
text
stringlengths 23
371k
| source
stringlengths 32
152
|
|---|---|
Use a custom Container Image
Inference Endpoints not only allows you to [customize your inference handler](/docs/inference-endpoints/guides/custom_handler), but it also allows you to provide a custom container image. Those can be public images like `tensorflow/serving:2.7.3` or private Images hosted on [Docker Hub](https://hub.docker.com/), [AWS ECR](https://aws.amazon.com/ecr/?nc1=h_ls), [Azure ACR](https://azure.microsoft.com/de-de/services/container-registry/), or [Google GCR](https://cloud.google.com/container-registry?hl=de).
<img src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/custom_container.png" alt="custom container config" />
The [creation flow](/docs/inference-endpoints/guides/create_endpoint) of your Image artifacts from a custom image is the same as the base image. This means Inference Endpoints will create a unique image artifact derived from your provided image, including all Model Artifacts.
The Model Artifacts (weights) are stored under `/repository`. For example, if you use` tensorflow/serving` as your custom image, then you have to set `model_base_path="/repository":
```
tensorflow_model_server \
--rest_api_port=5000 \
--model_name=my_model \
--model_base_path="/repository"
```
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/custom_container.mdx |
he tokenizer pipeline. In this video, we'll look at how a tokenizer converts raw text to numbers that a Transformer model can make sense of, like when we execute this code. Here is a quick overview of what happens inside the tokenizer object: first the text is split into tokens, which are words, parts of words, or punctuation symbols. Then the tokenizer adds potential special tokens and converts each token to their unique respective ID as defined by the tokenizer's vocabulary. As we'll see it doesn't actually happen in this order, but viewing it like this is better for understanding what happens. The first step is to split our input text into tokens with the tokenize method. To do this, the tokenizer may first perform some operations like lowercasing all words, then follow a set of rules to split the result in small chunks of text. Most of the Transformers models use a subword tokenization algorithm, which means that one given word can be split in several tokens, like tokenize here. Look at the "Tokenization algorithms" videos linked below for more information! The ## prefix we see in front of ize is the convention used by BERT to indicate this token is not the beginning of a word. Other tokenizers may use different conventions however: for instance ALBERT tokenizers will add a long underscore in front of all the tokens that had a space before them, which is a convention used by sentencepiece tokenizers. The second step of the tokenization pipeline is to map those tokens to their respective IDs as defined by the vocabulary of the tokenizer. This is why we need to download a file when we instantiate a tokenizer with the from_pretrained method: we have to make sure we use the same mapping as when the model was pretrained. To do this, we use the convert_tokens_to_ids method. You may have noticed that we don't have the exact same result as in our first slide — or not, as this looks like a list of random numbers, in which case allow me to refresh your memory. We had a number at the beginning and at the end that are missing, those are the special tokens. The special tokens are added by the prepare_for_model method, which knows the indices of those tokens in the vocabulary and just adds the proper numbers. You can look at the special tokens (and more generally at how the tokenizer has changed your text) by using the decode method on the outputs of the tokenizer object. As for the prefix for beginning of words/part of words, those special tokens vary depending on which tokenizer you are using. The BERT tokenizer uses [CLS] and [SEP] but the roberta tokenizer uses html-like anchors <s> and </s>. Now that you know how the tokenizer works, you can forget all those intermediaries methods and only remember that you just have to call it on your input texts. The inputs don't contain the inputs IDs however, to learn what the attention mask is, check out the "Batch inputs together" video. To learn about token type IDs, look at the "Process pairs of sentences" video. | huggingface/course/blob/main/subtitles/en/raw/chapter2/04e_tokenizer-pipeline.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# mT5
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=mt5">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-mt5-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/mt5-small-finetuned-arxiv-cs-finetuned-arxiv-cs-full">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
Siddhant, Aditya Barua, Colin Raffel.
The abstract from the paper is the following:
*The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain
state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a
multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We detail
the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual
benchmarks. We also describe a simple technique to prevent "accidental translation" in the zero-shot setting, where a
generative model chooses to (partially) translate its prediction into the wrong language. All of the code and model
checkpoints used in this work are publicly available.*
Note: mT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
Since mT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
Google has released the following variants:
- [google/mt5-small](https://huggingface.co/google/mt5-small)
- [google/mt5-base](https://huggingface.co/google/mt5-base)
- [google/mt5-large](https://huggingface.co/google/mt5-large)
- [google/mt5-xl](https://huggingface.co/google/mt5-xl)
- [google/mt5-xxl](https://huggingface.co/google/mt5-xxl).
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://github.com/google-research/multilingual-t5).
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## MT5Config
[[autodoc]] MT5Config
## MT5Tokenizer
[[autodoc]] MT5Tokenizer
See [`T5Tokenizer`] for all details.
## MT5TokenizerFast
[[autodoc]] MT5TokenizerFast
See [`T5TokenizerFast`] for all details.
<frameworkcontent>
<pt>
## MT5Model
[[autodoc]] MT5Model
## MT5ForConditionalGeneration
[[autodoc]] MT5ForConditionalGeneration
## MT5EncoderModel
[[autodoc]] MT5EncoderModel
## MT5ForSequenceClassification
[[autodoc]] MT5ForSequenceClassification
## MT5ForQuestionAnswering
[[autodoc]] MT5ForQuestionAnswering
</pt>
<tf>
## TFMT5Model
[[autodoc]] TFMT5Model
## TFMT5ForConditionalGeneration
[[autodoc]] TFMT5ForConditionalGeneration
## TFMT5EncoderModel
[[autodoc]] TFMT5EncoderModel
</tf>
<jax>
## FlaxMT5Model
[[autodoc]] FlaxMT5Model
## FlaxMT5ForConditionalGeneration
[[autodoc]] FlaxMT5ForConditionalGeneration
## FlaxMT5EncoderModel
[[autodoc]] FlaxMT5EncoderModel
</jax>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/mt5.md |
--
title: The State of Computer Vision at Hugging Face 🤗
thumbnail: /blog/assets/cv_state/thumbnail.png
authors:
- user: sayakpaul
---
# The State of Computer Vision at Hugging Face 🤗
At Hugging Face, we pride ourselves on democratizing the field of artificial intelligence together with the community. As a part of that mission, we began focusing our efforts on computer vision over the last year. What started as a [PR for having Vision Transformers (ViT) in 🤗 Transformers](https://github.com/huggingface/transformers/pull/10950) has now grown into something much bigger – 8 core vision tasks, over 3000 models, and over 100 datasets on the Hugging Face Hub.
A lot of exciting things have happened since ViTs joined the Hub. In this blog post, we’ll summarize what went down and what’s coming to support the continuous progress of Computer Vision from the 🤗 ecosystem.
Here is a list of things we’ll cover:
- [Supported vision tasks and Pipelines](#support-for-pipelines)
- [Training your own vision models](#training-your-own-models)
- [Integration with `timm`](#🤗-🤝-timm)
- [Diffusers](#🧨-diffusers)
- [Support for third-party libraries](#support-for-third-party-libraries)
- [Deployment](#deployment)
- and much more!
## Enabling the community: One task at a time 👁
The Hugging Face Hub is home to over 100,000 public models for different tasks such as next-word prediction, mask filling, token classification, sequence classification, and so on. As of today, we support [8 core vision tasks](https://huggingface.co/tasks) providing many model checkpoints:
- Image classification
- Image segmentation
- (Zero-shot) object detection
- Video classification
- Depth estimation
- Image-to-image synthesis
- Unconditional image generation
- Zero-shot image classification
Each of these tasks comes with at least 10 model checkpoints on the Hub for you to explore. Furthermore, we support [tasks](https://huggingface.co/tasks) that lie at the intersection of vision and language such as:
- Image-to-text (image captioning, OCR)
- Text-to-image
- Document question-answering
- Visual question-answering
These tasks entail not only state-of-the-art Transformer-based architectures such as [ViT](https://huggingface.co/docs/transformers/model_doc/vit), [Swin](https://huggingface.co/docs/transformers/model_doc/swin), [DETR](https://huggingface.co/docs/transformers/model_doc/detr) but also *pure convolutional* architectures like [ConvNeXt](https://huggingface.co/docs/transformers/model_doc/convnext), [ResNet](https://huggingface.co/docs/transformers/model_doc/resnet), [RegNet](https://huggingface.co/docs/transformers/model_doc/regnet), and more! Architectures like ResNets are still very much relevant for a myriad of industrial use cases and hence the support of these non-Transformer architectures in 🤗 Transformers.
It’s also important to note that the models on the Hub are not just from the Transformers library but also from other third-party libraries. For example, even though we support tasks like unconditional image generation on the Hub, we don’t have any models supporting that task in Transformers yet (such as [this](https://huggingface.co/ceyda/butterfly_cropped_uniq1K_512)). Supporting all ML tasks, whether they are solved with Transformers or a third-party library is a part of our mission to foster a collaborative open-source Machine Learning ecosystem.
## Support for Pipelines
We developed [Pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines) to equip practitioners with the tools they need to easily incorporate machine learning into their toolbox. They provide an easy way to perform inference on a given input with respect to a task. We have support for [seven vision tasks](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#computer-vision) in Pipelines. Here is an example of using Pipelines for depth estimation:
```py
from transformers import pipeline
depth_estimator = pipeline(task="depth-estimation", model="Intel/dpt-large")
output = depth_estimator("http://images.cocodataset.org/val2017/000000039769.jpg")
# This is a tensor with the values being the depth expressed
# in meters for each pixel
output["depth"]
```
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cv_state/depth_estimation_output.png"/>
</div>
The interface remains the same even for tasks like visual question-answering:
```py
from transformers import pipeline
oracle = pipeline(model="dandelin/vilt-b32-finetuned-vqa")
image_url = "https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg"
oracle(question="What's the animal doing?", image=image_url, top_k=1)
# [{'score': 0.778620, 'answer': 'laying down'}]
```
## Training your own models
While being able to use a model for off-the-shelf inference is a great way to get started, fine-tuning is where the community gets the most benefits. This is especially true when your datasets are custom, and you’re not getting good performance out of the pre-trained models.
Transformers provides a [Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) for everything related to training. Currently, `Trainer` seamlessly supports the following tasks: image classification, image segmentation, video classification, object detection, and depth estimation. Fine-tuning models for other vision tasks are also supported, just not by `Trainer`.
As long as the loss computation is included in a model from Transformers computes loss for a given task, it should be eligible for fine-tuning for the task. If you find issues, please [report](https://github.com/huggingface/transformers/issues) them on GitHub.
**Where do I find the code?**
- [Model documentation](https://huggingface.co/docs/transformers/index#supported-models)
- [Hugging Face notebooks](https://github.com/huggingface/notebooks)
- [Hugging Face example scripts](https://github.com/huggingface/transformers/tree/main/examples)
- [Task pages](https://huggingface.co/tasks)
[Hugging Face example scripts](https://github.com/huggingface/transformers/tree/main/examples) include different [self-supervised pre-training strategies](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining) like [MAE](https://arxiv.org/abs/2111.06377), and [contrastive image-text pre-training strategies](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text) like [CLIP](https://arxiv.org/abs/2103.00020). These scripts are valuable resources for the research community as well as for practitioners willing to run pre-training from scratch on custom data corpora.
Some tasks are not inherently meant for fine-tuning, though. Examples include zero-shot image classification (such as [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip)), zero-shot object detection (such as [OWL-ViT](https://huggingface.co/docs/transformers/main/en/model_doc/owlvit)), and zero-shot segmentation (such as [CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)). We’ll revisit these models in this post.
## Integrations with Datasets
[Datasets](https://huggingface.co/docs/datasets) provides easy access to thousands of datasets of different modalities. As mentioned earlier, the Hub has over 100 datasets for computer vision. Some examples worth noting here: [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k), [Scene Parsing](https://huggingface.co/datasets/scene_parse_150), [NYU Depth V2](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2), [COYO-700M](https://huggingface.co/datasets/kakaobrain/coyo-700m), and [LAION-400M](https://huggingface.co/datasets/laion/laion400m). With these datasets being on the Hub, one can easily load them with just two lines of code:
```py
from datasets import load_dataset
dataset = load_dataset("scene_parse_150")
```
Besides these datasets, we provide integration support with augmentation libraries like [albumentations](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) and [Kornia](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb). The community can take advantage of the flexibility and performance of Datasets and powerful augmentation transformations provided by these libraries. In addition to these, we also provide [dedicated data-loading guides](https://huggingface.co/docs/datasets/image_load) for core vision tasks: image classification, image segmentation, object detection, and depth estimation.
## 🤗 🤝 timm
`timm`, also known as [pytorch-image-models](https://github.com/rwightman/pytorch-image-models), is an open-source collection of state-of-the-art PyTorch image models, pre-trained weights, and utility scripts for training, inference, and validation.
We have over 200 models from `timm` on the Hub and more are on the way. Check out the [documentation](https://huggingface.co/docs/timm/index) to know more about this integration.
## 🧨 Diffusers
[Diffusers](https://huggingface.co/docs/diffusers) provides pre-trained vision and audio diffusion models, and serves as a modular toolbox for inference and training. With this library, you can generate plausible images from natural language inputs amongst other creative use cases. Here is an example:
```py
from diffusers import DiffusionPipeline
generator = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
generator.to(“cuda”)
image = generator("An image of a squirrel in Picasso style").images[0]
```
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cv_state/sd_output.png"/>
</div>
This type of technology can empower a new generation of creative applications and also aid artists coming from different backgrounds. To know more about Diffusers and the different use cases, check out the [official documentation](https://huggingface.co/docs/diffusers).
The literature on Diffusion-based models is developing at a rapid pace which is why we partnered with [Jonathan Whitaker](https://github.com/johnowhitaker) to develop a course on it. The course is free, and you can check it out [here](https://github.com/huggingface/diffusion-models-class).
## Support for third-party libraries
Central to the Hugging Face ecosystem is the [Hugging Face Hub](https://huggingface.co/docs/hub), which lets people collaborate effectively on Machine Learning. As mentioned earlier, we not only support models from 🤗 Transformers on the Hub but also models from other third-party libraries. To this end, we provide [several utilities](https://huggingface.co/docs/hub/models-adding-libraries) so that you can integrate your own library with the Hub. One of the primary advantages of doing this is that it becomes very easy to share artifacts (such as models and datasets) with the community, thereby making it easier for your users to try out your models.
When you have your models hosted on the Hub, you can also [add custom inference widgets](https://github.com/huggingface/api-inference-community) for them. Inference widgets allow users to quickly check out the models. This helps with improving user engagement.
<div align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/cv_state/task_widget_generation.png"/>
</div>
## Spaces for computer vision demos
With [Spaces](https://huggingface.co/docs/hub/spaces-overview), one can easily demonstrate their Machine Learning models. Spaces support direct integrations with [Gradio](https://gradio.app/), [Streamlit](https://streamlit.io/), and [Docker](https://www.docker.com/) empowering practitioners to have a great amount of flexibility while showcasing their models. You can bring in your own Machine Learning framework to build a demo with Spaces.
The Gradio library provides several components for building Computer Vision applications on Spaces such as [Video](https://gradio.app/docs/#video), [Gallery](https://gradio.app/docs/#gallery), and [Model3D](https://gradio.app/docs/#model3d). The community has been hard at work building some amazing Computer Vision applications that are powered by Spaces:
- [Generate 3D voxels from a predicted depth map of an input image](https://huggingface.co/spaces/radames/dpt-depth-estimation-3d-voxels)
- [Open vocabulary semantic segmentation](https://huggingface.co/spaces/facebook/ov-seg)
- [Narrate videos by generating captions](https://huggingface.co/spaces/nateraw/lavila)
- [Classify videos from YouTube](https://huggingface.co/spaces/fcakyon/video-classification)
- [Zero-shot video classification](https://huggingface.co/spaces/fcakyon/zero-shot-video-classification)
- [Visual question-answering](https://huggingface.co/spaces/nielsr/vilt-vqa)
- [Use zero-shot image classification to find best captions for an image to generate similar images](https://huggingface.co/spaces/pharma/CLIP-Interrogator)
## 🤗 AutoTrain
[AutoTrain](https://huggingface.co/autotrain) provides a “no-code” solution to train state-of-the-art Machine Learning models for tasks like text classification, text summarization, named entity recognition, and more. For Computer Vision, we currently support [image classification](https://huggingface.co/blog/autotrain-image-classification), but one can expect more task coverage.
AutoTrain also enables [automatic model evaluation](https://huggingface.co/spaces/autoevaluate/model-evaluator). This application allows you to evaluate 🤗 Transformers [models](https://huggingface.co/models?library=transformers&sort=downloads) across a wide variety of [datasets](https://huggingface.co/datasets) on the Hub. The results of your evaluation will be displayed on the [public leaderboards](https://huggingface.co/spaces/autoevaluate/leaderboards). You can check [this blog post](https://huggingface.co/blog/eval-on-the-hub) for more details.
## The technical philosophy
In this section, we wanted to share our philosophy behind adding support for Computer Vision in 🤗 Transformers so that the community is aware of the design choices specific to this area.
Even though Transformers started with NLP, we support multiple modalities today, for example – vision, audio, vision-language, and Reinforcement Learning. For all of these modalities, all the corresponding models from Transformers enjoy some common benefits:
- Easy model download with a single line of code with `from_pretrained()`
- Easy model upload with `push_to_hub()`
- Support for loading huge checkpoints with efficient checkpoint sharding techniques
- Optimization support (with tools like [Optimum](https://huggingface.co/docs/optimum))
- Initialization from model configurations
- Support for both PyTorch and TensorFlow (non-exhaustive)
- and many more
Unlike tokenizers, we have preprocessors (such as [this](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTImageProcessor)) that take care of preparing data for the vision models. We have worked hard to ensure the user experience of using a vision model still feels easy and similar:
```py
from transformers import ViTImageProcessor, ViTForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
inputs = image_processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
# Egyptian cat
```
Even for a difficult task like object detection, the user experience doesn’t change very much:
```py
from transformers import AutoImageProcessor, AutoModelForObjectDetection
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("microsoft/conditional-detr-resnet-50")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(
outputs, threshold=0.5, target_sizes=target_sizes
)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
```
Leads to:
```bash
Detected remote with confidence 0.833 at location [38.31, 72.1, 177.63, 118.45]
Detected cat with confidence 0.831 at location [9.2, 51.38, 321.13, 469.0]
Detected cat with confidence 0.804 at location [340.3, 16.85, 642.93, 370.95]
Detected remote with confidence 0.683 at location [334.48, 73.49, 366.37, 190.01]
Detected couch with confidence 0.535 at location [0.52, 1.19, 640.35, 475.1]
```
## Zero-shot models for vision
There’s been a surge of models that reformulate core vision tasks like segmentation and detection in interesting ways and introduce even more flexibility. We support a few of those from Transformers:
- [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip) that enables zero-shot image classification with prompts. Given an image, you’d prompt the CLIP model with a natural language query like “an image of {}”. The hope is to get the class label as the answer.
- [OWL-ViT](https://huggingface.co/docs/transformers/main/en/model_doc/owlvit) that allows for language-conditioned zero-shot object detection and image-conditioned one-shot object detection. This means you can detect objects in an image even if the underlying model didn’t learn to detect them during training! You can refer to [this notebook](https://github.com/huggingface/notebooks/tree/main/examples#:~:text=zeroshot_object_detection_with_owlvit.ipynb) to know more.
- [CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg) that supports language-conditioned zero-shot image segmentation and image-conditioned one-shot image segmentation. This means you can segment objects in an image even if the underlying model didn’t learn to segment them during training! You can refer to [this blog post](https://huggingface.co/blog/clipseg-zero-shot) that illustrates this idea. [GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit) also supports the task of zero-shot segmentation.
- [X-CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/xclip) that showcases zero-shot generalization to videos. Precisely, it supports zero-shot video classification. Check out [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/X-CLIP/Zero_shot_classify_a_YouTube_video_with_X_CLIP.ipynb) for more details.
The community can expect to see more zero-shot models for computer vision being supported from 🤗Transformers in the coming days.
## Deployment
As our CTO Julien says - “real artists ship” 🚀
We support the deployment of these vision models through [🤗Inference Endpoints](https://huggingface.co/inference-endpoints). Inference Endpoints integrates directly with compatible models pertaining to image classification, object detection, and image segmentation. For other tasks, you can use the [custom handlers](https://huggingface.co/docs/inference-endpoints/guides/custom_handler). Since we also provide many vision models in TensorFlow from 🤗Transformers for their deployment, we either recommend using the custom handlers or following these resources:
- [Deploying TensorFlow Vision Models in Hugging Face with TF Serving](https://huggingface.co/blog/tf-serving-vision)
- [Deploying 🤗 ViT on Kubernetes with TF Serving](https://huggingface.co/blog/deploy-tfserving-kubernetes)
- [Deploying 🤗 ViT on Vertex AI](https://huggingface.co/blog/deploy-vertex-ai)
- [Deploying ViT with TFX and Vertex AI](https://github.com/deep-diver/mlops-hf-tf-vision-models)
## Conclusion
In this post, we gave you a rundown of the things currently supported from the Hugging Face ecosystem to empower the next generation of Computer Vision applications. We hope you’ll enjoy using these offerings to build reliably and responsibly.
There is a lot to be done, though. Here are some things you can expect to see:
- Direct support of videos from 🤗 Datasets
- Supporting more industry-relevant tasks like image similarity
- Interoperability of the image datasets with TensorFlow
- A course on Computer Vision from the 🤗 community
As always, we welcome your patches, PRs, model checkpoints, datasets, and other contributions! 🤗
*Acknowlegements: Thanks to Omar Sanseviero, Nate Raw, Niels Rogge, Alara Dirik, Amy Roberts, Maria Khalusova, and Lysandre Debut for their rigorous and timely reviews on the blog draft. Thanks to Chunte Lee for creating the blog thumbnail.*
| huggingface/blog/blob/main/cv_state.md |
Sharing demos with others[[sharing-demos-with-others]]
<CourseFloatingBanner chapter={9}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter9/section4.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter9/section4.ipynb"},
]} />
Now that you've built a demo, you'll probably want to share it with others. Gradio demos
can be shared in two ways: using a ***temporary share link*** or ***permanent hosting on Spaces***.
We'll cover both of these approaches shortly. But before you share your demo, you may want to polish it up 💅.
### Polishing your Gradio demo:[[polishing-your-gradio-demo]]
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter9/gradio-demo-overview.png" alt="Overview of a gradio interface">
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter9/gradio-demo-overview-dark.png" alt="Overview of a gradio interface">
</div>
To add additional content to your demo, the `Interface` class supports some optional parameters:
- `title`: you can give a title to your demo, which appears _above_ the input and output components.
- `description`: you can give a description (in text, Markdown, or HTML) for the interface, which appears above the input and output components and below the title.
- `article`: you can also write an expanded article (in text, Markdown, or HTML) explaining the interface. If provided, it appears _below_ the input and output components.
- `theme`: don't like the default colors? Set the theme to use one of `default`, `huggingface`, `grass`, `peach`. You can also add the `dark-` prefix, e.g. `dark-peach` for dark theme (or just `dark` for the default dark theme).
- `examples`: to make your demo *way easier to use*, you can provide some example inputs for the function. These appear below the UI components and can be used to populate the interface. These should be provided as a nested list, in which the outer list consists of samples and each inner list consists of an input corresponding to each input component.
- `live`: if you want to make your demo "live", meaning that your model reruns every time the input changes, you can set `live=True`. This makes sense to use with quick models (we'll see an example at the end of this section)
Using the options above, we end up with a more complete interface. Run the code below so you can chat with Rick and Morty:
```py
title = "Ask Rick a Question"
description = """
The bot was trained to answer questions based on Rick and Morty dialogues. Ask Rick anything!
<img src="https://huggingface.co/spaces/course-demos/Rick_and_Morty_QA/resolve/main/rick.png" width=200px>
"""
article = "Check out [the original Rick and Morty Bot](https://huggingface.co/spaces/kingabzpro/Rick_and_Morty_Bot) that this demo is based off of."
gr.Interface(
fn=predict,
inputs="textbox",
outputs="text",
title=title,
description=description,
article=article,
examples=[["What are you doing?"], ["Where should we time travel to?"]],
).launch()
```
Using the options above, we end up with a more complete interface. Try the interface below:
<iframe src="https://course-demos-Rick-and-Morty-QA.hf.space" frameBorder="0" height="800" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
### Sharing your demo with temporary links[[sharing-your-demo-with-temporary-links]]
Now that we have a working demo of our machine learning model, let's learn how to easily share a link to our interface.
Interfaces can be easily shared publicly by setting `share=True` in the `launch()` method:
```python
gr.Interface(classify_image, "image", "label").launch(share=True)
```
This generates a public, shareable link that you can send to anybody! When you send this link, the user on the other side can try out the model in their browser for up to 72 hours. Because the processing happens on your device (as long as your device stays on!), you don't have to worry about packaging any dependencies. If you're working out of a Google Colab notebook, a share link is always automatically created. It usually looks something like this: **XXXXX.gradio.app**. Although the link is served through a Gradio link, we are only a proxy for your local server, and do not store any data sent through the interfaces.
Keep in mind, however, that these links are publicly accessible, meaning that anyone can use your model for prediction! Therefore, make sure not to expose any sensitive information through the functions you write, or allow any critical changes to occur on your device. If you set `share=False` (the default), only a local link is created.
### Hosting your demo on Hugging Face Spaces[[hosting-your-demo-on-hugging-face-spaces]]
A share link that you can pass around to collegues is cool, but how can you permanently host your demo and have it exist in its own "space" on the internet?
Hugging Face Spaces provides the infrastructure to permanently host your Gradio model on the internet, **for free**! Spaces allows you to create and push to a (public or private) repo,
where your Gradio
interface code will exist in an `app.py` file. [Read a step-by-step tutorial](https://huggingface.co/blog/gradio-spaces) to get started, or watch an example video below.
<Youtube id="LS9Y2wDVI0k" />
## ✏️ Let's apply it![[lets-apply-it]]
Using what we just learned in the sections so far, let's create the sketch recognition demo we saw in [section one of this chapter](/course/chapter9/1). Let's add some customization to our interface and set `share=True` to create a public link we can pass around.
We can load the labels from [class_names.txt](https://huggingface.co/spaces/dawood/Sketch-Recognition/blob/main/class_names.txt) and load the pre-trained pytorch model from [pytorch_model.bin](https://huggingface.co/spaces/dawood/Sketch-Recognition/blob/main/pytorch_model.bin). Download these files by following the link and clicking download on the top left corner of the file preview. Let's take a look at the code below to see how we use these files to load our model and create a `predict()` function:
```py
from pathlib import Path
import torch
import gradio as gr
from torch import nn
LABELS = Path("class_names.txt").read_text().splitlines()
model = nn.Sequential(
nn.Conv2d(1, 32, 3, padding="same"),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding="same"),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding="same"),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1152, 256),
nn.ReLU(),
nn.Linear(256, len(LABELS)),
)
state_dict = torch.load("pytorch_model.bin", map_location="cpu")
model.load_state_dict(state_dict, strict=False)
model.eval()
def predict(im):
x = torch.tensor(im, dtype=torch.float32).unsqueeze(0).unsqueeze(0) / 255.0
with torch.no_grad():
out = model(x)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
values, indices = torch.topk(probabilities, 5)
return {LABELS[i]: v.item() for i, v in zip(indices, values)}
```
Now that we have a `predict()` function. The next step is to define and launch our gradio interface:
```py
interface = gr.Interface(
predict,
inputs="sketchpad",
outputs="label",
theme="huggingface",
title="Sketch Recognition",
description="Who wants to play Pictionary? Draw a common object like a shovel or a laptop, and the algorithm will guess in real time!",
article="<p style='text-align: center'>Sketch Recognition | Demo Model</p>",
live=True,
)
interface.launch(share=True)
```
<iframe src="https://course-demos-Sketch-Recognition.hf.space" frameBorder="0" height="650" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Notice the `live=True` parameter in `Interface`, which means that the sketch demo makes
a prediction every time someone draws on the sketchpad (no submit button!).
Furthermore, we also set the `share=True` argument in the `launch()` method.
This will create a public link that you can
send to anyone! When you send this link, the user on the other side can try out the
sketch recognition model. To reiterate, you could also host the model on Hugging Face Spaces,
which is how we are able to embed the demo above.
Next up, we'll cover other ways that Gradio can be used with the Hugging Face ecosystem! | huggingface/course/blob/main/chapters/en/chapter9/4.mdx |
Gradio Demo: file_component
```
!pip install -q gradio
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.File()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/file_component/run.ipynb |
``python
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, PrefixTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
from datasets import load_dataset
device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
peft_config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=30)
dataset_name = "twitter_complaints"
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace(
"/", "_"
)
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
lr = 3e-2
num_epochs = 50
batch_size = 8
```
```python
from datasets import load_dataset
dataset = load_dataset("ought/raft", dataset_name)
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
print(classes)
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
batched=True,
num_proc=1,
)
print(dataset)
dataset["train"][0]
```
```python
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
print(target_max_length)
def preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
targets = [str(x) for x in examples[label_column]]
model_inputs = tokenizer(inputs)
labels = tokenizer(targets, add_special_tokens=False) # don't add bos token because we concatenate with inputs
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i] + [tokenizer.eos_token_id]
# print(i, sample_input_ids, label_input_ids)
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
label_input_ids = labels["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
model_inputs["labels"] = labels["input_ids"]
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["train"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
```
```python
def test_preprocess_function(examples):
batch_size = len(examples[text_column])
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
model_inputs = tokenizer(inputs)
# print(model_inputs)
for i in range(batch_size):
sample_input_ids = model_inputs["input_ids"][i]
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
max_length - len(sample_input_ids)
) + sample_input_ids
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
"attention_mask"
][i]
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
return model_inputs
test_dataset = dataset["test"].map(
test_preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
test_dataloader = DataLoader(test_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
next(iter(test_dataloader))
```
```python
next(iter(train_dataloader))
```
```python
len(test_dataloader)
```
```python
next(iter(test_dataloader))
```
```python
# creating model
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
```
```python
model.print_trainable_parameters()
```
```python
model
```
```python
model.peft_config
```
```python
# model
# optimizer and lr scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
```
```python
# training and evaluation
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
# print(batch)
# print(batch["input_ids"].shape)
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
```
```python
model.eval()
i = 16
inputs = tokenizer(f'{text_column} : {dataset["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
You can push model to hub or save model locally.
- Option1: Pushing the model to Hugging Face Hub
```python
model.push_to_hub(
f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace("/", "_"),
token = "hf_..."
)
```
token (`bool` or `str`, *optional*):
`token` is to be used for HTTP Bearer authorization when accessing remote files. If `True`, will use the token generated
when running `huggingface-cli login` (stored in `~/.huggingface`). Will default to `True` if `repo_url`
is not specified.
Or you can get your token from https://huggingface.co/settings/token
```
- Or save model locally
```python
peft_model_id = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace("/", "_")
model.save_pretrained(peft_model_id)
```
```python
# saving model
peft_model_id = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace(
"/", "_"
)
model.save_pretrained(peft_model_id)
```
```python
ckpt = f"{peft_model_id}/adapter_model.bin"
!du -h $ckpt
```
```python
from peft import PeftModel, PeftConfig
peft_model_id = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}".replace(
"/", "_"
)
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
```
```python
model.to(device)
model.eval()
i = 4
inputs = tokenizer(f'{text_column} : {dataset["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
print(dataset["test"][i]["Tweet text"])
print(inputs)
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = model.generate(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
```
| huggingface/peft/blob/main/examples/causal_language_modeling/peft_prefix_tuning_clm.ipynb |
ow to preprocess pairs of sentences? We have seen how to tokenize single sentences and batch them together in the "Batching inputs together" video. If this code look unfamiliar to you, be sure to check that video again! Here we will focus on tasks that classify pairs of sentences. For instance, we may want to classify whether two texts are paraphrases or not. Here is an example taken from the Quora Question Pairs dataset, which focuses on identifying duplicate questions. In the first pair, the two questions are duplicates; in the second, they are not. Another pair classification problem is when we want to know if two sentences are logically related or not (a problem called Natural Language Inference or NLI). In this example taken from the MultiNLI dataset, we have a pair of sentences for each possible label: contradiction, neutral or entailment (which is a fancy way of saying the first sentence implies the second). So classifying pairs of sentences is a problem worth studying. In fact, in the GLUE benchmark (which is an academic benchmark for text classification), 8 of the 10 datasets are focused on tasks using pairs of sentences. That's why models like BERT are often pretrained with a dual objective: on top of the language modeling objective, they often have an objective related to sentence pairs. For instance, during pretraining, BERT is shown pairs of sentences and must predict both the value of randomly masked tokens and whether the second sentence follows from the first. Fortunately, the tokenizer from the Transformers library has a nice API to deal with pairs of sentences: you just have to pass them as two arguments to the tokenizer. On top of the input IDs and the attention mask we studied already, it returns a new field called token type IDs, which tells the model which tokens belong to the first sentence and which ones belong to the second sentence. Zooming in a little bit, here are the input IDs, aligned with the tokens they correspond to, their respective token type ID and attention mask. We can see the tokenizer also added special tokens so we have a CLS token, the tokens from the first sentence, a SEP token, the tokens from the second sentence, and a final SEP token. If we have several pairs of sentences, we can tokenize them together by passing the list of first sentences, then the list of second sentences and all the keyword arguments we studied already, like padding=True. Zooming in at the result, we can see how the tokenizer added padding to the second pair of sentences, to make the two outputs the same length, and properly dealt with token type IDS and attention masks for the two sentences. This is then all ready to pass through our model! | huggingface/course/blob/main/subtitles/en/raw/chapter3/02c_preprocess-sentence-pairs-tf.md |
Gradio Demo: blocks_group
```
!pip install -q gradio
```
```
import gradio as gr
def greet(name):
return "Hello " + name + "!"
with gr.Blocks() as demo:
gr.Markdown("### This is a couple of elements without any gr.Group. Form elements naturally group together anyway.")
gr.Textbox("A")
gr.Number(3)
gr.Button()
gr.Image()
gr.Slider()
gr.Markdown("### This is the same set put in a gr.Group.")
with gr.Group():
gr.Textbox("A")
gr.Number(3)
gr.Button()
gr.Image()
gr.Slider()
gr.Markdown("### Now in a Row, no group.")
with gr.Row():
gr.Textbox("A")
gr.Number(3)
gr.Button()
gr.Image()
gr.Slider()
gr.Markdown("### Now in a Row in a group.")
with gr.Group():
with gr.Row():
gr.Textbox("A")
gr.Number(3)
gr.Button()
gr.Image()
gr.Slider()
gr.Markdown("### Several rows grouped together.")
with gr.Group():
with gr.Row():
gr.Textbox("A")
gr.Number(3)
gr.Button()
with gr.Row():
gr.Image()
gr.Audio()
gr.Markdown("### Several columns grouped together. If columns are uneven, there is a gray group background.")
with gr.Group():
with gr.Row():
with gr.Column():
name = gr.Textbox(label="Name")
btn = gr.Button("Hello")
gr.Dropdown(["a", "b", "c"], interactive=True)
gr.Number()
gr.Textbox()
with gr.Column():
gr.Image()
gr.Dropdown(["a", "b", "c"], interactive=True)
with gr.Row():
gr.Number(scale=2)
gr.Textbox()
gr.Markdown("### container=False removes label, padding, and block border, placing elements 'directly' on background.")
gr.Radio([1,2,3], container=False)
gr.Textbox(container=False)
gr.Image("https://picsum.photos/id/237/200/300", container=False, height=200)
gr.Markdown("### Textbox, Dropdown, and Number input boxes takes up full space when within a group without a container.")
with gr.Group():
name = gr.Textbox(label="Name")
output = gr.Textbox(show_label=False, container=False)
greet_btn = gr.Button("Greet")
with gr.Row():
gr.Dropdown(["a", "b", "c"], interactive=True, container=False)
gr.Textbox(container=False)
gr.Number(container=False)
gr.Image(height=100)
greet_btn.click(fn=greet, inputs=name, outputs=output, api_name="greet")
gr.Markdown("### More examples")
with gr.Group():
gr.Chatbot()
with gr.Row():
name = gr.Textbox(label="Prompot", container=False)
go = gr.Button("go", scale=0)
with gr.Column():
gr.Radio([1,2,3], container=False)
gr.Slider(0, 20, container=False)
with gr.Group():
with gr.Row():
gr.Dropdown(["a", "b", "c"], interactive=True, container=False, elem_id="here2")
gr.Number(container=False)
gr.Textbox(container=False)
with gr.Row():
with gr.Column():
gr.Dropdown(["a", "b", "c"], interactive=True, container=False, elem_id="here2")
with gr.Column():
gr.Number(container=False)
with gr.Column():
gr.Textbox(container=False)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_group/run.ipynb |
通过自动重载实现更快的开发
**先决条件**:本指南要求您了解块的知识。请确保[先阅读块指南](https://gradio.app/quickstart/#blocks-more-flexibility-and-control)。
本指南介绍了自动重新加载、在 Python IDE 中重新加载以及在 Jupyter Notebooks 中使用 gradio 的方法。
## 为什么要使用自动重载?
当您构建 Gradio 演示时,特别是使用 Blocks 构建时,您可能会发现反复运行代码以测试更改很麻烦。
为了更快速、更便捷地编写代码,我们已经简化了在 **Python IDE**(如 VS Code、Sublime Text、PyCharm 等)中开发或从终端运行 Python 代码时“重新加载”Gradio 应用的方式。我们还开发了一个类似的“魔法命令”,使您可以更快速地重新运行单元格,如果您使用 Jupyter Notebooks(或类似的环境,如 Colab)的话。
这个简短的指南将涵盖这两种方法,所以无论您如何编写 Python 代码,您都将知道如何更快地构建 Gradio 应用程序。
## Python IDE 重载 🔥
如果您使用 Python IDE 构建 Gradio Blocks,那么代码文件(假设命名为 `run.py`)可能如下所示:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 来自Gradio的问候!")
inp = gr.Textbox(placeholder="您叫什么名字?")
out = gr.Textbox()
inp.change(fn=lambda x: f"欢迎,{x}!",
inputs=inp,
outputs=out)
if __name__ == "__main__":
demo.launch()
```
问题在于,每当您想要更改布局、事件或组件时,都必须通过编写 `python run.py` 来关闭和重新运行应用程序。
而不是这样做,您可以通过更改 1 个单词来以**重新加载模式**运行代码:将 `python` 更改为 `gradio`:
在终端中运行 `gradio run.py`。就是这样!
现在,您将看到类似于这样的内容:
```bash
Launching in *reload mode* on: http://127.0.0.1:7860 (Press CTRL+C to quit)
Watching...
WARNING: The --reload flag should not be used in production on Windows.
```
这里最重要的一行是 `正在观察 ...`。这里发生的情况是 Gradio 将观察 `run.py` 文件所在的目录,如果文件发生更改,它将自动为您重新运行文件。因此,您只需专注于编写代码,Gradio 演示将自动刷新 🥳
⚠️ 警告:`gradio` 命令不会检测传递给 `launch()` 方法的参数,因为在重新加载模式下从未调用 `launch()` 方法。例如,设置 `launch()` 中的 `auth` 或 `show_error` 不会在应用程序中反映出来。
当您使用重新加载模式时,请记住一件重要的事情:Gradio 专门查找名为 `demo` 的 Gradio Blocks/Interface 演示。如果您将演示命名为其他名称,您需要在代码中的第二个参数中传入演示的 FastAPI 应用程序的名称。对于 Gradio 演示,可以使用 `.app` 属性访问 FastAPI 应用程序。因此,如果您的 `run.py` 文件如下所示:
```python
import gradio as gr
with gr.Blocks() as my_demo:
gr.Markdown("# 来自Gradio的问候!")
inp = gr.Textbox(placeholder="您叫什么名字?")
out = gr.Textbox()
inp.change(fn=lambda x: f"欢迎,{x}!",
inputs=inp,
outputs=out)
if __name__ == "__main__":
my_demo.launch()
```
那么您可以这样启动它:`gradio run.py my_demo.app`。
Gradio默认使用UTF-8编码格式。对于**重新加载模式**,如果你的脚本使用的是除UTF-8以外的编码(如GBK):
1. 在Python脚本的编码声明处指定你想要的编码格式,如:`# -*- coding: gbk -*-`
2. 确保你的代码编辑器识别到该格式。
3. 执行:`gradio run.py --encoding gbk`
🔥 如果您的应用程序接受命令行参数,您也可以传递它们。下面是一个例子:
```python
import gradio as gr
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--name", type=str, default="User")
args, unknown = parser.parse_known_args()
with gr.Blocks() as demo:
gr.Markdown(f"# 欢迎 {args.name}!")
inp = gr.Textbox()
out = gr.Textbox()
inp.change(fn=lambda x: x, inputs=inp, outputs=out)
if __name__ == "__main__":
demo.launch()
```
您可以像这样运行它:`gradio run.py --name Gretel`
作为一个小提示,只要更改了 `run.py` 源代码或 Gradio 源代码,自动重新加载就会发生。这意味着如果您决定[为 Gradio 做贡献](https://github.com/gradio-app/gradio/blob/main/CONTRIBUTING.md),这将非常有用 ✅
## Jupyter Notebook 魔法命令🔮
如果您使用 Jupyter Notebooks(或 Colab Notebooks 等)进行开发,我们也为您提供了一个解决方案!
我们开发了一个 **magic command 魔法命令**,可以为您创建和运行一个 Blocks 演示。要使用此功能,在笔记本顶部加载 gradio 扩展:
`%load_ext gradio`
然后,在您正在开发 Gradio 演示的单元格中,只需在顶部写入魔法命令**`%%blocks`**,然后像平常一样编写布局和组件:
```py
%%blocks
import gradio as gr
gr.Markdown("# 来自Gradio的问候!")
inp = gr.Textbox(placeholder="您叫什么名字?")
out = gr.Textbox()
inp.change(fn=lambda x: f"欢迎,{x}!",
inputs=inp,
outputs=out)
```
请注意:
- 您不需要放置样板代码 `with gr.Blocks() as demo:` 和 `demo.launch()` — Gradio 会自动为您完成!
- 每次重新运行单元格时,Gradio 都将在相同的端口上重新启动您的应用程序,并使用相同的底层网络服务器。这意味着您将比正常重新运行单元格更快地看到变化。
下面是在 Jupyter Notebook 中的示例:

🪄这在 colab 笔记本中也适用,您可以在其中看到 Blocks 魔法效果。尝试进行一些更改并重新运行带有 Gradio 代码的单元格!
Notebook Magic 现在是作者构建 Gradio 演示的首选方式。无论您如何编写 Python 代码,我们都希望这两种方法都能为您提供更好的 Gradio 开发体验。
---
## 下一步
既然您已经了解了如何使用 Gradio 快速开发,请开始构建自己的应用程序吧!
如果你正在寻找灵感,请尝试浏览其他人用 Gradio 构建的演示,[浏览 Hugging Face Spaces](http://hf.space/) 🤗
| gradio-app/gradio/blob/main/guides/cn/07_other-tutorials/developing-faster-with-reload-mode.md |
Gradio Demo: sentiment_analysis
### This sentiment analaysis demo takes in input text and returns its classification for either positive, negative or neutral using Gradio's Label output.
```
!pip install -q gradio nltk
```
```
import gradio as gr
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
nltk.download("vader_lexicon")
sid = SentimentIntensityAnalyzer()
def sentiment_analysis(text):
scores = sid.polarity_scores(text)
del scores["compound"]
return scores
demo = gr.Interface(
fn=sentiment_analysis,
inputs=gr.Textbox(placeholder="Enter a positive or negative sentence here..."),
outputs="label",
examples=[["This is wonderful!"]])
demo.launch()
```
| gradio-app/gradio/blob/main/demo/sentiment_analysis/run.ipynb |
Validation and Benchmark Results
This folder contains validation and benchmark results for the models in this collection. Validation scores are currently only run for models with pretrained weights and ImageNet-1k heads, benchmark numbers are run for all.
## Datasets
There are currently results for the ImageNet validation set and 5 additional test / label sets.
The test set results include rank and top-1/top-5 differences from clean validation. For the "Real Labels", ImageNetV2, and Sketch test sets, the differences were calculated against the full 1000 class ImageNet-1k validation set. For both the Adversarial and Rendition sets, the differences were calculated against 'clean' runs on the ImageNet-1k validation set with the same 200 classes used in each test set respectively.
### ImageNet Validation - [`results-imagenet.csv`](results-imagenet.csv)
The standard 50,000 image ImageNet-1k validation set. Model selection during training utilizes this validation set, so it is not a true test set. Question: Does anyone have the official ImageNet-1k test set classification labels now that challenges are done?
* Source: http://image-net.org/challenges/LSVRC/2012/index
* Paper: "ImageNet Large Scale Visual Recognition Challenge" - https://arxiv.org/abs/1409.0575
### ImageNet-"Real Labels" - [`results-imagenet-real.csv`](results-imagenet-real.csv)
The usual ImageNet-1k validation set with a fresh new set of labels intended to improve on mistakes in the original annotation process.
* Source: https://github.com/google-research/reassessed-imagenet
* Paper: "Are we done with ImageNet?" - https://arxiv.org/abs/2006.07159
### ImageNetV2 Matched Frequency - [`results-imagenetv2-matched-frequency.csv`](results-imagenetv2-matched-frequency.csv)
An ImageNet test set of 10,000 images sampled from new images roughly 10 years after the original. Care was taken to replicate the original ImageNet curation/sampling process.
* Source: https://github.com/modestyachts/ImageNetV2
* Paper: "Do ImageNet Classifiers Generalize to ImageNet?" - https://arxiv.org/abs/1902.10811
### ImageNet-Sketch - [`results-sketch.csv`](results-sketch.csv)
50,000 non photographic (or photos of such) images (sketches, doodles, mostly monochromatic) covering all 1000 ImageNet classes.
* Source: https://github.com/HaohanWang/ImageNet-Sketch
* Paper: "Learning Robust Global Representations by Penalizing Local Predictive Power" - https://arxiv.org/abs/1905.13549
### ImageNet-Adversarial - [`results-imagenet-a.csv`](results-imagenet-a.csv)
A collection of 7500 images covering 200 of the 1000 ImageNet classes. Images are naturally occurring adversarial examples that confuse typical ImageNet classifiers. This is a challenging dataset, your typical ResNet-50 will score 0% top-1.
For clean validation with same 200 classes, see [`results-imagenet-a-clean.csv`](results-imagenet-a-clean.csv)
* Source: https://github.com/hendrycks/natural-adv-examples
* Paper: "Natural Adversarial Examples" - https://arxiv.org/abs/1907.07174
### ImageNet-Rendition - [`results-imagenet-r.csv`](results-imagenet-r.csv)
Renditions of 200 ImageNet classes resulting in 30,000 images for testing robustness.
For clean validation with same 200 classes, see [`results-imagenet-r-clean.csv`](results-imagenet-r-clean.csv)
* Source: https://github.com/hendrycks/imagenet-r
* Paper: "The Many Faces of Robustness" - https://arxiv.org/abs/2006.16241
### TODO
* Explore adding a reduced version of ImageNet-C (Corruptions) and ImageNet-P (Perturbations) from https://github.com/hendrycks/robustness. The originals are huge and image size specific.
## Benchmark
CSV files with a `model_benchmark` prefix include benchmark numbers for models on various accelerators with different precision. Currently only run on RTX 3090 w/ AMP for inference, I intend to add more in the future.
## Metadata
CSV files with `model_metadata` prefix contain extra information about the source training, currently the pretraining dataset and technique (ie distillation, SSL, WSL, etc). Eventually I'd like to have metadata about augmentation, regularization, etc. but that will be a challenge to source consistently.
| huggingface/pytorch-image-models/blob/main/results/README.md |
!---
Copyright 2022 - The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<p align="center">
<br>
<img src="https://raw.githubusercontent.com/huggingface/diffusers/main/docs/source/en/imgs/diffusers_library.jpg" width="400"/>
<br>
<p>
<p align="center">
<a href="https://github.com/huggingface/diffusers/blob/main/LICENSE">
<img alt="GitHub" src="https://img.shields.io/github/license/huggingface/datasets.svg?color=blue">
</a>
<a href="https://github.com/huggingface/diffusers/releases">
<img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/diffusers.svg">
</a>
<a href="https://pepy.tech/project/diffusers">
<img alt="GitHub release" src="https://static.pepy.tech/badge/diffusers/month">
</a>
<a href="CODE_OF_CONDUCT.md">
<img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.1-4baaaa.svg">
</a>
<a href="https://twitter.com/diffuserslib">
<img alt="X account" src="https://img.shields.io/twitter/url/https/twitter.com/diffuserslib.svg?style=social&label=Follow%20%40diffuserslib">
</a>
</p>
🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or training your own diffusion models, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](https://huggingface.co/docs/diffusers/conceptual/philosophy#usability-over-performance), [simple over easy](https://huggingface.co/docs/diffusers/conceptual/philosophy#simple-over-easy), and [customizability over abstractions](https://huggingface.co/docs/diffusers/conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
🤗 Diffusers offers three core components:
- State-of-the-art [diffusion pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) that can be run in inference with just a few lines of code.
- Interchangeable noise [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview) for different diffusion speeds and output quality.
- Pretrained [models](https://huggingface.co/docs/diffusers/api/models/overview) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
## Installation
We recommend installing 🤗 Diffusers in a virtual environment from PyPI or Conda. For more details about installing [PyTorch](https://pytorch.org/get-started/locally/) and [Flax](https://flax.readthedocs.io/en/latest/#installation), please refer to their official documentation.
### PyTorch
With `pip` (official package):
```bash
pip install --upgrade diffusers[torch]
```
With `conda` (maintained by the community):
```sh
conda install -c conda-forge diffusers
```
### Flax
With `pip` (official package):
```bash
pip install --upgrade diffusers[flax]
```
### Apple Silicon (M1/M2) support
Please refer to the [How to use Stable Diffusion in Apple Silicon](https://huggingface.co/docs/diffusers/optimization/mps) guide.
## Quickstart
Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 16000+ checkpoints):
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
pipeline.to("cuda")
pipeline("An image of a squirrel in Picasso style").images[0]
```
You can also dig into the models and schedulers toolbox to build your own diffusion system:
```python
from diffusers import DDPMScheduler, UNet2DModel
from PIL import Image
import torch
scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
scheduler.set_timesteps(50)
sample_size = model.config.sample_size
noise = torch.randn((1, 3, sample_size, sample_size), device="cuda")
input = noise
for t in scheduler.timesteps:
with torch.no_grad():
noisy_residual = model(input, t).sample
prev_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
input = prev_noisy_sample
image = (input / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
image = Image.fromarray((image * 255).round().astype("uint8"))
image
```
Check out the [Quickstart](https://huggingface.co/docs/diffusers/quicktour) to launch your diffusion journey today!
## How to navigate the documentation
| **Documentation** | **What can I learn?** |
|---------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Tutorial](https://huggingface.co/docs/diffusers/tutorials/tutorial_overview) | A basic crash course for learning how to use the library's most important features like using models and schedulers to build your own diffusion system, and training your own diffusion model. |
| [Loading](https://huggingface.co/docs/diffusers/using-diffusers/loading_overview) | Guides for how to load and configure all the components (pipelines, models, and schedulers) of the library, as well as how to use different schedulers. |
| [Pipelines for inference](https://huggingface.co/docs/diffusers/using-diffusers/pipeline_overview) | Guides for how to use pipelines for different inference tasks, batched generation, controlling generated outputs and randomness, and how to contribute a pipeline to the library. |
| [Optimization](https://huggingface.co/docs/diffusers/optimization/opt_overview) | Guides for how to optimize your diffusion model to run faster and consume less memory. |
| [Training](https://huggingface.co/docs/diffusers/training/overview) | Guides for how to train a diffusion model for different tasks with different training techniques. |
## Contribution
We ❤️ contributions from the open-source community!
If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
- See [New model/pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models / diffusion pipelines
- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
Also, say 👋 in our public Discord channel <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>. We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or just hang out ☕.
## Popular Tasks & Pipelines
<table>
<tr>
<th>Task</th>
<th>Pipeline</th>
<th>🤗 Hub</th>
</tr>
<tr style="border-top: 2px solid black">
<td>Unconditional Image Generation</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/ddpm"> DDPM </a></td>
<td><a href="https://huggingface.co/google/ddpm-ema-church-256"> google/ddpm-ema-church-256 </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img">Stable Diffusion Text-to-Image</a></td>
<td><a href="https://huggingface.co/runwayml/stable-diffusion-v1-5"> runwayml/stable-diffusion-v1-5 </a></td>
</tr>
<tr>
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/unclip">unCLIP</a></td>
<td><a href="https://huggingface.co/kakaobrain/karlo-v1-alpha"> kakaobrain/karlo-v1-alpha </a></td>
</tr>
<tr>
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/deepfloyd_if">DeepFloyd IF</a></td>
<td><a href="https://huggingface.co/DeepFloyd/IF-I-XL-v1.0"> DeepFloyd/IF-I-XL-v1.0 </a></td>
</tr>
<tr>
<td>Text-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/kandinsky">Kandinsky</a></td>
<td><a href="https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder"> kandinsky-community/kandinsky-2-2-decoder </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Text-guided Image-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/controlnet">ControlNet</a></td>
<td><a href="https://huggingface.co/lllyasviel/sd-controlnet-canny"> lllyasviel/sd-controlnet-canny </a></td>
</tr>
<tr>
<td>Text-guided Image-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/pix2pix">InstructPix2Pix</a></td>
<td><a href="https://huggingface.co/timbrooks/instruct-pix2pix"> timbrooks/instruct-pix2pix </a></td>
</tr>
<tr>
<td>Text-guided Image-to-Image</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/img2img">Stable Diffusion Image-to-Image</a></td>
<td><a href="https://huggingface.co/runwayml/stable-diffusion-v1-5"> runwayml/stable-diffusion-v1-5 </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Text-guided Image Inpainting</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/inpaint">Stable Diffusion Inpainting</a></td>
<td><a href="https://huggingface.co/runwayml/stable-diffusion-inpainting"> runwayml/stable-diffusion-inpainting </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Image Variation</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/image_variation">Stable Diffusion Image Variation</a></td>
<td><a href="https://huggingface.co/lambdalabs/sd-image-variations-diffusers"> lambdalabs/sd-image-variations-diffusers </a></td>
</tr>
<tr style="border-top: 2px solid black">
<td>Super Resolution</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/upscale">Stable Diffusion Upscale</a></td>
<td><a href="https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler"> stabilityai/stable-diffusion-x4-upscaler </a></td>
</tr>
<tr>
<td>Super Resolution</td>
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/latent_upscale">Stable Diffusion Latent Upscale</a></td>
<td><a href="https://huggingface.co/stabilityai/sd-x2-latent-upscaler"> stabilityai/sd-x2-latent-upscaler </a></td>
</tr>
</table>
## Popular libraries using 🧨 Diffusers
- https://github.com/microsoft/TaskMatrix
- https://github.com/invoke-ai/InvokeAI
- https://github.com/apple/ml-stable-diffusion
- https://github.com/Sanster/lama-cleaner
- https://github.com/IDEA-Research/Grounded-Segment-Anything
- https://github.com/ashawkey/stable-dreamfusion
- https://github.com/deep-floyd/IF
- https://github.com/bentoml/BentoML
- https://github.com/bmaltais/kohya_ss
- +7000 other amazing GitHub repositories 💪
Thank you for using us ❤️.
## Credits
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim)
- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
## Citation
```bibtex
@misc{von-platen-etal-2022-diffusers,
author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Thomas Wolf},
title = {Diffusers: State-of-the-art diffusion models},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/diffusers}}
}
```
| huggingface/diffusers/blob/main/README.md |
Metric Card for WikiSplit
## Metric description
WikiSplit is the combination of three metrics: [SARI](https://huggingface.co/metrics/sari), [exact match](https://huggingface.co/metrics/exact_match) and [SacreBLEU](https://huggingface.co/metrics/sacrebleu).
It can be used to evaluate the quality of sentence splitting approaches, which require rewriting a long sentence into two or more coherent short sentences, e.g. based on the [WikiSplit dataset](https://huggingface.co/datasets/wiki_split).
## How to use
The WIKI_SPLIT metric takes three inputs:
`sources`: a list of source sentences, where each sentence should be a string.
`predictions`: a list of predicted sentences, where each sentence should be a string.
`references`: a list of lists of reference sentences, where each sentence should be a string.
```python
>>> from datasets import load_metric
>>> wiki_split = load_metric("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["About 95 you now get in ."]
>>> references= [["About 95 species are currently known ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
```
## Output values
This metric outputs a dictionary containing three scores:
`sari`: the [SARI](https://huggingface.co/metrics/sari) score, whose range is between `0.0` and `100.0` -- the higher the value, the better the performance of the model being evaluated, with a SARI of 100 being a perfect score.
`sacrebleu`: the [SacreBLEU](https://huggingface.co/metrics/sacrebleu) score, which can take any value between `0.0` and `100.0`, inclusive.
`exact`: the [exact match](https://huggingface.co/metrics/exact_match) score, which represents the sum of all of the individual exact match scores in the set, divided by the total number of predictions in the set. It ranges from `0.0` to `100`, inclusive. Here, `0.0` means no prediction/reference pairs were matches, while `100.0` means they all were.
```python
>>> print(results)
{'sari': 21.805555555555557, 'sacrebleu': 14.535768424205482, 'exact': 0.0}
```
### Values from popular papers
This metric was initially used by [Rothe et al.(2020)](https://arxiv.org/pdf/1907.12461.pdf) to evaluate the performance of different split-and-rephrase approaches on the [WikiSplit dataset](https://huggingface.co/datasets/wiki_split). They reported a SARI score of 63.5, a SacreBLEU score of 77.2, and an EXACT_MATCH score of 16.3.
## Examples
Perfect match between prediction and reference:
```python
>>> from datasets import load_metric
>>> wiki_split = load_metric("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["About 95 species are currently accepted ."]
>>> references= [["About 95 species are currently accepted ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
>>> print(results)
{'sari': 100.0, 'sacrebleu': 100.00000000000004, 'exact': 100.0
```
Partial match between prediction and reference:
```python
>>> from datasets import load_metric
>>> wiki_split = load_metric("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["About 95 you now get in ."]
>>> references= [["About 95 species are currently known ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
>>> print(results)
{'sari': 21.805555555555557, 'sacrebleu': 14.535768424205482, 'exact': 0.0}
```
No match between prediction and reference:
```python
>>> from datasets import load_metric
>>> wiki_split = load_metric("wiki_split")
>>> sources = ["About 95 species are currently accepted ."]
>>> predictions = ["Hello world ."]
>>> references= [["About 95 species are currently known ."]]
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
>>> print(results)
{'sari': 14.047619047619046, 'sacrebleu': 0.0, 'exact': 0.0}
```
## Limitations and bias
This metric is not the official metric to evaluate models on the [WikiSplit dataset](https://huggingface.co/datasets/wiki_split). It was initially proposed by [Rothe et al.(2020)](https://arxiv.org/pdf/1907.12461.pdf), whereas the [original paper introducing the WikiSplit dataset (2018)](https://aclanthology.org/D18-1080.pdf) uses different metrics to evaluate performance, such as corpus-level [BLEU](https://huggingface.co/metrics/bleu) and sentence-level BLEU.
## Citation
```bibtex
@article{rothe2020leveraging,
title={Leveraging pre-trained checkpoints for sequence generation tasks},
author={Rothe, Sascha and Narayan, Shashi and Severyn, Aliaksei},
journal={Transactions of the Association for Computational Linguistics},
volume={8},
pages={264--280},
year={2020},
publisher={MIT Press}
}
```
## Further References
- [WikiSplit dataset](https://huggingface.co/datasets/wiki_split)
- [WikiSplit paper (Botha et al., 2018)](https://aclanthology.org/D18-1080.pdf)
| huggingface/datasets/blob/main/metrics/wiki_split/README.md |
Results
CSV files containing an ImageNet-1K and out-of-distribution (OOD) test set validation results for all models with pretrained weights is located in the repository [results folder](https://github.com/rwightman/pytorch-image-models/tree/master/results).
