
Open-Vocabulary Audio-Visual Semantic Segmentation (ACM MM 24 Oral)
Ruohao Guo, Liao Qu, Dantong Niu, Yanyu Qi, Wenzhen Yue, Ji Shi, Bowei Xing, Xianghua Ying*
News
25.07.2024: Our paper is accepted by ACM MM 2024 as Oral!
Introduction
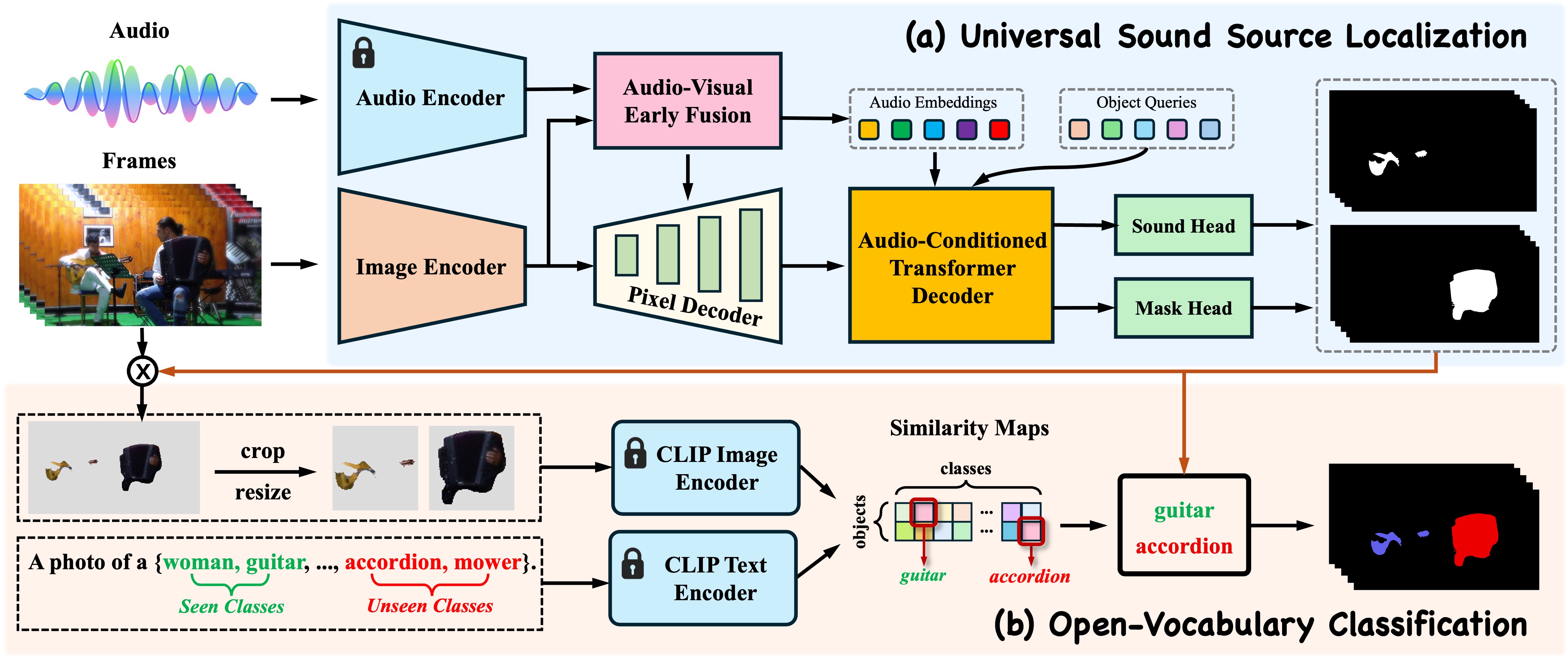
Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%.

Installation
Example 1
conda create -n ov_avss python==3.8 -y
conda activate ov_avss
git clone https://github.com/ruohaoguo/ovavss
cd ovavss
pip install torch torchvision
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron2
pip install -r requirements.txt
pip install git+https://github.com/openai/CLIP.git
pip install -e third_parties/mask_adapted_clip
cd ov_avss/modeling/pixel_decoder/ops
bash make.sh
pip install git+https://github.com/sennnnn/TrackEval.git
Example 2
conda create -n ov_avss python==3.8 -y
conda activate ov_avss
git clone https://github.com/ruohaoguo/ovavss
cd ovavss
conda install pytorch==1.9.0 torchvision==0.10.0 cudatoolkit=11.1 -c pytorch -c nvidia
pip install -U opencv-python
git clone https://github.com/facebookresearch/detectron2
cd detectron2
pip install -e .
cd ..
pip install -r requirements.txt
pip install git+https://github.com/openai/CLIP.git
pip install -e third_parties/mask_adapted_clip
cd ov_avss/modeling/pixel_decoder/ops
bash make.sh
pip install git+https://github.com/sennnnn/TrackEval.git
Setup
- Download pretrained weight model_final_3c8ec9.pkl and put it in
./pre_models. - Download pretrained weight model_final_83d103.pkl and put it in
./pre_models. - Download pretrained weight vggish-10086976.pth (code: 1234) and put it in
./pre_models. - Download and unzip datasets (code: 1234) and put it in
./datasets.
Training
For ResNet-50 backbone: Run the following command
python train_net.py \ --config-file configs/avsbench/OV_AVSS_R50.yaml \ --num-gpus 1For Swin-base backbone: Run the following command
python train_net.py \ --config-file configs/avsbench/swin/OV_AVSS_SwinB.yaml \ --num-gpus 1
Inference & Evaluation
For ResNet-50 backbone: Run the following command
Download the trained model model_ov_avss_r50.pth (code: 1234) an put it in
./pre_models.cd demo_video python test_net_video_avsbench_r50.pyFor Swin-base backbone: Run the following command
Download the trained model model_ov_avss_swinb.pth (code: 1234) an put it in
./pre_models.cd demo_video python test_net_video_avsbench_swinb.pyNote: The results tested on Example 1 and Example 2 have a slight performance difference.
FAQ
If you want to improve the usability or any piece of advice, please feel free to contant directly (ruohguo@foxmail.com).
Citation
Please consider citing our paper in your publications if the project helps your research. BibTeX reference is as follow.
@article{guo2024open,
title={Open-Vocabulary Audio-Visual Semantic Segmentation},
author={Guo, Ruohao and Qu, Liao and Niu, Dantong and Qi, Yanyu and Yue, Wenzhen and Shi, Ji and Xing, Bowei and Ying, Xianghua},
journal={arXiv preprint arXiv:2407.21721},
year={2024}
}
Acknowledgement
This repo is based on OpenVIS, Mask2Former and detectron2 Thanks for their wonderful works.