open Player Settings
In the Build Settings window, click the "Player Settings" button to open the Player Settings panel.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/5.png">
</figure>
## Step 6: Optionally, Download the Hugging Face Unity WebGL Template
You can enhance your game's appearance in a Space by downloading the Hugging Face Unity WebGL template, available [here](https://github.com/huggingface/Unity-WebGL-template-for-Hugging-Face-Spaces). Just download the repository and drop it in your project files.
Then, in the Player Settings panel, switch the WebGL template to Hugging Face. To do so, in Player Settings, click "Resolution and Presentation", then select the Hugging Face WebGL template.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/6.png">
</figure>
## Step 7: Change the Compression Format to Disabled
In the Player Settings panel, navigate to the "Publishing Settings" section and change the Compression Format to "Disabled".
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/7.png">
</figure>
## Step 8: Build your Project
Return to the Build Settings window and click the "Build" button. Choose a location to save your build files, and Unity will build the project for WebGL.
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/8.png">
</figure>
## Step 9: Copy the Contents of the Build Folder
After the build process is finished, navigate to the folder containing your build files. Copy the files in the build folder to the repository you cloned in [Step 2](#step-2-use-git-to-clone-the-space).
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/games-in-spaces/9.png">
</figure>
## Step 10: Enable Git-LFS for Large File Storage
Navigate to your repository. Use the following commands to track large build files.
```
git lfs install
git lfs track Build/*
```
## Step 11: Push your Changes
Finally, use the following Git commands to push your changes:
```
git add .
git commit -m "Add Unity WebGL build files"
git push
```
## Done!
Congratulations! Refresh your Space. You should now be able to play your game in a Hugging Face Space.
We hope you found this tutorial helpful. If you have any questions or would like to get more involved in using Hugging Face for Games, join the [Hugging Face Discord](https://hf.co/join/discord)! | huggingface/blog/blob/main/unity-in-spaces.md |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
This folder contains a template to add a tokenization test.
## Usage
Using the `cookiecutter` utility requires to have all the `dev` dependencies installed.
Let's first [fork](https://docs.github.com/en/get-started/quickstart/fork-a-repo) the `transformers` repo on github. Once it's done you can clone your fork and install `transformers` in our environment:
```shell script
git clone https://github.com/YOUR-USERNAME/transformers
cd transformers
pip install -e ".[dev]"
```
Once the installation is done, you can generate the template by running the following command. Be careful, the template will be generated inside a new folder in your current working directory.
```shell script
cookiecutter path-to-the folder/adding_a_missing_tokenization_test/
```
You will then have to answer some questions about the tokenizer for which you want to add tests. The `modelname` should be cased according to the plain text casing, i.e., BERT, RoBERTa, DeBERTa.
Once the command has finished, you should have a one new file inside the newly created folder named `test_tokenization_Xxx.py`. At this point the template is finished and you can move it to the sub-folder of the corresponding model in the test folder.
| huggingface/transformers/blob/main/templates/adding_a_missing_tokenization_test/README.md |
p align="center">
<br>
<img src="https://huggingface.co/landing/assets/tokenizers/tokenizers-logo.png" width="600"/>
<br>
<p>
<p align="center">
<a href="https://badge.fury.io/py/tokenizers">
<img alt="Build" src="https://badge.fury.io/py/tokenizers.svg">
</a>
<a href="https://github.com/huggingface/tokenizers/blob/master/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/tokenizers.svg?color=blue">
</a>
</p>
<br>
# Tokenizers
Provides an implementation of today's most used tokenizers, with a focus on performance and
versatility.
Bindings over the [Rust](https://github.com/huggingface/tokenizers/tree/master/tokenizers) implementation.
If you are interested in the High-level design, you can go check it there.
Otherwise, let's dive in!
## Main features:
- Train new vocabularies and tokenize using 4 pre-made tokenizers (Bert WordPiece and the 3
most common BPE versions).
- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes
less than 20 seconds to tokenize a GB of text on a server's CPU.
- Easy to use, but also extremely versatile.
- Designed for research and production.
- Normalization comes with alignments tracking. It's always possible to get the part of the
original sentence that corresponds to a given token.
- Does all the pre-processing: Truncate, Pad, add the special tokens your model needs.
### Installation
#### With pip:
```bash
pip install tokenizers
```
#### From sources:
To use this method, you need to have the Rust installed:
```bash
# Install with:
curl https://sh.rustup.rs -sSf | sh -s -- -y
export PATH="$HOME/.cargo/bin:$PATH"
```
Once Rust is installed, you can compile doing the following
```bash
git clone https://github.com/huggingface/tokenizers
cd tokenizers/bindings/python
# Create a virtual env (you can use yours as well)
python -m venv .env
source .env/bin/activate
# Install `tokenizers` in the current virtual env
pip install -e .
```
### Load a pretrained tokenizer from the Hub
```python
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained("bert-base-cased")
```
### Using the provided Tokenizers
We provide some pre-build tokenizers to cover the most common cases. You can easily load one of
these using some `vocab.json` and `merges.txt` files:
```python
from tokenizers import CharBPETokenizer
# Initialize a tokenizer
vocab = "./path/to/vocab.json"
merges = "./path/to/merges.txt"
tokenizer = CharBPETokenizer(vocab, merges)
# And then encode:
encoded = tokenizer.encode("I can feel the magic, can you?")
print(encoded.ids)
print(encoded.tokens)
```
And you can train them just as simply:
```python
from tokenizers import CharBPETokenizer
# Initialize a tokenizer
tokenizer = CharBPETokenizer()
# Then train it!
tokenizer.train([ "./path/to/files/1.txt", "./path/to/files/2.txt" ])
# Now, let's use it:
encoded = tokenizer.encode("I can feel the magic, can you?")
# And finally save it somewhere
tokenizer.save("./path/to/directory/my-bpe.tokenizer.json")
```
#### Provided Tokenizers
- `CharBPETokenizer`: The original BPE
- `ByteLevelBPETokenizer`: The byte level version of the BPE
- `SentencePieceBPETokenizer`: A BPE implementation compatible with the one used by SentencePiece
- `BertWordPieceTokenizer`: The famous Bert tokenizer, using WordPiece
All of these can be used and trained as explained above!
### Build your own
Whenever these provided tokenizers don't give you enough freedom, you can build your own tokenizer,
by putting all the different parts you need together.
You can check how we implemented the [provided tokenizers](https://github.com/huggingface/tokenizers/tree/master/bindings/python/py_src/tokenizers/implementations) and adapt them easily to your own needs.
#### Building a byte-level BPE
Here is an example showing how to build your own byte-level BPE by putting all the different pieces
together, and then saving it to a single file:
```python
from tokenizers import Tokenizer, models, pre_tokenizers, decoders, trainers, processors
# Initialize a tokenizer
tokenizer = Tokenizer(models.BPE())
# Customize pre-tokenization and decoding
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=True)
tokenizer.decoder = decoders.ByteLevel()
tokenizer.post_processor = processors.ByteLevel(trim_offsets=True)
# And then train
trainer = trainers.BpeTrainer(
vocab_size=20000,
min_frequency=2,
initial_alphabet=pre_tokenizers.ByteLevel.alphabet()
)
tokenizer.train([
"./path/to/dataset/1.txt",
"./path/to/dataset/2.txt",
"./path/to/dataset/3.txt"
], trainer=trainer)
# And Save it
tokenizer.save("byte-level-bpe.tokenizer.json", pretty=True)
```
Now, when you want to use this tokenizer, this is as simple as:
```python
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_file("byte-level-bpe.tokenizer.json")
encoded = tokenizer.encode("I can feel the magic, can you?")
```
| huggingface/tokenizers/blob/main/bindings/python/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# KarrasVeScheduler
`KarrasVeScheduler` is a stochastic sampler tailored to variance-expanding (VE) models. It is based on the [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) and [Score-based generative modeling through stochastic differential equations](https://huggingface.co/papers/2011.13456) papers.
## KarrasVeScheduler
[[autodoc]] KarrasVeScheduler
## KarrasVeOutput
[[autodoc]] schedulers.deprecated.scheduling_karras_ve.KarrasVeOutput | huggingface/diffusers/blob/main/docs/source/en/api/schedulers/stochastic_karras_ve.md |
Webhooks
<Tip>
Webhooks are now publicly available!
</Tip>
Webhooks are a foundation for MLOps-related features. They allow you to listen for new changes on specific repos or to all repos belonging to particular set of users/organizations (not just your repos, but any repo).
You can use them to auto-convert models, build community bots, or build CI/CD for your models, datasets, and Spaces (and much more!).
The documentation for Webhooks is below – or you can also browse our **guides** showcasing a few possible use cases of Webhooks:
- [Fine-tune a new model whenever a dataset gets updated (Python)](./webhooks-guide-auto-retrain)
- [Create a discussion bot on the Hub, using a LLM API (NodeJS)](./webhooks-guide-discussion-bot)
- [Create metadata quality reports (Python)](./webhooks-guide-metadata-review)
- and more to come…
## Create your Webhook
You can create new Webhooks and edit existing ones in your Webhooks [settings](https://huggingface.co/settings/webhooks):
Webhooks can watch for repos updates, Pull Requests, discussions, and new comments. It's even possible to create a Space to react to your Webhooks!
## Webhook Payloads
After registering a Webhook, you will be notified of new events via an `HTTP POST` call on the specified target URL. The payload is encoded in JSON.
You can view the history of payloads sent in the activity tab of the webhook settings page, it's also possible to replay past webhooks for easier debugging:
As an example, here is the full payload when a Pull Request is opened:
```json
{
"event": {
"action": "create",
"scope": "discussion"
},
"repo": {
"type": "model",
"name": "gpt2",
"id": "621ffdc036468d709f17434d",
"private": false,
"url": {
"web": "https://huggingface.co/gpt2",
"api": "https://huggingface.co/api/models/gpt2"
},
"owner": {
"id": "628b753283ef59b5be89e937"
}
},
"discussion": {
"id": "6399f58518721fdd27fc9ca9",
"title": "Update co2 emissions",
"url": {
"web": "https://huggingface.co/gpt2/discussions/19",
"api": "https://huggingface.co/api/models/gpt2/discussions/19"
},
"status": "open",
"author": {
"id": "61d2f90c3c2083e1c08af22d"
},
"num": 19,
"isPullRequest": true,
"changes": {
"base": "refs/heads/main"
}
},
"comment": {
"id": "6399f58518721fdd27fc9caa",
"author": {
"id": "61d2f90c3c2083e1c08af22d"
},
"content": "Add co2 emissions information to the model card",
"hidden": false,
"url": {
"web": "https://huggingface.co/gpt2/discussions/19#6399f58518721fdd27fc9caa"
}
},
"webhook": {
"id": "6390e855e30d9209411de93b",
"version": 3
}
}
```
### Event
The top-level properties `event` is always specified and used to determine the nature of the event.
It has two sub-properties: `event.action` and `event.scope`.
`event.scope` will be one of the following values:
- `"repo"` - Global events on repos. Possible values for the associated `action`: `"create"`, `"delete"`, `"update"`, `"move"`.
- `"repo.content"` - Events on the repo's content, such as new commits or tags. It triggers on new Pull Requests as well due to the newly created reference/commit. The associated `action` is always `"update"`.
- `"repo.config"` - Events on the config: update Space secrets, update settings, update DOIs, disabled or not, etc. The associated `action` is always `"update"`.
- `"discussion"` - Creating a discussion or Pull Request, updating the title or status, and merging. Possible values for the associated `action`: `"create"`, `"delete"`, `"update"`.
- `"discussion.comment"` - Creating, updating, and hiding a comment. Possible values for the associated `action`: `"create"`, `"update"`.
More scopes can be added in the future. To handle unknown events, your webhook handler can consider any action on a narrowed scope to be an `"update"` action on the broader scope.
For example, if the `"repo.config.dois"` scope is added in the future, any event with that scope can be considered by your webhook handler as an `"update"` action on the `"repo.config"` scope.
### Repo
In the current version of webhooks, the top-level property `repo` is always specified, as events can always be associated with a repo. For example, consider the following value:
```json
"repo": {
"type": "model",
"name": "some-user/some-repo",
"id": "6366c000a2abcdf2fd69a080",
"private": false,
"url": {
"web": "https://huggingface.co/some-user/some-repo",
"api": "https://huggingface.co/api/models/some-user/some-repo"
},
"headSha": "c379e821c9c95d613899e8c4343e4bfee2b0c600",
"tags": [
"license:other",
"has_space"
],
"owner": {
"id": "61d2000c3c2083e1c08af22d"
}
}
```
`repo.headSha` is the sha of the latest commit on the repo's `main` branch. It is only sent when `event.scope` starts with `"repo"`, not on community events like discussions and comments.
### Discussions and Pull Requests
The top-level property `discussion` is specified on community events (discussions and Pull Requests). The `discussion.isPullRequest` property is a boolean indicating if the discussion is also a Pull Request (on the Hub, a PR is a special type of discussion). Here is an example value:
```json
"discussion": {
"id": "639885d811ae2bad2b7ba461",
"title": "Hello!",
"url": {
"web": "https://huggingface.co/some-user/some-repo/discussions/3",
"api": "https://huggingface.co/api/models/some-user/some-repo/discussions/3"
},
"status": "open",
"author": {
"id": "61d2000c3c2083e1c08af22d"
},
"isPullRequest": true,
"changes": {
"base": "refs/heads/main"
}
"num": 3
}
```
### Comment
The top level property `comment` is specified when a comment is created (including on discussion creation) or updated. Here is an example value:
```json
"comment": {
"id": "6398872887bfcfb93a306f18",
"author": {
"id": "61d2000c3c2083e1c08af22d"
},
"content": "This adds an env key",
"hidden": false,
"url": {
"web": "https://huggingface.co/some-user/some-repo/discussions/4#6398872887bfcfb93a306f18"
}
}
```
## Webhook secret
Setting a Webhook secret is useful to make sure payloads sent to your Webhook handler URL are actually from Hugging Face.
If you set a secret for your Webhook, it will be sent along as an `X-Webhook-Secret` HTTP header on every request. Only ASCII characters are supported.
<Tip>
It's also possible to add the secret directly in the handler URL. For example, setting it as a query parameter: https://example.com/webhook?secret=XXX.
This can be helpful if accessing the HTTP headers of the request is complicated for your Webhook handler.
</Tip>
## Rate limiting
Each Webhook is limited to 1,000 triggers per 24 hours. You can view your usage in the Webhook settings page in the "Activity" tab.
If you need to increase the number of triggers for your Webhook, contact us at website@huggingface.co.
## Developing your Webhooks
If you do not have an HTTPS endpoint/URL, you can try out public tools for webhook testing. These tools act as catch-all (capture all requests) sent to them and give 200 OK status code. [Beeceptor](https://beeceptor.com/) is one tool you can use to create a temporary HTTP endpoint and review the incoming payload. Another such tool is [Webhook.site](https://webhook.site/).
Additionally, you can route a real Webhook payload to the code running locally on your machine during development. This is a great way to test and debug for faster integrations. You can do this by exposing your localhost port to the Internet. To be able to go this path, you can use [ngrok](https://ngrok.com/) or [localtunnel](https://theboroer.github.io/localtunnel-www/).
## Debugging Webhooks
You can easily find recently generated events for your webhooks. Open the activity tab for your webhook. There you will see the list of recent events.
Here you can review the HTTP status code and the payload of the generated events. Additionally, you can replay these events by clicking on the `Replay` button!
Note: When changing the target URL or secret of a Webhook, replaying an event will send the payload to the updated URL.
## FAQ
##### Can I define webhooks on my organization vs my user account?
No, this is not currently supported.
##### How can I subscribe to events on all repos (or across a whole repo type, like on all models)?
This is not currently exposed to end users but we can toggle this for you if you send an email to website@huggingface.co.
| huggingface/hub-docs/blob/main/docs/hub/webhooks.md |
Security Policy
## Supported Versions
<!--
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_check_mark: |
| < 4.0 | :x: |
-->
Each major version is currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 1.x.x | :white_check_mark: |
## Reporting a Vulnerability
<!--
Use this section to tell people how to report a vulnerability.
Tell them where to go, how often they can expect to get an update on a
reported vulnerability, what to expect if the vulnerability is accepted or
declined, etc.
-->
To report a security vulnerability, please contact: security@huggingface.co
| huggingface/datasets-server/blob/main/SECURITY.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Pipeline callbacks
The denoising loop of a pipeline can be modified with custom defined functions using the `callback_on_step_end` parameter. This can be really useful for *dynamically* adjusting certain pipeline attributes, or modifying tensor variables. The flexibility of callbacks opens up some interesting use-cases such as changing the prompt embeddings at each timestep, assigning different weights to the prompt embeddings, and editing the guidance scale.
This guide will show you how to use the `callback_on_step_end` parameter to disable classifier-free guidance (CFG) after 40% of the inference steps to save compute with minimal cost to performance.
The callback function should have the following arguments:
* `pipe` (or the pipeline instance) provides access to useful properties such as `num_timestep` and `guidance_scale`. You can modify these properties by updating the underlying attributes. For this example, you'll disable CFG by setting `pipe._guidance_scale=0.0`.
* `step_index` and `timestep` tell you where you are in the denoising loop. Use `step_index` to turn off CFG after reaching 40% of `num_timestep`.
* `callback_kwargs` is a dict that contains tensor variables you can modify during the denoising loop. It only includes variables specified in the `callback_on_step_end_tensor_inputs` argument, which is passed to the pipeline's `__call__` method. Different pipelines may use different sets of variables, so please check a pipeline's `_callback_tensor_inputs` attribute for the list of variables you can modify. Some common variables include `latents` and `prompt_embeds`. For this function, change the batch size of `prompt_embeds` after setting `guidance_scale=0.0` in order for it to work properly.
Your callback function should look something like this:
```python
def callback_dynamic_cfg(pipe, step_index, timestep, callback_kwargs):
# adjust the batch_size of prompt_embeds according to guidance_scale
if step_index == int(pipe.num_timestep * 0.4):
prompt_embeds = callback_kwargs["prompt_embeds"]
prompt_embeds = prompt_embeds.chunk(2)[-1]
# update guidance_scale and prompt_embeds
pipe._guidance_scale = 0.0
callback_kwargs["prompt_embeds"] = prompt_embeds
return callback_kwargs
```
Now, you can pass the callback function to the `callback_on_step_end` parameter and the `prompt_embeds` to `callback_on_step_end_tensor_inputs`.
```py
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
generator = torch.Generator(device="cuda").manual_seed(1)
out = pipe(prompt, generator=generator, callback_on_step_end=callback_custom_cfg, callback_on_step_end_tensor_inputs=['prompt_embeds'])
out.images[0].save("out_custom_cfg.png")
```
The callback function is executed at the end of each denoising step, and modifies the pipeline attributes and tensor variables for the next denoising step.
With callbacks, you can implement features such as dynamic CFG without having to modify the underlying code at all!
<Tip>
🤗 Diffusers currently only supports `callback_on_step_end`, but feel free to open a [feature request](https://github.com/huggingface/diffusers/issues/new/choose) if you have a cool use-case and require a callback function with a different execution point!
</Tip>
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/callback.md |
From Q-Learning to Deep Q-Learning [[from-q-to-dqn]]
We learned that **Q-Learning is an algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-function.jpg" alt="Q-function"/>
</figure>
The **Q comes from "the Quality" of that action at that state.**
Internally, our Q-function is encoded by **a Q-table, a table where each cell corresponds to a state-action pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
The problem is that Q-Learning is a *tabular method*. This becomes a problem if the states and actions spaces **are not small enough to be represented efficiently by arrays and tables**. In other words: it is **not scalable**.
Q-Learning worked well with small state space environments like:
- FrozenLake, we had 16 states.
- Taxi-v3, we had 500 states.
But think of what we're going to do today: we will train an agent to learn to play Space Invaders, a more complex game, using the frames as input.
As **[Nikita Melkozerov mentioned](https://twitter.com/meln1k), Atari environments** have an observation space with a shape of (210, 160, 3)*, containing values ranging from 0 to 255 so that gives us \\(256^{210 \times 160 \times 3} = 256^{100800}\\) possible observations (for comparison, we have approximately \\(10^{80}\\) atoms in the observable universe).
* A single frame in Atari is composed of an image of 210x160 pixels. Given that the images are in color (RGB), there are 3 channels. This is why the shape is (210, 160, 3). For each pixel, the value can go from 0 to 255.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari.jpg" alt="Atari State Space"/>
Therefore, the state space is gigantic; due to this, creating and updating a Q-table for that environment would not be efficient. In this case, the best idea is to approximate the Q-values using a parametrized Q-function \\(Q_{\theta}(s,a)\\) .
This neural network will approximate, given a state, the different Q-values for each possible action at that state. And that's exactly what Deep Q-Learning does.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/deep.jpg" alt="Deep Q Learning"/>
Now that we understand Deep Q-Learning, let's dive deeper into the Deep Q-Network.
| huggingface/deep-rl-class/blob/main/units/en/unit3/from-q-to-dqn.mdx |
Using the `evaluator` with custom pipelines
The evaluator is designed to work with `transformer` pipelines out-of-the-box. However, in many cases you might have a model or pipeline that's not part of the `transformer` ecosystem. You can still use `evaluator` to easily compute metrics for them. In this guide we show how to do this for a Scikit-Learn [pipeline](https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html#sklearn.pipeline.Pipeline) and a Spacy [pipeline](https://spacy.io). Let's start with the Scikit-Learn case.
## Scikit-Learn
First we need to train a model. We'll train a simple text classifier on the [IMDb dataset](https://huggingface.co/datasets/imdb), so let's start by downloading the dataset:
```py
from datasets import load_dataset
ds = load_dataset("imdb")
```
Then we can build a simple TF-IDF preprocessor and Naive Bayes classifier wrapped in a `Pipeline`:
```py
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
text_clf = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', MultinomialNB()),
])
text_clf.fit(ds["train"]["text"], ds["train"]["label"])
```
Following the convention in the `TextClassificationPipeline` of `transformers` our pipeline should be callable and return a list of dictionaries. In addition we use the `task` attribute to check if the pipeline is compatible with the `evaluator`. We can write a small wrapper class for that purpose:
```py
class ScikitEvalPipeline:
def __init__(self, pipeline):
self.pipeline = pipeline
self.task = "text-classification"
def __call__(self, input_texts, **kwargs):
return [{"label": p} for p in self.pipeline.predict(input_texts)]
pipe = ScikitEvalPipeline(text_clf)
```
We can now pass this `pipeline` to the `evaluator`:
```py
from evaluate import evaluator
task_evaluator = evaluator("text-classification")
task_evaluator.compute(pipe, ds["test"], "accuracy")
>>> {'accuracy': 0.82956}
```
Implementing that simple wrapper is all that's needed to use any model from any framework with the `evaluator`. In the `__call__` you can implement all logic necessary for efficient forward passes through your model.
## Spacy
We'll use the `polarity` feature of the `spacytextblob` project to get a simple sentiment analyzer. First you'll need to install the project and download the resources:
```bash
pip install spacytextblob
python -m textblob.download_corpora
python -m spacy download en_core_web_sm
```
Then we can simply load the `nlp` pipeline and add the `spacytextblob` pipeline:
```py
import spacy
nlp = spacy.load('en_core_web_sm')
nlp.add_pipe('spacytextblob')
```
This snippet shows how we can use the `polarity` feature added with `spacytextblob` to get the sentiment of a text:
```py
texts = ["This movie is horrible", "This movie is awesome"]
results = nlp.pipe(texts)
for txt, res in zip(texts, results):
print(f"{text} | Polarity: {res._.blob.polarity}")
```
Now we can wrap it in a simple wrapper class like in the Scikit-Learn example before. It just has to return a list of dictionaries with the predicted lables. If the polarity is larger than 0 we'll predict positive sentiment and negative otherwise:
```py
class SpacyEvalPipeline:
def __init__(self, nlp):
self.nlp = nlp
self.task = "text-classification"
def __call__(self, input_texts, **kwargs):
results =[]
for p in self.nlp.pipe(input_texts):
if p._.blob.polarity>=0:
results.append({"label": 1})
else:
results.append({"label": 0})
return results
pipe = SpacyEvalPipeline(nlp)
```
That class is compatible with the `evaluator` and we can use the same instance from the previous examlpe along with the IMDb test set:
```py
eval.compute(pipe, ds["test"], "accuracy")
>>> {'accuracy': 0.6914}
```
This will take a little longer than the Scikit-Learn example but after roughly 10-15min you will have the evaluation results!
| huggingface/evaluate/blob/main/docs/source/custom_evaluator.mdx |
Gradio Demo: spectogram
```
!pip install -q gradio scipy numpy matplotlib
```
```
import matplotlib.pyplot as plt
import numpy as np
from scipy import signal
import gradio as gr
def spectrogram(audio):
sr, data = audio
if len(data.shape) == 2:
data = np.mean(data, axis=0)
frequencies, times, spectrogram_data = signal.spectrogram(
data, sr, window="hamming"
)
plt.pcolormesh(times, frequencies, np.log10(spectrogram_data))
return plt
demo = gr.Interface(spectrogram, "audio", "plot")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/spectogram/run.ipynb |
Gradio Demo: clustering
### This demo built with Blocks generates 9 plots based on the input.
```
!pip install -q gradio matplotlib>=3.5.2 scikit-learn>=1.0.1
```
```
import gradio as gr
import math
from functools import partial
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import (
AgglomerativeClustering, Birch, DBSCAN, KMeans, MeanShift, OPTICS, SpectralClustering, estimate_bandwidth
)
from sklearn.datasets import make_blobs, make_circles, make_moons
from sklearn.mixture import GaussianMixture
from sklearn.neighbors import kneighbors_graph
from sklearn.preprocessing import StandardScaler
plt.style.use('seaborn-v0_8')
SEED = 0
MAX_CLUSTERS = 10
N_SAMPLES = 1000
N_COLS = 3
FIGSIZE = 7, 7 # does not affect size in webpage
COLORS = [
'blue', 'orange', 'green', 'red', 'purple', 'brown', 'pink', 'gray', 'olive', 'cyan'
]
if len(COLORS) <= MAX_CLUSTERS:
raise ValueError("Not enough different colors for all clusters")
np.random.seed(SEED)
def normalize(X):
return StandardScaler().fit_transform(X)
def get_regular(n_clusters):
# spiral pattern
centers = [
[0, 0],
[1, 0],
[1, 1],
[0, 1],
[-1, 1],
[-1, 0],
[-1, -1],
[0, -1],
[1, -1],
[2, -1],
][:n_clusters]
assert len(centers) == n_clusters
X, labels = make_blobs(n_samples=N_SAMPLES, centers=centers, cluster_std=0.25, random_state=SEED)
return normalize(X), labels
def get_circles(n_clusters):
X, labels = make_circles(n_samples=N_SAMPLES, factor=0.5, noise=0.05, random_state=SEED)
return normalize(X), labels
def get_moons(n_clusters):
X, labels = make_moons(n_samples=N_SAMPLES, noise=0.05, random_state=SEED)
return normalize(X), labels
def get_noise(n_clusters):
np.random.seed(SEED)
X, labels = np.random.rand(N_SAMPLES, 2), np.random.randint(0, n_clusters, size=(N_SAMPLES,))
return normalize(X), labels
def get_anisotropic(n_clusters):
X, labels = make_blobs(n_samples=N_SAMPLES, centers=n_clusters, random_state=170)
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X = np.dot(X, transformation)
return X, labels
def get_varied(n_clusters):
cluster_std = [1.0, 2.5, 0.5, 1.0, 2.5, 0.5, 1.0, 2.5, 0.5, 1.0][:n_clusters]
assert len(cluster_std) == n_clusters
X, labels = make_blobs(
n_samples=N_SAMPLES, centers=n_clusters, cluster_std=cluster_std, random_state=SEED
)
return normalize(X), labels
def get_spiral(n_clusters):
# from https://scikit-learn.org/stable/auto_examples/cluster/plot_agglomerative_clustering.html
np.random.seed(SEED)
t = 1.5 * np.pi * (1 + 3 * np.random.rand(1, N_SAMPLES))
x = t * np.cos(t)
y = t * np.sin(t)
X = np.concatenate((x, y))
X += 0.7 * np.random.randn(2, N_SAMPLES)
X = np.ascontiguousarray(X.T)
labels = np.zeros(N_SAMPLES, dtype=int)
return normalize(X), labels
DATA_MAPPING = {
'regular': get_regular,
'circles': get_circles,
'moons': get_moons,
'spiral': get_spiral,
'noise': get_noise,
'anisotropic': get_anisotropic,
'varied': get_varied,
}
def get_groundtruth_model(X, labels, n_clusters, **kwargs):
# dummy model to show true label distribution
class Dummy:
def __init__(self, y):
self.labels_ = labels
return Dummy(labels)
def get_kmeans(X, labels, n_clusters, **kwargs):
model = KMeans(init="k-means++", n_clusters=n_clusters, n_init=10, random_state=SEED)
model.set_params(**kwargs)
return model.fit(X)
def get_dbscan(X, labels, n_clusters, **kwargs):
model = DBSCAN(eps=0.3)
model.set_params(**kwargs)
return model.fit(X)
def get_agglomerative(X, labels, n_clusters, **kwargs):
connectivity = kneighbors_graph(
X, n_neighbors=n_clusters, include_self=False
)
# make connectivity symmetric
connectivity = 0.5 * (connectivity + connectivity.T)
model = AgglomerativeClustering(
n_clusters=n_clusters, linkage="ward", connectivity=connectivity
)
model.set_params(**kwargs)
return model.fit(X)
def get_meanshift(X, labels, n_clusters, **kwargs):
bandwidth = estimate_bandwidth(X, quantile=0.25)
model = MeanShift(bandwidth=bandwidth, bin_seeding=True)
model.set_params(**kwargs)
return model.fit(X)
def get_spectral(X, labels, n_clusters, **kwargs):
model = SpectralClustering(
n_clusters=n_clusters,
eigen_solver="arpack",
affinity="nearest_neighbors",
)
model.set_params(**kwargs)
return model.fit(X)
def get_optics(X, labels, n_clusters, **kwargs):
model = OPTICS(
min_samples=7,
xi=0.05,
min_cluster_size=0.1,
)
model.set_params(**kwargs)
return model.fit(X)
def get_birch(X, labels, n_clusters, **kwargs):
model = Birch(n_clusters=n_clusters)
model.set_params(**kwargs)
return model.fit(X)
def get_gaussianmixture(X, labels, n_clusters, **kwargs):
model = GaussianMixture(
n_components=n_clusters, covariance_type="full", random_state=SEED,
)
model.set_params(**kwargs)
return model.fit(X)
MODEL_MAPPING = {
'True labels': get_groundtruth_model,
'KMeans': get_kmeans,
'DBSCAN': get_dbscan,
'MeanShift': get_meanshift,
'SpectralClustering': get_spectral,
'OPTICS': get_optics,
'Birch': get_birch,
'GaussianMixture': get_gaussianmixture,
'AgglomerativeClustering': get_agglomerative,
}
def plot_clusters(ax, X, labels):
set_clusters = set(labels)
set_clusters.discard(-1) # -1 signifiies outliers, which we plot separately
for label, color in zip(sorted(set_clusters), COLORS):
idx = labels == label
if not sum(idx):
continue
ax.scatter(X[idx, 0], X[idx, 1], color=color)
# show outliers (if any)
idx = labels == -1
if sum(idx):
ax.scatter(X[idx, 0], X[idx, 1], c='k', marker='x')
ax.grid(None)
ax.set_xticks([])
ax.set_yticks([])
return ax
def cluster(dataset: str, n_clusters: int, clustering_algorithm: str):
if isinstance(n_clusters, dict):
n_clusters = n_clusters['value']
else:
n_clusters = int(n_clusters)
X, labels = DATA_MAPPING[dataset](n_clusters)
model = MODEL_MAPPING[clustering_algorithm](X, labels, n_clusters=n_clusters)
if hasattr(model, "labels_"):
y_pred = model.labels_.astype(int)
else:
y_pred = model.predict(X)
fig, ax = plt.subplots(figsize=FIGSIZE)
plot_clusters(ax, X, y_pred)
ax.set_title(clustering_algorithm, fontsize=16)
return fig
title = "Clustering with Scikit-learn"
description = (
"This example shows how different clustering algorithms work. Simply pick "
"the dataset and the number of clusters to see how the clustering algorithms work. "
"Colored circles are (predicted) labels and black x are outliers."
)
def iter_grid(n_rows, n_cols):
# create a grid using gradio Block
for _ in range(n_rows):
with gr.Row():
for _ in range(n_cols):
with gr.Column():
yield
with gr.Blocks(title=title) as demo:
gr.HTML(f"<b>{title}</b>")
gr.Markdown(description)
input_models = list(MODEL_MAPPING)
input_data = gr.Radio(
list(DATA_MAPPING),
value="regular",
label="dataset"
)
input_n_clusters = gr.Slider(
minimum=1,
maximum=MAX_CLUSTERS,
value=4,
step=1,
label='Number of clusters'
)
n_rows = int(math.ceil(len(input_models) / N_COLS))
counter = 0
for _ in iter_grid(n_rows, N_COLS):
if counter >= len(input_models):
break
input_model = input_models[counter]
plot = gr.Plot(label=input_model)
fn = partial(cluster, clustering_algorithm=input_model)
input_data.change(fn=fn, inputs=[input_data, input_n_clusters], outputs=plot)
input_n_clusters.change(fn=fn, inputs=[input_data, input_n_clusters], outputs=plot)
counter += 1
demo.launch()
```
| gradio-app/gradio/blob/main/demo/clustering/run.ipynb |
Datasets server admin machine
> Admin endpoints
## Configuration
The worker can be configured using environment variables. They are grouped by scope.
### Admin service
Set environment variables to configure the application (`ADMIN_` prefix):
- `ADMIN_HF_ORGANIZATION`: the huggingface organization from which the authenticated user must be part of in order to access the protected routes, eg. "huggingface". If empty, the authentication is disabled. Defaults to None.
- `ADMIN_CACHE_REPORTS_NUM_RESULTS`: the number of results in /cache-reports/... endpoints. Defaults to `100`.
- `ADMIN_CACHE_REPORTS_WITH_CONTENT_NUM_RESULTS`: the number of results in /cache-reports-with-content/... endpoints. Defaults to `100`.
- `ADMIN_HF_TIMEOUT_SECONDS`: the timeout in seconds for the requests to the Hugging Face Hub. Defaults to `0.2` (200 ms).
- `ADMIN_HF_WHOAMI_PATH`: the path of the external whoami service, on the hub (see `HF_ENDPOINT`), eg. "/api/whoami-v2". Defaults to `/api/whoami-v2`.
- `ADMIN_MAX_AGE`: number of seconds to set in the `max-age` header on technical endpoints. Defaults to `10` (10 seconds).
### Uvicorn
The following environment variables are used to configure the Uvicorn server (`ADMIN_UVICORN_` prefix):
- `ADMIN_UVICORN_HOSTNAME`: the hostname. Defaults to `"localhost"`.
- `ADMIN_UVICORN_NUM_WORKERS`: the number of uvicorn workers. Defaults to `2`.
- `ADMIN_UVICORN_PORT`: the port. Defaults to `8000`.
### Prometheus
- `PROMETHEUS_MULTIPROC_DIR`: the directory where the uvicorn workers share their prometheus metrics. See https://github.com/prometheus/client_python#multiprocess-mode-eg-gunicorn. Defaults to empty, in which case every worker manages its own metrics, and the /metrics endpoint returns the metrics of a random worker.
### Common
See [../../libs/libcommon/README.md](../../libs/libcommon/README.md) for more information about the common configuration.
## Endpoints
The admin service provides endpoints:
- `/healthcheck`
- `/metrics`: give info about the cache and the queue
- `/cache-reports{processing_step}`: give detailed reports on the content of the cache for a processing step
- `/cache-reports-with-content{processing_step}`: give detailed reports on the content of the cache for a processing step, including the content itself, which can be heavy
- `/pending-jobs`: give the pending jobs, classed by queue and status (waiting or started)
- `/force-refresh{processing_step}`: force refresh cache entries for the processing step. It's a POST endpoint. Pass the requested parameters, depending on the processing step's input type:
- `dataset`: `?dataset={dataset}`
- `config`: `?dataset={dataset}&config={config}`
- `split`: `?dataset={dataset}&config={config}&split={split}`
- `/recreate-dataset`: deletes all the cache entries related to a specific dataset, then run all the steps in order. It's a POST endpoint. Pass the requested parameters:
- `dataset`: the dataset name
- `priority`: `low` (default), `normal` or `high`
| huggingface/datasets-server/blob/main/services/admin/README.md |
Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, caste, color, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
feedback@huggingface.co.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
[https://www.contributor-covenant.org/version/2/0/code_of_conduct.html][v2.0].
Community Impact Guidelines were inspired by
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available
at [https://www.contributor-covenant.org/translations][translations].
[homepage]: https://www.contributor-covenant.org
[v2.0]: https://www.contributor-covenant.org/version/2/0/code_of_conduct.html
[Mozilla CoC]: https://github.com/mozilla/diversity
[FAQ]: https://www.contributor-covenant.org/faq
[translations]: https://www.contributor-covenant.org/translations
| huggingface/optimum/blob/main/CODE_OF_CONDUCT.md |
--
title: "Llama 2 on Amazon SageMaker a Benchmark"
thumbnail: /blog/assets/llama_sagemaker_benchmark/thumbnail.jpg
authors:
- user: philschmid
---
# Llama 2 on Amazon SageMaker a Benchmark

Deploying large language models (LLMs) and other generative AI models can be challenging due to their computational requirements and latency needs. To provide useful recommendations to companies looking to deploy Llama 2 on Amazon SageMaker with the [Hugging Face LLM Inference Container](https://huggingface.co/blog/sagemaker-huggingface-llm), we created a comprehensive benchmark analyzing over 60 different deployment configurations for Llama 2.
In this benchmark, we evaluated varying sizes of Llama 2 on a range of Amazon EC2 instance types with different load levels. Our goal was to measure latency (ms per token), and throughput (tokens per second) to find the optimal deployment strategies for three common use cases:
- Most Cost-Effective Deployment: For users looking for good performance at low cost
- Best Latency Deployment: Minimizing latency for real-time services
- Best Throughput Deployment: Maximizing tokens processed per second
To keep this benchmark fair, transparent, and reproducible, we share all of the assets, code, and data we used and collected:
- [GitHub Repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container)
- [Raw Data](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker)
- [Spreadsheet with processed data](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit?usp=sharing)
We hope to enable customers to use LLMs and Llama 2 efficiently and optimally for their use case. Before we get into the benchmark and data, let's look at the technologies and methods we used.
- [Llama 2 on Amazon SageMaker a Benchmark](#llama-2-on-amazon-sagemaker-a-benchmark)
- [What is the Hugging Face LLM Inference Container?](#what-is-the-hugging-face-llm-inference-container)
- [What is Llama 2?](#what-is-llama-2)
- [What is GPTQ?](#what-is-gptq)
- [Benchmark](#benchmark)
- [Recommendations \& Insights](#recommendations--insights)
- [Most Cost-Effective Deployment](#most-cost-effective-deployment)
- [Best Throughput Deployment](#best-throughput-deployment)
- [Best Latency Deployment](#best-latency-deployment)
- [Conclusions](#conclusions)
### What is the Hugging Face LLM Inference Container?
[Hugging Face LLM DLC](https://huggingface.co/blog/sagemaker-huggingface-llm) is a purpose-built Inference Container to easily deploy LLMs in a secure and managed environment. The DLC is powered by [Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference), an open-source, purpose-built solution for deploying and serving LLMs. TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, Falcon, Llama, and T5. VMware, IBM, Grammarly, Open-Assistant, Uber, Scale AI, and many more already use Text Generation Inference.
### What is Llama 2?
Llama 2 is a family of LLMs from Meta, trained on 2 trillion tokens. Llama 2 comes in three sizes - 7B, 13B, and 70B parameters - and introduces key improvements like longer context length, commercial licensing, and optimized chat abilities through reinforcement learning compared to Llama (1). If you want to learn more about Llama 2 check out this [blog post](https://huggingface.co/blog/llama2).
### What is GPTQ?
GPTQ is a post-training quantziation method to compress LLMs, like GPT. GPTQ compresses GPT (decoder) models by reducing the number of bits needed to store each weight in the model, from 32 bits down to just 3-4 bits. This means the model takes up much less memory and can run on less Hardware, e.g. Single GPU for 13B Llama2 models. GPTQ analyzes each layer of the model separately and approximates the weights to preserve the overall accuracy. If you want to learn more and how to use it, check out [Optimize open LLMs using GPTQ and Hugging Face Optimum](https://www.philschmid.de/gptq-llama).
## Benchmark
To benchmark the real-world performance of Llama 2, we tested 3 model sizes (7B, 13B, 70B parameters) on four different instance types with four different load levels, resulting in 60 different configurations:
- Models: We evaluated all currently available model sizes, including 7B, 13B, and 70B.
- Concurrent Requests: We tested configurations with 1, 5, 10, and 20 concurrent requests to determine the performance on different usage scenarios.
- Instance Types: We evaluated different GPU instances, including g5.2xlarge, g5.12xlarge, g5.48xlarge powered by NVIDIA A10G GPUs, and p4d.24xlarge powered by NVIDIA A100 40GB GPU.
- Quantization: We compared performance with and without quantization. We used GPTQ 4-bit as a quantization technique.
As metrics, we used Throughput and Latency defined as:
- Throughput (tokens/sec): Number of tokens being generated per second.
- Latency (ms/token): Time it takes to generate a single token
We used those to evaluate the performance of Llama across the different setups to understand the benefits and tradeoffs. If you want to run the benchmark yourself, we created a [Github repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container).
You can find the full data of the benchmark in the [Amazon SageMaker Benchmark: TGI 1.0.3 Llama 2](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit#gid=0) sheet. The raw data is available on [GitHub](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker).
If you are interested in all of the details, we recommend you to dive deep into the provided raw data.
## Recommendations & Insights
Based on the benchmark, we provide specific recommendations for optimal LLM deployment depending on your priorities between cost, throughput, and latency for all Llama 2 model sizes.
*Note: The recommendations are based on the configuration we tested. In the future, other environments or hardware offerings, such as Inferentia2, may be even more cost-efficient.*
### Most Cost-Effective Deployment
The most cost-effective configuration focuses on the right balance between performance (latency and throughput) and cost. Maximizing the output per dollar spent is the goal. We looked at the performance during 5 concurrent requests. We can see that GPTQ offers the best cost-effectiveness, allowing customers to deploy Llama 2 13B on a single GPU.
| Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) |
| ----------- | ------------ | -------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ |
| Llama 2 7B | GPTQ | g5.2xlarge | 5 | 34.245736 | 120.0941633 | $1.52 | 138.78 | $3.50 |
| Llama 2 13B | GPTQ | g5.2xlarge | 5 | 56.237484 | 71.70560104 | $1.52 | 232.43 | $5.87 |
| Llama 2 70B | GPTQ | ml.g5.12xlarge | 5 | 138.347928 | 33.33372399 | $7.09 | 499.99 | $59.08 |
### Best Throughput Deployment
The Best Throughput configuration maximizes the number of tokens that are generated per second. This might come with some reduction in overall latency since you process more tokens simultaneously. We looked at the highest tokens per second performance during twenty concurrent requests, with some respect to the cost of the instance. The highest throughput was for Llama 2 13B on the ml.p4d.24xlarge instance with 688 tokens/sec.
| Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) |
| ----------- | ------------ | --------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ |
| Llama 2 7B | None | ml.g5.12xlarge | 20 | 43.99524 | 449.9423027 | $7.09 | 33.59 | $3.97 |
| Llama 2 13B | None | ml.p4d.12xlarge | 20 | 67.4027465 | 668.0204881 | $37.69 | 24.95 | $15.67 |
| Llama 2 70B | None | ml.p4d.24xlarge | 20 | 59.798591 | 321.5369158 | $37.69 | 51.83 | $32.56 |
### Best Latency Deployment
The Best Latency configuration minimizes the time it takes to generate one token. Low latency is important for real-time use cases and providing a good experience to the customer, e.g. Chat applications. We looked at the lowest median for milliseconds per token during 1 concurrent request. The lowest overall latency was for Llama 2 7B on the ml.g5.12xlarge instance with 16.8ms/token.
| Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Thorughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) |
| ----------- | ------------ | --------------- | ------------------- | ------------------------- | -------------------------- | --------------------------------- | ------------------------------------- | ------------------------------ |
| Llama 2 7B | None | ml.g5.12xlarge | 1 | 16.812526 | 61.45733054 | $7.09 | 271.19 | $32.05 |
| Llama 2 13B | None | ml.g5.12xlarge | 1 | 21.002715 | 47.15736567 | $7.09 | 353.43 | $41.76 |
| Llama 2 70B | None | ml.p4d.24xlarge | 1 | 41.348543 | 24.5142928 | $37.69 | 679.88 | $427.05 |
## Conclusions
In this benchmark, we tested 60 configurations of Llama 2 on Amazon SageMaker. For cost-effective deployments, we found 13B Llama 2 with GPTQ on g5.2xlarge delivers 71 tokens/sec at an hourly cost of $1.55. For max throughput, 13B Llama 2 reached 296 tokens/sec on ml.g5.12xlarge at $2.21 per 1M tokens. And for minimum latency, 7B Llama 2 achieved 16ms per token on ml.g5.12xlarge.
We hope the benchmark will help companies deploy Llama 2 optimally based on their needs. If you want to get started deploying Llama 2 on Amazon SageMaker, check out [Introducing the Hugging Face LLM Inference Container for Amazon SageMaker](https://huggingface.co/blog/sagemaker-huggingface-llm) and [Deploy Llama 2 7B/13B/70B on Amazon SageMaker](https://www.philschmid.de/sagemaker-llama-llm) blog posts.
---
Thanks for reading! If you have any questions, feel free to contact me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
| huggingface/blog/blob/main/llama-sagemaker-benchmark.md |
Dataset viewer
The dataset page includes a table with the contents of the dataset, arranged by pages of 100 rows. You can navigate between pages using the buttons at the bottom of the table.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/dataset-viewer.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/dataset-viewer-dark.png"/>
</div>
## Inspect data distributions
At the top of the columns you can see the graphs representing the distribution of their data. This gives you a quick insight on how balanced your classes are, what are the range and distribution of numerical data and lengths of texts, and what portion of the column data is missing.
## Filter by value
If you click on a bar of a histogram from a numerical column, the dataset viewer will filter the data and show only the rows with values that fall in the selected range.
Similarly, if you select one class from a categorical column, it will show only the rows from the selected category.
## Search a word in the dataset
You can search for a word in the dataset by typing it in the search bar at the top of the table. The search is case-insensitive and will match any row containing the word. The text is searched in the columns of `string`, even if the values are nested in a dictionary or a list.
## Share a specific row
You can share a specific row by clicking on it, and then copying the URL in the address bar of your browser. For example https://huggingface.co/datasets/glue/viewer/mrpc/test?p=2&row=241 will open the dataset viewer on the MRPC dataset, on the test split, and on the 241st row.
## Access the parquet files
To power the dataset viewer, every dataset is auto-converted to the Parquet format. Click on [_"Auto-converted to Parquet"_](https://huggingface.co/datasets/glue/tree/refs%2Fconvert%2Fparquet/cola) to access the Parquet files. Refer to the [Datasets Server docs](/docs/datasets-server/parquet_process) to learn how to query the dataset parquet files with libraries such as Polars, Pandas or DuckDB.
You can also access the list of Parquet files programmatically using the [Hub API](./api#endpoints-table): https://huggingface.co/api/datasets/glue/parquet.
## Very large datasets
For datasets >5GB, we only auto-convert to Parquet the first ~5GB of the dataset.
In this case, an informational message lets you know that the Viewer is partial. This should be a large enough sample to represent the full dataset accurately, let us know if you need a bigger sample.
## Dataset preview
For the biggest datasets, the page shows a preview of the first 100 rows instead of a full-featured viewer. This restriction only applies for datasets over 5GB that are not natively in Parquet format.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/dataset-preview.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/dataset-preview-dark.png"/>
</div>
## Configure the Dataset Viewer
To have a properly working Dataset Viewer for your dataset, make sure your dataset is in a supported format and structure.
There is also an option to configure your dataset using YAML.
For more information see our guide on [How to configure the Dataset Viewer](./datasets-viewer-configure).
| huggingface/hub-docs/blob/main/docs/hub/datasets-viewer.md |
n this video, we will study together "the Unigram Language Model subword tokenization algorithm".
The overall training strategy of a Unigram LM tokenizer is to start with a very large vocabulary and then to remove tokens at each iteration until we reach the desired size. At each iteration, we will calculate a loss on our training corpus thanks to the Unigram model. As the loss calculation depends on the available vocabulary, we can use it to choose how to reduce the vocabulary. So we look at the evolution of the loss by removing in turn each token from the vocabulary. We will choose to remove the p percents which increase the loss the less.
Before going further in the explanation of the training algorithm, I need to explain what is an Unigram model. The Unigram LM model is a type of statistical Language Modem. A statistical LM will assign a probability to a text considering that the text is in fact a sequence of tokens. The simplest sequences of tokens to imagine are the words that compose the sentence or the characters. The particularity of Unigram LM is that it assumes that the occurrence of each word is independent of its previous word. This "assumption" allows us to write that the probability of a text is equal to the product of the probabilities of the tokens that compose it. It should be noted here that this is a very simple model which would not be adapted to the generation of text since this model would always generate the same token, the one which has the greatest probability. Nevertheless, to do tokenization, this model is very useful to us because it can be used to estimate the relative likelihood of different phrases. We are now ready to return to our explanation of the training algorithm. Let's say that we have as a training corpus 10 times the word hug, 12 times the word pug, 5 times the word lug, 4 times bug and 5 times dug. As said at the beginning of the video, the training starts with a big vocabulary. Obviously, as we are using a toy corpus, this vocabulary will not be that big but it should show you the principle. A first method is to list all the possible strict substrings that's what we'll do here. We could also have used the BPE algorithm with a very large vocabulary size. So we have our initial vocabulary. The training of the Unigram tokenizer is based on the Expectation-Maximization method: at each iteration. We estimate the probabilities of the tokens of the vocabulary. Then we remove the p percent of tokens that minimize the loss on the corpus and which do not belong to the basic characters as we want to keep in our final vocabulary the basic characters to be able to tokenize any word. Let's go for it! The probability of a token is simply estimated by the number of appearance of this token in our training corpus divided by the total number of appearance of all the tokens. We could use this vocabulary to tokenize our words according to the unigram model. We will do it together to understand two things: how we tokenize a word with a Unigram model and how the loss is calculated on our corpus. The Unigram LM tokenization of our text "Hug" will be the one with the highest probability of occurrence according to our Unigram model. To find it, the simplest way to proceed would be to list all the possible segmentations of our text "Hug", calculate the probability of each of these segmentations and then choose the one with the highest probability. With the current vocabulary, 2 tokenizations get exactly the same probability. So we choose one of them and keep in memory the associated probability. To compute the loss on our training corpus, we need to tokenize as we just did all the remaining words in the corpus. The loss is then the sum over all the words in the corpus of the frequency of occurrence of the word multiplied by the opposite of the log of the probability associated with the tokenization of the word. We obtain here a loss of one hundred and seventy. Remember, our initial goal was to reduce the vocabulary. To do this, we will remove a token from the vocabulary and calculate the associated loss. Let's remove for example the token 'ug'. We notice that the tokenization for "hug" with the letter h and the tuple ug is now impossible. Nevertheless, as we saw earlier that two tokenizations had the same probability and we can still choose the remaining tokenization with a probability of one point ten minus two. The tokenizations of the other words of the vocabulary also remain unchanged and finally even if we remove the token "ug" from our vocabulary the loss remains equal to 170. For this first iteration, if we continue the calculation, we would notice that we could remove any token without it impacting the loss. We will therefore choose at random to remove the token "ug" before starting a second iteration. We estimate again the probability of each token before calculating the impact of each token on the loss. For example, if we remove now the token composed of the letters "h" and "u", there is only one possible tokenization left for hug. The tokenization of the other words of the vocabulary is not changed. In the end, we obtain by removing the token composed of the letters "h" and "u" from the vocabulary a loss of one hundred and sixty-eight. Finally, to choose which token to remove, we will for each remaining token of the vocabulary which is not an elementary token calculate the associated loss then compare these losses between them. The token which we will remove is the token which impacts the least the loss: here the token "bu". We had mentioned at the beginning of the video that at each iteration we could remove p % of the tokens by iteration. The second token that could be removed at this iteration is the "du" token. And that's it, we just have to repeat these steps until we get the vocabulary of the desired size. One last thing, in practice, when we tokenize a word with a Unigram model we don't compute the set of probabilities of the possible splits of a word before comparing them to keep the best one but we use the Viterbi algorithm which is much more efficient. And that's it! I hope that this example has allowed you to better understand the Unigram tokenization algorithm. | huggingface/course/blob/main/subtitles/en/raw/chapter6/08_unigram.md |
@gradio/html
## 0.1.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.1.5
### Patch Changes
- Updated dependencies [[`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.1.4
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.1.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/statustracker@0.4.0
## 0.1.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/statustracker@0.3.2
## 0.1.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Remove duplicate `elem_ids` from components. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6152](https://github.com/gradio-app/gradio/pull/6152) [`982bff2fd`](https://github.com/gradio-app/gradio/commit/982bff2fdd938b798c400fb90d1cf0caf7278894) - Remove duplicate `elem_ids` from components. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.0.7
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
## 0.0.6
### Patch Changes
- Updated dependencies []:
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
## 0.0.5
### Patch Changes
- Updated dependencies []:
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.0.4
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.0.3
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/utils@0.1.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.0.2
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
| gradio-app/gradio/blob/main/js/html/CHANGELOG.md |
!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CLIP
## Overview
The CLIP model was proposed in [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh,
Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. CLIP
(Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be
instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing
for the task, similarly to the zero-shot capabilities of GPT-2 and 3.
The abstract from the paper is the following:
*State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This
restricted form of supervision limits their generality and usability since additional labeled data is needed to specify
any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a
much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes
with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400
million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference
learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study
the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks
such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The
model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need
for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot
without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained
model weights at this https URL.*
This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/openai/CLIP).
## Usage tips and example
CLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image
classification. CLIP uses a ViT like transformer to get visual features and a causal language model to get the text
features. Both the text and visual features are then projected to a latent space with identical dimension. The dot
product between the projected image and text features is then used as a similar score.
To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image. The authors
also add absolute position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder.
The [`CLIPImageProcessor`] can be used to resize (or rescale) and normalize images for the model.
The [`CLIPTokenizer`] is used to encode the text. The [`CLIPProcessor`] wraps
[`CLIPImageProcessor`] and [`CLIPTokenizer`] into a single instance to both
encode the text and prepare the images. The following example shows how to get the image-text similarity scores using
[`CLIPProcessor`] and [`CLIPModel`].
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import CLIPProcessor, CLIPModel
>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
>>> processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIP.
- [Fine tuning CLIP with Remote Sensing (Satellite) images and captions](https://huggingface.co/blog/fine-tune-clip-rsicd), a blog post about how to fine-tune CLIP with [RSICD dataset](https://github.com/201528014227051/RSICD_optimal) and comparison of performance changes due to data augmentation.
- This [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text) shows how to train a CLIP-like vision-text dual encoder model using a pre-trained vision and text encoder using [COCO dataset](https://cocodataset.org/#home).
<PipelineTag pipeline="image-to-text"/>
- A [notebook](https://colab.research.google.com/drive/1tuoAC5F4sC7qid56Z0ap-stR3rwdk0ZV?usp=sharing) on how to use a pretrained CLIP for inference with beam search for image captioning. 🌎
**Image retrieval**
- A [notebook](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing) on image retrieval using pretrained CLIP and computing MRR(Mean Reciprocal Rank) score. 🌎
- A [notebook](https://colab.research.google.com/github/deep-diver/image_search_with_natural_language/blob/main/notebooks/Image_Search_CLIP.ipynb) on image retrieval and showing the similarity score. 🌎
- A [notebook](https://colab.research.google.com/drive/1xO-wC_m_GNzgjIBQ4a4znvQkvDoZJvH4?usp=sharing) on how to map images and texts to the same vector space using Multilingual CLIP. 🌎
- A [notebook](https://colab.research.google.com/github/vivien000/clip-demo/blob/master/clip.ipynb#scrollTo=uzdFhRGqiWkR) on how to run CLIP on semantic image search using [Unsplash](https://unsplash.com) and [TMBD](https://www.themoviedb.org/) datasets. 🌎
**Explainability**
- A [notebook](https://colab.research.google.com/github/hila-chefer/Transformer-MM-Explainability/blob/main/CLIP_explainability.ipynb) on how to visualize similarity between input token and image segment. 🌎
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## CLIPConfig
[[autodoc]] CLIPConfig
- from_text_vision_configs
## CLIPTextConfig
[[autodoc]] CLIPTextConfig
## CLIPVisionConfig
[[autodoc]] CLIPVisionConfig
## CLIPTokenizer
[[autodoc]] CLIPTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## CLIPTokenizerFast
[[autodoc]] CLIPTokenizerFast
## CLIPImageProcessor
[[autodoc]] CLIPImageProcessor
- preprocess
## CLIPFeatureExtractor
[[autodoc]] CLIPFeatureExtractor
## CLIPProcessor
[[autodoc]] CLIPProcessor
<frameworkcontent>
<pt>
## CLIPModel
[[autodoc]] CLIPModel
- forward
- get_text_features
- get_image_features
## CLIPTextModel
[[autodoc]] CLIPTextModel
- forward
## CLIPTextModelWithProjection
[[autodoc]] CLIPTextModelWithProjection
- forward
## CLIPVisionModelWithProjection
[[autodoc]] CLIPVisionModelWithProjection
- forward
## CLIPVisionModel
[[autodoc]] CLIPVisionModel
- forward
</pt>
<tf>
## TFCLIPModel
[[autodoc]] TFCLIPModel
- call
- get_text_features
- get_image_features
## TFCLIPTextModel
[[autodoc]] TFCLIPTextModel
- call
## TFCLIPVisionModel
[[autodoc]] TFCLIPVisionModel
- call
</tf>
<jax>
## FlaxCLIPModel
[[autodoc]] FlaxCLIPModel
- __call__
- get_text_features
- get_image_features
## FlaxCLIPTextModel
[[autodoc]] FlaxCLIPTextModel
- __call__
## FlaxCLIPTextModelWithProjection
[[autodoc]] FlaxCLIPTextModelWithProjection
- __call__
## FlaxCLIPVisionModel
[[autodoc]] FlaxCLIPVisionModel
- __call__
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/clip.md |
--
title: Matthews Correlation Coefficient
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Compute the Matthews correlation coefficient (MCC)
The Matthews correlation coefficient is used in machine learning as a
measure of the quality of binary and multiclass classifications. It takes
into account true and false positives and negatives and is generally
regarded as a balanced measure which can be used even if the classes are of
very different sizes. The MCC is in essence a correlation coefficient value
between -1 and +1. A coefficient of +1 represents a perfect prediction, 0
an average random prediction and -1 an inverse prediction. The statistic
is also known as the phi coefficient. [source: Wikipedia]
---
# Metric Card for Matthews Correlation Coefficient
## Metric Description
The Matthews correlation coefficient is used in machine learning as a
measure of the quality of binary and multiclass classifications. It takes
into account true and false positives and negatives and is generally
regarded as a balanced measure which can be used even if the classes are of
very different sizes. The MCC is in essence a correlation coefficient value
between -1 and +1. A coefficient of +1 represents a perfect prediction, 0
an average random prediction and -1 an inverse prediction. The statistic
is also known as the phi coefficient. [source: Wikipedia]
## How to Use
At minimum, this metric requires a list of predictions and a list of references:
```python
>>> matthews_metric = evaluate.load("matthews_correlation")
>>> results = matthews_metric.compute(references=[0, 1], predictions=[0, 1])
>>> print(results)
{'matthews_correlation': 1.0}
```
### Inputs
- **`predictions`** (`list` of `int`s): Predicted class labels.
- **`references`** (`list` of `int`s): Ground truth labels.
- **`sample_weight`** (`list` of `int`s, `float`s, or `bool`s): Sample weights. Defaults to `None`.
- **`average`**(`None` or `macro`): For the multilabel case, whether to return one correlation coefficient per feature (`average=None`), or the average of them (`average='macro'`). Defaults to `None`.
### Output Values
- **`matthews_correlation`** (`float` or `list` of `float`s): Matthews correlation coefficient, or list of them in the multilabel case without averaging.
The metric output takes the following form:
```python
{'matthews_correlation': 0.54}
```
This metric can be any value from -1 to +1, inclusive.
#### Values from Popular Papers
### Examples
A basic example with only predictions and references as inputs:
```python
>>> matthews_metric = evaluate.load("matthews_correlation")
>>> results = matthews_metric.compute(references=[1, 3, 2, 0, 3, 2],
... predictions=[1, 2, 2, 0, 3, 3])
>>> print(results)
{'matthews_correlation': 0.5384615384615384}
```
The same example as above, but also including sample weights:
```python
>>> matthews_metric = evaluate.load("matthews_correlation")
>>> results = matthews_metric.compute(references=[1, 3, 2, 0, 3, 2],
... predictions=[1, 2, 2, 0, 3, 3],
... sample_weight=[0.5, 3, 1, 1, 1, 2])
>>> print(results)
{'matthews_correlation': 0.09782608695652174}
```
The same example as above, with sample weights that cause a negative correlation:
```python
>>> matthews_metric = evaluate.load("matthews_correlation")
>>> results = matthews_metric.compute(references=[1, 3, 2, 0, 3, 2],
... predictions=[1, 2, 2, 0, 3, 3],
... sample_weight=[0.5, 1, 0, 0, 0, 1])
>>> print(results)
{'matthews_correlation': -0.25}
```
## Limitations and Bias
*Note any limitations or biases that the metric has.*
## Citation
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
## Further References
- This Hugging Face implementation uses [this scikit-learn implementation](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.matthews_corrcoef.html) | huggingface/evaluate/blob/main/metrics/matthews_correlation/README.md |
`@gradio/gallery`
```html
<script>
import { BaseGallery } from "@gradio/gallery";
</script>
```
BaseGallery
```javascript
export let show_label = true;
export let label: string;
export let root = "";
export let root_url: null | string = null;
export let value: { image: FileData; caption: string | null }[] | null = null;
export let columns: number | number[] | undefined = [2];
export let rows: number | number[] | undefined = undefined;
export let height: number | "auto" = "auto";
export let preview: boolean;
export let allow_preview = true;
export let object_fit: "contain" | "cover" | "fill" | "none" | "scale-down" =
"cover";
export let show_share_button = false;
export let show_download_button = false;
export let i18n: I18nFormatter;
export let selected_index: number | null = null;
``` | gradio-app/gradio/blob/main/js/gallery/README.md |
命名实体识别 (Named-Entity Recognition)
相关空间:https://huggingface.co/spaces/rajistics/biobert_ner_demo,https://huggingface.co/spaces/abidlabs/ner,https://huggingface.co/spaces/rajistics/Financial_Analyst_AI
标签:NER,TEXT,HIGHLIGHT
## 简介
命名实体识别(NER)又称为标记分类或文本标记,它的任务是对一个句子进行分类,将每个单词(或 "token")归为不同的类别,比如人名、地名或词性等。
例如,给定以下句子:
> 芝加哥有巴基斯坦餐厅吗?
命名实体识别算法可以识别出:
- "Chicago" as a **location**
- "Pakistani" as an **ethnicity**
等等。
使用 `gradio`(特别是 `HighlightedText` 组件),您可以轻松构建一个 NER 模型的 Web 演示并与团队分享。
这是您将能够构建的一个演示的示例:
$demo_ner_pipeline
本教程将展示如何使用预训练的 NER 模型并使用 Gradio 界面部署该模型。我们将展示两种不同的使用 `HighlightedText` 组件的方法--根据您的 NER 模型,可以选择其中任何一种更容易学习的方式!
### 环境要求
确保您已经[安装](/getting_started)了 `gradio` Python 包。您还需要一个预训练的命名实体识别模型。在本教程中,我们将使用 `transformers` 库中的一个模型。
### 方法一:实体字典列表
许多命名实体识别模型输出的是一个字典列表。每个字典包含一个*实体*,一个 " 起始 " 索引和一个 " 结束 " 索引。这就是 `transformers` 库中的 NER 模型的操作方式。
```py
from transformers import pipeline
ner_pipeline = pipeline("ner")
ner_pipeline("芝加哥有巴基斯坦餐厅吗?")