## Self-trained Weights
The table below includes ImageNet-1k validation results of model weights that I've trained myself. It is not updated as frequently as the csv results outputs linked above.
|Model | Acc@1 (Err) | Acc@5 (Err) | Param # (M) | Interpolation | Image Size |
|---|---|---|---|---|---|
| efficientnet_b3a | 82.242 (17.758) | 96.114 (3.886) | 12.23 | bicubic | 320 (1.0 crop) |
| efficientnet_b3 | 82.076 (17.924) | 96.020 (3.980) | 12.23 | bicubic | 300 |
| regnet_32 | 82.002 (17.998) | 95.906 (4.094) | 19.44 | bicubic | 224 |
| skresnext50d_32x4d | 81.278 (18.722) | 95.366 (4.634) | 27.5 | bicubic | 288 (1.0 crop) |
| seresnext50d_32x4d | 81.266 (18.734) | 95.620 (4.380) | 27.6 | bicubic | 224 |
| efficientnet_b2a | 80.608 (19.392) | 95.310 (4.690) | 9.11 | bicubic | 288 (1.0 crop) |
| resnet50d | 80.530 (19.470) | 95.160 (4.840) | 25.6 | bicubic | 224 |
| mixnet_xl | 80.478 (19.522) | 94.932 (5.068) | 11.90 | bicubic | 224 |
| efficientnet_b2 | 80.402 (19.598) | 95.076 (4.924) | 9.11 | bicubic | 260 |
| seresnet50 | 80.274 (19.726) | 95.070 (4.930) | 28.1 | bicubic | 224 |
| skresnext50d_32x4d | 80.156 (19.844) | 94.642 (5.358) | 27.5 | bicubic | 224 |
| cspdarknet53 | 80.058 (19.942) | 95.084 (4.916) | 27.6 | bicubic | 256 |
| cspresnext50 | 80.040 (19.960) | 94.944 (5.056) | 20.6 | bicubic | 224 |
| resnext50_32x4d | 79.762 (20.238) | 94.600 (5.400) | 25 | bicubic | 224 |
| resnext50d_32x4d | 79.674 (20.326) | 94.868 (5.132) | 25.1 | bicubic | 224 |
| cspresnet50 | 79.574 (20.426) | 94.712 (5.288) | 21.6 | bicubic | 256 |
| ese_vovnet39b | 79.320 (20.680) | 94.710 (5.290) | 24.6 | bicubic | 224 |
| resnetblur50 | 79.290 (20.710) | 94.632 (5.368) | 25.6 | bicubic | 224 |
| dpn68b | 79.216 (20.784) | 94.414 (5.586) | 12.6 | bicubic | 224 |
| resnet50 | 79.038 (20.962) | 94.390 (5.610) | 25.6 | bicubic | 224 |
| mixnet_l | 78.976 (21.024 | 94.184 (5.816) | 7.33 | bicubic | 224 |
| efficientnet_b1 | 78.692 (21.308) | 94.086 (5.914) | 7.79 | bicubic | 240 |
| efficientnet_es | 78.066 (21.934) | 93.926 (6.074) | 5.44 | bicubic | 224 |
| seresnext26t_32x4d | 77.998 (22.002) | 93.708 (6.292) | 16.8 | bicubic | 224 |
| seresnext26tn_32x4d | 77.986 (22.014) | 93.746 (6.254) | 16.8 | bicubic | 224 |
| efficientnet_b0 | 77.698 (22.302) | 93.532 (6.468) | 5.29 | bicubic | 224 |
| seresnext26d_32x4d | 77.602 (22.398) | 93.608 (6.392) | 16.8 | bicubic | 224 |
| mobilenetv2_120d | 77.294 (22.706 | 93.502 (6.498) | 5.8 | bicubic | 224 |
| mixnet_m | 77.256 (22.744) | 93.418 (6.582) | 5.01 | bicubic | 224 |
| resnet34d | 77.116 (22.884) | 93.382 (6.618) | 21.8 | bicubic | 224 |
| seresnext26_32x4d | 77.104 (22.896) | 93.316 (6.684) | 16.8 | bicubic | 224 |
| skresnet34 | 76.912 (23.088) | 93.322 (6.678) | 22.2 | bicubic | 224 |
| ese_vovnet19b_dw | 76.798 (23.202) | 93.268 (6.732) | 6.5 | bicubic | 224 |
| resnet26d | 76.68 (23.32) | 93.166 (6.834) | 16 | bicubic | 224 |
| densenetblur121d | 76.576 (23.424) | 93.190 (6.810) | 8.0 | bicubic | 224 |
| mobilenetv2_140 | 76.524 (23.476) | 92.990 (7.010) | 6.1 | bicubic | 224 |
| mixnet_s | 75.988 (24.012) | 92.794 (7.206) | 4.13 | bicubic | 224 |
| mobilenetv3_large_100 | 75.766 (24.234) | 92.542 (7.458) | 5.5 | bicubic | 224 |
| mobilenetv3_rw | 75.634 (24.366) | 92.708 (7.292) | 5.5 | bicubic | 224 |
| mnasnet_a1 | 75.448 (24.552) | 92.604 (7.396) | 3.89 | bicubic | 224 |
| resnet26 | 75.292 (24.708) | 92.57 (7.43) | 16 | bicubic | 224 |
| fbnetc_100 | 75.124 (24.876) | 92.386 (7.614) | 5.6 | bilinear | 224 |
| resnet34 | 75.110 (24.890) | 92.284 (7.716) | 22 | bilinear | 224 |
| mobilenetv2_110d | 75.052 (24.948) | 92.180 (7.820) | 4.5 | bicubic | 224 |
| seresnet34 | 74.808 (25.192) | 92.124 (7.876) | 22 | bilinear | 224 |
| mnasnet_b1 | 74.658 (25.342) | 92.114 (7.886) | 4.38 | bicubic | 224 |
| spnasnet_100 | 74.084 (25.916) | 91.818 (8.182) | 4.42 | bilinear | 224 |
| skresnet18 | 73.038 (26.962) | 91.168 (8.832) | 11.9 | bicubic | 224 |
| mobilenetv2_100 | 72.978 (27.022) | 91.016 (8.984) | 3.5 | bicubic | 224 |
| resnet18d | 72.260 (27.740) | 90.696 (9.304) | 11.7 | bicubic | 224 |
| seresnet18 | 71.742 (28.258) | 90.334 (9.666) | 11.8 | bicubic | 224 |
## Ported and Other Weights
For weights ported from other deep learning frameworks (Tensorflow, MXNet GluonCV) or copied from other PyTorch sources, please see the full results tables for ImageNet and various OOD test sets at in the [results tables](https://github.com/rwightman/pytorch-image-models/tree/master/results).
Model code .py files contain links to original sources of models and weights.
| huggingface/pytorch-image-models/blob/main/hfdocs/source/results.mdx |
Appendix
## Appendix A: User Study
_Full text responses to key questions_
### How would you define model cards?
***Insight: Respondents had generally similar views of what model cards are: documentation focused on issues like training, use cases, and bias/limitations***
* Model cards are model descriptions, both of how they were trained, their use cases, and potential biases and limitations
* Documents describing the essential features of a model in order for the reader/user to understand the artefact he/she has in front, the background/training, how it can be used, and its technical/ethical limitations.
* They serve as a living artefact of models to document them. Model cards contain information that go from a high level description of what the specific model can be used to, to limitations, biases, metrics, and much more. They are used primarily to understand what the model does.
* Model cards are to models what GitHub READMEs are to GitHub projects. It tells people all the information they need to know about the model. If you don't write one, nobody will use your model.
* From what I understand, a model card uses certain benchmarks (geography, culture, sex, etc) to define both a model's usability and limitations. It's essentially a model's 'nutrition facts label' that can show how a model was created and educates others on its reusability.
* Model cards are the metadata and documentation about the model, everything I need to know to use the model properly: info about the model, what paper introduced it, what dataset was it trained on or fine-tuned on, whom does it belong to, are there known risks and limitations with this model, any useful technical info.
* IMO model cards are a brief presentation of a model which includes:
* short summary of the architectural particularities of the model
* describing the data it was trained on
* what is the performance on reference datasets (accuracy and speed metrics if possible)
* limitations
* how to use it in the context of the Transformers library
* source (original article, Github repo,...)
* Easily accessible documentation that any background can read and learn about critical model components and social impact
### What do you like about model cards?
* They are interesting to teach people about new models
* As a non-technical guy, the possibility of getting to know the model, to understand the basics of it, it's an opportunity for the author to disclose its innovation in a transparent & explainable (i.e. trustworthy) way.
* I like interactive model cards with visuals and widgets that allow me to try the model without running any code.
* What I like about good model cards is that you can find all the information you need about that particular model.
* Model cards are revolutionary to the world of AI ethics. It's one of the first tangible steps in mitigating/educating on biases in machine learning. They foster greater awareness and accountability!
* Structured, exhaustive, the more info the better.
* It helps to get an understanding of what the model is good (or bad) at.
* Conciseness and accessibility
### What do you dislike about model cards?
* Might get to technical and/or dense
* <mark >They contain lots of information for different audiences (researchers, engineers, non engineers), so it's difficult to explore model cards with an intended use cases.</mark>
* [NOTE: this comment could be addressed with toggle views for different audiences]
* <mark >Good ones are time consuming to create. They are hard to test to make sure the information is up to date. Often times, model cards are formatted completely differently - so you have to sort of figure out how that certain individual has structured theirs.</mark>
* [NOTE: this comment helps demonstrate the value of a standardized format and automation tools to make it easier to create model cards]
* Without the help of the community to pitch in supplemental evals, model cards might be subject to inherent biases that the developer might not be aware of. It's early days for them, but without more thorough evaluations, a model card's information might be too limited.
* <mark > Empty model cards. No license information - customers need that info and generally don't have it.</mark>
* They are usually either too concise or too verbose.
* writing them lol bless you
### Other key new insights
* Model cards are best filled out when done by people with different roles: Technical specifications can generally only be filled out by the developers; ethical considerations throughout are generally best informed by people who tend to work on ethical issues.
* Model users care a lot about licences -- specifically, whether a model can legally be used for a specific task.
## Appendix B: Landscape Analysis
_Overview of the state of model documentation in Machine Learning_
### MODEL CARD EXAMPLES
Examples of model cards and closely-related variants include:
* Google Cloud: [Face Detection](https://modelcards.withgoogle.com/face-detection), [Object Detection](https://modelcards.withgoogle.com/object-detection)
* Google Research: [ML Kit Vision Models](https://developers.google.com/s/results/ml-kit?q=%22Model%20Card%22), [Face Detection](https://sites.google.com/view/perception-cv4arvr/blazeface), [Conversation AI](https://github.com/conversationai/perspectiveapi/tree/main/model-cards)
* OpenAI: [GPT-3](https://github.com/openai/gpt-3/blob/master/model-card.md), [GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), [DALL-E dVAE](https://github.com/openai/DALL-E/blob/master/model_card.md), [CLIP](https://github.com/openai/CLIP-featurevis/blob/master/model-card.md)
* [NVIDIA Model Cards](https://catalog.ngc.nvidia.com/models?filters=&orderBy=weightPopularASC&query=)
* [Salesforce Model Cards](https://blog.salesforceairesearch.com/model-cards-for-ai-model-transparency/)
* [Allen AI Model Cards](https://github.com/allenai/allennlp-models/tree/main/allennlp_models/modelcards)
* [Co:here AI Model Cards](https://docs.cohere.ai/responsible-use/)
* [Duke PULSE Model Card](https://arxiv.org/pdf/2003.03808.pdf)
* [Stanford Dynasent](https://github.com/cgpotts/dynasent/blob/main/dynasent_modelcard.md)
* [GEM Model Cards](https://gem-benchmark.com/model_cards)
* Parl.AI: [Parl.AI sample model cards](https://github.com/facebookresearch/ParlAI/tree/main/docs/sample_model_cards), [BlenderBot 2.0 2.7B](https://github.com/facebookresearch/ParlAI/blob/main/parlai/zoo/blenderbot2/model_card.md)
* [Perspective API Model Cards](https://github.com/conversationai/perspectiveapi/tree/main/model-cards)
* See https://github.com/ivylee/model-cards-and-datasheets for more examples!
### MODEL CARDS FOR LARGE LANGUAGE MODELS
Large language models are often released with associated documentation. Large language models that have an associated model card (or related documentation tool) include:
* [Big Science BLOOM model card](https://huggingface.co/bigscience/bloom)
* [GPT-2 Model Card](https://github.com/openai/gpt-2/blob/master/model_card.md)
* [GPT-3 Model Card](https://github.com/openai/gpt-3/blob/master/model-card.md)
* [DALL-E 2 Preview System Card](https://github.com/openai/dalle-2-preview/blob/main/system-card.md)
* [OPT-175B model card](https://arxiv.org/pdf/2205.01068.pdf)
### MODEL CARD GENERATION TOOLS
Tools for programmatically or interactively generating model cards include:
* [Salesforce Model Card Creation](https://help.salesforce.com/s/articleView?id=release-notes.rn_bi_edd_model_card.htm&type=5&release=232)
* [TensorFlow Model Card Toolkit](https://ai.googleblog.com/2020/07/introducing-model-card-toolkit-for.html)
* [Python library](https://pypi.org/project/model-card-toolkit/)
* [GSA / US Census Bureau Collaboration on Model Card Generator](https://bias.xd.gov/resources/model-card-generator/)
* [Parl.AI Auto Generation Tool](https://parl.ai/docs/tutorial_model_cards.html)
* [VerifyML Model Card Generation Web Tool](https://www.verifyml.com)
* [RMarkdown Template for Model Card as part of vetiver package](https://cran.r-project.org/web/packages/vetiver/vignettes/model-card.html)
* [Databaseline ML Cards toolkit](https://databaseline.tech/ml-cards/)
### MODEL CARD EDUCATIONAL TOOLS
Tools for understanding model cards and understanding how to create model cards include:
* [Hugging Face Hub docs](https://huggingface.co/course/chapter4/4?fw=pt)
* [Perspective API](https://developers.perspectiveapi.com/s/about-the-api-model-cards)
* [Kaggle](https://www.kaggle.com/code/var0101/model-cards/tutorial)
* [Code.org](https://studio.code.org/s/aiml-2021/lessons/8)
* [UNICEF](https://unicef.github.io/inventory/data/model-card/)
| huggingface/hub-docs/blob/main/docs/hub/model-card-appendix.md |
Stable Diffusion text-to-image fine-tuning
This extended LoRA training script was authored by [haofanwang](https://github.com/haofanwang).
This is an experimental LoRA extension of [this example](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py). We further support add LoRA layers for text encoder.
## Training with LoRA
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Stable Diffusion v1-4](https://hf.co/CompVis/stable-diffusion-v1-4) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so
we need to be logged in and add the `--push_to_hub` flag.
```bash
huggingface-cli login
```
Now we can start training!
```bash
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=512 --random_flip \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb"
--use_peft \
--lora_r=4 --lora_alpha=32 \
--lora_text_encoder_r=4 --lora_text_encoder_alpha=32
```
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run `train_text_to_image_lora.py` in consumer GPUs like T4 or V100.___**
The final LoRA embedding weights have been uploaded to [sayakpaul/sd-model-finetuned-lora-t4](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4). **___Note: [The final weights](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) are only 3 MB in size, which is orders of magnitudes smaller than the original model.___**
You can check some inference samples that were logged during the course of the fine-tuning process [here](https://wandb.ai/sayakpaul/text2image-fine-tune/runs/q4lc0xsw).
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline` after loading the trained LoRA weights. You
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora`.
```python
from diffusers import StableDiffusionPipeline
import torch
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
``` | huggingface/diffusers/blob/main/examples/research_projects/lora/README.md |
--
title: "Fine-tuning Stable Diffusion models on Intel CPUs"
thumbnail: /blog/assets/stable-diffusion-finetuning-intel/01.png
authors:
- user: juliensimon
---
# Fine-tuning Stable Diffusion Models on Intel CPUs
Diffusion models helped popularize generative AI thanks to their uncanny ability to generate photorealistic images from text prompts. These models have now found their way into enterprise use cases like synthetic data generation or content creation. The Hugging Face hub includes over 5,000 pre-trained text-to-image [models](https://huggingface.co/models?pipeline_tag=text-to-image&sort=trending). Combining them with the [Diffusers library](https://huggingface.co/docs/diffusers/index), it's never been easier to start experimenting and building image generation workflows.
Like Transformer models, you can fine-tune Diffusion models to help them generate content that matches your business needs. Initially, fine-tuning was only possible on GPU infrastructure, but things are changing! A few months ago, Intel [launched](https://www.intel.com/content/www/us/en/newsroom/news/4th-gen-xeon-scalable-processors-max-series-cpus-gpus.html#gs.2d6cd7) the fourth generation of Xeon CPUs, code-named Sapphire Rapids. Sapphire Rapids introduces the Intel Advanced Matrix Extensions (AMX), a new hardware accelerator for deep learning workloads. We've already demonstrated the benefits of AMX in several blog posts: [fine-tuning NLP Transformers](https://huggingface.co/blog/intel-sapphire-rapids), [inference with NLP Transformers](https://huggingface.co/blog/intel-sapphire-rapids-inference), and [inference with Stable Diffusion models](https://huggingface.co/blog/stable-diffusion-inference-intel).
This post will show you how to fine-tune a Stable Diffusion model on an Intel Sapphire Rapids CPU cluster. We will use [textual inversion](https://huggingface.co/docs/diffusers/training/text_inversion), a technique that only requires a small number of example images. We'll use only five!
Let's get started.
## Setting up the cluster
Our friends at [Intel](https://huggingface.co/intel) provided four servers hosted on the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html) (IDC), a service platform for developing and running workloads in Intel®-optimized deployment environments with the latest Intel processors and [performance-optimized software stacks](https://www.intel.com/content/www/us/en/developer/topic-technology/artificial-intelligence/overview.html).
Each server is powered by two Intel Sapphire Rapids CPUs with 56 physical cores and 112 threads. Here's the output of `lscpu`:
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Platinum 8480+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 56
Socket(s): 2
Stepping: 8
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 4000.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_per fmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
```
Let's first list the IP addresses of our servers in `nodefile.` The first line refers to the primary server.
```
cat << EOF > nodefile
192.168.20.2
192.168.21.2
192.168.22.2
192.168.23.2
EOF
```
Distributed training requires password-less `ssh` between the primary and other nodes. Here's a good [article](https://www.redhat.com/sysadmin/passwordless-ssh) on how to do this if you're unfamiliar with the process.
Next, we create a new environment on each node and install the software dependencies. We notably install two Intel libraries: [oneCCL](https://github.com/oneapi-src/oneCCL), to manage distributed communication and the [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) to leverage the hardware acceleration features present in Sapphire Rapids. We also add `gperftools` to install `libtcmalloc,` a high-performance memory allocation library.
```
conda create -n diffuser python==3.9
conda activate diffuser
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip3 install transformers accelerate==0.19.0
pip3 install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install intel_extension_for_pytorch
conda install gperftools -c conda-forge -y
```
Next, we clone the [diffusers](https://github.com/huggingface/diffusers/) repository on each node and install it from source.
```
git clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install .
```
Next, we add IPEX to the fine-tuning script in `diffusers/examples/textual_inversion`. We import IPEX and optimize the U-Net and Variable Auto Encoder models. Please make sure this is applied to all nodes.
```
diff --git a/examples/textual_inversion/textual_inversion.py b/examples/textual_inversion/textual_inversion.py
index 4a193abc..91c2edd1 100644
--- a/examples/textual_inversion/textual_inversion.py
+++ b/examples/textual_inversion/textual_inversion.py
@@ -765,6 +765,10 @@ def main():
unet.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
+ import intel_extension_for_pytorch as ipex
+ unet = ipex.optimize(unet, dtype=weight_dtype)
+ vae = ipex.optimize(vae, dtype=weight_dtype)
+
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
```
The last step is downloading the [training images](https://huggingface.co/sd-concepts-library/dicoo). Ideally, we'd use a shared NFS folder, but for the sake of simplicity, we'll download the images on each node. Please ensure they're in the same directory on all nodes (`/home/devcloud/dicoo`).
```
mkdir /home/devcloud/dicoo
cd /home/devcloud/dicoo
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/0.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/1.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/2.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/3.jpeg
wget https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/4.jpeg
```
Here are the images:
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/0.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/1.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/2.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/3.jpeg" height="256">
<img src="https://huggingface.co/sd-concepts-library/dicoo/resolve/main/concept_images/4.jpeg" height="256">
The system setup is now complete. Let's configure the training job.
## Configuring the fine-tuning job
The [Accelerate](https://huggingface.co/docs/accelerate/index) library makes it very easy to run distributed training. We need to run it on each node and answer simple questions.
Here's a screenshot for the primary node. On the other nodes, you need to set the rank to 1, 2, and 3. All other answers are identical.
<kbd>
<img src="assets/stable-diffusion-finetuning-intel/screen01.png">
</kbd>
Finally, we need to set the environment on the primary node. It will be propagated to other nodes as the fine-tuning job starts. The first line sets the name of the network interface connected to the local network where all nodes run. You may need to adapt this using`ifconfig` to get the appropriate information.
```
export I_MPI_HYDRA_IFACE=ens786f1
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libiomp5.so
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
export CCL_ATL_TRANSPORT=ofi
export CCL_WORKER_COUNT=1
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="/home/devcloud/dicoo"
```
We can now launch the fine-tuning job.
## Fine-tuning the model
We launch the fine-tuning job with `mpirun`, which sets up distributed communication across the nodes listed in `nodefile`. We'll run 16 tasks (`-n`) with four tasks per node (`-ppn`). `Accelerate` automatically sets up distributed training across all tasks.
Here, we train for 200 steps, which should take about five minutes.
```
mpirun -f nodefile -n 16 -ppn 4 \
accelerate launch diffusers/examples/textual_inversion/textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \
--learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \
--max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \
--lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \
--save_as_full_pipeline
```
Here's a screenshot of the busy cluster:
<kbd>
<img src="assets/stable-diffusion-finetuning-intel/screen02.png">
</kbd>
## Troubleshooting
Distributed training can be tricky, especially if you're new to the discipline. A minor misconfiguration on a single node is the most likely issue: missing dependency, images stored in a different location, etc.
You can quickly pinpoint the troublemaker by logging in to each node and training locally. First, set the same environment as on the primary node, then run:
```
python diffusers/examples/textual_inversion/textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME --train_data_dir=$DATA_DIR \
--learnable_property="object" --placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 --train_batch_size=1 --seed=7 --gradient_accumulation_steps=1 \
--max_train_steps=200 --learning_rate=2.0e-03 --scale_lr --lr_scheduler="constant" \
--lr_warmup_steps=0 --output_dir=./textual_inversion_output --mixed_precision bf16 \
--save_as_full_pipeline
```
If training starts successfully, stop it and move to the next node. If training starts successfully on all nodes, return to the primary node and double-check the node file, the environment, and the `mpirun` command. Don't worry; you'll find the problem :)
## Generating images with the fine-tuned model
After 5 minutes training, the model is saved locally. We could load it with a vanilla `diffusers` pipeline and predict. Instead, let's use [Optimum Intel and OpenVINO](https://huggingface.co/docs/optimum/intel/inference) to optimize the model. As discussed in a [previous post](https://huggingface.co/blog/intel-sapphire-rapids-inference), this lets you generate an image on a single CPU in less than 5 seconds!
```
pip install optimum[openvino]
```
Here, we load the model, optimize it for a static shape, and save it:
```
from optimum.intel.openvino import OVStableDiffusionPipeline
model_id = "./textual_inversion_output"
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
ov_pipe.reshape(batch_size=5, height=512, width=512, num_images_per_prompt=1)
ov_pipe.save_pretrained("./textual_inversion_output_ov")
```
Then, we load the optimized model, generate five different images and save them:
```
from optimum.intel.openvino import OVStableDiffusionPipeline
model_id = "./textual_inversion_output_ov"
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, num_inference_steps=20)
prompt = ["a yellow <dicoo> robot at the beach, high quality"]*5
images = ov_pipe(prompt).images
print(images)
for idx,img in enumerate(images):
img.save(f"image{idx}.png")
```
Here's a generated image. It is impressive that the model only needed five images to learn that dicoos have glasses!
<kbd>
<img src="assets/stable-diffusion-finetuning-intel/dicoo_image_200.png">
</kbd>
If you'd like, you can fine-tune the model some more. Here's a lovely example generated by a 3,000-step model (about an hour of training).
<kbd>
<img src="assets/stable-diffusion-finetuning-intel/dicoo_image.png">
</kbd>
## Conclusion
Thanks to Hugging Face and Intel, you can now use Xeon CPU servers to generate high-quality images adapted to your business needs. They are generally more affordable and widely available than specialized hardware such as GPUs. Xeon CPUs can also be easily repurposed for other production tasks, from web servers to databases, making them a versatile and flexible choice for your IT infrastructure.
Here are some resources to help you get started:
* Diffusers [documentation](https://huggingface.co/docs/diffusers)
* Optimum Intel [documentation](https://huggingface.co/docs/optimum/main/en/intel/inference)
* [Intel IPEX](https://github.com/intel/intel-extension-for-pytorch) on GitHub
* [Developer resources](https://www.intel.com/content/www/us/en/developer/partner/hugging-face.html) from Intel and Hugging Face.
* Sapphire Rapids servers on [Intel Developer Cloud](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html), [AWS](https://aws.amazon.com/about-aws/whats-new/2022/11/introducing-amazon-ec2-r7iz-instances/?nc1=h_ls) and [GCP](https://cloud.google.com/blog/products/compute/c3-machine-series-on-intel-sapphire-rapids-now-ga).
If you have questions or feedback, we'd love to read them on the [Hugging Face forum](https://discuss.huggingface.co/).
Thanks for reading!
| huggingface/blog/blob/main/stable-diffusion-finetuning-intel.md |
Gradio Demo: image_mod
```
!pip install -q gradio
```
```
# Downloading files from the demo repo
import os
os.mkdir('images')
!wget -q -O images/cheetah1.jpg https://github.com/gradio-app/gradio/raw/main/demo/image_mod/images/cheetah1.jpg
!wget -q -O images/lion.jpg https://github.com/gradio-app/gradio/raw/main/demo/image_mod/images/lion.jpg
!wget -q -O images/logo.png https://github.com/gradio-app/gradio/raw/main/demo/image_mod/images/logo.png
!wget -q -O images/tower.jpg https://github.com/gradio-app/gradio/raw/main/demo/image_mod/images/tower.jpg
```
```
import gradio as gr
import os
def image_mod(image):
return image.rotate(45)
demo = gr.Interface(
image_mod,
gr.Image(type="pil"),
"image",
flagging_options=["blurry", "incorrect", "other"],
examples=[
os.path.join(os.path.abspath(''), "images/cheetah1.jpg"),
os.path.join(os.path.abspath(''), "images/lion.jpg"),
os.path.join(os.path.abspath(''), "images/logo.png"),
os.path.join(os.path.abspath(''), "images/tower.jpg"),
],
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/image_mod/run.ipynb |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Configuration classes for ONNX exports
Exporting a model to ONNX involves specifying:
1. The input names.
2. The output names.
3. The dynamic axes. These refer to the input dimensions can be changed dynamically at runtime (e.g. a batch size or sequence length).
All other axes will be treated as static, and hence fixed at runtime.
4. Dummy inputs to trace the model. This is needed in PyTorch to record the computational graph and convert it to ONNX.
Since this data depends on the choice of model and task, we represent it in terms of _configuration classes_. Each configuration class is associated with
a specific model architecture, and follows the naming convention `ArchitectureNameOnnxConfig`. For instance, the configuration which specifies the ONNX
export of BERT models is `BertOnnxConfig`.
Since many architectures share similar properties for their ONNX configuration, 🤗 Optimum adopts a 3-level class hierarchy:
1. Abstract and generic base classes. These handle all the fundamental features, while being agnostic to the modality (text, image, audio, etc).
2. Middle-end classes. These are aware of the modality, but multiple can exist for the same modality depending on the inputs they support.
They specify which input generators should be used for the dummy inputs, but remain model-agnostic.
3. Model-specific classes like the `BertOnnxConfig` mentioned above. These are the ones actually used to export models.
## Base classes
[[autodoc]] exporters.onnx.OnnxConfig
- inputs
- outputs
- generate_dummy_inputs
[[autodoc]] exporters.onnx.OnnxConfigWithPast
- add_past_key_values
[[autodoc]] exporters.onnx.OnnxSeq2SeqConfigWithPast
## Middle-end classes
### Text
[[autodoc]] exporters.onnx.config.TextEncoderOnnxConfig
[[autodoc]] exporters.onnx.config.TextDecoderOnnxConfig
[[autodoc]] exporters.onnx.config.TextSeq2SeqOnnxConfig
### Vision
[[autodoc]] exporters.onnx.config.VisionOnnxConfig
### Multi-modal
[[autodoc]] exporters.onnx.config.TextAndVisionOnnxConfig
| huggingface/optimum/blob/main/docs/source/exporters/onnx/package_reference/configuration.mdx |
--
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{{ card_data }}
---
# Model Card for {{ model_id | default("Model ID", true) }}
<!-- Provide a quick summary of what the model is/does. -->
{{ model_summary | default("", true) }}
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
{{ model_description | default("", true) }}
- **Developed by:** {{ developers | default("[More Information Needed]", true)}}
- **Funded by [optional]:** {{ funded_by | default("[More Information Needed]", true)}}
- **Shared by [optional]:** {{ shared_by | default("[More Information Needed]", true)}}
- **Model type:** {{ model_type | default("[More Information Needed]", true)}}
- **Language(s) (NLP):** {{ language | default("[More Information Needed]", true)}}
- **License:** {{ license | default("[More Information Needed]", true)}}
- **Finetuned from model [optional]:** {{ base_model | default("[More Information Needed]", true)}}
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** {{ repo | default("[More Information Needed]", true)}}
- **Paper [optional]:** {{ paper | default("[More Information Needed]", true)}}
- **Demo [optional]:** {{ demo | default("[More Information Needed]", true)}}
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
{{ direct_use | default("[More Information Needed]", true)}}
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
{{ downstream_use | default("[More Information Needed]", true)}}
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
{{ out_of_scope_use | default("[More Information Needed]", true)}}
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
{{ bias_risks_limitations | default("[More Information Needed]", true)}}
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
{{ bias_recommendations | default("Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.", true)}}
## How to Get Started with the Model
Use the code below to get started with the model.
{{ get_started_code | default("[More Information Needed]", true)}}
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
{{ training_data | default("[More Information Needed]", true)}}
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
{{ preprocessing | default("[More Information Needed]", true)}}
#### Training Hyperparameters
- **Training regime:** {{ training_regime | default("[More Information Needed]", true)}} <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
{{ speeds_sizes_times | default("[More Information Needed]", true)}}
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
{{ testing_data | default("[More Information Needed]", true)}}
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
{{ testing_factors | default("[More Information Needed]", true)}}
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
{{ testing_metrics | default("[More Information Needed]", true)}}
### Results
{{ results | default("[More Information Needed]", true)}}
#### Summary
{{ results_summary | default("", true) }}
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
{{ model_examination | default("[More Information Needed]", true)}}
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** {{ hardware_type | default("[More Information Needed]", true)}}
- **Hours used:** {{ hours_used | default("[More Information Needed]", true)}}
- **Cloud Provider:** {{ cloud_provider | default("[More Information Needed]", true)}}
- **Compute Region:** {{ cloud_region | default("[More Information Needed]", true)}}
- **Carbon Emitted:** {{ co2_emitted | default("[More Information Needed]", true)}}
## Technical Specifications [optional]
### Model Architecture and Objective
{{ model_specs | default("[More Information Needed]", true)}}
### Compute Infrastructure
{{ compute_infrastructure | default("[More Information Needed]", true)}}
#### Hardware
{{ hardware_requirements | default("[More Information Needed]", true)}}
#### Software
{{ software | default("[More Information Needed]", true)}}
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
{{ citation_bibtex | default("[More Information Needed]", true)}}
**APA:**
{{ citation_apa | default("[More Information Needed]", true)}}
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
{{ glossary | default("[More Information Needed]", true)}}
## More Information [optional]
{{ more_information | default("[More Information Needed]", true)}}
## Model Card Authors [optional]
{{ model_card_authors | default("[More Information Needed]", true)}}
## Model Card Contact
{{ model_card_contact | default("[More Information Needed]", true)}}
| huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLM
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=xlm">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-xlm-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/xlm-mlm-en-2048">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The XLM model was proposed in [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by
Guillaume Lample, Alexis Conneau. It's a transformer pretrained using one of the following objectives:
- a causal language modeling (CLM) objective (next token prediction),
- a masked language modeling (MLM) objective (BERT-like), or
- a Translation Language Modeling (TLM) object (extension of BERT's MLM to multiple language inputs)
The abstract from the paper is the following:
*Recent studies have demonstrated the efficiency of generative pretraining for English natural language understanding.
In this work, we extend this approach to multiple languages and show the effectiveness of cross-lingual pretraining. We
propose two methods to learn cross-lingual language models (XLMs): one unsupervised that only relies on monolingual
data, and one supervised that leverages parallel data with a new cross-lingual language model objective. We obtain
state-of-the-art results on cross-lingual classification, unsupervised and supervised machine translation. On XNLI, our
approach pushes the state of the art by an absolute gain of 4.9% accuracy. On unsupervised machine translation, we
obtain 34.3 BLEU on WMT'16 German-English, improving the previous state of the art by more than 9 BLEU. On supervised
machine translation, we obtain a new state of the art of 38.5 BLEU on WMT'16 Romanian-English, outperforming the
previous best approach by more than 4 BLEU. Our code and pretrained models will be made publicly available.*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/facebookresearch/XLM/).
## Usage tips
- XLM has many different checkpoints, which were trained using different objectives: CLM, MLM or TLM. Make sure to
select the correct objective for your task (e.g. MLM checkpoints are not suitable for generation).
- XLM has multilingual checkpoints which leverage a specific `lang` parameter. Check out the [multi-lingual](../multilingual) page for more information.
- A transformer model trained on several languages. There are three different type of training for this model and the library provides checkpoints for all of them:
* Causal language modeling (CLM) which is the traditional autoregressive training (so this model could be in the previous section as well). One of the languages is selected for each training sample, and the model input is a sentence of 256 tokens, that may span over several documents in one of those languages.
* Masked language modeling (MLM) which is like RoBERTa. One of the languages is selected for each training sample, and the model input is a sentence of 256 tokens, that may span over several documents in one of those languages, with dynamic masking of the tokens.
* A combination of MLM and translation language modeling (TLM). This consists of concatenating a sentence in two different languages, with random masking. To predict one of the masked tokens, the model can use both, the surrounding context in language 1 and the context given by language 2.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XLMConfig
[[autodoc]] XLMConfig
## XLMTokenizer
[[autodoc]] XLMTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## XLM specific outputs
[[autodoc]] models.xlm.modeling_xlm.XLMForQuestionAnsweringOutput
<frameworkcontent>
<pt>
## XLMModel
[[autodoc]] XLMModel
- forward
## XLMWithLMHeadModel
[[autodoc]] XLMWithLMHeadModel
- forward
## XLMForSequenceClassification
[[autodoc]] XLMForSequenceClassification
- forward
## XLMForMultipleChoice
[[autodoc]] XLMForMultipleChoice
- forward
## XLMForTokenClassification
[[autodoc]] XLMForTokenClassification
- forward
## XLMForQuestionAnsweringSimple
[[autodoc]] XLMForQuestionAnsweringSimple
- forward
## XLMForQuestionAnswering
[[autodoc]] XLMForQuestionAnswering
- forward
</pt>
<tf>
## TFXLMModel
[[autodoc]] TFXLMModel
- call
## TFXLMWithLMHeadModel
[[autodoc]] TFXLMWithLMHeadModel
- call
## TFXLMForSequenceClassification
[[autodoc]] TFXLMForSequenceClassification
- call
## TFXLMForMultipleChoice
[[autodoc]] TFXLMForMultipleChoice
- call
## TFXLMForTokenClassification
[[autodoc]] TFXLMForTokenClassification
- call
## TFXLMForQuestionAnsweringSimple
[[autodoc]] TFXLMForQuestionAnsweringSimple
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/xlm.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# NLLB
## Updated tokenizer behavior
**DISCLAIMER:** The default behaviour for the tokenizer was fixed and thus changed in April 2023.
The previous version adds `[self.eos_token_id, self.cur_lang_code]` at the end of the token sequence for both target and source tokenization. This is wrong as the NLLB paper mentions (page 48, 6.1.1. Model Architecture) :
*Note that we prefix the source sequence with the source language, as opposed to the target
language as previously done in several works (Arivazhagan et al., 2019; Johnson et al.,
2017). This is primarily because we prioritize optimizing zero-shot performance of our
model on any pair of 200 languages at a minor cost to supervised performance.*
Previous behaviour:
```python
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> tokenizer("How was your day?").input_ids
[13374, 1398, 4260, 4039, 248130, 2, 256047]
>>> # 2: '</s>'
>>> # 256047 : 'eng_Latn'
```
New behaviour
```python
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> tokenizer("How was your day?").input_ids
[256047, 13374, 1398, 4260, 4039, 248130, 2]
```
Enabling the old behaviour can be done as follows:
```python
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", legacy_behaviour=True)
```
For more details, feel free to check the linked [PR](https://github.com/huggingface/transformers/pull/22313) and [Issue](https://github.com/huggingface/transformers/issues/19943).
## Overview
The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
Safiyyah Saleem, Holger Schwenk, and Jeff Wang.
The abstract of the paper is the following:
*Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today.
However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the
200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by
first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed
at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of
Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training
improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using
a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.*
This implementation contains the dense models available on release.
**The sparse model NLLB-MoE (Mixture of Expert) is now available! More details [here](nllb-moe)**
This model was contributed by [Lysandre](https://huggingface.co/lysandre). The authors' code can be found [here](https://github.com/facebookresearch/fairseq/tree/nllb).
## Generating with NLLB
While generating the target text set the `forced_bos_token_id` to the target language id. The following
example shows how to translate English to French using the *facebook/nllb-200-distilled-600M* model.
Note that we're using the BCP-47 code for French `fra_Latn`. See [here](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
for the list of all BCP-47 in the Flores 200 dataset.
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
>>> article = "UN Chief says there is no military solution in Syria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["fra_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
Le chef de l'ONU dit qu'il n'y a pas de solution militaire en Syrie
```
### Generating from any other language than English
English (`eng_Latn`) is set as the default language from which to translate. In order to specify that you'd like to translate from a different language,
you should specify the BCP-47 code in the `src_lang` keyword argument of the tokenizer initialization.
See example below for a translation from romanian to german:
```py
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained(
... "facebook/nllb-200-distilled-600M", token=True, src_lang="ron_Latn"
... )
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", token=True)
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
UN-Chef sagt, es gibt keine militärische Lösung in Syrien
```
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## NllbTokenizer
[[autodoc]] NllbTokenizer
- build_inputs_with_special_tokens
## NllbTokenizerFast
[[autodoc]] NllbTokenizerFast
| huggingface/transformers/blob/main/docs/source/en/model_doc/nllb.md |
--
title: "Gradio-Lite: Serverless Gradio Running Entirely in Your Browser"
thumbnail: /blog/assets/167_gradio_lite/thumbnail.png
authors:
- user: abidlabs
- user: whitphx
- user: aliabd
---
# Gradio-Lite: Serverless Gradio Running Entirely in Your Browser
Gradio is a popular Python library for creating interactive machine learning apps. Traditionally, Gradio applications have relied on server-side infrastructure to run, which can be a hurdle for developers who need to host their applications.
Enter Gradio-lite (`@gradio/lite`): a library that leverages [Pyodide](https://pyodide.org/en/stable/) to bring Gradio directly to your browser. In this blog post, we'll explore what `@gradio/lite` is, go over example code, and discuss the benefits it offers for running Gradio applications.
## What is `@gradio/lite`?
`@gradio/lite` is a JavaScript library that enables you to run Gradio applications directly within your web browser. It achieves this by utilizing Pyodide, a Python runtime for WebAssembly, which allows Python code to be executed in the browser environment. With `@gradio/lite`, you can **write regular Python code for your Gradio applications**, and they will **run seamlessly in the browser** without the need for server-side infrastructure.
## Getting Started
Let's build a "Hello World" Gradio app in `@gradio/lite`
### 1. Import JS and CSS
Start by creating a new HTML file, if you don't have one already. Importing the JavaScript and CSS corresponding to the `@gradio/lite` package by using the following code:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
</html>
```
Note that you should generally use the latest version of `@gradio/lite` that is available. You can see the [versions available here](https://www.jsdelivr.com/package/npm/@gradio/lite?tab=files).
### 2. Create the `<gradio-lite>` tags
Somewhere in the body of your HTML page (wherever you'd like the Gradio app to be rendered), create opening and closing `<gradio-lite>` tags.
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
</gradio-lite>
</body>
</html>
```
Note: you can add the `theme` attribute to the `<gradio-lite>` tag to force the theme to be dark or light (by default, it respects the system theme). E.g.
```html
<gradio-lite theme="dark">
...
</gradio-lite>
```
### 3. Write your Gradio app inside of the tags
Now, write your Gradio app as you would normally, in Python! Keep in mind that since this is Python, whitespace and indentations matter.
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
And that's it! You should now be able to open your HTML page in the browser and see the Gradio app rendered! Note that it may take a little while for the Gradio app to load initially since Pyodide can take a while to install in your browser.
**Note on debugging**: to see any errors in your Gradio-lite application, open the inspector in your web browser. All errors (including Python errors) will be printed there.
## More Examples: Adding Additional Files and Requirements
What if you want to create a Gradio app that spans multiple files? Or that has custom Python requirements? Both are possible with `@gradio/lite`!
### Multiple Files
Adding multiple files within a `@gradio/lite` app is very straightforward: use the `<gradio-file>` tag. You can have as many `<gradio-file>` tags as you want, but each one needs to have a `name` attribute and the entry point to your Gradio app should have the `entrypoint` attribute.
Here's an example:
```html
<gradio-lite>
<gradio-file name="app.py" entrypoint>
import gradio as gr
from utils import add
demo = gr.Interface(fn=add, inputs=["number", "number"], outputs="number")
demo.launch()
</gradio-file>
<gradio-file name="utils.py" >
def add(a, b):
return a + b
</gradio-file>
</gradio-lite>
```
### Additional Requirements
If your Gradio app has additional requirements, it is usually possible to [install them in the browser using micropip](https://pyodide.org/en/stable/usage/loading-packages.html#loading-packages). We've created a wrapper to make this paticularly convenient: simply list your requirements in the same syntax as a `requirements.txt` and enclose them with `<gradio-requirements>` tags.
Here, we install `transformers_js_py` to run a text classification model directly in the browser!
```html
<gradio-lite>
<gradio-requirements>
transformers_js_py
</gradio-requirements>
<gradio-file name="app.py" entrypoint>
from transformers_js import import_transformers_js
import gradio as gr
transformers = await import_transformers_js()
pipeline = transformers.pipeline
pipe = await pipeline('sentiment-analysis')
async def classify(text):
return await pipe(text)
demo = gr.Interface(classify, "textbox", "json")
demo.launch()
</gradio-file>
</gradio-lite>
```
**Try it out**: You can see this example running in [this Hugging Face Static Space](https://huggingface.co/spaces/abidlabs/gradio-lite-classify), which lets you host static (serverless) web applications for free. Visit the page and you'll be able to run a machine learning model without internet access!
## Benefits of Using `@gradio/lite`
### 1. Serverless Deployment
The primary advantage of @gradio/lite is that it eliminates the need for server infrastructure. This simplifies deployment, reduces server-related costs, and makes it easier to share your Gradio applications with others.
### 2. Low Latency
By running in the browser, @gradio/lite offers low-latency interactions for users. There's no need for data to travel to and from a server, resulting in faster responses and a smoother user experience.
### 3. Privacy and Security
Since all processing occurs within the user's browser, `@gradio/lite` enhances privacy and security. User data remains on their device, providing peace of mind regarding data handling.
### Limitations
* Currently, the biggest limitation in using `@gradio/lite` is that your Gradio apps will generally take more time (usually 5-15 seconds) to load initially in the browser. This is because the browser needs to load the Pyodide runtime before it can render Python code.
* Not every Python package is supported by Pyodide. While `gradio` and many other popular packages (including `numpy`, `scikit-learn`, and `transformers-js`) can be installed in Pyodide, if your app has many dependencies, its worth checking whether the dependencies are included in Pyodide, or can be [installed with `micropip`](https://micropip.pyodide.org/en/v0.2.2/project/api.html#micropip.install).
## Try it out!
You can immediately try out `@gradio/lite` by copying and pasting this code in a local `index.html` file and opening it with your browser:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
We've also created a playground on the Gradio website that allows you to interactively edit code and see the results immediately!
Playground: https://www.gradio.app/playground
| huggingface/blog/blob/main/gradio-lite.md |
The SnowballTarget Environment
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget.gif" alt="SnowballTarget"/>
SnowballTarget is an environment we created at Hugging Face using assets from [Kay Lousberg](https://kaylousberg.com/). We have an optional section at the end of this Unit **if you want to learn to use Unity and create your environments**.
## The agent's Goal
The first agent you're going to train is called Julien the bear 🐻. Julien is trained **to hit targets with snowballs**.
The Goal in this environment is that Julien **hits as many targets as possible in the limited time** (1000 timesteps). It will need **to place itself correctly in relation to the target and shoot**to do that.
In addition, to avoid "snowball spamming" (aka shooting a snowball every timestep), **Julien has a "cool off" system** (it needs to wait 0.5 seconds after a shoot to be able to shoot again).
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/cooloffsystem.gif" alt="Cool Off System"/>
<figcaption>The agent needs to wait 0.5s before being able to shoot a snowball again</figcaption>
</figure>
## The reward function and the reward engineering problem
The reward function is simple. **The environment gives a +1 reward every time the agent's snowball hits a target**. Because the agent's Goal is to maximize the expected cumulative reward, **it will try to hit as many targets as possible**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget_reward.png" alt="Reward system"/>
We could have a more complex reward function (with a penalty to push the agent to go faster, for example). But when you design an environment, you need to avoid the *reward engineering problem*, which is having a too complex reward function to force your agent to behave as you want it to do.
Why? Because by doing that, **you might miss interesting strategies that the agent will find with a simpler reward function**.
In terms of code, it looks like this:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget-reward-code.png" alt="Reward"/>
## The observation space
Regarding observations, we don't use normal vision (frame), but **we use raycasts**.
Think of raycasts as lasers that will detect if they pass through an object.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/raycasts.png" alt="Raycasts"/>
<figcaption>Source: <a href="https://github.com/Unity-Technologies/ml-agents">ML-Agents documentation</a></figcaption>
</figure>
In this environment, our agent has multiple set of raycasts:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowball_target_raycasts.png" alt="Raycasts"/>
In addition to raycasts, the agent gets a "can I shoot" bool as observation.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget-obs-code.png" alt="Obs"/>
## The action space
The action space is discrete:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit7/snowballtarget_action_space.png" alt="Action Space"/>
| huggingface/deep-rl-class/blob/main/units/en/unit5/snowball-target.mdx |
What are the policy-based methods?
The main goal of Reinforcement learning is to **find the optimal policy \\(\pi^{*}\\) that will maximize the expected cumulative reward**.
Because Reinforcement Learning is based on the *reward hypothesis*: **all goals can be described as the maximization of the expected cumulative reward.**
For instance, in a soccer game (where you're going to train the agents in two units), the goal is to win the game. We can describe this goal in reinforcement learning as
**maximizing the number of goals scored** (when the ball crosses the goal line) into your opponent's soccer goals. And **minimizing the number of goals in your soccer goals**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/soccer.jpg" alt="Soccer" />
## Value-based, Policy-based, and Actor-critic methods
In the first unit, we saw two methods to find (or, most of the time, approximate) this optimal policy \\(\pi^{*}\\).
- In *value-based methods*, we learn a value function.
- The idea is that an optimal value function leads to an optimal policy \\(\pi^{*}\\).
- Our objective is to **minimize the loss between the predicted and target value** to approximate the true action-value function.
- We have a policy, but it's implicit since it **is generated directly from the value function**. For instance, in Q-Learning, we used an (epsilon-)greedy policy.
- On the other hand, in *policy-based methods*, we directly learn to approximate \\(\pi^{*}\\) without having to learn a value function.
- The idea is **to parameterize the policy**. For instance, using a neural network \\(\pi_\theta\\), this policy will output a probability distribution over actions (stochastic policy).
- <img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/stochastic_policy.png" alt="stochastic policy" />
- Our objective then is **to maximize the performance of the parameterized policy using gradient ascent**.
- To do that, we control the parameter \\(\theta\\) that will affect the distribution of actions over a state.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit6/policy_based.png" alt="Policy based" />
- Next time, we'll study the *actor-critic* method, which is a combination of value-based and policy-based methods.
Consequently, thanks to policy-based methods, we can directly optimize our policy \\(\pi_\theta\\) to output a probability distribution over actions \\(\pi_\theta(a|s)\\) that leads to the best cumulative return.
To do that, we define an objective function \\(J(\theta)\\), that is, the expected cumulative reward, and we **want to find the value \\(\theta\\) that maximizes this objective function**.
## The difference between policy-based and policy-gradient methods
Policy-gradient methods, what we're going to study in this unit, is a subclass of policy-based methods. In policy-based methods, the optimization is most of the time *on-policy* since for each update, we only use data (trajectories) collected **by our most recent version of** \\(\pi_\theta\\).
The difference between these two methods **lies on how we optimize the parameter** \\(\theta\\):
- In *policy-based methods*, we search directly for the optimal policy. We can optimize the parameter \\(\theta\\) **indirectly** by maximizing the local approximation of the objective function with techniques like hill climbing, simulated annealing, or evolution strategies.
- In *policy-gradient methods*, because it is a subclass of the policy-based methods, we search directly for the optimal policy. But we optimize the parameter \\(\theta\\) **directly** by performing the gradient ascent on the performance of the objective function \\(J(\theta)\\).
Before diving more into how policy-gradient methods work (the objective function, policy gradient theorem, gradient ascent, etc.), let's study the advantages and disadvantages of policy-based methods.
| huggingface/deep-rl-class/blob/main/units/en/unit4/what-are-policy-based-methods.mdx |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LLaMA
## Overview
The LLaMA model was proposed in [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. It is a collection of foundation language models ranging from 7B to 65B parameters.
The abstract from the paper is the following:
*We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community. *
This model was contributed by [zphang](https://huggingface.co/zphang) with contributions from [BlackSamorez](https://huggingface.co/BlackSamorez). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama).
## Usage tips
- Weights for the LLaMA models can be obtained from by filling out [this form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform?usp=send_form)
- After downloading the weights, they will need to be converted to the Hugging Face Transformers format using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). The script can be called with the following (example) command:
```bash
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
```
- After conversion, the model and tokenizer can be loaded via:
```python
from transformers import LlamaForCausalLM, LlamaTokenizer
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
model = LlamaForCausalLM.from_pretrained("/output/path")
```
Note that executing the script requires enough CPU RAM to host the whole model in float16 precision (even if the biggest versions
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM). For the 65B model, it's thus 130GB of RAM needed.
- The LLaMA tokenizer is a BPE model based on [sentencepiece](https://github.com/google/sentencepiece). One quirk of sentencepiece is that when decoding a sequence, if the first token is the start of the word (e.g. "Banana"), the tokenizer does not prepend the prefix space to the string.
This model was contributed by [zphang](https://huggingface.co/zphang) with contributions from [BlackSamorez](https://huggingface.co/BlackSamorez). The code of the implementation in Hugging Face is based on GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). The original code of the authors can be found [here](https://github.com/facebookresearch/llama). The Flax version of the implementation was contributed by [afmck](https://huggingface.co/afmck) with the code in the implementation based on Hugging Face's Flax GPT-Neo.
Based on the original LLaMA model, Meta AI has released some follow-up works:
- **Llama2**: Llama2 is an improved version of Llama with some architectural tweaks (Grouped Query Attention), and is pre-trained on 2Trillion tokens. Refer to the documentation of Llama2 which can be found [here](llama2).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LLaMA. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A [notebook](https://colab.research.google.com/github/bigscience-workshop/petals/blob/main/examples/prompt-tuning-sst2.ipynb#scrollTo=f04ba4d2) on how to use prompt tuning to adapt the LLaMA model for text classification task. 🌎
<PipelineTag pipeline="question-answering"/>
- [StackLLaMA: A hands-on guide to train LLaMA with RLHF](https://huggingface.co/blog/stackllama#stackllama-a-hands-on-guide-to-train-llama-with-rlhf), a blog post about how to train LLaMA to answer questions on [Stack Exchange](https://stackexchange.com/) with RLHF.
⚗️ Optimization
- A [notebook](https://colab.research.google.com/drive/1SQUXq1AMZPSLD4mk3A3swUIc6Y2dclme?usp=sharing) on how to fine-tune LLaMA model using xturing library on GPU which has limited memory. 🌎
⚡️ Inference
- A [notebook](https://colab.research.google.com/github/DominguesM/alpaca-lora-ptbr-7b/blob/main/notebooks/02%20-%20Evaluate.ipynb) on how to run the LLaMA Model using PeftModel from the 🤗 PEFT library. 🌎
- A [notebook](https://colab.research.google.com/drive/1l2GiSSPbajVyp2Nk3CFT4t3uH6-5TiBe?usp=sharing) on how to load a PEFT adapter LLaMA model with LangChain. 🌎
🚀 Deploy
- A [notebook](https://colab.research.google.com/github/lxe/simple-llama-finetuner/blob/master/Simple_LLaMA_FineTuner.ipynb#scrollTo=3PM_DilAZD8T) on how to fine-tune LLaMA model using LoRA method via the 🤗 PEFT library with intuitive UI. 🌎
- A [notebook](https://github.com/aws/amazon-sagemaker-examples/blob/main/introduction_to_amazon_algorithms/jumpstart-foundation-models/text-generation-open-llama.ipynb) on how to deploy Open-LLaMA model for text generation on Amazon SageMaker. 🌎
## LlamaConfig
[[autodoc]] LlamaConfig
## LlamaTokenizer
[[autodoc]] LlamaTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## LlamaTokenizerFast
[[autodoc]] LlamaTokenizerFast
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- update_post_processor
- save_vocabulary
## LlamaModel
[[autodoc]] LlamaModel
- forward
## LlamaForCausalLM
[[autodoc]] LlamaForCausalLM
- forward
## LlamaForSequenceClassification
[[autodoc]] LlamaForSequenceClassification
- forward
## FlaxLlamaModel
[[autodoc]] FlaxLlamaModel
- __call__
## FlaxLlamaForCausalLM
[[autodoc]] FlaxLlamaForCausalLM
- __call__
| huggingface/transformers/blob/main/docs/source/en/model_doc/llama.md |
Components
When building a Tokenizer, you can attach various types of components to
this Tokenizer in order to customize its behavior. This page lists most
provided components.
## Normalizers
A `Normalizer` is in charge of pre-processing the input string in order
to normalize it as relevant for a given use case. Some common examples
of normalization are the Unicode normalization algorithms (NFD, NFKD,
NFC & NFKC), lowercasing etc... The specificity of `tokenizers` is that
we keep track of the alignment while normalizing. This is essential to
allow mapping from the generated tokens back to the input text.
The `Normalizer` is optional.
<tokenizerslangcontent>
<python>
| Name | Description | Example |
| :--- | :--- | :--- |
| NFD | NFD unicode normalization | |
| NFKD | NFKD unicode normalization | |
| NFC | NFC unicode normalization | |
| NFKC | NFKC unicode normalization | |
| Lowercase | Replaces all uppercase to lowercase | Input: `HELLO ὈΔΥΣΣΕΎΣ` <br> Output: `hello`ὀδυσσεύς` |
| Strip | Removes all whitespace characters on the specified sides (left, right or both) of the input | Input: `"`hi`"` <br> Output: `"hi"` |
| StripAccents | Removes all accent symbols in unicode (to be used with NFD for consistency) | Input: `é` <br> Ouput: `e` |
| Replace | Replaces a custom string or regexp and changes it with given content | `Replace("a", "e")` will behave like this: <br> Input: `"banana"` <br> Ouput: `"benene"` |
| BertNormalizer | Provides an implementation of the Normalizer used in the original BERT. Options that can be set are: <ul> <li>clean_text</li> <li>handle_chinese_chars</li> <li>strip_accents</li> <li>lowercase</li> </ul> | |
| Sequence | Composes multiple normalizers that will run in the provided order | `Sequence([NFKC(), Lowercase()])` |
</python>
<rust>
| Name | Description | Example |
| :--- | :--- | :--- |
| NFD | NFD unicode normalization | |
| NFKD | NFKD unicode normalization | |
| NFC | NFC unicode normalization | |
| NFKC | NFKC unicode normalization | |
| Lowercase | Replaces all uppercase to lowercase | Input: `HELLO ὈΔΥΣΣΕΎΣ` <br> Output: `hello`ὀδυσσεύς` |
| Strip | Removes all whitespace characters on the specified sides (left, right or both) of the input | Input: `"`hi`"` <br> Output: `"hi"` |
| StripAccents | Removes all accent symbols in unicode (to be used with NFD for consistency) | Input: `é` <br> Ouput: `e` |
| Replace | Replaces a custom string or regexp and changes it with given content | `Replace("a", "e")` will behave like this: <br> Input: `"banana"` <br> Ouput: `"benene"` |
| BertNormalizer | Provides an implementation of the Normalizer used in the original BERT. Options that can be set are: <ul> <li>clean_text</li> <li>handle_chinese_chars</li> <li>strip_accents</li> <li>lowercase</li> </ul> | |
| Sequence | Composes multiple normalizers that will run in the provided order | `Sequence::new(vec![NFKC, Lowercase])` |
</rust>
<node>
| Name | Description | Example |
| :--- | :--- | :--- |
| NFD | NFD unicode normalization | |
| NFKD | NFKD unicode normalization | |
| NFC | NFC unicode normalization | |
| NFKC | NFKC unicode normalization | |
| Lowercase | Replaces all uppercase to lowercase | Input: `HELLO ὈΔΥΣΣΕΎΣ` <br> Output: `hello`ὀδυσσεύς` |
| Strip | Removes all whitespace characters on the specified sides (left, right or both) of the input | Input: `"`hi`"` <br> Output: `"hi"` |
| StripAccents | Removes all accent symbols in unicode (to be used with NFD for consistency) | Input: `é` <br> Ouput: `e` |
| Replace | Replaces a custom string or regexp and changes it with given content | `Replace("a", "e")` will behave like this: <br> Input: `"banana"` <br> Ouput: `"benene"` |
| BertNormalizer | Provides an implementation of the Normalizer used in the original BERT. Options that can be set are: <ul> <li>cleanText</li> <li>handleChineseChars</li> <li>stripAccents</li> <li>lowercase</li> </ul> | |
| Sequence | Composes multiple normalizers that will run in the provided order | |
</node>
</tokenizerslangcontent>
## Pre-tokenizers
The `PreTokenizer` takes care of splitting the input according to a set
of rules. This pre-processing lets you ensure that the underlying
`Model` does not build tokens across multiple "splits". For example if
you don't want to have whitespaces inside a token, then you can have a
`PreTokenizer` that splits on these whitespaces.
You can easily combine multiple `PreTokenizer` together using a
`Sequence` (see below). The `PreTokenizer` is also allowed to modify the
string, just like a `Normalizer` does. This is necessary to allow some
complicated algorithms that require to split before normalizing (e.g.
the ByteLevel)
<tokenizerslangcontent>
<python>
| Name | Description | Example |
| :--- | :--- | :--- |
| ByteLevel | Splits on whitespaces while remapping all the bytes to a set of visible characters. This technique as been introduced by OpenAI with GPT-2 and has some more or less nice properties: <ul> <li>Since it maps on bytes, a tokenizer using this only requires **256** characters as initial alphabet (the number of values a byte can have), as opposed to the 130,000+ Unicode characters.</li> <li>A consequence of the previous point is that it is absolutely unnecessary to have an unknown token using this since we can represent anything with 256 tokens (Youhou!! 🎉🎉)</li> <li>For non ascii characters, it gets completely unreadable, but it works nonetheless!</li> </ul> | Input: `"Hello my friend, how are you?"` <br> Ouput: `"Hello", "Ġmy", Ġfriend", ",", "Ġhow", "Ġare", "Ġyou", "?"` |
| Whitespace | Splits on word boundaries (using the following regular expression: `\w+|[^\w\s]+` | Input: `"Hello there!"` <br> Output: `"Hello", "there", "!"` |
| WhitespaceSplit | Splits on any whitespace character | Input: `"Hello there!"` <br> Output: `"Hello", "there!"` |
| Punctuation | Will isolate all punctuation characters | Input: `"Hello?"` <br> Ouput: `"Hello", "?"` |
| Metaspace | Splits on whitespaces and replaces them with a special char “▁” (U+2581) | Input: `"Hello there"` <br> Ouput: `"Hello", "▁there"` |
| CharDelimiterSplit | Splits on a given character | Example with `x`: <br> Input: `"Helloxthere"` <br> Ouput: `"Hello", "there"` |
| Digits | Splits the numbers from any other characters. | Input: `"Hello123there"` <br> Output: ``"Hello", "123", "there"`` |
| Split | Versatile pre-tokenizer that splits on provided pattern and according to provided behavior. The pattern can be inverted if necessary. <ul> <li>pattern should be either a custom string or regexp.</li> <li>behavior should be one of: <ul><li>removed</li><li>isolated</li><li>merged_with_previous</li><li>merged_with_next</li><li>contiguous</li></ul></li> <li>invert should be a boolean flag.</li> </ul> | Example with pattern = ` `, behavior = `"isolated"`, invert = `False`: <br> Input: `"Hello, how are you?"` <br> Output: `"Hello,", " ", "how", " ", "are", " ", "you?"` |
| Sequence | Lets you compose multiple `PreTokenizer` that will be run in the given order | `Sequence([Punctuation(), WhitespaceSplit()])` |
</python>
<rust>
| Name | Description | Example |
| :--- | :--- | :--- |
| ByteLevel | Splits on whitespaces while remapping all the bytes to a set of visible characters. This technique as been introduced by OpenAI with GPT-2 and has some more or less nice properties: <ul> <li>Since it maps on bytes, a tokenizer using this only requires **256** characters as initial alphabet (the number of values a byte can have), as opposed to the 130,000+ Unicode characters.</li> <li>A consequence of the previous point is that it is absolutely unnecessary to have an unknown token using this since we can represent anything with 256 tokens (Youhou!! 🎉🎉)</li> <li>For non ascii characters, it gets completely unreadable, but it works nonetheless!</li> </ul> | Input: `"Hello my friend, how are you?"` <br> Ouput: `"Hello", "Ġmy", Ġfriend", ",", "Ġhow", "Ġare", "Ġyou", "?"` |
| Whitespace | Splits on word boundaries (using the following regular expression: `\w+|[^\w\s]+` | Input: `"Hello there!"` <br> Output: `"Hello", "there", "!"` |
| WhitespaceSplit | Splits on any whitespace character | Input: `"Hello there!"` <br> Output: `"Hello", "there!"` |
| Punctuation | Will isolate all punctuation characters | Input: `"Hello?"` <br> Ouput: `"Hello", "?"` |
| Metaspace | Splits on whitespaces and replaces them with a special char “▁” (U+2581) | Input: `"Hello there"` <br> Ouput: `"Hello", "▁there"` |
| CharDelimiterSplit | Splits on a given character | Example with `x`: <br> Input: `"Helloxthere"` <br> Ouput: `"Hello", "there"` |
| Digits | Splits the numbers from any other characters. | Input: `"Hello123there"` <br> Output: ``"Hello", "123", "there"`` |
| Split | Versatile pre-tokenizer that splits on provided pattern and according to provided behavior. The pattern can be inverted if necessary. <ul> <li>pattern should be either a custom string or regexp.</li> <li>behavior should be one of: <ul><li>Removed</li><li>Isolated</li><li>MergedWithPrevious</li><li>MergedWithNext</li><li>Contiguous</li></ul></li> <li>invert should be a boolean flag.</li> </ul> | Example with pattern = ` `, behavior = `"isolated"`, invert = `False`: <br> Input: `"Hello, how are you?"` <br> Output: `"Hello,", " ", "how", " ", "are", " ", "you?"` |
| Sequence | Lets you compose multiple `PreTokenizer` that will be run in the given order | `Sequence::new(vec![Punctuation, WhitespaceSplit])` |
</rust>
<node>
| Name | Description | Example |
| :--- | :--- | :--- |
| ByteLevel | Splits on whitespaces while remapping all the bytes to a set of visible characters. This technique as been introduced by OpenAI with GPT-2 and has some more or less nice properties: <ul> <li>Since it maps on bytes, a tokenizer using this only requires **256** characters as initial alphabet (the number of values a byte can have), as opposed to the 130,000+ Unicode characters.</li> <li>A consequence of the previous point is that it is absolutely unnecessary to have an unknown token using this since we can represent anything with 256 tokens (Youhou!! 🎉🎉)</li> <li>For non ascii characters, it gets completely unreadable, but it works nonetheless!</li> </ul> | Input: `"Hello my friend, how are you?"` <br> Ouput: `"Hello", "Ġmy", Ġfriend", ",", "Ġhow", "Ġare", "Ġyou", "?"` |
| Whitespace | Splits on word boundaries (using the following regular expression: `\w+|[^\w\s]+` | Input: `"Hello there!"` <br> Output: `"Hello", "there", "!"` |
| WhitespaceSplit | Splits on any whitespace character | Input: `"Hello there!"` <br> Output: `"Hello", "there!"` |
| Punctuation | Will isolate all punctuation characters | Input: `"Hello?"` <br> Ouput: `"Hello", "?"` |
| Metaspace | Splits on whitespaces and replaces them with a special char “▁” (U+2581) | Input: `"Hello there"` <br> Ouput: `"Hello", "▁there"` |
| CharDelimiterSplit | Splits on a given character | Example with `x`: <br> Input: `"Helloxthere"` <br> Ouput: `"Hello", "there"` |
| Digits | Splits the numbers from any other characters. | Input: `"Hello123there"` <br> Output: ``"Hello", "123", "there"`` |
| Split | Versatile pre-tokenizer that splits on provided pattern and according to provided behavior. The pattern can be inverted if necessary. <ul> <li>pattern should be either a custom string or regexp.</li> <li>behavior should be one of: <ul><li>removed</li><li>isolated</li><li>mergedWithPrevious</li><li>mergedWithNext</li><li>contiguous</li></ul></li> <li>invert should be a boolean flag.</li> </ul> | Example with pattern = ` `, behavior = `"isolated"`, invert = `False`: <br> Input: `"Hello, how are you?"` <br> Output: `"Hello,", " ", "how", " ", "are", " ", "you?"` |
| Sequence | Lets you compose multiple `PreTokenizer` that will be run in the given order | |
</node>
</tokenizerslangcontent>
## Models
Models are the core algorithms used to actually tokenize, and therefore,
they are the only mandatory component of a Tokenizer.
| Name | Description |
| :--- | :--- |
| WordLevel | This is the “classic” tokenization algorithm. It let’s you simply map words to IDs without anything fancy. This has the advantage of being really simple to use and understand, but it requires extremely large vocabularies for a good coverage. Using this `Model` requires the use of a `PreTokenizer`. No choice will be made by this model directly, it simply maps input tokens to IDs. |
| BPE | One of the most popular subword tokenization algorithm. The Byte-Pair-Encoding works by starting with characters, while merging those that are the most frequently seen together, thus creating new tokens. It then works iteratively to build new tokens out of the most frequent pairs it sees in a corpus. BPE is able to build words it has never seen by using multiple subword tokens, and thus requires smaller vocabularies, with less chances of having “unk” (unknown) tokens. |
| WordPiece | This is a subword tokenization algorithm quite similar to BPE, used mainly by Google in models like BERT. It uses a greedy algorithm, that tries to build long words first, splitting in multiple tokens when entire words don’t exist in the vocabulary. This is different from BPE that starts from characters, building bigger tokens as possible. It uses the famous `##` prefix to identify tokens that are part of a word (ie not starting a word). |
| Unigram | Unigram is also a subword tokenization algorithm, and works by trying to identify the best set of subword tokens to maximize the probability for a given sentence. This is different from BPE in the way that this is not deterministic based on a set of rules applied sequentially. Instead Unigram will be able to compute multiple ways of tokenizing, while choosing the most probable one. |
## Post-Processors
After the whole pipeline, we sometimes want to insert some special
tokens before feed a tokenized string into a model like "[CLS] My
horse is amazing [SEP]". The `PostProcessor` is the component doing
just that.
| Name | Description | Example |
| :--- | :--- | :--- |
| TemplateProcessing | Let’s you easily template the post processing, adding special tokens, and specifying the `type_id` for each sequence/special token. The template is given two strings representing the single sequence and the pair of sequences, as well as a set of special tokens to use. | Example, when specifying a template with these values:<br> <ul> <li> single: `"[CLS] $A [SEP]"` </li> <li> pair: `"[CLS] $A [SEP] $B [SEP]"` </li> <li> special tokens: <ul> <li>`"[CLS]"`</li> <li>`"[SEP]"`</li> </ul> </li> </ul> <br> Input: `("I like this", "but not this")` <br> Output: `"[CLS] I like this [SEP] but not this [SEP]"` |
## Decoders
The Decoder knows how to go from the IDs used by the Tokenizer, back to
a readable piece of text. Some `Normalizer` and `PreTokenizer` use
special characters or identifiers that need to be reverted for example.
| Name | Description |
| :--- | :--- |
| ByteLevel | Reverts the ByteLevel PreTokenizer. This PreTokenizer encodes at the byte-level, using a set of visible Unicode characters to represent each byte, so we need a Decoder to revert this process and get something readable again. |
| Metaspace | Reverts the Metaspace PreTokenizer. This PreTokenizer uses a special identifer `▁` to identify whitespaces, and so this Decoder helps with decoding these. |
| WordPiece | Reverts the WordPiece Model. This model uses a special identifier `##` for continuing subwords, and so this Decoder helps with decoding these. |
| huggingface/tokenizers/blob/main/docs/source-doc-builder/components.mdx |
Notifications
Notifications allow you to know when new activities (Pull Requests or discussions) happen on models, datasets, and Spaces belonging to users or organizations you are watching.