```
输出结果:
```bash
[{'entity': 'I-LOC',
'score': 0.9988978,
'index': 2,
'word': 'Chicago',
'start': 5,
'end': 12},
{'entity': 'I-MISC',
'score': 0.9958592,
'index': 5,
'word': 'Pakistani',
'start': 22,
'end': 31}]
```
如果您有这样的模型,将其连接到 Gradio 的 `HighlightedText` 组件非常简单。您只需要将这个**实体列表**与**原始文本**以字典的形式传递给模型,其中键分别为 `"entities"` 和 `"text"`。
下面是一个完整的示例:
$code_ner_pipeline
$demo_ner_pipeline
### 方法二:元组列表
将数据传递给 `HighlightedText` 组件的另一种方法是使用元组列表。每个元组的第一个元素应该是被归类为特定实体的单词或词组。第二个元素应该是实体标签(如果不需要标签,则为 `None`)。`HighlightedText` 组件会自动组合单词和标签来显示实体。
在某些情况下,这比第一种方法更简单。下面是一个使用 Spacy 的词性标注器演示此方法的示例:
$code_text_analysis
$demo_text_analysis
---
到此为止!您已经了解了为您的 NER 模型构建基于 Web 的图形用户界面所需的全部内容。
有趣的提示:只需在 `launch()` 中设置 `share=True`,即可立即与其他人分享您的 NER 演示。
| gradio-app/gradio/blob/main/guides/cn/07_other-tutorials/named-entity-recognition.md |
Metric Card for BERT Score
## Metric description
BERTScore is an automatic evaluation metric for text generation that computes a similarity score for each token in the candidate sentence with each token in the reference sentence. It leverages the pre-trained contextual embeddings from [BERT](https://huggingface.co/bert-base-uncased) models and matches words in candidate and reference sentences by cosine similarity.
Moreover, BERTScore computes precision, recall, and F1 measure, which can be useful for evaluating different language generation tasks.
## How to use
BERTScore takes 3 mandatory arguments : `predictions` (a list of string of candidate sentences), `references` (a list of strings or list of list of strings of reference sentences) and either `lang` (a string of two letters indicating the language of the sentences, in [ISO 639-1 format](https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes)) or `model_type` (a string specififying which model to use, according to the BERT specification). The default behavior of the metric is to use the suggested model for the target language when one is specified, otherwise to use the `model_type` indicated.
```python
from datasets import load_metric
bertscore = load_metric("bertscore")
predictions = ["hello there", "general kenobi"]
references = ["hello there", "general kenobi"]
results = bertscore.compute(predictions=predictions, references=references, lang="en")
```
BERTScore also accepts multiple optional arguments:
`num_layers` (int): The layer of representation to use. The default is the number of layers tuned on WMT16 correlation data, which depends on the `model_type` used.
`verbose` (bool): Turn on intermediate status update. The default value is `False`.
`idf` (bool or dict): Use idf weighting; can also be a precomputed idf_dict.
`device` (str): On which the contextual embedding model will be allocated on. If this argument is `None`, the model lives on `cuda:0` if cuda is available.
`nthreads` (int): Number of threads used for computation. The default value is `4`.
`rescale_with_baseline` (bool): Rescale BERTScore with the pre-computed baseline. The default value is `False`.
`batch_size` (int): BERTScore processing batch size, at least one of `model_type` or `lang`. `lang` needs to be specified when `rescale_with_baseline` is `True`.
`baseline_path` (str): Customized baseline file.
`use_fast_tokenizer` (bool): `use_fast` parameter passed to HF tokenizer. The default value is `False`.
## Output values
BERTScore outputs a dictionary with the following values:
`precision`: The [precision](https://huggingface.co/metrics/precision) for each sentence from the `predictions` + `references` lists, which ranges from 0.0 to 1.0.
`recall`: The [recall](https://huggingface.co/metrics/recall) for each sentence from the `predictions` + `references` lists, which ranges from 0.0 to 1.0.
`f1`: The [F1 score](https://huggingface.co/metrics/f1) for each sentence from the `predictions` + `references` lists, which ranges from 0.0 to 1.0.
`hashcode:` The hashcode of the library.
### Values from popular papers
The [original BERTScore paper](https://openreview.net/pdf?id=SkeHuCVFDr) reported average model selection accuracies (Hits@1) on WMT18 hybrid systems for different language pairs, which ranged from 0.004 for `en<->tr` to 0.824 for `en<->de`.
For more recent model performance, see the [metric leaderboard](https://paperswithcode.com/paper/bertscore-evaluating-text-generation-with).
## Examples
Maximal values with the `distilbert-base-uncased` model:
```python
from datasets import load_metric
bertscore = load_metric("bertscore")
predictions = ["hello world", "general kenobi"]
references = ["hello world", "general kenobi"]
results = bertscore.compute(predictions=predictions, references=references, model_type="distilbert-base-uncased")
print(results)
{'precision': [1.0, 1.0], 'recall': [1.0, 1.0], 'f1': [1.0, 1.0], 'hashcode': 'distilbert-base-uncased_L5_no-idf_version=0.3.10(hug_trans=4.10.3)'}
```
Partial match with the `bert-base-uncased` model:
```python
from datasets import load_metric
bertscore = load_metric("bertscore")
predictions = ["hello world", "general kenobi"]
references = ["goodnight moon", "the sun is shining"]
results = bertscore.compute(predictions=predictions, references=references, model_type="distilbert-base-uncased")
print(results)
{'precision': [0.7380737066268921, 0.5584042072296143], 'recall': [0.7380737066268921, 0.5889028906822205], 'f1': [0.7380737066268921, 0.5732481479644775], 'hashcode': 'bert-base-uncased_L5_no-idf_version=0.3.10(hug_trans=4.10.3)'}
```
## Limitations and bias
The [original BERTScore paper](https://openreview.net/pdf?id=SkeHuCVFDr) showed that BERTScore correlates well with human judgment on sentence-level and system-level evaluation, but this depends on the model and language pair selected.
Furthermore, not all languages are supported by the metric -- see the [BERTScore supported language list](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages) for more information.
Finally, calculating the BERTScore metric involves downloading the BERT model that is used to compute the score-- the default model for `en`, `roberta-large`, takes over 1.4GB of storage space and downloading it can take a significant amount of time depending on the speed of your internet connection. If this is an issue, choose a smaller model; for instance `distilbert-base-uncased` is 268MB. A full list of compatible models can be found [here](https://docs.google.com/spreadsheets/d/1RKOVpselB98Nnh_EOC4A2BYn8_201tmPODpNWu4w7xI/edit#gid=0).
## Citation
```bibtex
@inproceedings{bert-score,
title={BERTScore: Evaluating Text Generation with BERT},
author={Tianyi Zhang* and Varsha Kishore* and Felix Wu* and Kilian Q. Weinberger and Yoav Artzi},
booktitle={International Conference on Learning Representations},
year={2020},
url={https://openreview.net/forum?id=SkeHuCVFDr}
}
```
## Further References
- [BERTScore Project README](https://github.com/Tiiiger/bert_score#readme)
- [BERTScore ICLR 2020 Poster Presentation](https://iclr.cc/virtual_2020/poster_SkeHuCVFDr.html)
| huggingface/datasets/blob/main/metrics/bertscore/README.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Contribute to 🤗 Transformers
Everyone is welcome to contribute, and we value everybody's contribution. Code
contributions are not the only way to help the community. Answering questions, helping
others, and improving the documentation are also immensely valuable.
It also helps us if you spread the word! Reference the library in blog posts
about the awesome projects it made possible, shout out on Twitter every time it has
helped you, or simply ⭐️ the repository to say thank you.
However you choose to contribute, please be mindful and respect our
[code of conduct](https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md).
**This guide was heavily inspired by the awesome [scikit-learn guide to contributing](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md).**
## Ways to contribute
There are several ways you can contribute to 🤗 Transformers:
* Fix outstanding issues with the existing code.
* Submit issues related to bugs or desired new features.
* Implement new models.
* Contribute to the examples or to the documentation.
If you don't know where to start, there is a special [Good First
Issue](https://github.com/huggingface/transformers/contribute) listing. It will give you a list of
open issues that are beginner-friendly and help you start contributing to open-source. Just comment on the issue that you'd like to work
on.
For something slightly more challenging, you can also take a look at the [Good Second Issue](https://github.com/huggingface/transformers/labels/Good%20Second%20Issue) list. In general though, if you feel like you know what you're doing, go for it and we'll help you get there! 🚀
> All contributions are equally valuable to the community. 🥰
## Fixing outstanding issues
If you notice an issue with the existing code and have a fix in mind, feel free to [start contributing](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#create-a-pull-request) and open a Pull Request!
## Submitting a bug-related issue or feature request
Do your best to follow these guidelines when submitting a bug-related issue or a feature
request. It will make it easier for us to come back to you quickly and with good
feedback.
### Did you find a bug?
The 🤗 Transformers library is robust and reliable thanks to users who report the problems they encounter.
Before you report an issue, we would really appreciate it if you could **make sure the bug was not
already reported** (use the search bar on GitHub under Issues). Your issue should also be related to bugs in the library itself, and not your code. If you're unsure whether the bug is in your code or the library, please ask in the [forum](https://discuss.huggingface.co/) first. This helps us respond quicker to fixing issues related to the library versus general questions.
Once you've confirmed the bug hasn't already been reported, please include the following information in your issue so we can quickly resolve it:
* Your **OS type and version** and **Python**, **PyTorch** and
**TensorFlow** versions when applicable.
* A short, self-contained, code snippet that allows us to reproduce the bug in
less than 30s.
* The *full* traceback if an exception is raised.
* Attach any other additional information, like screenshots, you think may help.
To get the OS and software versions automatically, run the following command:
```bash
transformers-cli env
```
You can also run the same command from the root of the repository:
```bash
python src/transformers/commands/transformers_cli.py env
```
### Do you want a new feature?
If there is a new feature you'd like to see in 🤗 Transformers, please open an issue and describe:
1. What is the *motivation* behind this feature? Is it related to a problem or frustration with the library? Is it a feature related to something you need for a project? Is it something you worked on and think it could benefit the community?
Whatever it is, we'd love to hear about it!
2. Describe your requested feature in as much detail as possible. The more you can tell us about it, the better we'll be able to help you.
3. Provide a *code snippet* that demonstrates the features usage.
4. If the feature is related to a paper, please include a link.
If your issue is well written we're already 80% of the way there by the time you create it.
We have added [templates](https://github.com/huggingface/transformers/tree/main/templates) to help you get started with your issue.
## Do you want to implement a new model?
New models are constantly released and if you want to implement a new model, please provide the following information
* A short description of the model and a link to the paper.
* Link to the implementation if it is open-sourced.
* Link to the model weights if they are available.
If you are willing to contribute the model yourself, let us know so we can help you add it to 🤗 Transformers!
We have added a [detailed guide and templates](https://github.com/huggingface/transformers/tree/main/templates) to help you get started with adding a new model, and we also have a more technical guide for [how to add a model to 🤗 Transformers](https://huggingface.co/docs/transformers/add_new_model).
## Do you want to add documentation?
We're always looking for improvements to the documentation that make it more clear and accurate. Please let us know how the documentation can be improved such as typos and any content that is missing, unclear or inaccurate. We'll be happy to make the changes or help you make a contribution if you're interested!
For more details about how to generate, build, and write the documentation, take a look at the documentation [README](https://github.com/huggingface/transformers/tree/main/docs).
## Create a Pull Request
Before writing any code, we strongly advise you to search through the existing PRs or
issues to make sure nobody is already working on the same thing. If you are
unsure, it is always a good idea to open an issue to get some feedback.
You will need basic `git` proficiency to contribute to
🤗 Transformers. While `git` is not the easiest tool to use, it has the greatest
manual. Type `git --help` in a shell and enjoy! If you prefer books, [Pro
Git](https://git-scm.com/book/en/v2) is a very good reference.
You'll need **[Python 3.8]((https://github.com/huggingface/transformers/blob/main/setup.py#L426))** or above to contribute to 🤗 Transformers. Follow the steps below to start contributing:
1. Fork the [repository](https://github.com/huggingface/transformers) by
clicking on the **[Fork](https://github.com/huggingface/transformers/fork)** button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
git clone git@github.com:<your Github handle>/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Create a new branch to hold your development changes:
```bash
git checkout -b a-descriptive-name-for-my-changes
```
🚨 **Do not** work on the `main` branch!
4. Set up a development environment by running the following command in a virtual environment:
```bash
pip install -e ".[dev]"
```
If 🤗 Transformers was already installed in the virtual environment, remove
it with `pip uninstall transformers` before reinstalling it in editable
mode with the `-e` flag.
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
which should be enough for most use cases.
5. Develop the features in your branch.
As you work on your code, you should make sure the test suite
passes. Run the tests impacted by your changes like this:
```bash
pytest tests/<TEST_TO_RUN>.py
```
For more information about tests, check out the
[Testing](https://huggingface.co/docs/transformers/testing) guide.
🤗 Transformers relies on `black` and `ruff` to format its source code
consistently. After you make changes, apply automatic style corrections and code verifications
that can't be automated in one go with:
```bash
make fixup
```
This target is also optimized to only work with files modified by the PR you're working on.
If you prefer to run the checks one after the other, the following command applies the
style corrections:
```bash
make style
```
🤗 Transformers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
controls are run by the CI, but you can run the same checks with:
```bash
make quality
```
Finally, we have a lot of scripts to make sure we don't forget to update
some files when adding a new model. You can run these scripts with:
```bash
make repo-consistency
```
To learn more about those checks and how to fix any issues with them, check out the
[Checks on a Pull Request](https://huggingface.co/docs/transformers/pr_checks) guide.
If you're modifying documents under the `docs/source` directory, make sure the documentation can still be built. This check will also run in the CI when you open a pull request. To run a local check
make sure you install the documentation builder:
```bash
pip install ".[docs]"
```
Run the following command from the root of the repository:
```bash
doc-builder build transformers docs/source/en --build_dir ~/tmp/test-build
```
This will build the documentation in the `~/tmp/test-build` folder where you can inspect the generated
Markdown files with your favorite editor. You can also preview the docs on GitHub when you open a pull request.
Once you're happy with your changes, add the changed files with `git add` and
record your changes locally with `git commit`:
```bash
git add modified_file.py
git commit
```
Please remember to write [good commit
messages](https://chris.beams.io/posts/git-commit/) to clearly communicate the changes you made!
To keep your copy of the code up to date with the original
repository, rebase your branch on `upstream/branch` *before* you open a pull request or if requested by a maintainer:
```bash
git fetch upstream
git rebase upstream/main
```
Push your changes to your branch:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
If you've already opened a pull request, you'll need to force push with the `--force` flag. Otherwise, if the pull request hasn't been opened yet, you can just push your changes normally.
6. Now you can go to your fork of the repository on GitHub and click on **Pull Request** to open a pull request. Make sure you tick off all the boxes on our [checklist](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#pull-request-checklist) below. When you're ready, you can send your changes to the project maintainers for review.
7. It's ok if maintainers request changes, it happens to our core contributors
too! So everyone can see the changes in the pull request, work in your local
branch and push the changes to your fork. They will automatically appear in
the pull request.
### Pull request checklist
☐ The pull request title should summarize your contribution.<br>
☐ If your pull request addresses an issue, please mention the issue number in the pull
request description to make sure they are linked (and people viewing the issue know you
are working on it).<br>
☐ To indicate a work in progress please prefix the title with `[WIP]`. These are
useful to avoid duplicated work, and to differentiate it from PRs ready to be merged.<br>
☐ Make sure existing tests pass.<br>
☐ If adding a new feature, also add tests for it.<br>
- If you are adding a new model, make sure you use
`ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)` to trigger the common tests.
- If you are adding new `@slow` tests, make sure they pass using
`RUN_SLOW=1 python -m pytest tests/models/my_new_model/test_my_new_model.py`.
- If you are adding a new tokenizer, write tests and make sure
`RUN_SLOW=1 python -m pytest tests/models/{your_model_name}/test_tokenization_{your_model_name}.py` passes.
- CircleCI does not run the slow tests, but GitHub Actions does every night!<br>
☐ All public methods must have informative docstrings (see
[`modeling_bert.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py)
for an example).<br>
☐ Due to the rapidly growing repository, don't add any images, videos and other
non-text files that'll significantly weigh down the repository. Instead, use a Hub
repository such as [`hf-internal-testing`](https://huggingface.co/hf-internal-testing)
to host these files and reference them by URL. We recommend placing documentation
related images in the following repository:
[huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
You can open a PR on this dataset repostitory and ask a Hugging Face member to merge it.
For more information about the checks run on a pull request, take a look at our [Checks on a Pull Request](https://huggingface.co/docs/transformers/pr_checks) guide.
### Tests
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
the [tests](https://github.com/huggingface/transformers/tree/main/tests) folder and examples tests in the
[examples](https://github.com/huggingface/transformers/tree/main/examples) folder.
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
repository, specify a *path to a subfolder or a test file* to run the test.
```bash
python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
```
Similarly, for the `examples` directory, specify a *path to a subfolder or test file* to run the test. For example, the following command tests the text classification subfolder in the PyTorch `examples` directory:
```bash
pip install -r examples/xxx/requirements.txt # only needed the first time
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
In fact, this is actually how our `make test` and `make test-examples` commands are implemented (not including the `pip install`)!
You can also specify a smaller set of tests in order to test only the feature
you're working on.
By default, slow tests are skipped but you can set the `RUN_SLOW` environment variable to
`yes` to run them. This will download many gigabytes of models so make sure you
have enough disk space, a good internet connection or a lot of patience!
<Tip warning={true}>
Remember to specify a *path to a subfolder or a test file* to run the test. Otherwise, you'll run all the tests in the `tests` or `examples` folder, which will take a very long time!
</Tip>
```bash
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
```
Like the slow tests, there are other environment variables available which not enabled by default during testing:
- `RUN_CUSTOM_TOKENIZERS`: Enables tests for custom tokenizers.
- `RUN_PT_FLAX_CROSS_TESTS`: Enables tests for PyTorch + Flax integration.
- `RUN_PT_TF_CROSS_TESTS`: Enables tests for TensorFlow + PyTorch integration.
More environment variables and additional information can be found in the [testing_utils.py](src/transformers/testing_utils.py).
🤗 Transformers uses `pytest` as a test runner only. It doesn't use any
`pytest`-specific features in the test suite itself.
This means `unittest` is fully supported. Here's how to run tests with
`unittest`:
```bash
python -m unittest discover -s tests -t . -v
python -m unittest discover -s examples -t examples -v
```
### Style guide
For documentation strings, 🤗 Transformers follows the [Google Python Style Guide](https://google.github.io/styleguide/pyguide.html).
Check our [documentation writing guide](https://github.com/huggingface/transformers/tree/main/docs#writing-documentation---specification)
for more information.
### Develop on Windows
On Windows (unless you're working in [Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/) or WSL), you need to configure git to transform Windows `CRLF` line endings to Linux `LF` line endings:
```bash
git config core.autocrlf input
```
One way to run the `make` command on Windows is with MSYS2:
1. [Download MSYS2](https://www.msys2.org/), and we assume it's installed in `C:\msys64`.
2. Open the command line `C:\msys64\msys2.exe` (it should be available from the **Start** menu).
3. Run in the shell: `pacman -Syu` and install `make` with `pacman -S make`.
4. Add `C:\msys64\usr\bin` to your PATH environment variable.
You can now use `make` from any terminal (Powershell, cmd.exe, etc.)! 🎉
### Sync a forked repository with upstream main (the Hugging Face repository)
When updating the main branch of a forked repository, please follow these steps to avoid pinging the upstream repository which adds reference notes to each upstream PR, and sends unnecessary notifications to the developers involved in these PRs.
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```bash
git checkout -b your-branch-for-syncing
git pull --squash --no-commit upstream main
git commit -m '<your message without GitHub references>'
git push --set-upstream origin your-branch-for-syncing
```
| huggingface/transformers/blob/main/docs/source/en/contributing.md |
Evaluator
The evaluator classes for automatic evaluation.
## Evaluator classes
The main entry point for using the evaluator:
[[autodoc]] evaluate.evaluator
The base class for all evaluator classes:
[[autodoc]] evaluate.Evaluator
## The task specific evaluators
### ImageClassificationEvaluator
[[autodoc]] evaluate.ImageClassificationEvaluator
### QuestionAnsweringEvaluator
[[autodoc]] evaluate.QuestionAnsweringEvaluator
- compute
### TextClassificationEvaluator
[[autodoc]] evaluate.TextClassificationEvaluator
### TokenClassificationEvaluator
[[autodoc]] evaluate.TokenClassificationEvaluator
- compute
### TextGenerationEvaluator
[[autodoc]] evaluate.TextGenerationEvaluator
- compute
### Text2TextGenerationEvaluator
[[autodoc]] evaluate.Text2TextGenerationEvaluator
- compute
### SummarizationEvaluator
[[autodoc]] evaluate.SummarizationEvaluator
- compute
### TranslationEvaluator
[[autodoc]] evaluate.TranslationEvaluator
- compute
### AutomaticSpeechRecognitionEvaluator
[[autodoc]] evaluate.AutomaticSpeechRecognitionEvaluator
- compute
### AudioClassificationEvaluator
[[autodoc]] evaluate.AudioClassificationEvaluator
- compute | huggingface/evaluate/blob/main/docs/source/package_reference/evaluator_classes.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 🧨 Diffusers’ Ethical Guidelines
## Preamble
[Diffusers](https://huggingface.co/docs/diffusers/index) provides pre-trained diffusion models and serves as a modular toolbox for inference and training.
Given its real case applications in the world and potential negative impacts on society, we think it is important to provide the project with ethical guidelines to guide the development, users’ contributions, and usage of the Diffusers library.
The risks associated with using this technology are still being examined, but to name a few: copyrights issues for artists; deep-fake exploitation; sexual content generation in inappropriate contexts; non-consensual impersonation; harmful social biases perpetuating the oppression of marginalized groups.
We will keep tracking risks and adapt the following guidelines based on the community's responsiveness and valuable feedback.
## Scope
The Diffusers community will apply the following ethical guidelines to the project’s development and help coordinate how the community will integrate the contributions, especially concerning sensitive topics related to ethical concerns.
## Ethical guidelines
The following ethical guidelines apply generally, but we will primarily implement them when dealing with ethically sensitive issues while making a technical choice. Furthermore, we commit to adapting those ethical principles over time following emerging harms related to the state of the art of the technology in question.
- **Transparency**: we are committed to being transparent in managing PRs, explaining our choices to users, and making technical decisions.
- **Consistency**: we are committed to guaranteeing our users the same level of attention in project management, keeping it technically stable and consistent.
- **Simplicity**: with a desire to make it easy to use and exploit the Diffusers library, we are committed to keeping the project’s goals lean and coherent.
- **Accessibility**: the Diffusers project helps lower the entry bar for contributors who can help run it even without technical expertise. Doing so makes research artifacts more accessible to the community.
- **Reproducibility**: we aim to be transparent about the reproducibility of upstream code, models, and datasets when made available through the Diffusers library.
- **Responsibility**: as a community and through teamwork, we hold a collective responsibility to our users by anticipating and mitigating this technology's potential risks and dangers.
## Examples of implementations: Safety features and Mechanisms
The team works daily to make the technical and non-technical tools available to deal with the potential ethical and social risks associated with diffusion technology. Moreover, the community's input is invaluable in ensuring these features' implementation and raising awareness with us.
- [**Community tab**](https://huggingface.co/docs/hub/repositories-pull-requests-discussions): it enables the community to discuss and better collaborate on a project.
- **Bias exploration and evaluation**: the Hugging Face team provides a [space](https://huggingface.co/spaces/society-ethics/DiffusionBiasExplorer) to demonstrate the biases in Stable Diffusion interactively. In this sense, we support and encourage bias explorers and evaluations.
- **Encouraging safety in deployment**
- [**Safe Stable Diffusion**](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_safe): It mitigates the well-known issue that models, like Stable Diffusion, that are trained on unfiltered, web-crawled datasets tend to suffer from inappropriate degeneration. Related paper: [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://arxiv.org/abs/2211.05105).
- [**Safety Checker**](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py): It checks and compares the class probability of a set of hard-coded harmful concepts in the embedding space against an image after it has been generated. The harmful concepts are intentionally hidden to prevent reverse engineering of the checker.
- **Staged released on the Hub**: in particularly sensitive situations, access to some repositories should be restricted. This staged release is an intermediary step that allows the repository’s authors to have more control over its use.
- **Licensing**: [OpenRAILs](https://huggingface.co/blog/open_rail), a new type of licensing, allow us to ensure free access while having a set of restrictions that ensure more responsible use.
| huggingface/diffusers/blob/main/docs/source/en/conceptual/ethical_guidelines.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DPMSolverSDEScheduler
The `DPMSolverSDEScheduler` is inspired by the stochastic sampler from the [Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) paper, and the scheduler is ported from and created by [Katherine Crowson](https://github.com/crowsonkb/).
## DPMSolverSDEScheduler
[[autodoc]] DPMSolverSDEScheduler
## SchedulerOutput
[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
| huggingface/diffusers/blob/main/docs/source/en/api/schedulers/dpm_sde.md |
Blocks and Event Listeners
We briefly descirbed the Blocks class in the [Quickstart](/main/guides/quickstart#custom-demos-with-gr-blocks) as a way to build custom demos. Let's dive deeper.
## Blocks Structure
Take a look at the demo below.
$code_hello_blocks
$demo_hello_blocks
- First, note the `with gr.Blocks() as demo:` clause. The Blocks app code will be contained within this clause.
- Next come the Components. These are the same Components used in `Interface`. However, instead of being passed to some constructor, Components are automatically added to the Blocks as they are created within the `with` clause.
- Finally, the `click()` event listener. Event listeners define the data flow within the app. In the example above, the listener ties the two Textboxes together. The Textbox `name` acts as the input and Textbox `output` acts as the output to the `greet` method. This dataflow is triggered when the Button `greet_btn` is clicked. Like an Interface, an event listener can take multiple inputs or outputs.
You can also attach event listeners using decorators - skip the `fn` argument and assign `inputs` and `outputs` directly:
$code_hello_blocks_decorator
## Event Listeners and Interactivity
In the example above, you'll notice that you are able to edit Textbox `name`, but not Textbox `output`. This is because any Component that acts as an input to an event listener is made interactive. However, since Textbox `output` acts only as an output, Gradio determines that it should not be made interactive. You can override the default behavior and directly configure the interactivity of a Component with the boolean `interactive` keyword argument.
```python
output = gr.Textbox(label="Output", interactive=True)
```
_Note_: What happens if a Gradio component is neither an input nor an output? If a component is constructed with a default value, then it is presumed to be displaying content and is rendered non-interactive. Otherwise, it is rendered interactive. Again, this behavior can be overridden by specifying a value for the `interactive` argument.
## Types of Event Listeners
Take a look at the demo below:
$code_blocks_hello
$demo_blocks_hello
Instead of being triggered by a click, the `welcome` function is triggered by typing in the Textbox `inp`. This is due to the `change()` event listener. Different Components support different event listeners. For example, the `Video` Component supports a `play()` event listener, triggered when a user presses play. See the [Docs](http://gradio.app/docs#components) for the event listeners for each Component.
## Multiple Data Flows
A Blocks app is not limited to a single data flow the way Interfaces are. Take a look at the demo below:
$code_reversible_flow
$demo_reversible_flow
Note that `num1` can act as input to `num2`, and also vice-versa! As your apps get more complex, you will have many data flows connecting various Components.
Here's an example of a "multi-step" demo, where the output of one model (a speech-to-text model) gets fed into the next model (a sentiment classifier).
$code_blocks_speech_text_sentiment
$demo_blocks_speech_text_sentiment
## Function Input List vs Dict
The event listeners you've seen so far have a single input component. If you'd like to have multiple input components pass data to the function, you have two options on how the function can accept input component values:
1. as a list of arguments, or
2. as a single dictionary of values, keyed by the component
Let's see an example of each:
$code_calculator_list_and_dict
Both `add()` and `sub()` take `a` and `b` as inputs. However, the syntax is different between these listeners.
1. To the `add_btn` listener, we pass the inputs as a list. The function `add()` takes each of these inputs as arguments. The value of `a` maps to the argument `num1`, and the value of `b` maps to the argument `num2`.
2. To the `sub_btn` listener, we pass the inputs as a set (note the curly brackets!). The function `sub()` takes a single dictionary argument `data`, where the keys are the input components, and the values are the values of those components.
It is a matter of preference which syntax you prefer! For functions with many input components, option 2 may be easier to manage.
$demo_calculator_list_and_dict
## Function Return List vs Dict
Similarly, you may return values for multiple output components either as:
1. a list of values, or
2. a dictionary keyed by the component
Let's first see an example of (1), where we set the values of two output components by returning two values:
```python
with gr.Blocks() as demo:
food_box = gr.Number(value=10, label="Food Count")
status_box = gr.Textbox()
def eat(food):
if food > 0:
return food - 1, "full"
else:
return 0, "hungry"
gr.Button("EAT").click(
fn=eat,
inputs=food_box,
outputs=[food_box, status_box]
)
```
Above, each return statement returns two values corresponding to `food_box` and `status_box`, respectively.
Instead of returning a list of values corresponding to each output component in order, you can also return a dictionary, with the key corresponding to the output component and the value as the new value. This also allows you to skip updating some output components.
```python
with gr.Blocks() as demo:
food_box = gr.Number(value=10, label="Food Count")
status_box = gr.Textbox()
def eat(food):
if food > 0:
return {food_box: food - 1, status_box: "full"}
else:
return {status_box: "hungry"}
gr.Button("EAT").click(
fn=eat,
inputs=food_box,
outputs=[food_box, status_box]
)
```
Notice how when there is no food, we only update the `status_box` element. We skipped updating the `food_box` component.
Dictionary returns are helpful when an event listener affects many components on return, or conditionally affects outputs and not others.
Keep in mind that with dictionary returns, we still need to specify the possible outputs in the event listener.
## Updating Component Configurations
The return value of an event listener function is usually the updated value of the corresponding output Component. Sometimes we want to update the configuration of the Component as well, such as the visibility. In this case, we return a new Component, setting the properties we want to change.
$code_blocks_essay_simple
$demo_blocks_essay_simple
See how we can configure the Textbox itself through a new `gr.Textbox()` method. The `value=` argument can still be used to update the value along with Component configuration. Any arguments we do not set will use their previous values.
## Examples
Just like with `gr.Interface`, you can also add examples for your functions when you are working with `gr.Blocks`. In this case, instantiate a `gr.Examples` similar to how you would instantiate any other component. The constructor of `gr.Examples` takes two required arguments:
* `examples`: a nested list of examples, in which the outer list consists of examples and each inner list consists of an input corresponding to each input component
* `inputs`: the component or list of components that should be populated when the examples are clicked
You can also set `cache_examples=True` similar to `gr.Interface`, in which case two additional arguments must be provided:
* `outputs`: the component or list of components corresponding to the output of the examples
* `fn`: the function to run to generate the outputs corresponding to the examples
Here's an example showing how to use `gr.Examples` in a `gr.Blocks` app:
$code_calculator_blocks
**Note**: In Gradio 4.0 or later, when you click on examples, not only does the value of the input component update to the example value, but the component's configuration also reverts to the properties with which you constructed the component. This ensures that the examples are compatible with the component even if its configuration has been changed.
## Running Events Consecutively
You can also run events consecutively by using the `then` method of an event listener. This will run an event after the previous event has finished running. This is useful for running events that update components in multiple steps.
For example, in the chatbot example below, we first update the chatbot with the user message immediately, and then update the chatbot with the computer response after a simulated delay.
$code_chatbot_consecutive
$demo_chatbot_consecutive
The `.then()` method of an event listener executes the subsequent event regardless of whether the previous event raised any errors. If you'd like to only run subsequent events if the previous event executed successfully, use the `.success()` method, which takes the same arguments as `.then()`.
## Running Events Continuously
You can run events on a fixed schedule using the `every` parameter of the event listener. This will run the event
`every` number of seconds while the client connection is open. If the connection is closed, the event will stop running after the following iteration.
Note that this does not take into account the runtime of the event itself. So a function
with a 1 second runtime running with `every=5`, would actually run every 6 seconds.
Here is an example of a sine curve that updates every second!
$code_sine_curve
$demo_sine_curve
## Gathering Event Data
You can gather specific data about an event by adding the associated event data class as a type hint to an argument in the event listener function.
For example, event data for `.select()` can be type hinted by a `gradio.SelectData` argument. This event is triggered when a user selects some part of the triggering component, and the event data includes information about what the user specifically selected. If a user selected a specific word in a `Textbox`, a specific image in a `Gallery`, or a specific cell in a `DataFrame`, the event data argument would contain information about the specific selection.
In the 2 player tic-tac-toe demo below, a user can select a cell in the `DataFrame` to make a move. The event data argument contains information about the specific cell that was selected. We can first check to see if the cell is empty, and then update the cell with the user's move.
$code_tictactoe
$demo_tictactoe
## Binding Multiple Triggers to a Function
Often times, you may want to bind multiple triggers to the same function. For example, you may want to allow a user to click a submit button, or press enter to submit a form. You can do this using the `gr.on` method and passing a list of triggers to the `trigger`.
$code_on_listener_basic
$demo_on_listener_basic
You can use decorator syntax as well:
$code_on_listener_decorator
You can use `gr.on` to create "live" events by binding to the change event of all components. If you do not specify any triggers, the function will automatically bind to the change event of all input components.
$code_on_listener_live
$demo_on_listener_live
You can follow `gr.on` with `.then`, just like any regular event listener. This handy method should save you from having to write a lot of repetitive code! | gradio-app/gradio/blob/main/guides/03_building-with-blocks/01_blocks-and-event-listeners.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PEFT
🤗 PEFT (Parameter-Efficient Fine-Tuning) is a library for efficiently adapting large pretrained models to various downstream applications without fine-tuning all of a model's parameters because it is prohibitively costly. PEFT methods only fine-tune a small number of (extra) model parameters - significantly decreasing computational and storage costs - while yielding performance comparable to a fully fine-tuned model. This makes it more accessible to train and store large language models (LLMs) on consumer hardware.
PEFT is integrated with the Transformers, Diffusers, and Accelerate libraries to provide a faster and easier way to load, train, and use large models for inference.
<div class="mt-10">
<div class="w-full flex flex-col space-y-4 md:space-y-0 md:grid md:grid-cols-2 md:gap-y-4 md:gap-x-5">
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="quicktour"
><div class="w-full text-center bg-gradient-to-br from-blue-400 to-blue-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Get started</div>
<p class="text-gray-700">Start here if you're new to 🤗 PEFT to get an overview of the library's main features, and how to train a model with a PEFT method.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./task_guides/image_classification_lora"
><div class="w-full text-center bg-gradient-to-br from-indigo-400 to-indigo-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">How-to guides</div>
<p class="text-gray-700">Practical guides demonstrating how to apply various PEFT methods across different types of tasks like image classification, causal language modeling, automatic speech recognition, and more. Learn how to use 🤗 PEFT with the DeepSpeed and Fully Sharded Data Parallel scripts.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./conceptual_guides/lora"
><div class="w-full text-center bg-gradient-to-br from-pink-400 to-pink-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Conceptual guides</div>
<p class="text-gray-700">Get a better theoretical understanding of how LoRA and various soft prompting methods help reduce the number of trainable parameters to make training more efficient.</p>
</a>
<a class="!no-underline border dark:border-gray-700 p-5 rounded-lg shadow hover:shadow-lg" href="./package_reference/config"
><div class="w-full text-center bg-gradient-to-br from-purple-400 to-purple-500 rounded-lg py-1.5 font-semibold mb-5 text-white text-lg leading-relaxed">Reference</div>
<p class="text-gray-700">Technical descriptions of how 🤗 PEFT classes and methods work.</p>
</a>
</div>
</div>
<iframe
src="https://stevhliu-peft-methods.hf.space"
frameborder="0"
width="850"
height="620"
></iframe>
| huggingface/peft/blob/main/docs/source/index.md |
--
title: "Announcing Evaluation on the Hub"
thumbnail: /blog/assets/82_eval_on_the_hub/thumbnail.png
authors:
- user: lewtun
- user: abhishek
- user: Tristan
- user: sasha
- user: lvwerra
- user: nazneen
- user: ola13
- user: osanseviero
- user: douwekiela
---
# Announcing Evaluation on the Hub
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
November 2023 Update:
This project has been archived. If you want to evaluate LLMs on the Hub, check out [this collection of leaderboards](https://huggingface.co/collections/clefourrier/llm-leaderboards-and-benchmarks-✨-64f99d2e11e92ca5568a7cce).
</div>
<em>TL;DR</em>: Today we introduce [Evaluation on the Hub](https://huggingface.co/spaces/autoevaluate/model-evaluator), a new tool powered by [AutoTrain](https://huggingface.co/autotrain) that lets you evaluate any model on any dataset on the Hub without writing a single line of code!
<figure class="image table text-center m-0">
<video
alt="Evaluating models from the Hugging Face Hub"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="/blog/assets/82_eval_on_the_hub/autoeval-demo.mp4" type="video/mp4">
</video>
<figcaption>Evaluate all the models 🔥🔥🔥!</figcaption>
</figure>
Progress in AI has been nothing short of amazing, to the point where some people are now seriously debating whether AI models may be better than humans at certain tasks. However, that progress has not at all been even: to a machine learner from several decades ago, modern hardware and algorithms might look incredible, as might the sheer quantity of data and compute at our disposal, but the way we evaluate these models has stayed roughly the same.
However, it is no exaggeration to say that modern AI is in an evaluation crisis. Proper evaluation these days involves measuring many models, often on many datasets and with multiple metrics. But doing so is unnecessarily cumbersome. This is especially the case if we care about reproducibility, since self-reported results may have suffered from inadvertent bugs, subtle differences in implementation, or worse.
We believe that better evaluation can happen, if we - the community - establish a better set of best practices and try to remove the hurdles. Over the past few months, we've been hard at work on [Evaluation on the Hub](https://huggingface.co/spaces/autoevaluate/model-evaluator): evaluate any model on any dataset using any metric, at the click of a button. To get started, we evaluated hundreds models on several key datasets, and using the nifty new [Pull Request feature](https://huggingface.co/blog/community-update) on the Hub, opened up loads of PRs on model cards to display their verified performance. Evaluation results are encoded directly in the model card metadata, following [a format](https://huggingface.co/docs/hub/models-cards) for all models on the Hub. Check out the model card for [DistilBERT](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/blob/main/README.md#L7-L42) to see how it looks!
## On the Hub
Evaluation on the Hub opens the door to so many interesting use cases. From the data scientist or executive who needs to decide which model to deploy, to the academic trying to reproduce a paper’s results on a new dataset, to the ethicist who wants to better understand risks of deployment. If we have to single out three primary initial use case scenarios, they are these:
**Finding the best model for your task**<br/>
Suppose you know exactly what your task is and you want to find the right model for the job. You can check out the leaderboard for a dataset representative of your task, which aggregates all the results. That’s great! And what if that fancy new model you’re interested in isn’t on the [leaderboard](https://huggingface.co/spaces/autoevaluate/leaderboards) yet for that dataset? Simply run an evaluation for it, without leaving the Hub.
**Evaluating models on your brand new dataset**<br/>
Now what if you have a brand spanking new dataset that you want to run baselines on? You can upload it to the Hub and evaluate as many models on it as you like. No code required. What’s more, you can be sure that the way you are evaluating these models on your dataset is exactly the same as how they’ve been evaluated on other datasets.
**Evaluating your model on many other related datasets**<br/>
Or suppose you have a brand new question answering model, trained on SQuAD? There are hundreds of different question answering datasets to evaluate on :scream: You can pick the ones you are interested in and evaluate your model, directly from the Hub.
## Ecosystem
<figcaption><center><i>Evaluation on the Hub fits neatly into the Hugging Face ecosystem.</i></center></figcaption>
Evaluation on the Hub is meant to make your life easier. But of course, there’s a lot happening in the background. What we really like about Evaluation on the Hub: it fits so neatly into the existing Hugging Face ecosystem, we almost had to do it. Users start on dataset pages, from where they can launch evaluations or see leaderboards. The model evaluation submission interface and the leaderboards are regular Hugging Face Spaces. The evaluation backend is powered by AutoTrain, which opens up a PR on the Hub for the given model’s model card.
## DogFood - Distinguishing Dogs, Muffins and Fried Chicken
So what does it look like in practice? Let’s run through an example. Suppose you are in the business of telling apart dogs, muffins and fried chicken (a.k.a. dogfooding!).

<figcaption><center><i>Example images of dogs and food (muffins and fried chicken). <a href="https://github.com/qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins-/">Source</a> / <a href="https://twitter.com/teenybiscuit/status/667777205397680129?s=20&t=wPgYJMp-JPwRsNAOMvEbxg">Original source</a>.</i></center></figcaption>
As the above image shows, to solve this problem, you’ll need:
* A dataset of dog, muffin, and fried chicken images
* Image classifiers that have been trained on these images
Fortunately, your data science team has uploaded [a dataset](https://huggingface.co/datasets/lewtun/dog_food) to the Hugging Face Hub and trained [a few different models on it](https://huggingface.co/models?datasets=lewtun/dog_food). So now you just need to pick the best one - let’s use Evaluation on the Hub to see how well they perform on the test set!
### Configuring an evaluation job
To get started, head over to the [`model-evaluator` Space](https://huggingface.co/spaces/autoevaluate/model-evaluator) and select the dataset you want to evaluate models on. For our dataset of dog and food images, you’ll see something like the image below:
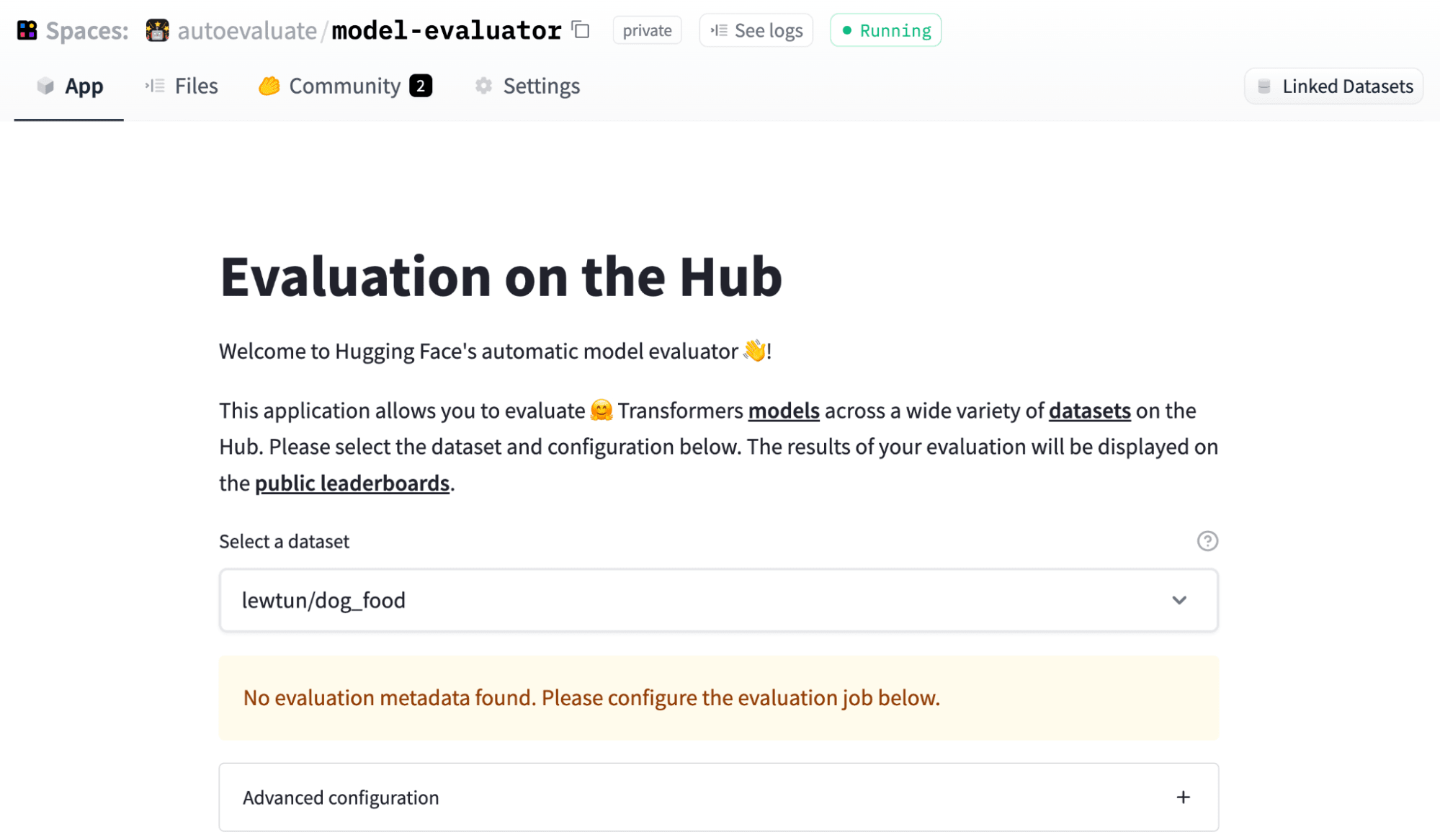
Now, many datasets on the Hub contain metadata that specifies how an evaluation should be configured (check out [acronym_identification](https://huggingface.co/datasets/acronym_identification/blob/main/README.md#L22-L30) for an example). This allows you to evaluate models with a single click, but in our case we’ll show you how to configure the evaluation manually.
Clicking on the <em>Advanced configuration</em> button will show you the various settings to choose from:
* The task, dataset, and split configuration
* The mapping of the dataset columns to a standard format
* The choice of metrics
As shown in the image below, configuring the task, dataset, and split to evaluate on is straightforward:

The next step is to define which dataset columns contain the images, and which ones contain the labels:
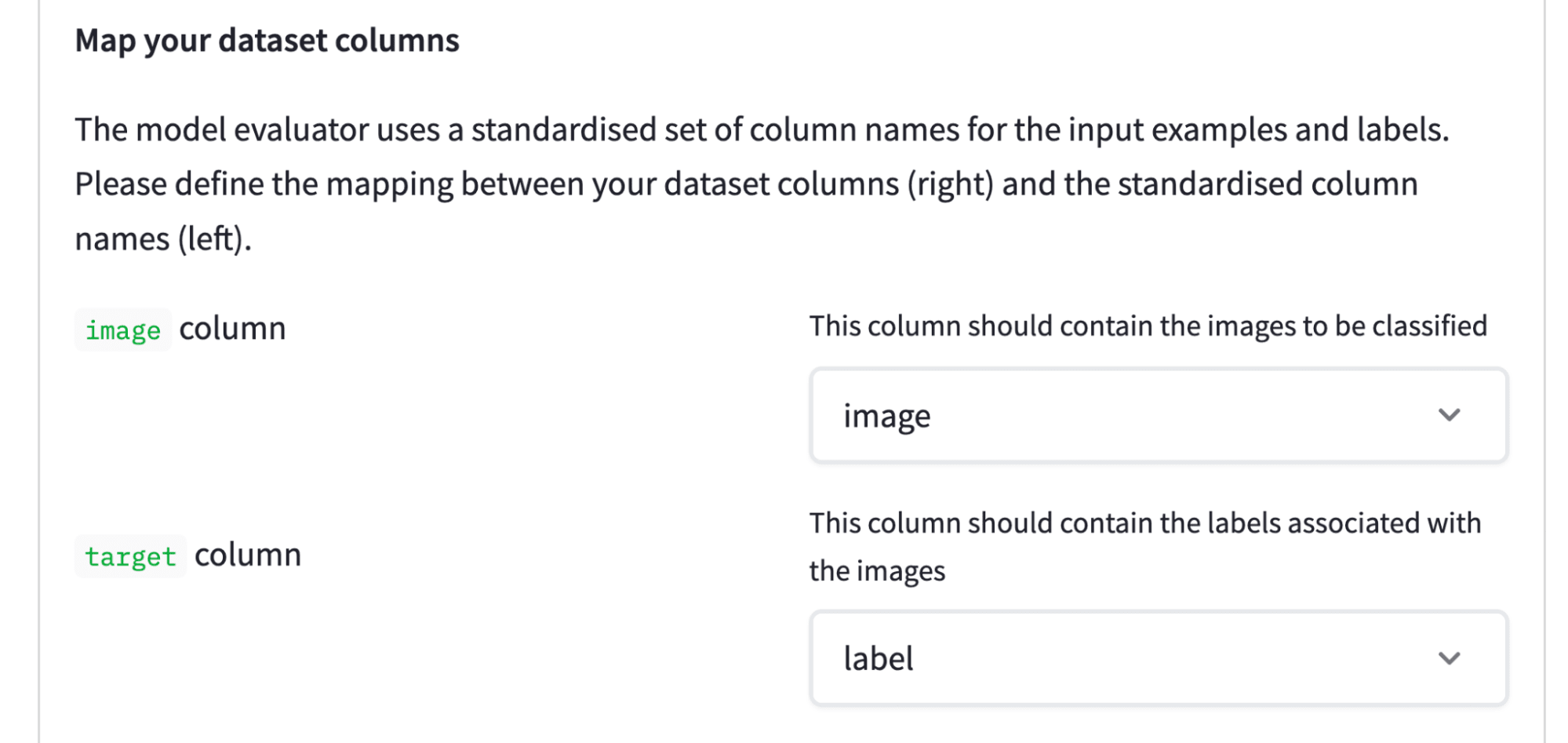
Now that the task and dataset are configured, the final (optional) step is to select the metrics to evaluate with. Each task is associated with a set of default metrics. For example, the image below shows that F1 score, accuracy etc will be computed automatically. To spice things up, we’ll also calculate the [Matthew’s correlation coefficient](https://huggingface.co/spaces/evaluate-metric/matthews_correlation), which provides a balanced measure of classifier performance:
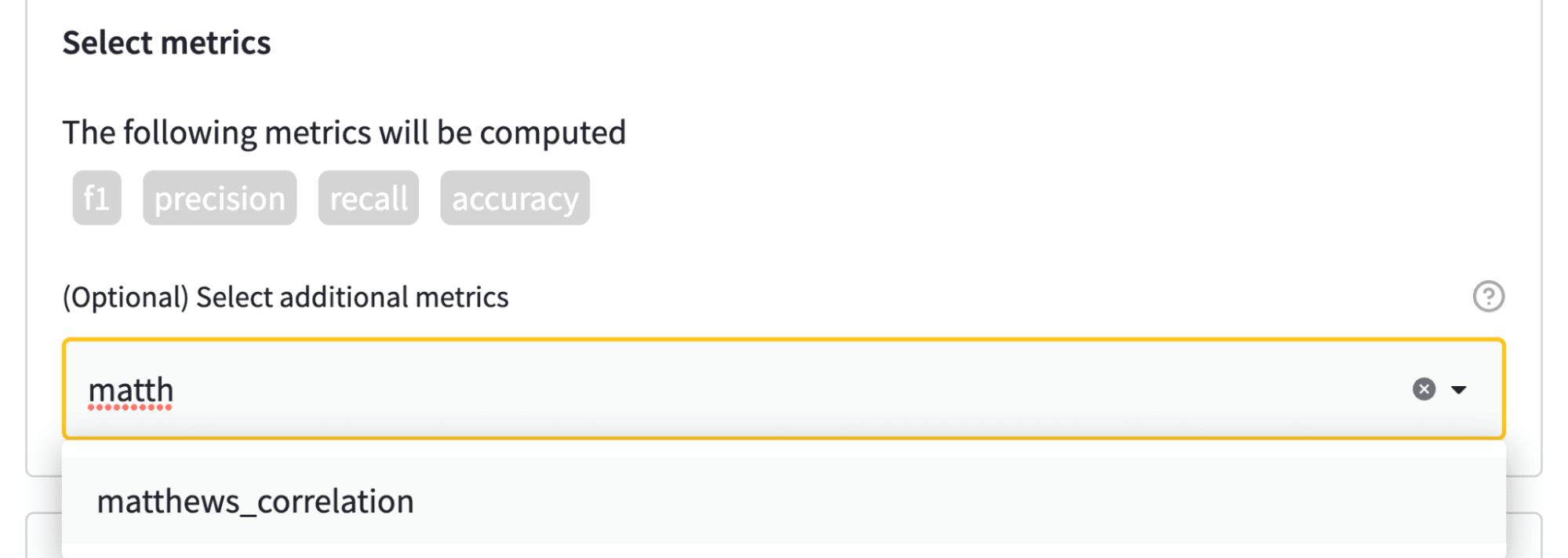
And that’s all it takes to configure an evaluation job! Now we just need to pick some models to evaluate - let’s take a look.
### Selecting models to evaluate
Evaluation on the Hub links datasets and models via tags in the model card metadata. In our example, we have three models to choose from, so let’s select them all!
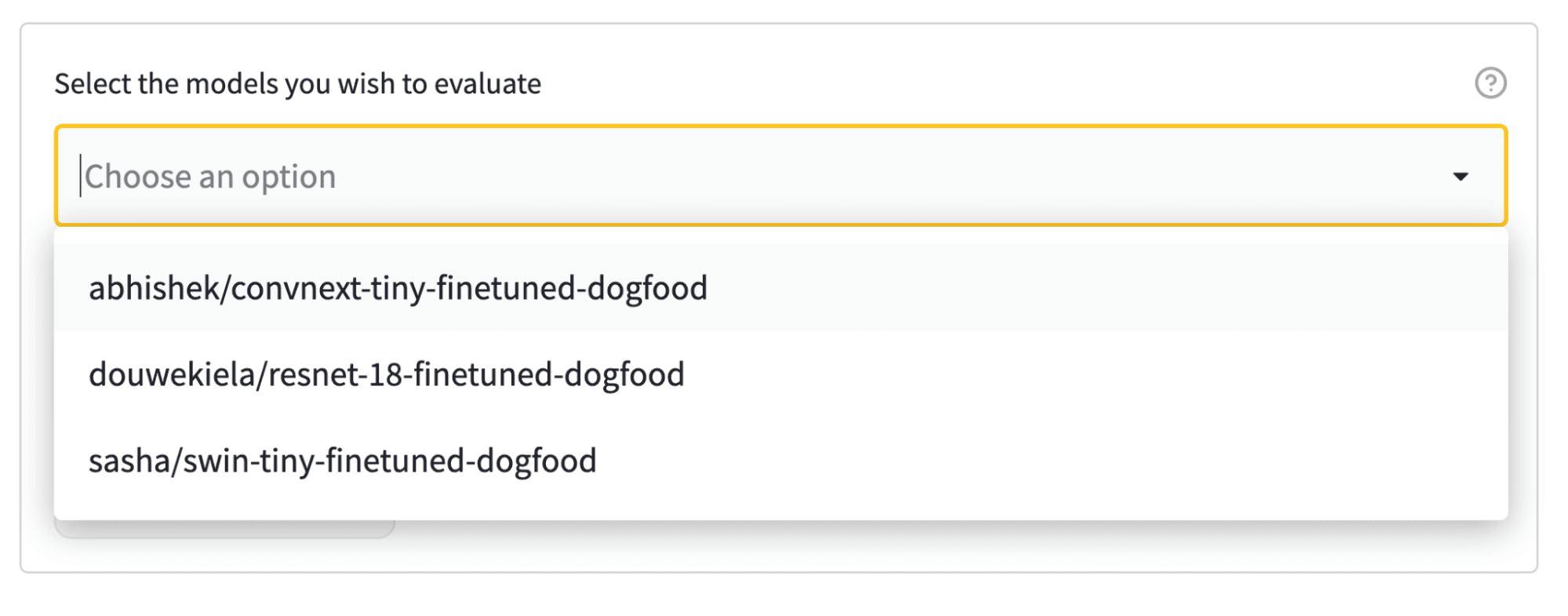
Once the models are selected, simply enter your Hugging Face Hub username (to be notified when the evaluation is complete) and hit the big <em>Evaluate models</em> button:
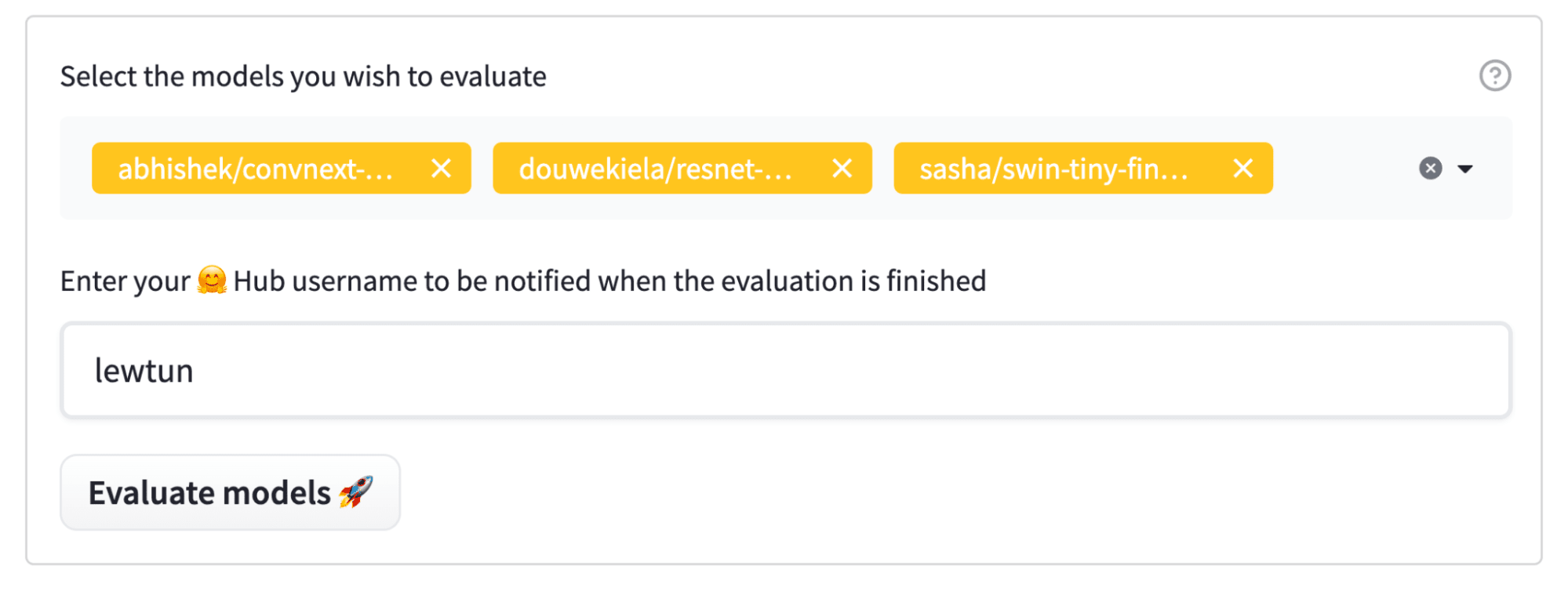
Once a job is submitted, the models will be automatically evaluated and a Hub pull request will be opened with the evaluation results:
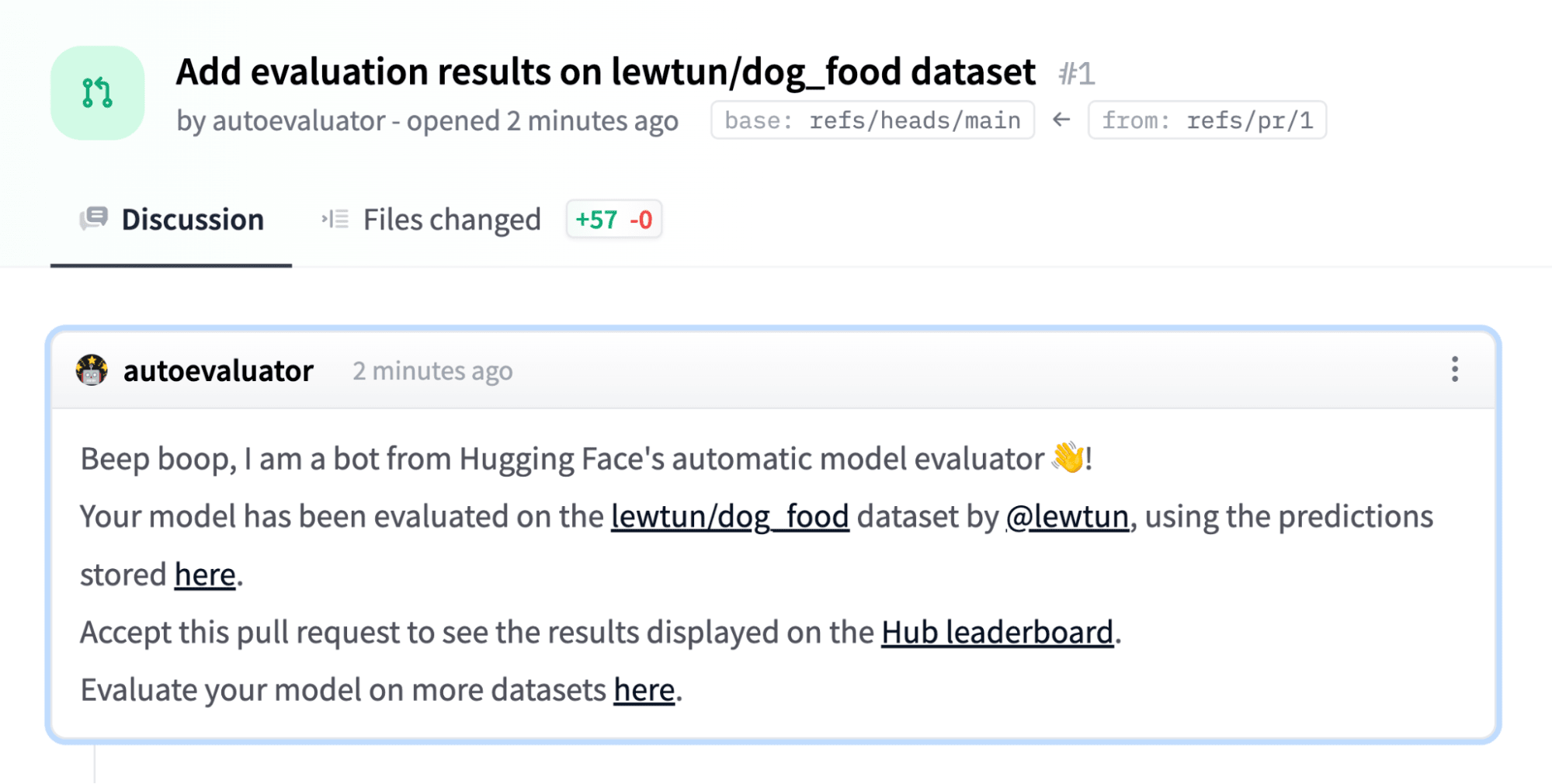
You can also copy-paste the evaluation metadata into the dataset card so that you and the community can skip the manual configuration next time!
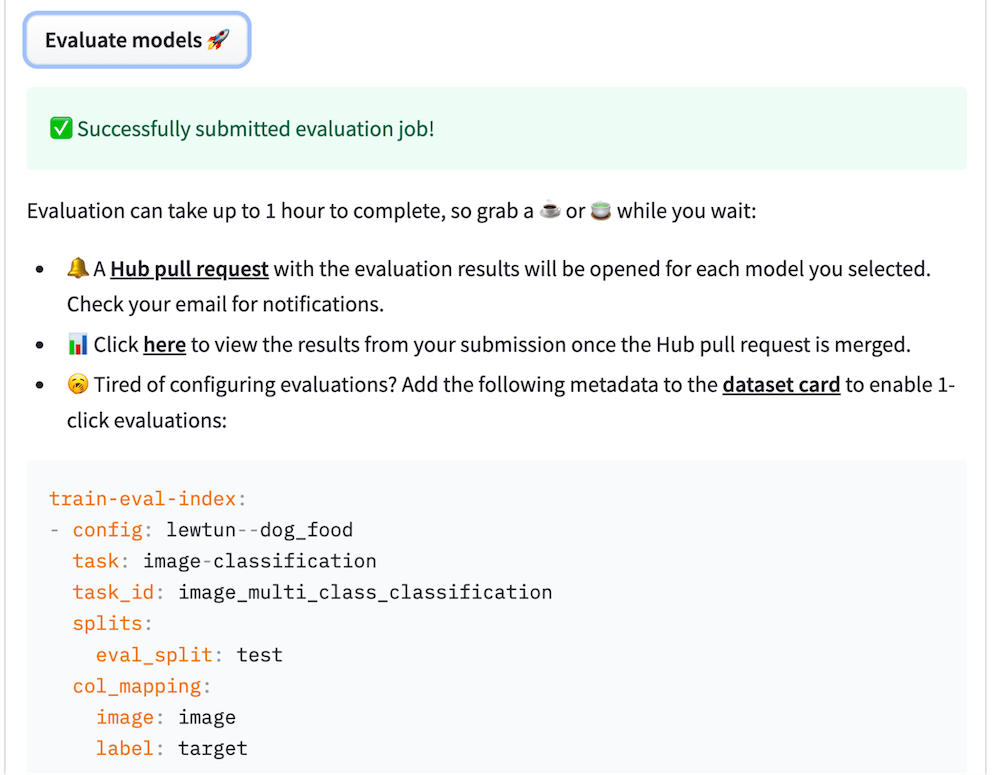
### Check out the leaderboard
To facilitate the comparison of models, Evaluation on the Hub also provides leaderboards that allow you to examine which models perform best on which split and metric:
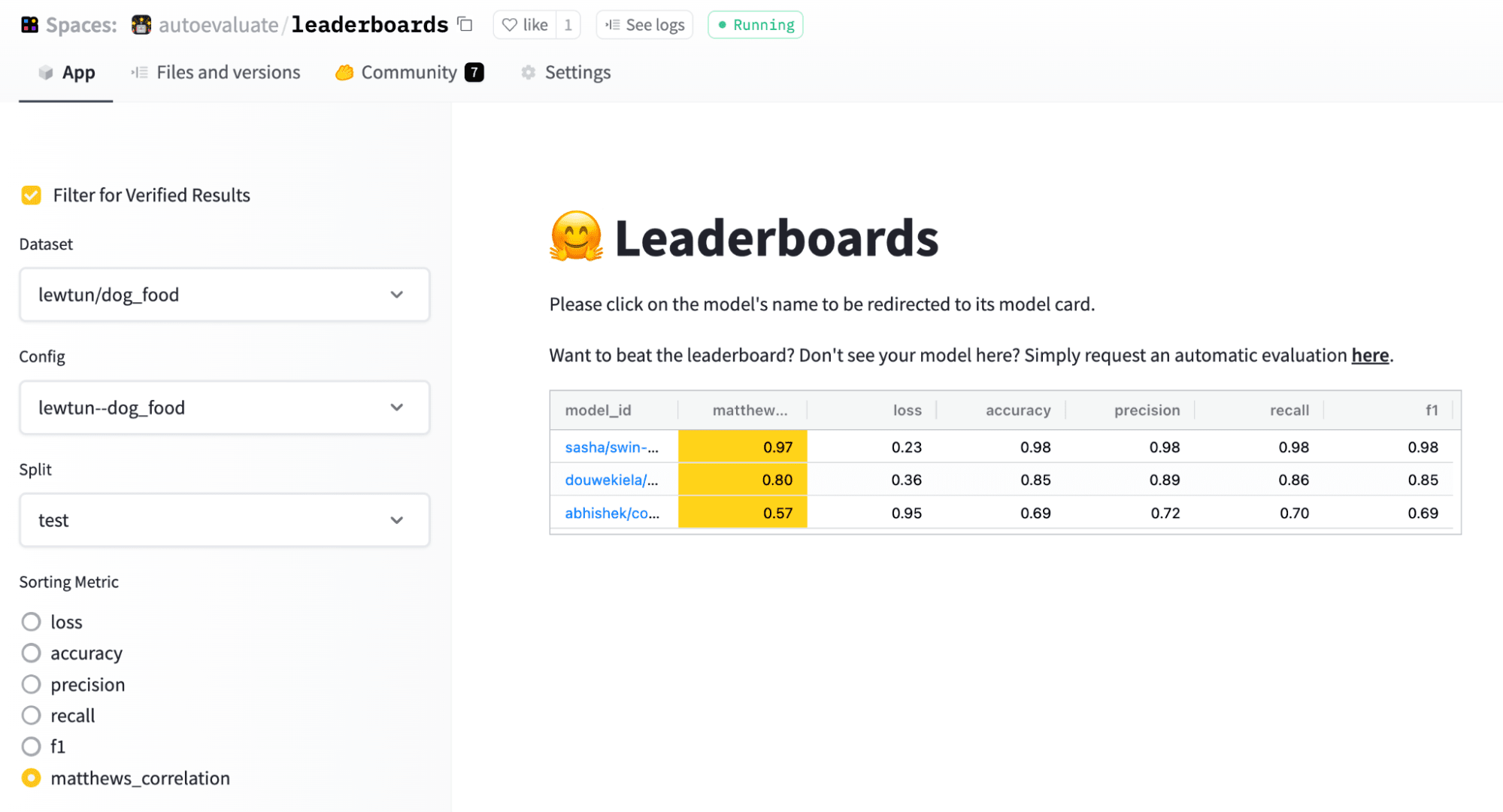
Looks like the Swin Transformer came out on top!
### Try it yourself!
If you’d like to evaluate your own choice of models, give Evaluation on the Hub a spin by checking out these popular datasets:
* [Emotion](https://huggingface.co/spaces/autoevaluate/model-evaluator?dataset=emotion) for text classification
* [MasakhaNER](https://huggingface.co/spaces/autoevaluate/model-evaluator?dataset=masakhaner) for named entity recognition
* [SAMSum](https://huggingface.co/spaces/autoevaluate/model-evaluator?dataset=samsum) for text summarization
## The Bigger Picture
Since the dawn of machine learning, we've evaluated models by computing some form of accuracy on a held-out test set that is assumed to be independent and identically distributed. Under the pressures of modern AI, that paradigm is now starting to show serious cracks.
Benchmarks are saturating, meaning that machines outperform humans on certain test sets, almost faster than we can come up with new ones. Yet, AI systems are known to be brittle and suffer from, or even worse amplify, severe malicious biases. Reproducibility is lacking. Openness is an afterthought. While people fixate on leaderboards, practical considerations for deploying models, such as efficiency and fairness, are often glossed over. The hugely important role data plays in model development is still not taken seriously enough. What is more, the practices of pretraining and prompt-based in-context learning have blurred what it means to be “in distribution” in the first place. Machine learning is slowly catching up to these things, and we hope to help the field move forward with our work.
## Next Steps
A few weeks ago, we launched the Hugging Face [Evaluate library](https://github.com/huggingface/evaluate), aimed at lowering barriers to the best practices of machine learning evaluation. We have also been hosting benchmarks, like [RAFT](https://huggingface.co/spaces/ought/raft-leaderboard) and [GEM](https://huggingface.co/spaces/GEM/submission-form). Evaluation on the Hub is a logical next step in our efforts to enable a future where models are evaluated in a more holistic fashion, along many axes of evaluation, in a trustable and guaranteeably reproducible manner. Stay tuned for more launches soon, including more tasks, and a new and improved [data measurements tool](https://huggingface.co/spaces/huggingface/data-measurements-tool)!
We’re excited to see where the community will take this! If you'd like to help out, evaluate as many models on as many datasets as you like. And as always, please give us lots of feedback, either on the [Community tabs](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions) or the [forums](https://discuss.huggingface.co/)!
| huggingface/blog/blob/main/eval-on-the-hub.md |
The Model Hub
## What is the Model Hub?
The Model Hub is where the members of the Hugging Face community can host all of their model checkpoints for simple storage, discovery, and sharing. Download pre-trained models with the [`huggingface_hub` client library](https://huggingface.co/docs/huggingface_hub/index), with 🤗 [`Transformers`](https://huggingface.co/docs/transformers/index) for fine-tuning and other usages or with any of the over [15 integrated libraries](./models-libraries). You can even leverage the [Inference API](./models-inference) to use models in production settings.
You can refer to the following video for a guide on navigating the Model Hub:
<iframe width="560" height="315" src="https://www.youtube-nocookie.com/embed/XvSGPZFEjDY" title="Model Hub Video" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
To learn how to upload models to the Hub, you can refer to the [Repositories Getting Started Guide](./repositories-getting-started). | huggingface/hub-docs/blob/main/docs/hub/models-the-hub.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# How to use `optimum` and `BetterTransformer`?
## Install dependencies
You can easily use the `BetterTransformer` integration with 🤗 Optimum, first install the dependencies as follows:
```bash
pip install transformers accelerate optimum
```
Also, make sure to install the latest version of PyTorch by following the guidelines on the [PyTorch official website](https://pytorch.org/get-started/locally/). Note that `BetterTransformer` API is only compatible with `torch>=1.13`, so make sure to have this version installed on your environement before starting.
If you want to benefit from the `scaled_dot_product_attention` function (for decoder-based models), make sure to use at least `torch>=2.0`.
## Step 1: Load your model
First, load your Hugging Face model using 🤗 Transformers. Make sure to download one of the models that is supported by the `BetterTransformer` API:
```python
>>> from transformers import AutoModel
>>> model_id = "roberta-base"
>>> model = AutoModel.from_pretrained(model_id)
```
<Tip>
Sometimes you can directly load your model on your GPU devices using `accelerate` library, therefore you can optionally try out the following command:
</Tip>
```python
>>> from transformers import AutoModel
>>> model_id = "roberta-base"
>>> model = AutoModel.from_pretrained(model_id, device_map="auto")
```
## Step 2: Set your model on your preferred device
If you did not used `device_map="auto"` to load your model (or if your model does not support `device_map="auto"`), you can manually set your model to a GPU:
```python
>>> model = model.to(0) # or model.to("cuda:0")
```
## Step 3: Convert your model to BetterTransformer!
Now time to convert your model using `BetterTransformer` API! You can run the commands below:
```python
>>> from optimum.bettertransformer import BetterTransformer
>>> model = BetterTransformer.transform(model)
```
By default, `BetterTransformer.transform` will overwrite your model, which means that your previous native model cannot be used anymore. If you want to keep it for some reasons, just add the flag `keep_original_model=True`!
```python
>>> from optimum.bettertransformer import BetterTransformer
>>> model_bt = BetterTransformer.transform(model, keep_original_model=True)
```
If your model does not support the `BetterTransformer` API, this will be displayed on an error trace. Note also that decoder-based models (OPT, BLOOM, etc.) are not supported yet but this is in the roadmap of PyTorch for the future.
## Pipeline compatibility
[Transformer's pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) is also compatible with this integration and you can use `BetterTransformer` as an accelerator for your pipelines. The code snippet below shows how:
```python
>>> from optimum.pipelines import pipeline
>>> pipe = pipeline("fill-mask", "distilbert-base-uncased", accelerator="bettertransformer")
>>> pipe("I am a student at [MASK] University.")
```
If you want to run a pipeline on a GPU device, run:
```python
>>> from optimum.pipelines import pipeline
>>> pipe = pipeline("fill-mask", "distilbert-base-uncased", accelerator="bettertransformer", device=0)
>>> ...
```
You can also use `transformers.pipeline` as usual and pass the converted model directly:
```python
>>> from transformers import pipeline
>>> pipe = pipeline("fill-mask", model=model_bt, tokenizer=tokenizer, device=0)
>>> ...
```
Please refer to the [official documentation of `pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines) for further usage. If you face into any issue, do not hesitate to open an isse on GitHub!
## Training compatibility
You can now benefit from the `BetterTransformer` API for your training scripts. Just make sure to convert back your model to its original version by calling `BetterTransformer.reverse` before saving your model.
The code snippet below shows how:
```python
from optimum.bettertransformer import BetterTransformer
from transformers import AutoModelForCausalLM
with torch.device(“cuda”):
model = AutoModelForCausalLM.from_pretrained(“gpt2-large”, torch_dtype=torch.float16)
model = BetterTransformer.transform(model)
# do your inference or training here
# if training and want to save the model
model = BetterTransformer.reverse(model)
model.save_pretrained("fine_tuned_model")
model.push_to_hub("fine_tuned_model")
``` | huggingface/optimum/blob/main/docs/source/bettertransformer/tutorials/convert.mdx |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Soft prompts
Training large pretrained language models is very time-consuming and compute-intensive. As they continue to grow in size, there is increasing interest in more efficient training methods such as *prompting*. Prompting primes a frozen pretrained model for a specific downstream task by including a text prompt that describes the task or even demonstrates an example of the task. With prompting, you can avoid fully training a separate model for each downstream task, and use the same frozen pretrained model instead. This is a lot easier because you can use the same model for several different tasks, and it is significantly more efficient to train and store a smaller set of prompt parameters than to train all the model's parameters.
There are two categories of prompting methods:
- hard prompts are manually handcrafted text prompts with discrete input tokens; the downside is that it requires a lot of effort to create a good prompt
- soft prompts are learnable tensors concatenated with the input embeddings that can be optimized to a dataset; the downside is that they aren't human readable because you aren't matching these "virtual tokens" to the embeddings of a real word
This conceptual guide provides a brief overview of the soft prompt methods included in 🤗 PEFT: prompt tuning, prefix tuning, P-tuning, and multitask prompt tuning.
## Prompt tuning
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/prompt-tuning.png"/>
</div>
<small>Only train and store a significantly smaller set of task-specific prompt parameters <a href="https://hf.co/papers/2104.08691">(image source)</a>.</small>
[Prompt tuning](https://hf.co/papers/2104.08691) was developed for text classification tasks on T5 models, and all downstream tasks are cast as a text generation task. For example, sequence classification usually assigns a single class label to a sequence of text. By casting it as a text generation task, the tokens that make up the class label are *generated*. Prompts are added to the input as a series of tokens. Typically, the model parameters are fixed which means the prompt tokens are also fixed by the model parameters.
The key idea behind prompt tuning is that prompt tokens have their own parameters that are updated independently. This means you can keep the pretrained model's parameters frozen, and only update the gradients of the prompt token embeddings. The results are comparable to the traditional method of training the entire model, and prompt tuning performance scales as model size increases.
Take a look at [Prompt tuning for causal language modeling](../task_guides/clm-prompt-tuning) for a step-by-step guide on how to train a model with prompt tuning.
## Prefix tuning
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/prefix-tuning.png"/>
</div>
<small>Optimize the prefix parameters for each task <a href="https://hf.co/papers/2101.00190">(image source)</a>.</small>
[Prefix tuning](https://hf.co/papers/2101.00190) was designed for natural language generation (NLG) tasks on GPT models. It is very similar to prompt tuning; prefix tuning also prepends a sequence of task-specific vectors to the input that can be trained and updated while keeping the rest of the pretrained model's parameters frozen.
The main difference is that the prefix parameters are inserted in **all** of the model layers, whereas prompt tuning only adds the prompt parameters to the model input embeddings. The prefix parameters are also optimized by a separate feed-forward network (FFN) instead of training directly on the soft prompts because it causes instability and hurts performance. The FFN is discarded after updating the soft prompts.
As a result, the authors found that prefix tuning demonstrates comparable performance to fully finetuning a model, despite having 1000x fewer parameters, and it performs even better in low-data settings.
Take a look at [Prefix tuning for conditional generation](../task_guides/seq2seq-prefix-tuning) for a step-by-step guide on how to train a model with prefix tuning.
## P-tuning
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/p-tuning.png"/>
</div>
<small>Prompt tokens can be inserted anywhere in the input sequence, and they are optimized by a prompt encoder <a href="https://hf.co/papers/2103.10385">(image source)</a>.</small>
[P-tuning](https://hf.co/papers/2103.10385) is designed for natural language understanding (NLU) tasks and all language models.
It is another variation of a soft prompt method; P-tuning also adds a trainable embedding tensor that can be optimized to find better prompts, and it uses a prompt encoder (a bidirectional long-short term memory network or LSTM) to optimize the prompt parameters. Unlike prefix tuning though:
- the prompt tokens can be inserted anywhere in the input sequence, and it isn't restricted to only the beginning
- the prompt tokens are only added to the input instead of adding them to every layer of the model
- introducing *anchor* tokens can improve performance because they indicate characteristics of a component in the input sequence
The results suggest that P-tuning is more efficient than manually crafting prompts, and it enables GPT-like models to compete with BERT-like models on NLU tasks.
Take a look at [P-tuning for sequence classification](../task_guides/ptuning-seq-classification) for a step-by-step guide on how to train a model with P-tuning.
## Multitask prompt tuning
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/mpt.png"/>
</div>
<small><a href="https://hf.co/papers/2103.10385">Multitask prompt tuning enables parameter-efficient transfer learning</a>.</small>
[Multitask prompt tuning (MPT)](https://hf.co/papers/2103.10385) learns a single prompt from data for multiple task types that can be shared for different target tasks. Other existing approaches learn a separate soft prompt for each task that need to be retrieved or aggregated for adaptation to target tasks. MPT consists of two stages:
1. source training - for each task, its soft prompt is decomposed into task-specific vectors. The task-specific vectors are multiplied together to form another matrix W, and the Hadamard product is used between W and a shared prompt matrix P to generate a task-specific prompt matrix. The task-specific prompts are distilled into a single prompt matrix that is shared across all tasks. This prompt is trained with multitask training.
2. target adaptation - to adapt the single prompt for a target task, a target prompt is initialized and expressed as the Hadamard product of the shared prompt matrix and the task-specific low-rank prompt matrix.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/mpt-decomposition.png"/>
</div>
<small><a href="https://hf.co/papers/2103.10385">Prompt decomposition</a>.</small>
| huggingface/peft/blob/main/docs/source/conceptual_guides/prompting.md |
Using the `evaluator`
The `Evaluator` classes allow to evaluate a triplet of model, dataset, and metric. The models wrapped in a pipeline, responsible for handling all preprocessing and post-processing and out-of-the-box, `Evaluator`s support transformers pipelines for the supported tasks, but custom pipelines can be passed, as showcased in the section [Using the `evaluator` with custom pipelines](custom_evaluator).
Currently supported tasks are:
- `"text-classification"`: will use the [`TextClassificationEvaluator`].
- `"token-classification"`: will use the [`TokenClassificationEvaluator`].
- `"question-answering"`: will use the [`QuestionAnsweringEvaluator`].
- `"image-classification"`: will use the [`ImageClassificationEvaluator`].
- `"text-generation"`: will use the [`TextGenerationEvaluator`].
- `"text2text-generation"`: will use the [`Text2TextGenerationEvaluator`].
- `"summarization"`: will use the [`SummarizationEvaluator`].
- `"translation"`: will use the [`TranslationEvaluator`].
- `"automatic-speech-recognition"`: will use the [`AutomaticSpeechRecognitionEvaluator`].
- `"audio-classification"`: will use the [`AudioClassificationEvaluator`].
To run an `Evaluator` with several tasks in a single call, use the [EvaluationSuite](evaluation_suite), which runs evaluations on a collection of `SubTask`s.
Each task has its own set of requirements for the dataset format and pipeline output, make sure to check them out for your custom use case. Let's have a look at some of them and see how you can use the evaluator to evalute a single or multiple of models, datasets, and metrics at the same time.
## Text classification
The text classification evaluator can be used to evaluate text models on classification datasets such as IMDb. Beside the model, data, and metric inputs it takes the following optional inputs:
- `input_column="text"`: with this argument the column with the data for the pipeline can be specified.
- `label_column="label"`: with this argument the column with the labels for the evaluation can be specified.
- `label_mapping=None`: the label mapping aligns the labels in the pipeline output with the labels need for evaluation. E.g. the labels in `label_column` can be integers (`0`/`1`) whereas the pipeline can produce label names such as `"positive"`/`"negative"`. With that dictionary the pipeline outputs are mapped to the labels.
By default the `"accuracy"` metric is computed.
### Evaluate models on the Hub
There are several ways to pass a model to the evaluator: you can pass the name of a model on the Hub, you can load a `transformers` model and pass it to the evaluator or you can pass an initialized `transformers.Pipeline`. Alternatively you can pass any callable function that behaves like a `pipeline` call for the task in any framework.
So any of the following works:
```py
from datasets import load_dataset
from evaluate import evaluator
from transformers import AutoModelForSequenceClassification, pipeline
data = load_dataset("imdb", split="test").shuffle(seed=42).select(range(1000))
task_evaluator = evaluator("text-classification")
# 1. Pass a model name or path
eval_results = task_evaluator.compute(
model_or_pipeline="lvwerra/distilbert-imdb",
data=data,
label_mapping={"NEGATIVE": 0, "POSITIVE": 1}
)
# 2. Pass an instantiated model
model = AutoModelForSequenceClassification.from_pretrained("lvwerra/distilbert-imdb")
eval_results = task_evaluator.compute(
model_or_pipeline=model,
data=data,
label_mapping={"NEGATIVE": 0, "POSITIVE": 1}
)
# 3. Pass an instantiated pipeline
pipe = pipeline("text-classification", model="lvwerra/distilbert-imdb")
eval_results = task_evaluator.compute(
model_or_pipeline=pipe,
data=data,
label_mapping={"NEGATIVE": 0, "POSITIVE": 1}
)
print(eval_results)
```
<Tip>
Without specifying a device, the default for model inference will be the first GPU on the machine if one is available, and else CPU. If you want to use a specific device you can pass `device` to `compute` where -1 will use the GPU and a positive integer (starting with 0) will use the associated CUDA device.
</Tip>
The results will look as follows:
```python
{
'accuracy': 0.918,
'latency_in_seconds': 0.013,
'samples_per_second': 78.887,
'total_time_in_seconds': 12.676
}
```
Note that evaluation results include both the requested metric, and information about the time it took to obtain predictions through the pipeline.
<Tip>
The time performances can give useful indication on model speed for inference but should be taken with a grain of salt: they include all the processing that goes on in the pipeline. This may include tokenizing, post-processing, that may be different depending on the model. Furthermore, it depends a lot on the hardware you are running the evaluation on and you may be able to improve the performance by optimizing things like the batch size.
</Tip>
### Evaluate multiple metrics
With the [`combine`] function one can bundle several metrics into an object that behaves like a single metric. We can use this to evaluate several metrics at once with the evaluator:
```python
import evaluate
eval_results = task_evaluator.compute(
model_or_pipeline="lvwerra/distilbert-imdb",
data=data,
metric=evaluate.combine(["accuracy", "recall", "precision", "f1"]),
label_mapping={"NEGATIVE": 0, "POSITIVE": 1}
)
print(eval_results)
```
The results will look as follows:
```python
{
'accuracy': 0.918,
'f1': 0.916,
'precision': 0.9147,
'recall': 0.9187,
'latency_in_seconds': 0.013,
'samples_per_second': 78.887,
'total_time_in_seconds': 12.676
}
```
Next let's have a look at token classification.
## Token Classification
With the token classification evaluator one can evaluate models for tasks such as NER or POS tagging. It has the following specific arguments:
- `input_column="text"`: with this argument the column with the data for the pipeline can be specified.
- `label_column="label"`: with this argument the column with the labels for the evaluation can be specified.
- `label_mapping=None`: the label mapping aligns the labels in the pipeline output with the labels need for evaluation. E.g. the labels in `label_column` can be integers (`0`/`1`) whereas the pipeline can produce label names such as `"positive"`/`"negative"`. With that dictionary the pipeline outputs are mapped to the labels.
- `join_by=" "`: While most datasets are already tokenized the pipeline expects a string. Thus the tokens need to be joined before passing to the pipeline. By default they are joined with a whitespace.
Let's have a look how we can use the evaluator to benchmark several models.
### Benchmarking several models
Here is an example where several models can be compared thanks to the `evaluator` in only a few lines of code, abstracting away the preprocessing, inference, postprocessing, metric computation:
```python
import pandas as pd
from datasets import load_dataset
from evaluate import evaluator
from transformers import pipeline
models = [
"xlm-roberta-large-finetuned-conll03-english",
"dbmdz/bert-large-cased-finetuned-conll03-english",
"elastic/distilbert-base-uncased-finetuned-conll03-english",
"dbmdz/electra-large-discriminator-finetuned-conll03-english",
"gunghio/distilbert-base-multilingual-cased-finetuned-conll2003-ner",
"philschmid/distilroberta-base-ner-conll2003",
"Jorgeutd/albert-base-v2-finetuned-ner",
]
data = load_dataset("conll2003", split="validation").shuffle().select(range(1000))
task_evaluator = evaluator("token-classification")
results = []
for model in models:
results.append(
task_evaluator.compute(
model_or_pipeline=model, data=data, metric="seqeval"
)
)
df = pd.DataFrame(results, index=models)
df[["overall_f1", "overall_accuracy", "total_time_in_seconds", "samples_per_second", "latency_in_seconds"]]
```
The result is a table that looks like this:
| model | overall_f1 | overall_accuracy | total_time_in_seconds | samples_per_second | latency_in_seconds |
|:-------------------------------------------------------------------|-------------:|-------------------:|------------------------:|---------------------:|---------------------:|
| Jorgeutd/albert-base-v2-finetuned-ner | 0.941 | 0.989 | 4.515 | 221.468 | 0.005 |
| dbmdz/bert-large-cased-finetuned-conll03-english | 0.962 | 0.881 | 11.648 | 85.850 | 0.012 |
| dbmdz/electra-large-discriminator-finetuned-conll03-english | 0.965 | 0.881 | 11.456 | 87.292 | 0.011 |
| elastic/distilbert-base-uncased-finetuned-conll03-english | 0.940 | 0.989 | 2.318 | 431.378 | 0.002 |
| gunghio/distilbert-base-multilingual-cased-finetuned-conll2003-ner | 0.947 | 0.991 | 2.376 | 420.873 | 0.002 |
| philschmid/distilroberta-base-ner-conll2003 | 0.961 | 0.994 | 2.436 | 410.579 | 0.002 |
| xlm-roberta-large-finetuned-conll03-english | 0.969 | 0.882 | 11.996 | 83.359 | 0.012 |
### Visualizing results
You can feed in the `results` list above into the `plot_radar()` function to visualize different aspects of their performance and choose the model that is the best fit, depending on the metric(s) that are relevant to your use case:
```python
import evaluate
from evaluate.visualization import radar_plot
>>> plot = radar_plot(data=results, model_names=models, invert_range=["latency_in_seconds"])
>>> plot.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/evaluate/media/resolve/main/viz.png" width="400"/>
</div>
Don't forget to specify `invert_range` for metrics for which smaller is better (such as the case for latency in seconds).
If you want to save the plot locally, you can use the `plot.savefig()` function with the option `bbox_inches='tight'`, to make sure no part of the image gets cut off.
## Question Answering
With the question-answering evaluator one can evaluate models for QA without needing to worry about the complicated pre- and post-processing that's required for these models. It has the following specific arguments:
- `question_column="question"`: the name of the column containing the question in the dataset
- `context_column="context"`: the name of the column containing the context
- `id_column="id"`: the name of the column cointaing the identification field of the question and answer pair
- `label_column="answers"`: the name of the column containing the answers
- `squad_v2_format=None`: whether the dataset follows the format of squad_v2 dataset where a question may have no answer in the context. If this parameter is not provided, the format will be automatically inferred.
Let's have a look how we can evaluate QA models and compute confidence intervals at the same time.
### Confidence intervals
Every evaluator comes with the options to compute confidence intervals using [bootstrapping](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.bootstrap.html). Simply pass `strategy="bootstrap"` and set the number of resanmples with `n_resamples`.
```python
from datasets import load_dataset
from evaluate import evaluator
task_evaluator = evaluator("question-answering")
data = load_dataset("squad", split="validation[:1000]")
eval_results = task_evaluator.compute(
model_or_pipeline="distilbert-base-uncased-distilled-squad",
data=data,
metric="squad",
strategy="bootstrap",
n_resamples=30
)
```
Results include confidence intervals as well as error estimates as follows:
```python
{
'exact_match':
{
'confidence_interval': (79.67, 84.54),
'score': 82.30,
'standard_error': 1.28
},
'f1':
{
'confidence_interval': (85.30, 88.88),
'score': 87.23,
'standard_error': 0.97
},
'latency_in_seconds': 0.0085,
'samples_per_second': 117.31,
'total_time_in_seconds': 8.52
}
```
## Image classification
With the image classification evaluator we can evaluate any image classifier. It uses the same keyword arguments at the text classifier:
- `input_column="image"`: the name of the column containing the images as PIL ImageFile
- `label_column="label"`: the name of the column containing the labels
- `label_mapping=None`: We want to map class labels defined by the model in the pipeline to values consistent with those defined in the `label_column`
Let's have a look at how can evaluate image classification models on large datasets.
### Handling large datasets
The evaluator can be used on large datasets! Below, an example shows how to use it on ImageNet-1k for image classification. Beware that this example will require to download ~150 GB.
```python
data = load_dataset("imagenet-1k", split="validation", use_auth_token=True)
pipe = pipeline(
task="image-classification",
model="facebook/deit-small-distilled-patch16-224"
)
task_evaluator = evaluator("image-classification")
eval_results = task_evaluator.compute(
model_or_pipeline=pipe,
data=data,
metric="accuracy",
label_mapping=pipe.model.config.label2id
)
```
Since we are using `datasets` to store data we make use of a technique called memory mappings. This means that the dataset is never fully loaded into memory which saves a lot of RAM. Running the above code only uses roughly 1.5 GB of RAM while the validation split is more than 30 GB big.
| huggingface/evaluate/blob/main/docs/source/base_evaluator.mdx |
Gradio Demo: no_input
```
!pip install -q gradio
```
```
import gradio as gr
import random
sentence_list = [
"Good morning!",
"Prayers are with you, have a safe day!",
"I love you!"
]
def random_sentence():
return sentence_list[random.randint(0, 2)]
demo = gr.Interface(fn=random_sentence, inputs=None, outputs="text")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/no_input/run.ipynb |
Creating your own dataset[[creating-your-own-dataset]]
<CourseFloatingBanner chapter={5}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter5/section5.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter5/section5.ipynb"},
]} />
Sometimes the dataset that you need to build an NLP application doesn't exist, so you'll need to create it yourself. In this section we'll show you how to create a corpus of [GitHub issues](https://github.com/features/issues/), which are commonly used to track bugs or features in GitHub repositories. This corpus could be used for various purposes, including:
* Exploring how long it takes to close open issues or pull requests
* Training a _multilabel classifier_ that can tag issues with metadata based on the issue's description (e.g., "bug," "enhancement," or "question")
* Creating a semantic search engine to find which issues match a user's query
Here we'll focus on creating the corpus, and in the next section we'll tackle the semantic search application. To keep things meta, we'll use the GitHub issues associated with a popular open source project: 🤗 Datasets! Let's take a look at how to get the data and explore the information contained in these issues.
## Getting the data[[getting-the-data]]
You can find all the issues in 🤗 Datasets by navigating to the repository's [Issues tab](https://github.com/huggingface/datasets/issues). As shown in the following screenshot, at the time of writing there were 331 open issues and 668 closed ones.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter5/datasets-issues.png" alt="The GitHub issues associated with 🤗 Datasets." width="80%"/>
</div>
If you click on one of these issues you'll find it contains a title, a description, and a set of labels that characterize the issue. An example is shown in the screenshot below.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter5/datasets-issues-single.png" alt="A typical GitHub issue in the 🤗 Datasets repository." width="80%"/>
</div>
To download all the repository's issues, we'll use the [GitHub REST API](https://docs.github.com/en/rest) to poll the [`Issues` endpoint](https://docs.github.com/en/rest/reference/issues#list-repository-issues). This endpoint returns a list of JSON objects, with each object containing a large number of fields that include the title and description as well as metadata about the status of the issue and so on.
A convenient way to download the issues is via the `requests` library, which is the standard way for making HTTP requests in Python. You can install the library by running:
```python
!pip install requests
```
Once the library is installed, you can make GET requests to the `Issues` endpoint by invoking the `requests.get()` function. For example, you can run the following command to retrieve the first issue on the first page:
```py
import requests
url = "https://api.github.com/repos/huggingface/datasets/issues?page=1&per_page=1"
response = requests.get(url)
```
The `response` object contains a lot of useful information about the request, including the HTTP status code:
```py
response.status_code
```
```python out
200
```
where a `200` status means the request was successful (you can find a list of possible HTTP status codes [here](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)). What we are really interested in, though, is the _payload_, which can be accessed in various formats like bytes, strings, or JSON. Since we know our issues are in JSON format, let's inspect the payload as follows:
```py
response.json()
```
```python out
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'repository_url': 'https://api.github.com/repos/huggingface/datasets',
'labels_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/labels{/name}',
'comments_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/comments',
'events_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792/events',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'id': 968650274,
'node_id': 'MDExOlB1bGxSZXF1ZXN0NzEwNzUyMjc0',
'number': 2792,
'title': 'Update GooAQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'labels': [],
'state': 'open',
'locked': False,
'assignee': None,
'assignees': [],
'milestone': None,
'comments': 1,
'created_at': '2021-08-12T11:40:18Z',
'updated_at': '2021-08-12T12:31:17Z',
'closed_at': None,
'author_association': 'CONTRIBUTOR',
'active_lock_reason': None,
'pull_request': {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/2792',
'html_url': 'https://github.com/huggingface/datasets/pull/2792',
'diff_url': 'https://github.com/huggingface/datasets/pull/2792.diff',
'patch_url': 'https://github.com/huggingface/datasets/pull/2792.patch'},
'body': '[GooAQ](https://github.com/allenai/gooaq) dataset was recently updated after splits were added for the same. This PR contains new updated GooAQ with train/val/test splits and updated README as well.',
'performed_via_github_app': None}]
```
Whoa, that's a lot of information! We can see useful fields like `title`, `body`, and `number` that describe the issue, as well as information about the GitHub user who opened the issue.
<Tip>
✏️ **Try it out!** Click on a few of the URLs in the JSON payload above to get a feel for what type of information each GitHub issue is linked to.
</Tip>
As described in the GitHub [documentation](https://docs.github.com/en/rest/overview/resources-in-the-rest-api#rate-limiting), unauthenticated requests are limited to 60 requests per hour. Although you can increase the `per_page` query parameter to reduce the number of requests you make, you will still hit the rate limit on any repository that has more than a few thousand issues. So instead, you should follow GitHub's [instructions](https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token) on creating a _personal access token_ so that you can boost the rate limit to 5,000 requests per hour. Once you have your token, you can include it as part of the request header:
```py
GITHUB_TOKEN = xxx # Copy your GitHub token here
headers = {"Authorization": f"token {GITHUB_TOKEN}"}
```
<Tip warning={true}>
⚠️ Do not share a notebook with your `GITHUB_TOKEN` pasted in it. We recommend you delete the last cell once you have executed it to avoid leaking this information accidentally. Even better, store the token in a *.env* file and use the [`python-dotenv` library](https://github.com/theskumar/python-dotenv) to load it automatically for you as an environment variable.
</Tip>
Now that we have our access token, let's create a function that can download all the issues from a GitHub repository:
```py
import time
import math
from pathlib import Path
import pandas as pd
from tqdm.notebook import tqdm
def fetch_issues(
owner="huggingface",
repo="datasets",
num_issues=10_000,
rate_limit=5_000,
issues_path=Path("."),
):
if not issues_path.is_dir():
issues_path.mkdir(exist_ok=True)
batch = []
all_issues = []
per_page = 100 # Number of issues to return per page
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Query with state=all to get both open and closed issues
query = f"issues?page={page}&per_page={per_page}&state=all"
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}", headers=headers)
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Flush batch for next time period
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"{issues_path}/{repo}-issues.jsonl", orient="records", lines=True)
print(
f"Downloaded all the issues for {repo}! Dataset stored at {issues_path}/{repo}-issues.jsonl"
)
```
Now when we call `fetch_issues()` it will download all the issues in batches to avoid exceeding GitHub's limit on the number of requests per hour; the result will be stored in a _repository_name-issues.jsonl_ file, where each line is a JSON object the represents an issue. Let's use this function to grab all the issues from 🤗 Datasets:
```py
# Depending on your internet connection, this can take several minutes to run...
fetch_issues()
```
Once the issues are downloaded we can load them locally using our newfound skills from [section 2](/course/chapter5/2):
```py
issues_dataset = load_dataset("json", data_files="datasets-issues.jsonl", split="train")
issues_dataset
```
```python out
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app'],
num_rows: 3019
})
```
Great, we've created our first dataset from scratch! But why are there several thousand issues when the [Issues tab](https://github.com/huggingface/datasets/issues) of the 🤗 Datasets repository only shows around 1,000 issues in total 🤔? As described in the GitHub [documentation](https://docs.github.com/en/rest/reference/issues#list-issues-assigned-to-the-authenticated-user), that's because we've downloaded all the pull requests as well:
> GitHub's REST API v3 considers every pull request an issue, but not every issue is a pull request. For this reason, "Issues" endpoints may return both issues and pull requests in the response. You can identify pull requests by the `pull_request` key. Be aware that the `id` of a pull request returned from "Issues" endpoints will be an issue id.
Since the contents of issues and pull requests are quite different, let's do some minor preprocessing to enable us to distinguish between them.
## Cleaning up the data[[cleaning-up-the-data]]
The above snippet from GitHub's documentation tells us that the `pull_request` column can be used to differentiate between issues and pull requests. Let's look at a random sample to see what the difference is. As we did in [section 3](/course/chapter5/3), we'll chain `Dataset.shuffle()` and `Dataset.select()` to create a random sample and then zip the `html_url` and `pull_request` columns so we can compare the various URLs:
```py
sample = issues_dataset.shuffle(seed=666).select(range(3))
# Print out the URL and pull request entries
for url, pr in zip(sample["html_url"], sample["pull_request"]):
print(f">> URL: {url}")
print(f">> Pull request: {pr}\n")
```
```python out
>> URL: https://github.com/huggingface/datasets/pull/850
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/850', 'html_url': 'https://github.com/huggingface/datasets/pull/850', 'diff_url': 'https://github.com/huggingface/datasets/pull/850.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/850.patch'}
>> URL: https://github.com/huggingface/datasets/issues/2773
>> Pull request: None
>> URL: https://github.com/huggingface/datasets/pull/783
>> Pull request: {'url': 'https://api.github.com/repos/huggingface/datasets/pulls/783', 'html_url': 'https://github.com/huggingface/datasets/pull/783', 'diff_url': 'https://github.com/huggingface/datasets/pull/783.diff', 'patch_url': 'https://github.com/huggingface/datasets/pull/783.patch'}
```
Here we can see that each pull request is associated with various URLs, while ordinary issues have a `None` entry. We can use this distinction to create a new `is_pull_request` column that checks whether the `pull_request` field is `None` or not:
```py
issues_dataset = issues_dataset.map(
lambda x: {"is_pull_request": False if x["pull_request"] is None else True}
)
```
<Tip>
✏️ **Try it out!** Calculate the average time it takes to close issues in 🤗 Datasets. You may find the `Dataset.filter()` function useful to filter out the pull requests and open issues, and you can use the `Dataset.set_format()` function to convert the dataset to a `DataFrame` so you can easily manipulate the `created_at` and `closed_at` timestamps. For bonus points, calculate the average time it takes to close pull requests.
</Tip>
Although we could proceed to further clean up the dataset by dropping or renaming some columns, it is generally a good practice to keep the dataset as "raw" as possible at this stage so that it can be easily used in multiple applications.
Before we push our dataset to the Hugging Face Hub, let's deal with one thing that's missing from it: the comments associated with each issue and pull request. We'll add them next with -- you guessed it -- the GitHub REST API!
## Augmenting the dataset[[augmenting-the-dataset]]
As shown in the following screenshot, the comments associated with an issue or pull request provide a rich source of information, especially if we're interested in building a search engine to answer user queries about the library.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter5/datasets-issues-comment.png" alt="Comments associated with an issue about 🤗 Datasets." width="80%"/>
</div>
The GitHub REST API provides a [`Comments` endpoint](https://docs.github.com/en/rest/reference/issues#list-issue-comments) that returns all the comments associated with an issue number. Let's test the endpoint to see what it returns:
```py
issue_number = 2792
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
response.json()
```
```python out
[{'url': 'https://api.github.com/repos/huggingface/datasets/issues/comments/897594128',
'html_url': 'https://github.com/huggingface/datasets/pull/2792#issuecomment-897594128',
'issue_url': 'https://api.github.com/repos/huggingface/datasets/issues/2792',
'id': 897594128,
'node_id': 'IC_kwDODunzps41gDMQ',
'user': {'login': 'bhavitvyamalik',
'id': 19718818,
'node_id': 'MDQ6VXNlcjE5NzE4ODE4',
'avatar_url': 'https://avatars.githubusercontent.com/u/19718818?v=4',
'gravatar_id': '',
'url': 'https://api.github.com/users/bhavitvyamalik',
'html_url': 'https://github.com/bhavitvyamalik',
'followers_url': 'https://api.github.com/users/bhavitvyamalik/followers',
'following_url': 'https://api.github.com/users/bhavitvyamalik/following{/other_user}',
'gists_url': 'https://api.github.com/users/bhavitvyamalik/gists{/gist_id}',
'starred_url': 'https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/bhavitvyamalik/subscriptions',
'organizations_url': 'https://api.github.com/users/bhavitvyamalik/orgs',
'repos_url': 'https://api.github.com/users/bhavitvyamalik/repos',
'events_url': 'https://api.github.com/users/bhavitvyamalik/events{/privacy}',
'received_events_url': 'https://api.github.com/users/bhavitvyamalik/received_events',
'type': 'User',
'site_admin': False},
'created_at': '2021-08-12T12:21:52Z',
'updated_at': '2021-08-12T12:31:17Z',
'author_association': 'CONTRIBUTOR',
'body': "@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?",
'performed_via_github_app': None}]
```
We can see that the comment is stored in the `body` field, so let's write a simple function that returns all the comments associated with an issue by picking out the `body` contents for each element in `response.json()`:
```py
def get_comments(issue_number):
url = f"https://api.github.com/repos/huggingface/datasets/issues/{issue_number}/comments"
response = requests.get(url, headers=headers)
return [r["body"] for r in response.json()]
# Test our function works as expected
get_comments(2792)
```
```python out
["@albertvillanova my tests are failing here:\r\n```\r\ndataset_name = 'gooaq'\r\n\r\n def test_load_dataset(self, dataset_name):\r\n configs = self.dataset_tester.load_all_configs(dataset_name, is_local=True)[:1]\r\n> self.dataset_tester.check_load_dataset(dataset_name, configs, is_local=True, use_local_dummy_data=True)\r\n\r\ntests/test_dataset_common.py:234: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_dataset_common.py:187: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```\r\nWhen I try loading dataset on local machine it works fine. Any suggestions on how can I avoid this error?"]
```
This looks good, so let's use `Dataset.map()` to add a new `comments` column to each issue in our dataset:
```py
# Depending on your internet connection, this can take a few minutes...
issues_with_comments_dataset = issues_dataset.map(
lambda x: {"comments": get_comments(x["number"])}
)
```
The final step is to push our dataset to the Hub. Let's take a look at how we can do that.
## Uploading the dataset to the Hugging Face Hub[[uploading-the-dataset-to-the-hugging-face-hub]]
<Youtube id="HaN6qCr_Afc"/>
Now that we have our augmented dataset, it's time to push it to the Hub so we can share it with the community! Uploading a dataset is very simple: just like models and tokenizers from 🤗 Transformers, we can use a `push_to_hub()` method to push a dataset. To do that we need an authentication token, which can be obtained by first logging into the Hugging Face Hub with the `notebook_login()` function:
```py
from huggingface_hub import notebook_login
notebook_login()
```
This will create a widget where you can enter your username and password, and an API token will be saved in *~/.huggingface/token*. If you're running the code in a terminal, you can log in via the CLI instead:
```bash
huggingface-cli login
```
Once we've done this, we can upload our dataset by running:
```py
issues_with_comments_dataset.push_to_hub("github-issues")
```
From here, anyone can download the dataset by simply providing `load_dataset()` with the repository ID as the `path` argument:
```py
remote_dataset = load_dataset("lewtun/github-issues", split="train")
remote_dataset
```
```python out
Dataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})
```
Cool, we've pushed our dataset to the Hub and it's available for others to use! There's just one important thing left to do: adding a _dataset card_ that explains how the corpus was created and provides other useful information for the community.
<Tip>
💡 You can also upload a dataset to the Hugging Face Hub directly from the terminal by using `huggingface-cli` and a bit of Git magic. See the [🤗 Datasets guide](https://huggingface.co/docs/datasets/share.html#add-a-community-dataset) for details on how to do this.
</Tip>
## Creating a dataset card[[creating-a-dataset-card]]
Well-documented datasets are more likely to be useful to others (including your future self!), as they provide the context to enable users to decide whether the dataset is relevant to their task and to evaluate any potential biases in or risks associated with using the dataset.
On the Hugging Face Hub, this information is stored in each dataset repository's *README.md* file. There are two main steps you should take before creating this file:
1. Use the [`datasets-tagging` application](https://huggingface.co/datasets/tagging/) to create metadata tags in YAML format. These tags are used for a variety of search features on the Hugging Face Hub and ensure your dataset can be easily found by members of the community. Since we have created a custom dataset here, you'll need to clone the `datasets-tagging` repository and run the application locally. Here's what the interface looks like:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter5/datasets-tagger.png" alt="The `datasets-tagging` interface." width="80%"/>
</div>
2. Read the [🤗 Datasets guide](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) on creating informative dataset cards and use it as a template.
You can create the *README.md* file directly on the Hub, and you can find a template dataset card in the `lewtun/github-issues` dataset repository. A screenshot of the filled-out dataset card is shown below.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter5/dataset-card.png" alt="A dataset card." width="80%"/>
</div>
<Tip>
✏️ **Try it out!** Use the `dataset-tagging` application and [🤗 Datasets guide](https://github.com/huggingface/datasets/blob/master/templates/README_guide.md) to complete the *README.md* file for your GitHub issues dataset.
</Tip>
That's it! We've seen in this section that creating a good dataset can be quite involved, but fortunately uploading it and sharing it with the community is not. In the next section we'll use our new dataset to create a semantic search engine with 🤗 Datasets that can match questions to the most relevant issues and comments.
<Tip>
✏️ **Try it out!** Go through the steps we took in this section to create a dataset of GitHub issues for your favorite open source library (pick something other than 🤗 Datasets, of course!). For bonus points, fine-tune a multilabel classifier to predict the tags present in the `labels` field.
</Tip>
| huggingface/course/blob/main/chapters/en/chapter5/5.mdx |
MixNet
**MixNet** is a type of convolutional neural network discovered via AutoML that utilises [MixConvs](https://paperswithcode.com/method/mixconv) instead of regular [depthwise convolutions](https://paperswithcode.com/method/depthwise-convolution).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('mixnet_l', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `mixnet_l`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('mixnet_l', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{tan2019mixconv,
title={MixConv: Mixed Depthwise Convolutional Kernels},
author={Mingxing Tan and Quoc V. Le},
year={2019},
eprint={1907.09595},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: MixNet
Paper:
Title: 'MixConv: Mixed Depthwise Convolutional Kernels'
URL: https://paperswithcode.com/paper/mixnet-mixed-depthwise-convolutional-kernels
Models:
- Name: mixnet_l
In Collection: MixNet
Metadata:
FLOPs: 738671316
Parameters: 7330000
File Size: 29608232
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_l
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1669
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_l-5a9a2ed8.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.98%
Top 5 Accuracy: 94.18%
- Name: mixnet_m
In Collection: MixNet
Metadata:
FLOPs: 454543374
Parameters: 5010000
File Size: 20298347
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_m
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1660
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_m-4647fc68.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.27%
Top 5 Accuracy: 93.42%
- Name: mixnet_s
In Collection: MixNet
Metadata:
FLOPs: 321264910
Parameters: 4130000
File Size: 16727982
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_s
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1651
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_s-a907afbc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.99%
Top 5 Accuracy: 92.79%
- Name: mixnet_xl
In Collection: MixNet
Metadata:
FLOPs: 1195880424
Parameters: 11900000
File Size: 48001170
Architecture:
- Batch Normalization
- Dense Connections
- Dropout
- Global Average Pooling
- Grouped Convolution
- MixConv
- Squeeze-and-Excitation Block
- Swish
Tasks:
- Image Classification
Training Techniques:
- MNAS
Training Data:
- ImageNet
ID: mixnet_xl
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L1678
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mixnet_xl_ra-aac3c00c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.47%
Top 5 Accuracy: 94.93%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/mixnet.mdx |
Gradio Demo: hello_world_2
```
!pip install -q gradio
```
```
import gradio as gr
def greet(name, intensity):
return "Hello " * intensity + name + "!"
demo = gr.Interface(
fn=greet,
inputs=["text", gr.Slider(value=2, minimum=1, maximum=10)],
outputs=[gr.Textbox(label="greeting", lines=3)],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/hello_world_2/run.ipynb |
--
title: Exact Match
emoji: 🤗
colorFrom: blue
colorTo: red
sdk: gradio
sdk_version: 3.19.1
app_file: app.py
pinned: false
tags:
- evaluate
- metric
description: >-
Returns the rate at which the input predicted strings exactly match their references, ignoring any strings input as part of the regexes_to_ignore list.
---
# Metric Card for Exact Match
## Metric Description
A given predicted string's exact match score is 1 if it is the exact same as its reference string, and is 0 otherwise.
- **Example 1**: The exact match score of prediction "Happy Birthday!" is 0, given its reference is "Happy New Year!".
- **Example 2**: The exact match score of prediction "The Colour of Magic (1983)" is 1, given its reference is also "The Colour of Magic (1983)".
The exact match score of a set of predictions is the sum of all of the individual exact match scores in the set, divided by the total number of predictions in the set.
- **Example**: The exact match score of the set {Example 1, Example 2} (above) is 0.5.
## How to Use
At minimum, this metric takes as input predictions and references:
```python
>>> from evaluate import load
>>> exact_match_metric = load("exact_match")
>>> results = exact_match_metric.compute(predictions=predictions, references=references)
```
### Inputs
- **`predictions`** (`list` of `str`): List of predicted texts.
- **`references`** (`list` of `str`): List of reference texts.
- **`regexes_to_ignore`** (`list` of `str`): Regex expressions of characters to ignore when calculating the exact matches. Defaults to `None`. Note: the regex changes are applied before capitalization is normalized.
- **`ignore_case`** (`bool`): If `True`, turns everything to lowercase so that capitalization differences are ignored. Defaults to `False`.
- **`ignore_punctuation`** (`bool`): If `True`, removes punctuation before comparing strings. Defaults to `False`.
- **`ignore_numbers`** (`bool`): If `True`, removes all digits before comparing strings. Defaults to `False`.
### Output Values
This metric outputs a dictionary with one value: the average exact match score.
```python
{'exact_match': 1.0}
```
This metric's range is 0-1, inclusive. Here, 0.0 means no prediction/reference pairs were matches, while 1.0 means they all were.
#### Values from Popular Papers
The exact match metric is often included in other metrics, such as SQuAD. For example, the [original SQuAD paper](https://nlp.stanford.edu/pubs/rajpurkar2016squad.pdf) reported an Exact Match score of 40.0%. They also report that the human performance Exact Match score on the dataset was 80.3%.
### Examples
Without including any regexes to ignore:
```python
>>> exact_match = evaluate.load("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds)
>>> print(round(results["exact_match"], 2))
0.25
```
Ignoring regexes "the" and "yell", as well as ignoring case and punctuation:
```python
>>> exact_match = evaluate.load("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds, regexes_to_ignore=["the ", "yell"], ignore_case=True, ignore_punctuation=True)
>>> print(round(results["exact_match"], 2))
0.5
```
Note that in the example above, because the regexes are ignored before the case is normalized, "yell" from "YELLING" is not deleted.
Ignoring "the", "yell", and "YELL", as well as ignoring case and punctuation:
```python
>>> exact_match = evaluate.load("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds, regexes_to_ignore=["the ", "yell", "YELL"], ignore_case=True, ignore_punctuation=True)
>>> print(round(results["exact_match"], 2))
0.75
```
Ignoring "the", "yell", and "YELL", as well as ignoring case, punctuation, and numbers:
```python
>>> exact_match = evaluate.load("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds, regexes_to_ignore=["the ", "yell", "YELL"], ignore_case=True, ignore_punctuation=True, ignore_numbers=True)
>>> print(round(results["exact_match"], 2))
1.0
```
An example that includes sentences:
```python
>>> exact_match = evaluate.load("exact_match")
>>> refs = ["The cat sat on the mat.", "Theaters are great.", "It's like comparing oranges and apples."]
>>> preds = ["The cat sat on the mat?", "Theaters are great.", "It's like comparing apples and oranges."]
>>> results = exact_match.compute(references=refs, predictions=preds)
>>> print(round(results["exact_match"], 2))
0.33
```
## Limitations and Bias
This metric is limited in that it outputs the same score for something that is completely wrong as for something that is correct except for a single character. In other words, there is no award for being *almost* right.
## Citation
## Further References
- Also used in the [SQuAD metric](https://github.com/huggingface/datasets/tree/master/metrics/squad)
| huggingface/evaluate/blob/main/metrics/exact_match/README.md |
Gradio Demo: blocks_plug
```
!pip install -q gradio
```
```
import gradio as gr
def change_tab():
return gr.Tabs(selected=2)
identity_demo, input_demo, output_demo = gr.Blocks(), gr.Blocks(), gr.Blocks()
with identity_demo:
gr.Interface(lambda x: x, "text", "text")
with input_demo:
t = gr.Textbox(label="Enter your text here")
with gr.Row():
btn = gr.Button("Submit")
clr = gr.ClearButton(t)
with output_demo:
gr.Textbox("This is a static output")
with gr.Blocks() as demo:
gr.Markdown("Three demos in one!")
with gr.Tabs(selected=1) as tabs:
with gr.TabItem("Text Identity", id=0) as tab0:
tab0.select(lambda: gr.Tabs(selected=0), None, tabs)
identity_demo.render()
with gr.TabItem("Text Input", id=1) as tab1:
tab1.select(lambda: gr.Tabs(selected=1), None, tabs)
input_demo.render()
with gr.TabItem("Text Static", id=2) as tab2:
tab2.select(lambda: gr.Tabs(selected=2), None, tabs)
output_demo.render()
btn = gr.Button("Change tab")
btn.click(inputs=None, outputs=tabs, fn=change_tab)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_plug/run.ipynb |
--
title: "Leveraging Pre-trained Language Model Checkpoints for Encoder-Decoder Models"
thumbnail: /blog/assets/08_warm_starting_encoder_decoder/thumbnail.png
authors:
- user: patrickvonplaten
---
# Leveraging Pre-trained Language Model Checkpoints for Encoder-Decoder Models
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Leveraging_Pre_trained_Checkpoints_for_Encoder_Decoder_Models.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Transformer-based encoder-decoder models were proposed in [Vaswani et
al. (2017)](https://arxiv.org/pdf/1706.03762.pdf) and have recently
experienced a surge of interest, *e.g.* [Lewis et al.
(2019)](https://arxiv.org/abs/1910.13461), [Raffel et al.
(2019)](https://arxiv.org/abs/1910.10683), [Zhang et al.
(2020)](https://arxiv.org/abs/1912.08777), [Zaheer et al.
(2020)](https://arxiv.org/abs/2007.14062), [Yan et al.
(2020)](https://arxiv.org/pdf/2001.04063.pdf).
Similar to BERT and GPT2, massive pre-trained encoder-decoder models
have shown to significantly boost performance on a variety of
*sequence-to-sequence* tasks [Lewis et al.
(2019)](https://arxiv.org/abs/1910.13461), [Raffel et al.
(2019)](https://arxiv.org/abs/1910.10683). However, due to the enormous
computational cost attached to pre-training encoder-decoder models, the
development of such models is mainly limited to large companies and
institutes.
In [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks
(2020)](https://arxiv.org/pdf/1907.12461.pdf), Sascha Rothe, Shashi
Narayan and Aliaksei Severyn initialize encoder-decoder model with
pre-trained *encoder and/or decoder-only* checkpoints (*e.g.* BERT,
GPT2) to skip the costly pre-training. The authors show that such
*warm-started* encoder-decoder models yield competitive results to large
pre-trained encoder-decoder models, such as
[*T5*](https://arxiv.org/abs/1910.10683), and
[*Pegasus*](https://arxiv.org/abs/1912.08777) on multiple
*sequence-to-sequence* tasks at a fraction of the training cost.
In this notebook, we will explain in detail how encoder-decoder models
can be warm-started, give practical tips based on [Rothe et al.
(2020)](https://arxiv.org/pdf/1907.12461.pdf), and finally go over a
complete code example showing how to warm-start encoder-decoder models
with 🤗Transformers.
This notebook is divided into 4 parts:
- **Introduction** - *Short summary of pre-trained language models in
NLP and the need for warm-starting encoder-decoder models.*
- **Warm-starting encoder-decoder models (Theory)** - *Illustrative
explanation on how encoder-decoder models are warm-started?*
- **Warm-starting encoder-decoder models (Analysis)** - *Summary of
[Leveraging Pre-trained Checkpoints for Sequence Generation
Tasks (2020)](https://arxiv.org/pdf/1907.12461.pdf) - What model
combinations are effective to warm-start encoder-decoder models; How
does it differ from task to task?*
- **Warm-starting encoder-decoder models with 🤗Transformers
(Practice)** - *Complete code example showcasing in-detail how to
use the* `EncoderDecoderModel` *framework to warm-start
transformer-based encoder-decoder models.*
It is highly recommended (probably even necessary) to have read [this
blog
post](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Encoder_Decoder_Model.ipynb)
about transformer-based encoder-decoder models.
Let\'s start by giving some back-ground on warm-starting encoder-decoder
models.
## **Introduction**
Recently, pre-trained language models \\({}^1\\) have revolutionized the
field of natural language processing (NLP).
The first pre-trained language models were based on recurrent neural
networks (RNN) as proposed [Dai et al.
(2015)](https://arxiv.org/pdf/1511.01432.pdf). *Dai et. al* showed that
pre-training an RNN-based model on unlabelled data and subsequently
fine-tuning \\({}^2\\) it on a specific task yields better results than
training a randomly initialized model directly on such a task. However,
it was only in 2018, when pre-trained language models become widely
accepted in NLP. [ELMO by Peters et
al.](https://arxiv.org/abs/1802.05365) and [ULMFit by Howard et
al.](https://arxiv.org/pdf/1801.06146.pdf) were the first pre-trained
language model to significantly improve the state-of-the-art on an array
of natural language understanding (NLU) tasks. Just a couple of months
later, OpenAI and Google published *transformer-based* pre-trained
language models, called [GPT by Radford et
al.](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)
and [BERT by Devlin et al.](https://arxiv.org/abs/1810.04805)
respectively. The improved efficiency of *transformer-based* language
models over RNNs allowed GPT2 and BERT to be pre-trained on massive
amounts of unlabeled text data. Once pre-trained, BERT and GPT were
shown to require very little fine-tuning to shatter state-of-art results
on more than a dozen NLU tasks \\({}^3\\).
The capability of pre-trained language models to effectively transfer
*task-agnostic* knowledge to *task-specific* knowledge turned out to be
a great catalyst for NLU. Whereas engineers and researchers previously
had to train a language model from scratch, now publicly available
checkpoints of large pre-trained language models can be fine-tuned at a
fraction of the cost and time. This can save millions in industry and
allows for faster prototyping and better benchmarks in research.
Pre-trained language models have established a new level of performance
on NLU tasks and more and more research has been built upon leveraging
such pre-trained language models for improved NLU systems. However,
standalone BERT and GPT models have been less successful for
*sequence-to-sequence* tasks, *e.g.* *text-summarization*, *machine
translation*, *sentence-rephrasing*, etc.
Sequence-to-sequence tasks are defined as a mapping from an input
sequence \\(\mathbf{X}_{1:n}\\) to an output sequence \\(\mathbf{Y}_{1:m}\\) of
*a-priori* unknown output length \\(m\\). Hence, a sequence-to-sequence
model should define the conditional probability distribution of the
output sequence \\(\mathbf{Y}_{1:m}\\) conditioned on the input sequence
\\(\mathbf{X}_{1:n}\\):
$$ p_{\theta_{\text{model}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}). $$
Without loss of generality, an input word sequence of \\(n\\) words is
hereby represented by the vector sequnece
\\(\mathbf{X}_{1:n} = \mathbf{x}_1, \ldots, \mathbf{x}_n\\) and an output
sequence of \\(m\\) words as
\\(\mathbf{Y}_{1:m} = \mathbf{y}_1, \ldots, \mathbf{y}_m\\).
Let\'s see how BERT and GPT2 would be fit to model sequence-to-sequence
tasks.
### **BERT**
BERT is an *encoder-only* model, which maps an input sequence
\\(\mathbf{X}_{1:n}\\) to a *contextualized* encoded sequence
\\(\mathbf{\overline{X}}_{1:n}\\):
$$ f_{\theta_{\text{BERT}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}. $$
BERT\'s contextualized encoded sequence \\(\mathbf{\overline{X}}_{1:n}\\)
can then further be processed by a classification layer for NLU
classification tasks, such as *sentiment analysis*, *natural language
inference*, etc. To do so, the classification layer, *i.e.* typically a
pooling layer followed by a feed-forward layer, is added as a final
layer on top of BERT to map the contextualized encoded sequence
\\(\mathbf{\overline{X}}_{1:n}\\) to a class \\(c\\):
$$
f_{\theta{\text{p,c}}}: \mathbf{\overline{X}}_{1:n} \to c.
$$
It has been shown that adding a pooling- and classification layer,
defined as \\(\theta_{\text{p,c}}\\), on top of a pre-trained BERT model
\\(\theta_{\text{BERT}}\\) and subsequently fine-tuning the complete model
\\(\{\theta_{\text{p,c}}, \theta_{\text{BERT}}\}\\) can yield
state-of-the-art performances on a variety of NLU tasks, *cf.* to [BERT
by Devlin et al.](https://arxiv.org/abs/1810.04805).
Let\'s visualize BERT.
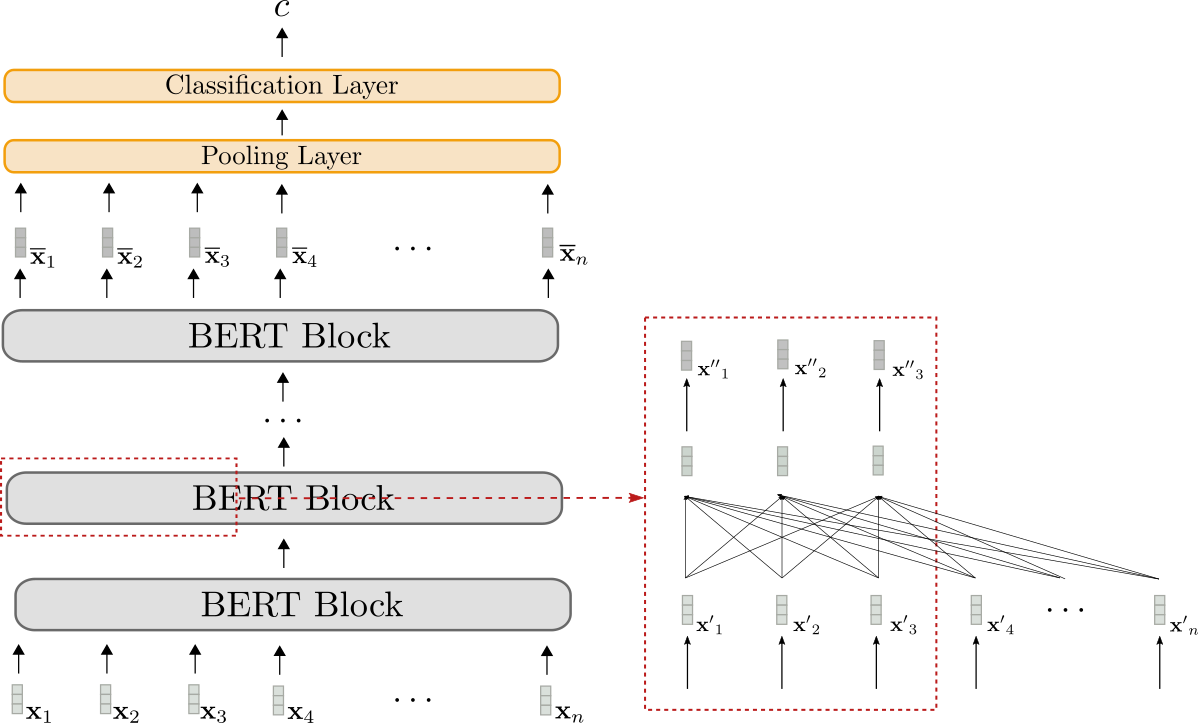
The BERT model is shown in grey. The model stacks multiple *BERT
blocks*, each of which is composed of *bi-directional* self-attention
layers (shown in the lower part of the red box) and two feed-forward
layers (short in the upper part of the red box).
Each BERT block makes use of **bi-directional** self-attention to
process an input sequence \\(\mathbf{x'}_1, \ldots, \mathbf{x'}_n\\) (shown
in light grey) to a more \"refined\" contextualized output sequence
\\(\mathbf{x''}_1, \ldots, \mathbf{x''}_n\\) (shown in slightly darker grey)
\\({}^4\\). The contextualized output sequence of the final BERT block,
*i.e.* \\(\mathbf{\overline{X}}_{1:n}\\), can then be mapped to a single
output class \\(c\\) by adding a *task-specific* classification layer (shown
in orange) as explained above.