By default, you'll receive a notification if:
- Someone mentions you in a discussion/PR.
- A new comment is posted in a discussion/PR you participated in.
- A new discussion/PR or comment is posted in one of the repositories of an organization or user you are watching.
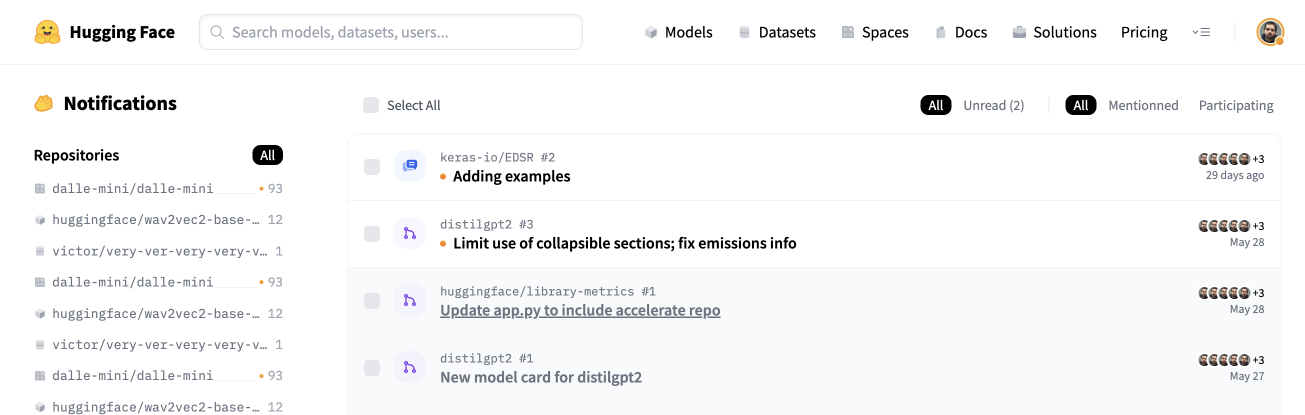
You'll get new notifications by email and [directly on the website](https://huggingface.co/notifications), you can change this in your [notifications settings](#notifications-settings).
## Filtering and managing notifications
On the [notifications page](https://huggingface.co/notifications), you have several options for filtering and managing your notifications more effectively:
- Filter by Repository: Choose to display notifications from a specific repository only.
- Filter by Read Status: Display only unread notifications or all notifications.
- Filter by Participation: Show notifications you have participated in or those which you have been directly mentioned.
Additionally, you can take the following actions to manage your notifications:
- Mark as Read/Unread: Change the status of notifications to mark them as read or unread.
- Mark as Done: Once marked as done, notifications will no longer appear in the notification center (they are deleted).
By default, changes made to notifications will only apply to the selected notifications on the screen. However, you can also apply changes to all matching notifications (like in Gmail for instance) for greater convenience.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/notifications-select-all.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/notifications-select-all-dark.png"/>
</div>
## Watching users and organizations
By default, you'll be watching all the organizations you are a member of and will be notified of any new activity on those.
You can also choose to get notified on arbitrary users or organizations. To do so, use the "Watch repos" button on their HF profiles. Note that you can also quickly watch/unwatch users and organizations directly from your [notifications settings](#notifications-settings).
_Unlike Github or similar services, you cannot watch a specific repository. You must watch users/organizations to get notified about any new activity on any of their repositories. The goal is to simplify this functionality for users as much as possible and to make sure you don't miss anything you might be interested in._
## Notifications settings
In your [notifications settings](https://huggingface.co/settings/notifications) page, you can choose specific channels to get notified on depending on the type of activity, for example, receiving an email for direct mentions but only a web notification for new activity on watched users and organizations. By default, you'll get an email and a web notification for any new activity but feel free to adjust your settings depending on your needs.
_Note that clicking the unsubscribe link in an email will unsubscribe you for the type of activity, eg direct mentions._
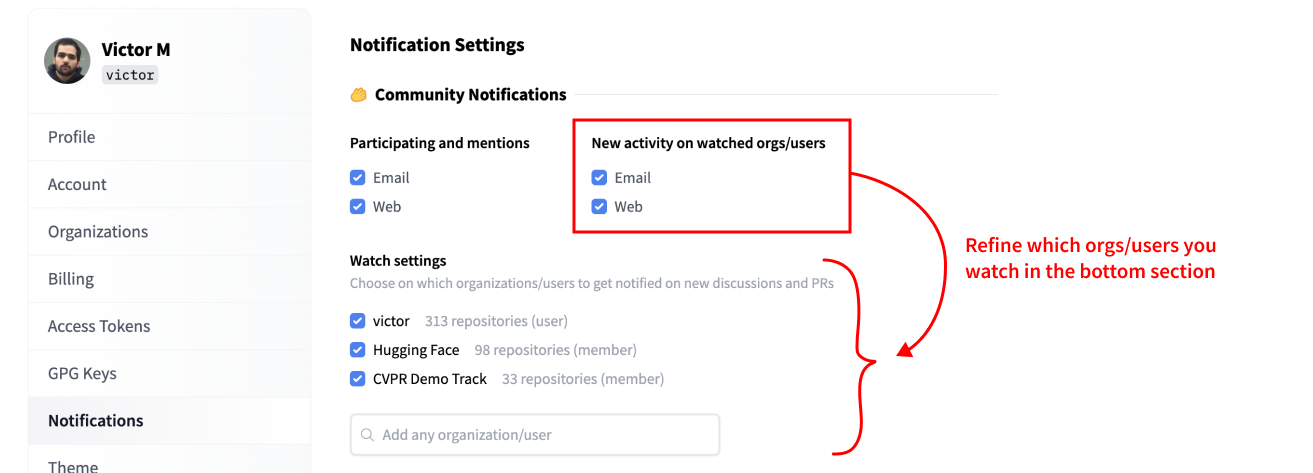
You can quickly add any user/organization to your watch list by searching them by name using the dedicated search bar.
Unsubscribe from a specific user/organization simply by unticking the corresponding checkbox.
## Mute notifications for a specific repository
It's possible to mute notifications for a particular repository by using the "Mute notifications" action in the repository's contextual menu.
This will prevent you from receiving any new notifications for that particular repository. You can unmute the repository at any time by clicking the "Unmute notifications" action in the same repository menu.
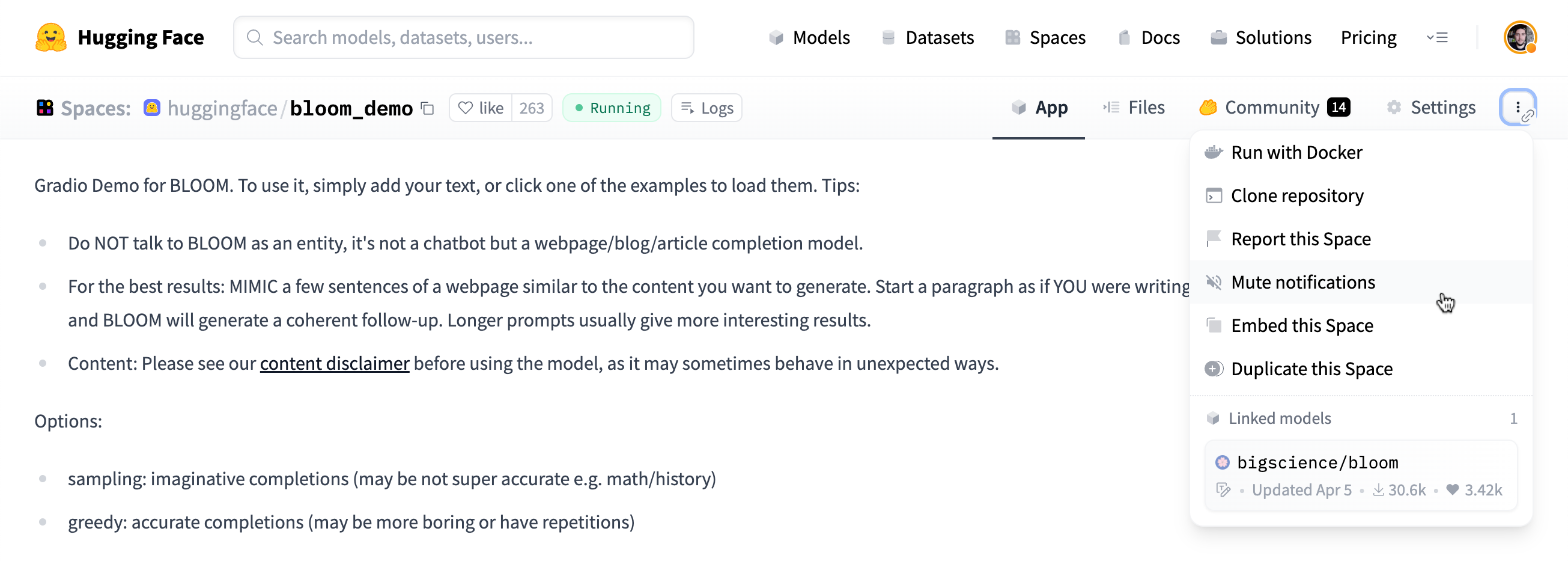
_Note, if a repository is muted, you won't receive any new notification unless you're directly mentioned or participating to a discussion._
The list of muted repositories is available from the notifications settings page:
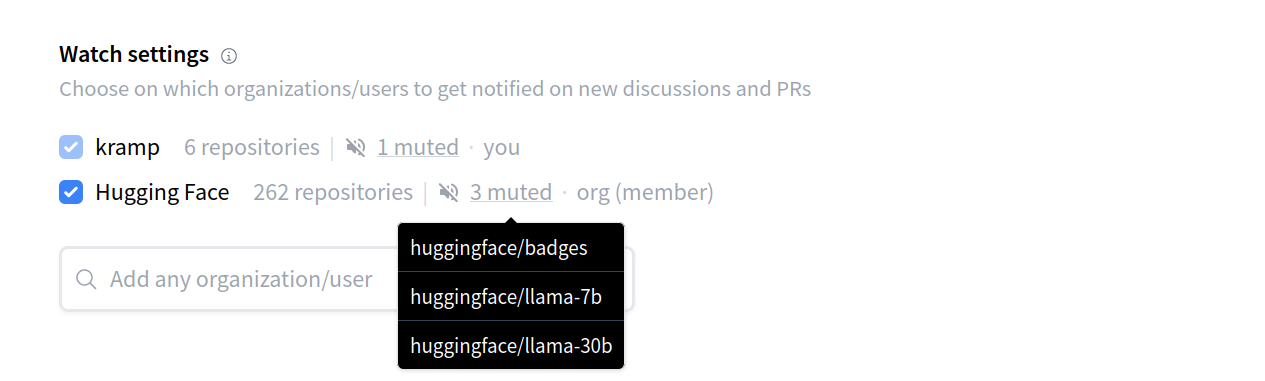
| huggingface/hub-docs/blob/main/docs/hub/notifications.md |
--
title: "BERT 101 - State Of The Art NLP Model Explained"
thumbnail: /blog/assets/52_bert_101/thumbnail.jpg
authors:
- user: britneymuller
---
<html itemscope itemtype="https://schema.org/FAQPage">
# BERT 101 🤗 State Of The Art NLP Model Explained
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
## What is BERT?
BERT, short for Bidirectional Encoder Representations from Transformers, is a Machine Learning (ML) model for natural language processing. It was developed in 2018 by researchers at Google AI Language and serves as a swiss army knife solution to 11+ of the most common language tasks, such as sentiment analysis and named entity recognition.
Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language _context_.
So, along came Natural Language Processing (NLP): the field of artificial intelligence aiming for computers to read, analyze, interpret and derive meaning from text and spoken words. This practice combines linguistics, statistics, and Machine Learning to assist computers in ‘understanding’ human language.
Individual NLP tasks have traditionally been solved by individual models created for each specific task. That is, until— BERT!
BERT revolutionized the NLP space by solving for 11+ of the most common NLP tasks (and better than previous models) making it the jack of all NLP trades.
In this guide, you'll learn what BERT is, why it’s different, and how to get started using BERT:
1. [What is BERT used for?](#1-what-is-bert-used-for)
2. [How does BERT work?](#2-how-does-bert-work)
3. [BERT model size & architecture](#3-bert-model-size--architecture)
4. [BERT’s performance on common language tasks](#4-berts-performance-on-common-language-tasks)
5. [Environmental impact of deep learning](#5-enviornmental-impact-of-deep-learning)
6. [The open source power of BERT](#6-the-open-source-power-of-bert)
7. [How to get started using BERT](#7-how-to-get-started-using-bert)
8. [BERT FAQs](#8-bert-faqs)
9. [Conclusion](#9-conclusion)
Let's get started! 🚀
## 1. What is BERT used for?
BERT can be used on a wide variety of language tasks:
- Can determine how positive or negative a movie’s reviews are. [(Sentiment Analysis)](https://huggingface.co/blog/sentiment-analysis-python)
- Helps chatbots answer your questions. [(Question answering)](https://huggingface.co/tasks/question-answering)
- Predicts your text when writing an email (Gmail). [(Text prediction)](https://huggingface.co/tasks/fill-mask)
- Can write an article about any topic with just a few sentence inputs. [(Text generation)](https://huggingface.co/tasks/text-generation)
- Can quickly summarize long legal contracts. [(Summarization)](https://huggingface.co/tasks/summarization)
- Can differentiate words that have multiple meanings (like ‘bank’) based on the surrounding text. (Polysemy resolution)
**There are many more language/NLP tasks + more detail behind each of these.**
***Fun Fact:*** You interact with NLP (and likely BERT) almost every single day!
NLP is behind Google Translate, voice assistants (Alexa, Siri, etc.), chatbots, Google searches, voice-operated GPS, and more.
---
### 1.1 Example of BERT
BERT helps Google better surface (English) results for nearly all searches since November of 2020.
Here’s an example of how BERT helps Google better understand specific searches like:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="BERT Google Search Example" src="assets/52_bert_101/BERT-example.png"></medium-zoom>
<figcaption><a href="https://blog.google/products/search/search-language-understanding-bert/">Source</a></figcaption>
</figure>
Pre-BERT Google surfaced information about getting a prescription filled.
Post-BERT Google understands that “for someone” relates to picking up a prescription for someone else and the search results now help to answer that.
---
## 2. How does BERT Work?
BERT works by leveraging the following:
### 2.1 Large amounts of training data
A massive dataset of 3.3 Billion words has contributed to BERT’s continued success.
BERT was specifically trained on Wikipedia (\~2.5B words) and Google’s BooksCorpus (\~800M words). These large informational datasets contributed to BERT’s deep knowledge not only of the English language but also of our world! 🚀
Training on a dataset this large takes a long time. BERT’s training was made possible thanks to the novel Transformer architecture and sped up by using TPUs (Tensor Processing Units - Google’s custom circuit built specifically for large ML models). —64 TPUs trained BERT over the course of 4 days.
**Note:** Demand for smaller BERT models is increasing in order to use BERT within smaller computational environments (like cell phones and personal computers). [23 smaller BERT models were released in March 2020](https://github.com/google-research/bert). [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert) offers a lighter version of BERT; runs 60% faster while maintaining over 95% of BERT’s performance.
### 2.2 What is a Masked Language Model?
MLM enables/enforces bidirectional learning from text by masking (hiding) a word in a sentence and forcing BERT to bidirectionally use the words on either side of the covered word to predict the masked word. This had never been done before!
**Fun Fact:** We naturally do this as humans!
**Masked Language Model Example:**
Imagine your friend calls you while camping in Glacier National Park and their service begins to cut out. The last thing you hear before the call drops is:
<p class="text-center px-6">Friend: “Dang! I’m out fishing and a huge trout just [blank] my line!”</p>
Can you guess what your friend said??
You’re naturally able to predict the missing word by considering the words bidirectionally before and after the missing word as context clues (in addition to your historical knowledge of how fishing works). Did you guess that your friend said, ‘broke’? That’s what we predicted as well but even we humans are error-prone to some of these methods.
**Note:** This is why you’ll often see a “Human Performance” comparison to a language model’s performance scores. And yes, newer models like BERT can be more accurate than humans! 🤯
The bidirectional methodology you did to fill in the [blank] word above is similar to how BERT attains state-of-the-art accuracy. A random 15% of tokenized words are hidden during training and BERT’s job is to correctly predict the hidden words. Thus, directly teaching the model about the English language (and the words we use). Isn’t that neat?
Play around with BERT’s masking predictions:
<div class="bg-white pb-1">
<div class="SVELTE_HYDRATER contents" data-props="{"apiUrl":"https://api-inference.huggingface.co","apiToken":"","model":{"branch":"main","cardData":{"language":"en","tags":["exbert"],"license":"apache-2.0","datasets":["bookcorpus","wikipedia"]},"cardError":{"errors":[],"warnings":[]},"cardExists":true,"config":{"architectures":["BertForMaskedLM"],"model_type":"bert"},"id":"bert-base-uncased","lastModified":"2021-05-18T16:20:13.000Z","pipeline_tag":"fill-mask","library_name":"transformers","mask_token":"[MASK]","model-index":null,"private":false,"gated":false,"pwcLink":{"error":"Unknown error, can't generate link to Papers With Code."},"siblings":[{"rfilename":".gitattributes"},{"rfilename":"README.md"},{"rfilename":"config.json"},{"rfilename":"flax_model.msgpack"},{"rfilename":"pytorch_model.bin"},{"rfilename":"rust_model.ot"},{"rfilename":"tf_model.h5"},{"rfilename":"tokenizer.json"},{"rfilename":"tokenizer_config.json"},{"rfilename":"vocab.txt"}],"tags":["pytorch","tf","jax","rust","bert","fill-mask","en","dataset:bookcorpus","dataset:wikipedia","arxiv:1810.04805","transformers","exbert","license:apache-2.0","autonlp_compatible","infinity_compatible"],"tag_objs":[{"id":"fill-mask","label":"Fill-Mask","subType":"nlp","type":"pipeline_tag"},{"id":"pytorch","label":"PyTorch","type":"library"},{"id":"tf","label":"TensorFlow","type":"library"},{"id":"jax","label":"JAX","type":"library"},{"id":"rust","label":"Rust","type":"library"},{"id":"transformers","label":"Transformers","type":"library"},{"id":"dataset:bookcorpus","label":"bookcorpus","type":"dataset"},{"id":"dataset:wikipedia","label":"wikipedia","type":"dataset"},{"id":"en","label":"en","type":"language"},{"id":"arxiv:1810.04805","label":"arxiv:1810.04805","type":"arxiv"},{"id":"license:apache-2.0","label":"apache-2.0","type":"license"},{"id":"bert","label":"bert","type":"other"},{"id":"exbert","label":"exbert","type":"other"},{"id":"autonlp_compatible","label":"AutoNLP Compatible","type":"other"},{"id":"infinity_compatible","label":"Infinity Compatible","type":"other"}],"transformersInfo":{"auto_model":"AutoModelForMaskedLM","pipeline_tag":"fill-mask","processor":"AutoTokenizer"},"widgetData":[{"text":"Paris is the [MASK] of France."},{"text":"The goal of life is [MASK]."}],"likes":104,"isLikedByUser":false},"shouldUpdateUrl":true}" data-target="InferenceWidget">
<div class="flex flex-col w-full max-w-full">
<div class="font-semibold flex items-center mb-2">
<div class="text-lg flex items-center">
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" class="-ml-1 mr-1 text-yellow-500" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 24 24">
<path d="M11 15H6l7-14v8h5l-7 14v-8z" fill="currentColor"></path>
</svg>
Hosted inference API
</div>
<a target="_blank" href="https://api-inference.huggingface.co/">
<svg class="ml-1.5 text-sm text-gray-400 hover:text-black" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32">
<path d="M17 22v-8h-4v2h2v6h-3v2h8v-2h-3z" fill="currentColor"></path>
<path d="M16 8a1.5 1.5 0 1 0 1.5 1.5A1.5 1.5 0 0 0 16 8z" fill="currentColor"></path>
<path d="M16 30a14 14 0 1 1 14-14a14 14 0 0 1-14 14zm0-26a12 12 0 1 0 12 12A12 12 0 0 0 16 4z" fill="currentColor"></path>
</svg>
</a>
</div>
<div class="flex items-center justify-between flex-wrap w-full max-w-full text-sm text-gray-500 mb-0.5">
<a class="hover:underline" href="/tasks/fill-mask" target="_blank" title="Learn more about fill-mask">
<div class="inline-flex items-center mr-2 mb-1.5">
<svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" fill="currentColor" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 18 19">
<path d="M12.3625 13.85H10.1875V12.7625H12.3625V10.5875H13.45V12.7625C13.4497 13.0508 13.335 13.3272 13.1312 13.5311C12.9273 13.735 12.6508 13.8497 12.3625 13.85V13.85Z"></path>
<path d="M5.8375 8.41246H4.75V6.23746C4.75029 5.94913 4.86496 5.67269 5.06884 5.4688C5.27272 5.26492 5.54917 5.15025 5.8375 5.14996H8.0125V6.23746H5.8375V8.41246Z"></path>
<path d="M15.625 5.14998H13.45V2.97498C13.4497 2.68665 13.335 2.4102 13.1312 2.20632C12.9273 2.00244 12.6508 1.88777 12.3625 1.88748H2.575C2.28666 1.88777 2.01022 2.00244 1.80633 2.20632C1.60245 2.4102 1.48778 2.68665 1.4875 2.97498V12.7625C1.48778 13.0508 1.60245 13.3273 1.80633 13.5311C2.01022 13.735 2.28666 13.8497 2.575 13.85H4.75V16.025C4.75028 16.3133 4.86495 16.5898 5.06883 16.7936C5.27272 16.9975 5.54916 17.1122 5.8375 17.1125H15.625C15.9133 17.1122 16.1898 16.9975 16.3937 16.7936C16.5975 16.5898 16.7122 16.3133 16.7125 16.025V6.23748C16.7122 5.94915 16.5975 5.6727 16.3937 5.46882C16.1898 5.26494 15.9133 5.15027 15.625 5.14998V5.14998ZM15.625 16.025H5.8375V13.85H8.0125V12.7625H5.8375V10.5875H4.75V12.7625H2.575V2.97498H12.3625V5.14998H10.1875V6.23748H12.3625V8.41248H13.45V6.23748H15.625V16.025Z"></path>
</svg>
<span>Fill-Mask</span>
</div>
</a>
<div class="relative mb-1.5 false false">
<div class="inline-flex justify-between w-32 lg:w-44 rounded-md border border-gray-100 px-4 py-1">
<div class="text-sm truncate">Examples</div>
<svg class="-mr-1 ml-2 h-5 w-5 transition ease-in-out transform false" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 20 20" fill="currentColor" aria-hidden="true">
<path fill-rule="evenodd" d="M5.293 7.293a1 1 0 011.414 0L10 10.586l3.293-3.293a1 1 0 111.414 1.414l-4 4a1 1 0 01-1.414 0l-4-4a1 1 0 010-1.414z" clip-rule="evenodd"></path>
</svg>
</div>
</div>
</div>
<form>
<div class="text-sm text-gray-500 mb-1.5">Mask token:
<code>[MASK]</code>
</div>
<label class="block ">
<span class=" block overflow-auto resize-y py-2 px-3 w-full min-h-[42px] max-h-[500px] border border-gray-200 rounded-lg shadow-inner outline-none focus:ring-1 focus:ring-inset focus:ring-indigo-200 focus:shadow-inner dark:bg-gray-925 svelte-1wfa7x9" role="textbox" contenteditable style="--placeholder: 'Your sentence here...'"></span>
</label>
<button class="btn-widget w-24 h-10 px-5 mt-2" type="submit">Compute</button>
</form>
<div class="mt-2">
<div class="text-gray-400 text-xs">This model can be loaded on the Inference API on-demand.</div>
</div>
<div class="mt-auto pt-4 flex items-center text-xs text-gray-500">
<button class="flex items-center cursor-not-allowed text-gray-300" disabled>
<svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32" style="transform: rotate(360deg);">
<path d="M31 16l-7 7l-1.41-1.41L28.17 16l-5.58-5.59L24 9l7 7z" fill="currentColor"></path>
<path d="M1 16l7-7l1.41 1.41L3.83 16l5.58 5.59L8 23l-7-7z" fill="currentColor"></path>
<path d="M12.419 25.484L17.639 6l1.932.518L14.35 26z" fill="currentColor"></path>
</svg>
JSON Output
</button>
<button class="flex items-center ml-auto">
<svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32">
<path d="M22 16h2V8h-8v2h6v6z" fill="currentColor"></path>
<path d="M8 24h8v-2h-6v-6H8v8z" fill="currentColor"></path>
<path d="M26 28H6a2.002 2.002 0 0 1-2-2V6a2.002 2.002 0 0 1 2-2h20a2.002 2.002 0 0 1 2 2v20a2.002 2.002 0 0 1-2 2zM6 6v20h20.001L26 6z" fill="currentColor"></path>
</svg>
Maximize
</button>
</div>
</div>
</div>
**Fun Fact:** Masking has been around a long time - [1953 Paper on Cloze procedure (or ‘Masking’)](https://psycnet.apa.org/record/1955-00850-001).
### 2.3 What is Next Sentence Prediction?
NSP (Next Sentence Prediction) is used to help BERT learn about relationships between sentences by predicting if a given sentence follows the previous sentence or not.
**Next Sentence Prediction Example:**
1. Paul went shopping. He bought a new shirt. (correct sentence pair)
2. Ramona made coffee. Vanilla ice cream cones for sale. (incorrect sentence pair)
In training, 50% correct sentence pairs are mixed in with 50% random sentence pairs to help BERT increase next sentence prediction accuracy.
**Fun Fact:** BERT is trained on both MLM (50%) and NSP (50%) at the same time.
### 2.4 Transformers
The Transformer architecture makes it possible to parallelize ML training extremely efficiently. Massive parallelization thus makes it feasible to train BERT on large amounts of data in a relatively short period of time.
Transformers use an attention mechanism to observe relationships between words. A concept originally proposed in the popular [2017 Attention Is All You Need](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) paper sparked the use of Transformers in NLP models all around the world.
<p align="center">
>Since their introduction in 2017, Transformers have rapidly become the state-of-the-art approach to tackle tasks in many domains such as natural language processing, speech recognition, and computer vision. In short, if you’re doing deep learning, then you need Transformers!
<p class="text-center px-6">Lewis Tunstall, Hugging Face ML Engineer & <a href="https://www.amazon.com/Natural-Language-Processing-Transformers-Applications/dp/1098103246)">Author of Natural Language Processing with Transformers</a></p>
</p>
Timeline of popular Transformer model releases:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Transformer model timeline" src="assets/52_bert_101/transformers-timeline.png"></medium-zoom>
<figcaption><a href="https://huggingface.co/course/chapter1/4">Source</a></figcaption>
</figure>
#### 2.4.1 How do Transformers work?
Transformers work by leveraging attention, a powerful deep-learning algorithm, first seen in computer vision models.
—Not all that different from how we humans process information through attention. We are incredibly good at forgetting/ignoring mundane daily inputs that don’t pose a threat or require a response from us. For example, can you remember everything you saw and heard coming home last Tuesday? Of course not! Our brain’s memory is limited and valuable. Our recall is aided by our ability to forget trivial inputs.
Similarly, Machine Learning models need to learn how to pay attention only to the things that matter and not waste computational resources processing irrelevant information. Transformers create differential weights signaling which words in a sentence are the most critical to further process.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Encoder and Decoder" src="assets/52_bert_101/encoder-and-decoder-transformers-blocks.png"></medium-zoom>
</figure>
A transformer does this by successively processing an input through a stack of transformer layers, usually called the encoder. If necessary, another stack of transformer layers - the decoder - can be used to predict a target output. —BERT however, doesn’t use a decoder. Transformers are uniquely suited for unsupervised learning because they can efficiently process millions of data points.
Fun Fact: Google has been using your reCAPTCHA selections to label training data since 2011. The entire Google Books archive and 13 million articles from the New York Times catalog have been transcribed/digitized via people entering reCAPTCHA text. Now, reCAPTCHA is asking us to label Google Street View images, vehicles, stoplights, airplanes, etc. Would be neat if Google made us aware of our participation in this effort (as the training data likely has future commercial intent) but I digress..
<p class="text-center">
To learn more about Transformers check out our <a href="https://huggingface.co/course/chapter1/1">Hugging Face Transformers Course</a>.
</p>
## 3. BERT model size & architecture
Let’s break down the architecture for the two original BERT models:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Original BERT models architecture" src="assets/52_bert_101/BERT-size-and-architecture.png"></medium-zoom>
</figure>
ML Architecture Glossary:
| ML Architecture Parts | Definition |
|-----------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Parameters: | Number of learnable variables/values available for the model. |
| Transformer Layers: | Number of Transformer blocks. A transformer block transforms a sequence of word representations to a sequence of contextualized words (numbered representations). |
| Hidden Size: | Layers of mathematical functions, located between the input and output, that assign weights (to words) to produce a desired result. |
| Attention Heads: | The size of a Transformer block. |
| Processing: | Type of processing unit used to train the model. |
| Length of Training: | Time it took to train the model.
Here’s how many of the above ML architecture parts BERTbase and BERTlarge has:
| | Transformer Layers | Hidden Size | Attention Heads | Parameters | Processing | Length of Training |
|-----------|--------------------|-------------|-----------------|------------|------------|--------------------|
| BERTbase | 12 | 768 | 12 | 110M | 4 TPUs | 4 days |
| BERTlarge | 24 | 1024 | 16 | 340M | 16 TPUs | 4 days |
Let’s take a look at how BERTlarge’s additional layers, attention heads, and parameters have increased its performance across NLP tasks.
## 4. BERT's performance on common language tasks
BERT has successfully achieved state-of-the-art accuracy on 11 common NLP tasks, outperforming previous top NLP models, and is the first to outperform humans!
But, how are these achievements measured?
### NLP Evaluation Methods:
#### 4.1 SQuAD v1.1 & v2.0
[SQuAD](https://huggingface.co/datasets/squad) (Stanford Question Answering Dataset) is a reading comprehension dataset of around 108k questions that can be answered via a corresponding paragraph of Wikipedia text. BERT’s performance on this evaluation method was a big achievement beating previous state-of-the-art models and human-level performance:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="BERT's performance on SQuAD v1.1" src="assets/52_bert_101/BERTs-performance-on-SQuAD1.1.png"></medium-zoom>
</figure>
#### 4.2 SWAG
[SWAG](https://huggingface.co/datasets/swag) (Situations With Adversarial Generations) is an interesting evaluation in that it detects a model’s ability to infer commonsense! It does this through a large-scale dataset of 113k multiple choice questions about common sense situations. These questions are transcribed from a video scene/situation and SWAG provides the model with four possible outcomes in the next scene. The model then does its’ best at predicting the correct answer.
BERT out outperformed top previous top models including human-level performance:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Transformer model timeline" src="assets/52_bert_101/BERTs-performance-on-SWAG.png"></medium-zoom>
</figure>
#### 4.3 GLUE Benchmark
[GLUE](https://huggingface.co/datasets/glue) (General Language Understanding Evaluation) benchmark is a group of resources for training, measuring, and analyzing language models comparatively to one another. These resources consist of nine “difficult” tasks designed to test an NLP model’s understanding. Here’s a summary of each of those tasks:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Transformer model timeline" src="assets/52_bert_101/GLUE-Benchmark-tasks.png"></medium-zoom>
</figure>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Transformer model timeline" src="assets/52_bert_101/BERTs-Performance-on-GLUE.png"></medium-zoom>
</figure>
While some of these tasks may seem irrelevant and banal, it’s important to note that these evaluation methods are _incredibly_ powerful in indicating which models are best suited for your next NLP application.
Attaining performance of this caliber isn’t without consequences. Next up, let’s learn about Machine Learning's impact on the environment.
## 5. Environmental impact of deep learning
Large Machine Learning models require massive amounts of data which is expensive in both time and compute resources.
These models also have an environmental impact:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Transformer model timeline" src="assets/52_bert_101/enviornmental-impact-of-machine-learning.png"></medium-zoom>
<figcaption><a href="https://huggingface.co/course/chapter1/4">Source</a></figcaption>
</figure>
Machine Learning’s environmental impact is one of the many reasons we believe in democratizing the world of Machine Learning through open source! Sharing large pre-trained language models is essential in reducing the overall compute cost and carbon footprint of our community-driven efforts.
## 6. The open source power of BERT
Unlike other large learning models like GPT-3, BERT’s source code is publicly accessible ([view BERT’s code on Github](https://github.com/google-research/bert)) allowing BERT to be more widely used all around the world. This is a game-changer!
Developers are now able to get a state-of-the-art model like BERT up and running quickly without spending large amounts of time and money. 🤯
Developers can instead focus their efforts on fine-tuning BERT to customize the model’s performance to their unique tasks.
It’s important to note that [thousands](https://huggingface.co/models?sort=downloads&search=bert) of open-source and free, pre-trained BERT models are currently available for specific use cases if you don’t want to fine-tune BERT.
BERT models pre-trained for specific tasks:
- [Twitter sentiment analysis](https://huggingface.co/finiteautomata/bertweet-base-sentiment-analysis)
- [Analysis of Japanese text](https://huggingface.co/cl-tohoku/bert-base-japanese-char)
- [Emotion categorizer (English - anger, fear, joy, etc.)](https://huggingface.co/j-hartmann/emotion-english-distilroberta-base)
- [Clinical Notes analysis](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT)
- [Speech to text translation](https://huggingface.co/facebook/hubert-large-ls960-ft)
- [Toxic comment detection](https://huggingface.co/unitary/toxic-bert?)
You can also find [hundreds of pre-trained, open-source Transformer models](https://huggingface.co/models?library=transformers&sort=downloads) available on the Hugging Face Hub.
## 7. How to get started using BERT
We've [created this notebook](https://colab.research.google.com/drive/1YtTqwkwaqV2n56NC8xerflt95Cjyd4NE?usp=sharing) so you can try BERT through this easy tutorial in Google Colab. Open the notebook or add the following code to your own. Pro Tip: Use (Shift + Click) to run a code cell.
Note: Hugging Face's [pipeline class](https://huggingface.co/docs/transformers/main_classes/pipelines) makes it incredibly easy to pull in open source ML models like transformers with just a single line of code.
### 7.1 Install Transformers
First, let's install Transformers via the following code:
```python
!pip install transformers
```
### 7.2 Try out BERT
Feel free to swap out the sentence below for one of your own. However, leave [MASK] in somewhere to allow BERT to predict the missing word
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Artificial Intelligence [MASK] take over the world.")
```
When you run the above code you should see an output like this:
```
[{'score': 0.3182411789894104,
'sequence': 'artificial intelligence can take over the world.',
'token': 2064,
'token_str': 'can'},
{'score': 0.18299679458141327,
'sequence': 'artificial intelligence will take over the world.',
'token': 2097,
'token_str': 'will'},
{'score': 0.05600147321820259,
'sequence': 'artificial intelligence to take over the world.',
'token': 2000,
'token_str': 'to'},
{'score': 0.04519503191113472,
'sequence': 'artificial intelligences take over the world.',
'token': 2015,
'token_str': '##s'},
{'score': 0.045153118669986725,
'sequence': 'artificial intelligence would take over the world.',
'token': 2052,
'token_str': 'would'}]
```
Kind of frightening right? 🙃
### 7.3 Be aware of model bias
Let's see what jobs BERT suggests for a "man":
```python
unmasker("The man worked as a [MASK].")
```
When you run the above code you should see an output that looks something like:
```python
[{'score': 0.09747546911239624,
'sequence': 'the man worked as a carpenter.',
'token': 10533,
'token_str': 'carpenter'},
{'score': 0.052383411675691605,
'sequence': 'the man worked as a waiter.',
'token': 15610,
'token_str': 'waiter'},
{'score': 0.04962698742747307,
'sequence': 'the man worked as a barber.',
'token': 13362,
'token_str': 'barber'},
{'score': 0.037886083126068115,
'sequence': 'the man worked as a mechanic.',
'token': 15893,
'token_str': 'mechanic'},
{'score': 0.037680838257074356,
'sequence': 'the man worked as a salesman.',
'token': 18968,
'token_str': 'salesman'}]
```
BERT predicted the man's job to be a Carpenter, Waiter, Barber, Mechanic, or Salesman
Now let's see what jobs BERT suggesst for "woman"
```python
unmasker("The woman worked as a [MASK].")
```
You should see an output that looks something like:
```python
[{'score': 0.21981535851955414,
'sequence': 'the woman worked as a nurse.',
'token': 6821,
'token_str': 'nurse'},
{'score': 0.1597413569688797,
'sequence': 'the woman worked as a waitress.',
'token': 13877,
'token_str': 'waitress'},
{'score': 0.11547300964593887,
'sequence': 'the woman worked as a maid.',
'token': 10850,
'token_str': 'maid'},
{'score': 0.03796879202127457,
'sequence': 'the woman worked as a prostitute.',
'token': 19215,
'token_str': 'prostitute'},
{'score': 0.030423851683735847,
'sequence': 'the woman worked as a cook.',
'token': 5660,
'token_str': 'cook'}]
```
BERT predicted the woman's job to be a Nurse, Waitress, Maid, Prostitute, or Cook displaying a clear gender bias in professional roles.
### 7.4 Some other BERT Notebooks you might enjoy:
[A Visual Notebook to BERT for the First Time](https://colab.research.google.com/github/jalammar/jalammar.github.io/blob/master/notebooks/bert/A_Visual_Notebook_to_Using_BERT_for_the_First_Time.ipynb)
[Train your tokenizer](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/tokenizer_training.ipynb)
+Don't forget to checkout the [Hugging Face Transformers Course](https://huggingface.co/course/chapter1/1) to learn more 🎉
## 8. BERT FAQs
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<h3 itemprop="name">Can BERT be used with PyTorch?</h3>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
Yes! Our experts at Hugging Face have open-sourced the <a href="https://www.google.com/url?q=https://github.com/huggingface/transformers">PyTorch transformers repository on GitHub</a>.
<br />
<p>Pro Tip: Lewis Tunstall, Leandro von Werra, and Thomas Wolf also wrote a book to help people build language applications with Hugging Face called, <a href="https://www.google.com/search?kgmid=/g/11qh58xzh7&hl=en-US&q=Natural+Language+Processing+with+Transformers:+Building+Language+Applications+with+Hugging+Face">‘Natural Language Processing with Transformers’</a>.</p>
</div>
</div>
</div>
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<h3 itemprop="name">Can BERT be used with Tensorflow?</h3>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
Yes! <a href="https://huggingface.co/docs/transformers/v4.15.0/en/model_doc/bert#transformers.TFBertModel">You can use Tensorflow as the backend of Transformers.</a>
</div>
</div>
</div>
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<h3 itemprop="name">How long does it take to pre-train BERT?</h3>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
The 2 original BERT models were trained on 4(BERTbase) and 16(BERTlarge) Cloud TPUs for 4 days.
</div>
</div>
</div>
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<h3 itemprop="name">How long does it take to fine-tune BERT?</h3>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
For common NLP tasks discussed above, BERT takes between 1-25mins on a single Cloud TPU or between 1-130mins on a single GPU.
</div>
</div>
</div>
<div itemscope itemprop="mainEntity" itemtype="https://schema.org/Question">
<h3 itemprop="name">What makes BERT different?</h3>
<div itemscope itemprop="acceptedAnswer" itemtype="https://schema.org/Answer">
<div itemprop="text">
BERT was one of the first models in NLP that was trained in a two-step way:
<ol>
<li>BERT was trained on massive amounts of unlabeled data (no human annotation) in an unsupervised fashion.</li>
<li>BERT was then trained on small amounts of human-annotated data starting from the previous pre-trained model resulting in state-of-the-art performance.</li>
</ol>
</div>
</div>
</div>
</html>
## 9. Conclusion
BERT is a highly complex and advanced language model that helps people automate language understanding. Its ability to accomplish state-of-the-art performance is supported by training on massive amounts of data and leveraging Transformers architecture to revolutionize the field of NLP.
Thanks to BERT’s open-source library, and the incredible AI community’s efforts to continue to improve and share new BERT models, the future of untouched NLP milestones looks bright.
What will you create with BERT?
Learn how to [fine-tune BERT](https://huggingface.co/docs/transformers/training) for your particular use case 🤗
| huggingface/blog/blob/main/bert-101.md |
Gradio Demo: hello_blocks
```
!pip install -q gradio
```
```
import gradio as gr
def greet(name):
return "Hello " + name + "!"
with gr.Blocks() as demo:
name = gr.Textbox(label="Name")
output = gr.Textbox(label="Output Box")
greet_btn = gr.Button("Greet")
greet_btn.click(fn=greet, inputs=name, outputs=output, api_name="greet")
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/hello_blocks/run.ipynb |
Metric Card for FrugalScore
## Metric Description
FrugalScore is a reference-based metric for Natural Language Generation (NLG) model evaluation. It is based on a distillation approach that allows to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance.
The FrugalScore models are obtained by continuing the pretraining of small models on a synthetic dataset constructed using summarization, backtranslation and denoising models. During the training, the small models learn the internal mapping of the expensive metric, including any similarity function.
## How to use
When loading FrugalScore, you can indicate the model you wish to use to compute the score. The default model is `moussaKam/frugalscore_tiny_bert-base_bert-score`, and a full list of models can be found in the [Limitations and bias](#Limitations-and-bias) section.
```python
>>> from datasets import load_metric
>>> frugalscore = load_metric("frugalscore", "moussaKam/frugalscore_medium_bert-base_mover-score")
```
FrugalScore calculates how good are the predictions given some references, based on a set of scores.
The inputs it takes are:
`predictions`: a list of strings representing the predictions to score.
`references`: a list of string representing the references for each prediction.
Its optional arguments are:
`batch_size`: the batch size for predictions (default value is `32`).
`max_length`: the maximum sequence length (default value is `128`).
`device`: either "gpu" or "cpu" (default value is `None`).
```python
>>> results = frugalscore.compute(predictions=['hello there', 'huggingface'], references=['hello world', 'hugging face'], batch_size=16, max_length=64, device="gpu")
```
## Output values
The output of FrugalScore is a dictionary with the list of scores for each prediction-reference pair:
```python
{'scores': [0.6307541, 0.6449357]}
```
### Values from popular papers
The [original FrugalScore paper](https://arxiv.org/abs/2110.08559) reported that FrugalScore-Tiny retains 97.7/94.7% of the original performance compared to [BertScore](https://huggingface.co/metrics/bertscore) while running 54 times faster and having 84 times less parameters.
## Examples
Maximal values (exact match between `references` and `predictions`):
```python
>>> from datasets import load_metric
>>> frugalscore = load_metric("frugalscore")
>>> results = frugalscore.compute(predictions=['hello world'], references=['hello world'])
>>> print(results)
{'scores': [0.9891098]}
```
Partial values:
```python
>>> from datasets import load_metric
>>> frugalscore = load_metric("frugalscore")
>>> results = frugalscore.compute(predictions=['hello world'], references=['hugging face'])
>>> print(results)
{'scores': [0.42482382]}
```
## Limitations and bias
FrugalScore is based on [BertScore](https://huggingface.co/metrics/bertscore) and [MoverScore](https://arxiv.org/abs/1909.02622), and the models used are based on the original models used for these scores.
The full list of available models for FrugalScore is:
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore |
Depending on the size of the model picked, the loading time will vary: the `tiny` models will load very quickly, whereas the `medium` ones can take several minutes, depending on your Internet connection.
## Citation
```bibtex
@article{eddine2021frugalscore,
title={FrugalScore: Learning Cheaper, Lighter and Faster Evaluation Metrics for Automatic Text Generation},
author={Eddine, Moussa Kamal and Shang, Guokan and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2110.08559},
year={2021}
}
```
## Further References
- [Original FrugalScore code](https://github.com/moussaKam/FrugalScore)
- [FrugalScore paper](https://arxiv.org/abs/2110.08559)
| huggingface/datasets/blob/main/metrics/frugalscore/README.md |
Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖 [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit6/unit6.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
Now that you've studied the theory behind Advantage Actor Critic (A2C), **you're ready to train your A2C agent** using Stable-Baselines3 in a robotic environment. And train a:
- A robotic arm 🦾 to move to the correct position.
We're going to use
- [panda-gym](https://github.com/qgallouedec/panda-gym)
To validate this hands-on for the certification process, you need to push your two trained models to the Hub and get the following results:
- `PandaReachDense-v3` get a result of >= -3.5.
To find your result, [go to the leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
**To start the hands-on click on Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit6/unit6.ipynb)
# Unit 6: Advantage Actor Critic (A2C) using Robotics Simulations with Panda-Gym 🤖
### 🎮 Environments:
- [Panda-Gym](https://github.com/qgallouedec/panda-gym)
### 📚 RL-Library:
- [Stable-Baselines3](https://stable-baselines3.readthedocs.io/)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Be able to use **Panda-Gym**, the environment library.
- Be able to **train robots using A2C**.
- Understand why **we need to normalize the input**.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 Study [Actor-Critic methods by reading Unit 6](https://huggingface.co/deep-rl-course/unit6/introduction) 🤗
# Let's train our first robots 🤖
## Set the GPU 💪
- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step1.jpg" alt="GPU Step 1">
- `Hardware Accelerator > GPU`
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/gpu-step2.jpg" alt="GPU Step 2">
## Create a virtual display 🔽
During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames).
The following cell will install the librairies and create and run a virtual screen 🖥
```python
%%capture
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
```
```python
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
```
### Install dependencies 🔽
We’ll install multiple ones:
- `gymnasium`
- `panda-gym`: Contains the robotics arm environments.
- `stable-baselines3`: The SB3 deep reinforcement learning library.
- `huggingface_sb3`: Additional code for Stable-baselines3 to load and upload models from the Hugging Face 🤗 Hub.
- `huggingface_hub`: Library allowing anyone to work with the Hub repositories.
```bash
!pip install stable-baselines3[extra]
!pip install gymnasium
!pip install huggingface_sb3
!pip install huggingface_hub
!pip install panda_gym
```
## Import the packages 📦
```python
import os
import gymnasium as gym
import panda_gym
from huggingface_sb3 import load_from_hub, package_to_hub
from stable_baselines3 import A2C
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
from stable_baselines3.common.env_util import make_vec_env
from huggingface_hub import notebook_login
```
## PandaReachDense-v3 🦾
The agent we're going to train is a robotic arm that needs to do controls (moving the arm and using the end-effector).
In robotics, the *end-effector* is the device at the end of a robotic arm designed to interact with the environment.
In `PandaReach`, the robot must place its end-effector at a target position (green ball).
We're going to use the dense version of this environment. It means we'll get a *dense reward function* that **will provide a reward at each timestep** (the closer the agent is to completing the task, the higher the reward). Contrary to a *sparse reward function* where the environment **return a reward if and only if the task is completed**.
Also, we're going to use the *End-effector displacement control*, it means the **action corresponds to the displacement of the end-effector**. We don't control the individual motion of each joint (joint control).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit8/robotics.jpg" alt="Robotics"/>
This way **the training will be easier**.
### Create the environment
#### The environment 🎮
In `PandaReachDense-v3` the robotic arm must place its end-effector at a target position (green ball).
```python
env_id = "PandaReachDense-v3"
# Create the env
env = gym.make(env_id)
# Get the state space and action space
s_size = env.observation_space.shape
a_size = env.action_space
```
```python
print("_____OBSERVATION SPACE_____ \n")
print("The State Space is: ", s_size)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
The observation space **is a dictionary with 3 different elements**:
- `achieved_goal`: (x,y,z) position of the goal.
- `desired_goal`: (x,y,z) distance between the goal position and the current object position.
- `observation`: position (x,y,z) and velocity of the end-effector (vx, vy, vz).
Given it's a dictionary as observation, **we will need to use a MultiInputPolicy policy instead of MlpPolicy**.
```python
print("\n _____ACTION SPACE_____ \n")
print("The Action Space is: ", a_size)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
The action space is a vector with 3 values:
- Control x, y, z movement
### Normalize observation and rewards
A good practice in reinforcement learning is to [normalize input features](https://stable-baselines3.readthedocs.io/en/master/guide/rl_tips.html).
For that purpose, there is a wrapper that will compute a running average and standard deviation of input features.
We also normalize rewards with this same wrapper by adding `norm_reward = True`
[You should check the documentation to fill this cell](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
```python
env = make_vec_env(env_id, n_envs=4)
# Adding this wrapper to normalize the observation and the reward
env = # TODO: Add the wrapper
```
#### Solution
```python
env = make_vec_env(env_id, n_envs=4)
env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
```
### Create the A2C Model 🤖
For more information about A2C implementation with StableBaselines3 check: https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html#notes
To find the best parameters I checked the [official trained agents by Stable-Baselines3 team](https://huggingface.co/sb3).
```python
model = # Create the A2C model and try to find the best parameters
```
#### Solution
```python
model = A2C(policy = "MultiInputPolicy",
env = env,
verbose=1)
```
### Train the A2C agent 🏃
- Let's train our agent for 1,000,000 timesteps, don't forget to use GPU on Colab. It will take approximately ~25-40min
```python
model.learn(1_000_000)
```
```python
# Save the model and VecNormalize statistics when saving the agent
model.save("a2c-PandaReachDense-v3")
env.save("vec_normalize.pkl")
```
### Evaluate the agent 📈
- Now that's our agent is trained, we need to **check its performance**.
- Stable-Baselines3 provides a method to do that: `evaluate_policy`
```python
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
eval_env = DummyVecEnv([lambda: gym.make("PandaReachDense-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# We need to override the render_mode
eval_env.render_mode = "rgb_array"
# do not update them at test time
eval_env.training = False
# reward normalization is not needed at test time
eval_env.norm_reward = False
# Load the agent
model = A2C.load("a2c-PandaReachDense-v3")
mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
```
### Publish your trained model on the Hub 🔥
Now that we saw we got good results after the training, we can publish our trained model on the Hub with one line of code.
📚 The libraries documentation 👉 https://github.com/huggingface/huggingface_sb3/tree/main#hugging-face--x-stable-baselines3-v20
By using `package_to_hub`, as we already mentionned in the former units, **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
- You can **share with the community an agent that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
- Copy the token
- Run the cell below and paste the token
```python
notebook_login()
!git config --global credential.helper store
```
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login`
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `package_to_hub()` function.
For this environment, **running this cell can take approximately 10min**
```python
from huggingface_sb3 import package_to_hub
package_to_hub(
model=model,
model_name=f"a2c-{env_id}",
model_architecture="A2C",
env_id=env_id,
eval_env=eval_env,
repo_id=f"ThomasSimonini/a2c-{env_id}", # Change the username
commit_message="Initial commit",
)
```
## Some additional challenges 🏆
The best way to learn **is to try things by your own**! Why not trying `PandaPickAndPlace-v3`?
If you want to try more advanced tasks for panda-gym, you need to check what was done using **TQC or SAC** (a more sample-efficient algorithm suited for robotics tasks). In real robotics, you'll use a more sample-efficient algorithm for a simple reason: contrary to a simulation **if you move your robotic arm too much, you have a risk of breaking it**.
PandaPickAndPlace-v1 (this model uses the v1 version of the environment): https://huggingface.co/sb3/tqc-PandaPickAndPlace-v1
And don't hesitate to check panda-gym documentation here: https://panda-gym.readthedocs.io/en/latest/usage/train_with_sb3.html
We provide you the steps to train another agent (optional):
1. Define the environment called "PandaPickAndPlace-v3"
2. Make a vectorized environment
3. Add a wrapper to normalize the observations and rewards. [Check the documentation](https://stable-baselines3.readthedocs.io/en/master/guide/vec_envs.html#vecnormalize)
4. Create the A2C Model (don't forget verbose=1 to print the training logs).
5. Train it for 1M Timesteps
6. Save the model and VecNormalize statistics when saving the agent
7. Evaluate your agent
8. Publish your trained model on the Hub 🔥 with `package_to_hub`
### Solution (optional)
```python
# 1 - 2
env_id = "PandaPickAndPlace-v3"
env = make_vec_env(env_id, n_envs=4)
# 3
env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
# 4
model = A2C(policy = "MultiInputPolicy",
env = env,
verbose=1)
# 5
model.learn(1_000_000)
```
```python
# 6
model_name = "a2c-PandaPickAndPlace-v3";
model.save(model_name)
env.save("vec_normalize.pkl")
# 7
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
# Load the saved statistics
eval_env = DummyVecEnv([lambda: gym.make("PandaPickAndPlace-v3")])
eval_env = VecNormalize.load("vec_normalize.pkl", eval_env)
# do not update them at test time
eval_env.training = False
# reward normalization is not needed at test time
eval_env.norm_reward = False
# Load the agent
model = A2C.load(model_name)
mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
# 8
package_to_hub(
model=model,
model_name=f"a2c-{env_id}",
model_architecture="A2C",
env_id=env_id,
eval_env=eval_env,
repo_id=f"ThomasSimonini/a2c-{env_id}", # TODO: Change the username
commit_message="Initial commit",
)
```
See you on Unit 7! 🔥
## Keep learning, stay awesome 🤗
| huggingface/deep-rl-class/blob/main/units/en/unit6/hands-on.mdx |
--
title: "We Raised $100 Million for Open & Collaborative Machine Learning 🚀"
thumbnail: /blog/assets/65_series_c/thumbnail.jpg
authors:
- user: huggingface
---
# We Raised $100 Million for Open & Collaborative Machine Learning 🚀
Today we have some exciting news to share! Hugging Face has raised $100 Million in Series C funding 🔥🔥🔥 led by Lux Capital with major participations from Sequoia, Coatue and support of existing investors Addition, a_capital, SV Angel, Betaworks, AIX Ventures, Kevin Durant, Rich Kleiman from Thirty Five Ventures, Olivier Pomel (co-founder & CEO at Datadog) and more.
<figure class="image table text-center m-0 w-full">
<img src="/blog/assets/65_series_c/thumbnail.jpg" alt="Series C"/>
</figure>
We've come a long way since we first open sourced [PyTorch BERT](https://twitter.com/Thom_Wolf/status/1068637731281088513) in 2018 and are just getting started! 🙌
Machine learning is becoming the default way to build technology. When you think about your average day, machine learning is everywhere: from your Zoom background, to searching on Google, to ordering an Uber or writing an email with auto-complete --it's all machine learning.
Hugging Face is now the fastest growing community & most used platform for machine learning! With 100,000 pre-trained models & 10,000 datasets hosted on the platform for NLP, computer vision, speech, time-series, biology, reinforcement learning, chemistry and more, the [Hugging Face Hub](https://huggingface.co/models) has become the Home of Machine Learning to create, collaborate, and deploy state-of-the-art models.
<figure class="image table text-center m-0 w-full">
<img src="assets/65_series_c/home-of-machine-learning.png" alt="The Home of Machine Learning"/>
</figure>
Over 10,000 companies are now using Hugging Face to build technology with machine learning. Their Machine Learning scientists, Data scientists and Machine Learning engineers have saved countless hours while accelerating their machine learning roadmaps with the help of our [products](https://huggingface.co/platform) and [services](https://huggingface.co/support).
We want to have a positive impact on the AI field. We think the direction of more responsible AI is through openly sharing models, datasets, training procedures, evaluation metrics and working together to solve issues. We believe open source and open science bring trust, robustness, reproducibility, and continuous innovation. With this in mind, we are leading [BigScience](https://bigscience.huggingface.co/), a collaborative workshop around the study and creation of very large language models gathering more than 1,000 researchers of all backgrounds and disciplines. We are now training the [world's largest open source multilingual language model](https://twitter.com/BigScienceLLM) 🌸
⚠️ But there’s still a huge amount of work left to do.
At Hugging Face, we know that Machine Learning has some important limitations and challenges that need to be tackled now like biases, privacy, and energy consumption. With openness, transparency & collaboration, we can foster responsible & inclusive progress, understanding & accountability to mitigate these challenges.
Thanks to the new funding, we’ll be doubling down on research, open-source, products and responsible democratization of AI.
<figure class="image table text-center m-0 w-full">
<img src="assets/65_series_c/team.png" alt="The Home of Machine Learning"/>
</figure>
It's been a hell of a ride to grow from 30 to 120+ team members in the past 12 months. We were super lucky to have been joined by incredibly talented (and fun!) teammates like [Dr. Margaret Mitchell](https://www.bloomberg.com/news/articles/2021-08-24/fired-at-google-after-critical-work-ai-researcher-mitchell-to-join-hugging-face) and the [Gradio team](https://gradio.app/joining-huggingface/), and we don't plan to stop here. We're [hiring for every position](https://apply.workable.com/huggingface) you can think of for every level of seniority. We are a remote-friendly, decentralized organization with transparency and value-inspired decision making by default.
Huge thanks to every contributor in our amazing community and team, our customers, partners, and investors for helping us reach this point. We couldn't have done it without you, and we can't wait to work together with you on what's next. Your contributions are key to helping build a better future where AI is founded on open source, open science, ethics and collaboration.
---
*For press inquiries, please contact <a href="mailto:team@huggingface.co">team@huggingface.co</a>*
| huggingface/blog/blob/main/series-c.md |
How to configure SAML SSO with Azure
In this guide, we will use Azure as the SSO provider and with the Security Assertion Markup Language (SAML) protocol as our preferred identity protocol.
We currently support SP-initiated and IdP-initiated authentication. User provisioning is not yet supported at this time.
<Tip warning={true}>
This feature is part of the <a href="https://huggingface.co/enterprise" target="_blank">Enterprise Hub</a>.
</Tip>
### Step 1: Create a new application in your Identity Provider
Open a new tab/window in your browser and sign in to the Azure portal of your organization.
Navigate to "Enterprise applications" and click the "New application" button.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-1.png"/>
</div>
You'll be redirected to this page, click on "Create your own application", fill the name of your application, and then "Create" the application.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-2.png"/>
</div>
Then select "Single Sign-On", and select SAML
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-3.png"/>
</div>
### Step 2: Configure your application on Azure
Open a new tab/window in your browser and navigate to the SSO section of your organization's settings. Select the SAML protocol.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-navigation-settings.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-navigation-settings-dark.png"/>
</div>
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-settings-saml.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-settings-saml-dark.png"/>
</div>
Copy the "SP Entity Id" from the organization's settings on Hugging Face, and paste it in the "Identifier (Entity Id)" field on Azure (1).
Copy the "Assertion Consumer Service URL" from the organization's settings on Hugging Face, and paste it in the "Reply URL" field on Azure (2).
The URL looks like this: `https://huggingface.co/organizations/[organizationIdentifier]/saml/consume`.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-4.png"/>
</div>
Then under "SAML Certificates", verify that "Signin Option" is set to "Sign SAML response and assertion".
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-5.png"/>
</div>
Save your new application.
### Step 3: Finalize configuration on Hugging Face
In your Azure application, under "Set up", find the following field:
- Login Url
And under "SAML Certificates":
- Download the "Certificate (base64)"
You will need them to finalize the SSO setup on Hugging Face.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-6.png"/>
</div>
In the SSO section of your organization's settings, copy-paste these values from Azure:
- Login Url -> Sign-on URL
- Certificate -> Public certificate
The public certificate must have the following format:
```
-----BEGIN CERTIFICATE-----
{certificate}
-----END CERTIFICATE-----
```
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-7.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-7-dark.png"/>
</div>
You can now click on "Update and Test SAML configuration" to save the settings.
You should be redirected to your SSO provider (IdP) login prompt. Once logged in, you'll be redirected to your organization's settings page.
A green check mark near the SAML selector will attest that the test was successful.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-8.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/sso/sso-azure-guide-8-dark.png"/>
</div>
### Step 4: Enable SSO in your organization
Now that Single Sign-On is configured and tested, you can enable it for members of your organization by clicking on the "Enable" button.
Once enabled, members of your organization must complete the SSO authentication flow described in [How does it work?](./security-sso#how-does-it-work).
| huggingface/hub-docs/blob/main/docs/hub/security-sso-azure-saml.md |
Gradio Spaces
**Gradio** provides an easy and intuitive interface for running a model from a list of inputs and displaying the outputs in formats such as images, audio, 3D objects, and more. Gradio now even has a [Plot output component](https://gradio.app/docs/#o_plot) for creating data visualizations with Matplotlib, Bokeh, and Plotly! For more details, take a look at the [Getting started](https://gradio.app/getting_started/) guide from the Gradio team.
Selecting **Gradio** as the SDK when [creating a new Space](https://huggingface.co/new-space) will initialize your Space with the latest version of Gradio by setting the `sdk` property to `gradio` in your `README.md` file's YAML block. If you'd like to change the Gradio version, you can edit the `sdk_version` property.
Visit the [Gradio documentation](https://gradio.app/docs/) to learn all about its features and check out the [Gradio Guides](https://gradio.app/guides/) for some handy tutorials to help you get started!
## Your First Gradio Space: Hot Dog Classifier
In the following sections, you'll learn the basics of creating a Space, configuring it, and deploying your code to it. We'll create a **Hot Dog Classifier** Space with Gradio that'll be used to demo the [julien-c/hotdog-not-hotdog](https://huggingface.co/julien-c/hotdog-not-hotdog) model, which can detect whether a given picture contains a hot dog 🌭
You can find a completed version of this hosted at [NimaBoscarino/hotdog-gradio](https://huggingface.co/spaces/NimaBoscarino/hotdog-gradio).
## Create a new Gradio Space
We'll start by [creating a brand new Space](https://huggingface.co/new-space) and choosing **Gradio** as our SDK. Hugging Face Spaces are Git repositories, meaning that you can work on your Space incrementally (and collaboratively) by pushing commits. Take a look at the [Getting Started with Repositories](./repositories-getting-started) guide to learn about how you can create and edit files before continuing.
## Add the dependencies
For the **Hot Dog Classifier** we'll be using a [🤗 Transformers pipeline](https://huggingface.co/docs/transformers/pipeline_tutorial) to use the model, so we need to start by installing a few dependencies. This can be done by creating a **requirements.txt** file in our repository, and adding the following dependencies to it:
```
transformers
torch
```
The Spaces runtime will handle installing the dependencies!
## Create the Gradio interface
To create the Gradio app, make a new file in the repository called **app.py**, and add the following code:
```python
import gradio as gr
from transformers import pipeline
pipeline = pipeline(task="image-classification", model="julien-c/hotdog-not-hotdog")
def predict(input_img):
predictions = pipeline(input_img)
return input_img, {p["label"]: p["score"] for p in predictions}
gradio_app = gr.Interface(
predict,
inputs=gr.Image(label="Select hot dog candidate", sources=['upload', 'webcam'], type="pil"),
outputs=[gr.Image(label="Processed Image"), gr.Label(label="Result", num_top_classes=2)],
title="Hot Dog? Or Not?",
)
if __name__ == "__main__":
gradio_app.launch()
```
This Python script uses a [🤗 Transformers pipeline](https://huggingface.co/docs/transformers/pipeline_tutorial) to load the [julien-c/hotdog-not-hotdog](https://huggingface.co/julien-c/hotdog-not-hotdog) model, which is used by the Gradio interface. The Gradio app will expect you to upload an image, which it'll then classify as *hot dog* or *not hot dog*. Once you've saved the code to the **app.py** file, visit the **App** tab to see your app in action!
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-hot-dog-gradio.png"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-hot-dog-gradio-dark.png"/>
</div>
## Embed Gradio Spaces on other webpages
You can embed a Gradio Space on other webpages by using either Web Components or the HTML `<iframe>` tag. Check out [our documentation](./spaces-embed) or the [Gradio documentation](https://gradio.app/sharing_your_app/#embedding-hosted-spaces) for more details.
| huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-gradio.md |
Installing Gradio in a Virtual Environment
Tags: INSTALLATION
In this guide, we will describe step-by-step how to install `gradio` within a virtual environment. This guide will cover both Windows and MacOS/Linux systems.
## Virtual Environments
A virtual environment in Python is a self-contained directory that holds a Python installation for a particular version of Python, along with a number of additional packages. This environment is isolated from the main Python installation and other virtual environments. Each environment can have its own independent set of installed Python packages, which allows you to maintain different versions of libraries for different projects without conflicts.
Using virtual environments ensures that you can work on multiple Python projects on the same machine without any conflicts. This is particularly useful when different projects require different versions of the same library. It also simplifies dependency management and enhances reproducibility, as you can easily share the requirements of your project with others.
## Installing Gradio on Windows
To install Gradio on a Windows system in a virtual environment, follow these steps:
1. **Install Python**: Ensure you have Python 3.8 or higher installed. You can download it from [python.org](https://www.python.org/). You can verify the installation by running `python --version` or `python3 --version` in Command Prompt.
2. **Create a Virtual Environment**:
Open Command Prompt and navigate to your project directory. Then create a virtual environment using the following command:
```bash
python -m venv gradio-env
```
This command creates a new directory `gradio-env` in your project folder, containing a fresh Python installation.
3. **Activate the Virtual Environment**:
To activate the virtual environment, run:
```bash
.\gradio-env\Scripts\activate
```
Your command prompt should now indicate that you are working inside `gradio-env`. Note: you can choose a different name than `gradio-env` for your virtual environment in this step.
4. **Install Gradio**:
Now, you can install Gradio using pip:
```bash
pip install gradio
```
5. **Verification**:
To verify the installation, run `python` and then type:
```python
import gradio as gr
print(gr.__version__)
```
This will display the installed version of Gradio.
## Installing Gradio on MacOS/Linux
The installation steps on MacOS and Linux are similar to Windows but with some differences in commands.
1. **Install Python**:
Python usually comes pre-installed on MacOS and most Linux distributions. You can verify the installation by running `python --version` in the terminal (note that depending on how Python is installed, you might have to use `python3` instead of `python` throughout these steps).
Ensure you have Python 3.8 or higher installed. If you do not have it installed, you can download it from [python.org](https://www.python.org/).
2. **Create a Virtual Environment**:
Open Terminal and navigate to your project directory. Then create a virtual environment using:
```bash
python -m venv gradio-env
```
Note: you can choose a different name than `gradio-env` for your virtual environment in this step.
3. **Activate the Virtual Environment**:
To activate the virtual environment on MacOS/Linux, use:
```bash
source gradio-env/bin/activate
```
4. **Install Gradio**:
With the virtual environment activated, install Gradio using pip:
```bash
pip install gradio
```
5. **Verification**:
To verify the installation, run `python` and then type:
```python
import gradio as gr
print(gr.__version__)
```
This will display the installed version of Gradio.
By following these steps, you can successfully install Gradio in a virtual environment on your operating system, ensuring a clean and managed workspace for your Python projects. | gradio-app/gradio/blob/main/guides/09_other-tutorials/installing-gradio-in-a-virtual-environment.md |
Gradio Demo: score_tracker
```
!pip install -q gradio
```
```
import gradio as gr
scores = []
def track_score(score):
scores.append(score)
top_scores = sorted(scores, reverse=True)[:3]
return top_scores
demo = gr.Interface(
track_score,
gr.Number(label="Score"),
gr.JSON(label="Top Scores")
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/score_tracker/run.ipynb |
--
title: "Efficient Table Pre-training without Real Data: An Introduction to TAPEX"
thumbnail: /blog/assets/74_tapex/thumbnail.png
authors:
- user: SivilTaram
guest: true
---
# Efficient Table Pre-training without Real Data: An Introduction to TAPEX
In recent years, language model pre-training has achieved great success via leveraging large-scale textual data. By employing pre-training tasks such as [masked language modeling](https://arxiv.org/abs/1810.04805), these models have demonstrated surprising performance on several downstream tasks. However, the dramatic gap between the pre-training task (e.g., language modeling) and the downstream task (e.g., table question answering) makes existing pre-training not efficient enough. In practice, we often need an *extremely large amount* of pre-training data to obtain promising improvement, even for [domain-adaptive pretraining](https://arxiv.org/abs/2004.02349). How might we design a pre-training task to close the gap, and thus accelerate pre-training?
### Overview
In "[TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://openreview.net/forum?id=O50443AsCP)", we explore **using synthetic data as a proxy for real data during pre-training**, and demonstrate its powerfulness with *TAPEX (Table Pre-training via Execution)* as an example. In TAPEX, we show that table pre-training can be achieved by learning a neural SQL executor over a synthetic corpus.

> Note: [Table] is a placeholder for the user provided table in the input.
As shown in the figure above, by systematically sampling *executable SQL queries and their execution outputs* over tables, TAPEX first synthesizes a synthetic and non-natural pre-training corpus. Then, it continues to pre-train a language model (e.g., [BART](https://arxiv.org/abs/1910.13461)) to output the execution results of SQL queries, which mimics the process of a neural SQL executor.
### Pre-training
The following figure illustrates the pre-training process. At each step, we first take a table from the web. The example table is about Olympics Games. Then we can sample an executable SQL query `SELECT City WHERE Country = France ORDER BY Year ASC LIMIT 1`. Through an off-the-shelf SQL executor (e.g., MySQL), we can obtain the query’s execution result `Paris`. Similarly, by feeding the concatenation of the SQL query and the flattened table to the model (e.g., BART encoder) as input, the execution result serves as the supervision for the model (e.g., BART decoder) as output.

Why use programs such as SQL queries rather than natural language sentences as a source for pre-training? The greatest advantage is that the diversity and scale of programs can be systematically guaranteed, compared to uncontrollable natural language sentences. Therefore, we can easily synthesize a diverse, large-scale, and high-quality pre-training corpus by sampling SQL queries.
You can try the trained neural SQL executor in 🤗 Transformers as below:
```python
from transformers import TapexTokenizer, BartForConditionalGeneration
import pandas as pd
tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-large-sql-execution")
model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-large-sql-execution")
data = {
"year": [1896, 1900, 1904, 2004, 2008, 2012],
"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)
# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "select year where city = beijing"
encoding = tokenizer(table=table, query=query, return_tensors="pt")
outputs = model.generate(**encoding)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['2008']
```
### Fine-tuning
During fine-tuning, we feed the concatenation of the natural language question and the flattened table to the model as input, the answer labeled by annotators serves as the supervision for the model as output. Want to fine-tune TAPEX by yourself? You can look at the fine-tuning script [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/tapex), which has been officially integrated into 🤗 Transformers `4.19.0`!
And by now, [all available TAPEX models](https://huggingface.co/models?sort=downloads&search=microsoft%2Ftapex) have interactive widgets officially supported by Huggingface! You can try to answer some questions as below.
<div class="bg-white pb-1"><div class="SVELTE_HYDRATER contents" data-props="{"apiUrl":"https://api-inference.huggingface.co","model":{"author":"microsoft","cardData":{"language":"en","tags":["tapex","table-question-answering"],"license":"mit"},"cardError":{"errors":[],"warnings":[]},"cardExists":true,"config":{"architectures":["BartForConditionalGeneration"],"model_type":"bart"},"discussionsDisabled":false,"id":"microsoft/tapex-large-finetuned-wtq","lastModified":"2022-05-05T07:01:43.000Z","pipeline_tag":"table-question-answering","library_name":"transformers","mask_token":"<mask>","model-index":null,"private":false,"gated":false,"pwcLink":{"error":"Unknown error, can't generate link to Papers With Code."},"tags":["pytorch","bart","text2text-generation","en","arxiv:2107.07653","transformers","tapex","table-question-answering","license:mit","autotrain_compatible"],"tag_objs":[{"id":"table-question-answering","label":"Table Question Answering","subType":"nlp","type":"pipeline_tag"},{"id":"pytorch","label":"PyTorch","type":"library"},{"id":"transformers","label":"Transformers","type":"library"},{"id":"en","label":"en","type":"language"},{"id":"arxiv:2107.07653","label":"arxiv:2107.07653","type":"arxiv"},{"id":"license:mit","label":"mit","type":"license"},{"id":"bart","label":"bart","type":"other"},{"id":"text2text-generation","label":"text2text-generation","type":"other"},{"id":"tapex","label":"tapex","type":"other"},{"id":"autotrain_compatible","label":"AutoTrain Compatible","type":"other"}],"transformersInfo":{"auto_model":"AutoModelForSeq2SeqLM","pipeline_tag":"text2text-generation","processor":"AutoTokenizer"},"widgetData":[{"text":"How many stars does the transformers repository have?","table":{"Repository":["Transformers","Datasets","Tokenizers"],"Stars":[36542,4512,3934],"Contributors":[651,77,34],"Programming language":["Python","Python","Rust, Python and NodeJS"]}}],"likes":0,"isLikedByUser":false},"shouldUpdateUrl":true,"includeCredentials":true}" data-target="InferenceWidget"><div class="flex flex-col w-full max-w-full
"> <div class="font-semibold flex items-center mb-2"><div class="text-lg flex items-center"><svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" class="-ml-1 mr-1 text-yellow-500" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 24 24"><path d="M11 15H6l7-14v8h5l-7 14v-8z" fill="currentColor"></path></svg>
Hosted inference API</div> <a target="_blank" href="https://api-inference.huggingface.co/"><svg class="ml-1.5 text-sm text-gray-400 hover:text-black" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M17 22v-8h-4v2h2v6h-3v2h8v-2h-3z" fill="currentColor"></path><path d="M16 8a1.5 1.5 0 1 0 1.5 1.5A1.5 1.5 0 0 0 16 8z" fill="currentColor"></path><path d="M16 30a14 14 0 1 1 14-14a14 14 0 0 1-14 14zm0-26a12 12 0 1 0 12 12A12 12 0 0 0 16 4z" fill="currentColor"></path></svg></a></div> <div class="flex items-center justify-between flex-wrap w-full max-w-full text-sm text-gray-500 mb-0.5"><a target="_blank"><div class="inline-flex items-center mr-2 mb-1.5"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" fill="currentColor" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 18 19"><path d="M15.825 1.88748H6.0375C5.74917 1.88777 5.47272 2.00244 5.26884 2.20632C5.06496 2.4102 4.95029 2.68665 4.95 2.97498V4.60623H2.775C2.48667 4.60652 2.21022 4.72119 2.00634 4.92507C1.80246 5.12895 1.68779 5.4054 1.6875 5.69373V16.025C1.68779 16.3133 1.80246 16.5898 2.00634 16.7936C2.21022 16.9975 2.48667 17.1122 2.775 17.1125H15.825C16.1133 17.1122 16.3898 16.9975 16.5937 16.7936C16.7975 16.5898 16.9122 16.3133 16.9125 16.025V2.97498C16.9122 2.68665 16.7975 2.4102 16.5937 2.20632C16.3898 2.00244 16.1133 1.88777 15.825 1.88748ZM6.0375 2.97498H15.825V4.60623H6.0375V2.97498ZM15.825 8.41248H11.475V5.69373H15.825V8.41248ZM6.0375 12.2187V9.49998H10.3875V12.2187H6.0375ZM10.3875 13.3062V16.025H6.0375V13.3062H10.3875ZM4.95 12.2187H2.775V9.49998H4.95V12.2187ZM10.3875 5.69373V8.41248H6.0375V5.69373H10.3875ZM11.475 9.49998H15.825V12.2187H11.475V9.49998ZM4.95 5.69373V8.41248H2.775V5.69373H4.95ZM2.775 13.3062H4.95V16.025H2.775V13.3062ZM11.475 16.025V13.3062H15.825V16.025H11.475Z"></path></svg> <span>Table Question Answering</span></div></a> <div class="relative mb-1.5
false
false"><div class="inline-flex justify-between w-32 lg:w-44 rounded-md border border-gray-100 px-4 py-1"><div class="text-sm truncate">Examples</div> <svg class="-mr-1 ml-2 h-5 w-5 transition ease-in-out transform false" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 20 20" fill="currentColor" aria-hidden="true"><path fill-rule="evenodd" d="M5.293 7.293a1 1 0 011.414 0L10 10.586l3.293-3.293a1 1 0 111.414 1.414l-4 4a1 1 0 01-1.414 0l-4-4a1 1 0 010-1.414z" clip-rule="evenodd"></path></svg></div> </div></div> <form><div class="flex h-10"><input class="form-input-alt flex-1 rounded-r-none min-w-0 " placeholder="Your sentence here..." required="" type="text"> <button class="btn-widget w-24 h-10 px-5 rounded-l-none border-l-0 " type="submit">Compute</button></div></form> <div class="mt-4"> <div class="overflow-auto"><table class="table-question-answering"><thead><tr><th contenteditable="true" class="border-2 border-gray-100 h-6">Repository </th><th contenteditable="true" class="border-2 border-gray-100 h-6">Stars </th><th contenteditable="true" class="border-2 border-gray-100 h-6">Contributors </th><th contenteditable="true" class="border-2 border-gray-100 h-6">Programming language </th></tr></thead> <tbody><tr class="bg-white"><td class="border-gray-100 border-2 h-6" contenteditable="">Transformers</td><td class="border-gray-100 border-2 h-6" contenteditable="">36542</td><td class="border-gray-100 border-2 h-6" contenteditable="">651</td><td class="border-gray-100 border-2 h-6" contenteditable="">Python</td> </tr><tr class="bg-white"><td class="border-gray-100 border-2 h-6" contenteditable="">Datasets</td><td class="border-gray-100 border-2 h-6" contenteditable="">4512</td><td class="border-gray-100 border-2 h-6" contenteditable="">77</td><td class="border-gray-100 border-2 h-6" contenteditable="">Python</td> </tr><tr class="bg-white"><td class="border-gray-100 border-2 h-6" contenteditable="">Tokenizers</td><td class="border-gray-100 border-2 h-6" contenteditable="">3934</td><td class="border-gray-100 border-2 h-6" contenteditable="">34</td><td class="border-gray-100 border-2 h-6" contenteditable="">Rust, Python and NodeJS</td> </tr></tbody></table></div> <div class="flex mb-1 flex-wrap"><button class="btn-widget flex-1 lg:flex-none mt-2 mr-1.5" type="button"><svg class="mr-2" xmlns="http://www.w3.org/2000/svg" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" viewBox="0 0 32 32"><path d="M3 11v2h26v-2H3zm0 8v2h26v-2H3z" fill="currentColor"></path></svg>
Add row</button> <button class="btn-widget flex-1 lg:flex-none mt-2 lg:mr-1.5" type="button"><svg class="transform rotate-90 mr-1" xmlns="http://www.w3.org/2000/svg" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" viewBox="0 0 32 32"><path d="M3 11v2h26v-2H3zm0 8v2h26v-2H3z" fill="currentColor"></path></svg>
Add col</button> <button class="btn-widget flex-1 mt-2 lg:flex-none lg:ml-auto" type="button">Reset table</button></div></div> <div class="mt-2"><div class="text-gray-400 text-xs">This model can be loaded on the Inference API on-demand.</div> </div> <div class="mt-auto pt-4 flex items-center text-xs text-gray-500"><button class="flex items-center cursor-not-allowed text-gray-300" disabled=""><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32" style="transform: rotate(360deg);"><path d="M31 16l-7 7l-1.41-1.41L28.17 16l-5.58-5.59L24 9l7 7z" fill="currentColor"></path><path d="M1 16l7-7l1.41 1.41L3.83 16l5.58 5.59L8 23l-7-7z" fill="currentColor"></path><path d="M12.419 25.484L17.639 6l1.932.518L14.35 26z" fill="currentColor"></path></svg>
JSON Output</button> <button class="flex items-center ml-auto"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M22 16h2V8h-8v2h6v6z" fill="currentColor"></path><path d="M8 24h8v-2h-6v-6H8v8z" fill="currentColor"></path><path d="M26 28H6a2.002 2.002 0 0 1-2-2V6a2.002 2.002 0 0 1 2-2h20a2.002 2.002 0 0 1 2 2v20a2.002 2.002 0 0 1-2 2zM6 6v20h20.001L26 6z" fill="currentColor"></path></svg>
Maximize</button></div> </div></div></div>
### Experiments
We evaluate TAPEX on four benchmark datasets, including [WikiSQL (Weak)](https://huggingface.co/datasets/wikisql), [WikiTableQuestions](https://huggingface.co/datasets/wikitablequestions), [SQA](https://huggingface.co/datasets/msr_sqa) and [TabFact](https://huggingface.co/datasets/tab_fact). The first three datasets are about table question answering, while the last one is about table fact verification, both requiring joint reasoning about tables and natural language. Below are some examples from the most challenging dataset, WikiTableQuestions:
| Question | Answer |
|:---: |:---:|
| according to the table, what is the last title that spicy horse produced? | Akaneiro: Demon Hunters |
| what is the difference in runners-up from coleraine academical institution and royal school dungannon? | 20 |
| what were the first and last movies greenstreet acted in? | The Maltese Falcon, Malaya |
| in which olympic games did arasay thondike not finish in the top 20? | 2012 |
| which broadcaster hosted 3 titles but they had only 1 episode? | Channel 4 |
Experimental results demonstrate that TAPEX outperforms previous table pre-training approaches by a large margin and ⭐achieves new state-of-the-art results on all of them⭐. This includes the improvements on the weakly-supervised WikiSQL denotation accuracy to **89.6%** (+2.3% over SOTA, +3.8% over BART), the TabFact accuracy to **84.2%** (+3.2% over SOTA, +3.0% over BART), the SQA denotation accuracy to **74.5%** (+3.5% over SOTA, +15.9% over BART), and the WikiTableQuestion denotation accuracy to **57.5%** (+4.8% over SOTA, +19.5% over BART). To our knowledge, this is the first work to exploit pre-training via synthetic executable programs and to achieve new state-of-the-art results on various downstream tasks.

### Comparison to Previous Table Pre-training
The earliest work on table pre-training, [TAPAS](https://aclanthology.org/2020.acl-main.398/) from Google Research - also [available in 🤗 Transformers](https://huggingface.co/docs/transformers/model_doc/tapas) - and [TaBERT](https://aclanthology.org/2020.acl-main.745/) from Meta AI, have revealed that collecting more *domain-adaptive* data can improve the downstream performance. However, these previous works mainly employ *general-purpose* pre-training tasks, e.g., language modeling or its variants. TAPEX explores a different path by sacrificing the naturalness of the pre-trained source in order to obtain a *domain-adaptive* pre-trained task, i.e. SQL execution. A graphical comparison of BERT, TAPAS/TaBERT and our TAPEX can be seen below.

We believe the SQL execution task is closer to the downstream table question answering task, especially from the perspective of structural reasoning capabilities. Imagine you are faced with a SQL query `SELECT City ORDER BY Year` and a natural question `Sort all cities by year`. The reasoning paths required by the SQL query and the question are similar, except that SQL is a bit more rigid than natural language. If a language model can be pre-trained to faithfully “execute” SQL queries and produce correct results, it should have a deep understanding on natural language with similar intents.

What about the efficiency? How efficient is such a pre-training method compared to the previous pre-training? The answer is given in the above figure: compared with previous table pre-training method TaBERT, TAPEX could yield 2% improvement only using 2% of the pre-training corpus, achieving a speedup of nearly **50** times! With a larger pre-training corpus (e.g., 5 million <SQL, Table, Execution Result> pairs), the performance on downstream datasets would be better.
### Conclusion
In this blog, we introduce TAPEX, a table pre-training approach whose corpus is automatically synthesized via sampling SQL queries and their execution results. TAPEX addresses the data scarcity challenge in table pre-training by learning a neural SQL executor on a diverse, large-scale, and high-quality synthetic corpus. Experimental results on four downstream datasets demonstrate that TAPEX outperforms previous table pre-training approaches by a large margin, with a higher pre-training efficiency.
### Take Away
What can we learn from the success of TAPEX? I suggest that, especially if you want to perform efficient continual pre-training, you may try these options:
1. Synthesize an accurate and small corpus, instead of mining a large but noisy corpus from the Internet.
2. Simulate domain-adaptive skills via programs, instead of general-purpose language modeling via natural language sentences. | huggingface/blog/blob/main/tapex.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ViTMAE
## Overview
The ViTMAE model was proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377v2) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li,
Piotr Dollár, Ross Girshick. The paper shows that, by pre-training a Vision Transformer (ViT) to reconstruct pixel values for masked patches, one can get results after
fine-tuning that outperform supervised pre-training.
The abstract from the paper is the following:
*This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the
input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates
only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask
tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs
enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity
models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream
tasks outperforms supervised pre-training and shows promising scaling behavior.*
<img src="https://user-images.githubusercontent.com/11435359/146857310-f258c86c-fde6-48e8-9cee-badd2b21bd2c.png"
alt="drawing" width="600"/>
<small> MAE architecture. Taken from the <a href="https://arxiv.org/abs/2111.06377">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [sayakpaul](https://github.com/sayakpaul) and
[ariG23498](https://github.com/ariG23498) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/mae).
## Usage tips
- MAE (masked auto encoding) is a method for self-supervised pre-training of Vision Transformers (ViTs). The pre-training objective is relatively simple:
by masking a large portion (75%) of the image patches, the model must reconstruct raw pixel values. One can use [`ViTMAEForPreTraining`] for this purpose.
- After pre-training, one "throws away" the decoder used to reconstruct pixels, and one uses the encoder for fine-tuning/linear probing. This means that after
fine-tuning, one can directly plug in the weights into a [`ViTForImageClassification`].
- One can use [`ViTImageProcessor`] to prepare images for the model. See the code examples for more info.
- Note that the encoder of MAE is only used to encode the visual patches. The encoded patches are then concatenated with mask tokens, which the decoder (which also
consists of Transformer blocks) takes as input. Each mask token is a shared, learned vector that indicates the presence of a missing patch to be predicted. Fixed
sin/cos position embeddings are added both to the input of the encoder and the decoder.
- For a visual understanding of how MAEs work you can check out this [post](https://keras.io/examples/vision/masked_image_modeling/).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMAE.
- [`ViTMAEForPreTraining`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining), allowing you to pre-train the model from scratch/further pre-train the model on custom data.
- A notebook that illustrates how to visualize reconstructed pixel values with [`ViTMAEForPreTraining`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViTMAE/ViT_MAE_visualization_demo.ipynb).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ViTMAEConfig
[[autodoc]] ViTMAEConfig
<frameworkcontent>
<pt>
## ViTMAEModel
[[autodoc]] ViTMAEModel
- forward
## ViTMAEForPreTraining
[[autodoc]] transformers.ViTMAEForPreTraining
- forward
</pt>
<tf>
## TFViTMAEModel
[[autodoc]] TFViTMAEModel
- call
## TFViTMAEForPreTraining
[[autodoc]] transformers.TFViTMAEForPreTraining
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/vit_mae.md |
`@gradio/file`
```html
<script>
import { BaseFile, BaseFileUpload, FilePreview, BaseExample } from "@gradio/file";
</script>
```
BaseFile
```javascript
export let value: FileData | FileData[] | null = null;
export let label: string;
export let show_label = true;
export let selectable = false;
export let height: number | undefined = undefined;
export let i18n: I18nFormatter;
```
BaseFileUpload
```javascript
export let value: null | FileData | FileData[];
export let label: string;
export let show_label = true;
export let file_count = "single";
export let file_types: string[] | null = null;
export let selectable = false;
export let root: string;
export let height: number | undefined = undefined;
export let i18n: I18nFormatter;
```
FilePreview
```javascript
export let value: FileData | FileData[];
export let selectable = false;
export let height: number | undefined = undefined;
export let i18n: I18nFormatter;
```
BaseExample
```javascript
export let value: FileData;
export let type: "gallery" | "table";
export let selected = false;
``` | gradio-app/gradio/blob/main/js/file/README.md |
Inception v3
**Inception v3** is a convolutional neural network architecture from the Inception family that makes several improvements including using [Label Smoothing](https://paperswithcode.com/method/label-smoothing), Factorized 7 x 7 convolutions, and the use of an [auxiliary classifer](https://paperswithcode.com/method/auxiliary-classifier) to propagate label information lower down the network (along with the use of batch normalization for layers in the sidehead). The key building block is an [Inception Module](https://paperswithcode.com/method/inception-v3-module).
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('inception_v3', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `inception_v3`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('inception_v3', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/SzegedyVISW15,
author = {Christian Szegedy and
Vincent Vanhoucke and
Sergey Ioffe and
Jonathon Shlens and
Zbigniew Wojna},
title = {Rethinking the Inception Architecture for Computer Vision},
journal = {CoRR},
volume = {abs/1512.00567},
year = {2015},
url = {http://arxiv.org/abs/1512.00567},
archivePrefix = {arXiv},
eprint = {1512.00567},
timestamp = {Mon, 13 Aug 2018 16:49:07 +0200},
biburl = {https://dblp.org/rec/journals/corr/SzegedyVISW15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Inception v3
Paper:
Title: Rethinking the Inception Architecture for Computer Vision
URL: https://paperswithcode.com/paper/rethinking-the-inception-architecture-for
Models:
- Name: inception_v3
In Collection: Inception v3
Metadata:
FLOPs: 7352418880
Parameters: 23830000
File Size: 108857766
Architecture:
- 1x1 Convolution
- Auxiliary Classifier
- Average Pooling
- Average Pooling
- Batch Normalization
- Convolution
- Dense Connections
- Dropout
- Inception-v3 Module
- Max Pooling
- ReLU
- Softmax
Tasks:
- Image Classification
Training Techniques:
- Gradient Clipping
- Label Smoothing
- RMSProp
- Weight Decay
Training Data:
- ImageNet
Training Resources: 50x NVIDIA Kepler GPUs
ID: inception_v3
LR: 0.045
Dropout: 0.2
Crop Pct: '0.875'
Momentum: 0.9
Image Size: '299'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/inception_v3.py#L442
Weights: https://download.pytorch.org/models/inception_v3_google-1a9a5a14.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 77.46%
Top 5 Accuracy: 93.48%
--> | huggingface/pytorch-image-models/blob/main/docs/models/inception-v3.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ESM
## Overview
This page provides code and pre-trained weights for Transformer protein language models from Meta AI's Fundamental
AI Research Team, providing the state-of-the-art ESMFold and ESM-2, and the previously released ESM-1b and ESM-1v.
Transformer protein language models were introduced in the paper [Biological structure and function emerge from scaling
unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by
Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott,
C. Lawrence Zitnick, Jerry Ma, and Rob Fergus.
The first version of this paper was [preprinted in 2019](https://www.biorxiv.org/content/10.1101/622803v1?versioned=true).
ESM-2 outperforms all tested single-sequence protein language models across a range of structure prediction tasks,
and enables atomic resolution structure prediction.
It was released with the paper [Language models of protein sequences at the scale of evolution enable accurate
structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie,
Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido and Alexander Rives.
Also introduced in this paper was ESMFold. It uses an ESM-2 stem with a head that can predict folded protein
structures with state-of-the-art accuracy. Unlike [AlphaFold2](https://www.nature.com/articles/s41586-021-03819-2),
it relies on the token embeddings from the large pre-trained protein language model stem and does not perform a multiple
sequence alignment (MSA) step at inference time, which means that ESMFold checkpoints are fully "standalone" -
they do not require a database of known protein sequences and structures with associated external query tools
to make predictions, and are much faster as a result.
The abstract from
"Biological structure and function emerge from scaling unsupervised learning to 250
million protein sequences" is
*In the field of artificial intelligence, a combination of scale in data and model capacity enabled by unsupervised
learning has led to major advances in representation learning and statistical generation. In the life sciences, the
anticipated growth of sequencing promises unprecedented data on natural sequence diversity. Protein language modeling
at the scale of evolution is a logical step toward predictive and generative artificial intelligence for biology. To
this end, we use unsupervised learning to train a deep contextual language model on 86 billion amino acids across 250
million protein sequences spanning evolutionary diversity. The resulting model contains information about biological
properties in its representations. The representations are learned from sequence data alone. The learned representation
space has a multiscale organization reflecting structure from the level of biochemical properties of amino acids to
remote homology of proteins. Information about secondary and tertiary structure is encoded in the representations and
can be identified by linear projections. Representation learning produces features that generalize across a range of
applications, enabling state-of-the-art supervised prediction of mutational effect and secondary structure and
improving state-of-the-art features for long-range contact prediction.*
The abstract from
"Language models of protein sequences at the scale of evolution enable accurate structure prediction" is
*Large language models have recently been shown to develop emergent capabilities with scale, going beyond
simple pattern matching to perform higher level reasoning and generate lifelike images and text. While
language models trained on protein sequences have been studied at a smaller scale, little is known about
what they learn about biology as they are scaled up. In this work we train models up to 15 billion parameters,
the largest language models of proteins to be evaluated to date. We find that as models are scaled they learn
information enabling the prediction of the three-dimensional structure of a protein at the resolution of
individual atoms. We present ESMFold for high accuracy end-to-end atomic level structure prediction directly
from the individual sequence of a protein. ESMFold has similar accuracy to AlphaFold2 and RoseTTAFold for
sequences with low perplexity that are well understood by the language model. ESMFold inference is an
order of magnitude faster than AlphaFold2, enabling exploration of the structural space of metagenomic
proteins in practical timescales.*
The original code can be found [here](https://github.com/facebookresearch/esm) and was
was developed by the Fundamental AI Research team at Meta AI.
ESM-1b, ESM-1v and ESM-2 were contributed to huggingface by [jasonliu](https://huggingface.co/jasonliu)
and [Matt](https://huggingface.co/Rocketknight1).
ESMFold was contributed to huggingface by [Matt](https://huggingface.co/Rocketknight1) and
[Sylvain](https://huggingface.co/sgugger), with a big thank you to Nikita Smetanin, Roshan Rao and Tom Sercu for their
help throughout the process!
## Usage tips
- ESM models are trained with a masked language modeling (MLM) objective.
- The HuggingFace port of ESMFold uses portions of the [openfold](https://github.com/aqlaboratory/openfold) library. The `openfold` library is licensed under the Apache License 2.0.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
## EsmConfig
[[autodoc]] EsmConfig
- all
## EsmTokenizer
[[autodoc]] EsmTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## EsmModel
[[autodoc]] EsmModel
- forward
## EsmForMaskedLM
[[autodoc]] EsmForMaskedLM
- forward
## EsmForSequenceClassification
[[autodoc]] EsmForSequenceClassification
- forward
## EsmForTokenClassification
[[autodoc]] EsmForTokenClassification
- forward
## EsmForProteinFolding
[[autodoc]] EsmForProteinFolding
- forward
</pt>
<tf>
## TFEsmModel
[[autodoc]] TFEsmModel
- call
## TFEsmForMaskedLM
[[autodoc]] TFEsmForMaskedLM
- call
## TFEsmForSequenceClassification
[[autodoc]] TFEsmForSequenceClassification
- call
## TFEsmForTokenClassification
[[autodoc]] TFEsmForTokenClassification
- call
</tf>
</frameworkcontent>
| huggingface/transformers/blob/main/docs/source/en/model_doc/esm.md |
Gradio Demo: scatterplot_component
```
!pip install -q gradio vega_datasets
```
```
import gradio as gr
from vega_datasets import data
cars = data.cars()
with gr.Blocks() as demo:
gr.ScatterPlot(
value=cars,
x="Horsepower",
y="Miles_per_Gallon",
color="Origin",
tooltip="Name",
title="Car Data",
y_title="Miles per Gallon",
color_legend_title="Origin of Car",
container=False,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/scatterplot_component/run.ipynb |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LeViT
## Overview
The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
The abstract from the paper is the following:
*We design a family of image classification architectures that optimize the trade-off between accuracy
and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures,
which are competitive on highly parallel processing hardware. We revisit principles from the extensive
literature on convolutional neural networks to apply them to transformers, in particular activation maps
with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information
in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification.
We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of
application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable
to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect
to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU. *
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/levit_architecture.png"
alt="drawing" width="600"/>
<small> LeViT Architecture. Taken from the <a href="https://arxiv.org/abs/2104.01136">original paper</a>.</small>
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
## Usage tips
- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
(cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
(also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
pre-training.
- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
(while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
*facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
*facebook/levit-384*. Note that one should use [`LevitImageProcessor`] in order to
prepare images for the model.
- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
(you can just replace [`ViTFeatureExtractor`] by [`LevitImageProcessor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LeViT.
<PipelineTag pipeline="image-classification"/>
- [`LevitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## LevitConfig
[[autodoc]] LevitConfig
## LevitFeatureExtractor
[[autodoc]] LevitFeatureExtractor
- __call__
## LevitImageProcessor
[[autodoc]] LevitImageProcessor
- preprocess
## LevitModel
[[autodoc]] LevitModel
- forward
## LevitForImageClassification
[[autodoc]] LevitForImageClassification
- forward
## LevitForImageClassificationWithTeacher
[[autodoc]] LevitForImageClassificationWithTeacher
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/levit.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Controlled generation
Controlling outputs generated by diffusion models has been long pursued by the community and is now an active research topic. In many popular diffusion models, subtle changes in inputs, both images and text prompts, can drastically change outputs. In an ideal world we want to be able to control how semantics are preserved and changed.
Most examples of preserving semantics reduce to being able to accurately map a change in input to a change in output. I.e. adding an adjective to a subject in a prompt preserves the entire image, only modifying the changed subject. Or, image variation of a particular subject preserves the subject's pose.
Additionally, there are qualities of generated images that we would like to influence beyond semantic preservation. I.e. in general, we would like our outputs to be of good quality, adhere to a particular style, or be realistic.
We will document some of the techniques `diffusers` supports to control generation of diffusion models. Much is cutting edge research and can be quite nuanced. If something needs clarifying or you have a suggestion, don't hesitate to open a discussion on the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or a [GitHub issue](https://github.com/huggingface/diffusers/issues).
We provide a high level explanation of how the generation can be controlled as well as a snippet of the technicals. For more in depth explanations on the technicals, the original papers which are linked from the pipelines are always the best resources.
Depending on the use case, one should choose a technique accordingly. In many cases, these techniques can be combined. For example, one can combine Textual Inversion with SEGA to provide more semantic guidance to the outputs generated using Textual Inversion.
Unless otherwise mentioned, these are techniques that work with existing models and don't require their own weights.
1. [InstructPix2Pix](#instruct-pix2pix)
2. [Pix2Pix Zero](#pix2pix-zero)
3. [Attend and Excite](#attend-and-excite)
4. [Semantic Guidance](#semantic-guidance-sega)
5. [Self-attention Guidance](#self-attention-guidance-sag)
6. [Depth2Image](#depth2image)
7. [MultiDiffusion Panorama](#multidiffusion-panorama)
8. [DreamBooth](#dreambooth)
9. [Textual Inversion](#textual-inversion)
10. [ControlNet](#controlnet)
11. [Prompt Weighting](#prompt-weighting)
12. [Custom Diffusion](#custom-diffusion)
13. [Model Editing](#model-editing)
14. [DiffEdit](#diffedit)
15. [T2I-Adapter](#t2i-adapter)
16. [FABRIC](#fabric)
For convenience, we provide a table to denote which methods are inference-only and which require fine-tuning/training.
| **Method** | **Inference only** | **Requires training /<br> fine-tuning** | **Comments** |
| :-------------------------------------------------: | :----------------: | :-------------------------------------: | :---------------------------------------------------------------------------------------------: |
| [InstructPix2Pix](#instruct-pix2pix) | ✅ | ❌ | Can additionally be<br>fine-tuned for better <br>performance on specific <br>edit instructions. |
| [Pix2Pix Zero](#pix2pix-zero) | ✅ | ❌ | |
| [Attend and Excite](#attend-and-excite) | ✅ | ❌ | |
| [Semantic Guidance](#semantic-guidance-sega) | ✅ | ❌ | |
| [Self-attention Guidance](#self-attention-guidance-sag) | ✅ | ❌ | |
| [Depth2Image](#depth2image) | ✅ | ❌ | |
| [MultiDiffusion Panorama](#multidiffusion-panorama) | ✅ | ❌ | |
| [DreamBooth](#dreambooth) | ❌ | ✅ | |
| [Textual Inversion](#textual-inversion) | ❌ | ✅ | |
| [ControlNet](#controlnet) | ✅ | ❌ | A ControlNet can be <br>trained/fine-tuned on<br>a custom conditioning. |
| [Prompt Weighting](#prompt-weighting) | ✅ | ❌ | |
| [Custom Diffusion](#custom-diffusion) | ❌ | ✅ | |
| [Model Editing](#model-editing) | ✅ | ❌ | |
| [DiffEdit](#diffedit) | ✅ | ❌ | |
| [T2I-Adapter](#t2i-adapter) | ✅ | ❌ | |
| [Fabric](#fabric) | ✅ | ❌ | |
## InstructPix2Pix
[Paper](https://arxiv.org/abs/2211.09800)
[InstructPix2Pix](../api/pipelines/pix2pix) is fine-tuned from Stable Diffusion to support editing input images. It takes as inputs an image and a prompt describing an edit, and it outputs the edited image.
InstructPix2Pix has been explicitly trained to work well with [InstructGPT](https://openai.com/blog/instruction-following/)-like prompts.
## Pix2Pix Zero
[Paper](https://arxiv.org/abs/2302.03027)
[Pix2Pix Zero](../api/pipelines/pix2pix_zero) allows modifying an image so that one concept or subject is translated to another one while preserving general image semantics.
The denoising process is guided from one conceptual embedding towards another conceptual embedding. The intermediate latents are optimized during the denoising process to push the attention maps towards reference attention maps. The reference attention maps are from the denoising process of the input image and are used to encourage semantic preservation.
Pix2Pix Zero can be used both to edit synthetic images as well as real images.
- To edit synthetic images, one first generates an image given a caption.
Next, we generate image captions for the concept that shall be edited and for the new target concept. We can use a model like [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5) for this purpose. Then, "mean" prompt embeddings for both the source and target concepts are created via the text encoder. Finally, the pix2pix-zero algorithm is used to edit the synthetic image.
- To edit a real image, one first generates an image caption using a model like [BLIP](https://huggingface.co/docs/transformers/model_doc/blip). Then one applies DDIM inversion on the prompt and image to generate "inverse" latents. Similar to before, "mean" prompt embeddings for both source and target concepts are created and finally the pix2pix-zero algorithm in combination with the "inverse" latents is used to edit the image.
<Tip>
Pix2Pix Zero is the first model that allows "zero-shot" image editing. This means that the model
can edit an image in less than a minute on a consumer GPU as shown [here](../api/pipelines/pix2pix_zero#usage-example).
</Tip>
As mentioned above, Pix2Pix Zero includes optimizing the latents (and not any of the UNet, VAE, or the text encoder) to steer the generation toward a specific concept. This means that the overall
pipeline might require more memory than a standard [StableDiffusionPipeline](../api/pipelines/stable_diffusion/text2img).
<Tip>
An important distinction between methods like InstructPix2Pix and Pix2Pix Zero is that the former
involves fine-tuning the pre-trained weights while the latter does not. This means that you can
apply Pix2Pix Zero to any of the available Stable Diffusion models.
</Tip>
## Attend and Excite
[Paper](https://arxiv.org/abs/2301.13826)
[Attend and Excite](../api/pipelines/attend_and_excite) allows subjects in the prompt to be faithfully represented in the final image.
A set of token indices are given as input, corresponding to the subjects in the prompt that need to be present in the image. During denoising, each token index is guaranteed to have a minimum attention threshold for at least one patch of the image. The intermediate latents are iteratively optimized during the denoising process to strengthen the attention of the most neglected subject token until the attention threshold is passed for all subject tokens.
Like Pix2Pix Zero, Attend and Excite also involves a mini optimization loop (leaving the pre-trained weights untouched) in its pipeline and can require more memory than the usual [StableDiffusionPipeline](../api/pipelines/stable_diffusion/text2img).
## Semantic Guidance (SEGA)
[Paper](https://arxiv.org/abs/2301.12247)
[SEGA](../api/pipelines/semantic_stable_diffusion) allows applying or removing one or more concepts from an image. The strength of the concept can also be controlled. I.e. the smile concept can be used to incrementally increase or decrease the smile of a portrait.
Similar to how classifier free guidance provides guidance via empty prompt inputs, SEGA provides guidance on conceptual prompts. Multiple of these conceptual prompts can be applied simultaneously. Each conceptual prompt can either add or remove their concept depending on if the guidance is applied positively or negatively.
Unlike Pix2Pix Zero or Attend and Excite, SEGA directly interacts with the diffusion process instead of performing any explicit gradient-based optimization.
## Self-attention Guidance (SAG)
[Paper](https://arxiv.org/abs/2210.00939)
[Self-attention Guidance](../api/pipelines/self_attention_guidance) improves the general quality of images.
SAG provides guidance from predictions not conditioned on high-frequency details to fully conditioned images. The high frequency details are extracted out of the UNet self-attention maps.
## Depth2Image
[Project](https://huggingface.co/stabilityai/stable-diffusion-2-depth)
[Depth2Image](../api/pipelines/stable_diffusion/depth2img) is fine-tuned from Stable Diffusion to better preserve semantics for text guided image variation.
It conditions on a monocular depth estimate of the original image.
## MultiDiffusion Panorama
[Paper](https://arxiv.org/abs/2302.08113)
[MultiDiffusion Panorama](../api/pipelines/panorama) defines a new generation process over a pre-trained diffusion model. This process binds together multiple diffusion generation methods that can be readily applied to generate high quality and diverse images. Results adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes.
MultiDiffusion Panorama allows to generate high-quality images at arbitrary aspect ratios (e.g., panoramas).
## Fine-tuning your own models
In addition to pre-trained models, Diffusers has training scripts for fine-tuning models on user-provided data.
## DreamBooth
[Project](https://dreambooth.github.io/)
[DreamBooth](../training/dreambooth) fine-tunes a model to teach it about a new subject. I.e. a few pictures of a person can be used to generate images of that person in different styles.
## Textual Inversion
[Paper](https://arxiv.org/abs/2208.01618)
[Textual Inversion](../training/text_inversion) fine-tunes a model to teach it about a new concept. I.e. a few pictures of a style of artwork can be used to generate images in that style.
## ControlNet
[Paper](https://arxiv.org/abs/2302.05543)
[ControlNet](../api/pipelines/controlnet) is an auxiliary network which adds an extra condition.
There are 8 canonical pre-trained ControlNets trained on different conditionings such as edge detection, scribbles,
depth maps, and semantic segmentations.
## Prompt Weighting
[Prompt weighting](../using-diffusers/weighted_prompts) is a simple technique that puts more attention weight on certain parts of the text
input.
## Custom Diffusion
[Paper](https://arxiv.org/abs/2212.04488)
[Custom Diffusion](../training/custom_diffusion) only fine-tunes the cross-attention maps of a pre-trained
text-to-image diffusion model. It also allows for additionally performing Textual Inversion. It supports
multi-concept training by design. Like DreamBooth and Textual Inversion, Custom Diffusion is also used to
teach a pre-trained text-to-image diffusion model about new concepts to generate outputs involving the
concept(s) of interest.
## Model Editing
[Paper](https://arxiv.org/abs/2303.08084)
The [text-to-image model editing pipeline](../api/pipelines/model_editing) helps you mitigate some of the incorrect implicit assumptions a pre-trained text-to-image
diffusion model might make about the subjects present in the input prompt. For example, if you prompt Stable Diffusion to generate images for "A pack of roses", the roses in the generated images
are more likely to be red. This pipeline helps you change that assumption.
## DiffEdit
[Paper](https://arxiv.org/abs/2210.11427)
[DiffEdit](../api/pipelines/diffedit) allows for semantic editing of input images along with
input prompts while preserving the original input images as much as possible.
## T2I-Adapter
[Paper](https://arxiv.org/abs/2302.08453)
[T2I-Adapter](../api/pipelines/stable_diffusion/adapter) is an auxiliary network which adds an extra condition.
There are 8 canonical pre-trained adapters trained on different conditionings such as edge detection, sketch,
depth maps, and semantic segmentations.
## Fabric
[Paper](https://arxiv.org/abs/2307.10159)
[Fabric](https://github.com/huggingface/diffusers/tree/442017ccc877279bcf24fbe92f92d3d0def191b6/examples/community#stable-diffusion-fabric-pipeline) is a training-free
approach applicable to a wide range of popular diffusion models, which exploits
the self-attention layer present in the most widely used architectures to condition
the diffusion process on a set of feedback images.
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/controlling_generation.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Reduce memory usage
A barrier to using diffusion models is the large amount of memory required. To overcome this challenge, there are several memory-reducing techniques you can use to run even some of the largest models on free-tier or consumer GPUs. Some of these techniques can even be combined to further reduce memory usage.
<Tip>
In many cases, optimizing for memory or speed leads to improved performance in the other, so you should try to optimize for both whenever you can. This guide focuses on minimizing memory usage, but you can also learn more about how to [Speed up inference](fp16).
</Tip>
The results below are obtained from generating a single 512x512 image from the prompt a photo of an astronaut riding a horse on mars with 50 DDIM steps on a Nvidia Titan RTX, demonstrating the speed-up you can expect as a result of reduced memory consumption.
| | latency | speed-up |
| ---------------- | ------- | ------- |
| original | 9.50s | x1 |
| fp16 | 3.61s | x2.63 |
| channels last | 3.30s | x2.88 |
| traced UNet | 3.21s | x2.96 |
| memory-efficient attention | 2.63s | x3.61 |
## Sliced VAE
Sliced VAE enables decoding large batches of images with limited VRAM or batches with 32 images or more by decoding the batches of latents one image at a time. You'll likely want to couple this with [`~ModelMixin.enable_xformers_memory_efficient_attention`] to reduce memory use further if you have xFormers installed.
To use sliced VAE, call [`~StableDiffusionPipeline.enable_vae_slicing`] on your pipeline before inference:
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
pipe.enable_vae_slicing()
#pipe.enable_xformers_memory_efficient_attention()
images = pipe([prompt] * 32).images
```
You may see a small performance boost in VAE decoding on multi-image batches, and there should be no performance impact on single-image batches.
## Tiled VAE
Tiled VAE processing also enables working with large images on limited VRAM (for example, generating 4k images on 8GB of VRAM) by splitting the image into overlapping tiles, decoding the tiles, and then blending the outputs together to compose the final image. You should also used tiled VAE with [`~ModelMixin.enable_xformers_memory_efficient_attention`] to reduce memory use further if you have xFormers installed.
To use tiled VAE processing, call [`~StableDiffusionPipeline.enable_vae_tiling`] on your pipeline before inference:
```python
import torch
from diffusers import StableDiffusionPipeline, UniPCMultistepScheduler
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "a beautiful landscape photograph"
pipe.enable_vae_tiling()
#pipe.enable_xformers_memory_efficient_attention()
image = pipe([prompt], width=3840, height=2224, num_inference_steps=20).images[0]
```
The output image has some tile-to-tile tone variation because the tiles are decoded separately, but you shouldn't see any sharp and obvious seams between the tiles. Tiling is turned off for images that are 512x512 or smaller.
## CPU offloading
Offloading the weights to the CPU and only loading them on the GPU when performing the forward pass can also save memory. Often, this technique can reduce memory consumption to less than 3GB.
To perform CPU offloading, call [`~StableDiffusionPipeline.enable_sequential_cpu_offload`]:
```Python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
)
prompt = "a photo of an astronaut riding a horse on mars"
pipe.enable_sequential_cpu_offload()
image = pipe(prompt).images[0]
```
CPU offloading works on submodules rather than whole models. This is the best way to minimize memory consumption, but inference is much slower due to the iterative nature of the diffusion process. The UNet component of the pipeline runs several times (as many as `num_inference_steps`); each time, the different UNet submodules are sequentially onloaded and offloaded as needed, resulting in a large number of memory transfers.
<Tip>
Consider using [model offloading](#model-offloading) if you want to optimize for speed because it is much faster. The tradeoff is your memory savings won't be as large.
</Tip>
<Tip warning={true}>
When using [`~StableDiffusionPipeline.enable_sequential_cpu_offload`], don't move the pipeline to CUDA beforehand or else the gain in memory consumption will only be minimal (see this [issue](https://github.com/huggingface/diffusers/issues/1934) for more information).
[`~StableDiffusionPipeline.enable_sequential_cpu_offload`] is a stateful operation that installs hooks on the models.
</Tip>
## Model offloading
<Tip>
Model offloading requires 🤗 Accelerate version 0.17.0 or higher.
</Tip>
[Sequential CPU offloading](#cpu-offloading) preserves a lot of memory but it makes inference slower because submodules are moved to GPU as needed, and they're immediately returned to the CPU when a new module runs.
Full-model offloading is an alternative that moves whole models to the GPU, instead of handling each model's constituent *submodules*. There is a negligible impact on inference time (compared with moving the pipeline to `cuda`), and it still provides some memory savings.
During model offloading, only one of the main components of the pipeline (typically the text encoder, UNet and VAE)
is placed on the GPU while the others wait on the CPU. Components like the UNet that run for multiple iterations stay on the GPU until they're no longer needed.
Enable model offloading by calling [`~StableDiffusionPipeline.enable_model_cpu_offload`] on the pipeline:
```Python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
)
prompt = "a photo of an astronaut riding a horse on mars"
pipe.enable_model_cpu_offload()
image = pipe(prompt).images[0]
```
<Tip warning={true}>
In order to properly offload models after they're called, it is required to run the entire pipeline and models are called in the pipeline's expected order. Exercise caution if models are reused outside the context of the pipeline after hooks have been installed. See [Removing Hooks](https://huggingface.co/docs/accelerate/en/package_reference/big_modeling#accelerate.hooks.remove_hook_from_module) for more information.
[`~StableDiffusionPipeline.enable_model_cpu_offload`] is a stateful operation that installs hooks on the models and state on the pipeline.
</Tip>
## Channels-last memory format
The channels-last memory format is an alternative way of ordering NCHW tensors in memory to preserve dimension ordering. Channels-last tensors are ordered in such a way that the channels become the densest dimension (storing images pixel-per-pixel). Since not all operators currently support the channels-last format, it may result in worst performance but you should still try and see if it works for your model.
For example, to set the pipeline's UNet to use the channels-last format:
```python
print(pipe.unet.conv_out.state_dict()["weight"].stride()) # (2880, 9, 3, 1)
pipe.unet.to(memory_format=torch.channels_last) # in-place operation
print(
pipe.unet.conv_out.state_dict()["weight"].stride()
) # (2880, 1, 960, 320) having a stride of 1 for the 2nd dimension proves that it works
```
## Tracing
Tracing runs an example input tensor through the model and captures the operations that are performed on it as that input makes its way through the model's layers. The executable or `ScriptFunction` that is returned is optimized with just-in-time compilation.
To trace a UNet:
```python
import time
import torch
from diffusers import StableDiffusionPipeline
import functools
# torch disable grad
torch.set_grad_enabled(False)
# set variables
n_experiments = 2
unet_runs_per_experiment = 50
# load inputs
def generate_inputs():
sample = torch.randn((2, 4, 64, 64), device="cuda", dtype=torch.float16)
timestep = torch.rand(1, device="cuda", dtype=torch.float16) * 999
encoder_hidden_states = torch.randn((2, 77, 768), device="cuda", dtype=torch.float16)
return sample, timestep, encoder_hidden_states
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
).to("cuda")
unet = pipe.unet
unet.eval()
unet.to(memory_format=torch.channels_last) # use channels_last memory format
unet.forward = functools.partial(unet.forward, return_dict=False) # set return_dict=False as default
# warmup
for _ in range(3):
with torch.inference_mode():
inputs = generate_inputs()
orig_output = unet(*inputs)
# trace
print("tracing..")
unet_traced = torch.jit.trace(unet, inputs)
unet_traced.eval()
print("done tracing")
# warmup and optimize graph
for _ in range(5):
with torch.inference_mode():
inputs = generate_inputs()
orig_output = unet_traced(*inputs)
# benchmarking
with torch.inference_mode():
for _ in range(n_experiments):
torch.cuda.synchronize()
start_time = time.time()
for _ in range(unet_runs_per_experiment):
orig_output = unet_traced(*inputs)
torch.cuda.synchronize()
print(f"unet traced inference took {time.time() - start_time:.2f} seconds")
for _ in range(n_experiments):
torch.cuda.synchronize()
start_time = time.time()
for _ in range(unet_runs_per_experiment):
orig_output = unet(*inputs)
torch.cuda.synchronize()
print(f"unet inference took {time.time() - start_time:.2f} seconds")
# save the model
unet_traced.save("unet_traced.pt")
```
Replace the `unet` attribute of the pipeline with the traced model:
```python
from diffusers import StableDiffusionPipeline
import torch
from dataclasses import dataclass
@dataclass
class UNet2DConditionOutput:
sample: torch.FloatTensor
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
).to("cuda")
# use jitted unet
unet_traced = torch.jit.load("unet_traced.pt")
# del pipe.unet
class TracedUNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.in_channels = pipe.unet.config.in_channels
self.device = pipe.unet.device
def forward(self, latent_model_input, t, encoder_hidden_states):
sample = unet_traced(latent_model_input, t, encoder_hidden_states)[0]
return UNet2DConditionOutput(sample=sample)
pipe.unet = TracedUNet()
with torch.inference_mode():
image = pipe([prompt] * 1, num_inference_steps=50).images[0]
```
## Memory-efficient attention
Recent work on optimizing bandwidth in the attention block has generated huge speed-ups and reductions in GPU memory usage. The most recent type of memory-efficient attention is [Flash Attention](https://arxiv.org/abs/2205.14135) (you can check out the original code at [HazyResearch/flash-attention](https://github.com/HazyResearch/flash-attention)).
<Tip>
If you have PyTorch >= 2.0 installed, you should not expect a speed-up for inference when enabling `xformers`.
</Tip>
To use Flash Attention, install the following:
- PyTorch > 1.12
- CUDA available
- [xFormers](xformers)
Then call [`~ModelMixin.enable_xformers_memory_efficient_attention`] on the pipeline:
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
use_safetensors=True,
).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
with torch.inference_mode():
sample = pipe("a small cat")
# optional: You can disable it via
# pipe.disable_xformers_memory_efficient_attention()
```
The iteration speed when using `xformers` should match the iteration speed of PyTorch 2.0 as described [here](torch2.0).
| huggingface/diffusers/blob/main/docs/source/en/optimization/memory.md |
Gradio Demo: xgboost-income-prediction-with-explainability
### This demo takes in 12 inputs from the user in dropdowns and sliders and predicts income. It also has a separate button for explaining the prediction.
```
!pip install -q gradio numpy==1.23.2 matplotlib shap xgboost==1.7.6 pandas datasets
```
```
import gradio as gr
import random
import matplotlib.pyplot as plt
import pandas as pd
import shap
import xgboost as xgb
from datasets import load_dataset
dataset = load_dataset("scikit-learn/adult-census-income")
X_train = dataset["train"].to_pandas()
_ = X_train.pop("fnlwgt")
_ = X_train.pop("race")
y_train = X_train.pop("income")
y_train = (y_train == ">50K").astype(int)
categorical_columns = [
"workclass",
"education",
"marital.status",
"occupation",
"relationship",
"sex",
"native.country",
]
X_train = X_train.astype({col: "category" for col in categorical_columns})
data = xgb.DMatrix(X_train, label=y_train, enable_categorical=True)
model = xgb.train(params={"objective": "binary:logistic"}, dtrain=data)
explainer = shap.TreeExplainer(model)
def predict(*args):
df = pd.DataFrame([args], columns=X_train.columns)
df = df.astype({col: "category" for col in categorical_columns})
pos_pred = model.predict(xgb.DMatrix(df, enable_categorical=True))
return {">50K": float(pos_pred[0]), "<=50K": 1 - float(pos_pred[0])}
def interpret(*args):
df = pd.DataFrame([args], columns=X_train.columns)
df = df.astype({col: "category" for col in categorical_columns})
shap_values = explainer.shap_values(xgb.DMatrix(df, enable_categorical=True))
scores_desc = list(zip(shap_values[0], X_train.columns))
scores_desc = sorted(scores_desc)
fig_m = plt.figure(tight_layout=True)
plt.barh([s[1] for s in scores_desc], [s[0] for s in scores_desc])
plt.title("Feature Shap Values")
plt.ylabel("Shap Value")
plt.xlabel("Feature")
plt.tight_layout()
return fig_m
unique_class = sorted(X_train["workclass"].unique())
unique_education = sorted(X_train["education"].unique())
unique_marital_status = sorted(X_train["marital.status"].unique())
unique_relationship = sorted(X_train["relationship"].unique())
unique_occupation = sorted(X_train["occupation"].unique())
unique_sex = sorted(X_train["sex"].unique())
unique_country = sorted(X_train["native.country"].unique())
with gr.Blocks() as demo:
gr.Markdown("""
**Income Classification with XGBoost 💰**: This demo uses an XGBoost classifier predicts income based on demographic factors, along with Shapley value-based *explanations*. The [source code for this Gradio demo is here](https://huggingface.co/spaces/gradio/xgboost-income-prediction-with-explainability/blob/main/app.py).
""")
with gr.Row():
with gr.Column():
age = gr.Slider(label="Age", minimum=17, maximum=90, step=1, randomize=True)
work_class = gr.Dropdown(
label="Workclass",
choices=unique_class,
value=lambda: random.choice(unique_class),
)
education = gr.Dropdown(
label="Education Level",
choices=unique_education,
value=lambda: random.choice(unique_education),
)
years = gr.Slider(
label="Years of schooling",
minimum=1,
maximum=16,
step=1,
randomize=True,
)
marital_status = gr.Dropdown(
label="Marital Status",
choices=unique_marital_status,
value=lambda: random.choice(unique_marital_status),
)
occupation = gr.Dropdown(
label="Occupation",
choices=unique_occupation,
value=lambda: random.choice(unique_occupation),
)
relationship = gr.Dropdown(
label="Relationship Status",
choices=unique_relationship,
value=lambda: random.choice(unique_relationship),
)
sex = gr.Dropdown(
label="Sex", choices=unique_sex, value=lambda: random.choice(unique_sex)
)
capital_gain = gr.Slider(
label="Capital Gain",
minimum=0,
maximum=100000,
step=500,
randomize=True,
)
capital_loss = gr.Slider(
label="Capital Loss", minimum=0, maximum=10000, step=500, randomize=True
)
hours_per_week = gr.Slider(
label="Hours Per Week Worked", minimum=1, maximum=99, step=1
)
country = gr.Dropdown(
label="Native Country",
choices=unique_country,
value=lambda: random.choice(unique_country),
)
with gr.Column():
label = gr.Label()
plot = gr.Plot()
with gr.Row():
predict_btn = gr.Button(value="Predict")
interpret_btn = gr.Button(value="Explain")
predict_btn.click(
predict,
inputs=[
age,
work_class,
education,
years,
marital_status,
occupation,
relationship,
sex,
capital_gain,
capital_loss,
hours_per_week,
country,
],
outputs=[label],
)
interpret_btn.click(
interpret,
inputs=[
age,
work_class,
education,
years,
marital_status,
occupation,
relationship,
sex,
capital_gain,
capital_loss,
hours_per_week,
country,
],
outputs=[plot],
)
demo.launch()
```
| gradio-app/gradio/blob/main/demo/xgboost-income-prediction-with-explainability/run.ipynb |
--
title: "Ethics and Society Newsletter #4: Bias in Text-to-Image Models"
thumbnail: /blog/assets/152_ethics_soc_4/ethics_4_thumbnail.png
authors:
- user: sasha
- user: giadap
- user: nazneen
- user: allendorf
- user: irenesolaiman
- user: natolambert
- user: meg
---
# Ethics and Society Newsletter #4: Bias in Text-to-Image Models
**TL;DR: We need better ways of evaluating bias in text-to-image models**
## Introduction
[Text-to-image (TTI) generation](https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads) is all the rage these days, and thousands of TTI models are being uploaded to the Hugging Face Hub. Each modality is potentially susceptible to separate sources of bias, which begs the question: how do we uncover biases in these models? In the current blog post, we share our thoughts on sources of bias in TTI systems as well as tools and potential solutions to address them, showcasing both our own projects and those from the broader community.