*Encoder-only* models can only map an input sequence to an output
sequence of *a priori* known output length. In conclusion, the output
dimension does not depend on the input sequence, which makes it
disadvantageous and impractical to use encoder-only models for
sequence-to-sequence tasks.
As for all *encoder-only* models, BERT\'s architecture corresponds
exactly to the architecture of the encoder part of *transformer-based*
encoder-decoder models as shown in the \"Encoder\" section in the
[Encoder-Decoder
notebook](https://colab.research.google.com/drive/19wkOLQIjBBXQ-j3WWTEiud6nGBEw4MdF?usp=sharing).
### **GPT2**
GPT2 is a *decoder-only* model, which makes use of *uni-directional*
(*i.e.* \"causal\") self-attention to define a mapping from an input
sequence \\(\mathbf{Y}_{0: m - 1}\\) \\({}^1\\) to a \"next-word\" logit vector
sequence \\(\mathbf{L}_{1:m}\\):
$$ f_{\theta_{\text{GPT2}}}: \mathbf{Y}_{0: m - 1} \to \mathbf{L}_{1:m}. $$
By processing the logit vectors \\(\mathbf{L}_{1:m}\\) with the *softmax*
operation, the model can define the probability distribution of the word
sequence \\(\mathbf{Y}_{1:m}\\). To be exact, the probability distribution
of the word sequence \\(\mathbf{Y}_{1:m}\\) can be factorized into \\(m-1\\)
conditional \"next word\" distributions:
$$ p_{\theta_{\text{GPT2}}}(\mathbf{Y}_{1:m}) = \prod_{i=1}^{m} p_{\theta_{\text{GPT2}}}(\mathbf{y}_i | \mathbf{Y}_{0:i-1}). $$
\\(p_{\theta_{\text{GPT2}}}(\mathbf{y}_i | \mathbf{Y}_{0:i-1})\\) hereby
presents the probability distribution of the next word \\(\mathbf{y}_i\\)
given all previous words \\(\mathbf{y}_0, \ldots, \mathbf{y}_{i-1}\\) \\({}^3\\)
and is defined as the softmax operation applied on the logit vector
\\(\mathbf{l}_i\\). To summarize, the following equations hold true.
$$ p_{\theta_{\text{gpt2}}}(\mathbf{y}_i | \mathbf{Y}_{0:i-1}) = \textbf{Softmax}(\mathbf{l}_i) = \textbf{Softmax}(f_{\theta_{\text{GPT2}}}(\mathbf{Y}_{0: i - 1})).$$
For more detail, please refer to the
[decoder](https://huggingface.co/blog/encoder-decoder#decoder) section
of the encoder-decoder blog post.
Let\'s visualize GPT2 now as well.
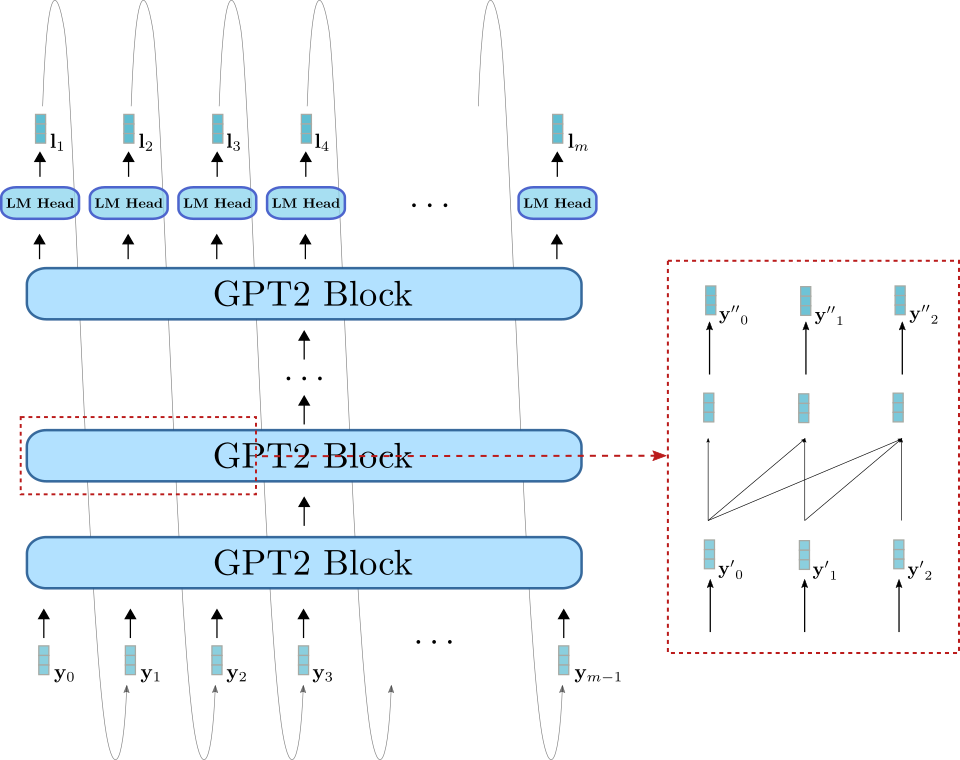
Analogous to BERT, GPT2 is composed of a stack of *GPT2 blocks*. In
contrast to BERT block, GPT2 block makes use of **uni-directional**
self-attention to process some input vectors
\\(\mathbf{y'}_0, \ldots, \mathbf{y'}_{m-1}\\) (shown in light blue on the
bottom right) to an output vector sequence
\\(\mathbf{y''}_0, \ldots, \mathbf{y''}_{m-1}\\) (shown in darker blue on
the top right). In addition to the GPT2 block stack, the model also has
a linear layer, called *LM Head*, which maps the output vectors of the
final GPT2 block to the logit vectors
\\(\mathbf{l}_1, \ldots, \mathbf{l}_m\\). As mentioned earlier, a logit
vector \\(\mathbf{l}_i\\) can then be used to sample of new input vector
\\(\mathbf{y}_i\\) \\({}^5\\).
GPT2 is mainly used for *open-domain* text generation. First, an input
prompt \\(\mathbf{Y}_{0:i-1}\\) is fed to the model to yield the conditional
distribution
\\(p_{\theta_{\text{gpt2}}}(\mathbf{y} | \mathbf{Y}_{0:i-1})\\). Then the
next word \\(\mathbf{y}_i\\) is sampled from the distribution (represented
by the grey arrows in the graph above) and consequently append to the
input. In an auto-regressive fashion the word \\(\mathbf{y}_{i+1}\\) can
then be sampled from
\\(p_{\theta_{\text{gpt2}}}(\mathbf{y} | \mathbf{Y}_{0:i})\\) and so on.
GPT2 is therefore well-suited for *language generation*, but less so for
*conditional* generation. By setting the input prompt
\\(\mathbf{Y}_{0: i-1}\\) equal to the sequence input \\(\mathbf{X}_{1:n}\\),
GPT2 can very well be used for conditional generation. However, the
model architecture has a fundamental drawback compared to the
encoder-decoder architecture as explained in [Raffel et al.
(2019)](https://arxiv.org/abs/1910.10683) on page 17. In short,
uni-directional self-attention forces the model\'s representation of the
sequence input \\(\mathbf{X}_{1:n}\\) to be unnecessarily limited since
\\(\mathbf{x}_i\\) cannot depend on
\\(\mathbf{x}_{i+1}, \forall i \in \{1,\ldots, n\}\\).
### **Encoder-Decoder**
Because *encoder-only* models require to know the output length *a
priori*, they seem unfit for sequence-to-sequence tasks. *Decoder-only*
models can function well for sequence-to-sequence tasks, but also have
certain architectural limitations as explained above.
The current predominant approach to tackle *sequence-to-sequence* tasks
are *transformer-based* **encoder-decoder** models - often also called
*seq2seq transformer* models. Encoder-decoder models were introduced in
[Vaswani et al. (2017)](https://arxiv.org/abs/1706.03762) and since then
have been shown to perform better on *sequence-to-sequence* tasks than
stand-alone language models (*i.e.* decoder-only models), *e.g.* [Raffel
et al. (2020)](https://arxiv.org/pdf/1910.10683.pdf). In essence, an
encoder-decoder model is the combination of a *stand-alone* encoder,
such as BERT, and a *stand-alone* decoder model, such as GPT2. For more
details on the exact architecture of transformer-based encoder-decoder
models, please refer to [this blog
post](https://huggingface.co/blog/encoder-decoder).
Now, we know that freely available checkpoints of large pre-trained
*stand-alone* encoder and decoder models, such as *BERT* and *GPT*, can
boost performance and reduce training cost for many NLU tasks, We also
know that encoder-decoder models are essentially the combination of
*stand-alone* encoder and decoder models. This naturally brings up the
question of how one can leverage stand-alone model checkpoints for
encoder-decoder models and which model combinations are most performant
on certain *sequence-to-sequence* tasks.
In 2020, Sascha Rothe, Shashi Narayan, and Aliaksei Severyn investigated
exactly this question in their paper [**Leveraging Pre-trained
Checkpoints for Sequence Generation
Tasks**](https://arxiv.org/abs/1907.12461). The paper offers a great
analysis of different encoder-decoder model combinations and fine-tuning
techniques, which we will study in more detail later.
Composing an encoder-decoder model of pre-trained stand-alone model
checkpoints is defined as *warm-starting* the encoder-decoder model. The
following sections show how warm-starting an encoder-decoder model works
in theory, how one can put the theory into practice with 🤗Transformers,
and also gives practical tips for better performance.
------------------------------------------------------------------------
\\({}^1\\) A *pre-trained language model* is defined as a neural network:
- that has been trained on *unlabeled* text data, *i.e.* in a
task-agnostic, unsupervised fashion, and
- that processes a sequence of input words into a *context-dependent*
embedding. *E.g.* the *continuous bag-of-words* and *skip-gram*
model from [Mikolov et al. (2013)](https://arxiv.org/abs/1301.3781)
is not considered a pre-trained language model because the
embeddings are context-agnostic.
\\({}^2\\) *Fine-tuning* is defined as the *task-specific* training of a
model that has been initialized with the weights of a pre-trained
language model.
\\({}^3\\) The input vector \\(\mathbf{y}_0\\) corresponds hereby to the
\\(\text{BOS}\\) embedding vector required to predict the very first output
word \\(\mathbf{y}_1\\).
\\({}^4\\) Without loss of generalitiy, we exclude the normalization layers
to not clutter the equations and illustrations.
\\({}^5\\) For more detail on why uni-directional self-attention is used for
\"decoder-only\" models, such as GPT2, and how sampling works exactly,
please refer to the
[decoder](https://huggingface.co/blog/encoder-decoder#decoder) section
of the encoder-decoder blog post.
## **Warm-starting encoder-decoder models (Theory)**
Having read the introduction, we are now familiar with *encoder-only*-
and *decoder-only* models. We have noticed that the encoder-decoder
model architecture is essentially a composition of a *stand-alone*
encoder model and a *stand-alone* decoder model, which led us to the
question of how one can *warm-start* encoder-decoder models from
*stand-alone* model checkpoints.
There are multiple possibilities to warm-start an encoder-decoder model.
One can
1. initialize both the encoder and decoder part from an *encoder-only*
model checkpoint, *e.g.* BERT,
2. initialize the encoder part from an *encoder-only* model checkpoint,
*e.g.* BERT, and the decoder part from and a *decoder-only*
checkpoint, *e.g.* GPT2,
3. initialize only the encoder part with an *encoder-only* model
checkpoint, or
4. initialize only the decoder part with a *decoder-only* model
checkpoint.
In the following, we will put the focus on possibilities 1. and 2.
Possibilities 3. and 4. are trivial after having understood the first
two.
### **Recap Encoder-Decoder Model**
First, let\'s do a quick recap of the encoder-decoder architecture.
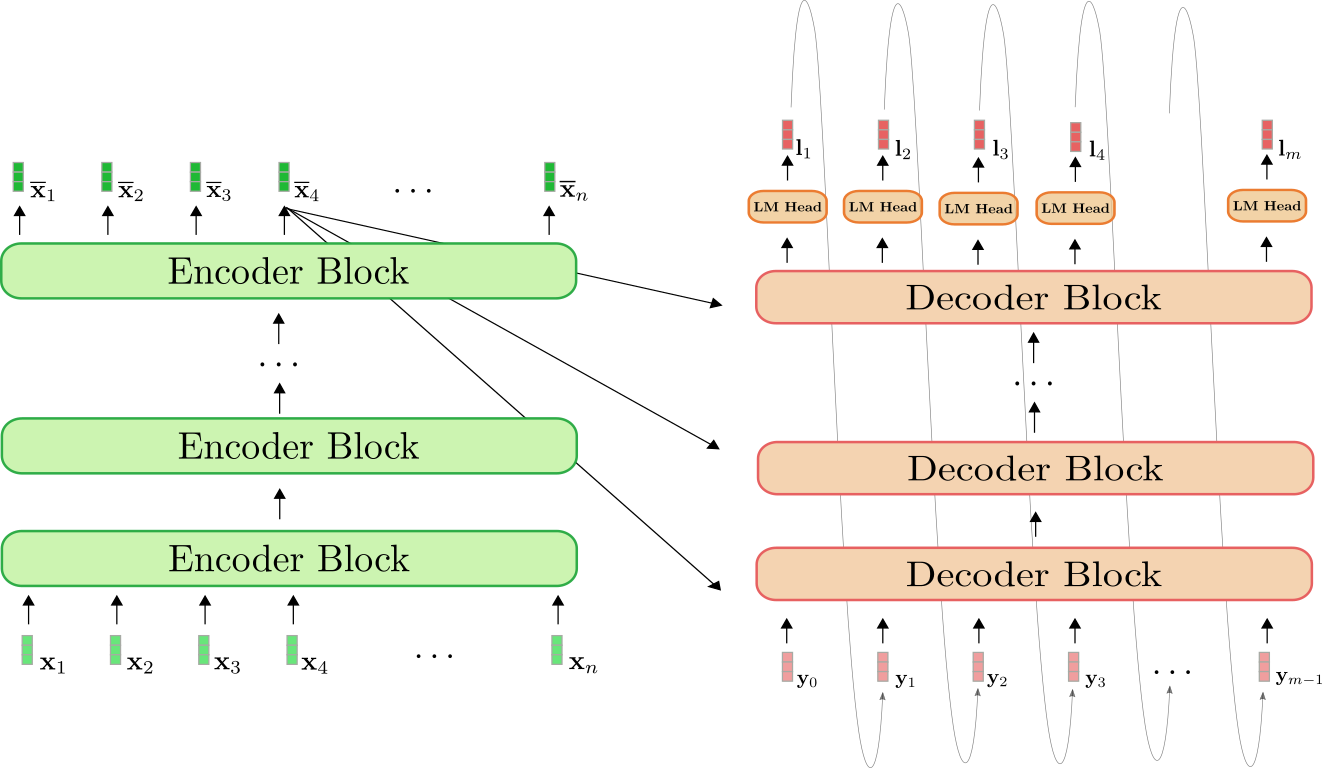
The encoder (shown in green) is a stack of *encoder blocks*. Each
encoder block is composed of a *bi-directional self-attention* layer,
and two feed-forward layers \\({}^1\\). The decoder (shown in orange) is a
stack of *decoder blocks*, followed by a dense layer, called *LM Head*.
Each decoder block is composed of a *uni-directional self-attention*
layer, a *cross-attention* layer, and two feed-forward layers.
The encoder maps the input sequence \\(\mathbf{X}_{1:n}\\) to a
contextualized encoded sequence \\(\mathbf{\overline{X}}_{1:n}\\) in the
exact same way BERT does. The decoder then maps the contextualized
encoded sequence \\(\mathbf{\overline{X}}_{1:n}\\) and a target sequence
\\(\mathbf{Y}_{0:m-1}\\) to the logit vectors \\(\mathbf{L}_{1:m}\\). Analogous
to GPT2, the logits are then used to define the distribution of the
target sequence \\(\mathbf{Y}_{1:m}\\) conditioned on the input sequence
\\(\mathbf{X}_{1:n}\\) by means of a *softmax* operation.
To put it into mathematical terms, first, the conditional distribution
is factorized into \\(m - 1\\) conditional distributions of the next word
\\(\mathbf{y}_i\\) by Bayes\' rule.
$$
p_{\theta_{\text{enc, dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = p_{\theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^m p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i -1}, \mathbf{\overline{X}}_{1:n}), \text{ with } \mathbf{\overline{X}}_{1:n} = f_{\theta_{\text{enc}}}(\mathbf{X}_{1:n}).
$$
Each \"next-word\" conditional distributions is thereby defined by the
*softmax* of the logit vector as follows.
$$ p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i -1}, \mathbf{\overline{X}}_{1:n}) = \textbf{Softmax}(\mathbf{l}_i). $$
For more detail, please refer to the [Encoder-Decoder
notebook](https://colab.research.google.com/drive/19wkOLQIjBBXQ-j3WWTEiud6nGBEw4MdF?usp=sharing).
### **Warm-staring Encoder-Decoder with BERT**
Let\'s now illustrate how a pre-trained BERT model can be used to
warm-start the encoder-decoder model. BERT\'s pre-trained weight
parameters are used to both initialize the encoder\'s weight parameters
as well as the decoder\'s weight parameters. To do so, BERT\'s
architecture is compared to the encoder\'s architecture and all layers
of the encoder that also exist in BERT will be initialized with the
pre-trained weight parameters of the respective layers. All layers of
the encoder that do not exist in BERT will simply have their weight
parameters be randomly initialized.
Let\'s visualize.
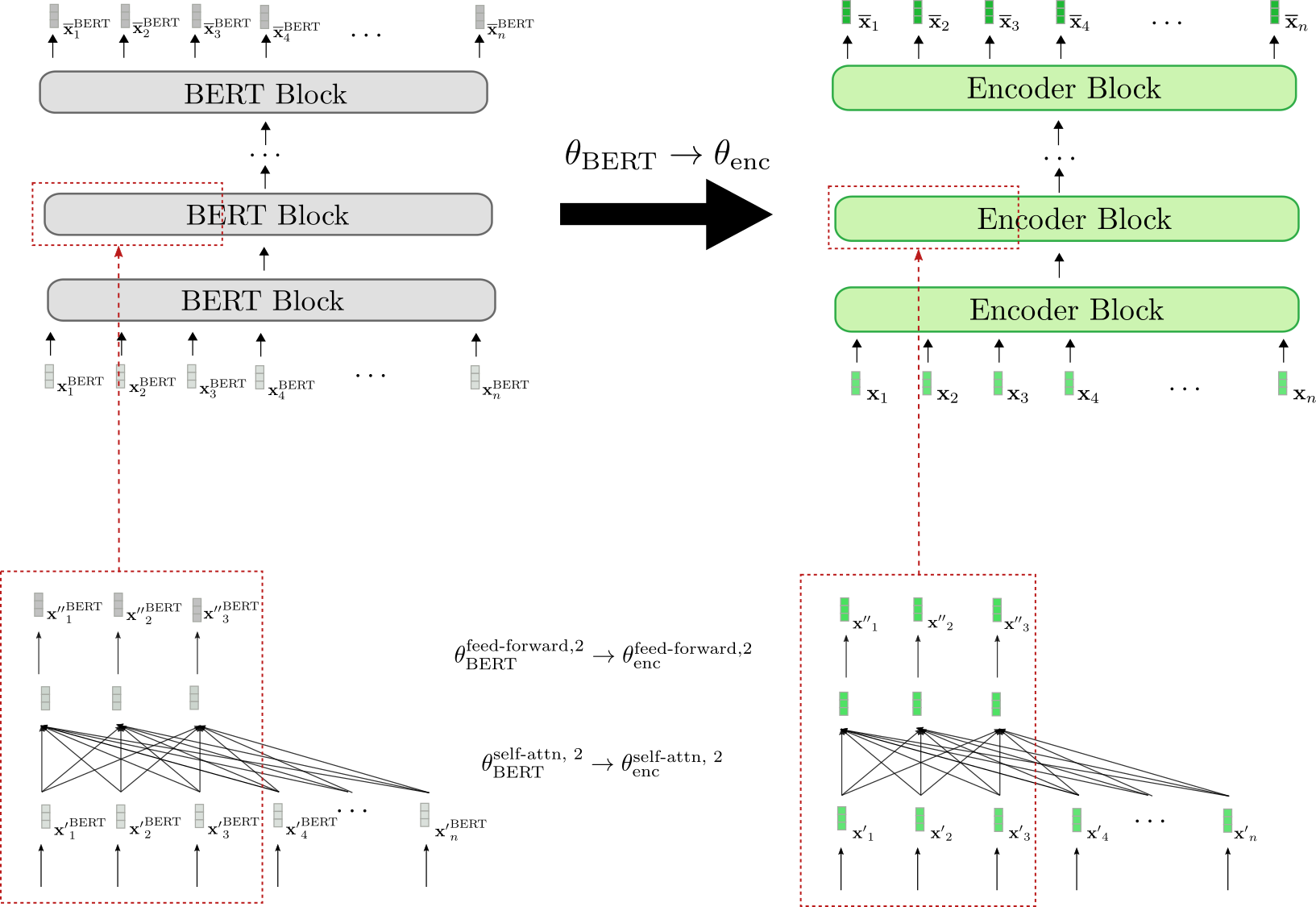
We can see that the encoder architecture corresponds 1-to-1 to BERT\'s
architecture. The weight parameters of the *bi-directional
self-attention layer* and the two *feed-forward layers* of **all**
encoder blocks are initialized with the weight parameters of the
respective BERT blocks. This is illustrated examplary for the second
encoder block (red boxes at bottow) whose weight parameters
\\(\theta_{\text{enc}}^{\text{self-attn}, 2}\\) and
\\(\theta_{\text{enc}}^{\text{feed-forward}, 2}\\) are set to BERT\'s weight
parameters \\(\theta_{\text{BERT}}^{\text{feed-forward}, 2}\\) and
\\(\theta_{\text{BERT}}^{\text{self-attn}, 2}\\), respectively at
initialization.
Before fine-tuning, the encoder therefore behaves exactly like a
pre-trained BERT model. Assuming the input sequence
\\(\mathbf{x}_1, \ldots, \mathbf{x}_n\\) (shown in green) passed to the
encoder is equal to the input sequence
\\(\mathbf{x}_1^{\text{BERT}}, \ldots, \mathbf{x}_n^{\text{BERT}}\\) (shown
in grey) passed to BERT, this means that the respective output vector
sequences \\(\mathbf{\overline{x}}_1, \ldots, \mathbf{\overline{x}}_n\\)
(shown in darker green) and
\\(\mathbf{\overline{x}}_1^{\text{BERT}}, \ldots, \mathbf{\overline{x}}_n^{\text{BERT}}\\)
(shown in darker grey) also have to be equal.
Next, let\'s illustrate how the decoder is warm-started.
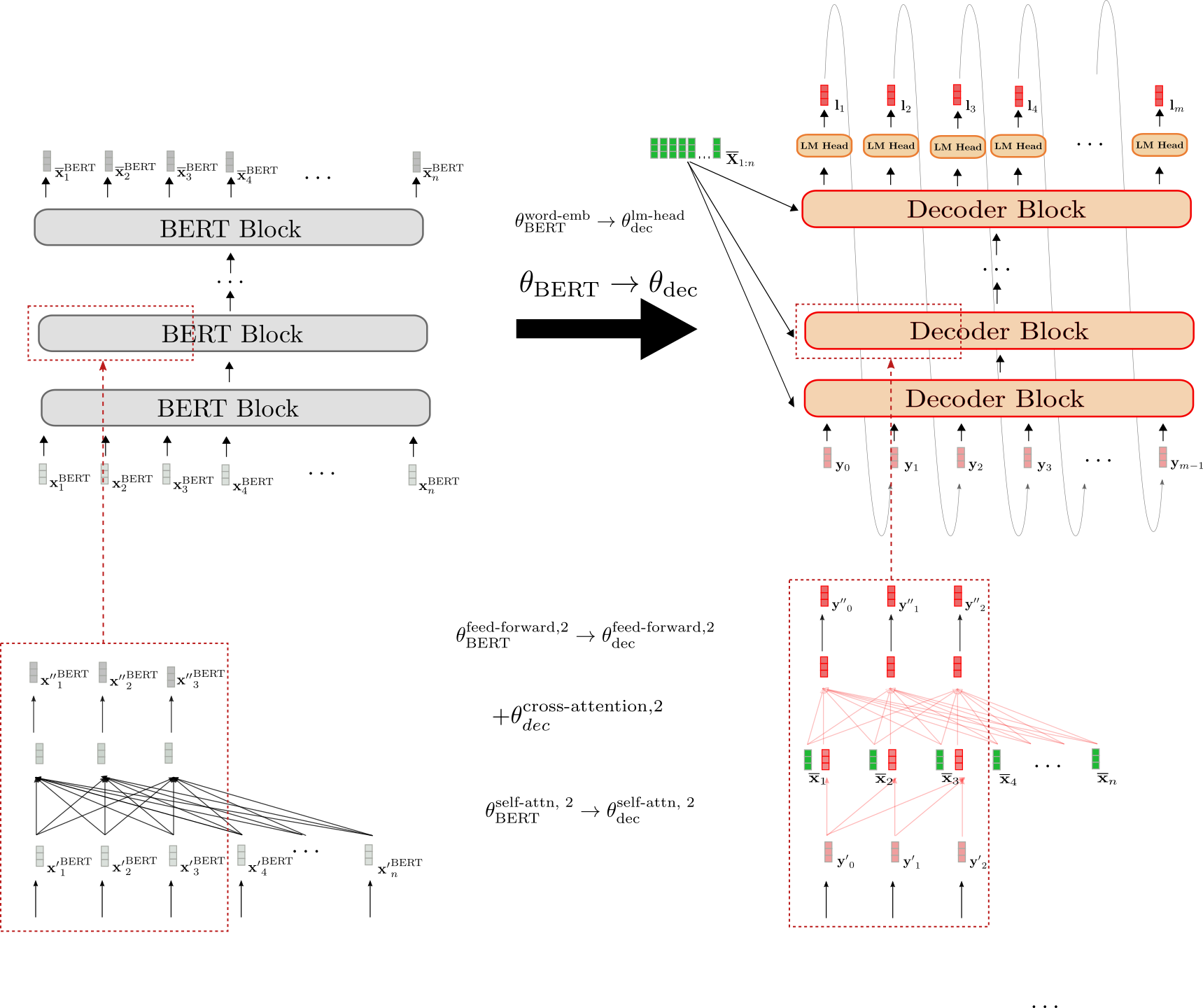
The architecture of the decoder is different from BERT\'s architecture
in three ways.
1. First, the decoder has to be conditioned on the contextualized
encoded sequence \\(\mathbf{\overline{X}}_{1:n}\\) by means of
cross-attention layers. Consequently, randomly initialized
cross-attention layers are added between the self-attention layer
and the two feed-forward layers in each BERT block. This is
represented exemplary for the second block by
\\(+\theta_{\text{dec}}^{\text{cross-attention, 2}}\\) and illustrated
by the newly added fully connected graph in red in the lower red box
on the right. This necessarily changes the behavior of each modified
BERT block so that an input vector, *e.g.* \\(\mathbf{y'}_0\\) now
yields a random output vector \\(\mathbf{y''}_0\\) (highlighted by the
red border around the output vector \\(\mathbf{y''}_0\\)).
2. Second, BERT\'s *bi-directional* self-attention layers have to be
changed to *uni-directional* self-attention layers to comply with
auto-regressive generation. Because both the bi-directional and the
uni-directional self-attention layer are based on the same *key*,
*query* and *value* projection weights, the decoder\'s
self-attention layer weights can be initialized with BERT\'s
self-attention layer weights. *E.g.* the query, key and value weight
parameters of the decoder\'s uni-directional self-attention layer
are initialized with those of BERT\'s bi-directional self-attention
layer \\(\theta_{\text{BERT}}^{\text{self-attn}, 2} = \{\mathbf{W}_{\text{BERT}, k}^{\text{self-attn}, 2}, \mathbf{W}_{\text{BERT}, v}^{\text{self-attn}, 2}, \mathbf{W}_{\text{BERT}, q}^{\text{self-attn}, 2} \} \to \theta_{\text{dec}}^{\text{self-attn}, 2} = \{\mathbf{W}_{\text{dec}, k}^{\text{self-attn}, 2}, \mathbf{W}_{\text{dec}, v}^{\text{self-attn}, 2}, \mathbf{W}_{\text{dec}, q}^{\text{self-attn}, 2} \}. \\) However, in *uni-directional* self-attention each token only
attends to all previous tokens, so that the decoder\'s
self-attention layers yield different output vectors than BERT\'s
self-attention layers even though they share the same weights.
Compare *e.g.*, the decoder\'s causally connected graph in the right
box versus BERT\'s fully connected graph in the left box.
3. Third, the decoder outputs a sequence of logit vectors
\\(\mathbf{L}_{1:m}\\) in order to define the conditional probability
distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{Y}_{1:n} | \mathbf{\overline{X}})\\).
As a result, a *LM Head* layer is added on top of the last decoder
block. The weight parameters of the *LM Head* layer usually
correspond to the weight parameters of the word embedding
\\(\mathbf{W}_{\text{emb}}\\) and thus are not randomly initialized.
This is illustrated in the top by the initialization
\\(\theta_{\text{BERT}}^{\text{word-emb}} \to \theta_{\text{dec}}^{\text{lm-head}}\\).
To conclude, when warm-starting the decoder from a pre-trained BERT
model only the cross-attention layer weights are randomly initialized.
All other weights including those of the self-attention layer and LM
Head are initialized with BERT\'s pre-trained weight parameters.
Having warm-stared the encoder-decoder model, the weights are then
fine-tuned on a *sequence-to-sequence* downstream task, such as
summarization.
### **Warm-staring Encoder-Decoder with BERT and GPT2**
Instead of warm-starting both the encoder and decoder with a BERT
checkpoint, we can instead leverage the BERT checkpoint for the encoder
and a GPT2 checkpoint for the decoder. At first glance, a decoder-only
GPT2 checkpoint seems to be better-suited to warm-start the decoder
because it has already been trained on causal language modeling and uses
*uni-directional* self-attention layers.
Let\'s illustrate how a GPT2 checkpoint can be used to warm-start the
decoder.
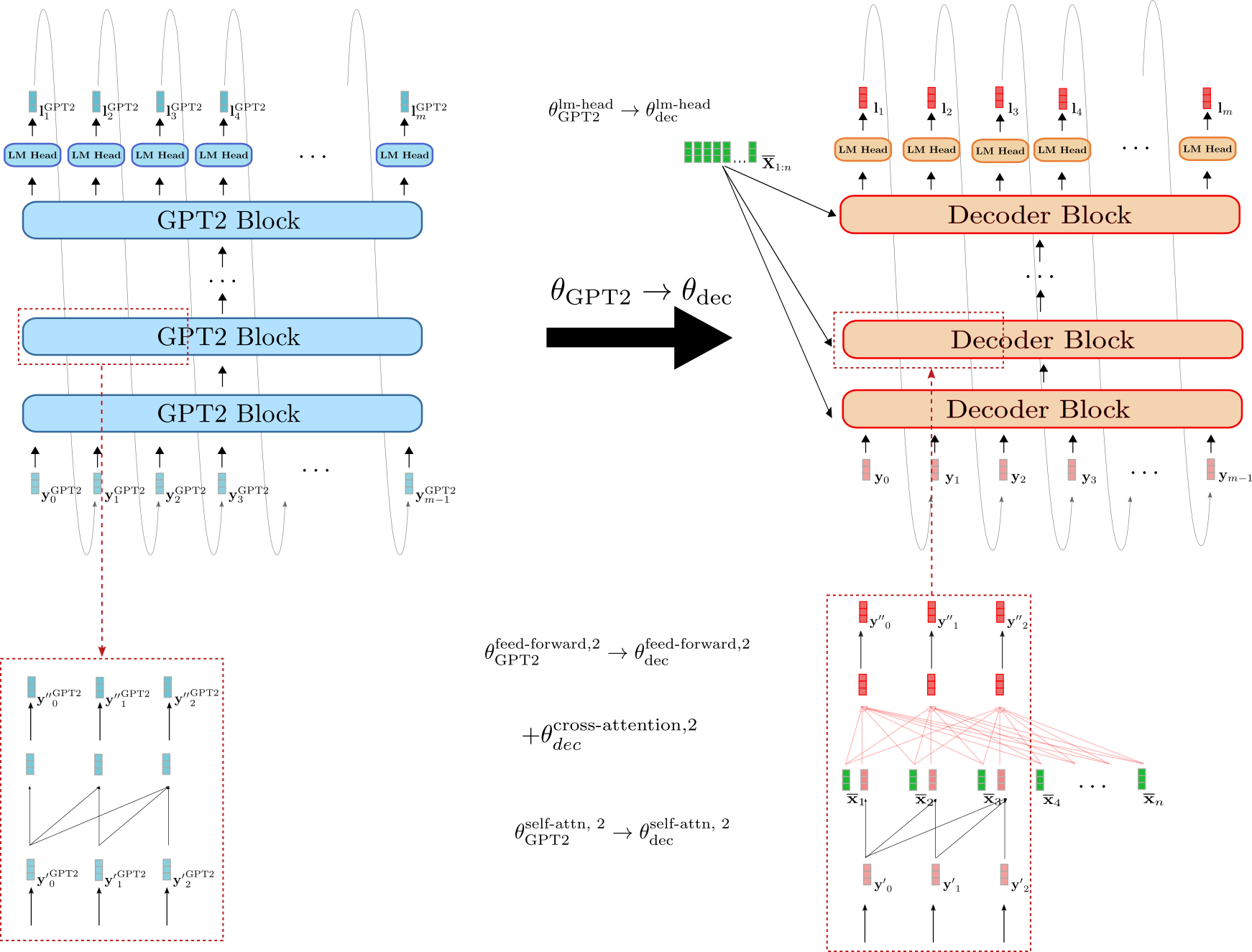
We can see that decoder is more similar to GPT2 than it is to BERT. The
weight parameters of decoder\'s *LM Head* can directly be initialized
with GPT2\'s *LM Head* weight parameters, *e.g.*
\\(\theta_{\text{GPT2}}^{\text{lm-head}} \to \theta_{\text{dec}}^{\text{lm-head}}\\).
In addition, the blocks of the decoder and GPT2 both make use of
*uni-directional* self-attention so that the output vectors of the
decoder\'s self-attention layer are equivalent to GPT2\'s output vectors
assuming the input vectors are the same, *e.g.*
\\(\mathbf{y'}_0^{\text{GPT2}} = \mathbf{y'}_0\\). In contrast to the
BERT-initialized decoder, the GPT2-initialized decoder, therefore, keeps
the causal connected graph of the self-attention layer as can be seen in
the red boxes on the bottom.
Nevertheless, the GPT2-initialized decoder also has to condition the
decoder on \\(\mathbf{\overline{X}}_{1:n}\\). Analoguos to the
BERT-initialized decoder, randomly initialized weight parameters for the
cross-attention layer are therefore added to each decoder block. This is
illustrated *e.g.* for the second encoder block by
\\(+\theta_{\text{dec}}^{\text{cross-attention, 2}}\\).
Even though GPT2 resembles the decoder part of an encoder-decoder model
more than BERT, a GPT2-initialized decoder will also yield random logit
vectors \\(\mathbf{L}_{1:m}\\) without fine-tuning due to randomly
initialized cross-attention layers in every decoder block. It would be
interesting to investigate whether a GPT2-initialized decoder yields
better results or can be fine-tuned more efficiently.
### **Encoder-Decoder Weight Sharing**
In [Raffel et al. (2020)](https://arxiv.org/pdf/1910.10683.pdf), the
authors show that a randomly-initialized encoder-decoder model that
shares the encoder\'s weights with the decoder, and therefore reduces
the memory footprint by half, performs only slightly worse than its
\"non-shared\" version. Sharing the encoder\'s weights with the decoder
means that all layers of the decoder that are found at the same position
in the encoder share the same weight parameters, *i.e.* the same node in
the network\'s computation graph.\
*E.g.* the query, key, and value projection matrices of the
self-attention layer in the third encoder block, defined as
\\(\mathbf{W}^{\text{self-attn}, 3}_{\text{Enc}, k}\\),
\\(\mathbf{W}^{\text{self-attn}, 3}_{\text{Enc}, v}\\),
\\(\mathbf{W}^{\text{self-attn}, 3}_{\text{Enc}, q}\\) are identical to the
respective query, key, and value projections matrices of the
self-attention layer in the third decoder block \\({}^2\\):
$$ \mathbf{W}^{\text{self-attn}, 3}_{k} = \mathbf{W}^{\text{self-attn}, 3}_{\text{enc}, k} \equiv \mathbf{W}^{\text{self-attn}, 3}_{\text{dec}, k}, $$
$$ \mathbf{W}^{\text{self-attn}, 3}_{q} = \mathbf{W}^{\text{self-attn}, 3}_{\text{enc}, q} \equiv \mathbf{W}^{\text{self-attn}, 3}_{\text{dec}, q}, $$
$$ \mathbf{W}^{\text{self-attn}, 3}_{v} = \mathbf{W}^{\text{self-attn}, 3}_{\text{enc}, v} \equiv \mathbf{W}^{\text{self-attn}, 3}_{\text{dec}, v}, $$
As a result, the key projection weights
\\(\mathbf{W}^{\text{self-attn}, 3}_{k}, \mathbf{W}^{\text{self-attn}, 3}_{v}, \mathbf{W}^{\text{self-attn}, 3}_{q}\\)
are updated twice for each backward propagation pass - once when the
gradient is backpropagated through the third decoder block and once when
the gradient is backprapageted thourgh the third encoder block.
In the same way, we can warm-start an encoder-decoder model by sharing
the encoder weights with the decoder. Being able to share the weights
between the encoder and decoder requires the decoder architecture
(excluding the cross-attention weights) to be identical to the encoder
architecture. Therefore, *encoder-decoder weight sharing* is only
relevant if the encoder-decoder model is warm-started from a single
*encoder-only* pre-trained checkpoint.
Great! That was the theory about warm-starting encoder-decoder models.
Let\'s now look at some results.
------------------------------------------------------------------------
\\({}^1\\) Without loss of generality, we exclude the normalization layers
to not clutter the equations and illustrations.
\\({}^2\\) For more detail on how self-attention layers function, please
refer to [this
section](https://huggingface.co/blog/encoder-decoder#encoder) of the
transformer-based encoder-decoder model blog post for the encoder-part
(and [this section](https://huggingface.co/blog/encoder-decoder#decoder)
for the decoder part respectively).
## **Warm-starting encoder-decoder models (Analysis)**
In this section, we will summarize the findings on warm-starting
encoder-decoder models as presented in [Leveraging Pre-trained
Checkpoints for Sequence Generation
Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi
Narayan, and Aliaksei Severyn. The authors compared the performance of
warm-started encoder-decoder models to randomly initialized
encoder-decoder models on multiple *sequence-to-sequence* tasks, notably
*summarization*, *translation*, *sentence splitting*, and *sentence
fusion*.
To be more precise, the publicly available pre-trained checkpoints of
**BERT**, **RoBERTa**, and **GPT2** were leveraged in different
variations to warm-start an encoder-decoder model. *E.g.* a
BERT-initialised encoder was paired with a BERT-initialized decoder
yielding a BERT2BERT model *or* a RoBERTa-initialized encoder was paired
with a GPT2-initialized decoder to yield a *RoBERTa2GPT2* model.
Additionally, the effect of sharing the encoder and decoder weights (as
explained in the previous section) was investigated for RoBERTa, *i.e.*
**RoBERTaShare**, and for BERT, *i.e.* **BERTShare**. Randomly or partly
randomly initialized encoder-decoder models were used as a baseline,
such as a fully randomly initialized encoder-decoder model, coined
**Rnd2Rnd** or a BERT-initialized decoder paired with a randomly
initialized encoder, defined as **Rnd2BERT**.
The following table shows a complete list of all investigated model
variants including the number of randomly initialized weights, *i.e.*
\"random\", and the number of weights initialized from the respective
pre-trained checkpoints, *i.e.* \"leveraged\". All models are based on a
12-layer architecture with 768-dim hidden size embeddings, corresponding
to the `bert-base-cased`, `bert-base-uncased`, `roberta-base`, and
`gpt2` checkpoints in the 🤗Transformers model hub.
|Model |random |leveraged |total
|-------------- |:------- |---------- |-------
|Rnd2Rnd |221M |0 |221M
|Rnd2BERT |112M |109M |221M
|BERT2Rnd |112M |109M |221M
|Rnd2GPT2 |114M |125M |238M
|BERT2BERT |26M |195M |221M
|BERTShare |26M |109M |135M
|RoBERTaShare |26M |126M |152M
|BERT2GPT2 |26M |234M |260M
|RoBERTa2GPT2 |26M |250M |276M
The model *Rnd2Rnd*, which is based on the BERT2BERT architecture,
contains 221M weight parameters - all of which are randomly initialized.
The other two \"BERT-based\" baselines *Rnd2BERT* and *BERT2Rnd* have
roughly half of their weights, *i.e.* 112M parameters, randomly
initialized. The other 109M weight parameters are leveraged from the
pre-trained `bert-base-uncased` checkpoint for the encoder- or decoder
part respectively. The models *BERT2BERT*, *BERT2GPT2*, and
*RoBERTa2GPT2* have all of their encoder weight parameters leveraged
(from `bert-base-uncased`, `roberta-base` respectively) and most of the
decoder weight parameter weights as well (from `gpt2`,
`bert-base-uncased` respectively). 26M decoder weight parameters, which
correspond to the 12 cross-attention layers, are thereby randomly
initialized. RoBERTa2GPT2 and BERT2GPT2 are compared to the *Rnd2GPT2*
baseline. Also, it should be noted that the shared model variants
*BERTShare* and *RoBERTaShare* have significantly fewer parameters
because all encoder weight parameters are shared with the respective
decoder weight parameters.
### **Experiments**
The above models were trained and evaluated on four sequence-to-sequence
tasks of increasing complexity: sentence-level fusion, sentence-level
splitting, translation, and abstractive summarization. The following
table shows which datasets were used for each task.
|Seq2Seq Task |Datasets |Paper |🤗datasets |
|-------------------------- |-----------------------------------------------------------------------|----------------------------------------------------------------------- |----------------------------------------------------------------------------------------- |
|Sentence Fusion |DiscoFuse |[Geva et al. (2019)](https://arxiv.org/abs/1902.10526) |[link](https://huggingface.co/nlp/viewer/?dataset=discofuse&config=discofuse-wikipedia) |
|Sentence Splitting |WikiSplit |[Botha et al. (2018)](https://arxiv.org/abs/1808.09468) |\-|
|Translation |WMT14 EN =\> DE |[Bojar et al. (2014)](http://www.aclweb.org/anthology/W/W14/W14-3302) |[link](https://huggingface.co/nlp/viewer/?dataset=wmt14&config=de-en)|
|WMT14 DE =\> EN |[Bojar et al. (2014)](http://www.aclweb.org/anthology/W/W14/W14-3302) | |[link](https://huggingface.co/nlp/viewer/?dataset=wmt14&config=de-en) |
|Abstractive Summarizaion |CNN/Dailymail | [Hermann et al. (2015)](http://arxiv.org/abs/1704.04368) |[link](https://huggingface.co/nlp/viewer/?dataset=cnn_dailymail&config=3.0.0)|
|BBC XSum |[Narayan et al. (2018a)](https://arxiv.org/abs/1808.08745) | |[link](https://huggingface.co/nlp/viewer/?dataset=xsum) |
|Gigaword |[Napoles et al. (2012)](http://dx.doi.org/10.18653/v1/D15-1044) | |[link](https://huggingface.co/nlp/viewer/?dataset=gigaword) |
Depending on the task, a slightly different training regime was used.
*E.g.* according to the size of the dataset and the specific task, the
number of training steps ranges from 200K to 500K, the batch size is set
to either 128 or 256, the input length ranges from 128 to 512 and the
output length varies between 32 to 128. It shall be emphasized however
that within each task, all models were trained and evaluated using the
same hyperparameters to ensure a fair comparison. For more information
on the task-specific hyperparameter settings, the reader is advised to
see the *Experiments* section in the
[paper](https://arxiv.org/pdf/1907.12461.pdf).
We will now give a condensed overview of the results for each task.
### Sentence Fusion and -Splitting (DiscoFuse, WikiSplit)
**Sentence Fusion** is the task of combining multiple sentences into a
single coherent sentence. *E.g.* the two sentences:
*As a run-blocker, Zeitler moves relatively well.* *Zeitler too often
struggles at the point of contact in space.*
should be connected with a fitting *linking word*, such as:
*As a run-blocker, Zeitler moves relatively well. **However**, **he**
too often struggles at the point of contact in space.*
As can be seen the linking word \"however\" provides a coherent
transition from the first sentence to the second one. A model that is
capable of generating such a linking word has arguably learned to infer
that the two sentences above contrast to each other.
The inverse task is called **Sentence splitting** and consists of
splitting a single complex sentence into multiple simpler ones that
together retain the same meaning. Sentence splitting is considered as an
important task in text simplification, *cf.* to [Botha et al.
(2018)](https://arxiv.org/pdf/1808.09468.pdf).
As an example, the sentence:
*Street Rod is the first in a series of two games released for the PC
and Commodore 64 in 1989*
can be simplified into
*Street Rod is the first in a series of two games **.** **It** was released
for the PC and Commodore 64 in 1989*
It can be seen that the long sentence tries to convey two important
pieces of information. One is that the game was the first of two games
being released for the PC, and the second being the year in which it was
released. Sentence splitting, therefore, requires the model to
understand which part of the sentence should be divided into two
sentences, making the task more difficult than sentence fusion.
A common metric to evaluate the performance of models on sentence fusion
resp. -splitting tasks is *SARI* [(Wu et al.
(2016)](https://www.aclweb.org/anthology/Q16-1029/), which is broadly
based on the F1-score of label and model output.
Let\'s see how the models perform on sentence fusion and -splitting.
|Model | 100% DiscoFuse (SARI) |10% DiscoFuse (SARI) |100% WikiSplit (SARI)
|---------------------- |----------------------- |---------------------- |-----------------------
|Rnd2Rnd | 86.9 | 81.5 | 61.7
|Rnd2BERT | 87.6 | 82.1 | 61.8
|BERT2Rnd | 89.3 | 86.1 | 63.1
|Rnd2GPT2 | 86.5 | 81.4 | 61.3
|BERT2BERT | 89.3 | 86.1 | 63.2
|BERTShare | 89.2 | 86.0 | **63.5**
|RoBERTaShare | 89.7 | 86.0 | 63.4
|BERT2GPT2 | 88.4 | 84.1 | 62.4
|RoBERTa2GPT2 | **89.9** | **87.1** | 63.2
|\-\-- | \-\-- | \-\-- | \-\--
|RoBERTaShare (large) | **90.3** | **87.7** | **63.8**
The first two columns show the performance of the encoder-decoder models
on the DiscoFuse evaluation data. The first column states the results of
encoder-decoder models trained on all (100%) of the training data, while
the second column shows the results of the models trained only on 10% of
the training data. We observe that warm-started models perform
significantly better than the randomly initialized baseline models
*Rnd2Rnd*, *Rnd2Bert*, and *Rnd2GPT2*. A warm-started *RoBERTa2GPT2*
model trained only on 10% of the training data is on par with an
*Rnd2Rnd* model trained on 100% of the training data. Interestingly, the
*Bert2Rnd* baseline performs equally well as a fully warm-started
*Bert2Bert* model, which indicates that warm-starting the encoder-part
is more effective than warm-starting the decoder-part. The best results
are obtained by *RoBERTa2GPT2*, followed by *RobertaShare*. Sharing
encoder and decoder weight parameters does seem to slightly increase the
model\'s performance.
On the more difficult sentence splitting task, a similar pattern
emerges. Warm-started encoder-decoder models significantly outperform
encoder-decoder models whose encoder is randomly initialized and
encoder-decoder models with shared weight parameters yield better
results than those with uncoupled weight parameters. On sentence
splitting the *BertShare* models yields the best performance closely
followed by *RobertaShare*.
In addition to the 12-layer model variants, the authors also trained and
evaluated a 24-layer *RobertaShare (large)* model which outperforms all
12-layer models significantly.
### Machine Translation (WMT14)
Next, the authors evaluated warm-started encoder-decoder models on the
probably most common benchmark in machine translation (MT) - the *En*
\\(\to\\) *De* and *De* \\(\to\\) *En* WMT14 dataset. In this notebook, we
present the results on the *newstest2014* eval dataset. Because the
benchmark requires the model to understand both an English and a German
vocabulary the BERT-initialized encoder-decoder models were warm-started
from the multilingual pre-trained checkpoint
`bert-base-multilingual-cased`. Because there is no publicly available
multilingual RoBERTa checkpoint, RoBERTa-initialized encoder-decoder
models were excluded for MT. GPT2-initialized models were initialized
from the `gpt2` pre-trained checkpoint as in the previous experiment.
The translation results are reported using the BLUE-4 score metric
\\({}^1\\).
|Model |En \\(\to\\) De (BLEU-4) |De \\(\to\\) En (BLEU-4)
|--------------------------- |---------------------- |----------------------
|Rnd2Rnd | 26.0 | 29.1
|Rnd2BERT | 27.2 | 30.4
|BERT2Rnd | **30.1** | **32.7**
|Rnd2GPT2 | 19.6 | 23.2
|BERT2BERT | **30.1** | **32.7**
|BERTShare | 29.6 | 32.6
|BERT2GPT2 | 23.2 | 31.4
|\-\-- | \-\-- | \-\--
|BERT2Rnd (large, custom) | **31.7** | **34.2**
|BERTShare (large, custom) | 30.5 | 33.8
Again, we observe a significant performance boost by warm-starting the
encoder-part, with *BERT2Rnd* and *BERT2BERT* yielding the best results
on both the *En* \\(\to\\) *De* and *De* \\(\to\\) *En* tasks. *GPT2*
initialized models perform significantly worse even than the *Rnd2Rnd*
baseline on *En* \\(\to\\) *De*. Taking into consideration that the `gpt2`
checkpoint was trained only on English text, it is not very surprising
that *BERT2GPT2* and *Rnd2GPT2* models have difficulties generating
German translations. This hypothesis is supported by the competitive
results (*e.g.* 31.4 vs. 32.7) of *BERT2GPT2* on the *De* \\(\to\\) *En*
task for which GPT2\'s vocabulary fits the English output format.
Contrary to the results obtained on sentence fusion and sentence
splitting, sharing encoder and decoder weight parameters does not yield
a performance boost in MT. Possible reasons for this as stated by the
authors include
- *the encoder-decoder model capacity is an important factor in MT,
and*
- *the encoder and decoder have to deal with different grammar and
vocabulary*
Since the *bert-base-multilingual-cased* checkpoint was trained on more
than 100 languages, its vocabulary is probably undesirably large for
*En* \\(\to\\) *De* and *De* \\(\to\\) *En* MT. Thus, the authors pre-trained a
large BERT encoder-only checkpoint on the English and German subset of
the Wikipedia dump and subsequently used it to warm-start a *BERT2Rnd*
and *BERTShare* encoder-decoder model. Thanks to the improved
vocabulary, another significant performance boost is observed, with
*BERT2Rnd (large, custom)* significantly outperforming all other models.
### Summarization (CNN/Dailymail, BBC XSum, Gigaword)
Finally, the encoder-decoder models were evaluated on the arguably most
challenging sequence-to-sequence task - *summarization*. The authors
picked three summarization datasets with different characteristics for
evaluation: Gigaword (*headline generation*), BBC XSum (*extreme
summarization*), and CNN/Dailymayl (*abstractive summarization*).
The Gigaword dataset contains sentence-level abstractive summarizations,
requiring the model to learn sentence-level understanding, abstraction,
and eventually paraphrasing. A typical data sample in Gigaword, such as
\"*venezuelan president hugo chavez said thursday he has ordered a probe
into a suspected coup plot allegedly involving active and retired
military officers .*\",
would have a corresponding headline as its label, *e.g.*:
\"*chavez orders probe into suspected coup plot*\".
The BBC XSum dataset consists of much longer *article-like* text inputs
with the labels being mostly single sentence summarizations. This
dataset requires the model not only to learn document-level inference
but also a high level of abstractive paraphrasing. Some data samples of
the BBC XSUM datasets are shown
[here](https://huggingface.co/nlp/viewer/?dataset=xsum).
For the CNN/Dailmail dataset, documents, which are of similar length
than those in the BBC XSum dataset, have to be summarized to
bullet-point story highlights. The labels therefore often consist of
multiple sentences. Besides document-level understanding, the
CNN/Dailymail dataset requires models to be good at copying the most
salient information. Some examples can be viewed
[here](https://huggingface.co/nlp/viewer/?dataset=cnn_dailymail).
The models are evaluated using the [Rouge
metric](https://www.aclweb.org/anthology/N03-1020/), whereas the Rouge-2
scores are shown below.
Alright, let\'s take a look at the results.
|Model |CNN/Dailymail (Rouge-2) |BBC XSum (Rouge-2) |Gigaword (Rouge-2)
|---------------------- |------------------------- |-------------------- |--------------------
|Rnd2Rnd | 14.00 | 10.23 | 18.71
|Rnd2BERT | 15.55 | 11.52 | 18.91
|BERT2Rnd | 17.76 | 15.83 | 19.26
|Rnd2GPT2 | 8.81 | 8.77 | 18.39
|BERT2BERT | 17.84 | 15.24 | 19.68
|BERTShare | 18.10 | 16.12 | **19.81**
|RoBERTaShare | **18.95** | **17.50** | 19.70
|BERT2GPT2 | 4.96 | 8.37 | 18.23
|RoBERTa2GPT2 | 14.72 | 5.20 | 19.21
|\-\-- | \-\-- | \-\-- | \-\--
|RoBERTaShare (large) | 18.91 | **18.79** | 19.78
We observe again that warm-starting the encoder-part gives a significant
improvement over models with randomly-initialized encoders, which is
especially visible for document-level abstraction tasks, *i.e.*
CNN/Dailymail and BBC XSum. This shows that tasks requiring a high level
of abstraction benefit more from a pre-trained encoder part than those
requiring only sentence-level abstraction. Except for Gigaword
GPT2-based encoder-decoder models seem to be unfit for summarization.
Furthermore, the shared encoder-decoder models are the best performing
models for summarization. *RoBERTaShare* and *BERTShare* are the best
performing models on all datasets whereas the margin is especially
significant on the BBC XSum dataset on which *RoBERTaShare (large)*
outperforms *BERT2BERT* and *BERT2Rnd* by *ca.* 3 Rouge-2 points and
*Rnd2Rnd* by more than 8 Rouge-2 points. As brought forward by the
authors, \"*this is probably because the BBC summary sentences follow a
distribution that is similar to that of the sentences in the document,
whereas this is not necessarily the case for the Gigaword headlines and
the CNN/DailyMail bullet-point highlights*\". Intuitively this means
that in BBC XSum, the input sentences processed by the encoder are very
similar in structure to the single sentence summary processed by the
decoder, *i.e.* same length, similar choice of words, similar syntax.
### **Conclusion**
Alright, let\'s draw a conclusion and try to derive some practical tips.
- We have observed on all tasks that a warm-started encoder-part gives
a significant performance boost compared to encoder-decoder models
having a randomly initialized encoder. On the other hand,
warm-starting the decoder seems to be less important, with
*BERT2BERT* being on par with *BERT2Rnd* on most tasks. An intuitive
reason would be that since a BERT- or RoBERTa-initialized encoder
part has none of its weight parameters randomly initialized, the
encoder can fully exploit the acquired knowledge of BERT\'s or
RoBERTa\'s pre-trained checkpoints, respectively. In contrast, the
warm-started decoder always has parts of its weight parameters
randomly initialized which possibly makes it much harder to
effectively leverage the knowledge acquired by the checkpoint used
to initialize the decoder.
- Next, we noticed that it is often beneficial to share encoder and
decoder weights, especially if the target distribution is similar to
the input distribution (*e.g.* BBC XSum). However, for datasets
whose target data distribution differs more significantly from the
input data distribution and for which model capacity \\({}^2\\) is known
to play an important role, *e.g.* WMT14, encoder-decoder weight
sharing seems to be disadvantageous.
- Finally, we have seen that it is very important that the vocabulary
of the pre-trained \"stand-alone\" checkpoints fit the vocabulary
required to solve the sequence-to-sequence task. *E.g.* a
warm-started BERT2GPT2 encoder-decoder will perform poorly on *En*
\\(\to\\) *De* MT because GPT2 was pre-trained on English whereas the
target language is German. The overall poor performance of the
*BERT2GPT2*, *Rnd2GPT2*, and *RoBERTa2GPT2* compared to *BERT2BERT*,
*BERTShared*, and *RoBERTaShared* suggests that it is more effective
to have a shared vocabulary. Also, it shows that initializing the
decoder part with a pre-trained GPT2 checkpoint is *not* more
effective than initializing it with a pre-trained BERT checkpoint
besides GPT2 being more similar to the decoder in its architecture.
For each of the above tasks, the most performant models were ported to
🤗Transformers and can be accessed here:
- *RoBERTaShared (large)* - *Wikisplit*:
[google/roberta2roberta\_L-24\_wikisplit](https://huggingface.co/google/roberta2roberta_L-24_wikisplit).
- *RoBERTaShared (large)* - *Discofuse*:
[google/roberta2roberta\_L-24\_discofuse](https://huggingface.co/google/roberta2roberta_L-24_discofuse).
- *BERT2BERT (large)* - *WMT en \\(\to\\) de*:
[google/bert2bert\_L-24\_wmt\_en\_de](https://huggingface.co/google/bert2bert_L-24_wmt_en_de).
- *BERT2BERT (large)* - *WMT de \\(\to\\) en*:
[google/bert2bert\_L-24\_wmt\_de\_en](https://huggingface.co/google/bert2bert_L-24_wmt_de_en).
- *RoBERTaShared (large)* - *CNN/Dailymail*:
[google/roberta2roberta\_L-24\_cnn\_daily\_mail](https://huggingface.co/google/roberta2roberta_L-24_cnn_daily_mail).
- *RoBERTaShared (large)* - *BBC XSum*:
[google/roberta2roberta\_L-24\_bbc](https://huggingface.co/google/roberta2roberta_L-24_bbc).
- *RoBERTaShared (large)* - *Gigaword*:
[google/roberta2roberta\_L-24\_gigaword](https://huggingface.co/google/roberta2roberta_L-24_gigaword).
------------------------------------------------------------------------
\\({}^1\\) To retrieve BLEU-4 scores, a script from the Tensorflow Official
Transformer implementation <https://github.com/tensorflow/models/tree>
master/official/nlp/transformer was used. Note that, differently from
the tensor2tensor/utils/ `get_ende_bleu.sh` used by Vaswani et al.
(2017), this script does not split noun compounds, but utf-8 quotes were
normalized to ascii quotes after having noted that the pre-processed
training set contains only ascii quotes.
\\({}^2\\) Model capacity is an informal definition of how good the model is
at modeling complex patterns. It is also sometimes defined as *the
ability of a model to learn from more and more data*. Model capacity is
broadly measured by the number of trainable parameters - the more
parameters, the higher the model capacity.
# **Warm-starting encoder-decoder models with 🤗Transformers (Practice)**
We have explained the theory of warm-starting encoder-decoder models,
analyzed empirical results on multiple datasets, and have derived
practical conclusions. Let\'s now walk through a complete code example
showcasing how a **BERT2BERT** model can be warm-started and
consequently fine-tuned on the *CNN/Dailymail* summarization task. We
will be leveraging the 🤗datasets and 🤗Transformers libraries.
In addition, the following list provides a condensed version of this and
other notebooks on warm-starting other combinations of encoder-decoder
models.
- for **BERT2BERT** on *CNN/Dailymail* (a condensed version of this
notebook), click
[here](https://colab.research.google.com/drive/1Ekd5pUeCX7VOrMx94_czTkwNtLN32Uyu?usp=sharing).
- for **RoBERTaShare** on *BBC XSum*, click
[here](https://colab.research.google.com/drive/1vHZHXOCFqOXIvdsF8j4WBRaAOAjAroTi?usp=sharing).
- for **BERT2Rnd** on *WMT14 En \\(\to\\) De*, click [here]().
- for **RoBERTa2GPT2** on *DiscoFuse*, click [here]().
***Note***: This notebook only uses a few training, validation, and test
data samples for demonstration purposes. To fine-tune an encoder-decoder
model on the full training data, the user should change the training and
data preprocessing parameters accordingly as highlighted by the
comments.
### **Data Preprocessing**
In this section, we show how the data can be pre-processed for training.
More importantly, we try to give the reader some insight into the
process of deciding how to preprocess the data.
We will need datasets and transformers to be installed.
```python
!pip install datasets==1.0.2
!pip install transformers==4.2.1
```
Let's start by downloading the *CNN/Dailymail* dataset.
```python
import datasets
train_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="train")
```
Alright, let\'s get a first impression of the dataset. Alternatively,
the dataset can also be visualized using the awesome [datasets
viewer](https://huggingface.co/nlp/viewer/?dataset=cnn_dailymail&config=3.0.0)
online.
```python
train_data.info.description
```
Our input is called *article* and our labels are called *highlights*.
Let\'s now print out the first example of the training data to get a
feeling for the data.
```python
import pandas as pd
from IPython.display import display, HTML
from datasets import ClassLabel
df = pd.DataFrame(train_data[:1])
del df["id"]
for column, typ in train_data.features.items():
if isinstance(typ, ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
```
```python
OUTPUT:
-------
Article:
"""It's official: U.S. President Barack Obama wants lawmakers to weigh in on whether to use military force in Syria. Obama sent a letter to the heads of the House and Senate on Saturday night, hours after announcing that he believes military action against Syrian targets is the right step to take over the alleged use of chemical weapons. The proposed legislation from Obama asks Congress to approve the use of military force "to deter, disrupt, prevent and degrade the potential for future uses of chemical weapons or other weapons of mass destruction." It's a step that is set to turn an international crisis into a fierce domestic political battle. There are key questions looming over the debate: What did U.N. weapons inspectors find in Syria? What happens if Congress votes no? And how will the Syrian government react? In a televised address from the White House Rose Garden earlier Saturday, the president said he would take his case to Congress, not because he has to -- but because he wants to. "While I believe I have the authority to carry out this military action without specific congressional authorization, I know that the country will be stronger if we take this course, and our actions will be even more effective," he said. "We should have this debate, because the issues are too big for business as usual." Obama said top congressional leaders had agreed to schedule a debate when the body returns to Washington on September 9. The Senate Foreign Relations Committee will hold a hearing over the matter on Tuesday, Sen. Robert Menendez said. Transcript: Read Obama's full remarks . Syrian crisis: Latest developments . U.N. inspectors leave Syria . Obama's remarks came shortly after U.N. inspectors left Syria, carrying evidence that will determine whether chemical weapons were used in an attack early last week in a Damascus suburb. "The aim of the game here, the mandate, is very clear -- and that is to ascertain whether chemical weapons were used -- and not by whom," U.N. spokesman Martin Nesirky told reporters on Saturday. But who used the weapons in the reported toxic gas attack in a Damascus suburb on August 21 has been a key point of global debate over the Syrian crisis. Top U.S. officials have said there's no doubt that the Syrian government was behind it, while Syrian officials have denied responsibility and blamed jihadists fighting with the rebels. British and U.S. intelligence reports say the attack involved chemical weapons, but U.N. officials have stressed the importance of waiting for an official report from inspectors. The inspectors will share their findings with U.N. Secretary-General Ban Ki-moon Ban, who has said he wants to wait until the U.N. team's final report is completed before presenting it to the U.N. Security Council. The Organization for the Prohibition of Chemical Weapons, which nine of the inspectors belong to, said Saturday that it could take up to three weeks to analyze the evidence they collected. "It needs time to be able to analyze the information and the samples," Nesirky said. He noted that Ban has repeatedly said there is no alternative to a political solution to the crisis in Syria, and that "a military solution is not an option." Bergen: Syria is a problem from hell for the U.S. Obama: 'This menace must be confronted' Obama's senior advisers have debated the next steps to take, and the president's comments Saturday came amid mounting political pressure over the situation in Syria. Some U.S. lawmakers have called for immediate action while others warn of stepping into what could become a quagmire. Some global leaders have expressed support, but the British Parliament's vote against military action earlier this week was a blow to Obama's hopes of getting strong backing from key NATO allies. On Saturday, Obama proposed what he said would be a limited military action against Syrian President Bashar al-Assad. Any military attack would not be open-ended or include U.S. ground forces, he said. Syria's alleged use of chemical weapons earlier this month "is an assault on human dignity," the president said. A failure to respond with force, Obama argued, "could lead to escalating use of chemical weapons or their proliferation to terrorist groups who would do our people harm. In a world with many dangers, this menace must be confronted." Syria missile strike: What would happen next? Map: U.S. and allied assets around Syria . Obama decision came Friday night . On Friday night, the president made a last-minute decision to consult lawmakers. What will happen if they vote no? It's unclear. A senior administration official told CNN that Obama has the authority to act without Congress -- even if Congress rejects his request for authorization to use force. Obama on Saturday continued to shore up support for a strike on the al-Assad government. He spoke by phone with French President Francois Hollande before his Rose Garden speech. "The two leaders agreed that the international community must deliver a resolute message to the Assad regime -- and others who would consider using chemical weapons -- that these crimes are unacceptable and those who violate this international norm will be held accountable by the world," the White House said. Meanwhile, as uncertainty loomed over how Congress would weigh in, U.S. military officials said they remained at the ready. 5 key assertions: U.S. intelligence report on Syria . Syria: Who wants what after chemical weapons horror . Reactions mixed to Obama's speech . A spokesman for the Syrian National Coalition said that the opposition group was disappointed by Obama's announcement. "Our fear now is that the lack of action could embolden the regime and they repeat his attacks in a more serious way," said spokesman Louay Safi. "So we are quite concerned." Some members of Congress applauded Obama's decision. House Speaker John Boehner, Majority Leader Eric Cantor, Majority Whip Kevin McCarthy and Conference Chair Cathy McMorris Rodgers issued a statement Saturday praising the president. "Under the Constitution, the responsibility to declare war lies with Congress," the Republican lawmakers said. "We are glad the president is seeking authorization for any military action in Syria in response to serious, substantive questions being raised." More than 160 legislators, including 63 of Obama's fellow Democrats, had signed letters calling for either a vote or at least a "full debate" before any U.S. action. British Prime Minister David Cameron, whose own attempt to get lawmakers in his country to support military action in Syria failed earlier this week, responded to Obama's speech in a Twitter post Saturday. "I understand and support Barack Obama's position on Syria," Cameron said. An influential lawmaker in Russia -- which has stood by Syria and criticized the United States -- had his own theory. "The main reason Obama is turning to the Congress: the military operation did not get enough support either in the world, among allies of the US or in the United States itself," Alexei Pushkov, chairman of the international-affairs committee of the Russian State Duma, said in a Twitter post. In the United States, scattered groups of anti-war protesters around the country took to the streets Saturday. "Like many other Americans...we're just tired of the United States getting involved and invading and bombing other countries," said Robin Rosecrans, who was among hundreds at a Los Angeles demonstration. What do Syria's neighbors think? Why Russia, China, Iran stand by Assad . Syria's government unfazed . After Obama's speech, a military and political analyst on Syrian state TV said Obama is "embarrassed" that Russia opposes military action against Syria, is "crying for help" for someone to come to his rescue and is facing two defeats -- on the political and military levels. Syria's prime minister appeared unfazed by the saber-rattling. "The Syrian Army's status is on maximum readiness and fingers are on the trigger to confront all challenges," Wael Nader al-Halqi said during a meeting with a delegation of Syrian expatriates from Italy, according to a banner on Syria State TV that was broadcast prior to Obama's address. An anchor on Syrian state television said Obama "appeared to be preparing for an aggression on Syria based on repeated lies." A top Syrian diplomat told the state television network that Obama was facing pressure to take military action from Israel, Turkey, some Arabs and right-wing extremists in the United States. "I think he has done well by doing what Cameron did in terms of taking the issue to Parliament," said Bashar Jaafari, Syria's ambassador to the United Nations. Both Obama and Cameron, he said, "climbed to the top of the tree and don't know how to get down." The Syrian government has denied that it used chemical weapons in the August 21 attack, saying that jihadists fighting with the rebels used them in an effort to turn global sentiments against it. British intelligence had put the number of people killed in the attack at more than 350. On Saturday, Obama said "all told, well over 1,000 people were murdered." U.S. Secretary of State John Kerry on Friday cited a death toll of 1,429, more than 400 of them children. No explanation was offered for the discrepancy. Iran: U.S. military action in Syria would spark 'disaster' Opinion: Why strikes in Syria are a bad idea ."""
Summary:
"""Syrian official: Obama climbed to the top of the tree, "doesn't know how to get down"\nObama sends a letter to the heads of the House and Senate .\nObama to seek congressional approval on military action against Syria .\nAim is to determine whether CW were used, not by whom, says U.N. spokesman"""
```
The input data seems to consist of short news articles. Interestingly,
the labels appear to be bullet-point-like summaries. At this point, one
should probably take a look at a couple of other examples to get a
better feeling for the data.
One should also notice here that the text is *case-sensitive*. This
means that we have to be careful if we want to use *case-insensitive*
models. As *CNN/Dailymail* is a summarization dataset, the model will be
evaluated using the *ROUGE* metric. Checking the description of *ROUGE*
in 🤗datasets, *cf.* [here](https://huggingface.co/metrics/rouge), we can
see that the metric is *case-insensitive*, meaning that *upper case*
letters will be normalized to *lower case* letters during evaluation.
Thus, we can safely leverage *uncased* checkpoints, such as
`bert-base-uncased`.
Cool! Next, let\'s get a sense of the length of input data and labels.
As models compute length in *token-length*, we will make use of the
`bert-base-uncased` tokenizer to compute the article and summary length.
First, we load the tokenizer.
```python
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
```
Next, we make use of `.map()` to compute the length of the article and
its summary. Since we know that the maximum length that
`bert-base-uncased` can process amounts to 512, we are also interested
in the percentage of input samples being longer than the maximum length.
Similarly, we compute the percentage of summaries that are longer than
64, and 128 respectively.
We can define the `.map()` function as follows.
```python
# map article and summary len to dict as well as if sample is longer than 512 tokens
def map_to_length(x):
x["article_len"] = len(tokenizer(x["article"]).input_ids)
x["article_longer_512"] = int(x["article_len"] > 512)
x["summary_len"] = len(tokenizer(x["highlights"]).input_ids)
x["summary_longer_64"] = int(x["summary_len"] > 64)
x["summary_longer_128"] = int(x["summary_len"] > 128)
return x
```
It should be sufficient to look at the first 10000 samples. We can speed
up the mapping by using multiple processes with `num_proc=4`.
```python
sample_size = 10000
data_stats = train_data.select(range(sample_size)).map(map_to_length, num_proc=4)
```
Having computed the length for the first 10000 samples, we should now
average them together. For this, we can make use of the `.map()`
function with `batched=True` and `batch_size=-1` to have access to all
10000 samples within the `.map()` function.
```python
def compute_and_print_stats(x):
if len(x["article_len"]) == sample_size:
print(
"Article Mean: {}, %-Articles > 512:{}, Summary Mean:{}, %-Summary > 64:{}, %-Summary > 128:{}".format(
sum(x["article_len"]) / sample_size,
sum(x["article_longer_512"]) / sample_size,
sum(x["summary_len"]) / sample_size,
sum(x["summary_longer_64"]) / sample_size,
sum(x["summary_longer_128"]) / sample_size,
)
)
output = data_stats.map(
compute_and_print_stats,
batched=True,
batch_size=-1,
)
```
```python
OUTPUT:
-------
Article Mean: 847.6216, %-Articles > 512:0.7355, Summary Mean:57.7742, %-Summary > 64:0.3185, %-Summary > 128:0.0
```
We can see that on average an article contains 848 tokens with *ca.* 3/4
of the articles being longer than the model\'s `max_length` 512. The
summary is on average 57 tokens long. Over 30% of our 10000-sample
summaries are longer than 64 tokens, but none are longer than 128
tokens.
`bert-base-cased` is limited to 512 tokens, which means we would have to
cut possibly important information from the article. Because most of the
important information is often found at the beginning of articles and
because we want to be computationally efficient, we decide to stick to
`bert-base-cased` with a `max_length` of 512 in this notebook. This
choice is not optimal but has shown to yield [good
results](https://arxiv.org/abs/1907.12461) on CNN/Dailymail.
Alternatively, one could leverage long-range sequence models, such as
[Longformer](https://huggingface.co/allenai/longformer-large-4096) to be
used as the encoder.
Regarding the summary length, we can see that a length of 128 already
includes all of the summary labels. 128 is easily within the limits of
`bert-base-cased`, so we decide to limit the generation to 128.
Again, we will make use of the `.map()` function - this time to
transform each training batch into a batch of model inputs.
`"article"` and `"highlights"` are tokenized and prepared as the
Encoder\'s `"input_ids"` and Decoder\'s `"decoder_input_ids"`
respectively.
`"labels"` are shifted automatically to the left for language modeling
training.
Lastly, it is very important to remember to ignore the loss of the
padded labels. In 🤗Transformers this can be done by setting the label to
-100. Great, let\'s write down our mapping function then.
```python
encoder_max_length=512
decoder_max_length=128
def process_data_to_model_inputs(batch):
# tokenize the inputs and labels
inputs = tokenizer(batch["article"], padding="max_length", truncation=True, max_length=encoder_max_length)
outputs = tokenizer(batch["highlights"], padding="max_length", truncation=True, max_length=decoder_max_length)
batch["input_ids"] = inputs.input_ids
batch["attention_mask"] = inputs.attention_mask
batch["labels"] = outputs.input_ids.copy()
# because BERT automatically shifts the labels, the labels correspond exactly to `decoder_input_ids`.
# We have to make sure that the PAD token is ignored
batch["labels"] = [[-100 if token == tokenizer.pad_token_id else token for token in labels] for labels in batch["labels"]]
return batch
```
In this notebook, we train and evaluate the model just on a few training
examples for demonstration and set the `batch_size` to 4 to prevent
out-of-memory issues.
The following line reduces the training data to only the first `32`
examples. The cell can be commented out or not run for a full training
run. Good results were obtained with a `batch_size` of 16.
```python
train_data = train_data.select(range(32))
```
Alright, let\'s prepare the training data.
```python
# batch_size = 16
batch_size=4
train_data = train_data.map(
process_data_to_model_inputs,
batched=True,
batch_size=batch_size,
remove_columns=["article", "highlights", "id"]
)
```
Taking a look at the processed training dataset we can see that the
column names `article`, `highlights`, and `id` have been replaced by the
arguments expected by the `EncoderDecoderModel`.
```python
train_data
```
```python
OUTPUT:
-------
Dataset(features: {'attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'decoder_attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'decoder_input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'labels': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None)}, num_rows: 32)
```
So far, the data was manipulated using Python\'s `List` format. Let\'s
convert the data to PyTorch Tensors to be trained on GPU.
```python
train_data.set_format(
type="torch", columns=["input_ids", "attention_mask", "labels"],
)
```
Awesome, the data processing of the training data is finished.
Analogous, we can do the same for the validation data.
First, we load 10% of the validation dataset:
```python
val_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="validation[:10%]")
```
For demonstration purposes, the validation data is then reduced to just
8 samples,
```python
val_data = val_data.select(range(8))
```
the mapping function is applied,
```python
val_data = val_data.map(
process_data_to_model_inputs,
batched=True,
batch_size=batch_size,
remove_columns=["article", "highlights", "id"]
)
```
and, finally, the validation data is also converted to PyTorch tensors.
```python
val_data.set_format(
type="torch", columns=["input_ids", "attention_mask", "labels"],
)
```
Great! Now we can move to warm-starting the `EncoderDecoderModel`.
### **Warm-starting the Encoder-Decoder Model**
This section explains how an Encoder-Decoder model can be warm-started
using the `bert-base-cased` checkpoint.
Let\'s start by importing the `EncoderDecoderModel`. For more detailed
information about the `EncoderDecoderModel` class, the reader is advised
to take a look at the
[documentation](https://huggingface.co/transformers/model_doc/encoderdecoder.html).
```python
from transformers import EncoderDecoderModel
```
In contrast to other model classes in 🤗Transformers, the
`EncoderDecoderModel` class has two methods to load pre-trained weights,
namely:
1. the \"standard\" `.from_pretrained(...)` method is derived from the
general `PretrainedModel.from_pretrained(...)` method and thus
corresponds exactly to the the one of other model classes. The
function expects a single model identifier, *e.g.*
`.from_pretrained("google/bert2bert_L-24_wmt_de_en")` and will load
a single `.pt` checkpoint file into the `EncoderDecoderModel` class.
2. a special `.from_encoder_decoder_pretrained(...)` method, which can
be used to warm-start an encoder-decoder model from two model
identifiers - one for the encoder and one for the decoder. The first
model identifier is thereby used to load the *encoder*, via
`AutoModel.from_pretrained(...)` (see doc
[here](https://huggingface.co/transformers/master/model_doc/auto.html?highlight=automodel#automodel))
and the second model identifier is used to load the *decoder* via
`AutoModelForCausalLM` (see doc
[here](https://huggingface.co/transformers/master/model_doc/auto.html#automodelforcausallm).
Alright, let\'s warm-start our *BERT2BERT* model. As mentioned earlier
we will warm-start both the encoder and decoder with the
`"bert-base-cased"` checkpoint.
```python
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased", "bert-base-uncased")
```
```python
OUTPUT:
-------
"""Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertLMHeadModel: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing BertLMHeadModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing BertLMHeadModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertLMHeadModel were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['bert.encoder.layer.0.crossattention.self.query.weight', 'bert.encoder.layer.0.crossattention.self.query.bias', 'bert.encoder.layer.0.crossattention.self.key.weight', 'bert.encoder.layer.0.crossattention.self.key.bias', 'bert.encoder.layer.0.crossattention.self.value.weight', 'bert.encoder.layer.0.crossattention.self.value.bias', 'bert.encoder.layer.0.crossattention.output.dense.weight', 'bert.encoder.layer.0.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.0.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.1.crossattention.self.query.weight', 'bert.encoder.layer.1.crossattention.self.query.bias', 'bert.encoder.layer.1.crossattention.self.key.weight', 'bert.encoder.layer.1.crossattention.self.key.bias', 'bert.encoder.layer.1.crossattention.self.value.weight', 'bert.encoder.layer.1.crossattention.self.value.bias', 'bert.encoder.layer.1.crossattention.output.dense.weight', 'bert.encoder.layer.1.crossattention.output.dense.bias', 'bert.encoder.layer.1.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.1.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.2.crossattention.self.query.weight', 'bert.encoder.layer.2.crossattention.self.query.bias', 'bert.encoder.layer.2.crossattention.self.key.weight', 'bert.encoder.layer.2.crossattention.self.key.bias', 'bert.encoder.layer.2.crossattention.self.value.weight', 'bert.encoder.layer.2.crossattention.self.value.bias', 'bert.encoder.layer.2.crossattention.output.dense.weight', 'bert.encoder.layer.2.crossattention.output.dense.bias', 'bert.encoder.layer.2.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.2.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.3.crossattention.self.query.weight', 'bert.encoder.layer.3.crossattention.self.query.bias', 'bert.encoder.layer.3.crossattention.self.key.weight', 'bert.encoder.layer.3.crossattention.self.key.bias', 'bert.encoder.layer.3.crossattention.self.value.weight', 'bert.encoder.layer.3.crossattention.self.value.bias', 'bert.encoder.layer.3.crossattention.output.dense.weight', 'bert.encoder.layer.3.crossattention.output.dense.bias', 'bert.encoder.layer.3.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.3.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.4.crossattention.self.query.weight', 'bert.encoder.layer.4.crossattention.self.query.bias', 'bert.encoder.layer.4.crossattention.self.key.weight', 'bert.encoder.layer.4.crossattention.self.key.bias', 'bert.encoder.layer.4.crossattention.self.value.weight', 'bert.encoder.layer.4.crossattention.self.value.bias', 'bert.encoder.layer.4.crossattention.output.dense.weight', 'bert.encoder.layer.4.crossattention.output.dense.bias', 'bert.encoder.layer.4.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.4.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.5.crossattention.self.query.weight', 'bert.encoder.layer.5.crossattention.self.query.bias', 'bert.encoder.layer.5.crossattention.self.key.weight', 'bert.encoder.layer.5.crossattention.self.key.bias', 'bert.encoder.layer.5.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.self.value.bias', 'bert.encoder.layer.5.crossattention.output.dense.weight', 'bert.encoder.layer.5.crossattention.output.dense.bias', 'bert.encoder.layer.5.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.5.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.6.crossattention.self.query.weight', 'bert.encoder.layer.6.crossattention.self.query.bias', 'bert.encoder.layer.6.crossattention.self.key.weight', 'bert.encoder.layer.6.crossattention.self.key.bias', 'bert.encoder.layer.6.crossattention.self.value.weight', 'bert.encoder.layer.6.crossattention.self.value.bias', 'bert.encoder.layer.6.crossattention.output.dense.weight', 'bert.encoder.layer.6.crossattention.output.dense.bias', 'bert.encoder.layer.6.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.6.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.7.crossattention.self.query.weight', 'bert.encoder.layer.7.crossattention.self.query.bias', 'bert.encoder.layer.7.crossattention.self.key.weight', 'bert.encoder.layer.7.crossattention.self.key.bias', 'bert.encoder.layer.7.crossattention.self.value.weight', 'bert.encoder.layer.7.crossattention.self.value.bias', 'bert.encoder.layer.7.crossattention.output.dense.weight', 'bert.encoder.layer.7.crossattention.output.dense.bias', 'bert.encoder.layer.7.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.7.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.8.crossattention.self.query.weight', 'bert.encoder.layer.8.crossattention.self.query.bias', 'bert.encoder.layer.8.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.self.key.bias', 'bert.encoder.layer.8.crossattention.self.value.weight', 'bert.encoder.layer.8.crossattention.self.value.bias', 'bert.encoder.layer.8.crossattention.output.dense.weight', 'bert.encoder.layer.8.crossattention.output.dense.bias', 'bert.encoder.layer.8.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.8.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.9.crossattention.self.query.weight', 'bert.encoder.layer.9.crossattention.self.query.bias', 'bert.encoder.layer.9.crossattention.self.key.weight', 'bert.encoder.layer.9.crossattention.self.key.bias', 'bert.encoder.layer.9.crossattention.self.value.weight', 'bert.encoder.layer.9.crossattention.self.value.bias', 'bert.encoder.layer.9.crossattention.output.dense.weight', 'bert.encoder.layer.9.crossattention.output.dense.bias', 'bert.encoder.layer.9.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.9.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.10.crossattention.self.query.weight', 'bert.encoder.layer.10.crossattention.self.query.bias', 'bert.encoder.layer.10.crossattention.self.key.weight', 'bert.encoder.layer.10.crossattention.self.key.bias', 'bert.encoder.layer.10.crossattention.self.value.weight', 'bert.encoder.layer.10.crossattention.self.value.bias', 'bert.encoder.layer.10.crossattention.output.dense.weight', 'bert.encoder.layer.10.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.10.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.11.crossattention.self.query.weight', 'bert.encoder.layer.11.crossattention.self.query.bias', 'bert.encoder.layer.11.crossattention.self.key.weight', 'bert.encoder.layer.11.crossattention.self.key.bias', 'bert.encoder.layer.11.crossattention.self.value.weight', 'bert.encoder.layer.11.crossattention.self.value.bias', 'bert.encoder.layer.11.crossattention.output.dense.weight', 'bert.encoder.layer.11.crossattention.output.dense.bias', 'bert.encoder.layer.11.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.11.crossattention.output.LayerNorm.bias']"""
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference."""
```
For once, we should take a good look at the warning here. We can see
that two weights corresponding to a `"cls"` layer were not used. This
should not be a problem because we don\'t need BERT\'s CLS layer for
*sequence-to-sequence* tasks. Also, we notice that a lot of weights are
\"newly\" or randomly initialized. When taking a closer look these
weights all correspond to the cross-attention layer, which is exactly
what we would expect after having read the theory above.
Let\'s take a closer look at the model.
```python
bert2bert
```
```python
OUTPUT:
-------
EncoderDecoderModel(
(encoder): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
),
...
,
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(decoder): BertLMHeadModel(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
),
...,
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(crossattention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(cls): BertOnlyMLMHead(
(predictions): BertLMPredictionHead(
(transform): BertPredictionHeadTransform(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(decoder): Linear(in_features=768, out_features=30522, bias=True)
)
)
)
)
```
We see that `bert2bert.encoder` is an instance of `BertModel` and that
`bert2bert.decoder` one of `BertLMHeadModel`. However, both instances
are now combined into a single `torch.nn.Module` and can thus be saved
as a single `.pt` checkpoint file.
Let\'s try it out using the standard `.save_pretrained(...)` method.
```python
bert2bert.save_pretrained("bert2bert")
```
Similarly, the model can be reloaded using the standard
`.from_pretrained(...)` method.
```python
bert2bert = EncoderDecoderModel.from_pretrained("bert2bert")
```
Awesome. Let\'s also checkpoint the config.
```python
bert2bert.config
```
```python
OUTPUT:
-------
EncoderDecoderConfig {
"_name_or_path": "bert2bert",
"architectures": [
"EncoderDecoderModel"
],
"decoder": {
"_name_or_path": "bert-base-uncased",
"add_cross_attention": true,
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bad_words_ids": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"decoder_start_token_id": null,
"do_sample": false,
"early_stopping": false,
"eos_token_id": null,
"finetuning_task": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": true,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"min_length": 0,
"model_type": "bert",
"no_repeat_ngram_size": 0,
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"pad_token_id": 0,
"prefix": null,
"pruned_heads": {},
"repetition_penalty": 1.0,
"return_dict": false,
"sep_token_id": null,
"task_specific_params": null,
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 30522,
"xla_device": null
},
"encoder": {
"_name_or_path": "bert-base-uncased",
"add_cross_attention": false,
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bad_words_ids": null,
"bos_token_id": null,
"chunk_size_feed_forward": 0,
"decoder_start_token_id": null,
"do_sample": false,
"early_stopping": false,
"eos_token_id": null,
"finetuning_task": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"is_encoder_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"min_length": 0,
"model_type": "bert",
"no_repeat_ngram_size": 0,
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"pad_token_id": 0,
"prefix": null,
"pruned_heads": {},
"repetition_penalty": 1.0,
"return_dict": false,
"sep_token_id": null,
"task_specific_params": null,
"temperature": 1.0,
"tie_encoder_decoder": false,
"tie_word_embeddings": true,
"tokenizer_class": null,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"use_cache": true,
"vocab_size": 30522,
"xla_device": null
},
"is_encoder_decoder": true,
"model_type": "encoder_decoder"
}
```
The config is similarly composed of an encoder config and a decoder
config both of which are instances of `BertConfig` in our case. However,
the overall config is of type `EncoderDecoderConfig` and is therefore
saved as a single `.json` file.
In conclusion, one should remember that once an `EncoderDecoderModel`
object is instantiated, it provides the same functionality as any other
Encoder-Decoder model in 🤗Transformers, *e.g.*
[BART](https://huggingface.co/transformers/model_doc/bart.html),
[T5](https://huggingface.co/transformers/model_doc/t5.html),
[ProphetNet](https://huggingface.co/transformers/model_doc/prophetnet.html),
\... The only difference is that an `EncoderDecoderModel` provides the
additional `from_encoder_decoder_pretrained(...)` function allowing the
model class to be warm-started from any two encoder and decoder
checkpoints.
On a side-note, if one would want to create a shared encoder-decoder
model, the parameter `tie_encoder_decoder=True` can additionally be
passed as follows:
```python
shared_bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-cased", "bert-base-cased", tie_encoder_decoder=True)
```
As a comparison, we can see that the tied model has much fewer
parameters as expected.
```python
print(f"\n\nNum Params. Shared: {shared_bert2bert.num_parameters()}, Non-Shared: {bert2bert.num_parameters()}")
```
```python
OUTPUT:
-------
Num Params. Shared: 137298244, Non-Shared: 247363386
```
In this notebook, we will however train a non-shared *Bert2Bert* model,
so we continue with `bert2bert` and not `shared_bert2bert`.
```python
# free memory
del shared_bert2bert
```
We have warm-started a `bert2bert` model, but we have not defined all
the relevant parameters used for beam search decoding yet.
Let\'s start by setting the special tokens. `bert-base-cased` does not
have a `decoder_start_token_id` or `eos_token_id`, so we will use its
`cls_token_id` and `sep_token_id` respectively. Also, we should define a
`pad_token_id` on the config and make sure the correct `vocab_size` is
set.
```python
bert2bert.config.decoder_start_token_id = tokenizer.cls_token_id
bert2bert.config.eos_token_id = tokenizer.sep_token_id
bert2bert.config.pad_token_id = tokenizer.pad_token_id
bert2bert.config.vocab_size = bert2bert.config.encoder.vocab_size
```
Next, let\'s define all parameters related to beam search decoding.
Since `bart-large-cnn` yields good results on CNN/Dailymail, we will
just copy its beam search decoding parameters.
For more details on what each of these parameters does, please take a
look at [this](https://huggingface.co/blog/how-to-generate) blog post or
the
[docs](https://huggingface.co/transformers/main_classes/model.html#generative-models).
```python
bert2bert.config.max_length = 142
bert2bert.config.min_length = 56
bert2bert.config.no_repeat_ngram_size = 3
bert2bert.config.early_stopping = True
bert2bert.config.length_penalty = 2.0
bert2bert.config.num_beams = 4
```
Alright, let\'s now start fine-tuning the warm-started *BERT2BERT*
model.
### **Fine-Tuning Warm-Started Encoder-Decoder Models**
In this section, we will show how one can make use of the
`Seq2SeqTrainer` to fine-tune a warm-started encoder-decoder model.
Let\'s first import the `Seq2SeqTrainer` and its training arguments
`Seq2SeqTrainingArguments`.
```python
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
```
In addition, we need a couple of python packages to make the
`Seq2SeqTrainer` work.
```python
!pip install git-python==1.0.3
!pip install rouge_score
!pip install sacrebleu
```
The `Seq2SeqTrainer` extends 🤗Transformer\'s Trainer for encoder-decoder
models. In short, it allows using the `generate(...)` function during
evaluation, which is necessary to validate the performance of
encoder-decoder models on most *sequence-to-sequence* tasks, such as
*summarization*.
For more information on the `Trainer`, one should read through
[this](https://huggingface.co/transformers/training.html#trainer) short
tutorial.
Let\'s begin by configuring the `Seq2SeqTrainingArguments`.
The argument `predict_with_generate` should be set to `True`, so that
the `Seq2SeqTrainer` runs the `generate(...)` on the validation data and
passes the generated output as `predictions` to the
`compute_metric(...)` function which we will define later. The
additional arguments are derived from `TrainingArguments` and can be
read upon
[here](https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments).
For a complete training run, one should change those arguments as
needed. Good default values are commented out below.
For more information on the `Seq2SeqTrainer`, the reader is advised to
take a look at the
[code](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/seq2seq_trainer.py).
```python
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
evaluation_strategy="steps",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
fp16=True,
output_dir="./",
logging_steps=2,
save_steps=10,
eval_steps=4,
# logging_steps=1000,
# save_steps=500,
# eval_steps=7500,
# warmup_steps=2000,
# save_total_limit=3,
)
```
Also, we need to define a function to correctly compute the ROUGE score
during validation. Since we activated `predict_with_generate`, the
`compute_metrics(...)` function expects `predictions` that were obtained
using the `generate(...)` function. Like most summarization tasks,
CNN/Dailymail is typically evaluated using the ROUGE score.
Let\'s first load the ROUGE metric using the 🤗datasets library.
```python
rouge = datasets.load_metric("rouge")
```
Next, we will define the `compute_metrics(...)` function. The `rouge`
metric computes the score from two lists of strings. Thus we decode both
the `predictions` and `labels` - making sure that `-100` is correctly
replaced by the `pad_token_id` and remove all special characters by
setting `skip_special_tokens=True`.
```python
def compute_metrics(pred):
labels_ids = pred.label_ids
pred_ids = pred.predictions
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_ids[labels_ids == -100] = tokenizer.pad_token_id
label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
rouge_output = rouge.compute(predictions=pred_str, references=label_str, rouge_types=["rouge2"])["rouge2"].mid
return {
"rouge2_precision": round(rouge_output.precision, 4),
"rouge2_recall": round(rouge_output.recall, 4),
"rouge2_fmeasure": round(rouge_output.fmeasure, 4),
}
```
Great, now we can pass all arguments to the `Seq2SeqTrainer` and start
finetuning. Executing the following cell will take *ca.* 10 minutes ☕.
Finetuning *BERT2BERT* on the complete *CNN/Dailymail* training data
takes *ca.* model takes *ca.* 8h on a single *TITAN RTX* GPU.
```python
# instantiate trainer
trainer = Seq2SeqTrainer(
model=bert2bert,
tokenizer=tokenizer,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_data,
eval_dataset=val_data,
)
trainer.train()
```
Awesome, we should now be fully equipped to finetune a warm-started
encoder-decoder model. To check the result of our fine-tuning let\'s
take a look at the saved checkpoints.
```python
!ls
```
```bash
OUTPUT:
-------
bert2bert checkpoint-20 runs seq2seq_trainer.py
checkpoint-10 __pycache__ sample_data seq2seq_training_args.py
```
Finally, we can load the checkpoint as usual via the
`EncoderDecoderModel.from_pretrained(...)` method.
```python
dummy_bert2bert = EncoderDecoderModel.from_pretrained("./checkpoint-20")
```
### **Evaluation**
In a final step, we might want to evaluate the *BERT2BERT* model on the
test data.
To start, instead of loading the dummy model, let\'s load a *BERT2BERT*
model that was finetuned on the full training dataset. Also, we load its
tokenizer, which is just a copy of `bert-base-cased`\'s tokenizer.
```python
from transformers import BertTokenizer
bert2bert = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail").to("cuda")
tokenizer = BertTokenizer.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail")
```
Next, we load just 2% of *CNN/Dailymail\'s* test data. For the full
evaluation, one should obviously use 100% of the data.
```python
test_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="test[:2%]")
```
Now, we can again leverage 🤗dataset\'s handy `map()` function to
generate a summary for each test sample.
For each data sample we:
- first, tokenize the `"article"`,
- second, generate the output token ids, and
- third, decode the output token ids to obtain our predicted summary.
```python
def generate_summary(batch):
# cut off at BERT max length 512
inputs = tokenizer(batch["article"], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to("cuda")
attention_mask = inputs.attention_mask.to("cuda")
outputs = bert2bert.generate(input_ids, attention_mask=attention_mask)
output_str = tokenizer.batch_decode(outputs, skip_special_tokens=True)
batch["pred_summary"] = output_str
return batch
```
Let\'s run the map function to obtain the *results* dictionary that has
the model\'s predicted summary stored for each sample. Executing the
following cell may take *ca.* 10min ☕.
```python
batch_size = 16 # change to 64 for full evaluation
results = test_data.map(generate_summary, batched=True, batch_size=batch_size, remove_columns=["article"])
```
Finally, we compute the ROUGE score.
```python
rouge.compute(predictions=results["pred_summary"], references=results["highlights"], rouge_types=["rouge2"])["rouge2"].mid
```
```python
OUTPUT:
-------
Score(precision=0.10389454113300968, recall=0.1564771201053348, fmeasure=0.12175271663717585)
```
That\'s it. We\'ve shown how to warm-start a *BERT2BERT* model and
fine-tune/evaluate it on the CNN/Dailymail dataset.
The fully trained *BERT2BERT* model is uploaded to the 🤗model hub under
[patrickvonplaten/bert2bert\_cnn\_daily\_mail](https://huggingface.co/patrickvonplaten/bert2bert_cnn_daily_mail).
The model achieves a ROUGE-2 score of **18.22** on the full evaluation
data, which is even a little better than reported in the paper.
For some summarization examples, the reader is advised to use the online
inference API of the model,
[here](https://huggingface.co/patrickvonplaten/bert2bert_cnn_daily_mail).
Thanks a lot to Sascha Rothe, Shashi Narayan, and Aliaksei Severyn from
Google Research, and Victor Sanh, Sylvain Gugger, and Thomas Wolf from
🤗Hugging Face for proof-reading and giving very much appreciated
feedback.
| huggingface/blog/blob/main/warm-starting-encoder-decoder.md |
FrameworkSwitchCourse {fw} />
<!-- DISABLE-FRONTMATTER-SECTIONS -->
# End-of-chapter quiz[[end-of-chapter-quiz]]
<CourseFloatingBanner
chapter={2}
classNames="absolute z-10 right-0 top-0"
/>
### 1. What is the order of the language modeling pipeline?
<Question
choices={[
{
text: "First, the model, which handles text and returns raw predictions. The tokenizer then makes sense of these predictions and converts them back to text when needed.",
explain: "The model cannot understand text! The tokenizer must first tokenize the text and convert it to IDs so that it is understandable by the model."
},
{
text: "First, the tokenizer, which handles text and returns IDs. The model handles these IDs and outputs a prediction, which can be some text.",
explain: "The model's prediction cannot be text straight away. The tokenizer has to be used in order to convert the prediction back to text!"
},
{
text: "The tokenizer handles text and returns IDs. The model handles these IDs and outputs a prediction. The tokenizer can then be used once again to convert these predictions back to some text.",
explain: "Correct! The tokenizer can be used for both tokenizing and de-tokenizing.",
correct: true
}
]}
/>
### 2. How many dimensions does the tensor output by the base Transformer model have, and what are they?
<Question
choices={[
{
text: "2: The sequence length and the batch size",
explain: "False! The tensor output by the model has a third dimension: hidden size."
},
{
text: "2: The sequence length and the hidden size",
explain: "False! All Transformer models handle batches, even with a single sequence; that would be a batch size of 1!"
},
{
text: "3: The sequence length, the batch size, and the hidden size",
explain: "Correct!",
correct: true
}
]}
/>
### 3. Which of the following is an example of subword tokenization?
<Question
choices={[
{
text: "WordPiece",
explain: "Yes, that's one example of subword tokenization!",
correct: true
},
{
text: "Character-based tokenization",
explain: "Character-based tokenization is not a type of subword tokenization."
},
{
text: "Splitting on whitespace and punctuation",
explain: "That's a word-based tokenization scheme!"
},
{
text: "BPE",
explain: "Yes, that's one example of subword tokenization!",
correct: true
},
{
text: "Unigram",
explain: "Yes, that's one example of subword tokenization!",
correct: true
},
{
text: "None of the above",
explain: "Incorrect!"
}
]}
/>
### 4. What is a model head?
<Question
choices={[
{
text: "A component of the base Transformer network that redirects tensors to their correct layers",
explain: "Incorrect! There's no such component."
},
{
text: "Also known as the self-attention mechanism, it adapts the representation of a token according to the other tokens of the sequence",
explain: "Incorrect! The self-attention layer does contain attention \"heads,\" but these are not adaptation heads."
},
{
text: "An additional component, usually made up of one or a few layers, to convert the transformer predictions to a task-specific output",
explain: "That's right. Adaptation heads, also known simply as heads, come up in different forms: language modeling heads, question answering heads, sequence classification heads... ",
correct: true
}
]}
/>
{#if fw === 'pt'}
### 5. What is an AutoModel?
<Question
choices={[
{
text: "A model that automatically trains on your data",
explain: "Incorrect. Are you mistaking this with our <a href='https://huggingface.co/autotrain'>AutoTrain</a> product?"
},
{
text: "An object that returns the correct architecture based on the checkpoint",
explain: "Exactly: the <code>AutoModel</code> only needs to know the checkpoint from which to initialize to return the correct architecture.",
correct: true
},
{
text: "A model that automatically detects the language used for its inputs to load the correct weights",
explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the <a href='https://huggingface.co/models'>Model Hub</a> to find the best checkpoint for your task!"
}
]}
/>
{:else}
### 5. What is an TFAutoModel?
<Question
choices={[
{
text: "A model that automatically trains on your data",
explain: "Incorrect. Are you mistaking this with our <a href='https://huggingface.co/autotrain'>AutoTrain</a> product?"
},
{
text: "An object that returns the correct architecture based on the checkpoint",
explain: "Exactly: the <code>TFAutoModel</code> only needs to know the checkpoint from which to initialize to return the correct architecture.",
correct: true
},
{
text: "A model that automatically detects the language used for its inputs to load the correct weights",
explain: "Incorrect; while some checkpoints and models are capable of handling multiple languages, there are no built-in tools for automatic checkpoint selection according to language. You should head over to the <a href='https://huggingface.co/models'>Model Hub</a> to find the best checkpoint for your task!"
}
]}
/>
{/if}
### 6. What are the techniques to be aware of when batching sequences of different lengths together?
<Question
choices={[
{
text: "Truncating",
explain: "Yes, truncation is a correct way of evening out sequences so that they fit in a rectangular shape. Is it the only one, though?",
correct: true
},
{
text: "Returning tensors",
explain: "While the other techniques allow you to return rectangular tensors, returning tensors isn't helpful when batching sequences together."
},
{
text: "Padding",
explain: "Yes, padding is a correct way of evening out sequences so that they fit in a rectangular shape. Is it the only one, though?",
correct: true
},
{
text: "Attention masking",
explain: "Absolutely! Attention masks are of prime importance when handling sequences of different lengths. That's not the only technique to be aware of, however.",
correct: true
}
]}
/>
### 7. What is the point of applying a SoftMax function to the logits output by a sequence classification model?
<Question
choices={[
{
text: "It softens the logits so that they're more reliable.",
explain: "No, the SoftMax function does not affect the reliability of results."
},
{
text: "It applies a lower and upper bound so that they're understandable.",
explain: "Correct! The resulting values are bound between 0 and 1. That's not the only reason we use a SoftMax function, though.",
correct: true
},
{
text: "The total sum of the output is then 1, resulting in a possible probabilistic interpretation.",
explain: "Correct! That's not the only reason we use a SoftMax function, though.",
correct: true
}
]}
/>
### 8. What method is most of the tokenizer API centered around?
<Question
choices={[
{
text: "<code>encode</code>, as it can encode text into IDs and IDs into predictions",
explain: "Wrong! While the <code>encode</code> method does exist on tokenizers, it does not exist on models."
},
{
text: "Calling the tokenizer object directly.",
explain: "Exactly! The <code>__call__</code> method of the tokenizer is a very powerful method which can handle pretty much anything. It is also the method used to retrieve predictions from a model.",
correct: true
},
{
text: "<code>pad</code>",
explain: "Wrong! Padding is very useful, but it's just one part of the tokenizer API."
},
{
text: "<code>tokenize</code>",
explain: "The <code>tokenize</code> method is arguably one of the most useful methods, but it isn't the core of the tokenizer API."
}
]}
/>
### 9. What does the `result` variable contain in this code sample?
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
result = tokenizer.tokenize("Hello!")
```
<Question
choices={[
{
text: "A list of strings, each string being a token",
explain: "Absolutely! Convert this to IDs, and send them to a model!",
correct: true
},
{
text: "A list of IDs",
explain: "Incorrect; that's what the <code>__call__</code> or <code>convert_tokens_to_ids</code> method is for!"
},
{
text: "A string containing all of the tokens",
explain: "This would be suboptimal, as the goal is to split the string into multiple tokens."
}
]}
/>
{#if fw === 'pt'}
### 10. Is there something wrong with the following code?
```py
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
model = AutoModel.from_pretrained("gpt2")
encoded = tokenizer("Hey!", return_tensors="pt")
result = model(**encoded)
```
<Question
choices={[
{
text: "No, it seems correct.",
explain: "Unfortunately, coupling a model with a tokenizer that was trained with a different checkpoint is rarely a good idea. The model was not trained to make sense out of this tokenizer's output, so the model output (if it can even run!) will not make any sense."
},
{
text: "The tokenizer and model should always be from the same checkpoint.",
explain: "Right!",
correct: true
},
{
text: "It's good practice to pad and truncate with the tokenizer as every input is a batch.",
explain: "It's true that every model input needs to be a batch. However, truncating or padding this sequence wouldn't necessarily make sense as there is only one of it, and those are techniques to batch together a list of sentences."
}
]}
/>
{:else}
### 10. Is there something wrong with the following code?
```py
from transformers import AutoTokenizer, TFAutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
model = TFAutoModel.from_pretrained("gpt2")
encoded = tokenizer("Hey!", return_tensors="pt")
result = model(**encoded)
```
<Question
choices={[
{
text: "No, it seems correct.",
explain: "Unfortunately, coupling a model with a tokenizer that was trained with a different checkpoint is rarely a good idea. The model was not trained to make sense out of this tokenizer's output, so the model output (if it can even run!) will not make any sense."
},
{
text: "The tokenizer and model should always be from the same checkpoint.",
explain: "Right!",
correct: true
},
{
text: "It's good practice to pad and truncate with the tokenizer as every input is a batch.",
explain: "It's true that every model input needs to be a batch. However, truncating or padding this sequence wouldn't necessarily make sense as there is only one of it, and those are techniques to batch together a list of sentences."
}
]}
/>
{/if}
| huggingface/course/blob/main/chapters/en/chapter2/8.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Optimization
The `optimum.fx.optimization` module provides a set of torch.fx graph transformations, along with classes and functions to write your own transformations and compose them.
## The transformation guide
In 🤗 Optimum, there are two kinds of transformations: reversible and non-reversible transformations.
### Write a non-reversible transformation
The most basic case of transformations is non-reversible transformations. Those transformations cannot be reversed, meaning that after applying them to a graph module, there is no way to get the original model back. To implement such transformations in 🤗 Optimum, it is very easy: you just need to subclass [`~optimum.fx.optimization.Transformation`] and implement the [`~optimum.fx.optimization.Transformation.transform`] method.
For instance, the following transformation changes all the multiplications to additions:
```python
>>> import operator
>>> from optimum.fx.optimization import Transformation
>>> class ChangeMulToAdd(Transformation):
... def transform(self, graph_module):
... for node in graph_module.graph.nodes:
... if node.op == "call_function" and node.target == operator.mul:
... node.target = operator.add
... return graph_module
```
After implementing it, your transformation can be used as a regular function:
```python
>>> from transformers import BertModel
>>> from transformers.utils.fx import symbolic_trace
>>> model = BertModel.from_pretrained("bert-base-uncased")
>>> traced = symbolic_trace(
... model,
... input_names=["input_ids", "attention_mask", "token_type_ids"],
... )
>>> transformation = ChangeMulToAdd()
>>> transformed_model = transformation(traced)
```
### Write a reversible transformation
A reversible transformation implements both the transformation and its reverse, allowing to retrieve the original model from the transformed one. To implement such transformation, you need to subclass [`~optimum.fx.optimization.ReversibleTransformation`] and implement the [`~optimum.fx.optimization.ReversibleTransformation.transform`] and [`~optimum.fx.optimization.ReversibleTransformation.reverse`] methods.
For instance, the following transformation is reversible:
```python
>>> import operator
>>> from optimum.fx.optimization import ReversibleTransformation
>>> class MulToMulTimesTwo(ReversibleTransformation):
... def transform(self, graph_module):
... for node in graph_module.graph.nodes:
... if node.op == "call_function" and node.target == operator.mul:
... x, y = node.args
... node.args = (2 * x, y)
... return graph_module
...
... def reverse(self, graph_module):
... for node in graph_module.graph.nodes:
... if node.op == "call_function" and node.target == operator.mul:
... x, y = node.args
... node.args = (x / 2, y)
... return graph_module
```
### Composing transformations together
As applying multiple transformations in chain is needed more often that not, [`~optimum.fx.optimization.compose`] is provided. It is an utility function that allows you to create a transformation by chaining multiple other transformations.
```python
>>> from optimum.fx.optimization import compose
>>> composition = compose(MulToMulTimesTwo(), ChangeMulToAdd())
```
| huggingface/optimum/blob/main/docs/source/torch_fx/usage_guides/optimization.mdx |
PyTorch 图像分类
Related spaces: https://huggingface.co/spaces/abidlabs/pytorch-image-classifier, https://huggingface.co/spaces/pytorch/ResNet, https://huggingface.co/spaces/pytorch/ResNext, https://huggingface.co/spaces/pytorch/SqueezeNet
Tags: VISION, RESNET, PYTORCH
## 介绍
图像分类是计算机视觉中的一个核心任务。构建更好的分类器以区分图片中存在的物体是当前研究的一个热点领域,因为它的应用范围从自动驾驶车辆到医学成像等领域都很广泛。
这样的模型非常适合 Gradio 的 _image_ 输入组件,因此在本教程中,我们将使用 Gradio 构建一个用于图像分类的 Web 演示。我们将能够在 Python 中构建整个 Web 应用程序,效果如下(试试其中一个示例!):
<iframe src="https://abidlabs-pytorch-image-classifier.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
让我们开始吧!
### 先决条件
确保您已经[安装](/getting_started)了 `gradio` Python 包。我们将使用一个预训练的图像分类模型,所以您还应该安装了 `torch`。
## 第一步 - 设置图像分类模型
首先,我们需要一个图像分类模型。在本教程中,我们将使用一个预训练的 Resnet-18 模型,因为它可以从[PyTorch Hub](https://pytorch.org/hub/pytorch_vision_resnet/)轻松下载。您可以使用其他预训练模型或训练自己的模型。
```python
import torch
model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet18', pretrained=True).eval()
```
由于我们将使用模型进行推断,所以我们调用了 `.eval()` 方法。
## 第二步 - 定义 `predict` 函数
接下来,我们需要定义一个函数,该函数接受*用户输入*,在本示例中是一张图片,并返回预测结果。预测结果应该以字典的形式返回,其中键是类别名称,值是置信度概率。我们将从这个[text 文件](https://git.io/JJkYN)中加载类别名称。
对于我们的预训练模型,它的代码如下:
```python
import requests
from PIL import Image
from torchvision import transforms
# 下载ImageNet的可读标签。
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def predict(inp):
inp = transforms.ToTensor()(inp).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(inp)[0], dim=0)
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
return confidences
```
让我们逐步来看一下这段代码。该函数接受一个参数:
- `inp`:输入图片,类型为 `PIL` 图像
然后,该函数将图像转换为 PIL 图像,最终转换为 PyTorch 的 `tensor`,将其输入模型,并返回:
- `confidences`:预测结果,以字典形式表示,其中键是类别标签,值是置信度概率
## 第三步 - 创建 Gradio 界面
现在我们已经设置好了预测函数,我们可以创建一个 Gradio 界面。
在本例中,输入组件是一个拖放图片的组件。为了创建这个输入组件,我们使用 `Image(type="pil")` 来创建该组件,并处理预处理操作将其转换为 `PIL` 图像。
输出组件将是一个 `Label`,它以良好的形式显示顶部标签。由于我们不想显示所有 1000 个类别标签,所以我们将其定制为只显示前 3 个标签,构造为 `Label(num_top_classes=3)`。
最后,我们添加了一个 `examples` 参数,允许我们预填一些预定义的示例到界面中。Gradio 的代码如下:
```python
import gradio as gr
gr.Interface(fn=predict,
inputs=gr.Image(type="pil"),
outputs=gr.Label(num_top_classes=3),
examples=["lion.jpg", "cheetah.jpg"]).launch()
```
这将产生以下界面,您可以在浏览器中直接尝试(试试上传自己的示例图片!):
<iframe src="https://abidlabs-pytorch-image-classifier.hf.space" frameBorder="0" height="660" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
---
完成了!这就是构建图像分类器 Web 演示所需的所有代码。如果您想与他人共享,请在 `launch()` 接口时设置 `share=True`!
| gradio-app/gradio/blob/main/guides/cn/04_integrating-other-frameworks/image-classification-in-pytorch.md |
Gradio Demo: video_subtitle
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('files')
!wget -q -O files/a.mp4 https://github.com/gradio-app/gradio/raw/main/demo/video_subtitle/files/a.mp4
!wget -q -O files/b.mp4 https://github.com/gradio-app/gradio/raw/main/demo/video_subtitle/files/b.mp4
!wget -q -O files/s1.srt https://github.com/gradio-app/gradio/raw/main/demo/video_subtitle/files/s1.srt
!wget -q -O files/s2.vtt https://github.com/gradio-app/gradio/raw/main/demo/video_subtitle/files/s2.vtt
```
```
import gradio as gr
import os
a = os.path.join(os.path.abspath(''), "files/a.mp4") # Video
b = os.path.join(os.path.abspath(''), "files/b.mp4") # Video
s1 = os.path.join(os.path.abspath(''), "files/s1.srt") # Subtitle
s2 = os.path.join(os.path.abspath(''), "files/s2.vtt") # Subtitle
def video_demo(video, subtitle=None):
if subtitle is None:
return video
return [video, subtitle.name]
demo = gr.Interface(
fn=video_demo,
inputs=[
gr.Video(label="In", interactive=True),
gr.File(label="Subtitle", file_types=[".srt", ".vtt"]),
],
outputs=gr.Video(label="Out"),
examples=[
[a, s1],
[b, s2],
[a, None],
],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/video_subtitle/run.ipynb |
@gradio/state
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Adds the ability to build the frontend and backend of custom components in preparation for publishing to pypi using `gradio_component build`. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.2
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.1
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`85ba6de13`](https://github.com/gradio-app/gradio/commit/85ba6de136a45b3e92c74e410bb27e3cbe7138d7) - Adds the ability to build the frontend and backend of custom components in preparation for publishing to pypi using `gradio_component build`. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.2-beta.0
### Features
- [#5648](https://github.com/gradio-app/gradio/pull/5648) [`c573e2339`](https://github.com/gradio-app/gradio/commit/c573e2339b86c85b378dc349de5e9223a3c3b04a) - Publish all components to npm. Thanks [@freddyaboulton](https://github.com/freddyaboulton)! | gradio-app/gradio/blob/main/js/state/CHANGELOG.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Text-guided depth-to-image generation
[[open-in-colab]]
The [`StableDiffusionDepth2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images. In addition, you can also pass a `depth_map` to preserve the image structure. If no `depth_map` is provided, the pipeline automatically predicts the depth via an integrated [depth-estimation model](https://github.com/isl-org/MiDaS).
Start by creating an instance of the [`StableDiffusionDepth2ImgPipeline`]:
```python
import torch
from diffusers import StableDiffusionDepth2ImgPipeline
from diffusers.utils import load_image, make_image_grid
pipeline = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
use_safetensors=True,
).to("cuda")
```
Now pass your prompt to the pipeline. You can also pass a `negative_prompt` to prevent certain words from guiding how an image is generated:
```python
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
init_image = load_image(url)
prompt = "two tigers"
negative_prompt = "bad, deformed, ugly, bad anatomy"
image = pipeline(prompt=prompt, image=init_image, negative_prompt=negative_prompt, strength=0.7).images[0]
make_image_grid([init_image, image], rows=1, cols=2)
```
| Input | Output |
|---------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------|
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/coco-cats.png" width="500"/> | <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/depth2img-tigers.png" width="500"/> |
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/depth2img.md |
--
title: "Introducing Hugging Face for Education 🤗"
thumbnail: /blog/assets/61_education/thumbnail.png
authors:
- user: Violette
---
# Introducing Hugging Face for Education 🤗
Given that machine learning will make up the overwhelming majority of software development and that non-technical people will be exposed to AI systems more and more, one of the main challenges of AI is adapting and enhancing employee skills. It is also becoming necessary to support teaching staff in proactively taking AI's ethical and critical issues into account.
As an open-source company democratizing machine learning, [Hugging Face](https://huggingface.co/) believes it is essential to educate people from all backgrounds worldwide.
We launched the [ML demo.cratization tour](https://www.notion.so/ML-Demo-cratization-tour-with-66847a294abd4e9785e85663f5239652) in March 2022, where experts from Hugging Face taught hands-on classes on Building Machine Learning Collaboratively to more than 1000 students from 16 countries. Our new goal: **to teach machine learning to 5 million people by the end of 2023**.
*This blog post provides a high-level description of how we will reach our goals around education.*
## 🤗 **Education for All**
🗣️ Our goal is to make the potential and limitations of machine learning understandable to everyone. We believe that doing so will help evolve the field in a direction where the application of these technologies will lead to net benefits for society as a whole.
Some examples of our existing efforts:
- we describe in a very accessible way [different uses of ML models](https://huggingface.co/tasks) (summarization, text generation, object detection…),
- we allow everyone to try out models directly in their browser through widgets in the model pages, hence lowering the need for technical skills to do so ([example](https://huggingface.co/cmarkea/distilcamembert-base-sentiment)),
- we document and warn about harmful biases identified in systems (like [GPT-2](https://huggingface.co/gpt2#limitations-and-bias)).
- we provide tools to create open-source [ML apps](https://huggingface.co/spaces) that allow anyone to understand the potential of ML in one click.
## 🤗 **Education for Beginners**
🗣️ We want to lower the barrier to becoming a machine learning engineer by providing online courses, hands-on workshops, and other innovative techniques.
- We provide a free [course](https://huggingface.co/course/chapter1/1) about natural language processing (NLP) and more domains (soon) using free tools and libraries from the Hugging Face ecosystem. It’s completely free and without ads. The ultimate goal of this course is to learn how to apply Transformers to (almost) any machine learning problem!
- We provide a free [course](https://github.com/huggingface/deep-rl-class) about Deep Reinforcement Learning. In this course, you can study Deep Reinforcement Learning in theory and practice, learn to use famous Deep RL libraries, train agents in unique environments, publish your trained agents in one line of code to the Hugging Face Hub, and more!
- We provide a free [course](https://huggingface.co/course/chapter9/1) on how to build interactive demos for your machine learning models. The ultimate goal of this course is to allow ML developers to easily present their work to a wide audience including non-technical teams or customers, researchers to more easily reproduce machine learning models and behavior, end users to more easily identify and debug failure points of models, and more!
- Experts at Hugging Face wrote a [book](https://transformersbook.com/) on Transformers and their applications to a wide range of NLP tasks.
Apart from those efforts, many team members are involved in other educational efforts such as:
- Participating in meetups, conferences and workshops.
- Creating podcasts, YouTube videos, and blog posts.
- [Organizing events](https://github.com/huggingface/community-events/tree/main/huggan) in which free GPUs are provided for anyone to be able to train and share models and create demos for them.
## 🤗 **Education for Instructors**
🗣️ We want to empower educators with tools and offer collaborative spaces where students can build machine learning using open-source technologies and state-of-the-art machine learning models.
- We provide to educators free infrastructure and resources to quickly introduce real-world applications of ML to theirs students and make learning more fun and interesting. By creating a [classroom](https://huggingface.co/classrooms) for free from the hub, instructors can turn their classes into collaborative environments where students can learn and build ML-powered applications using free open-source technologies and state-of-the-art models.
- We’ve assembled [a free toolkit](https://github.com/huggingface/education-toolkit) translated to 8 languages that instructors of machine learning or Data Science can use to easily prepare labs, homework, or classes. The content is self-contained so that it can be easily incorporated into an existing curriculum. This content is free and uses well-known Open Source technologies (🤗 transformers, gradio, etc). Feel free to pick a tutorial and teach it!
1️⃣ [A Tour through the Hugging Face Hub](https://github.com/huggingface/education-toolkit/blob/main/01_huggingface-hub-tour.md)
2️⃣ [Build and Host Machine Learning Demos with Gradio & Hugging Face](https://colab.research.google.com/github/huggingface/education-toolkit/blob/main/02_ml-demos-with-gradio.ipynb)
3️⃣ [Getting Started with Transformers](https://colab.research.google.com/github/huggingface/education-toolkit/blob/main/03_getting-started-with-transformers.ipynb)
- We're organizing a dedicated, free workshop (June 6) on how to teach our educational resources in your machine learning and data science classes. Do not hesitate to [register](https://www.eventbrite.com/e/how-to-teach-open-source-machine-learning-tools-tickets-310980931337).
- We are currently doing a worldwide tour in collaboration with university instructors to teach more than 10000 students one of our core topics: How to build machine learning collaboratively? You can request someone on the Hugging Face team to run the session for your class via the [ML demo.cratization tour initiative](https://www.notion.so/ML-Demo-cratization-tour-with-66847a294abd4e9785e85663f5239652)**.**
<img width="535" alt="image" src="https://user-images.githubusercontent.com/95622912/164271167-58ec0115-dda1-4217-a308-9d4b2fbf86f5.png">
## 🤗 **Education Events & News**
- **09/08**[EVENT]: ML Demo.cratization tour in Argentina at 2pm (GMT-3). [Link here](https://www.uade.edu.ar/agenda/clase-pr%C3%A1ctica-con-hugging-face-c%C3%B3mo-construir-machine-learning-de-forma-colaborativa/)
🔥 We are currently working on more content in the course, and more! Stay tuned!
| huggingface/blog/blob/main/education.md |
FrameworkSwitchCourse {fw} />
# Processing the data[[processing-the-data]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={3}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter3/section2_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter3/section2_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={3}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter3/section2_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter3/section2_tf.ipynb"},
]} />
{/if}
{#if fw === 'pt'}
Continuing with the example from the [previous chapter](/course/chapter2), here is how we would train a sequence classifier on one batch in PyTorch:
```python
import torch
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
# Same as before
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
# This is new
batch["labels"] = torch.tensor([1, 1])
optimizer = AdamW(model.parameters())
loss = model(**batch).loss
loss.backward()
optimizer.step()
```
{:else}
Continuing with the example from the [previous chapter](/course/chapter2), here is how we would train a sequence classifier on one batch in TensorFlow:
```python
import tensorflow as tf
import numpy as np
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
# Same as before
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = TFAutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",
]
batch = dict(tokenizer(sequences, padding=True, truncation=True, return_tensors="tf"))
# This is new
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy")
labels = tf.convert_to_tensor([1, 1])
model.train_on_batch(batch, labels)
```
{/if}
Of course, just training the model on two sentences is not going to yield very good results. To get better results, you will need to prepare a bigger dataset.
In this section we will use as an example the MRPC (Microsoft Research Paraphrase Corpus) dataset, introduced in a [paper](https://www.aclweb.org/anthology/I05-5002.pdf) by William B. Dolan and Chris Brockett. The dataset consists of 5,801 pairs of sentences, with a label indicating if they are paraphrases or not (i.e., if both sentences mean the same thing). We've selected it for this chapter because it's a small dataset, so it's easy to experiment with training on it.
### Loading a dataset from the Hub[[loading-a-dataset-from-the-hub]]
{#if fw === 'pt'}
<Youtube id="_BZearw7f0w"/>
{:else}
<Youtube id="W_gMJF0xomE"/>
{/if}
The Hub doesn't just contain models; it also has multiple datasets in lots of different languages. You can browse the datasets [here](https://huggingface.co/datasets), and we recommend you try to load and process a new dataset once you have gone through this section (see the general documentation [here](https://huggingface.co/docs/datasets/loading)). But for now, let's focus on the MRPC dataset! This is one of the 10 datasets composing the [GLUE benchmark](https://gluebenchmark.com/), which is an academic benchmark that is used to measure the performance of ML models across 10 different text classification tasks.
The 🤗 Datasets library provides a very simple command to download and cache a dataset on the Hub. We can download the MRPC dataset like this:
```py
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
```
```python out
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
```
As you can see, we get a `DatasetDict` object which contains the training set, the validation set, and the test set. Each of those contains several columns (`sentence1`, `sentence2`, `label`, and `idx`) and a variable number of rows, which are the number of elements in each set (so, there are 3,668 pairs of sentences in the training set, 408 in the validation set, and 1,725 in the test set).
This command downloads and caches the dataset, by default in *~/.cache/huggingface/datasets*. Recall from Chapter 2 that you can customize your cache folder by setting the `HF_HOME` environment variable.
We can access each pair of sentences in our `raw_datasets` object by indexing, like with a dictionary:
```py
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
```
```python out
{'idx': 0,
'label': 1,
'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
```
We can see the labels are already integers, so we won't have to do any preprocessing there. To know which integer corresponds to which label, we can inspect the `features` of our `raw_train_dataset`. This will tell us the type of each column:
```py
raw_train_dataset.features
```
```python out
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
```
Behind the scenes, `label` is of type `ClassLabel`, and the mapping of integers to label name is stored in the *names* folder. `0` corresponds to `not_equivalent`, and `1` corresponds to `equivalent`.
<Tip>
✏️ **Try it out!** Look at element 15 of the training set and element 87 of the validation set. What are their labels?
</Tip>
### Preprocessing a dataset[[preprocessing-a-dataset]]
{#if fw === 'pt'}
<Youtube id="0u3ioSwev3s"/>
{:else}
<Youtube id="P-rZWqcB6CE"/>
{/if}
To preprocess the dataset, we need to convert the text to numbers the model can make sense of. As you saw in the [previous chapter](/course/chapter2), this is done with a tokenizer. We can feed the tokenizer one sentence or a list of sentences, so we can directly tokenize all the first sentences and all the second sentences of each pair like this:
```py
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
```
However, we can't just pass two sequences to the model and get a prediction of whether the two sentences are paraphrases or not. We need to handle the two sequences as a pair, and apply the appropriate preprocessing. Fortunately, the tokenizer can also take a pair of sequences and prepare it the way our BERT model expects:
```py
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
```
```python out
{
'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
```
We discussed the `input_ids` and `attention_mask` keys in [Chapter 2](/course/chapter2), but we put off talking about `token_type_ids`. In this example, this is what tells the model which part of the input is the first sentence and which is the second sentence.
<Tip>
✏️ **Try it out!** Take element 15 of the training set and tokenize the two sentences separately and as a pair. What's the difference between the two results?
</Tip>
If we decode the IDs inside `input_ids` back to words:
```py
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
```
we will get:
```python out
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
```
So we see the model expects the inputs to be of the form `[CLS] sentence1 [SEP] sentence2 [SEP]` when there are two sentences. Aligning this with the `token_type_ids` gives us:
```python out
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
[ 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
```
As you can see, the parts of the input corresponding to `[CLS] sentence1 [SEP]` all have a token type ID of `0`, while the other parts, corresponding to `sentence2 [SEP]`, all have a token type ID of `1`.
Note that if you select a different checkpoint, you won't necessarily have the `token_type_ids` in your tokenized inputs (for instance, they're not returned if you use a DistilBERT model). They are only returned when the model will know what to do with them, because it has seen them during its pretraining.
Here, BERT is pretrained with token type IDs, and on top of the masked language modeling objective we talked about in [Chapter 1](/course/chapter1), it has an additional objective called _next sentence prediction_. The goal with this task is to model the relationship between pairs of sentences.
With next sentence prediction, the model is provided pairs of sentences (with randomly masked tokens) and asked to predict whether the second sentence follows the first. To make the task non-trivial, half of the time the sentences follow each other in the original document they were extracted from, and the other half of the time the two sentences come from two different documents.
In general, you don't need to worry about whether or not there are `token_type_ids` in your tokenized inputs: as long as you use the same checkpoint for the tokenizer and the model, everything will be fine as the tokenizer knows what to provide to its model.
Now that we have seen how our tokenizer can deal with one pair of sentences, we can use it to tokenize our whole dataset: like in the [previous chapter](/course/chapter2), we can feed the tokenizer a list of pairs of sentences by giving it the list of first sentences, then the list of second sentences. This is also compatible with the padding and truncation options we saw in [Chapter 2](/course/chapter2). So, one way to preprocess the training dataset is:
```py
tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)
```
This works well, but it has the disadvantage of returning a dictionary (with our keys, `input_ids`, `attention_mask`, and `token_type_ids`, and values that are lists of lists). It will also only work if you have enough RAM to store your whole dataset during the tokenization (whereas the datasets from the 🤗 Datasets library are [Apache Arrow](https://arrow.apache.org/) files stored on the disk, so you only keep the samples you ask for loaded in memory).
To keep the data as a dataset, we will use the [`Dataset.map()`](https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map) method. This also allows us some extra flexibility, if we need more preprocessing done than just tokenization. The `map()` method works by applying a function on each element of the dataset, so let's define a function that tokenizes our inputs:
```py
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
```
This function takes a dictionary (like the items of our dataset) and returns a new dictionary with the keys `input_ids`, `attention_mask`, and `token_type_ids`. Note that it also works if the `example` dictionary contains several samples (each key as a list of sentences) since the `tokenizer` works on lists of pairs of sentences, as seen before. This will allow us to use the option `batched=True` in our call to `map()`, which will greatly speed up the tokenization. The `tokenizer` is backed by a tokenizer written in Rust from the [🤗 Tokenizers](https://github.com/huggingface/tokenizers) library. This tokenizer can be very fast, but only if we give it lots of inputs at once.
Note that we've left the `padding` argument out in our tokenization function for now. This is because padding all the samples to the maximum length is not efficient: it's better to pad the samples when we're building a batch, as then we only need to pad to the maximum length in that batch, and not the maximum length in the entire dataset. This can save a lot of time and processing power when the inputs have very variable lengths!
Here is how we apply the tokenization function on all our datasets at once. We're using `batched=True` in our call to `map` so the function is applied to multiple elements of our dataset at once, and not on each element separately. This allows for faster preprocessing.