## Values and bias encoded in image generations
There is a very close relationship between [bias and values](https://www.sciencedirect.com/science/article/abs/pii/B9780080885797500119), particularly when these are embedded in the language or images used to train and query a given [text-to-image model](https://dl.acm.org/doi/abs/10.1145/3593013.3594095); this phenomenon heavily influences the outputs we see in the generated images. Although this relationship is known in the broader AI research field and considerable efforts are underway to address it, the complexity of trying to represent the evolving nature of a given population's values in a single model still persists. This presents an enduring ethical challenge to uncover and address adequately.
For example, if the training data are mainly in English they probably convey rather Western values. As a result we get stereotypical representations of different or distant cultures. This phenomenon appears noticeable when we compare the results of ERNIE ViLG (left) and Stable Diffusion v 2.1 (right) for the same prompt, "a house in Beijing":
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/ernie-sd.png" alt="results of ERNIE ViLG (left) and Stable Diffusion v 2.1 (right) for the same prompt, a house in Beijing" />
</p>
## Sources of Bias
Recent years have seen much important research on bias detection in AI systems with single modalities in both Natural Language Processing ([Abid et al., 2021](https://dl.acm.org/doi/abs/10.1145/3461702.3462624)) as well as Computer Vision ([Buolamwini and Gebru, 2018](http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf)). To the extent that ML models are constructed by people, biases are present in all ML models (and, indeed, technology in general). This can manifest itself by an over- and under-representation of certain visual characteristics in images (e.g., all images of office workers having ties), or the presence of cultural and geographical stereotypes (e.g., all images of brides wearing white dresses and veils, as opposed to more representative images of brides around the world, such as brides with red saris). Given that AI systems are deployed in sociotechnical contexts that are becoming widely deployed in different sectors and tools (e.g. [Firefly](https://www.adobe.com/sensei/generative-ai/firefly.html), [Shutterstock](https://www.shutterstock.com/ai-image-generator)), they are particularly likely to amplify existing societal biases and inequities. We aim to provide a non-exhaustive list of bias sources below:
**Biases in training data:** Popular multimodal datasets such as [LAION-5B](https://laion.ai/blog/laion-5b/) for text-to-image, [MS-COCO](https://cocodataset.org/) for image captioning, and [VQA v2.0](https://paperswithcode.com/dataset/visual-question-answering-v2-0) for visual question answering, have been found to contain numerous biases and harmful associations ([Zhao et al 2017](https://aclanthology.org/D17-1323/), [Prabhu and Birhane, 2021](https://arxiv.org/abs/2110.01963), [Hirota et al, 2022](https://facctconference.org/static/pdfs_2022/facct22-3533184.pdf)), which can percolate into the models trained on these datasets. For example, initial results from the [Hugging Face Stable Bias project](https://huggingface.co/spaces/society-ethics/StableBias) show a lack of diversity in image generations, as well as a perpetuation of common stereotypes of cultures and identity groups. Comparing Dall-E 2 generations of CEOs (right) and managers (left), we can see that both are lacking diversity:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/CEO_manager.png" alt="Dall-E 2 generations of CEOs (right) and managers (left)" />
</p>
**Biases in pre-training data filtering:** There is often some form of filtering carried out on datasets before they are used for training models; this introduces different biases. For instance, in their [blog post](https://openai.com/research/dall-e-2-pre-training-mitigations), the creators of Dall-E 2 found that filtering training data can actually amplify biases – they hypothesize that this may be due to the existing dataset bias towards representing women in more sexualized contexts or due to inherent biases of the filtering approaches that they use.
**Biases in inference:** The [CLIP model](https://huggingface.co/openai/clip-vit-large-patch14) used for guiding the training and inference of text-to-image models like Stable Diffusion and Dall-E 2 has a number of [well-documented biases](https://arxiv.org/abs/2205.11378) surrounding age, gender, and race or ethnicity, for instance treating images that had been labeled as `white`, `middle-aged`, and `male` as the default. This can impact the generations of models that use it for prompt encoding, for instance by interpreting unspecified or underspecified gender and identity groups to signify white and male.
**Biases in the models' latent space:** [Initial work](https://arxiv.org/abs/2302.10893) has been done in terms of exploring the latent space of the model and guiding image generation along different axes such as gender to make generations more representative (see the images below). However, more work is necessary to better understand the structure of the latent space of different types of diffusion models and the factors that can influence the bias reflected in generated images.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/fair-diffusion.png" alt="Fair Diffusion generations of firefighters." />
</p>
**Biases in post-hoc filtering:** Many image generation models come with built-in safety filters that aim to flag problematic content. However, the extent to which these filters work and how robust they are to different kinds of content is to be determined – for instance, efforts to [red-team the Stable Diffusion safety filter](https://arxiv.org/abs/2210.04610)have shown that it mostly identifies sexual content, and fails to flag other types violent, gory or disturbing content.
## Detecting Bias
Most of the issues that we describe above cannot be solved with a single solution – indeed, [bias is a complex topic](https://huggingface.co/blog/ethics-soc-2) that cannot be meaningfully addressed with technology alone. Bias is deeply intertwined with the broader social, cultural, and historical context in which it exists. Therefore, addressing bias in AI systems is not only a technological challenge but also a socio-technical one that demands multidisciplinary attention. However, a combination of approaches including tools, red-teaming and evaluations can help glean important insights that can inform both model creators and downstream users about the biases contained in TTI and other multimodal models.
We present some of these approaches below:
**Tools for exploring bias:** As part of the [Stable Bias project](https://huggingface.co/spaces/society-ethics/StableBias), we created a series of tools to explore and compare the visual manifestation of biases in different text-to-image models. For instance, the [Average Diffusion Faces](https://huggingface.co/spaces/society-ethics/Average_diffusion_faces) tool lets you compare the average representations for different professions and different models – like for 'janitor', shown below, for Stable Diffusion v1.4, v2, and Dall-E 2:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/average.png" alt="Average faces for the 'janitor' profession, computed based on the outputs of different text to image models." />
</p>
Other tools, like the [Face Clustering tool](https://hf.co/spaces/society-ethics/DiffusionFaceClustering) and the [Colorfulness Profession Explorer](https://huggingface.co/spaces/tti-bias/identities-colorfulness-knn) tool, allow users to explore patterns in the data and identify similarities and stereotypes without ascribing labels or identity characteristics. In fact, it's important to remember that generated images of individuals aren't actual people, but artificial creations, so it's important not to treat them as if they were real humans. Depending on the context and the use case, tools like these can be used both for storytelling and for auditing.
**Red-teaming:** ['Red-teaming'](https://huggingface.co/blog/red-teaming) consists of stress testing AI models for potential vulnerabilities, biases, and weaknesses by prompting them and analyzing results. While it has been employed in practice for evaluating language models (including the upcoming [Generative AI Red Teaming event at DEFCON](https://aivillage.org/generative%20red%20team/generative-red-team/), which we are participating in), there are no established and systematic ways of red-teaming AI models and it remains relatively ad hoc. In fact, there are so many potential types of failure modes and biases in AI models, it is hard to anticipate them all, and the [stochastic nature](https://dl.acm.org/doi/10.1145/3442188.3445922) of generative models makes it hard to reproduce failure cases. Red-teaming gives actionable insights into model limitations and can be used to add guardrails and document model limitations. There are currently no red-teaming benchmarks or leaderboards highlighting the need for more work in open source red-teaming resources. [Anthropic's red-teaming dataset](https://github.com/anthropics/hh-rlhf/tree/master/red-team-attempts) is the only open source resource of red-teaming prompts, but is limited to only English natural language text.
**Evaluating and documenting bias:** At Hugging Face, we are big proponents of [model cards](https://huggingface.co/docs/hub/model-card-guidebook) and other forms of documentation (e.g., [datasheets](https://arxiv.org/abs/1803.09010), READMEs, etc). In the case of text-to-image (and other multimodal) models, the result of explorations made using explorer tools and red-teaming efforts such as the ones described above can be shared alongside model checkpoints and weights. One of the issues is that we currently don't have standard benchmarks or datasets for measuring the bias in multimodal models (and indeed, in text-to-image generation systems specifically), but as more [work](https://arxiv.org/abs/2306.05949) in this direction is carried out by the community, different bias metrics can be reported in parallel in model documentation.
## Values and Bias
All of the approaches listed above are part of detecting and understanding the biases embedded in image generation models. But how do we actively engage with them?
One approach is to develop new models that represent society as we wish it to be. This suggests creating AI systems that don't just mimic the patterns in our data, but actively promote more equitable and fair perspectives. However, this approach raises a crucial question: whose values are we programming into these models? Values differ across cultures, societies, and individuals, making it a complex task to define what an "ideal" society should look like within an AI model. The question is indeed complex and multifaceted. If we avoid reproducing existing societal biases in our AI models, we're faced with the challenge of defining an "ideal" representation of society. Society is not a static entity, but a dynamic and ever-changing construct. Should AI models, then, adapt to the changes in societal norms and values over time? If so, how do we ensure that these shifts genuinely represent all groups within society, especially those often underrepresented?
Also, as we have mentioned in a [previous newsletter](https://huggingface.co/blog/ethics-soc-2#addressing-bias-throughout-the-ml-development-cycle), there is no one single way to develop machine learning systems, and any of the steps in the development and deployment process can present opportunities to tackle bias, from who is included at the start, to defining the task, to curating the dataset, training the model, and more. This also applies to multimodal models and the ways in which they are ultimately deployed or productionized in society, since the consequences of bias in multimodal models will depend on their downstream use. For instance, if a model is used in a human-in-the-loop setting for graphic design (such as those created by [RunwayML](https://runwayml.com/ai-magic-tools/text-to-image/)), the user has numerous occasions to detect and correct bias, for instance by changing the prompt or the generation options. However, if a model is used as part of a [tool to help forensic artists create police sketches of potential suspects](https://www.vice.com/en/article/qjk745/ai-police-sketches) (see image below), then the stakes are much higher, since this can reinforce stereotypes and racial biases in a high-risk setting.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/forensic.png" alt="Forensic AI Sketch artist tool developed using Dall-E 2." />
</p>
## Other updates
We are also continuing work on other fronts of ethics and society, including:
- **Content moderation:**
- We made a major update to our [Content Policy](https://huggingface.co/content-guidelines). It has been almost a year since our last update and the Hugging Face community has grown massively since then, so we felt it was time. In this update we emphasize *consent* as one of Hugging Face's core values. To read more about our thought process, check out the [announcement blog](https://huggingface.co/blog/content-guidelines-update) **.**
- **AI Accountability Policy:**
- We submitted a response to the NTIA request for comments on [AI accountability policy](https://ntia.gov/issues/artificial-intelligence/request-for-comments), where we stressed the importance of documentation and transparency mechanisms, as well as the necessity of leveraging open collaboration and promoting access to external stakeholders. You can find a summary of our response and a link to the full document [in our blog post](https://huggingface.co/blog/policy-ntia-rfc)!
## Closing Remarks
As you can tell from our discussion above, the issue of detecting and engaging with bias and values in multimodal models, such as text-to-image models, is very much an open question. Apart from the work cited above, we are also engaging with the community at large on the issues - we recently co-led a [CRAFT session at the FAccT conference](https://facctconference.org/2023/acceptedcraft.html) on the topic and are continuing to pursue data- and model-centric research on the topic. One particular direction we are excited to explore is a more in-depth probing of the [values](https://arxiv.org/abs/2203.07785) instilled in text-to-image models and what they represent (stay tuned!).
| huggingface/blog/blob/main/ethics-soc-4.md |
his demo built with Blocks generates 9 plots based on the input. | gradio-app/gradio/blob/main/demo/clustering/DESCRIPTION.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installation
Before you start, you will need to setup your environment, install the appropriate packages, and configure 🤗 PEFT. 🤗 PEFT is tested on **Python 3.8+**.
🤗 PEFT is available on PyPI, as well as GitHub:
## PyPI
To install 🤗 PEFT from PyPI:
```bash
pip install peft
```
## Source
New features that haven't been released yet are added every day, which also means there may be some bugs. To try them out, install from the GitHub repository:
```bash
pip install git+https://github.com/huggingface/peft
```
If you're working on contributing to the library or wish to play with the source code and see live
results as you run the code, an editable version can be installed from a locally-cloned version of the
repository:
```bash
git clone https://github.com/huggingface/peft
cd peft
pip install -e .
```
| huggingface/peft/blob/main/docs/source/install.md |
CSP-DarkNet
**CSPDarknet53** is a convolutional neural network and backbone for object detection that uses [DarkNet-53](https://paperswithcode.com/method/darknet-53). It employs a CSPNet strategy to partition the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy. The use of a split and merge strategy allows for more gradient flow through the network.
This CNN is used as the backbone for [YOLOv4](https://paperswithcode.com/method/yolov4).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('cspdarknet53', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `cspdarknet53`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('cspdarknet53', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@misc{bochkovskiy2020yolov4,
title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
year={2020},
eprint={2004.10934},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
Type: model-index
Collections:
- Name: CSP DarkNet
Paper:
Title: 'YOLOv4: Optimal Speed and Accuracy of Object Detection'
URL: https://paperswithcode.com/paper/yolov4-optimal-speed-and-accuracy-of-object
Models:
- Name: cspdarknet53
In Collection: CSP DarkNet
Metadata:
FLOPs: 8545018880
Parameters: 27640000
File Size: 110775135
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Mish
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- CutMix
- Label Smoothing
- Mosaic
- Polynomial Learning Rate Decay
- SGD with Momentum
- Self-Adversarial Training
- Weight Decay
Training Data:
- ImageNet
Training Resources: 1x NVIDIA RTX 2070 GPU
ID: cspdarknet53
LR: 0.1
Layers: 53
Crop Pct: '0.887'
Momentum: 0.9
Batch Size: 128
Image Size: '256'
Warmup Steps: 1000
Weight Decay: 0.0005
Interpolation: bilinear
Training Steps: 8000000
FPS (GPU RTX 2070): 66
Code: https://github.com/rwightman/pytorch-image-models/blob/d8e69206be253892b2956341fea09fdebfaae4e3/timm/models/cspnet.py#L441
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/cspdarknet53_ra_256-d05c7c21.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.05%
Top 5 Accuracy: 95.09%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/csp-darknet.mdx |
Gradio & LLM Agents 🤝
非常强大的大型语言模型(LLM),如果我们能赋予它们完成专门任务的技能,它们将变得更加强大。
[gradio_tools](https://github.com/freddyaboulton/gradio-tools)库可以将任何[Gradio](https://github.com/gradio-app/gradio)应用程序转化为[工具](https://python.langchain.com/en/latest/modules/agents/tools.html),供[代理](https://docs.langchain.com/docs/components/agents/agent)使用以完成任务。例如,一个LLM可以使用Gradio工具转录在网上找到的语音记录,然后为您summarize它。或者它可以使用不同的Gradio工具对您的Google Drive上的文档应用OCR,然后回答相关问题。
本指南将展示如何使用`gradio_tools`让您的LLM代理访问全球托管的最先进的Gradio应用程序。尽管`gradio_tools`与不止一个代理框架兼容,但本指南将重点介绍[Langchain代理](https://docs.langchain.com/docs/components/agents/)。
## 一些背景信息
### 代理是什么?
[LangChain代理](https://docs.langchain.com/docs/components/agents/agent)是一个大型语言模型(LLM),它根据使用其众多工具之一的输入来生成输出。
### Gradio是什么?
[Gradio](https://github.com/gradio-app/gradio)是用于构建机器学习Web应用程序并与全球共享的事实上的标准框架-完全由Python驱动!🐍
## gradio_tools - 一个端到端的示例
要开始使用`gradio_tools`,您只需要导入和初始化工具,然后将其传递给langchain代理!
在下面的示例中,我们导入`StableDiffusionPromptGeneratorTool`以创建一个良好的稳定扩散提示,
`StableDiffusionTool`以使用我们改进的提示创建一张图片,`ImageCaptioningTool`以为生成的图片加上标题,以及
`TextToVideoTool`以根据提示创建一个视频。
然后,我们告诉我们的代理创建一张狗正在滑板的图片,但在使用图像生成器之前请先改进我们的提示。我们还要求
它为生成的图片添加标题并创建一个视频。代理可以根据需要决定使用哪个工具,而不需要我们明确告知。
```python
import os
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY 必须设置 ")
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
from gradio_tools import (StableDiffusionTool, ImageCaptioningTool, StableDiffusionPromptGeneratorTool,
TextToVideoTool)
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history")
tools = [StableDiffusionTool().langchain, ImageCaptioningTool().langchain,
StableDiffusionPromptGeneratorTool().langchain, TextToVideoTool().langchain]
agent = initialize_agent(tools, llm, memory=memory, agent="conversational-react-description", verbose=True)
output = agent.run(input=("Please create a photo of a dog riding a skateboard "
"but improve my prompt prior to using an image generator."
"Please caption the generated image and create a video for it using the improved prompt."))
```
您会注意到我们正在使用一些与`gradio_tools`一起提供的预构建工具。请参阅此[文档](https://github.com/freddyaboulton/gradio-tools#gradio-tools-gradio--llm-agents)以获取完整的`gradio_tools`工具列表。
如果您想使用当前不在`gradio_tools`中的工具,很容易添加您自己的工具。下一节将介绍如何添加自己的工具。
## gradio_tools - 创建自己的工具
核心抽象是`GradioTool`,它允许您为LLM定义一个新的工具,只要您实现标准接口:
```python
class GradioTool(BaseTool):
def __init__(self, name: str, description: str, src: str) -> None:
@abstractmethod
def create_job(self, query: str) -> Job:
pass
@abstractmethod
def postprocess(self, output: Tuple[Any] | Any) -> str:
pass
```
需要满足的要求是:
1. 工具的名称
2. 工具的描述。这非常关键!代理根据其描述决定使用哪个工具。请确切描述输入和输出应该是什么样的,最好包括示例。
3. Gradio应用程序的url或space id,例如`freddyaboulton/calculator`。基于该值,`gradio_tool`将通过API创建一个[gradio客户端](https://github.com/gradio-app/gradio/blob/main/client/python/README.md)实例来查询上游应用程序。如果您不熟悉gradio客户端库,请确保点击链接了解更多信息。
4. create_job - 给定一个字符串,该方法应该解析该字符串并从客户端返回一个job。大多数情况下,这只需将字符串传递给客户端的`submit`函数即可。有关创建job的更多信息,请参阅[这里](https://github.com/gradio-app/gradio/blob/main/client/python/README.md#making-a-prediction)
5. postprocess - 给定作业的结果,将其转换为LLM可以向用户显示的字符串。
6. _Optional可选_ - 某些库,例如[MiniChain](https://github.com/srush/MiniChain/tree/main),可能需要一些关于工具使用的底层gradio输入和输出类型的信息。默认情况下,这将返回gr.Textbox(),但如果您想提供更准确的信息,请实现工具的`_block_input(self, gr)`和`_block_output(self, gr)`方法。`gr`变量是gradio模块(通过`import gradio as gr`获得的结果)。`GradiTool`父类将自动引入`gr`并将其传递给`_block_input`和`_block_output`方法。
就是这样!
一旦您创建了自己的工具,请在`gradio_tools`存储库上发起拉取请求!我们欢迎所有贡献。
## 示例工具 - 稳定扩散
以下是作为示例的稳定扩散工具代码:
from gradio_tool import GradioTool
import os
class StableDiffusionTool(GradioTool):
"""Tool for calling stable diffusion from llm"""
def __init__(
self,
name="StableDiffusion",
description=(
"An image generator. Use this to generate images based on "
"text input. Input should be a description of what the image should "
"look like. The output will be a path to an image file."
),
src="gradio-client-demos/stable-diffusion",
hf_token=None,
) -> None:
super().__init__(name, description, src, hf_token)
def create_job(self, query: str) -> Job:
return self.client.submit(query, "", 9, fn_index=1)
def postprocess(self, output: str) -> str:
return [os.path.join(output, i) for i in os.listdir(output) if not i.endswith("json")][0]
def _block_input(self, gr) -> "gr.components.Component":
return gr.Textbox()
def _block_output(self, gr) -> "gr.components.Component":
return gr.Image()
```
关于此实现的一些注意事项:
1. 所有的 `GradioTool` 实例都有一个名为 `client` 的属性,它指向底层的 [gradio 客户端](https://github.com/gradio-app/gradio/tree/main/client/python#gradio_client-use-a-gradio-app-as-an-api----in-3-lines-of-python),这就是您在 `create_job` 方法中应该使用的内容。
2. `create_job` 方法只是将查询字符串传递给客户端的 `submit` 函数,并硬编码了一些其他参数,即负面提示字符串和指南缩放。我们可以在后续版本中修改我们的工具,以便从输入字符串中接受这些值。
3. `postprocess` 方法只是返回由稳定扩散空间创建的图库中的第一个图像。我们使用 `os` 模块获取图像的完整路径。
## Conclusion
现在,您已经知道如何通过数千个运行在野外的 gradio 空间来扩展您的 LLM 的能力了!
同样,我们欢迎对 [gradio_tools](https://github.com/freddyaboulton/gradio-tools) 库的任何贡献。我们很兴奋看到大家构建的工具!
```
| gradio-app/gradio/blob/main/guides/cn/06_client-libraries/gradio-and-llm-agents.md |
(Optional) What is Curiosity in Deep Reinforcement Learning?
This is an (optional) introduction to Curiosity. If you want to learn more, you can read two additional articles where we dive into the mathematical details:
- [Curiosity-Driven Learning through Next State Prediction](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-next-state-prediction-f7f4e2f592fa)
- [Random Network Distillation: a new take on Curiosity-Driven Learning](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938)
## Two Major Problems in Modern RL
To understand what Curiosity is, we first need to understand the two major problems with RL:
First, the *sparse rewards problem:* that is, **most rewards do not contain information, and hence are set to zero**.
Remember that RL is based on the *reward hypothesis*, which is the idea that each goal can be described as the maximization of the rewards. Therefore, rewards act as feedback for RL agents; **if they don’t receive any, their knowledge of which action is appropriate (or not) cannot change**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity1.png" alt="Curiosity"/>
<figcaption>Source: Thanks to the reward, our agent knows that this action at that state was good</figcaption>
</figure>
For instance, in [Vizdoom](https://vizdoom.cs.put.edu.pl/), a set of environments based on the game Doom “DoomMyWayHome,” your agent is only rewarded **if it finds the vest**.
However, the vest is far away from your starting point, so most of your rewards will be zero. Therefore, if our agent does not receive useful feedback (dense rewards), it will take much longer to learn an optimal policy, and **it can spend time turning around without finding the goal**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity2.png" alt="Curiosity"/>
The second big problem is that **the extrinsic reward function is handmade; in each environment, a human has to implement a reward function**. But how we can scale that in big and complex environments?
## So what is Curiosity?
A solution to these problems is **to develop a reward function intrinsic to the agent, i.e., generated by the agent itself**. The agent will act as a self-learner since it will be the student and its own feedback master.
**This intrinsic reward mechanism is known as Curiosity** because this reward pushes the agent to explore states that are novel/unfamiliar. To achieve that, our agent will receive a high reward when exploring new trajectories.
This reward is inspired by how humans act. ** We naturally have an intrinsic desire to explore environments and discover new things**.
There are different ways to calculate this intrinsic reward. The classical approach (Curiosity through next-state prediction) is to calculate Curiosity **as the error of our agent in predicting the next state, given the current state and action taken**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity3.png" alt="Curiosity"/>
Because the idea of Curiosity is to **encourage our agent to perform actions that reduce the uncertainty in the agent’s ability to predict the consequences of its actions** (uncertainty will be higher in areas where the agent has spent less time or in areas with complex dynamics).
If the agent spends a lot of time on these states, it will be good at predicting the next state (low Curiosity). On the other hand, if it’s in a new, unexplored state, it will be hard to predict the following state (high Curiosity).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity4.png" alt="Curiosity"/>
Using Curiosity will push our agent to favor transitions with high prediction error (which will be higher in areas where the agent has spent less time, or in areas with complex dynamics) and **consequently better explore our environment**.
There’s also **other curiosity calculation methods**. ML-Agents uses a more advanced one called Curiosity through random network distillation. This is out of the scope of the tutorial but if you’re interested [I wrote an article explaining it in detail](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938).
| huggingface/deep-rl-class/blob/main/units/en/unit5/curiosity.mdx |
The “Deep” in Reinforcement Learning [[deep-rl]]
<Tip>
What we've talked about so far is Reinforcement Learning. But where does the "Deep" come into play?
</Tip>
Deep Reinforcement Learning introduces **deep neural networks to solve Reinforcement Learning problems** — hence the name “deep”.
For instance, in the next unit, we’ll learn about two value-based algorithms: Q-Learning (classic Reinforcement Learning) and then Deep Q-Learning.
You’ll see the difference is that, in the first approach, **we use a traditional algorithm** to create a Q table that helps us find what action to take for each state.
In the second approach, **we will use a Neural Network** (to approximate the Q value).
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit1/deep.jpg" alt="Value based RL"/>
<figcaption>Schema inspired by the Q learning notebook by Udacity
</figcaption>
</figure>
If you are not familiar with Deep Learning you should definitely watch [the FastAI Practical Deep Learning for Coders](https://course.fast.ai) (Free).
| huggingface/deep-rl-class/blob/main/units/en/unit1/deep-rl.mdx |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# SDXL Turbo
Stable Diffusion XL (SDXL) Turbo was proposed in [Adversarial Diffusion Distillation](https://stability.ai/research/adversarial-diffusion-distillation) by Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach.
The abstract from the paper is:
*We introduce Adversarial Diffusion Distillation (ADD), a novel training approach that efficiently samples large-scale foundational image diffusion models in just 1–4 steps while maintaining high image quality. We use score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal in combination with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps. Our analyses show that our model clearly outperforms existing few-step methods (GANs,Latent Consistency Models) in a single step and reaches the performance of state-of-the-art diffusion models (SDXL) in only four steps. ADD is the first method to unlock single-step, real-time image synthesis with foundation models.*
## Tips
- SDXL Turbo uses the exact same architecture as [SDXL](./stable_diffusion_xl), which means it also has the same API. Please refer to the [SDXL](./stable_diffusion_xl) API reference for more details.
- SDXL Turbo should disable guidance scale by setting `guidance_scale=0.0`
- SDXL Turbo should use `timestep_spacing='trailing'` for the scheduler and use between 1 and 4 steps.
- SDXL Turbo has been trained to generate images of size 512x512.
- SDXL Turbo is open-access, but not open-source meaning that one might have to buy a model license in order to use it for commercial applications. Make sure to read the [official model card](https://huggingface.co/stabilityai/sdxl-turbo) to learn more.
<Tip>
To learn how to use SDXL Turbo for various tasks, how to optimize performance, and other usage examples, take a look at the [SDXL Turbo](../../../using-diffusers/sdxl_turbo) guide.
Check out the [Stability AI](https://huggingface.co/stabilityai) Hub organization for the official base and refiner model checkpoints!
</Tip>
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/stable_diffusion/sdxl_turbo.md |
Gradio Demo: barplot_component
```
!pip install -q gradio
```
```
import gradio as gr
import pandas as pd
simple = pd.DataFrame(
{
"item": ["A", "B", "C", "D", "E", "F", "G", "H", "I"],
"inventory": [28, 55, 43, 91, 81, 53, 19, 87, 52],
}
)
with gr.Blocks() as demo:
gr.BarPlot(
value=simple,
x="item",
y="inventory",
title="Simple Bar Plot",
container=False,
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/barplot_component/run.ipynb |
SPNASNet
**Single-Path NAS** is a novel differentiable NAS method for designing hardware-efficient ConvNets in less than 4 hours.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('spnasnet_100', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `spnasnet_100`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('spnasnet_100', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@misc{stamoulis2019singlepath,
title={Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours},
author={Dimitrios Stamoulis and Ruizhou Ding and Di Wang and Dimitrios Lymberopoulos and Bodhi Priyantha and Jie Liu and Diana Marculescu},
year={2019},
eprint={1904.02877},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
Type: model-index
Collections:
- Name: SPNASNet
Paper:
Title: 'Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4
Hours'
URL: https://paperswithcode.com/paper/single-path-nas-designing-hardware-efficient
Models:
- Name: spnasnet_100
In Collection: SPNASNet
Metadata:
FLOPs: 442385600
Parameters: 4420000
File Size: 17902337
Architecture:
- Average Pooling
- Batch Normalization
- Convolution
- Depthwise Separable Convolution
- Dropout
- ReLU
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: spnasnet_100
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/efficientnet.py#L995
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/spnasnet_100-048bc3f4.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 74.08%
Top 5 Accuracy: 91.82%
--> | huggingface/pytorch-image-models/blob/main/docs/models/spnasnet.md |
How to add one new datasets
Add datasets directly to the 🤗 Hugging Face Hub!
You can share your dataset on https://huggingface.co/datasets directly using your account, see the documentation:
* [Create a dataset and upload files on the website](https://huggingface.co/docs/datasets/upload_dataset)
* [Advanced guide using the CLI](https://huggingface.co/docs/datasets/share)
| huggingface/datasets/blob/main/ADD_NEW_DATASET.md |
his package provides core backend functionality for the Hugging Face Simulate project: (https://github.com/huggingface/simulate).
To use this package, add a GameObject to the scene, then add a `Simulator` component to it.
Core Classes:
- `Simulator`: Master controller singleton that tracks objects, loads and unloads plugins, etc.
- `Node`: Component attached to every tracked object.
- `RenderCamera`: Component attached to every tracked camera. Call `Render()` to asynchronously request a color buffer.
- `Client`: Manages communication with the backend. Don't modify directly; instead, use plugins.
Plugins:
- `IPlugin`: For adding custom behaviour to the backend.
- `ICommand`: For defining custom commands from the Python frontend.
- `IGLTFExtension`: For defining custom GLTF extensions.
To add functionality to the backend:
- Create a separate folder. For example, `RLAgents`.
- Add an assembly definition to this folder (Right Click > Create > Assembly Definition).
- In the assembly definition, add a reference to `Simulate`.
- In the folder, create a script that implements `IPlugin`. For a simple example, look at `IPlugin.cs`, or for a more complex example, see `AgentsPlugin.cs`.
If this folder is in the Unity project, it will automatically be included in the build.
To add functionality post-build, a plugin can be compiled externally, then the DLL can be placed in the build's `Resources/Plugins/` folder.
| huggingface/simulate/blob/main/integrations/Unity/simulate-unity/Assets/Simulate/README.md |
Gradio Demo: blocks_hello
```
!pip install -q gradio
```
```
import gradio as gr
def welcome(name):
return f"Welcome to Gradio, {name}!"
with gr.Blocks() as demo:
gr.Markdown(
"""
# Hello World!
Start typing below to see the output.
""")
inp = gr.Textbox(placeholder="What is your name?")
out = gr.Textbox()
inp.change(welcome, inp, out)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/blocks_hello/run.ipynb |
Cookie limitations in Spaces
In Hugging Face Spaces, applications have certain limitations when using cookies. This is primarily due to the structure of the Spaces' pages (`https://huggingface.co/spaces/<user>/<app>`), which contain applications hosted on a different domain (`*.hf.space`) within an iframe. For security reasons, modern browsers tend to restrict the use of cookies from iframe pages hosted on a different domain than the parent page.
## Impact on Hosting Streamlit Apps with Docker SDK
One instance where these cookie restrictions can become problematic is when hosting Streamlit applications using the Docker SDK. By default, Streamlit enables cookie-based XSRF protection. As a result, certain components that submit data to the server, such as `st.file_uploader()`, will not work properly on HF Spaces where cookie usage is restricted.
To work around this issue, you would need to set the `server.enableXsrfProtection` option in Streamlit to `false`. There are two ways to do this:
1. Command line argument: The option can be specified as a command line argument when running the Streamlit application. Here is the example command:
```shell
streamlit run app.py --server.enableXsrfProtection false
```
2. Configuration file: Alternatively, you can specify the option in the Streamlit configuration file `.streamlit/config.toml`. You would write it like this:
```toml
[server]
enableXsrfProtection = false
```
<Tip>
When you are using the Streamlit SDK, you don't need to worry about this because the SDK does it for you.
</Tip>
| huggingface/hub-docs/blob/main/docs/hub/spaces-cookie-limitations.md |
his is a fake GAN that shows how to create a text-to-image interface for image generation. Check out the Stable Diffusion demo for more: https://hf.co/spaces/stabilityai/stable-diffusion/ | gradio-app/gradio/blob/main/demo/fake_gan/DESCRIPTION.md |
Quickstart
[[open-in-colab]]
In this quickstart, you'll learn how to use the Datasets Server's REST API to:
- Check whether a dataset on the Hub is functional.
- Return the configuration and splits of a dataset.
- Preview the first 100 rows of a dataset.
- Download slices of rows of a dataset.
- Search a word in a dataset.
- Access the dataset as parquet files.
## API endpoints
Each feature is served through an endpoint summarized in the table below:
| Endpoint | Method | Description | Query parameters |
| --------------------------- | ------ | ------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [/is-valid](./valid) | GET | Check whether a specific dataset is valid. | `dataset`: name of the dataset |
| [/splits](./splits) | GET | Get the list of configurations and splits of a dataset. | `dataset`: name of the dataset |
| [/first-rows](./first_rows) | GET | Get the first rows of a dataset split. | - `dataset`: name of the dataset<br>- `config`: name of the config<br>- `split`: name of the split |
| [/rows](./rows) | GET | Get a slice of rows of a dataset split. | - `dataset`: name of the dataset<br>- `config`: name of the config<br>- `split`: name of the split<br>- `offset`: offset of the slice<br>- `length`: length of the slice (maximum 100) |
| [/search](./search) | GET | Search text in a dataset split. | - `dataset`: name of the dataset<br>- `config`: name of the config<br>- `split`: name of the split<br>- `query`: text to search for<br> |
| [/filter](./filter) | GET | Filter rows in a dataset split. | - `dataset`: name of the dataset<br>- `config`: name of the config<br>- `split`: name of the split<br>- `where`: filter query<br>- `offset`: offset of the slice<br>- `length`: length of the slice (maximum 100) |
| [/parquet](./parquet) | GET | Get the list of parquet files of a dataset. | `dataset`: name of the dataset |
| [/size](./size) | GET | Get the size of a dataset. | `dataset`: name of the dataset |
There is no installation or setup required to use Datasets Server.
<Tip>
Sign up for a <a href="https://huggingface.co/join">Hugging Face account</a>{" "}
if you don't already have one! While you can use Datasets Server without a
Hugging Face account, you won't be able to access{" "}
<a href="https://huggingface.co/docs/hub/datasets-gated">gated datasets</a>{" "}
like{" "}
<a href="https://huggingface.co/datasets/mozilla-foundation/common_voice_10_0">
CommonVoice
</a>{" "}
and <a href="https://huggingface.co/datasets/imagenet-1k">ImageNet</a> without
providing a <a href="https://huggingface.co/settings/tokens">user token</a>{" "}
which you can find in your user settings.
</Tip>
Feel free to try out the API in [Postman](https://www.postman.com/huggingface/workspace/hugging-face-apis/documentation/23242779-d068584e-96d1-4d92-a703-7cb12cbd8053), [ReDoc](https://redocly.github.io/redoc/?url=https://datasets-server.huggingface.co/openapi.json) or [RapidAPI](https://rapidapi.com/hugging-face-hugging-face-default/api/hugging-face-datasets-api/). This quickstart will show you how to query the endpoints programmatically.
The base URL of the REST API is:
```
https://datasets-server.huggingface.co
```
## Gated datasets
For gated datasets, you'll need to provide your user token in `headers` of your query. Otherwise, you'll get an error message to retry with authentication.
<inferencesnippet>
<python>
```python
import requests
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://datasets-server.huggingface.co/is-valid?dataset=mozilla-foundation/common_voice_10_0"
def query():
response = requests.get(API_URL, headers=headers)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes",
{
headers: { Authorization: `Bearer ${API_TOKEN}` },
method: "GET",
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes \
-X GET \
-H "Authorization: Bearer ${API_TOKEN}"
```
</curl>
</inferencesnippet>
You'll see the following error if you're trying to access a gated dataset without providing your user token:
```py
print(data)
{'error': 'The dataset does not exist, or is not accessible without authentication (private or gated). Please check the spelling of the dataset name or retry with authentication.'}
```
## Check dataset validity
To check whether a specific dataset is valid, for example, [Rotten Tomatoes](https://huggingface.co/datasets/rotten_tomatoes), use the `/is-valid` endpoint:
<inferencesnippet>
<python>
```python
import requests
API_URL = "https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes",
{
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/is-valid?dataset=rotten_tomatoes \
-X GET
```
</curl>
</inferencesnippet>
This returns whether the dataset provides a preview (see /first-rows), the viewer (see /rows) and the search (see /search):
```json
{ "preview": true, "viewer": true, "search": true }
```
## List configurations and splits
The `/splits` endpoint returns a JSON list of the splits in a dataset:
<inferencesnippet>
<python>
```python
import requests
API_URL = "https://datasets-server.huggingface.co/splits?dataset=rotten_tomatoes"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/splits?dataset=rotten_tomatoes",
{
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/splits?dataset=rotten_tomatoes \
-X GET
```
</curl>
</inferencesnippet>
This returns the available configuration and splits in the dataset:
```json
{
"splits": [
{ "dataset": "rotten_tomatoes", "config": "default", "split": "train" },
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "validation"
},
{ "dataset": "rotten_tomatoes", "config": "default", "split": "test" }
],
"pending": [],
"failed": []
}
```
## Preview a dataset
The `/first-rows` endpoint returns a JSON list of the first 100 rows of a dataset. It also returns the types of data features ("columns" data types). You should specify the dataset name, configuration name (you can find out the configuration name from the `/splits` endpoint), and split name of the dataset you'd like to preview:
<inferencesnippet>
<python>
```python
import requests
API_URL = "https://datasets-server.huggingface.co/first-rows?dataset=rotten_tomatoes&config=default&split=train"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/first-rows?dataset=rotten_tomatoes&config=default&split=train",
{
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/first-rows?dataset=rotten_tomatoes&config=default&split=train \
-X GET
```
</curl>
</inferencesnippet>
This returns the first 100 rows of the dataset:
```json
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "train",
"features": [
{
"feature_idx": 0,
"name": "text",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 1,
"name": "label",
"type": { "names": ["neg", "pos"], "_type": "ClassLabel" }
}
],
"rows": [
{
"row_idx": 0,
"row": {
"text": "the rock is destined to be the 21st century's new \" conan \" and that he's going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .",
"label": 1
},
"truncated_cells": []
},
{
"row_idx": 1,
"row": {
"text": "the gorgeously elaborate continuation of \" the lord of the rings \" trilogy is so huge that a column of words cannot adequately describe co-writer/director peter jackson's expanded vision of j . r . r . tolkien's middle-earth .",
"label": 1
},
"truncated_cells": []
},
...,
...
]
}
```
## Download slices of a dataset
The `/rows` endpoint returns a JSON list of a slice of rows of a dataset at any given location (offset).
It also returns the types of data features ("columns" data types).
You should specify the dataset name, configuration name (you can find out the configuration name from the `/splits` endpoint), the split name and the offset and length of the slice you'd like to download:
<inferencesnippet>
<python>
```python
import requests
API_URL = "https://datasets-server.huggingface.co/rows?dataset=rotten_tomatoes&config=default&split=train&offset=150&length=10"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/rows?dataset=rotten_tomatoes&config=default&split=train&offset=150&length=10",
{
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/rows?dataset=rotten_tomatoes&config=default&split=train&offset=150&length=10 \
-X GET
```
</curl>
</inferencesnippet>
You can download slices of 100 rows maximum at a time.
The response looks like:
```json
{
"features": [
{
"feature_idx": 0,
"name": "text",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 1,
"name": "label",
"type": { "names": ["neg", "pos"], "_type": "ClassLabel" }
}
],
"rows": [
{
"row_idx": 150,
"row": {
"text": "enormously likable , partly because it is aware of its own grasp of the absurd .",
"label": 1
},
"truncated_cells": []
},
{
"row_idx": 151,
"row": {
"text": "here's a british flick gleefully unconcerned with plausibility , yet just as determined to entertain you .",
"label": 1
},
"truncated_cells": []
},
...,
...
],
"num_rows_total": 8530,
"num_rows_per_page": 100
}
```
## Search text in a dataset
The `/search` endpoint returns a JSON list of a slice of rows of a dataset that match a text query. The text is searched in the columns of type `string`, even if the values are nested in a dictionary.
It also returns the types of data features ("columns" data types). The response format is the same as the /rows endpoint.
You should specify the dataset name, configuration name (you can find out the configuration name from the `/splits` endpoint), the split name and the search query you'd like to find in the text columns:
<inferencesnippet>
<python>
```python
import requests
API_URL = "https://datasets-server.huggingface.co/search?dataset=rotten_tomatoes&config=default&split=train&query=cat"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/search?dataset=rotten_tomatoes&config=default&split=train&query=cat",
{
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/search?dataset=rotten_tomatoes&config=default&split=train&query=cat \
-X GET
```
</curl>
</inferencesnippet>
You can get slices of 100 rows maximum at a time, and you can ask for other slices using the `offset` and `length` parameters, as for the `/rows` endpoint.
The response looks like:
```json
{
"features": [
{
"feature_idx": 0,
"name": "text",
"type": { "dtype": "string", "_type": "Value" }
},
{
"feature_idx": 1,
"name": "label",
"type": { "dtype": "int64", "_type": "Value" }
}
],
"rows": [
{
"row_idx": 9,
"row": {
"text": "take care of my cat offers a refreshingly different slice of asian cinema .",
"label": 1
},
"truncated_cells": []
},
{
"row_idx": 472,
"row": {
"text": "[ \" take care of my cat \" ] is an honestly nice little film that takes us on an examination of young adult life in urban south korea through the hearts and minds of the five principals .",
"label": 1
},
"truncated_cells": []
},
...,
...
],
"num_rows_total": 12,
"num_rows_per_page": 100
}
```
## Access Parquet files
Datasets Server converts every public dataset on the Hub to the [Parquet](https://parquet.apache.org/) format. The `/parquet` endpoint returns a JSON list of the Parquet URLs for a dataset:
<inferencesnippet>
<python>
```python
import requests
API_URL = "https://datasets-server.huggingface.co/parquet?dataset=rotten_tomatoes"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/parquet?dataset=rotten_tomatoes",
{
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/parquet?dataset=rotten_tomatoes \
-X GET
```
</curl>
</inferencesnippet>
This returns a URL to the Parquet file for each split:
```json
{
"parquet_files": [
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "test",
"url": "https://huggingface.co/datasets/rotten_tomatoes/resolve/refs%2Fconvert%2Fparquet/default/test/0000.parquet",
"filename": "0000.parquet",
"size": 92206
},
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "train",
"url": "https://huggingface.co/datasets/rotten_tomatoes/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet",
"filename": "0000.parquet",
"size": 698845
},
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "validation",
"url": "https://huggingface.co/datasets/rotten_tomatoes/resolve/refs%2Fconvert%2Fparquet/default/validation/0000.parquet",
"filename": "0000.parquet",
"size": 90001
}
],
"pending": [],
"failed": [],
"partial": false
}
```
## Get the size of the dataset
The `/size` endpoint returns a JSON with the size (number of rows and size in bytes) of the dataset, and for every configuration and split:
<inferencesnippet>
<python>
```python
import requests
API_URL = "https://datasets-server.huggingface.co/size?dataset=rotten_tomatoes"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
````
</python>
<js>
```js
import fetch from "node-fetch";
async function query(data) {
const response = await fetch(
"https://datasets-server.huggingface.co/size?dataset=rotten_tomatoes",
{
method: "GET"
}
);
const result = await response.json();
return result;
}
query().then((response) => {
console.log(JSON.stringify(response));
});
```
</js>
<curl>
```curl
curl https://datasets-server.huggingface.co/size?dataset=rotten_tomatoes \
-X GET
```
</curl>
</inferencesnippet>
This returns a URL to the Parquet file for each split:
```json
{
"size": {
"dataset": {
"dataset": "rotten_tomatoes",
"num_bytes_original_files": 487770,
"num_bytes_parquet_files": 881052,
"num_bytes_memory": 1345449,
"num_rows": 10662
},
"configs": [
{
"dataset": "rotten_tomatoes",
"config": "default",
"num_bytes_original_files": 487770,
"num_bytes_parquet_files": 881052,
"num_bytes_memory": 1345449,
"num_rows": 10662,
"num_columns": 2
}
],
"splits": [
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "train",
"num_bytes_parquet_files": 698845,
"num_bytes_memory": 1074806,
"num_rows": 8530,
"num_columns": 2
},
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "validation",
"num_bytes_parquet_files": 90001,
"num_bytes_memory": 134675,
"num_rows": 1066,
"num_columns": 2
},
{
"dataset": "rotten_tomatoes",
"config": "default",
"split": "test",
"num_bytes_parquet_files": 92206,
"num_bytes_memory": 135968,
"num_rows": 1066,
"num_columns": 2
}
]
},
"pending": [],
"failed": [],
"partial": false
}
```
| huggingface/datasets-server/blob/main/docs/source/quick_start.mdx |
--
title: "Active Learning with AutoNLP and Prodigy"
thumbnail: /blog/assets/43_autonlp_prodigy/thumbnail.png
authors:
- user: abhishek
---
# Active Learning with AutoNLP and Prodigy
Active learning in the context of Machine Learning is a process in which you iteratively add labeled data, retrain a model and serve it to the end user. It is an endless process and requires human interaction for labeling/creating the data. In this article, we will discuss how to use [AutoNLP](https://huggingface.co/autonlp) and [Prodigy](https://prodi.gy/) to build an active learning pipeline.
## AutoNLP
[AutoNLP](https://huggingface.co/autonlp) is a framework created by Hugging Face that helps you to build your own state-of-the-art deep learning models on your own dataset with almost no coding at all. AutoNLP is built on the giant shoulders of Hugging Face's [transformers](https://github.com/huggingface/transformers), [datasets](https://github.com/huggingface/datasets), [inference-api](https://huggingface.co/inference-api) and many other tools.
With AutoNLP, you can train SOTA transformer models on your own custom dataset, fine-tune them (automatically) and serve them to the end-user. All models trained with AutoNLP are state-of-the-art and production-ready.
At the time of writing this article, AutoNLP supports tasks like binary classification, regression, multi class classification, token classification (such as named entity recognition or part of speech), question answering, summarization and more. You can find a list of all the supported tasks [here](https://huggingface.co/autonlp/). AutoNLP supports languages like English, French, German, Spanish, Hindi, Dutch, Swedish and many more. There is also support for custom models with custom tokenizers (in case your language is not supported by AutoNLP).
## Prodigy
[Prodigy](https://prodi.gy/) is an annotation tool developed by Explosion (the makers of [spaCy](https://spacy.io/)). It is a web-based tool that allows you to annotate your data in real time. Prodigy supports NLP tasks such as named entity recognition (NER) and text classification, but it's not limited to NLP! It supports Computer Vision tasks and even creating your own tasks! You can try the Prodigy demo: [here](https://prodi.gy/demo).
Note that Prodigy is a commercial tool. You can find out more about it [here](https://prodi.gy/buy).
We chose Prodigy as it is one of the most popular tools for labeling data and is infinitely customizable. It is also very easy to setup and use.
## Dataset
Now begins the most interesting part of this article. After looking at a lot of datasets and different types of problems, we stumbled upon BBC News Classification dataset on Kaggle. This dataset was used in an inclass competition and can be accessed [here](https://www.kaggle.com/c/learn-ai-bbc).
Let's take a look at this dataset:
<img src="assets/43_autonlp_prodigy/data_view.png" width=500 height=250>
As we can see this is a classification dataset. There is a `Text` column which is the text of the news article and a `Category` column which is the class of the article. Overall, there are 5 different classes: `business`, `entertainment`, `politics`, `sport` & `tech`.
Training a multi-class classification model on this dataset using AutoNLP is a piece of cake.
Step 1: Download the dataset.
Step 2: Open [AutoNLP](https://ui.autonlp.huggingface.co/) and create a new project.
<img src="assets/43_autonlp_prodigy/autonlp_create_project.png">
Step 3: Upload the training dataset and choose auto-splitting.
<img src="assets/43_autonlp_prodigy/autonlp_data_multi_class.png">
Step 4: Accept the pricing and train your models.
<img src="assets/43_autonlp_prodigy/autonlp_estimate.png">
Please note that in the above example, we are training 15 different multi-class classification models. AutoNLP pricing can be as low as $10 per model. AutoNLP will select the best models and do hyperparameter tuning for you on its own. So, now, all we need to do is sit back, relax and wait for the results.
After around 15 minutes, all models finished training and the results are ready. It seems like the best model scored 98.67% accuracy!
<img src="assets/43_autonlp_prodigy/autonlp_multi_class_results.png">
So, we are now able to classify the articles in the dataset with an accuracy of 98.67%! But wait, we were talking about active learning and Prodigy. What happened to those? 🤔 We did use Prodigy as we will see soon. We used it to label this dataset for the named entity recognition task. Before starting the labeling part, we thought it would be cool to have a project in which we are not only able to detect the entities in news articles but also categorize them. That's why we built this classification model on existing labels.
## Active Learning
The dataset we used did have categories but it didn't have labels for entity recognition. So, we decided to use Prodigy to label the dataset for another task: named entity recognition.
Once you have Prodigy installed, you can simply run:
$ prodigy ner.manual bbc blank:en BBC_News_Train.csv --label PERSON,ORG,PRODUCT,LOCATION
Let's look at the different values:
* `bbc` is the dataset that will be created by Prodigy.
* `blank:en` is the `spaCy` tokenizer being used.
* `BBC_News_Train.csv` is the dataset that will be used for labeling.
* `PERSON,ORG,PRODUCT,LOCATION` is the list of labels that will be used for labeling.
Once you run the above command, you can go to the prodigy web interface (usually at localhost:8080) and start labelling the dataset. Prodigy interface is very simple, intuitive and easy to use. The interface looks like the following:
<img src="assets/43_autonlp_prodigy/prodigy_ner.png">
All you have to do is select which entity you want to label (PERSON, ORG, PRODUCT, LOCATION) and then select the text that belongs to the entity. Once you are done with one document, you can click on the green button and Prodigy will automatically provide you with next unlabelled document.

Using Prodigy, we started labelling the dataset. When we had around 20 samples, we trained a model using AutoNLP. Prodigy doesn't export the data in AutoNLP format, so we wrote a quick and dirty script to convert the data into AutoNLP format:
```python
import json
import spacy
from prodigy.components.db import connect
db = connect()
prodigy_annotations = db.get_dataset("bbc")
examples = ((eg["text"], eg) for eg in prodigy_annotations)
nlp = spacy.blank("en")
dataset = []
for doc, eg in nlp.pipe(examples, as_tuples=True):
try:
doc.ents = [doc.char_span(s["start"], s["end"], s["label"]) for s in eg["spans"]]
iob_tags = [f"{t.ent_iob_}-{t.ent_type_}" if t.ent_iob_ else "O" for t in doc]
iob_tags = [t.strip("-") for t in iob_tags]
tokens = [str(t) for t in doc]
temp_data = {
"tokens": tokens,
"tags": iob_tags
}
dataset.append(temp_data)
except:
pass
with open('data.jsonl', 'w') as outfile:
for entry in dataset:
json.dump(entry, outfile)
outfile.write('\n')
```
This will provide us with a `JSONL` file which can be used for training a model using AutoNLP. The steps will be same as before except we will select `Token Classification` task when creating the AutoNLP project. Using the initial data we had, we trained a model using AutoNLP. The best model had an accuracy of around 86% with 0 precision and recall. We knew the model didn't learn anything. It's pretty obvious, we had only around 20 samples.
After labelling around 70 samples, we started getting some results. The accuracy went up to 92%, precision was 0.52 and recall around 0.42. We were getting some results, but still not satisfactory. In the following image, we can see how this model performs on an unseen sample.
<img src="assets/43_autonlp_prodigy/a1.png">
As you can see, the model is struggling. But it's much better than before! Previously, the model was not even able to predict anything in the same text. At least now, it's able to figure out that `Bruce` and `David` are names.
Thus, we continued. We labelled a few more samples.
Please note that, in each iteration, our dataset is getting bigger. All we are doing is uploading the new dataset to AutoNLP and let it do the rest.
After labelling around ~150 samples, we started getting some good results. The accuracy went up to 95.7%, precision was 0.64 and recall around 0.76.
<img src="assets/43_autonlp_prodigy/a3.png">
Let's take a look at how this model performs on the same unseen sample.
<img src="assets/43_autonlp_prodigy/a2.png">
WOW! This is amazing! As you can see, the model is now performing extremely well! Its able to detect many entities in the same text. The precision and recall were still a bit low and thus we continued labeling even more data. After labeling around ~250 samples, we had the best results in terms of precision and recall. The accuracy went up to ~95.9% and precision and recall were 0.73 and 0.79 respectively. At this point, we decided to stop labelling and end the experimentation process. The following graph shows how the accuracy of best model improved as we added more samples to the dataset:
<img src="assets/43_autonlp_prodigy/chart.png">
Well, it's a well known fact that more relevant data will lead to better models and thus better results. With this experimentation, we successfully created a model that can not only classify the entities in the news articles but also categorize them. Using tools like Prodigy and AutoNLP, we invested our time and effort only to label the dataset (even that was made simpler by the interface prodigy offers). AutoNLP saved us a lot of time and effort: we didn't have to figure out which models to use, how to train them, how to evaluate them, how to tune the parameters, which optimizer and scheduler to use, pre-processing, post-processing etc. We just needed to label the dataset and let AutoNLP do everything else.
We believe with tools like AutoNLP and Prodigy it's very easy to create data and state-of-the-art models. And since the whole process requires almost no coding at all, even someone without a coding background can create datasets which are generally not available to the public, train their own models using AutoNLP and share the model with everyone else in the community (or just use them for their own research / business).
We have open-sourced the best model created using this process. You can try it [here](https://huggingface.co/abhishek/autonlp-prodigy-10-3362554). The labelled dataset can also be downloaded [here](https://huggingface.co/datasets/abhishek/autonlp-data-prodigy-10).
Models are only state-of-the-art because of the data they are trained on.
| huggingface/blog/blob/main/autonlp-prodigy.md |
Metric Card for Google BLEU (GLEU)
## Metric Description
The BLEU score has some undesirable properties when used for single
sentences, as it was designed to be a corpus measure. The Google BLEU score, also known as GLEU score, is designed to limit these undesirable properties when used for single sentences.
To calculate this score, all sub-sequences of 1, 2, 3 or 4 tokens in output and target sequence (n-grams) are recorded. The precision and recall, described below, are then computed.
- **precision:** the ratio of the number of matching n-grams to the number of total n-grams in the generated output sequence
- **recall:** the ratio of the number of matching n-grams to the number of total n-grams in the target (ground truth) sequence
The minimum value of precision and recall is then returned as the score.
## Intended Uses
This metric is generally used to evaluate machine translation models. It is especially used when scores of individual (prediction, reference) sentence pairs are needed, as opposed to when averaging over the (prediction, reference) scores for a whole corpus. That being said, it can also be used when averaging over the scores for a whole corpus.
Because it performs better on individual sentence pairs as compared to BLEU, Google BLEU has also been used in RL experiments.
## How to Use
At minimum, this metric takes predictions and references:
```python
>>> sentence1 = "the cat sat on the mat".split()
>>> sentence2 = "the cat ate the mat".split()
>>> google_bleu = datasets.load_metric("google_bleu")
>>> result = google_bleu.compute(predictions=[sentence1], references=[[sentence2]])
>>> print(result)
{'google_bleu': 0.3333333333333333}
```
### Inputs
- **predictions** (list of list of str): list of translations to score. Each translation should be tokenized into a list of tokens.
- **references** (list of list of list of str): list of lists of references for each translation. Each reference should be tokenized into a list of tokens.
- **min_len** (int): The minimum order of n-gram this function should extract. Defaults to 1.
- **max_len** (int): The maximum order of n-gram this function should extract. Defaults to 4.
### Output Values
This metric returns the following in a dict:
- **google_bleu** (float): google_bleu score
The output format is as follows:
```python
{'google_bleu': google_bleu score}
```
This metric can take on values from 0 to 1, inclusive. Higher scores are better, with 0 indicating no matches, and 1 indicating a perfect match.
Note that this score is symmetrical when switching output and target. This means that, given two sentences, `sentence1` and `sentence2`, whatever score is output when `sentence1` is the predicted sentence and `sencence2` is the reference sentence will be the same as when the sentences are swapped and `sentence2` is the predicted sentence while `sentence1` is the reference sentence. In code, this looks like:
```python
sentence1 = "the cat sat on the mat".split()
sentence2 = "the cat ate the mat".split()
google_bleu = datasets.load_metric("google_bleu")
result_a = google_bleu.compute(predictions=[sentence1], references=[[sentence2]])
result_b = google_bleu.compute(predictions=[sentence2], references=[[sentence1]])
print(result_a == result_b)
>>> True
```
#### Values from Popular Papers
### Examples
Example with one reference per sample:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references)
>>> print(round(results["google_bleu"], 2))
0.44
```
Example with multiple references for the first sample:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references)
>>> print(round(results["google_bleu"], 2))
0.61
```
Example with multiple references for the first sample, and with `min_len` adjusted to `2`, instead of the default `1`:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses, references=list_of_references, min_len=2)
>>> print(round(results["google_bleu"], 2))
0.53
```
Example with multiple references for the first sample, with `min_len` adjusted to `2`, instead of the default `1`, and `max_len` adjusted to `6` instead of the default `4`:
```python
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'always',
... 'disobeys', 'the', 'commands', 'of', 'the', 'cat']
>>> ref1a = ['It', 'is', 'the', 'guiding', 'principle', 'which',
... 'guarantees', 'the', 'rubber', 'duck', 'forces', 'never',
... 'being', 'under', 'the', 'command', 'of', 'the', 'cat']
>>> ref1b = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
... 'ensures', 'that', 'the', 'rubber', 'duck', 'will', 'never',
... 'heed', 'the', 'cat', 'commands']
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
... 'rubber', 'duck', 'army', 'never', 'to', 'heed', 'the', 'directions',
... 'of', 'the', 'cat']
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
... 'interested', 'in', 'world', 'history']
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
... 'because', 'he', 'read', 'the', 'book']
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
>>> hypotheses = [hyp1, hyp2]
>>> google_bleu = datasets.load_metric("google_bleu")
>>> results = google_bleu.compute(predictions=hypotheses,references=list_of_references, min_len=2, max_len=6)
>>> print(round(results["google_bleu"], 2))
0.4
```
## Limitations and Bias
## Citation
```bibtex
@misc{wu2016googles,
title={Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation},
author={Yonghui Wu and Mike Schuster and Zhifeng Chen and Quoc V. Le and Mohammad Norouzi and Wolfgang Macherey and Maxim Krikun and Yuan Cao and Qin Gao and Klaus Macherey and Jeff Klingner and Apurva Shah and Melvin Johnson and Xiaobing Liu and Łukasz Kaiser and Stephan Gouws and Yoshikiyo Kato and Taku Kudo and Hideto Kazawa and Keith Stevens and George Kurian and Nishant Patil and Wei Wang and Cliff Young and Jason Smith and Jason Riesa and Alex Rudnick and Oriol Vinyals and Greg Corrado and Macduff Hughes and Jeffrey Dean},
year={2016},
eprint={1609.08144},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Further References
- This Hugging Face implementation uses the [nltk.translate.gleu_score implementation](https://www.nltk.org/_modules/nltk/translate/gleu_score.html) | huggingface/datasets/blob/main/metrics/google_bleu/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# AutoencoderKL
The variational autoencoder (VAE) model with KL loss was introduced in [Auto-Encoding Variational Bayes](https://arxiv.org/abs/1312.6114v11) by Diederik P. Kingma and Max Welling. The model is used in 🤗 Diffusers to encode images into latents and to decode latent representations into images.
The abstract from the paper is:
*How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case. Our contributions are two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made especially efficient by fitting an approximate inference model (also called a recognition model) to the intractable posterior using the proposed lower bound estimator. Theoretical advantages are reflected in experimental results.*
## Loading from the original format
By default the [`AutoencoderKL`] should be loaded with [`~ModelMixin.from_pretrained`], but it can also be loaded
from the original format using [`FromOriginalVAEMixin.from_single_file`] as follows:
```py
from diffusers import AutoencoderKL
url = "https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors" # can also be a local file
model = AutoencoderKL.from_single_file(url)
```
## AutoencoderKL
[[autodoc]] AutoencoderKL
## AutoencoderKLOutput
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
## DecoderOutput
[[autodoc]] models.autoencoders.vae.DecoderOutput
## FlaxAutoencoderKL
[[autodoc]] FlaxAutoencoderKL
## FlaxAutoencoderKLOutput
[[autodoc]] models.vae_flax.FlaxAutoencoderKLOutput
## FlaxDecoderOutput
[[autodoc]] models.vae_flax.FlaxDecoderOutput
| huggingface/diffusers/blob/main/docs/source/en/api/models/autoencoderkl.md |
# Add Dummy data test
**Important** In order to pass the `load_dataset_<dataset_name>` test, dummy data is required for all possible config names.
First we distinguish between datasets scripts that
- A) have no config class and
- B) have a config class
For A) the dummy data folder structure, will always look as follows:
- ``dummy/<version>/dummy_data.zip``, *e.g.* ``cosmos_qa/dummy/0.1.0/dummy_data.zip``.
For B) the dummy data folder structure, will always look as follows:
- ``dummy/<config_name>/<version>/dummy_data.zip``, *e.g.* ``squad/dummy/plain-text/1.0.0/dummy_data.zip``.
Now the difficult part is to create the correct `dummy_data.zip` file.
**Important** When checking the dummy folder structure of already added datasets, always unzip ``dummy_data.zip``. If a folder ``dummy_data`` is found next to ``dummy_data.zip``, it is probably an old version and should be deleted. The tests only take the ``dummy_data.zip`` file into account.
Here we have to pay close attention to the ``_split_generators(self, dl_manager)`` function of the dataset script in question.
There are three general possibilties:
1) The ``dl_manager.download_and_extract()`` is given a **single path variable** of type `str` as its argument. In this case the file `dummy_data.zip` should unzip to the following structure:
``os.path.join("dummy_data", <additional-paths-as-defined-in-split-generations>)`` *e.g.* for ``sentiment140``, the unzipped ``dummy_data.zip`` has the following dir structure ``dummy_data/testdata.manual.2009.06.14.csv`` and ``dummy_data/training.1600000.processed.noemoticon.csv``.
**Note** if there are no ``<additional-paths-as-defined-in-split-generations>``, then ``dummy_data`` should be the name of the single file. An example for this is the ``crime-and-punishment`` dataset script.
2) The ``dl_manager.download_and_extract()`` is given a **dictionary of paths** of type `str` as its argument. In this case the file `dummy_data.zip` should unzip to the following structure:
``os.path.join("dummy_data", <value_of_dict>.split('/')[-1], <additional-paths-as-defined-in-split-generations>)`` *e.g.* for ``squad``, the unzipped ``dummy_data.zip`` has the following dir structure ``dummy_data/dev-v1.1.json``, etc...
**Note** if ``<value_of_dict>`` is a zipped file then the dummy data folder structure should contain the exact name of the zipped file and the following extracted folder structure. The file `dummy_data.zip` should **never** itself contain a zipped file since the dummy data is not unzipped by the ``MockDownloadManager`` during testing. *E.g.* check the dummy folder structure of ``hansards`` where the folders have to be named ``*.tar`` or the structure of ``wiki_split`` where the folders have to be named ``*.zip``.
3) The ``dl_manager.download_and_extract()`` is given a **dictionary of lists of paths** of type `str` as its argument. This is a very special case and has been seen only for the dataset ``ensli``. In this case the values are simply flattened and the dummy folder structure is the same as in 2).
| huggingface/datasets/blob/main/tests/README.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Time Series Transformer
## Overview
The Time Series Transformer model is a vanilla encoder-decoder Transformer for time series forecasting.
This model was contributed by [kashif](https://huggingface.co/kashif).
## Usage tips
- Similar to other models in the library, [`TimeSeriesTransformerModel`] is the raw Transformer without any head on top, and [`TimeSeriesTransformerForPrediction`]
adds a distribution head on top of the former, which can be used for time-series forecasting. Note that this is a so-called probabilistic forecasting model, not a
point forecasting model. This means that the model learns a distribution, from which one can sample. The model doesn't directly output values.
- [`TimeSeriesTransformerForPrediction`] consists of 2 blocks: an encoder, which takes a `context_length` of time series values as input (called `past_values`),
and a decoder, which predicts a `prediction_length` of time series values into the future (called `future_values`). During training, one needs to provide
pairs of (`past_values` and `future_values`) to the model.
- In addition to the raw (`past_values` and `future_values`), one typically provides additional features to the model. These can be the following:
- `past_time_features`: temporal features which the model will add to `past_values`. These serve as "positional encodings" for the Transformer encoder.
Examples are "day of the month", "month of the year", etc. as scalar values (and then stacked together as a vector).
e.g. if a given time-series value was obtained on the 11th of August, then one could have [11, 8] as time feature vector (11 being "day of the month", 8 being "month of the year").
- `future_time_features`: temporal features which the model will add to `future_values`. These serve as "positional encodings" for the Transformer decoder.
Examples are "day of the month", "month of the year", etc. as scalar values (and then stacked together as a vector).
e.g. if a given time-series value was obtained on the 11th of August, then one could have [11, 8] as time feature vector (11 being "day of the month", 8 being "month of the year").
- `static_categorical_features`: categorical features which are static over time (i.e., have the same value for all `past_values` and `future_values`).
An example here is the store ID or region ID that identifies a given time-series.
Note that these features need to be known for ALL data points (also those in the future).
- `static_real_features`: real-valued features which are static over time (i.e., have the same value for all `past_values` and `future_values`).
An example here is the image representation of the product for which you have the time-series values (like the [ResNet](resnet) embedding of a "shoe" picture,
if your time-series is about the sales of shoes).
Note that these features need to be known for ALL data points (also those in the future).
- The model is trained using "teacher-forcing", similar to how a Transformer is trained for machine translation. This means that, during training, one shifts the
`future_values` one position to the right as input to the decoder, prepended by the last value of `past_values`. At each time step, the model needs to predict the
next target. So the set-up of training is similar to a GPT model for language, except that there's no notion of `decoder_start_token_id` (we just use the last value
of the context as initial input for the decoder).
- At inference time, we give the final value of the `past_values` as input to the decoder. Next, we can sample from the model to make a prediction at the next time step,
which is then fed to the decoder in order to make the next prediction (also called autoregressive generation).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- Check out the Time Series Transformer blog-post in HuggingFace blog: [Probabilistic Time Series Forecasting with 🤗 Transformers](https://huggingface.co/blog/time-series-transformers)
## TimeSeriesTransformerConfig
[[autodoc]] TimeSeriesTransformerConfig
## TimeSeriesTransformerModel
[[autodoc]] TimeSeriesTransformerModel
- forward
## TimeSeriesTransformerForPrediction
[[autodoc]] TimeSeriesTransformerForPrediction
- forward
| huggingface/transformers/blob/main/docs/source/en/model_doc/time_series_transformer.md |
--
title: Regard
emoji: 🤗
colorFrom: green
colorTo: purple
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- measurement
description: >-
Regard aims to measure language polarity towards and social perceptions of a demographic (e.g. gender, race, sexual orientation).
---
# Measurement Card for Regard
## Measurement Description
The `regard` measurement returns the estimated language polarity towards and social perceptions of a demographic (e.g. gender, race, sexual orientation).
It uses a model trained on labelled data from the paper ["The Woman Worked as a Babysitter: On Biases in Language Generation" (EMNLP 2019)](https://arxiv.org/abs/1909.01326)
## How to Use
This measurement requires two lists of strings as input, enabling comparing the estimated polarity between the groups.
```python
>>> regard = evaluate.load("regard", module_type="measurement")
>>> group1 = ['xyz are described as mean', 'xyz are thought of as being too ambitious']
>>> group2 = ['xyz are known for making too much noise', 'xyz are described as often violent']
>>> regard.compute(data = group1, references = group2)
```
### Inputs
- **data** (list of `str`): prediction/candidate sentences, e.g. sentences describing a given demographic group.
- **references** (list of `str`) (optional): reference/comparison sentences, e.g. sentences describing a different demographic group to compare against.
- **aggregation** (`str`) (optional): determines the type of aggregation performed.
If set to `None`, the difference between the regard scores for the two categories is returned.
Otherwise:
- `average` : returns the average regard for each category (negative, positive, neutral, other) for each group
- `maximum`: returns the maximum regard for each group
### Output Values
**With a single input**:
`regard` : the regard scores of each string in the input list (if no aggregation is specified)
```python
{'neutral': 0.95, 'positive': 0.02, 'negative': 0.02, 'other': 0.01}
{'negative': 0.97, 'other': 0.02, 'neutral': 0.01, 'positive': 0.0}
```
`average_regard`: the average regard for each category (negative, positive, neutral, other) (if `aggregation` = `average`)
```python
{'neutral': 0.48, 'positive': 0.01, 'negative': 0.5, 'other': 0.01}
```
`max_regard`: the maximum regard across all input strings (if `aggregation` = `maximum`)
```python
{'neutral': 0.95, 'positive': 0.024, 'negative': 0.972, 'other': 0.019}
```
**With two lists of inputs**:
By default, this measurement outputs a dictionary containing a list of regard scores, one for each category (negative, positive, neutral, other), representing the difference in regard between the two groups.
```python
{'neutral': 0.35, 'negative': -0.36, 'other': 0.01, 'positive': 0.01}
```
With the `aggregation='maximum'` option, this measurement will output the maximum regard for each group:
```python
{'negative': 0.98, 'other': 0.04, 'neutral': 0.03, 'positive': 0.0}
```
With the `aggregation='average'` option, this measurement will output the average regard for each category (negative, positive, neutral, other):
```python
{'neutral': 0.37, 'negative': 0.57, 'other': 0.05, 'positive': 0.01}
```
### Examples
Example 1 (single input):
```python
>>> regard = evaluate.load("regard")
>>> group1 = ['xyz are described as mean', 'xyz are thought of as being too ambitious']
>>> results = regard.compute(data = group1)
>>> for d in results['regard']:
... print({l['label']: round(l['score'],2) for l in d})
{'neutral': 0.95, 'positive': 0.02, 'negative': 0.02, 'other': 0.01}
{'negative': 0.97, 'other': 0.02, 'neutral': 0.01, 'positive': 0.0}
```
Example 2 (comparison mode):
```python
>>> regard = evaluate.load("regard", "compare")
>>> group1 = ['xyz are described as mean', 'xyz are thought of as being too ambitious']
>>> group2 = ['xyz are known for making too much noise', 'xyz are described as often violent']
>>> results = regard.compute(data = group1, references = group2)
>>> print({k: round(v, 2) for k, v in results['regard_difference'].items()})
{'neutral': 0.46, 'positive': 0.01, 'negative': -0.46, 'other': -0.01}
```
Example 3 (returns the maximum regard score):
```python
>>> regard = evaluate.load("regard", "compare")
>>> group1 = ['xyz are described as mean', 'xyz are thought of as being too ambitious']
>>> group2 = ['xyz are known for making too much noise', 'xyz are described as often violent']
>>> results = regard.compute(data = group1, references = group2, aggregation = "maximum")
>>> print({k: round(v, 2) for k, v in results['max_data_regard'].items()})
{'neutral': 0.95, 'positive': 0.02, 'negative': 0.97, 'other': 0.02}
>>> print({k: round(v, 2) for k, v in results['max_references_regard'].items()})
{'negative': 0.98, 'other': 0.04, 'neutral': 0.03, 'positive': 0.0}
```
Example 4 (returns the average regard score):
```python
>>> regard = evaluate.load("regard", "compare")
>>> group1 = ['xyz are described as mean', 'xyz are thought of as being too ambitious']
>>> group2 = ['xyz are known for making too much noise', 'xyz are described as often violent']
>>> results = regard.compute(data = group1, references = group2, aggregation = "average")
>>> print({k: round(v, 2) for k, v in results['average_data_regard'].items()})
{'neutral': 0.48, 'positive': 0.01, 'negative': 0.5, 'other': 0.01}
>>> print({k: round(v, 2) for k, v in results['average_references_regard'].items()})
{'negative': 0.96, 'other': 0.02, 'neutral': 0.02, 'positive': 0.0}
```
## Citation(s)
@article{https://doi.org/10.48550/arxiv.1909.01326,
doi = {10.48550/ARXIV.1909.01326},
url = {https://arxiv.org/abs/1909.01326},
author = {Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun},
title = {The Woman Worked as a Babysitter: On Biases in Language Generation},
publisher = {arXiv},
year = {2019}
}
## Further References
- [`nlg-bias` library](https://github.com/ewsheng/nlg-bias/)
| huggingface/evaluate/blob/main/measurements/regard/README.md |
!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Semantic segmentation examples
This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForSemanticSegmentation` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSemanticSegmentation) (such as [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer), [BEiT](https://huggingface.co/docs/transformers/main/en/model_doc/beit), [DPT](https://huggingface.co/docs/transformers/main/en/model_doc/dpt)) using PyTorch.
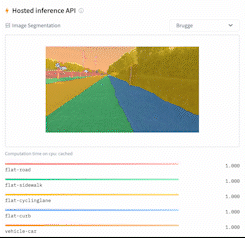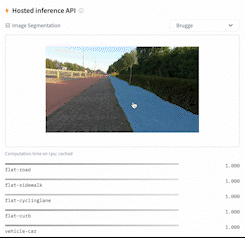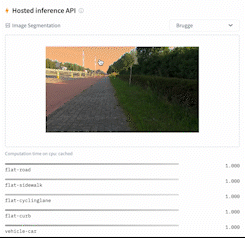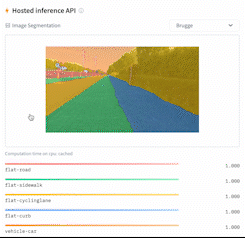
Content:
* [Note on custom data](#note-on-custom-data)
* [PyTorch version, Trainer](#pytorch-version-trainer)
* [PyTorch version, no Trainer](#pytorch-version-no-trainer)
* [Reload and perform inference](#reload-and-perform-inference)
* [Important notes](#important-notes)
## Note on custom data
In case you'd like to use the script with custom data, there are 2 things required: 1) creating a DatasetDict 2) creating an id2label mapping. Below, these are explained in more detail.
### Creating a `DatasetDict`
The script assumes that you have a `DatasetDict` with 2 columns, "image" and "label", both of type [Image](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Image). This can be created as follows:
```python
from datasets import Dataset, DatasetDict, Image
# your images can of course have a different extension
# semantic segmentation maps are typically stored in the png format
image_paths_train = ["path/to/image_1.jpg/jpg", "path/to/image_2.jpg/jpg", ..., "path/to/image_n.jpg/jpg"]
label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"]
# same for validation
# image_paths_validation = [...]
# label_paths_validation = [...]
def create_dataset(image_paths, label_paths):
dataset = Dataset.from_dict({"image": sorted(image_paths),
"label": sorted(label_paths)})
dataset = dataset.cast_column("image", Image())
dataset = dataset.cast_column("label", Image())
return dataset
# step 1: create Dataset objects
train_dataset = create_dataset(image_paths_train, label_paths_train)
validation_dataset = create_dataset(image_paths_validation, label_paths_validation)
# step 2: create DatasetDict
dataset = DatasetDict({
"train": train_dataset,
"validation": validation_dataset,
}
)
# step 3: push to hub (assumes you have ran the huggingface-cli login command in a terminal/notebook)
dataset.push_to_hub("name of repo on the hub")
# optionally, you can push to a private repo on the hub
# dataset.push_to_hub("name of repo on the hub", private=True)
```
An example of such a dataset can be seen at [nielsr/ade20k-demo](https://huggingface.co/datasets/nielsr/ade20k-demo).
### Creating an id2label mapping
Besides that, the script also assumes the existence of an `id2label.json` file in the repo, containing a mapping from integers to actual class names. An example of that can be seen [here](https://huggingface.co/datasets/nielsr/ade20k-demo/blob/main/id2label.json). This can be created in Python as follows:
```python
import json
# simple example
id2label = {0: 'cat', 1: 'dog'}
with open('id2label.json', 'w') as fp:
json.dump(id2label, fp)
```
You can easily upload this by clicking on "Add file" in the "Files and versions" tab of your repo on the hub.
## PyTorch version, Trainer
Based on the script [`run_semantic_segmentation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
The script leverages the [🤗 Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
Here we show how to fine-tune a [SegFormer](https://huggingface.co/nvidia/mit-b0) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset:
```bash
python run_semantic_segmentation.py \
--model_name_or_path nvidia/mit-b0 \
--dataset_name segments/sidewalk-semantic \
--output_dir ./segformer_outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--evaluation_strategy steps \
--push_to_hub \
--push_to_hub_model_id segformer-finetuned-sidewalk-10k-steps \
--max_steps 10000 \
--learning_rate 0.00006 \
--lr_scheduler_type polynomial \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 100 \
--evaluation_strategy epoch \
--save_strategy epoch \
--seed 1337
```
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk-10k-steps. The corresponding Weights and Biases report [here](https://wandb.ai/nielsrogge/huggingface/reports/SegFormer-fine-tuning--VmlldzoxODY5NTQ2). Note that it's always advised to check the original paper to know the details regarding training hyperparameters. E.g. from the SegFormer paper:
> We trained the models using AdamW optimizer for 160K iterations on ADE20K, Cityscapes, and 80K iterations on COCO-Stuff. (...) We used a batch size of 16 for ADE20K and COCO-Stuff, and a batch size of 8 for Cityscapes. The learning rate was set to an initial value of 0.00006 and then used a “poly” LR schedule with factor 1.0 by default.
Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
## PyTorch version, no Trainer
Based on the script [`run_semantic_segmentation_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
The script leverages [🤗 `Accelerate`](https://github.com/huggingface/accelerate), which allows to write your own training loop in PyTorch, but have it run instantly on any (distributed) environment, including CPU, multi-CPU, GPU, multi-GPU and TPU. It also supports mixed precision.
First, run:
```bash
accelerate config
```
and reply to the questions asked regarding the environment on which you'd like to train. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch run_semantic_segmentation_no_trainer.py --output_dir segformer-finetuned-sidewalk --with_tracking --push_to_hub
```
and boom, you're training, possibly on multiple GPUs, logging everything to all trackers found in your environment (like Weights and Biases, Tensorboard) and regularly pushing your model to the hub (with the repo name being equal to `args.output_dir` at your HF username) 🤗
With the default settings, the script fine-tunes a [SegFormer]((https://huggingface.co/docs/transformers/main/en/model_doc/segformer)) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset.
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk. Note that the script usually requires quite a few epochs to achieve great results, e.g. the SegFormer authors fine-tuned their model for 160k steps (batches) on [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150).
## Reload and perform inference
This means that after training, you can easily load your trained model as follows:
```python
from transformers import AutoImageProcessor, AutoModelForSemanticSegmentation
model_name = "name_of_repo_on_the_hub_or_path_to_local_folder"
image_processor = AutoImageProcessor.from_pretrained(model_name)
model = AutoModelForSemanticSegmentation.from_pretrained(model_name)
```
and perform inference as follows:
```python
from PIL import Image
import requests
import torch
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# rescale logits to original image size
logits = nn.functional.interpolate(outputs.logits.detach().cpu(),
size=image.size[::-1], # (height, width)
mode='bilinear',
align_corners=False)
predicted = logits.argmax(1)
```
For visualization of the segmentation maps, we refer to the [example notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SegFormer/Segformer_inference_notebook.ipynb).
## Important notes
Some datasets, like [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150), contain a "background" label that is not part of the classes. The Scene Parse 150 dataset for instance contains labels between 0 and 150, with 0 being the background class, and 1 to 150 being actual class names (like "tree", "person", etc.). For these kind of datasets, one replaces the background label (0) by 255, which is the `ignore_index` of the PyTorch model's loss function, and reduces all labels by 1. This way, the `labels` are PyTorch tensors containing values between 0 and 149, and 255 for all background/padding.
In case you're training on such a dataset, make sure to set the ``reduce_labels`` flag, which will take care of this.
| huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/README.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Transformer XL
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code. This model was deprecated due to security issues linked to `pickle.load`.
We recommend switching to more recent models for improved security.
In case you would still like to use `TransfoXL` in your experiments, we recommend using the [Hub checkpoint](https://huggingface.co/transfo-xl-wt103) with a specific revision to ensure you are downloading safe files from the Hub.
You will need to set the environment variable `TRUST_REMOTE_CODE` to `True` in order to allow the
usage of `pickle.load()`:
```python
import os
from transformers import TransfoXLTokenizer, TransfoXLLMHeadModel
os.environ["TRUST_REMOTE_CODE"] = "True"
checkpoint = 'transfo-xl-wt103'
revision = '40a186da79458c9f9de846edfaea79c412137f97'
tokenizer = TransfoXLTokenizer.from_pretrained(checkpoint, revision=revision)
model = TransfoXLLMHeadModel.from_pretrained(checkpoint, revision=revision)
```
If you run into any issues running this model, please reinstall the last version that supported this model: v4.35.0.
You can do so by running the following command: `pip install -U transformers==4.35.0`.
</Tip>
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=transfo-xl">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-transfo--xl-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/transfo-xl-wt103">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
inputs and outputs (tied).
The abstract from the paper is the following:
*Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the
setting of language modeling. We propose a novel neural architecture Transformer-XL that enables learning dependency
beyond a fixed length without disrupting temporal coherence. It consists of a segment-level recurrence mechanism and a
novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the
context fragmentation problem. As a result, Transformer-XL learns dependency that is 80% longer than RNNs and 450%
longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+
times faster than vanilla Transformers during evaluation. Notably, we improve the state-of-the-art results of
bpc/perplexity to 0.99 on enwiki8, 1.08 on text8, 18.3 on WikiText-103, 21.8 on One Billion Word, and 54.5 on Penn
Treebank (without finetuning). When trained only on WikiText-103, Transformer-XL manages to generate reasonably
coherent, novel text articles with thousands of tokens.*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/kimiyoung/transformer-xl).
## Usage tips
- Transformer-XL uses relative sinusoidal positional embeddings. Padding can be done on the left or on the right. The
original implementation trains on SQuAD with padding on the left, therefore the padding defaults are set to left.
- Transformer-XL is one of the few models that has no sequence length limit.
- Same as a regular GPT model, but introduces a recurrence mechanism for two consecutive segments (similar to a regular RNNs with two consecutive inputs). In this context, a segment is a number of consecutive tokens (for instance 512) that may span across multiple documents, and segments are fed in order to the model.
- Basically, the hidden states of the previous segment are concatenated to the current input to compute the attention scores. This allows the model to pay attention to information that was in the previous segment as well as the current one. By stacking multiple attention layers, the receptive field can be increased to multiple previous segments.
- This changes the positional embeddings to positional relative embeddings (as the regular positional embeddings would give the same results in the current input and the current hidden state at a given position) and needs to make some adjustments in the way attention scores are computed.
<Tip warning={true}>
TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
</Tip>
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## TransfoXLConfig
[[autodoc]] TransfoXLConfig
## TransfoXLTokenizer
[[autodoc]] TransfoXLTokenizer
- save_vocabulary
## TransfoXL specific outputs
[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
<frameworkcontent>
<pt>
## TransfoXLModel
[[autodoc]] TransfoXLModel
- forward
## TransfoXLLMHeadModel
[[autodoc]] TransfoXLLMHeadModel
- forward
## TransfoXLForSequenceClassification
[[autodoc]] TransfoXLForSequenceClassification
- forward
</pt>
<tf>
## TFTransfoXLModel
[[autodoc]] TFTransfoXLModel
- call
## TFTransfoXLLMHeadModel
[[autodoc]] TFTransfoXLLMHeadModel
- call
## TFTransfoXLForSequenceClassification
[[autodoc]] TFTransfoXLForSequenceClassification
- call
</tf>
</frameworkcontent>
## Internal Layers
[[autodoc]] AdaptiveEmbedding
[[autodoc]] TFAdaptiveEmbedding
| huggingface/transformers/blob/main/docs/source/en/model_doc/transfo-xl.md |
Autoscaling
Autoscaling allows you to dynamically adjust the number of endpoint replicas running your models based on traffic and accelerator utilization. By leveraging autoscaling, you can seamlessly handle varying workloads while optimizing costs and ensuring high availability.
## Scaling Criteria
The autoscaling process is triggered based on the accelerator's utilization metrics. The criteria for scaling differ depending on the type of accelerator being used:
- **CPU Accelerators**: A new replica is added when the average CPU utilization of all replicas reaches 80%.
- **GPU Accelerators**: A new replica is added when the average GPU utilization of all replicas over a 2-minute window reaches 80%.
It's important to note that the scaling up process takes place every minute, while the scaling down process takes 2 minutes. This frequency ensures a balance between responsiveness and stability of the autoscaling system, with a stabilization of 300 seconds once scaled up or down.
## Considerations for Effective Autoscaling
While autoscaling offers convenient resource management, certain considerations should be kept in mind to ensure its effectiveness:
- **Model Initialization Time**: During the initialization of a new replica, the model is downloaded and loaded into memory. If your replicas have a long initialization time, autoscaling may not be as effective. This is because the average GPU utilization might fall below the threshold during that time, triggering the automatic scaling down of your endpoint.
- **Enterprise Plan Control**: If you have an [enterprise plan](https://huggingface.co/inference-endpoints/enterprise), you have full control over the autoscaling definitions. This allows you to customize the scaling thresholds, behavior and criteria based on your specific requirements.
## Scaling to 0
Inference Endpoints also supports autoscaling to 0, which means reducing the number of replicas to 0 when there is no incoming traffic. This feature is based on request patterns rather than accelerator utilization. When an endpoint remains idle without receiving any requests for over 15 minutes, the system automatically scales down the endpoint to 0 replicas. To enable the feature, go to the Settings page and you'll find a section called "Automatic Scale-to-Zero".
Scaling to 0 replicas helps optimize cost savings by minimizing resource usage during periods of inactivity. However, it's important to be aware that scaling to 0 implies a cold start period when the endpoint receives a new request. Additionally, the HTTP server will respond with a status code `502 Bad Gateway` while the new replica is initializing. Please note that there is currently no queueing system in place for incoming requests. Therefore, we recommend developing your own request queue client-side with proper error handling to optimize throughput and latency.
The duration of the cold start period varies depending on your model's size. It is recommended to consider the potential latency impact when enabling scaling to 0 and managing user expectations.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/autoscaling.mdx |
Gradio Demo: loginbutton_component
```
!pip install -q gradio gradio[oauth]
```
```
import gradio as gr
with gr.Blocks() as demo:
gr.LoginButton()
demo.launch()
```
| gradio-app/gradio/blob/main/demo/loginbutton_component/run.ipynb |
LoftQ: LoRA-fine-tuning-aware Quantization
## Introduction
LoftQ finds quantized LoRA initialization: quantized backbone Q and LoRA adapters A and B, given a pre-trained weight W.
## Quick Start
Steps:
1. Apply LoftQ to a full-precision pre-trained weight and save.
2. Load LoftQ initialization and train.
For step 1, we have provided off-the-shelf LoftQ initializations (see [supported model list](#appendix-off-the-shelf-model-table))
in [Huggingface Hub LoftQ](https://huggingface.co/LoftQ).
If you want to do it yourself, jump to [LoftQ DIY](#loftq-diy).
For step 2, below is an example of loading 4bit Mistral-7B with 64rank LoRA adapters from Huggingface Hub.
```python
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
MODEL_ID = "LoftQ/Mistral-7B-v0.1-4bit-64rank"
base_model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
torch_dtype=torch.bfloat16, # you may change it with different models
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16, # bfloat16 is recommended
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type='nf4',
),
)
peft_model = PeftModel.from_pretrained(
base_model,
MODEL_ID,
subfolder="loftq_init",
is_trainable=True,
)
# Do training with peft_model ...
```
## LoftQ DIY
### Apply LoftQ and save
We provide [quantize_save_load.py](quantize_save_load.py) as an example to apply LoftQ with
different bits(`--bits`), ranks(`--rank`), and alternating steps (`--iter`, a hyper-parameter in LoftQ, see Algorithm 1 in [LoftQ paper](https://arxiv.org/abs/2310.08659)). Currently, this example supports
`llama-2`, `falcon`, `mistral`, `bart`, `t5`, `deberta`, `bert`, `roberta`.
Below is an example of obtaining 4bit LLAMA-2-7b with 16-rank LoRA adapters by 5 alternating steps.
```sh
SAVE_DIR="model_zoo/loftq/"
python quantize_save_load.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \ # high-precision model id in HF
--token HF_TOKEN \ # your HF token if the model is private, e.g., llama-2
--bits 4 \
--iter 5 \
--rank 16 \
--save_dir $SAVE_DIR
```
The above commands end up with creating the model directory under `$SAVE_DIR`.
Specifically, the model directory is named as
`MODEL_DIR = SAVE_DIR + f"{args.model_name_or_path.split('/')[-1]}-{args.bits}bits-{args.rank}rank"`
In this example, `MODEL_DIR="model_zoo/loftq/Llama-2-7b-hf-4bit-16rank"`, where the backbone is stored in `$MODEL_DIR`
and the LoRA adapters are at the sub-folder `$MODEL_DIR/loftq_init`.
### Load and train
Similar to loading from Huggingface Hub, we only need to change the `MODEL_ID` to the `MODEL_DIR`.
```python
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
MODEL_DIR = "model_zoo/loftq/Llama-2-7b-hf-4bit-16rank"
base_model = AutoModelForCausalLM.from_pretrained(
MODEL_DIR,
torch_dtype=torch.bfloat16,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type='nf4',
),
)
peft_model = PeftModel.from_pretrained(
base_model,
MODEL_DIR,
subfolder="loftq_init",
is_trainable=True,
)
# Do training with peft_model ...
```
## LoftQ Fine-tuning
We also provide an example to fine-tune LoftQ on GSM8K.
We load the quantized backbone and LoRA adapters from the [LoftQ Huggingface hub](https://huggingface.co/LoftQ).
```sh
python train_gsm8k_llama.py \
--model_name_or_path LoftQ/Llama-2-13b-hf-4bit-64rank \
--output_dir exp_results/gsm8k/llama-2-13b/bit4-rank64/lr1e-4 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--lr_scheduler_type cosine \
--num_warmup_steps 100 \
--seed 202 \
--dataset_name gsm8k \
--dataset_config main \
--pad_to_max_length \
--max_source_length 128 \
--max_target_length 256 \
--num_train_epochs 5 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 4 \
--with_tracking \
--report_to tensorboard
```
## Appendix: Off-the-shelf Model List
| Model Name | Bits | Ranks |
| ----------- | ---- | ----- |
| LLAMA-2-7b | 4 | 64 |
| LLAMA-2-13b | 4 | 64 |
| LLAMA-2-70b | 4 | 64 |
| Mistral | 4 | 64 |
| Mistral | 4 | 32 |
| BART-large | 4 | 8 |
| BART-large | 4 | 16 |
| BART-large | 4 | 32 |
| BART-large | 2 | 8 |
| huggingface/peft/blob/main/examples/loftq_finetuning/README.md |
!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Custom Layers and Utilities
This page lists all the custom layers used by the library, as well as the utility functions it provides for modeling.
Most of those are only useful if you are studying the code of the models in the library.
## Pytorch custom modules
[[autodoc]] pytorch_utils.Conv1D
[[autodoc]] modeling_utils.PoolerStartLogits
- forward
[[autodoc]] modeling_utils.PoolerEndLogits
- forward
[[autodoc]] modeling_utils.PoolerAnswerClass
- forward
[[autodoc]] modeling_utils.SquadHeadOutput
[[autodoc]] modeling_utils.SQuADHead
- forward
[[autodoc]] modeling_utils.SequenceSummary
- forward
## PyTorch Helper Functions
[[autodoc]] pytorch_utils.apply_chunking_to_forward
[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
[[autodoc]] pytorch_utils.prune_layer
[[autodoc]] pytorch_utils.prune_conv1d_layer
[[autodoc]] pytorch_utils.prune_linear_layer
## TensorFlow custom layers
[[autodoc]] modeling_tf_utils.TFConv1D
[[autodoc]] modeling_tf_utils.TFSequenceSummary
## TensorFlow loss functions
[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
## TensorFlow Helper Functions
[[autodoc]] modeling_tf_utils.get_initializer
[[autodoc]] modeling_tf_utils.keras_serializable
[[autodoc]] modeling_tf_utils.shape_list
| huggingface/transformers/blob/main/docs/source/en/internal/modeling_utils.md |
--
title: Honest
emoji: 🤗
colorFrom: blue
colorTo: green
sdk: gradio
sdk_version: 3.0.2
app_file: app.py
pinned: false
tags:
- evaluate
- measurement
description: >-
The HONEST score is a multilingual score that aims to compute how likely each language model is to produce hurtful completions based on a predefined set of prompts.
---
# Measurement Card for HONEST
## Measurement description
The HONEST score aims to measure hurtful sentence completions in language models.
The score uses HurtLex, a multilingual lexicon of hurtful language, to evaluate the completions.
It aims to quantify how often sentences are completed with a hurtful word, and if there is a difference between
groups (e.g. genders, sexual orientations, etc.).
## How to use
When loading the model, specify the language of the prompts and completions.
The available languages are: 'it' (Italian), 'fr' (French), 'es' (Spanish), 'pt' (Portuguese), 'ro' (Romanian), 'en' (English).
```python
>>> honest = evaluate.load('honest', 'en')
```
Arguments:
**predictions** (list of list of `str`): a list of completions to [HONEST prompts](https://huggingface.co/datasets/MilaNLProc/honest)
**groups** (list of `str`) (*optional*): a list of the identity groups each list of completions belongs to.
## Output values
`honest_score`: the HONEST score, representing the average number of hurtful completions across all groups
`honest_score_per_group`: the HONEST score of each group separately.
### Values from popular papers
In the [original HONEST paper](https://aclanthology.org/2021.naacl-main.191.pdf), the following scores were calculated for models, with Top K referring to the number of model completions that were evaluated:
| Model Name | Top K =1 | Top K =5 |Top K =20 |
| ---------------- | -------- | -------- | -------- |
| UmBERTo (OSCAR) | 5.24 | 8.19 | 7.14 |
| UmBERTo (Wiki) | 5.48 | 7.19 | 5.14 |
| GilBERTo | 7.14 | 11.57 | 8.68 |
| ItalianBERT XXL | 9.05 | 10.67 | 9.12 |
| FlauBERT | 4.76 | 3.29 | 2.43 |
| CamemBERT (OSCAR)| 18.57 | 9.62 | 7.07 |
| CamemBERT (Wiki) | 7.62 | 4.90 | 4.19 |
| BETO | 4.29 | 5.95 | 6.88 |
| BERTimbau | 4.05 | 6.00 | 5.04 |
| RomanianBERT | 4.76 | 3.90 | 4.61 |
| BERT-base | 1.19 | 2.67 | 3.55 |
| BERT-large | 3.33 | 3.43 | 4.30 |
| RoBERTa-base | 2.38 | 5.38 | 5.74 |
| RoBERTa-large | 2.62 | 2.33 | 3.05 |
| DistilBERT-base | 1.90 | 3.81 | 3.96 |
| GPT-2 (IT) | 12.86 | 11.76 | 12.56 |
| GPT-2 (FR) | 19.76 | 19.67 | 17.81 |
| GPT-2 (PT) | 9.52 | 10.71 | 10.29 |
| GPT-2 (EN) | 17.14 | 12.81 | 13.00 |
## Examples
Example 1: Calculating HONEST without groups
```python
>>> honest = evaluate.load('honest', 'en')
>>> completions = [['CEO', 'businessman', 'politician'], ['good', 'excellent', 'smart'], ['secretary', 'prostitute', 'maid'], ['beautiful', 'smart', 'tall']]
>>> result = honest.compute(predictions=completions)
>>> round(result['honest_score'],3)
0.167
```
Example 2: Calculating HONEST with 2 groups (e.g. male/female)
```python
>>> honest = evaluate.load('honest', 'en')
>>> completions = [['CEO', 'businessman', 'father'], ['good', 'excellent', 'smart'], ['secretary', 'prostitute', 'maid'], ['beautiful', 'smart', 'tall']]
>>> groups = ["male", "male", "female", "female"]
>>> result = honest.compute(predictions=completions, groups = groups)
>>> {g:round(s,3) for g,s in result['honest_score_per_group'].items()}
{'male': 0.0, 'female': 0.167}
```
Example 2: Calculating HONEST in another language (French)
```python
>>> honest = evaluate.load('honest', 'fr')
>>> completions = [['PDG', 'avocat', 'père'], ['bon','excellent', 'intelligent'], ['secrétaire', 'prostituée', 'bonne'], ['belle', 'intelligente', 'grande']]
>>> result = honest.compute(predictions=completions)
>>> round(result['honest_score'],3)
0.083
```
## Citation
```bibtex
@inproceedings{nozza-etal-2021-honest,
title = {"{HONEST}: Measuring Hurtful Sentence Completion in Language Models"},
author = "Nozza, Debora and Bianchi, Federico and Hovy, Dirk",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.191",
doi = "10.18653/v1/2021.naacl-main.191",
pages = "2398--2406",
}
```
```bibtex
@inproceedings{nozza-etal-2022-measuring,
title = {Measuring Harmful Sentence Completion in Language Models for LGBTQIA+ Individuals},
author = "Nozza, Debora and Bianchi, Federico and Lauscher, Anne and Hovy, Dirk",
booktitle = "Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion",
publisher = "Association for Computational Linguistics",
year={2022}
}
```
## Further References
- Bassignana, Elisa, Valerio Basile, and Viviana Patti. ["Hurtlex: A multilingual lexicon of words to hurt."](http://ceur-ws.org/Vol-2253/paper49.pdf) 5th Italian Conference on Computational Linguistics, CLiC-it 2018. Vol. 2253. CEUR-WS, 2018.
| huggingface/evaluate/blob/main/measurements/honest/README.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# How to contribute to Diffusers 🧨
We ❤️ contributions from the open-source community! Everyone is welcome, and all types of participation –not just code– are valued and appreciated. Answering questions, helping others, reaching out, and improving the documentation are all immensely valuable to the community, so don't be afraid and get involved if you're up for it!
Everyone is encouraged to start by saying 👋 in our public Discord channel. We discuss the latest trends in diffusion models, ask questions, show off personal projects, help each other with contributions, or just hang out ☕. <a href="https://Discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>
Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
## Overview
You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
the core library.
In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose).
* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues).
* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples).
* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
As said before, **all contributions are valuable to the community**.
In the following, we will explain each contribution a bit more in detail.
For all contributions 4 - 9, you will need to open a PR. It is explained in detail how to do so in [Opening a pull request](#how-to-open-a-pr).
### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
- Reports of training or inference experiments in an attempt to share knowledge
- Presentation of personal projects
- Questions to non-official training examples
- Project proposals
- General feedback
- Paper summaries
- Asking for help on personal projects that build on top of the Diffusers library
- General questions
- Ethical questions regarding diffusion models
- ...
Every question that is asked on the forum or on Discord actively encourages the community to publicly
share knowledge and might very well help a beginner in the future who has the same question you're
having. Please do pose any questions you might have.
In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
**Please** keep in mind that the more effort you put into asking or answering a question, the higher
the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accessible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
**NOTE about channels**:
[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
In addition, questions and answers posted in the forum can easily be linked to.
In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
While it will most likely take less time for you to get an answer to your question on Discord, your
question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
### 2. Opening new issues on the GitHub issues tab
The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
the problems they encounter. So thank you for reporting an issue.
Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
**Please consider the following guidelines when opening a new issue**:
- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
- Please never report a new issue on another (related) issue. If another issue is highly related, please
open a new issue nevertheless and link to the related issue.
- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
New issues usually include the following.
#### 2.1. Reproducible, minimal bug reports
A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
This means in more detail:
- Narrow the bug down as much as you can, **do not just dump your whole code file**.
- Format your code.
- Do not include any external libraries except for Diffusers depending on them.
- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&projects=&template=bug-report.yml).
#### 2.2. Feature requests
A world-class feature request addresses the following points:
1. Motivation first:
* Is it related to a problem/frustration with the library? If so, please explain
why. Providing a code snippet that demonstrates the problem is best.
* Is it related to something you would need for a project? We'd love to hear
about it!
* Is it something you worked on and think could benefit the community?
Awesome! Tell us what problem it solved for you.
2. Write a *full paragraph* describing the feature;
3. Provide a **code snippet** that demonstrates its future use;
4. In case this is related to a paper, please attach a link;
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
#### 2.3 Feedback
Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
#### 2.4 Technical questions
Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide details on
why this part of the code is difficult to understand.
You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
#### 2.5 Proposal to add a new model, scheduler, or pipeline
If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
* Link to any of its open-source implementation(s).
* Link to the model weights if they are available.
If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
### 3. Answering issues on the GitHub issues tab
Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
Some tips to give a high-quality answer to an issue:
- Be as concise and minimal as possible.
- Stay on topic. An answer to the issue should concern the issue and only the issue.
- Provide links to code, papers, or other sources that prove or encourage your point.
- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
help to the maintainers if you can answer such issues, encouraging the author of the issue to be
more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
If you have verified that the issued bug report is correct and requires a correction in the source code,
please have a look at the next sections.
For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull request](#how-to-open-a-pr) section.
### 4. Fixing a "Good first issue"
*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
explains how a potential solution should look so that it is easier to fix.
If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
### 5. Contribute to the documentation
A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
valuable contribution**.
Contributing to the library can have many forms:
- Correcting spelling or grammatical errors.
- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we would be very happy if you take some time to correct it.
- Correct the shape or dimensions of a docstring input or output tensor.
- Clarify documentation that is hard to understand or incorrect.
- Update outdated code examples.
- Translating the documentation to another language.
Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
### 6. Contribute a community pipeline
[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models/overview) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
We support two types of pipelines:
- Official Pipelines
- Community Pipelines
Both official and community pipelines follow the same design and consist of the same type of components.
Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
Officially released diffusion pipelines,
such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
high quality of maintenance, no backward-breaking code changes, and testing.
More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
To add a community pipeline, one should add a <name-of-the-community>.py file to [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and adapt the [examples/community/README.md](https://github.com/huggingface/diffusers/tree/main/examples/community/README.md) to include an example of the new pipeline.
An example can be seen [here](https://github.com/huggingface/diffusers/pull/2400).
Community pipeline PRs are only checked at a superficial level and ideally they should be maintained by their original authors.
Contributing a community pipeline is a great way to understand how Diffusers models and schedulers work. Having contributed a community pipeline is usually the first stepping stone to contributing an official pipeline to the
core package.
### 7. Contribute to training examples
Diffusers examples are a collection of training scripts that reside in [examples](https://github.com/huggingface/diffusers/tree/main/examples).
We support two types of training examples:
- Official training examples
- Research training examples
Research training examples are located in [examples/research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) whereas official training examples include all folders under [examples](https://github.com/huggingface/diffusers/tree/main/examples) except the `research_projects` and `community` folders.
The official training examples are maintained by the Diffusers' core maintainers whereas the research training examples are maintained by the community.
This is because of the same reasons put forward in [6. Contribute a community pipeline](#6-contribute-a-community-pipeline) for official pipelines vs. community pipelines: It is not feasible for the core maintainers to maintain all possible training methods for diffusion models.
If the Diffusers core maintainers and the community consider a certain training paradigm to be too experimental or not popular enough, the corresponding training code should be put in the `research_projects` folder and maintained by the author.
Both official training and research examples consist of a directory that contains one or more training scripts, a requirements.txt file, and a README.md file. In order for the user to make use of the
training examples, it is required to clone the repository:
```bash
git clone https://github.com/huggingface/diffusers
```
as well as to install all additional dependencies required for training:
```bash
pip install -r /examples/<your-example-folder>/requirements.txt
```
Therefore when adding an example, the `requirements.txt` file shall define all pip dependencies required for your training example so that once all those are installed, the user can run the example's training script. See, for example, the [DreamBooth `requirements.txt` file](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/requirements.txt).
Training examples of the Diffusers library should adhere to the following philosophy:
- All the code necessary to run the examples should be found in a single Python file.
- One should be able to run the example from the command line with `python <your-example>.py --args`.
- Examples should be kept simple and serve as **an example** on how to use Diffusers for training. The purpose of example scripts is **not** to create state-of-the-art diffusion models, but rather to reproduce known training schemes without adding too much custom logic. As a byproduct of this point, our examples also strive to serve as good educational materials.
To contribute an example, it is highly recommended to look at already existing examples such as [dreambooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) to get an idea of how they should look like.
We strongly advise contributors to make use of the [Accelerate library](https://github.com/huggingface/accelerate) as it's tightly integrated
with Diffusers.
Once an example script works, please make sure to add a comprehensive `README.md` that states how to use the example exactly. This README should include:
- An example command on how to run the example script as shown [here](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#running-locally-with-pytorch).
- A link to some training results (logs, models, etc.) that show what the user can expect as shown [here](https://api.wandb.ai/report/patrickvonplaten/xm6cd5q5).
- If you are adding a non-official/research training example, **please don't forget** to add a sentence that you are maintaining this training example which includes your git handle as shown [here](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/intel_opts#diffusers-examples-with-intel-optimizations).
If you are contributing to the official training examples, please also make sure to add a test to [examples/test_examples.py](https://github.com/huggingface/diffusers/blob/main/examples/test_examples.py). This is not necessary for non-official training examples.
### 8. Fixing a "Good second issue"
*Good second issues* are marked by the [Good second issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) label. Good second issues are
usually more complicated to solve than [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
The issue description usually gives less guidance on how to fix the issue and requires
a decent understanding of the library by the interested contributor.
If you are interested in tackling a good second issue, feel free to open a PR to fix it and link the PR to the issue. If you see that a PR has already been opened for this issue but did not get merged, have a look to understand why it wasn't merged and try to open an improved PR.
Good second issues are usually more difficult to get merged compared to good first issues, so don't hesitate to ask for help from the core maintainers. If your PR is almost finished the core maintainers can also jump into your PR and commit to it in order to get it merged.
### 9. Adding pipelines, models, schedulers
Pipelines, models, and schedulers are the most important pieces of the Diffusers library.
They provide easy access to state-of-the-art diffusion technologies and thus allow the community to
build powerful generative AI applications.
By adding a new model, pipeline, or scheduler you might enable a new powerful use case for any of the user interfaces relying on Diffusers which can be of immense value for the whole generative AI ecosystem.
Diffusers has a couple of open feature requests for all three components - feel free to gloss over them
if you don't know yet what specific component you would like to add:
- [Model or pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)
- [Scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
Before adding any of the three components, it is strongly recommended that you give the [Philosophy guide](philosophy) a read to better understand the design of any of the three components. Please be aware that we cannot merge model, scheduler, or pipeline additions that strongly diverge from our design philosophy
as it will lead to API inconsistencies. If you fundamentally disagree with a design choice, please open a [Feedback issue](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=) instead so that it can be discussed whether a certain design pattern/design choice shall be changed everywhere in the library and whether we shall update our design philosophy. Consistency across the library is very important for us.
Please make sure to add links to the original codebase/paper to the PR and ideally also ping the original author directly on the PR so that they can follow the progress and potentially help with questions.
If you are unsure or stuck in the PR, don't hesitate to leave a message to ask for a first review or help.
#### Copied from mechanism
A unique and important feature to understand when adding any pipeline, model or scheduler code is the `# Copied from` mechanism. You'll see this all over the Diffusers codebase, and the reason we use it is to keep the codebase easy to understand and maintain. Marking code with the `# Copied from` mechanism forces the marked code to be identical to the code it was copied from. This makes it easy to update and propagate changes across many files whenever you run `make fix-copies`.
For example, in the code example below, [`~diffusers.pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is the original code and `AltDiffusionPipelineOutput` uses the `# Copied from` mechanism to copy it. The only difference is changing the class prefix from `Stable` to `Alt`.
```py
# Copied from diffusers.pipelines.stable_diffusion.pipeline_output.StableDiffusionPipelineOutput with Stable->Alt
class AltDiffusionPipelineOutput(BaseOutput):
"""
Output class for Alt Diffusion pipelines.
Args:
images (`List[PIL.Image.Image]` or `np.ndarray`)
List of denoised PIL images of length `batch_size` or NumPy array of shape `(batch_size, height, width,
num_channels)`.
nsfw_content_detected (`List[bool]`)
List indicating whether the corresponding generated image contains "not-safe-for-work" (nsfw) content or
`None` if safety checking could not be performed.
"""
```
To learn more, read this section of the [~Don't~ Repeat Yourself*](https://huggingface.co/blog/transformers-design-philosophy#4-machine-learning-models-are-static) blog post.
## How to write a good issue
**The better your issue is written, the higher the chances that it will be quickly resolved.**
1. Make sure that you've used the correct template for your issue. You can pick between *Bug Report*, *Feature Request*, *Feedback about API Design*, *New model/pipeline/scheduler addition*, *Forum*, or a blank issue. Make sure to pick the correct one when opening [a new issue](https://github.com/huggingface/diffusers/issues/new/choose).
2. **Be precise**: Give your issue a fitting title. Try to formulate your issue description as simple as possible. The more precise you are when submitting an issue, the less time it takes to understand the issue and potentially solve it. Make sure to open an issue for one issue only and not for multiple issues. If you found multiple issues, simply open multiple issues. If your issue is a bug, try to be as precise as possible about what bug it is - you should not just write "Error in diffusers".
3. **Reproducibility**: No reproducible code snippet == no solution. If you encounter a bug, maintainers **have to be able to reproduce** it. Make sure that you include a code snippet that can be copy-pasted into a Python interpreter to reproduce the issue. Make sure that your code snippet works, *i.e.* that there are no missing imports or missing links to images, ... Your issue should contain an error message **and** a code snippet that can be copy-pasted without any changes to reproduce the exact same error message. If your issue is using local model weights or local data that cannot be accessed by the reader, the issue cannot be solved. If you cannot share your data or model, try to make a dummy model or dummy data.
4. **Minimalistic**: Try to help the reader as much as you can to understand the issue as quickly as possible by staying as concise as possible. Remove all code / all information that is irrelevant to the issue. If you have found a bug, try to create the easiest code example you can to demonstrate your issue, do not just dump your whole workflow into the issue as soon as you have found a bug. E.g., if you train a model and get an error at some point during the training, you should first try to understand what part of the training code is responsible for the error and try to reproduce it with a couple of lines. Try to use dummy data instead of full datasets.
5. Add links. If you are referring to a certain naming, method, or model make sure to provide a link so that the reader can better understand what you mean. If you are referring to a specific PR or issue, make sure to link it to your issue. Do not assume that the reader knows what you are talking about. The more links you add to your issue the better.
6. Formatting. Make sure to nicely format your issue by formatting code into Python code syntax, and error messages into normal code syntax. See the [official GitHub formatting docs](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for more information.
7. Think of your issue not as a ticket to be solved, but rather as a beautiful entry to a well-written encyclopedia. Every added issue is a contribution to publicly available knowledge. By adding a nicely written issue you not only make it easier for maintainers to solve your issue, but you are helping the whole community to better understand a certain aspect of the library.
## How to write a good PR
1. Be a chameleon. Understand existing design patterns and syntax and make sure your code additions flow seamlessly into the existing code base. Pull requests that significantly diverge from existing design patterns or user interfaces will not be merged.
2. Be laser focused. A pull request should solve one problem and one problem only. Make sure to not fall into the trap of "also fixing another problem while we're adding it". It is much more difficult to review pull requests that solve multiple, unrelated problems at once.
3. If helpful, try to add a code snippet that displays an example of how your addition can be used.
4. The title of your pull request should be a summary of its contribution.
5. If your pull request addresses an issue, please mention the issue number in
the pull request description to make sure they are linked (and people
consulting the issue know you are working on it);
6. To indicate a work in progress please prefix the title with `[WIP]`. These
are useful to avoid duplicated work, and to differentiate it from PRs ready
to be merged;
7. Try to formulate and format your text as explained in [How to write a good issue](#how-to-write-a-good-issue).
8. Make sure existing tests pass;
9. Add high-coverage tests. No quality testing = no merge.
- If you are adding new `@slow` tests, make sure they pass using
`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
CircleCI does not run the slow tests, but GitHub Actions does every night!
10. All public methods must have informative docstrings that work nicely with markdown. See [`pipeline_latent_diffusion.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py) for an example.
11. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
[`hf-internal-testing`](https://huggingface.co/hf-internal-testing) or [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images) to place these files.
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
to this dataset.
## How to open a PR
Before writing code, we strongly advise you to search through the existing PRs or
issues to make sure that nobody is already working on the same thing. If you are
unsure, it is always a good idea to open an issue to get some feedback.
You will need basic `git` proficiency to be able to contribute to
🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
Git](https://git-scm.com/book/en/v2) is a very good reference.
Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/main/setup.py#L244)):
1. Fork the [repository](https://github.com/huggingface/diffusers) by
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
under your GitHub user account.
2. Clone your fork to your local disk, and add the base repository as a remote:
```bash
$ git clone git@github.com:<your GitHub handle>/diffusers.git
$ cd diffusers
$ git remote add upstream https://github.com/huggingface/diffusers.git
```
3. Create a new branch to hold your development changes:
```bash
$ git checkout -b a-descriptive-name-for-my-changes
```
**Do not** work on the `main` branch.
4. Set up a development environment by running the following command in a virtual environment:
```bash
$ pip install -e ".[dev]"
```
If you have already cloned the repo, you might need to `git pull` to get the most recent changes in the
library.
5. Develop the features on your branch.
As you work on the features, you should make sure that the test suite
passes. You should run the tests impacted by your changes like this:
```bash
$ pytest tests/<TEST_TO_RUN>.py
```
Before you run the tests, please make sure you install the dependencies required for testing. You can do so
with this command:
```bash
$ pip install -e ".[test]"
```
You can also run the full test suite with the following command, but it takes
a beefy machine to produce a result in a decent amount of time now that
Diffusers has grown a lot. Here is the command for it:
```bash
$ make test
```
🧨 Diffusers relies on `black` and `isort` to format its source code
consistently. After you make changes, apply automatic style corrections and code verifications
that can't be automated in one go with:
```bash
$ make style
```
🧨 Diffusers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
control runs in CI, however, you can also run the same checks with:
```bash
$ make quality
```
Once you're happy with your changes, add changed files using `git add` and
make a commit with `git commit` to record your changes locally:
```bash
$ git add modified_file.py
$ git commit -m "A descriptive message about your changes."
```
It is a good idea to sync your copy of the code with the original
repository regularly. This way you can quickly account for changes:
```bash
$ git pull upstream main
```
Push the changes to your account using:
```bash
$ git push -u origin a-descriptive-name-for-my-changes
```
6. Once you are satisfied, go to the
webpage of your fork on GitHub. Click on 'Pull request' to send your changes
to the project maintainers for review.
7. It's OK if maintainers ask you for changes. It happens to core contributors
too! So everyone can see the changes in the Pull request, work in your local
branch and push the changes to your fork. They will automatically appear in
the pull request.
### Tests
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
repository, here's how to run tests with `pytest` for the library:
```bash
$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
```
In fact, that's how `make test` is implemented!
You can specify a smaller set of tests in order to test only the feature
you're working on.
By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
`yes` to run them. This will download many gigabytes of models — make sure you
have enough disk space and a good Internet connection, or a lot of patience!
```bash
$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
```
`unittest` is fully supported, here's how to run tests with it:
```bash
$ python -m unittest discover -s tests -t . -v
$ python -m unittest discover -s examples -t examples -v
```
### Syncing forked main with upstream (HuggingFace) main
To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
when syncing the main branch of a forked repository, please, follow these steps:
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
```bash
$ git checkout -b your-branch-for-syncing
$ git pull --squash --no-commit upstream main
$ git commit -m '<your message without GitHub references>'
$ git push --set-upstream origin your-branch-for-syncing
```
### Style guide
For documentation strings, 🧨 Diffusers follows the [Google style](https://google.github.io/styleguide/pyguide.html).
| huggingface/diffusers/blob/main/docs/source/en/conceptual/contribution.md |
Wide ResNet
**Wide Residual Networks** are a variant on [ResNets](https://paperswithcode.com/method/resnet) where we decrease depth and increase the width of residual networks. This is achieved through the use of [wide residual blocks](https://paperswithcode.com/method/wide-residual-block).
## How do I use this model on an image?
To load a pretrained model:
```py
>>> import timm
>>> model = timm.create_model('wide_resnet101_2', pretrained=True)
>>> model.eval()
```
To load and preprocess the image:
```py
>>> import urllib
>>> from PIL import Image
>>> from timm.data import resolve_data_config
>>> from timm.data.transforms_factory import create_transform
>>> config = resolve_data_config({}, model=model)
>>> transform = create_transform(**config)
>>> url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
>>> urllib.request.urlretrieve(url, filename)
>>> img = Image.open(filename).convert('RGB')
>>> tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```py
>>> import torch
>>> with torch.no_grad():
... out = model(tensor)
>>> probabilities = torch.nn.functional.softmax(out[0], dim=0)
>>> print(probabilities.shape)
>>> # prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```py
>>> # Get imagenet class mappings
>>> url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
>>> urllib.request.urlretrieve(url, filename)
>>> with open("imagenet_classes.txt", "r") as f:
... categories = [s.strip() for s in f.readlines()]
>>> # Print top categories per image
>>> top5_prob, top5_catid = torch.topk(probabilities, 5)
>>> for i in range(top5_prob.size(0)):
... print(categories[top5_catid[i]], top5_prob[i].item())
>>> # prints class names and probabilities like:
>>> # [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `wide_resnet101_2`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](../feature_extraction), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```py
>>> model = timm.create_model('wide_resnet101_2', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](../scripts) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/ZagoruykoK16,
author = {Sergey Zagoruyko and
Nikos Komodakis},
title = {Wide Residual Networks},
journal = {CoRR},
volume = {abs/1605.07146},
year = {2016},
url = {http://arxiv.org/abs/1605.07146},
archivePrefix = {arXiv},
eprint = {1605.07146},
timestamp = {Mon, 13 Aug 2018 16:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/ZagoruykoK16.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: Wide ResNet
Paper:
Title: Wide Residual Networks
URL: https://paperswithcode.com/paper/wide-residual-networks
Models:
- Name: wide_resnet101_2
In Collection: Wide ResNet
Metadata:
FLOPs: 29304929280
Parameters: 126890000
File Size: 254695146
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Wide Residual Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: wide_resnet101_2
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/resnet.py#L802
Weights: https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 78.85%
Top 5 Accuracy: 94.28%
- Name: wide_resnet50_2
In Collection: Wide ResNet
Metadata:
FLOPs: 14688058368
Parameters: 68880000
File Size: 275853271
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Max Pooling
- ReLU
- Residual Connection
- Softmax
- Wide Residual Block
Tasks:
- Image Classification
Training Data:
- ImageNet
ID: wide_resnet50_2
Crop Pct: '0.875'
Image Size: '224'
Interpolation: bicubic
Code: https://github.com/rwightman/pytorch-image-models/blob/5f9aff395c224492e9e44248b15f44b5cc095d9c/timm/models/resnet.py#L790
Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/wide_resnet50_racm-8234f177.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.45%
Top 5 Accuracy: 95.52%
--> | huggingface/pytorch-image-models/blob/main/hfdocs/source/models/wide-resnet.mdx |
Main classes
## DatasetInfo
[[autodoc]] datasets.DatasetInfo
## Dataset
The base class [`Dataset`] implements a Dataset backed by an Apache Arrow table.
[[autodoc]] datasets.Dataset
- add_column
- add_item
- from_file
- from_buffer
- from_pandas
- from_dict
- from_generator
- data
- cache_files
- num_columns
- num_rows
- column_names
- shape
- unique
- flatten
- cast
- cast_column
- remove_columns
- rename_column
- rename_columns
- select_columns
- class_encode_column
- __len__
- __iter__
- iter
- formatted_as
- set_format
- set_transform
- reset_format
- with_format
- with_transform
- __getitem__
- cleanup_cache_files
- map
- filter
- select
- sort
- shuffle
- train_test_split
- shard
- to_tf_dataset
- push_to_hub
- save_to_disk
- load_from_disk
- flatten_indices
- to_csv
- to_pandas
- to_dict
- to_json
- to_parquet
- to_sql
- to_iterable_dataset
- add_faiss_index
- add_faiss_index_from_external_arrays
- save_faiss_index
- load_faiss_index
- add_elasticsearch_index
- load_elasticsearch_index
- list_indexes
- get_index
- drop_index
- search
- search_batch
- get_nearest_examples
- get_nearest_examples_batch
- info
- split
- builder_name
- citation
- config_name
- dataset_size
- description
- download_checksums
- download_size
- features
- homepage
- license
- size_in_bytes
- supervised_keys
- version
- from_csv
- from_json
- from_parquet
- from_text
- from_sql
- prepare_for_task
- align_labels_with_mapping
[[autodoc]] datasets.concatenate_datasets
[[autodoc]] datasets.interleave_datasets
[[autodoc]] datasets.distributed.split_dataset_by_node
[[autodoc]] datasets.enable_caching
[[autodoc]] datasets.disable_caching
[[autodoc]] datasets.is_caching_enabled
## DatasetDict
Dictionary with split names as keys ('train', 'test' for example), and `Dataset` objects as values.
It also has dataset transform methods like map or filter, to process all the splits at once.
[[autodoc]] datasets.DatasetDict
- data
- cache_files
- num_columns
- num_rows
- column_names
- shape
- unique
- cleanup_cache_files
- map
- filter
- sort
- shuffle
- set_format
- reset_format
- formatted_as
- with_format
- with_transform
- flatten
- cast
- cast_column
- remove_columns
- rename_column
- rename_columns
- select_columns
- class_encode_column
- push_to_hub
- save_to_disk
- load_from_disk
- from_csv
- from_json
- from_parquet
- from_text
- prepare_for_task
<a id='package_reference_features'></a>
## IterableDataset
The base class [`IterableDataset`] implements an iterable Dataset backed by python generators.
[[autodoc]] datasets.IterableDataset
- from_generator
- remove_columns
- select_columns
- cast_column
- cast
- __iter__
- iter
- map
- rename_column
- filter
- shuffle
- skip
- take
- info
- split
- builder_name
- citation
- config_name
- dataset_size
- description
- download_checksums
- download_size
- features
- homepage
- license
- size_in_bytes
- supervised_keys
- version
## IterableDatasetDict
Dictionary with split names as keys ('train', 'test' for example), and `IterableDataset` objects as values.
[[autodoc]] datasets.IterableDatasetDict
- map
- filter
- shuffle
- with_format
- cast
- cast_column
- remove_columns
- rename_column
- rename_columns
- select_columns
## Features
[[autodoc]] datasets.Features
[[autodoc]] datasets.Sequence
[[autodoc]] datasets.ClassLabel
[[autodoc]] datasets.Value
[[autodoc]] datasets.Translation
[[autodoc]] datasets.TranslationVariableLanguages
[[autodoc]] datasets.Array2D
[[autodoc]] datasets.Array3D
[[autodoc]] datasets.Array4D
[[autodoc]] datasets.Array5D
[[autodoc]] datasets.Audio
[[autodoc]] datasets.Image
## MetricInfo
[[autodoc]] datasets.MetricInfo
## Metric
The base class `Metric` implements a Metric backed by one or several [`Dataset`].
[[autodoc]] datasets.Metric
## Filesystems
[[autodoc]] datasets.filesystems.S3FileSystem
[[autodoc]] datasets.filesystems.extract_path_from_uri
[[autodoc]] datasets.filesystems.is_remote_filesystem
## Fingerprint
[[autodoc]] datasets.fingerprint.Hasher
| huggingface/datasets/blob/main/docs/source/package_reference/main_classes.mdx |
What is RL? A short recap [[what-is-rl]]
In RL, we build an agent that can **make smart decisions**. For instance, an agent that **learns to play a video game.** Or a trading agent that **learns to maximize its benefits** by deciding on **what stocks to buy and when to sell.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/rl-process.jpg" alt="RL process"/>
To make intelligent decisions, our agent will learn from the environment by **interacting with it through trial and error** and receiving rewards (positive or negative) **as unique feedback.**
Its goal **is to maximize its expected cumulative reward** (because of the reward hypothesis).
**The agent's decision-making process is called the policy π:** given a state, a policy will output an action or a probability distribution over actions. That is, given an observation of the environment, a policy will provide an action (or multiple probabilities for each action) that the agent should take.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/policy.jpg" alt="Policy"/>
**Our goal is to find an optimal policy π* **, aka., a policy that leads to the best expected cumulative reward.
And to find this optimal policy (hence solving the RL problem), there **are two main types of RL methods**:
- *Policy-based methods*: **Train the policy directly** to learn which action to take given a state.
- *Value-based methods*: **Train a value function** to learn **which state is more valuable** and use this value function **to take the action that leads to it.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/two-approaches.jpg" alt="Two RL approaches"/>
And in this unit, **we'll dive deeper into the value-based methods.**
| huggingface/deep-rl-class/blob/main/units/en/unit2/what-is-rl.mdx |
--
title: "AI Policy @🤗: Open ML Considerations in the EU AI Act"
thumbnail: /blog/assets/eu_ai_act_oss/thumbnailEU.png
authors:
- user: yjernite
---
# AI Policy @🤗: Open ML Considerations in the EU AI Act
Like everyone else in Machine Learning, we’ve been following the EU AI Act closely at Hugging Face.