```py
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
```
The way the 🤗 Datasets library applies this processing is by adding new fields to the datasets, one for each key in the dictionary returned by the preprocessing function:
```python out
DatasetDict({
train: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})
```
You can even use multiprocessing when applying your preprocessing function with `map()` by passing along a `num_proc` argument. We didn't do this here because the 🤗 Tokenizers library already uses multiple threads to tokenize our samples faster, but if you are not using a fast tokenizer backed by this library, this could speed up your preprocessing.
Our `tokenize_function` returns a dictionary with the keys `input_ids`, `attention_mask`, and `token_type_ids`, so those three fields are added to all splits of our dataset. Note that we could also have changed existing fields if our preprocessing function returned a new value for an existing key in the dataset to which we applied `map()`.
The last thing we will need to do is pad all the examples to the length of the longest element when we batch elements together — a technique we refer to as *dynamic padding*.
### Dynamic padding[[dynamic-padding]]
<Youtube id="7q5NyFT8REg"/>
{#if fw === 'pt'}
The function that is responsible for putting together samples inside a batch is called a *collate function*. It's an argument you can pass when you build a `DataLoader`, the default being a function that will just convert your samples to PyTorch tensors and concatenate them (recursively if your elements are lists, tuples, or dictionaries). This won't be possible in our case since the inputs we have won't all be of the same size. We have deliberately postponed the padding, to only apply it as necessary on each batch and avoid having over-long inputs with a lot of padding. This will speed up training by quite a bit, but note that if you're training on a TPU it can cause problems — TPUs prefer fixed shapes, even when that requires extra padding.
{:else}
The function that is responsible for putting together samples inside a batch is called a *collate function*. The default collator is a function that will just convert your samples to tf.Tensor and concatenate them (recursively if your elements are lists, tuples, or dictionaries). This won't be possible in our case since the inputs we have won't all be of the same size. We have deliberately postponed the padding, to only apply it as necessary on each batch and avoid having over-long inputs with a lot of padding. This will speed up training by quite a bit, but note that if you're training on a TPU it can cause problems — TPUs prefer fixed shapes, even when that requires extra padding.
{/if}
To do this in practice, we have to define a collate function that will apply the correct amount of padding to the items of the dataset we want to batch together. Fortunately, the 🤗 Transformers library provides us with such a function via `DataCollatorWithPadding`. It takes a tokenizer when you instantiate it (to know which padding token to use, and whether the model expects padding to be on the left or on the right of the inputs) and will do everything you need:
{#if fw === 'pt'}
```py
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
{:else}
```py
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
```
{/if}
To test this new toy, let's grab a few samples from our training set that we would like to batch together. Here, we remove the columns `idx`, `sentence1`, and `sentence2` as they won't be needed and contain strings (and we can't create tensors with strings) and have a look at the lengths of each entry in the batch:
```py
samples = tokenized_datasets["train"][:8]
samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
[len(x) for x in samples["input_ids"]]
```
```python out
[50, 59, 47, 67, 59, 50, 62, 32]
```
No surprise, we get samples of varying length, from 32 to 67. Dynamic padding means the samples in this batch should all be padded to a length of 67, the maximum length inside the batch. Without dynamic padding, all of the samples would have to be padded to the maximum length in the whole dataset, or the maximum length the model can accept. Let's double-check that our `data_collator` is dynamically padding the batch properly:
```py
batch = data_collator(samples)
{k: v.shape for k, v in batch.items()}
```
{#if fw === 'tf'}
```python out
{'attention_mask': TensorShape([8, 67]),
'input_ids': TensorShape([8, 67]),
'token_type_ids': TensorShape([8, 67]),
'labels': TensorShape([8])}
```
{:else}
```python out
{'attention_mask': torch.Size([8, 67]),
'input_ids': torch.Size([8, 67]),
'token_type_ids': torch.Size([8, 67]),
'labels': torch.Size([8])}
```
Looking good! Now that we've gone from raw text to batches our model can deal with, we're ready to fine-tune it!
{/if}
<Tip>
✏️ **Try it out!** Replicate the preprocessing on the GLUE SST-2 dataset. It's a little bit different since it's composed of single sentences instead of pairs, but the rest of what we did should look the same. For a harder challenge, try to write a preprocessing function that works on any of the GLUE tasks.
</Tip>
{#if fw === 'tf'}
Now that we have our dataset and a data collator, we need to put them together. We could manually load batches and collate them, but that's a lot of work, and probably not very performant either. Instead, there's a simple method that offers a performant solution to this problem: `to_tf_dataset()`. This will wrap a `tf.data.Dataset` around your dataset, with an optional collation function. `tf.data.Dataset` is a native TensorFlow format that Keras can use for `model.fit()`, so this one method immediately converts a 🤗 Dataset to a format that's ready for training. Let's see it in action with our dataset!
```py
tf_train_dataset = tokenized_datasets["train"].to_tf_dataset(
columns=["attention_mask", "input_ids", "token_type_ids"],
label_cols=["labels"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
tf_validation_dataset = tokenized_datasets["validation"].to_tf_dataset(
columns=["attention_mask", "input_ids", "token_type_ids"],
label_cols=["labels"],
shuffle=False,
collate_fn=data_collator,
batch_size=8,
)
```
And that's it! We can take those datasets forward into the next lecture, where training will be pleasantly straightforward after all the hard work of data preprocessing.
{/if}
| huggingface/course/blob/main/chapters/en/chapter3/2.mdx |
Metric Card for ROUGE
## Metric Description
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing. The metrics compare an automatically produced summary or translation against a reference or a set of references (human-produced) summary or translation.
Note that ROUGE is case insensitive, meaning that upper case letters are treated the same way as lower case letters.
This metrics is a wrapper around the [Google Research reimplementation of ROUGE](https://github.com/google-research/google-research/tree/master/rouge)
## How to Use
At minimum, this metric takes as input a list of predictions and a list of references:
```python
>>> rouge = datasets.load_metric('rouge')
>>> predictions = ["hello there", "general kenobi"]
>>> references = ["hello there", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references)
>>> print(list(results.keys()))
['rouge1', 'rouge2', 'rougeL', 'rougeLsum']
>>> print(results["rouge1"])
AggregateScore(low=Score(precision=1.0, recall=1.0, fmeasure=1.0), mid=Score(precision=1.0, recall=1.0, fmeasure=1.0), high=Score(precision=1.0, recall=1.0, fmeasure=1.0))
>>> print(results["rouge1"].mid.fmeasure)
1.0
```
### Inputs
- **predictions** (`list`): list of predictions to score. Each prediction
should be a string with tokens separated by spaces.
- **references** (`list`): list of reference for each prediction. Each
reference should be a string with tokens separated by spaces.
- **rouge_types** (`list`): A list of rouge types to calculate. Defaults to `['rouge1', 'rouge2', 'rougeL', 'rougeLsum']`.
- Valid rouge types:
- `"rouge1"`: unigram (1-gram) based scoring
- `"rouge2"`: bigram (2-gram) based scoring
- `"rougeL"`: Longest common subsequence based scoring.
- `"rougeLSum"`: splits text using `"\n"`
- See [here](https://github.com/huggingface/datasets/issues/617) for more information
- **use_aggregator** (`boolean`): If True, returns aggregates. Defaults to `True`.
- **use_stemmer** (`boolean`): If `True`, uses Porter stemmer to strip word suffixes. Defaults to `False`.
### Output Values
The output is a dictionary with one entry for each rouge type in the input list `rouge_types`. If `use_aggregator=False`, each dictionary entry is a list of Score objects, with one score for each sentence. Each Score object includes the `precision`, `recall`, and `fmeasure`. E.g. if `rouge_types=['rouge1', 'rouge2']` and `use_aggregator=False`, the output is:
```python
{'rouge1': [Score(precision=1.0, recall=0.5, fmeasure=0.6666666666666666), Score(precision=1.0, recall=1.0, fmeasure=1.0)], 'rouge2': [Score(precision=0.0, recall=0.0, fmeasure=0.0), Score(precision=1.0, recall=1.0, fmeasure=1.0)]}
```
If `rouge_types=['rouge1', 'rouge2']` and `use_aggregator=True`, the output is of the following format:
```python
{'rouge1': AggregateScore(low=Score(precision=1.0, recall=1.0, fmeasure=1.0), mid=Score(precision=1.0, recall=1.0, fmeasure=1.0), high=Score(precision=1.0, recall=1.0, fmeasure=1.0)), 'rouge2': AggregateScore(low=Score(precision=1.0, recall=1.0, fmeasure=1.0), mid=Score(precision=1.0, recall=1.0, fmeasure=1.0), high=Score(precision=1.0, recall=1.0, fmeasure=1.0))}
```
The `precision`, `recall`, and `fmeasure` values all have a range of 0 to 1.
#### Values from Popular Papers
### Examples
An example without aggregation:
```python
>>> rouge = datasets.load_metric('rouge')
>>> predictions = ["hello goodbye", "ankh morpork"]
>>> references = ["goodbye", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references)
>>> print(list(results.keys()))
['rouge1', 'rouge2', 'rougeL', 'rougeLsum']
>>> print(results["rouge1"])
[Score(precision=0.5, recall=0.5, fmeasure=0.5), Score(precision=0.0, recall=0.0, fmeasure=0.0)]
```
The same example, but with aggregation:
```python
>>> rouge = datasets.load_metric('rouge')
>>> predictions = ["hello goodbye", "ankh morpork"]
>>> references = ["goodbye", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references,
... use_aggregator=True)
>>> print(list(results.keys()))
['rouge1', 'rouge2', 'rougeL', 'rougeLsum']
>>> print(results["rouge1"])
AggregateScore(low=Score(precision=0.0, recall=0.0, fmeasure=0.0), mid=Score(precision=0.25, recall=0.25, fmeasure=0.25), high=Score(precision=0.5, recall=0.5, fmeasure=0.5))
```
The same example, but only calculating `rouge_1`:
```python
>>> rouge = datasets.load_metric('rouge')
>>> predictions = ["hello goodbye", "ankh morpork"]
>>> references = ["goodbye", "general kenobi"]
>>> results = rouge.compute(predictions=predictions,
... references=references,
... rouge_types=['rouge_1'],
... use_aggregator=True)
>>> print(list(results.keys()))
['rouge1']
>>> print(results["rouge1"])
AggregateScore(low=Score(precision=0.0, recall=0.0, fmeasure=0.0), mid=Score(precision=0.25, recall=0.25, fmeasure=0.25), high=Score(precision=0.5, recall=0.5, fmeasure=0.5))
```
## Limitations and Bias
See [Schluter (2017)](https://aclanthology.org/E17-2007/) for an in-depth discussion of many of ROUGE's limits.
## Citation
```bibtex
@inproceedings{lin-2004-rouge,
title = "{ROUGE}: A Package for Automatic Evaluation of Summaries",
author = "Lin, Chin-Yew",
booktitle = "Text Summarization Branches Out",
month = jul,
year = "2004",
address = "Barcelona, Spain",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W04-1013",
pages = "74--81",
}
```
## Further References
- This metrics is a wrapper around the [Google Research reimplementation of ROUGE](https://github.com/google-research/google-research/tree/master/rouge) | huggingface/datasets/blob/main/metrics/rouge/README.md |
--
title: "How Hugging Face Accelerated Development of Witty Works Writing Assistant"
thumbnail: /blog/assets/78_ml_director_insights/witty-works.png
authors:
- user: juliensimon
- user: Violette
- user: florentgbelidji
- user: oknerazan
guest: true
- user: lsmith
guest: true
---
# How Hugging Face Accelerated Development of Witty Works Writing Assistant
## The Success Story of Witty Works with the Hugging Face Expert Acceleration Program.
_If you're interested in building ML solutions faster, visit the [Expert Acceleration Program](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case) landing page and contact us [here](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case#form)!_
### Business Context
As IT continues to evolve and reshape our world, creating a more diverse and inclusive environment within the industry is imperative. [Witty Works](https://www.witty.works/) was built in 2018 to address this challenge. Starting as a consulting company advising organizations on becoming more diverse, Witty Works first helped them write job ads using inclusive language. To scale this effort, in 2019, they built a web app to assist users in writing inclusive job ads in English, French and German. They enlarged the scope rapidly with a writing assistant working as a browser extension that automatically fixes and explains potential bias in emails, Linkedin posts, job ads, etc. The aim was to offer a solution for internal and external communication that fosters a cultural change by providing micro-learning bites that explain the underlying bias of highlighted words and phrases.
<p align="center">
<img src="/blog/assets/78_ml_director_insights/wittyworks.png"><br>
<em>Example of suggestions by the writing assistant</em>
</p>
### First experiments
Witty Works first chose a basic machine learning approach to build their assistant from scratch. Using transfer learning with pre-trained spaCy models, the assistant was able to:
- Analyze text and transform words into lemmas,
- Perform a linguistic analysis,
- Extract the linguistic features from the text (plural and singular forms, gender), part-of-speech tags (pronouns, verbs, nouns, adjectives, etc.), word dependencies labels, named entity recognition, etc.
By detecting and filtering words according to a specific knowledge base using linguistic features, the assistant could highlight non-inclusive words and suggest alternatives in real-time.
### Challenge
The vocabulary had around 2300 non-inclusive words and idioms in German and English correspondingly. And the above described basic approach worked well for 85% of the vocabulary but failed for context-dependent words. Therefore the task was to build a context-dependent classifier of non-inclusive words. Such a challenge (understanding the context rather than recognizing linguistic features) led to using Hugging Face transformers.
```diff
Example of context dependent non-inclusive words:
Fossil fuels are not renewable resources. Vs He is an old fossil
You will have a flexible schedule. Vs You should keep your schedule flexible.
```
### Solutions provided by the [Hugging Face Experts](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case)
- #### **Get guidance for deciding on the right ML approach.**
The initial chosen approach was vanilla transformers (used to extract token embeddings of specific non-inclusive words). The Hugging Face Expert recommended switching from contextualized word embeddings to contextualized sentence embeddings. In this approach, the representation of each word in a sentence depends on its surrounding context.
Hugging Face Experts suggested the use of a [Sentence Transformers](https://www.sbert.net/) architecture. This architecture generates embeddings for sentences as a whole. The distance between semantically similar sentences is minimized and maximized for distant sentences.
In this approach, Sentence Transformers use Siamese networks and triplet network structures to modify the pre-trained transformer models to generate “semantically meaningful” sentence embeddings.
The resulting sentence embedding serves as input for a classical classifier based on KNN or logistic regression to build a context-dependent classifier of non-inclusive words.
```diff
Elena Nazarenko, Lead Data Scientist at Witty Works:
“We generate contextualized embedding vectors for every word depending on its
sentence (BERT embedding). Then, we keep only the embedding for the “problem”
word’s token, and calculate the smallest angle (cosine similarity)”
```
To fine-tune a vanilla transformers-based classifier, such as a simple BERT model, Witty Works would have needed a substantial amount of annotated data. Hundreds of samples for each category of flagged words would have been necessary. However, such an annotation process would have been costly and time-consuming, which Witty Works couldn’t afford.
- #### **Get guidance on selecting the right ML library.**
The Hugging Face Expert suggested using the Sentence Transformers Fine-tuning library (aka [SetFit](https://github.com/huggingface/setfit)), an efficient framework for few-shot fine-tuning of Sentence Transformers models. Combining contrastive learning and semantic sentence similarity, SetFit achieves high accuracy on text classification tasks with very little labeled data.
```diff
Julien Simon, Chief Evangelist at Hugging Face:
“SetFit for text classification tasks is a great tool to add to the ML toolbox”
```
The Witty Works team found the performance was adequate with as little as 15-20 labeled sentences per specific word.
```diff
Elena Nazarenko, Lead Data Scientist at Witty Works:
“At the end of the day, we saved time and money by not creating this large data set”
```
Reducing the number of sentences was essential to ensure that model training remained fast and that running the model was efficient. However, it was also necessary for another reason: Witty explicitly takes a highly supervised/rule-based approach to [actively manage bias](https://www.witty.works/en/blog/is-chatgpt-able-to-generate-inclusive-language). Reducing the number of sentences is very important to reduce the effort in manually reviewing the training sentences.
- #### **Get guidance on selecting the right ML models.**
One major challenge for Witty Works was deploying a model with low latency. No one expects to wait 3 minutes to get suggestions to improve one’s text! Both Hugging Face and Witty Works experimented with a few sentence transformers models and settled for [mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) combined with logistic regression and KNN.
After a first test on Google Colab, the Hugging Face experts guided Witty Works on deploying the model on Azure. No optimization was necessary as the model was fast enough.
```diff
Elena Nazarenko, Lead Data Scientist at Witty Works:
“Working with Hugging Face saved us a lot of time and money.
One can feel lost when implementing complex text classification use cases.
As it is one of the most popular tasks, there are a lot of models on the Hub.
The Hugging Face experts guided me through the massive amount of transformer-based
models to choose the best possible approach.
Plus, I felt very well supported during the model deployment”
```
### **Results and conclusion**
The number of training sentences dropped from 100-200 per word to 15-20 per word. Witty Works achieved an accuracy of 0.92 and successfully deployed a custom model on Azure with minimal DevOps effort!
```diff
Lukas Kahwe Smith CTO & Co-founder of Witty Works:
“Working on an IT project by oneself can be challenging and even if
the EAP is a significant investment for a startup, it is the cheaper
and most meaningful way to get a sparring partner“
```
With the guidance of the Hugging Face experts, Witty Works saved time and money by implementing a new ML workflow in the Hugging Face way.
```diff
Julien Simon, Chief Evangelist at Hugging Face:
“The Hugging way to build workflows:
find open-source pre-trained models,
evaluate them right away,
see what works, see what does not.
By iterating, you start learning things immediately”
```
---
🤗 If you or your team are interested in accelerating your ML roadmap with Hugging Face Experts, please visit [hf.co/support](https://huggingface.co/support?utm_source=blog-post&utm_medium=blog-post&utm_campaign=blog-post-classification-use-case) to learn more.
| huggingface/blog/blob/main/classification-use-cases.md |
分享您的应用
如何分享您的 Gradio 应用:
1. [使用 share 参数分享演示](#sharing-demos)
2. [在 HF Spaces 上托管](#hosting-on-hf-spaces)
3. [嵌入托管的空间](#embedding-hosted-spaces)
4. [使用 Web 组件嵌入](#embedding-with-web-components)
5. [使用 API 页面](#api-page)
6. [在页面上添加身份验证](#authentication)
7. [访问网络请求](#accessing-the-network-request-directly)
8. [在 FastAPI 中挂载](#mounting-within-another-fastapi-app)
9. [安全性](#security-and-file-access)
## 分享演示
通过在 `launch()` 方法中设置 `share=True`,可以轻松公开分享 Gradio 演示。就像这样:
```python
demo.launch(share=True)
```
这将生成一个公开的可分享链接,您可以将其发送给任何人!当您发送此链接时,对方用户可以在其浏览器中尝试模型。因为处理过程发生在您的设备上(只要您的设备保持开启!),您不必担心任何打包依赖项的问题。一个分享链接通常看起来像这样:**XXXXX.gradio.app**。尽管链接是通过 Gradio URL 提供的,但我们只是您本地服务器的代理,并不会存储通过您的应用发送的任何数据。
但请记住,这些链接可以被公开访问,这意味着任何人都可以使用您的模型进行预测!因此,请确保不要通过您编写的函数公开任何敏感信息,也不要允许在您的设备上进行任何关键更改。如果您设置 `share=False`(默认值,在 colab 笔记本中除外),则只创建一个本地链接,可以通过[端口转发](https://www.ssh.com/ssh/tunneling/example)与特定用户共享。
<img style="width: 40%" src="/assets/guides/sharing.svg">
分享链接在 72 小时后过期。
## 在 HF Spaces 上托管
如果您想在互联网上获得您的 Gradio 演示的永久链接,请使用 Hugging Face Spaces。 [Hugging Face Spaces](http://huggingface.co/spaces/) 提供了免费托管您的机器学习模型的基础设施!
在您创建了一个免费的 Hugging Face 账户后,有三种方法可以将您的 Gradio 应用部署到 Hugging Face Spaces:
1. 从终端:在应用目录中运行 `gradio deploy`。CLI 将收集一些基本元数据,然后启动您的应用。要更新您的空间,可以重新运行此命令或启用 Github Actions 选项,在 `git push` 时自动更新 Spaces。
2. 从浏览器:将包含 Gradio 模型和所有相关文件的文件夹拖放到 [此处](https://huggingface.co/new-space)。
3. 将 Spaces 与您的 Git 存储库连接,Spaces 将从那里拉取 Gradio 应用。有关更多信息,请参阅 [此指南如何在 Hugging Face Spaces 上托管](https://huggingface.co/blog/gradio-spaces)。
<video autoplay muted loop>
<source src="/assets/guides/hf_demo.mp4" type="video/mp4" />
</video>
## 嵌入托管的空间
一旦您将应用托管在 Hugging Face Spaces(或您自己的服务器上),您可能希望将演示嵌入到不同的网站上,例如您的博客或个人作品集。嵌入交互式演示使人们可以在他们的浏览器中尝试您构建的机器学习模型,而无需下载或安装任何内容!最好的部分是,您甚至可以将交互式演示嵌入到静态网站中,例如 GitHub 页面。
有两种方法可以嵌入您的 Gradio 演示。您可以在 Hugging Face Space 页面的“嵌入此空间”下拉选项中直接找到这两个选项的快速链接:

### 使用 Web 组件嵌入
与 IFrames 相比,Web 组件通常为用户提供更好的体验。Web 组件进行延迟加载,这意味着它们不会减慢您网站的加载时间,并且它们会根据 Gradio 应用的大小自动调整其高度。
要使用 Web 组件嵌入:
1. 通过在您的网站中添加以下脚本来导入 gradio JS 库(在 URL 中替换{GRADIO_VERSION}为您使用的 Gradio 库的版本)。
```html
<script type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/{GRADIO_VERSION}/gradio.js">
</script>
```
2. 在您想放置应用的位置添加
`html
<gradio-app src="https://$your_space_host.hf.space"></gradio-app>
`
元素。将 `src=` 属性设置为您的 Space 的嵌入 URL,您可以在“嵌入此空间”按钮中找到。例如:
```html
<gradio-app src="https://abidlabs-pytorch-image-classifier.hf.space"></gradio-app>
```
<script>
fetch("https://pypi.org/pypi/gradio/json"
).then(r => r.json()
).then(obj => {
let v = obj.info.version;
content = document.querySelector('.prose');
content.innerHTML = content.innerHTML.replaceAll("{GRADIO_VERSION}", v);
});
</script>
您可以在 <a href="https://www.gradio.app">Gradio 首页 </a> 上查看 Web 组件的示例。
您还可以使用传递给 `<gradio-app>` 标签的属性来自定义 Web 组件的外观和行为:
- `src`:如前所述,`src` 属性链接到您想要嵌入的托管 Gradio 演示的 URL
- `space`:一个可选的缩写,如果您的 Gradio 演示托管在 Hugging Face Space 上。接受 `username/space_name` 而不是完整的 URL。示例:`gradio/Echocardiogram-Segmentation`。如果提供了此属性,则不需要提供 `src`。
- `control_page_title`:一个布尔值,指定是否将 html 标题设置为 Gradio 应用的标题(默认为 `"false"`)
- `initial_height`:加载 Gradio 应用时 Web 组件的初始高度(默认为 `"300px"`)。请注意,最终高度是根据 Gradio 应用的大小设置的。
- `container`:是否显示边框框架和有关 Space 托管位置的信息(默认为 `"true"`)
- `info`:是否仅显示有关 Space 托管位置的信息在嵌入的应用程序下方(默认为 `"true"`)
- `autoscroll`:在预测完成后是否自动滚动到输出(默认为 `"false"`)
- `eager`:在页面加载时是否立即加载 Gradio 应用(默认为 `"false"`)
- `theme_mode`:是否使用 `dark`,`light` 或默认的 `system` 主题模式(默认为 `"system"`)
以下是使用这些属性创建一个懒加载且初始高度为 0px 的 Gradio 应用的示例。
```html
<gradio-app space="gradio/Echocardiogram-Segmentation" eager="true"
initial_height="0px"></gradio-app>
```
_ 注意:Gradio 的 CSS 永远不会影响嵌入页面,但嵌入页面可以影响嵌入的 Gradio 应用的样式。请确保父页面中的任何 CSS 不是如此通用,以至于它也可能适用于嵌入的 Gradio 应用并导致样式破裂。例如,元素选择器如 `header { ... }` 和 `footer { ... }` 最可能引起问题。_
### 使用 IFrames 嵌入
如果您无法向网站添加 javascript(例如),则可以改为使用 IFrames 进行嵌入,请添加以下元素:
```html
<iframe src="https://$your_space_host.hf.space"></iframe>
```
同样,您可以在“嵌入此空间”按钮中找到您的 Space 的嵌入 URL 的 `src=` 属性。
注意:如果您使用 IFrames,您可能希望添加一个固定的 `height` 属性,并设置 `style="border:0;"` 以去除边框。此外,如果您的应用程序需要诸如访问摄像头或麦克风之类的权限,您还需要使用 `allow` 属性提供它们。
## API 页面
$demo_hello_world
如果您点击并打开上面的空间,您会在应用的页脚看到一个“通过 API 使用”链接。

这是一个文档页面,记录了用户可以使用的 REST API 来查询“Interface”函数。`Blocks` 应用程序也可以生成 API 页面,但必须为每个事件监听器显式命名 API,例如:
```python
btn.click(add, [num1, num2], output, api_name="addition")
```
这将记录自动生成的 API 页面的端点 `/api/addition/`。
_注意_:对于启用了[队列功能](https://gradio.app/key-features#queuing)的 Gradio 应用程序,如果用户向您的 API 端点发出 POST 请求,他们可以绕过队列。要禁用此行为,请在 `queue()` 方法中设置 `api_open=False`。
## 鉴权
您可能希望在您的应用程序前面放置一个鉴权页面,以限制谁可以打开您的应用程序。使用 `launch()` 方法中的 `auth=` 关键字参数,您可以提供一个包含用户名和密码的元组,或者一个可接受的用户名 / 密码元组列表;以下是一个为单个名为“admin”的用户提供基于密码的身份验证的示例:
```python
demo.launch(auth=("admin", "pass1234"))
```
对于更复杂的身份验证处理,您甚至可以传递一个以用户名和密码作为参数的函数,并返回 True 以允许身份验证,否则返回 False。这可用于访问第三方身份验证服务等其他功能。
以下是一个接受任何用户名和密码相同的登录的函数示例:
```python
def same_auth(username, password):
return username == password
demo.launch(auth=same_auth)
```
为了使身份验证正常工作,必须在浏览器中启用第三方 Cookie。
默认情况下,Safari、Chrome 隐私模式不会启用此功能。
## 直接访问网络请求
当用户向您的应用程序进行预测时,您可能需要底层的网络请求,以获取请求标头(例如用于高级身份验证)、记录客户端的 IP 地址或其他原因。Gradio 支持与 FastAPI 类似的方式:只需添加一个类型提示为 `gr.Request` 的函数参数,Gradio 将将网络请求作为该参数传递进来。以下是一个示例:
```python
import gradio as gr
def echo(name, request: gr.Request):
if request:
print("Request headers dictionary:", request.headers)
print("IP address:", request.client.host)
return name
io = gr.Interface(echo, "textbox", "textbox").launch()
```
注意:如果直接调用函数而不是通过 UI(例如在缓存示例时),则 `request` 将为 `None`。您应该明确处理此情况,以确保您的应用程序不会抛出任何错误。这就是为什么我们有显式检查 `if request`。
## 嵌入到另一个 FastAPI 应用程序中
在某些情况下,您可能已经有一个现有的 FastAPI 应用程序,并且您想要为 Gradio 演示添加一个路径。
您可以使用 `gradio.mount_gradio_app()` 来轻松实现此目的。
以下是一个完整的示例:
$code_custom_path
请注意,此方法还允许您在自定义路径上运行 Gradio 应用程序(例如上面的 `http://localhost:8000/gradio`)。
## 安全性和文件访问
与他人共享 Gradio 应用程序(通过 Spaces、您自己的服务器或临时共享链接进行托管)将主机机器上的某些文件**暴露**给您的 Gradio 应用程序的用户。
特别是,Gradio 应用程序允许用户访问以下三类文件:
- **与 Gradio 脚本所在目录(或子目录)中的文件相同。** 例如,如果您的 Gradio 脚本的路径是 `/home/usr/scripts/project/app.py`,并且您从 `/home/usr/scripts/project/` 启动它,则共享 Gradio 应用程序的用户将能够访问 `/home/usr/scripts/project/` 中的任何文件。这样做是为了您可以在 Gradio 应用程序中轻松引用这些文件(例如应用程序的“示例”)。
- **Gradio 创建的临时文件。** 这些是由 Gradio 作为运行您的预测函数的一部分创建的文件。例如,如果您的预测函数返回一个视频文件,则 Gradio 将该视频保存到临时文件中,然后将临时文件的路径发送到前端。您可以通过设置环境变量 `GRADIO_TEMP_DIR` 为绝对路径(例如 `/home/usr/scripts/project/temp/`)来自定义 Gradio 创建的临时文件的位置。
- **通过 `launch()` 中的 `allowed_paths` 参数允许的文件。** 此参数允许您传递一个包含其他目录或确切文件路径的列表,以允许用户访问它们。(默认情况下,此参数为空列表)。
Gradio**不允许**访问以下内容:
- **点文件**(其名称以 '.' 开头的任何文件)或其名称以 '.' 开头的任何目录中的任何文件。
- **通过 `launch()` 中的 `blocked_paths` 参数允许的文件。** 您可以将其他目录或确切文件路径的列表传递给 `launch()` 中的 `blocked_paths` 参数。此参数优先于 Gradio 默认或 `allowed_paths` 允许的文件。
- **主机机器上的任何其他路径**。用户不应能够访问主机上的其他任意路径。
请确保您正在运行最新版本的 `gradio`,以使这些安全设置生效。
| gradio-app/gradio/blob/main/guides/cn/01_getting-started/03_sharing-your-app.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# AdaLoRA
[AdaLoRA](https://hf.co/papers/2303.10512) is a method for optimizing the number of trainable parameters to assign to weight matrices and layers, unlike LoRA, which distributes parameters evenly across all modules. More parameters are budgeted for important weight matrices and layers while less important ones receive fewer parameters.
The abstract from the paper is:
*Fine-tuning large pre-trained language models on downstream tasks has become an important paradigm in NLP. However, common practice fine-tunes all of the parameters in a pre-trained model, which becomes prohibitive when a large number of downstream tasks are present. Therefore, many fine-tuning methods are proposed to learn incremental updates of pre-trained weights in a parameter efficient way, e.g., low-rank increments. These methods often evenly distribute the budget of incremental updates across all pre-trained weight matrices, and overlook the varying importance of different weight parameters. As a consequence, the fine-tuning performance is suboptimal. To bridge this gap, we propose AdaLoRA, which adaptively allocates the parameter budget among weight matrices according to their importance score. In particular, AdaLoRA parameterizes the incremental updates in the form of singular value decomposition. Such a novel approach allows us to effectively prune the singular values of unimportant updates, which is essentially to reduce their parameter budget but circumvent intensive exact SVD computations. We conduct extensive experiments with several pre-trained models on natural language processing, question answering, and natural language generation to validate the effectiveness of AdaLoRA. Results demonstrate that AdaLoRA manifests notable improvement over baselines, especially in the low budget settings. Our code is publicly available at https://github.com/QingruZhang/AdaLoRA*.
## AdaLoraConfig
[[autodoc]] tuners.adalora.config.AdaLoraConfig
## AdaLoraModel
[[autodoc]] tuners.adalora.model.AdaLoraModel | huggingface/peft/blob/main/docs/source/package_reference/adalora.md |
DenseNet
**DenseNet** is a type of convolutional neural network that utilises dense connections between layers, through [Dense Blocks](http://www.paperswithcode.com/method/dense-block), where we connect *all layers* (with matching feature-map sizes) directly with each other. To preserve the feed-forward nature, each layer obtains additional inputs from all preceding layers and passes on its own feature-maps to all subsequent layers.
The **DenseNet Blur** variant in this collection by Ross Wightman employs [Blur Pooling](http://www.paperswithcode.com/method/blur-pooling)
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('densenet121', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `densenet121`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('densenet121', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/HuangLW16a,
author = {Gao Huang and
Zhuang Liu and
Kilian Q. Weinberger},
title = {Densely Connected Convolutional Networks},
journal = {CoRR},
volume = {abs/1608.06993},
year = {2016},
url = {http://arxiv.org/abs/1608.06993},
archivePrefix = {arXiv},
eprint = {1608.06993},
timestamp = {Mon, 10 Sep 2018 15:49:32 +0200},
biburl = {https://dblp.org/rec/journals/corr/HuangLW16a.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
<!--
Type: model-index
Collections:
- Name: DenseNet
Paper:
Title: Densely Connected Convolutional Networks
URL: https://paperswithcode.com/paper/densely-connected-convolutional-networks
Models:
- Name: densenet121
In Collection: DenseNet
Metadata:
FLOPs: 3641843200
Parameters: 7980000
File Size: 32376726
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Block
- Dense Connections
- Dropout
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Kaiming Initialization
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
ID: densenet121
LR: 0.1
Epochs: 90
Layers: 121
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/densenet.py#L295
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/densenet121_ra-50efcf5c.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.56%
Top 5 Accuracy: 92.65%
- Name: densenet161
In Collection: DenseNet
Metadata:
FLOPs: 9931959264
Parameters: 28680000
File Size: 115730790
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Block
- Dense Connections
- Dropout
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Kaiming Initialization
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
ID: densenet161
LR: 0.1
Epochs: 90
Layers: 161
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/densenet.py#L347
Weights: https://download.pytorch.org/models/densenet161-8d451a50.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.36%
Top 5 Accuracy: 93.63%
- Name: densenet169
In Collection: DenseNet
Metadata:
FLOPs: 4316945792
Parameters: 14150000
File Size: 57365526
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Block
- Dense Connections
- Dropout
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Kaiming Initialization
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
ID: densenet169
LR: 0.1
Epochs: 90
Layers: 169
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/densenet.py#L327
Weights: https://download.pytorch.org/models/densenet169-b2777c0a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 75.9%
Top 5 Accuracy: 93.02%
- Name: densenet201
In Collection: DenseNet
Metadata:
FLOPs: 5514321024
Parameters: 20010000
File Size: 81131730
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Block
- Dense Connections
- Dropout
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Kaiming Initialization
- Nesterov Accelerated Gradient
- Weight Decay
Training Data:
- ImageNet
ID: densenet201
LR: 0.1
Epochs: 90
Layers: 201
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/densenet.py#L337
Weights: https://download.pytorch.org/models/densenet201-c1103571.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.29%
Top 5 Accuracy: 93.48%
- Name: densenetblur121d
In Collection: DenseNet
Metadata:
FLOPs: 3947812864
Parameters: 8000000
File Size: 32456500
Architecture:
- 1x1 Convolution
- Batch Normalization
- Blur Pooling
- Convolution
- Dense Block
- Dense Connections
- Dropout
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: densenetblur121d
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/densenet.py#L305
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/densenetblur121d_ra-100dcfbc.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 76.59%
Top 5 Accuracy: 93.2%
- Name: tv_densenet121
In Collection: DenseNet
Metadata:
FLOPs: 3641843200
Parameters: 7980000
File Size: 32342954
Architecture:
- 1x1 Convolution
- Average Pooling
- Batch Normalization
- Convolution
- Dense Block
- Dense Connections
- Dropout
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
ID: tv_densenet121
LR: 0.1
Epochs: 90
Crop Pct: '0.875'
LR Gamma: 0.1
Momentum: 0.9
Batch Size: 32
Image Size: '224'
LR Step Size: 30
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/densenet.py#L379
Weights: https://download.pytorch.org/models/densenet121-a639ec97.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.74%
Top 5 Accuracy: 92.15%
--> | huggingface/pytorch-image-models/blob/main/docs/models/densenet.md |
!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Repository Cards
The huggingface_hub library provides a Python interface to create, share, and update Model/Dataset Cards.
Visit the [dedicated documentation page](https://huggingface.co/docs/hub/models-cards) for a deeper view of what
Model Cards on the Hub are, and how they work under the hood. You can also check out our [Model Cards guide](../how-to-model-cards) to
get a feel for how you would use these utilities in your own projects.
## Repo Card
The `RepoCard` object is the parent class of [`ModelCard`], [`DatasetCard`] and `SpaceCard`.
[[autodoc]] huggingface_hub.repocard.RepoCard
- __init__
- all
## Card Data
The [`CardData`] object is the parent class of [`ModelCardData`] and [`DatasetCardData`].
[[autodoc]] huggingface_hub.repocard_data.CardData
## Model Cards
### ModelCard
[[autodoc]] ModelCard
### ModelCardData
[[autodoc]] ModelCardData
## Dataset Cards
Dataset cards are also known as Data Cards in the ML Community.
### DatasetCard
[[autodoc]] DatasetCard
### DatasetCardData
[[autodoc]] DatasetCardData
## Space Cards
### SpaceCard
[[autodoc]] SpaceCard
### SpaceCardData
[[autodoc]] SpaceCardData
## Utilities
### EvalResult
[[autodoc]] EvalResult
### model_index_to_eval_results
[[autodoc]] huggingface_hub.repocard_data.model_index_to_eval_results
### eval_results_to_model_index
[[autodoc]] huggingface_hub.repocard_data.eval_results_to_model_index
### metadata_eval_result
[[autodoc]] huggingface_hub.repocard.metadata_eval_result
### metadata_update
[[autodoc]] huggingface_hub.repocard.metadata_update | huggingface/huggingface_hub/blob/main/docs/source/en/package_reference/cards.md |
Signing commits with GPG
`git` has an authentication layer to control who can push commits to a repo, but it does not authenticate the actual commit authors.
In other words, you can commit changes as `Elon Musk <elon@tesla.com>`, push them to your preferred `git` host (for instance github.com), and your commit will link to Elon's GitHub profile. (Try it! But don't blame us if Elon gets mad at you for impersonating him.)
The reasons we implemented GPG signing were:
- To provide finer-grained security, especially as more and more Enterprise users rely on the Hub.
- To provide ML benchmarks backed by a cryptographically-secure source.
See Ale Segala's [How (and why) to sign `git` commits](https://withblue.ink/2020/05/17/how-and-why-to-sign-git-commits.html) for more context.
You can prove a commit was authored by you with GNU Privacy Guard (GPG) and a key server. GPG is a cryptographic tool used to verify the authenticity of a message's origin. We'll explain how to set this up on Hugging Face below.
The Pro Git book is, as usual, a good resource about commit signing: [Pro Git: Signing your work](https://git-scm.com/book/en/v2/Git-Tools-Signing-Your-Work).
## Setting up signed commits verification
You will need to install [GPG](https://gnupg.org/) on your system in order to execute the following commands.
> It's included by default in most Linux distributions.
> On Windows, it is included in Git Bash (which comes with `git` for Windows).
You can sign your commits locally using [GPG](https://gnupg.org/).
Then configure your profile to mark these commits as **verified** on the Hub,
so other people can be confident that they come from a trusted source.
For a more in-depth explanation of how git and GPG interact, please visit the the [git documentation on the subject](https://git-scm.com/book/en/v2/Git-Tools-Signing-Your-Work)
Commits can have the following signing statuses:
| Status | Explanation |
| ----------------- | ------------------------------------------------------------ |
| Verified | The commit is signed and the signature is verified |
| Unverified | The commit is signed but the signature could not be verified |
| No signing status | The commit is not signed |
For a commit to be marked as **verified**, you need to upload the public key used to sign it on your Hugging Face account.
Use the `gpg --list-secret-keys` command to list the GPG keys for which you have both a public and private key.
A private key is required for signing commits or tags.
If you don't have a GPG key pair or you don't want to use the existing keys to sign your commits, go to **Generating a new GPG key**.
Otherwise, go straight to [Adding a GPG key to your account](#adding-a-gpg-key-to-your-account).
## Generating a new GPG key
To generate a GPG key, run the following:
```bash
gpg --gen-key
```
GPG will then guide you through the process of creating a GPG key pair.
Make sure you specify an email address for this key, and that the email address matches the one you specified in your Hugging Face [account](https://huggingface.co/settings/account).
## Adding a GPG key to your account
1. First, select or generate a GPG key on your computer. Make sure the email address of the key matches the one in your Hugging Face [account](https://huggingface.co/settings/account) and that the email of your account is verified.
2. Export the public part of the selected key:
```bash
gpg --armor --export <YOUR KEY ID>
```
3. Then visit your profile [settings page](https://huggingface.co/settings/keys) and click on **Add GPG Key**.
Copy & paste the output of the `gpg --export` command in the text area and click on **Add Key**.
4. Congratulations! 🎉 You've just added a GPG key to your account!
## Configure git to sign your commits with GPG
The last step is to configure git to sign your commits:
```bash
git config user.signingkey <Your GPG Key ID>
git config user.email <Your email on hf.co>
```
Then add the `-S` flag to your `git commit` commands to sign your commits!
```bash
git commit -S -m "My first signed commit"
```
Once pushed on the Hub, you should see the commit with a "Verified" badge.
<Tip>
To sign all commits by default in any local repository on your computer, you can run <code>git config --global commit.gpgsign true</code>.
</Tip>
| huggingface/hub-docs/blob/main/docs/hub/security-gpg.md |
Additional Readings [[additional-readings]]
These are **optional readings** if you want to go deeper.
## Deep Reinforcement Learning [[deep-rl]]
- [Reinforcement Learning: An Introduction, Richard Sutton and Andrew G. Barto Chapter 1, 2 and 3](http://incompleteideas.net/book/RLbook2020.pdf)
- [Foundations of Deep RL Series, L1 MDPs, Exact Solution Methods, Max-ent RL by Pieter Abbeel](https://youtu.be/2GwBez0D20A)
- [Spinning Up RL by OpenAI Part 1: Key concepts of RL](https://spinningup.openai.com/en/latest/spinningup/rl_intro.html)
## Gym [[gym]]
- [Getting Started With OpenAI Gym: The Basic Building Blocks](https://blog.paperspace.com/getting-started-with-openai-gym/)
- [Make your own Gym custom environment](https://www.gymlibrary.dev/content/environment_creation/)
| huggingface/deep-rl-class/blob/main/units/en/unit1/additional-readings.mdx |
Security Policy
## Supported Versions
<!--
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_check_mark: |
| < 4.0 | :x: |
-->
Each major version is currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 1.x.x | :white_check_mark: |
## Reporting a Vulnerability
<!--
Use this section to tell people how to report a vulnerability.
Tell them where to go, how often they can expect to get an update on a
reported vulnerability, what to expect if the vulnerability is accepted or
declined, etc.
-->
To report a security vulnerability, please contact: feedback@huggingface.co
| huggingface/simulate/blob/main/SECURITY.md |
p align="center">
<br>
<img src="https://huggingface.co/landing/assets/tokenizers/tokenizers-logo.png" width="600"/>
<br>
<p>
<p align="center">
<img alt="Build" src="https://github.com/huggingface/tokenizers/workflows/Rust/badge.svg">
<a href="https://github.com/huggingface/tokenizers/blob/master/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/tokenizers.svg?color=blue">
</a>
<a href="https://docs.rs/tokenizers/">
<img alt="Doc" src="https://docs.rs/tokenizers/badge.svg">
</a>
</p>
<br>
The core of `tokenizers`, written in Rust.
Provides an implementation of today's most used tokenizers, with a focus on performance and
versatility.
## What is a Tokenizer
A Tokenizer works as a pipeline, it processes some raw text as input and outputs an `Encoding`.
The various steps of the pipeline are:
1. The `Normalizer`: in charge of normalizing the text. Common examples of normalization are
the [unicode normalization standards](https://unicode.org/reports/tr15/#Norm_Forms), such as `NFD` or `NFKC`.
More details about how to use the `Normalizers` are available on the
[Hugging Face blog](https://huggingface.co/docs/tokenizers/components#normalizers)
2. The `PreTokenizer`: in charge of creating initial words splits in the text. The most common way of
splitting text is simply on whitespace.
3. The `Model`: in charge of doing the actual tokenization. An example of a `Model` would be
`BPE` or `WordPiece`.
4. The `PostProcessor`: in charge of post-processing the `Encoding` to add anything relevant
that, for example, a language model would need, such as special tokens.
### Loading a pretrained tokenizer from the Hub
```rust
use tokenizers::tokenizer::{Result, Tokenizer};
fn main() -> Result<()> {
# #[cfg(feature = "http")]
# {
let tokenizer = Tokenizer::from_pretrained("bert-base-cased", None)?;
let encoding = tokenizer.encode("Hey there!", false)?;
println!("{:?}", encoding.get_tokens());
# }
Ok(())
}
```
### Deserialization and tokenization example
```rust
use tokenizers::tokenizer::{Result, Tokenizer, EncodeInput};
use tokenizers::models::bpe::BPE;
fn main() -> Result<()> {
let bpe_builder = BPE::from_file("./path/to/vocab.json", "./path/to/merges.txt");
let bpe = bpe_builder
.dropout(0.1)
.unk_token("[UNK]".into())
.build()?;
let mut tokenizer = Tokenizer::new(bpe);
let encoding = tokenizer.encode("Hey there!", false)?;
println!("{:?}", encoding.get_tokens());
Ok(())
}
```
### Training and serialization example
```rust
use tokenizers::decoders::DecoderWrapper;
use tokenizers::models::bpe::{BpeTrainerBuilder, BPE};
use tokenizers::normalizers::{strip::Strip, unicode::NFC, utils::Sequence, NormalizerWrapper};
use tokenizers::pre_tokenizers::byte_level::ByteLevel;
use tokenizers::pre_tokenizers::PreTokenizerWrapper;
use tokenizers::processors::PostProcessorWrapper;
use tokenizers::{AddedToken, Model, Result, TokenizerBuilder};
use std::path::Path;
fn main() -> Result<()> {
let vocab_size: usize = 100;
let mut trainer = BpeTrainerBuilder::new()
.show_progress(true)
.vocab_size(vocab_size)
.min_frequency(0)
.special_tokens(vec![
AddedToken::from(String::from("<s>"), true),
AddedToken::from(String::from("<pad>"), true),
AddedToken::from(String::from("</s>"), true),
AddedToken::from(String::from("<unk>"), true),
AddedToken::from(String::from("<mask>"), true),
])
.build();
let mut tokenizer = TokenizerBuilder::new()
.with_model(BPE::default())
.with_normalizer(Some(Sequence::new(vec![
Strip::new(true, true).into(),
NFC.into(),
])))
.with_pre_tokenizer(Some(ByteLevel::default()))
.with_post_processor(Some(ByteLevel::default()))
.with_decoder(Some(ByteLevel::default()))
.build()?;
let pretty = false;
tokenizer
.train_from_files(
&mut trainer,
vec!["path/to/vocab.txt".to_string()],
)?
.save("tokenizer.json", pretty)?;
Ok(())
}
```
## Additional information
- tokenizers is designed to leverage CPU parallelism when possible. The level of parallelism is determined
by the total number of core/threads your CPU provides but this can be tuned by setting the `RAYON_RS_NUM_THREADS`
environment variable. As an example setting `RAYON_RS_NUM_THREADS=4` will allocate a maximum of 4 threads.
**_Please note this behavior may evolve in the future_**
## Features
**progressbar**: The progress bar visualization is enabled by default. It might be disabled if
compilation for certain targets is not supported by the [termios](https://crates.io/crates/termios)
dependency of the [indicatif](https://crates.io/crates/indicatif) progress bar.
| huggingface/tokenizers/blob/main/tokenizers/README.md |
!--Copyright 2023 The Intel Labs Team Authors, The Microsoft Research Team Authors and HuggingFace Inc. team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BridgeTower
## Overview
The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
This paper has been accepted to the [AAAI'23](https://aaai.org/Conferences/AAAI-23/) conference.
The abstract from the paper is the following:
*Vision-Language (VL) models with the TWO-TOWER architecture have dominated visual-language representation learning in recent years.
Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder.
Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BRIDGETOWER, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the crossmodal encoder.
This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BRIDGETOWER achieves state-of-the-art performance on various downstream vision-language tasks.
In particular, on the VQAv2 test-std set, BRIDGETOWER achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs.
Notably, when further scaling the model, BRIDGETOWER achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/bridgetower_architecture%20.jpg"
alt="drawing" width="600"/>
<small> BridgeTower architecture. Taken from the <a href="https://arxiv.org/abs/2206.08657">original paper.</a> </small>
This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
## Usage tips and examples
BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
The [`BridgeTowerProcessor`] wraps [`RobertaTokenizer`] and [`BridgeTowerImageProcessor`] into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run contrastive learning using [`BridgeTowerProcessor`] and [`BridgeTowerForContrastiveLearning`].
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs
```
The following example shows how to run image-text retrieval using [`BridgeTowerProcessor`] and [`BridgeTowerForImageAndTextRetrieval`].
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```
The following example shows how to run masked language modeling using [`BridgeTowerProcessor`] and [`BridgeTowerForMaskedLM`].
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```
Tips:
- This implementation of BridgeTower uses [`RobertaTokenizer`] to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings.
- Checkpoints for pre-trained [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) and [bridgetower masked language modeling and image text matching](https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm) are released.
- Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other down stream tasks.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## BridgeTowerConfig
[[autodoc]] BridgeTowerConfig
## BridgeTowerTextConfig
[[autodoc]] BridgeTowerTextConfig
## BridgeTowerVisionConfig
[[autodoc]] BridgeTowerVisionConfig
## BridgeTowerImageProcessor
[[autodoc]] BridgeTowerImageProcessor
- preprocess
## BridgeTowerProcessor
[[autodoc]] BridgeTowerProcessor
- __call__
## BridgeTowerModel
[[autodoc]] BridgeTowerModel
- forward
## BridgeTowerForContrastiveLearning
[[autodoc]] BridgeTowerForContrastiveLearning
- forward
## BridgeTowerForMaskedLM
[[autodoc]] BridgeTowerForMaskedLM
- forward
## BridgeTowerForImageAndTextRetrieval
[[autodoc]] BridgeTowerForImageAndTextRetrieval
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/bridgetower.md |
SK-ResNeXt
**SK ResNeXt** is a variant of a [ResNeXt](https://www.paperswithcode.com/method/resnext) that employs a [Selective Kernel](https://paperswithcode.com/method/selective-kernel) unit. In general, all the large kernel convolutions in the original bottleneck blocks in ResNext are replaced by the proposed [SK convolutions](https://paperswithcode.com/method/selective-kernel-convolution), enabling the network to choose appropriate receptive field sizes in an adaptive manner.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('skresnext50_32x4d', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `skresnext50_32x4d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('skresnext50_32x4d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{li2019selective,
title={Selective Kernel Networks},
author={Xiang Li and Wenhai Wang and Xiaolin Hu and Jian Yang},
year={2019},
eprint={1903.06586},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: SKResNeXt
Paper:
Title: Selective Kernel Networks
URL: https://paperswithcode.com/paper/selective-kernel-networks
Models:
- Name: skresnext50_32x4d
In Collection: SKResNeXt
Metadata:
FLOPs: 5739845824
Parameters: 27480000
File Size: 110340975
Architecture:
- Convolution
- Dense Connections
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- Residual Connection
- Selective Kernel
- Softmax
Tasks:
- Image Classification
Training Data:
- ImageNet
Training Resources: 8x GPUs
ID: skresnext50_32x4d
LR: 0.1
Epochs: 100
Layers: 50
Crop Pct: '0.875'
Momentum: 0.9
Batch Size: 256
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/a7f95818e44b281137503bcf4b3e3e94d8ffa52f/timm/models/sknet.py#L210
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/skresnext50_ra-f40e40bf.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.15%
Top 5 Accuracy: 94.64%
--> | huggingface/pytorch-image-models/blob/main/docs/models/skresnext.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for `FeatureExtractors`
This page lists all the utility functions that can be used by the audio [`FeatureExtractor`] in order to compute special features from a raw audio using common algorithms such as *Short Time Fourier Transform* or *log mel spectrogram*.
Most of those are only useful if you are studying the code of the audio processors in the library.
## Audio Transformations
[[autodoc]] audio_utils.hertz_to_mel
[[autodoc]] audio_utils.mel_to_hertz
[[autodoc]] audio_utils.mel_filter_bank
[[autodoc]] audio_utils.optimal_fft_length
[[autodoc]] audio_utils.window_function
[[autodoc]] audio_utils.spectrogram
[[autodoc]] audio_utils.power_to_db
[[autodoc]] audio_utils.amplitude_to_db
| huggingface/transformers/blob/main/docs/source/en/internal/audio_utils.md |
# FAQs
### Q: In which regions are Inference Endpoints available?
A: Inference Endpoints are currently available on AWS in us-east-1 (N. Virginia) & eu-west-1 (Ireland) and on Azure in eastus (Virginia). If you need to deploy in a different region, please let us know.
### Q: Can I access the instance my Endpoint is running on?
A: No, you cannot access the instance hosting your Endpoint. But if you are missing information or need more insights on the machine where the Endpoint is running, please contact us.
### Q: Can I see my Private Endpoint running on my VPC account?
A: No, when creating a Private Endpoint (a Hugging Face Inference Endpoint linked to your VPC via AWS/Azure PrivateLink), you can only see the ENI in your VPC where the Endpoint is available.
### Q: Can I run inference in batches?
A: It depends on the Task. The [supported Tasks](/docs/inference-endpoints/supported_tasks) are using the transformers or sentence-transformers pipelines under the hood. If your Task pipeline supports batching, e.g. Zero-Shot Classification then batch inference is supported. In any case, you can always create your own [inference handler](/docs/inference-endpoints/guides/custom_handler) and implement batching.
### Q: How can I scale my deployment?
A: The Endpoints are scaled automatically for you, the only information you need to provide is a min replica target and a max replica target. Then the system will scale your Endpoint based on the load. Scaling to zero is supported.
### Q: Will my endpoint still be running if no more requests are processed?
A: Yes, your Endpoint will always stay available/up with the number of min replicas defined in the Advanced configuration.
### Q: I would like to deploy a model which is not in the supported tasks, is this possible?
A: Yes, you can deploy any repository from the [Hugging Face Hub](https://huggingface.co/models) and if your task/model/framework is not supported out of the box, you can [create your own inference handler](/docs/inference-endpoints/guides/custom_handler) and then deploy your model to an Endpoint.
### Q: How much does it cost to run my Endpoint?
A: The Endpoints are billed based on the compute hours of your Running Endpoints, and the associated instance types. We may add usage costs for load balancers and Private Links in the future.
### Q: Is the data transiting to the Endpoint encrypted?
A: Yes, data is encrypted during transit with TLS/SSL.
### Q: How can I reduce the latency of my Endpoint?
A: There are several ways to reduce the latency of your Endpoint. One is to deploy your Endpoint in a region close to your application to reduce the network overhead. Another is to optimize your model using [Hugging Face Optimum](https://huggingface.co/docs/optimum/index) before creating your Endpoint. If you need help or have more questions about reducing latency, please contact us.
### Q: How do I monitor my deployed Endpoint?
A: You can currently monitor your Endpoint through the [🤗 Inference Endpoints web application](https://ui.endpoints.huggingface.co/endpoints), where you have access to the [Logs of your Endpoints](/docs/inference-endpoints/guides/logs) as well as a [metrics dashboard](/docs/inference-endpoints/guides/metrics). If you need programmatic access or more information, please contact us.
### Q: What if I would like to deploy to a different instance type that is not listed?
A: Please contact us if you feel your model would do better on a different instance type than what is listed.
### Q: I accidentally leaked my token. Do I need to delete my endpoint?
A: You can invalidate existing personal tokens and create new ones in your settings here: [https://huggingface.co/settings/tokens](https://huggingface.co/settings/tokens). For organization tokens, go to the organization settings.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/faq.mdx |
!---
Copyright 2021 NVIDIA Corporation. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Huggingface QDQBERT Quantization Example
The QDQBERT model adds fake quantization (pair of QuantizeLinear/DequantizeLinear ops) to:
* linear layer inputs and weights
* matmul inputs
* residual add inputs
In this example, we use QDQBERT model to do quantization on SQuAD task, including Quantization Aware Training (QAT), Post Training Quantization (PTQ) and inferencing using TensorRT.
Required:
- [pytorch-quantization toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization)
- [TensorRT >= 8.2](https://developer.nvidia.com/tensorrt)
- PyTorch >= 1.10.0
## Setup the environment with Dockerfile
Under the directory of `transformers/`, build the docker image:
```
docker build . -f examples/research_projects/quantization-qdqbert/Dockerfile -t bert_quantization:latest
```
Run the docker:
```
docker run --gpus all --privileged --rm -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 bert_quantization:latest
```
In the container:
```
cd transformers/examples/research_projects/quantization-qdqbert/
```
## Quantization Aware Training (QAT)
Calibrate the pretrained model and finetune with quantization awared:
```
python3 run_quant_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir calib/bert-base-uncased \
--do_calib \
--calibrator percentile \
--percentile 99.99
```
```
python3 run_quant_qa.py \
--model_name_or_path calib/bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 4e-5 \
--num_train_epochs 2 \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir finetuned_int8/bert-base-uncased \
--tokenizer_name bert-base-uncased \
--save_steps 0
```
### Export QAT model to ONNX
To export the QAT model finetuned above:
```
python3 run_quant_qa.py \
--model_name_or_path finetuned_int8/bert-base-uncased \
--output_dir ./ \
--save_onnx \
--per_device_eval_batch_size 1 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased
```
Use `--recalibrate-weights` to calibrate the weight ranges according to the quantizer axis. Use `--quant-per-tensor` for per tensor quantization (default is per channel).
Recalibrating will affect the accuracy of the model, but the change should be minimal (< 0.5 F1).
### Benchmark the INT8 QAT ONNX model inference with TensorRT using dummy input
```
trtexec --onnx=model.onnx --explicitBatch --workspace=16384 --int8 --shapes=input_ids:64x128,attention_mask:64x128,token_type_ids:64x128 --verbose
```
### Benchmark the INT8 QAT ONNX model inference with [ONNX Runtime-TRT](https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html) using dummy input
```
python3 ort-infer-benchmark.py
```
### Evaluate the INT8 QAT ONNX model inference with TensorRT
```
python3 evaluate-hf-trt-qa.py \
--onnx_model_path=./model.onnx \
--output_dir ./ \
--per_device_eval_batch_size 64 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased \
--int8 \
--seed 42
```
## Fine-tuning of FP32 model for comparison
Finetune a fp32 precision model with [transformers/examples/pytorch/question-answering/](../../pytorch/question-answering/):
```
python3 ../../pytorch/question-answering/run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir ./finetuned_fp32/bert-base-uncased \
--save_steps 0 \
--do_train \
--do_eval
```
## Post Training Quantization (PTQ)
### PTQ by calibrating and evaluating the finetuned FP32 model above:
```
python3 run_quant_qa.py \
--model_name_or_path ./finetuned_fp32/bert-base-uncased \
--dataset_name squad \
--calibrator percentile \
--percentile 99.99 \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir ./calib/bert-base-uncased \
--save_steps 0 \
--do_calib \
--do_eval
```
### Export the INT8 PTQ model to ONNX
```
python3 run_quant_qa.py \
--model_name_or_path ./calib/bert-base-uncased \
--output_dir ./ \
--save_onnx \
--per_device_eval_batch_size 1 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased
```
### Evaluate the INT8 PTQ ONNX model inference with TensorRT
```
python3 evaluate-hf-trt-qa.py \
--onnx_model_path=./model.onnx \
--output_dir ./ \
--per_device_eval_batch_size 64 \
--max_seq_length 128 \
--doc_stride 32 \
--dataset_name squad \
--tokenizer_name bert-base-uncased \
--int8 \
--seed 42
```
### Quantization options
Some useful options to support different implementations and optimizations. These should be specified for both calibration and finetuning.
|argument|description|
|--------|-----------|
|`--quant-per-tensor`| quantize weights with one quantization range per tensor |
|`--fuse-qkv` | use a single range (the max) for quantizing QKV weights and output activations |
|`--clip-gelu N` | clip the output of GELU to a maximum of N when quantizing (e.g. 10) |
|`--disable-dropout` | disable dropout for consistent activation ranges |
| huggingface/transformers/blob/main/examples/research_projects/quantization-qdqbert/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CLAP
## Overview
The CLAP model was proposed in [Large Scale Contrastive Language-Audio pretraining with
feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
CLAP (Contrastive Language-Audio Pretraining) is a neural network trained on a variety of (audio, text) pairs. It can be instructed in to predict the most relevant text snippet, given an audio, without directly optimizing for the task. The CLAP model uses a SWINTransformer to get audio features from a log-Mel spectrogram input, and a RoBERTa model to get text features. Both the text and audio features are then projected to a latent space with identical dimension. The dot product between the projected audio and text features is then used as a similar score.
The abstract from the paper is the following:
*Contrastive learning has shown remarkable success in the field of multimodal representation learning. In this paper, we propose a pipeline of contrastive language-audio pretraining to develop an audio representation by combining audio data with natural language descriptions. To accomplish this target, we first release LAION-Audio-630K, a large collection of 633,526 audio-text pairs from different data sources. Second, we construct a contrastive language-audio pretraining model by considering different audio encoders and text encoders. We incorporate the feature fusion mechanism and keyword-to-caption augmentation into the model design to further enable the model to process audio inputs of variable lengths and enhance the performance. Third, we perform comprehensive experiments to evaluate our model across three tasks: text-to-audio retrieval, zero-shot audio classification, and supervised audio classification. The results demonstrate that our model achieves superior performance in text-to-audio retrieval task. In audio classification tasks, the model achieves state-of-the-art performance in the zeroshot setting and is able to obtain performance comparable to models' results in the non-zero-shot setting. LAION-Audio-6*
This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
The original code can be found [here](https://github.com/LAION-AI/Clap).
## ClapConfig
[[autodoc]] ClapConfig
- from_text_audio_configs
## ClapTextConfig
[[autodoc]] ClapTextConfig
## ClapAudioConfig
[[autodoc]] ClapAudioConfig
## ClapFeatureExtractor
[[autodoc]] ClapFeatureExtractor
## ClapProcessor
[[autodoc]] ClapProcessor
## ClapModel
[[autodoc]] ClapModel
- forward
- get_text_features
- get_audio_features
## ClapTextModel
[[autodoc]] ClapTextModel
- forward
## ClapTextModelWithProjection
[[autodoc]] ClapTextModelWithProjection
- forward
## ClapAudioModel
[[autodoc]] ClapAudioModel
- forward
## ClapAudioModelWithProjection
[[autodoc]] ClapAudioModelWithProjection
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/clap.md |
Gradio Demo: english_translator
```
!pip install -q gradio transformers torch
```
```
import gradio as gr
from transformers import pipeline
pipe = pipeline("translation", model="t5-base")
def translate(text):
return pipe(text)[0]["translation_text"]
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
english = gr.Textbox(label="English text")
translate_btn = gr.Button(value="Translate")
with gr.Column():
german = gr.Textbox(label="German Text")
translate_btn.click(translate, inputs=english, outputs=german, api_name="translate-to-german")
examples = gr.Examples(examples=["I went to the supermarket yesterday.", "Helen is a good swimmer."],
inputs=[english])
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/english_translator/run.ipynb |
@gradio/row
## 0.1.1
### Features
- [#6399](https://github.com/gradio-app/gradio/pull/6399) [`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142) - Improve CSS token documentation in Storybook. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
## 0.1.0-beta.2
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.1.0-beta.1
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
## 0.0.2-beta.0
### Features
- [#5648](https://github.com/gradio-app/gradio/pull/5648) [`c573e2339`](https://github.com/gradio-app/gradio/commit/c573e2339b86c85b378dc349de5e9223a3c3b04a) - Publish all components to npm. Thanks [@freddyaboulton](https://github.com/freddyaboulton)! | gradio-app/gradio/blob/main/js/row/CHANGELOG.md |
--
title: Inference for PROs
thumbnail: /blog/assets/inference_pro/thumbnail.png
authors:
- user: osanseviero
- user: pcuenq
- user: victor
---
# Inference for PROs

Today, we're introducing Inference for PRO users - a community offering that gives you access to APIs of curated endpoints for some of the most exciting models available, as well as improved rate limits for the usage of free Inference API. Use the following page to [subscribe to PRO](https://huggingface.co/subscribe/pro).
Hugging Face PRO users now have access to exclusive API endpoints for a curated list of powerful models that benefit from ultra-fast inference powered by [text-generation-inference](https://github.com/huggingface/text-generation-inference). This is a benefit on top of the free inference API, which is available to all Hugging Face users to facilitate testing and prototyping on 200,000+ models. PRO users enjoy higher rate limits on these models, as well as exclusive access to some of the best models available today.