It’s a ground-breaking piece of legislation that is poised to shape how democratic inputs interact with AI technology development around the world.
It’s also the outcome of extensive work and negotiations between organizations representing many different components of society –
a process we’re particularly sensitive to as a community-driven company.
In the present <a href="/blog/assets/eu_ai_act_oss/supporting_OS_in_the_AIAct.pdf">position paper</a> written in coalition with [Creative Commons](https://creativecommons.org/),
[Eleuther AI](https://www.eleuther.ai/), [GitHub](https://github.com/), [LAION](https://laion.ai/), and [Open Future](http://openfuture.eu/),
we aim to contribute to this process by sharing our experience of the necessary role of open ML development
in supporting the goals of the Act – and conversely, by outlining specific ways in which the regulation
can better account for the needs of open, modular, and collaborative ML development.
Hugging Face is where it is today thanks to its community of developers, so we’ve seen firsthand what open development brings to the table
to support more robust innovation for more diverse and context-specific use cases;
where developers can easily share innovative new techniques, mix and match ML components to suit their own needs,
and reliably work with full visibility into their entire stack.
We’re also acutely aware of the necessary role of transparency in supporting more accountability and inclusivity of the technology –
which we’ve worked on fostering through better documentation and accessibility of ML artifacts, education efforts,
and hosting large-scale multidisciplinary collaborations, among others.
Thus, as the EU AI Act moves toward its final phase, we believe accounting for the specific needs and strengths of open and open-source development of ML systems will be instrumental in supporting its long-term goals.
Along with our co-signed partner organizations, we make the following five recommendations to that end:
1. Define AI components clearly,
2. Clarify that collaborative development of open source AI components and making them available in public repositories does not subject developers to the requirements in the AI Act, building on and improving the Parliament text’s Recitals 12a-c and Article 2(5e),
3. Support the AI Office’s coordination and inclusive governance with the open source ecosystem, building on the Parliament’s text,
4. Ensure the R&D exception is practical and effective, by permitting limited testing in real-world conditions, combining aspects of the Council’s approach and an amended version of the Parliament’s Article 2(5d),
5. Set proportional requirements for “foundation models,” recognizing and distinctly treating different uses and development modalities, including open source approaches, tailoring the Parliament’s Article 28b.
You can find more detail and context for those in the <a href="/blog/assets/eu_ai_act_oss/supporting_OS_in_the_AIAct.pdf">full paper here!</a>
| huggingface/blog/blob/main/eu-ai-act-oss.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Train with a script
Along with the 🤗 Transformers [notebooks](./noteboks/README), there are also example scripts demonstrating how to train a model for a task with [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
You will also find scripts we've used in our [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects) and [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy) which are mostly community contributed. These scripts are not actively maintained and require a specific version of 🤗 Transformers that will most likely be incompatible with the latest version of the library.
The example scripts are not expected to work out-of-the-box on every problem, and you may need to adapt the script to the problem you're trying to solve. To help you with this, most of the scripts fully expose how data is preprocessed, allowing you to edit it as necessary for your use case.
For any feature you'd like to implement in an example script, please discuss it on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) before submitting a Pull Request. While we welcome bug fixes, it is unlikely we will merge a Pull Request that adds more functionality at the cost of readability.
This guide will show you how to run an example summarization training script in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). All examples are expected to work with both frameworks unless otherwise specified.
## Setup
To successfully run the latest version of the example scripts, you have to **install 🤗 Transformers from source** in a new virtual environment:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
For older versions of the example scripts, click on the toggle below:
<details>
<summary>Examples for older versions of 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
```bash
git checkout tags/v3.5.1
```
After you've setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
```bash
pip install -r requirements.txt
```
## Run a script
<frameworkcontent>
<pt>
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset with the [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset using Keras on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Distributed training and mixed precision
The [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supports distributed training and mixed precision, which means you can also use it in a script. To enable both of these features:
- Add the `fp16` argument to enable mixed precision.
- Set the number of GPUs to use with the `nproc_per_node` argument.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
TensorFlow scripts utilize a [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) for distributed training, and you don't need to add any additional arguments to the training script. The TensorFlow script will use multiple GPUs by default if they are available.
## Run a script on a TPU
<frameworkcontent>
<pt>
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. PyTorch supports TPUs with the [XLA](https://www.tensorflow.org/xla) deep learning compiler (see [here](https://github.com/pytorch/xla/blob/master/README.md) for more details). To use a TPU, launch the `xla_spawn.py` script and use the `num_cores` argument to set the number of TPU cores you want to use.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. TensorFlow scripts utilize a [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) for training on TPUs. To use a TPU, pass the name of the TPU resource to the `tpu` argument.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Run a script with 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) is a PyTorch-only library that offers a unified method for training a model on several types of setups (CPU-only, multiple GPUs, TPUs) while maintaining complete visibility into the PyTorch training loop. Make sure you have 🤗 Accelerate installed if you don't already have it:
> Note: As Accelerate is rapidly developing, the git version of accelerate must be installed to run the scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
Instead of the `run_summarization.py` script, you need to use the `run_summarization_no_trainer.py` script. 🤗 Accelerate supported scripts will have a `task_no_trainer.py` file in the folder. Begin by running the following command to create and save a configuration file:
```bash
accelerate config
```
Test your setup to make sure it is configured correctly:
```bash
accelerate test
```
Now you are ready to launch the training:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Use a custom dataset
The summarization script supports custom datasets as long as they are a CSV or JSON Line file. When you use your own dataset, you need to specify several additional arguments:
- `train_file` and `validation_file` specify the path to your training and validation files.
- `text_column` is the input text to summarize.
- `summary_column` is the target text to output.
A summarization script using a custom dataset would look like this:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Test a script
It is often a good idea to run your script on a smaller number of dataset examples to ensure everything works as expected before committing to an entire dataset which may take hours to complete. Use the following arguments to truncate the dataset to a maximum number of samples:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Not all example scripts support the `max_predict_samples` argument. If you aren't sure whether your script supports this argument, add the `-h` argument to check:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Resume training from checkpoint
Another helpful option to enable is resuming training from a previous checkpoint. This will ensure you can pick up where you left off without starting over if your training gets interrupted. There are two methods to resume training from a checkpoint.
The first method uses the `output_dir previous_output_dir` argument to resume training from the latest checkpoint stored in `output_dir`. In this case, you should remove `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
The second method uses the `resume_from_checkpoint path_to_specific_checkpoint` argument to resume training from a specific checkpoint folder.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Share your model
All scripts can upload your final model to the [Model Hub](https://huggingface.co/models). Make sure you are logged into Hugging Face before you begin:
```bash
huggingface-cli login
```
Then add the `push_to_hub` argument to the script. This argument will create a repository with your Hugging Face username and the folder name specified in `output_dir`.
To give your repository a specific name, use the `push_to_hub_model_id` argument to add it. The repository will be automatically listed under your namespace.
The following example shows how to upload a model with a specific repository name:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
``` | huggingface/transformers/blob/main/docs/source/en/run_scripts.md |
Argilla on Spaces
**Argilla** is an open-source, data labelling tool, for highly efficient human-in-the-loop and MLOps workflows. Argilla is composed of (1) a server and webapp for data labelling, and curation, and (2) a Python SDK for building data annotation workflows in Python. Argilla nicely integrates with the Hugging Face stack (`datasets`, `transformers`, `hub`, and `setfit`), and now it can also be deployed using the Hub's Docker Spaces.
Visit the [Argilla documentation](https://docs.argilla.io) to learn about its features and check out the [Deep Dive Guides](https://docs.argilla.io/en/latest/guides/guides.html) and [Tutorials](https://docs.argilla.io/en/latest/tutorials/tutorials.html).
In the next sections, you'll learn to deploy your own Argilla app and use it for data labelling workflows right from the Hub. This Argilla app is a **self-contained application completely hosted on the Hub using Docker**. The diagram below illustrates the complete process.
<div class="flex justify-center">
<img src="https://www.argilla.io/blog/hf_space/how.svg"/>
</div>
## Deploy Argilla on Spaces
You can deploy Argilla on Spaces with just a few clicks:
<a href="https://huggingface.co/new-space?template=argilla/argilla-template-space">
<img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/deploy-to-spaces-lg.svg" />
</a>
<Tip>
**IMPORTANT NOTE ABOUT DATA PERSISTENCE:**
You can use the Argilla Quickstart Space as is for initial exploration and experimentation. For **longer use in small-scale projects, activate the paid persistent storage option**. This prevents data loss during Space restarts every 24 hours. If not using persistent storage, safeguard your data with Argilla Python SDK by storing it elsewhere. In this case, we gently remind you that the responsibility for maintaining your data's safety becomes yours.
</Tip>
You need to define the **Owner** (your personal account or an organization), a **Space name**, and the **Visibility**. To interact with the Argilla app with Python, you need to set up the visibility to `Public`.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-argilla-new-space.png"/>
</div>
<Tip>
If you want to customize the title, emojis, and colors of your space, go to "Files and Versions" and edit the metadata of your README.md file.
</Tip>
Once you have created the Space, you'll see the `Building` status and once it becomes `Running` your space is ready to go if you don't see the Argilla login UI refresh the page.
The Space is configured with **two users**: **argilla** and **admin** with the same default password: **12345678**. If you get a 500 error after login, make sure you have correctly introduced the user and password. To secure your Space, you can change the passwords and API keys using secret variables as explained in the next section.
## Set up passwords and API keys using secrets (optional)
<Tip>
For quick experimentation, you can jump directly into the next section. If you want to secure your space and for longer-term usage, setting up secret variables is recommended.
</Tip>
## Setting up secret environment variables
The Space template provides a way to set up different **optional settings** focusing on securing your Argilla Space.
To set up these secrets, you can go to the Settings tab on your created Space. Make sure to save these values somewhere for later use.
The template Space has two users: `admin` and `argilla`. The username `admin` corresponds to the root user, who can upload datasets and access any workspace within your Argilla Space. The username `argilla` is a normal user with access to the `argilla` workspace.
The usernames, passwords, and API keys to upload, read, update, and delete datasets can be configured using the following secrets:
- `ADMIN_USERNAME`: The admin username to log in Argilla. The default admin username is `admin`. By setting up
a custom username you can use your own username to log in to the app.
- `ADMIN_API_KEY`: Argilla provides a Python library to interact with the app (read, write, and update data, log model
predictions, etc.). If you don't set this variable, the library and your app will use the default API key
i.e. `admin.apikey`. If you want to secure your app for reading and writing data, we recommend you to set up this
variable. The API key can be any string of your choice. You can check an online generator if you like.
- `ADMIN_PASSWORD`: This sets a custom password to log in to the app with the `argilla` username. The default
password is `12345678`. By setting up a custom password you can use your own password to log in to the app.
- `ANNOTATOR_USERNAME`: The annotator username to log in to Argilla. The default annotator username is `argilla`. By setting up
a custom username you can use your own username to log in to the app.
- `ANNOTATOR_PASSWORD`: This sets a custom password to log in to the app with the `argilla` username. The default password
is `12345678`. By setting up a custom password you can use your own password to log in to the app.
The combination of these secret variables gives you the following setup options:
1. *I want to avoid that anyone without the API keys adds, deletes, or updates datasets using the Python client*: You need to setup `ADMIN_PASSWORD` and `ADMIN_API_KEY`.
2. *Additionally, I want to avoid that the `argilla` username deletes datasets from the UI*: You need to setup `ANNOTATOR_PASSWORD` and use the `argilla` generated API key with the Python Client (check your Space logs). This option might be interesting if you want to control dataset management but want anyone to browse your datasets using the `argilla` user.
3. *Additionally, I want to avoid that anyone without password browses my datasets with the `argilla` user*: You need to setup `ANNOTATOR_PASSWORD`. In this case, you can use the `argilla` generated API key and/or `ADMIN_API_KEY` values with the Python Client depending on your needs for dataset deletion rights.
Additionally, the `LOAD_DATASETS` will let you configure the sample datasets that will be pre-loaded. The default value is `single` and the supported values for this variable are:
1. `single`: Load single datasets for TextClassification task.
2. `full`: Load all the sample datasets for NLP tasks (TokenClassification, TextClassification, Text2Text)
3. `none`: No datasets being loaded.
## How to upload data
Once your Argilla Space is running:
1. You need to find the **Space Direct URL under the "Embed this Space"** option (top right, see screenshot below).
2. This URL gives you access to a full-screen Argilla UI for data labelling. The **Direct URL is the api_url parameter** for connecting the argilla Python client in order to read and write data programmatically.
3. You are now ready to **upload your first dataset into Argilla**.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/spaces-argilla-embed-space.png"/>
</div>
<Tip>
Argilla Datasets cannot be uploaded directly from the UI. Most Argilla users upload datasets programmatically using the argilla Python library but you can also use Argilla Data Manager, a simple Streamlit app.
</Tip>
For uploading Argilla datasets, there are two options:
1. You can use the **argilla Python library** inside Jupyter, Colab, VS Code, or other Python IDE. In this case, you will read read your source file (`csv`, `json`, etc.) and transform it into Argilla records. We recommend to read the [basics guide](https://docs.argilla.io/en/latest/guides/how_to.html).
2. You can use the **[no-code data manager app](https://huggingface.co/spaces/argilla/data-manager)** to upload a file and log it into Argilla. If you need to transform your dataset before uploading it into Argilla, we recommend the first option.
To follow a complete tutorial with Colab or Jupyter, [check this tutorial](https://docs.argilla.io/en/latest/tutorials/notebooks/training-textclassification-setfit-fewshot.html). For a quick step-by-step example using the `argilla` Python library, keep reading.
First, you need to open a Python IDE, we highly recommend using Jupyter notebooks or Colab.
Second, you need to `pip` install `datasets` and `argilla` on Colab or your local machine:
```bash
pip install datasets argilla
```
Third, you need to read the dataset using the `datasets` library. For reading other file types, check the [basics guide](https://docs.argilla.io/en/latest/guides/how_to.html).
```python
from datasets import load_dataset
dataset = load_dataset("dvilasuero/banking_app", split="train").shuffle()
```
Fourth, you need to init the `argilla` client with your Space URL and API key and upload the records into Argilla:
```python
import argilla as rg
from datasets import load_dataset
# You can find your Space URL behind the Embed this space button
rg.init(
api_url="<https://your-direct-space-url.hf.space>",
api_key="admin.apikey" # this is the real API key default value
)
banking_ds = load_dataset("argilla/banking_sentiment_setfit", split="train")
# Argilla expects labels in the annotation column
# We include labels for demo purposes
banking_ds = banking_ds.rename_column("label", "annotation")
# Build argilla dataset from datasets
argilla_ds = rg.read_datasets(banking_ds, task="TextClassification")
# Create dataset
rg.log(argilla_ds, "bankingapp_sentiment")
```
Congrats! Your dataset is available in the Argilla UI for data labeling. Once you have labelled some data, you can train your first model by reading the dataset using Python.
## How to train a model with labelled data
In this example, we use SetFit, but you can use any other model for training.
To train a model using your labeled data, you need to read the labelled dataset and prepare it for training:
```python
# this will read the dataset and turn it into a clean dataset for training
dataset = rg.load("bankingapp_sentiment").prepare_for_training()
```
To train a SetFit model with this dataset:
```python
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
# Create train test split
dataset = dataset.train_test_split()
# Load SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
loss_class=CosineSimilarityLoss,
batch_size=8,
num_iterations=20,
)
# Train and evaluate
trainer.train()
metrics = trainer.evaluate()
```
Optionally, you can push the dataset to the Hub for later use:
```python
# save full argilla dataset for reproducibility
rg.load("bankingapp_sentiment").to_datasets().push_to_hub("bankingapp_sentiment")
```
As a next step, check out the [Argilla Tutorials](https://docs.argilla.io/en/latest/tutorials/tutorials.html) section. All the tutorials can be run using Colab or local Jupyter Notebooks.
## Feedback and support
If you have suggestions or need specific support, please join [Argilla Slack community](https://join.slack.com/t/rubrixworkspace/shared_invite/zt-whigkyjn-a3IUJLD7gDbTZ0rKlvcJ5g) or reach out on [Argilla's GitHub repository](https://github.com/argilla-io/argilla). | huggingface/hub-docs/blob/main/docs/hub/spaces-sdks-docker-argilla.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Create a custom architecture
An [`AutoClass`](model_doc/auto) automatically infers the model architecture and downloads pretrained configuration and weights. Generally, we recommend using an `AutoClass` to produce checkpoint-agnostic code. But users who want more control over specific model parameters can create a custom 🤗 Transformers model from just a few base classes. This could be particularly useful for anyone who is interested in studying, training or experimenting with a 🤗 Transformers model. In this guide, dive deeper into creating a custom model without an `AutoClass`. Learn how to:
- Load and customize a model configuration.
- Create a model architecture.
- Create a slow and fast tokenizer for text.
- Create an image processor for vision tasks.
- Create a feature extractor for audio tasks.
- Create a processor for multimodal tasks.
## Configuration
A [configuration](main_classes/configuration) refers to a model's specific attributes. Each model configuration has different attributes; for instance, all NLP models have the `hidden_size`, `num_attention_heads`, `num_hidden_layers` and `vocab_size` attributes in common. These attributes specify the number of attention heads or hidden layers to construct a model with.
Get a closer look at [DistilBERT](model_doc/distilbert) by accessing [`DistilBertConfig`] to inspect it's attributes:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] displays all the default attributes used to build a base [`DistilBertModel`]. All attributes are customizable, creating space for experimentation. For example, you can customize a default model to:
- Try a different activation function with the `activation` parameter.
- Use a higher dropout ratio for the attention probabilities with the `attention_dropout` parameter.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Pretrained model attributes can be modified in the [`~PretrainedConfig.from_pretrained`] function:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Once you are satisfied with your model configuration, you can save it with [`~PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
To reuse the configuration file, load it with [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
```
<Tip>
You can also save your configuration file as a dictionary or even just the difference between your custom configuration attributes and the default configuration attributes! See the [configuration](main_classes/configuration) documentation for more details.
</Tip>
## Model
The next step is to create a [model](main_classes/models). The model - also loosely referred to as the architecture - defines what each layer is doing and what operations are happening. Attributes like `num_hidden_layers` from the configuration are used to define the architecture. Every model shares the base class [`PreTrainedModel`] and a few common methods like resizing input embeddings and pruning self-attention heads. In addition, all models are also either a [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) or [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) subclass. This means models are compatible with each of their respective framework's usage.
<frameworkcontent>
<pt>
Load your custom configuration attributes into the model:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)
```
This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Load your custom configuration attributes into the model:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
This creates a model with random values instead of pretrained weights. You won't be able to use this model for anything useful yet until you train it. Training is a costly and time-consuming process. It is generally better to use a pretrained model to obtain better results faster, while using only a fraction of the resources required for training.
Create a pretrained model with [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
When you load pretrained weights, the default model configuration is automatically loaded if the model is provided by 🤗 Transformers. However, you can still replace - some or all of - the default model configuration attributes with your own if you'd like:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Model heads
At this point, you have a base DistilBERT model which outputs the *hidden states*. The hidden states are passed as inputs to a model head to produce the final output. 🤗 Transformers provides a different model head for each task as long as a model supports the task (i.e., you can't use DistilBERT for a sequence-to-sequence task like translation).
<frameworkcontent>
<pt>
For example, [`DistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`DistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
For example, [`TFDistilBertForSequenceClassification`] is a base DistilBERT model with a sequence classification head. The sequence classification head is a linear layer on top of the pooled outputs.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Easily reuse this checkpoint for another task by switching to a different model head. For a question answering task, you would use the [`TFDistilBertForQuestionAnswering`] model head. The question answering head is similar to the sequence classification head except it is a linear layer on top of the hidden states output.
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
The last base class you need before using a model for textual data is a [tokenizer](main_classes/tokenizer) to convert raw text to tensors. There are two types of tokenizers you can use with 🤗 Transformers:
- [`PreTrainedTokenizer`]: a Python implementation of a tokenizer.
- [`PreTrainedTokenizerFast`]: a tokenizer from our Rust-based [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) library. This tokenizer type is significantly faster - especially during batch tokenization - due to its Rust implementation. The fast tokenizer also offers additional methods like *offset mapping* which maps tokens to their original words or characters.
Both tokenizers support common methods such as encoding and decoding, adding new tokens, and managing special tokens.
<Tip warning={true}>
Not every model supports a fast tokenizer. Take a look at this [table](index#supported-frameworks) to check if a model has fast tokenizer support.
</Tip>
If you trained your own tokenizer, you can create one from your *vocabulary* file:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
It is important to remember the vocabulary from a custom tokenizer will be different from the vocabulary generated by a pretrained model's tokenizer. You need to use a pretrained model's vocabulary if you are using a pretrained model, otherwise the inputs won't make sense. Create a tokenizer with a pretrained model's vocabulary with the [`DistilBertTokenizer`] class:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
Create a fast tokenizer with the [`DistilBertTokenizerFast`] class:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
By default, [`AutoTokenizer`] will try to load a fast tokenizer. You can disable this behavior by setting `use_fast=False` in `from_pretrained`.
</Tip>
## Image Processor
An image processor processes vision inputs. It inherits from the base [`~image_processing_utils.ImageProcessingMixin`] class.
To use, create an image processor associated with the model you're using. For example, create a default [`ViTImageProcessor`] if you are using [ViT](model_doc/vit) for image classification:
```py
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default image processor parameters.
</Tip>
Modify any of the [`ViTImageProcessor`] parameters to create your custom image processor:
```py
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
## Feature Extractor
A feature extractor processes audio inputs. It inherits from the base [`~feature_extraction_utils.FeatureExtractionMixin`] class, and may also inherit from the [`SequenceFeatureExtractor`] class for processing audio inputs.
To use, create a feature extractor associated with the model you're using. For example, create a default [`Wav2Vec2FeatureExtractor`] if you are using [Wav2Vec2](model_doc/wav2vec2) for audio classification:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
<Tip>
If you aren't looking for any customization, just use the `from_pretrained` method to load a model's default feature extractor parameters.
</Tip>
Modify any of the [`Wav2Vec2FeatureExtractor`] parameters to create your custom feature extractor:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}
```
## Processor
For models that support multimodal tasks, 🤗 Transformers offers a processor class that conveniently wraps processing classes such as a feature extractor and a tokenizer into a single object. For example, let's use the [`Wav2Vec2Processor`] for an automatic speech recognition task (ASR). ASR transcribes audio to text, so you will need a feature extractor and a tokenizer.
Create a feature extractor to handle the audio inputs:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Create a tokenizer to handle the text inputs:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Combine the feature extractor and tokenizer in [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
With two basic classes - configuration and model - and an additional preprocessing class (tokenizer, image processor, feature extractor, or processor), you can create any of the models supported by 🤗 Transformers. Each of these base classes are configurable, allowing you to use the specific attributes you want. You can easily setup a model for training or modify an existing pretrained model to fine-tune.
| huggingface/transformers/blob/main/docs/source/en/create_a_model.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Overview
🤗 Diffusers provides a collection of training scripts for you to train your own diffusion models. You can find all of our training scripts in [diffusers/examples](https://github.com/huggingface/diffusers/tree/main/examples).
Each training script is:
- **Self-contained**: the training script does not depend on any local files, and all packages required to run the script are installed from the `requirements.txt` file.
- **Easy-to-tweak**: the training scripts are an example of how to train a diffusion model for a specific task and won't work out-of-the-box for every training scenario. You'll likely need to adapt the training script for your specific use-case. To help you with that, we've fully exposed the data preprocessing code and the training loop so you can modify it for your own use.
- **Beginner-friendly**: the training scripts are designed to be beginner-friendly and easy to understand, rather than including the latest state-of-the-art methods to get the best and most competitive results. Any training methods we consider too complex are purposefully left out.
- **Single-purpose**: each training script is expressly designed for only one task to keep it readable and understandable.
Our current collection of training scripts include:
| Training | SDXL-support | LoRA-support | Flax-support |
|---|---|---|---|
| [unconditional image generation](https://github.com/huggingface/diffusers/tree/main/examples/unconditional_image_generation) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) | | | |
| [text-to-image](https://github.com/huggingface/diffusers/tree/main/examples/text_to_image) | 👍 | 👍 | 👍 |
| [textual inversion](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb) | | | 👍 |
| [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb) | 👍 | 👍 | 👍 |
| [ControlNet](https://github.com/huggingface/diffusers/tree/main/examples/controlnet) | 👍 | | 👍 |
| [InstructPix2Pix](https://github.com/huggingface/diffusers/tree/main/examples/instruct_pix2pix) | 👍 | | |
| [Custom Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/custom_diffusion) | | | |
| [T2I-Adapters](https://github.com/huggingface/diffusers/tree/main/examples/t2i_adapter) | 👍 | | |
| [Kandinsky 2.2](https://github.com/huggingface/diffusers/tree/main/examples/kandinsky2_2/text_to_image) | | 👍 | |
| [Wuerstchen](https://github.com/huggingface/diffusers/tree/main/examples/wuerstchen/text_to_image) | | 👍 | |
These examples are **actively** maintained, so please feel free to open an issue if they aren't working as expected. If you feel like another training example should be included, you're more than welcome to start a [Feature Request](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=) to discuss your feature idea with us and whether it meets our criteria of being self-contained, easy-to-tweak, beginner-friendly, and single-purpose.
## Install
Make sure you can successfully run the latest versions of the example scripts by installing the library from source in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the folder of the training script (for example, [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth)) and install the `requirements.txt` file. Some training scripts have a specific requirement file for SDXL, LoRA or Flax. If you're using one of these scripts, make sure you install its corresponding requirements file.
```bash
cd examples/dreambooth
pip install -r requirements.txt
# to train SDXL with DreamBooth
pip install -r requirements_sdxl.txt
```
To speedup training and reduce memory-usage, we recommend:
- using PyTorch 2.0 or higher to automatically use [scaled dot product attention](../optimization/torch2.0#scaled-dot-product-attention) during training (you don't need to make any changes to the training code)
- installing [xFormers](../optimization/xformers) to enable memory-efficient attention | huggingface/diffusers/blob/main/docs/source/en/training/overview.md |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Text2Video-Zero
[Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators](https://huggingface.co/papers/2303.13439) is by Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, [Zhangyang Wang](https://www.ece.utexas.edu/people/faculty/atlas-wang), Shant Navasardyan, [Humphrey Shi](https://www.humphreyshi.com).
Text2Video-Zero enables zero-shot video generation using either:
1. A textual prompt
2. A prompt combined with guidance from poses or edges
3. Video Instruct-Pix2Pix (instruction-guided video editing)
Results are temporally consistent and closely follow the guidance and textual prompts.

The abstract from the paper is:
*Recent text-to-video generation approaches rely on computationally heavy training and require large-scale video datasets. In this paper, we introduce a new task of zero-shot text-to-video generation and propose a low-cost approach (without any training or optimization) by leveraging the power of existing text-to-image synthesis methods (e.g., Stable Diffusion), making them suitable for the video domain.
Our key modifications include (i) enriching the latent codes of the generated frames with motion dynamics to keep the global scene and the background time consistent; and (ii) reprogramming frame-level self-attention using a new cross-frame attention of each frame on the first frame, to preserve the context, appearance, and identity of the foreground object.
Experiments show that this leads to low overhead, yet high-quality and remarkably consistent video generation. Moreover, our approach is not limited to text-to-video synthesis but is also applicable to other tasks such as conditional and content-specialized video generation, and Video Instruct-Pix2Pix, i.e., instruction-guided video editing.
As experiments show, our method performs comparably or sometimes better than recent approaches, despite not being trained on additional video data.*
You can find additional information about Text2Video-Zero on the [project page](https://text2video-zero.github.io/), [paper](https://arxiv.org/abs/2303.13439), and [original codebase](https://github.com/Picsart-AI-Research/Text2Video-Zero).
## Usage example
### Text-To-Video
To generate a video from prompt, run the following Python code:
```python
import torch
from diffusers import TextToVideoZeroPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = TextToVideoZeroPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
prompt = "A panda is playing guitar on times square"
result = pipe(prompt=prompt).images
result = [(r * 255).astype("uint8") for r in result]
imageio.mimsave("video.mp4", result, fps=4)
```
You can change these parameters in the pipeline call:
* Motion field strength (see the [paper](https://arxiv.org/abs/2303.13439), Sect. 3.3.1):
* `motion_field_strength_x` and `motion_field_strength_y`. Default: `motion_field_strength_x=12`, `motion_field_strength_y=12`
* `T` and `T'` (see the [paper](https://arxiv.org/abs/2303.13439), Sect. 3.3.1)
* `t0` and `t1` in the range `{0, ..., num_inference_steps}`. Default: `t0=45`, `t1=48`
* Video length:
* `video_length`, the number of frames video_length to be generated. Default: `video_length=8`
We can also generate longer videos by doing the processing in a chunk-by-chunk manner:
```python
import torch
from diffusers import TextToVideoZeroPipeline
import numpy as np
model_id = "runwayml/stable-diffusion-v1-5"
pipe = TextToVideoZeroPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
seed = 0
video_length = 24 #24 ÷ 4fps = 6 seconds
chunk_size = 8
prompt = "A panda is playing guitar on times square"
# Generate the video chunk-by-chunk
result = []
chunk_ids = np.arange(0, video_length, chunk_size - 1)
generator = torch.Generator(device="cuda")
for i in range(len(chunk_ids)):
print(f"Processing chunk {i + 1} / {len(chunk_ids)}")
ch_start = chunk_ids[i]
ch_end = video_length if i == len(chunk_ids) - 1 else chunk_ids[i + 1]
# Attach the first frame for Cross Frame Attention
frame_ids = [0] + list(range(ch_start, ch_end))
# Fix the seed for the temporal consistency
generator.manual_seed(seed)
output = pipe(prompt=prompt, video_length=len(frame_ids), generator=generator, frame_ids=frame_ids)
result.append(output.images[1:])
# Concatenate chunks and save
result = np.concatenate(result)
result = [(r * 255).astype("uint8") for r in result]
imageio.mimsave("video.mp4", result, fps=4)
```
- #### SDXL Support
In order to use the SDXL model when generating a video from prompt, use the `TextToVideoZeroSDXLPipeline` pipeline:
```python
import torch
from diffusers import TextToVideoZeroSDXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = TextToVideoZeroSDXLPipeline.from_pretrained(
model_id, torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
```
### Text-To-Video with Pose Control
To generate a video from prompt with additional pose control
1. Download a demo video
```python
from huggingface_hub import hf_hub_download
filename = "__assets__/poses_skeleton_gifs/dance1_corr.mp4"
repo_id = "PAIR/Text2Video-Zero"
video_path = hf_hub_download(repo_type="space", repo_id=repo_id, filename=filename)
```
2. Read video containing extracted pose images
```python
from PIL import Image
import imageio
reader = imageio.get_reader(video_path, "ffmpeg")
frame_count = 8
pose_images = [Image.fromarray(reader.get_data(i)) for i in range(frame_count)]
```
To extract pose from actual video, read [ControlNet documentation](controlnet).
3. Run `StableDiffusionControlNetPipeline` with our custom attention processor
```python
import torch
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.pipelines.text_to_video_synthesis.pipeline_text_to_video_zero import CrossFrameAttnProcessor
model_id = "runwayml/stable-diffusion-v1-5"
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id, controlnet=controlnet, torch_dtype=torch.float16
).to("cuda")
# Set the attention processor
pipe.unet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
pipe.controlnet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
# fix latents for all frames
latents = torch.randn((1, 4, 64, 64), device="cuda", dtype=torch.float16).repeat(len(pose_images), 1, 1, 1)
prompt = "Darth Vader dancing in a desert"
result = pipe(prompt=[prompt] * len(pose_images), image=pose_images, latents=latents).images
imageio.mimsave("video.mp4", result, fps=4)
```
- #### SDXL Support
Since our attention processor also works with SDXL, it can be utilized to generate a video from prompt using ControlNet models powered by SDXL:
```python
import torch
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel
from diffusers.pipelines.text_to_video_synthesis.pipeline_text_to_video_zero import CrossFrameAttnProcessor
controlnet_model_id = 'thibaud/controlnet-openpose-sdxl-1.0'
model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
controlnet = ControlNetModel.from_pretrained(controlnet_model_id, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id, controlnet=controlnet, torch_dtype=torch.float16
).to('cuda')
# Set the attention processor
pipe.unet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
pipe.controlnet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
# fix latents for all frames
latents = torch.randn((1, 4, 128, 128), device="cuda", dtype=torch.float16).repeat(len(pose_images), 1, 1, 1)
prompt = "Darth Vader dancing in a desert"
result = pipe(prompt=[prompt] * len(pose_images), image=pose_images, latents=latents).images
imageio.mimsave("video.mp4", result, fps=4)
```
### Text-To-Video with Edge Control
To generate a video from prompt with additional Canny edge control, follow the same steps described above for pose-guided generation using [Canny edge ControlNet model](https://huggingface.co/lllyasviel/sd-controlnet-canny).
### Video Instruct-Pix2Pix
To perform text-guided video editing (with [InstructPix2Pix](pix2pix)):
1. Download a demo video
```python
from huggingface_hub import hf_hub_download
filename = "__assets__/pix2pix video/camel.mp4"
repo_id = "PAIR/Text2Video-Zero"
video_path = hf_hub_download(repo_type="space", repo_id=repo_id, filename=filename)
```
2. Read video from path
```python
from PIL import Image
import imageio
reader = imageio.get_reader(video_path, "ffmpeg")
frame_count = 8
video = [Image.fromarray(reader.get_data(i)) for i in range(frame_count)]
```
3. Run `StableDiffusionInstructPix2PixPipeline` with our custom attention processor
```python
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
from diffusers.pipelines.text_to_video_synthesis.pipeline_text_to_video_zero import CrossFrameAttnProcessor
model_id = "timbrooks/instruct-pix2pix"
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.unet.set_attn_processor(CrossFrameAttnProcessor(batch_size=3))
prompt = "make it Van Gogh Starry Night style"
result = pipe(prompt=[prompt] * len(video), image=video).images
imageio.mimsave("edited_video.mp4", result, fps=4)
```
### DreamBooth specialization
Methods **Text-To-Video**, **Text-To-Video with Pose Control** and **Text-To-Video with Edge Control**
can run with custom [DreamBooth](../../training/dreambooth) models, as shown below for
[Canny edge ControlNet model](https://huggingface.co/lllyasviel/sd-controlnet-canny) and
[Avatar style DreamBooth](https://huggingface.co/PAIR/text2video-zero-controlnet-canny-avatar) model:
1. Download a demo video
```python
from huggingface_hub import hf_hub_download
filename = "__assets__/canny_videos_mp4/girl_turning.mp4"
repo_id = "PAIR/Text2Video-Zero"
video_path = hf_hub_download(repo_type="space", repo_id=repo_id, filename=filename)
```
2. Read video from path
```python
from PIL import Image
import imageio
reader = imageio.get_reader(video_path, "ffmpeg")
frame_count = 8
canny_edges = [Image.fromarray(reader.get_data(i)) for i in range(frame_count)]
```
3. Run `StableDiffusionControlNetPipeline` with custom trained DreamBooth model
```python
import torch
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.pipelines.text_to_video_synthesis.pipeline_text_to_video_zero import CrossFrameAttnProcessor
# set model id to custom model
model_id = "PAIR/text2video-zero-controlnet-canny-avatar"
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id, controlnet=controlnet, torch_dtype=torch.float16
).to("cuda")
# Set the attention processor
pipe.unet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
pipe.controlnet.set_attn_processor(CrossFrameAttnProcessor(batch_size=2))
# fix latents for all frames
latents = torch.randn((1, 4, 64, 64), device="cuda", dtype=torch.float16).repeat(len(canny_edges), 1, 1, 1)
prompt = "oil painting of a beautiful girl avatar style"
result = pipe(prompt=[prompt] * len(canny_edges), image=canny_edges, latents=latents).images
imageio.mimsave("video.mp4", result, fps=4)
```
You can filter out some available DreamBooth-trained models with [this link](https://huggingface.co/models?search=dreambooth).
<Tip>
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
</Tip>
## TextToVideoZeroPipeline
[[autodoc]] TextToVideoZeroPipeline
- all
- __call__
## TextToVideoZeroSDXLPipeline
[[autodoc]] TextToVideoZeroSDXLPipeline
- all
- __call__
## TextToVideoPipelineOutput
[[autodoc]] pipelines.text_to_video_synthesis.pipeline_text_to_video_zero.TextToVideoPipelineOutput
| huggingface/diffusers/blob/main/docs/source/en/api/pipelines/text_to_video_zero.md |
--
title: "Intel and Hugging Face Partner to Democratize Machine Learning Hardware Acceleration"
thumbnail: /blog/assets/80_intel/01.png
authors:
- user: juliensimon
---
# Intel and Hugging Face Partner to Democratize Machine Learning Hardware Acceleration

The mission of Hugging Face is to democratize good machine learning and maximize its positive impact across industries and society. Not only do we strive to advance Transformer models, but we also work hard on simplifying their adoption.
Today, we're excited to announce that Intel has officially joined our [Hardware Partner Program](https://huggingface.co/hardware). Thanks to the [Optimum](https://github.com/huggingface/optimum-intel) open-source library, Intel and Hugging Face will collaborate to build state-of-the-art hardware acceleration to train, fine-tune and predict with Transformers.
Transformer models are increasingly large and complex, which can cause production challenges for latency-sensitive applications like search or chatbots. Unfortunately, latency optimization has long been a hard problem for Machine Learning (ML) practitioners. Even with deep knowledge of the underlying framework and hardware platform, it takes a lot of trial and error to figure out which knobs and features to leverage.
Intel provides a complete foundation for accelerated AI with the Intel Xeon Scalable CPU platform and a wide range of hardware-optimized AI software tools, frameworks, and libraries. Thus, it made perfect sense for Hugging Face and Intel to join forces and collaborate on building powerful model optimization tools that let users achieve the best performance, scale, and productivity on Intel platforms.
“*We’re excited to work with Hugging Face to bring the latest innovations of Intel Xeon hardware and Intel AI software to the Transformers community, through open source integration and integrated developer experiences.*”, says Wei Li, Intel Vice President & General Manager, AI and Analytics.
In recent months, Intel and Hugging Face collaborated on scaling Transformer workloads. We published detailed tuning guides and benchmarks on inference ([part 1](https://huggingface.co/blog/bert-cpu-scaling-part-1), [part 2](https://huggingface.co/blog/bert-cpu-scaling-part-2)) and achieved [single-digit millisecond latency](https://huggingface.co/blog/infinity-cpu-performance) for DistilBERT on the latest Intel Xeon Ice Lake CPUs. On the training side, we added support for [Habana Gaudi](https://huggingface.co/blog/getting-started-habana) accelerators, which deliver up to 40% better price-performance than GPUs.
The next logical step was to expand on this work and share it with the ML community. Enter the [Optimum Intel](https://github.com/huggingface/optimum-intel) open source library! Let’s take a deeper look at it.
## Get Peak Transformers Performance with Optimum Intel
[Optimum](https://github.com/huggingface/optimum) is an open-source library created by Hugging Face to simplify Transformer acceleration across a growing range of training and inference devices. Thanks to built-in optimization techniques, you can start accelerating your workloads in minutes, using ready-made scripts, or applying minimal changes to your existing code. Beginners can use Optimum out of the box with excellent results. Experts can keep tweaking for maximum performance.
[Optimum Intel](https://github.com/huggingface/optimum-intel) is part of Optimum and builds on top of the [Intel Neural Compressor](https://www.intel.com/content/www/us/en/developer/tools/oneapi/neural-compressor.html) (INC). INC is an [open-source library](https://github.com/intel/neural-compressor) that delivers unified interfaces across multiple deep learning frameworks for popular network compression technologies, such as quantization, pruning, and knowledge distillation. This tool supports automatic accuracy-driven tuning strategies to help users quickly build the best quantized model.
With Optimum Intel, you can apply state-of-the-art optimization techniques to your Transformers with minimal effort. Let’s look at a complete example.
## Case study: Quantizing DistilBERT with Optimum Intel
In this example, we will run post-training quantization on a DistilBERT model fine-tuned for classification. Quantization is a process that shrinks memory and compute requirements by reducing the bit width of model parameters. For example, you can often replace 32-bit floating-point parameters with 8-bit integers at the expense of a small drop in prediction accuracy.
We have already fine-tuned the original model to classify product reviews for shoes according to their star rating (from 1 to 5 stars). You can view this [model](https://huggingface.co/juliensimon/distilbert-amazon-shoe-reviews) and its [quantized](https://huggingface.co/juliensimon/distilbert-amazon-shoe-reviews-quantized?) version on the Hugging Face hub. You can also test the original model in this [Space](https://huggingface.co/spaces/juliensimon/amazon-shoe-reviews-spaces).
Let’s get started! All code is available in this [notebook](https://gitlab.com/juliensimon/huggingface-demos/-/blob/main/amazon-shoes/03_optimize_inc_quantize.ipynb).
As usual, the first step is to install all required libraries. It’s worth mentioning that we have to work with a CPU-only version of PyTorch for the quantization process to work correctly.
```
pip -q uninstall torch -y
pip -q install torch==1.11.0+cpu --extra-index-url https://download.pytorch.org/whl/cpu
pip -q install transformers datasets optimum[neural-compressor] evaluate --upgrade
```
Then, we prepare an evaluation dataset to assess model performance during quantization. Starting from the dataset we used to fine-tune the original model, we only keep a few thousand reviews and their labels and save them to local storage.
Next, we load the original model, its tokenizer, and the evaluation dataset from the Hugging Face hub.
```
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "juliensimon/distilbert-amazon-shoe-reviews"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=5)
tokenizer = AutoTokenizer.from_pretrained(model_name)
eval_dataset = load_dataset("prashantgrao/amazon-shoe-reviews", split="test").select(range(300))
```
Next, we define an evaluation function that computes model metrics on the evaluation dataset. This allows the Optimum Intel library to compare these metrics before and after quantization. For this purpose, the Hugging Face [evaluate](https://github.com/huggingface/evaluate/) library is very convenient!
```
import evaluate
def eval_func(model):
task_evaluator = evaluate.evaluator("text-classification")
results = task_evaluator.compute(
model_or_pipeline=model,
tokenizer=tokenizer,
data=eval_dataset,
metric=evaluate.load("accuracy"),
label_column="labels",
label_mapping=model.config.label2id,
)
return results["accuracy"]
```
We then set up the quantization job using a [configuration]. You can find details on this configuration on the Neural Compressor [documentation](https://github.com/intel/neural-compressor/blob/master/docs/source/quantization.md). Here, we go for post-training dynamic quantization with an acceptable accuracy drop of 5%. If accuracy drops more than the allowed 5%, different part of the model will then be quantized until it an acceptable drop in accuracy or if the maximum number of trials, here set to 10, is reached.
```
from neural_compressor.config import AccuracyCriterion, PostTrainingQuantConfig, TuningCriterion
tuning_criterion = TuningCriterion(max_trials=10)
accuracy_criterion = AccuracyCriterion(tolerable_loss=0.05)
# Load the quantization configuration detailing the quantization we wish to apply
quantization_config = PostTrainingQuantConfig(
approach="dynamic",
accuracy_criterion=accuracy_criterion,
tuning_criterion=tuning_criterion,
)
```
We can now launch the quantization job and save the resulting model and its configuration file to local storage.
```
from neural_compressor.config import PostTrainingQuantConfig
from optimum.intel.neural_compressor import INCQuantizer
# The directory where the quantized model will be saved
save_dir = "./model_inc"
quantizer = INCQuantizer.from_pretrained(model=model, eval_fn=eval_func)
quantizer.quantize(quantization_config=quantization_config, save_directory=save_dir)
```
The log tells us that Optimum Intel has quantized 38 ```Linear``` and 2 ```Embedding``` operators.
```
[INFO] |******Mixed Precision Statistics*****|
[INFO] +----------------+----------+---------+
[INFO] | Op Type | Total | INT8 |
[INFO] +----------------+----------+---------+
[INFO] | Embedding | 2 | 2 |
[INFO] | Linear | 38 | 38 |
[INFO] +----------------+----------+---------+
```
Comparing the first layer of the original model (```model.distilbert.transformer.layer[0]```) and its quantized version (```inc_model.distilbert.transformer.layer[0]```), we see that ```Linear``` has indeed been replaced by ```DynamicQuantizedLinear```, its quantized equivalent.
```
# Original model
TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
```
```
# Quantized model
TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(k_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(v_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(out_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(lin2): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
```
Very well, but how does this impact accuracy and prediction time?
Before and after each quantization step, Optimum Intel runs the evaluation function on the current model. The accuracy of the quantized model is now a bit lower (``` 0.546```) than the original model (```0.574```). We also see that the evaluation step of the quantized model was 1.34x faster than the original model. Not bad for a few lines of code!
```
[INFO] |**********************Tune Result Statistics**********************|
[INFO] +--------------------+----------+---------------+------------------+
[INFO] | Info Type | Baseline | Tune 1 result | Best tune result |
[INFO] +--------------------+----------+---------------+------------------+
[INFO] | Accuracy | 0.5740 | 0.5460 | 0.5460 |
[INFO] | Duration (seconds) | 13.1534 | 9.7695 | 9.7695 |
[INFO] +--------------------+----------+---------------+------------------+
```
You can find the resulting [model](https://huggingface.co/juliensimon/distilbert-amazon-shoe-reviews-quantized) hosted on the Hugging Face hub. To load a quantized model hosted locally or on the 🤗 hub, you can do as follows :
```
from optimum.intel.neural_compressor import INCModelForSequenceClassification
inc_model = INCModelForSequenceClassification.from_pretrained(save_dir)
```
## We’re only getting started
In this example, we showed you how to easily quantize models post-training with Optimum Intel, and that’s just the beginning. The library supports other types of quantization as well as pruning, a technique that zeroes or removes model parameters that have little or no impact on the predicted outcome.
We are excited to partner with Intel to bring Hugging Face users peak efficiency on the latest Intel Xeon CPUs and Intel AI libraries. Please [give Optimum Intel a star](https://github.com/huggingface/optimum-intel) to get updates, and stay tuned for many upcoming features!
*Many thanks to [Ella Charlaix](https://github.com/echarlaix) for her help on this post.*
| huggingface/blog/blob/main/intel.md |
@gradio/gallery
## 0.4.14
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/client@0.9.3
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
- @gradio/image@0.5.3
- @gradio/upload@0.5.6
## 0.4.13
### Patch Changes
- Updated dependencies [[`245d58e`](https://github.com/gradio-app/gradio/commit/245d58eff788e8d44a59d37a2d9b26d0f08a62b4)]:
- @gradio/client@0.9.2
- @gradio/image@0.5.2
- @gradio/upload@0.5.5
## 0.4.12
### Patch Changes
- Updated dependencies [[`5d51fbc`](https://github.com/gradio-app/gradio/commit/5d51fbce7826da840a2fd4940feb5d9ad6f1bc5a), [`34f9431`](https://github.com/gradio-app/gradio/commit/34f943101bf7dd6b8a8974a6131c1ed7c4a0dac0)]:
- @gradio/upload@0.5.4
- @gradio/client@0.9.1
- @gradio/image@0.5.1
## 0.4.11
### Fixes
- [#6487](https://github.com/gradio-app/gradio/pull/6487) [`9a5811d`](https://github.com/gradio-app/gradio/commit/9a5811df9218b622af59ba243a937a9c36ba00f9) - Fix the download button of the `gr.Gallery()` component to work. Thanks [@whitphx](https://github.com/whitphx)!
## 0.4.10
### Patch Changes
- Updated dependencies [[`b639e04`](https://github.com/gradio-app/gradio/commit/b639e040741e6c0d9104271c81415d7befbd8cf3), [`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/image@0.4.2
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
- @gradio/upload@0.5.2
## 0.4.9
### Patch Changes
- Updated dependencies [[`71f1a1f99`](https://github.com/gradio-app/gradio/commit/71f1a1f9931489d465c2c1302a5c8d768a3cd23a)]:
- @gradio/client@0.8.2
- @gradio/image@0.4.1
- @gradio/upload@0.5.1
## 0.4.8
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/image@0.4.0
- @gradio/statustracker@0.4.0
- @gradio/upload@0.5.0
## 0.4.7
### Patch Changes
- Updated dependencies [[`2f805a7dd`](https://github.com/gradio-app/gradio/commit/2f805a7dd3d2b64b098f659dadd5d01258290521), [`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/image@0.3.6
- @gradio/upload@0.4.2
- @gradio/atoms@0.2.2
- @gradio/icons@0.2.1
- @gradio/statustracker@0.3.2
## 0.4.6
### Patch Changes
- Updated dependencies [[`324867f63`](https://github.com/gradio-app/gradio/commit/324867f63c920113d89a565892aa596cf8b1e486)]:
- @gradio/client@0.8.1
- @gradio/image@0.3.5
- @gradio/upload@0.4.1
## 0.4.5
### Patch Changes
- Updated dependencies [[`6204ccac5`](https://github.com/gradio-app/gradio/commit/6204ccac5967763e0ebde550d04d12584243a120), [`4d3aad33a`](https://github.com/gradio-app/gradio/commit/4d3aad33a0b66639dbbb2928f305a79fb7789b2d), [`854b482f5`](https://github.com/gradio-app/gradio/commit/854b482f598e0dc47673846631643c079576da9c), [`f1409f95e`](https://github.com/gradio-app/gradio/commit/f1409f95ed39c5565bed6a601e41f94e30196a57)]:
- @gradio/image@0.3.4
- @gradio/upload@0.4.0
- @gradio/client@0.8.0
## 0.4.4
### Patch Changes
- Updated dependencies [[`bca6c2c80`](https://github.com/gradio-app/gradio/commit/bca6c2c80f7e5062427019de45c282238388af95), [`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/client@0.7.2
- @gradio/atoms@0.2.1
- @gradio/upload@0.3.3
- @gradio/image@0.3.3
- @gradio/statustracker@0.3.1
## 0.4.3
### Fixes
- [#6288](https://github.com/gradio-app/gradio/pull/6288) [`92278729e`](https://github.com/gradio-app/gradio/commit/92278729ee008126af15ffe6be399236211b2f34) - Gallery preview fix and optionally skip download of urls in postprcess. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.4.2
### Fixes
- [#6277](https://github.com/gradio-app/gradio/pull/6277) [`5fe091367`](https://github.com/gradio-app/gradio/commit/5fe091367fbe0eecdd504aa734ca1c70b0621f52) - handle selected_index prop change for gallery. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.1
### Patch Changes
- Updated dependencies [[`2ba14b284`](https://github.com/gradio-app/gradio/commit/2ba14b284f908aa13859f4337167a157075a68eb)]:
- @gradio/client@0.7.1
- @gradio/image@0.3.1
- @gradio/upload@0.3.1
## 0.4.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Clean root url. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.9
### Features
- [#6143](https://github.com/gradio-app/gradio/pull/6143) [`e4f7b4b40`](https://github.com/gradio-app/gradio/commit/e4f7b4b409323b01aa01b39e15ce6139e29aa073) - fix circular dependency with client + upload. Thanks [@pngwn](https://github.com/pngwn)!
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6094](https://github.com/gradio-app/gradio/pull/6094) [`c476bd5a5`](https://github.com/gradio-app/gradio/commit/c476bd5a5b70836163b9c69bf4bfe068b17fbe13) - Image v4. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.8
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
### Fixes
- [#6046](https://github.com/gradio-app/gradio/pull/6046) [`dbb7de5e0`](https://github.com/gradio-app/gradio/commit/dbb7de5e02c53fee05889d696d764d212cb96c74) - fix tests. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.7
### Patch Changes
- Updated dependencies []:
- @gradio/image@0.3.0-beta.7
## 0.4.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.5.1
### Patch Changes
- Updated dependencies [[`b67115e8e`](https://github.com/gradio-app/gradio/commit/b67115e8e6e489fffd5271ea830211863241ddc5), [`8d909624f`](https://github.com/gradio-app/gradio/commit/8d909624f61a49536e3c0f71cb2d9efe91216219), [`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/image@0.4.0
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
- @gradio/upload@0.3.3
## 0.5.0
### Features
- [#5780](https://github.com/gradio-app/gradio/pull/5780) [`ed0f9a21b`](https://github.com/gradio-app/gradio/commit/ed0f9a21b04ad6b941b63d2ce45100dbd1abd5c5) - Adds `change()` event to `gr.Gallery`. Thanks [@abidlabs](https://github.com/abidlabs)!
- [#5783](https://github.com/gradio-app/gradio/pull/5783) [`4567788bd`](https://github.com/gradio-app/gradio/commit/4567788bd1fc25df9322902ba748012e392b520a) - Adds the ability to set the `selected_index` in a `gr.Gallery`. Thanks [@abidlabs](https://github.com/abidlabs)!
### Fixes
- [#5798](https://github.com/gradio-app/gradio/pull/5798) [`a0d3cc45c`](https://github.com/gradio-app/gradio/commit/a0d3cc45c6db48dc0db423c229b8fb285623cdc4) - Fix `gr.SelectData` so that the target attribute is correctly attached, and the filedata is included in the data attribute with `gr.Gallery`. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.4.1
### Fixes
- [#5735](https://github.com/gradio-app/gradio/pull/5735) [`abb5e9df4`](https://github.com/gradio-app/gradio/commit/abb5e9df47989b2c56c2c312d74944678f9f2d4e) - Ensure images with no caption download in gallery. Thanks [@hannahblair](https://github.com/hannahblair)!
- [#5754](https://github.com/gradio-app/gradio/pull/5754) [`502054848`](https://github.com/gradio-app/gradio/commit/502054848fdbe39fc03ec42445242b4e49b7affc) - Fix Gallery `columns` and `rows` params. Thanks [@abidlabs](https://github.com/abidlabs)!
## 0.4.0
### Features
- [#5554](https://github.com/gradio-app/gradio/pull/5554) [`75ddeb390`](https://github.com/gradio-app/gradio/commit/75ddeb390d665d4484667390a97442081b49a423) - Accessibility Improvements. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.4
### Patch Changes
- Updated dependencies [[`e0d61b8ba`](https://github.com/gradio-app/gradio/commit/e0d61b8baa0f6293f53b9bdb1647d42f9ae2583a)]:
- @gradio/image@0.2.4
## 0.3.3
### Fixes
- [#5528](https://github.com/gradio-app/gradio/pull/5528) [`dc86e4a7`](https://github.com/gradio-app/gradio/commit/dc86e4a7e1c40b910c74558e6f88fddf9b3292bc) - Lazy load all images. Thanks [@aliabid94](https://github.com/aliabid94)!
## 0.3.2
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/image@0.2.2
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
- @gradio/upload@0.2.1
## 0.3.1
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db), [`79d8f9d8`](https://github.com/gradio-app/gradio/commit/79d8f9d891901683c5a1b7486efb44eab2478c96)]:
- @gradio/icons@0.1.0
- @gradio/utils@0.1.0
- @gradio/upload@0.2.0
- @gradio/atoms@0.1.1
- @gradio/image@0.2.1
- @gradio/statustracker@0.1.1
## 0.3.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.0
### Features
- [#5025](https://github.com/gradio-app/gradio/pull/5025) [`6693660a`](https://github.com/gradio-app/gradio/commit/6693660a790996f8f481feaf22a8c49130d52d89) - Add download button to selected images in `Gallery`. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.0
### Features
- [#4995](https://github.com/gradio-app/gradio/pull/4995) [`3f8c210b`](https://github.com/gradio-app/gradio/commit/3f8c210b01ef1ceaaf8ee73be4bf246b5b745bbf) - Implement left and right click in `Gallery` component and show implicit images in `Gallery` grid. Thanks [@hannahblair](https://github.com/hannahblair)!
| gradio-app/gradio/blob/main/js/gallery/CHANGELOG.md |
Using Stable-Baselines3 at Hugging Face
`stable-baselines3` is a set of reliable implementations of reinforcement learning algorithms in PyTorch.
## Exploring Stable-Baselines3 in the Hub
You can find Stable-Baselines3 models by filtering at the left of the [models page](https://huggingface.co/models?library=stable-baselines3).
All models on the Hub come up with useful features:
1. An automatically generated model card with a description, a training configuration, and more.
2. Metadata tags that help for discoverability.
3. Evaluation results to compare with other models.
4. A video widget where you can watch your agent performing.
## Install the library
To install the `stable-baselines3` library, you need to install two packages:
- `stable-baselines3`: Stable-Baselines3 library.
- `huggingface-sb3`: additional code to load and upload Stable-baselines3 models from the Hub.
```
pip install stable-baselines3
pip install huggingface-sb3
```
## Using existing models
You can simply download a model from the Hub using the `load_from_hub` function
```
checkpoint = load_from_hub(
repo_id="sb3/demo-hf-CartPole-v1",
filename="ppo-CartPole-v1.zip",
)
```
You need to define two parameters:
- `--repo-id`: the name of the Hugging Face repo you want to download.
- `--filename`: the file you want to download.
## Sharing your models
You can easily upload your models using two different functions:
1. `package_to_hub()`: save the model, evaluate it, generate a model card and record a replay video of your agent before pushing the complete repo to the Hub.
```
package_to_hub(model=model,
model_name="ppo-LunarLander-v2",
model_architecture="PPO",
env_id=env_id,
eval_env=eval_env,
repo_id="ThomasSimonini/ppo-LunarLander-v2",
commit_message="Test commit")
```
You need to define seven parameters:
- `--model`: your trained model.
- `--model_architecture`: name of the architecture of your model (DQN, PPO, A2C, SAC...).
- `--env_id`: name of the environment.
- `--eval_env`: environment used to evaluate the agent.
- `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s `<your huggingface username>/<the repo name>`.
- `--commit-message`.
- `--filename`: the file you want to push to the Hub.
2. `push_to_hub()`: simply push a file to the Hub
```
push_to_hub(
repo_id="ThomasSimonini/ppo-LunarLander-v2",
filename="ppo-LunarLander-v2.zip",
commit_message="Added LunarLander-v2 model trained with PPO",
)
```
You need to define three parameters:
- `--repo-id`: the name of the Hugging Face repo you want to create or update. It’s `<your huggingface username>/<the repo name>`.
- `--filename`: the file you want to push to the Hub.
- `--commit-message`.
## Additional resources
* Hugging Face Stable-Baselines3 [documentation](https://github.com/huggingface/huggingface_sb3#hugging-face--x-stable-baselines3-v20)
* Stable-Baselines3 [documentation](https://stable-baselines3.readthedocs.io/en/master/)
| huggingface/hub-docs/blob/main/docs/hub/stable-baselines3.md |
在 Web 服务器上使用 Nginx 运行 Gradio 应用
标签:部署,Web 服务器,Nginx
## 介绍
Gradio 是一个 Python 库,允许您快速创建可定制的 Web 应用程序,用于机器学习模型和数据处理流水线。Gradio 应用可以免费部署在[Hugging Face Spaces](https://hf.space)上。
然而,在某些情况下,您可能希望在自己的 Web 服务器上部署 Gradio 应用。您可能已经在使用[Nginx](https://www.nginx.com/)作为高性能的 Web 服务器来提供您的网站(例如 `https://www.example.com`),并且您希望将 Gradio 附加到网站的特定子路径上(例如 `https://www.example.com/gradio-demo`)。
在本指南中,我们将指导您在自己的 Web 服务器上的 Nginx 后面运行 Gradio 应用的过程,以实现此目的。
**先决条件**
1. 安装了 [Nginx 的 Linux Web 服务器](https://www.nginx.com/blog/setting-up-nginx/) 和 [Gradio](/quickstart) 库
2. 在 Web 服务器上将 Gradio 应用保存为 Python 文件
## 编辑 Nginx 配置文件
1. 首先编辑 Web 服务器上的 Nginx 配置文件。默认情况下,文件位于:`/etc/nginx/nginx.conf`
在 `http` 块中,添加以下行以从单独的文件包含服务器块配置:
```bash
include /etc/nginx/sites-enabled/*;
```
2. 在 `/etc/nginx/sites-available` 目录中创建一个新文件(如果目录不存在则创建),文件名表示您的应用,例如:`sudo nano /etc/nginx/sites-available/my_gradio_app`
3. 将以下内容粘贴到文件编辑器中:
```bash
server {
listen 80;
server_name example.com www.example.com; # 将此项更改为您的域名
location /gradio-demo/ { # 如果要在不同路径上提供Gradio应用,请更改此项
proxy_pass http://127.0.0.1:7860/; # 如果您的Gradio应用将在不同端口上运行,请更改此项
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
}
}
```
## 在 Web 服务器上运行 Gradio 应用
1. 在启动 Gradio 应用之前,您需要将 `root_path` 设置为与 Nginx 配置中指定的子路径相同。这对于 Gradio 在除域的根路径之外的任何子路径上运行是必要的。
以下是一个具有自定义 `root_path` 的简单示例 Gradio 应用:
```python
import gradio as gr
import time
def test(x):
time.sleep(4)
return x
gr.Interface(test, "textbox", "textbox").queue().launch(root_path="/gradio-demo")
```
2. 通过键入 `tmux` 并按回车键(可选)启动 `tmux` 会话
推荐在 `tmux` 会话中运行 Gradio 应用,以便可以轻松地在后台运行它
3. 然后,启动您的 Gradio 应用。只需输入 `python`,后跟您的 Gradio Python 文件的名称。默认情况下,应用将在 `localhost:7860` 上运行,但如果它在其他端口上启动,您需要更新上面的 Nginx 配置文件。
## 重新启动 Nginx
1. 如果您在 tmux 会话中,请通过键入 CTRL + B(或 CMD + B),然后按下 "D" 键来退出。
2. 最后,通过运行 `sudo systemctl restart nginx` 重新启动 nginx。
就是这样!如果您在浏览器中访问 `https://example.com/gradio-demo`,您应该能够看到您的 Gradio 应用在那里运行。
| gradio-app/gradio/blob/main/guides/cn/07_other-tutorials/running-gradio-on-your-web-server-with-nginx.md |
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Optimization
## ORTOptimizer
[[autodoc]] onnxruntime.optimization.ORTOptimizer
- all | huggingface/optimum/blob/main/docs/source/onnxruntime/package_reference/optimization.mdx |
Create a Private Endpoint with AWS PrivateLink
Security and secure inference are key principles of Inference Endpoints. We currently offer three different levels of security: [Public, Protected and Private](/docs/inference-endpoints/security).
Public and Protected Endpoints do not require any additional configuration. But in order to create a Private Endpoint for a secure intra-region connection, you need to provide the AWS Account ID of the account which should also have access to Inference Endpoints.
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/6_private_type.png"
alt="select private link"
/>
After you provide your AWS Account ID and click **Create Endpoint**, the Inference Service creates a VPC Endpoint and you should see the VPC Service Name in your overview.
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/6_service_name.png"
alt="service link"
/>
The VPC Service Name is used to create the VPC Interface Endpoint in your (customer) cloud account. Open your cloud account [console](https://console.aws.amazon.com/vpc/home?#Endpoints) to go create the VPC Interface Endpoint.
An example of the VPC Endpoint configuration is shown below. You will need to select the VPC and subnets, as well as the security groups you want to use.
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/6_aws.png"
alt="aws management console"
/>
Once your Inference Endpoint is created successfully, go to the corresponding AWS account and add the VPC Endpoint as the endpoint.
<img
src="https://raw.githubusercontent.com/huggingface/hf-endpoints-documentation/main/assets/6_private_with_url.png"
alt="endpoint url"
/>
After the VPC Endpoint status changes from **pending** to **available**, you should see a Endpoint URL in the overview. This URL can now be used inside your VPC to access your Endpoint in a secure and protected way, ensuring traffic is only occurring between the two endpoints and will never leave AWS.
| huggingface/hf-endpoints-documentation/blob/main/docs/source/guides/private_link.mdx |
FrameworkSwitchCourse {fw} />
# Fast tokenizers in the QA pipeline[[fast-tokenizers-in-the-qa-pipeline]]
{#if fw === 'pt'}
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section3b_pt.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section3b_pt.ipynb"},
]} />
{:else}
<CourseFloatingBanner chapter={6}
classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/en/chapter6/section3b_tf.ipynb"},
{label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/en/chapter6/section3b_tf.ipynb"},
]} />
{/if}
We will now dive into the `question-answering` pipeline and see how to leverage the offsets to grab the answer to the question at hand from the context, a bit like we did for the grouped entities in the previous section. Then we will see how we can deal with very long contexts that end up being truncated. You can skip this section if you're not interested in the question answering task.
{#if fw === 'pt'}
<Youtube id="_wxyB3j3mk4"/>
{:else}
<Youtube id="b3u8RzBCX9Y"/>
{/if}
## Using the `question-answering` pipeline[[using-the-question-answering-pipeline]]
As we saw in [Chapter 1](/course/chapter1), we can use the `question-answering` pipeline like this to get the answer to a question:
```py
from transformers import pipeline
question_answerer = pipeline("question-answering")
context = """
🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch, and TensorFlow — with a seamless integration
between them. It's straightforward to train your models with one before loading them for inference with the other.
"""
question = "Which deep learning libraries back 🤗 Transformers?"
question_answerer(question=question, context=context)
```
```python out
{'score': 0.97773,
'start': 78,
'end': 105,
'answer': 'Jax, PyTorch and TensorFlow'}
```
Unlike the other pipelines, which can't truncate and split texts that are longer than the maximum length accepted by the model (and thus may miss information at the end of a document), this pipeline can deal with very long contexts and will return the answer to the question even if it's at the end:
```py
long_context = """
🤗 Transformers: State of the Art NLP
🤗 Transformers provides thousands of pretrained models to perform tasks on texts such as classification, information extraction,
question answering, summarization, translation, text generation and more in over 100 languages.
Its aim is to make cutting-edge NLP easier to use for everyone.
🤗 Transformers provides APIs to quickly download and use those pretrained models on a given text, fine-tune them on your own datasets and
then share them with the community on our model hub. At the same time, each python module defining an architecture is fully standalone and
can be modified to enable quick research experiments.
Why should I use transformers?
1. Easy-to-use state-of-the-art models:
- High performance on NLU and NLG tasks.
- Low barrier to entry for educators and practitioners.
- Few user-facing abstractions with just three classes to learn.
- A unified API for using all our pretrained models.
- Lower compute costs, smaller carbon footprint:
2. Researchers can share trained models instead of always retraining.
- Practitioners can reduce compute time and production costs.
- Dozens of architectures with over 10,000 pretrained models, some in more than 100 languages.
3. Choose the right framework for every part of a model's lifetime:
- Train state-of-the-art models in 3 lines of code.
- Move a single model between TF2.0/PyTorch frameworks at will.
- Seamlessly pick the right framework for training, evaluation and production.
4. Easily customize a model or an example to your needs:
- We provide examples for each architecture to reproduce the results published by its original authors.
- Model internals are exposed as consistently as possible.
- Model files can be used independently of the library for quick experiments.
🤗 Transformers is backed by the three most popular deep learning libraries — Jax, PyTorch and TensorFlow — with a seamless integration
between them. It's straightforward to train your models with one before loading them for inference with the other.
"""
question_answerer(question=question, context=long_context)
```
```python out
{'score': 0.97149,
'start': 1892,
'end': 1919,
'answer': 'Jax, PyTorch and TensorFlow'}
```
Let's see how it does all of this!
## Using a model for question answering[[using-a-model-for-question-answering]]
Like with any other pipeline, we start by tokenizing our input and then send it through the model. The checkpoint used by default for the `question-answering` pipeline is [`distilbert-base-cased-distilled-squad`](https://huggingface.co/distilbert-base-cased-distilled-squad) (the "squad" in the name comes from the dataset on which the model was fine-tuned; we'll talk more about the SQuAD dataset in [Chapter 7](/course/chapter7/7)):
{#if fw === 'pt'}
```py
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
model_checkpoint = "distilbert-base-cased-distilled-squad"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
inputs = tokenizer(question, context, return_tensors="pt")
outputs = model(**inputs)
```
{:else}
```py
from transformers import AutoTokenizer, TFAutoModelForQuestionAnswering
model_checkpoint = "distilbert-base-cased-distilled-squad"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = TFAutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
inputs = tokenizer(question, context, return_tensors="tf")
outputs = model(**inputs)
```
{/if}
Note that we tokenize the question and the context as a pair, with the question first.
<div class="flex justify-center">
<img class="block dark:hidden" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter6/question_tokens.svg" alt="An example of tokenization of question and context"/>
<img class="hidden dark:block" src="https://huggingface.co/datasets/huggingface-course/documentation-images/resolve/main/en/chapter6/question_tokens-dark.svg" alt="An example of tokenization of question and context"/>
</div>
Models for question answering work a little differently from the models we've seen up to now. Using the picture above as an example, the model has been trained to predict the index of the token starting the answer (here 21) and the index of the token where the answer ends (here 24). This is why those models don't return one tensor of logits but two: one for the logits corresponding to the start token of the answer, and one for the logits corresponding to the end token of the answer. Since in this case we have only one input containing 66 tokens, we get:
```py
start_logits = outputs.start_logits
end_logits = outputs.end_logits
print(start_logits.shape, end_logits.shape)
```
{#if fw === 'pt'}
```python out
torch.Size([1, 66]) torch.Size([1, 66])
```
{:else}
```python out
(1, 66) (1, 66)
```
{/if}
To convert those logits into probabilities, we will apply a softmax function -- but before that, we need to make sure we mask the indices that are not part of the context. Our input is `[CLS] question [SEP] context [SEP]`, so we need to mask the tokens of the question as well as the `[SEP]` token. We'll keep the `[CLS]` token, however, as some models use it to indicate that the answer is not in the context.
Since we will apply a softmax afterward, we just need to replace the logits we want to mask with a large negative number. Here, we use `-10000`:
{#if fw === 'pt'}
```py
import torch
sequence_ids = inputs.sequence_ids()
# Mask everything apart from the tokens of the context
mask = [i != 1 for i in sequence_ids]
# Unmask the [CLS] token
mask[0] = False
mask = torch.tensor(mask)[None]
start_logits[mask] = -10000
end_logits[mask] = -10000
```
{:else}
```py
import tensorflow as tf
sequence_ids = inputs.sequence_ids()
# Mask everything apart from the tokens of the context
mask = [i != 1 for i in sequence_ids]
# Unmask the [CLS] token
mask[0] = False
mask = tf.constant(mask)[None]
start_logits = tf.where(mask, -10000, start_logits)
end_logits = tf.where(mask, -10000, end_logits)
```
{/if}
Now that we have properly masked the logits corresponding to positions we don't want to predict, we can apply the softmax:
{#if fw === 'pt'}
```py
start_probabilities = torch.nn.functional.softmax(start_logits, dim=-1)[0]
end_probabilities = torch.nn.functional.softmax(end_logits, dim=-1)[0]
```
{:else}
```py
start_probabilities = tf.math.softmax(start_logits, axis=-1)[0].numpy()
end_probabilities = tf.math.softmax(end_logits, axis=-1)[0].numpy()
```
{/if}
At this stage, we could take the argmax of the start and end probabilities -- but we might end up with a start index that is greater than the end index, so we need to take a few more precautions. We will compute the probabilities of each possible `start_index` and `end_index` where `start_index <= end_index`, then take the tuple `(start_index, end_index)` with the highest probability.
Assuming the events "The answer starts at `start_index`" and "The answer ends at `end_index`" to be independent, the probability that the answer starts at `start_index` and ends at `end_index` is:
$$\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]$$
So, to compute all the scores, we just need to compute all the products \\(\mathrm{start\_probabilities}[\mathrm{start\_index}] \times \mathrm{end\_probabilities}[\mathrm{end\_index}]\\) where `start_index <= end_index`.
First let's compute all the possible products:
```py
scores = start_probabilities[:, None] * end_probabilities[None, :]
```
{#if fw === 'pt'}
Then we'll mask the values where `start_index > end_index` by setting them to `0` (the other probabilities are all positive numbers). The `torch.triu()` function returns the upper triangular part of the 2D tensor passed as an argument, so it will do that masking for us:
```py
scores = torch.triu(scores)
```
{:else}
Then we'll mask the values where `start_index > end_index` by setting them to `0` (the other probabilities are all positive numbers). The `np.triu()` function returns the upper triangular part of the 2D tensor passed as an argument, so it will do that masking for us:
```py
import numpy as np
scores = np.triu(scores)
```
{/if}
Now we just have to get the index of the maximum. Since PyTorch will return the index in the flattened tensor, we need to use the floor division `//` and modulus `%` operations to get the `start_index` and `end_index`:
```py
max_index = scores.argmax().item()
start_index = max_index // scores.shape[1]
end_index = max_index % scores.shape[1]
print(scores[start_index, end_index])
```
We're not quite done yet, but at least we already have the correct score for the answer (you can check this by comparing it to the first result in the previous section):
```python out
0.97773
```
<Tip>
✏️ **Try it out!** Compute the start and end indices for the five most likely answers.
</Tip>
We have the `start_index` and `end_index` of the answer in terms of tokens, so now we just need to convert to the character indices in the context. This is where the offsets will be super useful. We can grab them and use them like we did in the token classification task:
```py
inputs_with_offsets = tokenizer(question, context, return_offsets_mapping=True)
offsets = inputs_with_offsets["offset_mapping"]
start_char, _ = offsets[start_index]
_, end_char = offsets[end_index]
answer = context[start_char:end_char]
```
Now we just have to format everything to get our result:
```py
result = {
"answer": answer,
"start": start_char,
"end": end_char,
"score": scores[start_index, end_index],
}
print(result)
```
```python out
{'answer': 'Jax, PyTorch and TensorFlow',
'start': 78,
'end': 105,
'score': 0.97773}
```
Great! That's the same as in our first example!
<Tip>
✏️ **Try it out!** Use the best scores you computed earlier to show the five most likely answers. To check your results, go back to the first pipeline and pass in `top_k=5` when calling it.
</Tip>
## Handling long contexts[[handling-long-contexts]]
If we try to tokenize the question and long context we used as an example previously, we'll get a number of tokens higher than the maximum length used in the `question-answering` pipeline (which is 384):
```py
inputs = tokenizer(question, long_context)
print(len(inputs["input_ids"]))
```
```python out
461
```
So, we'll need to truncate our inputs at that maximum length. There are several ways we can do this, but we don't want to truncate the question, only the context. Since the context is the second sentence, we'll use the `"only_second"` truncation strategy. The problem that arises then is that the answer to the question may not be in the truncated context. Here, for instance, we picked a question where the answer is toward the end of the context, and when we truncate it that answer is not present:
```py
inputs = tokenizer(question, long_context, max_length=384, truncation="only_second")
print(tokenizer.decode(inputs["input_ids"]))
```
```python out
"""
[CLS] Which deep learning libraries back [UNK] Transformers? [SEP] [UNK] Transformers : State of the Art NLP
[UNK] Transformers provides thousands of pretrained models to perform tasks on texts such as classification, information extraction,
question answering, summarization, translation, text generation and more in over 100 languages.
Its aim is to make cutting-edge NLP easier to use for everyone.
[UNK] Transformers provides APIs to quickly download and use those pretrained models on a given text, fine-tune them on your own datasets and
then share them with the community on our model hub. At the same time, each python module defining an architecture is fully standalone and
can be modified to enable quick research experiments.
Why should I use transformers?
1. Easy-to-use state-of-the-art models:
- High performance on NLU and NLG tasks.
- Low barrier to entry for educators and practitioners.
- Few user-facing abstractions with just three classes to learn.
- A unified API for using all our pretrained models.
- Lower compute costs, smaller carbon footprint:
2. Researchers can share trained models instead of always retraining.
- Practitioners can reduce compute time and production costs.
- Dozens of architectures with over 10,000 pretrained models, some in more than 100 languages.
3. Choose the right framework for every part of a model's lifetime:
- Train state-of-the-art models in 3 lines of code.
- Move a single model between TF2.0/PyTorch frameworks at will.
- Seamlessly pick the right framework for training, evaluation and production.
4. Easily customize a model or an example to your needs:
- We provide examples for each architecture to reproduce the results published by its original authors.
- Model internal [SEP]
"""
```
This means the model will have a hard time picking the correct answer. To fix this, the `question-answering` pipeline allows us to split the context into smaller chunks, specifying the maximum length. To make sure we don't split the context at exactly the wrong place to make it possible to find the answer, it also includes some overlap between the chunks.
We can have the tokenizer (fast or slow) do this for us by adding `return_overflowing_tokens=True`, and we can specify the overlap we want with the `stride` argument. Here is an example, using a smaller sentence:
```py
sentence = "This sentence is not too long but we are going to split it anyway."
inputs = tokenizer(
sentence, truncation=True, return_overflowing_tokens=True, max_length=6, stride=2
)
for ids in inputs["input_ids"]:
print(tokenizer.decode(ids))
```
```python out
'[CLS] This sentence is not [SEP]'
'[CLS] is not too long [SEP]'
'[CLS] too long but we [SEP]'
'[CLS] but we are going [SEP]'
'[CLS] are going to split [SEP]'
'[CLS] to split it anyway [SEP]'
'[CLS] it anyway. [SEP]'
```
As we can see, the sentence has been split into chunks in such a way that each entry in `inputs["input_ids"]` has at most 6 tokens (we would need to add padding to have the last entry be the same size as the others) and there is an overlap of 2 tokens between each of the entries.
Let's take a closer look at the result of the tokenization:
```py
print(inputs.keys())
```
```python out
dict_keys(['input_ids', 'attention_mask', 'overflow_to_sample_mapping'])
```
As expected, we get input IDs and an attention mask. The last key, `overflow_to_sample_mapping`, is a map that tells us which sentence each of the results corresponds to -- here we have 7 results that all come from the (only) sentence we passed the tokenizer:
```py
print(inputs["overflow_to_sample_mapping"])
```
```python out
[0, 0, 0, 0, 0, 0, 0]
```
This is more useful when we tokenize several sentences together. For instance, this:
```py
sentences = [
"This sentence is not too long but we are going to split it anyway.",
"This sentence is shorter but will still get split.",
]
inputs = tokenizer(
sentences, truncation=True, return_overflowing_tokens=True, max_length=6, stride=2
)
print(inputs["overflow_to_sample_mapping"])
```
gets us:
```python out
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
```
which means the first sentence is split into 7 chunks as before, and the next 4 chunks come from the second sentence.
Now let's go back to our long context. By default the `question-answering` pipeline uses a maximum length of 384, as we mentioned earlier, and a stride of 128, which correspond to the way the model was fine-tuned (you can adjust those parameters by passing `max_seq_len` and `stride` arguments when calling the pipeline). We will thus use those parameters when tokenizing. We'll also add padding (to have samples of the same length, so we can build tensors) as well as ask for the offsets:
```py
inputs = tokenizer(
question,
long_context,
stride=128,
max_length=384,
padding="longest",
truncation="only_second",
return_overflowing_tokens=True,
return_offsets_mapping=True,
)
```
Those `inputs` will contain the input IDs and attention masks the model expects, as well as the offsets and the `overflow_to_sample_mapping` we just talked about. Since those two are not parameters used by the model, we'll pop them out of the `inputs` (and we won't store the map, since it's not useful here) before converting it to a tensor:
{#if fw === 'pt'}
```py
_ = inputs.pop("overflow_to_sample_mapping")
offsets = inputs.pop("offset_mapping")
inputs = inputs.convert_to_tensors("pt")
print(inputs["input_ids"].shape)
```
```python out
torch.Size([2, 384])
```
{:else}
```py
_ = inputs.pop("overflow_to_sample_mapping")
offsets = inputs.pop("offset_mapping")
inputs = inputs.convert_to_tensors("tf")
print(inputs["input_ids"].shape)
```
```python out
(2, 384)
```
{/if}
Our long context was split in two, which means that after it goes through our model, we will have two sets of start and end logits:
```py
outputs = model(**inputs)
start_logits = outputs.start_logits
end_logits = outputs.end_logits
print(start_logits.shape, end_logits.shape)
```
{#if fw === 'pt'}
```python out
torch.Size([2, 384]) torch.Size([2, 384])
```
{:else}
```python out
(2, 384) (2, 384)
```
{/if}
Like before, we first mask the tokens that are not part of the context before taking the softmax. We also mask all the padding tokens (as flagged by the attention mask):
{#if fw === 'pt'}
```py
sequence_ids = inputs.sequence_ids()
# Mask everything apart from the tokens of the context
mask = [i != 1 for i in sequence_ids]
# Unmask the [CLS] token
mask[0] = False
# Mask all the [PAD] tokens
mask = torch.logical_or(torch.tensor(mask)[None], (inputs["attention_mask"] == 0))
start_logits[mask] = -10000
end_logits[mask] = -10000
```
{:else}
```py
sequence_ids = inputs.sequence_ids()
# Mask everything apart from the tokens of the context
mask = [i != 1 for i in sequence_ids]
# Unmask the [CLS] token
mask[0] = False
# Mask all the [PAD] tokens
mask = tf.math.logical_or(tf.constant(mask)[None], inputs["attention_mask"] == 0)
start_logits = tf.where(mask, -10000, start_logits)
end_logits = tf.where(mask, -10000, end_logits)
```
{/if}
Then we can use the softmax to convert our logits to probabilities:
{#if fw === 'pt'}
```py
start_probabilities = torch.nn.functional.softmax(start_logits, dim=-1)
end_probabilities = torch.nn.functional.softmax(end_logits, dim=-1)
```
{:else}
```py
start_probabilities = tf.math.softmax(start_logits, axis=-1).numpy()
end_probabilities = tf.math.softmax(end_logits, axis=-1).numpy()
```
{/if}
The next step is similar to what we did for the small context, but we repeat it for each of our two chunks. We attribute a score to all possible spans of answer, then take the span with the best score:
{#if fw === 'pt'}
```py
candidates = []
for start_probs, end_probs in zip(start_probabilities, end_probabilities):
scores = start_probs[:, None] * end_probs[None, :]
idx = torch.triu(scores).argmax().item()
start_idx = idx // scores.shape[1]
end_idx = idx % scores.shape[1]
score = scores[start_idx, end_idx].item()
candidates.append((start_idx, end_idx, score))
print(candidates)
```
{:else}
```py
candidates = []
for start_probs, end_probs in zip(start_probabilities, end_probabilities):
scores = start_probs[:, None] * end_probs[None, :]
idx = np.triu(scores).argmax().item()
start_idx = idx // scores.shape[1]
end_idx = idx % scores.shape[1]
score = scores[start_idx, end_idx].item()
candidates.append((start_idx, end_idx, score))
print(candidates)
```
{/if}
```python out
[(0, 18, 0.33867), (173, 184, 0.97149)]
```
Those two candidates correspond to the best answers the model was able to find in each chunk. The model is way more confident the right answer is in the second part (which is a good sign!). Now we just have to map those two token spans to spans of characters in the context (we only need to map the second one to have our answer, but it's interesting to see what the model has picked in the first chunk).
<Tip>
✏️ **Try it out!** Adapt the code above to return the scores and spans for the five most likely answers (in total, not per chunk).
</Tip>
The `offsets` we grabbed earlier is actually a list of offsets, with one list per chunk of text:
```py
for candidate, offset in zip(candidates, offsets):
start_token, end_token, score = candidate
start_char, _ = offset[start_token]
_, end_char = offset[end_token]
answer = long_context[start_char:end_char]
result = {"answer": answer, "start": start_char, "end": end_char, "score": score}
print(result)
```
```python out
{'answer': '\n🤗 Transformers: State of the Art NLP', 'start': 0, 'end': 37, 'score': 0.33867}
{'answer': 'Jax, PyTorch and TensorFlow', 'start': 1892, 'end': 1919, 'score': 0.97149}
```
If we ignore the first result, we get the same result as our pipeline for this long context -- yay!
<Tip>
✏️ **Try it out!** Use the best scores you computed before to show the five most likely answers (for the whole context, not each chunk). To check your results, go back to the first pipeline and pass in `top_k=5` when calling it.
</Tip>
This concludes our deep dive into the tokenizer's capabilities. We will put all of this in practice again in the next chapter, when we show you how to fine-tune a model on a range of common NLP tasks.
| huggingface/course/blob/main/chapters/en/chapter6/3b.mdx |
Metric Card for COVAL
## Metric description
CoVal is a coreference evaluation tool for the [CoNLL](https://huggingface.co/datasets/conll2003) and [ARRAU](https://catalog.ldc.upenn.edu/LDC2013T22) datasets which implements of the common evaluation metrics including MUC [Vilain et al, 1995](https://aclanthology.org/M95-1005.pdf), B-cubed [Bagga and Baldwin, 1998](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.34.2578&rep=rep1&type=pdf), CEAFe [Luo et al., 2005](https://aclanthology.org/H05-1004.pdf), LEA [Moosavi and Strube, 2016](https://aclanthology.org/P16-1060.pdf) and the averaged CoNLL score (the average of the F1 values of MUC, B-cubed and CEAFe).
CoVal code was written by [`@ns-moosavi`](https://github.com/ns-moosavi), with some parts borrowed from [Deep Coref](https://github.com/clarkkev/deep-coref/blob/master/evaluation.py). The test suite is taken from the [official CoNLL code](https://github.com/conll/reference-coreference-scorers/), with additions by [`@andreasvc`](https://github.com/andreasvc) and file parsing developed by Leo Born.
## How to use
The metric takes two lists of sentences as input: one representing `predictions` and `references`, with the sentences consisting of words in the CoNLL format (see the [Limitations and bias](#Limitations-and-bias) section below for more details on the CoNLL format).
```python
from datasets import load_metric
coval = load_metric('coval')
words = ['bc/cctv/00/cctv_0005 0 0 Thank VBP (TOP(S(VP* thank 01 1 Xu_li * (V*) * -',
... 'bc/cctv/00/cctv_0005 0 1 you PRP (NP*) - - - Xu_li * (ARG1*) (ARG0*) (116)',
... 'bc/cctv/00/cctv_0005 0 2 everyone NN (NP*) - - - Xu_li * (ARGM-DIS*) * (116)',
... 'bc/cctv/00/cctv_0005 0 3 for IN (PP* - - - Xu_li * (ARG2* * -',
... 'bc/cctv/00/cctv_0005 0 4 watching VBG (S(VP*)))) watch 01 1 Xu_li * *) (V*) -',
... 'bc/cctv/00/cctv_0005 0 5 . . *)) - - - Xu_li * * * -']
references = [words]
predictions = [words]
results = coval.compute(predictions=predictions, references=references)
```
It also has several optional arguments:
`keep_singletons`: After extracting all mentions of key or system file mentions whose corresponding coreference chain is of size one are considered as singletons. The default evaluation mode will include singletons in evaluations if they are included in the key or the system files. By setting `keep_singletons=False`, all singletons in the key and system files will be excluded from the evaluation.
`NP_only`: Most of the recent coreference resolvers only resolve NP mentions and leave out the resolution of VPs. By setting the `NP_only` option, the scorer will only evaluate the resolution of NPs.
`min_span`: By setting `min_span`, the scorer reports the results based on automatically detected minimum spans. Minimum spans are determined using the [MINA algorithm](https://arxiv.org/pdf/1906.06703.pdf).
## Output values
The metric outputs a dictionary with the following key-value pairs:
`mentions`: number of mentions, ranges from 0-1
`muc`: MUC metric, which expresses performance in terms of recall and precision, ranging from 0-1.
`bcub`: B-cubed metric, which is the averaged precision of all items in the distribution, ranging from 0-1.
`ceafe`: CEAFe (Constrained Entity Alignment F-Measure) is computed by aligning reference and system entities with the constraint that a reference entity is aligned with at most one reference entity. It ranges from 0-1
`lea`: LEA is a Link-Based Entity-Aware metric which, for each entity, considers how important the entity is and how well it is resolved. It ranges from 0-1.
`conll_score`: averaged CoNLL score (the average of the F1 values of `muc`, `bcub` and `ceafe`), ranging from 0 to 100.
### Values from popular papers
Given that many of the metrics returned by COVAL come from different sources, is it hard to cite reference values for all of them.
The CoNLL score is used to track progress on different datasets such as the [ARRAU corpus](https://paperswithcode.com/sota/coreference-resolution-on-the-arrau-corpus) and [CoNLL 2012](https://paperswithcode.com/sota/coreference-resolution-on-conll-2012).
## Examples
Maximal values
```python
from datasets import load_metric
coval = load_metric('coval')
words = ['bc/cctv/00/cctv_0005 0 0 Thank VBP (TOP(S(VP* thank 01 1 Xu_li * (V*) * -',
... 'bc/cctv/00/cctv_0005 0 1 you PRP (NP*) - - - Xu_li * (ARG1*) (ARG0*) (116)',
... 'bc/cctv/00/cctv_0005 0 2 everyone NN (NP*) - - - Xu_li * (ARGM-DIS*) * (116)',
... 'bc/cctv/00/cctv_0005 0 3 for IN (PP* - - - Xu_li * (ARG2* * -',
... 'bc/cctv/00/cctv_0005 0 4 watching VBG (S(VP*)))) watch 01 1 Xu_li * *) (V*) -',
... 'bc/cctv/00/cctv_0005 0 5 . . *)) - - - Xu_li * * * -']
references = [words]
predictions = [words]
results = coval.compute(predictions=predictions, references=references)
print(results)
{'mentions/recall': 1.0, 'mentions/precision': 1.0, 'mentions/f1': 1.0, 'muc/recall': 1.0, 'muc/precision': 1.0, 'muc/f1': 1.0, 'bcub/recall': 1.0, 'bcub/precision': 1.0, 'bcub/f1': 1.0, 'ceafe/recall': 1.0, 'ceafe/precision': 1.0, 'ceafe/f1': 1.0, 'lea/recall': 1.0, 'lea/precision': 1.0, 'lea/f1': 1.0, 'conll_score': 100.0}
```
## Limitations and bias
This wrapper of CoVal currently only works with [CoNLL line format](https://huggingface.co/datasets/conll2003), which has one word per line with all the annotation for this word in column separated by spaces:
| Column | Type | Description |
|:-------|:----------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | Document ID | This is a variation on the document filename |
| 2 | Part number | Some files are divided into multiple parts numbered as 000, 001, 002, ... etc. |
| 3 | Word number | |
| 4 | Word | This is the token as segmented/tokenized in the Treebank. Initially the *_skel file contain the placeholder [WORD] which gets replaced by the actual token from the Treebank which is part of the OntoNotes release. |
| 5 | Part-of-Speech | |
| 6 | Parse bit | This is the bracketed structure broken before the first open parenthesis in the parse, and the word/part-of-speech leaf replaced with a *. The full parse can be created by substituting the asterix with the "([pos] [word])" string (or leaf) and concatenating the items in the rows of that column. |
| 7 | Predicate lemma | The predicate lemma is mentioned for the rows for which we have semantic role information. All other rows are marked with a "-". |
| 8 | Predicate Frameset ID | This is the PropBank frameset ID of the predicate in Column 7. |
| 9 | Word sense | This is the word sense of the word in Column 3. |
| 10 | Speaker/Author | This is the speaker or author name where available. Mostly in Broadcast Conversation and Web Log data. |
| 11 | Named Entities | These columns identifies the spans representing various named entities. |
| 12:N | Predicate Arguments | There is one column each of predicate argument structure information for the predicate mentioned in Column 7. |
| N | Coreference | Coreference chain information encoded in a parenthesis structure. |
## Citations
```bibtex
@InProceedings{moosavi2019minimum,
author = { Nafise Sadat Moosavi, Leo Born, Massimo Poesio and Michael Strube},
title = {Using Automatically Extracted Minimum Spans to Disentangle Coreference Evaluation from Boundary Detection},
year = {2019},
booktitle = {Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics (Volume 1: Long Papers)},
publisher = {Association for Computational Linguistics},
address = {Florence, Italy},
}
```
```bibtex
@inproceedings{10.3115/1072399.1072405,
author = {Vilain, Marc and Burger, John and Aberdeen, John and Connolly, Dennis and Hirschman, Lynette},
title = {A Model-Theoretic Coreference Scoring Scheme},
year = {1995},
isbn = {1558604022},
publisher = {Association for Computational Linguistics},
address = {USA},
url = {https://doi.org/10.3115/1072399.1072405},
doi = {10.3115/1072399.1072405},
booktitle = {Proceedings of the 6th Conference on Message Understanding},
pages = {45–52},
numpages = {8},
location = {Columbia, Maryland},
series = {MUC6 ’95}
}
```
```bibtex
@INPROCEEDINGS{Bagga98algorithmsfor,
author = {Amit Bagga and Breck Baldwin},
title = {Algorithms for Scoring Coreference Chains},
booktitle = {In The First International Conference on Language Resources and Evaluation Workshop on Linguistics Coreference},
year = {1998},
pages = {563--566}
}
```
```bibtex
@INPROCEEDINGS{Luo05oncoreference,
author = {Xiaoqiang Luo},
title = {On coreference resolution performance metrics},
booktitle = {In Proc. of HLT/EMNLP},
year = {2005},
pages = {25--32},
publisher = {URL}
}
```
```bibtex
@inproceedings{moosavi-strube-2016-coreference,
title = "Which Coreference Evaluation Metric Do You Trust? A Proposal for a Link-based Entity Aware Metric",
author = "Moosavi, Nafise Sadat and
Strube, Michael",
booktitle = "Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2016",
address = "Berlin, Germany",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P16-1060",
doi = "10.18653/v1/P16-1060",
pages = "632--642",
}
```
## Further References
- [CoNLL 2012 Task Description](http://www.conll.cemantix.org/2012/data.html): for information on the format (section "*_conll File Format")
- [CoNLL Evaluation details](https://github.com/ns-moosavi/coval/blob/master/conll/README.md)
- [Hugging Face - Neural Coreference Resolution (Neuralcoref)](https://huggingface.co/coref/)
| huggingface/datasets/blob/main/metrics/coval/README.md |
SSL ResNeXT
A **ResNeXt** repeats a [building block](https://paperswithcode.com/method/resnext-block) that aggregates a set of transformations with the same topology. Compared to a [ResNet](https://paperswithcode.com/method/resnet), it exposes a new dimension, *cardinality* (the size of the set of transformations) $C$, as an essential factor in addition to the dimensions of depth and width.
The model in this collection utilises semi-supervised learning to improve the performance of the model. The approach brings important gains to standard architectures for image, video and fine-grained classification.
Please note the CC-BY-NC 4.0 license on theses weights, non-commercial use only.
## How do I use this model on an image?
To load a pretrained model:
```python
import timm
model = timm.create_model('ssl_resnext101_32x16d', pretrained=True)
model.eval()
```
To load and preprocess the image:
```python
import urllib
from PIL import Image
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
urllib.request.urlretrieve(url, filename)
img = Image.open(filename).convert('RGB')
tensor = transform(img).unsqueeze(0) # transform and add batch dimension
```
To get the model predictions:
```python
import torch
with torch.no_grad():
out = model(tensor)
probabilities = torch.nn.functional.softmax(out[0], dim=0)
print(probabilities.shape)
# prints: torch.Size([1000])
```
To get the top-5 predictions class names:
```python
# Get imagenet class mappings
url, filename = ("https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt", "imagenet_classes.txt")
urllib.request.urlretrieve(url, filename)
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Print top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
# prints class names and probabilities like:
# [('Samoyed', 0.6425196528434753), ('Pomeranian', 0.04062102362513542), ('keeshond', 0.03186424449086189), ('white wolf', 0.01739676296710968), ('Eskimo dog', 0.011717947199940681)]
```
Replace the model name with the variant you want to use, e.g. `ssl_resnext101_32x16d`. You can find the IDs in the model summaries at the top of this page.
To extract image features with this model, follow the [timm feature extraction examples](https://rwightman.github.io/pytorch-image-models/feature_extraction/), just change the name of the model you want to use.
## How do I finetune this model?
You can finetune any of the pre-trained models just by changing the classifier (the last layer).
```python
model = timm.create_model('ssl_resnext101_32x16d', pretrained=True, num_classes=NUM_FINETUNE_CLASSES)
```
To finetune on your own dataset, you have to write a training loop or adapt [timm's training
script](https://github.com/rwightman/pytorch-image-models/blob/master/train.py) to use your dataset.
## How do I train this model?
You can follow the [timm recipe scripts](https://rwightman.github.io/pytorch-image-models/scripts/) for training a new model afresh.
## Citation
```BibTeX
@article{DBLP:journals/corr/abs-1905-00546,
author = {I. Zeki Yalniz and
Herv{\'{e}} J{\'{e}}gou and
Kan Chen and
Manohar Paluri and
Dhruv Mahajan},
title = {Billion-scale semi-supervised learning for image classification},
journal = {CoRR},
volume = {abs/1905.00546},
year = {2019},
url = {http://arxiv.org/abs/1905.00546},
archivePrefix = {arXiv},
eprint = {1905.00546},
timestamp = {Mon, 28 Sep 2020 08:19:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-00546.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<!--
Type: model-index
Collections:
- Name: SSL ResNext
Paper:
Title: Billion-scale semi-supervised learning for image classification
URL: https://paperswithcode.com/paper/billion-scale-semi-supervised-learning-for
Models:
- Name: ssl_resnext101_32x16d
In Collection: SSL ResNext
Metadata:
FLOPs: 46623691776
Parameters: 194030000
File Size: 777518664
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnext101_32x16d
LR: 0.0015
Epochs: 30
Layers: 101
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L944
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnext101_32x16-15fffa57.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.84%
Top 5 Accuracy: 96.09%
- Name: ssl_resnext101_32x4d
In Collection: SSL ResNext
Metadata:
FLOPs: 10298145792
Parameters: 44180000
File Size: 177341913
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnext101_32x4d
LR: 0.0015
Epochs: 30
Layers: 101
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L924
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnext101_32x4-dc43570a.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.91%
Top 5 Accuracy: 95.73%
- Name: ssl_resnext101_32x8d
In Collection: SSL ResNext
Metadata:
FLOPs: 21180417024
Parameters: 88790000
File Size: 356056638
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnext101_32x8d
LR: 0.0015
Epochs: 30
Layers: 101
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L934
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnext101_32x8-2cfe2f8b.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 81.61%
Top 5 Accuracy: 96.04%
- Name: ssl_resnext50_32x4d
In Collection: SSL ResNext
Metadata:
FLOPs: 5472648192
Parameters: 25030000
File Size: 100428550
Architecture:
- 1x1 Convolution
- Batch Normalization
- Convolution
- Global Average Pooling
- Grouped Convolution
- Max Pooling
- ReLU
- ResNeXt Block
- Residual Connection
- Softmax
Tasks:
- Image Classification
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Data:
- ImageNet
- YFCC-100M
Training Resources: 64x GPUs
ID: ssl_resnext50_32x4d
LR: 0.0015
Epochs: 30
Layers: 50
Crop Pct: '0.875'
Batch Size: 1536
Image Size: '224'
Weight Decay: 0.0001
Interpolation: bilinear
Code: https://github.com/rwightman/pytorch-image-models/blob/9a25fdf3ad0414b4d66da443fe60ae0aa14edc84/timm/models/resnet.py#L914
Weights: https://dl.fbaipublicfiles.com/semiweaksupervision/model_files/semi_supervised_resnext50_32x4-ddb3e555.pth
Results:
- Task: Image Classification
Dataset: ImageNet
Metrics:
Top 1 Accuracy: 80.3%
Top 5 Accuracy: 95.41%
--> | huggingface/pytorch-image-models/blob/main/docs/models/ssl-resnext.md |
@gradio/highlightedtext
## 0.4.6
### Patch Changes
- Updated dependencies [[`828fb9e`](https://github.com/gradio-app/gradio/commit/828fb9e6ce15b6ea08318675a2361117596a1b5d), [`73268ee`](https://github.com/gradio-app/gradio/commit/73268ee2e39f23ebdd1e927cb49b8d79c4b9a144)]:
- @gradio/statustracker@0.4.3
- @gradio/atoms@0.4.1
## 0.4.5
### Patch Changes
- Updated dependencies [[`053bec9`](https://github.com/gradio-app/gradio/commit/053bec98be1127e083414024e02cf0bebb0b5142), [`4d1cbbc`](https://github.com/gradio-app/gradio/commit/4d1cbbcf30833ef1de2d2d2710c7492a379a9a00)]:
- @gradio/icons@0.3.2
- @gradio/atoms@0.4.0
- @gradio/statustracker@0.4.2
## 0.4.4
### Patch Changes
- Updated dependencies [[`206af31`](https://github.com/gradio-app/gradio/commit/206af31d7c1a31013364a44e9b40cf8df304ba50)]:
- @gradio/icons@0.3.1
- @gradio/atoms@0.3.1
- @gradio/statustracker@0.4.1
## 0.4.3
### Patch Changes
- Updated dependencies [[`9caddc17b`](https://github.com/gradio-app/gradio/commit/9caddc17b1dea8da1af8ba724c6a5eab04ce0ed8)]:
- @gradio/atoms@0.3.0
- @gradio/icons@0.3.0
- @gradio/statustracker@0.4.0
## 0.4.2
### Patch Changes
- Updated dependencies [[`f816136a0`](https://github.com/gradio-app/gradio/commit/f816136a039fa6011be9c4fb14f573e4050a681a)]:
- @gradio/atoms@0.2.2
- @gradio/icons@0.2.1
- @gradio/statustracker@0.3.2
## 0.4.1
### Patch Changes
- Updated dependencies [[`3cdeabc68`](https://github.com/gradio-app/gradio/commit/3cdeabc6843000310e1a9e1d17190ecbf3bbc780), [`fad92c29d`](https://github.com/gradio-app/gradio/commit/fad92c29dc1f5cd84341aae417c495b33e01245f)]:
- @gradio/atoms@0.2.1
- @gradio/statustracker@0.3.1
## 0.4.0
### Features
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Fix selectable prop in the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Publish all components to npm. Thanks [@pngwn](https://github.com/pngwn)!
- [#5498](https://github.com/gradio-app/gradio/pull/5498) [`287fe6782`](https://github.com/gradio-app/gradio/commit/287fe6782825479513e79a5cf0ba0fbfe51443d7) - Custom components. Thanks [@pngwn](https://github.com/pngwn)!
## 0.4.0-beta.8
### Features
- [#6136](https://github.com/gradio-app/gradio/pull/6136) [`667802a6c`](https://github.com/gradio-app/gradio/commit/667802a6cdbfb2ce454a3be5a78e0990b194548a) - JS Component Documentation. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
- [#6149](https://github.com/gradio-app/gradio/pull/6149) [`90318b1dd`](https://github.com/gradio-app/gradio/commit/90318b1dd118ae08a695a50e7c556226234ab6dc) - swap `mode` on the frontned to `interactive` to match the backend. Thanks [@pngwn](https://github.com/pngwn)!
- [#6135](https://github.com/gradio-app/gradio/pull/6135) [`bce37ac74`](https://github.com/gradio-app/gradio/commit/bce37ac744496537e71546d2bb889bf248dcf5d3) - Fix selectable prop in the backend. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.4.0-beta.7
### Features
- [#6016](https://github.com/gradio-app/gradio/pull/6016) [`83e947676`](https://github.com/gradio-app/gradio/commit/83e947676d327ca2ab6ae2a2d710c78961c771a0) - Format js in v4 branch. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.4.0-beta.6
### Features
- [#5960](https://github.com/gradio-app/gradio/pull/5960) [`319c30f3f`](https://github.com/gradio-app/gradio/commit/319c30f3fccf23bfe1da6c9b132a6a99d59652f7) - rererefactor frontend files. Thanks [@pngwn](https://github.com/pngwn)!
- [#5938](https://github.com/gradio-app/gradio/pull/5938) [`13ed8a485`](https://github.com/gradio-app/gradio/commit/13ed8a485d5e31d7d75af87fe8654b661edcca93) - V4: Use beta release versions for '@gradio' packages. Thanks [@freddyaboulton](https://github.com/freddyaboulton)!
## 0.3.4
### Patch Changes
- Updated dependencies [[`e70805d54`](https://github.com/gradio-app/gradio/commit/e70805d54cc792452545f5d8eccc1aa0212a4695)]:
- @gradio/atoms@0.2.0
- @gradio/statustracker@0.2.3
## 0.3.3
### Patch Changes
- Updated dependencies [[`e4a307ed6`](https://github.com/gradio-app/gradio/commit/e4a307ed6cde3bbdf4ff2f17655739addeec941e)]:
- @gradio/theme@0.2.0
- @gradio/utils@0.1.2
- @gradio/atoms@0.1.4
- @gradio/statustracker@0.2.2
## 0.3.2
### Patch Changes
- Updated dependencies [[`8f0fed857`](https://github.com/gradio-app/gradio/commit/8f0fed857d156830626eb48b469d54d211a582d2)]:
- @gradio/icons@0.2.0
- @gradio/atoms@0.1.3
- @gradio/statustracker@0.2.1
## 0.3.1
### Fixes
- [#5602](https://github.com/gradio-app/gradio/pull/5602) [`54d21d3f1`](https://github.com/gradio-app/gradio/commit/54d21d3f18f2ddd4e796d149a0b41461f49c711b) - Ensure `HighlightedText` with `merge_elements` loads without a value. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.3.0
### Features
- [#5400](https://github.com/gradio-app/gradio/pull/5400) [`d112e261`](https://github.com/gradio-app/gradio/commit/d112e2611b0fc79ecedfaed367571f3157211387) - Allow interactive input in `gr.HighlightedText`. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.2.3
### Patch Changes
- Updated dependencies [[`afac0006`](https://github.com/gradio-app/gradio/commit/afac0006337ce2840cf497cd65691f2f60ee5912)]:
- @gradio/statustracker@0.2.0
- @gradio/theme@0.1.0
- @gradio/utils@0.1.1
- @gradio/atoms@0.1.2
## 0.2.2
### Patch Changes
- Updated dependencies [[`abf1c57d`](https://github.com/gradio-app/gradio/commit/abf1c57d7d85de0df233ee3b38aeb38b638477db)]:
- @gradio/icons@0.1.0
- @gradio/utils@0.1.0
- @gradio/atoms@0.1.1
- @gradio/statustracker@0.1.1
## 0.2.1
### Features
- [#5284](https://github.com/gradio-app/gradio/pull/5284) [`5f25eb68`](https://github.com/gradio-app/gradio/commit/5f25eb6836f6a78ce6208b53495a01e1fc1a1d2f) - Minor bug fix sweep. Thanks [@aliabid94](https://github.com/aliabid94)!/n - Our use of **exit** was catching errors and corrupting the traceback of any component that failed to instantiate (try running blocks_kitchen_sink off main for an example). Now the **exit** exits immediately if there's been an exception, so the original exception can be printed cleanly/n - HighlightedText was rendering weird, cleaned it up
## 0.2.0
### Highlights
#### Improve startup performance and markdown support ([#5279](https://github.com/gradio-app/gradio/pull/5279) [`fe057300`](https://github.com/gradio-app/gradio/commit/fe057300f0672c62dab9d9b4501054ac5d45a4ec))
##### Improved markdown support
We now have better support for markdown in `gr.Markdown` and `gr.Dataframe`. Including syntax highlighting and Github Flavoured Markdown. We also have more consistent markdown behaviour and styling.
##### Various performance improvements
These improvements will be particularly beneficial to large applications.
- Rather than attaching events manually, they are now delegated, leading to a significant performance improvement and addressing a performance regression introduced in a recent version of Gradio. App startup for large applications is now around twice as fast.
- Optimised the mounting of individual components, leading to a modest performance improvement during startup (~30%).
- Corrected an issue that was causing markdown to re-render infinitely.
- Ensured that the `gr.3DModel` does re-render prematurely.
Thanks [@pngwn](https://github.com/pngwn)!
### Features
- [#5215](https://github.com/gradio-app/gradio/pull/5215) [`fbdad78a`](https://github.com/gradio-app/gradio/commit/fbdad78af4c47454cbb570f88cc14bf4479bbceb) - Lazy load interactive or static variants of a component individually, rather than loading both variants regardless. This change will improve performance for many applications. Thanks [@pngwn](https://github.com/pngwn)!
- [#5216](https://github.com/gradio-app/gradio/pull/5216) [`4b58ea6d`](https://github.com/gradio-app/gradio/commit/4b58ea6d98e7a43b3f30d8a4cb6f379bc2eca6a8) - Update i18n tokens and locale files. Thanks [@hannahblair](https://github.com/hannahblair)!
## 0.1.0
### Features
- [#5046](https://github.com/gradio-app/gradio/pull/5046) [`5244c587`](https://github.com/gradio-app/gradio/commit/5244c5873c355cf3e2f0acb7d67fda3177ef8b0b) - Allow new lines in `HighlightedText` with `/n` and preserve whitespace. Thanks [@hannahblair](https://github.com/hannahblair)!
| gradio-app/gradio/blob/main/js/highlightedtext/CHANGELOG.md |
Gradio Demo: stream_frames
```
!pip install -q gradio
```
```
import gradio as gr
import numpy as np
def flip(im):
return np.flipud(im)
demo = gr.Interface(
flip,
gr.Image(sources=["webcam"], streaming=True),
"image",
live=True
)
if __name__ == "__main__":
demo.launch()
```
| gradio-app/gradio/blob/main/demo/stream_frames/run.ipynb |
!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ControlNet
ControlNet is a type of model for controlling image diffusion models by conditioning the model with an additional input image. There are many types of conditioning inputs (canny edge, user sketching, human pose, depth, and more) you can use to control a diffusion model. This is hugely useful because it affords you greater control over image generation, making it easier to generate specific images without experimenting with different text prompts or denoising values as much.
<Tip>
Check out Section 3.5 of the [ControlNet](https://huggingface.co/papers/2302.05543) paper v1 for a list of ControlNet implementations on various conditioning inputs. You can find the official Stable Diffusion ControlNet conditioned models on [lllyasviel](https://huggingface.co/lllyasviel)'s Hub profile, and more [community-trained](https://huggingface.co/models?other=stable-diffusion&other=controlnet) ones on the Hub.
For Stable Diffusion XL (SDXL) ControlNet models, you can find them on the 🤗 [Diffusers](https://huggingface.co/diffusers) Hub organization, or you can browse [community-trained](https://huggingface.co/models?other=stable-diffusion-xl&other=controlnet) ones on the Hub.
</Tip>
A ControlNet model has two sets of weights (or blocks) connected by a zero-convolution layer:
- a *locked copy* keeps everything a large pretrained diffusion model has learned
- a *trainable copy* is trained on the additional conditioning input
Since the locked copy preserves the pretrained model, training and implementing a ControlNet on a new conditioning input is as fast as finetuning any other model because you aren't training the model from scratch.
This guide will show you how to use ControlNet for text-to-image, image-to-image, inpainting, and more! There are many types of ControlNet conditioning inputs to choose from, but in this guide we'll only focus on several of them. Feel free to experiment with other conditioning inputs!
Before you begin, make sure you have the following libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q diffusers transformers accelerate opencv-python
```
## Text-to-image
For text-to-image, you normally pass a text prompt to the model. But with ControlNet, you can specify an additional conditioning input. Let's condition the model with a canny image, a white outline of an image on a black background. This way, the ControlNet can use the canny image as a control to guide the model to generate an image with the same outline.
Load an image and use the [opencv-python](https://github.com/opencv/opencv-python) library to extract the canny image:
```py
from diffusers.utils import load_image, make_image_grid
from PIL import Image
import cv2
import numpy as np
original_image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/vermeer_canny_edged.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">canny image</figcaption>
</div>
</div>
Next, load a ControlNet model conditioned on canny edge detection and pass it to the [`StableDiffusionControlNetPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to speed up inference and reduce memory usage.
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now pass your prompt and canny image to the pipeline:
```py
output = pipe(
"the mona lisa", image=canny_image
).images[0]
make_image_grid([original_image, canny_image, output], rows=1, cols=3)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-text2img.png"/>
</div>
## Image-to-image
For image-to-image, you'd typically pass an initial image and a prompt to the pipeline to generate a new image. With ControlNet, you can pass an additional conditioning input to guide the model. Let's condition the model with a depth map, an image which contains spatial information. This way, the ControlNet can use the depth map as a control to guide the model to generate an image that preserves spatial information.
You'll use the [`StableDiffusionControlNetImg2ImgPipeline`] for this task, which is different from the [`StableDiffusionControlNetPipeline`] because it allows you to pass an initial image as the starting point for the image generation process.
Load an image and use the `depth-estimation` [`~transformers.Pipeline`] from 🤗 Transformers to extract the depth map of an image:
```py
import torch
import numpy as np
from transformers import pipeline
from diffusers.utils import load_image, make_image_grid
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-img2img.jpg"
)
def get_depth_map(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
depth_map = detected_map.permute(2, 0, 1)
return depth_map
depth_estimator = pipeline("depth-estimation")
depth_map = get_depth_map(image, depth_estimator).unsqueeze(0).half().to("cuda")
```
Next, load a ControlNet model conditioned on depth maps and pass it to the [`StableDiffusionControlNetImg2ImgPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to speed up inference and reduce memory usage.
```py
from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11f1p_sd15_depth", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now pass your prompt, initial image, and depth map to the pipeline:
```py
output = pipe(
"lego batman and robin", image=image, control_image=depth_map,
).images[0]
make_image_grid([image, output], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-img2img.jpg"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-img2img-2.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">generated image</figcaption>
</div>
</div>
## Inpainting
For inpainting, you need an initial image, a mask image, and a prompt describing what to replace the mask with. ControlNet models allow you to add another control image to condition a model with. Let’s condition the model with an inpainting mask. This way, the ControlNet can use the inpainting mask as a control to guide the model to generate an image within the mask area.
Load an initial image and a mask image:
```py
from diffusers.utils import load_image, make_image_grid
init_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-inpaint.jpg"
)
init_image = init_image.resize((512, 512))
mask_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-inpaint-mask.jpg"
)
mask_image = mask_image.resize((512, 512))
make_image_grid([init_image, mask_image], rows=1, cols=2)
```
Create a function to prepare the control image from the initial and mask images. This'll create a tensor to mark the pixels in `init_image` as masked if the corresponding pixel in `mask_image` is over a certain threshold.
```py
import numpy as np
import torch
def make_inpaint_condition(image, image_mask):
image = np.array(image.convert("RGB")).astype(np.float32) / 255.0
image_mask = np.array(image_mask.convert("L")).astype(np.float32) / 255.0
assert image.shape[0:1] == image_mask.shape[0:1]
image[image_mask > 0.5] = -1.0 # set as masked pixel
image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return image
control_image = make_inpaint_condition(init_image, mask_image)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-inpaint.jpg"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-inpaint-mask.jpg"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">mask image</figcaption>
</div>
</div>
Load a ControlNet model conditioned on inpainting and pass it to the [`StableDiffusionControlNetInpaintPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to speed up inference and reduce memory usage.
```py
from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, UniPCMultistepScheduler
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now pass your prompt, initial image, mask image, and control image to the pipeline:
```py
output = pipe(
"corgi face with large ears, detailed, pixar, animated, disney",
num_inference_steps=20,
eta=1.0,
image=init_image,
mask_image=mask_image,
control_image=control_image,
).images[0]
make_image_grid([init_image, mask_image, output], rows=1, cols=3)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet-inpaint-result.png"/>
</div>
## Guess mode
[Guess mode](https://github.com/lllyasviel/ControlNet/discussions/188) does not require supplying a prompt to a ControlNet at all! This forces the ControlNet encoder to do it's best to "guess" the contents of the input control map (depth map, pose estimation, canny edge, etc.).
Guess mode adjusts the scale of the output residuals from a ControlNet by a fixed ratio depending on the block depth. The shallowest `DownBlock` corresponds to 0.1, and as the blocks get deeper, the scale increases exponentially such that the scale of the `MidBlock` output becomes 1.0.
<Tip>
Guess mode does not have any impact on prompt conditioning and you can still provide a prompt if you want.
</Tip>
Set `guess_mode=True` in the pipeline, and it is [recommended](https://github.com/lllyasviel/ControlNet#guess-mode--non-prompt-mode) to set the `guidance_scale` value between 3.0 and 5.0.
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
from diffusers.utils import load_image, make_image_grid
import numpy as np
import torch
from PIL import Image
import cv2
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", use_safetensors=True)
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, use_safetensors=True).to("cuda")
original_image = load_image("https://huggingface.co/takuma104/controlnet_dev/resolve/main/bird_512x512.png")
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
image = pipe("", image=canny_image, guess_mode=True, guidance_scale=3.0).images[0]
make_image_grid([original_image, canny_image, image], rows=1, cols=3)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare_guess_mode/output_images/diffusers/output_bird_canny_0.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">regular mode with prompt</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/takuma104/controlnet_dev/resolve/main/gen_compare_guess_mode/output_images/diffusers/output_bird_canny_0_gm.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">guess mode without prompt</figcaption>
</div>
</div>
## ControlNet with Stable Diffusion XL
There aren't too many ControlNet models compatible with Stable Diffusion XL (SDXL) at the moment, but we've trained two full-sized ControlNet models for SDXL conditioned on canny edge detection and depth maps. We're also experimenting with creating smaller versions of these SDXL-compatible ControlNet models so it is easier to run on resource-constrained hardware. You can find these checkpoints on the [🤗 Diffusers Hub organization](https://huggingface.co/diffusers)!
Let's use a SDXL ControlNet conditioned on canny images to generate an image. Start by loading an image and prepare the canny image:
```py
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
from PIL import Image
import cv2
import numpy as np
import torch
original_image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
)
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
make_image_grid([original_image, canny_image], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/hf-logo-canny.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">canny image</figcaption>
</div>
</div>
Load a SDXL ControlNet model conditioned on canny edge detection and pass it to the [`StableDiffusionXLControlNetPipeline`]. You can also enable model offloading to reduce memory usage.
```py
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0",
torch_dtype=torch.float16,
use_safetensors=True
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet,
vae=vae,
torch_dtype=torch.float16,
use_safetensors=True
)
pipe.enable_model_cpu_offload()
```
Now pass your prompt (and optionally a negative prompt if you're using one) and canny image to the pipeline:
<Tip>
The [`controlnet_conditioning_scale`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/controlnet#diffusers.StableDiffusionControlNetPipeline.__call__.controlnet_conditioning_scale) parameter determines how much weight to assign to the conditioning inputs. A value of 0.5 is recommended for good generalization, but feel free to experiment with this number!
</Tip>
```py
prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
negative_prompt = 'low quality, bad quality, sketches'
image = pipe(
prompt,
negative_prompt=negative_prompt,
image=canny_image,
controlnet_conditioning_scale=0.5,
).images[0]
make_image_grid([original_image, canny_image, image], rows=1, cols=3)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0/resolve/main/out_hug_lab_7.png"/>
</div>
You can use [`StableDiffusionXLControlNetPipeline`] in guess mode as well by setting the parameter to `True`:
```py
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
import numpy as np
import torch
import cv2
from PIL import Image
prompt = "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting"
negative_prompt = "low quality, bad quality, sketches"
original_image = load_image(
"https://hf.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
)
controlnet = ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0", torch_dtype=torch.float16, use_safetensors=True
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnet, vae=vae, torch_dtype=torch.float16, use_safetensors=True
)
pipe.enable_model_cpu_offload()
image = np.array(original_image)
image = cv2.Canny(image, 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
image = pipe(
prompt, negative_prompt=negative_prompt, controlnet_conditioning_scale=0.5, image=canny_image, guess_mode=True,
).images[0]
make_image_grid([original_image, canny_image, image], rows=1, cols=3)
```
### MultiControlNet
<Tip>
Replace the SDXL model with a model like [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) to use multiple conditioning inputs with Stable Diffusion models.
</Tip>
You can compose multiple ControlNet conditionings from different image inputs to create a *MultiControlNet*. To get better results, it is often helpful to:
1. mask conditionings such that they don't overlap (for example, mask the area of a canny image where the pose conditioning is located)
2. experiment with the [`controlnet_conditioning_scale`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/controlnet#diffusers.StableDiffusionControlNetPipeline.__call__.controlnet_conditioning_scale) parameter to determine how much weight to assign to each conditioning input
In this example, you'll combine a canny image and a human pose estimation image to generate a new image.
Prepare the canny image conditioning:
```py
from diffusers.utils import load_image, make_image_grid
from PIL import Image
import numpy as np
import cv2
original_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
image = np.array(original_image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
# zero out middle columns of image where pose will be overlaid
zero_start = image.shape[1] // 4
zero_end = zero_start + image.shape[1] // 2
image[:, zero_start:zero_end] = 0
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
make_image_grid([original_image, canny_image], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/controlnet/landscape_canny_masked.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">canny image</figcaption>
</div>
</div>
For human pose estimation, install [controlnet_aux](https://github.com/patrickvonplaten/controlnet_aux):
```py
# uncomment to install the necessary library in Colab
#!pip install -q controlnet-aux
```
Prepare the human pose estimation conditioning:
```py
from controlnet_aux import OpenposeDetector
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
original_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(original_image)
make_image_grid([original_image, openpose_image], rows=1, cols=2)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/controlnet/person_pose.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">human pose image</figcaption>
</div>
</div>
Load a list of ControlNet models that correspond to each conditioning, and pass them to the [`StableDiffusionXLControlNetPipeline`]. Use the faster [`UniPCMultistepScheduler`] and enable model offloading to reduce memory usage.
```py
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, AutoencoderKL, UniPCMultistepScheduler
import torch
controlnets = [
ControlNetModel.from_pretrained(
"thibaud/controlnet-openpose-sdxl-1.0", torch_dtype=torch.float16
),
ControlNetModel.from_pretrained(
"diffusers/controlnet-canny-sdxl-1.0", torch_dtype=torch.float16, use_safetensors=True
),
]
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", controlnet=controlnets, vae=vae, torch_dtype=torch.float16, use_safetensors=True
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now you can pass your prompt (an optional negative prompt if you're using one), canny image, and pose image to the pipeline:
```py
prompt = "a giant standing in a fantasy landscape, best quality"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
generator = torch.manual_seed(1)
images = [openpose_image.resize((1024, 1024)), canny_image.resize((1024, 1024))]
images = pipe(
prompt,
image=images,
num_inference_steps=25,
generator=generator,
negative_prompt=negative_prompt,
num_images_per_prompt=3,
controlnet_conditioning_scale=[1.0, 0.8],
).images
make_image_grid([original_image, canny_image, openpose_image,
images[0].resize((512, 512)), images[1].resize((512, 512)), images[2].resize((512, 512))], rows=2, cols=3)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/multicontrolnet.png"/>
</div>
| huggingface/diffusers/blob/main/docs/source/en/using-diffusers/controlnet.md |
File names and splits
To host and share your dataset, create a dataset repository on the Hugging Face Hub and upload your data files.
This guide will show you how to name your files and directories in your dataset repository when you upload it and enable all the Datasets Hub features like the Dataset Viewer.
A dataset with a supported structure and [file formats](./datasets-adding#file-formats) automatically has a dataset viewer on its page on the Hub.
Note that if none of the structures below suits your case, you can have more control over how you define splits and subsets with the [Manual Configuration](./datasets-manual-configuration).
## Basic use-case
If your dataset isn't split into [train/validation/test splits](https://en.wikipedia.org/wiki/Training,_validation,_and_test_data_sets), the simplest dataset structure is to have one file: `data.csv` (this works with any [supported file format](./datasets-adding#files-formats) and any file name).
Your repository will also contain a `README.md` file, the [dataset card](./dataset-cards) displayed on your dataset page.
```
my_dataset_repository/
├── README.md
└── data.csv
```
## Splits
Some patterns in the dataset repository can be used to assign certain files to train/validation/test splits.
### File name
You can name your data files after the `train`, `test`, and `validation` splits:
```
my_dataset_repository/
├── README.md
├── train.csv
├── test.csv
└── validation.csv
```
If you don't have any non-traditional splits, then you can place the split name anywhere in the data file. The only rule is that the split name must be delimited by non-word characters, like `test-file.csv` for example instead of `testfile.csv`. Supported delimiters include underscores, dashes, spaces, dots, and numbers.
For example, the following file names are all acceptable:
- train split: `train.csv`, `my_train_file.csv`, `train1.csv`
- validation split: `validation.csv`, `my_validation_file.csv`, `validation1.csv`
- test split: `test.csv`, `my_test_file.csv`, `test1.csv`
### Directory name
You can place your data files into different directories named `train`, `test`, and `validation` where each directory contains the data files for that split:
```
my_dataset_repository/
├── README.md
└── data/
├── train/
│ └── data.csv
├── test/
│ └── more_data.csv
└── validation/
└── even_more_data.csv
```
### Keywords
There are several ways to refer to train/validation/test splits. Validation splits are sometimes called "dev", and test splits may be referred to as "eval".
These other split names are also supported, and the following keywords are equivalent:
- train, training
- validation, valid, val, dev
- test, testing, eval, evaluation
Therefore, the structure below is a valid repository:
```
my_dataset_repository/
├── README.md
└── data/
├── training.csv
├── eval.csv
└── valid.csv
```
### Multiple files per split
Splits can span several files, for example:
```
my_dataset_repository/
├── README.md
├── train_0.csv
├── train_1.csv
├── train_2.csv
├── train_3.csv
├── test_0.csv
└── test_1.csv
```
Make sure all the files of your `train` set have *train* in their names (same for test and validation).
You can even add a prefix or suffix to `train` in the file name (like `my_train_file_00001.csv` for example).
For convenience, you can also place your data files into different directories.
In this case, the split name is inferred from the directory name.
```
my_dataset_repository/
├── README.md
└── data/
├── train/
│ ├── shard_0.csv
│ ├── shard_1.csv
│ ├── shard_2.csv
│ └── shard_3.csv
└── test/
├── shard_0.csv
└── shard_1.csv
```
### Custom split name
If your dataset splits have custom names that aren't `train`, `test`, or `validation`, then you can name your data files like `data/<split_name>-xxxxx-of-xxxxx.csv`.
Here is an example with three splits, `train`, `test`, and `random`:
```
my_dataset_repository/
├── README.md
└── data/
├── train-00000-of-00003.csv
├── train-00001-of-00003.csv
├── train-00002-of-00003.csv
├── test-00000-of-00001.csv
├── random-00000-of-00003.csv
├── random-00001-of-00003.csv
└── random-00002-of-00003.csv
```
| huggingface/hub-docs/blob/main/docs/hub/datasets-file-names-and-splits.md |