## Contents
- [Supported Models](#supported-models)
- [Getting started with Inference for PROs](#getting-started-with-inference-for-pros)
- [Applications](#applications)
- [Chat with Llama 2 and Code Llama](#chat-with-llama-2-and-code-llama)
- [Code infilling with Code Llama](#code-infilling-with-code-llama)
- [Stable Diffusion XL](#stable-diffusion-xl)
- [Generation Parameters](#generation-parameters)
- [Controlling Text Generation](#controlling-text-generation)
- [Controlling Image Generation](#controlling-image-generation)
- [Caching](#caching)
- [Streaming](#streaming)
- [Subscribe to PRO](#subscribe-to-pro)
- [FAQ](#faq)
## Supported Models
In addition to thousands of public models available in the Hub, PRO users get free access and higher rate limits to the following state-of-the-art models:
| Model | Size | Context Length | Use |
| ------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------------- | ------------------------------------- |
| Zephyr 7B β | [7B](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | 4k tokens | Highest-ranked chat model at the 7B weight |
| Llama 2 Chat | [7B](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf), [13B](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf), and [70B](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | 4k tokens | One of the best conversational models |
| Code Llama Base | [7B](https://huggingface.co/codellama/CodeLlama-7b-hf) and [13B](https://huggingface.co/codellama/CodeLlama-13b-hf) | 4k tokens | Autocomplete and infill code |
| Code Llama Instruct | [34B](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) | 16k tokens | Conversational code assistant |
| Stable Diffusion XL | [3B UNet](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) | - | Generate images |
Inference for PROs makes it easy to experiment and prototype with new models without having to deploy them on your own infrastructure. It gives PRO users access to ready-to-use HTTP endpoints for all the models listed above. It’s not meant to be used for heavy production applications - for that, we recommend using [Inference Endpoints](https://ui.endpoints.huggingface.co/catalog). Inference for PROs also allows using applications that depend upon an LLM endpoint, such as using a [VS Code extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) for code completion, or have your own version of [Hugging Chat](http://hf.co/chat).
## Getting started with Inference For PROs
Using Inference for PROs is as simple as sending a POST request to the API endpoint for the model you want to run. You'll also need to get a PRO account authentication token from [your token settings page](https://huggingface.co/settings/tokens) and use it in the request. For example, to generate text using [Llama 2 70B Chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) in a terminal session, you'd do something like:
```bash
curl https://api-inference.huggingface.co/models/meta-llama/Llama-2-70b-chat-hf \
-X POST \
-d '{"inputs": "In a surprising turn of events, "}' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_TOKEN>"
```
Which would print something like this:
```json
[
{
"generated_text": "In a surprising turn of events, 20th Century Fox has released a new trailer for Ridley Scott's Alien"
}
]
```
You can also use many of the familiar transformers generation parameters, like `temperature` or `max_new_tokens`:
```bash
curl https://api-inference.huggingface.co/models/meta-llama/Llama-2-70b-chat-hf \
-X POST \
-d '{"inputs": "In a surprising turn of events, ", "parameters": {"temperature": 0.7, "max_new_tokens": 100}}' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_TOKEN>"
```
```json
[
{
"generated_text": "In a surprising turn of events, 2K has announced that it will be releasing a new free-to-play game called NBA 2K23 Arcade Edition. This game will be available on Apple iOS devices and will allow players to compete against each other in quick, 3-on-3 basketball matches.\n\nThe game promises to deliver fast-paced, action-packed gameplay, with players able to choose from a variety of NBA teams and players, including some of the biggest"
}
]
```
For more details on the generation parameters, please take a look at [_Controlling Text Generation_](#controlling-text-generation) below.
To send your requests in Python, you can take advantage of `InferenceClient`, a convenient utility available in the `huggingface_hub` Python library:
```bash
pip install huggingface_hub
```
`InferenceClient` is a helpful wrapper that allows you to make calls to the Inference API and Inference Endpoints easily:
```python
from huggingface_hub import InferenceClient
client = InferenceClient(model="meta-llama/Llama-2-70b-chat-hf", token=YOUR_TOKEN)
output = client.text_generation("Can you please let us know more details about your ")
print(output)
```
If you don't want to pass the token explicitly every time you instantiate the client, you can use `notebook_login()` (in Jupyter notebooks), `huggingface-cli login` (in the terminal), or `login(token=YOUR_TOKEN)` (everywhere else) to log in a single time. The token will then be automatically used from here.
In addition to Python, you can also use JavaScript to integrate inference calls inside your JS or node apps. Take a look at [huggingface.js](https://huggingface.co/docs/huggingface.js/index) to get started!
## Applications
### Chat with Llama 2 and Code Llama
Models prepared to follow chat conversations are trained with very particular and specific chat templates that depend on the model used. You need to be careful about the format the model expects and replicate it in your queries.
The following example was taken from [our Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), that describes in full detail how to query the model for conversation:
```Python
prompt = """<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
There's a llama in my garden 😱 What should I do? [/INST]
"""
response = client.text_generation(prompt, max_new_tokens=200)
print(response)
```
This example shows the structure of the first message in a multi-turn conversation. Note how the `<<SYS>>` delimiter is used to provide the _system prompt_, which tells the model how we expect it to behave. Then our query is inserted between `[INST]` delimiters.
If we wish to continue the conversation, we have to append the model response to the sequence, and issue a new followup instruction afterwards. This is the general structure of the prompt template we need to use for Llama 2:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
This same format can be used with Code Llama Instruct to engage in technical conversations with a code-savvy assistant!
Please, refer to [our Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2) for more details.
### Code infilling with Code Llama
Code models like Code Llama can be used for code completion using the same generation strategy we used in the previous examples: you provide a starting string that may contain code or comments, and the model will try to continue the sequence with plausible content. Code models can also be used for _infilling_, a more specialized task where you provide prefix and suffix sequences, and the model will predict what should go in between. This is great for applications such as IDE extensions. Let's see an example using Code Llama:
```Python
client = InferenceClient(model="codellama/CodeLlama-13b-hf", token=YOUR_TOKEN)
prompt_prefix = 'def remove_non_ascii(s: str) -> str:\n """ '
prompt_suffix = "\n return result"
prompt = f"<PRE> {prompt_prefix} <SUF>{prompt_suffix} <MID>"
infilled = client.text_generation(prompt, max_new_tokens=150)
infilled = infilled.rstrip(" <EOT>")
print(f"{prompt_prefix}{infilled}{prompt_suffix}")
```
```
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s (str): The string to remove non-ASCII characters from.
Returns:
str: The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
```
As you can see, the format used for infilling follows this pattern:
```
prompt = f"<PRE> {prompt_prefix} <SUF>{prompt_suffix} <MID>"
```
For more details on how this task works, please take a look at https://huggingface.co/blog/codellama#code-completion.
### Stable Diffusion XL
SDXL is also available for PRO users. The response returned by the endpoint consists of a byte stream representing the generated image. If you use `InferenceClient`, it will automatically decode to a `PIL` image for you:
```Python
sdxl = InferenceClient(model="stabilityai/stable-diffusion-xl-base-1.0", token=YOUR_TOKEN)
image = sdxl.text_to_image(
"Dark gothic city in a misty night, lit by street lamps. A man in a cape is walking away from us",
guidance_scale=9,
)
```

For more details on how to control generation, please take a look at [this section](#controlling-image-generation).
## Generation Parameters
### Controlling Text Generation
Text generation is a rich topic, and there exist several generation strategies for different purposes. We recommend [this excellent overview](https://huggingface.co/blog/how-to-generate) on the subject. Many generation algorithms are supported by the text generation endpoints, and they can be configured using the following parameters:
- `do_sample`: If set to `False` (the default), the generation method will be _greedy search_, which selects the most probable continuation sequence after the prompt you provide. Greedy search is deterministic, so the same results will always be returned from the same input. When `do_sample` is `True`, tokens will be sampled from a probability distribution and will therefore vary across invocations.
- `temperature`: Controls the amount of variation we desire from the generation. A temperature of `0` is equivalent to greedy search. If we set a value for `temperature`, then `do_sample` will automatically be enabled. The same thing happens for `top_k` and `top_p`. When doing code-related tasks, we want less variability and hence recommend a low `temperature`. For other tasks, such as open-ended text generation, we recommend a higher one.
- `top_k`. Enables "Top-K" sampling: the model will choose from the `K` most probable tokens that may occur after the input sequence. Typical values are between 10 to 50.
- `top_p`. Enables "nucleus sampling": the model will choose from as many tokens as necessary to cover a particular probability mass. If `top_p` is 0.9, the 90% most probable tokens will be considered for sampling, and the trailing 10% will be ignored.
- `repetition_penalty`: Tries to avoid repeated words in the generated sequence.
- `seed`: Random seed that you can use in combination with sampling, for reproducibility purposes.
In addition to the sampling parameters above, you can also control general aspects of the generation with the following:
- `max_new_tokens`: maximum number of new tokens to generate. The default is `20`, feel free to increase if you want longer sequences.
- `return_full_text`: whether to include the input sequence in the output returned by the endpoint. The default used by `InferenceClient` is `False`, but the endpoint itself uses `True` by default.
- `stop_sequences`: a list of sequences that will cause generation to stop when encountered in the output.
### Controlling Image Generation
If you want finer-grained control over images generated with the SDXL endpoint, you can use the following parameters:
- `negative_prompt`: A text describing content that you want the model to steer _away_ from.
- `guidance_scale`: How closely you want the model to match the prompt. Lower numbers are less accurate, very high numbers might decrease image quality or generate artifacts.
- `width` and `height`: The desired image dimensions. SDXL works best for sizes between 768 and 1024.
- `num_inference_steps`: The number of denoising steps to run. Larger numbers may produce better quality but will be slower. Typical values are between 20 and 50 steps.
For additional details on text-to-image generation, we recommend you check the [diffusers library documentation](https://huggingface.co/docs/diffusers/using-diffusers/sdxl).
### Caching
If you run the same generation multiple times, you’ll see that the result returned by the API is the same (even if you are using sampling instead of greedy decoding). This is because recent results are cached. To force a different response each time, we can use an HTTP header to tell the server to run a new generation each time: `x-use-cache: 0`.
If you are using `InferenceClient`, you can simply append it to the `headers` client property:
```Python
client = InferenceClient(model="meta-llama/Llama-2-70b-chat-hf", token=YOUR_TOKEN)
client.headers["x-use-cache"] = "0"
output = client.text_generation("In a surprising turn of events, ", do_sample=True)
print(output)
```
### Streaming
Token streaming is the mode in which the server returns the tokens one by one as the model generates them. This enables showing progressive generations to the user rather than waiting for the whole generation. Streaming is an essential aspect of the end-user experience as it reduces latency, one of the most critical aspects of a smooth experience.
<div class="flex justify-center">
<img
class="block dark:hidden"
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tgi/streaming-generation-visual_360.gif"
/>
<img
class="hidden dark:block"
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tgi/streaming-generation-visual-dark_360.gif"
/>
</div>
To stream tokens with `InferenceClient`, simply pass `stream=True` and iterate over the response.
```python
for token in client.text_generation("How do you make cheese?", max_new_tokens=12, stream=True):
print(token)
# To
# make
# cheese
#,
# you
# need
# to
# start
# with
# milk
```
To use the generate_stream endpoint with curl, you can add the `-N`/`--no-buffer` flag, which disables curl default buffering and shows data as it arrives from the server.
```
curl -N https://api-inference.huggingface.co/models/meta-llama/Llama-2-70b-chat-hf \
-X POST \
-d '{"inputs": "In a surprising turn of events, ", "parameters": {"temperature": 0.7, "max_new_tokens": 100}}' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_TOKEN>"
```
## Subscribe to PRO
You can sign up today for a PRO subscription [here](https://huggingface.co/subscribe/pro). Benefit from higher rate limits, custom accelerated endpoints for the latest models, and early access to features. If you've built some exciting projects with the Inference API or are looking for a model not available in Inference for PROs, please [use this discussion](https://huggingface.co/spaces/huggingface/HuggingDiscussions/discussions/13). [Enterprise users](https://huggingface.co/enterprise) also benefit from PRO Inference API on top of other features, such as SSO.
## FAQ
**Does this affect the free Inference API?**
No. We still expose thousands of models through free APIs that allow people to prototype and explore model capabilities quickly.
**Does this affect Enterprise users?**
Users with an Enterprise subscription also benefit from accelerated inference API for curated models.
**Can I use my own models with PRO Inference API?**
The free Inference API already supports a wide range of small and medium models from a variety of libraries (such as diffusers, transformers, and sentence transformers). If you have a custom model or custom inference logic, we recommend using [Inference Endpoints](https://ui.endpoints.huggingface.co/catalog).
| huggingface/blog/blob/main/inference-pro.md |
--
title: "Towards Encrypted Large Language Models with FHE"
thumbnail: /blog/assets/encrypted-llm/thumbnail.png
authors:
- user: RomanBredehoft
guest: true
- user: jfrery-zama
guest: true
---
# Towards Encrypted Large Language Models with FHE
Large Language Models (LLM) have recently been proven as reliable tools for improving productivity in many areas such as programming, content creation, text analysis, web search, and distance learning.
## The Impact of Large Language Models on Users' Privacy
Despite the appeal of LLMs, privacy concerns persist surrounding user queries that are processed by these models. On the one hand, leveraging the power of LLMs is desirable, but on the other hand, there is a risk of leaking sensitive information to the LLM service provider. In some areas, such as healthcare, finance, or law, this privacy risk is a showstopper.
One possible solution to this problem is on-premise deployment, where the LLM owner would deploy their model on the client’s machine. This is however not an optimal solution, as building an LLM may cost millions of dollars ([4.6M$ for GPT3](https://lambdalabs.com/blog/demystifying-gpt-3)) and on-premise deployment runs the risk of leaking the model intellectual property (IP).
Zama believes you can get the best of both worlds: our ambition is to protect both the privacy of the user and the IP of the model. In this blog, you’ll see how to leverage the Hugging Face transformers library and have parts of these models run on encrypted data. The complete code can be found in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm).
## Fully Homomorphic Encryption (FHE) Can Solve LLM Privacy Challenges
Zama’s solution to the challenges of LLM deployment is to use Fully Homomorphic Encryption (FHE) which enables the execution of functions on encrypted data. It is possible to achieve the goal of protecting the model owner’s IP while still maintaining the privacy of the user's data. This demo shows that an LLM model implemented in FHE maintains the quality of the original model’s predictions. To do this, it’s necessary to adapt the [GPT2](https://huggingface.co/gpt2) implementation from the Hugging Face [transformers library](https://github.com/huggingface/transformers), reworking sections of the inference using Concrete-Python, which enables the conversion of Python functions into their FHE equivalents.
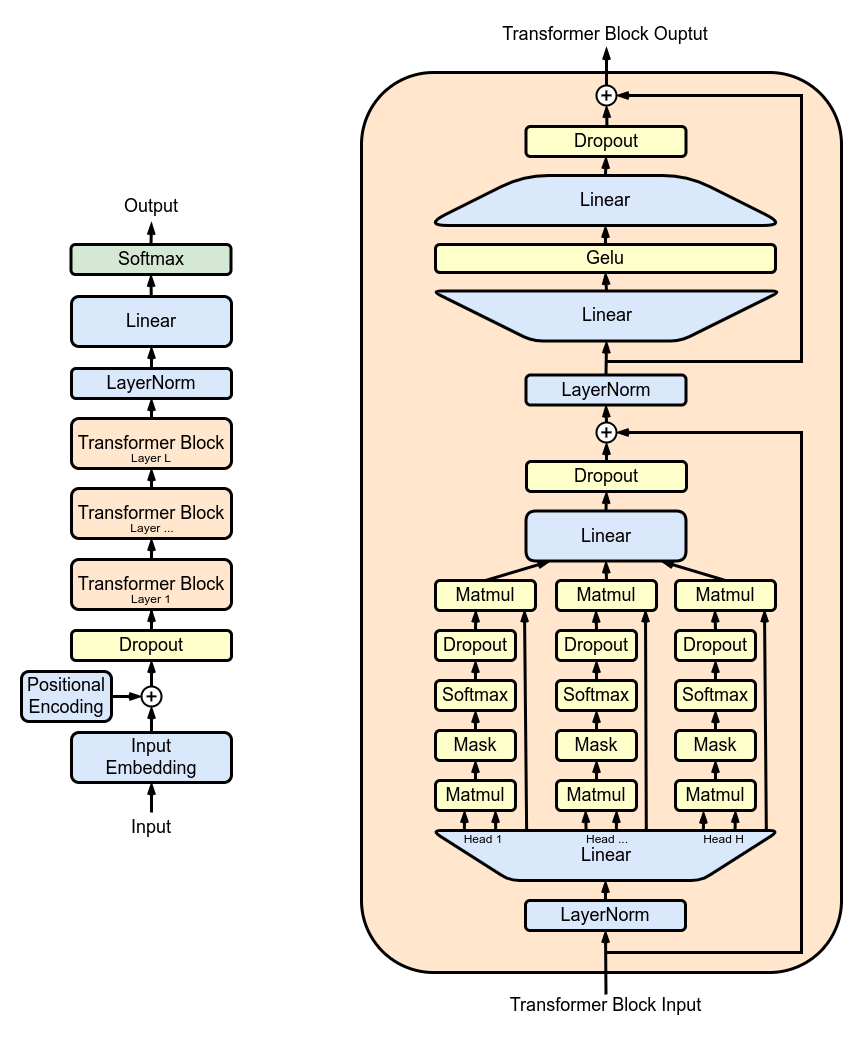
Figure 1 shows the GPT2 architecture which has a repeating structure: a series of multi-head attention (MHA) layers applied successively. Each MHA layer projects the inputs using the model weights, computes the attention mechanism, and re-projects the output of the attention into a new tensor.
In [TFHE](https://www.zama.ai/post/tfhe-deep-dive-part-1), model weights and activations are represented with integers. Nonlinear functions must be implemented with a Programmable Bootstrapping (PBS) operation. PBS implements a table lookup (TLU) operation on encrypted data while also refreshing ciphertexts to allow [arbitrary computation](https://whitepaper.zama.ai/). On the downside, the computation time of PBS dominates the one of linear operations. Leveraging these two types of operations, you can express any sub-part of, or, even the full LLM computation, in FHE.
## Implementation of a LLM layer with FHE
Next, you’ll see how to encrypt a single attention head of the multi-head attention (MHA) block. You can also find an example for the full MHA block in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm).

Figure 2. shows a simplified overview of the underlying implementation. A client starts the inference locally up to the first layer which has been removed from the shared model. The user encrypts the intermediate operations and sends them to the server. The server applies part of the attention mechanism and the results are then returned to the client who can decrypt them and continue the local inference.
### Quantization
First, in order to perform the model inference on encrypted values, the weights and activations of the model must be quantized and converted to integers. The ideal is to use [post-training quantization](https://docs.zama.ai/concrete-ml/advanced-topics/quantization) which does not require re-training the model. The process is to implement an FHE compatible attention mechanism, use integers and PBS, and then examine the impact on LLM accuracy.
To evaluate the impact of quantization, run the full GPT2 model with a single LLM Head operating over encrypted data. Then, evaluate the accuracy obtained when varying the number of quantization bits for both weights and activations.
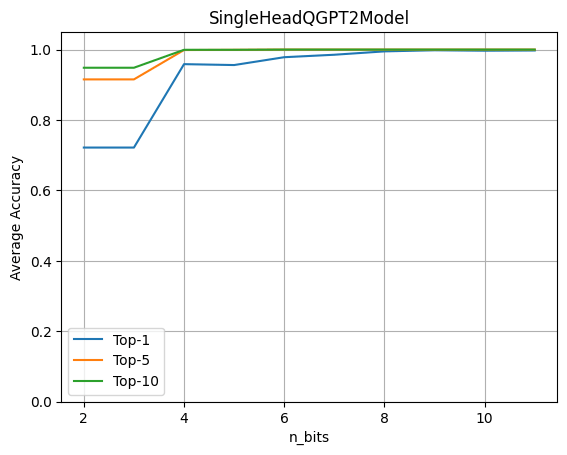
This graph shows that 4-bit quantization maintains 96% of the original accuracy. The experiment is done using a data-set of ~80 sentences. The metrics are computed by comparing the logits prediction from the original model against the model with the quantized head model.
### Applying FHE to the Hugging Face GPT2 model
Building upon the transformers library from Hugging Face, rewrite the forward pass of modules that you want to encrypt, in order to include the quantized operators. Build a SingleHeadQGPT2Model instance by first loading a [GPT2LMHeadModel](https://huggingface.co/docs/transformers/model_doc/gpt2#transformers.GPT2LMHeadModel) and then manually replace the first multi-head attention module as following using a [QGPT2SingleHeadAttention](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_models.py#L191) module. The complete implementation can be found [here](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_models.py).
```python
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)
```
The forward pass is then overwritten so that the first head of the multi-head attention mechanism, including the projections made for building the query, keys and value matrices, is performed with FHE-friendly operators. The following QGPT2 module can be found [here](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_class.py#L196).
```python
class SingleHeadAttention(QGPT2):
"""Class representing a single attention head implemented with quantization methods."""
def run_numpy(self, q_hidden_states: np.ndarray):
# Convert the input to a DualArray instance
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# Extract the attention base module name
mha_weights_name = f"transformer.h.{self.layer}.attn."
# Extract the query, key and value weight and bias values using the proper indices
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# Apply the first projection in order to extract Q, K and V as a single array
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# Extract the queries, keys and vales
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# Compute attention mechanism
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)
```
Other computations in the model remain in floating point, non-encrypted and are expected to be executed by the client on-premise.
Loading pre-trained weights into the GPT2 model modified in this way, you can then call the _generate_ method:
```python
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)
```
As an example, you can ask the quantized model to complete the phrase ”Cryptography is a”. With sufficient quantization precision when running the model in FHE, the output of the generation is:
“Cryptography is a very important part of the security of your computer”
When quantization precision is too low you will get:
“Cryptography is a great way to learn about the world around you”
### Compilation to FHE
You can now compile the attention head using the following Concrete-ML code:
```python
circuit_head = qgpt2_model.compile(input_ids)
```
Running this, you will see the following print out: “Circuit compiled with 8 bit-width”. This configuration, compatible with FHE, shows the maximum bit-width necessary to perform operations in FHE.
### Complexity
In transformer models, the most computationally intensive operation is the attention mechanism which multiplies the queries, keys, and values. In FHE, the cost is compounded by the specificity of multiplications in the encrypted domain. Furthermore, as the sequence length increases, the number of these challenging multiplications increases quadratically.
For the encrypted head, a sequence of length 6 requires 11,622 PBS operations. This is a first experiment that has not been optimized for performance. While it can run in a matter of seconds, it would require quite a lot of computing power. Fortunately, hardware will improve latency by 1000x to 10000x, making things go from several minutes on CPU to < 100ms on ASIC once they are available in a few years. For more information about these projections, see [this blog post](https://www.zama.ai/post/chatgpt-privacy-with-homomorphic-encryption).
## Conclusion
Large Language Models are great assistance tools in a wide variety of use cases but their implementation raises major issues for user privacy. In this blog, you saw a first step toward having the whole LLM work on encrypted data where the model would run entirely in the cloud while users' privacy would be fully respected.
This step includes the conversion of a specific part in a model like GPT2 to the FHE realm. This implementation leverages the transformers library and allows you to evaluate the impact on the accuracy when part of the model runs on encrypted data. In addition to preserving user privacy, this approach also allows a model owner to keep a major part of their model private. The complete code can be found in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm).
Zama libraries [Concrete](https://github.com/zama-ai/concrete) and [Concrete-ML](https://github.com/zama-ai/concrete-ml) (Don't forget to star the repos on GitHub ⭐️💛) allow straightforward ML model building and conversion to the FHE equivalent to being able to compute and predict over encrypted data.
Hope you enjoyed this post; feel free to share your thoughts/feedback!
| huggingface/blog/blob/main/encrypted-llm.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Multilingual models for inference
[[open-in-colab]]
There are several multilingual models in 🤗 Transformers, and their inference usage differs from monolingual models. Not *all* multilingual model usage is different though. Some models, like [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), can be used just like a monolingual model. This guide will show you how to use multilingual models whose usage differs for inference.
## XLM
XLM has ten different checkpoints, only one of which is monolingual. The nine remaining model checkpoints can be split into two categories: the checkpoints that use language embeddings and those that don't.
### XLM with language embeddings
The following XLM models use language embeddings to specify the language used at inference:
- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
- `xlm-clm-ende-1024` (Causal language modeling, English-German)
Language embeddings are represented as a tensor of the same shape as the `input_ids` passed to the model. The values in these tensors depend on the language used and are identified by the tokenizer's `lang2id` and `id2lang` attributes.
In this example, load the `xlm-clm-enfr-1024` checkpoint (Causal language modeling, English-French):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
The `lang2id` attribute of the tokenizer displays this model's languages and their ids:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
Next, create an example input:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
Set the language id as `"en"` and use it to define the language embedding. The language embedding is a tensor filled with `0` since that is the language id for English. This tensor should be the same size as `input_ids`.
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
Now you can pass the `input_ids` and language embedding to the model:
```py
>>> outputs = model(input_ids, langs=langs)
```
The [run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) script can generate text with language embeddings using the `xlm-clm` checkpoints.
### XLM without language embeddings
The following XLM models do not require language embeddings during inference:
- `xlm-mlm-17-1280` (Masked language modeling, 17 languages)
- `xlm-mlm-100-1280` (Masked language modeling, 100 languages)
These models are used for generic sentence representations, unlike the previous XLM checkpoints.
## BERT
The following BERT models can be used for multilingual tasks:
- `bert-base-multilingual-uncased` (Masked language modeling + Next sentence prediction, 102 languages)
- `bert-base-multilingual-cased` (Masked language modeling + Next sentence prediction, 104 languages)
These models do not require language embeddings during inference. They should identify the language from the
context and infer accordingly.
## XLM-RoBERTa
The following XLM-RoBERTa models can be used for multilingual tasks:
- `xlm-roberta-base` (Masked language modeling, 100 languages)
- `xlm-roberta-large` (Masked language modeling, 100 languages)
XLM-RoBERTa was trained on 2.5TB of newly created and cleaned CommonCrawl data in 100 languages. It provides strong gains over previously released multilingual models like mBERT or XLM on downstream tasks like classification, sequence labeling, and question answering.
## M2M100
The following M2M100 models can be used for multilingual translation:
- `facebook/m2m100_418M` (Translation)
- `facebook/m2m100_1.2B` (Translation)
In this example, load the `facebook/m2m100_418M` checkpoint to translate from Chinese to English. You can set the source language in the tokenizer:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
Tokenize the text:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
The following MBart models can be used for multilingual translation:
- `facebook/mbart-large-50-one-to-many-mmt` (One-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-many-mmt` (Many-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-one-mmt` (Many-to-one multilingual machine translation, 50 languages)
- `facebook/mbart-large-50` (Multilingual translation, 50 languages)
- `facebook/mbart-large-cc25`
In this example, load the `facebook/mbart-large-50-many-to-many-mmt` checkpoint to translate Finnish to English. You can set the source language in the tokenizer:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
Tokenize the text:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
If you are using the `facebook/mbart-large-50-many-to-one-mmt` checkpoint, you don't need to force the target language id as the first generated token otherwise the usage is the same.
| huggingface/transformers/blob/main/docs/source/en/multilingual.md |
Gradio Demo: image_editor
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
!wget -q https://github.com/gradio-app/gradio/raw/main/demo/image_editor/cheetah.jpg
```
```
import gradio as gr
import time
def sleep(im):
time.sleep(5)
return [im["background"], im["layers"][0], im["layers"][1], im["composite"]]
with gr.Blocks() as demo:
im = gr.ImageEditor(
type="pil",
crop_size="1:1",
)
with gr.Group():
with gr.Row():
im_out_1 = gr.Image(type="pil")
im_out_2 = gr.Image(type="pil")
im_out_3 = gr.Image(type="pil")
im_out_4 = gr.Image(type="pil")
btn = gr.Button()
im.change(sleep, outputs=[im_out_1, im_out_2, im_out_3, im_out_4], inputs=im)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/image_editor/run.ipynb |
分块状态 (State in Blocks)
我们已经介绍了[接口状态](https://gradio.app/interface-state),这篇指南将介绍分块状态,它的工作原理大致相同。
## 全局状态 (Global State)
分块中的全局状态与接口中的全局状态相同。在函数调用外创建的任何变量都是在所有用户之间共享的引用。
## 会话状态 (Session State)
Gradio 在分块应用程序中同样支持会话**状态**,即在页面会话中跨多次提交保持的数据。需要再次强调,会话数据*不会*在模型的不同用户之间共享。要在会话状态中存储数据,需要完成以下三个步骤:
1. 创建一个 `gr.State()` 对象。如果此可状态对象有一个默认值,请将其传递给构造函数。
2. 在事件监听器中,将 `State` 对象作为输入和输出。
3. 在事件监听器函数中,将变量添加到输入参数和返回值中。
让我们来看一个猜词游戏的例子。
$code_hangman
$demo_hangman
让我们看看在这个游戏中如何完成上述的 3 个步骤:
1. 我们将已使用的字母存储在 `used_letters_var` 中。在 `State` 的构造函数中,将其初始值设置为空列表`[]`。
2. 在 `btn.click()` 中,我们在输入和输出中都引用了 `used_letters_var`。
3. 在 `guess_letter` 中,我们将此 `State` 的值传递给 `used_letters`,然后在返回语句中返回更新后的该 `State` 的值。
对于更复杂的应用程序,您可能会在一个单独的分块应用程序中使用许多存储会话状态的 `State` 变量。
在[文档](https://gradio.app/docs#state)中了解更多关于 `State` 的信息。
| gradio-app/gradio/blob/main/guides/cn/03_building-with-blocks/03_state-in-blocks.md |
Recent Changes
### Aug 29, 2022
* MaxVit window size scales with img_size by default. Add new RelPosMlp MaxViT weight that leverages this:
* `maxvit_rmlp_nano_rw_256` - 83.0 @ 256, 83.6 @ 320 (T)
### Aug 26, 2022
* CoAtNet (https://arxiv.org/abs/2106.04803) and MaxVit (https://arxiv.org/abs/2204.01697) `timm` original models
* both found in [`maxxvit.py`](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/maxxvit.py) model def, contains numerous experiments outside scope of original papers
* an unfinished Tensorflow version from MaxVit authors can be found https://github.com/google-research/maxvit
* Initial CoAtNet and MaxVit timm pretrained weights (working on more):
* `coatnet_nano_rw_224` - 81.7 @ 224 (T)
* `coatnet_rmlp_nano_rw_224` - 82.0 @ 224, 82.8 @ 320 (T)
* `coatnet_0_rw_224` - 82.4 (T) -- NOTE timm '0' coatnets have 2 more 3rd stage blocks
* `coatnet_bn_0_rw_224` - 82.4 (T)
* `maxvit_nano_rw_256` - 82.9 @ 256 (T)
* `coatnet_rmlp_1_rw_224` - 83.4 @ 224, 84 @ 320 (T)
* `coatnet_1_rw_224` - 83.6 @ 224 (G)
* (T) = TPU trained with `bits_and_tpu` branch training code, (G) = GPU trained
* GCVit (weights adapted from https://github.com/NVlabs/GCVit, code 100% `timm` re-write for license purposes)
* MViT-V2 (multi-scale vit, adapted from https://github.com/facebookresearch/mvit)
* EfficientFormer (adapted from https://github.com/snap-research/EfficientFormer)
* PyramidVisionTransformer-V2 (adapted from https://github.com/whai362/PVT)
* 'Fast Norm' support for LayerNorm and GroupNorm that avoids float32 upcast w/ AMP (uses APEX LN if available for further boost)
### Aug 15, 2022
* ConvNeXt atto weights added
* `convnext_atto` - 75.7 @ 224, 77.0 @ 288
* `convnext_atto_ols` - 75.9 @ 224, 77.2 @ 288
### Aug 5, 2022
* More custom ConvNeXt smaller model defs with weights
* `convnext_femto` - 77.5 @ 224, 78.7 @ 288
* `convnext_femto_ols` - 77.9 @ 224, 78.9 @ 288
* `convnext_pico` - 79.5 @ 224, 80.4 @ 288
* `convnext_pico_ols` - 79.5 @ 224, 80.5 @ 288
* `convnext_nano_ols` - 80.9 @ 224, 81.6 @ 288
* Updated EdgeNeXt to improve ONNX export, add new base variant and weights from original (https://github.com/mmaaz60/EdgeNeXt)
### July 28, 2022
* Add freshly minted DeiT-III Medium (width=512, depth=12, num_heads=8) model weights. Thanks [Hugo Touvron](https://github.com/TouvronHugo)!
### July 27, 2022
* All runtime benchmark and validation result csv files are finally up-to-date!
* A few more weights & model defs added:
* `darknetaa53` - 79.8 @ 256, 80.5 @ 288
* `convnext_nano` - 80.8 @ 224, 81.5 @ 288
* `cs3sedarknet_l` - 81.2 @ 256, 81.8 @ 288
* `cs3darknet_x` - 81.8 @ 256, 82.2 @ 288
* `cs3sedarknet_x` - 82.2 @ 256, 82.7 @ 288
* `cs3edgenet_x` - 82.2 @ 256, 82.7 @ 288
* `cs3se_edgenet_x` - 82.8 @ 256, 83.5 @ 320
* `cs3*` weights above all trained on TPU w/ `bits_and_tpu` branch. Thanks to TRC program!
* Add output_stride=8 and 16 support to ConvNeXt (dilation)
* deit3 models not being able to resize pos_emb fixed
* Version 0.6.7 PyPi release (/w above bug fixes and new weighs since 0.6.5)
### July 8, 2022
More models, more fixes
* Official research models (w/ weights) added:
* EdgeNeXt from (https://github.com/mmaaz60/EdgeNeXt)
* MobileViT-V2 from (https://github.com/apple/ml-cvnets)
* DeiT III (Revenge of the ViT) from (https://github.com/facebookresearch/deit)
* My own models:
* Small `ResNet` defs added by request with 1 block repeats for both basic and bottleneck (resnet10 and resnet14)
* `CspNet` refactored with dataclass config, simplified CrossStage3 (`cs3`) option. These are closer to YOLO-v5+ backbone defs.
* More relative position vit fiddling. Two `srelpos` (shared relative position) models trained, and a medium w/ class token.
* Add an alternate downsample mode to EdgeNeXt and train a `small` model. Better than original small, but not their new USI trained weights.
* My own model weight results (all ImageNet-1k training)
* `resnet10t` - 66.5 @ 176, 68.3 @ 224
* `resnet14t` - 71.3 @ 176, 72.3 @ 224
* `resnetaa50` - 80.6 @ 224 , 81.6 @ 288
* `darknet53` - 80.0 @ 256, 80.5 @ 288
* `cs3darknet_m` - 77.0 @ 256, 77.6 @ 288
* `cs3darknet_focus_m` - 76.7 @ 256, 77.3 @ 288
* `cs3darknet_l` - 80.4 @ 256, 80.9 @ 288
* `cs3darknet_focus_l` - 80.3 @ 256, 80.9 @ 288
* `vit_srelpos_small_patch16_224` - 81.1 @ 224, 82.1 @ 320
* `vit_srelpos_medium_patch16_224` - 82.3 @ 224, 83.1 @ 320
* `vit_relpos_small_patch16_cls_224` - 82.6 @ 224, 83.6 @ 320
* `edgnext_small_rw` - 79.6 @ 224, 80.4 @ 320
* `cs3`, `darknet`, and `vit_*relpos` weights above all trained on TPU thanks to TRC program! Rest trained on overheating GPUs.
* Hugging Face Hub support fixes verified, demo notebook TBA
* Pretrained weights / configs can be loaded externally (ie from local disk) w/ support for head adaptation.
* Add support to change image extensions scanned by `timm` datasets/readers. See (https://github.com/rwightman/pytorch-image-models/pull/1274#issuecomment-1178303103)
* Default ConvNeXt LayerNorm impl to use `F.layer_norm(x.permute(0, 2, 3, 1), ...).permute(0, 3, 1, 2)` via `LayerNorm2d` in all cases.
* a bit slower than previous custom impl on some hardware (ie Ampere w/ CL), but overall fewer regressions across wider HW / PyTorch version ranges.
* previous impl exists as `LayerNormExp2d` in `models/layers/norm.py`
* Numerous bug fixes
* Currently testing for imminent PyPi 0.6.x release
* LeViT pretraining of larger models still a WIP, they don't train well / easily without distillation. Time to add distill support (finally)?
* ImageNet-22k weight training + finetune ongoing, work on multi-weight support (slowly) chugging along (there are a LOT of weights, sigh) ...
### May 13, 2022
* Official Swin-V2 models and weights added from (https://github.com/microsoft/Swin-Transformer). Cleaned up to support torchscript.
* Some refactoring for existing `timm` Swin-V2-CR impl, will likely do a bit more to bring parts closer to official and decide whether to merge some aspects.
* More Vision Transformer relative position / residual post-norm experiments (all trained on TPU thanks to TRC program)
* `vit_relpos_small_patch16_224` - 81.5 @ 224, 82.5 @ 320 -- rel pos, layer scale, no class token, avg pool
* `vit_relpos_medium_patch16_rpn_224` - 82.3 @ 224, 83.1 @ 320 -- rel pos + res-post-norm, no class token, avg pool
* `vit_relpos_medium_patch16_224` - 82.5 @ 224, 83.3 @ 320 -- rel pos, layer scale, no class token, avg pool
* `vit_relpos_base_patch16_gapcls_224` - 82.8 @ 224, 83.9 @ 320 -- rel pos, layer scale, class token, avg pool (by mistake)
* Bring 512 dim, 8-head 'medium' ViT model variant back to life (after using in a pre DeiT 'small' model for first ViT impl back in 2020)
* Add ViT relative position support for switching btw existing impl and some additions in official Swin-V2 impl for future trials
* Sequencer2D impl (https://arxiv.org/abs/2205.01972), added via PR from author (https://github.com/okojoalg)
### May 2, 2022
* Vision Transformer experiments adding Relative Position (Swin-V2 log-coord) (`vision_transformer_relpos.py`) and Residual Post-Norm branches (from Swin-V2) (`vision_transformer*.py`)
* `vit_relpos_base_patch32_plus_rpn_256` - 79.5 @ 256, 80.6 @ 320 -- rel pos + extended width + res-post-norm, no class token, avg pool
* `vit_relpos_base_patch16_224` - 82.5 @ 224, 83.6 @ 320 -- rel pos, layer scale, no class token, avg pool
* `vit_base_patch16_rpn_224` - 82.3 @ 224 -- rel pos + res-post-norm, no class token, avg pool
* Vision Transformer refactor to remove representation layer that was only used in initial vit and rarely used since with newer pretrain (ie `How to Train Your ViT`)
* `vit_*` models support removal of class token, use of global average pool, use of fc_norm (ala beit, mae).
### April 22, 2022
* `timm` models are now officially supported in [fast.ai](https://www.fast.ai/)! Just in time for the new Practical Deep Learning course. `timmdocs` documentation link updated to [timm.fast.ai](http://timm.fast.ai/).
* Two more model weights added in the TPU trained [series](https://github.com/rwightman/pytorch-image-models/releases/tag/v0.1-tpu-weights). Some In22k pretrain still in progress.
* `seresnext101d_32x8d` - 83.69 @ 224, 84.35 @ 288
* `seresnextaa101d_32x8d` (anti-aliased w/ AvgPool2d) - 83.85 @ 224, 84.57 @ 288
### March 23, 2022
* Add `ParallelBlock` and `LayerScale` option to base vit models to support model configs in [Three things everyone should know about ViT](https://arxiv.org/abs/2203.09795)
* `convnext_tiny_hnf` (head norm first) weights trained with (close to) A2 recipe, 82.2% top-1, could do better with more epochs.
### March 21, 2022
* Merge `norm_norm_norm`. **IMPORTANT** this update for a coming 0.6.x release will likely de-stabilize the master branch for a while. Branch [`0.5.x`](https://github.com/rwightman/pytorch-image-models/tree/0.5.x) or a previous 0.5.x release can be used if stability is required.
* Significant weights update (all TPU trained) as described in this [release](https://github.com/rwightman/pytorch-image-models/releases/tag/v0.1-tpu-weights)
* `regnety_040` - 82.3 @ 224, 82.96 @ 288
* `regnety_064` - 83.0 @ 224, 83.65 @ 288
* `regnety_080` - 83.17 @ 224, 83.86 @ 288
* `regnetv_040` - 82.44 @ 224, 83.18 @ 288 (timm pre-act)
* `regnetv_064` - 83.1 @ 224, 83.71 @ 288 (timm pre-act)
* `regnetz_040` - 83.67 @ 256, 84.25 @ 320
* `regnetz_040h` - 83.77 @ 256, 84.5 @ 320 (w/ extra fc in head)
* `resnetv2_50d_gn` - 80.8 @ 224, 81.96 @ 288 (pre-act GroupNorm)
* `resnetv2_50d_evos` 80.77 @ 224, 82.04 @ 288 (pre-act EvoNormS)
* `regnetz_c16_evos` - 81.9 @ 256, 82.64 @ 320 (EvoNormS)
* `regnetz_d8_evos` - 83.42 @ 256, 84.04 @ 320 (EvoNormS)
* `xception41p` - 82 @ 299 (timm pre-act)
* `xception65` - 83.17 @ 299
* `xception65p` - 83.14 @ 299 (timm pre-act)
* `resnext101_64x4d` - 82.46 @ 224, 83.16 @ 288
* `seresnext101_32x8d` - 83.57 @ 224, 84.270 @ 288
* `resnetrs200` - 83.85 @ 256, 84.44 @ 320
* HuggingFace hub support fixed w/ initial groundwork for allowing alternative 'config sources' for pretrained model definitions and weights (generic local file / remote url support soon)
* SwinTransformer-V2 implementation added. Submitted by [Christoph Reich](https://github.com/ChristophReich1996). Training experiments and model changes by myself are ongoing so expect compat breaks.
* Swin-S3 (AutoFormerV2) models / weights added from https://github.com/microsoft/Cream/tree/main/AutoFormerV2
* MobileViT models w/ weights adapted from https://github.com/apple/ml-cvnets
* PoolFormer models w/ weights adapted from https://github.com/sail-sg/poolformer
* VOLO models w/ weights adapted from https://github.com/sail-sg/volo
* Significant work experimenting with non-BatchNorm norm layers such as EvoNorm, FilterResponseNorm, GroupNorm, etc
* Enhance support for alternate norm + act ('NormAct') layers added to a number of models, esp EfficientNet/MobileNetV3, RegNet, and aligned Xception
* Grouped conv support added to EfficientNet family
* Add 'group matching' API to all models to allow grouping model parameters for application of 'layer-wise' LR decay, lr scale added to LR scheduler
* Gradient checkpointing support added to many models
* `forward_head(x, pre_logits=False)` fn added to all models to allow separate calls of `forward_features` + `forward_head`
* All vision transformer and vision MLP models update to return non-pooled / non-token selected features from `foward_features`, for consistency with CNN models, token selection or pooling now applied in `forward_head`
### Feb 2, 2022
* [Chris Hughes](https://github.com/Chris-hughes10) posted an exhaustive run through of `timm` on his blog yesterday. Well worth a read. [Getting Started with PyTorch Image Models (timm): A Practitioner’s Guide](https://towardsdatascience.com/getting-started-with-pytorch-image-models-timm-a-practitioners-guide-4e77b4bf9055)
* I'm currently prepping to merge the `norm_norm_norm` branch back to master (ver 0.6.x) in next week or so.
* The changes are more extensive than usual and may destabilize and break some model API use (aiming for full backwards compat). So, beware `pip install git+https://github.com/rwightman/pytorch-image-models` installs!
* `0.5.x` releases and a `0.5.x` branch will remain stable with a cherry pick or two until dust clears. Recommend sticking to pypi install for a bit if you want stable.
### Jan 14, 2022
* Version 0.5.4 w/ release to be pushed to pypi. It's been a while since last pypi update and riskier changes will be merged to main branch soon....
* Add ConvNeXT models /w weights from official impl (https://github.com/facebookresearch/ConvNeXt), a few perf tweaks, compatible with timm features
* Tried training a few small (~1.8-3M param) / mobile optimized models, a few are good so far, more on the way...
* `mnasnet_small` - 65.6 top-1
* `mobilenetv2_050` - 65.9
* `lcnet_100/075/050` - 72.1 / 68.8 / 63.1
* `semnasnet_075` - 73
* `fbnetv3_b/d/g` - 79.1 / 79.7 / 82.0
* TinyNet models added by [rsomani95](https://github.com/rsomani95)
* LCNet added via MobileNetV3 architecture
### Jan 5, 2023
* ConvNeXt-V2 models and weights added to existing `convnext.py`
* Paper: [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](http://arxiv.org/abs/2301.00808)
* Reference impl: https://github.com/facebookresearch/ConvNeXt-V2 (NOTE: weights currently CC-BY-NC)
### Dec 23, 2022 🎄☃
* Add FlexiViT models and weights from https://github.com/google-research/big_vision (check out paper at https://arxiv.org/abs/2212.08013)
* NOTE currently resizing is static on model creation, on-the-fly dynamic / train patch size sampling is a WIP
* Many more models updated to multi-weight and downloadable via HF hub now (convnext, efficientnet, mobilenet, vision_transformer*, beit)
* More model pretrained tag and adjustments, some model names changed (working on deprecation translations, consider main branch DEV branch right now, use 0.6.x for stable use)
* More ImageNet-12k (subset of 22k) pretrain models popping up:
* `efficientnet_b5.in12k_ft_in1k` - 85.9 @ 448x448
* `vit_medium_patch16_gap_384.in12k_ft_in1k` - 85.5 @ 384x384
* `vit_medium_patch16_gap_256.in12k_ft_in1k` - 84.5 @ 256x256
* `convnext_nano.in12k_ft_in1k` - 82.9 @ 288x288
### Dec 8, 2022
* Add 'EVA l' to `vision_transformer.py`, MAE style ViT-L/14 MIM pretrain w/ EVA-CLIP targets, FT on ImageNet-1k (w/ ImageNet-22k intermediate for some)
* original source: https://github.com/baaivision/EVA
| model | top1 | param_count | gmac | macts | hub |
|:------------------------------------------|-----:|------------:|------:|------:|:----------------------------------------|
| eva_large_patch14_336.in22k_ft_in22k_in1k | 89.2 | 304.5 | 191.1 | 270.2 | [link](https://huggingface.co/BAAI/EVA) |
| eva_large_patch14_336.in22k_ft_in1k | 88.7 | 304.5 | 191.1 | 270.2 | [link](https://huggingface.co/BAAI/EVA) |
| eva_large_patch14_196.in22k_ft_in22k_in1k | 88.6 | 304.1 | 61.6 | 63.5 | [link](https://huggingface.co/BAAI/EVA) |
| eva_large_patch14_196.in22k_ft_in1k | 87.9 | 304.1 | 61.6 | 63.5 | [link](https://huggingface.co/BAAI/EVA) |
### Dec 6, 2022
* Add 'EVA g', BEiT style ViT-g/14 model weights w/ both MIM pretrain and CLIP pretrain to `beit.py`.
* original source: https://github.com/baaivision/EVA
* paper: https://arxiv.org/abs/2211.07636
| model | top1 | param_count | gmac | macts | hub |
|:-----------------------------------------|-------:|--------------:|-------:|--------:|:----------------------------------------|
| eva_giant_patch14_560.m30m_ft_in22k_in1k | 89.8 | 1014.4 | 1906.8 | 2577.2 | [link](https://huggingface.co/BAAI/EVA) |
| eva_giant_patch14_336.m30m_ft_in22k_in1k | 89.6 | 1013 | 620.6 | 550.7 | [link](https://huggingface.co/BAAI/EVA) |
| eva_giant_patch14_336.clip_ft_in1k | 89.4 | 1013 | 620.6 | 550.7 | [link](https://huggingface.co/BAAI/EVA) |
| eva_giant_patch14_224.clip_ft_in1k | 89.1 | 1012.6 | 267.2 | 192.6 | [link](https://huggingface.co/BAAI/EVA) |
### Dec 5, 2022
* Pre-release (`0.8.0dev0`) of multi-weight support (`model_arch.pretrained_tag`). Install with `pip install --pre timm`
* vision_transformer, maxvit, convnext are the first three model impl w/ support
* model names are changing with this (previous _21k, etc. fn will merge), still sorting out deprecation handling
* bugs are likely, but I need feedback so please try it out
* if stability is needed, please use 0.6.x pypi releases or clone from [0.6.x branch](https://github.com/rwightman/pytorch-image-models/tree/0.6.x)
* Support for PyTorch 2.0 compile is added in train/validate/inference/benchmark, use `--torchcompile` argument
* Inference script allows more control over output, select k for top-class index + prob json, csv or parquet output
* Add a full set of fine-tuned CLIP image tower weights from both LAION-2B and original OpenAI CLIP models
| model | top1 | param_count | gmac | macts | hub |
|:-------------------------------------------------|-------:|--------------:|-------:|--------:|:-------------------------------------------------------------------------------------|
| vit_huge_patch14_clip_336.laion2b_ft_in12k_in1k | 88.6 | 632.5 | 391 | 407.5 | [link](https://huggingface.co/timm/vit_huge_patch14_clip_336.laion2b_ft_in12k_in1k) |
| vit_large_patch14_clip_336.openai_ft_in12k_in1k | 88.3 | 304.5 | 191.1 | 270.2 | [link](https://huggingface.co/timm/vit_large_patch14_clip_336.openai_ft_in12k_in1k) |
| vit_huge_patch14_clip_224.laion2b_ft_in12k_in1k | 88.2 | 632 | 167.4 | 139.4 | [link](https://huggingface.co/timm/vit_huge_patch14_clip_224.laion2b_ft_in12k_in1k) |
| vit_large_patch14_clip_336.laion2b_ft_in12k_in1k | 88.2 | 304.5 | 191.1 | 270.2 | [link](https://huggingface.co/timm/vit_large_patch14_clip_336.laion2b_ft_in12k_in1k) |
| vit_large_patch14_clip_224.openai_ft_in12k_in1k | 88.2 | 304.2 | 81.1 | 88.8 | [link](https://huggingface.co/timm/vit_large_patch14_clip_224.openai_ft_in12k_in1k) |
| vit_large_patch14_clip_224.laion2b_ft_in12k_in1k | 87.9 | 304.2 | 81.1 | 88.8 | [link](https://huggingface.co/timm/vit_large_patch14_clip_224.laion2b_ft_in12k_in1k) |
| vit_large_patch14_clip_224.openai_ft_in1k | 87.9 | 304.2 | 81.1 | 88.8 | [link](https://huggingface.co/timm/vit_large_patch14_clip_224.openai_ft_in1k) |
| vit_large_patch14_clip_336.laion2b_ft_in1k | 87.9 | 304.5 | 191.1 | 270.2 | [link](https://huggingface.co/timm/vit_large_patch14_clip_336.laion2b_ft_in1k) |
| vit_huge_patch14_clip_224.laion2b_ft_in1k | 87.6 | 632 | 167.4 | 139.4 | [link](https://huggingface.co/timm/vit_huge_patch14_clip_224.laion2b_ft_in1k) |
| vit_large_patch14_clip_224.laion2b_ft_in1k | 87.3 | 304.2 | 81.1 | 88.8 | [link](https://huggingface.co/timm/vit_large_patch14_clip_224.laion2b_ft_in1k) |
| vit_base_patch16_clip_384.laion2b_ft_in12k_in1k | 87.2 | 86.9 | 55.5 | 101.6 | [link](https://huggingface.co/timm/vit_base_patch16_clip_384.laion2b_ft_in12k_in1k) |
| vit_base_patch16_clip_384.openai_ft_in12k_in1k | 87 | 86.9 | 55.5 | 101.6 | [link](https://huggingface.co/timm/vit_base_patch16_clip_384.openai_ft_in12k_in1k) |
| vit_base_patch16_clip_384.laion2b_ft_in1k | 86.6 | 86.9 | 55.5 | 101.6 | [link](https://huggingface.co/timm/vit_base_patch16_clip_384.laion2b_ft_in1k) |
| vit_base_patch16_clip_384.openai_ft_in1k | 86.2 | 86.9 | 55.5 | 101.6 | [link](https://huggingface.co/timm/vit_base_patch16_clip_384.openai_ft_in1k) |
| vit_base_patch16_clip_224.laion2b_ft_in12k_in1k | 86.2 | 86.6 | 17.6 | 23.9 | [link](https://huggingface.co/timm/vit_base_patch16_clip_224.laion2b_ft_in12k_in1k) |
| vit_base_patch16_clip_224.openai_ft_in12k_in1k | 85.9 | 86.6 | 17.6 | 23.9 | [link](https://huggingface.co/timm/vit_base_patch16_clip_224.openai_ft_in12k_in1k) |
| vit_base_patch32_clip_448.laion2b_ft_in12k_in1k | 85.8 | 88.3 | 17.9 | 23.9 | [link](https://huggingface.co/timm/vit_base_patch32_clip_448.laion2b_ft_in12k_in1k) |
| vit_base_patch16_clip_224.laion2b_ft_in1k | 85.5 | 86.6 | 17.6 | 23.9 | [link](https://huggingface.co/timm/vit_base_patch16_clip_224.laion2b_ft_in1k) |
| vit_base_patch32_clip_384.laion2b_ft_in12k_in1k | 85.4 | 88.3 | 13.1 | 16.5 | [link](https://huggingface.co/timm/vit_base_patch32_clip_384.laion2b_ft_in12k_in1k) |
| vit_base_patch16_clip_224.openai_ft_in1k | 85.3 | 86.6 | 17.6 | 23.9 | [link](https://huggingface.co/timm/vit_base_patch16_clip_224.openai_ft_in1k) |
| vit_base_patch32_clip_384.openai_ft_in12k_in1k | 85.2 | 88.3 | 13.1 | 16.5 | [link](https://huggingface.co/timm/vit_base_patch32_clip_384.openai_ft_in12k_in1k) |
| vit_base_patch32_clip_224.laion2b_ft_in12k_in1k | 83.3 | 88.2 | 4.4 | 5 | [link](https://huggingface.co/timm/vit_base_patch32_clip_224.laion2b_ft_in12k_in1k) |
| vit_base_patch32_clip_224.laion2b_ft_in1k | 82.6 | 88.2 | 4.4 | 5 | [link](https://huggingface.co/timm/vit_base_patch32_clip_224.laion2b_ft_in1k) |
| vit_base_patch32_clip_224.openai_ft_in1k | 81.9 | 88.2 | 4.4 | 5 | [link](https://huggingface.co/timm/vit_base_patch32_clip_224.openai_ft_in1k) |
* Port of MaxViT Tensorflow Weights from official impl at https://github.com/google-research/maxvit
* There was larger than expected drops for the upscaled 384/512 in21k fine-tune weights, possible detail missing, but the 21k FT did seem sensitive to small preprocessing
| model | top1 | param_count | gmac | macts | hub |
|:-----------------------------------|-------:|--------------:|-------:|--------:|:-----------------------------------------------------------------------|
| maxvit_xlarge_tf_512.in21k_ft_in1k | 88.5 | 475.8 | 534.1 | 1413.2 | [link](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |
| maxvit_xlarge_tf_384.in21k_ft_in1k | 88.3 | 475.3 | 292.8 | 668.8 | [link](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |
| maxvit_base_tf_512.in21k_ft_in1k | 88.2 | 119.9 | 138 | 704 | [link](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |
| maxvit_large_tf_512.in21k_ft_in1k | 88 | 212.3 | 244.8 | 942.2 | [link](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |
| maxvit_large_tf_384.in21k_ft_in1k | 88 | 212 | 132.6 | 445.8 | [link](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |
| maxvit_base_tf_384.in21k_ft_in1k | 87.9 | 119.6 | 73.8 | 332.9 | [link](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |
| maxvit_base_tf_512.in1k | 86.6 | 119.9 | 138 | 704 | [link](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |
| maxvit_large_tf_512.in1k | 86.5 | 212.3 | 244.8 | 942.2 | [link](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |
| maxvit_base_tf_384.in1k | 86.3 | 119.6 | 73.8 | 332.9 | [link](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |
| maxvit_large_tf_384.in1k | 86.2 | 212 | 132.6 | 445.8 | [link](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |
| maxvit_small_tf_512.in1k | 86.1 | 69.1 | 67.3 | 383.8 | [link](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |
| maxvit_tiny_tf_512.in1k | 85.7 | 31 | 33.5 | 257.6 | [link](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |
| maxvit_small_tf_384.in1k | 85.5 | 69 | 35.9 | 183.6 | [link](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |
| maxvit_tiny_tf_384.in1k | 85.1 | 31 | 17.5 | 123.4 | [link](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |
| maxvit_large_tf_224.in1k | 84.9 | 211.8 | 43.7 | 127.4 | [link](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |
| maxvit_base_tf_224.in1k | 84.9 | 119.5 | 24 | 95 | [link](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |
| maxvit_small_tf_224.in1k | 84.4 | 68.9 | 11.7 | 53.2 | [link](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |
| maxvit_tiny_tf_224.in1k | 83.4 | 30.9 | 5.6 | 35.8 | [link](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |
### Oct 15, 2022
* Train and validation script enhancements
* Non-GPU (ie CPU) device support
* SLURM compatibility for train script
* HF datasets support (via ReaderHfds)
* TFDS/WDS dataloading improvements (sample padding/wrap for distributed use fixed wrt sample count estimate)
* in_chans !=3 support for scripts / loader
* Adan optimizer
* Can enable per-step LR scheduling via args
* Dataset 'parsers' renamed to 'readers', more descriptive of purpose
* AMP args changed, APEX via `--amp-impl apex`, bfloat16 supportedf via `--amp-dtype bfloat16`
* main branch switched to 0.7.x version, 0.6x forked for stable release of weight only adds
* master -> main branch rename
### Oct 10, 2022
* More weights in `maxxvit` series, incl first ConvNeXt block based `coatnext` and `maxxvit` experiments:
* `coatnext_nano_rw_224` - 82.0 @ 224 (G) -- (uses ConvNeXt conv block, no BatchNorm)
* `maxxvit_rmlp_nano_rw_256` - 83.0 @ 256, 83.7 @ 320 (G) (uses ConvNeXt conv block, no BN)
* `maxvit_rmlp_small_rw_224` - 84.5 @ 224, 85.1 @ 320 (G)
* `maxxvit_rmlp_small_rw_256` - 84.6 @ 256, 84.9 @ 288 (G) -- could be trained better, hparams need tuning (uses ConvNeXt block, no BN)
* `coatnet_rmlp_2_rw_224` - 84.6 @ 224, 85 @ 320 (T)
* NOTE: official MaxVit weights (in1k) have been released at https://github.com/google-research/maxvit -- some extra work is needed to port and adapt since my impl was created independently of theirs and has a few small differences + the whole TF same padding fun.
### Sept 23, 2022
* LAION-2B CLIP image towers supported as pretrained backbones for fine-tune or features (no classifier)
* vit_base_patch32_224_clip_laion2b
* vit_large_patch14_224_clip_laion2b
* vit_huge_patch14_224_clip_laion2b
* vit_giant_patch14_224_clip_laion2b
### Sept 7, 2022
* Hugging Face [`timm` docs](https://huggingface.co/docs/hub/timm) home now exists, look for more here in the future
* Add BEiT-v2 weights for base and large 224x224 models from https://github.com/microsoft/unilm/tree/master/beit2
* Add more weights in `maxxvit` series incl a `pico` (7.5M params, 1.9 GMACs), two `tiny` variants:
* `maxvit_rmlp_pico_rw_256` - 80.5 @ 256, 81.3 @ 320 (T)
* `maxvit_tiny_rw_224` - 83.5 @ 224 (G)
* `maxvit_rmlp_tiny_rw_256` - 84.2 @ 256, 84.8 @ 320 (T)
### Aug 29, 2022
* MaxVit window size scales with img_size by default. Add new RelPosMlp MaxViT weight that leverages this:
* `maxvit_rmlp_nano_rw_256` - 83.0 @ 256, 83.6 @ 320 (T)
### Aug 26, 2022
* CoAtNet (https://arxiv.org/abs/2106.04803) and MaxVit (https://arxiv.org/abs/2204.01697) `timm` original models
* both found in [`maxxvit.py`](https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/maxxvit.py) model def, contains numerous experiments outside scope of original papers
* an unfinished Tensorflow version from MaxVit authors can be found https://github.com/google-research/maxvit
* Initial CoAtNet and MaxVit timm pretrained weights (working on more):
* `coatnet_nano_rw_224` - 81.7 @ 224 (T)
* `coatnet_rmlp_nano_rw_224` - 82.0 @ 224, 82.8 @ 320 (T)
* `coatnet_0_rw_224` - 82.4 (T) -- NOTE timm '0' coatnets have 2 more 3rd stage blocks
* `coatnet_bn_0_rw_224` - 82.4 (T)
* `maxvit_nano_rw_256` - 82.9 @ 256 (T)
* `coatnet_rmlp_1_rw_224` - 83.4 @ 224, 84 @ 320 (T)
* `coatnet_1_rw_224` - 83.6 @ 224 (G)
* (T) = TPU trained with `bits_and_tpu` branch training code, (G) = GPU trained
* GCVit (weights adapted from https://github.com/NVlabs/GCVit, code 100% `timm` re-write for license purposes)
* MViT-V2 (multi-scale vit, adapted from https://github.com/facebookresearch/mvit)
* EfficientFormer (adapted from https://github.com/snap-research/EfficientFormer)
* PyramidVisionTransformer-V2 (adapted from https://github.com/whai362/PVT)
* 'Fast Norm' support for LayerNorm and GroupNorm that avoids float32 upcast w/ AMP (uses APEX LN if available for further boost)
### Aug 15, 2022
* ConvNeXt atto weights added
* `convnext_atto` - 75.7 @ 224, 77.0 @ 288
* `convnext_atto_ols` - 75.9 @ 224, 77.2 @ 288
### Aug 5, 2022
* More custom ConvNeXt smaller model defs with weights
* `convnext_femto` - 77.5 @ 224, 78.7 @ 288
* `convnext_femto_ols` - 77.9 @ 224, 78.9 @ 288
* `convnext_pico` - 79.5 @ 224, 80.4 @ 288
* `convnext_pico_ols` - 79.5 @ 224, 80.5 @ 288
* `convnext_nano_ols` - 80.9 @ 224, 81.6 @ 288
* Updated EdgeNeXt to improve ONNX export, add new base variant and weights from original (https://github.com/mmaaz60/EdgeNeXt)
### July 28, 2022
* Add freshly minted DeiT-III Medium (width=512, depth=12, num_heads=8) model weights. Thanks [Hugo Touvron](https://github.com/TouvronHugo)!
### July 27, 2022
* All runtime benchmark and validation result csv files are up-to-date!
* A few more weights & model defs added:
* `darknetaa53` - 79.8 @ 256, 80.5 @ 288
* `convnext_nano` - 80.8 @ 224, 81.5 @ 288
* `cs3sedarknet_l` - 81.2 @ 256, 81.8 @ 288
* `cs3darknet_x` - 81.8 @ 256, 82.2 @ 288
* `cs3sedarknet_x` - 82.2 @ 256, 82.7 @ 288
* `cs3edgenet_x` - 82.2 @ 256, 82.7 @ 288
* `cs3se_edgenet_x` - 82.8 @ 256, 83.5 @ 320
* `cs3*` weights above all trained on TPU w/ `bits_and_tpu` branch. Thanks to TRC program!
* Add output_stride=8 and 16 support to ConvNeXt (dilation)
* deit3 models not being able to resize pos_emb fixed
* Version 0.6.7 PyPi release (/w above bug fixes and new weighs since 0.6.5)
### July 8, 2022
More models, more fixes
* Official research models (w/ weights) added:
* EdgeNeXt from (https://github.com/mmaaz60/EdgeNeXt)
* MobileViT-V2 from (https://github.com/apple/ml-cvnets)
* DeiT III (Revenge of the ViT) from (https://github.com/facebookresearch/deit)
* My own models:
* Small `ResNet` defs added by request with 1 block repeats for both basic and bottleneck (resnet10 and resnet14)
* `CspNet` refactored with dataclass config, simplified CrossStage3 (`cs3`) option. These are closer to YOLO-v5+ backbone defs.
* More relative position vit fiddling. Two `srelpos` (shared relative position) models trained, and a medium w/ class token.
* Add an alternate downsample mode to EdgeNeXt and train a `small` model. Better than original small, but not their new USI trained weights.
* My own model weight results (all ImageNet-1k training)
* `resnet10t` - 66.5 @ 176, 68.3 @ 224
* `resnet14t` - 71.3 @ 176, 72.3 @ 224
* `resnetaa50` - 80.6 @ 224 , 81.6 @ 288
* `darknet53` - 80.0 @ 256, 80.5 @ 288
* `cs3darknet_m` - 77.0 @ 256, 77.6 @ 288
* `cs3darknet_focus_m` - 76.7 @ 256, 77.3 @ 288
* `cs3darknet_l` - 80.4 @ 256, 80.9 @ 288
* `cs3darknet_focus_l` - 80.3 @ 256, 80.9 @ 288
* `vit_srelpos_small_patch16_224` - 81.1 @ 224, 82.1 @ 320
* `vit_srelpos_medium_patch16_224` - 82.3 @ 224, 83.1 @ 320
* `vit_relpos_small_patch16_cls_224` - 82.6 @ 224, 83.6 @ 320
* `edgnext_small_rw` - 79.6 @ 224, 80.4 @ 320
* `cs3`, `darknet`, and `vit_*relpos` weights above all trained on TPU thanks to TRC program! Rest trained on overheating GPUs.
* Hugging Face Hub support fixes verified, demo notebook TBA
* Pretrained weights / configs can be loaded externally (ie from local disk) w/ support for head adaptation.
* Add support to change image extensions scanned by `timm` datasets/parsers. See (https://github.com/rwightman/pytorch-image-models/pull/1274#issuecomment-1178303103)
* Default ConvNeXt LayerNorm impl to use `F.layer_norm(x.permute(0, 2, 3, 1), ...).permute(0, 3, 1, 2)` via `LayerNorm2d` in all cases.
* a bit slower than previous custom impl on some hardware (ie Ampere w/ CL), but overall fewer regressions across wider HW / PyTorch version ranges.
* previous impl exists as `LayerNormExp2d` in `models/layers/norm.py`
* Numerous bug fixes
* Currently testing for imminent PyPi 0.6.x release
* LeViT pretraining of larger models still a WIP, they don't train well / easily without distillation. Time to add distill support (finally)?
* ImageNet-22k weight training + finetune ongoing, work on multi-weight support (slowly) chugging along (there are a LOT of weights, sigh) ...
### May 13, 2022
* Official Swin-V2 models and weights added from (https://github.com/microsoft/Swin-Transformer). Cleaned up to support torchscript.
* Some refactoring for existing `timm` Swin-V2-CR impl, will likely do a bit more to bring parts closer to official and decide whether to merge some aspects.
* More Vision Transformer relative position / residual post-norm experiments (all trained on TPU thanks to TRC program)
* `vit_relpos_small_patch16_224` - 81.5 @ 224, 82.5 @ 320 -- rel pos, layer scale, no class token, avg pool
* `vit_relpos_medium_patch16_rpn_224` - 82.3 @ 224, 83.1 @ 320 -- rel pos + res-post-norm, no class token, avg pool
* `vit_relpos_medium_patch16_224` - 82.5 @ 224, 83.3 @ 320 -- rel pos, layer scale, no class token, avg pool
* `vit_relpos_base_patch16_gapcls_224` - 82.8 @ 224, 83.9 @ 320 -- rel pos, layer scale, class token, avg pool (by mistake)
* Bring 512 dim, 8-head 'medium' ViT model variant back to life (after using in a pre DeiT 'small' model for first ViT impl back in 2020)
* Add ViT relative position support for switching btw existing impl and some additions in official Swin-V2 impl for future trials
* Sequencer2D impl (https://arxiv.org/abs/2205.01972), added via PR from author (https://github.com/okojoalg)
### May 2, 2022
* Vision Transformer experiments adding Relative Position (Swin-V2 log-coord) (`vision_transformer_relpos.py`) and Residual Post-Norm branches (from Swin-V2) (`vision_transformer*.py`)
* `vit_relpos_base_patch32_plus_rpn_256` - 79.5 @ 256, 80.6 @ 320 -- rel pos + extended width + res-post-norm, no class token, avg pool
* `vit_relpos_base_patch16_224` - 82.5 @ 224, 83.6 @ 320 -- rel pos, layer scale, no class token, avg pool
* `vit_base_patch16_rpn_224` - 82.3 @ 224 -- rel pos + res-post-norm, no class token, avg pool
* Vision Transformer refactor to remove representation layer that was only used in initial vit and rarely used since with newer pretrain (ie `How to Train Your ViT`)
* `vit_*` models support removal of class token, use of global average pool, use of fc_norm (ala beit, mae).
### April 22, 2022
* `timm` models are now officially supported in [fast.ai](https://www.fast.ai/)! Just in time for the new Practical Deep Learning course. `timmdocs` documentation link updated to [timm.fast.ai](http://timm.fast.ai/).
* Two more model weights added in the TPU trained [series](https://github.com/rwightman/pytorch-image-models/releases/tag/v0.1-tpu-weights). Some In22k pretrain still in progress.
* `seresnext101d_32x8d` - 83.69 @ 224, 84.35 @ 288
* `seresnextaa101d_32x8d` (anti-aliased w/ AvgPool2d) - 83.85 @ 224, 84.57 @ 288
### March 23, 2022
* Add `ParallelBlock` and `LayerScale` option to base vit models to support model configs in [Three things everyone should know about ViT](https://arxiv.org/abs/2203.09795)
* `convnext_tiny_hnf` (head norm first) weights trained with (close to) A2 recipe, 82.2% top-1, could do better with more epochs.
### March 21, 2022
* Merge `norm_norm_norm`. **IMPORTANT** this update for a coming 0.6.x release will likely de-stabilize the master branch for a while. Branch [`0.5.x`](https://github.com/rwightman/pytorch-image-models/tree/0.5.x) or a previous 0.5.x release can be used if stability is required.
* Significant weights update (all TPU trained) as described in this [release](https://github.com/rwightman/pytorch-image-models/releases/tag/v0.1-tpu-weights)
* `regnety_040` - 82.3 @ 224, 82.96 @ 288
* `regnety_064` - 83.0 @ 224, 83.65 @ 288
* `regnety_080` - 83.17 @ 224, 83.86 @ 288
* `regnetv_040` - 82.44 @ 224, 83.18 @ 288 (timm pre-act)
* `regnetv_064` - 83.1 @ 224, 83.71 @ 288 (timm pre-act)
* `regnetz_040` - 83.67 @ 256, 84.25 @ 320
* `regnetz_040h` - 83.77 @ 256, 84.5 @ 320 (w/ extra fc in head)
* `resnetv2_50d_gn` - 80.8 @ 224, 81.96 @ 288 (pre-act GroupNorm)
* `resnetv2_50d_evos` 80.77 @ 224, 82.04 @ 288 (pre-act EvoNormS)
* `regnetz_c16_evos` - 81.9 @ 256, 82.64 @ 320 (EvoNormS)
* `regnetz_d8_evos` - 83.42 @ 256, 84.04 @ 320 (EvoNormS)
* `xception41p` - 82 @ 299 (timm pre-act)
* `xception65` - 83.17 @ 299
* `xception65p` - 83.14 @ 299 (timm pre-act)
* `resnext101_64x4d` - 82.46 @ 224, 83.16 @ 288
* `seresnext101_32x8d` - 83.57 @ 224, 84.270 @ 288
* `resnetrs200` - 83.85 @ 256, 84.44 @ 320
* HuggingFace hub support fixed w/ initial groundwork for allowing alternative 'config sources' for pretrained model definitions and weights (generic local file / remote url support soon)
* SwinTransformer-V2 implementation added. Submitted by [Christoph Reich](https://github.com/ChristophReich1996). Training experiments and model changes by myself are ongoing so expect compat breaks.
* Swin-S3 (AutoFormerV2) models / weights added from https://github.com/microsoft/Cream/tree/main/AutoFormerV2
* MobileViT models w/ weights adapted from https://github.com/apple/ml-cvnets
* PoolFormer models w/ weights adapted from https://github.com/sail-sg/poolformer
* VOLO models w/ weights adapted from https://github.com/sail-sg/volo
* Significant work experimenting with non-BatchNorm norm layers such as EvoNorm, FilterResponseNorm, GroupNorm, etc
* Enhance support for alternate norm + act ('NormAct') layers added to a number of models, esp EfficientNet/MobileNetV3, RegNet, and aligned Xception
* Grouped conv support added to EfficientNet family
* Add 'group matching' API to all models to allow grouping model parameters for application of 'layer-wise' LR decay, lr scale added to LR scheduler
* Gradient checkpointing support added to many models
* `forward_head(x, pre_logits=False)` fn added to all models to allow separate calls of `forward_features` + `forward_head`
* All vision transformer and vision MLP models update to return non-pooled / non-token selected features from `foward_features`, for consistency with CNN models, token selection or pooling now applied in `forward_head`
### Feb 2, 2022
* [Chris Hughes](https://github.com/Chris-hughes10) posted an exhaustive run through of `timm` on his blog yesterday. Well worth a read. [Getting Started with PyTorch Image Models (timm): A Practitioner’s Guide](https://towardsdatascience.com/getting-started-with-pytorch-image-models-timm-a-practitioners-guide-4e77b4bf9055)
* I'm currently prepping to merge the `norm_norm_norm` branch back to master (ver 0.6.x) in next week or so.
* The changes are more extensive than usual and may destabilize and break some model API use (aiming for full backwards compat). So, beware `pip install git+https://github.com/rwightman/pytorch-image-models` installs!
* `0.5.x` releases and a `0.5.x` branch will remain stable with a cherry pick or two until dust clears. Recommend sticking to pypi install for a bit if you want stable.
### Jan 14, 2022
* Version 0.5.4 w/ release to be pushed to pypi. It's been a while since last pypi update and riskier changes will be merged to main branch soon....
* Add ConvNeXT models /w weights from official impl (https://github.com/facebookresearch/ConvNeXt), a few perf tweaks, compatible with timm features
* Tried training a few small (~1.8-3M param) / mobile optimized models, a few are good so far, more on the way...
* `mnasnet_small` - 65.6 top-1
* `mobilenetv2_050` - 65.9
* `lcnet_100/075/050` - 72.1 / 68.8 / 63.1
* `semnasnet_075` - 73
* `fbnetv3_b/d/g` - 79.1 / 79.7 / 82.0
* TinyNet models added by [rsomani95](https://github.com/rsomani95)
* LCNet added via MobileNetV3 architecture
| huggingface/pytorch-image-models/blob/main/docs/changes.md |
Metric Card for Exact Match
## Metric Description
A given predicted string's exact match score is 1 if it is the exact same as its reference string, and is 0 otherwise.
- **Example 1**: The exact match score of prediction "Happy Birthday!" is 0, given its reference is "Happy New Year!".
- **Example 2**: The exact match score of prediction "The Colour of Magic (1983)" is 1, given its reference is also "The Colour of Magic (1983)".
The exact match score of a set of predictions is the sum of all of the individual exact match scores in the set, divided by the total number of predictions in the set.
- **Example**: The exact match score of the set {Example 1, Example 2} (above) is 0.5.
## How to Use
At minimum, this metric takes as input predictions and references:
```python
>>> from datasets import load_metric
>>> exact_match_metric = load_metric("exact_match")
>>> results = exact_match_metric.compute(predictions=predictions, references=references)
```
### Inputs
- **`predictions`** (`list` of `str`): List of predicted texts.
- **`references`** (`list` of `str`): List of reference texts.
- **`regexes_to_ignore`** (`list` of `str`): Regex expressions of characters to ignore when calculating the exact matches. Defaults to `None`. Note: the regex changes are applied before capitalization is normalized.
- **`ignore_case`** (`bool`): If `True`, turns everything to lowercase so that capitalization differences are ignored. Defaults to `False`.
- **`ignore_punctuation`** (`bool`): If `True`, removes punctuation before comparing strings. Defaults to `False`.
- **`ignore_numbers`** (`bool`): If `True`, removes all digits before comparing strings. Defaults to `False`.
### Output Values
This metric outputs a dictionary with one value: the average exact match score.
```python
{'exact_match': 100.0}
```
This metric's range is 0-100, inclusive. Here, 0.0 means no prediction/reference pairs were matches, while 100.0 means they all were.
#### Values from Popular Papers
The exact match metric is often included in other metrics, such as SQuAD. For example, the [original SQuAD paper](https://nlp.stanford.edu/pubs/rajpurkar2016squad.pdf) reported an Exact Match score of 40.0%. They also report that the human performance Exact Match score on the dataset was 80.3%.
### Examples
Without including any regexes to ignore:
```python
>>> exact_match = datasets.load_metric("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds)
>>> print(round(results["exact_match"], 1))
25.0
```
Ignoring regexes "the" and "yell", as well as ignoring case and punctuation:
```python
>>> exact_match = datasets.load_metric("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds, regexes_to_ignore=["the ", "yell"], ignore_case=True, ignore_punctuation=True)
>>> print(round(results["exact_match"], 1))
50.0
```
Note that in the example above, because the regexes are ignored before the case is normalized, "yell" from "YELLING" is not deleted.
Ignoring "the", "yell", and "YELL", as well as ignoring case and punctuation:
```python
>>> exact_match = datasets.load_metric("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds, regexes_to_ignore=["the ", "yell", "YELL"], ignore_case=True, ignore_punctuation=True)
>>> print(round(results["exact_match"], 1))
75.0
```
Ignoring "the", "yell", and "YELL", as well as ignoring case, punctuation, and numbers:
```python
>>> exact_match = datasets.load_metric("exact_match")
>>> refs = ["the cat", "theater", "YELLING", "agent007"]
>>> preds = ["cat?", "theater", "yelling", "agent"]
>>> results = exact_match.compute(references=refs, predictions=preds, regexes_to_ignore=["the ", "yell", "YELL"], ignore_case=True, ignore_punctuation=True, ignore_numbers=True)
>>> print(round(results["exact_match"], 1))
100.0
```
An example that includes sentences:
```python
>>> exact_match = datasets.load_metric("exact_match")
>>> refs = ["The cat sat on the mat.", "Theaters are great.", "It's like comparing oranges and apples."]
>>> preds = ["The cat sat on the mat?", "Theaters are great.", "It's like comparing apples and oranges."]
>>> results = exact_match.compute(references=refs, predictions=preds)
>>> print(round(results["exact_match"], 1))
33.3
```
## Limitations and Bias
This metric is limited in that it outputs the same score for something that is completely wrong as for something that is correct except for a single character. In other words, there is no award for being *almost* right.
## Citation
## Further References
- Also used in the [SQuAD metric](https://github.com/huggingface/datasets/tree/main/metrics/squad)
| huggingface/datasets/blob/main/metrics/exact_match/README.md |
!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# How to add a new example script in 🤗 Transformers
This folder provide a template for adding a new example script implementing a training or inference task with the
models in the 🤗 Transformers library. To use it, you will need to install cookiecutter:
```
pip install cookiecutter
```
or refer to the installation page of the [cookiecutter documentation](https://cookiecutter.readthedocs.io/).
You can then run the following command inside the `examples` folder of the transformers repo:
```
cookiecutter ../templates/adding_a_new_example_script/
```
and answer the questions asked, which will generate a new folder where you will find a pre-filled template for your
example following the best practices we recommend for them.
Adjust the way the data is preprocessed, the model is loaded or the Trainer is instantiated then when you're happy, add
a `README.md` in the folder (or complete the existing one if you added a script to an existing folder) telling a user
how to run your script.
Make a PR to the 🤗 Transformers repo. Don't forget to tweet about your new example with a carbon screenshot of how to
run it and tag @huggingface!
| huggingface/transformers/blob/main/templates/adding_a_new_example_script/README.md |
ote: This is a simplified version of the code needed to create the Stable Diffusion demo. See full code here: https://hf.co/spaces/stabilityai/stable-diffusion/tree/main | gradio-app/gradio/blob/main/demo/stable-diffusion/DESCRIPTION.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
🤗 Optimum handles the export of TensorFlow models to TFLite in the `exporters.tflite` module. In addition, models hosted on the Hugging Face Hub with PyTorch weights but having a TensorFlow implementation will also be supported in the export thanks to Transformers' [TFPreTrainedModel.from_pretrained()](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.from_pretrained) auto-conversion to TensorFlow.
The TFLite export support provides classes, functions and a command line interface to export a model easily.
Supported architectures:
- Albert
- BERT
- Camembert
- ConvBert
- Deberta
- Deberta V2
- DistilBert
- Electra
- Flaubert
- MobileBert
- MPNet
- ResNet
- Roberta
- RoFormer
- XLM
- XLMRoberta
| huggingface/optimum/blob/main/docs/source/exporters/tflite/overview.mdx |
--
title: "Open-sourcing Knowledge Distillation Code and Weights of SD-Small and SD-Tiny"
thumbnail: /blog/assets/distill_sd/thumbnail.png
authors:
- user: harishsegmind
guest: true
- user: Warlord-K
guest: true
- user: Gothos
guest: true
---
# Open-sourcing Knowledge Distillation Code and Weights of SD-Small and SD-Tiny
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture1.png" width=500>
</p>
In recent times, the AI community has witnessed a remarkable surge in the development of larger and more performant language models, such as Falcon 40B, LLaMa-2 70B, Falcon 40B, MPT 30B, and in the imaging domain with models like SD2.1 and SDXL. These advancements have undoubtedly pushed the boundaries of what AI can achieve, enabling highly versatile and state-of-the-art image generation and language understanding capabilities. However, as we marvel at the power and complexity of these models, it is essential to recognize a growing need to make AI models smaller, efficient, and more accessible, particularly by open-sourcing them.
At [Segmind](https://www.segmind.com/models), we have been working on how to make generative AI models faster and cheaper. Last year, we have open-sourced our accelerated SD-WebUI library called [voltaML](https://github.com/VoltaML/voltaML-fast-stable-diffusion), which is a AITemplate/TensorRT based inference acceleration library that has delivered between 4-6X increase in the inference speed. To continue towards the goal of making generative models faster, smaller and cheaper, we are open-sourcing the weights and training code of our compressed **SD models; SD-Small and SD-Tiny**. The pretrained checkpoints are available on [Huggingface 🤗](https://huggingface.co/segmind)
## Knowledge Distillation
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture2.png" width=500>
</p>
Our new compressed models have been trained on Knowledge-Distillation (KD) techniques and the work has been largely based on [this paper](https://openreview.net/forum?id=bOVydU0XKC). The authors describe a Block-removal Knowledge-Distillation method where some of the UNet layers are removed and the student model weights are trained. Using the KD methods described in the paper, we were able to train two compressed models using the [🧨 diffusers](https://github.com/huggingface/diffusers) library; **Small** and **Tiny**, that have 35% and 55% fewer parameters, respectively than the base model while achieving comparable image fidelity as the base model. We have open-sourced our distillation code in this [repo](https://github.com/segmind/distill-sd) and pretrained checkpoints on [Huggingface 🤗](https://huggingface.co/segmind).
Knowledge-Distillation training a neural network is similar to a teacher guiding a student step-by-step. A large teacher model is pre-trained on a large amount of data and then a smaller model is trained on a smaller dataset, to imitate the outputs of the larger model along with classical training on the dataset.
In this particular type of knowledge distillation, the student model is trained to do the normal diffusion task of recovering an image from pure noise, but at the same time, the model is made to match the output of the larger teacher model. The matching of outputs happens at every block of the U-nets, hence the model quality is mostly preserved. So, using the previous analogy, we can say that during this kind of distillation, the student will not only try to learn from the Questions and Answers but also from the Teacher’s answers, as well as the step by step method of getting to the answer. We have 3 components in the loss function to achieve this, firstly the traditional loss between latents of the target image and latents of the generated image. Secondly, the loss between latents of the image generated by the teacher and latents of image generated by the student. And lastly, and the most important component, is the feature level loss, which is the loss between the outputs of each of the blocks of the teacher and the student.
Combining all of this makes up the Knowledge-Distillation training. Below is an architecture of the Block Removed UNet used in the KD as described in the paper.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture3.png" width=500>
</p>
Image taken from the [paper](https://arxiv.org/abs/2305.15798) “On Architectural Compression of Text-to-Image Diffusion Models” by Shinkook. et. al
We have taken [Realistic-Vision 4.0](https://huggingface.co/SG161222/Realistic_Vision_V4.0_noVAE) as our base teacher model and have trained on the [LAION Art Aesthetic dataset](https://huggingface.co/datasets/recastai/LAION-art-EN-improved-captions) with image scores above 7.5, because of their high quality image descriptions. Unlike the paper, we have chosen to train the two models on 1M images for 100K steps for the Small and 125K steps for the Tiny mode respectively. The code for the distillation training can be found [here](https://github.com/segmind/distill-sd).
## Model Usage
The Model can be used using the DiffusionPipeline from [🧨 diffusers](https://github.com/huggingface/diffusers)
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "Portrait of a pretty girl"
negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
image = pipeline(prompt, negative_prompt = negative_prompt).images[0]
image.save("my_image.png")
```
## Speed in terms of inference latency
We have observed that distilled models are up to 100% faster than the original base models. The Benchmarking code can be found [here](https://github.com/segmind/distill-sd/blob/master/inference.py).
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture4.jpeg" width=500>
</p>
## Potential Limitations
The distilled models are in early phase and the outputs may not be at a production quality yet.
These models may not be the best general models. They are best used as fine-tuned or LoRA trained on specific concepts/styles.
Distilled models are not very good at composibility or multiconcepts yet.
## Fine-tuning SD-tiny model on portrait dataset
We have fine-tuned our sd-tiny model on portrait images generated with the Realistic Vision v4.0 model. Below are the fine tuning parameters used.
- Steps: 131000
- Learning rate: 1e-4
- Batch size: 32
- Gradient accumulation steps: 4
- Image resolution: 768
- Dataset size - 7k images
- Mixed-precision: fp16
We were able to produce image quality close to the images produced by the original model, with almost 40% fewer parameters and the sample results below speak for themselves:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture5.png" width=500>
</p>
The code for fine-tuning the base models can be found [here](https://github.com/segmind/distill-sd/blob/master/checkpoint_training.py).
## LoRA Training
One of the advantages of LoRA training on a distilled model is faster training. Below are some of the images of the first LoRA we trained on the distilled model on some abstract concepts. The code for the LoRA training can be found [here](https://github.com/segmind/distill-sd/blob/master/lora_training.py).
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture6.png" width=500>
</p>
## Conclusion
We invite the open-source community to help us improve and achieve wider adoption of these distilled SD models. Users can join our [Discord](https://discord.gg/s6E6eHJk) server, where we will be announcing the latest updates to these models, releasing more checkpoints and some exciting new LoRAs. And if you like our work, please give us a star on our [Github](https://github.com/segmind/distill-sd).
| huggingface/blog/blob/main/sd_distillation.md |
Register commands in the Optimum CLI from a subpackage
It is possible to register a command in the Optimum CLI, either as a command or a subcommand of an already existing command.
Steps to follow:
1. Create a command as a subclass of `optimum.commands.BaseOptimumCLICommand`.
2. Create a Python file under `optimum/commands/register/`, and define a `REGISTER_COMMANDS` list variable there.
3. Fill the `REGISTER_COMMANDS` as follows:
```python
# CustomCommand1 and CustomCommand2 could also be defined in this file actually.
from ..my_custom_commands import CustomCommand1, CustomCommand2
from ..export import ExportCommand
REGISTER_COMMANDS = [
# CustomCommand1 will be registered as a subcommand of the root Optimum CLI.
CustomCommand1,
# CustomCommand2 will be registered as a subcommand of the `optimum-cli export` command.
(CustomCommand2, ExportCommand) # CustomCommand2 will be registered
]
```
| huggingface/optimum/blob/main/optimum/commands/register/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generation with LLMs
[[open-in-colab]]
LLMs, or Large Language Models, are the key component behind text generation. In a nutshell, they consist of large pretrained transformer models trained to predict the next word (or, more precisely, token) given some input text. Since they predict one token at a time, you need to do something more elaborate to generate new sentences other than just calling the model -- you need to do autoregressive generation.
Autoregressive generation is the inference-time procedure of iteratively calling a model with its own generated outputs, given a few initial inputs. In 🤗 Transformers, this is handled by the [`~generation.GenerationMixin.generate`] method, which is available to all models with generative capabilities.
This tutorial will show you how to:
* Generate text with an LLM
* Avoid common pitfalls
* Next steps to help you get the most out of your LLM
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
## Generate text
A language model trained for [causal language modeling](tasks/language_modeling) takes a sequence of text tokens as input and returns the probability distribution for the next token.
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"Forward pass of an LLM"</figcaption>
</figure>
A critical aspect of autoregressive generation with LLMs is how to select the next token from this probability distribution. Anything goes in this step as long as you end up with a token for the next iteration. This means it can be as simple as selecting the most likely token from the probability distribution or as complex as applying a dozen transformations before sampling from the resulting distribution.
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"Autoregressive generation iteratively selects the next token from a probability distribution to generate text"</figcaption>
</figure>
The process depicted above is repeated iteratively until some stopping condition is reached. Ideally, the stopping condition is dictated by the model, which should learn when to output an end-of-sequence (`EOS`) token. If this is not the case, generation stops when some predefined maximum length is reached.
Properly setting up the token selection step and the stopping condition is essential to make your model behave as you'd expect on your task. That is why we have a [`~generation.GenerationConfig`] file associated with each model, which contains a good default generative parameterization and is loaded alongside your model.
Let's talk code!
<Tip>
If you're interested in basic LLM usage, our high-level [`Pipeline`](pipeline_tutorial) interface is a great starting point. However, LLMs often require advanced features like quantization and fine control of the token selection step, which is best done through [`~generation.GenerationMixin.generate`]. Autoregressive generation with LLMs is also resource-intensive and should be executed on a GPU for adequate throughput.
</Tip>
First, you need to load the model.
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
You'll notice two flags in the `from_pretrained` call:
- `device_map` ensures the model is moved to your GPU(s)
- `load_in_4bit` applies [4-bit dynamic quantization](main_classes/quantization) to massively reduce the resource requirements
There are other ways to initialize a model, but this is a good baseline to begin with an LLM.
Next, you need to preprocess your text input with a [tokenizer](tokenizer_summary).
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
```
The `model_inputs` variable holds the tokenized text input, as well as the attention mask. While [`~generation.GenerationMixin.generate`] does its best effort to infer the attention mask when it is not passed, we recommend passing it whenever possible for optimal results.
After tokenizing the inputs, you can call the [`~generation.GenerationMixin.generate`] method to returns the generated tokens. The generated tokens then should be converted to text before printing.
```py
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'
```
Finally, you don't need to do it one sequence at a time! You can batch your inputs, which will greatly improve the throughput at a small latency and memory cost. All you need to do is to make sure you pad your inputs properly (more on that below).
```py
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']
```
And that's it! In a few lines of code, you can harness the power of an LLM.
## Common pitfalls
There are many [generation strategies](generation_strategies), and sometimes the default values may not be appropriate for your use case. If your outputs aren't aligned with what you're expecting, we've created a list of the most common pitfalls and how to avoid them.
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
### Generated output is too short/long
If not specified in the [`~generation.GenerationConfig`] file, `generate` returns up to 20 tokens by default. We highly recommend manually setting `max_new_tokens` in your `generate` call to control the maximum number of new tokens it can return. Keep in mind LLMs (more precisely, [decoder-only models](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)) also return the input prompt as part of the output.
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### Incorrect generation mode
By default, and unless specified in the [`~generation.GenerationConfig`] file, `generate` selects the most likely token at each iteration (greedy decoding). Depending on your task, this may be undesirable; creative tasks like chatbots or writing an essay benefit from sampling. On the other hand, input-grounded tasks like audio transcription or translation benefit from greedy decoding. Enable sampling with `do_sample=True`, and you can learn more about this topic in this [blog post](https://huggingface.co/blog/how-to-generate).
```py
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(42)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'
```
### Wrong padding side
LLMs are [decoder-only](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt) architectures, meaning they continue to iterate on your input prompt. If your inputs do not have the same length, they need to be padded. Since LLMs are not trained to continue from pad tokens, your input needs to be left-padded. Make sure you also don't forget to pass the attention mask to generate!
```py
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
### Wrong prompt
Some models and tasks expect a certain input prompt format to work properly. When this format is not applied, you will get a silent performance degradation: the model kinda works, but not as well as if you were following the expected prompt. More information about prompting, including which models and tasks need to be careful, is available in this [guide](tasks/prompting). Let's see an example with a chat LLM, which makes use of [chat templating](chat_templating):
```python
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
>>> model = AutoModelForCausalLM.from_pretrained(
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
... )
>>> set_seed(0)
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> input_length = model_inputs.input_ids.shape[1]
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
>>> set_seed(0)
>>> messages = [
... {
... "role": "system",
... "content": "You are a friendly chatbot who always responds in the style of a thug",
... },
... {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
>>> input_length = model_inputs.shape[1]
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
>>> # As we can see, it followed a proper thug style 😎
```
## Further resources
While the autoregressive generation process is relatively straightforward, making the most out of your LLM can be a challenging endeavor because there are many moving parts. For your next steps to help you dive deeper into LLM usage and understanding:
### Advanced generate usage
1. [Guide](generation_strategies) on how to control different generation methods, how to set up the generation configuration file, and how to stream the output;
2. [Guide](chat_templating) on the prompt template for chat LLMs;
3. [Guide](tasks/prompting) on to get the most of prompt design;
4. API reference on [`~generation.GenerationConfig`], [`~generation.GenerationMixin.generate`], and [generate-related classes](internal/generation_utils). Most of the classes, including the logits processors, have usage examples!
### LLM leaderboards
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), which focuses on the quality of the open-source models;
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), which focuses on LLM throughput.
### Latency, throughput and memory utilization
1. [Guide](llm_tutorial_optimization) on how to optimize LLMs for speed and memory;
2. [Guide](main_classes/quantization) on quantization such as bitsandbytes and autogptq, which shows you how to drastically reduce your memory requirements.
### Related libraries
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), a production-ready server for LLMs;
2. [`optimum`](https://github.com/huggingface/optimum), an extension of 🤗 Transformers that optimizes for specific hardware devices.
| huggingface/transformers/blob/main/docs/source/en/llm_tutorial.md |
Spaces Changelog
## [2023-07-28] - Upstream Streamlit frontend for `>=1.23.0`
- Streamlit SDK uses the upstream packages published on PyPI for `>=1.23.0`, so the newly released versions are available from the day of release.
## [2023-05-30] - Add support for Streamlit 1.23.x and 1.24.0
- Added support for Streamlit `1.23.0`, `1.23.1`, and `1.24.0`.
- Since `1.23.0`, the Streamlit frontend has been changed to the upstream version from the HF-customized one.
## [2023-05-30] - Add support for Streamlit 1.22.0
- Added support for Streamlit `1.22.0`.
## [2023-05-15] - The default Streamlit version
- The default Streamlit version is set as `1.21.0`.
## [2023-04-12] - Add support for Streamlit up to 1.19.0
- Support for `1.16.0`, `1.17.0`, `1.18.1`, and `1.19.0` is added and the default SDK version is set as `1.19.0`.
## [2023-03-28] - Bug fix
- Fixed a bug causing inability to scroll on iframe-embedded or directly accessed Streamlit apps, which was reported at https://discuss.huggingface.co/t/how-to-add-scroll-bars-to-a-streamlit-app-using-space-direct-embed-url/34101. The patch has been applied to Streamlit>=1.18.1.
## [2022-12-15] - Spaces supports Docker Containers
- Read more doc about: [Docker Spaces](./spaces-sdks-docker)
## [2022-12-14] - Ability to set a custom `sleep` time
- Read more doc here: [Spaces sleep time](./spaces-gpus#sleep-time)
## [2022-12-07] - Add support for Streamlit 1.15
- Announcement : https://twitter.com/osanseviero/status/1600881584214638592.
## [2022-06-07] - Add support for Streamlit 1.10.0
- The new multipage apps feature is working out-of-the-box on Spaces.
- Streamlit blogpost : https://blog.streamlit.io/introducing-multipage-apps.
## [2022-05-23] - Spaces speedup and reactive system theme
- All Spaces using Gradio 3+ and Streamlit 1.x.x have a significant speedup in loading.
- System theme is now reactive inside the app. If the user changes to dark mode, it automatically changes.
## [2022-05-21] - Default Debian packages and Factory Reboot
- Spaces environments now come with pre-installed popular packages (`ffmpeg`, `libsndfile1`, etc.).
- This way, most of the time, you don't need to specify any additional package for your Space to work properly.
- The `packages.txt` file can still be used if needed.
- Added factory reboot button to Spaces, which allows users to do a full restart avoiding cached requirements and freeing GPU memory.
## [2022-05-17] - Add support for Streamlit 1.9.0
- All `1.x.0` versions are now supported (up to `1.9.0`).
## [2022-05-16] - Gradio 3 is out!
- This is the default version when creating a new Space, don't hesitate to [check it out](https://huggingface.co/blog/gradio-blocks).
## [2022-03-04] - SDK version lock
- The `sdk_version` field is now automatically pre-filled at Space creation time.
- It ensures that your Space stays on the same SDK version after an updatE.
## [2022-03-02] - Gradio version pinning
- The `sdk_version` configuration field now works with the Gradio SDK.
## [2022-02-21] - Python versions
- You can specify the version of Python that you want your Space to run on.
- Only Python 3 versions are supported.
## [2022-01-24] - Automatic model and dataset linking from Spaces
- We attempt to automatically extract model and dataset repo ids used in your code
- You can always manually define them with `models` and `datasets` in your YAML.
## [2021-10-20] - Add support for Streamlit 1.0
- We now support all versions between 0.79.0 and 1.0.0
## [2021-09-07] - Streamlit version pinning
- You can now choose which version of Streamlit will be installed within your Space
## [2021-09-06] - Upgrade Streamlit to `0.84.2`
- Supporting Session State API
- [Streamlit changelog](https://github.com/streamlit/streamlit/releases/tag/0.84.0)
## [2021-08-10] - Upgrade Streamlit to `0.83.0`
- [Streamlit changelog](https://github.com/streamlit/streamlit/releases/tag/0.83.0)
## [2021-08-04] - Debian packages
- You can now add your `apt-get` dependencies into a `packages.txt` file
## [2021-08-03] - Streamlit components
- Add support for [Streamlit components](https://streamlit.io/components)
## [2021-08-03] - Flax/Jax GPU improvements
- For GPU-activated Spaces, make sure Flax / Jax runs smoothly on GPU
## [2021-08-02] - Upgrade Streamlit to `0.82.0`
- [Streamlit changelog](https://github.com/streamlit/streamlit/releases/tag/0.82.0)
## [2021-08-01] - Raw logs available
- Add link to raw logs (build and container) from the space repository (viewable by users with write access to a Space)
| huggingface/hub-docs/blob/main/docs/hub/spaces-changelog.md |
Hands-on
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit5/unit5.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
We learned what ML-Agents is and how it works. We also studied the two environments we're going to use. Now we're ready to train our agents!
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/envs.png" alt="Environments" />
To validate this hands-on for the certification process, you **just need to push your trained models to the Hub.**
There are **no minimum results to attain** in order to validate this Hands On. But if you want to get nice results, you can try to reach the following:
- For [Pyramids](https://huggingface.co/spaces/unity/ML-Agents-Pyramids): Mean Reward = 1.75
- For [SnowballTarget](https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget): Mean Reward = 15 or 30 targets shoot in an episode.
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
**To start the hands-on, click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit5/unit5.ipynb)
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
# Unit 5: An Introduction to ML-Agents
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/thumbnail.png" alt="Thumbnail"/>
In this notebook, you'll learn about ML-Agents and train two agents.
- The first one will learn to **shoot snowballs onto spawning targets**.
- The second needs to press a button to spawn a pyramid, then navigate to the pyramid, knock it over, **and move to the gold brick at the top**. To do that, it will need to explore its environment, and we will use a technique called curiosity.
After that, you'll be able **to watch your agents playing directly on your browser**.
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
⬇️ Here is an example of what **you will achieve at the end of this unit.** ⬇️
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids.gif" alt="Pyramids"/>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget.gif" alt="SnowballTarget"/>
### 🎮 Environments:
- [Pyramids](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Learning-Environment-Examples.md#pyramids)
- SnowballTarget
### 📚 RL-Library:
- [ML-Agents](https://github.com/Unity-Technologies/ml-agents)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Understand how **ML-Agents** works and the environment library.
- Be able to **train agents in Unity Environments**.
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 **Study [what ML-Agents is and how it works by reading Unit 5](https://huggingface.co/deep-rl-course/unit5/introduction)** 🤗
# Let's train our agents 🚀
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
## Clone the repository and install the dependencies 🔽
- We need to clone the repository that **contains the experimental version of the library that allows you to push your trained agent to the Hub.**
```bash
# Clone the repository
git clone --depth 1 https://github.com/Unity-Technologies/ml-agents
```
```bash
# Go inside the repository and install the package
cd ml-agents
pip install -e ./ml-agents-envs
pip install -e ./ml-agents
```
## SnowballTarget ⛄
If you need a refresher on how this environment works check this section 👉
https://huggingface.co/deep-rl-course/unit5/snowball-target
### Download and move the environment zip file in `./training-envs-executables/linux/`
- Our environment executable is in a zip file.
- We need to download it and place it to `./training-envs-executables/linux/`
- We use a linux executable because we use colab, and colab machines OS is Ubuntu (linux)
```bash
# Here, we create training-envs-executables and linux
mkdir ./training-envs-executables
mkdir ./training-envs-executables/linux
```
Download the file SnowballTarget.zip from https://drive.google.com/file/d/1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5 using `wget`.
Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
```bash
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1YHHLjyj6gaZ3Gemx1hQgqrPgSS2ZhmB5" -O ./training-envs-executables/linux/SnowballTarget.zip && rm -rf /tmp/cookies.txt
```
We unzip the executable.zip file
```bash
unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/SnowballTarget.zip
```
Make sure your file is accessible
```bash
chmod -R 755 ./training-envs-executables/linux/SnowballTarget
```
### Define the SnowballTarget config file
- In ML-Agents, you define the **training hyperparameters in config.yaml files.**
There are multiple hyperparameters. To understand them better, you should read the explanation for each one in [the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)
You need to create a `SnowballTarget.yaml` config file in ./content/ml-agents/config/ppo/
We'll give you a preliminary version of this config (to copy and paste into your `SnowballTarget.yaml file`), **but you should modify it**.
```yaml
behaviors:
SnowballTarget:
trainer_type: ppo
summary_freq: 10000
keep_checkpoints: 10
checkpoint_interval: 50000
max_steps: 200000
time_horizon: 64
threaded: true
hyperparameters:
learning_rate: 0.0003
learning_rate_schedule: linear
batch_size: 128
buffer_size: 2048
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
```
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballfight_config1.png" alt="Config SnowballTarget"/>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballfight_config2.png" alt="Config SnowballTarget"/>
As an experiment, try to modify some other hyperparameters. Unity provides very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md).
Now that you've created the config file and understand what most hyperparameters do, we're ready to train our agent 🔥.
### Train the agent
To train our agent, we need to **launch mlagents-learn and select the executable containing the environment.**
We define four parameters:
1. `mlagents-learn <config>`: the path where the hyperparameter config file is.
2. `--env`: where the environment executable is.
3. `--run_id`: the name you want to give to your training run id.
4. `--no-graphics`: to not launch the visualization during the training.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/mlagentslearn.png" alt="MlAgents learn"/>
Train the model and use the `--resume` flag to continue training in case of interruption.
> It will fail the first time if and when you use `--resume`. Try rerunning the block to bypass the error.
The training will take 10 to 35min depending on your config. Go take a ☕️ you deserve it 🤗.
```bash
mlagents-learn ./config/ppo/SnowballTarget.yaml --env=./training-envs-executables/linux/SnowballTarget/SnowballTarget --run-id="SnowballTarget1" --no-graphics
```
### Push the agent to the Hugging Face Hub
- Now that we've trained our agent, we’re **ready to push it to the Hub and visualize it playing on your browser🔥.**
To be able to share your model with the community, there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and paste the token
```python
from huggingface_hub import notebook_login
notebook_login()
```
If you don't want to use Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
Then we need to run `mlagents-push-to-hf`.
And we define four parameters:
1. `--run-id`: the name of the training run id.
2. `--local-dir`: where the agent was saved, it’s results/<run_id name>, so in my case results/First Training.
3. `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s always <your huggingface username>/<the repo name>
If the repo does not exist **it will be created automatically**
4. `--commit-message`: since HF repos are git repositories you need to give a commit message.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/mlagentspushtohub.png" alt="Push to Hub"/>
For instance:
`mlagents-push-to-hf --run-id="SnowballTarget1" --local-dir="./results/SnowballTarget1" --repo-id="ThomasSimonini/ppo-SnowballTarget" --commit-message="First Push"`
```python
mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
If everything worked you should see this at the end of the process (but with a different url 😆) :
```
Your model is pushed to the hub. You can view your model here: https://huggingface.co/ThomasSimonini/ppo-SnowballTarget
```
It's the link to your model. It contains a model card that explains how to use it, your Tensorboard, and your config file. **What's awesome is that it's a git repository, which means you can have different commits, update your repository with a new push, etc.**
But now comes the best: **being able to visualize your agent online 👀.**
### Watch your agent playing 👀
This step it's simple:
1. Remember your repo-id
2. Go here: https://huggingface.co/spaces/ThomasSimonini/ML-Agents-SnowballTarget
3. Launch the game and put it in full screen by clicking on the bottom right button
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget_load.png" alt="Snowballtarget load"/>
1. In step 1, choose your model repository, which is the model id (in my case ThomasSimonini/ppo-SnowballTarget).
2. In step 2, **choose what model you want to replay**:
- I have multiple ones since we saved a model every 500000 timesteps.
- But if I want the more recent I choose `SnowballTarget.onnx`
👉 It's nice to **try different model stages to see the improvement of the agent.**
And don't hesitate to share the best score your agent gets on discord in the #rl-i-made-this channel 🔥
Now let's try a more challenging environment called Pyramids.
## Pyramids 🏆
### Download and move the environment zip file in `./training-envs-executables/linux/`
- Our environment executable is in a zip file.
- We need to download it and place it into `./training-envs-executables/linux/`
- We use a linux executable because we're using colab, and the colab machine's OS is Ubuntu (linux)
Download the file Pyramids.zip from https://drive.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H using `wget`. Check out the full solution to download large files from GDrive [here](https://bcrf.biochem.wisc.edu/2021/02/05/download-google-drive-files-using-wget/)
```python
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1UiFNdKlsH0NTu32xV-giYUEVKV4-vc7H" -O ./training-envs-executables/linux/Pyramids.zip && rm -rf /tmp/cookies.txt
```
Unzip it
```python
%%capture
!unzip -d ./training-envs-executables/linux/ ./training-envs-executables/linux/Pyramids.zip
```
Make sure your file is accessible
```bash
chmod -R 755 ./training-envs-executables/linux/Pyramids/Pyramids
```
### Modify the PyramidsRND config file
- Contrary to the first environment, which was a custom one, **Pyramids was made by the Unity team**.
- So the PyramidsRND config file already exists and is in ./content/ml-agents/config/ppo/PyramidsRND.yaml
- You might ask why "RND" is in PyramidsRND. RND stands for *random network distillation* it's a way to generate curiosity rewards. If you want to know more about that, we wrote an article explaining this technique: https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938
For this training, we’ll modify one thing:
- The total training steps hyperparameter is too high since we can hit the benchmark (mean reward = 1.75) in only 1M training steps.
👉 To do that, we go to config/ppo/PyramidsRND.yaml,**and change max_steps to 1000000.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/pyramids-config.png" alt="Pyramids config"/>
As an experiment, you should also try to modify some other hyperparameters. Unity provides very [good documentation explaining each of them here](https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md).
We’re now ready to train our agent 🔥.
### Train the agent
The training will take 30 to 45min depending on your machine, go take a ☕️ you deserve it 🤗.
```python
mlagents-learn ./config/ppo/PyramidsRND.yaml --env=./training-envs-executables/linux/Pyramids/Pyramids --run-id="Pyramids Training" --no-graphics
```
### Push the agent to the Hugging Face Hub
- Now that we trained our agent, we’re **ready to push it to the Hub to be able to visualize it playing on your browser🔥.**
```python
mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message= # Your commit message
```
### Watch your agent playing 👀
👉 https://huggingface.co/spaces/unity/ML-Agents-Pyramids
### 🎁 Bonus: Why not train on another environment?
Now that you know how to train an agent using MLAgents, **why not try another environment?**
MLAgents provides 17 different environments and we’re building some custom ones. The best way to learn is to try things on your own, have fun.

You have the full list of the one currently available environments on Hugging Face here 👉 https://github.com/huggingface/ml-agents#the-environments
For the demos to visualize your agent 👉 https://huggingface.co/unity
For now we have integrated:
- [Worm](https://huggingface.co/spaces/unity/ML-Agents-Worm) demo where you teach a **worm to crawl**.
- [Walker](https://huggingface.co/spaces/unity/ML-Agents-Walker) demo where you teach an agent **to walk towards a goal**.
That’s all for today. Congrats on finishing this tutorial!
The best way to learn is to practice and try stuff. Why not try another environment? ML-Agents has 18 different environments, but you can also create your own. Check the documentation and have fun!
See you on Unit 6 🔥,
## Keep Learning, Stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit5/hands-on.mdx |
Gradio Demo: matrix_transpose
```
!pip install -q gradio
```
```
import numpy as np
import gradio as gr
def transpose(matrix):
return matrix.T
demo = gr.Interface(
transpose,
gr.Dataframe(type="numpy", datatype="number", row_count=5, col_count=3),
"numpy",
examples=[
[np.zeros((3, 3)).tolist()],
[np.ones((2, 2)).tolist()],
[np.random.randint(0, 10, (3, 10)).tolist()],
[np.random.randint(0, 10, (10, 3)).tolist()],
[np.random.randint(0, 10, (10, 10)).tolist()],
],
cache_examples=False
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/matrix_transpose/run.ipynb |
FrameworkSwitchCourse {fw} />
# Models[[models]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section3_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section3_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={2}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter2/section3_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter2/section3_tf.ipynb"},
]} />
{/if}
{#if fw === 'pt'}
<Youtube id="AhChOFRegn4"/>
{:else}
<Youtube id="d3JVgghSOew"/>
{/if}
{#if fw === 'pt'}
In this section we'll take a closer look at creating and using a model. We'll use the `AutoModel` class, which is handy when you want to instantiate any model from a checkpoint.
The `AutoModel` class and all of its relatives are actually simple wrappers over the wide variety of models available in the library. It's a clever wrapper as it can automatically guess the appropriate model architecture for your checkpoint, and then instantiates a model with this architecture.
{:else}
In this section we'll take a closer look at creating and using a model. We'll use the `TFAutoModel` class, which is handy when you want to instantiate any model from a checkpoint.
The `TFAutoModel` class and all of its relatives are actually simple wrappers over the wide variety of models available in the library. It's a clever wrapper as it can automatically guess the appropriate model architecture for your checkpoint, and then instantiates a model with this architecture.
{/if}
However, if you know the type of model you want to use, you can use the class that defines its architecture directly. Let's take a look at how this works with a BERT model.
## Creating a Transformer[[creating-a-transformer]]
The first thing we'll need to do to initialize a BERT model is load a configuration object:
{#if fw === 'pt'}
```py
from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = BertModel(config)
```
{:else}
```py
from transformers import BertConfig, TFBertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = TFBertModel(config)
```
{/if}
The configuration contains many attributes that are used to build the model:
```py
print(config)
```
```python out
BertConfig {
[...]
"hidden_size": 768,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
[...]
}
```
While you haven't seen what all of these attributes do yet, you should recognize some of them: the `hidden_size` attribute defines the size of the `hidden_states` vector, and `num_hidden_layers` defines the number of layers the Transformer model has.
### Different loading methods[[different-loading-methods]]
Creating a model from the default configuration initializes it with random values:
{#if fw === 'pt'}
```py
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
# Model is randomly initialized!
```
{:else}
```py
from transformers import BertConfig, TFBertModel
config = BertConfig()
model = TFBertModel(config)
# Model is randomly initialized!
```
{/if}
The model can be used in this state, but it will output gibberish; it needs to be trained first. We could train the model from scratch on the task at hand, but as you saw in [Chapter 1](/course/chapter1), this would require a long time and a lot of data, and it would have a non-negligible environmental impact. To avoid unnecessary and duplicated effort, it's imperative to be able to share and reuse models that have already been trained.
Loading a Transformer model that is already trained is simple — we can do this using the `from_pretrained()` method:
{#if fw === 'pt'}
```py
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
```
As you saw earlier, we could replace `BertModel` with the equivalent `AutoModel` class. We'll do this from now on as this produces checkpoint-agnostic code; if your code works for one checkpoint, it should work seamlessly with another. This applies even if the architecture is different, as long as the checkpoint was trained for a similar task (for example, a sentiment analysis task).
{:else}
```py
from transformers import TFBertModel
model = TFBertModel.from_pretrained("bert-base-cased")
```
As you saw earlier, we could replace `TFBertModel` with the equivalent `TFAutoModel` class. We'll do this from now on as this produces checkpoint-agnostic code; if your code works for one checkpoint, it should work seamlessly with another. This applies even if the architecture is different, as long as the checkpoint was trained for a similar task (for example, a sentiment analysis task).
{/if}
In the code sample above we didn't use `BertConfig`, and instead loaded a pretrained model via the `bert-base-cased` identifier. This is a model checkpoint that was trained by the authors of BERT themselves; you can find more details about it in its [model card](https://huggingface.co/bert-base-cased).
This model is now initialized with all the weights of the checkpoint. It can be used directly for inference on the tasks it was trained on, and it can also be fine-tuned on a new task. By training with pretrained weights rather than from scratch, we can quickly achieve good results.
The weights have been downloaded and cached (so future calls to the `from_pretrained()` method won't re-download them) in the cache folder, which defaults to *~/.cache/huggingface/transformers*. You can customize your cache folder by setting the `HF_HOME` environment variable.
The identifier used to load the model can be the identifier of any model on the Model Hub, as long as it is compatible with the BERT architecture. The entire list of available BERT checkpoints can be found [here](https://huggingface.co/models?filter=bert).
### Saving methods[[saving-methods]]
Saving a model is as easy as loading one — we use the `save_pretrained()` method, which is analogous to the `from_pretrained()` method:
```py
model.save_pretrained("directory_on_my_computer")
```
This saves two files to your disk:
{#if fw === 'pt'}
```
ls directory_on_my_computer
config.json pytorch_model.bin
```
{:else}
```
ls directory_on_my_computer
config.json tf_model.h5
```
{/if}
If you take a look at the *config.json* file, you'll recognize the attributes necessary to build the model architecture. This file also contains some metadata, such as where the checkpoint originated and what 🤗 Transformers version you were using when you last saved the checkpoint.
{#if fw === 'pt'}
The *pytorch_model.bin* file is known as the *state dictionary*; it contains all your model's weights. The two files go hand in hand; the configuration is necessary to know your model's architecture, while the model weights are your model's parameters.
{:else}
The *tf_model.h5* file is known as the *state dictionary*; it contains all your model's weights. The two files go hand in hand; the configuration is necessary to know your model's architecture, while the model weights are your model's parameters.
{/if}
## Using a Transformer model for inference[[using-a-transformer-model-for-inference]]
Now that you know how to load and save a model, let's try using it to make some predictions. Transformer models can only process numbers — numbers that the tokenizer generates. But before we discuss tokenizers, let's explore what inputs the model accepts.
Tokenizers can take care of casting the inputs to the appropriate framework's tensors, but to help you understand what's going on, we'll take a quick look at what must be done before sending the inputs to the model.
Let's say we have a couple of sequences:
```py
sequences = ["Hello!", "Cool.", "Nice!"]
```
The tokenizer converts these to vocabulary indices which are typically called *input IDs*. Each sequence is now a list of numbers! The resulting output is:
```py no-format
encoded_sequences = [
[101, 7592, 999, 102],
[101, 4658, 1012, 102],
[101, 3835, 999, 102],
]
```
This is a list of encoded sequences: a list of lists. Tensors only accept rectangular shapes (think matrices). This "array" is already of rectangular shape, so converting it to a tensor is easy:
{#if fw === 'pt'}
```py
import torch
model_inputs = torch.tensor(encoded_sequences)
```
{:else}
```py
import tensorflow as tf
model_inputs = tf.constant(encoded_sequences)
```
{/if}
### Using the tensors as inputs to the model[[using-the-tensors-as-inputs-to-the-model]]
Making use of the tensors with the model is extremely simple — we just call the model with the inputs:
```py
output = model(model_inputs)
```
While the model accepts a lot of different arguments, only the input IDs are necessary. We'll explain what the other arguments do and when they are required later,
but first we need to take a closer look at the tokenizers that build the inputs that a Transformer model can understand.
| huggingface/course/blob/main/chapters/en/chapter2/3.mdx |
`tokenizers-win32-x64-msvc`
This is the **x86_64-pc-windows-msvc** binary for `tokenizers`
| huggingface/tokenizers/blob/main/bindings/node/npm/win32-x64-msvc/README.md |
--
title: "The Hugging Face Hub for Galleries, Libraries, Archives and Museums"
thumbnail: /blog/assets/144_hf_hub_glam_guide/thumbnail.png
authors:
- user: davanstrien
---
## The Hugging Face Hub for Galleries, Libraries, Archives and Museums
### What is the Hugging Face Hub?
Hugging Face aims to make high-quality machine learning accessible to everyone. This goal is pursued in various ways, including developing open-source code libraries such as the widely-used Transformers library, offering [free courses](https://huggingface.co/learn), and providing the Hugging Face Hub.
The [Hugging Face Hub](https://huggingface.co/) is a central repository where people can share and access machine learning models, datasets and demos. The Hub hosts over 190,000 machine learning models, 33,000 datasets and over 100,000 machine learning applications and demos. These models cover a wide range of tasks from pre-trained language models, text, image and audio classification models, object detection models, and a wide range of generative models.
The models, datasets and demos hosted on the Hub span a wide range of domains and languages, with regular community efforts to expand the scope of what is available via the Hub. This blog post intends to offer people working in or with the galleries, libraries, archives and museums (GLAM) sector to understand how they can use — and contribute to — the Hugging Face Hub.
You can read the whole post or jump to the most relevant sections!
- If you don't know what the Hub is, start with: [What is the Hugging Face Hub?](#what-is-the-hugging-face-hub)
- If you want to know how you can find machine learning models on the Hub, start with: [How can you use the Hugging Face Hub: finding relevant models on the Hub](#how-can-you-use-the-hugging-face-hub-finding-relevant-models-on-the-hub)
- If you want to know how you can share GLAM datasets on the Hub, start with [Walkthrough: Adding a GLAM dataset to the Hub?](#walkthrough-adding-a-glam-dataset-to-the-hub)
- If you want to see some examples, check out: [Example uses of the Hugging Face Hub](#example-uses-of-the-hugging-face-hub)
## What can you find on the Hugging Face Hub?
### Models
The Hugging Face Hub provides access to machine learning models covering various tasks and domains. Many machine learning libraries have integrations with the Hugging Face Hub, allowing you to directly use or share models to the Hub via these libraries.
### Datasets
The Hugging Face hub hosts over 30,000 datasets. These datasets cover a range of domains and modalities, including text, image, audio and multi-modal datasets. These datasets are valuable for training and evaluating machine learning models.
### Spaces
Hugging Face [Spaces](https://huggingface.co/docs/hub/spaces) is a platform that allows you to host machine learning demos and applications. These Spaces range from simple demos allowing you to explore the predictions made by a machine learning model to more involved applications.
Spaces make hosting and making your application accessible for others to use much more straightforward. You can use Spaces to host [Gradio](gradio.app/) and [Streamlit](https://streamlit.io/) applications, or you can use Spaces to [custom docker images](https://huggingface.co/docs/hub/spaces-sdks-docker). Using Gradio and Spaces in combination often means you can have an application created and hosted with access for others to use within minutes. You can use Spaces to host a Docker image if you want complete control over your application. There are also Docker templates that can give you quick access to a hosted version of many popular tools, including the [Argailla](https://argilla.io/) and [Label Studio](https://labelstud.io/) annotations tools.
## How can you use the Hugging Face Hub: finding relevant models on the Hub
There are many potential use cases in the GLAM sector where machine learning models can be helpful. Whilst some institutions may have the resources required to train machine learning models from scratch, you can use the Hub to find openly shared models that either already do what you want or are very close to your goal.
As an example, if you are working with a collection of digitized Norwegian documents with minimal metadata. One way to better understand what's in the collection is to use a Named Entity Recognition (NER) model. This model extracts entities from a text, for example, identifying the locations mentioned in a text. Knowing which entities are contained in a text can be a valuable way of better understanding what a document is about.
We can find NER models on the Hub by filtering models by task. In this case, we choose `token-classification`, which is the task which includes named entity recognition models. [This filter](https://huggingface.co/datasets?task_categories=task_categories:token-classification) returns models labelled as doing `token-classification`. Since we are working with Norwegian documents, we may also want to [filter by language](https://huggingface.co/models?pipeline_tag=token-classification&language=no&sort=downloads); this gets us to a smaller set of models we want to explore. Many of these models will also contain a [model widget](https://huggingface.co/saattrupdan/nbailab-base-ner-scandi), allowing us to test the model.

A model widget can quickly show how well a model will likely perform on our data. Once you've found a model that interests you, the Hub provides different ways of using that tool. If you are already familiar with the Transformers library, you can click the use in Transformers button to get a pop-up which shows how to load the model in Transformers.


If you prefer to use a model via an API, clicking the
`deploy` button in a model repository gives you various options for hosting the model behind an API. This can be particularly useful if you want to try out a model on a larger amount of data but need the infrastructure to run models locally.
A similar approach can also be used to find relevant models and datasets
on the Hugging Face Hub.
## Walkthrough: how can you add a GLAM dataset to the Hub?
We can make datasets available via the Hugging Face hub in various ways. I'll walk through an example of adding a CSV dataset to the Hugging Face hub.
<figure class="image table text-center m-0 w-full">
<video
alt="Uploading a file to the Hugging Face Hub"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/hf-hub-glam-guide/Upload%20dataset%20to%20hub.mp4" type="video/mp4">
</video>
</figure>
*Overview of the process of uploading a dataset to the Hub via the browser interface*
For our example, we'll work on making the [On the Books Training Set
](https://cdr.lib.unc.edu/concern/data_sets/6q182v788?locale=en) available via the Hub. This dataset comprises a CSV file containing data that can be used to train a text classification model. Since the CSV format is one of the [supported formats](https://huggingface.co/docs/datasets/upload_dataset#upload-dataset) for uploading data to the Hugging Face Hub, we can share this dataset directly on the Hub without needing to write any code.
### Create a new dataset repository
The first step to uploading a dataset to the Hub is to create a new dataset repository. This can be done by clicking the `New Dataset` button on the dropdown menu in the top right-hand corner of the Hugging Face hub.
Once you have done this you can choose a name for your new dataset repository. You can also create the dataset under a different owner i.e. an organization, and optionally specify a license.

### Upload files
Once you have created a dataset repository you will need to upload the data files. You can do this by clicking on `Add file` under the `Files` tab on the dataset repository.

You can now select the data you wish to upload to the Hub.

You can upload a single file or multiple files using the upload interface. Once you have uploaded your file, you commit your changes to finalize the upload.
### Adding metadata
It is important to add metadata to your dataset repository to make your dataset more discoverable and helpful for others. This will allow others to find your dataset and understand what it contains.
You can edit metadata using the `Metadata UI` editor. This allows you to specify the license, language, tags etc., for the dataset.

It is also very helpful to outline in more detail what your dataset is, how and why it was constructed, and it's strengths and weaknesses. This can be done in a dataset repository by filling out the `README.md` file. This file will serve as a [dataset card](https://huggingface.co/docs/datasets/dataset_card) for your dataset. A dataset card is a semi-structured form of documentation for machine learning datasets that aims to ensure datasets are sufficiently well documented. When you edit the `README.md` file you will be given the option to import a template dataset card. This template will give you helpful prompts for what is useful to include in a dataset card.
*Tip: Writing a good dataset card can be a lot of work. However, you do not need to do all of this work in one go necessarily, and because people can ask questions or make suggestions for datasets hosted on the Hub the processes of documenting datasets can be a collective activity.*
### Datasets preview
Once we've uploaded our dataset to the Hub, we'll get a preview of the dataset. The dataset preview can be a beneficial way of better understanding the dataset.

### Other ways of sharing datasets
You can use many other approaches for sharing datasets on the Hub. The datasets [documentation](https://huggingface.co/docs/datasets/share) will help you better understand what will likely work best for your particular use case.
## Why might Galleries, Libraries, Archives and Museums want to use the Hugging Face hub?
There are many different reasons why institutions want to contribute to
the Hugging Face Hub:
- **Exposure to a new audience**: the Hub has become a central destination for people working in machine learning, AI and related fields. Sharing on the Hub will help expose your collections and work to this audience. This also opens up the opportunity for further collaboration with this audience.
- **Community:** The Hub has many community-oriented features, allowing users and potential users of your material to ask questions and engage with materials you share via the Hub. Sharing trained models and machine learning datasets also allows people to build on each other's work and lowers the barrier to using machine learning in the sector.
- **Diversity of training data:** One of the barriers to the GLAM using machine learning is the availability of relevant data for training and evaluation of machine learning models. Machine learning models that work well on benchmark datasets may not work as well on GLAM organizations' data. Building a community to share domain-specific datasets will ensure machine learning can be more effectively pursued in the GLAM sector.
- **Climate change:** Training machine learning models produces a carbon footprint. The size of this footprint depends on various factors. One way we can collectively reduce this footprint is to share trained models with the community so that people aren't duplicating the same models (and generating more carbon emissions in the process).
## Example uses of the Hugging Face Hub
Individuals and organizations already use the Hugging Face hub to share machine learning models, datasets and demos related to the GLAM sector.
### [BigLAM](https://huggingface.co/biglam)
An initiative developed out of the [BigScience project](https://bigscience.huggingface.co/) is focused on making datasets from GLAM with relevance to machine learning are made more accessible. BigLAM has so far made over 30 datasets related to GLAM available via the Hugging Face hub.
### [Nasjonalbiblioteket AI Lab](https://huggingface.co/NbAiLab)
The AI lab at the National Library of Norway is a very active user of the Hugging Face hub, with ~120 models, 23 datasets and six machine learning demos shared publicly. These models include language models trained on Norwegian texts from the National Library of Norway and Whisper (speech-to-text) models trained on Sámi languages.
### [Smithsonian Institution](https://huggingface.co/Smithsonian)
The Smithsonian shared an application hosted on Hugging Face Spaces, demonstrating two machine learning models trained to identify Amazon fish species. This project aims to empower communities with tools that will allow more accurate measurement of fish species numbers in the Amazon. Making tools such as this available via a Spaces demo further lowers the barrier for people wanting to use these tools.
<html>
<iframe
src="https://smithsonian-amazonian-fish-classifier.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
</html>
[Source](https://huggingface.co/Smithsonian)
## Hub features for Galleries, Libraries, Archives and Museums
The Hub supports many features which help make machine learning more accessible. Some features which may be particularly helpful for GLAM institutions include:
- **Organizations**: you can create an organization on the Hub. This allows you to create a place to share your organization's artefacts.
- **Minting DOIs**: A [DOI](https://www.doi.org/) (Digital Object Identifier) is a persistent digital identifier for an object. DOIs have become essential for creating persistent identifiers for publications, datasets and software. A persistent identifier is often required by journals, conferences or researcher funders when referencing academic outputs. The Hugging Face Hub supports issuing DOIs for models, datasets, and demos shared on the Hub.
- **Usage tracking**: you can view download stats for datasets and models hosted in the Hub monthly or see the total number of downloads over all time. These stats can be a valuable way for institutions to demonstrate their impact.
- **Script-based dataset sharing**: if you already have dataset hosted somewhere, you can still provide access to them via the Hugging Face hub using a [dataset loading script](https://huggingface.co/docs/datasets/dataset_script).
- **Model and dataset gating**: there are circumstances where you want more control over who is accessing models and datasets. The Hugging Face hub supports model and dataset gating, allowing you to add access controls.
## How can I get help using the Hub?
The Hub [docs](https://huggingface.co/docs/hub/index) go into more detail about the various features of the Hugging Face Hub. You can also find more information about [sharing datasets on the Hub](https://huggingface.co/docs/datasets/upload_dataset) and information about [sharing Transformers models to the Hub](https://huggingface.co/docs/transformers/model_sharing).
If you require any assistance while using the Hugging Face Hub, there are several avenues you can explore. You may seek help by utilizing the [discussion forum](https://discuss.huggingface.co/) or through a [Discord](https://discord.com/invite/hugging-face-879548962464493619).
| huggingface/blog/blob/main/hf-hub-glam-guide.md |